
Abstract
Agreement between raters does not, by itself, show how that agreement is produced. In binary judgement tasks, raters may classify cases similarly either because they rely on similar decision thresholds or because those thresholds operate under favourable marginal conditions. The present study examined whether convergence in raters’ decision thresholds must be imposed exogenously or can emerge endogenously through strategic adjustment. Within an equal-variance signal-detection framework, raters were modelled as choosing thresholds that balance expected classification accuracy against an incentive to align with the rest of the panel. Equilibrium thresholds were obtained by Nash best-response updating, and threshold variance, the Strategic Convergence Index (SCI), and mean pairwise Cohen’s
Introduction
Whether raters arrive at similar classifications is not the same question as how such similarity is generated. Recent signal-detection work has clarified that observable agreement and convergence in raters’ decision thresholds are analytically distinct properties of a binary rating system (Gianeselli, 2026). The question left open is whether such threshold convergence must be imposed as part of the model or can emerge endogenously through strategic adjustment among raters. The present study addresses that question. This issue matters because inter-rater reliability in binary judgement tasks is still commonly evaluated through chance-corrected agreement coefficients, most notably Cohen’s
Signal-detection theory (SDT) offers a framework for making this distinction explicit because binary judgements can be modelled as decisions generated by comparing latent evidence with rater-specific thresholds (DeCarlo, 1998; Green & Swets, 1966). In that setting, heterogeneity in observed agreement can be examined in relation to heterogeneity in the decision criteria applied by raters. This perspective is reinforced by work showing that decision criteria are not fixed observer properties but may be learned and adjusted as a function of task structure, reward contingencies, and response goals (Maddox, 2002). Signal-detection research has also challenged the assumption that criterion placement is perfectly stable, pointing instead to the possible contribution of criterion noise to observed responding (Benjamin et al., 2009). In the present context, however, the focus is not on trial-level variability in criterion placement but on the degree of convergence among raters in their operative decision thresholds at the level of decision policy. The Strategic Convergence Index (SCI) was proposed as a model-based summary of convergence in those thresholds (Gianeselli, 2026). Specifically, SCI is not introduced here as a new agreement coefficient but as a model-based quantity that helps clarify what changes in Cohen’s
The further question, and the one taken up here, is whether convergence in decision thresholds can be generated within the model itself. The present study addresses this issue by modelling threshold convergence as a possible equilibrium outcome of strategic adjustment in a binary diagnostic task. Raters are assumed to balance expected classification accuracy against an incentive to align their decision thresholds, so that each threshold depends on the thresholds selected by others. This formulation is motivated by two considerations. First, binary decisions are often made in social settings in which the judgements of others can influence individual responding, even though the locus of that influence may vary across tasks and models (Germar et al., 2014). Second, signal-detection approaches have previously been extended to the analysis of collective decision-making, showing that group-level judgement can be modelled formally without being reduced to isolated individual performance (Sorkin et al., 2001). Under this formulation, convergence is evaluated using a Nash best-response criterion (Nash, 1951), allowing the simulation to examine whether a shared threshold structure can arise endogenously.
The simulation examined the behaviour of threshold variance, the SCI, and mean pairwise Cohen’s
Method
Design
The Monte Carlo simulation examined whether convergence in rater decision thresholds can arise through strategic adjustment in a binary diagnostic task. Multiple raters classified cases as diseased (1) or non-diseased (0). The SCI was used as a model-based summary of convergence in rater decision thresholds and, more specifically, of alignment at the level of decision policy (Gianeselli, 2026). In this formulation, threshold variation was allowed to emerge endogenously from strategic adjustment rather than being imposed exogenously as a design feature. The simulation therefore tested whether the distinction between observable agreement and latent decision-policy alignment remained visible under strategically generated convergence.
