
Abstract
Chylous blood is the main cause of unqualified and scrapped blood among volunteer blood donors. Therefore, a diagnostic method that can quickly and accurately identify chylous blood before donation is needed. In this study, the GaiaSorter “Gaia” hyperspectral sorter was used to extract 254 bands of plasma images, ranging from 900 nm to 1700 nm. Four different machine learning algorithms were used, including decision tree, Gaussian Naive Bayes (GaussianNB), perceptron, and stochastic gradient descent models. First, the preliminary classification accuracies were compared with the original data, which showed that the effects of the decision tree and GaussianNB models were better; their average accuracies could reach over 90%. Then, the feature dimension reduction was performed on the original data. The results showed that the effects of the decision tree were better with a classification accuracy of 93.33%. the classification of chylous plasma using different chylous indices suggested that the accuracies of the decision trees model both before and after the feature dimension reductions were the best with over 80% accuracy. The results of feature dimension reduction showed that the characteristic bands corresponded to all kinds of plasma, thereby showing their classification and identification potential. By applying the spectral characteristics of plasma to medical technology, this study suggested a rapid and effective method for the identification of chylous plasma and provided a reference for the blood detection technology to achieve the goal of reducing wasting blood resources and improving the work efficiency of the medical staff.
This is a visual representation of the abstract.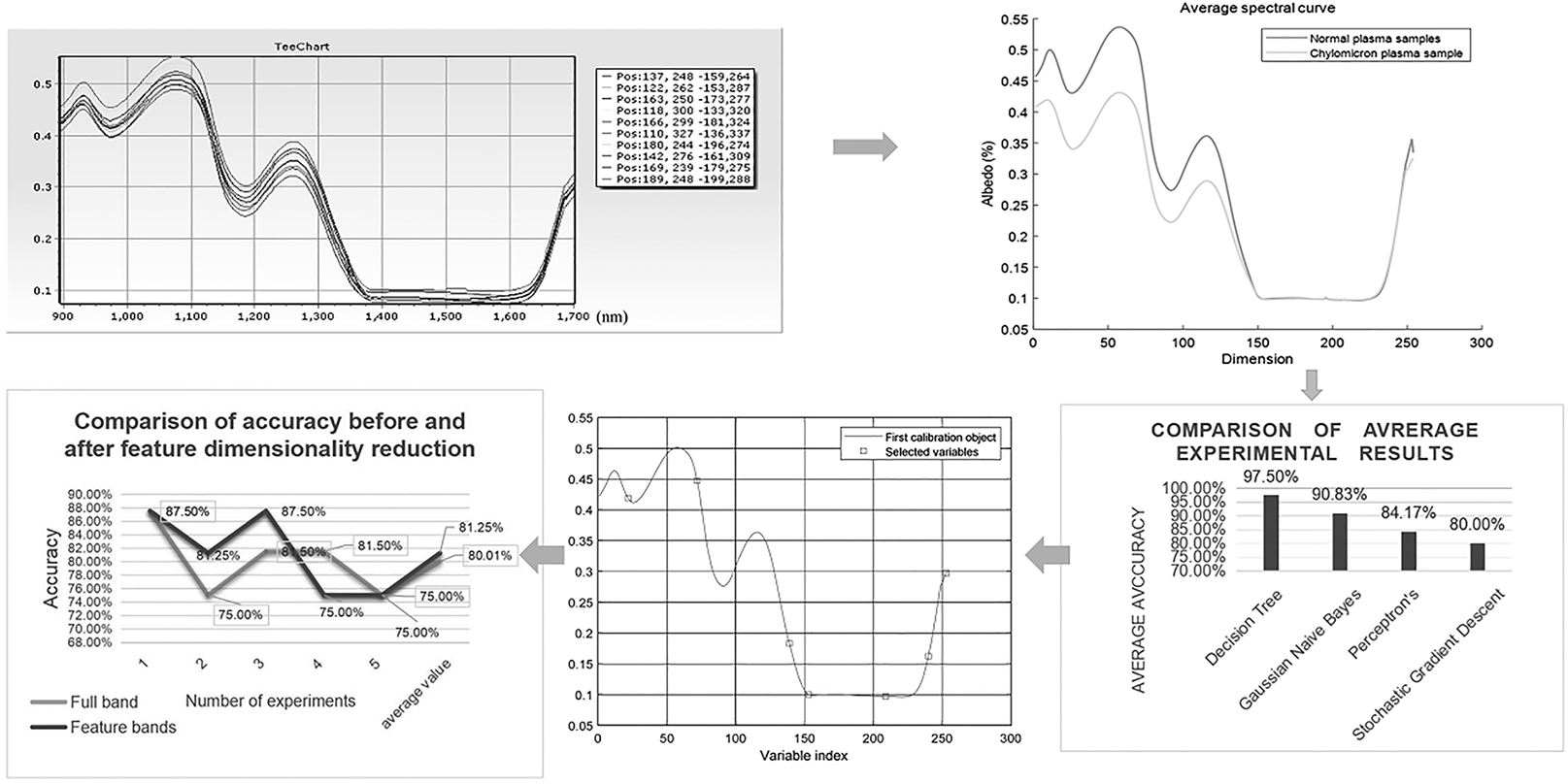
Keywords
Introduction
Currently, the lifespan of modern people is constantly improving, but the lifestyle is getting unhealthy. A large amount of high-fat content food is being consumed in daily life, which in combination with a lack of exercise results in a large amount of fat accumulation in the body, 1 thereby increasing the fat content in blood. 2 The increase in blood fat contents makes the blood plasma appear milky white or cloudy, thereby forming chylous blood. 3 Chylous blood should not be used for clinical purposes. 4 Its injection into the patients causes adverse reactions, such as allergy, fever, and fat embolism, 5 thereby further harming the patient. Therefore, a convenient and fast method for differentiating between chylous and normal healthy blood should be urgently developed. 6
Currently, the direct and accurate method for differentiating between chylous and normal healthy blood includes the detection of plasma components and identification of chylous blood by components. Although the results are very accurate, it is a time-consuming process. The detection of a single component takes about 5 min, thereby greatly reducing the detection efficiency and failing to meet the current detection requirements. 7 However, the detection methods for chylous blood, which are based on machine vision and image analysis, have also been widely used and can improve detection efficiency. However, the detection method based on image analysis is limited to the calculation of image grayscale values and can easily be affected by background noise, resulting in inaccurate detection results. 8 Hyperspectral imaging is a combination of imaging and spectral technologies and is based on a very large number of narrow-band imaging data. It detects the two-dimensional geometric space and one-dimensional spectral information of the target object and obtains continuous and narrow-band imaging data with high spectral resolution. 9 Therefore, this technology has near-continuous spectral information, and after spectral reflectance reconstruction, the hyperspectral images can obtain the near-continuous spectral reflectance curve of the measured sample; this data matches the actual measured value of the object. 10 The hyperspectral data can be used to determine the absorption spectral characteristics of a sample, thereby accurately determining the components of the sample. 11 Visible light and near-infrared spectroscopy has been shown to human blood to identify effectively, and studies of the reflection spectrum are being used to identify human blood. 12
Currently, studies on the use of hyperspectral imaging technology for the identification of chylous blood are lacking. In this study, hyperspectral technology was used to identify the chylous plasma and the detection results could not be easily disturbed by external noise, thereby improving the detection efficiency. A full-band hyperspectral sorter was used to obtain the rich spectral data from plasma samples as well as their reflectance to each band. The normal plasma and chylous plasma were distinguished by the differences in their reflectance, and the chylous plasmas with different chylous indices (CIs) were further divided. A method for detecting blood spots in light brown eggshells on the basis of hyperspectral transmission image is reported. Five feature wavelengths of intact eggs selected by the successive projections algorithm and three absorption peak locations of eggshells were regarded as characteristic bands to obtain better results. 13 The feature dimensions of the data were reduced, and the characteristic bands were selected to classify the samples, which greatly reduced the calculation amount and detection time, thereby obtaining an accurate classification effect and greatly improving the detection efficiency. Using hyperspectral imaging technology for the identification of chylous blood does not require medical reagents and other instruments to identify the blood components. Moreover, there is no need to worry about blood contamination caused by sample collection. The medical staff can easily perform numerous blood identification tests, thereby greatly reducing the waste of material and human resources.
