
Abstract
Despite the rich insights they offer, open-ended survey responses remain underutilized in educational research, often due to a lack of awareness of emergent methods that can efficiently analyze such data. This methodological brief addresses this gap by introducing the topic modeling technique, particularly the latent Dirichlet allocation, as a tool for analyzing open-ended responses and facilitating the investigation of relationships between textual responses and measurable outcomes. This brief outlines the rationale behind topic modeling and details the implementation process through the analysis of open-ended responses on students’ career interests as an example. In addition, we discuss the advantages and limitations of this technique and provide practical considerations for its application in educational research.
In educational research, surveys often comprise both closed-ended and open-ended questions. Closed-ended questions are exemplified by the multiple-choice items and rating scale items, for which respondents are asked to select one or more options from a predefined set. Responses to closed-ended questions can be readily recoded into numerical values in categorical or continuous variables for diverse statistical analyses. In contrast, open-ended items ask respondents to construct answers in their own words. This format invites more detailed, nuanced responses and can reveal deeper insights that are often not captured by closed-ended questions (Lamb et al., 2003). However, the unstructured text also brings challenges for analysis, making such types of data significantly underutilized in current educational research (Singer & Couper, 2017).
To utilize open-ended responses, the traditional approach primarily relies on manual coding (Woike, 2007). Researchers develop a coding scheme, read, and categorize responses into thematic groups (Hsieh & Shannon, 2005). This process typically converts the textual data into one or more categorical variables, allowing it to be incorporated into the quantitative analysis framework. However, this approach is labor-intensive and time-consuming, especially when dealing with large sample sizes and long textual responses. Fortunately, the advancement in Natural Language Processing (NLP) techniques provides novel methods to address the challenges, allowing researchers to draw insights into a huge volume of textual data efficiently (Chang et al., 2021).
Topic modeling, a statistics-based NLP method, can be used to identify the main topics from a large collection of open-ended responses and quantify the proportion of each response discussing each topic (Blei, 2012). These features are highly beneficial for enhancing the efficiency of analysis and for expanding the usability of open-ended responses in educational research, particularly when dealing with large data sets. With the identified topics, researchers can streamline their qualitative analysis, concentrating on the most relevant responses linked to each topic rather than sifting through the entirety of the collected textual data. Moreover, quantified topic proportions facilitate the integration of textual and numerical data, enabling researchers to investigate the relationship between open-ended responses and measurable outcomes, thereby drawing further insights from the survey data (e.g., Chung et al., 2022; Roberts et al., 2014).
In gifted education research, long-standing debates persist regarding the definition of giftedness, identification of its evidence-based characteristics, and strategies to reduce excellence gaps across diverse cultural contexts (Baccassino & Pinnelli, 2023; Dai & Chen, 2013; Vuyk et al., 2016). Addressing these issues often requires larger, more diverse samples, which has prompted the field to rely increasingly on quantitative data (e.g., Lee et al., 2024; McCoach et al., 2024). However, bridging quantitative and qualitative methods (Creswell & Plano Clark, 2018) can further enrich our understanding of gifted learners. Topic modeling offers a systematic way to analyze qualitative data, such as students’ open-ended responses, across substantial sample sizes. This data-driven approach can reveal novel themes related to nontraditional talents and social-emotional needs, thereby inspiring new research questions and potentially refining current conceptualizations of giftedness. It may also address pressing concerns in gifted education, such as underrepresentation (see Peters, 2022), by offering nuanced insights into the experiences of diverse learners. Ultimately, integrating topic modeling with traditional quantitative measures enables more comprehensive student profiles by combining standardized measures with the rich information gleaned from open-ended text data. Generally, researchers may employ topic models to uncover latent themes in various types of textual data beyond open-ended responses, such as student essays, interview transcripts, and discussion forum posts, and integrate these findings with conventional quantitative or qualitative approaches.
To introduce the topic modeling technique to educational researchers in an informative but accessible way, this methodological brief consists of three main sections:
An introduction to topic models. We highlight the conceptual similarities between topic models and traditional latent variable models (e.g., factor analysis) commonly used in educational research. Furthermore, a foundational topic model, Latent Dirichlet Allocation (LDA; Blei et al., 2003), is presented, and the key statistical elements are explained.
An application example of topic modeling in gifted education. We demonstrate how the LDA topic modeling is implemented to identify the main themes in students’ open-ended responses about their career interests, and how their interests are related to their demographics and giftedness.
Discussion and practical considerations. We discuss the advantages and limitations of the topic modeling method and provide practical guidance for researchers considering its use.
Topic Models
Topic models are a type of statistical model that is used to identify themes within a collection of documents based on frequency and co-occurrence of words (Blei, 2012; Blei et al., 2003). In the context of survey research, a participant’s open-ended response can be treated as a document, and word co-occurrence refers to certain words that appear together in the same response. Topic modeling refers to the analysis of textual data using topic models. This technique stands at the intersection of NLP and machine learning (Barde & Bainwad, 2017). It utilizes NLP to prepare the textual data and employs unsupervised machine learning algorithms to identify topics, without the need for predefined labels or categories.
Conceptual Similarities to Traditional Latent Variable Models
Although topic models originate from computer science, they are conceptually analogous to latent variable models (e.g., factor analysis, latent class analysis) which are widely used in educational and psychological research. From our perspective, topic models can be considered as a type of latent variable model operating on textual data. Both topic models and traditional latent variable models share a fundamental principle: they aim to uncover unobserved constructs (topics or factors) from observed data (words or item-level responses).
Figure 1 illustrates the conceptual similarities. Traditional latent variable models, such as factor analysis, assume that the observed item-level responses are caused by one or more latent factors (Brown, 2015); similarly, topic models postulate that the observed words are generated from a set of latent topics (Blei, 2012). In factor analysis, the factors are unobservable but can be identified through covariances among the observed variables (Brown, 2015); analogously, in topic models, the topics are hidden but can be discovered through the co-occurrence of the words across the documents (Blei, 2012). Despite operating on different types of data (i.e., numbers or text), both models fall within the broader family of latent variable models.
