
Abstract
Objective
This study used the looking-at-nothing phenomenon to explore situation awareness (SA) and the effects of working memory (WM) load in driving situations.
Background
While driving, people develop a mental representation of the environment. Since errors in retrieving information from this representation can have fatal consequences, it is essential for road safety to investigate this process. During retrieval, people tend to fixate spatial positions of visually encoded information, even if it is no longer available at that location. Previous research has shown that this “looking-at-nothing” behavior can be used to trace retrieval processes.
Method
In a video-based laboratory experiment with 2 (WM) x 3 (SA level) within-subjects design, participants (N = 33) viewed a reduced screen and evaluated auditory statements relating to different SA levels on previously seen dynamic traffic scenarios while eye movements were recorded.
Results
When retrieving information, subjects more frequently fixated emptied spatial locations associated with the information relevant for the probed SA level. The retrieval of anticipations (SA level 3) in contrast to the other SA level information resulted in more frequent gaze transitions that corresponded to the spatial dynamics of future driving behavior.
Conclusion
The results support the idea that people build a visual-spatial mental image of a driving situation. Different gaze patterns when retrieving level-specific information indicate divergent retrieval processes.
Application
Potential applications include developing new methodologies to assess the mental representation and SA of drivers objectively.
Keywords
Introduction
Knowledge and experience are the basis for safe and anticipatory driving decisions to prevent accidents. The first step is taken in driving school by teaching declarative and procedural content. However, drivers require more than mere knowledge of traffic rules and signs for safe driving. They need to build up a comprehensive systems knowledge that meaningfully represents interrelationships between traffic elements. Moreover, drivers need to keep an overview of the dynamic changing situation (Gugerty, 1997) to plan and execute their driving behavior appropriate to the situation (Baumann & Krems, 2009). This is only possible if drivers correctly perceive, process, and maintain relevant information in a traffic situation.
The majority of information when driving is perceived visually (Sivak, 1996), whereby prior knowledge is also automatically activated. Especially, the retrieval of information relating to prior experienced situations stored in memory can be decisive for appropriate decisions and behavior in road traffic and is, therefore, a safety-relevant aspect of the driving task (Ma & Kaber, 2005). In previous applied research, this aspect has received less attention. However, it may be crucial to advance prior knowledge about the process itself and further develop a minimally invasive method that can objectively capture the retrieval in the development of situational comprehension as the basis for safe decisions in traffic.
The basis for this retrieval is the mental representation of a current traffic situation which is termed situation awareness (SA) and characterized by three hierarchical information levels, including perception (SA1), interpretation (SA2), and anticipation (SA3) of situational elements (Endsley, 1995). Various researchers investigated situation awareness during driving, but only a few focused on the cognitive processes underlying the construction, maintenance, and updating of the mental representation (Baumann & Krems, 2007; Durso et al., 2007). The basic assumption is that the construction of situation awareness is comparable to the construction process of text comprehension proposed by Kintsch (1998). This process describes how knowledge is retrieved and actively held in memory, and further knowledge content is triggered based on different activation strengths. In combination with the directly perceived information, the situation model is developed, which is considered to be the key to interpretation and anticipation of the situation (Baumann & Krems, 2007).
Depending on the information needed for driving, this can be reconstructed in a simpler or more complex way. For example, to follow the speed rules, one must “only” perceive and remember the speed sign. Suppose you want to decide who is allowed to drive first at the intersection. In that case, you have to know which rules are active (interpretation of perceived signs) and also integrate information about the movement trajectories of the vehicles involved in connection with previously experienced comparable situations. Some information can be accessed directly; others must be reconstructed by accessing individual pieces of information and mentally combining them using the knowledge system. Hence, information related to the different levels of situation awareness might be represented differently in the driver’s memory. These differences may also become apparent during information retrieval. However, to our knowledge, no theoretical assumptions or empirical studies are targeting this topic in the traffic context so far. Therefore, focusing on this aspect is necessary to better understand situation comprehension and the processes underlying it.
To investigate the retrieval of driving-relevant information, a driver’s knowledge of a traffic situation has to be assessed. Various methods have been developed to capture this situational representation, most of which involve the direct measurement of knowledge (Durso et al., 2007). The situation awareness global assessment technique (SAGAT; Endsley, 1988) is the most frequently used method in this context (Endsley, 2020). It is a simulator-based method in which the simulation is stopped several times at unpredictable time points. A blank screen is displayed, and the knowledge regarding previously visible information is tested using direct questions. In addition to this objective measure of correct answers, the measurement of subjective confidence of SA received more attention in research recently (Endsley, 2020). The disadvantage of these methods is that they only capture the accuracy as a result of the retrieval process or subjective impression rather than allowing inferences about the process of information storage and retrieval prior to the action taken. One complementary method for further investigating these cognitive processes is studying eye movements (Durso et al., 2007).
