
Abstract
Objective
This study investigates the effectiveness of an AI-powered interactive vehicle owner’s manual compared to a traditional static manual in improving users’ understanding of Advanced Driver Assistance Systems (ADAS) using a production vehicle’s owner’s manual.
Background
As vehicle automation becomes increasingly complex, drivers face challenges in understanding ADAS features. While traditional owner’s manuals have demonstrated effectiveness when they are used, there remains potential to enhance driver engagement through AI and provide more interactive and accessible learning experiences.
Methods
Using a between-subjects design, 38 participants were randomly assigned to learn about four commercially available ADAS features using either a PDF manual or a Retrieval-Augmented Generation (RAG) AI manual. Mental model accuracy was assessed through multiple-choice questions, while participants’ reasoning patterns were analyzed using structural topic modeling (STM) of open-ended responses.
Results
Both training methods improved mental model accuracy from pre- to post-training, with no significant differences between PDF and RAG conditions in quantitative learning outcomes. However, STM analysis revealed distinct qualitative differences in the participants’ reasoning patterns. RAG-trained participants demonstrated more sophisticated systems-level thinking, particularly in feature integration reasoning. Analysis through the lens of the Technology Acceptance Model revealed that both methods operate through similar psychological mechanisms, with perceived usefulness aiding user acceptance.
Conclusion
AI-augmented owner’s manuals achieve comparable learning effectiveness to traditional documentation while enhancing feature integration reasoning. Interactive AI systems serve as effective enhancements rather than replacements for proven educational approaches, guiding users toward more sophisticated mental models of complex automated systems.
Application
This research provides insights for automotive manufacturers and documentation specialists on effective approaches for educating drivers about complex vehicle automation systems, potentially improving safety and user experience.
Introduction
As vehicle systems grow increasingly complex, users face significant challenges in accessing and understanding the information contained in technical documentation. SAE Level 2 driving automation requires drivers’ engagement while using Advanced Driver Assistance Systems (ADAS) features and can represent a particularly challenging domain, where misunderstanding features can potentially affect safety, such as not fulfilling drivers’ responsibility when required. However, research shows that less than half of the vehicle owners are offered training on how to use ADAS features (McDonald et al., 2018). In addition to this, traditional approaches to vehicle documentation—printed manuals and static digital documents—often do not meet users’ needs for contextual information of the vehicle system.
Recent advances in artificial intelligence (AI), particularly in natural language processing and generation, offer promising solutions to these challenges. Retrieval-Augmented Generation (RAG) systems combine the benefits of information retrieval with generative AI to produce responses that are both contextually relevant and factually grounded in authoritative sources (Lewis et al., 2020). These systems can transform static documentation into interactive knowledge bases that respond to natural language queries while maintaining factual accuracy.
This paper presents the development and evaluation of a RAG system designed specifically for vehicle documentation. Our system focuses on documentation from a commercially available vehicle (Mercedes E-class ADAS) as a test case, demonstrating effectiveness of AI-augmented documentation on user comprehension and usability.
Background
Mental Models in Automated Driving
Mental models in automated driving represent a driver’s conceptual understanding of system functions and limitations (Beggiato et al., 2015; Beggiato & Krems, 2013). A correct mental model is important for safety, as drivers with accurate understanding can use ADAS appropriately and intervene when needed, while those who misunderstand system capabilities risk misuse (Carney et al., 2022). Specifically, accurate mental models enable drivers to: (a) engage ADAS features appropriately within their designed operational boundaries, (b) anticipate system limitations and edge case when automation may fail, and (c) intervene effectively when system behavior deviates from expectations. These mechanisms explain why education that builds accurate mental models translates to safer ADAS use.
Research reveals significant knowledge gaps among ADAS users. For example, research found that only 42% of Adaptive Cruise Control (ACC) equipped vehicle owners aware of all queried system limitations (Dickie & Boyle, 2009). Similarly, another study revealed that 72% of ACC owners were not aware of some critical ACC limitations (Jenness et al., 2008). This widespread incomplete understanding may affect safety, as drivers with better mental models are less likely to engage systems outside their Operational Design Domain (Carney et al., 2022).
Previous research consistently demonstrates that when drivers actively engage with owner’s manuals, learning outcomes can be comparable to other educational methods. A previous study (McDonald et al., 2017) directly compared ADAS learning outcomes across different educational methods. In their experiment with 120 drivers, participants learned about five ADAS features through owner’s manuals, hands-on demonstrations, or both approaches combined. Knowledge testing revealed improvement across all groups but found no statistically significant difference between the three learning methods, suggesting that manuals can be as effective as demonstrations for immediate ADAS knowledge acquisition under controlled conditions. Forster et al. (2019) further confirmed that both interactive tutorials (using Microsoft PowerPoint) and thorough manual reading before first use enhanced understanding and interaction performance compared to generic information. Similarly, Hungund et al. (2024) found that drivers who read text-based owner’s manual explanations about ACC achieved comparable or even slightly higher knowledge scores than those who received visual state-diagram training, demonstrating that traditional instruction manuals can impart useful understanding when drivers use them. Their finding that learning from manuals can be effective when users actively engage with content suggests the potential value of accessible documentation.