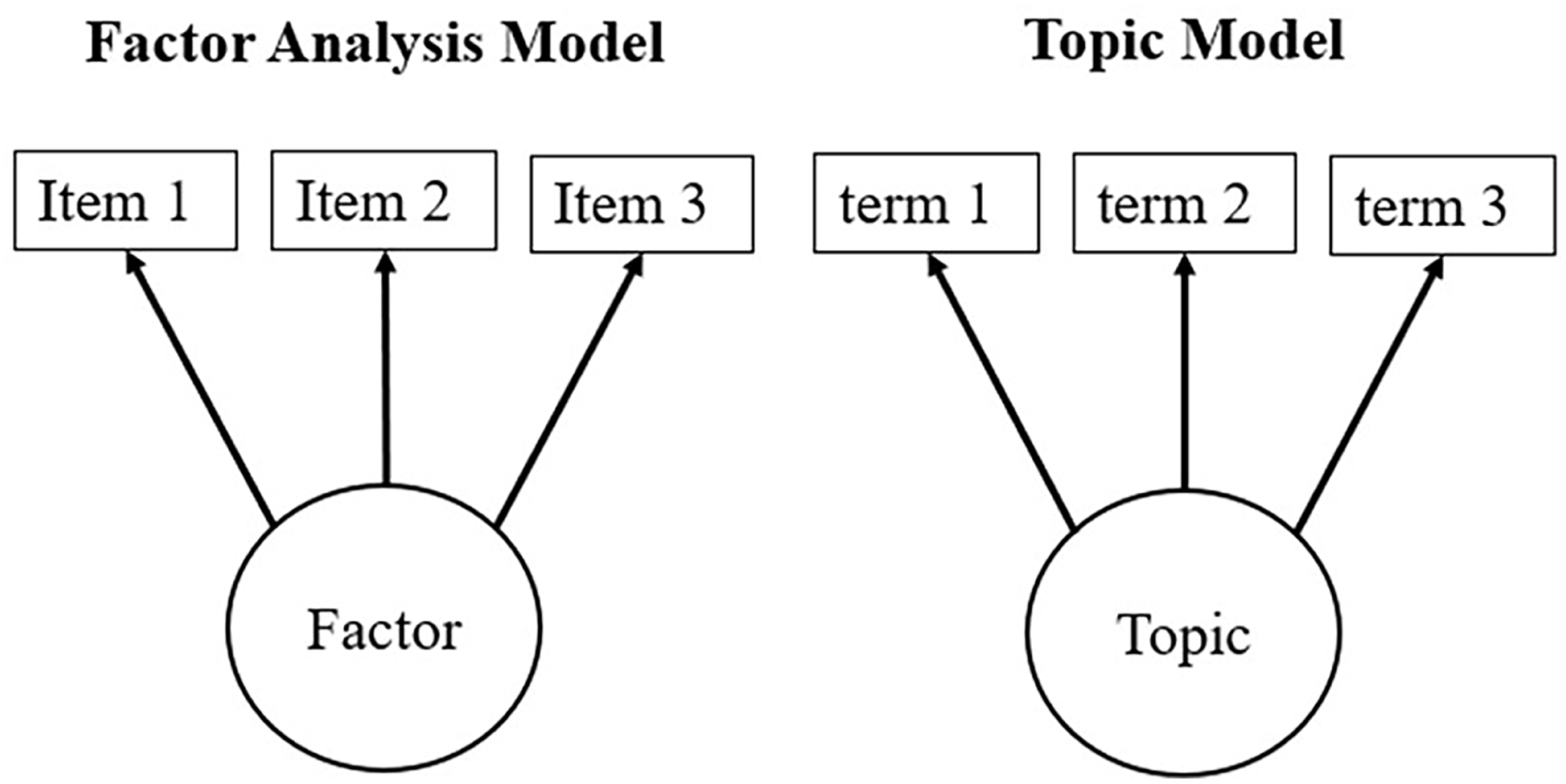
Diagrams of the Factor Analysis Model and Topic Model.
A Foundational Topic Model: LDA
LDA (Blei et al., 2003) is a foundational topic model in widespread use. It laid down the conceptual and mathematical groundwork for topic modeling techniques (Jelodar et al., 2018). Equation (1) is the statistical model of LDA (Blei et al., 2003), which calculates the likelihood of observing all the words across all collected documents to search for a coherent set of topics that maximizes this likelihood. This is analogous to finding a set of factors that make the observed response data most probable in factor analysis:
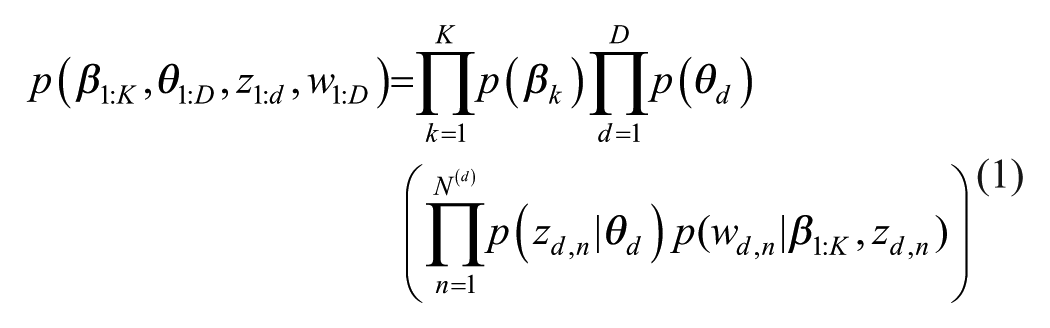
In Equation (1), K is the number of topics, D is the number of documents,
In the LDA model, two sets of parameters are essential for results interpretation: (a)
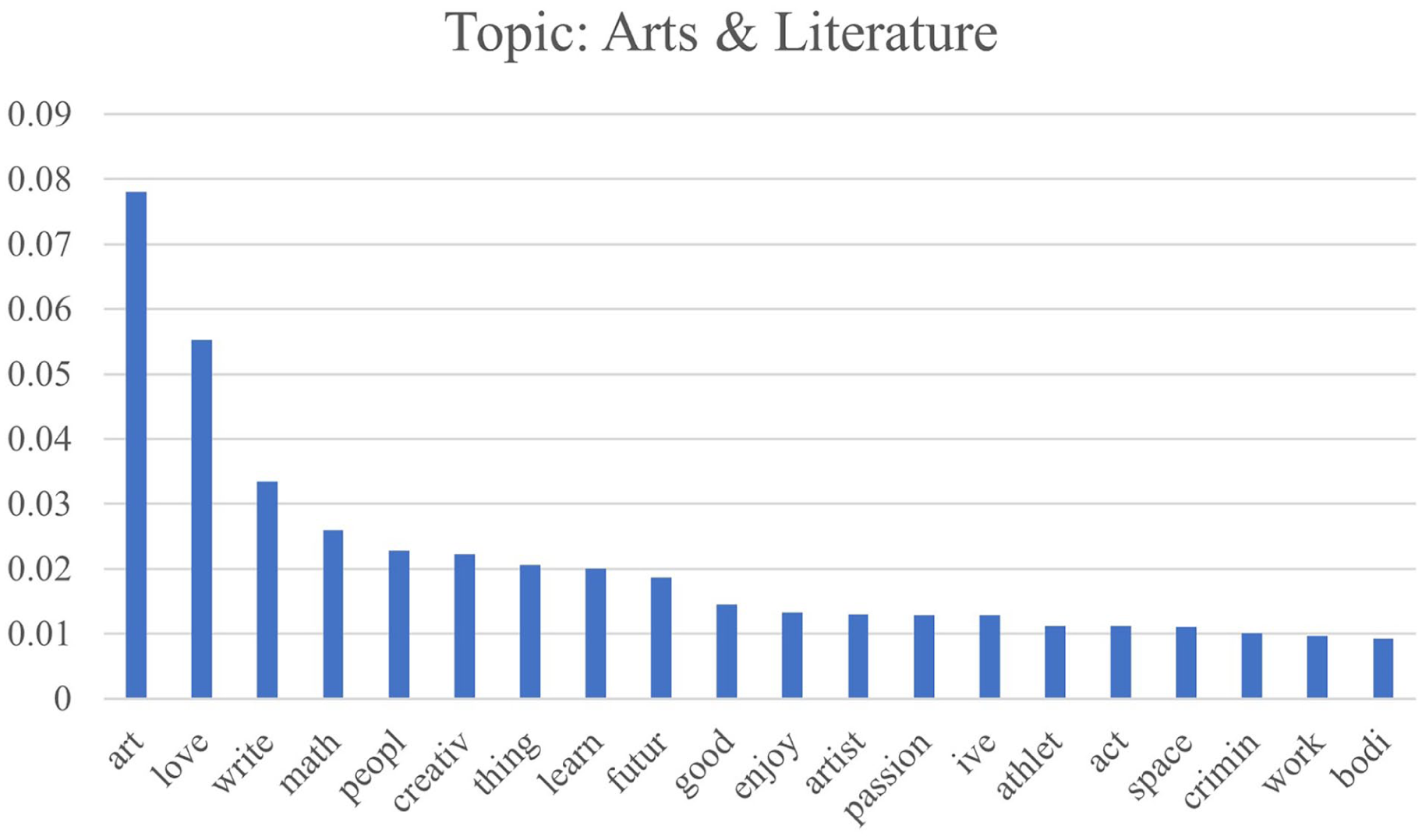
A Term Distribution for a Topic.
A Topic Distribution for a Document.
To summarize, although the LDA model does not understand the text as humans do, it can derive a human-understandable thematic structure from a large collection of documents in a statistical approach (Blei, 2012). It identifies a set of primary topics and annotates each document with its topic proportions. Essentially, the LDA model transforms unstructured text into structured, topic-based numerical representations. This facilitates the inclusion of textual data (e.g., open-ended responses) in various statistical analyses, enhancing the overall utility of the data.
Real Data Example: Student Career Interests
This section delves into an application example of topic modeling in gifted education research, illustrating the utility of this technique. Please note that the example is provided solely for methodological demonstration; the results should not be interpreted as definitive empirical findings or generalized to broader contexts. The data used in this example were collected as part of a federally funded Javits grant and contain students’ open-ended survey responses about their career interests. The analysis revolves around two primary research questions:
RQ1. What are the main career areas that students are interested in pursuing?
RQ2. How are student career interests related to their demographics and giftedness, both self-perceived and teacher-evaluated?
Sample and Instrument
The sample consisted of 503 students from six public secondary schools in the Midwest, USA. Forty-seven percent of the students (n = 238) are males; 53% of them (n = 265) are White or European Americans; the students’ grade levels ranged from 6th to 12th grade, with 91% of students in 9th grade or below.
An open-ended question, “What career(s) or career field(s) would you like to explore and why?” was used to elicit students’ open-ended responses regarding their career interests. Four hundred seventy-seven students responded to this question, which led to a response rate of 95% and maintained the representativeness of the data. The average length of the responses was 21 words, with a maximum of 235.
