
Abstract
Although cluster-robust standard errors (CRSEs) are commonly used to account for violations of observations independence found in nested data, an underappreciated issue is that there are several instances when CRSEs can fail to properly maintain the nominally accepted Type I error rate. These situations (e.g., analyzing data with imbalanced cluster sizes) can readily be found in various types of education-related datasets and are important to consider when computing statistical inference tests when using cluster-level predictors. Using a Monte Carlo simulation, we investigated these conditions and tested alternative estimators and degrees of freedom (df) adjustments to assess how well they could ameliorate the issues related to the use of the traditional CRSE (CR1) estimator using both continuous and dichotomous predictors. Findings showed that the bias-reduced linearization estimator (CR2) and the jackknife estimator (CR3) together with df adjustments were generally effective at maintaining Type I error rates for most of the conditions tested. Results also indicated that the CR1 when paired with df based on the effective cluster size was also acceptable. We emphasize the importance of clearly describing the nested data structure as the characteristics of the dataset can influence Type I error rates when using CRSEs.
Nested (or clustered) data are commonly encountered in educational research (e.g., students within schools), which violates a well-known regression assumption of observation independence (Cohen et al., 2003). Ignoring or not accounting for the dependent nature of clustered data can result in incorrect statistical inference tests for cluster-level predictors, resulting in higher Type I errors or erroneous claims of statistical significance (Baldwin et al., 2005; Murray et al., 2004). Although various modeling approaches have been developed for the analysis of dependent data (Huang, 2016) such as multilevel modeling (Laird & Ware, 1982) or using a generalized estimating equations (Liang & Zeger, 1986) approach, cluster-robust standard errors (CRSEs) have been routinely applied, especially in fields such as applied econometrics (Chiang et al., 2025) and epidemiology (Mansournia et al., 2021), to account for the presence of clustered data.
Developments in CRSEs can be traced back to the original formulation of Liang and Zeger (1986), and CRSEs are often applied to account for clustered data when using ordinary least squares (OLS) or generalized linear models (GLMs). Although methods such as multilevel models (MLMs) are powerful and flexible, MLMs have strong assumptions that when violated (e.g., correct specification of random effects) can result in biased estimates (Huang & Zhang, 2025; Huang, Wiedermann, & Zhang, 2023). As a result, CRSEs can also be used with MLMs (Huang, Wiedermann, & Zhang, 2023) and when using a GEE approach (Huang, 2022) to account not just for clustering, but for any form of unobserved heterogeneity. Over the years, several articles (e.g., Esarey & Menger, 2019; Weiss, 2024; Young, 2016) have investigated the use of CRSEs and degrees of freedom (df) adjustments in relation to statistical inference tests with clustered data.
However, it may not be widely recognized (or underappreciated) that there are several instances where using CRSEs can still result in incorrect statistical inference tests (Cameron & Miller, 2015; MacKinnon et al., 2023a). A review of empirical research, even from well-known journals such as the American Economic Review and Econometrica (from 2020 to 2021) showed that a nontrivial percent (77%) of published research had used CRSEs under certain conditions, which raises questions related to the validity of their findings (Chiang et al., 2025). As CRSEs have been used in various types of models (e.g., MLMs, GLMs), being able to recognize the conditions where CRSEs may not be adequate is then of importance if researchers are concerned about making correct statistical inferences.
The article is outlined as follows: We first begin by providing a brief background on the traditional CRSE. Next, we describe several instances where the use of CRSEs may not maintain the nominally stated Type I error rate for cluster-level predictors. Third, we discuss alternative approaches that involve both the computation of the CRSEs and the choice of df. Fourth, we conduct a Monte Carlo experiment where we replicate conditions where traditional CRSEs will fail and then test alternative approaches if they fare any better. We conclude with a discussion and summary of results.
Brief Background on Cluster-Robust Standard Errors
In matrix form, the linear regression model is written as
Standard errors can be estimated using
Extended to a clustered data setting, the variance/covariance matrix of the coefficients can be estimated using
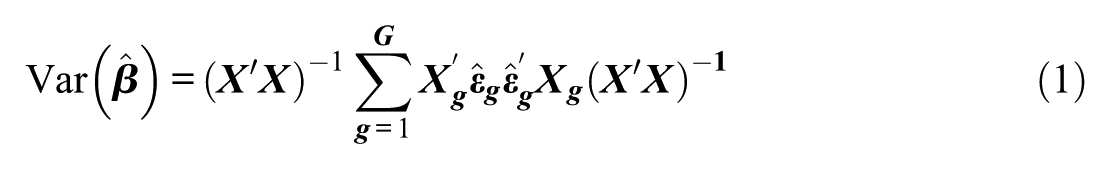
where now, the term in the middle is estimated per cluster g and then summed together (G is the total number of clusters). In this formulation,
The unadjusted CR0 is the default CRSE estimator used in procedures when using generalized estimating equations (Liang & Zeger, 1986) or in software (with some modifications to account for random effects) such as HLM (Raudenbush & Congdon, 2021). However, finite-sample modifications (due to having small G) can be used to slightly reduce the downward bias of the CRSE. Different software may implement adjustments to account for a limited number of clusters such as scaling the
In applied econometrics, the most widely used CRSE is the CR1 (MacKinnon et al., 2023b), which is the CR0 multiplied by a scaling factor of
When Do CRSEs Fail?
Analyzing Data With Only a Few Clusters
The most commonly mentioned limitation when using the traditional CR0 estimator is that it works well when the number of clusters is reasonably large and performs poorly when there are only a few clusters (Bell & McCaffrey, 2002; Cameron & Miller, 2015). Conventional guidelines indicate that when there are around 20 (Muthen, 2005) 2 or 40 (Angrist & Pischke, 2008) clusters, the use of CRSEs should not be an issue. With a limited number of clusters, CR0 standard errors are well-known to be underestimated for cluster-level coefficients (Bell & McCaffrey, 2002). However, less known is that inferences may still be incorrect even in some situations when there are even 100 or 200 clusters (Djogbenou et al., 2019; MacKinnon et al., 2023a). Being able to discern when situations may be problematic is thus of importance to the applied researcher.
