
Abstract
Computerized adaptive testing (CAT) aims to optimize measurement by tailoring item administration to individual examinees. The efficiency and precision of a CAT heavily depend on the choice of ability (
Keywords
Introduction
Computerized adaptive testing (CAT) is designed to deliver an optimal test for each examinee by administering fewer items while preserving or improving measurement precision relative to paper-and-pencil or other fixed-length tests (Meijer & Nering, 1999; Weiss, 1982, 2014). To implement a CAT, six components are required: (a) a specific response model; (b) a bank of pre-tested items; (c) an entry rule; (d) a method for selecting the next item; (e) an ability (
Stopping Rules in CAT
The fixed-length rule ends the CAT when a predetermined number of items have been administered; all examinees receive the same number of items regardless of their interim ability estimates or the degree of precision achieved. Although simple, this approach entails two drawbacks: efficiency and quality of measurement. Some examinees are administered more items than necessary, increasing testing time, whereas others receive fewer items than needed, yielding lower measurement precision. Therefore, to ensure that examinees are measured to a desired degree of precision, variable-length CAT is typically preferred (Weiss & Kingsbury, 1984), and prior research has shown that variable-length CAT performs as well as, or better than, fixed-length CAT (Babcock & Weiss, 2012).
There are three general types of variable-length stopping rules. The most popular and most researched is the standard error of measurement (SEM) cutoff rule (Weiss & Kingsbury, 1984). Under the SEM rule, the test terminates when the SEM of the ability (
The second type of termination rule is the minimum information (MI) criterion. Used in early CAT research, MI specifies that the CAT should stop when no item in the bank can provide information exceeding a prespecified cutoff at the examinee’s current
The third type of termination rule is the change-in-estimate (
Effects of
Estimator
Beyond termination criteria, the choice of
Bayesian methods (MAP and EAP) do not suffer from boundary problems because they incorporate a prior distribution; both form a posterior distribution by combining the prior with the likelihood, with MAP using the posterior mode and EAP using the posterior mean. Several simulation studies have found that EAP often exhibits lower bias than MAP, particularly in short tests (Hambleton & Swaminathan, 1985; S. Wang & Wang, 2001; T. Wang & Vispoel, 1998). However, when priors are misspecified, estimation can be highly biased; even with default priors centered at 0, examinees with extreme
When T. Wang et al. (1999) evaluated
Purpose
The present study aimed to quantify how different termination criteria interacted with
Method
IRT Model
The three-parameter logistic dichotomous IRT model (3PLM) was used. Assume an IRT model with
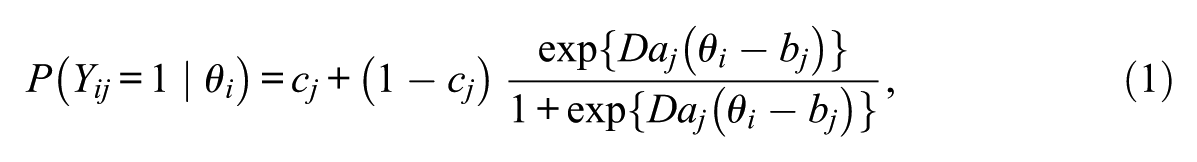
where
Item Banks
To approximate real-world variation in test information, four item-bank design conditions were manipulated: (a) 100-item banks with normally distributed
To ensure the generalizability of findings across different item banks, item banks were treated as a random factor. The simulation employed 1,000 independent replications for each of the four conditions (resulting in 4,000 unique generated item banks in total). Example bank information functions from a single replication are shown in Figure 1. Because of the guessing parameter in the 3PLM (Equation 1), tails naturally possess lower information than the mid-range even under flat
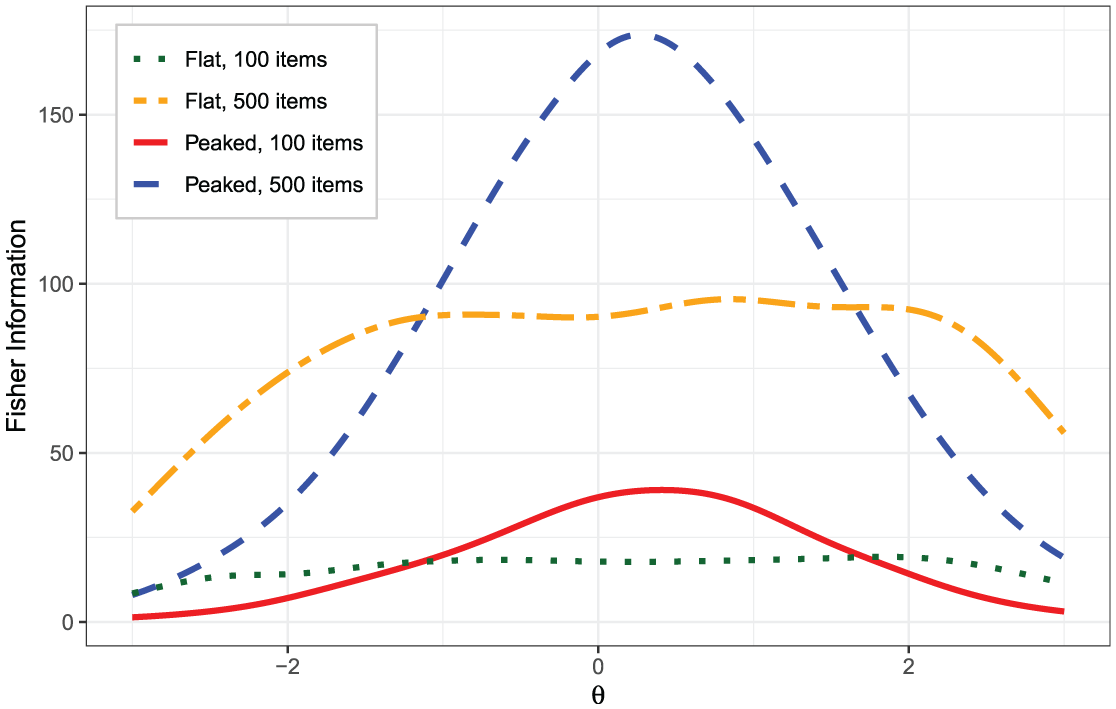
Bank information functions for the first bank in each condition.
For each bank, 3PLM parameters were generated as follows: discriminations
Termination Criteria
Four termination criteria were investigated.
Fixed-Length Rule
The fixed-length rule served as a reference. These CATs terminated after 20 (low precision), 25, 30 and 35 (high precision) administered items.