Besides the open-ended question, the surveys include the teacher and student versions of the HOPE Rating Scale (Gentry et al., 2015) which assesses students’ giftedness. The teacher version captures teachers’ evaluation of student giftedness, and the student version reflects student self-perceived giftedness. Both versions measure academic and social aspects of giftedness, using a 6-point scale (Gentry et al., 2015). These giftedness measures were used in the topic-informed relational analysis.
Topic Modeling Implementation
The implementation of LDA topic modeling consists of three primary phases: (1) text preprocessing, (2) core LDA analysis, and (3) topic-informed relational analysis. The first phase focuses on removing the irrelevant data in the text, the second phase applies the statistical model to uncover the latent topics, and the third phase investigates the relationship between the open-ended responses (represented by the identified topics) and external variables (i.e., giftedness scores, demographics). The primary analyses were performed in the programming environment R 4.0.5 (R Core Team, 2021) using the “tm” (Feinerer et al., 2008), “ldatuning” (Nikita, 2020), and “topicmodels” (Grün & Hornik, 2011) packages. The sample R codes are provided in the Supplemental Appendix.
Phase 1: Text Preprocessing
Before applying topic modeling techniques such as LDA, it is essential to undertake text preprocessing to ensure the data are optimally structured for analysis (Fan et al., 2021). This phase includes several key steps, conducted using the R package “tm” (Feinerer et al., 2008): (1) Normalization: Text was converted to lowercase, and extraneous content such as stop word (e.g., “the,” “is,” “at”), numbers, and punctuation marks was removed. (2) Stemming: Words were reduced to their root forms, for example, “teaching” and “teaches” were both converted to “teach.” (3) Custom Word Removal: Specific words that frequently appeared but were contextually irrelevant were dropped. In this data set, seven words (“explor,” “career,” “interest,” “field,” “make,” “dont,” “lot”) were manually identified by examining the top 20 high-frequency words and removed. These included words often repeated by students from the question stem and other common but uninformative words.
After preprocessing, a document-term matrix (DTM), describing the frequency of terms (i.e., words) that occur in a collection of documents, was created for LDA modeling. Table 1 provides a simplified example of a DTM for illustration. For the present study, 13 responses (e.g., “I am not sure,” “I don't know,” “None,” and “n/a”) were automatically dropped during preprocessing. This occurred because the R package removed all words in these responses as part of the three described steps: normalization, stemming, and custom word removal. Therefore, the DTM created contained 464 rows, representing unique open-ended responses, and 898 columns, each corresponding to a unique key term identified across all responses.
A Simplified Example of a Document-Term Matrix.
