
Abstract
Lithium compounds such as lithium hydride (LiH) and lithium hydroxide (LiOH) have a wide range of industrial applications, but are highly reactive in environments with H2O and CO2. These reactions lead to the ingrowth of secondary lithium compounds, which can alter the homogeneity and affect the application of particular lithium chemicals. This study performed an exploratory analysis of different lithium compounds using laser-induced breakdown spectroscopy (LIBS) and Raman spectroscopy. Machine learning models are trained on the recorded spectral data to discriminate emission features that differ between LiH, LiOH, and Li2CO3 to perform high-fidelity classification. Support vector machine classifiers yield perfect prediction accuracy between the three compounds with optimal training time. Multivariate methods are then used to produce regression models quantifying the ingrowth of LiOH in LiH. Performing a mid-level data fusion of selected LIBS and Raman features with partial least-squares regression produces the superlative model with a root mean square error of 2.5 wt
Keywords
Introduction
Lithium compounds are critical to several major industries, including the production of commercial batteries
1
and a variety of pharmaceuticals.
2
Lithium also plays an important role in radiation science and in the nuclear fuel cycle. Lithium compounds enable the production of lightweight materials for neutron shielding, specifically to capture thermal neutrons without emitting a capture gamma.3,4 Lithium salts are key components of the breeding blanket in next-generation nuclear power reactors; the formation of tritium from lithium enables deuterium–tritium fusion reactions.5–8 The quality and homogeneity of lithium compounds must be ensured via chemical analysis; the ingrowth of secondary lithium compounds can change fundamental reaction cross sections of the material, ultimately affecting its performance for a given application.
9
The compounds lithium hydride (LiH), lithium hydroxide (LiOH), and Li2CO3 are of particular interest to this ingrowth and characterization problem. The formation of LiOH is described by chemical Eq. 1, while the formation of Li2CO3 is governed by chemical Eqs. 2 to 4.10,11

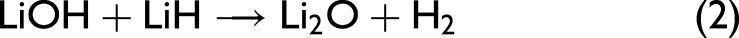

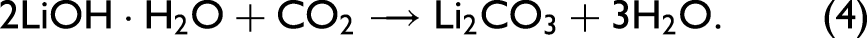
Laser-induced breakdown spectroscopy (LIBS) and Raman have previously been used in tandem for analytical chemistry applications such as the identification of minerals and organics in geological samples,21,22 space exploration,23,24 and the analysis of archaeological artifacts. 25 Recent studies have used both techniques with machine learning (ML) models and data fusion methodologies to perform high-fidelity classification and regression analyses of geochemical samples26–30 and hydrocarbon fuels. 31 A wide variety of ML models have been implemented for the analysis of complex actinide spectra from nuclear debris and plutonium alloys, yielding markedly improved results in diagnostic analysis of nuclear material. 32 These advances in analytical techniques and the results of these investigations prove the utility of data science techniques in discriminating feature changes across complex spectral data sets. This paper explores the capabilities of ML models to learn differences between several lithium compounds based on spectral emission features and to produce high-fidelity models that relate spectral differences to the chemical properties of a set of lithium samples.
We present the analysis of lithium compounds using spectra recorded from a tandem LIBS–Raman experimental setup. We analyzed recorded spectra of pure LiH, LiOH, and Li2CO3, along with three different mixed LiH–LiOH samples (90/10, 75/25, and 50/50 wt% LiH/LiOH). We implement ensemble methods, support vector machines (SVMs), neural networks, and
Experimental
Sample Preparation
Powder samples of LiH (Sigma Aldrich, 95% pure), LiOH (Sigma Aldrich, 98% pure), and Li2CO3 (Sigma Aldrich, 99% pure) were pressed into pellets inside a dry nitrogen glove box. Previous work by Sifuentes et al. 12 showed that a relative humidity of 1% has led to a very low mass increase in LiH samples. Liquid nitrogen boil-off was used to purge a glove box and successfully kept the humidity conditions at or near this level (ranging from 1.1% to 1.7%) as measured with a humidity probe. Table I outlines the sample composition matrix with all values having units of weight percent mass. The relative uncertainty is <1% for all concentration values in the table with the dominant form of error resulting from the accuracy of the scale. The powders for the mixed samples were ground with a mortar and pestle to ensure uniform particle size, weighed, then combined in a Fluxana MUK mixer, shaken to achieve homogeneity, and then pressed using a Specac Ltd. minipress at 1.5 tons for 3 min. The sample matrix was structured to mimic the degradation process of LiOH ingrowth into LiH by pairing each set of analytes together at multiple concentrations.
Concentration (wt

Once pressurized, the samples were placed in a conflat flange sample cell with a top viewport, as shown in Figure 1, to maintain the dry environment while transferring the sample to the laser table and throughout the analysis. The viewport allowed for laser interaction with the sample as well as atomic emission collection. Samples were affixed to the bottom of the conflat flange cell using a thin layer of vacuum grease. The grease served to keep the samples from shifting while maneuvering the equipment and during the ablation process. The sample cells were thoroughly disassembled and cleaned between sample set tests to prevent cross-contamination. It should be noted that although LIBS experiments often use vacuum, argon, or helium as buffer gases to enhance the signal, this work used nitrogen to simulate the most common environments for LiH handling and storage.

Conflat flange sample cell with 3.2 mm thick ultraviolet fused silica viewport; samples are 2.5 cm from the outside face of the viewport.
Spectroscopic Setup and Measurements
A dual Raman–LIBS experimental setup illustrated in Figure 2 was implemented in this study. The use of a single setup to conduct both Raman and LIBS has the obvious advantage of reducing the experimental time, maintaining the sample condition, and streamlining the analytical process. Shameem et al. 33 demonstrated the versatility of the echelle spectrograph for use in both LIBS and Raman spectroscopy using a single set-up. The only parameter changed between LIBS and Raman measurements is energy fluence. This is accomplished by using a defocusing lens and reducing the laser power during Raman measurements to prevent ablation.
