
Abstract
Discrete frequency infrared (IR) imaging is an exciting experimental technique that has shown promise in various applications in biomedical science. This technique often involves acquiring IR absorptive images at specific frequencies of interest that enable pathologically relevant chemical contrast. However, certain applications, such as tracking the spatial variations in protein secondary structure of tissue specimens, necessary for the characterization of neurodegenerative diseases, require deeper analysis of spectral data. In such cases, the conventional analytical approach involves band fitting the hyperspectral data to extract the relative populations of different structures through their fitted areas under the curve (AUC). While Gaussian spectral fitting for one spectrum is viable, expanding that to an image with millions of pixels, as often applicable for tissue specimens, becomes a computationally expensive process. Alternatives like principal component analysis (PCA) are less structurally interpretable and incompatible with sparsely sampled data. Furthermore, this detracts from the key advantages of discrete frequency imaging by necessitating the acquisition of more finely sampled spectral data that is optimal for curve fitting, resulting in significantly longer data acquisition times, larger datasets, and additional computational overhead. In this work, we demonstrate that a simple two-step regressive neural network model can be utilized to mitigate these challenges and employ discrete frequency imaging for retrieving the results from band fitting without significant loss of fidelity. Our model reduces the data acquisition time nearly six-fold by requiring only seven wavenumbers to accurately interpolate spectral information at a higher resolution and subsequently using the upscaled spectra to accurately predict the component AUCs, which is more than 3000 times faster than spectral fitting. Our approach thus drastically cuts down the data acquisition and analysis time and predicts key differences in protein structure that can be vital towards broadening potential applications of discrete frequency imaging.
This is a visual representation of the abstract.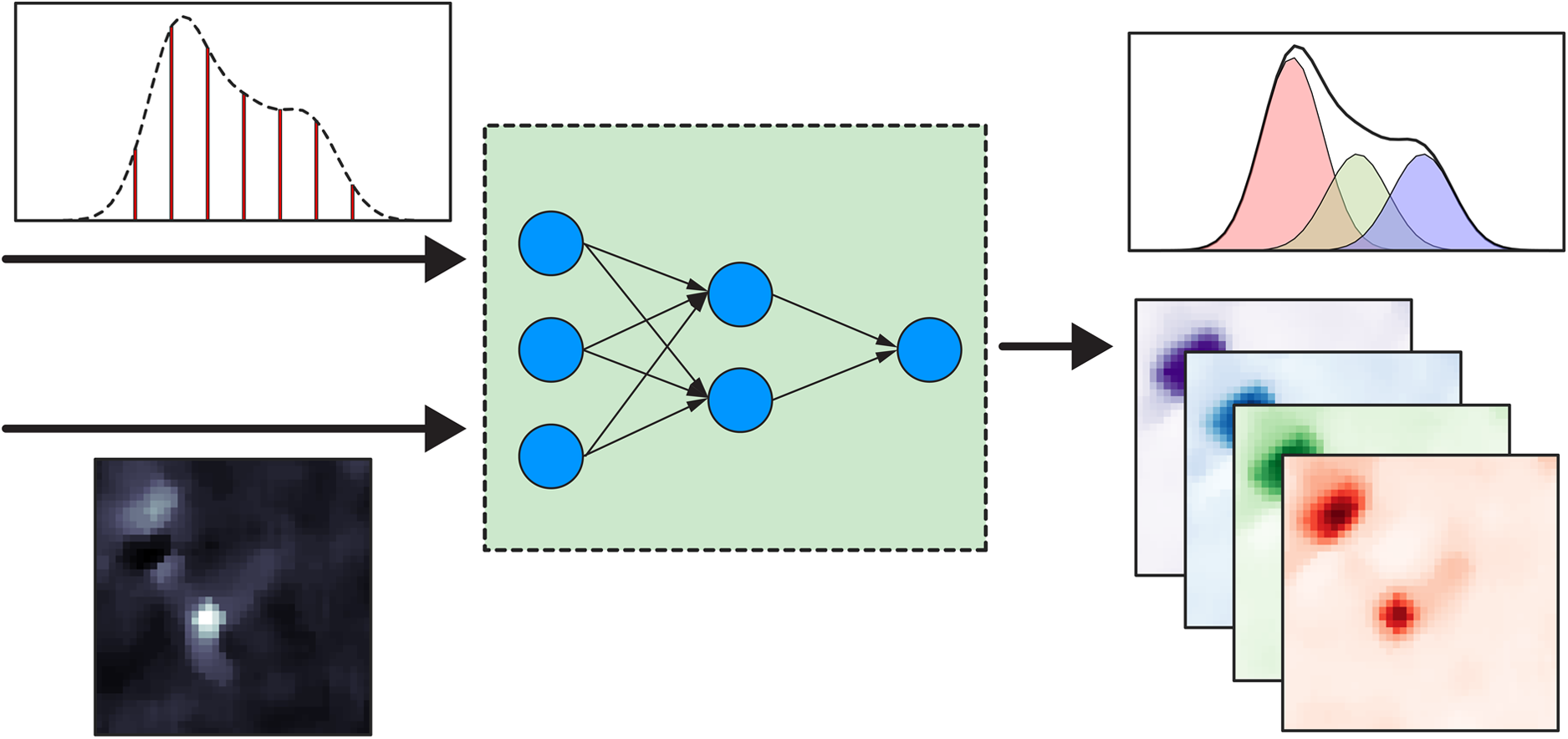
Keywords
Introduction
Infrared spectroscopy-based chemical Imaging modalities like Fourier transform infrared (FT-IR) imaging, discrete frequency infrared (DFIR), and optical photothermal infrared (O-PTIR) Imaging have seen a resurgence in recent years as label-free imaging modalities that can augment conventional histopathology.1,2 In particular, the ability to map the chemistry of biospecimens for diagnostic and fundamental insights into disease pathologies has been galvanized by the development of discrete frequency-based approaches, wherein only the desired spectral bands of interest can be acquired for chemical contrast. As opposed to staining with dyes that differentially bind to different tissue components, chemical contrast is generated from the differences in their IR spectra arising out of biochemical compositions. These differences can then be exploited with unsupervised clustering methods 3 or supervised learning algorithms 4 to generate label-free segmentation of tissue histology. While significant spectral differences exist between cellular (epithelial cells, malignant cells) and extracellular components (stroma, secretions), subtle differences in amide I line shapes arising from protein secondary structural variations can also be clinically important and are increasingly recognized for their pathophysiological significance. The characterization of protein bands is of relevance for disease pathologies involving amyloid aggregates, collectively termed amyloidosis.
