
Abstract
Spectral pre-processing is an essential step in data analysis for biomedical diagnostic applications of Raman spectroscopy, allowing the removal of undesirable spectral contributions that could mask biological information used for diagnosis. However, due to the specificity of pre-processing for a given sample type and the vast number of potential pre-processing combinations, optimisation of pre-processing via a manual “trial and error” format is often time intensive with no guarantee that the chosen method is optimal for the sample type. Here we present the use of high-performance computing (HPC) to trial over 2.4 million pre-processing permutations to demonstrate the optimisation on the pre-processing of human serum Raman spectra for colorectal cancer detection. The effect of varying pre-processing order, using extended multiplicative scatter correction, spectral smoothing, baseline correction, binning and normalization was considered. Permutations were assessed on their ability to detect patients with disease using a random forest (RF) algorithm trained with 102 patients (510 spectra) and independently tested with a set of 439 patients (1317 spectra) in a primary care patient cohort. Optimising via HPC enables improved performance in diagnostic abilities, with sensitivity increasing by 14.6%, specificity increasing by 6.9%, positive predictive value increasing by 3.4%, and negative predictive value increasing by 2.4% when compared to a standard pre-processing optimisation. Ultimate values of these metrics are very important for diagnostic adoption, and once diagnostics demonstrate good accuracy these types of optimisations can make a significant difference to roll-out of a test and demonstrating advantages over existing tests. We also provide tips/recommendations for pre-processing optimisation without the use of HPC. From the HPC permutations, recommendations for appropriate parameter constraints for conducting a more basic pre-processing optimisation are also detailed, thus helping model development for researchers not having access to HPC.
Keywords
Introduction
Raman spectroscopy (RS) offers the ability to obtain the complex structural fingerprint of the molecular constituents in a sample by the inelastic scattering of electromagnetic (EM) radiation. 1 The analysis of biological samples using RS and machine learning algorithms is becoming ever more prevalent, with applications highlighted to analyse bio-fluids,2–6 tissue samples7–10 and cells.11–13 Translating RS techniques into a clinical setting is in prospect, 14 with the potential to dramatically shape modern medicine and diagnostics.
Raman spectra are inherently multivariate, requiring further analytical tools to analyse effectively, making them a prime candidate for machine learning (ML) methods. ML is often used in conjunction with RS for disease detection;11,15,16 however, ML for diagnostics has yet to become ubiquitous in a clinical setting. Opportunities for ML to assist in clinical diagnostics are rapidly developing but have its own challenges with respect to model development, validation and implementation. 17 The model development phase is heavily reliant on the available data and ensuring this is high-quality to enable ML to learn patterns. In the context of RS, pre-processing is integral to ensuring the data quality is sufficient for building a robust model for further diagnosis.
Included with the useful molecular information, raw Raman spectra can also contain undesirable contributions due to experimental, instrumental and sampling variations which can affect the diagnostic capability of ML models. The additional contributions often contain fluorescence intrinsic to the sample itself, or from other contaminants relating to the choice of substrate and objective. 18 The use of pre-processing on raw spectra has been shown to perform better for quantification or classification than using only raw spectra.19,20 Therefore, the ability to effectively pre-process spectra to remove such undesirable contributions is essential.21,22
There are many reported methods of removing unwanted signals from spectroscopic data, which in themselves contain further parameters to tune. 21 This variety of pre-processing choice, and range of applications leads to a lack of consensus as to which is “best”. A robust method for choosing this method is required. Previous studies have investigated pre-processing optimisation of Raman spectra.23–25 However, due to the time-consuming nature of classical grid-search approaches, small ranges of parameters are typically chosen to reduce computational burden. High-performance computing (HPC) offers the ability to complete wide explorations of the pre-processing parameter space in relatively small time periods. A typical optimisation in this regime testing 2.4 million permutations is reduced from 800 000 h of computational time to 369 h. Here we address the plethora of possible pre-processing techniques and their parameters using HPC to optimise pre-processing routines. HPC provides a powerful tool for pre-processing optimisation, allowing vast amounts of computations evaluated on a separate machine. HPC has been utilised previously for pre-processing optimisation of attenuated total reflection Fourier transform infrared spectra. 26
The methods used in this study encompass many of the common pre-processing techniques, and aims to explore the effect of reordering the pre-processing steps, using extended multiplicative scatter correction (EMSC), wavenumber binning, smoothing and normalization on disease diagnosis using Raman spectroscopy and ML. We explore the use of EMSC in conjunction with other pre-processing methods and describe the effect on classification, and the isolated effect of pre-processing steps. A brief outline of each pre-processing is provided in the materials and methods section. While we apply these methods to Raman spectra, they are applicable to other forms of spectroscopy and have potential application beyond Raman.