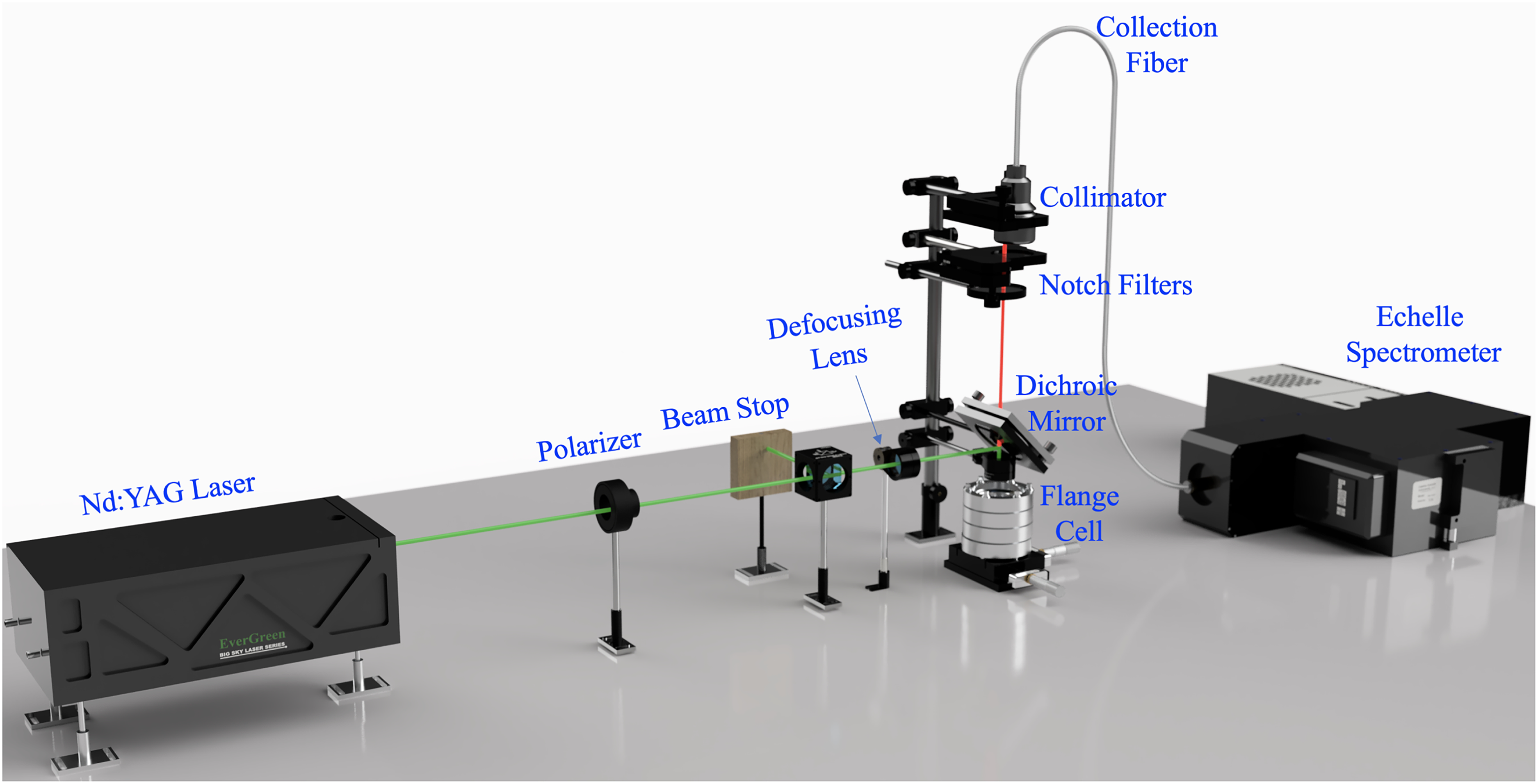
Tandem LIBS–Raman setup used for sample analysis.
This study employed a 10 Hz Q-switched neodymium-doped yttrium aluminum garnet laser (Quantel Evergreen) operating at 532 nm with a 10 ns pulse width. A digital delay generator (Berkeley Nucleonics 577) was used as a trigger source for both the laser and the intensified charge-coupled device (iCCD) camera. For Raman measurements, the light is directed through a defocusing lens set twice the focal length (
An Echelle spectrograph (Catalina Scientific EMU-120/65) was used to record broadband spectra from 325 to 925 nm with
Raman measurements were taken prior to LIBS measurements, because of the non-destructive nature of the former. Due to the spot size of the laser at the sample and the field of view of the light collection optics, spectra were taken from five positions on each of the samples. The Raman spectra were acquired by integrating recordings in a single exposure and then accumulating multiple recordings to form the final image. This was done at a repetition rate of 10 Hz for 600 pulses per exposure, repeated for five exposures per sample with a 1 ms exposure time. The iCCD camera gate delay was set at 140 ns with a gate width of 40 ns. The microchannel plate gain was set to a moderate value of 2500 on a 0–4000 nonlinear scale. For LIBS measurements, an unperturbed position was chosen for the beginning of each set of shots. Each set of shots consisted of 20 ablations in a single position. Each sample was ablated in 10 separate positions for a total of 200 spectra per sample. The camera was adjusted to have a gate delay of 1.5
Analytical Methods
Data Preprocessing and Feature Selection
The raw classification data set consisted of 600 LIBS spectra (200 of each compound), each with 60,001 features. The raw regression data set consisted of 20 LIBS and 20 Raman spectra each of pure LiOH, as well as the Mix 1–3 samples. Each LIBS spectrum had 60 001 features, while each Raman spectrum had 60 295 features. The sheer size of the feature space in this problem underscores the need to follow the ML workflow and implement basic feature selection.