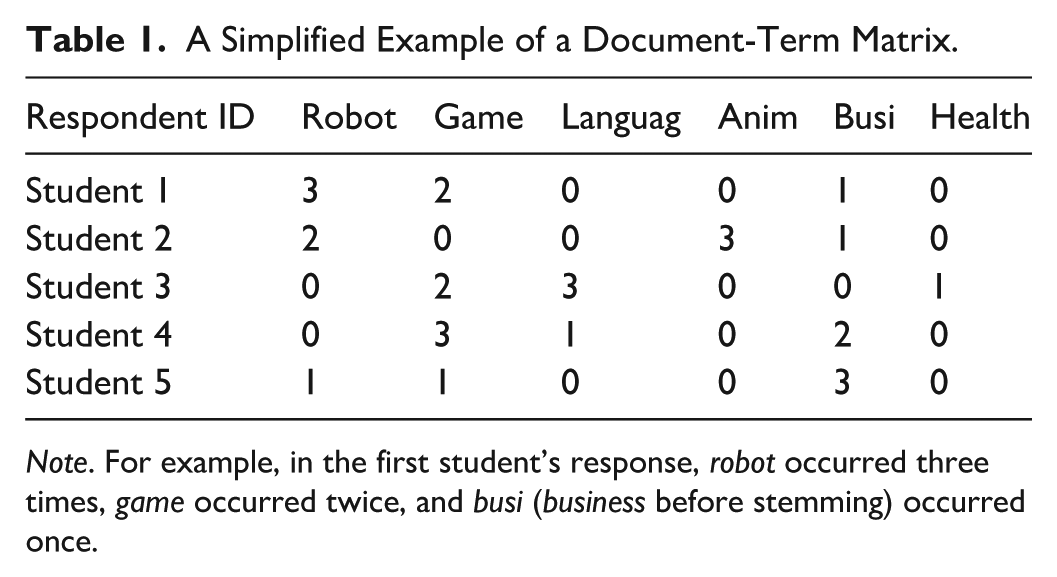
Note. For example, in the first student’s response, robot occurred three times, game occurred twice, and busi (business before stemming) occurred once.
Phase 2: Core LDA Analysis
This phase involves two steps: (1) Model Selection, where models with varying numbers of topics are compared to identify the most suitable one and (2) Model Fitting, where the selected model is fitted to the data and the semantic meanings of the identified topics are interpreted.
Determining the Number of Topics
LDA, as an unsupervised machine learning algorithm, requires researchers to set the number of topics. This is akin to specifying the number of factors in exploratory factor analysis (Brown, 2015) or the number of classes in latent class analysis (Collins & Lanza, 2010) in traditional latent variable models. Analogously, there are metrics that evaluate the performance of LDA models with different numbers of topics, offering insights into the optimal number of topics. In this example, we utilized three common metrics, topic cosine similarity (Cao et al., 2009), topic distribution divergence (Deveaud et al., 2014), and topic prevalence divergence (Arun et al., 2010). Cosine similarity (Cao et al., 2009) and distribution divergence (Deveaud et al., 2014) assess the similarity of the identified topics within a model. Lower cosine similarity scores and higher distribution divergence values indicate that the identified topics within the model are more distinct and less overlapping compared to those in other models, and thus, the model is favored. The topic prevalence divergence (Arun et al., 2010) evaluates the difference between topic prevalences derived from the topic-word distributions and document-topic distributions. Small divergence suggests that the identified topics within a model are consistently found as groups of words and as portions of documents, supporting that the topics are semantically meaningful themes. Therefore, models with lower values on topic prevalence divergence are desired.
In our example, we utilized the R package “ldatuning” (Nikita, 2020) to fit LDA models with a range of topics from two to 10 to the DTM. These models were estimated using the variational expectation-maximization method (Blei et al., 2003; Jordan et al., 1999). Figure 4 presents the evaluation scores on the three metrics for each LDA model. Despite the initial emergence of a nine-topic model, its complexity hindered interpretation and was discarded. The five-topic model was ultimately selected for its interpretability and parsimony. It should be acknowledged that choosing the optimal number of topics is fundamentally a judgment call, and there are no absolutely correct choices. In general, the decision should balance statistical measures with the interpretability and practical utility of the topics (Zhao et al., 2015).
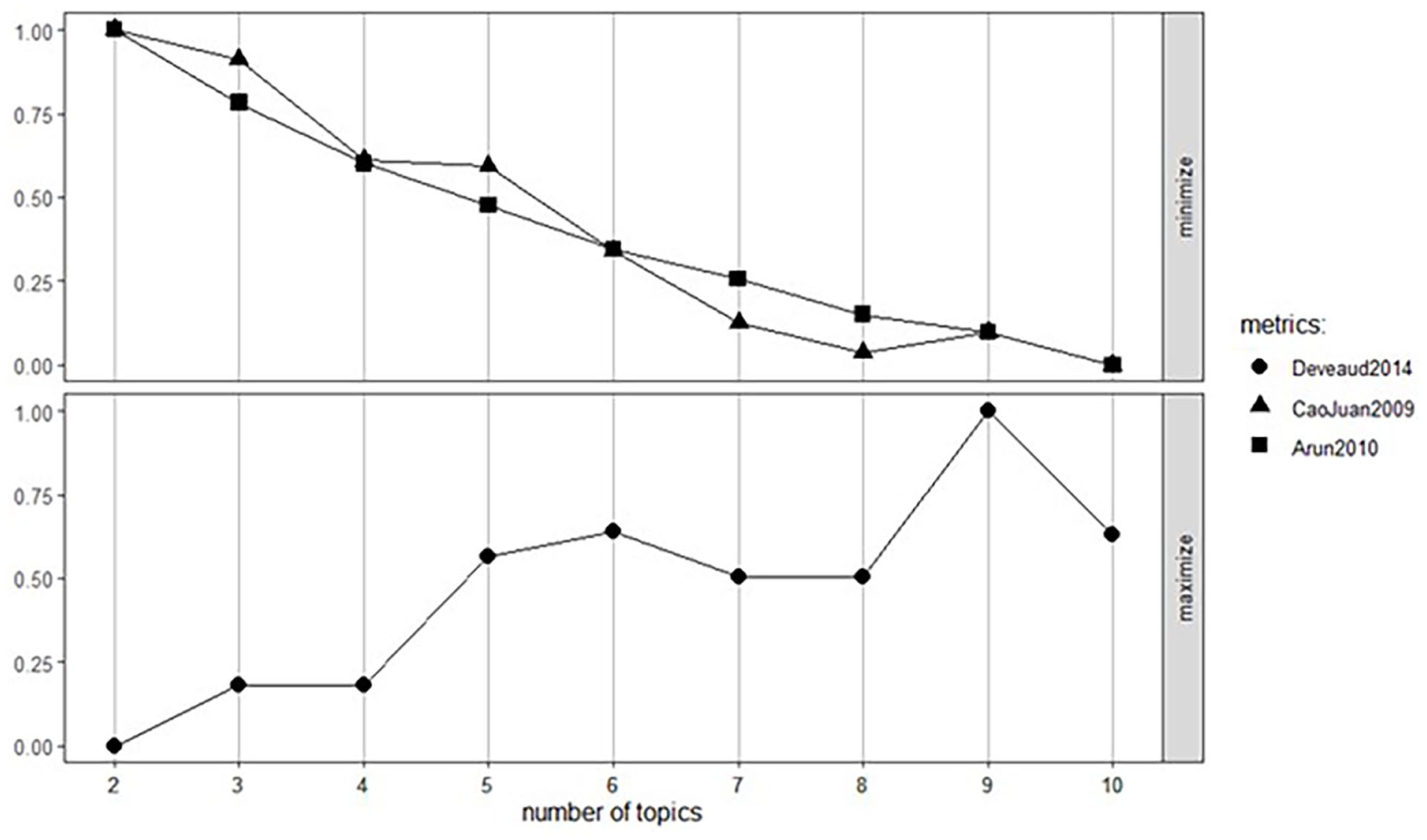
Performance Evaluation of the LDA Model Across 2 to 10 Topics.