Amyloidosis contributes significantly to neurodegenerative diseases like Alzheimer’s, Parkinson’s, Huntington’s, and chronic traumatic encephalopathy (CTE) through the accumulation of misfolded protein aggregates. Each of these diseases involve aggregates of specific proteins that misfold to form amyloid fibrils. In Alzheimer’s disease, amyloid-beta (Aβ) plaques and neurofibrillary tangles disrupt synapses and intracellular transport, leading to cognitive decline.5–7 In Parkinson’s, alpha-synuclein aggregates form Lewy bodies, impairing mitochondrial function and killing dopaminergic neurons, which causes motor dysfunction.8,9 Huntington’s involves mutant Huntington protein aggregates that interfere with transcription and metabolism, leading to progressive neuronal loss in the striatum.10,11 In chronic traumatic encephalopathy (CTE), repeated trauma promotes tau aggregation and neuroinflammation, damaging neurons and causing cognitive and behavioral symptoms.12,13 Across these diseases, and more,14,15 misfolded proteins disrupt cellular function, trigger neuroinflammation, and propagate in a prion-like manner16,17 under the term protein aggregation.18,19
Infrared spectroscopy-based imaging approaches have been applied to study these pathologically relevant protein aggregates,7,20–24 and these studies underscore the importance of quantifying protein secondary structural distributions for gaining key insights into the molecular biology of the disease. Traditionally, quantification of protein secondary structure from amide I IR spectra is achieved by deconvolving the spectra into a predetermined number of Gaussian peaks (usually three to four), where the relative peak intensities, linewidths, and central frequencies are extracted with a constrained non-linear least squares curve-fitting approach. The area under the curve (AUC) of the peaks can subsequently be interpreted as proportional to the populations of the constituent species, assuming similar transition dipole moment strengths. 25 Although the Gaussian-fitting method is relatively straightforward for a few spectra, it can become prohibitively computationally expensive when scaled up for whole-slide images (∼10–100 million spectra per patient) and is susceptible to convergence issues for noisy data. 26 As a result, only a tiny fraction of IR imaging studies have used spectral deconvolution via band fitting to get structural insights into proteins.7–29 Alternatives to deconvolution approaches such as principal component analysis (PCA) are used more commonly;30–33 however, the results from such analyses cannot be readily interpreted from a structural perspective 25 and are incompatible with sparsely sampled IR/photothermal data 34 often employed to circumvent the data acquisition overhead for a large specimen. 35 Furthermore, spectral band fitting negates the advantages of discrete frequency-based approaches because it necessitates hyperspectral data acquisition. Since the experimental time for data acquisition linearly scales with the number of bands, such an approach becomes unfeasible for generating a statistically significant data set containing a large cohort of patients. Neural networks, particularly convolutional neural networks (CNNs), have shown great promise in the classification and segmentation of complex images. In the context of infrared spectroscopic imaging,1,36–39 CNNs can be trained to accurately identify and delineate pathological lesions for a variety of tissue samples, by leveraging both visual and near-infrared spectroscopic data. 40 Neural networks (NNs) can also optimize the process of data collection. By using image upscaling models, NNs can improve the spatial and spectral resolution of the collected images, 41 allowing high-resolution data to be obtained from lower-resolution images, thereby reducing the need for expensive and time-consuming data collection. This is particularly beneficial in medical imaging, where high-resolution images are crucial for accurate diagnostics but can be difficult and expensive to obtain.42–44 However, efforts to upscale chemical images have largely focused on the spatial dimension, 42 while the importance of the spectral dimension has somewhat gone unnoticed. The data acquisition challenges detailed above can be significantly mitigated if spectral upscaling can be implemented in addition to spatial resolution enhancement, wherein only a handful of bands can be used to reconstruct finer sampled spectral data. This advancement allows for discrete frequency imaging to be applied in applications that typically require spectral deconvolution, eliminating the need to acquire a full spectrum for each pixel. Even for applications that traditionally rely on full spectra, this method demonstrates that they can be retrained to use infrared spectra from a few measured bands, streamlining the process and enhancing efficiency.
In this work, we implement a two-step NN regression-based approach to perform spectral reconstruction and extract the appropriate fit parameters from sparsely sampled discrete frequency IR images with an aim of overcoming the aforementioned limitations of spectroscopic imaging. Our approach utilizes two distinct models, the first of which takes a sparsely sampled seven-wavenumber spectral input of key spectroscopic frequencies selected in order to preserve the maximum amount of spectroscopic information and upsamples it to a 41-wavenumber (4 cm–1 spectral resolution) output, which is subsequently forwarded into an AUC prediction model. We first trained NN models with simulated data with underlying distribution analogous to experimental data. Subsequently, we forward the model to various selections of experimental data. The advantage of our method over the traditional Gaussian fitting approach is two-fold: (i) The computational time needed to forward the pre-trained model is up to 3100 times faster than the conventional approach, and (ii) by only acquiring these seven select discrete frequency bands instead of a hyperspectral dataset, we cut the experimental scan time by approximately a factor of six.
Experimental
Materials and Methods
Tissue Samples
The study utilized three formalin-fixed paraffin-embedded (FFPE) diseased frontal lobe tissue samples from Alzheimer's disease (AD) patients acquired from Advanced Tissue Services (USA), and one diseased temporal lobe tissue sample from BioChain Institute Inc. (USA). These postmortem tissue samples were deidentified and classified as non-human subjects research by the University of Alabama's Office of Research Compliance. Before infrared (IR) imaging, the tissues underwent a 24-hour deparaffinization process in n-hexane and were stored under mild vacuum conditions. Adjacent tissue sections were used for immunohistochemistry (IHC) staining with anti-amyloid MOAB-2 antibody (Sigma-Aldrich)45,46 and silver staining, 47 and brightfield images of these stained tissues were acquired at 20× magnification using an Olympus BX43 microscope using manual WSI software (Microvisioneer) for image stitching. The resulting optical images were then used to assist in identifying the location and morphological characteristics of Aβ plaques.
IR Imaging
A custom-built stage scanning infrared (IR) microscope using a quantum cascade laser system (Block Engineering, LaserTune) was utilized to capture IR images,48,49 This microscope offers tunable illumination ranges from approximately 1000 to 1800 cm−1. The IR imaging was performed in transflection mode on IR reflective low-emissivity slides (Kevley Technologies, MirrIR) 50 from 1584 to 1730 cm−1, with a frequency resolution of 4 cm–1, with a 0.71 NA objective, and a pixel size of 2 μm.