In the traffic context, eye movements have been mainly used to examine factors influencing visual attention and search or to assess driver states like fatigue or workload (Rosner et al., 2019). Eye movements have not been used to investigate information retrieval in the traffic context, which is, however, critical for understanding the cognitive processes involved in the driving task. As recent research indicates that the looking-at-nothing behavior can be used to trace memory retrieval, we propose using this phenomenon to study memory retrieval in the traffic context. Looking-at-nothing describes the tendency of people to look at spatial locations where information was presented when they retrieve this information from memory–even if the information is no longer visible (e.g., Altmann, 2004; Ferreira et al., 2008; Johansson et al., 2006; Klichowicz et al., 2020; Laeng et al., 2014; Renkewitz & Jahn, 2012; Richardson & Spivey, 2000; Scholz et al., 2016; Wantz et al., 2016; Wynn et al., 2019). In the classic paradigm, Richardson and Spivey (2000) presented participants a computer screen divided into four equal-sized quadrants. Successively, the heads of different people appeared in each quadrant, speaking a piece of factual information (e.g., “Although the largest city in Australia is Sydney, the capital is Canberra”) that had to be memorized. Then, participants looked at an empty screen, heard a statement regarding one of the previously presented facts and had to judge the statement’s truth while their eye movements were recorded. Even though the screen was blank during this retrieval phase, participants fixated more often on the empty quadrant where the to-be-retrieved information had been presented (i.e., where the person who spoke the fact in question was presented) than on other quadrants. This phenomenon has mainly been shown for static (e.g., Richardson & Spivey, 2000) information but also occurs for animated figures (Hoover & Richardson, 2008) and stationary 3D objects in an immersive virtual reality setting (Chiquet et al., 2020). However, these studies have been conducted with rather abstract learning materials (e.g., a moving rabbit associated with information to be learned at an arbitrary screen position). It has not yet been investigated whether LAN also occurs in more realistic, moving, and logically coherent environments, such as traffic scenarios.
Most likely, people show looking-at-nothing because during encoding, information from multiple input sources, including the locations of perceived objects, is stored in an episodic memory representation. Once the episodic memory representation is reactivated during retrieval, it activates the motor system, which leads to the execution of eye movements back to the locations linked with the representation (for an overview, see Wynn et al., 2019). Even the retrieval of dynamic information seems to trigger such eye movements “to nothing”. Its retrieval seems to resemble a mental imagery process in which the same eye movements are shown as during perception (Noton & Stark, 1971). For example, auditory descriptions of dynamic scenes triggered saccades in the same spatio-temporal direction on a blank screen (Spivey & Geng, 2001). Thus, imagining an event activates similar perceptual-motor mechanisms as viewing that event. A comparable process may occur when a future behavior is anticipated.
A further assumption is that looking-at-nothing is used to reduce working memory load, especially when dealing with complex content (Johansson & Johansson, 2014; Scholz et al., 2016). Evidence has been provided by Kumcu and Thompson (2020), who compared memory performance and eye movements during retrieval of low- and high-difficulty words. They showed that people referred to blank positions when remembering difficult words but not when remembering easy words. Accordingly, high working memory load triggered more looking-at-nothing.
Not only the retrieval but also the construction of a memory representation is affected by cognitive load. Several studies in road traffic have shown that interpretation (SA2) and anticipation (SA3) are disturbed when working memory is strained (Mühl et al., 2020; Muhrer & Vollrath, 2011), as the integration of prior knowledge with currently perceived information requires cognitive capacity (Baumann & Krems, 2007).
Against this background, we strive to investigate memory retrieval in the context of situation awareness and aspire to offer inspiration for a complementary methodological approach to gain deeper insights into situation comprehension. We assume eye movements can be used to investigate memory retrieval in traffic situations as looking-at-nothing and SAGAT can be easily combined. In both methods, information is first encoded and then queried when the screen is empty.
Consequently, as a first step, this study aims to investigate whether looking-at-nothing occurs when people retrieve information about a previously seen traffic situation. This insight provides the basis for developing an objective method to capture information retrieval by referring to dynamic situations with reference to situation comprehension. Furthermore, this approach enables expanding the knowledge about the retrieval processes in the context of situation comprehension in traffic.
To allow assertions about this retrieval, we combined a memory-based direct measurement of the situation model with a process-oriented eye movement measurement in a video-based laboratory experiment. We examined (1) whether people tend to fixate emptied locations on the screen where information was previously visible when retrieving this information about a previously seen traffic situation from a driver’s position. More precisely, we assume that the locations where the relevant information to-be-retrieved was encoded are fixated more often than other locations (H1). Considering this aspect in the context of situation awareness, we further investigated (2) whether gaze patterns during retrieval are affected by the type of information that is retrieved and that determines the level of situation awareness. We assume (H2.1) that participants look more often at locations that are specifically addressed in SA1 (perception) and SA2 (interpretation). Furthermore, we postulate that when retrieving information about the spatio-temporal dynamics of future driving trajectories (SA3, anticipation), saccades that correspond to the spatial dynamics of these trajectories are performed more often than others (H2.2). We further explored (3) whether gaze patterns during retrieval are influenced by working memory load when the load is increased during a preceding encoding and retention interval. Based on prior findings, we expect that higher working memory load due to a cognitive secondary task leads to more frequent looks to associated blank locations during retrieval (H3).
Method
Design
To investigate looking-at-nothing in the applied context of traffic, a video-based laboratory experiment was conducted. Participants watched a traffic scenario at an intersection from a driver’s perspective and were instructed to memorize the information and to build up an understanding of the situation. While viewing a reduced scenery, subjects’ eye movements were recorded, and their knowledge of the situation was assessed directly by evaluating auditory statements (see Figure 1). To investigate the influence of the type of information to-be-retrieved on looking-at-nothing, the content of the auditory statements was varied so that one-third of the statements each required the retrieval of information on SA levels 1, 2, and 3 (see Materials and Table S1 in Supplement S1). To examine the effect of working memory load on looking-at-nothing, half of the trials included a verbal memory load task (see Figure 1). Therefore, our study followed a 2 (WM load) x 3 (SA level) within-subjects design. It was approved by the institutional ethical review board and complied with the tenets of the Declaration of Helsinki of 2013. Informed consent was obtained from each participant. Schematic illustration of the temporal procedure of an experimental trial.