Experimental
Materials and Methods
A GaiaSorter (Specim) (Figure S1, Supplemental Material) was used in this study, which is a core component of the Gaia hyperspectral sorting instrument and a high-performance ground object hyperspectral scanning system with a wavelength, covering 400–1000 nm and 900–1700 nm.
Data Collection Methods
In the first step, a total of eight bags of plasma were used for sampling, including four chylous and four healthy plasma samples, which were collected and vacuum-packed in Ganzhou Central Blood Station, Ganzhou, China. In the second step, the plasma samples with different CIs, including 12 bags of plasma with CIs of 7, 8, and 9, were collected, as shown in Figure S2 (Supplemental Materials).
On the left, the numbers 2–5 and 6–9 represent the normal and chylous plasma samples, respectively. On the right, the first one is a normal plasma sample while the other three are chylous plasma samples with CIs represented as numbers 7, 8, and 9.
Data Pre-Processing
Before data acquisition, the instrument was turned on and preheated for 30 min to eliminate the effects of baseline drift. Then, the forward and backward speeds of the mobile radio were set to 1.6 and 2 cm/s, respectively. Furthermore, the camera exposure time and region of interest band were set to 19.1 ms and 895.91–1700.97 nm, respectively. The plasma samples were manually placed on a mobile platform for collection. The black and white calibration was performed to eliminate the effects of uneven illumination and dark current.
14
The lens cover was put on to collect the blackboard “H” and removed to collect whiteboard “B,” obtaining the original data image “I.” The black and white calibrations were calculated according to Eq. 1:

Due to the small amount of plasma sample data, 10 sample points need to be collected for one plasma sample. Moreover, the sample is a viscous fluid packed in vacuum, which cannot make the plasma volume at each position the same. Therefore, the method of regional average is adopted to approximately achieve more accurate sample point data. For the random regions, their average data were selected as sample point data. The plasma distribution in the selected regions was relatively uniform, as shown in Figure S3 (Supplemental Material).
A first data set was built using the 80 collected samples, which were randomly divided into a training set (70%) and test set (30%) and labeled as “1” and “0” for normal and chylous plasma samples, respectively. The second collected 120 plasma samples were randomly divided into a training set (80%) and a test set (20%). The samples with CIs of 7, 8, and 9 were labeled as “0”, “1”, and “2”, respectively.
Data Analysis Methods and Evaluation
Machine Learning Algorithms
In this study, four machine learning algorithms were used to test the model with the collected hyperspectral data sets, and the most suitable model was selected by comparing the results. The models included decision tree, 15 Gaussian Naive Bayes (GaussianNB), 16 perceptron, 17 and stochastic gradient descent. 18
Decision Tree Model
The decision tree model is a tree diagram, which consists of decision points, survey points, and results. The benefit values of various schemes under different conditions were solved graphically by taking the maximum expected revenue or minimum expected cost as the decision criteria, and the decision was made by comparison. This experimental model used the feature weight calculation method based on Gini gain. The specific methods were as follows. First, the increase in impurity in the feature fork was calculated in each tree. Second, if there were multiple trees, the mean value of impurity improvement in each feature was calculated. Third, the mean value was used as the feature weight.
Gaussian Naive Bayes (GaussianNB)
The GaussianNB model estimates the conditional probability value of each category in each feature using the Gaussian distribution of the probability of obtaining eigenvalue Xi. For any value of Y, Bayes aims to solve for the maximum P(Xi|Y) to identify the category to which the samples are closer under different labels. GaussianNB was calculated according to Eq. 2:
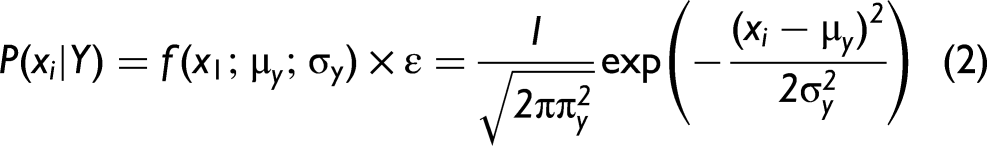
Perceptron
Perceptron corresponds to a separated hyperplane, which divides the features into positive and negative categories in the feature space. Perceptron is represented as a mapping function from the input space to the output space, as given in Eq. 3:
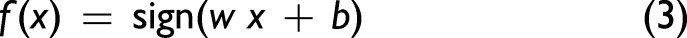

Stochastic Gradient Descent
The stochastic gradient descent model is an effective and simple method for the discriminant learning of linear classifiers under the convex loss function. The SGDClassifier was used to execute a common stochastic gradient descent program for obtaining a well-fitted model. Then, the fitted model was used to predict the new value.
Feature Dimensionality Reduction Method
The collected hyperspectral data included a data set with 254 bands. There might be a large amount of redundant data in this high-dimensional data; this redundancy was avoided by reducing the feature dimension using the continuous projection method. The continuous projection algorithm is a forward iterative search method,
19
starting from the wavelength, and adding a new variable in each iteration until the number of selected variables reaches the set value of N. The algorithm is performed in the following steps:
The initial iteration vector and number of variables to be extracted were denoted as xk(0) and N, respectively, and the spectral matrix was J columns. One column of the special matrix was selected and assigned as xj, denoting xk(0). The unselected column vectors were denoted as: The projection of xj on the remaining column vectors was calculated. The spectral wavelength of the maximum projection vector was extracted. Steps (iii), (iv), and (v) were repeated for n = n + 1 and n < N.