SEM Rule
The SEM rule terminates a CAT when the standard error of the current
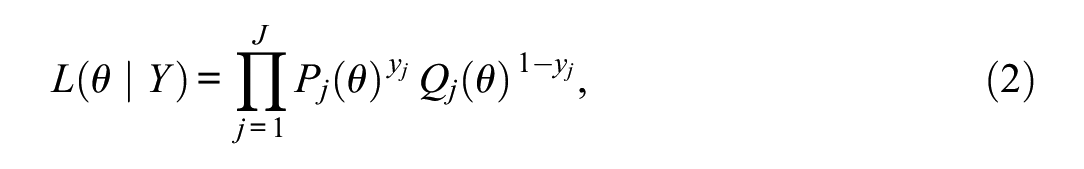
where

and the test information is
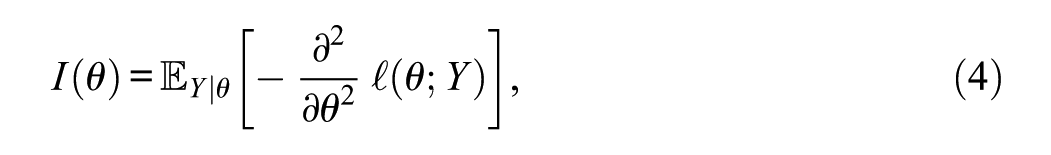
where

evaluated at the current
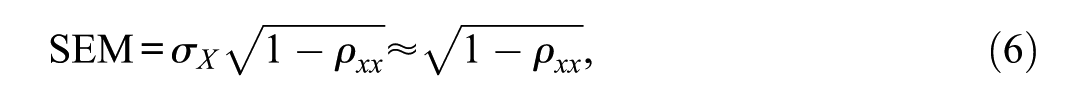
where
Minimum Information Rule
The MI rule terminates when no unused item provides information at the current
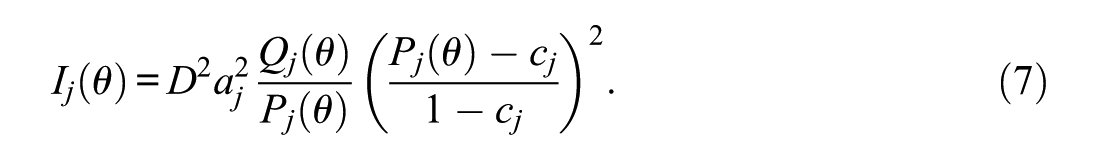
Early MI cutoffs were bank specific (e.g., Gialluca & Weiss, 1979; Maurelli & Weiss, 1981); simulations suggested that
Change in
Rule
The change-in-
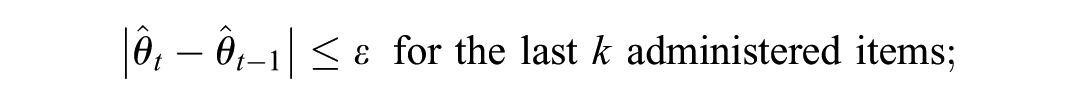
where
Estimation Procedures
Maximum Likelihood Estimation
The maximum likelihood estimation (MLE),
Maximum a Posteriori
Samejima (1969) proposed maximum a posteriori (MAP) as an alternative to MLE in cases where a prior distribution of
Expected a Posteriori
Expected a posteriori (EAP) estimation also used a standard normal prior. The EAP estimate is the posterior mean,
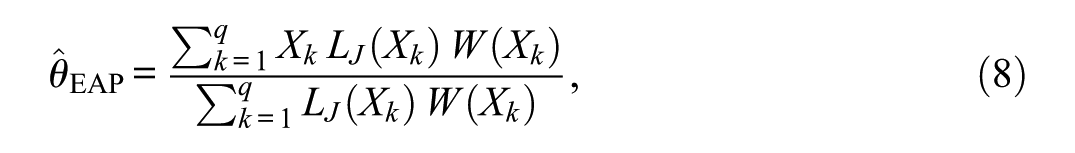
where
Weighted Likelihood Estimation
Weighted likelihood estimation (WLE, Warm, 1989) maximizes a weighted likelihood
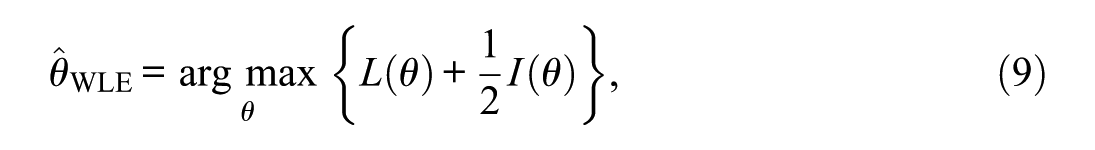
which can be viewed as a Jeffreys—prior in MAP form. In practice, WLE reduces small-sample bias relative to MLE, while not introducing bias due to a prior distribution (S. Wang & Wang, 2001; Warm, 1989).
Simulated Examinees
This study used
CAT Implementation
All simulees started at
While operational CATs frequently utilize item exposure control and content balancing constraints, these mechanisms were deliberately excluded from the current simulation. Implementing such constraints forces the selection algorithm to deviate from maximum information, which would introduce confounding variables and mask the pure mathematical interactions between the
Evaluation
Three outcomes were used to evaluate estimator–stopping-rule combinations.
Test Length
For each simulee the number of administered items was recorded; mean length was computed per condition to assess efficiency.
Bias
For each grid point of
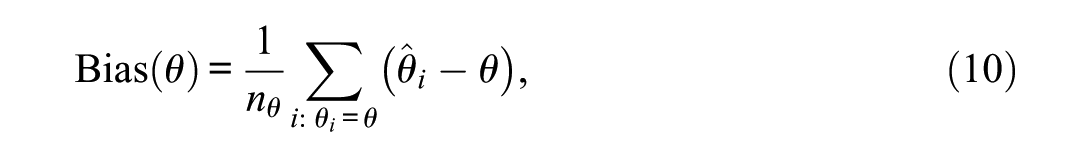
which reflects the signed total difference between estimated
Root Mean Squared Error
For each grid point of
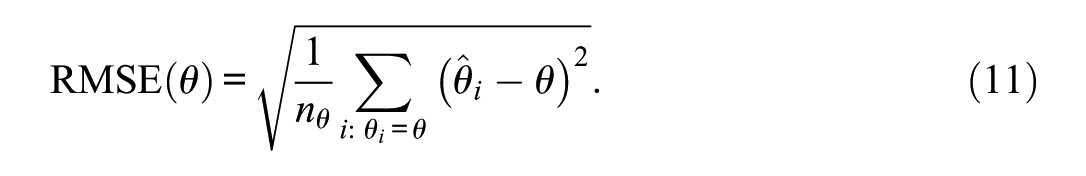
Together, Bias and root mean squared error (RMSE) summarize overall accuracy.