Procedure
Participants were told that the study would examine the effect of workload by measuring pupil dilation during a memory task to mask study intentions. Debriefing confirmed that the participants were naïve to the study purpose. The experiment consisted of n = 36 trials and lasted approximately 70 minutes. Trials were divided into two blocks (each including n = 18 trials) based on working memory load conditions, namely high and low load blocks. The blocks were displayed in random order. Stimuli were identical in both blocks. Each block started with three practice trials, followed by eighteen randomly assigned experimental trials.
As described in detail below, each trial consisted of four consecutive phases: (1) encoding, (2) retention, (3) retrieval and (4) rating (see Figure 1). (1) Encoding phase: In the low WM condition, a fixation cross appeared on a black screen for 2000 ms, followed by a traffic video. In the high WM condition, a fixation cross appeared for 500 ms, followed by a white two-digit number for 500 ms. After a fixation cross was presented for another 1000 ms, the traffic video was displayed. (2) Retention phase: In the low WM condition, a reduced scenery was presented for 5000 ms without a specific task. In the high WM condition, a two-digit number was additionally presented via headphones, and subjects were required to indicate whether this auditory number corresponded to the number visually presented prior to the video by pressing a button. (3) Retrieval phase: A statement was presented via headphones and subjects had to press a button to indicate whether the statement matched the content of the driving scenario or not (forced-choice). Pressing a button was only possible at the end of the statement. There was no time limit for the response, but participants were instructed to respond as quickly and accurately as possible. Eye movements were recorded from the beginning of the statement to the response reaction. (4) Rating phase: Subjects were required to rate their confidence with respect to their prior evaluation of the SA statement as a subjective measure of SA (Balk et al., 2010; Endsley, 2020; Mühl et al., 2020), the subjectively perceived criticality of the encoded traffic situation (Neukum et al., 2008) and the extent to which the evaluation of the statement was demanding on their working memory (Vidulich & Tsang, 1987).
Materials
For the encoding phase, eighteen traffic scenarios (and three practice videos) were created with VicomEditor (version 1.5.2547 provided by TÜV | DEKRA arge tp 21). All videos had a ratio of 16:10 (1680 x 1050 pixels) and a duration of 7000 ms. The structure of all scenarios was identical. From a driver’s perspective, an x-junction was approached. Each scene ended before the intersection and contained four situational elements, two dynamic (e.g., cars) and two static (e.g., signs; see Figure 2A), which were displayed at distinct spatial positions on the screen to allow the investigation of looking-at-nothing. For the retrieval phase, reduced scenery images were created (see Figure 2B). Moreover, for the high WM load condition trials, eighteen images (and three practice images) of two-digit white numbers (3.01° × 1.95°) above a fixation cross (1.52° × 1.52°) were created (see Figure 1). In addition, eighteen auditory statements (and three practice statements) were developed to assess situation awareness on all three levels (six statements per level, see Table S1 in Supplement S1). Scenario structure. Note. (A) An exemplary traffic scene ending with the four areas of interest (not displayed during the experiment), of which AOI 2 and AOI 3 (outlined in red) were relevant; (B) the reduced scenery screen displayed during the retrieval phase.
For each traffic scenario, SA level was randomly assigned in advance to create fixed video-statement combinations. Half of the statements contained congruent (i.e., true), the other half incongruent information (i.e., false) about the respective video. Information that decided on the correctness of a test statement was always placed at the end of the statement. Original materials were in German (see Table S1 in the Supplement S1). All statements were recorded using a MacOs text-to-speech function with the female German voice Anna and converted and cut to a standardized length of 3500 ms using Audacity (version 2.1.10; https://www.audacityteam.org). For the retention phase in the high WM load condition, 18 two-digit numbers between 10 and 99 (and three for practice trials) were recorded using the same technology (with a length of 1000 ms). Half of the numbers were congruent to the visual two-digit number presented before the traffic scenario.
Apparatus
Subjects were seated at a distance of 630 mm in front of a 22″ computer screen (1680 x 1050 pixels) with their head in a chin rest to improve data quality. Eye movements were recorded using a SMI iViewX RED120 eye tracker, which sampled gaze data from the right eye at 120 Hz with a precision of 0.05°. Gaze data were recorded with iViewX 2.8 following 9-point calibration. Recalibrations were performed automatically at fixed intervals to improve data quality. Stimuli were presented and behavioral data were recorded with PsychoPy (version 1.92). Auditory stimuli were presented via headphones. A response time keyboard (Response Box RB-844, Cedrus, San Pedro/USA) was used to enable a more accurate response time measurement.
Participants
Thirty-six participants took part in the experiment (18 female; M age = 25.55, SD = 5.64, range 18–46). Three subjects had to be excluded due to technical issues during recording. All participants were native German speakers, had normal or corrected-to-normal vision, and held a driver’s license (M years = 7.82, SD = 5.40, range 1–29). They received either 15 € or course credit for participation.
Results
Memory performance and eye-tracking data were analyzed and visualized using the statistical programming language R (R-Core-Team 2018). Repeated-measures ANOVAs and mixed-effects models were fit using the afex package (Singmann et al., 2018) and the significance level was set at
Memory Performance
As measures of situation awareness and memory performance, accuracy, response times and confidence ratings were analyzed using repeated-measures ANOVAs with post hoc analyses using pairwise t-tests with Bonferroni, and if required, Greenhouse-Geisser correction. For details on statistical preprocessing, analyses, and results, including descriptive and post hoc analyses, see Supplement S2 and Table S2.