However, equivalent knowledge scores do not necessarily reflect depth of understanding. The Interactive, Constructive, Active, and Passive (ICAP) framework from educational psychology demonstrates that interactive engagement, such as questioning and receiving adaptive responses, produces deeper learning than passive reception of information (Chi & Wylie, 2014). Similarly, comparisons across ADAS training modalities suggest that even when knowledge gains appear comparable, the format of instruction may shape other aspects of learning outcomes (Sportillo et al., 2018; Zahabi et al., 2021). These considerations, combined with the accessibility and usability challenges of traditional technical documentation, motivate exploring whether interactive AI-based manuals might yield qualitative differences beyond what conventional assessments capture.
Technical Documentation and User Comprehension
Traditional technical documentation faces usability challenges, particularly in complex domains, such as automotive systems. Vehicle owner’s manuals often exceed 300–500 pages and ADAS details are often in dense text (Forster et al., 2019; Leonard, 2001). Also, owner’s manuals are usually passive and text-heavy, requiring the reader to self-direct their leaning (Forster et al., 2019). Previous research found that owner’s manuals are infrequently read, except for some specific information and only 2 out of 78 respondents in the study actively looked for safety information in the manual (Leonard, 2001). Another survey found that just over half of drivers (55%) reported learning about their ADAS features by reading the owner’s manual and a similar proportion by “trial-and-error” experimentation (Kaye et al., 2022). Contents analyses further reveal that ADAS manuals far exceed recommended readability levels and that 41% of vehicle owners had not read their manual at all (Mehlenbacher et al., 2002; Oviedo-Trespalacios et al., 2021).
While owner’s manuals contain the necessary facts about ADAS, their usability is limited. Manuals alone cannot ensure that drivers grasp system capabilities, limitations, and their own responsibilities, especially as technology evolves. This challenge becomes particularly acute as the volume and complexity of technical content continues to increase with advancing automation systems. This motivates exploring new ways—including AI-driven tools and better training—to supplement traditional documentation. Since many drivers avoid reading manuals or voluntarily learning about their systems, innovative approaches may be needed. AI assistants could play a crucial role by providing immediate, accurate answers to specific questions, such as “when should I not use this feature?”—potentially preventing drivers from misunderstanding system capabilities. However, AI assistants must be factually grounded in authoritative sources and avoid delivering incorrect information.
Retrieval-Augmented Generation (RAG) for Technical Documentation
RAG represents an advancement in question-answering systems. RAG enables AI to respond to user queries by referencing pre-existing documented information rather than relying solely on trained parameters. This approach addresses the “hallucination” problem common in pure generative systems—confident but incorrect statements lacking basis in authoritative sources—by anchoring responses in retrieved documents. This anchoring is important in technical documentation, such as owner’s manual, where misinformation about ADAS features and driver responsibility can lead to safety-critical outcomes. For automotive applications, RAG enables an interactive owner’s manual where a driver can ask natural language questions about their ADAS, and the system retrieves and synthesizes answers from official documentation. This eliminates searching through the manual and quickly provides precise answers.
RAG operates in two phases: preparation and response generation. During preparation, source documents are divided into smaller segments, each converted into a numerical representation capturing the semantic meaning. These representations enable semantic matching regardless of exact wording. During response generation, the system converts the user’s question into the same numerical format, searches for similar document segments, and provides retrieved segments as a context to a language model, which synthesizes a coherent response while maintaining source fidelity.
RAG differs from both general-purpose AI assistants and existing driver education resources. Platforms such as “My Car Does What” (https://www.mycardoeswhat.org/) offer valuable standardized ADAS information but cannot respond to individualized queries for specific vehicle models. RAG combines factual grounding in curated documentation with natural language flexibility, enabling users to query in their own words while receiving responses anchored in authoritative sources.
Research Questions
This study develops an AI-powered interactive vehicle owner’s manual and evaluates whether AI-augmented manuals can maintain comparable learning effectiveness while providing qualitative improvements in understanding depth and user experience. Drivers’ mental models were measured across levels of cognitive complexity based on Bloom’s taxonomy (Bloom, 1956), while participants’ reasoning patterns and attitudes were assessed through structural topic modeling (STM) (Roberts et al., 2014) and the technology acceptance model (TAM) (Davis, 1989). The following research questions were assessed: 1. How does an AI-powered interactive vehicle owner’s manual compare to traditional static manuals in supporting drivers’ understanding of ADAS features? 2. What qualitative differences in reasoning patterns and user perceptions emerge between AI-powered interactive manuals and traditional static manuals?