First, the raw spectra in both the classification and regression data sets were normalized using the standard normal variate (SNV) method in Eq. 5: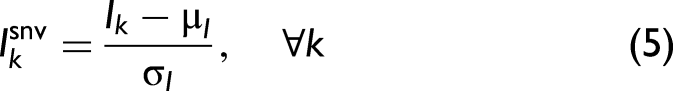
Feature selection was then implemented on the classification data set by performing a principal component analysis (PCA) on the normalized data and examining the values of the loadings of the wavelengths of the first principal component (PC). This method has been implemented in prior studies to determine which emission wavelengths contribute the most variance in the data set. The wavelength region between 575 and 690 nm was found to have the highest loading values of the first PC, indicating that the features that contribute the most to the differences in the spectral data sets manifest in this region. Figure 3a shows the averaged spectra of each of the three compounds in the classification data set. The feature comparison indicates noticeable differences in the Li I atomic emissions at 610 and 671 nm, as well as the lack of Hα at 656 nm in the Li2CO3 spectra. The presence of the Na D1/D2 emissions at 589/590 nm stems from minor impurities in the powders used to create the samples. Cutting the LIBS classification data set to this wavelength range reduced the feature size from 60 001 to 23 001.
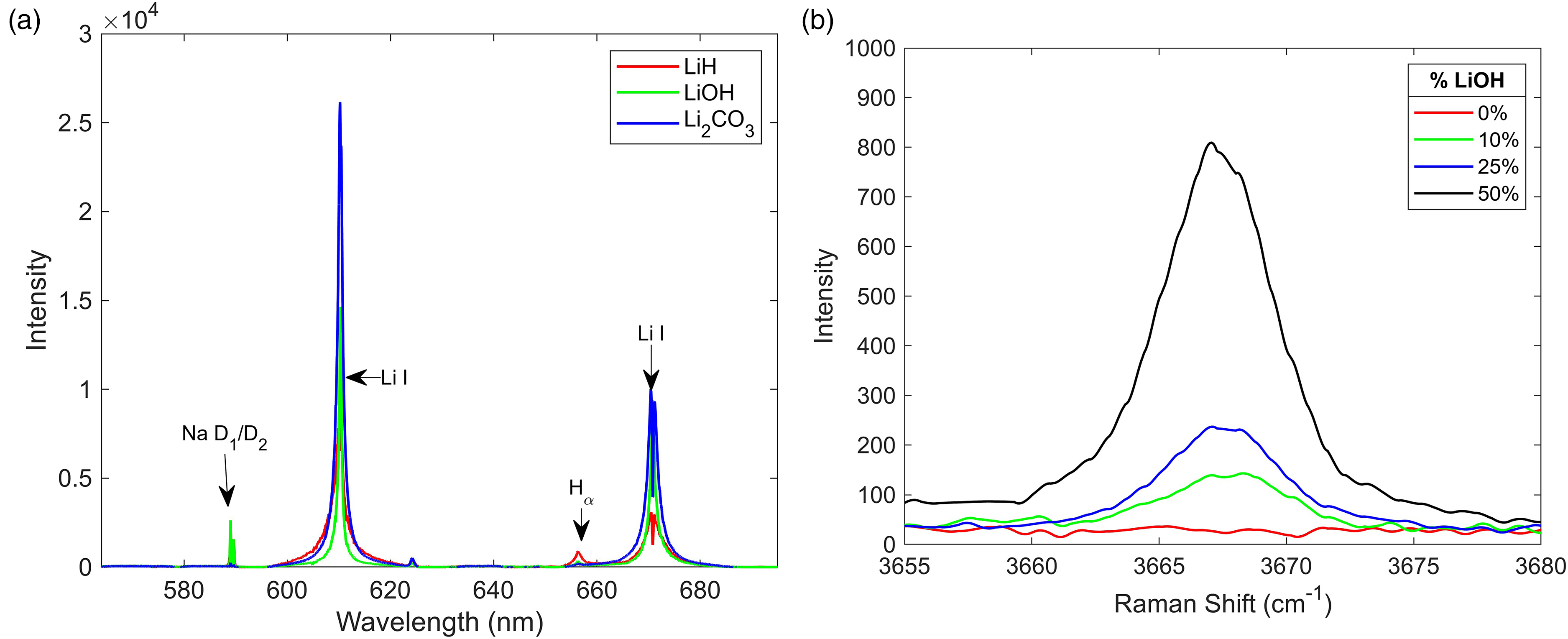
(a) Laser-induced breakdown spectroscopy (LIBS) emission differences between pure LiH, LiOH, and Li2CO3 and (b) Raman LiOH
The same feature selection process was applied to the regression data set; the LIBS regression data features varied most between 595 and 680 nm in the LiH/LiOH mixed sample set. This also follows from Figure 3(a), as most of the variance between these two compounds comes from Li I emissions and Hα at 656 nm. This reduced the size of the LIBS feature space from 60 001 to 17 001. The Raman data set had one major peak at 3667 cm−1 with a high PC loading value, shown in Figure 3b. This peak is attributed to the intermediary compound LiOH
Machine Learning Methods and Optimization
Support Vector Machine (SVM)
SVMs classify samples in an
Ensemble Methods
Tree-based ensemble methods are ML constructs based on decision trees, a supervised learning technique that relates input variables to an output by following branches at decision nodes based on the input attribute values. Tree-based ensembles use groups of decision trees together to achieve better predictive performance by reducing variance and increasing bias. The most common ensemble techniques are bootstrap-aggregating (bagging) and boosting; these are graphically depicted in Figure S2 (Supplemental Material). Bagging uses random replacement sampling to create subsets (S) of the data and independently trains the individual classifier (M), while boosting introduces an adaptive algorithm that focuses on areas in the data set that generates higher misclassifications and trains each model sequentially.39,40 Whereas bagged models run in parallel and the final prediction is made from an aggregate of each trained model, boosting changes in the input weights for each model depending on the error of the previous iteration to improve the accuracy of subsequent learners.