Accuracy. Over all conditions, participants gave correct responses in M = 85.1% with the highest accuracy in retrieving SA2 information (MSA2 = 90.4% > MSA3 = 84.1% > MSA1 = 80.8%), F (1.86, 59.38) = 7.23, p < .01,
Moreover, accuracy was observed to be higher under low (Mlow = 90.1%) than high (Mhigh = 80.1%) working memory load, F (1, 32) = 22.28, p < .001,
Response time. On average, participants needed M = 5.65 s to retrieve information and evaluate a statement. Correct responses were given faster than incorrect answers (MHit = 5.55 s < MFalse = 6.94 s), and response times differed depending on the type of information-to-be-retrieved, but not on working memory load. That is, participants responded fastest when retrieving SA2 information (MSA2 = 5.41 s < MSA1 = 5.58 s < MSA3 = 5.97 s, F (1.69, 54.17) = 3.45, p < .05,
Confidence. Participants had, on average high confidence (M = 78.34) in their statement evaluations. Correct responses were given with higher subjective confidence (MHit = 81.10 > MFalse = 55.31) and confidence differed depending on the type of information-to-be-retrieved. That is, participants responded with highest confidence when retrieving SA2 information (MSA2 = 81.96 > MSA1 = 77.90 > MSA3 = 75.19), F (1.95, 62.42) = 9.26, p < .001,
Gaze Behavior
As main gaze measures, the number of fixations (H1, H2.1, H3) and transitions (H2.2) were used as in previous looking-at-nothing studies (e.g., Martarelli & Mast, 2011; Renkewitz & Jahn, 2012). A fixation had a maximum dispersion of 100 pixels (2.4° visual angle) and a minimum duration of 80 ms (see also Scholz et al., 2018) and transitions were defined as saccades between two different AOIs. Four non-overlapping rectangular areas of interest (AOIs) of the same size were defined for each situational element (see Figures 2A and 3). Numbers of fixations in every AOI and transitions between AOIs during the retrieval phase (i.e., from the beginning of the retrieval phase until the participant’s response), were counted per person and trial. AOIs containing information-to-be-retrieved were coded as probed AOIs, all others as non-probed AOIs (for a detailed description, see Supplement S2). Figure 3 shows exemplary fixation patterns during information retrieval on the three SA levels under low and high workload conditions. It is noticeable that there is a strong tendency towards the middle across all conditions. To control for this bias, participants’ fixations during the retention phase were used as baseline conditions to correct participants’ fixations during the retrieval phase (see Figure 1) on a trial-by-trial basis. This baseline fixation retraction method was performed in a stepwise approach. In a first step, we calculated a central fixation baseline measure based on retention phase fixations. Therefore, for each trial and participant, we summed up the number of fixations during the retention interval per second for each of the four retrieval phase AOIs. In a second step, we multiplied these resulting retention fixation numbers with the respective retrieval phase duration to act on the same time scale. These retention fixation numbers are assumed to reflect the fixation numbers that would be expected if fixations during retrieval are assumed to be guided only by a central fixation bias (and rather not by retrieval processes; see Equation 1 and an illustrating calculation example in the Supplement S2). Exemplary illustrations of fixations during the retrieval phase (aggregated over participants). Note. Rectangles from left to right: AOI 1, AOI 2, AOI 3, AOI 4. Probed AOIs: AOI 3 (SA level 1), AOI 2 - AOI 3 (SA level 2), AOI 1 - AOI 3 (SA level 3).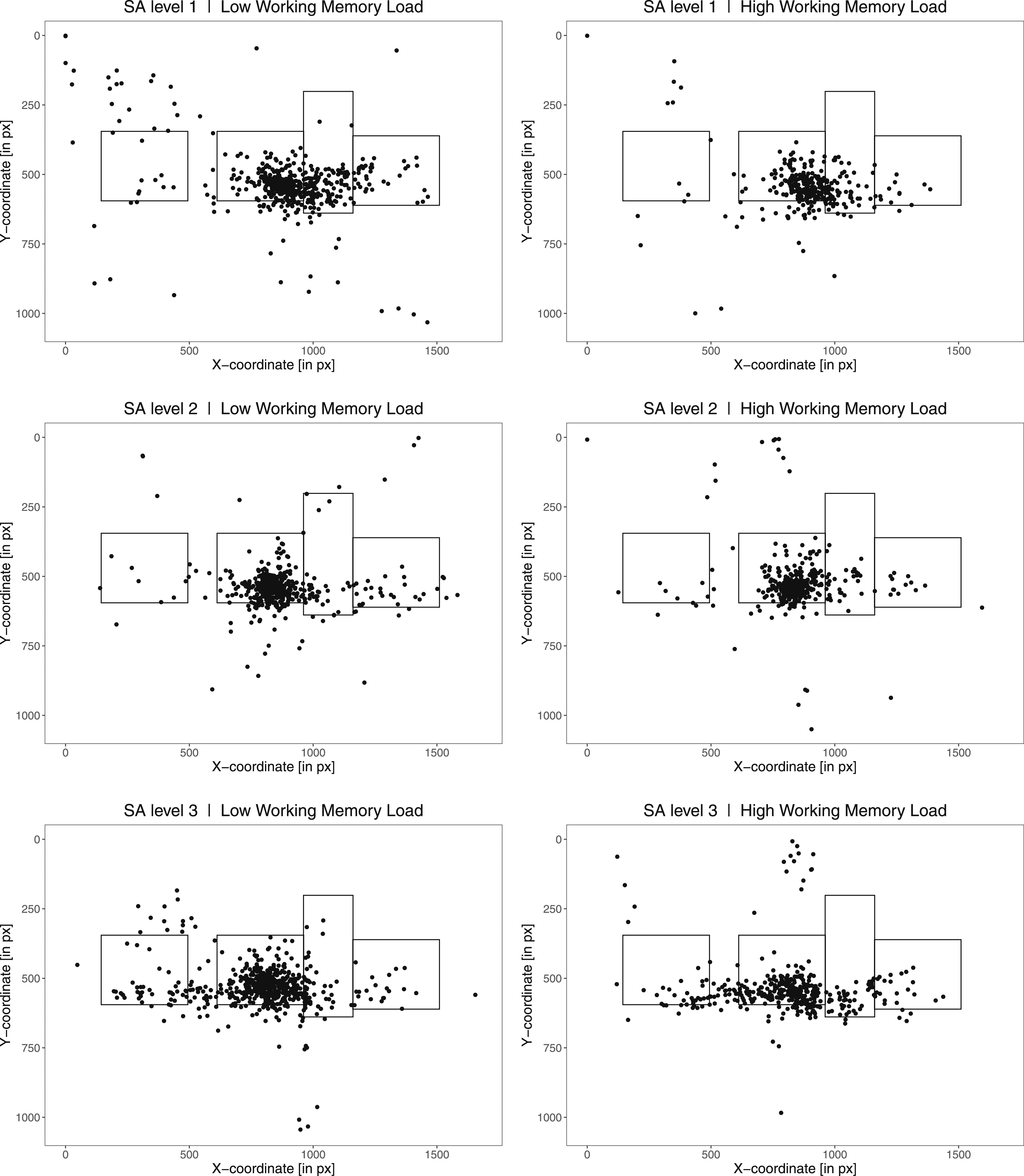