Four hypotheses were tested. Hypotheses 1 (H1) stated that increasing alignment pressure (
Generative Model
Each simulated case had a binary latent state,

In the baseline condition,
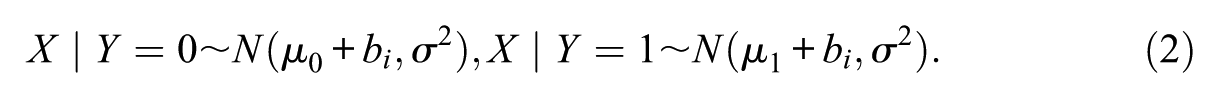
The baseline parameters were

In the main analyses,
Strategic Decision Model
Each rater selected a decision threshold
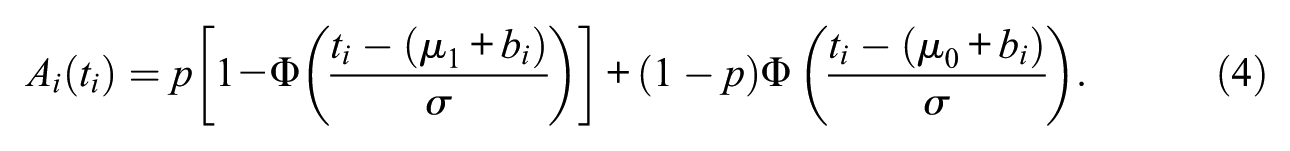
here,
Strategic adjustment was introduced through a quadratic penalty on deviation from the mean threshold of the remaining raters. Let

denote the mean threshold of all raters other than
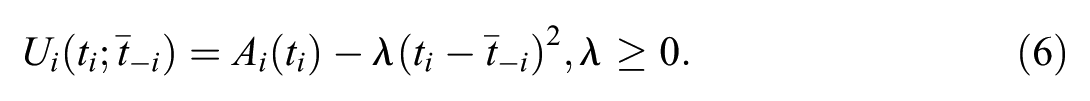
This utility function represents the trade-off between individual diagnostic accuracy and an incentive to align the decision criterion with that of the panel. When
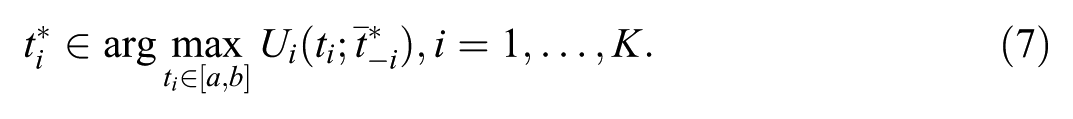
Equilibrium thresholds were approximated by asynchronous best-response updating. At the start of each replication, each
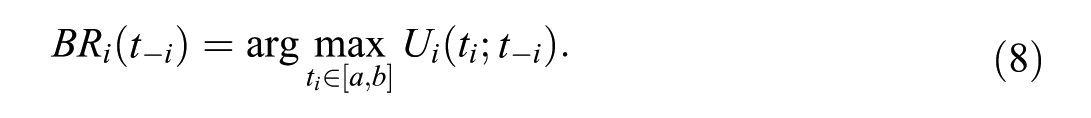
The threshold vector was updated in place, so that each rater responded to the most recently available thresholds within the same iteration cycle. Iteration stopped when
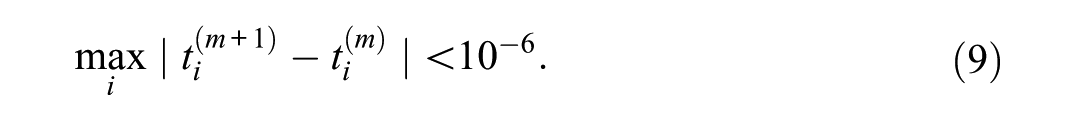
or when 1,000 iterations had been reached. The final threshold vector was retained as the simulated equilibrium profile. For each replication, the code stored convergence status, number of iterations, and final maximum update size. After the equilibrium threshold profile had been obtained, a binary rating matrix was generated. Each replication contained

Conditional on

where

The bias parameter affected the utility stage only and did not enter the realised evidence draws used to generate observed ratings. Thus, between-rater heterogeneity influenced the strategic formation of thresholds, whereas observed agreement was evaluated under a shared class-conditional distributional structure rather than a common realised evidence draw.