This research contributes to our understanding of how different documentation approaches shape both quantitative learning outcomes and qualitative reasoning patterns in complex technical domains, offering insights for automotive manufacturers seeking to enhance driver education and safety through documentation design.
Methods
This research complied with the American Psychological Association’s Code of Ethics and was approved by University of Wisconsin-Madison Institutional Review Board (Approval #: 2024-0477-CP001). Informed consent was obtained from each participant.
System Architecture
We developed an RAG system for vehicle documentation using PDF manuals of a Mercedes E-class. These PDF manuals were selected because the ADAS information was easily obtained through text rather than images or more complex information structures. The system architecture consists of three primary components: (a) vector store creation and document embedding, (b) knowledge retrieval mechanism, and (c) question-answering synthesis.
Document Processing and Vector Store Creation
Document chunking (dividing source documents into smaller retrievable segments) is a foundational design choice in RAG systems that directly affect retrieval precision and response quality (Lee, 2026). Smaller chunks enable more targeted retrieval but may lose important context, while larger chunks preserve context but risk including irrelevant information. Chunk overlap (the degree to which consecutive segments share content) affects context continuity: higher overlap ensures that information spanning chunk boundaries remains retrievable, while lower overlap reduces redundancy but may fragment coherent passages. Our implementation used OpenAI’s vector store service with default chunking parameters: tokens per chunk with 400-token overlap (50% overlap ratio). From the 11 ADAS features documented in the Mercedes E-class manual, four were selected and uploaded to the service to balance longitudinal control (Active Distance Assist DISTRONIC, Active Stop-and-Go Assist) and lateral control (Active Steering Assist, Active Lane Change Assist). The service converts each chunk into a 256-dimensional vector representation using the text-embedding-3-large model, enabling semantic matching regardless of exact wording. These parameter choices reflect the technical documentation domain. The 800-token chunk size accommodates typical paragraph lengths in owner’s manuals while remaining small enough for precise retrieval. The 50% overlap ensures that explanations spanning multiple paragraphs remain intact across chunk boundaries—important for ADAS documentation where feature descriptions often reference prerequisites or limitations discussed in adjacent passages.
Retrieval Mechanism
Retrieval determines which document segments inform each response. The number of segments retrieved affects response quality: fewer segments yield focused but potentially incomplete answers, while more segments provide broader coverage but risk including tangential information that dilutes response precision (Lee, 2026).
Our implementation retrieves up to 20 relevant chunks per query using automatic ranking. When a query is received, the system: (a) converts the user query into a vector representation using the same embedding model, (b) performs a cosine similarity search against all document vectors in the store, (c) retrieves the most relevant document segments based on similarity scores, and (d) returns both the content and source metadata (including file names) for transparency.
The 20-chunk maximum accommodates multi-feature queries common in ADAS documentation where users ask about interactions between systems, while automatic ranking ensures that highly relevant chunks receive priority. Source metadata transparency enables users to trace responses to specific manual sections, supporting the verification behavior essential for developing appropriate trust in AI-generated information.
Question-Answering Synthesis
Response generation transforms retrieved chunks into coherent answers. Model selection involves tradeoffs between capability, response latency, and behavioral consistency. More capable models produce nuanced responses but may introduce information beyond the retrieved context; smaller models are faster and more constrained but may struggle with complex synthesis tasks. Temperature settings control response variability: higher temperatures increase creativity but reduce consistency, while lower temperatures produce deterministic outputs suitable for factual documentation.
Our implementation uses GPT-4o-mini with default temperature settings. This process: (a) takes the user query and passes it to the model, (b) simultaneously provides the top retrieved document segments as context, (c) instructs the model to formulate a response based on the provided context, (d) records citation information about which source documents were used, and (e) returns both the synthesized answer and source citations to the user.
GPT-4o-mini balances capability with consistency appropriate for safety-critical documentation. The model’s instruction-following capability enables explicit constraints against incorporating external knowledge, while default temperature settings ensure reproducible responses—important for documentation systems where identical queries should yield consistent answers. This approach ensures responses are grounded in actual manual content while benefiting from the language model’s ability to rephrase and synthesize information accessibly.
Ensuring Response Fidelity
For safety-critical applications, responses must accurately reflect source documents without incorporating external information. Our implementation used three mechanisms to ensure fidelity: (a) the knowledge base contained exclusively official Mercedes E-class documentation with no external sources; (b) the language model received instructions to base responses solely on retrieved content and acknowledge uncertainty when relevant information was unavailable; and (c) source citations accompanied each response, enabling verification against original documents.
