
Abstract
Panel count data arise when recurrent events experienced by the study subjects are recorded only at discrete observation times. In this article, we focus on the regression analysis of panel count data with multiple modes of recurrence. We introduce a proportional mean model to assess the effects of covariates on the underlying counting processes corresponding to different recurrence modes. The methodology includes the joint estimation of baseline cumulative cause-specific mean functions and regression coefficients. We also establish the asymptotic properties of the proposed estimators. A Monte Carlo simulation study is conducted to examine the performance of the proposed estimators in finite samples. We illustrate the practical applicability of the procedures using two real-life data sets.
Introduction
In many longitudinal studies on recurrent events, instead of observing the exact time to the occurrence of an event, we may only observe the number of recurrences experienced by a subject in a given time interval. If each subject can be observed at more than one time point, the number of recurrences between two successive observation times is available. The data collected in this form are referred to as panel count data.[1] Panel count data frequently arise in many fields, such as clinical trials, epidemiological studies and engineering, when continuous follow-up to obtain the exact event times of each subject is infeasible or too costly. [2] Some authors refer to panel count data as interval count data or interval censored recurrent event data.[3, 4] Sun and Zhao[5] provide a comprehensive review of various methodologies for modelling panel count data. In certain situations, subjects can be observed at only a single monitoring time, and only the information on whether the event of interest has occurred or not by that time is available. This type of data are referred to as current status data in the literature. For a detailed study on current status data, one may refer to the study of Sun.[6]
The analysis of panel count data can be approached either by modelling the mean function or the rate function of the underlying recurrent event process. Sun and Kalbfleisch[7] developed an estimator for the mean function based on isotonic regression theory. Likelihood-based non-parametric estimation methods for the mean function are discussed by Wellner and Zhang,[8] and they proposed a non-parametric maximum likelihood estimator (NPMLE) as well as a non- parametric maximum pseudo-likelihood estimator (NPMPLE) for the same. The asymptotic properties of both NPMPLE and NPMLE are studied in detail by Wellner and Zhang.[8] The analysis of panel count data using rate functions is studied by Lawless and Zhan[3] and Thall and Lachin.[9]
In most of the studies involving panel count data, we observe a covariate vector Z for each subject that affects the underlying counting process of the recurrent events. Two important approaches employed for analyzing regression models for panel count data are the maximum likelihood method and the generalized estimating equation approach. Regression analysis of panel count data using the likelihood approach is studied extensively by Zhang[10] and Wellner and Zhang,[11] while Hu et al.[12] explored the generalized estimating equation approach for the same. The regression analysis of panel count data with informative censoring is addressed by Sun and Wei,[13] Huang et al.[14] and Zhao and Tong.[15] Notably, Zhao et al.[16] proposed a non-parametric regression model for panel count data to accommodate the potential non-linear covariate effect. Regression analysis of multivariate panel count data is considered by He et al.[17] and Zhang et al.[18] Various semiparametric regression models for panel count data using the R programming language are reviewed by Chiou et al.[2]
Consider a study where each of the study subjects is exposed to the recurrent events due to more than one mode of recurrence. In this situation, the number of recurrences due to each distinct mode (cause) at different observation times is available. Consequently, we obtain panel count data with multiple modes of recurrence. It is important to distinguish this data type from multivariate panel count data, where multiple related events are observed exclusively at discrete time points. While panel count data have attracted research interest for the past two decades, the literature addressing cases with multiple recurrence modes remains limited. The non-parametric estimation of cause-specific mean functions is addressed by Sreedevi and Sankaran[19] while Paduthol et al.[20] developed non-parametric estimators for the cause-specific rate functions. Both these works considered panel count data without covariates. Regression analysis of panel count data with multiple modes of recurrence has not been studied yet. Motivated by this, in this article, we propose a proportional mean model to assess the covariate effect on the cumulative mean functions for different modes of recurrence.
