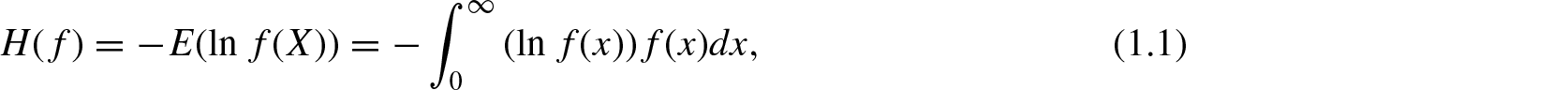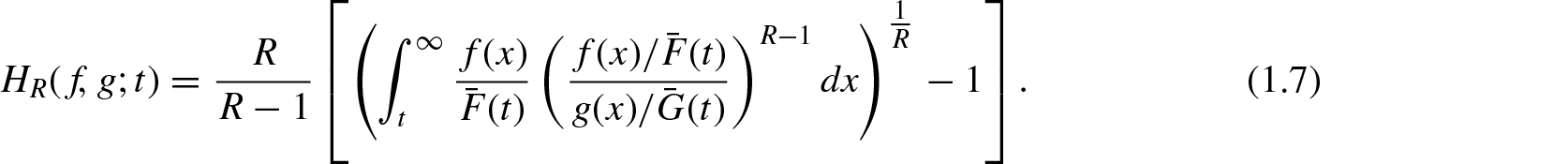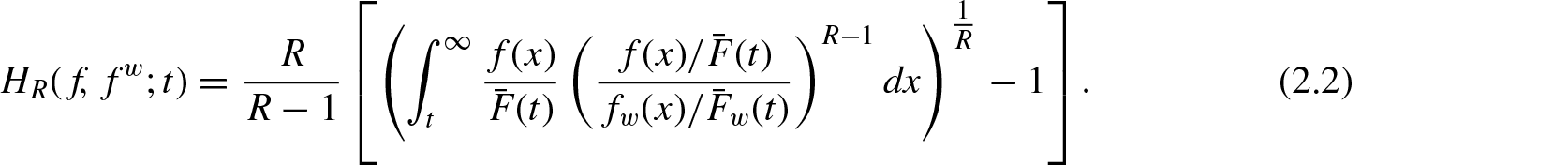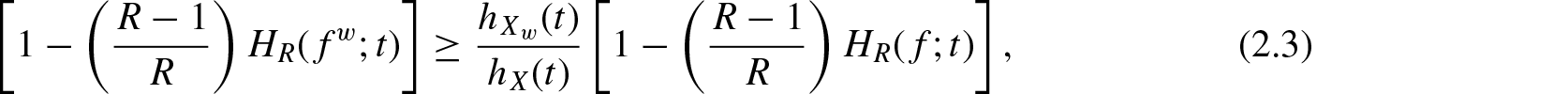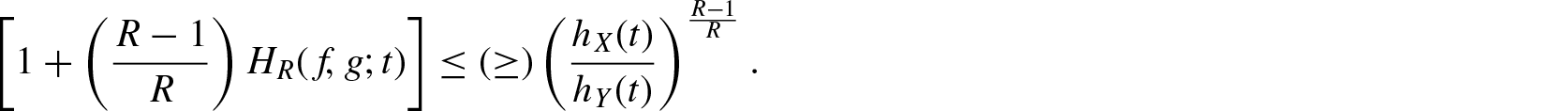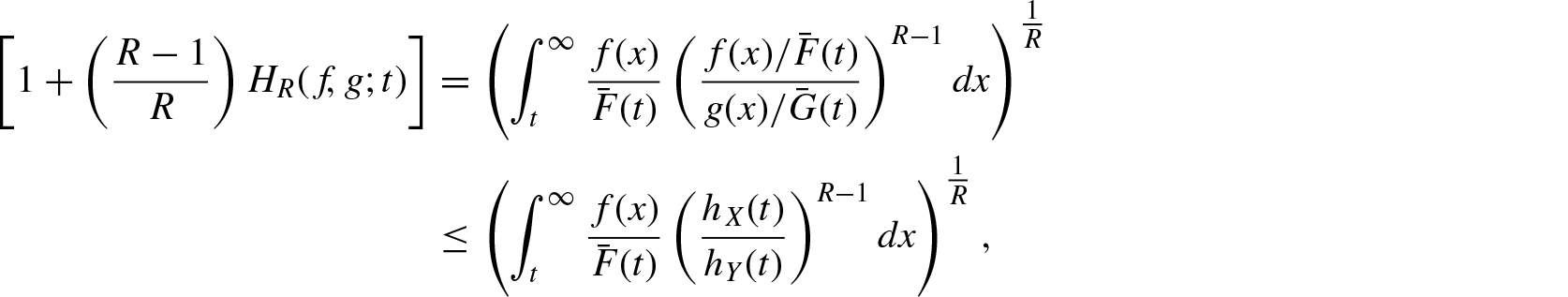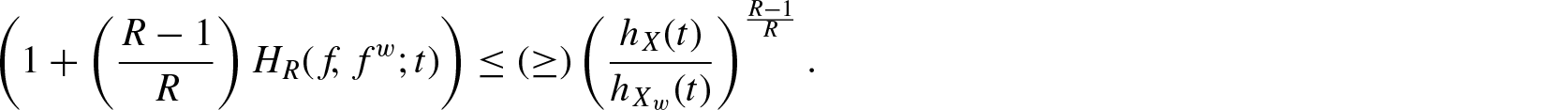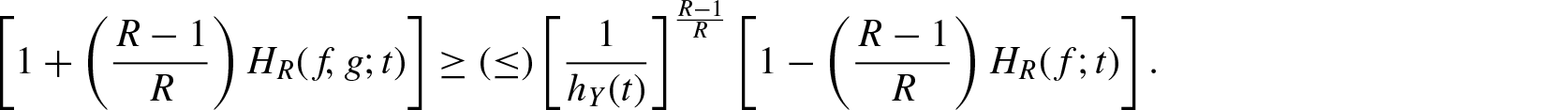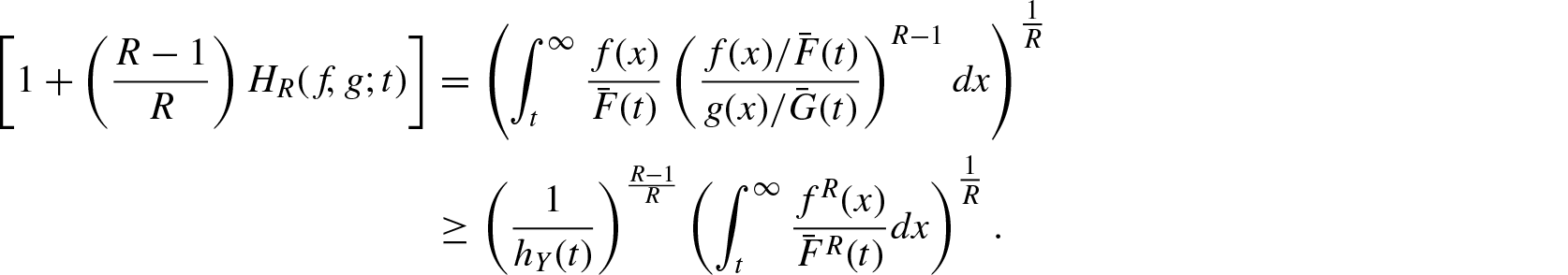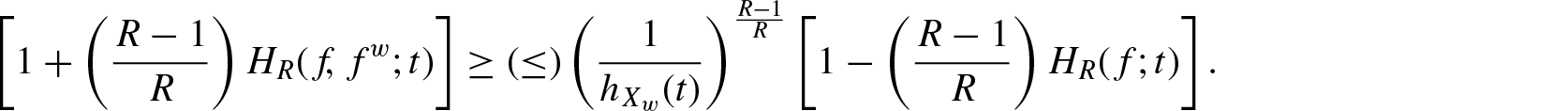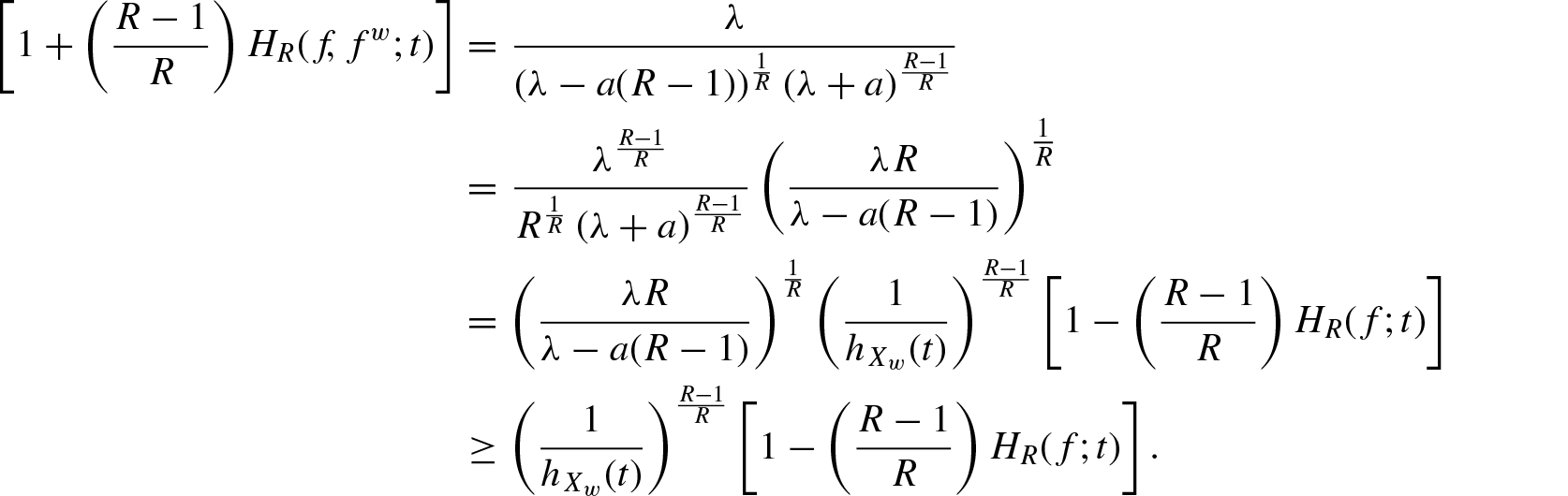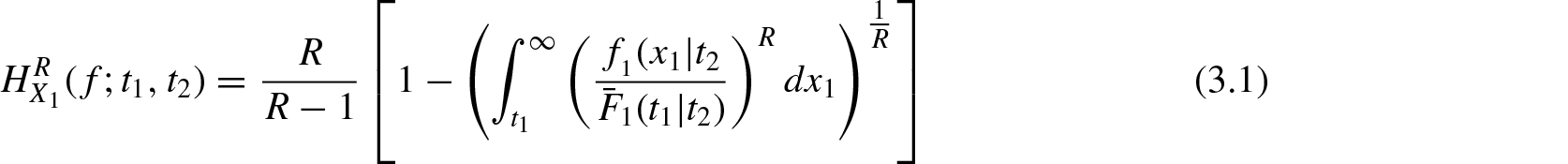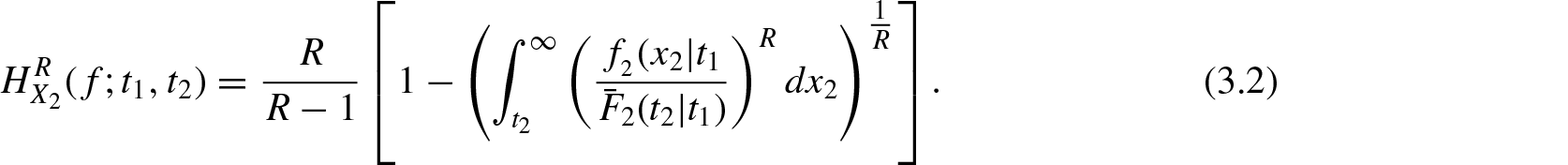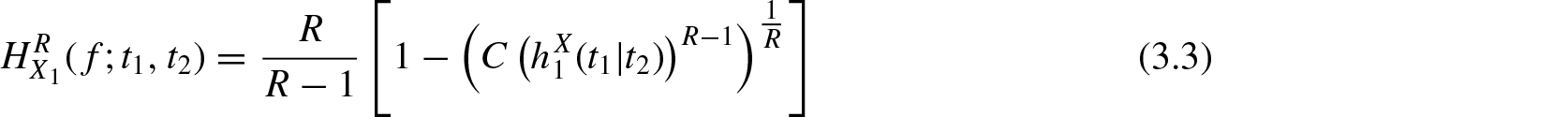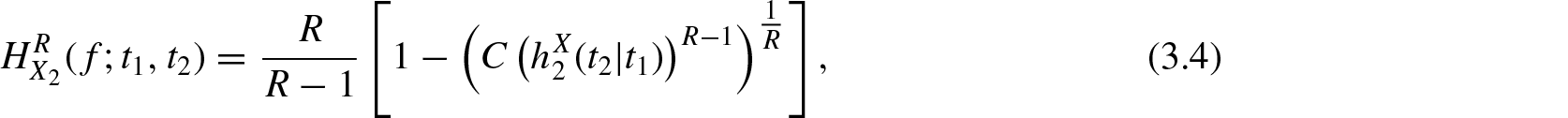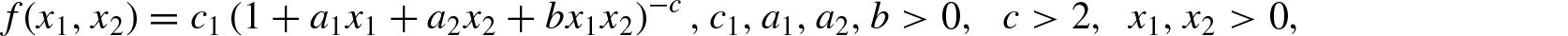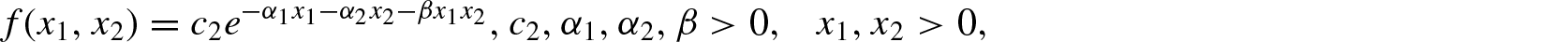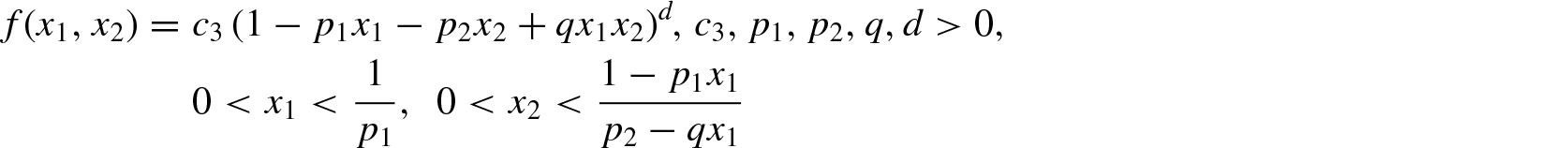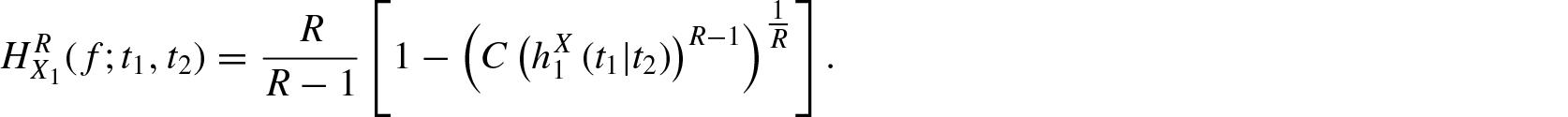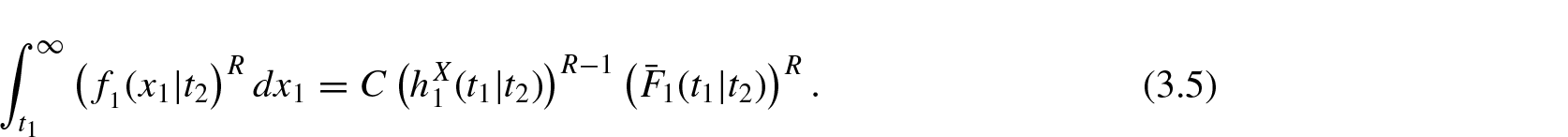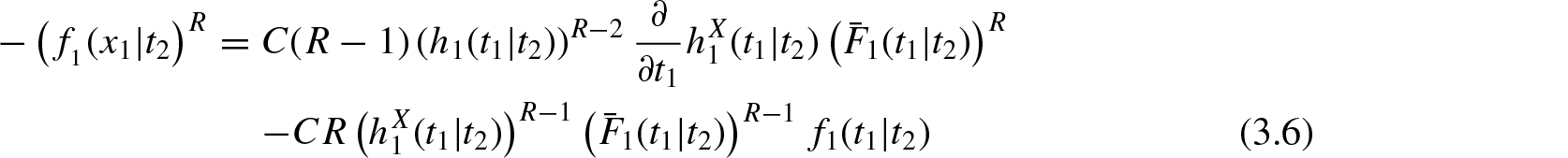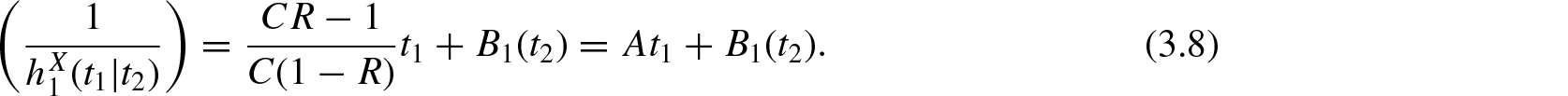