User Interfaces
The interface was implemented using Python with key libraries, including Gradio (for user interface development) (Abid et al., 2019), NetworkX (Hagberg et al., 2008), and Matplotlib (for knowledge visualization) (Hunter, 2007), and deployed in Hugging Face (Wolf et al., 2019) (Figure 1). Interface of the RAG manual. A simple text interface allows users to type questions and receive text responses with source citations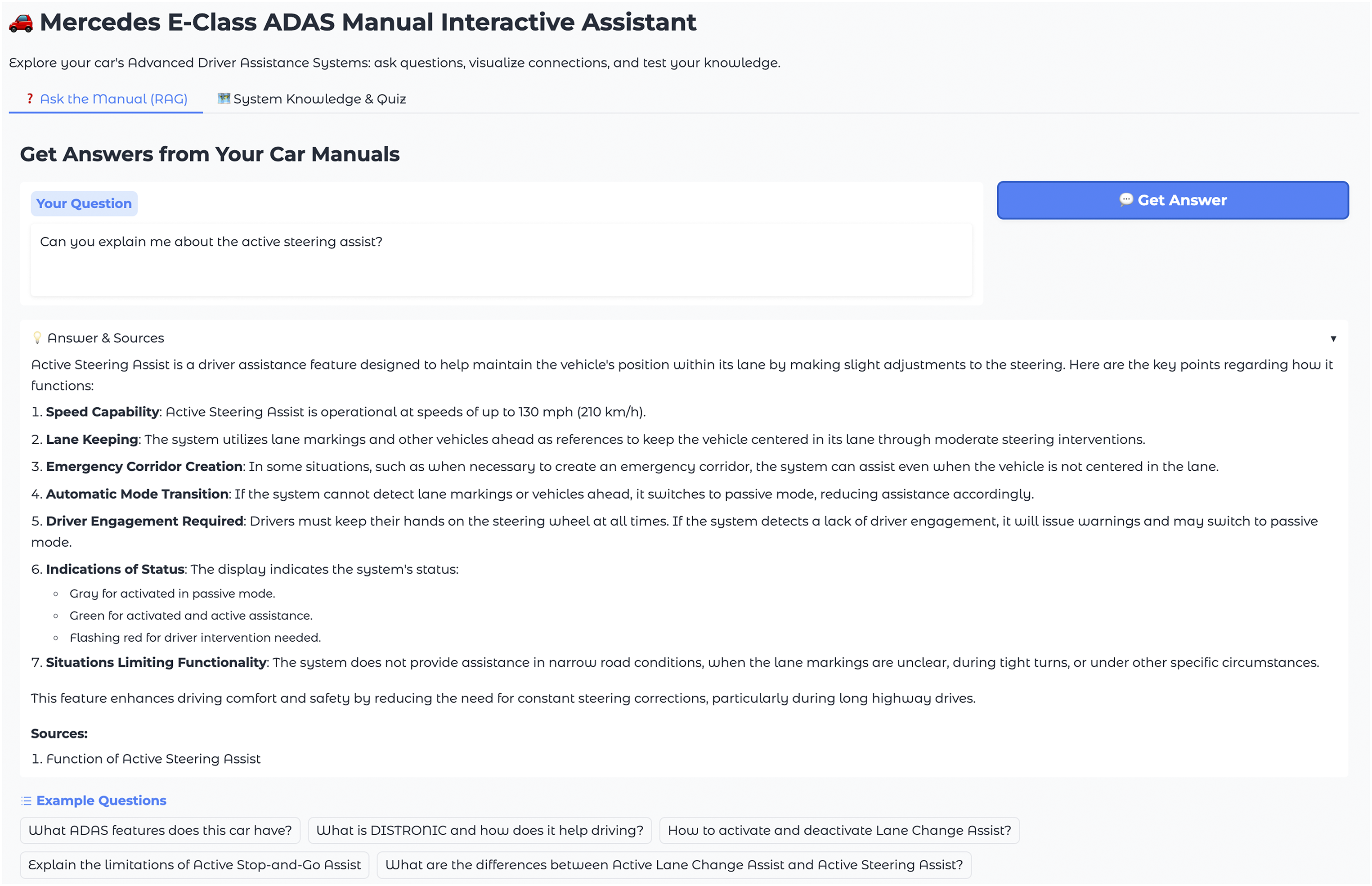
Additional features including knowledge graphs, similarity heatmaps, and Bloom’s taxonomy-based assessment were implemented but disabled during the experiment to isolate the core conversational capabilities and establish whether natural language queries alone could match PDF manual effectiveness.
Participants
Thirty-eight participants (19 per condition; 21 females, 17 males; M age = 33.89 years, SD = 9.76) were recruited from the university community and surrounding area. Inclusion criteria were: (a) valid driver’s license, (b) age 21–65 years, (c) normal or corrected-to-normal vision, and (d) no prior experience with Mercedes E-class ADAS features. Participants were randomly assigned to PDF or RAG manual conditions and compensated $18 per hour for approximately 1.2 h, plus performance-based bonuses tied to post-training assessment accuracy ($5 for ≥90%, $4 for 80–89%, $3 for 70–79%, $2 for 60–69%, $0 for <60% accuracy).