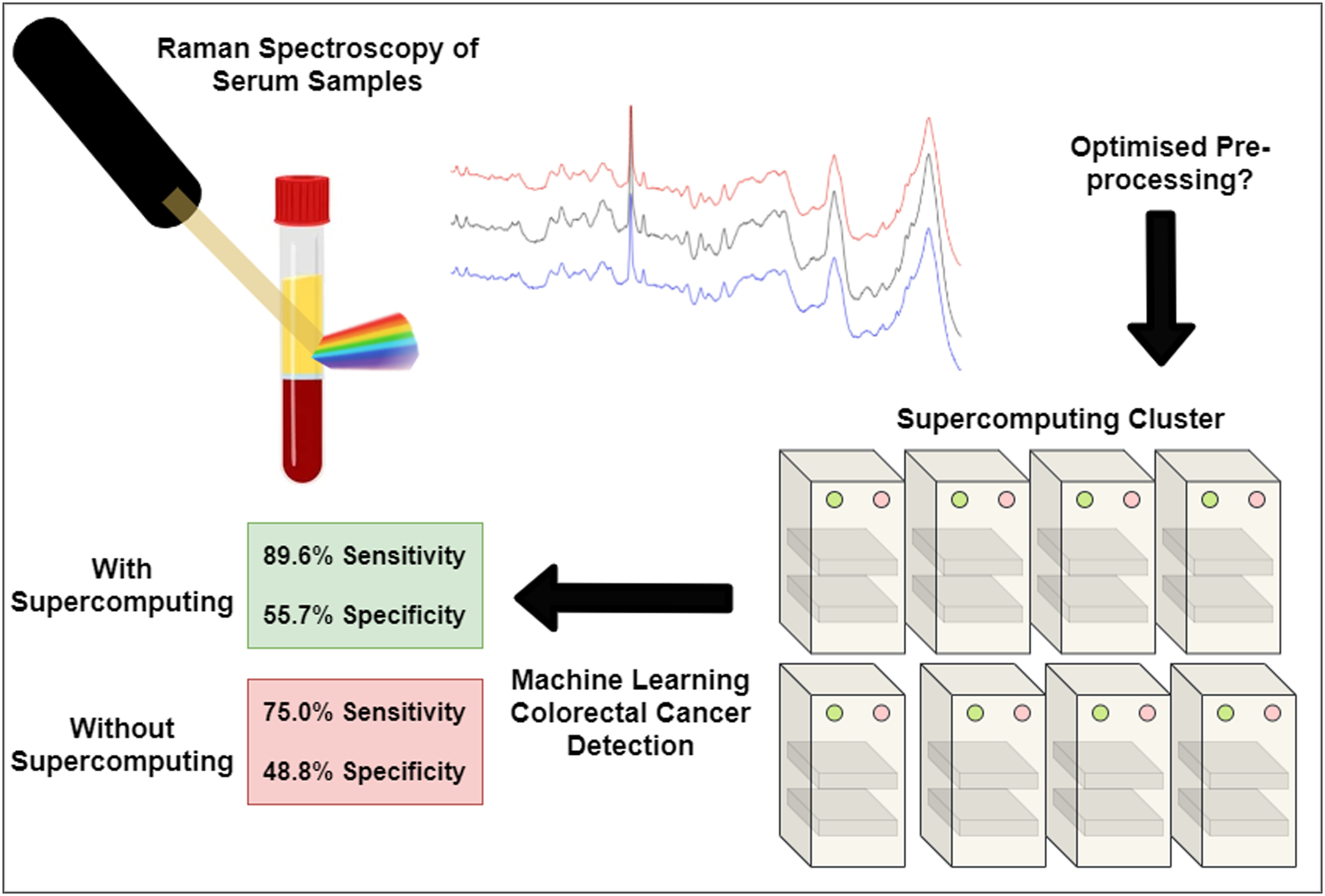
In order to demonstrate the application of HPC-based optimisation on the pre-processing of Raman spectra for algorithm building and ML diagnostics, we have utilised a data set from control and diseased patients (testing set, n = 102, training set n = 439). Our design is to maximise diagnostic performance of a random forest (RF) ML model due to the ability of RF tending to outperform other classification methods without issues of overfitting. 27 Standardising spectral pre-processing is a critical step, and the development of a method to achieve this and maximise diagnostic capability can see dramatic improvements in performance of > 20% sensitivity compared to using raw Raman spectra. We demonstrate here a method of exploiting HPC capabilities and the effect on diagnostic model performance with varying pre-processing choice.
Materials and Methods
Ethics Statement
Informed consent was obtained from all participants in the study prior to blood sample and data collection. Ethics approval was given through Wales Research and Ethics Committee (14/WA/0028).
Sample Collection and Preparation
Venous blood samples were collected from fasted patients in Vacutainer SST collection tubes (BD, USA). Whole blood samples were centrifuged and serum aliquoted via a standardised Swansea Bay University Health Board hospital laboratory workflow. Serum samples were stored at −80 °C until thawing for RS analysis.
Spectral Acquisition
All spectra were collected using a Reflex inVia Raman system (Renishaw, UK) with 785 nm laser excitation (diode laser). The Raman system was calibrated each day prior to data acquisition using an internal silicon reference to the peak at 520 cm−1, and spectra acquired from a polystyrene standard (Starna Scientific, UK) for wavenumber calibration. Intensity response calibration is applied using an external white light calibration (Ocean Optics, USA) performed every three months. Liquid serum samples (200 μl) were pipetted into a high-throughput acquisition platform as reported previously. 2 Samples were excited with 93 mW of laser power using a silica singlet objective (Thorlabs, USA) and five repeat spectra were collected per sample for the training set, and three repeat spectra for the testing set. Acquisition time for one spectrum was around 3 min. Cosmic rays have been removed from the serum spectra using Renishaw’s WiRE software during spectral acquisition.
High-Performance Computing
High-performance computing utilises a system of interconnected computers. Each node typically contains 8–40 cores which can be thought of as microprocessors. This means by parallelising scripts (calculations carried out simultaneously) to utilise full computational power, it is possible to run up to 40 permutations of different pre-processing combinations per node. The HPC system used in this study was the Swansea Sunbird Supercomputer which consists of 126 nodes, with 5040 cores in total with CPU: 2x Intel Xeon Gold 6148 CPU @ 2.40GHz with cores each; RAM: 384 GB per nodes and GPU: 8x Nvidia V100 GPUs. 28
Pre-Processing Methods
Figure 1 provides a visual description of the pre-processing methods trialled within this study. All spectra were processed using a pre-processing package PPRaman in R developed in-house and fed into bespoke batch scripts for HPC computations.
