
Abstract
Objective:
Computer-aided analysis of laryngoscopy images has potential to add objectivity to subjective evaluations. Automated classification of biomedical images is extremely challenging due to the precision required and the limited amount of annotated data available for training. Convolutional neural networks (CNNs) have the potential to improve image analysis and have demonstrated good performance in many settings. This study applied machine-learning technologies to laryngoscopy to determine the accuracy of computer recognition of known laryngeal lesions found in patients post-extubation.
Methods:
This is a proof of concept study that used a convenience sample of transnasal, flexible, distal-chip laryngoscopy images from patients post-extubation in the intensive care unit. After manually annotating images at the pixel-level, we applied a CNN-based method for analysis of granulomas and ulcerations to test potential machine-learning approaches for laryngoscopy analysis.
Results:
A total of 127 images from 25 patients were manually annotated for presence and shape of these lesions—100 for training, 27 for evaluating the system. There were 193 ulcerations (148 in the training set; 45 in the evaluation set) and 272 granulomas (208 in the training set; 64 in the evaluation set) identified. Time to annotate each image was approximately 3 minutes. Machine-based analysis demonstrated per-pixel sensitivity of 82.0% and 62.8% for granulomas and ulcerations respectively; specificity was 99.0% and 99.6%.
Conclusion:
This work demonstrates the feasibility of machine learning via CNN-based methods to add objectivity to laryngoscopy analysis, suggesting that CNN may aid in laryngoscopy analysis for other conditions in the future.
Keywords
Introduction
Machine learning models have contributed to advances in medical imaging tasks and medical procedure training with high accuracy, including detection of disease and objective measurements of function.1-3 These advances have spurred additional research on more challenging problems in biomedical image analysis, such as semantic segmentation of biomedical images. Semantic segmentation encompasses both separation of an image into objects per-pixel and the classification of these regions. Semantic segmentation is a challenging task because the models must learn classifications on a per-pixel basis, whereas typical clinical tasks only involve classification of a full image. An additional challenge in the biomedical domain is the high cost of annotation training data. Training images must be segmented at the pixel level, yielding a time intensive process dependent upon clinical expertise. As a result, biomedical datasets tend to contain relatively few samples (ie, hundreds), especially in comparison to similar tasks in other domains that often contain more than 200 000 samples, resulting in difficulty learning and reduced accuracy of machine-learning algorithms. Within the context of these challenges, we seek to demonstrate feasibility of applying machine-learning analysis to laryngoscopy.
Since the introduction of mirror laryngoscopy in 1855, 4 identification of laryngeal lesions and disease continues to improve while description of laryngeal structure and function remains largely subjective.5-8 This subjectivity not only limits use of laryngoscopy to trained observers, it limits identification and measurement of disease and disorder, interpretation of function, and tracking patient outcomes. With computer-aided analysis of laryngoscopic/stroboscopic images, potential exists to add objectivity by improving the quantification of lesion size, vocal fold motion, and vibration to what has heretofore been a subjective field. Whereas machine-learning models have yielded advances in medical imaging tasks and medical procedure training, their application to image analysis in clinical laryngology has been limited. To date, studies with machine learning in laryngeal endoscopy have been preliminary, often requiring specialized lighting/processing (eg, narrow band imaging; high-speed laryngoscopy) during the exam with techniques that are not widely available.9-11
We are aware of only one article that applied machine learning to white light and/or stroboscopic laryngeal imaging to identify laryngeal disorders by the shape of and vascular defects in the vocal folds, 12 but disorders also occur outside the boundaries of the vocal folds. Recent work has demonstrated the efficacy of convolutional neural networks (CNNs) at segmenting frames from laryngeal endoscopy. 13 Identifying lesion boundaries must occur before computer-aided measurements are possible. However, segmenting lesions poses challenges, among them color/contrast differences between lesions and normal, healthy tissue. Our goal in this proof of concept study was to apply machine-learning to laryngoscopy to determine the accuracy of computer recognition of known laryngeal lesions.
Methods
This study was approved by the Johns Hopkins University-School of Medicine Institutional Review Board (IRB00029289). Analyzed images were obtained from a convenience sample of patients from the PReventing the EffectS of Intubation on DEglutition (PRESIDE) clinical trial (ClinicalTrials.gov: NCT02442102). This prospective, Phase II clinical trial enrolls patients with acute respiratory failure who have been intubated with mechanical ventilation >96 hours. Within 2 days of extubation, all patients complete flexible laryngeal endoscopy to identify laryngeal injury and swallowing impairments. All patients were ≥18 years old and orally intubated with mechanical ventilation in an intensive care unit.