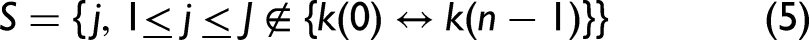
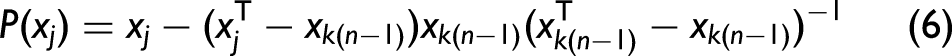
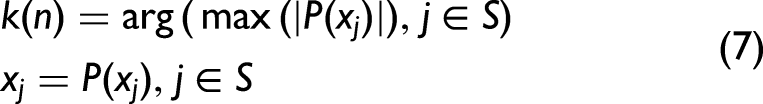
After the wavelength combination was obtained corresponding to k(0) and N in each cycle, the prediction model was established, and the xk(0) and N corresponding to the minimum root mean square error (RMSE) were taken.
Model Evaluation Method
In this study, two methods were used for the evaluation of the model. One method drew the receiver operating characteristic (ROC) curve of the model and calculated the area under the ROC (AUC) values, 20 while the other calculated the recall rate and compared the model performance to evaluate the model. 21
The ROC curve of the model was drawn, and the evaluation method of AUC value was calculated, which was suitable for the performance evaluation of normal and chylous plasma classification models.
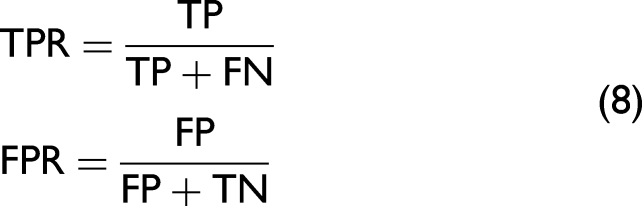
A new set of false positive rates (FPRs) and true positive rates (TPRs) were obtained by selecting the different thresholds each time. The ROC curve could be drawn by taking the FPRs as the abscissa and TPRs as the ordinate. The TPRs and FPRs were calculated as given in Eq. 8:
In the second method, for calling the model recall function, the default value of the parameter “average” was changed to “Macro”. This evaluation method was applied to models for differentiating between the different CIs. This method first calculated the recall for each category, and then calculated the average value as the final recall of the model (Recall), which was calculated as given in Eq. 9:

Results and Discussion
Separability of Plasma Samples
The spectral data of 80 sample points were collected and exported to tables, and the spectral curves of various samples were respectively viewed, as shown in Figures 1a and 1b.
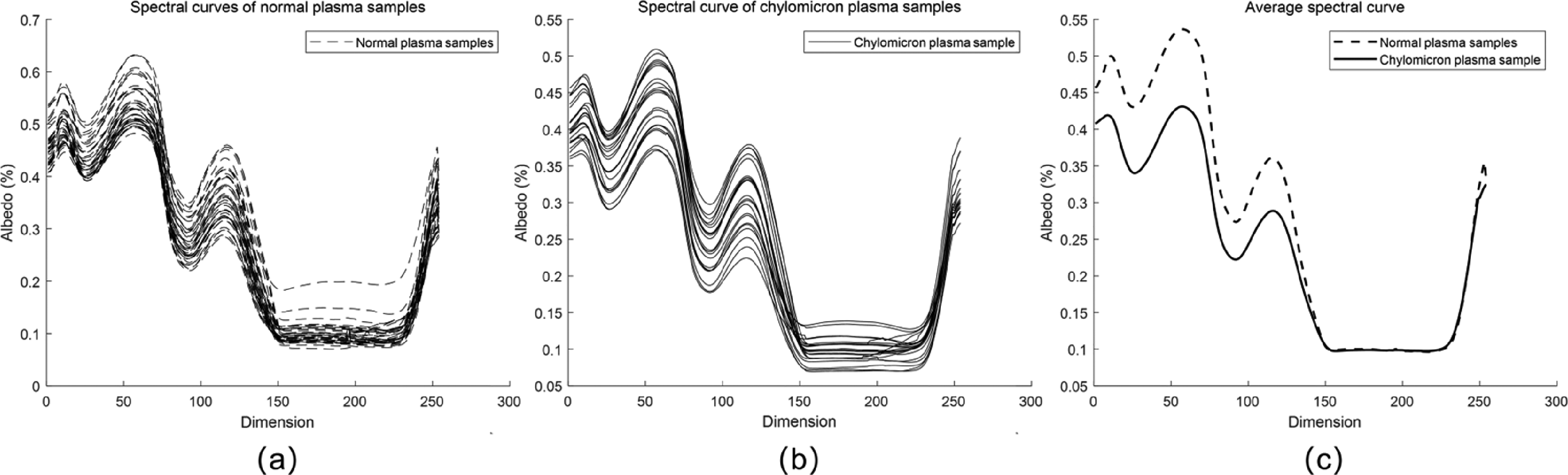
(a) Spectral curves of the normal plasma samples. (b) Spectral curves of the chylous plasma samples. (c) Mean curve of the spectral data between the normal and chylous plasma samples.
The results showed that the variations in trends in the spectral curves of all the plasma samples were roughly similar, and obvious wave peaks could be observed with relatively clear spectral characteristics. The average spectral curves of various samples were obtained, as shown in Figure 1c.
The first 150 characteristic bands showed significant differences between the reflectance of normal and chylous plasma; the reflectance of normal plasma was higher as compared to that of chylous plasma in each band. These results showed that the classification based on plasma spectral reflectance was feasible.
Analysis of the Results of a Plasma Classification Model
Normal and chylous plasma were classified using the first collected data set. Classification effect comparison of different models, set up the same random number in the function, to ensure the consistency between the training set and testing set. In each experiment using different random numbers reduces the happening of the accident.
The effects of each model are presented in Figure 2. The accuracies of the decision tree, GaussianNB, perceptron, and stochastic gradient descent models were 95.83%, 91.67%, 79.17%, and 75%, respectively.