The rest of the article is organized as follows. In Section 2, we propose a new proportional mean model to estimate the baseline cumulative mean functions and regression parameters due to each mode of recurrence simultaneously. A simple iterative algorithm is derived for the estimation procedure. Asymptotic properties of the proposed estimators are established in Section 3. In Section 4, the finite sample behaviour of the proposed estimators is validated through a Monte Carlo simulation study. The proposed procedures are illustrated using two real data sets in Section 5. Finally, Section 6 gives concluding remarks.
The Proportional Mean Model
Consider a study on n individuals exposed to the recurrent events due to {1, 2, …, k} distinct modes. Assume that the event process can be observed only at a sequence of random monitoring times. As a result, only the counts of event recurrences for each mode of recurrence, between observation times, are available, while the exact recurrence times remain unknown.
Define a counting process Nj(t) = {Nj(t); t ≥ 0}, where Nj(t) denotes the number of recurrences of the event due to cause j up to time t. Now, E(Nj(t)) = Λ
j
(t) for j = 1, 2, …, k denotes the expected number of cumulative events due to mode (cause) j up to time t. The function Λ
j
(t) for j = 1, 2, …, k is the mean function of the counting process Nj(t), which is termed as the cause-specific mean function.[19] Assume that, corresponding to each subject, we observe a d × 1 vector of covariates denoted by Z. Our interest is to study E(Nj(t)|Z) = Λ
j
(t|Z) for j = 1, 2, …, k, the expected number of cumulative events due to cause j up to time t conditionally on covariate vector Z. To estimate the effect of covariate vector Z on lifetime T, we propose the proportional mean model given by
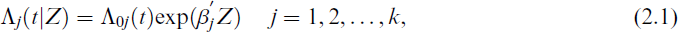
where Λ0 j (.) is the completely unspecified baseline cumulative cause-specific mean function and βj is the d × 1 vector of regression parameters corresponding to cause j. When k = 1, the model in Eq. (2.1) reduces to the proportional mean model for panel count data with a single mode of recurrence, studied by Zhang,[10] Wellner and Zhang[11] and Sun and Wei.[13]
We now discuss the structure of panel count data exposed to multiple modes of recurrence in the presence of covariates. Let M be an integer-valued random variable denoting the number of observation times, which may be different for each individual, and
For each subject, we also observe a d × 1 vector of covariates Z. Now, we observe n independent and identically distributed (i.i.d) copies of
The regression analysis of panel count data based on maximum likelihood methods with a single recurrence mode is explored by Zhang[10] and Wellner and Zhang.[11] They constructed a pseudo-likelihood of the observed data using the marginal distributions of the counting process N(t|Z), which denote the number of recurrences up to time t, conditional on Z. N(t|Z) is specified by a non-homogeneous Poisson process given by
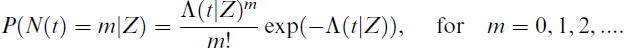
where m is the total number of observations. In the construction of pseudo-likelihood, they only consider the factors relevant in estimating the regression parameters β and the baseline cumulative mean function Λ0(t), while ignoring the dependence between event counts within a subject. Notably, Wellner and Zhang[11] pointed out that the procedures based on pseudo-likelihood considerably reduce the complexity of the estimation procedures, compared to those based on complete likelihood.