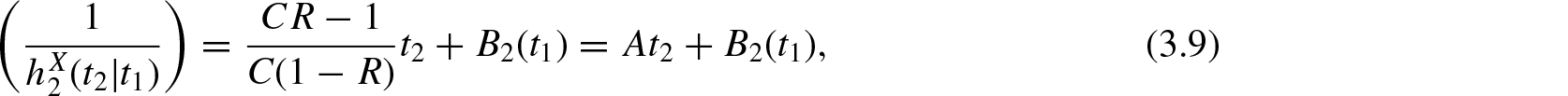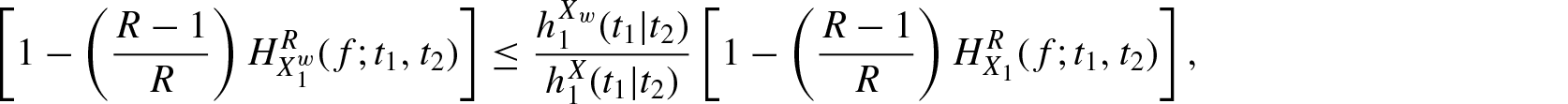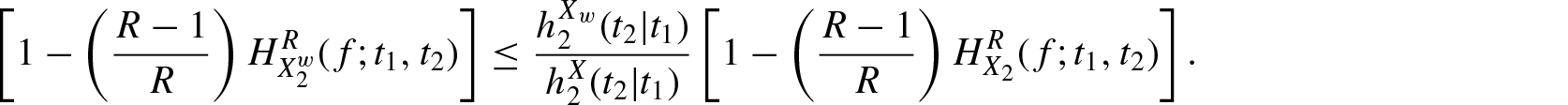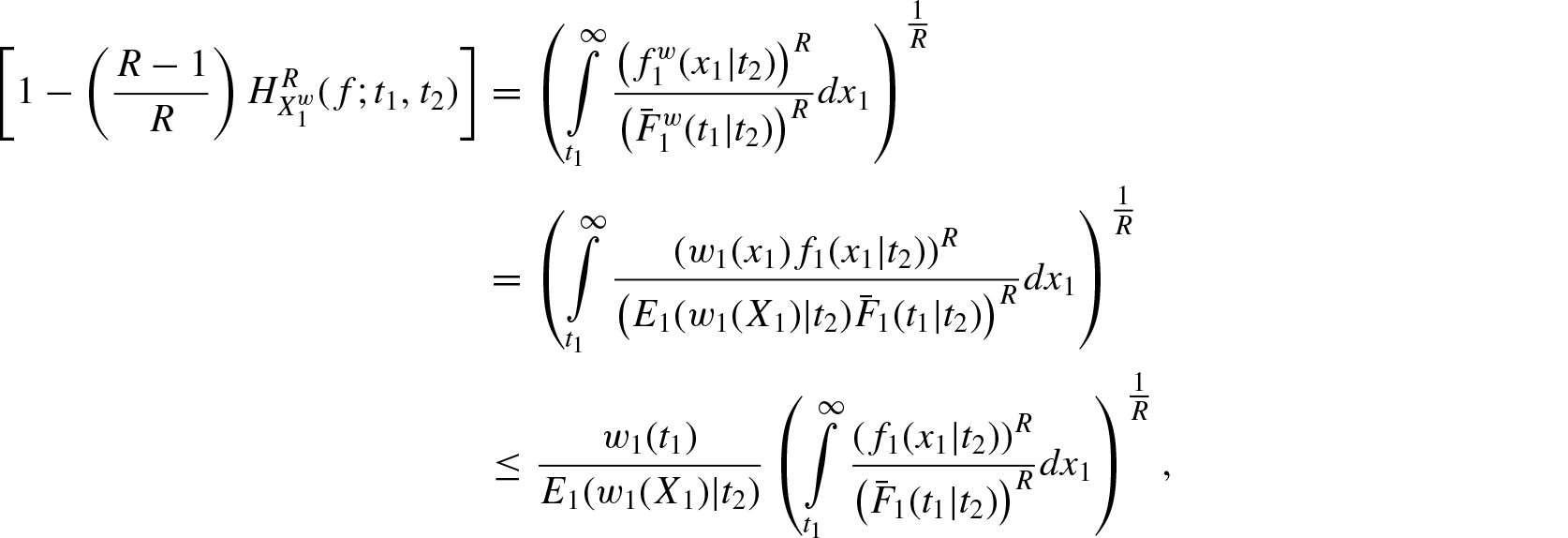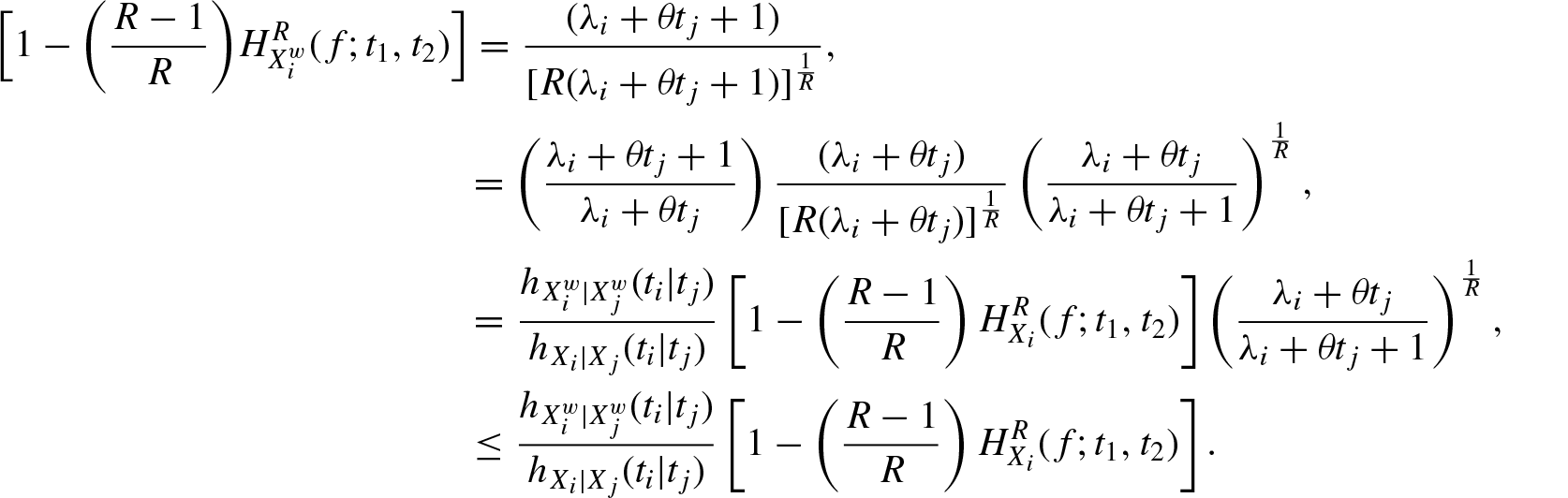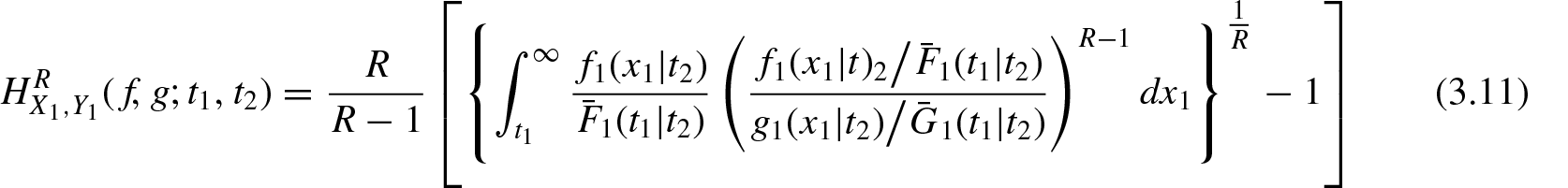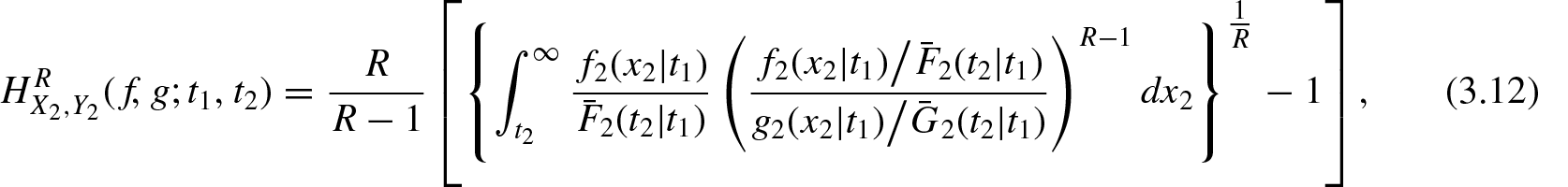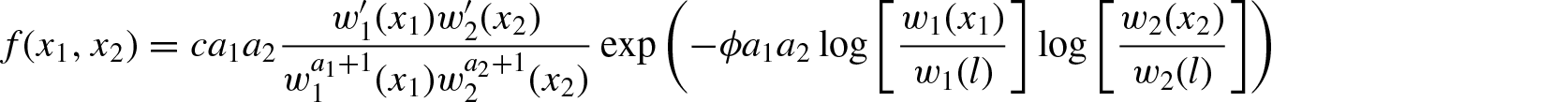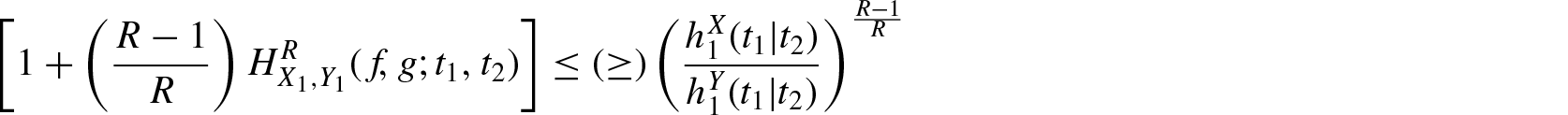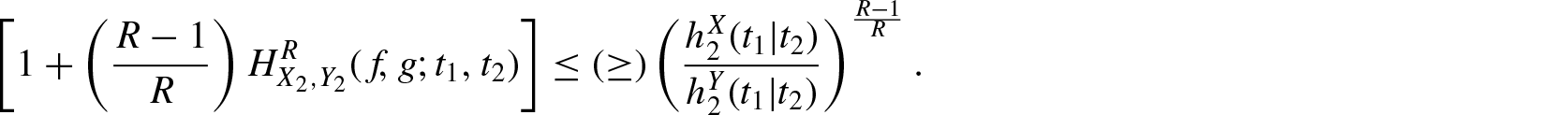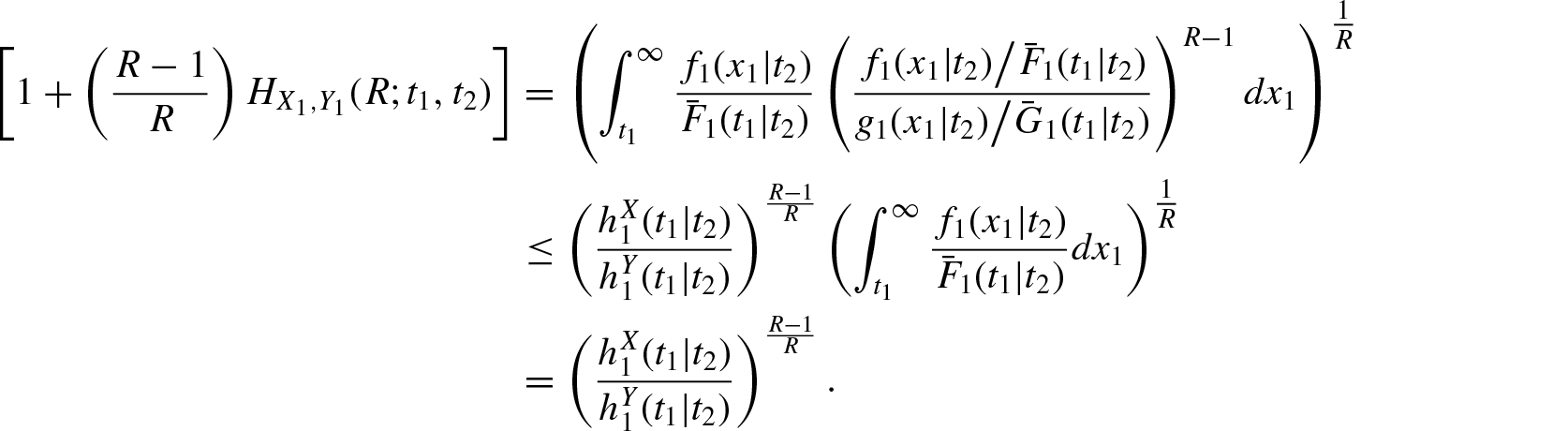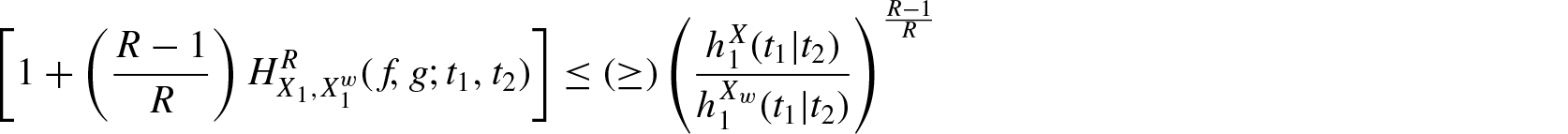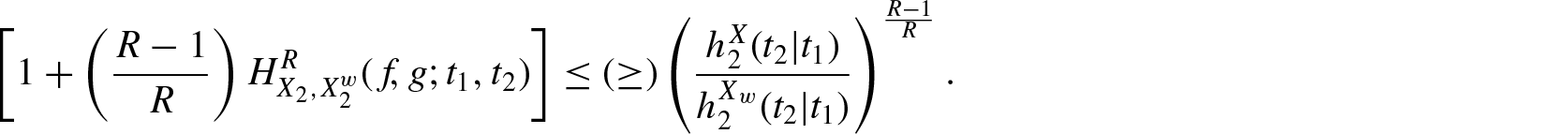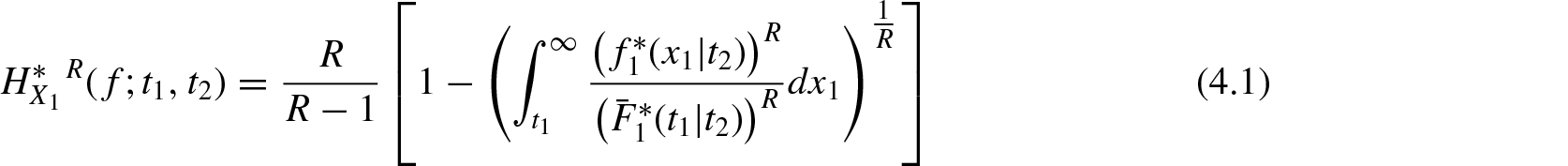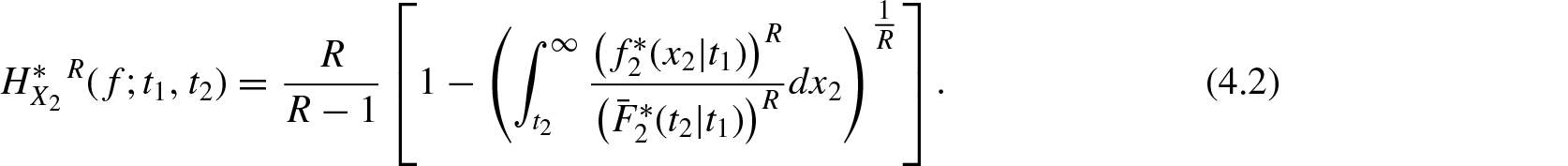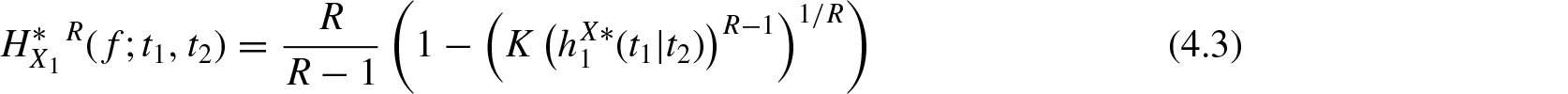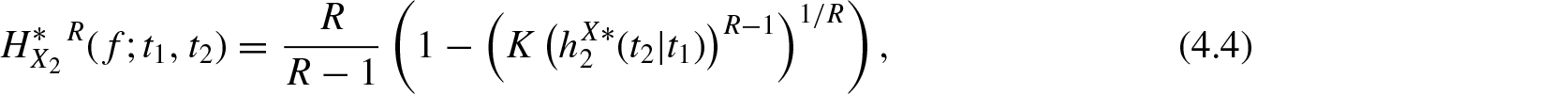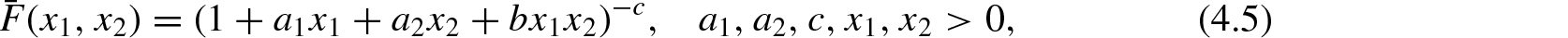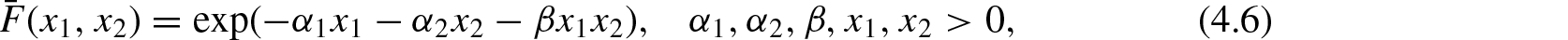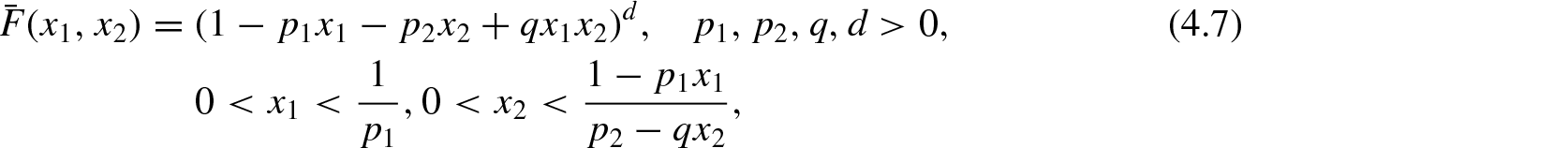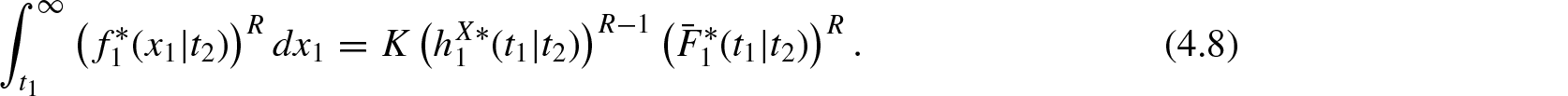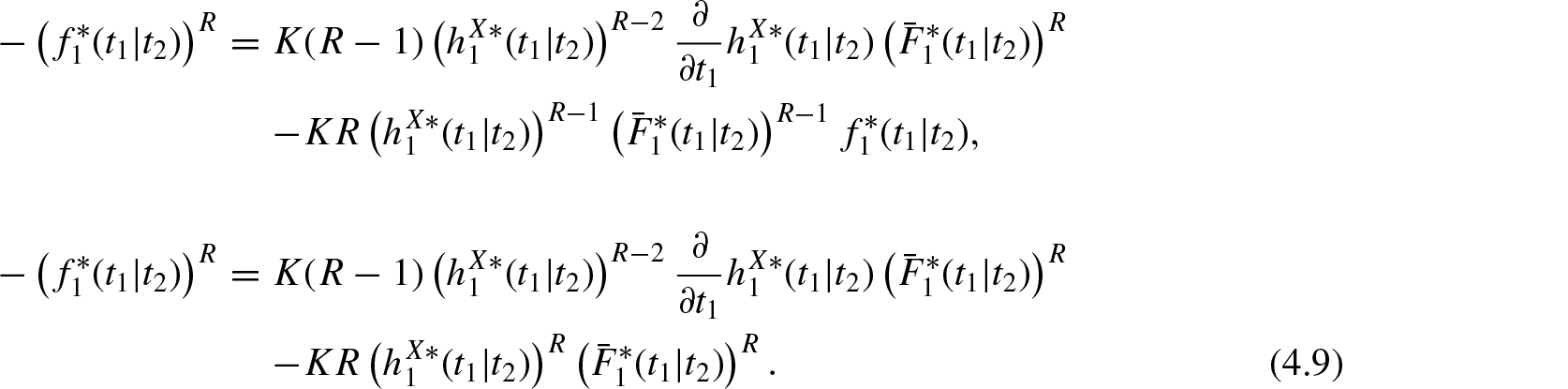