Deriving the Semantic Meaning of Topics
After determining the number of topics, the next step is to understand the meaning of topics in the selected model. In this example, we interpreted the identified topics using a two-step approach, which was widely adopted in topic modeling application literature (e.g., Buenaño-Fernández et al., 2020; Nanda et al., 2021). In the first step, each topic’s thematic essence was derived based on the top 20 high-probability words associated with it. This provides a preliminary insight into the topic’s content. To validate and refine each initial theme, in the second step, we reviewed the top 20 open-ended responses that had the highest proportions of the topic. This two-step approach fosters a deeper understanding and enhances the validity of the topics’ semantic meaning.
Alongside the count-based approach (i.e., review top-N words and responses) used in our example, there is an alternative probability-based method for selecting top words and responses. For instance, Finch et al. (2018) identified top words within a topic by selecting those with a probability exceeding .1 (i.e., 10%). Each approach offers advantages: the count-based method ensures a consistent volume of data is reviewed across all topics, maintaining uniformity in data analysis; the probability-based approach adapts the volumes of data reviewed to the characteristics of each topic, potentially offering a more nuanced understanding.
Phase 3: Topic-Informed Relational Analysis
A topic-informed relational analysis, which utilizes the topic proportions derived from LDA, can be conducted to explore the multimodal relationships between open-ended responses and numerical variables available from the study. In our example, we included the variables for demographics (categorical) and giftedness scores (continuous) as predictors to explain the variations in career interest topic proportions through multivariate linear regression, a method previously adopted by Roberts et al. (2014, 2016). To fully capture the effects of the predictors on career interests, we analyzed each predictor using a separate multivariate regression model.
Topic Modeling Results
This section presents the key findings from the LDA analysis, focusing on the topic interpretation and exploring how these topics relate to other variables.
Interpretation of Topics in Career Interests Responses
In Figure 5, word clouds were used to visually summarize the top 20 high-probability words within each identified topic. These graphical representations showed words in sizes proportional to their probability (i.e., importance) within the topic, offering an intuitive view of the topic’s thematic essence.
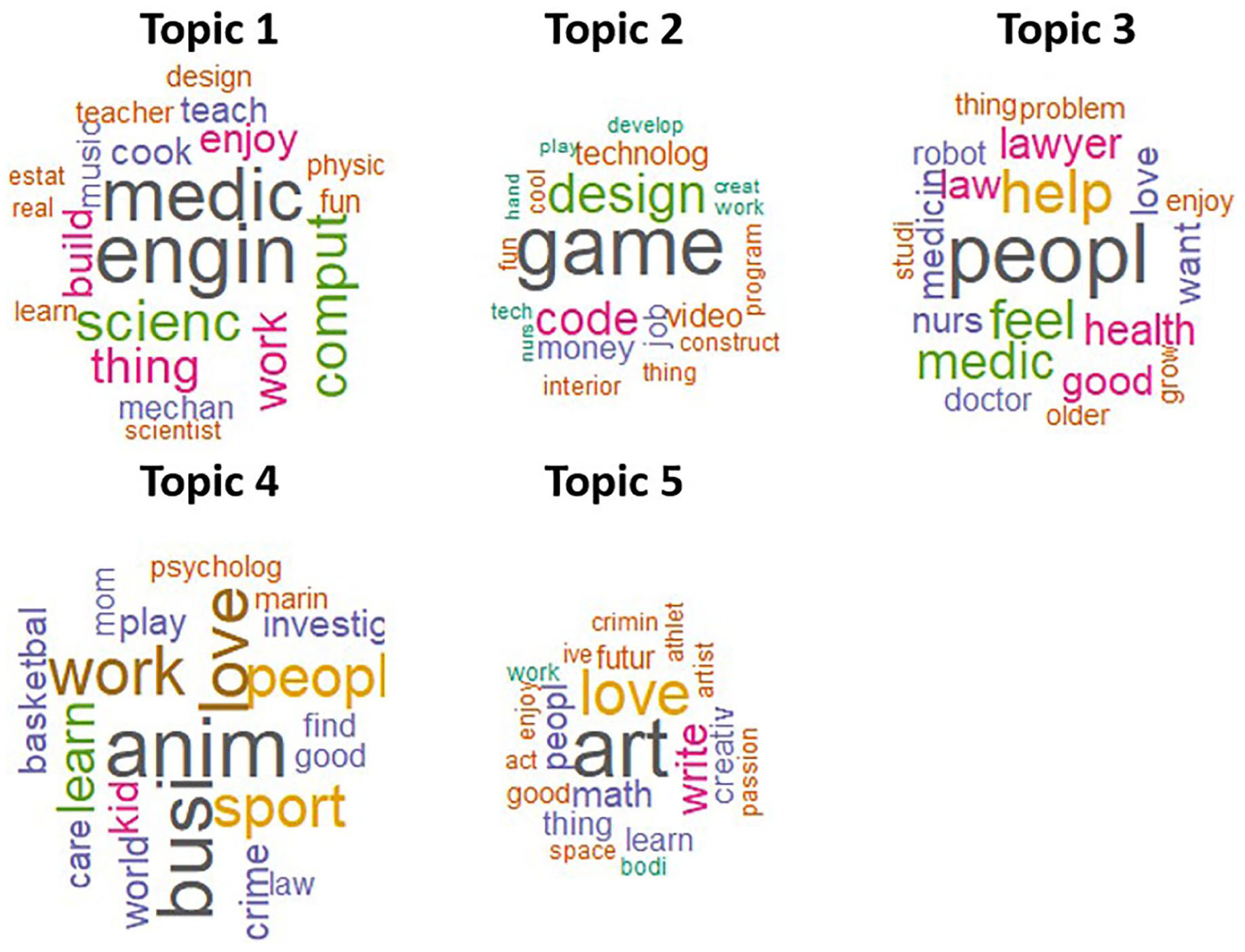
Word Cloud of the Top 20 Terms for Each Identified Topic.