Using Inappropriate df
Although standard errors are important, when p-values and confidence intervals are obtained, this is done in conjunction with the t-critical values based on the df used. Traditional OLS df are determined by the sample size and the number of predictors; the t-critical value is based on N−k. However, with clustered data, researchers may have hundreds of observations but only a limited number of clusters actually present (e.g., 600 students nested within 20 schools).
To obtain t-critical values of ±1.96 when constructing confidence intervals, this assumes a large number of clusters (i.e., G = ∞) and that the test statistic follows a normal distribution. Certain software (e.g., Mplus) may assume by default a z-critical value of 1.96. However, if t-tests for cluster-level predictors are done using the traditional df of N−k, then the critical values may be too low when there are only a few clusters. As indicated by Elff et al. (2016, p. 16) “it is very misleading to construct p-values, hypothesis tests, and confidence intervals for the coefficients of upper-level variables using the assumption that the corresponding t-statistic (i.e., the coefficient estimate divided by its standard error) follows the standard normal distribution.”
Instead, critical values can be constructed based on the number of G clusters and often, G− 1 (Cameron & Miller, 2015) or G−L− 1 (Donald & Lang, 2007) where L represents the number of cluster-level predictors, can be used (Stata uses G− 1 by default). If there are many clusters, the difference in critical values may be trivial (e.g., with G = 200, the t-critical values are ±1.97). However, when there are fewer clusters, the choice of df can have more consequential results, perhaps even more so than the choice of the CRSE alone (Pustejovsky & Tipton, 2018; Young, 2016). Basing the df on G instead of N is more conservative (as long as G≠N) but can still result in higher Type I errors with only a few clusters (MacKinnon & Webb, 2017).
Having Clusters That Wildly Vary in Size
Additional issues related to the adequate number of clusters for CRSEs stem from what is referred to as cluster heterogeneity (Carter et al., 2017) that can be brought about as a result of large imbalances in cluster size. As a result of cluster heterogeneity, the effective number of clusters, referred to as G*, is often much less than the observed number of clusters G (we discuss computations for G* in a succeeding section). Large differences in the number of observations per cluster can also have an effect on Type I errors (MacKinnon et al., 2023a).
A classic example of this type of dataset comes from applied economics and involves studies that compare different outcomes across 50 U.S. states (e.g., based on the introduction of some policy). If using data representative of the population of each state, California accounts for 12% of the total U.S. population and 20 states (e.g., Iowa, Wyoming) each comprise less than 1% of the U.S. population. Although in this case, G = 50, the results of one cluster may have a disproportional effect compared to the rest of the sample, which will then influence the regression coefficients. However, when computing the CRSE, each cluster contributes equally to the variance of the coefficients. As indicated by Bell and McCaffrey (2002, p. 7), “greater bias appears to occur when certain [clusters] account for most of the variability in the covariates and have disproportionate impact on the determination of the [the regression coefficients].” The CR1 performs well with relatively balanced cluster sizes but has higher Type I error rates with the presence of extremely large clusters (relative to the rest of the sample) (MacKinnon & Webb, 2017).
School-based research may also find situations with large variations in cluster sizes. This may be less of an issue with properly controlled experimental studies, though it may become increasingly more common with secondary data analysis with the availability of statewide longitudinal data systems (SLDS) and other statewide administrative databases. For example, in the Virginia Secondary School Climate Survey (Cornell et al., 2017) in 2017, there were 85,762 middle-school respondents from 410 schools. The mean number of respondents per school was 209 students, with a range from 7 to 1,620. Twenty-five percent of the schools had fewer than 68 respondents, and there were 9 schools with more than 1,000 respondents.
Of importance as well is that variation in cluster sizes can be represented as a coefficient of variation (cv), which is the ratio of the standard deviation of the cluster sizes to the mean of the cluster sizes (
Having Too Few (or Too Many) Treated Clusters
CRSEs may also fail to provide accurate statistical inference tests in the presence of too few or too many “treated” clusters. As indicated by Cameron and Miller (2015), Problems arise if most of the variation in the regressor is concentrated in just a few clusters, even when G is sufficiently large. This occurs if the key regressor is a cluster-specific binary treatment dummy and there are few treated groups. (p. 349)
In this case, a treated cluster has predictor T = 1 if in a treatment condition and T = 0 if in a control condition, and this is assigned at the cluster level (all observations in the same cluster have the same measure of T). However, in the case where there are only a limited number of clusters that get treated (e.g., 2 out of 20 clusters have T = 1), then Type I errors are larger than the nominally accepted .05 (MacKinnon & Webb, 2017). 3
In an educational context, when doing school-based research, binary cluster-level predictors are not uncommon. For example, if comparing the performance of students attending public or private schools, school type is a cluster-level predictor. Often, in large-scale international assessments, data are collected from public and private schools and depending on the country, the number of private schools sampled is far less than public schools. In the Programme for International Student Assessment (PISA) 2018 dataset (OECD, 2020), in the U.S. sample, there were only 10 private schools compared to 138 public schools or 6.7%.
Dealing With the Deficiencies of Traditional CRSEs
Although several specific situations have been identified when cluster robust inferences may fail, a few approaches have been proposed that may ameliorate such issues. For the current article, we focus on using an alternative cluster-robust estimator and using different df estimation techniques (which may not be commonly used).