Instrumentation
Following extubation, patients had transnasal flexible distal-chip laryngoscopy performed (Olympus ENF-V3 scope, Olympus America, Southborough, MA, USA). Images were captured using an LED light source (Olympus CV-170) and a digital data capturing system (ENDODigi software, Ecleris S.R.L., Medley, FL, USA) via a notebook computer using standard definition 640 × 480 video at 30 frames per second.
Data Annotation
Videos were reviewed to identify and collect images (ie, frames of video) that contained clinically diagnosed ulcerations and granulation tissue. Frames were selected based on clarity and adequate light to identify each lesion while standardizing the view of the larynx (anterior commissure to arytenoid complex in full view) and saved as PNG files for segmentation and analyses. To maximize the robustness of the model with respect to varying viewpoints, selections purposely included multiple angles and views from different distances of the endoscope while maintaining the standardized view, with a minimum of 2 images captured per endoscopy session. All lesions were identified and segmented by drawing (M.B.B.) with 100% review/validation by agreement (L.M.A.), fine bounding polygons around each lesion in each frame with pixel-level accuracy. Each lesion was discretely annotated by its tissue as either identifying it as an ulceration tissue or granulation tissue, even when granulation was found within an ulceration. Annotated frames were divided into two groups, one for training the machine learning model and one for evaluating its performance. This division was performed by a computer program that randomly assigned a group identifier to each patient repeatedly until an assignment was found that yielded the desired ratio of frames in the training set to frames in the evaluation set. No patient’s frames were divided between sets, including across recordings post-extubation and prior to hospital discharge, ensuring that the model is evaluated on its ability to generalize to new patients, not its ability to memorize features of particular patients.
Convolutional Neural Network
We performed automated classification and segmentation of lesions using supervised machine learning. This involves training a model by showing it pairs of inputs and desired outputs, and using algorithms to teach the model to find patterns in the input that correspond to patterns in the output, so that the trained model can then infer the desired output for any new input data. Concretely, we gave the model an image, represented as an array of numerical pixel values, and a segmentation that contained the correct classification (ulceration, granuloma, or other) for each pixel. We employed a U-Net 14 as our model, a CNN developed for the purpose of semantic segmentation of biomedical images. CNNs iteratively perform simple transformations to these pixel values, which together allow it to represent the highly complex relationship between an image and which pixels correspond to a specific type of lesion. A CNN can be seen as looking for informative features in an image (ie, patterns that compose or are characteristic of a granuloma), which it uses to make decisions about what the output should be. The primary advantage that CNNs have over other machine learning models is that CNNs learn to find these informative features from the training data instead of relying on human-designed features. These features are determined by the parameters of the CNN (~8 000 000 in U-Net). During training, all parameters are adjusted >10 000 times using stochastic gradient descent, an optimization method that operates to decrease the difference between the output of this neural network and the desired output on each iteration. The CNN’s large size, layered structure, and training procedure enable it to accurately learn the complex relationships required to segment and classify the lesions in an image at the pixel level. A single U-Net was used with three output values per pixel, corresponding to the predicted likelihood that the pixel belongs to an ulceration, a granuloma, or anything else. The final predicted classification at each pixel was taken to be the class with the highest likelihood.
Implementation
The model was implemented in PyTorch version 1.3, running on Python 3.7. All statistical analysis was performed in Python as well. Frames were selected from the video using a custom web application, and were annotated using Labelbox. The code used to train and evaluate the model is available here: https://github.com/flixpar/larynx-semseg.
Primary Outcome
The model was evaluated using per-pixel sensitivity and specificity for each class of lesion.
Results
Laryngoscopy was completed in 25 patients ≤48 hours post-extubation; nine patients also repeated laryngoscopy at hospital discharge, yielding 34 unique recordings. A median of 5 (interquartile range: 3, 7) frames were selected from each patient, totaling 127 frames acquired for analysis. These frames contained 193 ulcerations and 272 granulomas. Frames representing different angles created by movements of the endoscope during the clinical evaluation were chosen for analysis. These varying angles were chosen to provide additional learning opportunities for the model. Variability in the number of frames per patient was the result of a number of factors, including the capture of frames that maintained our operating definition of a standardized view, the length of the video, clarity of the images, and the purposeful attempt to obtain multiple angles and views from varying distances of the larynx. After acquisition, the 127 frames were divided into a training set (100 frames) and an evaluation set (27 frames) using random assignment, with all frames from each patient placed into the same set. After division of the patients into these two sets, there were 208 granulomas and 148 ulcerations in the training set and 64 granulomas and 45 ulcerations in the evaluation set.