Outcome Measures
Dispersion of equilibrium thresholds was quantified by the sample variance
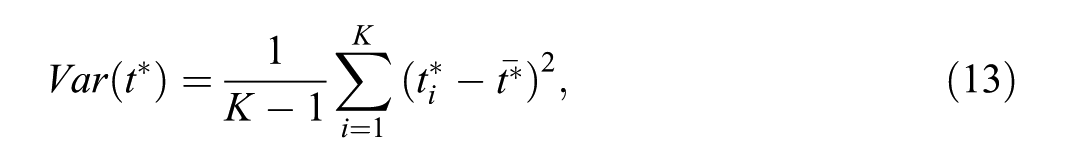
where

where

with
For each replication, Cohen’s

where
Simulation Conditions
All analyses were conducted in R (version 4.5.2; see Appendix). The default panel size was
The first analysis manipulated alignment pressure across 16 equally spaced values from 0 to 5. At each value of
The second analysis fixed alignment pressure at
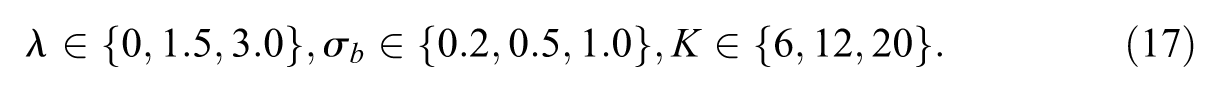
This produced 27 design cells. Each cell was replicated 30 times. For each cell, the simulation retained mean threshold variance, mean SCI, mean pairwise
Rationale for Parameter Choices
The parameterisation was chosen to keep the strategic extension interpretable within an equal-variance SDT setting. The values