Results
Recovery in Low-Information (100-Item) Banks
Bias
Figure 2 illustrates the conditional bias across estimators and termination criteria conditional on
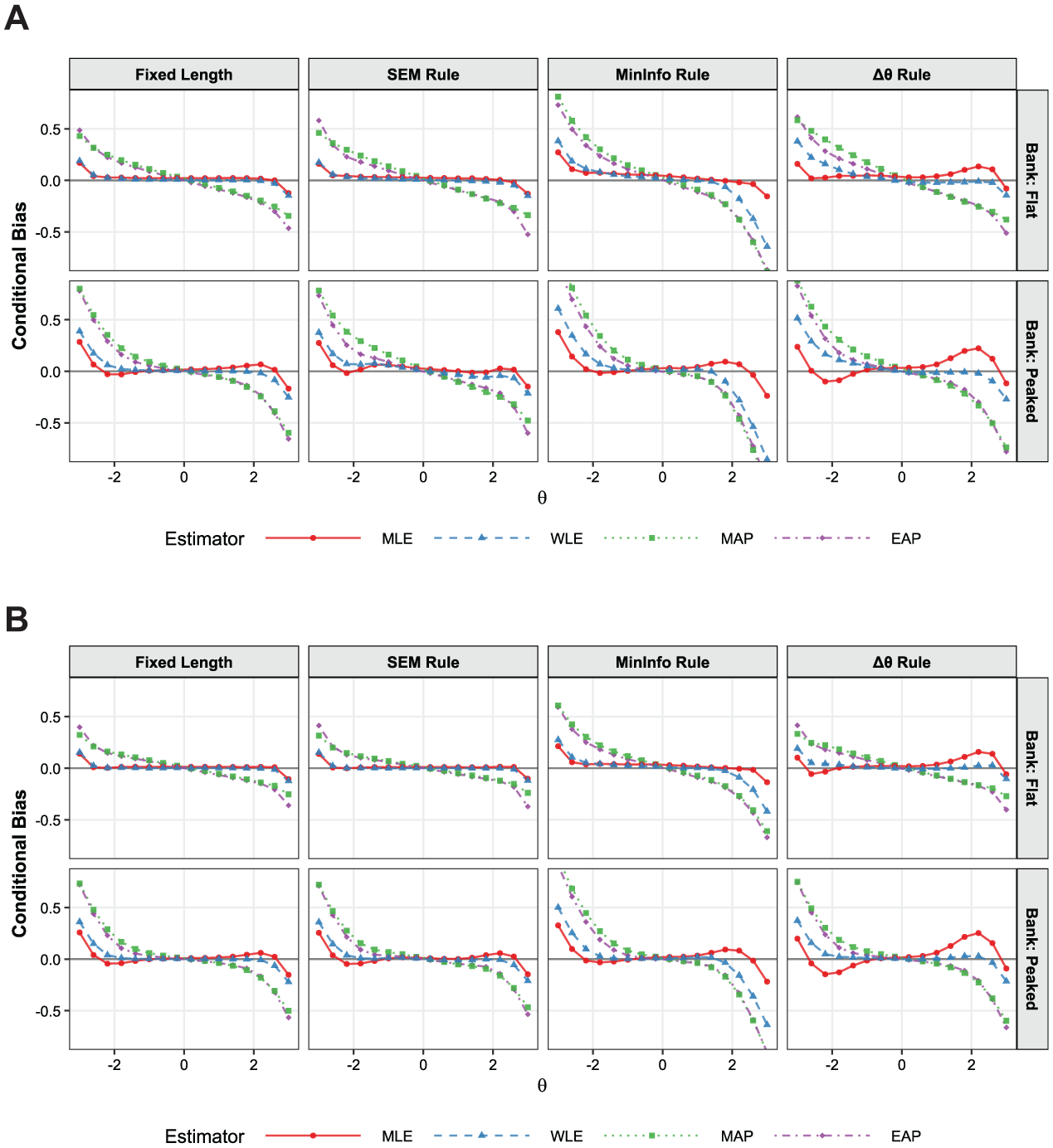
Conditional bias by estimator and termination rule with the low-information bank. (A) Low precision condition. (B) High precision condition.