Frame annotation consumed 6 hours, or a mean of 2.8 (standard deviation: 3.1) minutes per frame (Figure 1). After training the machine learning model was completed on the training set of 100 frames, computer analysis of the remaining 27 frames from the evaluation set was compared to manual annotation of the same set of frames. At the pixel level, sensitivity for identifying granulomas and ulcerations was 82.0% and 62.8%, respectively; specificity was ≥99% for both lesions (Table 1; Figure 2). Through inspection of the evaluation frames we found that the CNN successfully learned the area where lesions occurred and did not predict (0%) any lesions outside this region.
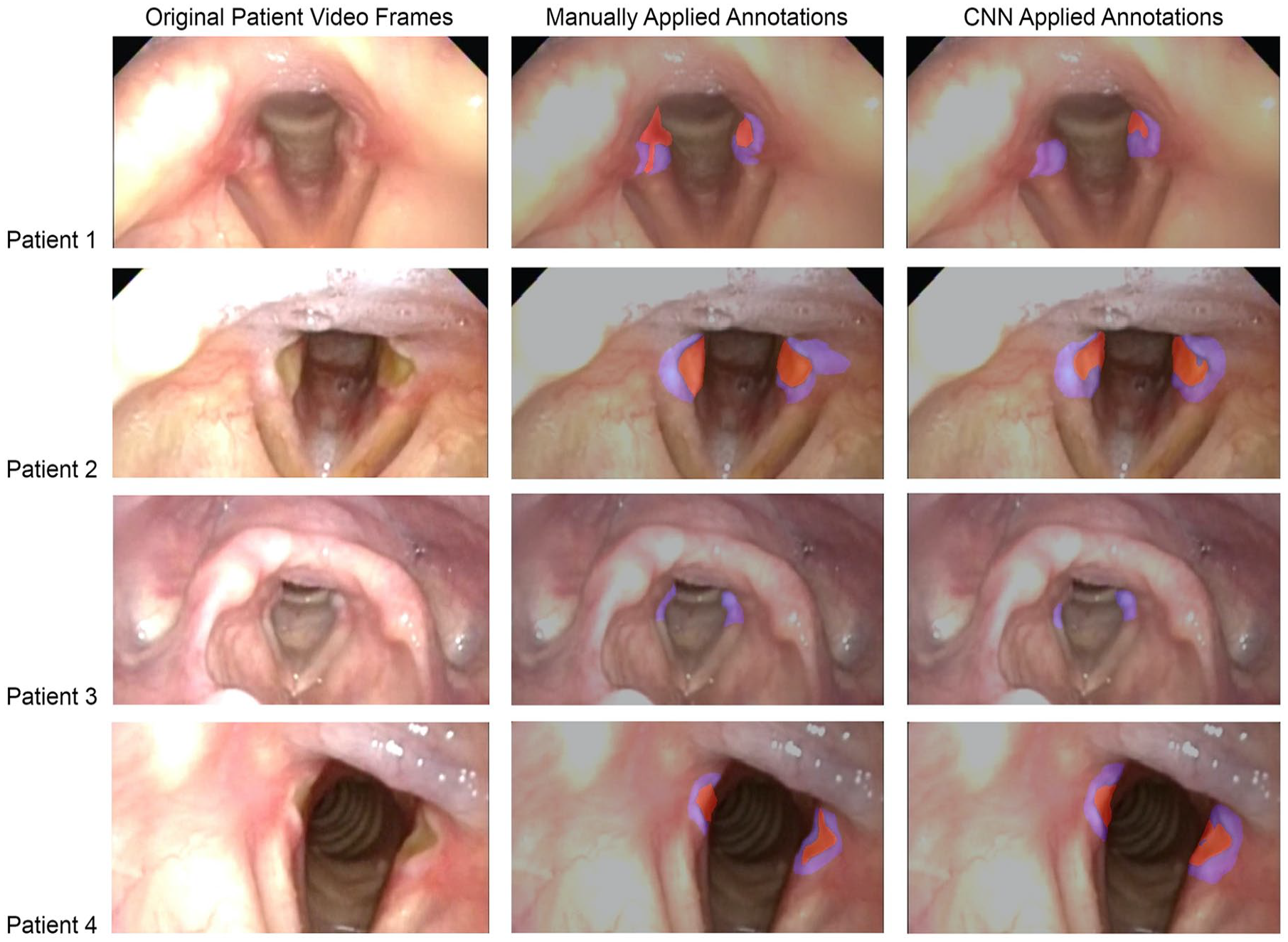
Comparison of clinician segmentations to segmentations produced by the trained CNN of four sample frames from the evaluation set, cropped to the region of interest.