In a third step, we calculated a corrected retrieval fixation number variable, which was then used as the dependent variable in the Poisson mixed-effects model. Therefore, we subtracted the central fixation measure for each AOI from the summed number of fixations in the same AOI during the respective retrieval phase (see Equation 3 in the Supplement S2). This corrected retrieval fixation number is assumed to reflect eye fixations resulting from the retrieval of information from memory. For further details on preprocessing and the rationale underlying this baseline fixation retraction method as well as an example illustrating the calculation, see Supplement S2.
To test our hypotheses, two Poisson mixed-effects models were fitted for two count variables (corrected number of fixations and transitions) to account for dependencies in the data due to the repeated-measures design (ICCtotal= 17.5%), because standard Poisson regression cannot be used for within-subjects designs (Singmann & Kellen, 2019). Model structures were specified following a maximal approach (Barr et al., 2013) to provide the best protection against inflated Type I errors. That is, random effects were included as long as they were justified by design; even if they did not improve model fit to account for dependencies (Barr, et al., 2013) and participants and videos were treated as random effects grouping variables to explain by-participant and by-item variation (Baayen, et al., 2008).
Fixation number. We first examined whether participants made more fixations in probed than non-probed AOIs during retrieval (i.e., looking-at-nothing, H1) and whether this pattern differed dependent on working memory load (H3) and information-to-be-retrieved (H2) by fitting the Poisson mixed-effects model with fixation number as dependent variable (see Table S3 in Supplement S2).
In accordance with H1, results showed that Relevance significantly predicted fixation number, χ2 (1) = 36.30, p < .001. Thus, during retrieval, participants looked on average significantly more to probed AOIs (i.e., blank locations at which they previously encoded the information-to-be-retrieved), β = −0.33, z = −8.08, p < .001 (see Figure 4A and Table S3 in Supplement S2). Thus, looking-at-nothing occurs when drivers retrieve information from memory. Mean fixation number in probed and non-probed AOIs. Note. Depictions are notched box plots and means are represented as rhombuses.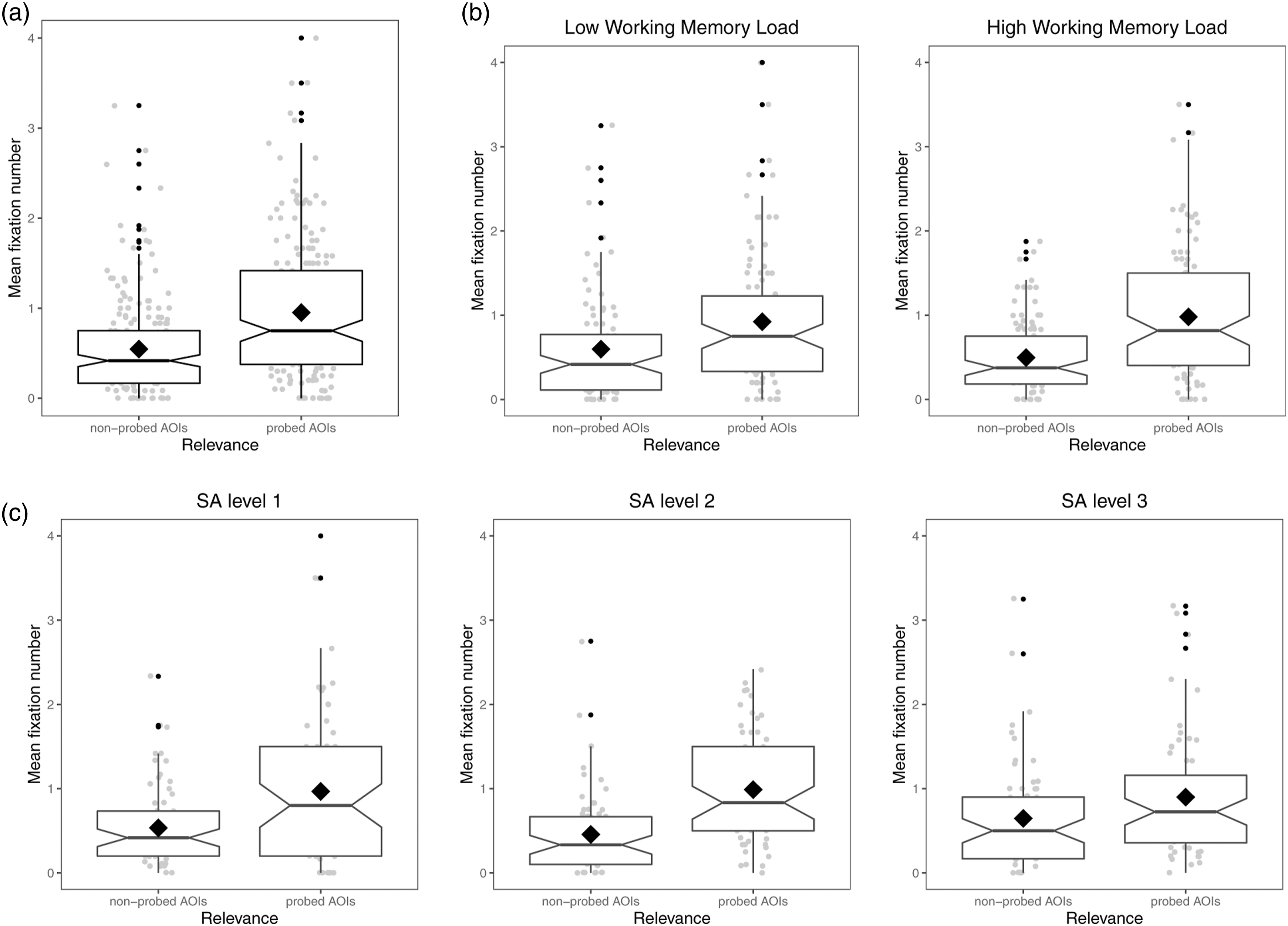
We further explored whether this looking-at-nothing behavior is amplified under high working memory load (H3) by drawing on the interaction between the fixed effects Relevance and working memory load. Results showed that WM load did not significantly influence the effect of Relevance on fixation number, χ2 (1) = 0.35, p = .555. Thus, participants looked on average more to probed than to non-probed AOIs both under low and high working memory load (see Figure 4B). Therefore, opposed to H3, looking-at-nothing was not amplified under high working memory load (see Table S3 in Supplement S2).