Test Length and Efficiency
As shown in Figure 3, the superior accuracy of the SEM rule was achieved at the expense of test efficiency. In the flat bank condition requiring high precision (SEM
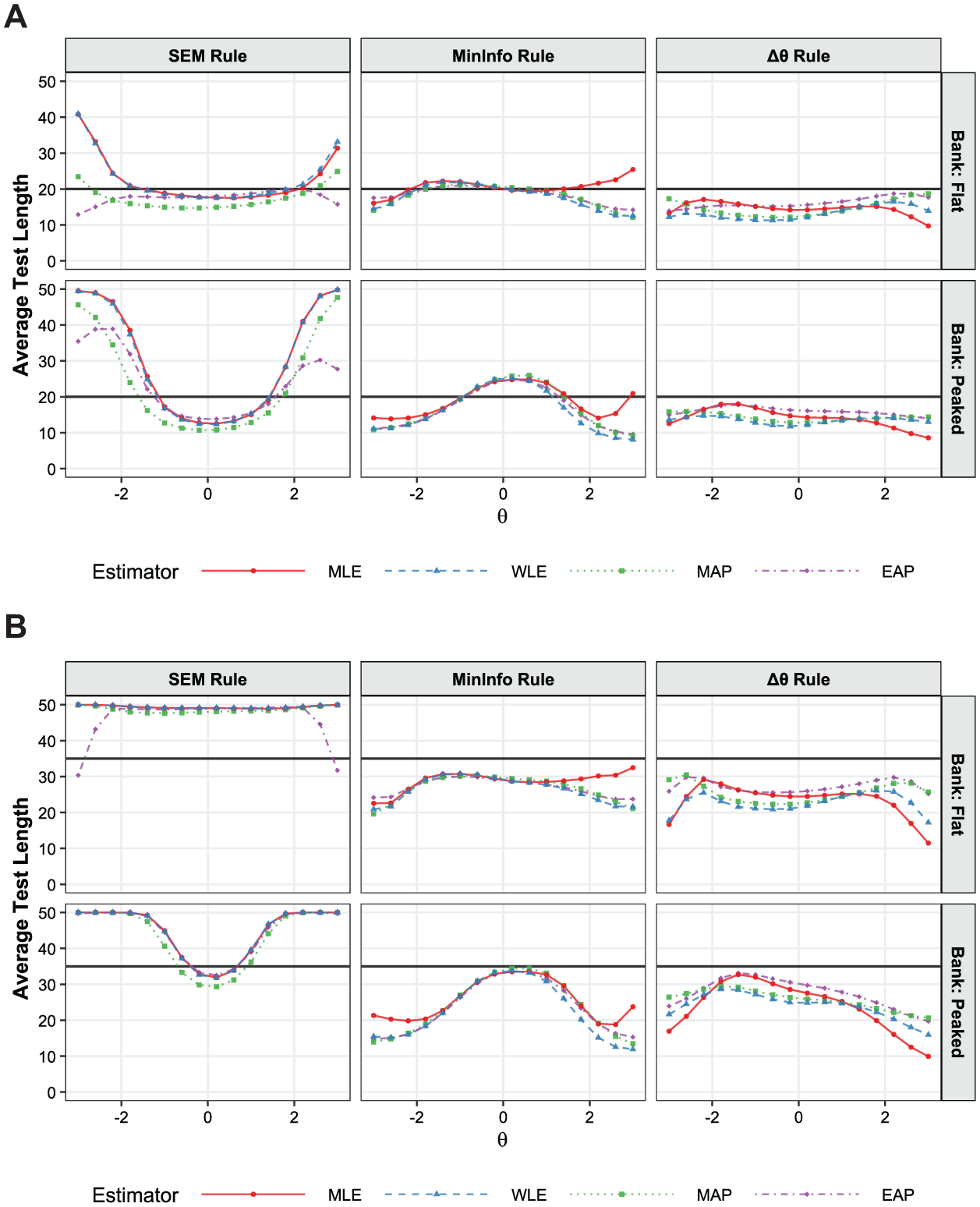
Conditional test length by estimator and termination rule with the low-information bank. (A) Low precision condition. (B) High precision condition.
The
Conditional RMSE
As illustrated in Figure 4, the conditional RMSE results indicate that the SEM and fixed-length rules generally outperformed the alternative stopping criteria in terms of measurement precision. Both rules exhibited similar error profiles; specifically, when using MLE and WLE estimators, the lowest RMSE values are observed in the center of the
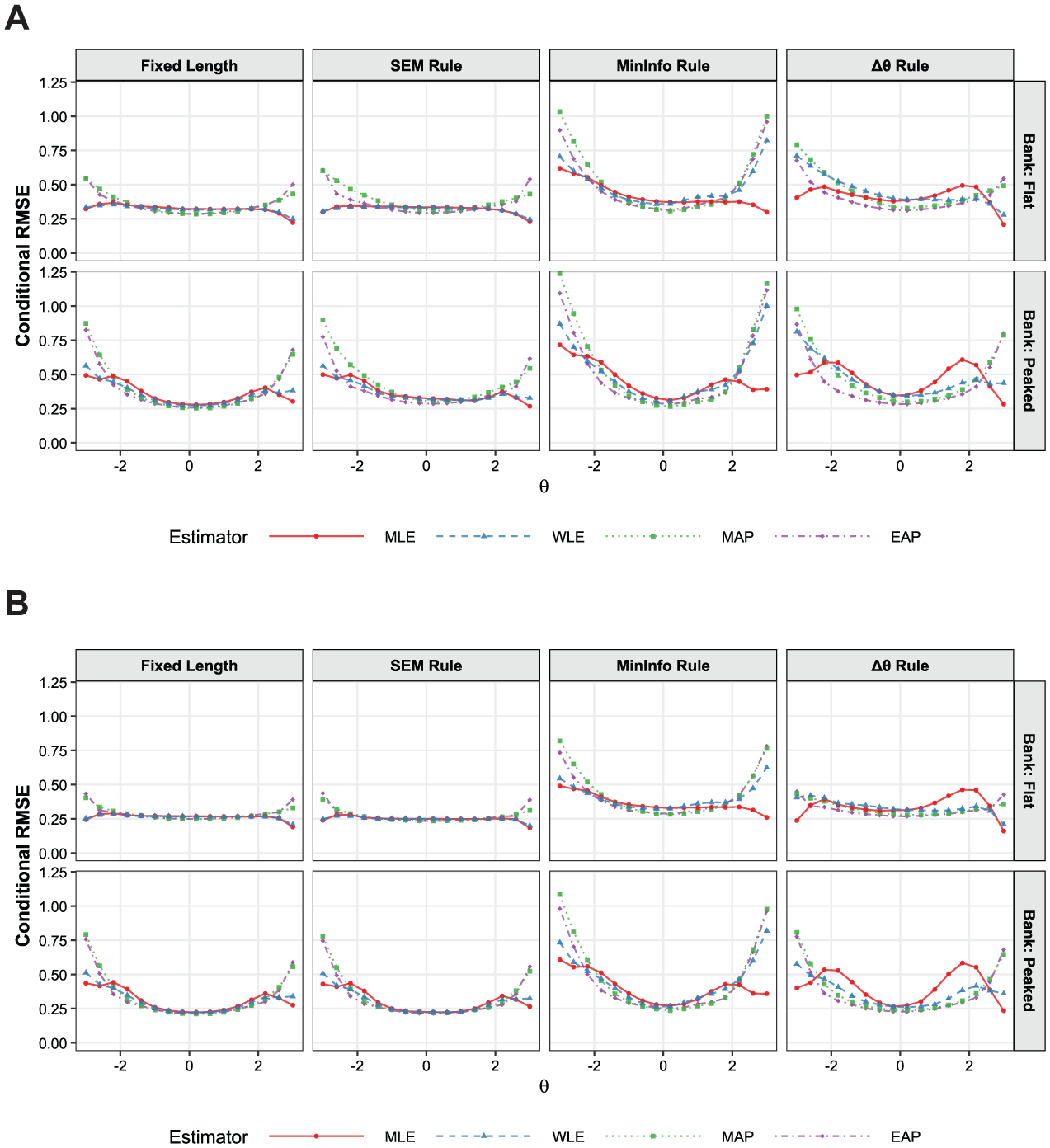
Conditional RMSE by estimator and termination rule with the low-information bank. (A) Low precision condition. (B) High precision condition.