Network Construction
The neural network models were trained using simulated data containing 200 000 spectra of the amide I band spectral region (1584 cm–1–1744 cm–1). The synthetic spectral dataset was split in half prior to training the two models: 100 000 were used to train the sparse data upscaling model while 100 000 were used to train the AUC prediction model. The spectral upscaling training dataset was augmented with 20 000 additional spectra from Alzheimer’s disease brain tissues. To sample the spectral heterogeneity of tissue infrared spectra, the training dataset was designed to encompass varying levels of noise, non-zero baselines arising from scattering effects, and variations of central peak positions and spectral widths. The spectral upscaling model was trained using the sparsely sampled seven-wavenumber input (1588 cm–1, 1612 cm–1, 1636 cm–1, 1660 cm–1, 1684 cm–1, 1708 cm–1, 1732 cm–1). It is important to note that the choice of the specific seven wavenumbers is not predicated on their association with specific secondary structures; rather, these wavenumbers constitute optimal spectral bands necessary for the accurate reconstruction of a complete spectrum. This model contains three hidden layers with 16, 32, and 64 hidden neurons and an output layer which contains 41 neurons corresponding to a full amide I bands spectral region with a spectral resolution of 4 cm–1. A schematic representation of this model is shown in Figure S5 (Supplemental Material). This output is then used as input to the second model, which has two hidden layers with 16 and nine neurons, respectively, and an output layer with three neurons corresponding to the three AUC values. A schematic representation of this model is shown in Figure S4 (Supplemental Material). All the neurons in our model were fully connected. We used a scaled exponential linear units (SELU) activation function for the hidden layer neurons in the AUC prediction model and a rectified linear unit (ReLU) activation function for the output layer neurons and hidden neurons within the spectral upscaling model. The weights and biases of the networks were trained using the adaptive moment estimation (ADAM) algorithm, and the AUC prediction model used LeCun normal initialization of weights within the network's hidden layer to minimize the mean absolute error (MAE) loss function. All training was performed with Python (3.8.17), and TensorFlow (2.13.0).
Gaussian Fitting
Experimental and simulated spectra were linear baseline corrected and fitted to three Gaussian peaks roughly centered at 1632 cm–1, 1666 cm–1, and 1690 cm–1 with a range value of 5 cm–1 using the native Gaussian fitting option in Matlab (nonlinear least square fit with Levenberg–Marquardt Algorithm) to extract the peak parameters for the three bands, fitting parameters detailed in Table S2 (Supplemental Material).
Results and Discussion
As summarized in Figure 1, we simulate 200 000 spectra as the sum of three intensity normalized Gaussian peaks with known AUC values. Also added to the training dataset were 20 000 additional spectra from Alzheimer’s disease brain tissue data for the spectral upscaling model. It has been shown previously that FFPE brain tissue amide I spectra can be adequately deconvoluted as a sum of three bands;7,24 thus, the choice of three Gaussian bands for our model is suitable. Subsequently, 120 000 spectra were split randomly into training (80%) and testing (20%) datasets and used to train and evaluate each model, respectively. The spectra were discretely sampled at 1588 cm–1, 1612 cm–1, 1636 cm–1, 1660 cm–1, 1684 cm–1, 1708 cm–1, and 1732 cm–1 to generate the input dataset for training the spectral upscaling model with the densely sampled 41 wavenumber spectra as the target. Following the training of the upscaling model, the second set of 100 000 spectra were also split randomly into a training (80%) and testing (20%) and sparsely sampled at the seven wavenumbers previously mentioned and forwarded through the upscaling model, an artificial neural network, or ANN (ANN1); the resulting output is then used to train an NN-regression model (ANN2) with the AUC values as the target. The combined pre-trained network is then forwarded on actual experimental data and the extracted AUC values are compared to those obtained from the conventional fitting approach.
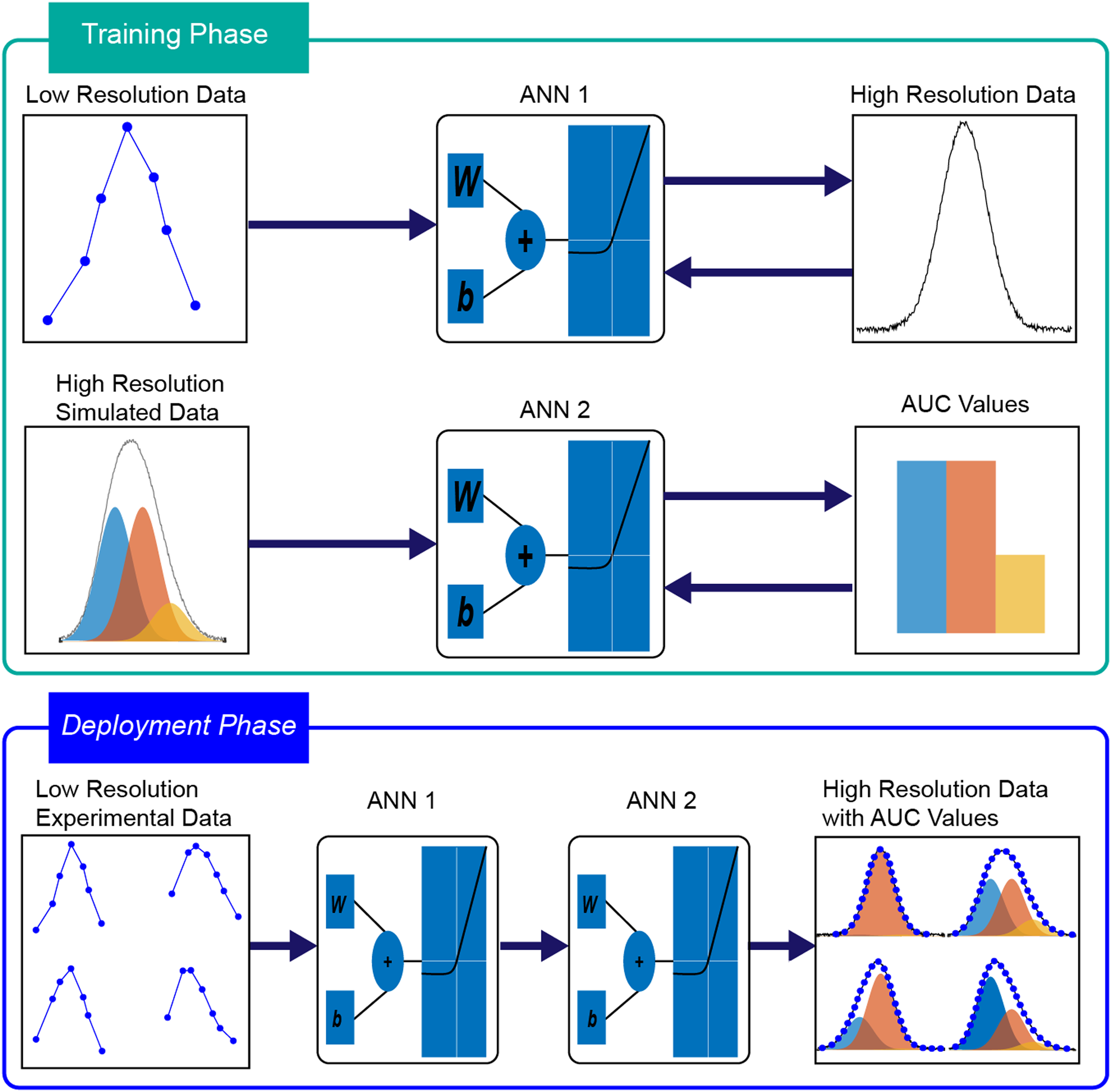
Schematic representation of the method presented in this paper. AUC1: blue, AUC2: orange, AUC3: yellow. ANN 1: Artificial neural network responsible for upscaling of spectroscopic data. ANN 2: Artificial neural network responsible for estimating the deconvolution of said upscaled spectroscopic data.