Alternative Estimator: The CR2
Alternative variants of the CR0 CRSE have been developed over the years to account for the presence of a few clusters (see Cameron & Miller, 2015). One CRSE variant that has received more recent attention is the CR2 adjustment (Huang, 2022; Imbens & Kolesar, 2016; Pustejovsky, 2018) or the bias-reduced linearization (BRL) estimator of Bell and McCaffrey (2002). Instead of the variance/covariance matrix estimated using equation (1), adjusted residuals are included so that
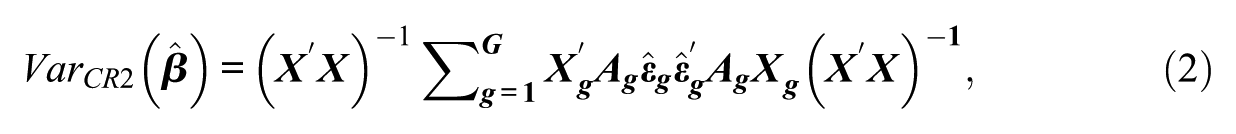
where an adjustment matrix,

where

The inverse of the symmetric square root of the quantity has been shown to help reduce the estimated standard error bias when residuals within the cluster are correlated and the cluster-level hat matrix reduces bias from overrepresented clusters (Bell & McCaffrey, 2002). As a result, the CR2 adjusts for leverage and improves inferences in the presence of unbalanced clusters. Even though the CR2 estimator has been available for over two decades, it has seen limited use in applied research though recent studies have found that it performs well (i.e., less biased, lower Type I errors), even with a limited number of clusters compared to the CR0 (Huang & Li, 2022; Pustejovsky & Tipton, 2018). MacKinnon and Webb (2017) considered the CR2 adjustment in their simulation investigating solutions to cluster heterogeneity, but given their interest in large samples (e.g., >500,000 observations), which required extensive computational time and memory (i.e., obtaining the inverse symmetric square roots of the adjustment matrices can be challenging), they decided it was not feasible to study its performance. Niccodemi et al. (2020) presented a faster formulation of the CR2 (in Appendix A of their paper) which requires an inversion of smaller k×k matrices instead which would circumvent this problem.
Alternative Estimator: The CR3
Bell and McCaffrey (2002), in the same article that introduced the CR2, presented the formulation for the jackknife operator also referred to as the CR3 (MacKinnon & Webb, 2017). The formulation of the CR3 is the same as the CR2 with the exception that instead of equation (3) which requires the inverse of the symmetric square root, only the inverse is required for the adjustment matrix:

MacKinnon et al. (2023b) also included a scaling factor of
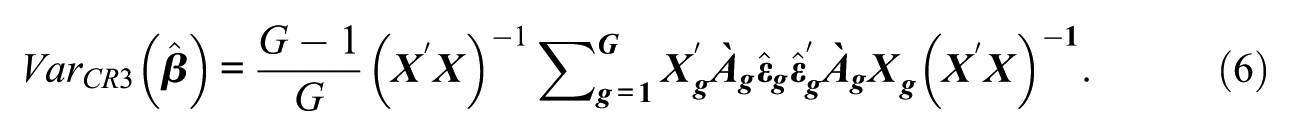
Although the CR2 has often been recommended (Imbens & Kolesar, 2016; Pustejovsky & Tipton, 2018), others have suggested the use of the CR3 as well (MacKinnon et al., 2023a, 2023b) indicating that it performs as well as or better than the CR2 (in some situations) and is computationally less demanding. Hansen (2025) recommended its routine use compared to the CR1 estimator and indicated that the CR3 will tend to be conservative (i.e., underreject the null) which was also reported by Bell and McCaffrey (2002).
As a jackknife estimator, which uses a “leave-one-out” resampling process, MacKinnon et al. (2023b) presented an alternative formulation of the CR3. The OLS estimates of
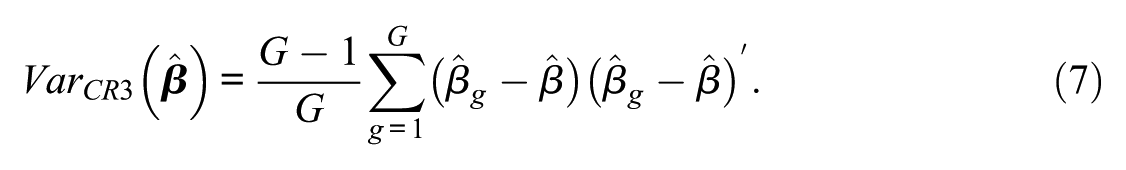
Results using equations (6) and (7) are the same though the latter is more efficient as it does not depend on the adjustment matrix which can be large. In R, packages such as sandwich (Zeileis, 2006) and clubSandwich (Pustejovsky, 2018) compute the CR3 without the scaling factor. Niccodemi et al. (2020) also showed an efficient way to compute the CR3 in addition to the CR2, and Hansen (2025) showed computations for the CR3 using a generalized inverse instead.
Alternative df: Using the Effective Number of Clusters Versus Observed Number of Clusters
Clusters that vary in size can lower what is referred to as the effective number of clusters. At a basic level, from the survey sampling literature (Asparouhov, 2006; Potthoff et al., 1992), the effective number of clusters can be computed using:
In the computation of
Comparing G to G*-1 can be informative (i.e., comparing the observed number of clusters to the effective number of clusters). For example, Carter et al. (2017) used the well-known Tennessee Project Star (Achilles et al., 2008) dataset analyzed by Krueger (1999). In the dataset, Carter et al. reported that there were 318 kindergarten teachers (the number of clusters G), but the number of students varied across classrooms from 9 to 27 (M = 18, s2 = 15.7). Computing the effective number of clusters, G* = 192, a reduction of 40%. 6 In this case, the coefficient of variation was a modest cv = 0.22.