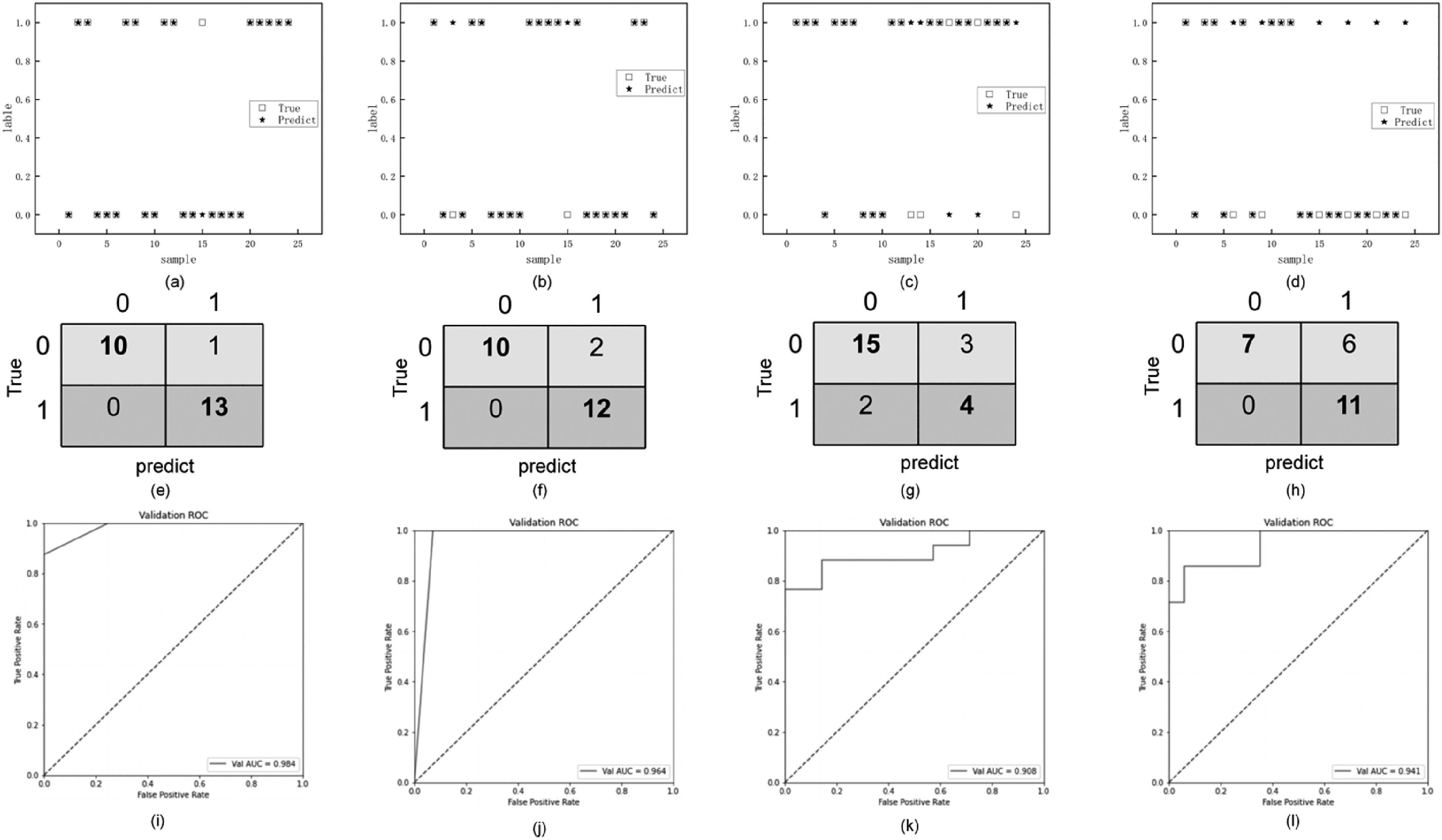
Comparison between the classification results of each model and the real results.
Figures 2a–2d show the comparison between the classification results of each model and the real results. The pink five-pointed star and blue circular patterns represent the predicted and real results. The results showed a successive decrease in the classification effects. The confusion matrix of each model was drawn to compare the classification results of the models more intuitively, as shown in Figures 2e–2h. The results presented by the confusion matrix further confirmed that the classification effects of decision tree, GaussianNB, perceptron, and stochastic gradient descent showed sequentially decreasing results. The ROC curve was drawn based on the confusion matrix to obtain the AUC values and evaluate the prediction ability of the model, as shown in Figures 2i–2l. The AUC value of the decision tree was the highest, which indicates that this model has the best prediction.
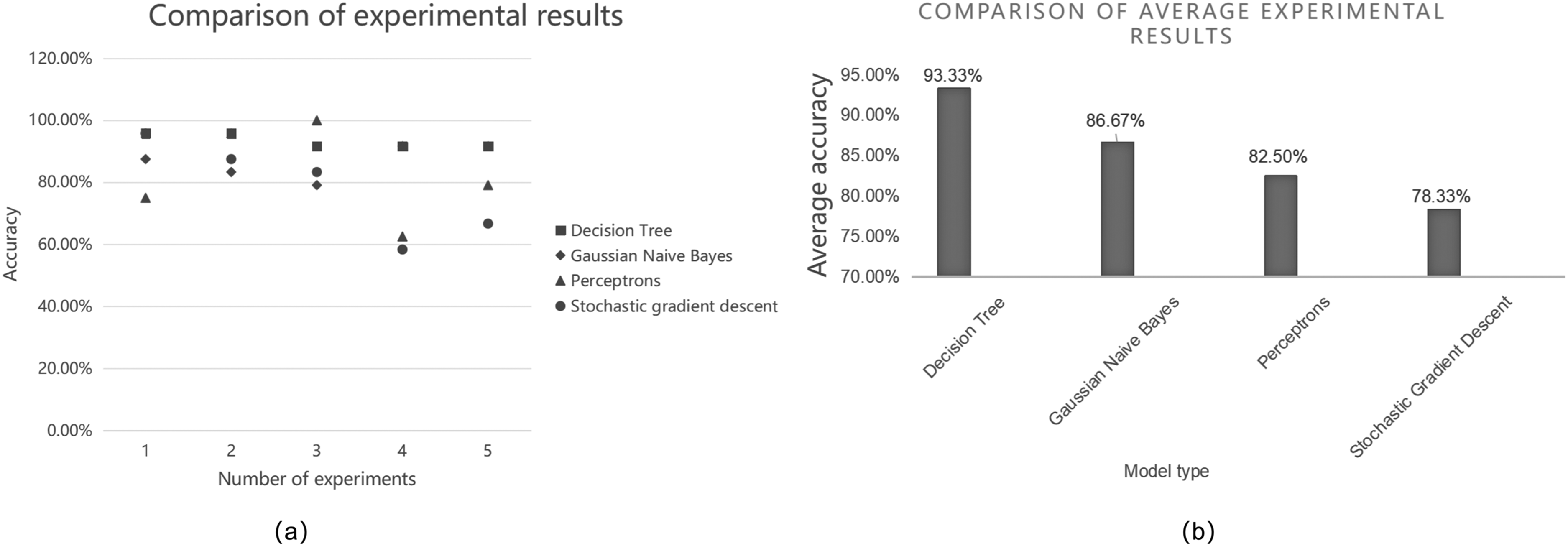
In order to reduce the contingency of the training process, five experiments were performed on the model, and the results of each time were compared, as shown in Figure 3a.