29
The methods investigated cover some of the most common techniques with a wide range of chosen parameters. Options for pre-processing permutations explored.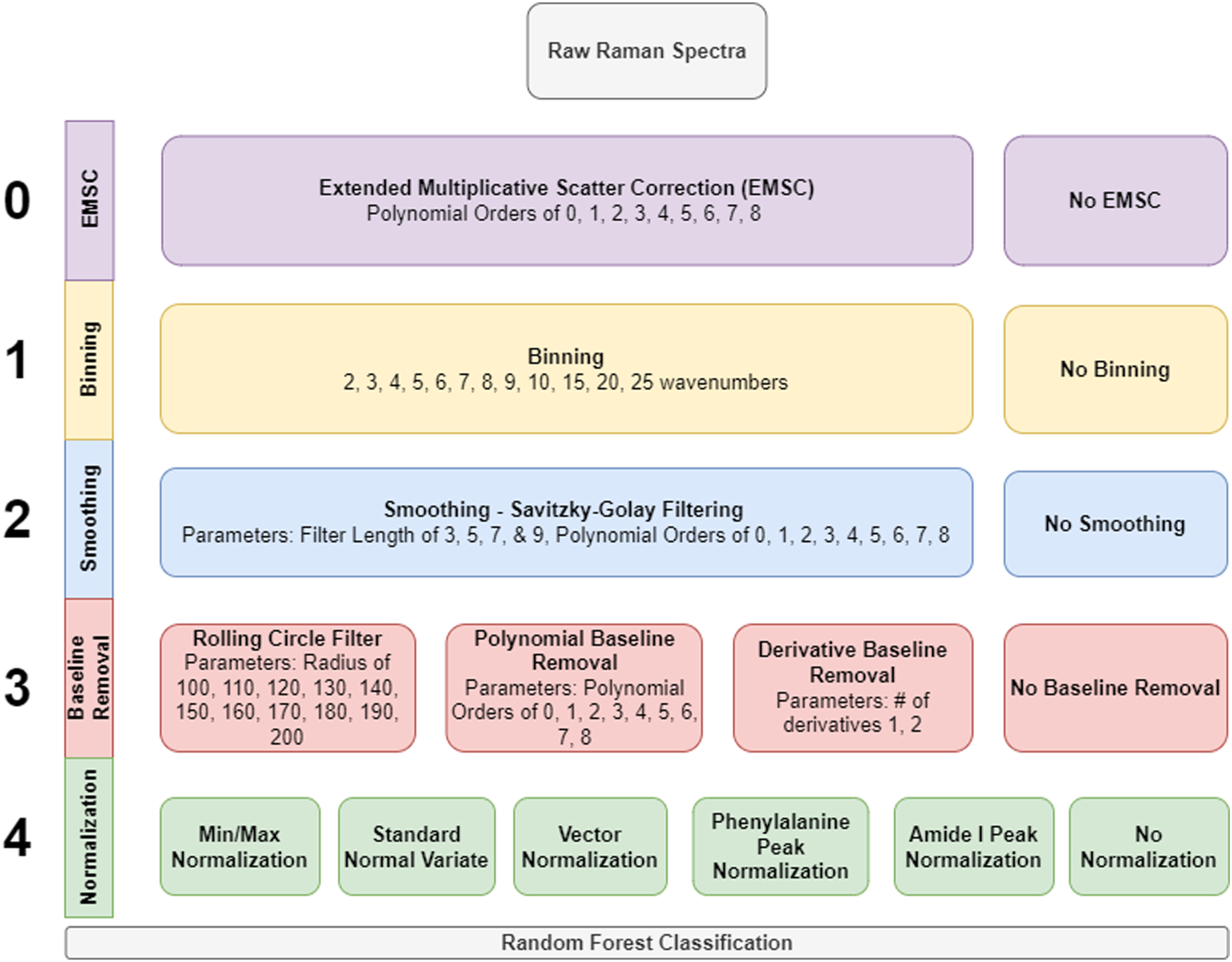
Extended Multiplicative Scatter Correction
Extended multiplicative scatter correction is a powerful method used in spectroscopy which allows for the separation of physical light-scattering effects from physical light absorbance effects. 30 EMSC provides a model-based approach for the correction of unwanted additive and multiplicative effects within spectra. It is used for various applications in Raman spectroscopy, from tracking metabolic products via EMSC coefficients, 31 as a pre-processing step,32–34 and recently enabling the removal of water from human blood serum. 35
Extended multiplicative scatter correction works by modelling the additive and multiplicative effects in a sample which are not indicative of the chemical fingerprint of the sample but external factors.
30
Briefly, for a single spectrum, x, the corrected spectrum xcor following EMSC with a d-order polynomial can be expressed as
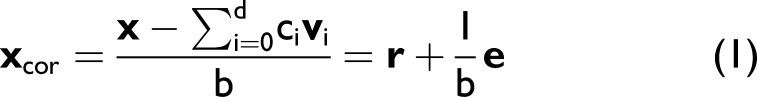
In addition to the standard EMSC model, one can include an “interferent” spectrum which can enable the specific removal of a contribution to the spectrum. 32 In this work, an interferent was chosen as the empty stainless-steel substrate to isolate the serum spectra further, reducing any varying fluorescent contribution from the substrate and objective lens. EMSC is often used as the entire pre-processing protocol since it scales and models the non-chemical effects in the sample. 37 We also trialled EMSC as a pre-treatment prior to other methods to study the effect on classification. All implementations of EMSC were performed using the R package, “EMSC”. 38
Data Binning
Wavenumber binning example with five data points averaged to produce one.