To explore whether looking-at-nothing differs depending on the type of information to-be-retrieved, the interaction between the fixed effects Relevance and SA level is drawn on. In contrast to H2.1, the effect of Relevance (i.e., looking-at-nothing) on fixation number was not influenced by SA level, χ2 (2) = 2.73, p = .256. Thus, participants made more looks to probed than non-probed AOIs during retrieval independent of the SA level of the information to-be-retrieved (see Figure 4C).
Transition number. To further examine whether SA level 3 invokes gazes that correspond to the spatial dynamics of anticipated future driving trajectories (H2.2), we fitted a Poisson mixed-effects model with transition number as the dependent variable and tested whether there were more probed than non-probed transitions during retrieval of SA level 1, 2, and 3 information (see Table S4 in Supplement S2). Probed and non-probed transitions were defined a-priori for each video-statement-combination and, thus, differed between SA levels. For SA1, all transitions into or out of the probed AOI were probed transitions. For SA2, transitions between the two probed AOIs were probed transitions. For SA3, all transitions that reflected the spatial dynamics of the future driving trajectory of a vehicle (e.g., a left turn from a vehicle’s position in AOI2 in the direction of AOI4) in a given statement were coded as probed transitions (see Supplement S2 for a detailed description).
Results showed that Relevance significantly predicted transition number during retrieval, χ2 (1) = 7.62, p < .01, that is, probed transitions were performed significantly more often than the unweighted grand mean; β = 0.40, z = 3.05, p < .01 (see Table S4 in Supplement S2). In line with H2.2, however, results further revealed that the effect of Relevance was influenced by the SA level, χ2 (2) = 12.35, p < .01 (see Figure 5). More specifically, post hoc analyses showed that participants only made significantly more probed than non-probed transitions when retrieving anticipation (SA3; z (Inf) = 4.68, p < .001) not when retrieving object properties (SA1; z (Inf) = 1.84, p = 0.07) or right-of-way rules (SA2; z (Inf) = −1.15, p = .25). Thus, when retrieving information about a future driving behavior of a vehicle in a traffic video, participants performed significantly more saccades between AOIs that correspond to the spatial dynamics of this driving trajectory. Mean transition number between probed and non-probed AOIs. Note. Depictions are notched box plots, means are represented as rhombuses, and significance values refer to the result of post hoc analyses with Bonferroni-correction, *** p < .001.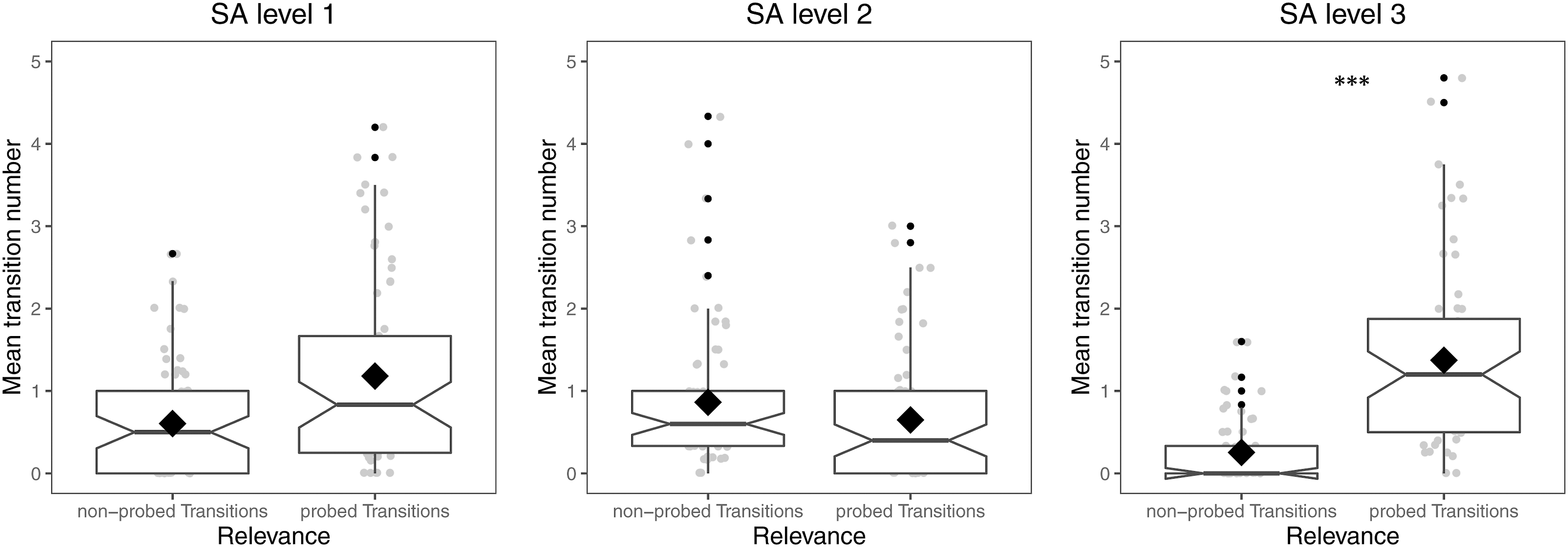
Discussion
This study examined gaze patterns occurring in traffic situations during memory retrieval in a video-based laboratory experiment. In this context, we investigated (1) whether people showed looking-at-nothing, that is, whether they fixated blank locations where visual information about a traffic situation has previously been encoded. We further explored (2) whether looking-at-nothing is influenced by working memory load and the type of information-to-be-retrieved as a function of the level of situation awareness.