Artificial Neural Network (ANN)
A neural network takes a series of input variables and multiplies them by weights. Predictors enter an ANN through an input layer and are fed forward to subsequent layers. Each hidden layer contains neurons (nodes), wherein each neuron sums weighted inputs from the previous layer and generates an output by applying an activation function. The output layer sums weighted inputs from the last hidden layer and generates a numerical output via an activation function.39,41 This process is modeled as a mathematical analog of synaptic communication in biological neural pathways; Figure S3 (Supplemental Material) illustrates a single hidden layer ANN architecture.
K-Nearest Neighbors (KNNs)
K-nearest neighbors (KNN) is a non-parametric technique that predicts the class of an unknown sample based on its proximity to other known samples in the feature space of the data set.
42
This is illustrated in Figure S4 (Supplemental Material); the number of nearest neighbors
Hyperparameter Optimization
Hyperparameter optimization is a key part of the ML workflow needed to produce models that can make accurate predictions from complex input data without overfitting during training. An automated hyperparameter optimization routine was implemented on all selected classification models discussed above, using a Bayesian optimizer to run through different values of all tunable hyperparameters of each model and changing the values from one iteration to the next to minimize the model error (mean square error). Bayesian optimizers are commonly used in hyperparameter tuning and ML model design to achieve the hyperparameter configuration with the lowest feasible model error.43,44 The entire LIBS classification data set (800 samples and 2001 features) was split into an 80/20
Hyperparameter optimization options and final tuned values for all implemented models.
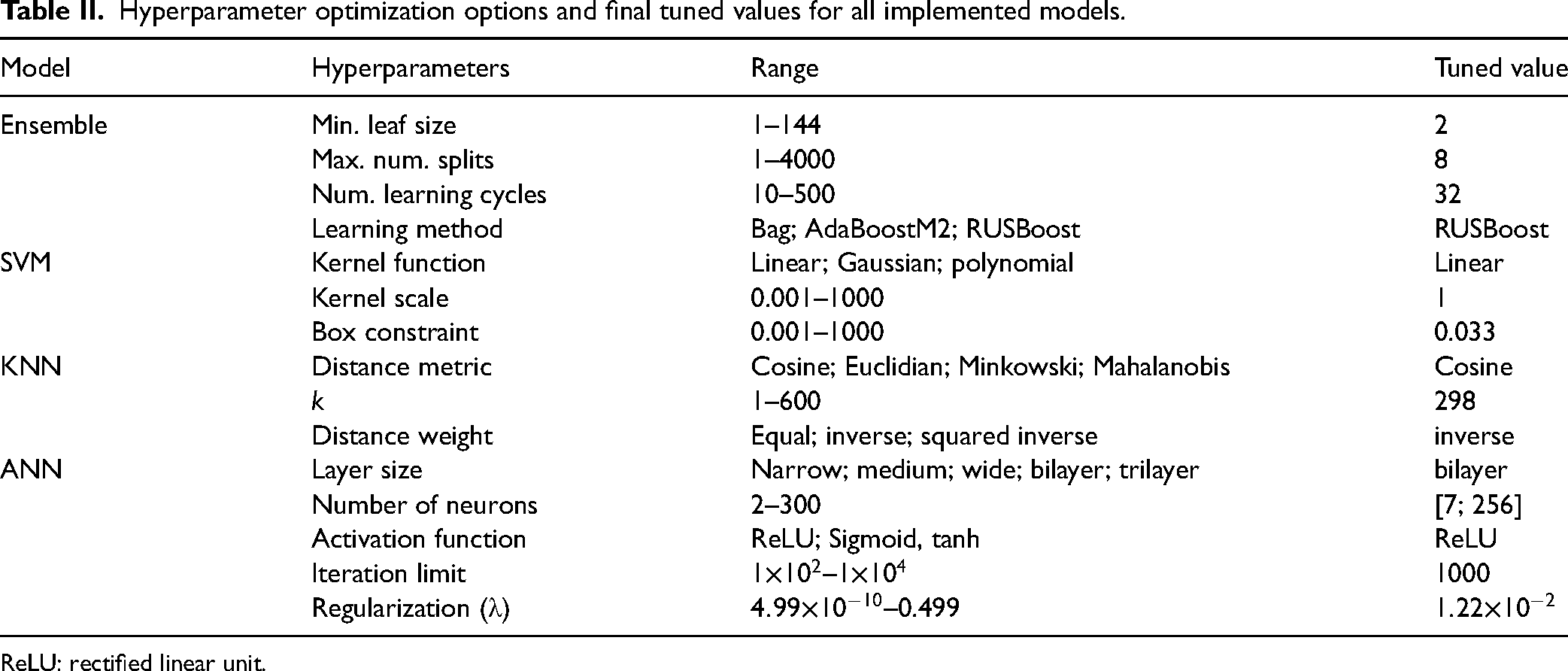
ReLU: rectified linear unit.