Results
Alignment Pressure, Equilibrium Thresholds, and Convergence
Increasing alignment pressure was associated with a marked reduction in the variance of equilibrium thresholds. Mean
Main Simulation Results Across Alignment-Pressure Conditions.
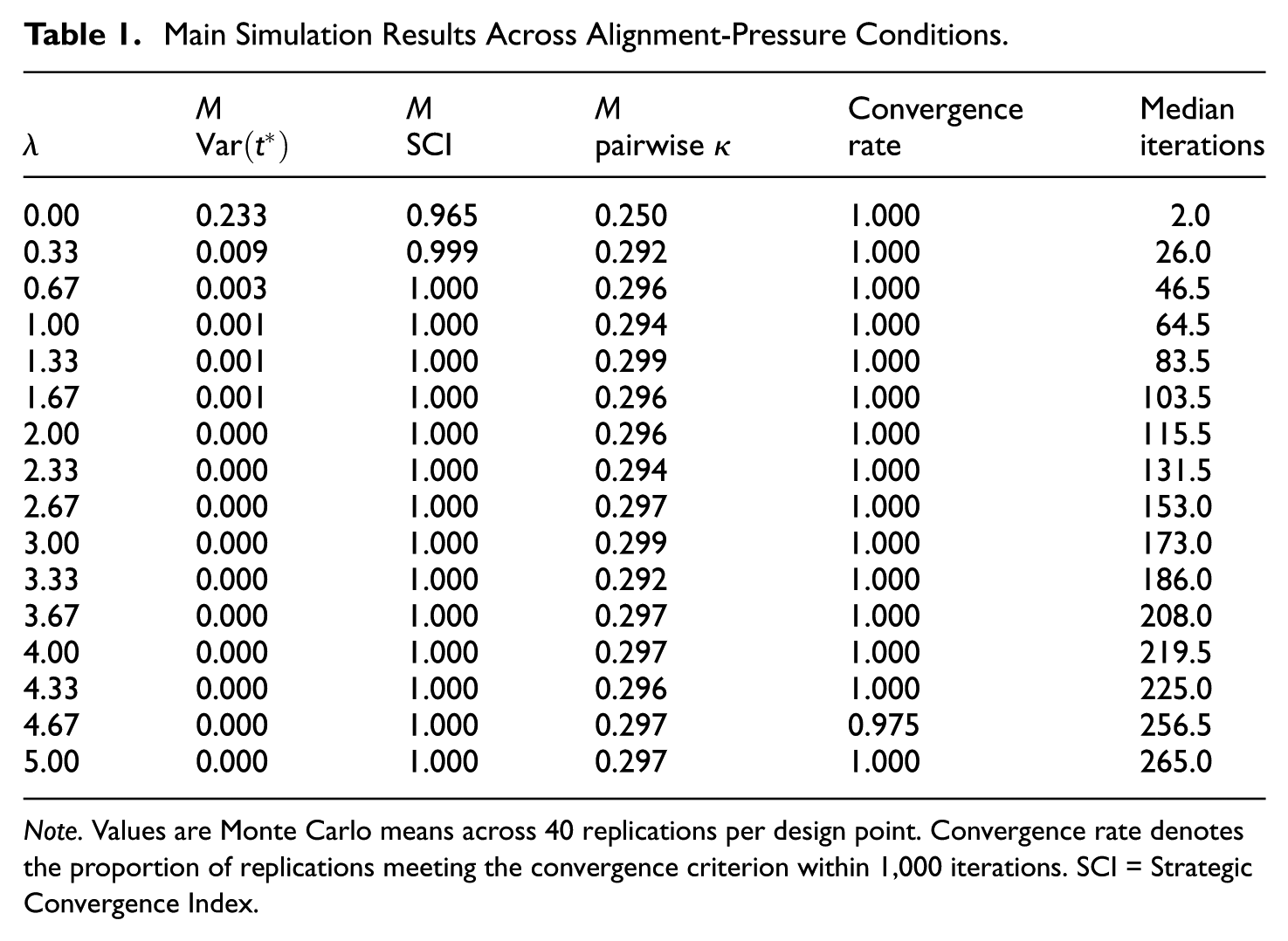
Note. Values are Monte Carlo means across 40 replications per design point. Convergence rate denotes the proportion of replications meeting the convergence criterion within 1,000 iterations. SCI = Strategic Convergence Index.
As shown in Figure 1, most of the reduction in threshold variance occurred at low values of
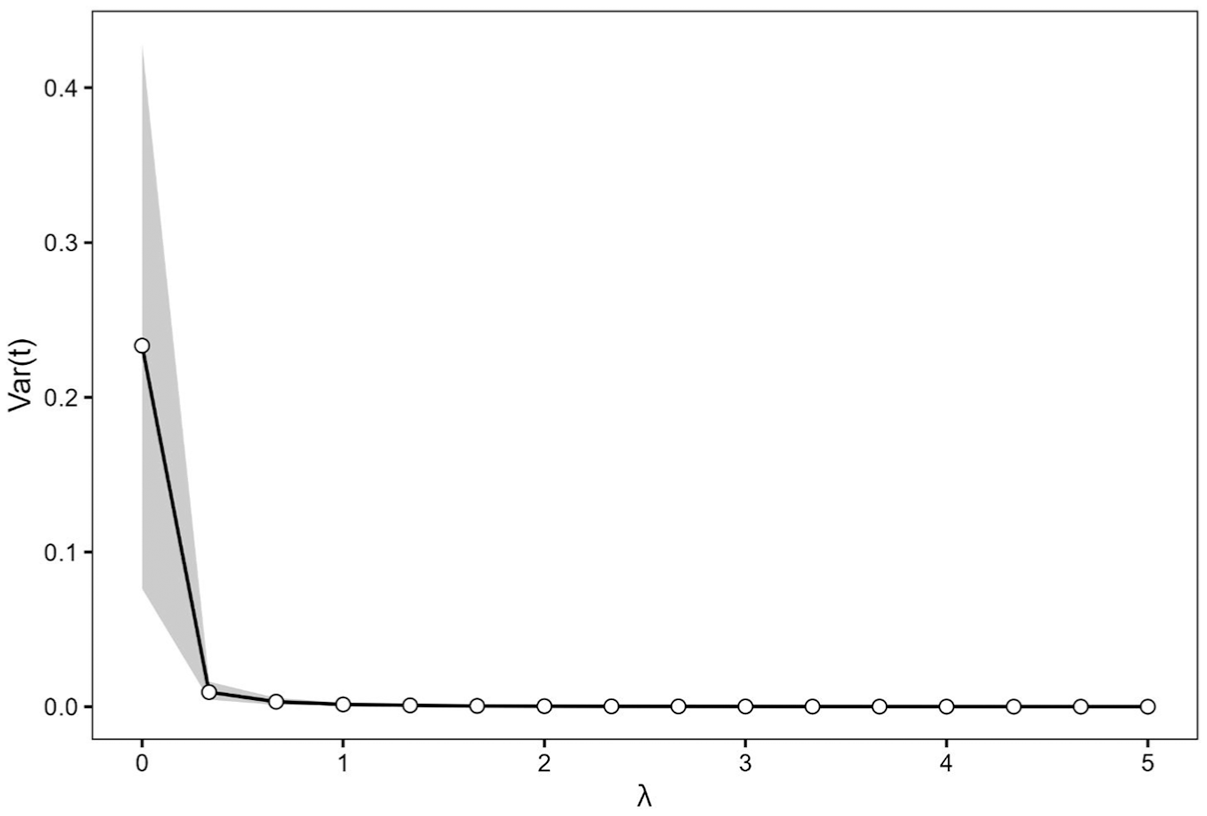
Variance collapse under alignment pressure.