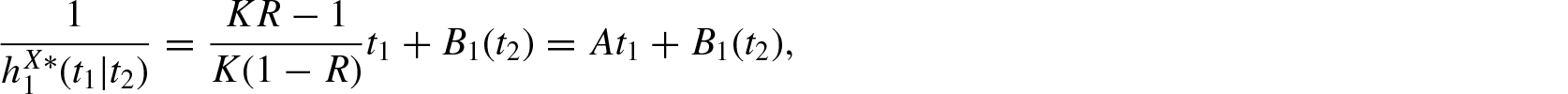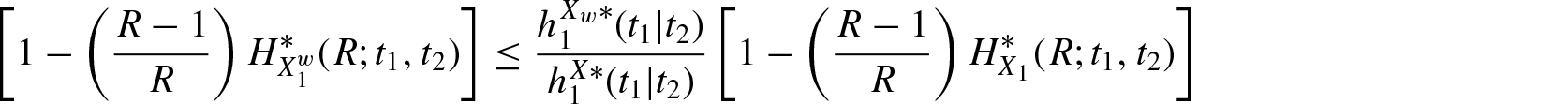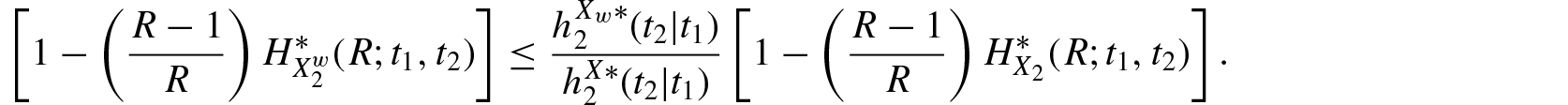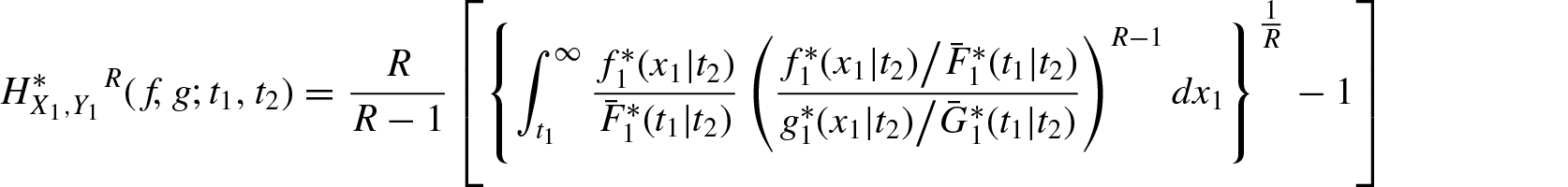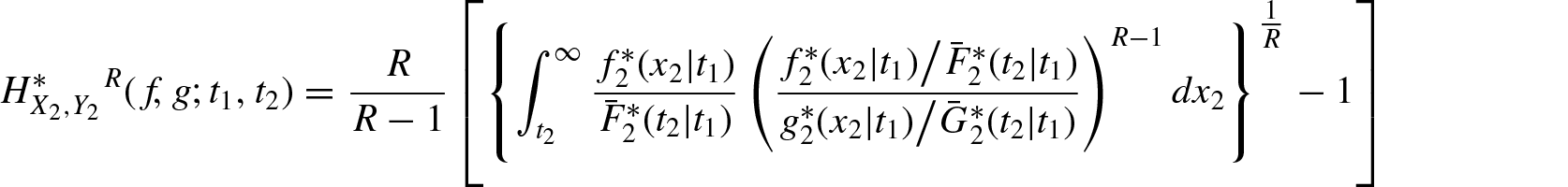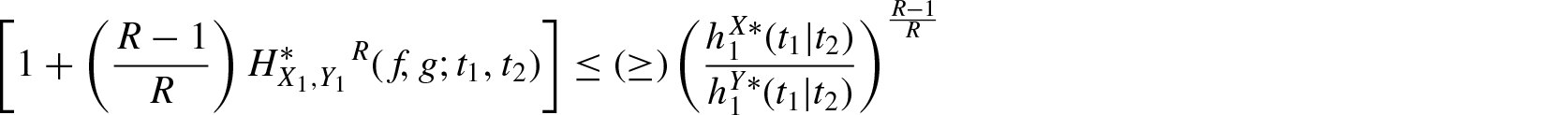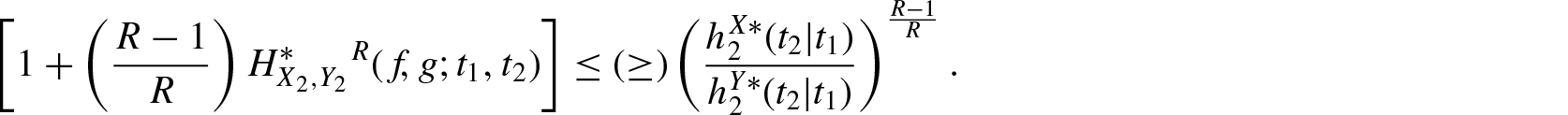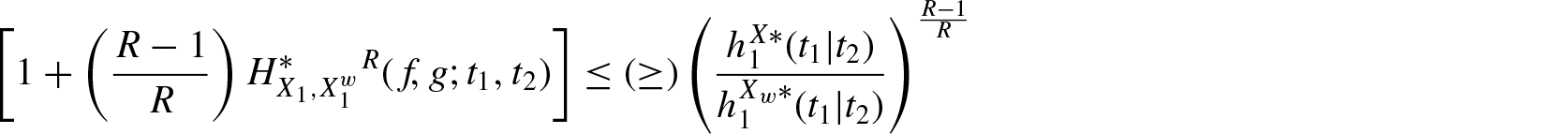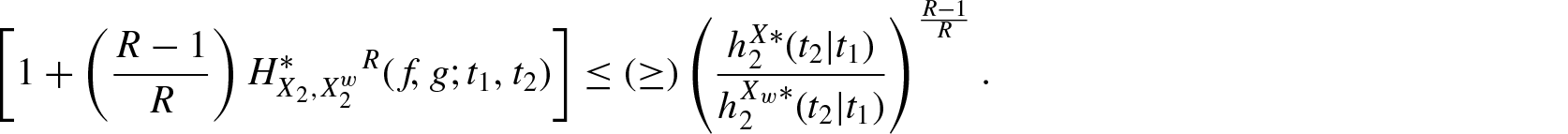Shannon entropy plays an important role in measuring the expected uncertainty contained in the probability density function about the predictability of an outcome of a random variable. However, in certain systems, Shannon entropy may not be appropriate, where some generalized versions of it are only suitable. One such generalization is due to Boekee and Lubee[1], called R-norm entropy. Recently, Nanda and Das[2] studied the R-norm entropy and its divergence measure in the context of used