Sensitivity and Specificity in a Per-Pixel Analysis to Automatically Identify Laryngeal Granulomas and Ulcerations from a Machine Learning Model’s Evaluation Set of Frames (N = 27).
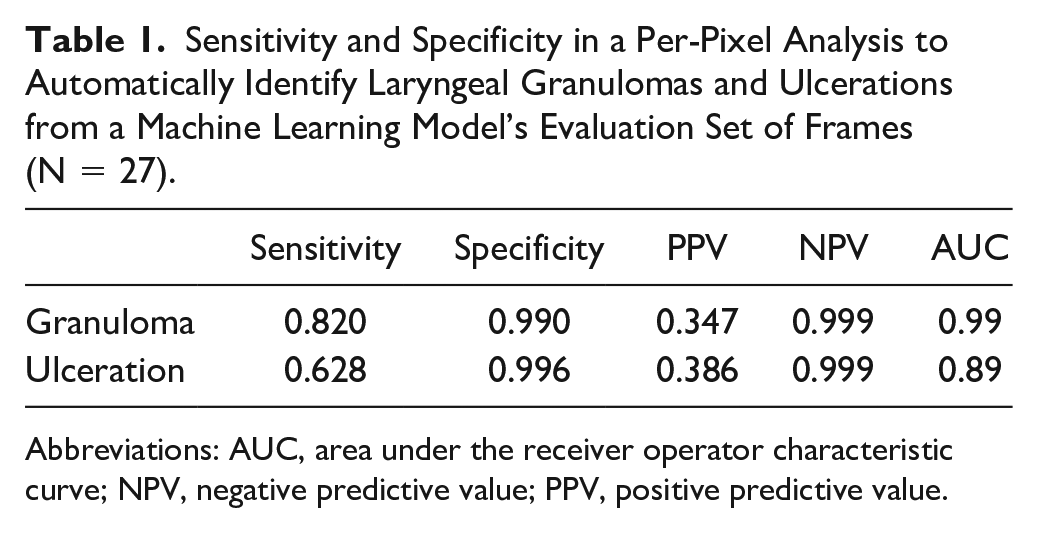
Abbreviations: AUC, area under the receiver operator characteristic curve; NPV, negative predictive value; PPV, positive predictive value.
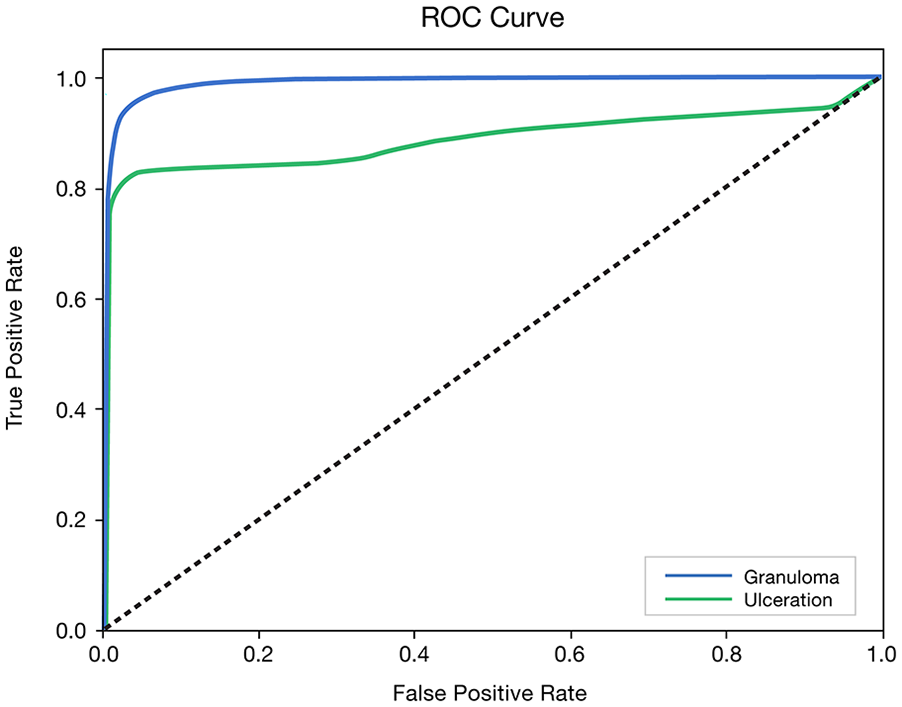
Receiver operating characteristic curve (ROC) for the machine learning model on the evaluation set of laryngeal frames.