In the presence of multiple modes of recurrence, Sreedevi and Sankaran[19] developed a pseudo-likelihood function for the observed data and derived an isotonic regression estimator (IRE) for cause-specific mean functions. They constructed a pseudo-likelihood function for the observed data (which does not involve covariates) by extending methods by Wellner and Zhang.[11]
We now derive a pseudo-likelihood function in the presence of multiple recurrence modes and covariates, to estimate both Λ0
j
(.) and βj simultaneously. The estimates are obtained as the values that maximize the pseudo-likelihood. Under the assumption that the underlying counting process Nj(t) is a non-homogeneous Poisson process with conditional mean function given in Eq. (2.1), for j = 1, 2, …, k, we obtain
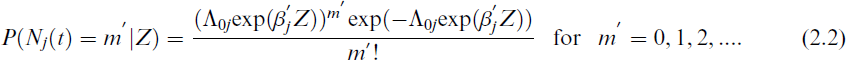
where
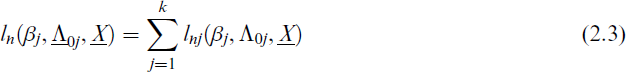
where
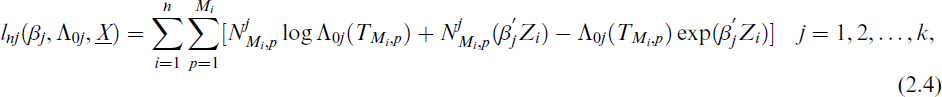
where Mi is the number of observation times, TMi,p, p = 1, 2, …, Mi, is the different observation times and
We now discuss the computational procedures. Based on the observed data X discussed above, we define the following terms. Let I(A) be the indicator function of the set A and s1 < s2 < … < sr be the distinct ordered observation time points in the set {TMi,p, p = 1, 2, …, Mi, i = 1, 2, …, n}. For q ∈ {1, 2, …, r} and for any particular cause of recurrence J, define
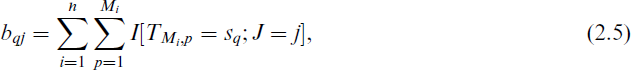
the number of observations made at sq due to cause j and
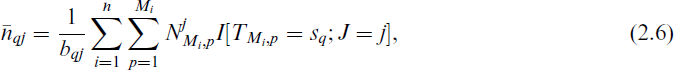
as the mean value of the recurrences made at sq due to cause j for j = 1, 2, …, k. Also define
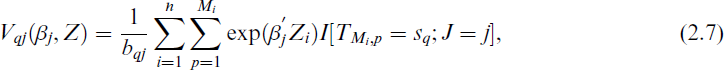
and
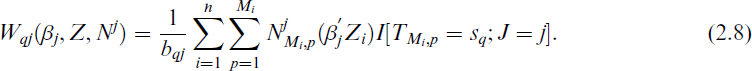
Now we can rewrite the log pseudo-likelihood for the jth mode of recurrence given in Eq. (2.4) as
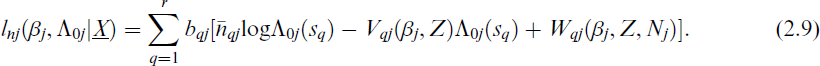
We maximize Eq. (2.9) to obtain the estimates of βj and Λ
j
(.) for j = 1, 2, …, k. The obtained semiparametric maximum pseudo-likelihood estimators will be the values of parameters that maximize Eq. (2.9) over the set Rd × Ω+, where R is the set of real numbers and Ω+ = {(y1, y2, …, yr) ∈ Rr : y1 ≤ y2 ≤ … ≤ yr}. Under the assumption that Λ
j
(0) = 0 and r is related to n, the estimators can be obtained as
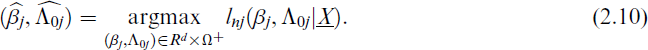
To solve the optimization problem numerically, we first choose an initial value of βj, say
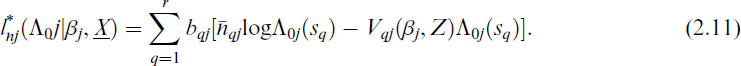
Let
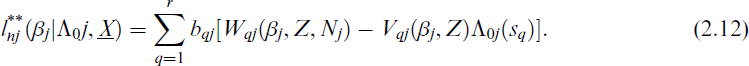
The process is continued until the estimators converge. The convergence criteria can be chosen as

where
To estimate (βj, Λ0 j ) for j = 1, 2, …, k, the computational algorithm can be summarized as follows:
Step 1. Choose an initial value βj, say
Step 2. For the given
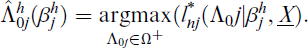
Step 3. Update the estimate of
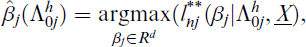
and obtain the value of
Step 4. Repeat steps 2 and 3 for h = 1, 2, …, until the convergence criteria in Eq. (2.13) are obtained.