Alternative df: Using Satterthwaite df Approximations
In the same manuscript where they proposed the CR2 estimator, Bell and McCaffrey (2002) also provided a Satterthwaite df adjustment given by
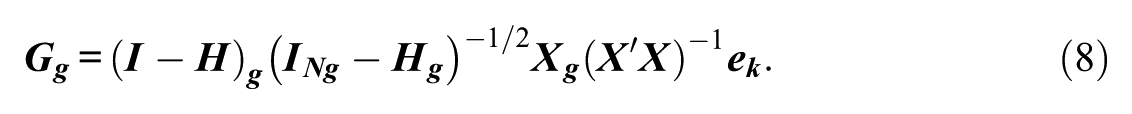
The first term,
The Current Study
As the issues related to the fallibility of CRSEs are based on having a few clusters, large imbalances in cluster sizes, and analyzing clustered treatments with low prevalence rates, we conducted a simulation to assess the performance of the CR1, CR2, and CR3 together with df variations using dfG-1, dfG*-1, dfBM. Although prior studies have investigated the use of the CR2 with dfBM (e.g., Huang & Li, 2022), the combination of factors directly related to the issues with statistical inference tests were not directly manipulated (e.g., cluster sizes were not largely unbalanced). MacKinnon and Webb (2017) investigated the use of G*− 1 vs. G− 1 as a df alternative and found that using G* performed better than just using G, but their simulation was limited in terms of the number of clusters used (e.g., 50 and 100) and did not consider dfBM nor the CR2. As the CR2 and CR3 account for cluster heterogeneity and the choice of df can be consequential (Pustejovsky & Tipton, 2018), testing out the combinations of CRSEs and df in situations where inferences may fail can provide valuable insights into the robustness of statistical conclusions under different assumptions.
Method
Data Generating Process (DGP)
To investigate the conditions where cluster-robust inferences may fail and assess approaches that may ameliorate the issue, we conducted a Monte Carlo simulation using R (R Core Team, 2025). We simulated a two-level linear model (e.g., students within schools) with dependent variable
As we were interested in situations where cluster robust inferences may be problematic (based on Type I error rates), which is why
The ICCs represent what may be considered typical ICCs in an educational context (see Hedges & Hedberg, 2007) with higher ICCs indicating a higher proportion of a cluster-level effect and is directly controlled by the value of
For each simulated dataset, the effects of T and
Results
Type I Error Rates for the Cluster-Level Binary Predictor
For the binary cluster-level predictor, Type I error rates are shown in Figure 1 for all conditions for models estimated using CR1:dfG-1 and MLM. The multilevel models all had Type I error rates within the noted thresholds of 2.5% to 7.5%, regardless of the condition manipulated.
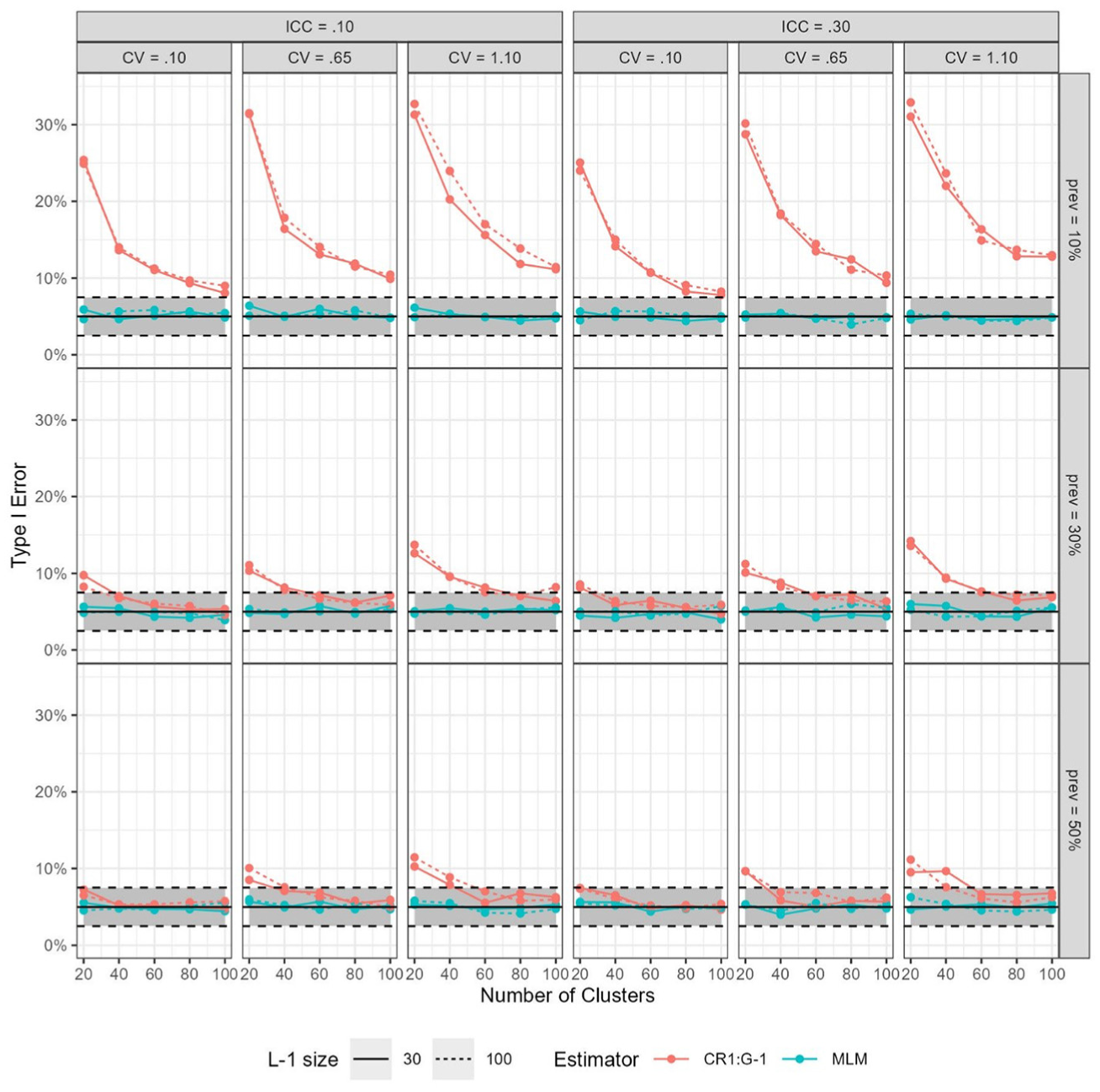
Type I Error Rates per Condition Using the CR1 Estimator and MLM (Multilevel Models) Using 2,000 Replications for the Level-2 Binary Predictor.