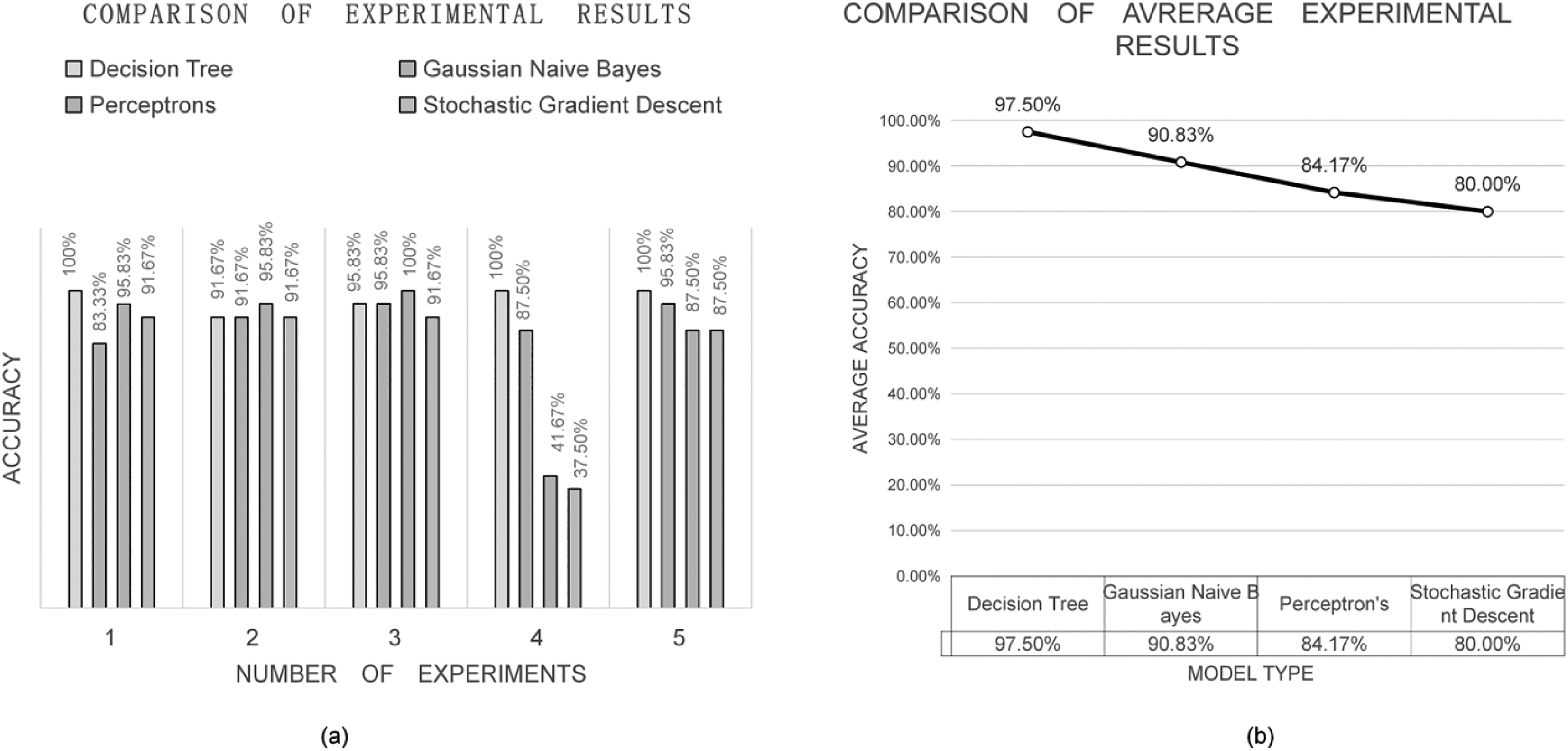
(a) Comparison of the results of five experiments. (b) Comparison of the training results with mean values.
The accuracy of the decision tree was the most stable and high in each experiment. Moreover, the accuracies of other models decreased significantly in the fourth experiment, showing high instability. In order to demonstrate the model effects more comprehensively, the results were compared with the mean values, as shown in Figure 3b.
Among the models, the decision tree exhibited high accuracy, while that of the other three models decreased. The good effect of the decision tree was largely due to its high stability, showing good results in all the experiments.
Analysis of the Effects of Feature Dimension Reduction on the Model
The originally collected data contained 254 bands. The feature dimensions were reduced using the continuous projection method. The results after dimensionality reduction are shown in Figure 4.
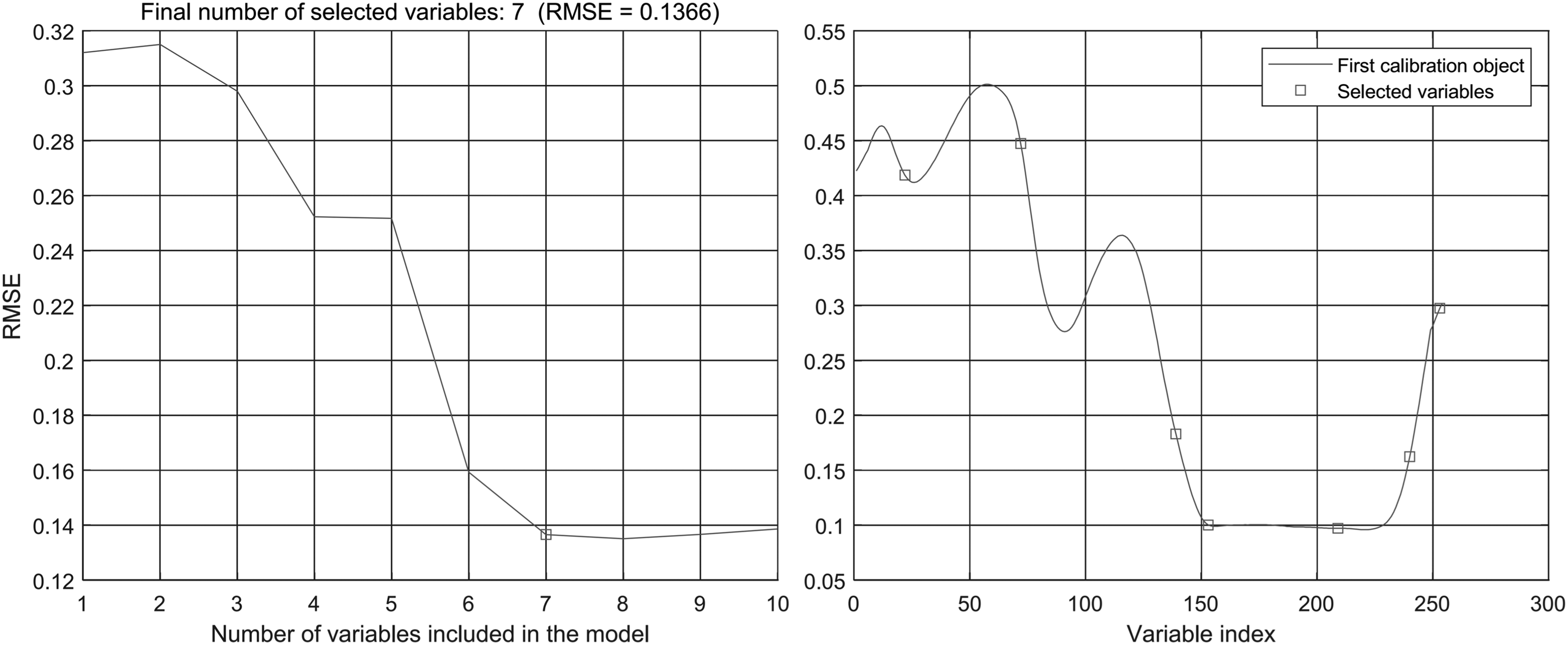
Results of the feature dimension reduction using the continuous projection method.