We establish strong consistency of the proposed estimators in the Appendix. The rate of convergence of estimators in an L2 metric related to the observation scheme is also derived. We also establish the asymptotic normality of
We carry out a Monte Carlo simulation study to assess the performance of the proposed estimation procedure in finite samples. We consider the situation with two competing modes of recurrence. Based on the assumption that event counts from two recurrence modes follow a non-homogeneous Poisson process, we model the event counts for both modes of recurrence simultaneously using a bivariate Poisson process. A similar approach was previously employed by Balakrishnan and Zhao[21] in a non-competing risks framework. We generate panel count data of the form
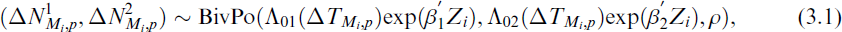
where
We consider various forms of Λ01(t) and Λ02(t) specified as t, 2t and t2 to generate panel count data. The sample size n is chosen to have three different values, that is, n = 50, 100 and 200. The process is repeated 10,000 times to estimate the efficiency of the estimators. The absolute bias and mean square error (MSE) of the estimates of β1 = {β11, β12} and β2 = {β21, β22} are obtained. Various parameter values of β1 and β2 are considered. Since the results are similar, we present the same only for three different combinations of β1 for β2 in Table 1. We choose ϵ = 10−5 to obtain the convergence. The covariance ρ is set to be 0.5 in our studies. The simulations are carried out using the R programming language.