Taking Topic 3 as an example to illustrate the semantic interpretation of the identified topics, the high-probability words (in their stemmed forms) medic, lawyer, health, law, nurs, and doctor suggested interests in the medical field and law, and the top two words people and help imply a preference for human-oriented fields. In the responses with the highest proportions on this topic, students expressed their interest in medicine across various roles, including nursing, anesthesiology, and general medicine, as well as their law-related aspirations ranging from lawyering to judiciary roles. A strong preference for other types of human services, particularly psychology and therapy, was also evident. To summarize, students strongly associated with Topic 3 were interested in people-oriented careers that involve helping others, through health care, law, or other types of human service; hence, the topic was titled Human Services.
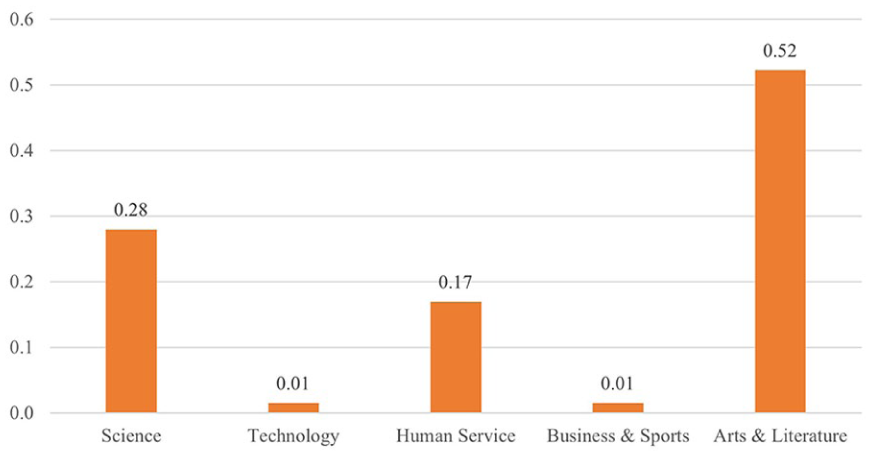
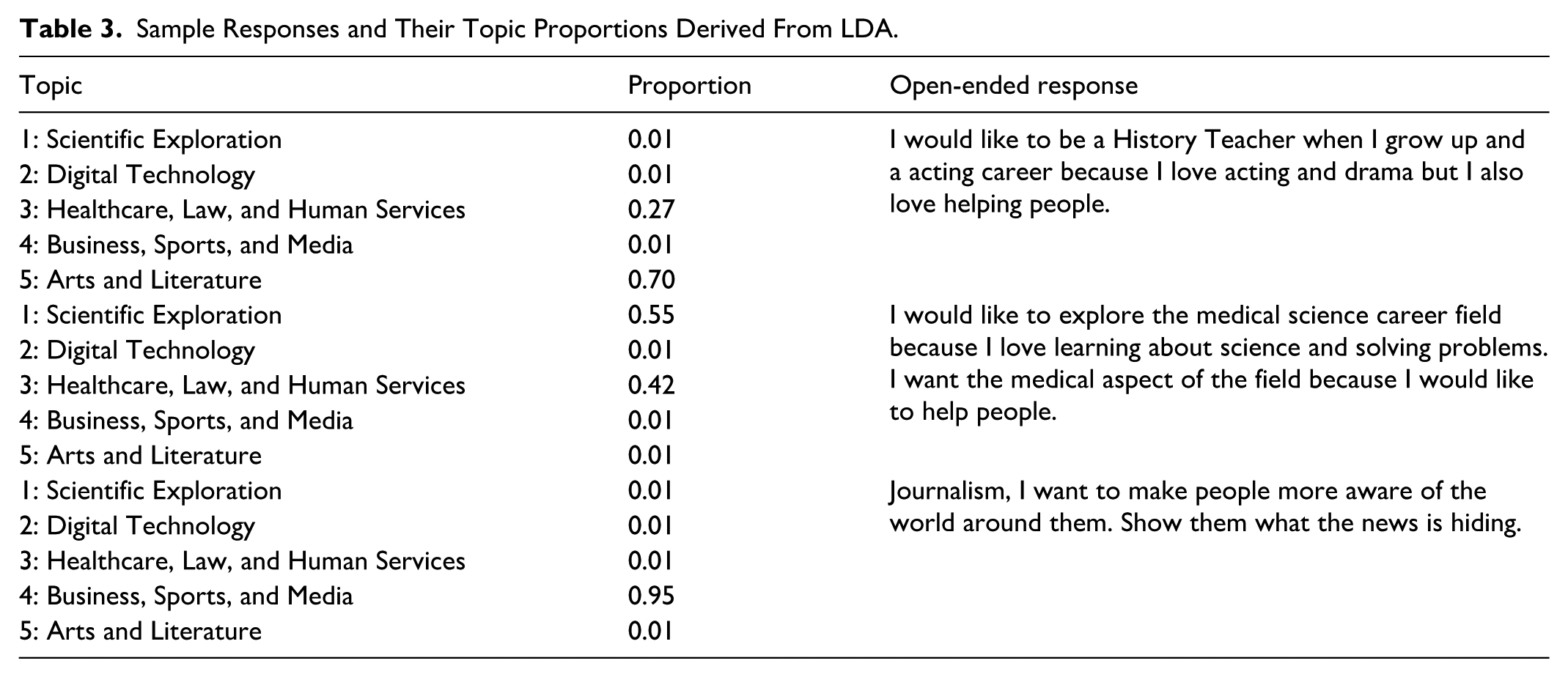
Following the same procedure, the five topics were named: (1) Scientific Exploration, (2) Digital Technology, (3) Human Services, (4) Business, Sports, and Media, and (5) Arts and Literature. To situate these findings within the established career theories, the corresponding career categories (or personality types) in Holland’s theory of career choices (Holland, 1973) were presented in the last column of Table 2. Holland’s theory posits that both people and work environments can be classified into six categories: Realistic, Investigative, Artistic, Social, Enterprising, and Conventional (RIASEC). By mapping the discovered topics to these categories, we provided a recognizable framework for interpreting students’ career interests in a way that aligns with established vocational research. Furthermore, Table 3 presents three exemplary student responses alongside their corresponding topic proportions derived from the LDA model, offering a tangible understanding of the method’s utility.