Overall Accuracy
Table 1 summarizes the RMSE and test length distributions. For flat banks, the lowest RMSE was achieved by the WLE and MLE estimators paired with the strict SEM rule (SEM
Low-Information Bank Results (J = 100).
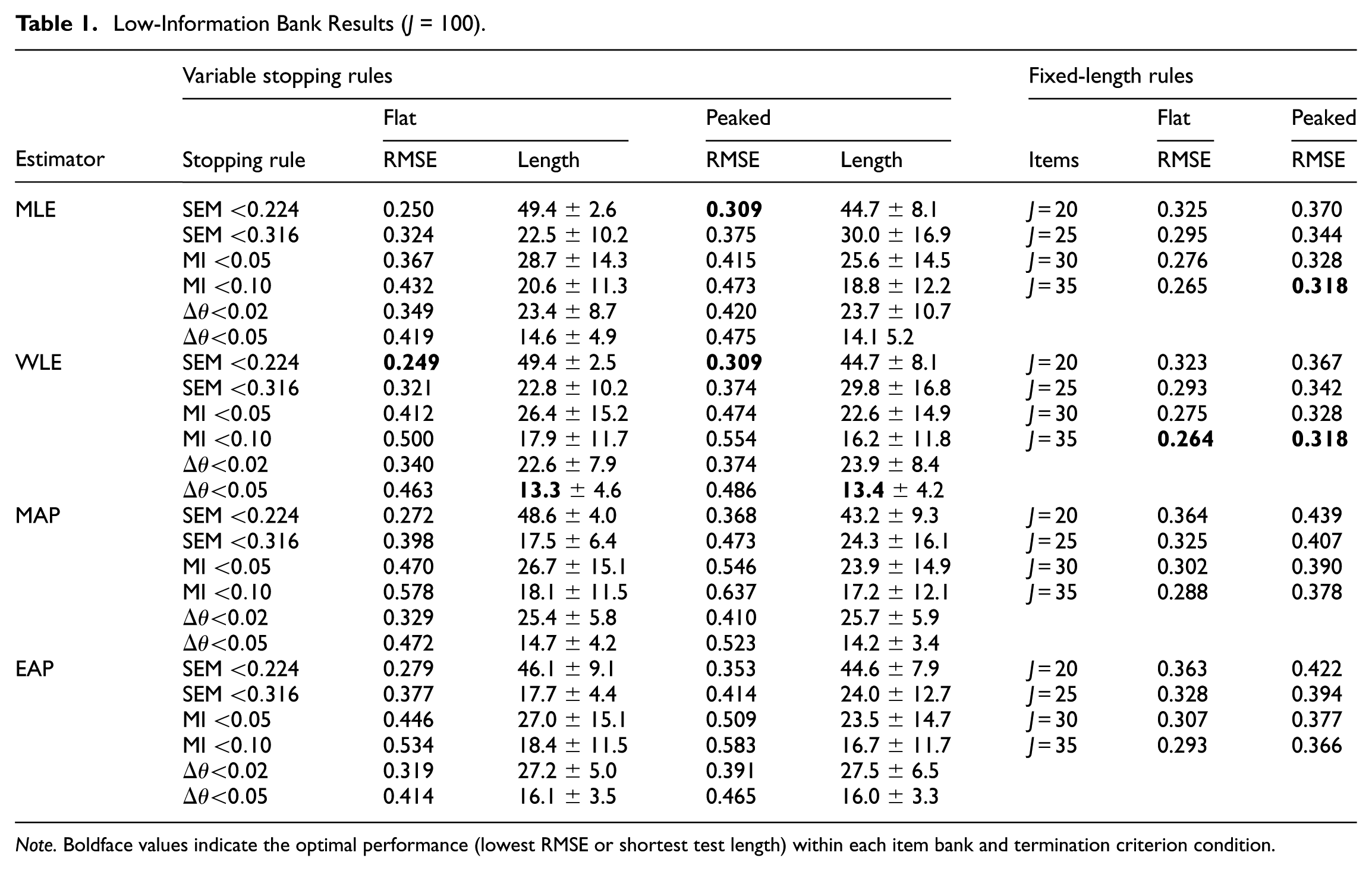
Note. Boldface values indicate the optimal performance (lowest RMSE or shortest test length) within each item bank and termination criterion condition.
Recovery in High-Information (500-Item) Banks
Bias
Figure 5 illustrates the conditional bias across
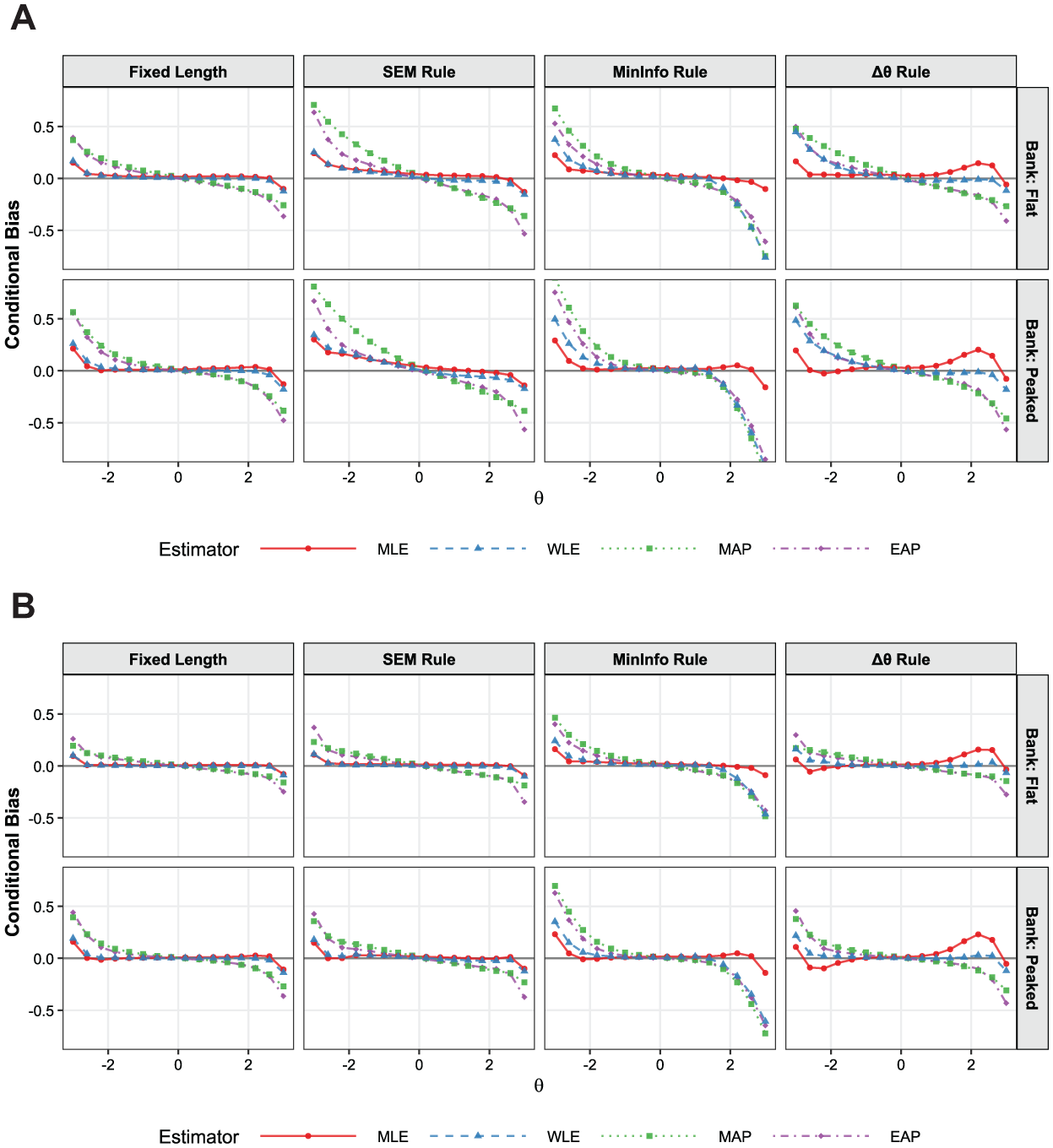