Mean pairwise Cohen’s
Prevalence Effects on Agreement and Alignment
When alignment pressure was held constant at
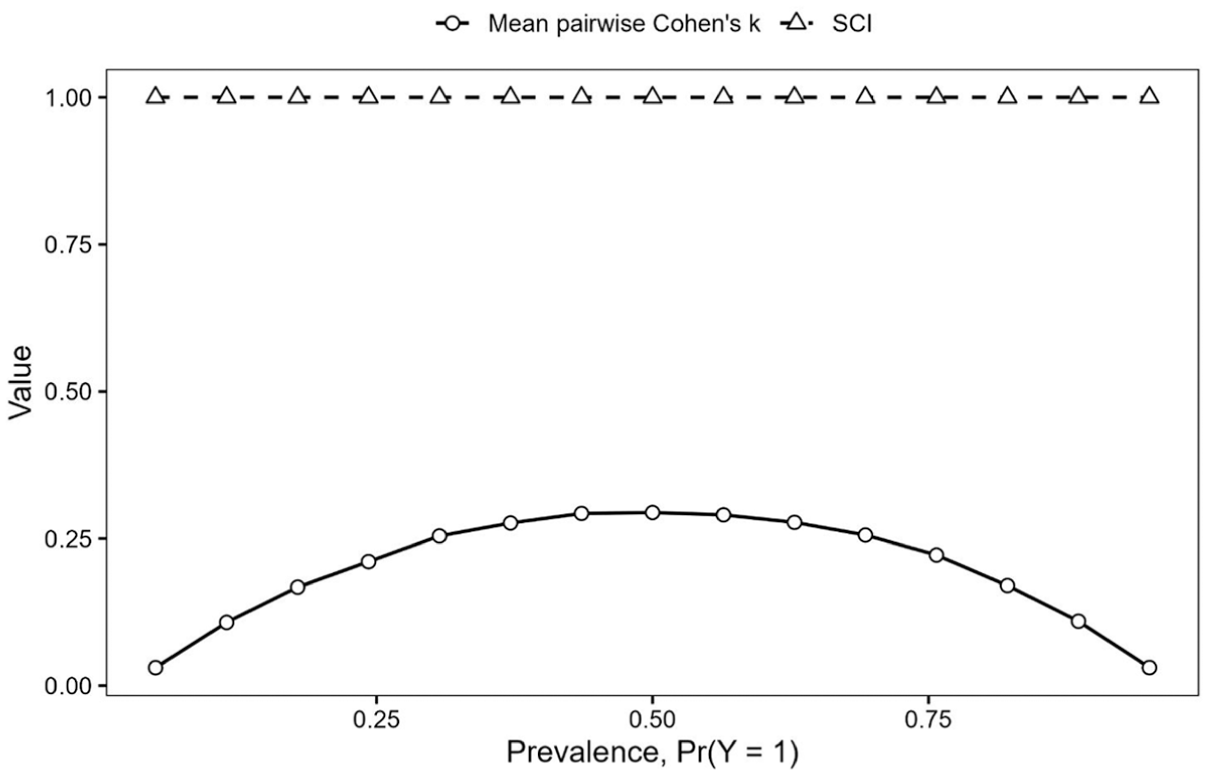
Prevalence effects on agreement and alignment.
Figure 2 shows that mean
Robustness Checks
The same general pattern was observed across variation in bias dispersion and panel size (Table 2). At
Robustness Checks Across Bias Dispersion, Panel Size, and Alignment Pressure.