LDA-Identified Topics and Their Corresponding Holland’s Career Choice Categories.

Note. Holland’s (1973) RIASEC categories are defined as follows: Realistic—involving practical, hands-on activities and problem-solving; Investigative—characterized by analytical thinking and scientific inquiry; Artistic—emphasizing creativity and self-expression; Social—focused on helping, teaching, and collaborating with others; Enterprising—involving leadership, persuasion, and business ventures; and Conventional—characterized by a preference for structure, organization, and detail-oriented tasks.
Sample Responses and Their Topic Proportions Derived From LDA.
Topic-Informed Multimodal Relationship Analysis
This section examines how demographics and giftedness are linked to career interests, using topic proportions derived from the LDA analysis.
Career Interests and Demographics (Categorical Variable)
In analyzing the effects of demographics on students’ career interest responses, significant differences were observed based on gender and ethnicity. Specifically, male students discussed Topic 2—Digital Technology significantly more than female students, spending on average 16% more of their responses to this topic, b = 0.16, t (461) = 5.56, p < .001. Conversely, compared to female students, male students discussed Topic 3—Human Services and Topic 5—Arts and Literature 8% and 7% less, respectively, with b = −0.08, t (461) = −3.18, p = .002 for Topic 3, and b = −0.07, t (461) = −2.82, p = .005 for Topic 5. In addition, when examining the effect of ethnicity, Asian students were found to spend 20% more of their response on Topic 2—Digital Technology than White students, b = 0.20, t (460) = 3.95, p < .001.
An underlying assumption of our analysis is that the proportion with which students discuss specific topics in their responses serves as a proxy for their interest in the corresponding fields. This assumption allows us to infer that a greater proportion of a particular topic indicates a higher level of interest in the field it represents. Based on this premise, our findings suggest notable variations in career interests according to demographic differences. Specifically, compared to female students, male students exhibit a stronger interest in fields related to digital technology (Topic 2), and a lesser interest in human services (Topic 3) and arts and literature (Topic 5); Asian students show a higher preference for digital technology (Topic 2) compared to their White counterparts.
Career Interest and Giftedness (Continuous Variable)
In examining the association between giftedness and career interests, several significant relationships were identified. On average, an increase in student self-perceived academic giftedness by one point was associated with a 3% decrease in discussions related to Topic 4—Business, Sports, and Media, b = −0.03, t (462) = −1.98, p = .049; a one-point increase in student self-perceived social giftedness was associated with a 3% increase in the proportion of responses discussing Topic 3—Human Services, b = 0.03, t (462) = 2.30, p = .022, and Topic 5—Arts and Literature, b = 0.03, t (462) = 2.20, p = .029. In addition, a one-point increase in teacher-evaluated social giftedness is linked to a 6% decrease in mention of Topic 2—Digital Technology, b = −0.06, t (113) = −2.22, p = .028. While the effects of giftedness on topic proportions, ranging from 3% to 6% per point increase, may appear modest, it is important to note that the giftedness scores were measured on the six-point HOPE scale. It means that a three-point difference translates to approximately 10% to 20% change in the proportion of responses around certain topics. This indicates that variation in perceived giftedness is effectively related to students’ expressed career interests.
Our findings suggest nuanced relationships between students' self-perceptions of their abilities (i.e., self-perceived giftedness) and their career interests. Specifically, students who believe they have strong academic abilities tend to be less interested in business, sports, and media (Topic 4), possibly due to these fields being viewed as less reliant on academic skills. Students confident in their social abilities were more enthusiastic about human services (Topic 3), aligning with the interpersonal nature of these fields. In addition, the negative relationship between teacher-evaluated social giftedness and interest in digital technology (Topic 2) may reflect a stereotype that individuals passionate about technology are less socially adept. These topic-informed multimodal relationship analyses highlight how self-concept and teacher perceptions could be related to students’ enthusiasm for various career paths.
Discussion and Practical Insights
In this section, we discuss the key advantages and limitations of the topic modeling approach, along with practical considerations for applying it in educational research.
Advantages and Limitations of Topic Modeling
As demonstrated in our data example, topic modeling, being a data-driven and statistics-based method, offers several advantages for analyzing open-ended responses, including (1) Efficiency: Unlike the traditional manual coding approach, which requires that coders read and interpret each text, topic modeling automates the extraction of themes. Through analyzing the DTM, it efficiently identifies primary topics as probabilistic distributions of words (Blei, 2012). This automation significantly reduces the time and labor required for text analysis, allowing researchers to focus qualitative interpretations on the most thematically relevant portions of the text. In our real data example, topic modeling reduced the number of open-ended responses requiring detailed review from 477 to 100, and the benefit would be more pronounced as sample size and text lengths increase. (2) Objectivity: Topic modeling enhances objectivity by relying on the verifiable DTM (Roberts et al., 2014). By engaging human experts to interpret topics rather than directly classifying or scoring the text, this method reduces potential inconsistencies and biases inherent in manual text analysis. (3) Discovery of New Themes: As a data-driven and bottom-up method, topic modeling is capable of detecting themes that may not be preconceived in existing theories (Boyd-Graber et al., 2017). This feature is valuable in exploratory research, where the goal is to complement and refine theoretical frameworks with empirical data. In the context of gifted education, novel themes emerging from students’ open-ended responses or essays may highlight underrecognized aspects of giftedness. These insights can be tested in subsequent confirmatory studies, fostering an iterative cycle of theory building that gradually enhances our conceptualization of giftedness. (4) Enhanced Data Integration: By converting unstructured texts into a set of meaningful topics and their proportions, topic modeling enables researchers to correlate textual data with other measurable variables to obtain deeper and more nuanced insights into multimodal survey data. For example, linking the traditional giftedness measures (e.g., achievement tests or survey scales) with the themes students expressed in their freely written text might reveal nontraditional manifestations of giftedness.