The RMSE of the model decreased with the increase in the number of bands from 1 to 7. Finally, a total of seven feature bands were selected to replace the 254 bands in the original data. The selected band locations were 22, 72, 139, 153, 209, 240, and 253, corresponding to 962.93, 1122.37, 1338.87, 1380.21, 1558.16, 1656.56, and 1697.8 nm, respectively.
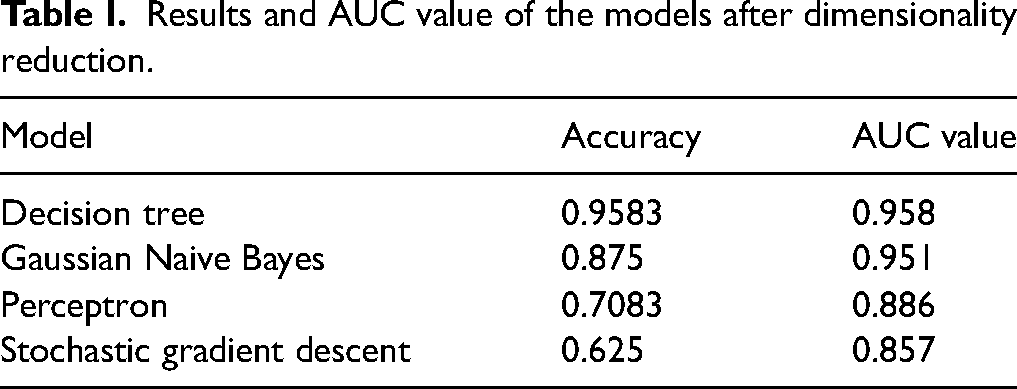
The dimensionality reduction tests were performed, and the effects of each model are listed in Table I. The accuracies of the models decreased in the order of decision tree, GaussianNB, perceptron, and stochastic gradient descent models, and the effects of the models, except the decision tree model, showed a greater decrease as compared to that of the whole band. The AUC value of each model was calculated and compared. The results showed that the AUC value of the decision tree model was the highest, suggesting the best prediction result.
Results and AUC value of the models after dimensionality reduction.
Each model underwent five experiments to reduce the contingency of the training process, as shown in Figure 5a.
(a) Comparison of the five experiments results after feature dimension reduction. (b) Comparison of training average results after feature dimension reduction.
After dimensionality reduction, the accuracy of the decision tree maintained good stability, while that of GaussianNB showed an overall reduction. Moreover, the accuracies of perceptron and stochastic gradient descent models also showed a significant decrease in accuracy with obvious volatility in the fourth experiment. The averages of these results were taken to present the effectiveness of the model, as shown in Figure 5b.
After dimensionality reduction, the decision tree model still exhibited high average accuracy, while those of the other three models decreased, and the differences between each model and the full band were more obvious. Therefore, the decision tree model could achieve a better classification effect after the dimensionality reduction. After the automatic standardization of data, the average accuracy of the five experiments was compared to eliminate noise interference, as listed in Table II.
Comparison of model average accuracies before and after data pre-processing.

The data comparison showed that the automatic standardized data pre-processing could not greatly improve the accuracy of the full-band test; instead, the accuracy of the perceptron model decreased. In the feature band test, the accuracy of the pre-processed data of the decision tree and GaussianNB models improved.
Classification of Plasma Using CIs
In addition to the classification of plasma as normal and chylous plasma, the degree of chylous was further differentiated. The data set collected for the second time is used for the experiment. Similarly, the same random number is set during the comparison of different model experiments to ensure that the divided training set is consistent with the test set. In order to avoid contingency in each experiment, different random numbers were set for the experiment. Four models, including decision tree, GaussianNB, perceptron, and stochastic gradient descent models, were used in this study. The decision tree model exhibited the best effect with an accuracy of 87.5%, while the accuracies of GaussianNB, perceptron, and stochastic gradient descent models were 50%, 43.75%, and 56.25%, respectively. The results of the decision tree models are presented in Figures 6a and 6b.
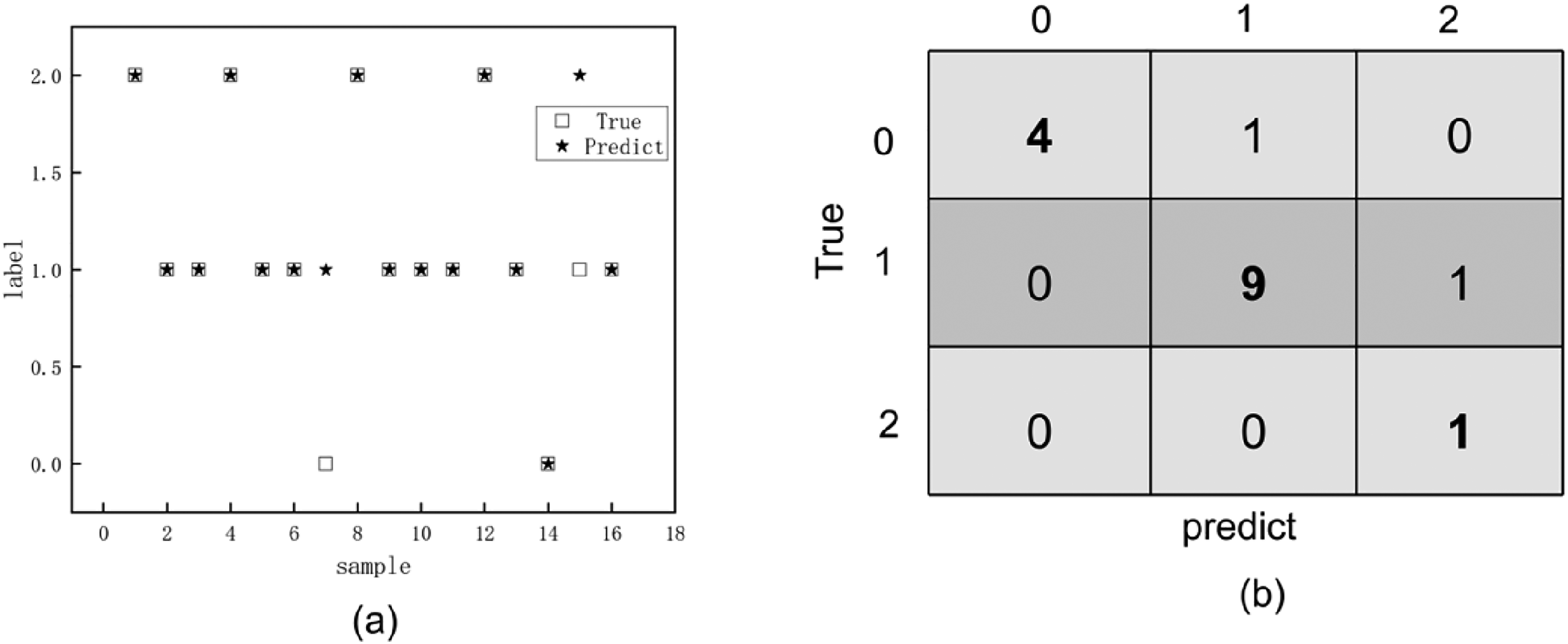
(a) Classification results of decision tree model. (b) Confusion matrix of classification results.