Discussion
Our goal was to provide an initial step toward automatic and objective measurements of lesions during laryngoscopy. To accomplish this goal, lesions first must be identified. This proof of concept study explored the potential of applying machine learning to identify and delineate two classes of laryngeal lesions—ulcerations and granulomas. We chose to identify these lesions from a homogeneous convenience sample of critically ill patients post-extubation in the intensive care unit. The goal of this preliminary work was explicitly to identify and delineate lesions when they are known to be present, and therefore control images without lesions were not used. Using standard, white light laryngoscopy, we demonstrated good sensitivity for identifying granulomas and modest sensitivity for identifying ulcerations post-extubation. The precision of pixel-level annotations was counter-balanced with a lengthy time required to annotate frames and may be impracticable for large dataset analyses.
The model implicitly learned the area of interest well and did not predict lesions outside of this region in any test cases. This enabled our model to be fully automated, with no reliance on human pre-processing steps such as cropping to a region of interest to predict lesions in a frame. Clinically, this translates to the exportation of several representative laryngoscopy frames by trained personnel. The model made predictions quickly, such that it could be used by clinicians to identify lesions during laryngoscopy in real time, without requiring personnel (eg, clinician or technologist) to have the expertise necessary to identify lesions. The caveat is, however, that personnel responsible for acquiring the frames for analysis must also consider image quality for lighting, blur, motion artifact, and other image qualities that may reduce the accuracy of the model’s predictions.
We found that the model achieves very high specificity on the validation images, even when there are erroneous lesions predicted. This occurs because the vast majority of pixels are still predicted to not belong to a lesion, so the number of true negatives dwarfs the number of false positives, leading to high specificity. This means that sensitivity can be increased significantly while maintaining high specificity; however, this introduces erroneous predictions which degrade the clinical usefulness of the output. We found that simply taking the most likely classification at each pixel as predicted by the model subjectively yields the best tradeoff between sensitivity and specificity.
It is currently unclear how other laryngeal lesions or conditions would perform under similar circumstances. We speculate that lesions with uniform colors that are distinct from background color will yield greater sensitivity in detection and categorization of pixels. If this hypothesis were true, it may be easier for automated analysis to better define boundaries of a bright red hemorrhagic polyp than a sessile nodule of similar color to the remaining vocal fold, for example. We also speculate that the performance will depend strongly on the number of training examples because CNNs tend to require large datasets with thousands to hundreds of thousands of examples to achieve optimal performance. This may explain our observation that the model has a significantly higher sensitivity for granulomas than for ulcerations as our dataset contains 41% more granulomas than ulcerations. Due to the success of machine learning at detecting a wide array of conditions,2,3,6,7,12 we expect similar success with laryngeal lesions and conditions given sufficient training data.
There are many methods for potential improvement. Higher quality video would enable the CNN to analyze more details that could be useful for classification. Modifications to U-Net or the training procedure have been shown to improve the performance of other applications of biomedical semantic segmentation, offering potential utility for this application. 15 Finally, deep learning relies on having large amounts of training data available, thus annotating lesions in more frames of video would likely improve performance, but to do so manually would require considerably more annotation effort. One way to reduce this cost would be to use active learning, which involves letting a neural network select frames for expert annotation. The approach has been shown to yield significant improvement in accuracy at 50% of the annotation time on similar tasks. 16 We could also annotate additional frames automatically by propagating annotations between frames that have been manually annotated and others in the same video, removing the additional human effort required entirely.
Conclusion
This study demonstrated the feasibility of using machine learning to recognize and segment lesions, a preliminary step toward our goal of creating a system that performs at expert-level accuracy but with more objectivity and an easy translation for clinical use. Achieving this goal will require improved sensitivity, obtaining an objective dataset of frames to train our models by aggregating annotations from multiple experts, and performing further testing and analysis to ensure robustness. As this technology evolves, the potential to add objective quantitative, computer-analysis of motion, vibration, and size/shape of lesions to laryngoscopy will aid patient care by standardizing laryngoscopy reporting.
Footnotes
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This study was supported, in part, by the National Institutes of Health/National Institute on Deafness and Other Communication Disorders (5K23DC013569).