Conditional bias by estimator and termination rule with the high information bank. (A) Low precision condition. (B) High precision condition.
Test Length and Efficiency
As shown in Figure 6, the three variable-length rules produced distinct test length distributions. Under the SEM rule, higher item quality allowed simulees with central
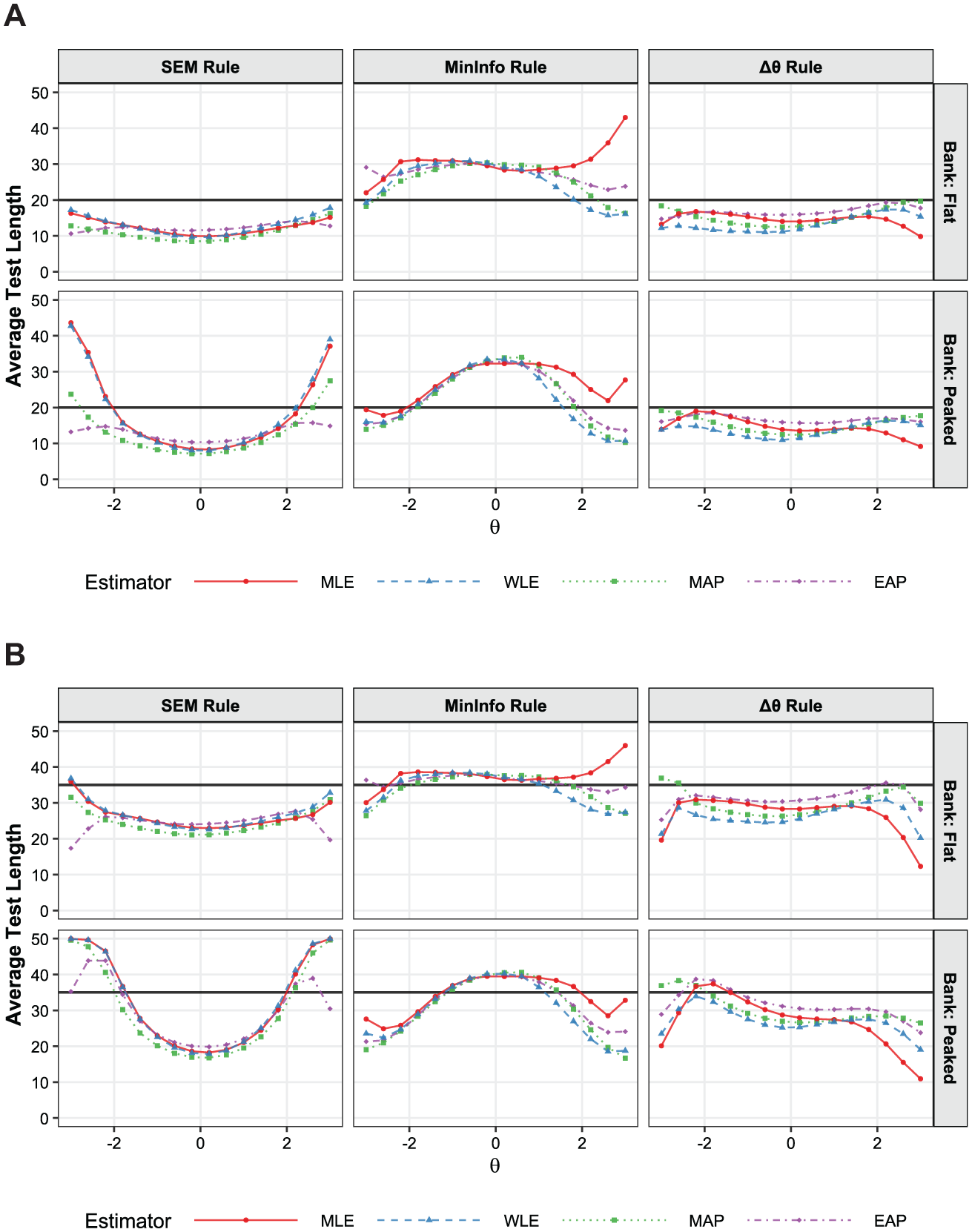
Conditional test length by estimator and termination rule with the high information bank. (A) Low precision condition. (B) High precision condition.