However, of all the conditions tested, the low-prevalence-rate condition (prev = 10%) had the largest effect in contributing to the extremely high rejection rates for the CR1:dfG-1 estimator. When prev = 10%, all of the CR1:dfG-1 Type I errors were above the 7.5% threshold and could be as high as around 35% (compared to the nominally expected 5%) in the prev = 10%, cv = 1.10, and G = 20 condition. Notably, in the prev = 10% condition, even with G = 100, Type I error rates could still be as high as 15% when cluster sizes were extremely imbalanced (cv = 1.10).
Even when prevalence rates were not as extreme (e.g., prev = 30%), rejection rates could still be higher than 5% for the CR1:dfG-1 estimator with G = 60, with the highly imbalanced condition. In the balanced condition where prev = 50%, Type I errors could still be higher when G was low and/or cv was high.
Alternative Estimators for the Binary Predictor
As the number of units per cluster (i.e., 30 vs.100) did not show a stark difference in Figure 1 (i.e., the dashed and solid lines were almost parallel to each other), for the alternative estimators, we show the results for Ng = 30 for clarity to avoid cluttering the plots. For the low-prevalence condition (prev = 10%), the CR1:dfBM could have Type I errors a little over 10% when G = 20 and cluster sizes were highly imbalanced (see Figure 2). Regardless of prevalence rates, the higher Type I error rates persisted when G = 20 and cluster sizes were extremely unbalanced (regardless of ICC) when using the CR1:dfBM.
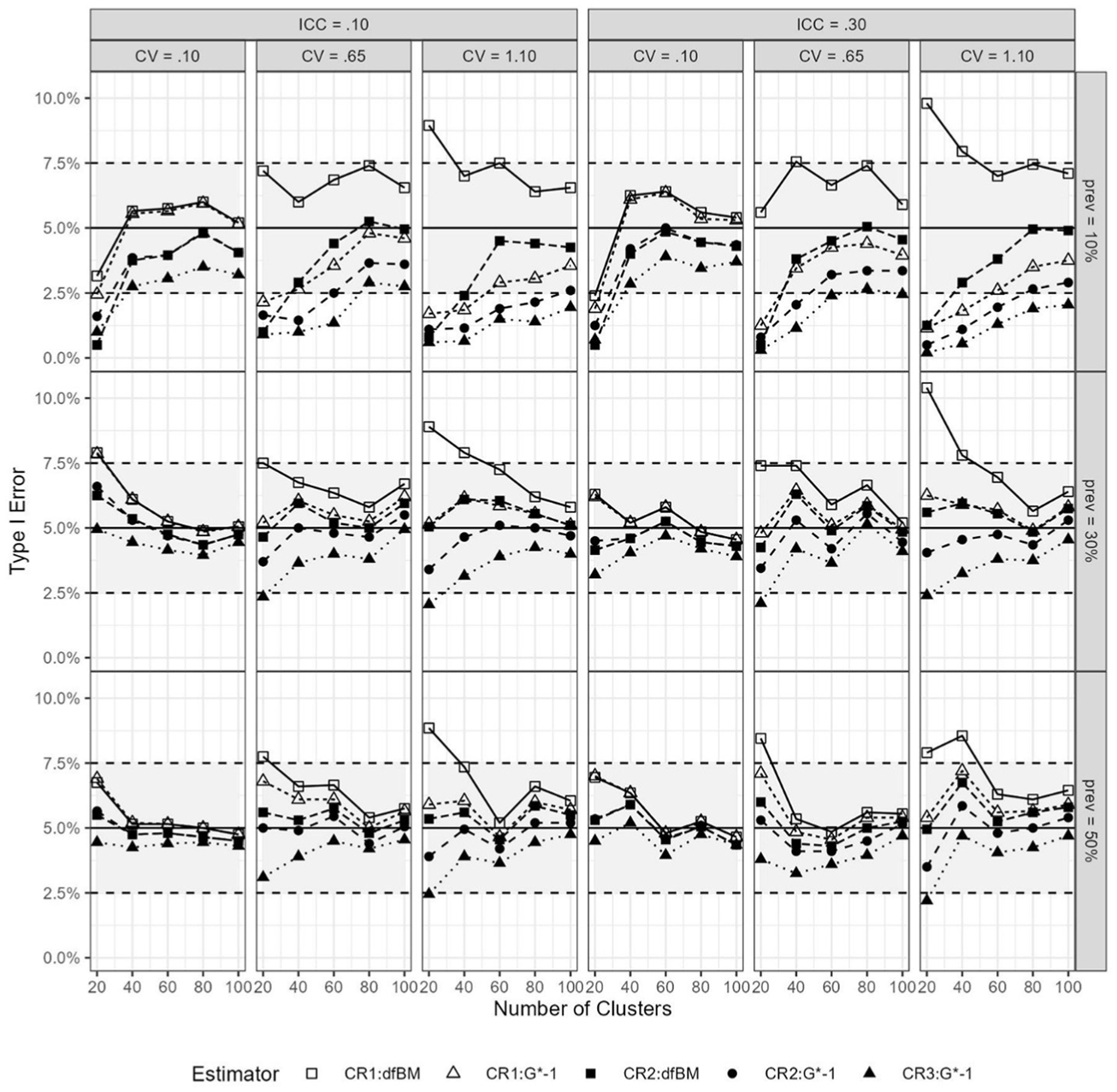
Type I Error Rates per Condition Using the CR1, CR2, and CR3 Estimators and Degrees of Freedom Adjustments Using 2,000 Replications for Level-2 Binary Predictor.
When the prevalence rates were ≥30%, the CR1:dfG*-1 and CR2 estimators had rejection rates that were generally in the acceptable established thresholds ranges. The CR3 estimator tended to be more conservative as well, with lower rejection rates compared to the other estimators.