To account for absorbance variations between tissues originating from the thickness and other artifacts, the input to the neural networks was mean intensity normalized. Figure 2 highlights the accuracy of the spectral upscaling model by displaying three representative examples of actual versus model predicted spectra (Figure 2a) along with an example of images from amyloid plaques, a key morphological feature in Alzheimer's disease.51–53 An infrared spectral image from this plaque was collected at 1628 cm–1 and displayed below (Figure 2c). This example agrees well with the corresponding upscaling model output predicted for 1628 cm–1, resulting in a structural similarity index measure (SSIM) of 0.9969. The spectral upscaling model was also evaluated using the test dataset and was found to have a 0.015 MAE. To optimize the accuracy of our spectral upscaling model with the speed of experiment and analysis, we evaluated the dependence of MAE on the number of input bands to the AUC prediction model (Figure S1, Supplemental Material). This analysis indicated clear diminishing returns in terms of model performance when training with additional wavenumbers beyond seven. During this series of tests, the amide I band was under sampled with seven uniformly spaced measurements. The final model uses seven wavenumbers that are not equally spaced but are rather chosen better to sample the characteristics of the three underlying bands. We verified that this specific wavenumber set slightly improves the model accuracy compared to using seven equally spaced bands and the results are shown in Figure S1, where the red dot represents our modified selection of wavenumbers, and the corresponding seven-wavenumber blue dot represents seven equally spaced wavenumbers.
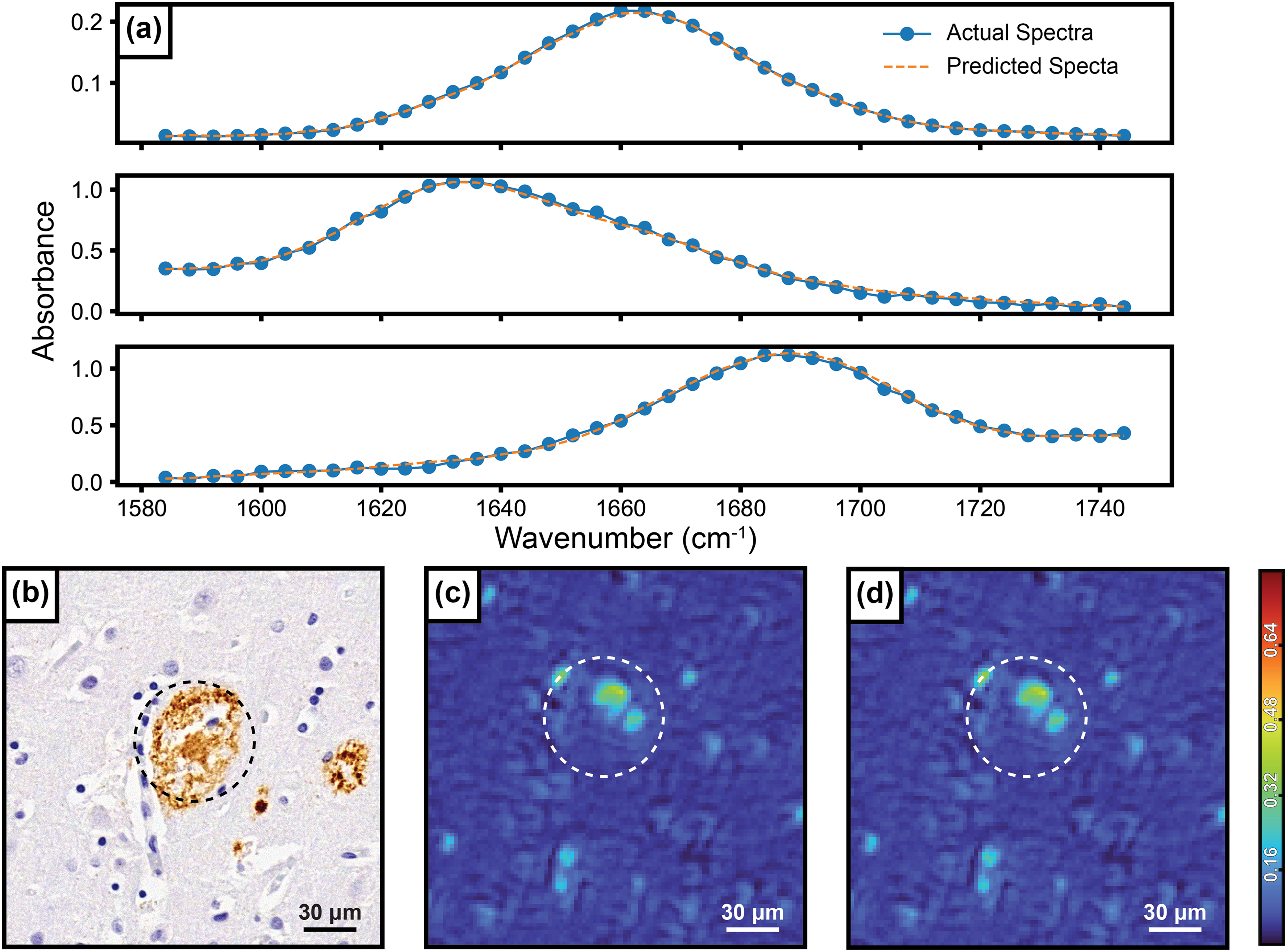
(a) Various example spectra from the test dataset and their corresponding predicted spectral output, (b) optical IHC stained Aβ plaque, (c) intensity image collected at 1628 cm–1 of the plaque corresponding plaque with the approximate position estimated by the white dashed circle, (d) the same intensity image predicted by model output.
Upon validation of the fidelity of the predicted spectra, we applied the second model to the spectra generated from Model 1 to predict the AUCs of the constituent bands. Figure 3 displays the simulated dataset's predicted AUC versus ground truth AUC and the corresponding R2 values and linear fits. The high R2 values and small intercepts (relative to the mean AUCs) validate our AUC prediction model’s performance. The MAE of our test set evaluated for all three AUC values was 5.16. Out of the three fitted peaks, the lowest R2 value is for AUC2 (0.880) because of the possibility of overlap from the two Gaussian peaks on either side. This is a well-known issue with deconvoluting broad spectra and arises due to the extent of a fundamental ambiguity in the deconvolution approach. 54 By leveraging this model, the time required for spectral acquisition is cut dramatically. The experimental time for discrete frequency imaging typically scales linearly with the number of bands, meaning measuring a sparse seven-wavenumber dataset compared to the typical 41 wavenumbers required to investigate the slightly expanded amide I band spectral region (1584–1748 cm–1) with 4 cm–1 spectral resolution leads to a roughly six-fold decrease in experimental time for biological samples where it is essential to sample the interpatient heterogeneity for statistically significant results, such reduction of experimental and computational times is invaluable.