Absolute Bias and MSE of the Estimators of Regression Coefficients for Various Parameter Combinations of (β11, β12) and (β21, β22).
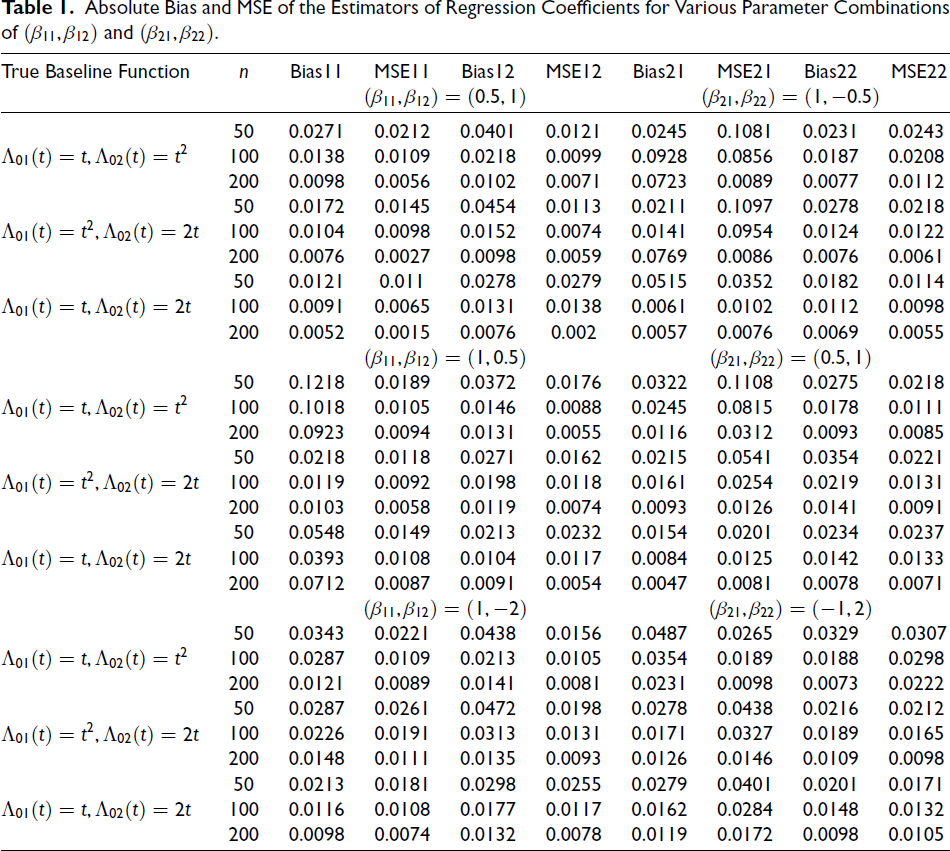
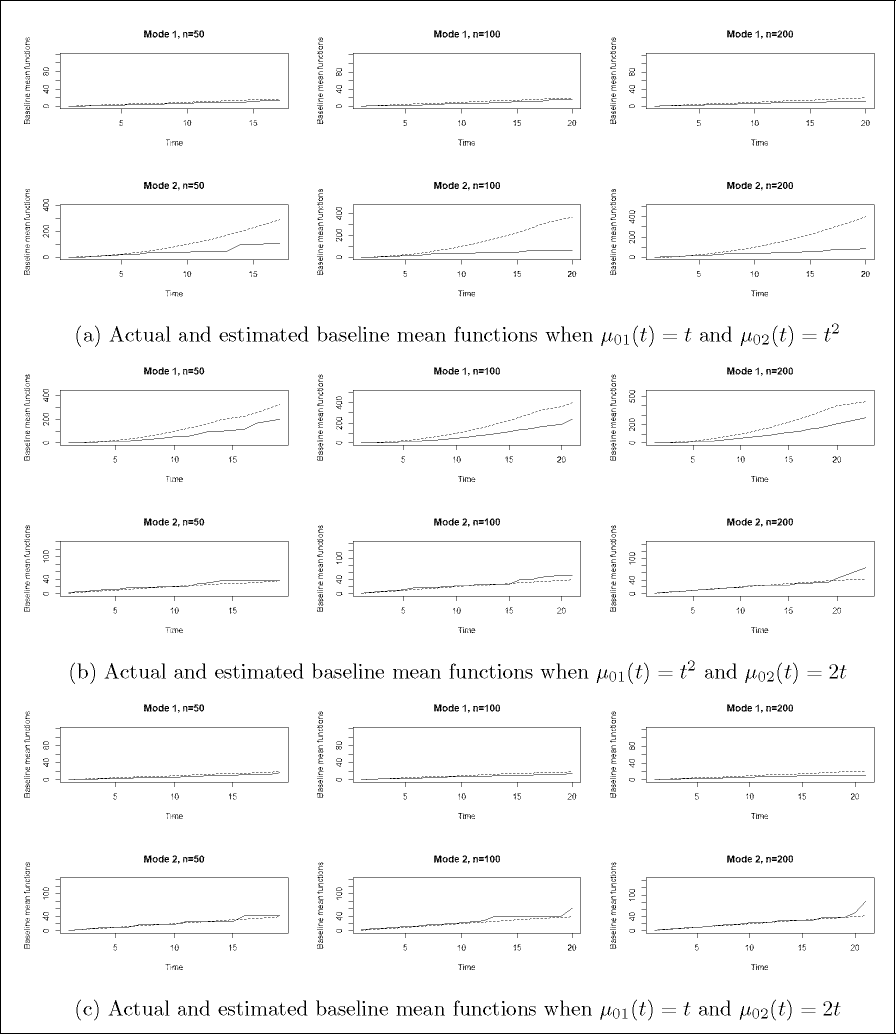
From simulation studies, we observe that the absolute bias and MSE of the estimators of regression coefficients approach zero as the sample size increases. This ensures that the proposed estimators are unbiased with nominal variance. Further, to corroborate the results, we plot the true baseline mean functions and the estimated baseline mean functions for all the parameter combinations considered in the study. The plots of same for the parameter combinations (β11, β12) = (0.5, 1) and (β21, β22) = (1, −0.5) for both modes of recurrence and for n = 50, 100 and 200 for all the choices of Λ0 j (t) are given in Figure 1. From Figure 1, we can see that the estimated baseline mean functions align with the assumed form when Λ01(t) or Λ02(t) = t and Λ01(t) or Λ02(t) = 2t. A slight deviation is observed for large values of t, when Λ01(t) or Λ02(t) = t2. For the other parameter combinations of (β11, β12) and (β21, β22), we also obtain similar results, for which the plots are not included. The plots in Figure 1 validate the results of simulation studies.
Plots of Baseline Mean Functions.