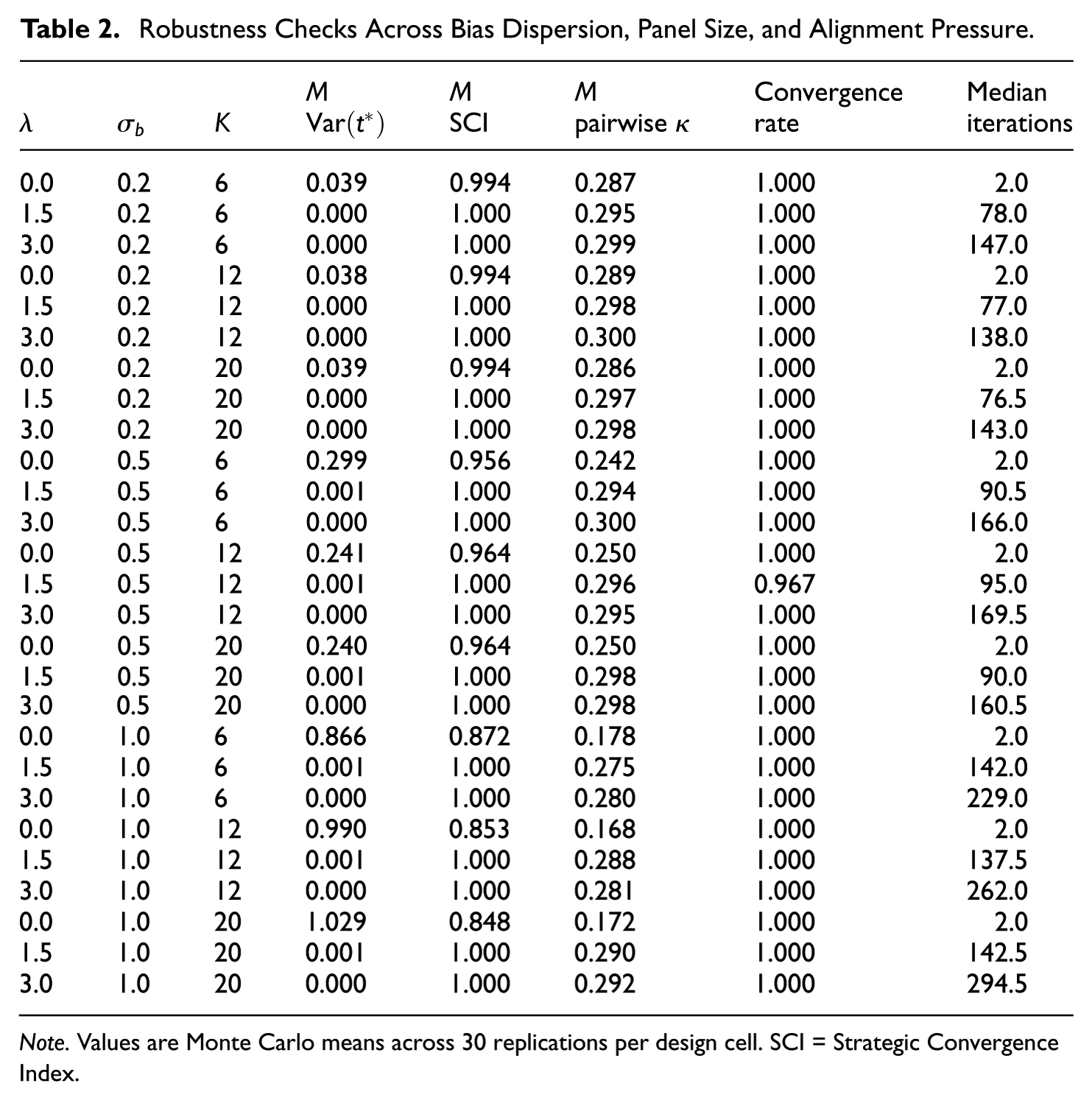
Note. Values are Monte Carlo means across 30 replications per design cell. SCI = Strategic Convergence Index.
At positive values of
Discussion
Convergence in rater decision thresholds can emerge endogenously as an equilibrium outcome of strategic adjustment. As alignment pressure increased, equilibrium thresholds became more concentrated, SCI moved towards the upper end of its normalised scale and mean pairwise Cohen’s
Relation Between the SCI Baseline Framework and the Strategic Convergence as an Equilibrium Outcome Model.