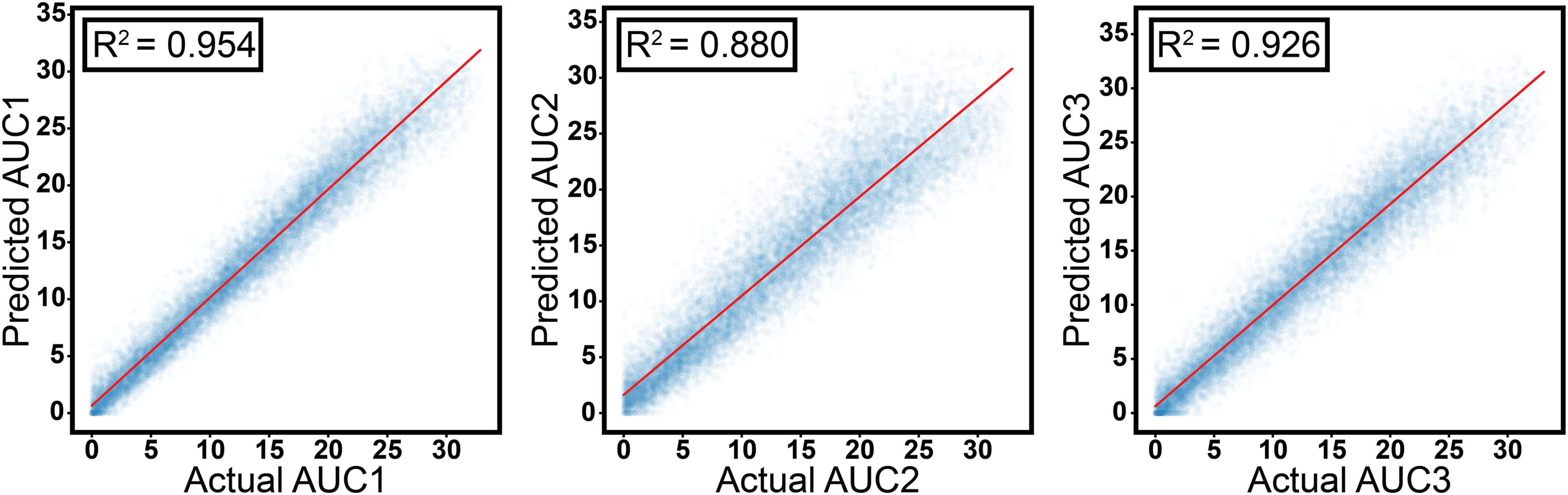
Scatter plots of actual versus predicted AUC values corresponding to the test dataset split.
After the training phase, the model’s performance was evaluated on experimental hyperspectral images from Alzheimer’s disease brain tissue specimens. Neuropathological diseases such as Alzheimer’s, Parkinson’s, etc., involve the aggregation of specific proteins into extra and intracellular deposits, which are believed to play important roles in the development and progression of the disease. However, protein structures in the brain are yet to be fully understood, and how these aggregates truly influence disease pathology at a molecular level is unclear. In particular, how the secondary structure of these aggregates evolves with disease pathology and if/how that parallels in-vitro studies remains a topic of intensive investigation. Accurately mapping protein secondary structure requires spectral deconvolution, making our model ideal for such applications. To compare the model output with the current gold standard in spectral deconvolution, namely band fitting, the infrared amide I band spectral contribution collected from measuring these plaques was deconvoluted into three Gaussian peaks with both the model and Gaussian fitting algorithm. These three Gaussian peaks are centered at approximately 1628 cm–1, 1660 cm–1, and 1690 cm–1 the integrated area under the curve (AUC) of these three peaks will be referred to as AUC1, AUC2, and AUC3, respectively, in this article. Integrating each peak allows for a comparison of the relative strength of each from one pixel to the next, in the context of protein spectroscopy the relative abundance of AUC1 is of particular importance, since the 1628 cm–1 peak correlates to relative parallel β-sheet concentration, 55 which can be predictive of many key neurodegenerative morphological features like Aβ plaques. Figures 4a and d shows the optical images of the IHC stained parallel section for the two plaques, while Figures 4b and e and Figures 4c and f show the spectral fitting and network outputs, respectively. We can observe a clear correspondence between the fitted AUC1 images (Figures 4b and e), and network-measured AUC1 images (Figures 4c and f). An important distinction between the fitted AUC image and the Model AUC image is the difference in baseline (non-β-sheet values), where the Gaussian fitting presents significantly more background noise than the Model output. This issue is well documented in the context of Gaussian fitting where the fitting process can amplify noise and create artificial peaks in the background, leading to misinterpretations of the spectral data. Gaussian fitting often struggles with distinguishing between actual signal and background noise, particularly in complex biological samples where spectral overlap and variations are common. 56 In the characterization of amyloid plaques, it is generally mitigated by concentrating on the region containing the plaque. However, increased image noise complicates the identification of the desired morphological feature.