In this section, we demonstrate the practical utility of the proposed inference procedures using two real-life data sets.
Estimates of the Regression Parameters with Corresponding for Males.

Estimates of the Regression Parameters with Corresponding for Males.
Estimates of the Regression Parameters with Corresponding Standard Error for Females.

The proposed estimation procedure is applied to real data on a skin cancer chemoprevention trial given by Sun and Zhao[5] for illustration. The primary objective of this study was to evaluate the effectiveness of the drug difluoromethylornithine (DFMO) in reducing new skin cancers in a population with a history of non-melanoma skin cancers, basal cell carcinoma (BCC) and squamous cell carcinoma (SCC). The patients were randomly assigned into two groups, that is, a treatment group with oral DFMO at a daily dose of 0.5 g and a placebo group with a matching dosage. The data consist of the details of 290 patients with a history of non-melanoma skin cancers who were supposed to be assessed or observed every 6 months. However, the real observation and follow-up times differ from patient to patient. The data include the number of recurrences of two types of recurrent events, that is, BCC and SCC. We treat these two types of cancers as two modes of recurrence following Sreedevi and Sankaran.[19]
In the data set, the number of observations on an individual varies from 1 to 17 and time of observation varies from 12 to 1,766 days. For each individual, the pieces of information on age, gender, DFMO status and the number of prior tumours are observed. We consider all 290 patients in our analysis that includes 174 male and 116 female patients. To obtain more explicit conclusions, we analyze the data on males and females separately by taking the covariate information on DFMO status and number of prior tumours. Out of 290 patients, 147 were assigned to the placebo group and the remaining 143 were treated with oral DFMO. The number of prior tumours varies from 1 to 35. The estimates of regression parameters with corresponding standard errors (SEs) for males are given in Table 2. The baseline cumulative cause-specific mean functions for males are plotted in Figure 2. The estimates of regression parameters for females are given in Table 3, and the baseline cumulative cause-specific mean functions are plotted in Figure 3. The solid line represents the baseline cumulative mean function for patients with BCC, and dotted line represents the baseline cumulative mean function for patients with SCC in Figures 2 and 3.
From Tables 2 and 3, we can see that modes of cancer recurrences, BCC and SCC, affect males and females in different ways. The estimates of regression coefficients for the number of prior tumours are greater than zero for both males and females and for both modes BCC and SCC. This implies that as the number of prior tumours increases, the recurrence rate always increases. While considering the covariate effect of drug DFMO, since the mean ratio is less than unity, we can say that the drug DFMO decreases the recurrence rate of BCC for males and females, as well as SCC for males. We can note that similar inference was made Sun and Zhao.[5] From Figure 2, we can see that the recurrence rate of BCC is higher in males than the recurrence rate of SCC up to 1,800 days (approximately) and from that point the recurrence rate of SCC crosses that of BCC, while Figure 3 shows that for females, the recurrence rate of SCC is always lower than that of BCC. The plots also show the difference in recurrence patterns of the events due BCC and SCC for males and females.
Baseline Cumulative Cause-Specific Cumulative Mean Functions for Males.
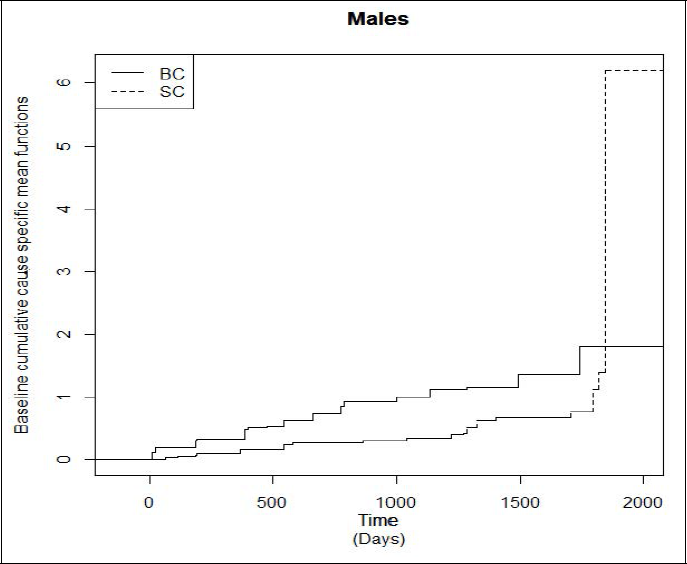
Baseline Cumulative Cause-Specific Cumulative Mean Functions for Males.