Multivariate Regression and Data Fusion
The regression data set, composed of LIBS and Raman spectra of the LiH/LiOH mixes, was used to construct predictive regression models relating changes in spectral feature intensity to the LiOH content of a sample. Principal component regression (PCR) and partial least-squares regression (PLSR) were used; these multivariate regression techniques are very common in a range of quantitative LIBS studies.47–52 PCR is an unsupervised regression technique that only accounts for variance in the feature data, while PLSR is a supervised technique that generates covariances between the feature and target data sets. Chemometric regressions generated from LIBS data are evaluated for precision and sensitivity using the metrics of root mean square error (RMSE), mean absolute error (MAE), and limit of detection (LOD), respectively. RMSE, defined by Eq. 6: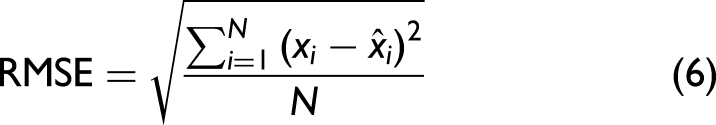
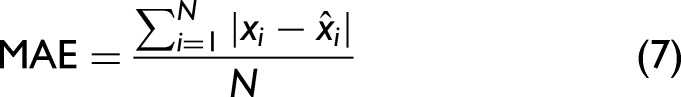
Furthermore, LOD is defined as the IUPAC standard representing the minimum quantity of analyte that must be present in the sample for the regression to distinguish it from a blank sample with 99

Principal component regression (PCR) and PLSR were performed on the individual LIBS and Raman data sets. Additionally, the mid-level data fusion approach depicted in Figure 4 was implemented, aggregating previously selected features from both LIBS and Raman spectra to create combined spectra for regression. As discussed in the Introduction section, data fusion methods have gained popularity in spectroscopy, as combined predictions with features from different spectroscopic methods can be more accurate than predictions made using an individual technique.
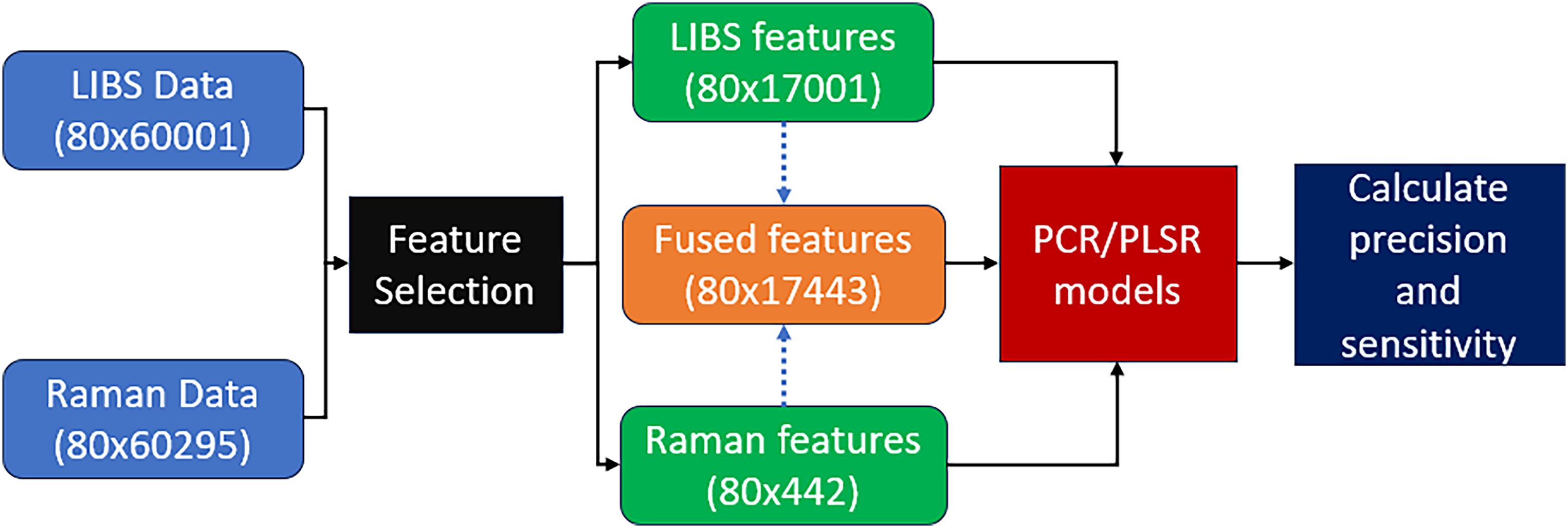
Mid-level data fusion workflow.