Apparatus
The experiment was conducted in a laboratory environment using the same physical space for both conditions to control for environmental factors. In the traditional PDF manual condition, participants used a laptop displaying a PDF file of Mercedes E-class ADAS features (Active Distance Assist DISTRONIC, Active Stop-and-Go Assist, Active Steering Assist, and Active Lane Change Assist) at a standard desk and chair setup with a visible timer. The RAG interactive manual condition used the same setup but with a laptop running the RAG-based interactive manual system that allowed natural language queries about the same four ADAS features. Assessment was conducted through a computer-based testing platform that delivered multiple-choice and open-ended questions.
Experiment Design
The study used a between-subjects design with manual type (PDF vs. RAG) as the independent variable. Main dependent variables included mental model accuracy (percentage of correct answers on pre- and post-test), rationale for answers (open-ended responses), perceived ease of use, perceived usefulness, attitude, and behavioral intention ratings (Davis, 1989) for the manual type. Mental model accuracy was assessed using 44 multiple-choice questions: 10 questions per ADAS feature testing individual feature knowledge plus four multi-feature scenario questions testing feature interaction understanding. Multi-feature scenarios presented situations where multiple ADAS features interact, such as “If Active Steering Assist is in passive mode, how does it affect Active Lane Change Assist?” Each response was scored as binary correct or incorrect, and accuracy was calculated as the percentage of correct responses per test phase (pre- or post-training). Following each multiple-choice question, participants provided a brief written rationale by responding to the prompt: “Could you briefly explain why you selected that option?” These open-ended responses formed the corpus for STM analysis. Both groups had equal learning time (20 min), identical ADAS features, balanced demographic distribution, and consistent instruction delivery.
Procedure
The experiment began with a 10-min introduction and consent phase where participants were informed about the study, signed consent forms, and completed a demographic questionnaire. Participants then completed a computer-based pre-assessment measuring their baseline mental model of four ADAS features through 44 multiple-choice questions (10 per feature and four for multi-feature scenarios), followed by confidence ratings for each response. Participants received 20 min of training with their assigned material (PDF or RAG manual). All participants received identical scenario-based instructions: “Imagine that you recently purchased a new Mercedes E-Class vehicle. You have 20 min to learn about the four Advanced Driver Assistance Systems (ADAS) features available on this vehicle: Active Distance Assist DISTRONIC, Active Stop-and-Go Assist, Active Steering Assist, and Active Lane Change Assist. You are free to learn about these features in any order you prefer and spend as much time on each feature as you like, but please make sure you learn about all four features.” PDF group participants received guidance on locating the four features in the manual (see Figure 2), while RAG group participants received brief instructions on using the interactive system before exploring the same features. Both groups were free to navigate and explore the materials at their own pace within the 20-min period, without experimenter intervention during training. Following training, participants completed a post-assessment using the same format with new questions, then a 10-min survey assessing training material and ADAS feature acceptance using the Technology Acceptance Model (TAM; Davis, 1989) and collecting general feedback. The experiment concluded with a 5-min debriefing explaining the study purpose, after which compensation was provided based on performance. Example page from the Mercedes E-class owner’s manual PDF used in the control condition. Participants navigated this static document for learn about ADAS feature during the 20-min training period
Analytic Methods
Three data sources were collected and analyzed using methods appropriate to each data type: (a) multiple-choice responses measuring mental model accuracy were analyzed using mixed-effects regression to account for repeated measures within participants; (b) open-ended text responses explaining participants’ reasoning were analyzed using STM to identify latent themes that differ across training conditions; and (c) TAM questionnaire ratings were analyzed using multi-group path analysis to test theoretical relationships across conditions.
First, to examine drivers’ understanding of the four ADAS features, we applied mixed-effects regression. Mixed-effects models were chosen because accuracy was measured across four ADAS features for each participant, creating a nested data structure where multiple observations are clustered within individuals. Mixed-effects regression accounts for this non-independence by modeling individual differences as random effects, providing more accurate standard errors than approaches that assume independent observations. The model predicted post-training accuracy with pre-training accuracy and manual type as fixed effects, and participant as a random intercept to account for individual baseline differences in learning ability.
Second, to examine qualitative differences in participants’ rationale behind their answers for the mental model questions, STM was conducted on the open-ended responses. STM extends traditional topic modeling by incorporating document-level covariates to model how both topic prevalence and content vary across groups (Roberts et al., 2014). STM uses an unsupervised approach to discover topics algorithmically from the data rather than relying on predefined categories, identifying latent themes that abstract beyond individual word usage (Lee & Kolodge, 2018). Prior to analysis, feedback text was preprocessed using standard natural language processing techniques, including tokenization, stopword removal, stemming, and removal of infrequent terms. The optimal number of topics was determined through a systematic search where K (the number of topics to extract) was varied from 2 to 6. Each candidate model was evaluated based on semantic coherence (whether high-probability words within a topic tend to co-occur), exclusivity (whether top words are unique to each topic), and residual fit. The five-topic solution (K = 5) provided the best balance of interpretability and model fit. The final model incorporated training group (PDF vs. RAG) and training phase (pre vs. post) as prevalence covariates, allowing for statistical testing of whether certain feedback themes were significantly more or less prevalent in one training condition versus the other. Topics are characterized by four word metrics: Prob (highest probability words most likely to appear in the topic), FREX (words that are both frequent and exclusive to the topic), Lift (words appearing more frequently in the topic than expected based on overall corpus frequency, highlighting distinctive vocabulary), and Score (a combined metric weighting both probability and exclusivity). The STM analysis was conducted using the R package “stm” (Roberts et al., 2019).