We also consider the data from a clinical trial study given by Crowder[22] to illustrate the procedures. The data consist of the treatment specification and medical conditions of 29 patients in a clinical study, to compare two different treatment regimes. The specifics of the treatment and the medical condition are concealed. The severity scores of patients are listed on an increasing scale from 0 to 5. The recurrent times and the severity levels for each patient are available. We define the first mode of recurrence as recurrent episodes of severity 1 (which occurs most frequently) and the second mode of recurrence as recurrent episodes of severity 2 or above. Out of a total of 77 recurrences, 48 are due to recurrence mode 1 and the remaining 29 happened as a result of recurrence mode 2. The longest follow-up time reported in the study is 28 days. To generate panel count data, we arbitrarily select the observation time points as 7, 14, 21 and 28 days, keeping the patient’s original end-of-study time unchanged, and the number of recurrences in between the observation times is noted. We consider the treatment regime (Z = 0 for treatment 1 and Z = 0 for treatment 2) and the patient’s age as covariates in our analysis. The estimates of regression parameters with corresponding SEs are given in Table 4.
Baseline Cumulative Cause-Specific Cumulative Mean Functions for Females.
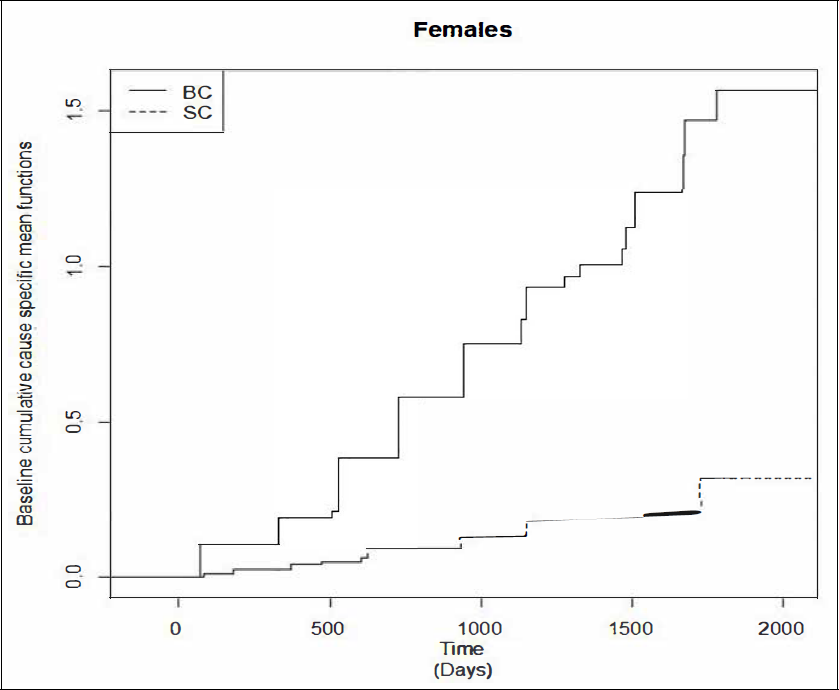
Baseline Cumulative Cause-Specific Cumulative Mean Functions for Females.
Estimates of the Regression Parameters with Corresponding SE for Severity Score Data.