Conditional RMSE
As illustrated in Figure 7, the conditional RMSE patterns in the high-information banks closely mirrored those observed in the low-information conditions, albeit with an overall reduction in absolute measurement error. The fixed-length rule consistently yielded the lowest RMSE across both flat and peaked bank shapes, with the SEM rule demonstrating a comparable error profile across the
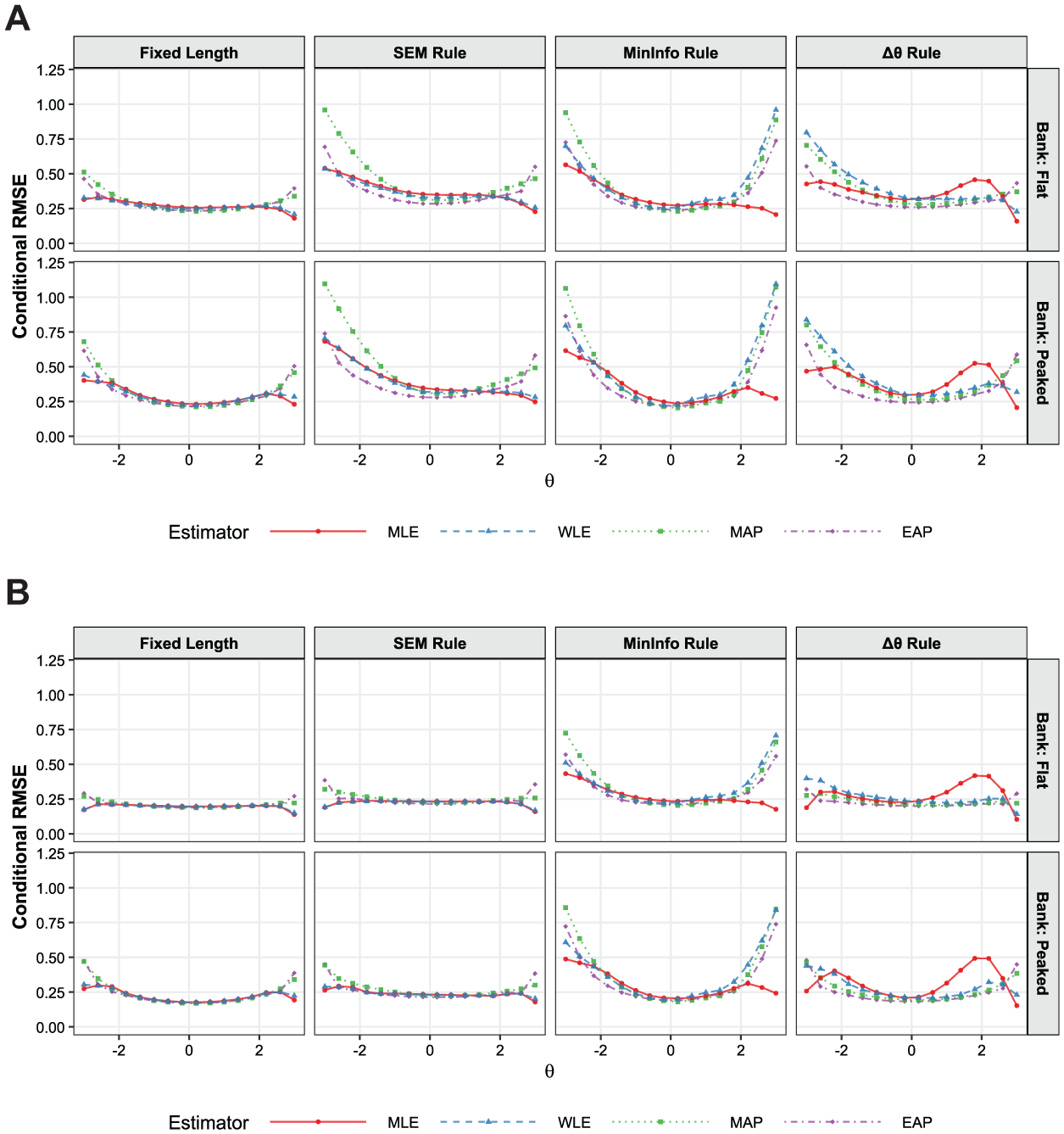
Conditional RMSE by estimator and termination rule with the high information bank. (A) Low precision condition. (B) High precision condition.
Overall Accuracy (RMSE)
Table 2 summarizes the RMSE and test length distributions. For flat banks, the lowest RMSE was achieved by the WLE and MLE estimators paired with the 35-item fixed-length rule. When factoring in efficiency, optimal performance—defined as minimizing RMSE while maintaining moderate test length—was observed using WLE and MLE estimators paired with the SEM
High Information Bank Results (J = 500).
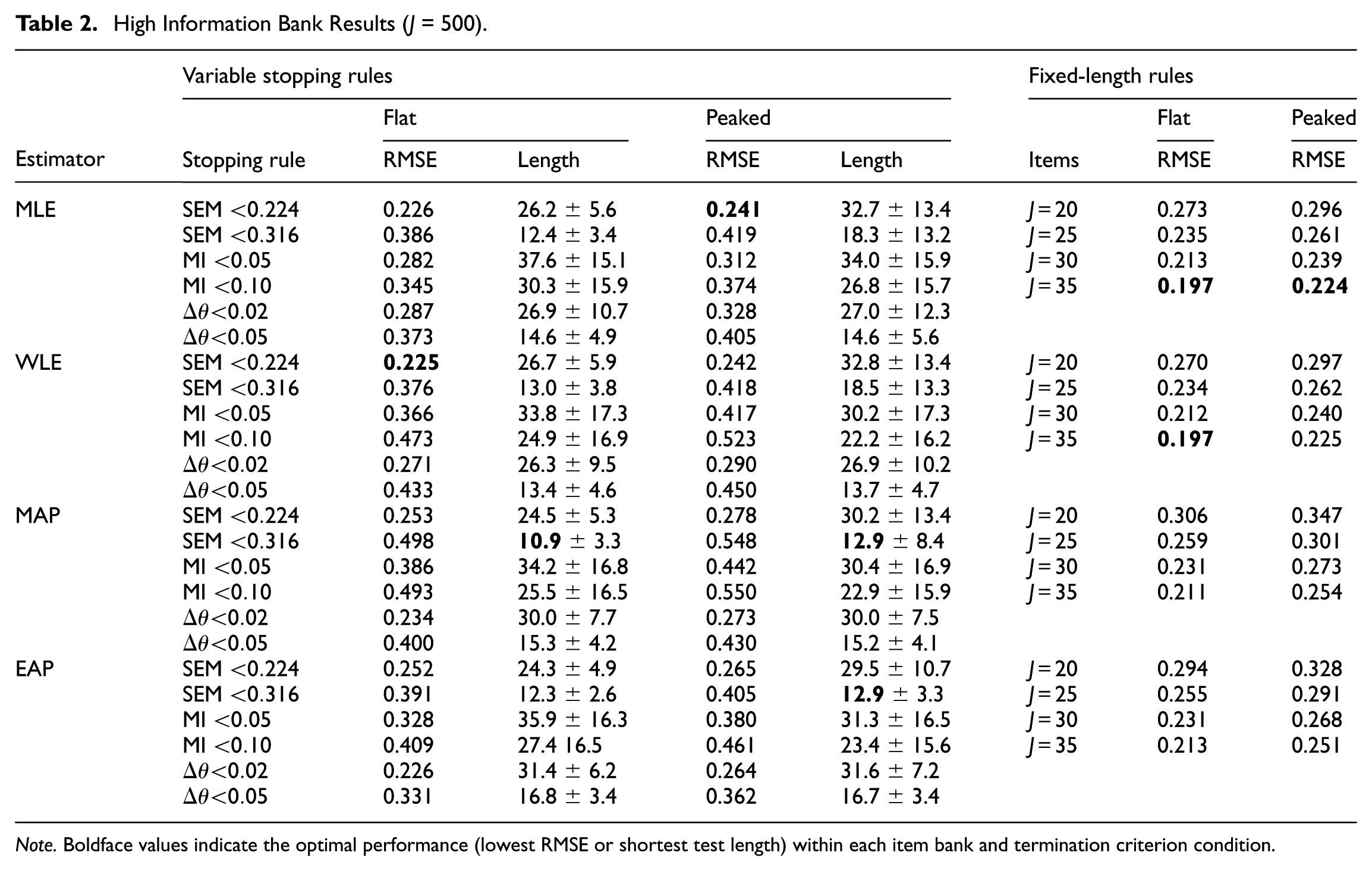
Note. Boldface values indicate the optimal performance (lowest RMSE or shortest test length) within each item bank and termination criterion condition.