Smoothing
Spectral smoothing is the process in which noise is minimised in a data set by fitting a curve to replace the raw data thus increasing the signal-to-noise ratio. In this study, where the pre-processing sequence contains a smoothing step the Savitzky–Golay (SG) filter has been applied. 42 SG remains prevalent in spectroscopic analysis.40,43–45 SG functions by operating a sliding window along the data set and fitting a polynomial of order n to that window thus replacing spectra with a fitted polynomial of that window. SG is common in spectral analysis and due to having multiple tuning parameters is the only smoothing method trialled in this case.
Baseline Removal
Baseline removal is the process of removing any background contributions to the spectra from fluorescence without removing Raman features. In this study, three types of baseline removal have been trialled: rolling circle filter (RCF), polynomial baseline removal, and the use of spectra derivatives.
A rolling circle filter (RCF) is a background removal technique used in spectral pre-processing.46–48 RCF acts as a high-pass filter for the removal of background fluorescence which works by rolling under the spectra storing the minimum distance the between the circle and the data. 46 This is repeated and evaluated for shifted windows along the spectra, resulting in a list of the minimum distance between the circumference of the circle and the spectra which are then removed from the spectra as the background contribution. The RCF removes broad features from the spectra, thus maintaining the sharp characteristic Raman peaks. The tuneable parameter with the RCF is the radius of the circle, which is typically chosen such that broad features are effectively removed and such that the circle cannot ‘roll’ into Raman peaks, hence diminishing them.
Polynomial baseline removal is a common method in pre-processing of Raman spectra.45,49,50 A polynomial of n order models the broad background fluorescence by searching for support points beneath the spectrum and is subsequently subtracted aiming to leave behind only the chemical contributions from a sample. Polynomial baseline removal fits an n order polynomial to the spectra, aiming to remove broader features uncharacteristic of Raman while maintaining peak structures. The polynomial removal algorithm used in this study has been taken from the hyperSpec R package, 51 which iteratively searches for appropriate spectral regions to fit a baseline to remove using least squares. Here the tuneable parameter is the order of the fitted polynomial.
Derivative baseline removal involves taking the derivative of Raman spectra as a high pass method of filtering and is a common technique in data pre-processing.52–54 It can be highly effective in isolating the characteristically sharp peaks in Raman spectra from background contributions by focusing on stark changes in the spectra gradient. A drawback of using derivatives is an increase in apparent noise in a signal due to its nature of suppressing low frequency signals while enhancing high frequency signals. By taking the derivative of the measured response with respect to the wavenumber (or index), one can evaluate derivative of spectra, accentuating the maxima and minima indicative of the Raman effect. One can either take the first or second derivative to achieve this, both of which remove low frequency signals from the spectra as a high pass filter. The implementation in this study is via the Savitzky–Golay (SG) method which contains an option for derivative computation.
Normalization
Normalization aims to account for general intensity differences between spectral measurements e.g. due to relative concentration or laser power fluctuations. In this study, we trialled five types of normalization as well as an option of no normalization; min–max, min–max with the phenylalanine peak set to 1, min–max with the amide I peak set to 1, standard normal variate (SNV) and vector normalization. Min–max normalization is often used with spectroscopic data, 55 and can be focused on a particular region within the spectra to ensure a common peak is set to 1.56–58 We used the phenylalanine peak at 1004 cm−1, and the amide I peak at 1659 cm−1 in human blood serum as regions to scale spectra to. Standard normal variate (SNV) is another method used in the removal of multiplicative scattering effects, 59 and as a method for scaling spectra adjusts based on the mean and standard deviation of the spectrum.60,61 Vector normalization is also commonly used for normalization by scaling the spectra such that it sums to one.58,62,63
Performance Comparison Using Random Forest
Each pre-processing permutation was assessed using a random forest (RF) classification algorithm. 64 Briefly, RFs build an ensemble of random decision trees, in this case 500, and uses the average result of the cohort as the final classification of the given spectra. RF is an example of a supervised learning algorithm in which the classification of a training sample is given to provide a model target, as opposed to unsupervised in which the classification of training samples is not given in model development. In RF, the number of descriptors (variables) used to determine the classification is set to the square root of the number of wavenumbers in the data set (n.b. this value may vary depending on pre-processing due to changes in data shape after pre-processing steps). These factors equate to an out-of-the-bag/default RF implementation using the R package “randomForest”, based on the original Breiman algorithm. 64 RFs are prevalent in spectroscopy,65–67 tending to perform well without hyperparameter tuning and having the ability to extract feature importance which can be indicative of biomarkers in studies such as this. We also compare a subset of pre-processing permutations (including the top performing and bottom performing) using a support vector machine (SVM) model with linear, radial and polynomial basis functions included in the appendices to emphasise RF superiority in this context.
To train a RF model for colorectal cancer (CRC) detection, a training set containing 510 spectra from 102 patients (51 CRC, 51 control) was used with five repeat measurements each. Example raw spectra from human blood serum can be found in Jenkins et al. 2 An independent testing set containing 1317 spectra from 439 patients (32 CRC, 407 control) with three repeat measurements was used to evaluate the model performance for each pre-processing permutation. The distribution of CRC and controls within the independent testing set is reflective of a symptomatic patient cohort presenting in primary care and receiving referral for further investigation. Diagnosis of all patients in the training and independent testing set was confirmed via the gold standard for colorectal cancer, i.e., by colonoscopy. 68 Colonoscopy has a miss rate of up to 4%, which corresponds to a sensitivity of 96%.69,70 100 implementations of the RF algorithm were trained and tested per pre-processing permutation with the average predicted probability of a spectra classifying as CRC or control taken. The cut-off probability for CRC/control was set to a default of majority rule (> 0.5 for either CRC or control).