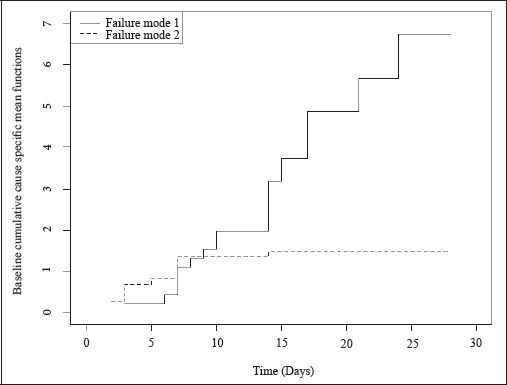
From the estimates of regression coefficients, we can conclude that treatment 1 reduces the number of recurrences of individuals for both modes of failure, but extensively for recurrences due to mode 2. Moreover, we see that the covariate age has no effect on the recurrence pattern due to both modes 1 and 2 failures for patients. From the plots of baseline cumulative cause-specific mean functions plotted in Figure 4, we note that recurrence rate of mode 1 is greater than the recurrence rate due to mode 2 up to 9 days (approximately), and after that, the recurrence rate due to mode 2 dominates.
Baseline Cumulative Cause-Specific Cumulative Mean Functions for 29 Patients.
Panel count data with multiple modes of recurrence often arise in periodic follow-up studies. In this article, we proposed a new proportional mean model to assess the covariate effect on various modes of recurrence for panel count data with multiple modes of recurrence. We can note that panel count data with multiple modes of recurrence are different from multivariate panel count data, where the recurrent events of several related events are studied. We derived the estimators for regression parameters and baseline cumulative mean functions due to each recurrence mode. A simple iterative procedure was developed for the estimation of parameters. The finite sample performance of the estimators in terms of bias and MSE was assessed through a Monte Carlo simulation study. The proposed procedures were applied to two real-life data sets.
In this article, we follow the assumption that the modes of recurrence are independent. In many real-life scenarios, we observe the modes of recurrence to be dependent on each other. Regression models for panel count data with multiple dependent recurrence modes are an area of future research. The estimation procedure we developed in this article considered the pseudo-likelihood function of panel count data. Maximum likelihood estimators in this context can be developed by extending the results of Wellner and Zhang,[11] which involves a more complex iterative procedure. The regression analysis of panel count data with multiple recurrence modes can also be approached using generalized estimating equations. In many situations, rate functions of the underlying recurrent event process are more important than mean functions. Cause-specific rate functions developed by Sankaran et al.[20] can be used to study panel count data when the study subjects are exposed to multiple recurrence modes. Empirical likelihood methods that combine the flexibility of nonparametric methods with the strength of likelihood-based inference can also be employed in analyzing panel count data with multiple recurrence modes.
Footnotes
Acknowledgements
The authors would like to express their gratitude to the associate editor and the unknown referees for their valuable comments and constructive suggestions, which have significantly enhanced the quality of this research article.
Data Availability
The source of the data set used for illustrative purposes is mentioned in the manuscript.
Declaration of Conflicting Interest
The authors declare no conflict of financial or non-financial interests that are directly or indirectly related to this research work.
Ethical Statement
The submitted work is original and has not been published elsewhere.
Funding
The authors received no financial support for the research, authorship and/or publication of this article.
APPENDIX
The asymptotic properties of the proposed estimators can be derived using results from empirical process theory. Notably, Zhang[10] proved some results about the asymptotic behaviour of the semiparametric pseudo maximum likelihood estimators when only a single mode of recurrence is observed and later Wellner and Zhang[11] modified the results. When recurrence due to multiple modes is observed, Sreedevi and Sankaran[19] studied the asymptotic properties of cause-specific mean functions. We extend the results of Wellner and Zhang[8] into a multiple-mode scenario and generalize the results discussed by Sreedevi and Sankaran[19] to incorporate covariates. We establish the asymptotic normality and strong consistency of the proposed estimators.
As we discuss, we estimate βj and Λ0
j
for j = 1, 2, …, k as the maximum points of the pseudo-likelihood function given in Eq. (2.4). We assume that the estimators as well as the true value of the parameters include in the parameter domain
To prove the asymptotic properties of the estimators, we define the following. Let
A similar measure is defined by Schick and Yu [23] to study the consistency of the likelihood estimators for mixed case interval censored data. Define the L2 metric d1(.) in parameter space
where (βj1, Λ0
j
1) and (βj2, Λ0
j
2) are elements of the parameter space