items, useful in reliability modelling. In the present article, we further study R-norm entropy and divergence in the context of weighted models. We also extend these measures to the conditionally specified and conditional survival models, and studied their properties.
Let f be the probability density function of an absolutely continuous non-negative random variable (rv) X. A classical measure of uncertainty for X is the differential entropy, known as Shannon entropy, defined as
where ‘ln’ means natural logarithm. If a unit has survived to an age t, then is not a useful tool for measuring the uncertainty about remaining lifetime of the unit. Accordingly, Ebrahimi[3] introduced a dynamic measure of uncertainty based on the residual lifetime , defined by
where is the survival function of the rv X. After the unit has elapsed time t, Equation (1.2) measures the expected uncertainty contained in the conditional density of , given about the predictability of remaining lifetime of the unit.
Several generalizations of the classical Shannon entropy are available in literature, obtained by introducing some additional parameters to it[5],[6],[7]. All these entropies, when the additional parameters tend to one, reduces to Equation (1.1). These generalized information measures have many important properties such as smoothness, large dynamic range with respect to certain conditions that make them applicable in practice. Pharwaha and Singh[8] showed that non-Shannon measures can be used to determine the randomness of mammograms because of having higher dynamic range than Shannon's entropy over a variety of scattering conditions. Non-Shannon measures are also applicable in estimating scatter density and regularity[9]. A generalization of Shannon entropy useful in pattern recognition and coding theory is due to Boekee and Lubee[1], called R-norm entropy, in the discrete case. It has simple relationships with other generalizations of Shannon entropy, namely Renyi's entropy of order α[5] and information of type β[10]. If we define an appropriate measure for the average length of codewords, then coding theorems can be obtained using R-norm entropy. For more recent works and applications of R-norm entropy in coding theory, one could refer to Kumar and Choudhary[11] and Kumar, Ram, and Gupta[12]. A continuous version of R-norm entropy is introduced by Nanda and Das[2], given as
which is a real-valued function, for . When , Equation (1.3) reduces to Equation (1.1).
Nanda and Das[2] has introduced the residual R-norm entropy, given by
for . Note that as , Equation (1.4) approaches to Equation (1.2).