As shown in Figure 6a, the two labels were not correctly classified. The results were further clarified by drawing the confusion matrix of the model, as shown in Figure 6b. The data on the diagonal of the matrix were correctly classified, showing two misclassified samples. The continuous projection method was used for the feature dimension reduction. The results of dimension reduction are shown in Figures 7a and 7b.
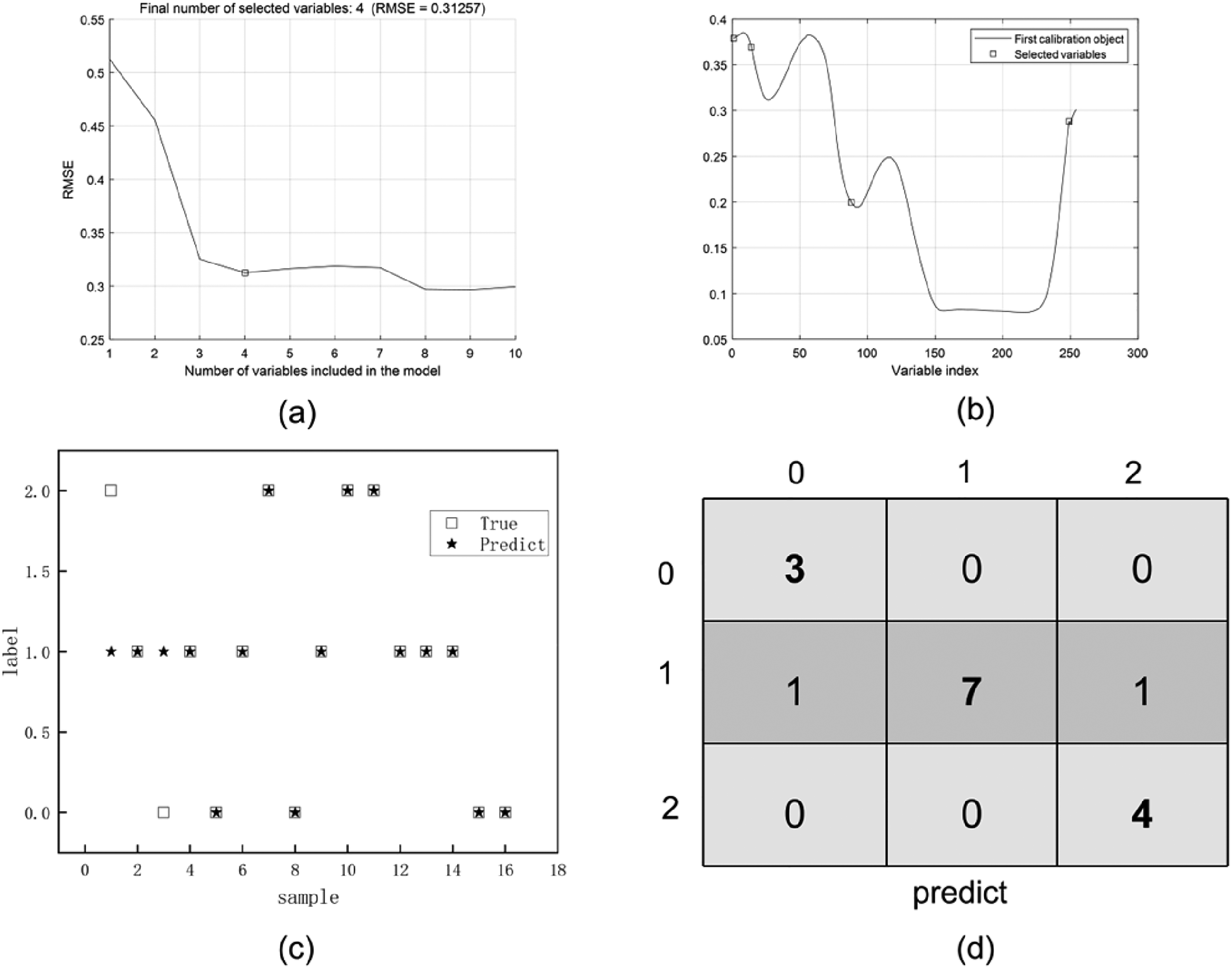
(a, b) Results of feature dimension reduction using the continuous projection method. (c, d) Classification results of the decision tree model after the feature dimension reduction.
The RMSE of the model continuously decreased with the increase in the number of bands from 1 to 4, and finally, four feature bands were selected. The selected band locations were 1, 14, 88, and 249, which corresponded to 895.91, 937.41, 1173.34, and 1685.11 nm, respectively. The test accuracy of the decision tree was 87.5%, showing the best accuracy, as shown in Figures 7c and 7d.
The two misclassified samples, as shown in Figure 7c, further showed that the classification prediction effect was more intuitive. The confusion matrix of the model was drawn, as shown in Figure 7d, demonstrating more careful classification results. The decision process of the decision tree model is presented in Figure S4 (Supplemental Material).
In the whole decision-making process, there were four layers down from the top node with different discriminant conditions. First, the fourth band was analyzed, and the 64 training samples were divided into 39 samples labeled as “1”, and 25 samples labeled as “0” and developed downward based on their respective discriminative conditions.
In order to reduce the contingency of experimental results, five experiments were performed on the model, and the mean values of the results were compared. The decision tree model exhibited the best results, as shown in Figure 8.