However, in the low-prevalence-rate condition (prev = 10%), specifically when G = 20, Type I error rates could be too low (< 2.5%) for the other estimators. With more extreme imbalances in cluster sizes and prev = 10%, the CR3 tended to have low rejection rates, regardless of the number of clusters. The CR2:dfBM performed well in most conditions, except for when G = 20 and the prevalence rate was only 10%.
Type I Error Rates for the Cluster-Level Continuous Predictor
For the continuous predictor, Type I error rates could be too high for the CR1:dfG-1 estimator and rates were highest (e.g., 15%) when cluster sizes were extremely unbalanced (see Figure 3). The imbalance in cluster sizes was the main cause of the higher Type I error rates, regardless of all other conditions. With the case of the continuous predictor, unlike the binary predictor, the prevalence rates did not influence the rejection rates (as expected). Again, the multilevel model results were near the nominally stated 5%.
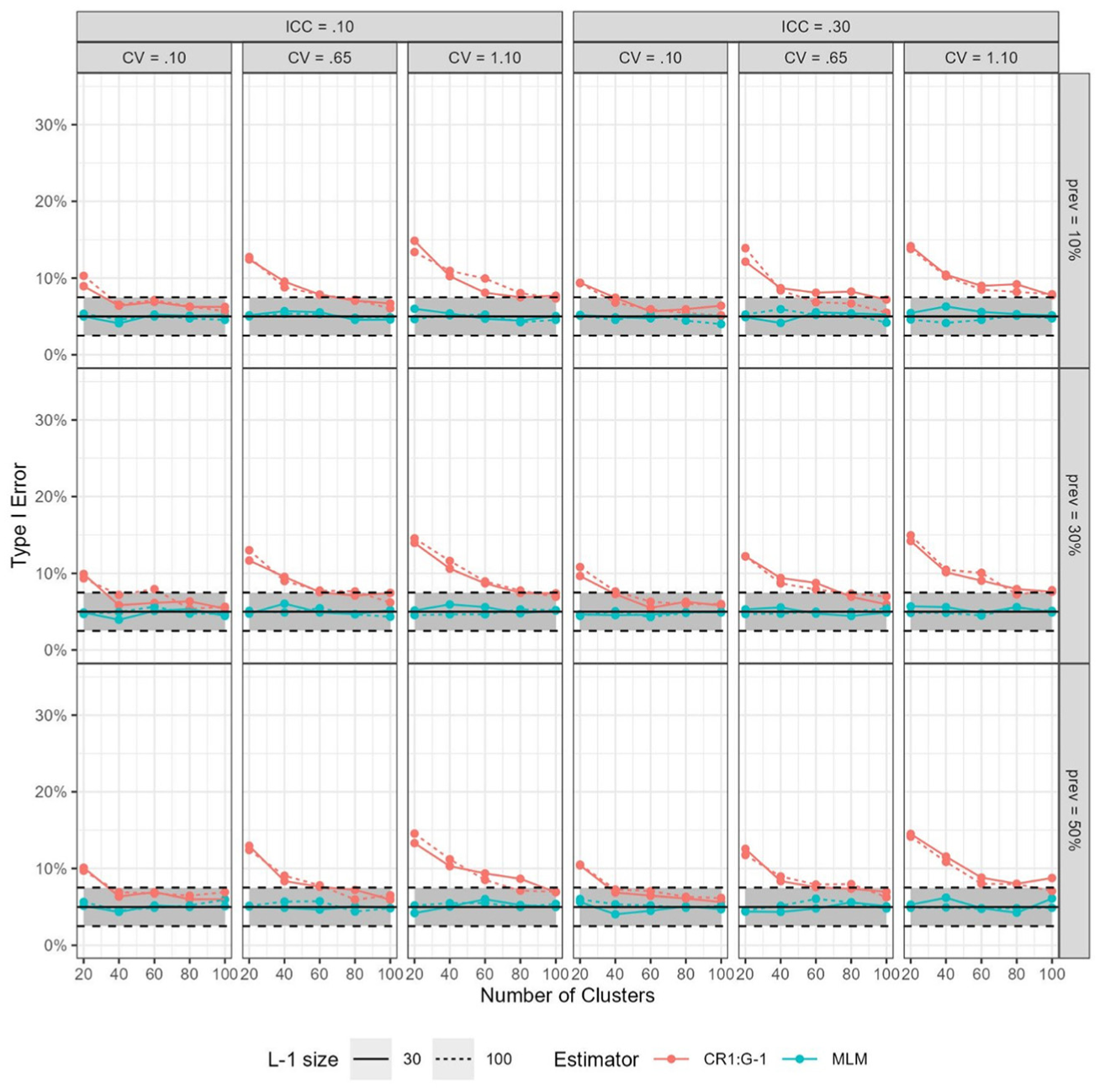
Type I Error Rates per Condition Using the CR1 Estimator and MLM (multilevel models) Using 2,000 Replications for the Level-2 Continuous Predictor.
Alternative Estimators for the Continuous Predictor
Both the CR1:dfG*-1 and the CR2 estimators (regardless of dfBM or dfG*-1) had Type I errors that were within the generally established thresholds for all conditions (see Figure 4). However, with the CR1:dfBM, Type I error rates could still be too high when the imbalance in cluster sizes was moderate (cv = 0.65) to high (cv = 1.10). The CR3 also tended to have lower rejection rates when G = 20.