Machine Learning (ML) Classification Results
To begin the classification analysis, a PCA decomposition of the reduced LIBS data was done. The scores for the first three PC, which explain a total of 94
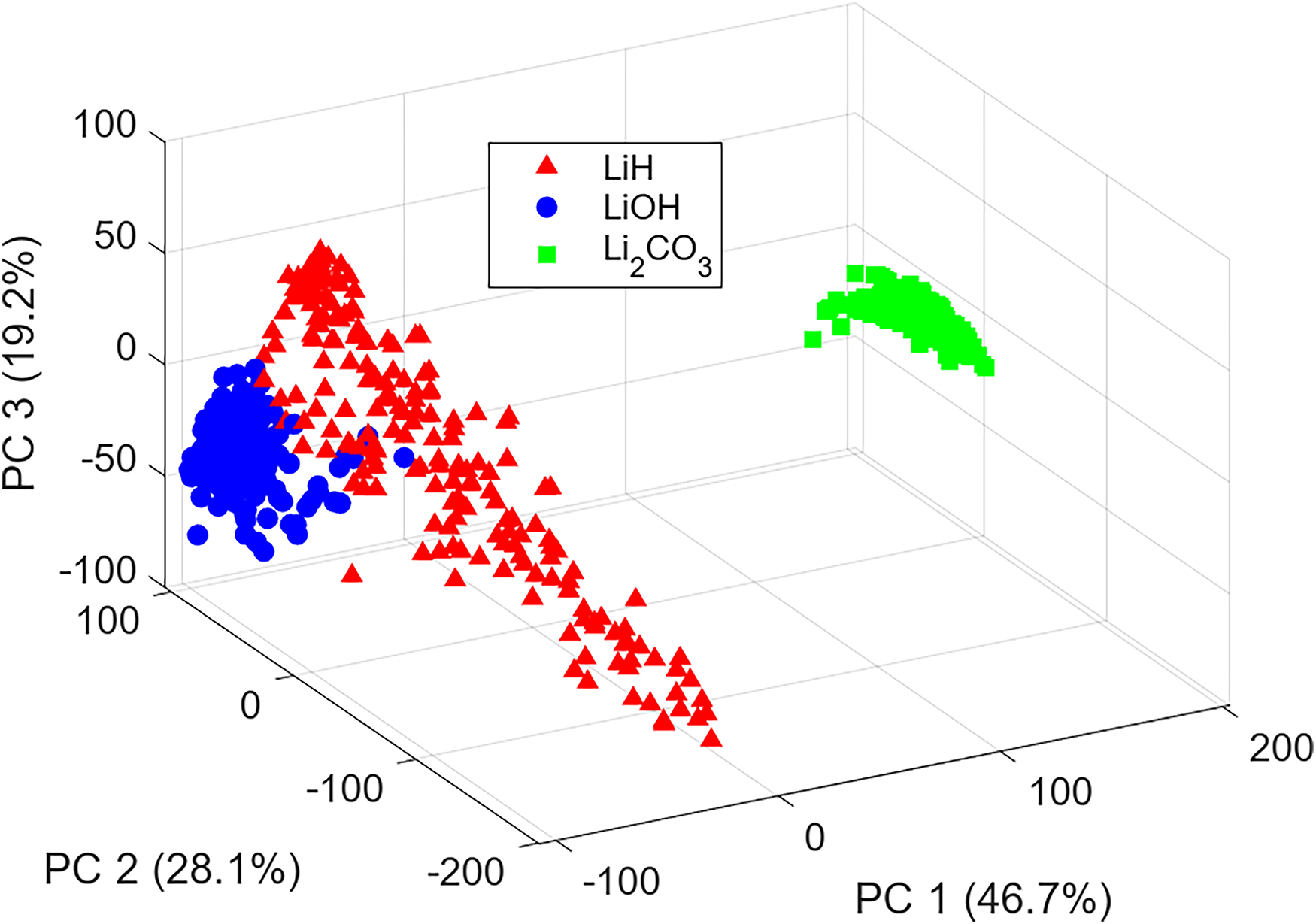
Principal component (PC) scores clustering of LiH, LiOH, and Li2CO3 in feature space of PCs 1–3.
The test data split was used to make predictions with each tuned classification model discussed in the Analytical Methods section. Figure 6 provides a visualization of the test classification performance of each model using confusion matrices to categorize the true and false predictions in each class. Some interesting trends can be discussed from these results. Firstly, none of the models improperly classified a spectrum of Li2CO3, indicating that the differences in Li2CO3 emission features identified in Figure 3a, particularly the lack of atomic hydrogen, are sufficiently distinct in the spectra for these samples to be easily discriminated from LiH/LiOH. The sole source of error in all four models came from misclassifying LiOH as LiH (eight occurrences) or vice-versa (one occurrence). This trend indicates that it may be more difficult for certain ML models to learn the subtle differences between the LIBS spectra of these two chemicals, which parallels the visual overlap of some LiH/LiOH data points seen in the PC clustering.
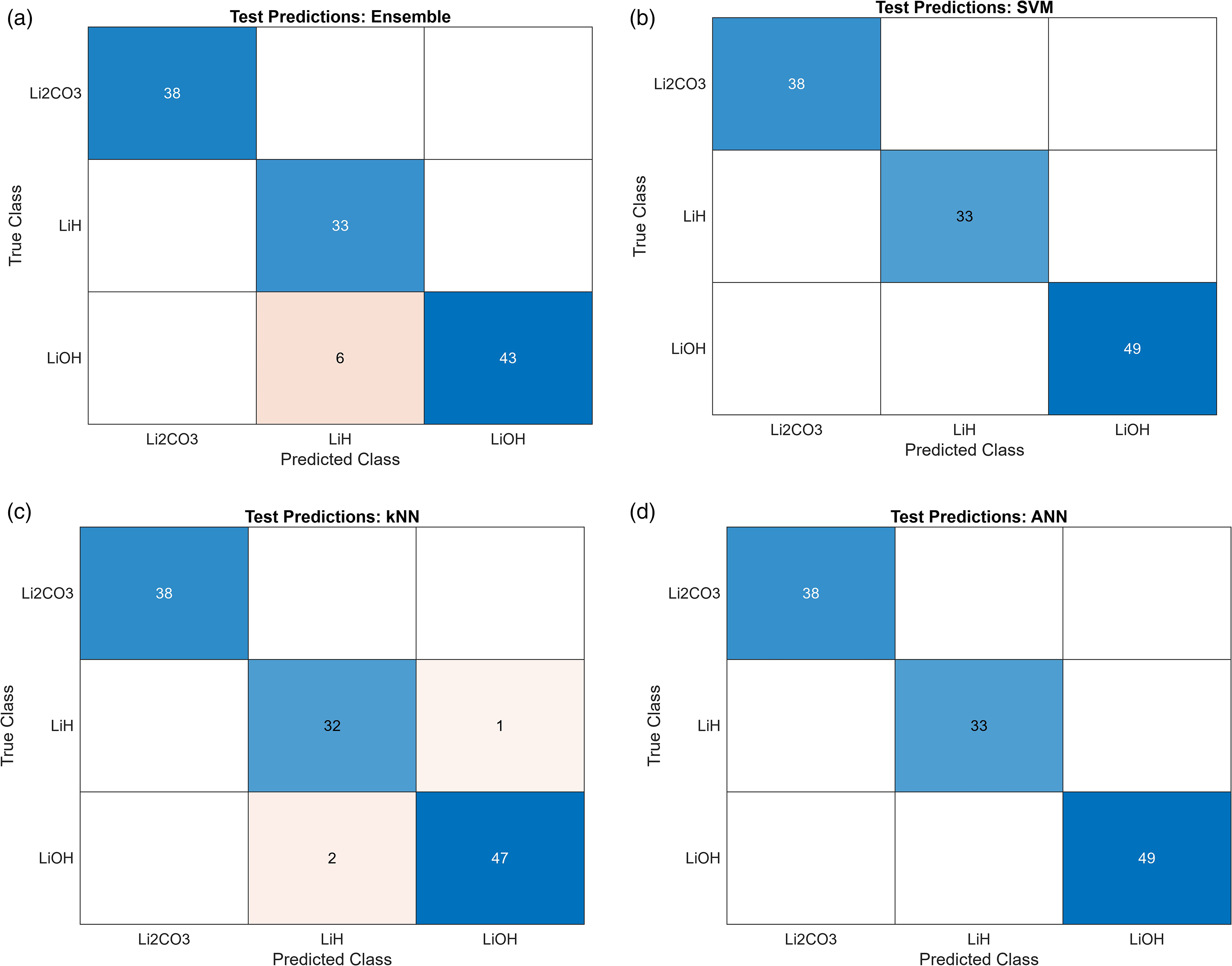
Confusion matrices for test data predictions of each tuned classifier.
Additionally, the SVM and ANN models, both known for their versatility and accuracy in classification problems, yielded perfect predictions of the test data set. This poses the question: which model is the superlative classifier if both can perfectly discriminate between these three lithium compounds? While prediction accuracy is certainly the objective, the computational cost of training a model is another factor to be evaluated in data science problems. Small gains in performance from one model to the next may not be worth the difference in the time it takes for the model to be trained, particularly when computational resources are limited or costly. Table III contrasts the test classification accuracy of each model with the training time recorded by Matlab. These metrics provide clear evidence of the computational cost of models that rely on more complex structures, as the ensemble and ANN classifiers took an order of magnitude more time to train than the SVM and KNN classifiers.