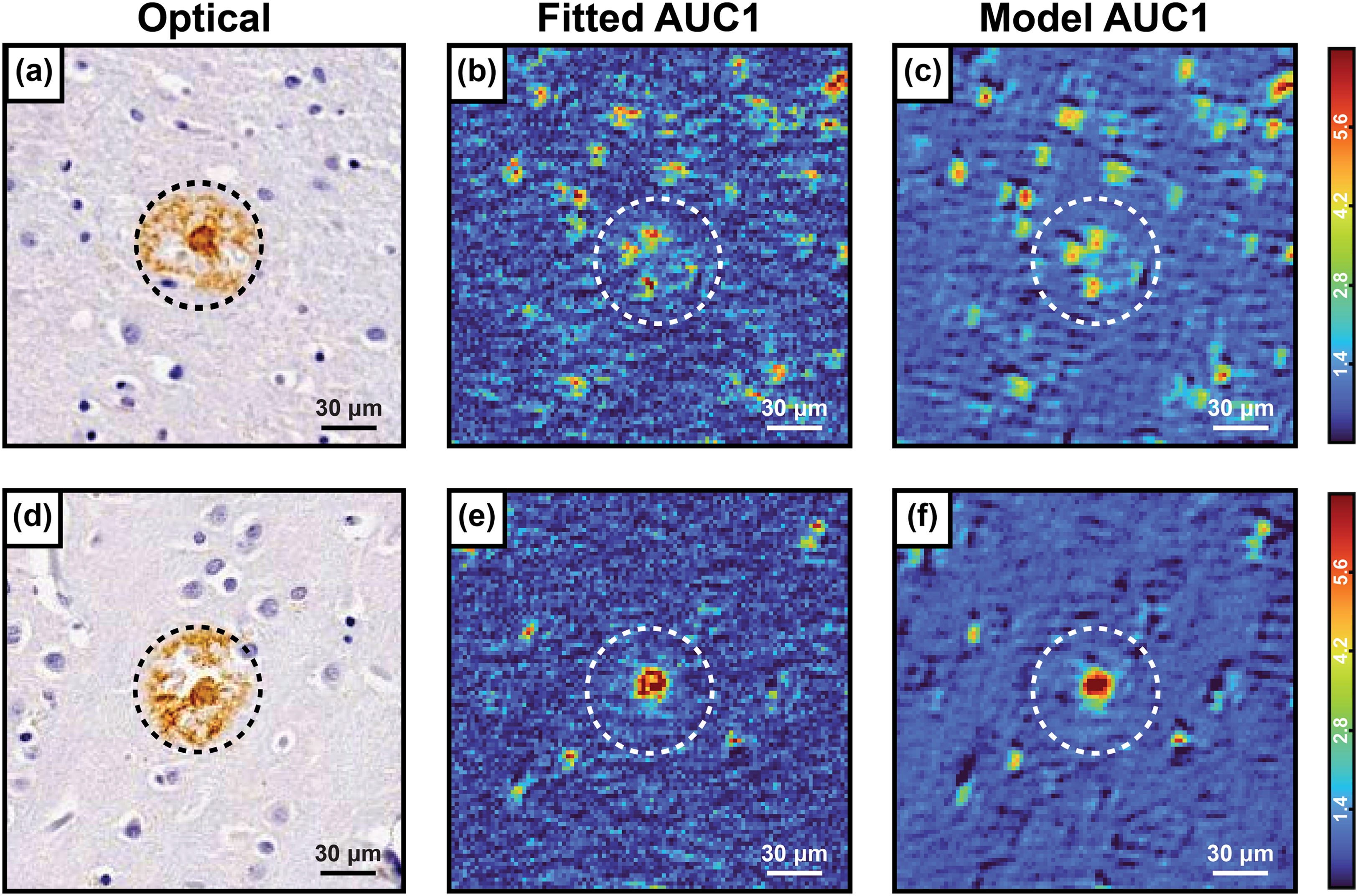
(a, d) Optical IHC stained images of Aβ plaques with the plaque identified by the black dashed circle, (b, e) deconvoluted AUC1 images from collected hyperspectral data, and (c, f) reconstructed AUC1 images from network predictions with the approximate position of the plaque estimated by the white dashed circle.
The high versatility of our model also allows it to be utilized for much larger specimens, where the acquisition of a hyperspectral dataset can become prohibitively time-consuming. Furthermore, the size of such datasets also poses a challenge for analysis. Spectral fitting for such data would become a computationally expensive process that can significantly strain or even overwhelm available computational resources. Figure 5a displays AUC1 images reconstructed from the neural network model output of an entire frontal lobe tissue section. Figure 5b and Figure 5c display the Gaussian fitted and Model predicted AUC1 values respectively within a smaller area of interest indicated by the dashed white line in Figure 5a, which clearly demonstrates the fidelity of our model when compared to spectral fitting. Figures S2–S4 (Supplemental Material) present additional examples of AUC1 images reconstructed from the neural network model output.
(a) Network predicted AUC1 image from collected hyperspectral data of a frontal lobe Alzheimer’s tissue section, and a smaller cropped region of interest denoted by the dashed white box where the AUC1 was predicted using Gaussian fitting (b), and our pre-trained model (c).
A single band at a 2 μm/pixel resolution for this specimen requires ∼67 minutes to acquire and results in an image with approximately 154 million pixels. Acquisition of a hyperspectral dataset optimal for subsequent deconvolution would thus require nearly two days and lead to approximately 6.3 billion pixel measurements. Subsequent spectral analysis of a dataset of this size is also expected to be significantly time and resource consuming. Our model allows for the reproduction of the spectral features and subsequent deconvolution with high fidelity and approximately six-fold faster data acquisition without additional computational overhead.
Finally, the model prediction performance on simulated spectra with varying levels of added random noise was compared to the accuracy of the Gaussian fitting method outlined previously. The results of this analysis are presented in Figure 6 (tabulated in Table S1, Supplemental Material) and indicate that the model consistently outperforms Gaussian fitting. Figure 6 shows the relative MAE of the two deconvolution methods versus the signal-to-noise (SNR) ratio for various sets of simulated spectra; this value was assessed in the simulated datasets by calculating the standard deviation of the signal at the tail of the amide I region (1742–1748 cm–1) where there is no expected signal. The noticeable difference in the slopes of the corresponding models in Figure 6 suggests that Gaussian fitting is much more susceptible to an increase in noise than our model. This agrees well with current literature, which suggests that Gaussian fitting has difficulty fitting to lower SNR data. 56
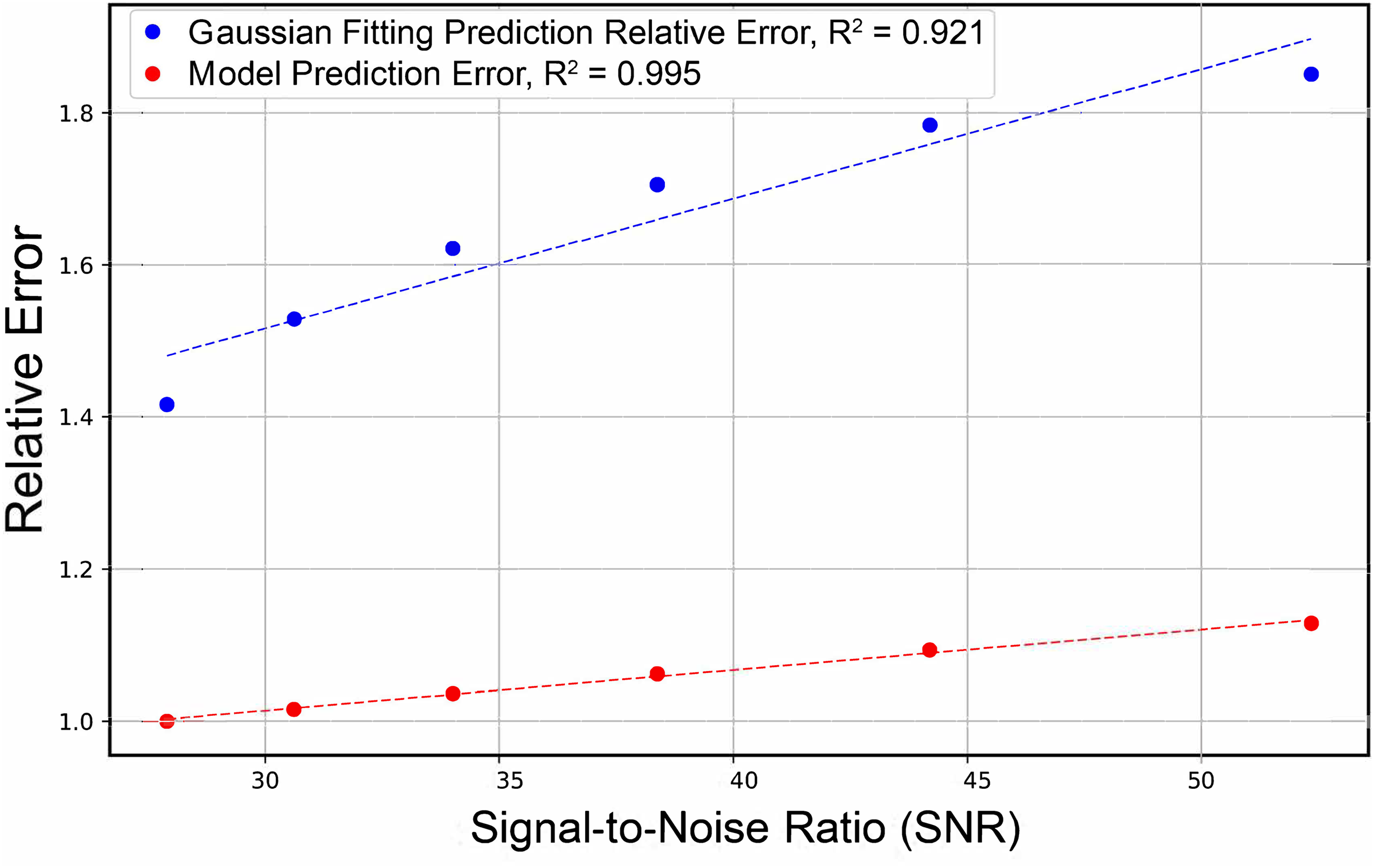
Comparison of trends for relative MAE in AUC prediction versus SNR for both Gaussian fitting and the model.