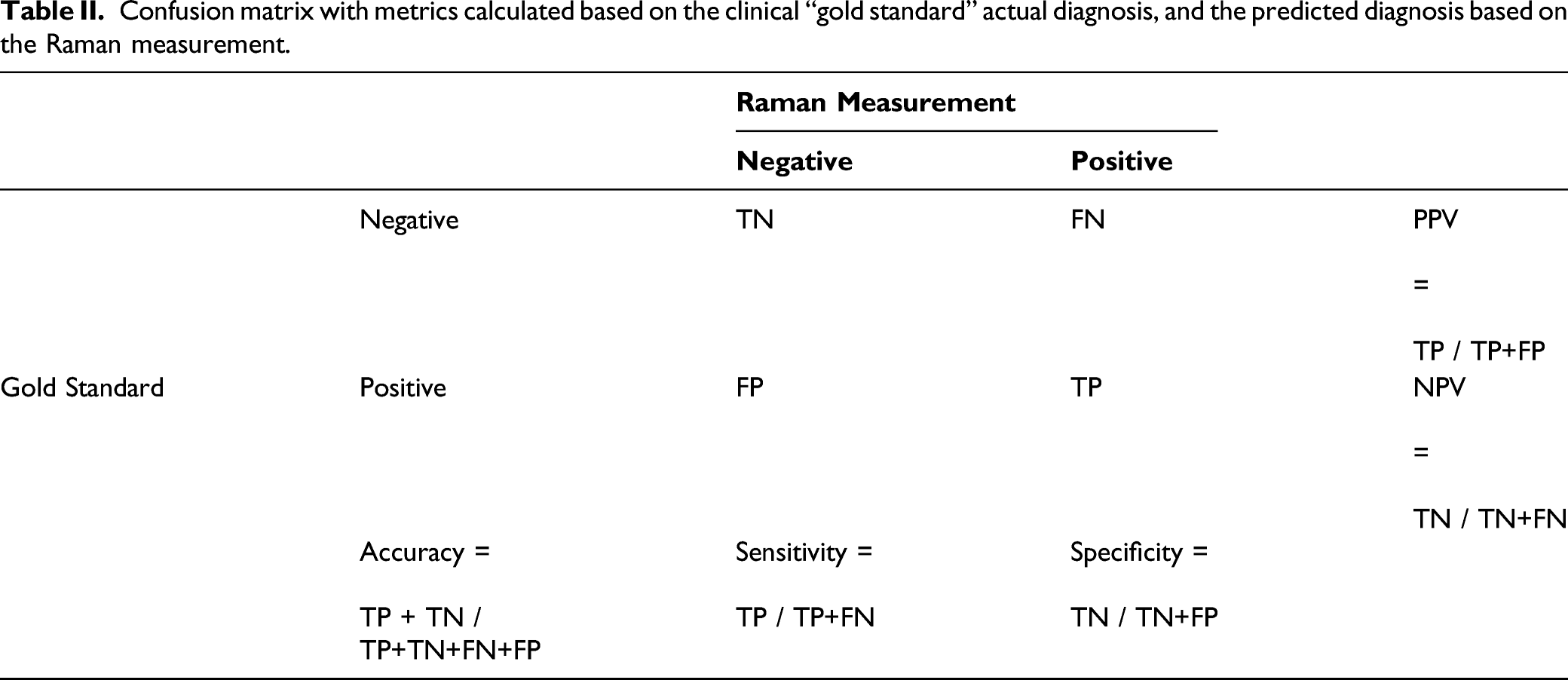
Confusion matrix with metrics calculated based on the clinical “gold standard” actual diagnosis, and the predicted diagnosis based on the Raman measurement.
With a maximum possible value of 6. A score of 3 indicates a model with no distinguishing capability (i.e., 50%/0.5 for all values). However, prevalence of disease can affect the score, and in this study, a prevalence of ∼7% CRC meaning a score of ∼3.75 performs well.
Analysis of pre-processing permutation performance included ascertaining general trends observed and the effect individual pre-processing steps have on performance. General trend analysis included PPV NPV qualitative analysis, with a focus of the effect EMSC has on PPV and NPV on a global scale.
To select the top performing pre-processing method, the results were thresholded to obtain permutations with a sensitivity of ≥ 75% and a specificity of ≥ 50% to filter out any which do not meet this minimum requirement. In this scenario, the data are representative of a symptomatic primary care patient population with the goal of using the model as a triage tool for referrals and hence CRC prevalence in the test set is ∼ 7%. High sensitivity is favourable for a test to correctly identify CRC patients, but a trade-off with specificity (ability to correctly identify controls) must be negotiated. 72 These thresholded permutations were then sorted to maximise the Score given in Eq. 2 to find the top performing pre-processing permutation.
Over 2.4 m pre-processing permutations in sequences shown in Fig. 1 have been tested to optimise the pre-processing methodology for RS CRC diagnosis using HPC. First, we explore the effect of each permutation on sensitivity and specificity, and a deeper analysis into the top performer using EMSC as a pre-treatment in comparison to EMSC alone. We then observe general trends for pre-processing steps on sensitivity and specificity and on the variance observed in the score metric (Eq. 2) when fixing all other pre-processing steps. The top pre-processing method is then compared to a result using no pre-processing, a standard pre-processing procedure with minimal optimisation, EMSC as a standalone method, and the worst performance we observed.