Discussion
The current study evaluated the interactive effects of item bank information, bank shape,
Robustness of
Estimators
Generally, WLE proved to be the most robust estimator among the four methods across both low- and high-information conditions. As theoretically expected, likelihood-based bias remained negligible until the extremes of the
Conversely, the Bayesian methods (MAP and EAP) utilize a standard normal prior, which inevitably shrinks estimates toward the mean of
Estimator and Stopping Rule Interaction
A distinct interaction was observed between EAP and the termination criteria: EAP tended to terminate prematurely under the SEM rule but performed robustly with the
The Moderating Role of Bank Characteristics
The impact of bank shape was heavily moderated by the total information available in the bank, a finding that supports and refines the results of Babcock and Weiss (2012). In the low-information condition (100 items), the SEM rule failed to reach precision targets at the extremes of peaked banks, forcing simulees to take maximum-length tests. This aligns with C. Wang et al. (2019), who demonstrated analytically that when an item bank lacks informative items (a “bank gap”), the reduction in standard error becomes negligible. Because the standard SEM rule monitors only absolute precision rather than the rate of improvement, it fails to detect this stagnation. This mechanism offers a plausible explanation for Dwahdh and Alshraifin (2025), whose finding that SEM yielded no advantage over fixed-length rules was likely confounded by the density of their item bank. Crucially, however, this inefficiency disappeared in high-information banks (500 items), where the abundance of items allowed the SEM rule to function as intended regardless of shape. These results underscore the theoretical importance of the minimum information (MI) rule. Conceptually similar to the predicted standard error reduction (PSER; Choi et al., 2011) and standard error change (SEC; C. Wang et al., 2019) criterion, the MI rule is designed to detect exactly the type of local bank exhaustion that the standard SEM rule misses. Consequently, present findings suggest that MI’s true utility lies not as a standalone rule, but as a conditional constraint or secondary termination rule—a “fail-safe” that prevents the runaway test lengths observed when strict SEM rules are applied to finite banks.
Practical Implications
For high-stakes testing where legal defensibility and equal precision are paramount, the optimal configuration depends on the bank size. For large, high-information banks (e.g., 500 items), WLE paired with a fixed-length rule (e.g., 35 items) yielded the lowest absolute bias, while WLE paired with a strict SEM rule provided the best balance of efficiency and accuracy. For smaller, low-information banks (e.g., 100 items), practitioners face a stricter trade-off. In these cases, WLE paired with the
Limitations and Future Research
A key limitation of this study is the use of simulated, unidimensional 3PLM data. Operational item banks often exhibit non-ideal characteristics, including multidimensionality and parameter drift. Furthermore, this study represents a “best-case scenario” as it did not incorporate content balancing or exposure control constraints. Future research should evaluate advanced termination criteria under more realistic constraints that include content balancing and exposure control mechanisms in testing environments where these constraints are appropriate.
Conclusion
The present study demonstrates that optimal CAT design relies heavily on the interaction between item bank information density, bank shape, and psychometric specifications. Overall, weighted likelihood estimation (WLE) emerged as the most robust estimator across all conditions. It offered stable parameter recovery without the shrinkage bias associated with Bayesian methods and successfully mitigated the extreme boundary estimation issues that persisted for MLE, even in high-information banks.
The simulations revealed that the influence of item bank shape is distinctly moderated by bank size. In low-information settings, a critical trade-off exists: while the SEM stopping rule ensures uniform precision, it results in excessive test lengths for peaked banks as the algorithm exhausts informative items. For these sparse, peaked banks, the
Consequently, practical CAT configurations must be tailored to item bank quality. For high-stakes examinations utilizing large, high-information banks, practitioners should pair WLE with either a fixed-length rule (for maximum accuracy) or a strict SEM rule (for optimal efficiency). For lower-quality, peaked banks, a hybrid termination strategy is advisable. A strict SEM rule can serve as the primary criterion, paired with a minimum information (MI) constraint acting as a fail-safe to prevent inefficient test elongation when local items are exhausted. Alternatively, WLE paired with the
Finally, while this study provides a comprehensive baseline using simulated unidimensional 3PLM data, operational testing introduces additional complexities. Future research should extend these findings by incorporating realistic operational constraints, such as content balancing and exposure control. In addition, systematically varying the arbitrary simulation parameters used in this study (e.g., threshold values for stopping rules, specific bank sizes, and length constraints) will further establish the generalizability of these optimal CAT configurations.
Footnotes
Appendix
Funding
The authors received no financial support for the research, authorship, and/or publication of this article.
Declaration of Conflicting Interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.