It is essential to consider the optimal number of components that constitute the amide band and their corresponding lineshape functions in this context. The deconvolution of amide I spectra typically employs multiple sub-components to represent secondary structural elements. To balance model complexity and accuracy, we selected three bands that optimally fit the spectra. This decision is supported by prior work, 7 which demonstrated that adding more components does not significantly improve the fit. The three bands correspond to β-sheets, random coils, and turns, 57 which are the predominant secondary structural elements, with α-helices excluded due to their spectral overlap with random coils. The choice of Gaussian lineshapes was informed by the Gauss–Markov model,58,59 which attributes Lorentzian components to solvent-induced fast frequency fluctuations that are absent in fixed tissues. Additionally, distortions in IR spectra caused by sample size, imaging geometry, and refractive index effects60,61 complicate the physical relevance of Lorentzian parameters in Voigt models. Previous studies 7 have also shown that Gaussian lineshapes adequately describe tissue spectra.
It is also important to note that several analysis methods besides band fitting can be employed to extract information about protein secondary structure from IR spectra. These include two-dimensional correlation spectroscopy, Fourier self-deconvolution, and second derivative analysis. The latter involves calculating the second derivative of the IR spectrum, which enhances the separation of overlapping peaks and reveals subtle features that may not be apparent in the original spectrum and has been widely applied to the analysis of protein IR spectra.7,62,63 Fourier self-deconvolution techniques aim to enhance the resolution of the IR spectrum by removing instrumental broadening and separating overlapping peaks by use of apodization in the Fourier transformed time domain signal. This allows for a more accurate determination of the number and positions of underlying peaks, which can then be assigned to different secondary structures.64,65 Two-dimensional correlation spectroscopy generates maps that reveal positive and negative correlations between different spectral components, which in turn reveals insights into the dynamic behavior of molecules and their interactions. 66 These approaches can also be augmented with other complementary approaches such as circular dichroism spectroscopy to provide a more nuanced and comprehensive picture of protein secondary structure. 67 However, all the above strategies rely on the acquisition of a full spectrum. Herein, we demonstrate a computational pipeline comprised of two separate neural network models for recovering the hyperspectral information content of IR imaging from sparsely sampled DFIR data. Our networks were trained using a combination of experimental and simulated data to capture the distribution of line shapes, widths, and noise found in spectra from a wide range of biological samples. Our approach enables the reconstruction of the entire spectrum from sparsely sampled bands, which can consequently be analyzed using any method as appropriate and thus can expand the applicability of these analytical approaches in spectroscopic imaging further. The second neural network reported in this study aims to reproduce the AUCs as typically determined from curve fitting; in principle, other networks can be envisioned and trained to predict the parameters of different spectral analysis methods. We hope to address this in future work.
While the upscaling of spectral data on its own may not be a new concept, integrating this technique with a machine learning-based deconvolution method is an integral step forward in the analysis of IR imaging data. By requiring the measurement of only seven key wavenumbers for the reconstruction of spectra, our first model can circumvent the data acquisition overhead that so often burdens traditional spectroscopic imaging techniques, allowing for the rapid investigation of even the largest specimens. Most efforts aimed at optimizing the experimental acquisition time in spectroscopic imaging have focused on coarser spatial sampling, 68 wherein only a subset of the pixels need to be sampled for reconstruction of the image at a given IR band. AI-based tools have been employed to that end as well. 68 On the other hand, it is common practice to use some form of spectral deconvolution for hyperspectral data, such as those acquired in FT-IR and spontaneous Raman imaging.69–71 However, to the best of our knowledge, no AI-based approach has been implemented towards coarsely sampling the spectral domain, as has been implemented in our work. While recording intensities at desired frequencies can suffice for well separated transitions in vibrational spectra, for bands that are convolutions of multiple transitions, such as protein vibrations this analysis becomes much more complex65,72 The analysis of hyperspectral data in such cases requires additional deconvolution, typically through band fitting, and the resulting AUCs of the fitted components can be interpreted as proportional to corresponding concentrations or abundance. The AUC prediction model outlined here, presents clear advantages in data analysis time, prediction accuracy, and noise tolerance over traditional Gaussian-fitting-based approaches to spectral deconvolution. Our model, despite using more sparsely sampled data than traditional Gaussian fitting, can evaluate spectral features like AUC values with higher accuracy. Because of Gaussian fitting’s increased sensitivity to noise, our model also shows a better ability to adjust to lower SNR within spectral data. We note that the two models can be combined into a single model that simply predicts AUCs from seven spectral bands. However, we trained two separate models, because even individually they can benefit data acquisition and analysis approaches of different experimental implementations of IR imaging. For example, FT-IR imaging systems, where the entire mid-IR spectra are acquired by design, can just utilize the second model for deconvolution. On the other hand, imaging systems capable of acquiring discrete frequencies (DFIR) can make use of only the first model for spectral reconstruction, or both models in conjunction when deconvolution is desired. The framework reported herein is useful for different modalities of IR imaging, particularly for DFIR, where the time required for data acquisition and analysis can be significantly reduced.