Results
Extended Multiplicative Scatter Correction Effect on Sensitivity and Specificity.
In Fig. 2, we observe a sample of ∼ 10% of the full results data set for PPV versus NPV for plotting efficiency while maintaining the top and bottom 1000 performers. Points in Fig. 2 are coloured by whether EMSC has been used as a pre-treatment or not to demonstrate general behaviour. The cone structure appears due to the “allowed” solutions given the number of patients in each category (TP, TN, FP, FN). The use of EMSC qualitatively causing PPV and NPV to fan out to the corners of the cone, unlocking regions with higher PPV results. Sensitivity vs. 1-Specificity for a sample of ∼10% of the trialled pre-processing permutations with top 1000 and bottom 1000 maintained. Spectra are coloured by whether extended multiplicative scatter correction has been used as a pre-treatment (blue) or not (red).
Top Performing Pre-processing Method
Pre-processing ID key for top 15 permutations.

Sample of results from high-performance computing pre-processing optimisations including the top performing method in the first row (1423-EMSC-3-B-5-S-9-1-RCF-120-nor-m-˙a), the worst performing pre-processing method in the bottom row (1324-6-NO-˙EMSC-2-B-S-5-RCF-200-norm-˙a), and a sample of other methods in between.
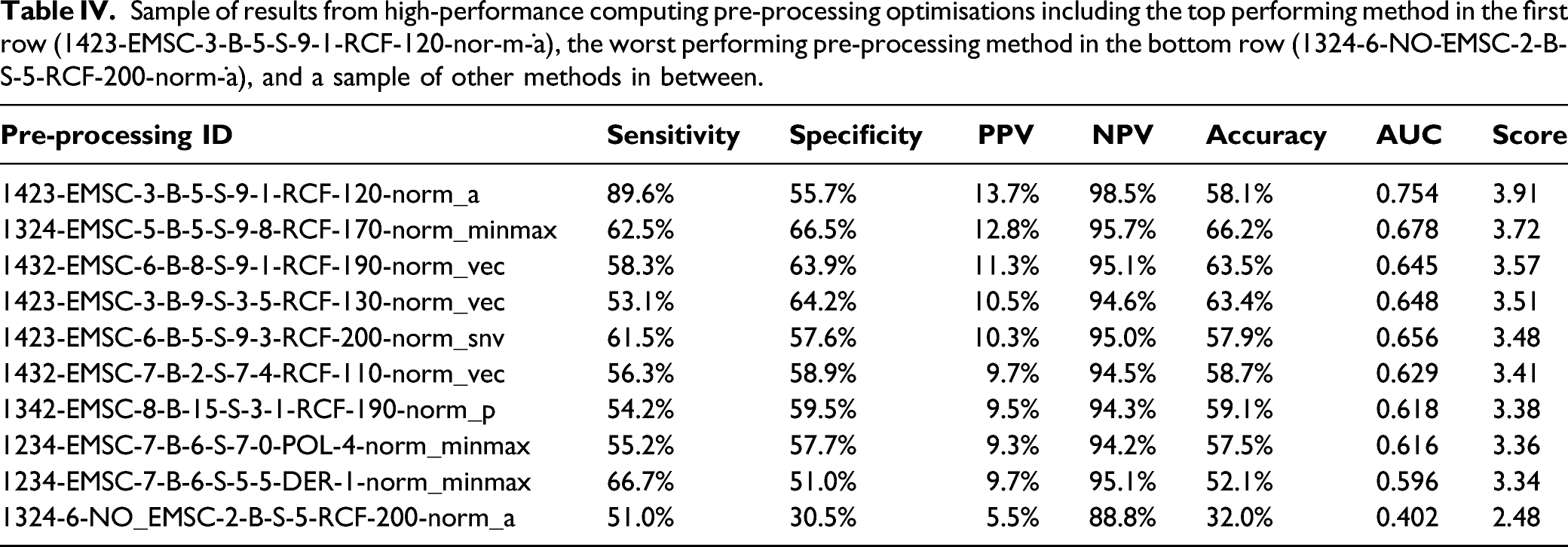
When focusing on only the top 100 pre-processing permutations, the Score metric varies by at most by 0.1, that is, 10% in total across all performance metrics. Only one pre-processing method arises in the majority (
General Trends
Figure 3 demonstrates a random sample of ∼10% of pre-processing methods trialled and their corresponding sensitivity and specificity, in this case, coloured by baseline correction technique. The use of the derivative for baseline correction of spectra tends to perform with low PPV, with only a few permutations appearing more centrally in the cone. RCF and polynomial baseline removal dominate the thresholded region which focuses on results with sensitivity ≥ 75% and specificity ≥ 50%, however a small number of derivative implementations also perform in this region too. Pre-processing permutations trialled coloured by baseline correction algorithm. The plot contains ∼ 10% of the full cohort of pre-processing permutations for plotting efficiency. Zoomed in region is thresholded with sensitivity ≥ 75% and an specificity ≥ 50% and contains all data points that meet this criteria (∼800 000).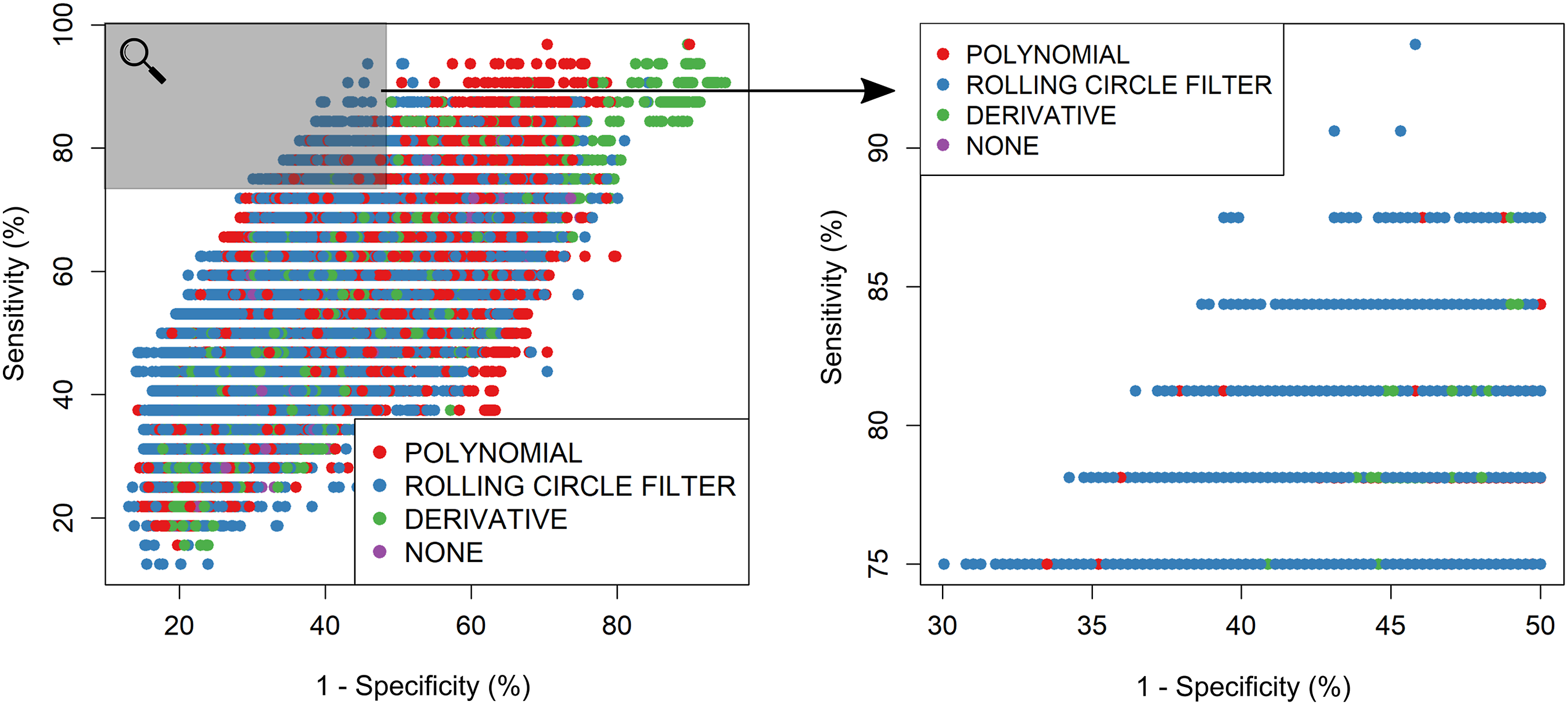
In Fig. 4, we observed the standard deviation in the score (Eq. 2) for each pre-processing step or ordering when all other steps are fixed, isolating the change in score to only one step. This is computed by grouping together pre-processing IDs with the step we wish to vary not included and hence computing the standard deviation of the score in the group. EMSC affects the score-value the highest on average, which is to be expected due to the nature of EMSC modelling spectra to a reference, and hence altering the raw spectra immediately. Baseline correction and ordering of pre-processing then have the next highest effect on Score on average, and notably the order of pre-processing sees some large outlying effects on scores. Binning spectra also causes significant outliers, with deviations up to 0.4 in score metric. Normalization typically has a small effect on average, however, does have large outliers which is overwhelmingly due to the normalization step coming before other pre-processing steps. Smoothing has the smallest effect on average which may be due to the type of data trialled in this study, that is, Raman spectra from human blood serum where the average of the training set is 31 ± 24 computed from the mean intensity divided by standard deviation between replicate spectra.
73
An example of serum spectra with varying SNR is shown in the Supplemental Material. Variance in the Score when altering a single step in the process while fixing all other parameters. Smoothing has the smallest effect when fixing other parameters and the ordering sees the largest spread.