Third, to test the theoretical relationships proposed by the TAM and compare these relationships across the two training conditions, a multi-group path analysis was conducted. Prior to the analysis, composite scores for the four core TAM constructs (Perceived Usefulness, Perceived Ease of Use, Attitude Toward Using, and Behavioral Intention) were calculated by averaging the corresponding items for each participant. These composite scores were then treated as observed variables in the path model. The overall model fit was assessed using the chi-square goodness-of-fit test, with a non-significant result (p > .05) indicating a good fit between the proposed model and the observed data. Model fit was assessed using multiple indices: chi-square goodness-of-fit test (with non-significant p > .05 indicating acceptable fit), Comparative Fit Index (CFI > .95), Tucker-Lewis Index (TLI > .95), Root Mean Square Error of Approximation (RMSEA < .06), and Standardized Root Mean Square Residual (SRMR < .08). To determine if the strengths of the causal paths differed significantly between the PDF and RAG groups, chi-square difference tests were performed. A non-significant result from the chi-square difference test was interpreted as evidence that the path’s strength did not statistically differ between the training conditions. A multi-group path analysis was conducted using the R package “lavaan” (Rosseel et al., 2012).
Results
Understanding of the ADAS Features
First, a linear model with training phase and manual type as fixed effects revealed significant improvement from pre- to post-training, t(72) = 5.69, p < .001, adjusted R
2
= .36, with no significant effect of manual type, t(72) = 0.75, p = .45, or interaction, t(72) = −1.52, p = .13. Taken together, these results indicate that neither the level of learning nor learning gained statistically differed between participants who used the PDF manual and those who used the RAG-based manual (Figure 3). The figure illustrates the change in mental model accuracy from the pre-training to the post-training phase for the PDF group (left panel) and the RAG group (right panel). The plot shows a clear increase in accuracy from pre- to post-training for both groups. Furthermore, it shows that the baseline (Pre) scores and the magnitude of improvement from Pre to Post are comparable across both conditions, which aligns with the non-significant main effect of manual type and the non-significant interaction effect reported in the linear model analysis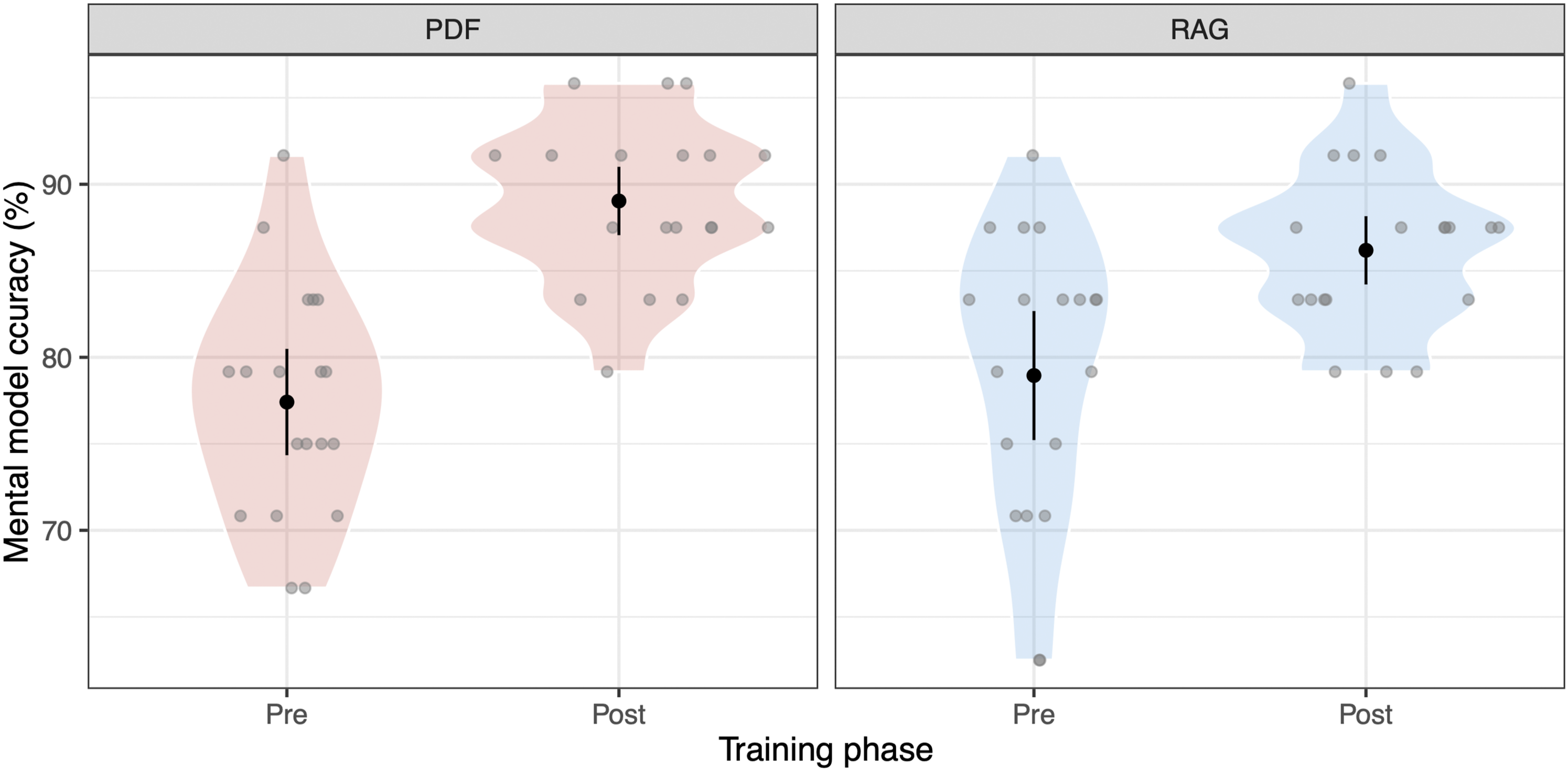