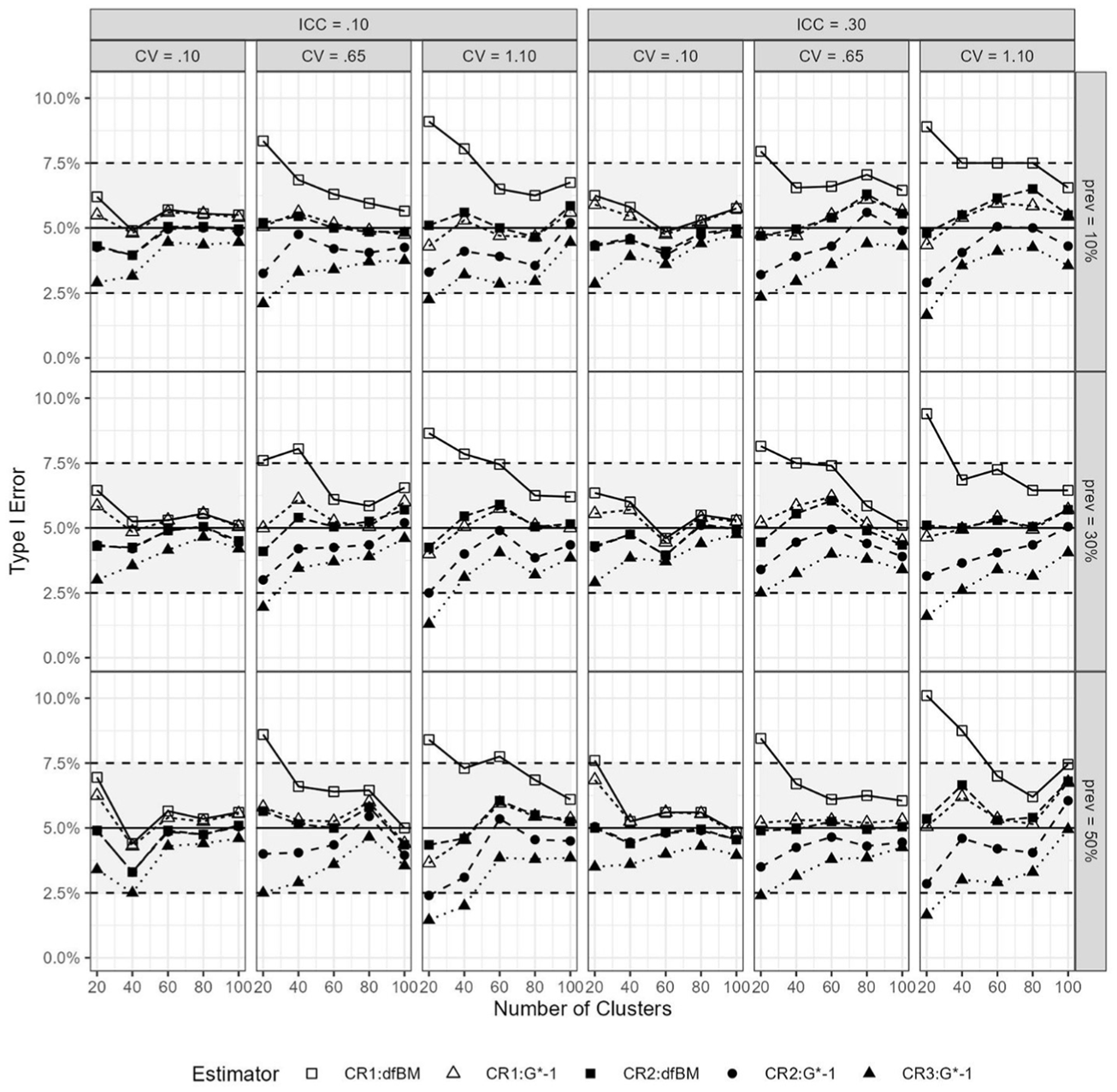
Type I Error Rates per Condition Using the CR1, CR2, and CR3 Estimators and Degrees of Freedom Adjustments Using 2,000 Replications for Level-2 Continuous Predictor.
Discussion
The current study investigated the performance of CRSEs under a range of conditions (using both continuous and dichotomous cluster-level predictors) commonly encountered in educational research, specifically in situations where the traditional use of CRSEs has been known to not perform as well. Using a Monte Carlo simulation, we evaluated the Type I error rates associated with the traditional CR1 estimator and the alternative CR2 and CR3 estimators used together with df adjustments based on the number of clusters (G), the effective number of clusters (G*), and the Satterthwaite approximation (dfBM). The findings underscore the importance of carefully considering both the estimator and the df when conducting inference tests with clustered data.
Our results revealed that the often-used CR1:dfG–1 estimator frequently produced inflated Type I error rates, particularly under conditions involving a small number of clusters, high variability in cluster sizes, and low prevalence rates when using a binary cluster-level predictor. The inflated rejection rates were also found when using continuous cluster-level predictors when there were few clusters and/or imbalanced cluster sizes (the “few treated clusters” does not apply to continuous predictors). These conditions are not uncommon in educational research, where studies may involve a limited number of schools or classrooms, where cluster-level predictor prevalence rates may be rare (e.g., alternative schools vs. traditional K-12 schools), and the number of observations per cluster may vary to a large degree. Although often, a rule-of-thumb for using CRSEs may only revolve around the number of clusters (e.g., using CRSEs with around 40 clusters is acceptable, Angrist & Pischke, 2008), we test a variety of conditions and show that even with 100 clusters, Type I error rates may still be too high, similar to findings of MacKinnon and Webb (2017). The large imbalance in cluster sizes exacerbates the Type I error rates for both continuous and binary cluster-level predictors.
However, the CR2 estimator, when paired with the dfBM approximation, demonstrated improved control over Type I error rates across most conditions. The exception would be when the prevalence rate for the binary predictor was low (i.e., 10%) and there were only 20 clusters. In those cases, the rejection rates were far too low (i.e., <2.5%). Though this may be of concern for cluster-randomized controlled trials that aim to reject the null hypothesis of equality, proper power analysis and practical experimental design will remedy this situation (i.e., researchers would not assign 2 out of 20 groups to a treatment condition as power would already be too low, not unless planned effect sizes were extremely large). With a continuous cluster-level predictor, the CR2:dfBM had near the nominally acceptable 5% for all conditions tested. The CR3 estimator was the most conservative estimate as a result of having the lowest Type I error rates among all estimators.
Although researchers have been warned about using the CR1 estimator with a limited number of clusters (e.g., Cameron & Miller, 2015), our findings show that, depending on the df used, acceptable Type I rates are possible. It should be clear that using the naïve G–1 should not be used, but then the CR1:dfBM can still result in higher Type I error rates as well with a binary predictor, with a few clusters, and imbalanced cluster sizes. The Type I error rates for the CR1 with G– 1 could be used, as long as cluster sizes are relatively balanced (i.e., cv ≤ 0.10), and this applies to both continuous and dichotomous cluster-level predictors.