Measures of divergence plays an important role in measuring the distance between two populations or distribution functions. Among the different discrimination measures available in literature, a popular one is the Kullback–Leibler (KL) divergence measure. Let X and be two absolutely continuous rvs with the common support for . Denote by f, f and , the probability density function (pdf), the cumulative distribution function (cdf) and the survival function (sf) of X, respectively, and by , and , the corresponding functions of . As an information distance between X and , Kullback and Leibler[13] proposed a directed divergence (also known as information divergence, information gain, relative entropy or discrimination measure) defined by
Note that if (a.e.), then . As the pdf of is dissimilar or farther from the pdf of f, then is large. For used items, KL divergence of f and at time t[4], is of the form
For , Equation (1.6) reduces to Equation (1.5) for . There are different generalizations on KL divergence and a recent approach is due to Nanda and Das[2], based on the R-norm entropy and its residual form. The residual R-norm entropy divergence is given by
For more properties of the residual R-norm entropy Equation (1.4) and its divergence Equation (1.7), we refer to Nanda and Das.[2]
The concept of weighted distributions is usually considered in connection with modelling statistical data, where the usual practice of employing standard distributions is not found appropriate in some cases. Associated to a rv X with probability density function f and to a non-negative real function , we can define the weighted random varaible with density function
where we assume . When , is called the length (or size) biased rv, and it is denoted by . For recent works on weighted distributions, we refer the reader to Navarro, Ruiz, and del Aguila,[14] Bartoszewicz,[15] Kumar and Taneja,[16] and Sunoj and Sreejith.[17]
It is inherently difficult to visualize bivariate distributions. Conditional densities can be easily visualized unlike marginal or joint densities. A variety of transformation are being used to characterize the joint distribution function. Joint characteristic function, joint moment generating function, and joint hazard function are some among them. They are well defined and will determine the joint distribution function uniquely. Sometimes one could identify joint distribution by specifying one of the marginal and a conditional density. That is, the knowledge of one marginal density say (or ) and the conditional density of , say (or the conditional density of , say ) will completely specify the joint density density function . Alternatively, one may specify the distribution solely in terms of the features of two families of conditional densities. This approach is called conditional specification of the joint distribution[18]. Another conditioning popular in literature is the conditional survival models, in which component survival, that is, on events such as and , have been conditioned. These two types of models are often useful in two component reliability systems where the operational status of one component is known in advance. For more recent works on conditionally specified and survival models, we refer to Arnold[19], Arnold, Castillo, and Sarabia[18], Sunoj and Sankaran[20], Navarro and Sarabia[21], Sunoj and Linu[22],23], and Navarro, Sunoj, and Linu[24],[25], and the references therein.
In the present article, the residual R-norm entropy Equation (1.4) and its relative form Equation (1.7) are extended to the weighted models, and obtain some bounds based on it. These two measures are also extended to the conditionally specified and survival models. For the conditonally specified models, the concept of proportional hazard rate (PHR) models and R-norm divergence in the context of weighted distribution are studied to obtain some new properties. Moreover, bounds for these entropy measures in terms of hazard rates have been obtained using the likelihood ratio (LR) ordering.
Weighted Residual R-norm Entropy
Using Equations (1.4) and (1.8), the residual R-norm entropy for weighted rv is given by
The corresponding weighted residual R-norm divergence measure based on Equation (1.7) is of the form
For certain probability distributions, the computation of becomes difficult and in such cases bounds of the measure in terms of other known measures are much useful. The following inequality provides an upper bound for .
Theorem 2.1. For and if is increasing in X, then
where and denotes the failure (hazard) rate functions ofX and , respectively.
Proof: Since is increasing in X, we have . Therefore,
Example 2.1Considering Pareto I distribution with pdf, and , we can easily illustrate Theorem 2.1.
Definition 2.1. If X and have probability density function f and , respectively, then X is said to be less than in the LR order (denoted by ), if is increasing in the union of their supports.
We now obtain a bound for the residual R-norm divergence using LR order. It gives simple upper (lower) bound to in terms of hazard functions of the rvs X and . Thus, the bounds of can be easily accomplished with the knowledge of reliability functions of X and .
Theorem 2.2. If , then for
Proof: Since , is decreasing in X. Therefore, for every . For ,
proves the result. The case for is similar.
Corollary 2.1. If is increasing in X (or ), then for
Example 2.2.Corrolary 2.1 follows easily from Example 2.1.
The following theorem provides bounds for , in terms of the hazard funtion of Y and .
Theorem 2.3. If is decreasing in X, then for
Proof: Since is decreasing in X, . For , we have
Corollary 2.2. If is decreasing in X, then for
Example 2.3.Considering an exponential rv with probability density function, and. Then, is decreasing inX. Then, for, we get
Residual R-norm Entropy for Conditionally Specified Models
In this section, we study the residual R-norm entropy measure Equation (2.1) and its divergence measure Equation (2.2) for conditionally specified models. Let and be two bivariate random vectors with respect to Lebesgue measure in the positive quadrant of the two-dimensional Euclidean space . The joint probability density function and survival function of are denoted by f and and that of by and , respectively. Consider the conditionally specified rvs and for , . Their probability density function, survival function, and hazard rates are denoted by , , , , , and , respectively for . Using Equation (2.1), the conditionally specified residual R-norm entropy for and are defined respectively by
and
Note that and .
A basic problem in reliability analysis, when the data on lifetimes is the only input, is to identify the underlying distribution that is supposed to generate the observations. A standard practice adopted in such modelling situations is to ascertain the physical properties of some basic reliability concepts such as failure rate, mean residual life, vitality, etc., express them by means of equations or inequalities, and then solve them to obtain the model. Accordingly, the following theorem characterizes three important bivariate lifetime models based on a functional relationships between conditional residual R-norm entropy and conditional hazard rates.
Theorem 3.1.For the random vector, the relationships
and
whereis a constant independent of and hold, if and only if, it is distributed as
(a) bivariate distribution with Pareto conditional given in Arnold[26]with pdf
or
(b) bivariate distribution with exponential conditionals of Arnold and Strauss[27]with pdf
or
(c) bivariate distribution with beta conditionals with pdf
accordingly as for and for .
Proof: The first part is straightforward. To prove the converse, we assume that Equation (3.3) holds and assume that . Then, Equation (3.3) is equivalent to
Then,
Differentiating Equation (3.5) with respect to , we get
where . Equations (3.8) and (3.9) are equivalent to
and
The remaining part of the proof follows directly from Theorem 4.2 of Sunoj and Linu[22]. Similar steps hold for .
Consider the random vector which has bivariate weighted distribution associated to and non-negative real functions and , whose probability density function is given by
where f is the joint probability density function of and . From Equation (3.10), it is easy to see that the marginal rv has the univariate weighted distribution associated with with weight function
Similarly, we can easily show that has the univariate weighted distribution associated with and for , given by
Now we obtain the following bounds based on the weighted conditional rv and for .
Theorem 3.2. If is decreasing in for , then for
and
Proof: By definition, we have
which completes the theorem.
Example 3.1.Supposefollows Arnold and Strauss bivariate exponential distribution given in Theorem 3.1, and taking the weight function, a decreasing function, we obtain
We now define the conditional residual R-norm divergence between the rvs and , and and as
and
where , and . Hence, Equations (3.11) and (3.12) provide dynamic information on the distance between the conditionally specified rvs and , and and .
Cox's PHR model is the most widely used semi-parametric model in survival studies. Two rvs X and and with common support satisfy the PHR model, when
for all , where , and and are the respective failure (or hazard) rate functions. Equivalently, X and satisfy the PHR model, when for all [28]. Nanda and Das[2] obtained the following result.
Theorem 3.3. (Nanda and Das (2006)) is independent of t, if and only if, f and satisfy the PHR model in Equation (3.13).
In a similar way, the random vectors and satisfy the conditional proportional hazard rate (CPHR) model[29], when the corresponding conditional hazard rate functions of and satisfy
for and , where and are positive functions of and , respectively. Then, we have the following result.
Theorem 3.4. For , the function depends only on , if and only if, and satisfy the CPHR model in Equation (3.14).
Proof: The proof is obtained from Theorem (3.3) and using Equation (3.14).
Theorem 3.5. Let be a random vector having bivariate weighted distribution associated to and to non-negative differentiable functions and . Assume that the support of is for . Then, the following conditions are equivalent.
(a) and satisfy the CPHR model in Equation (3.14) for .
(b) is independent of for and .
(c) The conditional reliability functions of satisfy
(d) has the following joint PDF
for , where , and or for .
Proof: The equivalence between (a) and (b) is a consequence of Theorem (3.2). The rest of the proof is similar to Theorem 3 of Navarro, Sunoj, and Linu[24].
In analogy with Theorem 2.2 of the univariate case, in the next theorem, we obtain a bound for conditional residual R-norm divergence using the LR order.