Second, to assess the effect of the manual type on learning outcomes while controlling for baseline knowledge, we fit a linear mixed-effects model to predict post-training mental model accuracy with manual type (PDF vs. RAG) and pre-training accuracy as fixed effects, with random intercepts for participants. While there was no significant effect of manual type on post-training accuracy (p = .13), pre-training accuracy was a significant positive predictor, t(223) = 6.07, p < .001, Marginal R2 = .15. This result indicates that participants who had a higher mental model accuracy before the training also achieved higher accuracy after the training, regardless of the manual type they used.
Qualitative Differences in Reasoning Patterns
Participants responded to four multi-feature scenario questions that assessed understanding of ADAS feature interactions (e.g., “If Active Steering Assist is in passive mode, how does it affect Active Lane Change Assist?”). Each question was followed by an open-ended prompt asking participants to briefly explain their reasoning. To examine qualitative differences in understanding that may not be captured by multiple-choice assessments, we applied STM to participants’ open-ended explanations for their reasoning. We examined the STM outcomes from three perspectives: (a) covariate effects, (b) vocabulary and keyword patterns, and (c) the distribution of topic proportions. The STM analysis revealed that while both training methods achieved similar quantitative outcomes, they fostered distinctly different reasoning approaches and depth of system understanding.
Covariate Effects
STM covariate effects
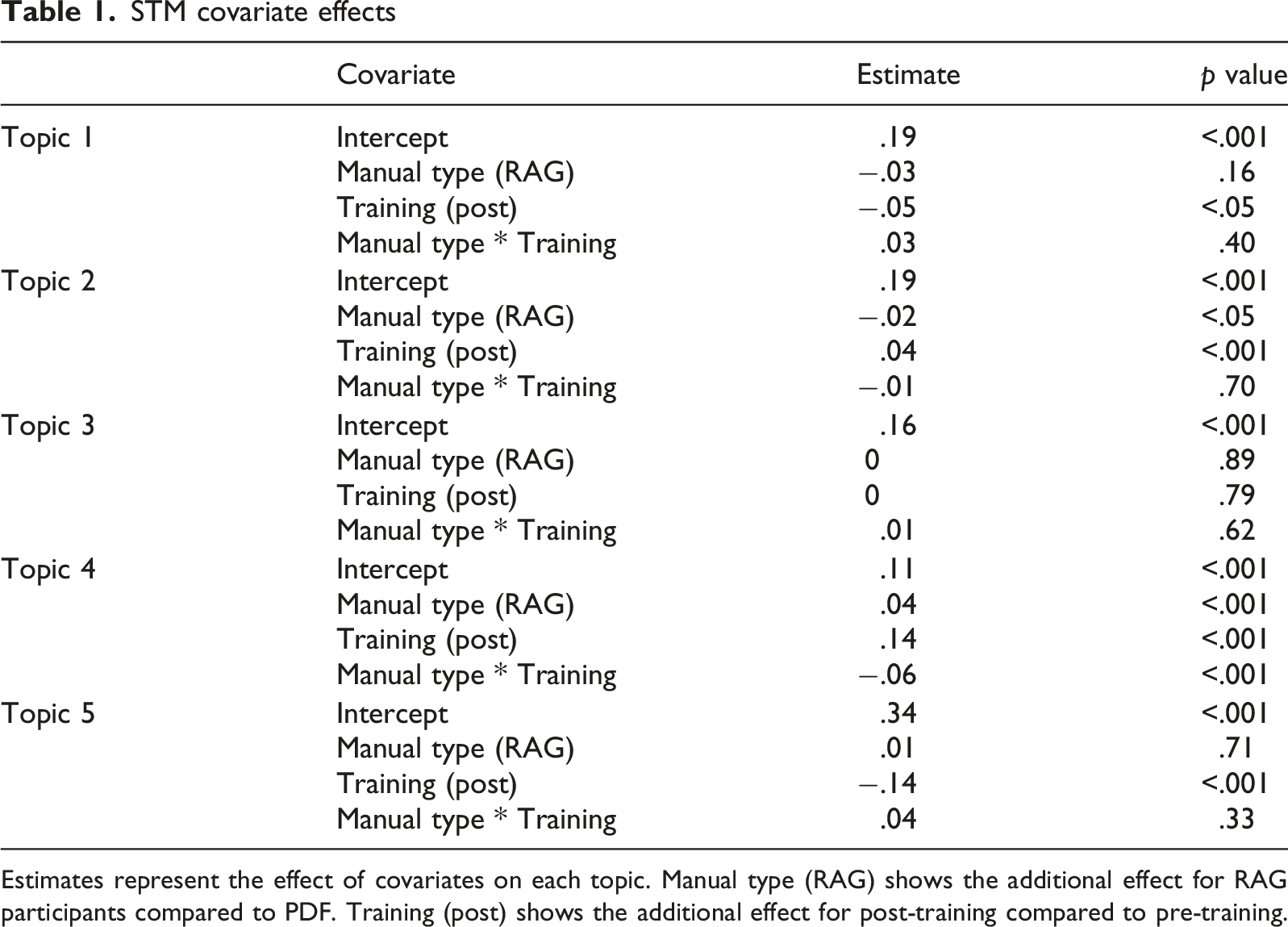
Estimates represent the effect of covariates on each topic. Manual type (RAG) shows the additional effect for RAG participants compared to PDF. Training (post) shows the additional effect for post-training compared to pre-training.
Five topics identified from participant responses with manual type and training phase covariates (Topic 2 is PDF-dominant and Topic 4 is RAG-dominant). Each topic displays four types of keywords: Prob (highest probability words), FREX (frequent and exclusive words), Lift (words with high lift scores), and Score (overall weighted importance)

Vocabulary and Keyword Patterns
Topic 1 is pre-training prevalent and represented by “uncertainty and name-based reasoning,” where participants rely on system names and basic logic while expressing explicit uncertainty with phrases like “based on,” “sounds like,” and “I don’t know.” Topic 2 is PDF-dominant and characterized by “simple behavioral control focus,” emphasizing individual system functions and basic control