In accordance with our hypothesis (H1), the looking-at-nothing phenomenon occurred when retrieving information from a visual-spatial representation. This finding is consistent with prior basic research studies (e.g., Chiquet et al., 2020; Laeng et al., 2014; Richardson & Spivey, 2000; Scholz et al., 2016; Spivey & Geng, 2001). Moreover, we provide first evidence that looking-at-nothing occurs in the applied context of driving situations when retrieving information relating to previously perceived moving visual elements within a meaningful environment. Results further revealed that the looking-at-nothing pattern occurred in all levels of situation awareness and cannot simply be explained through a central fixation tendency. This finding was contrary to our hypothesis expecting differences between the levels of situation awareness but could be seen as an artifact of operationalization, as the number of relevant elements (probed AOIs) was adjusted according to the respective level of situation awareness (one probed AOI for SA1 vs. two probed AOIs for SA2 and SA3). Thus, the difference of the respective level of situation awareness in information retrieval might not have become visible in the number of fixations (looking-at-nothing) because it was already indirectly taken into account (in the operationalization). When retrieving information about element properties (e.g., sign, SA 1), situational interpretations (e.g., right-of-way; SA2), or anticipations (e.g., the spatial trajectory of another road user, SA3), participants tended to look more towards the blank location where related elements were visible in the end of the traffic scenario (i.e., sign and road users). This demonstrates that not only observable characteristics but also conceptual knowledge, that is situational interpretations and anticipations relating to specific situational elements, elicit eye movement to associated but emptied spatial positions (H2.1).
Results further showed that when retrieving information relating to future other road users’ driving behavior (SA3), participants instead performed significantly more saccades between empty locations on the screen (i.e., transitions) that reflected the spatial dynamics of the anticipated movement trajectories. This was not the case when participants retrieved SA1 or SA2 information. This suggests that the retrieval of behavioral anticipation may have resembled a mental imagery process of the movement trajectory rather than the retrieval of individual pieces of information. Thus, not only an auditory scene description (Spivey & Geng, 2001) but also a mental imagination of future behavior triggers saccades in the same spatial direction. All these findings support the idea that people integrate multiple pieces of information during situation comprehension while viewing traffic situations (Baumann & Krems, 2007; Durso et al., 2007). During retrieval, distinct eye movement patterns seem to reflect that information related to specific SA levels is differentially represented in memory. Additionally, these findings support the idea of an integrated memory system where people build a mental representation of a traffic situation in which perceived information is integrated and attached with their spatial positions (Ferreira et al., 2008).
It should be noted here that we only evaluated whether a spatial pattern is visible in fixations during the retrieval of spatio-dynamic information. A further step would be to additionally analyze dynamic-temporal patterns to gain deeper insights into the processes of information retrieval that are crucial for anticipation.