A key aspect of our approach is the potential for application towards other spectroscopic modalities and spectral regions. Since the networks are trained using largely simulated spectral data, we anticipate that they will be readily extendable towards analyzing discrete frequency IR images from a wide variety of tissue specimens, including but not limited to brain sections from neuro-degenerative diseases. We aim to investigate the transferability of these models in future work. In this work we have focused on the amide I region (1600–1700 cm–1) due to its significant relevance in identifying protein secondary structures, making it immensely informative for studies related to protein conformation and interactions. We anticipate the expansion of this framework beyond Amide vibrations to other spectral regions that are rich in molecular information, such as the 3 μm region (approximately 2500–3700 cm–1). The C–H, O–H, and N–H stretching modes from different molecular moieties such as lipids, proteins, nucleic acids, etc., absorb in this spectral region. These bands are also convolutions of different molecular components, and our method can be easily applied to deciphering molecular compositions in these spectral regions as well. Furthermore, our methodology is not limited to conventional IR spectroscopic imaging but is also generalizable to various forms of discrete frequency imaging techniques, such as photothermal IR imaging and stimulated Raman scattering (SRS) microscopy. These techniques are particularly beneficial in biological and medical research for their label-free and non-destructive nature, allowing for in vivo and dynamic studies with high specificity and sensitivity. It should be noted that successfully applying our approach to these modalities requires meticulous construction of the training dataset. It is essential that the dataset accurately represents the SNR inherent in the respective methods to ensure robust and reliable predictive performance. However, given our model leverages the fundamental variations in the amide I spectra for spectral reconstruction and deconvolution, this approach should be directly extendable to imaging modalities that use mid IR spectra for chemical contrast, such as photothermal IR imaging. This also allows for the wide applicability of this approach. Since our model is trained to recognize only the variations in the spectral domain by using largely simulated spectra, it is not limited in the same way as networks trained on specific imaging systems would be in terms of transferability, which remains a key challenge in developing “turn-key” solutions for data analysis in chemical imaging using machine learning. Our model is readily usable on all forms of IR data encompassing the amide I region and can be easily retrained to be compatible with other spectral regions or methods such as Raman microspectroscopy. We aim to apply this model to other modalities of spectral imaging in future work.
It is important to note that the weights and biases of our network have been trained using largely simulated data, guided by the known and observed secondary structure distributions within the amide I spectra of tissue samples. Specifically, the upscaling model is trained using a combination of synthetic and experimental data, while the AUC prediction model is trained on entirely simulated data. The spectra for training were simulated to capture the same distribution of line shapes, widths, and noise as our experimental data. The reason for the choice of simulated data is the following. First, it allows for sampling for a broader range of training data for the model without the burden of experimental data acquisition. The fitting and theoretical simulation of protein amide vibrations has been extensively studied and used in IR spectroscopy, which allows us to adopt this approach without any loss of generality. Of course, this may not be viable for all kinds of spectroscopic imaging techniques, where an extensive database for protein spectra does not exist. Second, in the case of experimental data, determining the ground truth (AUC) values requires Gaussian fitting, a process we aim to avoid. Gaussian fitting is time-consuming and plagued by the issues mentioned earlier, such as sensitivity to noise. Given the assumption that the spectra can be represented as the sum of three Gaussians, it is more suitable to consider this as the actual ground truth. In essence, our goal is to deduce the fundamental Gaussian parameters of the amide I spectra. Of course, this does not apply to our first model, which only reconstructs spectra at higher frequency resolution from discrete bands, and hence we have used both simulated and experimental data to train this network. An important aspect to consider here is that Gaussian fitting of hyperspectral image data essentially deconvolutes each spectrum individually, without leveraging any information from the adjacent pixels corresponding to spectral location. Neural network based approaches, like the one used here, can be further optimized by factoring in the relationship of localized spectra to those from adjoining pixels whose properties are inherently related. This can potentially further the fidelity and applicability of these approaches towards analysis of complex spectral data in a wide variety of specimens, which would be otherwise challenging to address with conventional deconvolution strategies.
Conclusion
In summary, we have introduced a novel approach that harnesses the power of machine learning to address challenges associated with acquiring and analyzing discrete frequency IR imaging. We show that a simple two-step regressive neural network model can be trained to use spectral intensities at discrete frequencies to accurately replicate results from Gaussian curve fitting. The first network uses only seven wavenumbers to upscale spectra to higher resolutions, thus achieving a six-fold reduction in data acquisition time. This upscaled spectral data is then utilized by a second network to predict AUCs of the spectral components, akin to Gaussian fitting, but 3000 times faster. As a result, our approach drastically reduces both the time required for data acquisition and analysis, enabling the prediction of important variations in protein structure, which could be crucial for expanding the applications of discrete frequency imaging to proteinopathies. Since the networks are trained using largely simulated spectral data, they can be readily extended toward analyzing discrete frequency IR images from a wide variety of tissue specimens, including but not limited to brain sections from various neurodegenerative diseases. We note that our model reproduces both the amyloid positive and negative regions with high fidelity, which underscores the robustness of our approach. It should be noted that this study does not aim to classify spectral data as diseased or benign. Instead, it focuses on developing neural networks capable of reconstructing any amide I spectrum, regardless of its origin and relevance to disease, from a discrete set of bands and generating AUCs of constituent bands using a comprehensive library of simulated spectra. Thus, these models can have a broader application toward the characterization of other diseases beyond Alzheimer’s, as studied here. Furthermore, our approach is independent of the spatial image parameters that may vary from different imaging systems and recognizes only the intensity variations arising from fundamental changes in protein secondary structure distributions. As a result, this also has the potential to be adapted for application for other spectroscopic modalities and spectral regions of interest, such as Raman spectroscopy. By tailoring the training datasets and expanding the application scope, our approach can substantially enhance the utility of spectroscopic imaging across various scientific fields, providing a powerful tool for detailed molecular characterization in diverse applications ranging from materials science to biomedical diagnostics.
Supplemental Material
sj-docx-1-asp-10.1177_00037028251325553 - Supplemental material for Quantification of Protein Secondary Structures from Discrete Frequency Infrared Images Using Machine Learning
Supplemental material, sj-docx-1-asp-10.1177_00037028251325553 for Quantification of Protein Secondary Structures from Discrete Frequency Infrared Images Using Machine Learning by Harrison Edmonds, Sudipta S. Mukherjee, Brooke Holcombe, Kevin Yeh, Rohit Bhargava and Ayanjeet Ghosh in Applied Spectroscopy
Footnotes
Acknowledgments
This work was supported by the National Institutes of Health (Award R35 GM138162 to A.G.). The content is solely the responsibility of the authors and does not necessarily represent the official views of the National Institutes of Health.
ORCID iDs
Supplemental Material
All supplemental material mentioned in the text is available in the online version of the journal.
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.