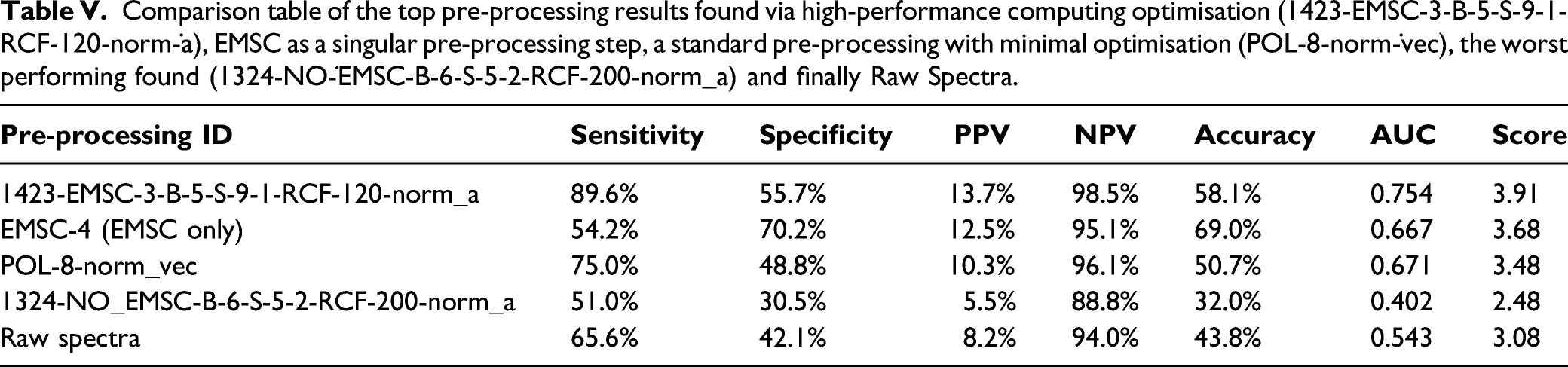
Comparison table of the top pre-processing results found via high-performance computing optimisation (1423-EMSC-3-B-5-S-9-1-RCF-120-norm-˙a), EMSC as a singular pre-processing step, a standard pre-processing with minimal optimisation (POL-8-norm-˙vec), the worst performing found (1324-NO-˙EMSC-B-6-S-5-2-RCF-200-norm_a) and finally Raw Spectra.
Conclusion
Choice of pre-processing in RS is a task with many variables from instrumentation, to sample type, to task at hand and a lack of consensus in the community leads to time-consuming trial and error optimisations. In this contribution, we have explored the use of HPC for the task of optimising spectral pre-processing with a disease diagnostic aim.
Over 2.4 million different permutations of pre-processing have been trialled to understand the effect of reordering pre-processing, using EMSC, binning of wavenumbers, SG smoothing, baseline correction, and normalization. We have found EMSC in conjunction with other pre-processing steps to obtain the highest performance with sensitivity of 89.6%, specificity of 55.7%, PPV of 13.7% and NPV of 98.5% in comparison to using EMSC as a standalone pre-processing achieving sensitivity of 54.2%, specificity of 70.2%, PPV of 12.5%, and NPV of 95.1%. EMSC is typically used as a comprehensive pre-processing technique which we find to improve performance when used in conjunction with other pre-processing techniques to smooth, bin, baseline correct, and normalise. EMSC is reliant on representative reference spectra to model all other spectra to. In this study, the reference spectra have been set to average spectra, a common choice. Other options have been studied, however it has been noted the reference choice is not important but must remain consistent. 74 In a regime using minimal pre-processing optimisation, a sensitivity of 75.0%, specificity of 48.8%, PPV of 10.3% and NPV of 96.1% is achieved. However, due to the small training set used in development, the top pre-processing established may be finding a non-scalable solution. Future work will re-optimise pre-processing with a larger training set.
While this study is specifically targeted to optimise model performance for diseased and non-diseased state classification, the aim is to demonstrate a methodology for approaching similar tasks where consensus has not been met in the community. Optimal pre-processing may vary depending on task, instrumentation (Raman instrument, objective, laser, etc.) and on sample/substrate and hence should be repeated for new tasks.
In this study we have exploited HPC, however it is possible to achieve significant improvements in model performance using local scripts for optimisation of pre-processing. We cover a wide range of pre-processing parameters to understand the edge cases but searching in a smaller parameter space can still be of benefit, particularly if paired with parallelisation of one’s local computer.
In the case where a supercomputer is not available for use, the authors have the following recommendations; ordering of pre-processing is not important as long as the baseline correction algorithm is scaling to the data. Smoothing may be skipped, or just fixed if it is necessary for the data set due to the small effect over many different parameters. Binning with large wavenumbers can produce a large variance between different permutations, hence keeping this below 10 should be sufficient for systems with similar spectral resolution (∼0.5 cm−1).
High-performance computing offers a powerful tool for data processing and optimisation, in this case utilised to optimise RS pre-processing of blood serum samples for disease detection. Harnessing supercomputing capabilities unlocks the ability to generate and analyse large quantities of data rapidly which can enable optimisation of computations with ease. While this study has focused on a Raman data set for disease detection, the methodology set out can be applied to other applications and other spectra-type data sets for improved model classification ability or other relevant measures of performance.
Supplemental Material
sj-pdf-1-asp-10.1177_00037028221088320 – Supplemental Material for Optimised Pre-Processing of Raman Spectra for Colorectal Cancer Detection Using High-Performance Computing
Supplemental Material, sj-pdf-1-asp-10.1177_00037028221088320 for Optimised Pre-Processing of Raman Spectra for Colorectal Cancer Detection Using High-Performance Computing by Freya E. R. Woods, Cerys A. Jenkins, Rhys A. Jenkins, Susan Chandler, Dean A. Harris and Peter R. Dunstan in Applied Spectroscopy
Footnotes
Declaration of Conflicting Interests
The author(s) declared the following potential conflicts of interest with respect to the research, authorship, and/or publication of this article: PRD, DAH and CAJ declare their involvement in CanSense Ltd, a recently incorporated cancer diagnosis spin-out company from Swansea University (company no. 11367637).
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work has been funded through a PhD studentship by Cancer Research Wales (Registered Charitable Incorporated Organisation Number: 1167290) to whom we are grateful for continued support. The authors wish to acknowledge the support of the Supercomputing Wales project, which is part-funded by the European Regional Development Fund (ERDF) via the Welsh Government.
Supplemental Material
All supplemental material mentioned in the text is available in the online version of the journal.
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.