Note. SCI = Strategic Convergence Index; SDT = signal-detection theory.
The behaviour of mean pairwise Cohen’s
This distinction also helps situate the argument within the broader debate on alternative agreement coefficients. In applied research, the prevalence sensitivity of
SCI is informative in a different way. In the present model, it tracks convergence in the equilibrium distribution of decision thresholds and therefore operates at the level of decision policy, not observable agreement. Its near invariance across prevalence conditions, once alignment pressure was held constant, reflects that role: SCI captures the concentration of thresholds generated by the strategic process, not the marginal conditions under which those thresholds are expressed. For that reason, SCI is not offered as a replacement for classical agreement coefficients, nor as another candidate chance-corrected index. Its value is explanatory: it provides a model-based summary of threshold convergence and makes explicit a process-level property that remains only partly visible in outcome-level agreement statistics (Gianeselli, 2026).
Methodologically, these findings suggest that inter-rater reliability becomes more informative when observable agreement is distinguished from the latent structure of decision policies that produces it. Under the present framework, changes in agreement do not necessarily map directly onto changes in threshold convergence, and substantial convergence in decision thresholds may remain only partially visible in observed classifications. This distinction matters for the interpretation of calibration, training, and panel consistency. A rating system may appear only modestly more consistent in its outcomes while having become substantially more aligned in its underlying decision criteria. More broadly, the results support a two-level view of reliability, in which agreement coefficients summarise realised concordance, whereas model-based indices such as SCI characterise the alignment structure underlying that concordance.
Several limitations should be noted. The analysis was conducted within a stylised equal-variance signal-detection model and relied on a deliberately simple utility function in which raters traded off expected accuracy against quadratic alignment costs. These assumptions made the equilibrium structure tractable, but they do not exhaust the forms of strategic adjustment that may arise in applied settings. In addition, the Nash best-response criterion was used as an operational equilibrium device, not as the basis for a general claim about existence or uniqueness (Nash, 1951). The study is therefore generative rather than inferential: it shows how threshold convergence can emerge within a strategic framework, but it does not establish how such convergence should be estimated from empirical data under latent-truth uncertainty. That limitation is substantial, because when true class labels are unobserved, the problem becomes one of latent-structure inference rather than forward specification alone. In such settings, rater-specific parameters cannot be recovered directly from observed classifications without further modelling assumptions, and approaches such as Dawid and Skene (1979) become relevant because they treat latent truth and observer error as jointly unobserved. The present model stops short of providing that estimation framework. Future work should therefore extend the model to alternative utility structures, heterogeneous sensitivities, and estimation strategies capable of linking observed rating data to latent threshold dynamics. A particularly relevant direction would be to examine generalised Bayesian approaches to learning under misspecification, especially those that combine likelihood-based fit with decision-relevant objectives under latent uncertainty (e.g., Massari & Newton, 2026).
In sum, the present findings show that threshold convergence can emerge endogenously through strategic adjustment while remaining distinct from observable agreement. Inter-rater reliability may therefore be understood more clearly when these two levels are kept separate. Agreement coefficients describe realised classificatory concordance, whereas latent threshold alignment concerns the decision structure from which that concordance arises.
Conclusion
This study shows that linking Cohen’s
Footnotes
Appendix
Minimal R Simulation Code.

|
|
Note. The appendix reports the minimal R simulation code. The code retains the parameterization, equilibrium routine, and Monte Carlo structure used in the main analyses, while omitting figure-generation and export routines for brevity. It reproduces the main results table, the robustness checks, and the sanity checks reported in the text. Progress bars are included only to monitor execution of the Monte Carlo loops. The complete R code, including all supplementary analyses, figures, and data export routines, is available from the corresponding author upon reasonable request.
Ethical Considerations
Ethical approval was not required for this study, as all analyses were based on simulated data and did not involve human participants.
Funding
The author received no financial support for the research, authorship, and/or publication of this article.
Declaration of Conflicting Interests
The author declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Data Availability Statement
The complete R code used for the simulations is available from the author upon reasonable request.
Informed Consent
Informed consent was not required for this study, as no data from human participants were collected.