Furthermore, we found that higher working memory load induced by a passive verbal secondary task during encoding (i.e., remembering a two-digit number) was only demanding enough to modulate memory performance substantially, but not eye movements. More precisely, high working memory load resulted in lower memory performance, but looking-at-nothing was not amplified under high working memory load. That is, looking-at-nothing occurred equally across working memory load conditions. This contradicts the frequently formulated assumption that looking-at-nothing is performed to relieve working memory during retrieval (e.g., Hoover & Richardson, 2008; Johansson et al., 2010; Scholz et al., 2011; Wantz et al., 2016) and thus, is modulated by working memory load (Kumcu & Thompson, 2020). One of the main reasons for this discrepancy could be the difference in the operationalization of working memory load as we used a secondary task while others manipulated the difficulty of the learning materials (Kumcu & Thompson, 2020). Another reason may be the design of the retrieval phase, as in this study, a reduced scenery was shown instead of a blank screen, which might have influenced the ease of retrieval (Humphrey & Underwood, 2008). Future studies should re-investigate the effect of working memory load on looking-at-nothing in the driving context using other operationalizations, such as varying the complexity of traffic scenarios (cf. Kumcu & Thompson, 2020), or using another, more demanding secondary task, e.g., an active verbal secondary or n-back task.
Overall, our study showed that looking-at-nothing occurs when people retrieve information about prior visually perceived dynamic traffic situations from memory. This could be shown, although, as expected, we found a strong central fixation bias from the driver’s perspective. As a compromise, as it is often necessary when using basic research methods in an applied context, we developed and used a specific baseline correction. Future studies might focus on the influence of this bias and, for example, choose other scenarios or angles lacking relevant elements in the center. Another limiting factor regarding the validity of our findings is that our participants only viewed driving scenes and knew that their memory for the scene would be tested (similar to SAGAT). Thus, it is still a challenge to assess the influence of information retrieval in real driving situations, emphasizing the relevance of the approach.
The application of this method in the context of traffic is new and still at an early stage. More specific research is needed to apply looking-at-nothing during situation comprehension to allow predictions about drivers’ situation awareness based on gaze data. First results show that eye movements during retrieval are related to the remembered information and allow assertions about the prior perceived visual dynamic information integrated into the situation model. The specific gaze patterns serve as a process measure that provides information about retrieved elements before a decision is made. This could be a valuable addendum to approved methods in this context (e.g., SAGAT), as it offers further insights into the process of information retrieval, which is a necessary component of situation awareness. With the combination of these methods, it might not only be possible to determine whether a statement is true or false. Additionally, one could evaluate whether an incorrect answer is due to a retrieval error or to another part of the situation comprehension process. Therefore, further testing should be conducted by combining an approved method of situation awareness, such as SAGAT, with the looking-at-nothing approach. This has not been done in this study, as we first strived to determine whether looking-at-nothing is sensitive at all levels of situation awareness.
This method may thus serve as an objective measure for the quality of decisions in investigating road traffic. In particular, it may be used to identify why poor decisions occur that may be the cause of accidents. As mentioned above, such a methodological approach needs to be further developed in order to gain reliable knowledge and insights in the applied context of dynamic situations. Moreover, findings based on this approach could serve as a basis for designing specific assistance supporting humans in driving safely and anticipatory.
Conclusion
Our findings show preliminary evidence that looking-at-nothing occurs in the retrieval of information related to visually perceived dynamic elements in traffic situations. From a wider perspective, our results support the idea of an integrated memory system. People build a visual-spatial representation, a mental image, of a driving situation where information is attached with spatial information. Different looking-at-nothing patterns when retrieving level-specific information indicate divergent representation and retrieval processes. Based on our findings, we believe that applying looking-at-nothing in situation awareness research by combining memory-based direct measurement of the situation model with a process-oriented eye movement measurement may allow new insights into how the situational representation is built, which information is included, and how it is stored and accessed by drivers.
Key Points
This study investigated (1) whether looking-at-nothing occurs when retrieving information about a driving situation from memory and (2) whether its occurrence is influenced by working memory load or by the information to-be retrieved. Using the looking-at-nothing approach offers insights into the process of retrieving specific information relating to different levels of situation awareness from a mental representation. Participants more frequently fixated on empty locations where the information-to-be-remembered was previously encoded in a traffic situation. This looking-at-nothing behavior was independent of working memory load but differed depending on the type of information-to-be-retrieved (i.e., SA Level). The study supports the idea that people build up a visual-spatial mental image of a dynamic traffic situation where every information is stored with a spatial index, and the retrieval of information triggers eye movements to the indexed location.
Supplemental Material
sj-pdf-1-hfs-10.1177_00187208211063693 – Supplemental Material for Advancing Knowledge on Situation Comprehension in Dynamic Traffic Situations by Studying Eye Movements to Empty Spatial Locations
Supplemental Material, sj-pdf-1-hfs-10.1177_00187208211063693 for Advancing Knowledge on Situation Comprehension in Dynamic Traffic Situations by Studying Eye Movements to Empty Spatial Locations by Wiebke Frank, Kristin Mühl, Agnes Rosner, and Martin Baumann in Human Factors: The Journal of Human Factors and Ergonomics Society.
Footnotes
Acknowledgments
Agnes Rosner gratefully acknowledges funding from Grants 157432 and 186032 from the Swiss National Science Foundation.
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported by Swiss National Science Foundation (157432 and 186032).
Supplemental Material
Supplemental material for this article is available online.
Wiebke Frank is currently affiliated with the Department of Neurology at Ulm University. She obtained her master’s degree in Psychology from Ulm University in 2019.
Kristin Mühl is affiliated with Ulm University’s Human Factors group. She obtained her master’s degree in Human Factors from TU Berlin in 2014.
Agnes Rosner is affiliated with the Department of Psychology at the University of Zurich, Switzerland. She obtained her doctoral degree in Psychology from the TU Chemnitz in 2015. She is currently a Senior Research Fellow at the Cognition Lab of the University of Zurich funded by the Swiss National Science Foundation.
Martin Baumann is currently affiliated with Ulm University. He obtained his doctorate degree in Psychology from the TU Chemnitz in 2001. He is currently a full professor of Human Factors at Ulm University.
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.