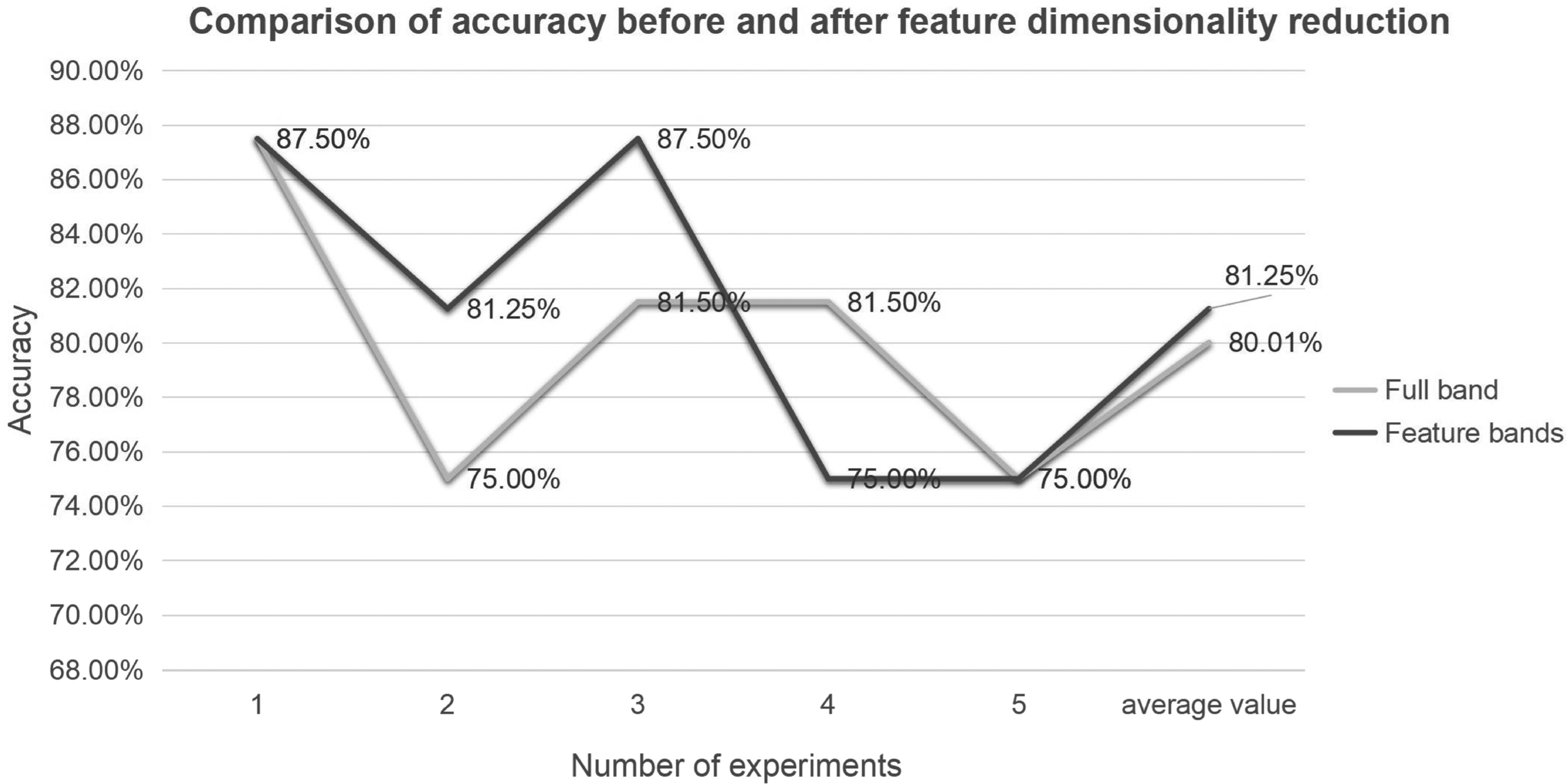
Comparison of accuracy before and after feature dimension reduction.
The results before and after the feature dimensionality reduction were not very stable, showing a certain range of fluctuations. However, the final mean value remained above 80%. The effects of feature dimensionality reduction reached those of the whole band. The performance of the model was evaluated using its recall ratio. The recall ratio of each model before and after feature dimension reduction is listed in Table III.
Comparison of the recall of each model before and after the feature dimension reduction.

The closer the recall ratio to 1, the better the performance of the model. Only the recall ratio of the decision tree model reached above 0.8 before and after the dimension reduction. Therefore, the decision tree model was identified to have the best performance.
Data Pre-Processing Effect Comparison
In order to eliminate the noise interference, the average accuracy of each model was compared after the automatic standardization of data, as listed in Table IV.
Comparison of the average accuracy of the models, before and after data pre-processing.

The data comparison showed that the accuracy of each model improved to a certain extent after the automatic standardization of data during the full-band test. In the feature band test, the effects of the decision tree model on the pre-processed data remained the same, while those of GaussianNB and stochastic gradient descent models improved. Moreover, the effects of perceptron decreased.
Conclusion
The results showed that the analysis and testing of the full band data of plasma samples showed that the classification of decision tree and GaussianNB models was better. The average accuracy of the decision tree and GaussianNB models was over 90%, and that of the decision tree model was 97.5%. The feature dimension reduction using the continuous projection method resulted in the selection of seven feature bands for testing. These seven bands included 962.93, 1122.37, 1338.87, 1380.21, 1558.16, 1656.56, and 1697.8 nm. The results of these seven feature bands showed that the accuracy of decision tree classification could reach 93.33%. Therefore, the comparison of the four models showed that the effects of the decision tree model were the most stable, and those of the full-band analysis could be achieved using the seven feature bands. The automatic standardization of data pre-processing improved the accuracy, but it was not obvious.
Four algorithms, including decision tree, GaussianNB, perceptron, and stochastic gradient descent, were used to detect the chylous plasma using different CIs. The best accuracy was that of the decision tree model, which reached 87.5%. After the feature dimension reduction of the data, four feature bands, including 895.91, 937.41, 1173.34, and 1685.11 nm, were selected. After the feature dimension reduction of data, the decision tree model showed the best effects, with an average accuracy of 80.01% and the effects close to the full band.
Chylous plasma could be easily determined based on a few characteristic bands. Furthermore, the chylous plasma with different CIs could also be distinguished, thereby greatly reducing the calculation amount and complexity of detection work, saving detection time, and improving work efficiency. However, the number of samples collected in this study was small, and the data was not rich enough; this might affect the accuracy of these results as well as the generalization ability of the model to a certain extent. In future studies, the data sets should be enriched and expanded to further optimize the model parameters and achieve better results. At the same time, further studies on the chemical interpretation of selected features should be strengthened in future studies, so as to make the relationship between extracted features and chylous plasma detection clearer.
Supplemental Material
sj-docx-1-asp-10.1177_00037028231214802 - Supplemental material for Detection of Chylous Plasma Based on Machine Learning and Hyperspectral Techniques
Supplemental material, sj-docx-1-asp-10.1177_00037028231214802 for Detection of Chylous Plasma Based on Machine Learning and Hyperspectral Techniques by Yafei Liu, Jianxiu Lai, Liying Hu, Meiyan Kang, Siqi Wei, Suyun Lian and Haijun Huang, Hao Cheng, Mengshan Li, Lixin Guan in Applied Spectroscopy
Footnotes
Data Availability Statement
The data sets generated during or analyzed during the current study are available from the corresponding author upon reasonable request.
Declaration of Conflicting Interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported by the National Natural Science Foundation of China (grant numbers 51663001, 52063002, and 42061067).
Supplemental Material
All supplemental material mentioned in the text is available in the online version of the journal.
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.