One approach that has not seen much use would be to use the G*-1 as the df instead of G-1. Using G* in the df computation resulted in more conservative and often more accurate inferential tests. The CR1:dfG*-1 had very similar performance to the CR2:dfBM estimator for both the continuous and binary cluster-level predictors. However, like the CR2:dfBM and the CR3, the CR1:dfG*-1 could have Type I error rates that were far too low when G = 20 (MacKinnon & Webb, 2017), and the interest was in a binary predictor. An advantage of using the CR1:dfG*-1 estimator over the CR2:dfBM is that the CR1:dfG*-1 is less computationally demanding (i.e., it is easier to compute) and does not require computing the inverse symmetric square root of a matrix.
Although MacKinnon and Webb (2017) indicated that the number of observations within a cluster was immaterial, they had only tested this with 50 and 100 clusters. For the most part in our simulation, our results were similar and there were minimal differences when the level-1 sample size was 30 or 100, except in the case where the CR1:dfBM was used with a binary predictor and there were only 20 clusters and cv ≥.65. With a large imbalance (i.e., cv = 1.10), with 100 observations on average per cluster, CR1:dfBM Type I error rates were approximately 15% compared to <10% when there were only 30 observations per cluster (on average).
Although not the focus of the article, the multilevel random-intercept model (which matched the data-generating process) consistently maintained Type I error rates near the nominal level of 5% under all conditions. Applied economists may eschew the use of MLMs, which may provide inconsistent results and have more model assumptions (when compared to fixed effects [FE] models) (Angrist & Pischke, 2008), but MLMs can be specified in a manner that yield the same results as FE models (Huang, 2018, 2023). In addition, the same CRSEs discussed can also be used with MLMs (Huang, Wiedermann, & Zhang, 2023) to account for cluster heterogeneity that may be present, such as when random slopes are warranted (Huang & Zhang, 2025). Models estimated with a properly specified MLM are more powerful than models that use CRSEs (Huang & Zhang, 2025) though as indicated by MacKinnon et al. (2023, p. 275), the “principal objective of cluster-robust inference . . . [is for the model] to be robust to arbitrary and unknown dependence and heteroskedasticity within clusters.”
Implications
Our findings have direct implications for applied education researchers. First, the use of CRSEs (although applied routinely and automatically for some researchers) requires some care and, depending on the conditions in the dataset, may result in inflated claims of statistical significance. Second, our results support the adoption of more robust estimators, such as the CR2 or the CR3, which are available in statistical software such as R, Stata, and SPSS (see Huang & Li, 2022). These estimators can offer improved inferential protection without requiring changes to model specifications, making them accessible to applied researchers. An alternative is to use the traditional CR1 estimator but base the df on the effective (instead of the observed) number of clusters if interested in the cluster-level predictors, as shown as well by MacKinnon and Webb (2017). Also, caution is warranted when using software that do not allow the choice of estimator or df. In those cases, the CR1 may be used and the effective number of clusters can still be computed and inferential tests using revised df can be performed manually. Third, this study highlights the importance of transparency in reporting the nested data structure. Researchers should clearly document the number of clusters, the effective number of clusters, the distribution of cluster sizes (using M, SD, range, and the coefficient of variation), the prevalence rates of cluster-level binary predictors, and the specific CRSE and df adjustments used. Such transparency is important for evaluating the robustness of findings and for facilitating future replication studies. Often, when clustered datasets are used, the number of clusters are reported but that is not enough to show how much cluster size imbalance is present (which has been shown to have an effect on rejection rates).
Limitations
Some limitations should be considered when interpreting results. The simulation focused on two-level linear models and did not examine other types of nested data structures (e.g., random slopes, cross-classified models) or nonlinear models (e.g., logistic regression). Future research could extend these findings to such models, which are also common in educational research. Huang, Zhang, and Li (2023) showed that using the CR2 was effective in a clustered logistic regression setting but did not investigate conditions where inferential tests may fail. In addition, while the CR2:dfBM estimator performed well in many conditions, it is computationally intensive (which was the reason why MacKinnon & Webb, 2017 did not consider it in their simulation), particularly for large datasets or models with many predictors. Although this was not a barrier in the current study, it may limit feasibility in some settings (e.g., datasets with over 500,000 observations) though more efficient computation of the CR2 may help (Niccodemi et al., 2020). In addition, the CR3 may also be considered as well. However, other methods may also be computationally demanding (e.g., Bayesian regression) but should not be a reason to limit their use.
Conclusion
The findings from this study highlight the limitations of traditional CRSEs (i.e., the CR1) under certain conditions that are common in educational research that can result in higher Type I error rates For example, with educational data, it is not uncommon to find clustered datasets with large imbalances in cluster sizes (resulting in cluster heterogeneity) which have been found to result in higher than expected rejection rates, even when analyzing data with 100 clusters and affects both continuous and dichotomous cluster-level predictors. Our findings demonstrate the value of more robust alternatives, specifically the CR2 and CR3 estimators of Bell and McCaffrey (2002) together with df adjustments. Results also show that the CR1 can show similar performance to the CR2:dfBM if the CR1 is paired with G*-1 df adjustment using the effective number of clusters instead of the observed number of clusters. We also highlight the importance of describing the clustered data structure, in particular showing the coefficient of variation as it relates to the imbalance of cluster sizes. As the field continues to embrace the use of large-scale administrative data, it is imperative that educational statisticians adopt inference methods that are both theoretically sound and empirically validated. By doing so, researchers can enhance the credibility and reproducibility of their findings and contribute to a more rigorous and transparent evidence base for educational policy and practice.
Footnotes
Acknowledgements
Funding
The author received no financial support for the research, authorship, and/or publication of this article.
Declaration of Conflicting Interests
The author declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.