Classification accuracy and training time of each tuned ML model.

Even though the ANN made perfect test predictions, it took the longest time to generate the trained model, indicating potential impracticality for applying ANNs to classification problems with high-resolution spectral data. The tuned SVM clearly provides the superlative model, yielding the same result as the ANN with 13
Multivariate Regression Results
Regressions predicting LiOH content in LiH were constructed with 10-component PCR and PLSR as per Figure 4. Figures 7a and b show the regression results using the pre-processed LIBS and Raman data sets individually. As expected, PCR performs worse than PLSR with far less linearity and larger error because it is an unsupervised learning technique. LOD calculated for each model is listed in Table IV with the best performance parameters bolded; overall, the results indicate poor model generalization, predictive capability, and sensitivity when data from the two spectroscopic methods are used individually to create a multivariate regression. However, the fused data regressions show marked improvement in regression fidelity; the PLSR model in particular yielded the lowest RMSE of 2.49 wt
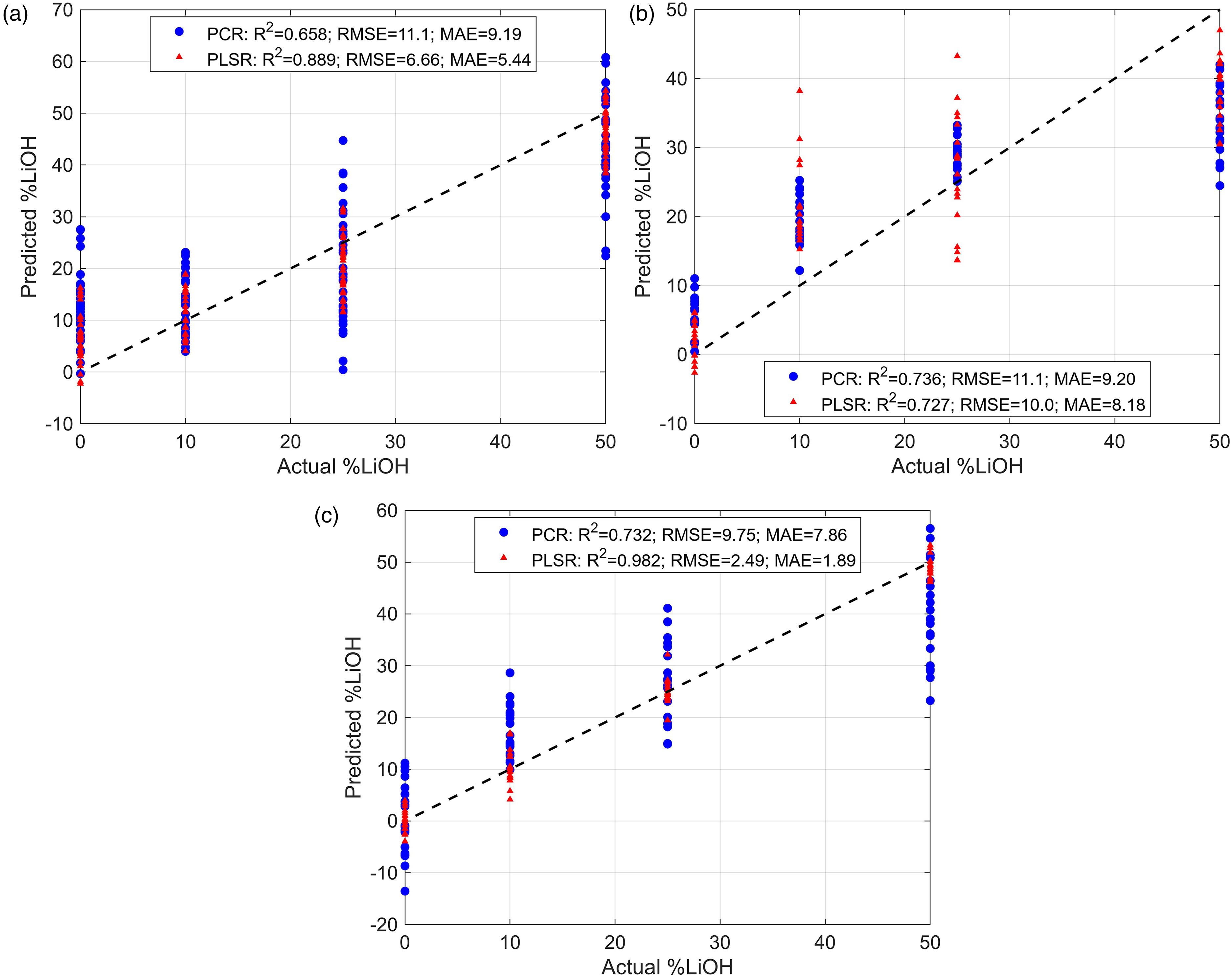
Principal component regression (PCR) and PLSR results using (a) LIBS, (b) Raman, and (c) fused feature data sets.
Precision and sensitivity comparison of multivariate models using individual spectral data sets and mid-level fused spectral data. All metrics are in units of wt
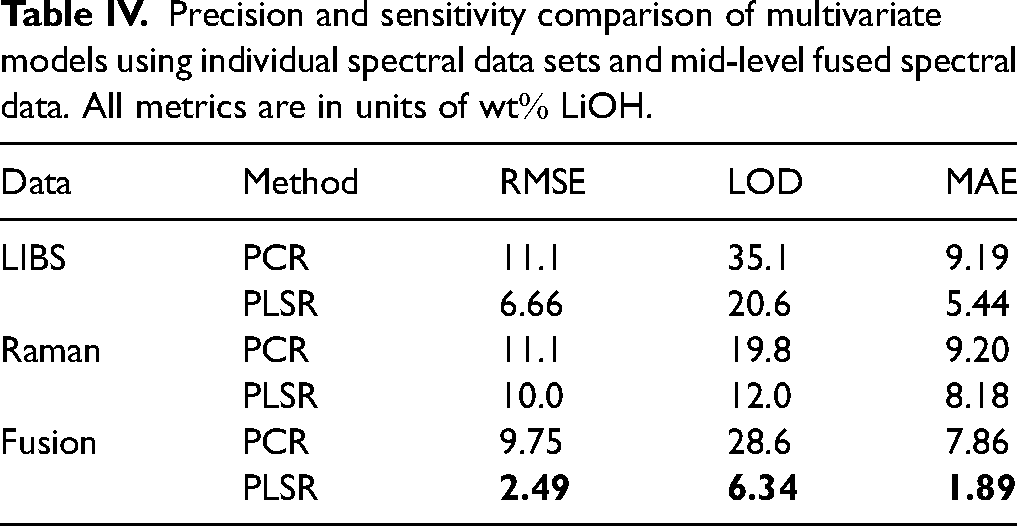
The regression analysis conducted with the data set, albeit simple in concept, highlights several important points for future endeavors in performing similar analysis. Differences in recorded spectra between samples with small differences in LiOH concentration can be difficult to generalize with basic multivariate models. To push the state-of-the-art and develop truly