Theorem 3.6. If for , then for
and
Proof: We first consider . Then, implies that is decreasing in , that is, . Now using Equation (3.11) and for , we obtain
The case of and for is similar.
Corollary 3.1.If for , then for
and
Remark 3.1.Recently, Evren and Tuna[30]compared different goodness of fit statistics including those based on divergences measures, namely KL, Jeffrey's and Hellinger distance. Sincehas simple relationships with many of these generalized divergence measures, can be equally useful as a goodness of fit test to compare two probability distributions. One can also refer to Baratpour and Rad[31,[32]for using cumulative KL divergence as deriving a consistent test statistic for testing the hypothesis of exponentiality against some alternatives.
Residual R-norm Entropy for Conditional Survival Models
In this section, we consider the conditional survival rvs and ; . Their probability density function, survival function, and hazard rates are denoted by , , , , , and , respectively for , where and . Using Equation (2.1), the conditional survival residual R-norm entropy for and are defined respectively as
and
Similar to Theorem 3.1, now we prove another characterization theorem which uniquely determines three bivariate lifetime probability models using the functional relationships between the residual R-entropy defined in Equations (4.2) and (4.3) and hazard rates in the conditional survival case. Thus, the knowledge on the functional relationships between conditional R-norm entropy and hazard rates easily derives the underlying bivariate distributions.
Theorem 4.1.For the random vector, the relationships
and
whereis a constant independent ofand, hold, if and only if, it is distributed as
(a) bivariate Pareto with sf
or
(b) Gumbel's exponential with sf
or
(c) bivariate beta density with sf
accordingly asforandfor.
Proof: The first part is direct. To prove the converse, assume that Equation (4.3) holds. For , Equation (4.3) is equivalent to
and
Differentiating Equation (4.8) with respect to , we get
Integrating Equation (4.10) with respect to , we obtain
where . Thus, . Applying similar steps on Equation (4.4), we obtain . Now using the result of Roy[33], the models (4.5), (4.6), and (4.7) follow. The case for can be similarly obtained.
The following theorems give the bounds for conditional survival residual R-norm entropy.
Theorem 4.2.Ifis decreasing in for , then for
and
We now define the conditional survival residual R-norm divergence between the rvs and , and and as
and
It is to be noted that and . Hence, and provide dynamic information on the distance between the conditionally specified rvs and , and and .
The following theorems provide simple bounds for conditional survival residual R-norm divergence as ratio of conditional hazard rates of and , .
Theorem 4.3.If, then for
and
Corollary 4.1.If, then for
and
Conclusion
The article studies the residual R-norm entropy and its relative form, and obtains certain bounds to them in the context of weighted models. It provides some simple bounds for R-norm entropy in terms of hazard functions. We have also introduced R-norm entropy and its relative measure for the conditionally specified and survival models, which are useful in deriving some new bounds to these measures and for identifying bivariate models based on its relationships with corresponding conditional hazard functions. The concept of conditional proportional hazard rate (CPHR) models and R-norm divergence measures are also used to obtain new results.
Footnotes
Acknowledgments
The authors wish to thank the editor and referees for their constructive comments. The second author would like to thank the support of the University Grants Commission, India, under the Special Assistance Programme.
References
1.
BoekeeDEvan derLubbe JCA.. The R-norm information measure. Inform Control.1980; 45(2): 136–155.
EbrahimiN.How to measure uncertainty about residual lifetime. Sankhya, A.1996; 58(1): 48–57.
4.
EbrahimiNKirmaniSNUA.A characterization of the proportional hazards model through a measure of discrimination between two residual life distributions. Biometrika.1996; 83(1): 233–235.
5.
RenyiA.On measures of entropy and information. Proceedings of the 4th Berkeley Symposium on Mathematical Statistics and Probability (Volume 1, pp. 547–561).Berkeley, California: University of California Press; 1961
6.
KapurJN.Generalized entropy of order α and type β.Math Sem.1967; 4(4): 78–94.
7.
TsallisC.Possible generalization of Boltzmann–Gibbs statistics. J Statistic Phys.1988; 52(1–2): 479–487.
8.
PharwahaAPSSinghB.Shannon and non-Shannon measures of entropy for statistical texture feature extraction in digitized mammograms. Proceedings of the World Congress on Engineering and Computer Science (Volume 2, pp. 1286–1291).San Francisco, USA; 20–22 October 2009.
9.
SmolkovdRWachowiakMPTourassiGDElmaghrabyAZuradaJM.Characterization of ultrasonic backscatter based on generalized entropy. Proceedings of the second joint Biomedical Engineering Society EMBS/BMES Conference, Houston, USA (Volume 2, pp. 953–954). 2002.
10.
HavrdaJCharvatF.Quantification method of classification processes: Concept of structural α-entropy, Kybernetika. 1967; 3(1): 30–35.
11.
KumarSChoudharyA.R-norm Shannon–Gibbs type inequality. J Appl Sci.2011; 11(15): 2866–2869.
12.
KumarSRamGGuptaV. On ’useful’ R-norm relative information and J-divergence measures. Int J Pure Appl Math.2012; 77(3):349–358.
13.
KullbackSLeiblerRA.On information and sufficiency. Annal Math Statistics.1951; 22(1): 79–86.
BartoszewiczJ.On a representation of weighted distributions. Statistics Probab Letters.2009; 79(15): 1690–1694.
16.
KumarVTanejaHJ.On length biased dynamic measure of past inaccuracy. Metrika.2012; 75(1): 73–84.
17.
SunojSMSreejithTB.Some results on reciprocal subtangent in the context of weighted models. Comm Statistics: Theor Method.2012; 41(8): 1397–1410.
18.
ArnoldBCCastilloESarabiaJM.Conditional specification of statistical models. New York, NY: Springer Verlag; 1999.
19.
ArnoldBC.Conditional survival models. In: Balakrishnan N, editors. Recent advances in lifetesting and reliability.Boca Raton, FL: CRC Press; 1995: 589–601.
20.
SunojSMSankaranPG.Some characterizations of bivariate weighted distributions in the context of reliability modeling. Calcutta Statistic Assoc Bull.2005; 27(227–228): 179–194.
21.
NavarroJSarabiaJM.Alternative definitions of bivariate equilibrium distributions. J Statistic Plan Infer.2010; 140(7):2046–2056.
SunojSMLinuMN.Cumulative measure of uncertainty for conditionally specified models. Calcutta Statistic Assoc Bull.2012b; 64(253–254): 59–78.
24.
NavarroJSunojSMLinuMN.Characterizations of bivariate models using dynamic Kullback–Leibler discrimination measures. Statistics Probab Letters.2011; 81(11): 1594–1598.
25.
NavarroJSunojSMLinuMN.Characterizations of bivariate models using some dynamic conditional information divergence measures. Comm Statistics: Theor Method.2014; 43(9): 1939–1948.
26.
ArnoldBC.Bivariate distributions with Pareto conditionals, Statistics and Probability Letters. 1987; 5(4): 263–266.
27.
ArnoldBCStraussD.Bivariate distributions with exponential conditionals. Journal of American Statistical Association.1988; 83(402): 522–527.
28.
CoxDR.The analysis of exponentially distributed lifetimes with two types of failure. Journal of Royal Statistical Society, Series B.1959; 21(2): 411–421.
29.
SankaranPGSreejaVN.Proportional hazard model for multivariate failure time data. Comm Statistics: Theor Method.2007; 36(8): 1627–1641.
30.
EvrenATunaE.On some properties of goodness of t measures based on statistical entropy. Int J Research Review Appl Sci.2012; 13(1): 192–205.
31.
BaratpourSRadAH.Testing goodness-of-fit for exponential distribution based on cumulative residual entropy. Comm Statistic: Theor Method.2012; 41(8): 1387–1396.
32.
BaratpourSRadAH.Exponentiality test based on the progressive type II censoring via cumulative entropy. Comm Statistic: Simulation Comput.2016; 45(7): 2625–2637.
33.
RoyD.A characterization of Gumbel's bivariate exponential and Lindley and Singpurwalla's bivariate Lomax distributions. Journal of Applied Probability.1989; 26(4): 886–891