While topic modeling offers substantial benefits, it also comes with several inherent limitations that researchers should consider. Particularly, we observed the following challenges. (1) Neglect of Word Order: Most topic models, including LDA, operate under the assumption that the order of words within text data is irrelevant, which can lead to a loss of contextual information that might be important in some textual analysis. In our real data example, the topic modeling approach does not account for the order in which students list their fields of interest, which may reflect varying degrees of preference. (2) Lack of Handling for Negation and Qualification: Participants often use negations or qualifiers in their responses (e.g., “I am not interested in math,” “I am slightly interested in math,” or “I am very interested in math”), which convey different attitudes. However, topic modeling treats these statements similarly because they all mention the same keyword (“math”). This can lead to information loss or misinterpretation of the underlying sentiment without further treatment. In our data example, we mitigated this issue by manually reviewing responses containing negation. We found that terms such as “don’t” and “not” mostly appeared in contexts like “don’t know” or “not sure,” which helped us avoid major misinterpretations. (3) Data Volume Requirements: Topic modeling requires sufficiently large amounts of textual data, both in terms of the number of documents (open-ended responses) and the length of each document. In many educational studies, sample sizes are usually small to medium (e.g., a few hundred respondents), and open-ended responses tend to be brief (often just one or two sentences). These conditions can lead to oversimplified or unstable topics, limiting the utility of topic modeling. (4) Reliance on Researcher Judgment: Although topic modeling is generally more “objective” than purely manual coding, researchers still make key decisions that shape results. Choices such as the number of topics to extract, which custom words to remove, and how to interpret each topic introduce subjectivity into the process. In addition, the selection of hyperparameters (e.g., the Dirichlet priors for the topic-word and document-topic distributions in LDA) is also determined by the researcher and can influence the results. (5) Challenges in Topic Interpretability: As a computational method, topic modeling groups words into topics based solely on their co-occurrence patterns without understanding their meaning in context. In our example, frequently co-occurring interests were grouped together (e.g., business, sports, and media in Topic 4), which may not align perfectly with human interpretations. This can sometimes decrease the interpretability of the results. (6) Non-Deterministic Nature: The estimation of LDA and many other topic models begins with a random initialization, using randomly assigned topic-word distributions (
Practical Considerations
In addition to this brief, researchers interested in topic modeling can explore a variety of online resources to deepen their understanding of the method. Numerous online tutorials offer intuitive, hands-on introductions to topic modeling. For example, the Kaggle platform hosts practical examples with accessible data sets and code that can be beneficial for self-learning. For peer-reviewed literature, Blei (2012) provides a comprehensive overview of probabilistic topic models, which is ideal for developing a deeper theoretical understanding of topic modeling. Application-specific insights are also available in the literature. Topic modeling (including LDA and other variants) has been applied to analyze open-ended survey responses (e.g., Buenaño-Fernández et al., 2020; Nanda et al., 2021), constructed response in assessments (e.g., Xiong et al., 2020), student essays (e.g., Karatas et al., 2025), interview transcripts (e.g., Miyaoka et al., 2023), and academic articles (e.g., Chen et al., 2020; Şakar & Tan, 2025) within educational research. In gifted education specifically, Sakar and Tan (2025) applied topic modeling to analyze the abstracts of thousands of gifted education journal papers. They identified five themes, including identification tools and thinking skills, and examined how the prevalence of these themes evolved over the past six decades. In another example, Karatas et al. (2025) employed topic modeling to analyze hundreds of gifted students’ application essays for an enrichment program, revealing students’ motivational factors as topics and examining differences in motivation across demographic groups. In other areas of educational research, Nanda et al. (2021) analyzed hundreds of thousands of course evaluation comments from online learners to identify the key factors affecting learning experiences, while Chen et al. (2020) examined the titles, keywords, and abstracts of thousands of academic journal articles in educational technology to trace important topics and their evolution over time.
For implementing topic modeling analysis, besides using R as demonstrated in our example, Python (with libraries “scikit-learn” or “Gensim”) is another viable programming option. In addition, for researchers preferring a code-free tool, Machine Driven Classification of Open-Ended Responses (MDCOR), developed by Canché (2023), is available. Regarding the data volume requirements, there is no established guideline to the best of our knowledge. In general, models with more topics necessitate larger sample sizes and longer responses (Wheeler et al., 2021). Specifically, for LDA, Finch et al. (2018) recommended that models with seven or fewer topics can be reliably identified with at least 200 documents, provided the average document length is above 30 words. Finally, topic modeling is applicable to various textual formats in education research. In existing studies, it has also been applied to analyze student essays (Xiong et al., 2020), focus group interview transcripts (Miyaoka et al., 2023), and academic articles (Chen et al., 2020).
Conclusion
In this methodological brief, we have demonstrated the utility of topic modeling for analyzing open-ended survey responses in educational research. By applying LDA to student career interest responses, we illustrated how latent themes can be identified and interpreted. Our approach shows that topic modeling can complement conventional methods by streamlining text data analysis and offering new insights through multimodal data analysis that links quantitative measures with qualitative expressions.
Although LDA offers notable advantages, we also acknowledge its limitations, such as challenges with short text responses, the lack of handling for negation and qualification, and the reliance on researcher judgment. These issues call for further research to integrate more advanced NLP techniques (e.g., transformer-based models) and to validate this approach in empirical studies. Overall, this brief highlights the potential of topic modeling and invites future studies to explore its broader applications in gifted education research.
Supplemental Material
sj-pdf-1-gcq-10.1177_00169862251378446 – Supplemental material for Using Topic Modeling in Gifted Education Research: Drawing Insights From Open-Ended Survey Responses
Supplemental material, sj-pdf-1-gcq-10.1177_00169862251378446 for Using Topic Modeling in Gifted Education Research: Drawing Insights From Open-Ended Survey Responses by Yuxiao Zhang, Nielsen Pereira, David Arthur, Hernán Castillo-Hermosilla, Zafer Ozen and Hua-Hua Chang in Gifted Child Quarterly
Footnotes
Acknowledgements
The authors extend their heartfelt appreciation to the INSTEM Project Team members, Dr. Sarah Bright, Ms. Tugce Karatas, Ms. Brenda Matos, and Ms. Shahnaz Safitri, for their kind support to this work. The first author also expresses sincere gratitude to Dr. Yukiko Maeda and Dr. Anne Traynor for their invaluable feedback in improving the manuscript, as well as to Dr. Jiawei Xiong and Dr. Gaurav Nanda for their generous advice in shaping the analysis.
ORCID iDs
Ethical Considerations
Ethical approval for this study was obtained from the Purdue University Institutional Review Board, Human Research Protection Program (approval no. IRB-2019-874) on March 15, 2023.
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This research was funded by the United States Department of Education, The Javits Gifted and Talented Students Education Program (Award No. S206A190020).
Conflicting Interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Open Science Disclosure Statement
The data analyzed in this study are not available for purposes of reproducing the results. The code used to generate the findings reported in the article is available in the Supplemental Appendix for purposes of reproducing the results or replicating the study. There are no other newly created, unique materials used to conduct the research.
Artificial Intelligence Use
The authors used OpenAI’s ChatGPT 4 and 4o solely to improve the clarity, grammar and overall readability of the text. The authors declared all intellectual contributions, analyses, and conclusions remain their work, and they took steps to ensure accuracy of AI-generated content, and that it contained no plagiarism or bias.
Supplemental Material
Supplemental material for this article is available online at 10.1177/00169862251378446.
Author Biographies
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.