high-fidelity models, it is imperative to expand the scale of the collected data and the number of different chemical mixtures used in the experiment. Having a larger data set with more concentration points will enable higher-level ML methods, such as those discussed in the ML Classification Results section, to be used in the construction of better regression models. This will enable the construction of models that can better learn the relationship between spectral feature changes and analyte content, and allow for further experimentation with data fusion methodologies to reduce prediction error and model sensitivity.
Conclusion
This work demonstrated the efficacy of a tandem LIBS–Raman spectroscopy setup for the analysis of lithium compounds (LiH, LiOH, and Li2CO3). SVM classification using LIBS data of the three compounds provided a perfectly accurate discrimination model with a relatively low computational training cost. A mid-level data fusion methodology, combining selected features from individual LIBS and Raman spectra, was able to quantify LiOH in LiH with a prediction error as low as 2.5
Supplemental Material
sj-pdf-1-asp-10.1177_00037028241235679 - Supplemental material for Analysis of Lithium Aging Using Machine Learning-Enhanced Spectroscopy Techniques
Supplemental material, sj-pdf-1-asp-10.1177_00037028241235679 for Analysis of Lithium Aging Using Machine Learning-Enhanced Spectroscopy Techniques by James T. Stofel, Ashwin P. Rao, Anil K. Patnaik, Andrew V. Giminaro, and Michael B. Shattan in Applied Spectroscopy
Footnotes
Declaration of Conflicting Interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was funded by the Defense Threat Reduction Agency’s Nuclear Science and Engineering Research Center. Distribution Unlimited; approved for public release under cases 88ABW-2021-0154 and AFRL-2023-6449. The views expressed are those of the authors and do not necessarily reflect the official policy or position of the Department of the Air Force, the Department of Defense, or the U.S. government.
Supplemental Material
All supplemental material mentioned in the text is available in the online version of the journal.
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.