mechanisms. Topic 3 shows no group prevalence or dominance and represents technical function separation, demonstrating clear understanding of distinct system roles such as steering versus acceleration and braking functions. Topic 4 is RAG-dominant and reflects “integrated systems coordination,” showing sophisticated understanding of how multiple systems work “together” and “in conjunction” with systems-level thinking. Topic 5 is pre-training prevalent and characterized by “assumption and speculation-based responses,” with heavy reliance on assumptions and tentative speculation about system behaviors, particularly around lane-changing scenarios.
The key group differences emerge in Topics 2 and 4. PDF-trained participants showed higher engagement with Topic 2, developing mental models focused on simple control operations and individual system behaviors. In contrast, RAG-trained participants showed higher engagement with Topic 4, developing understanding of interactions between multiple ADAS features using language that emphasizes system coordination and conjunction.
Both topics 1 and 5 represent pre-training knowledge states characterized by inference-based reasoning, explicit uncertainty, and assumption-heavy speculation. Participants in pre-training conditions rely on system names, basic logic, and tentative assumptions rather than learned technical knowledge, indicating the baseline knowledge state before manual exposure and highlighting how training materials shape the development of more sophisticated mental models.
Distribution of Topic Proportions
Further analysis examining topic proportion distributions revealed distinct patterns for each identified topic, providing insights into how participants engaged with different aspects of automated driving systems across training conditions (Figure 4). Each topic showed unique prevalence and variability characteristics that reflect underlying cognitive processes and training effects. Distribution of topic proportions across individual responses for each of the five STM topics: Topic 1 (Uncertainty & name-based reasoning), Topic 2 (Simple control operations), Topic 3 (Technical function separation), Topic 4 (Feature Integration), and Topic 5 (Assumption & speculation-based reasoning). Black vertical lines indicate mean topic prevalence; red dashed lines indicate median values. Topics 2 and 4 show significant group differences: PDF participants engaged more with Topic 2 (individual system operations), while RAG participants engaged more with Topic 4 (multi-feature integration). Topics 1, 3, and 5 show comparable distributions across both groups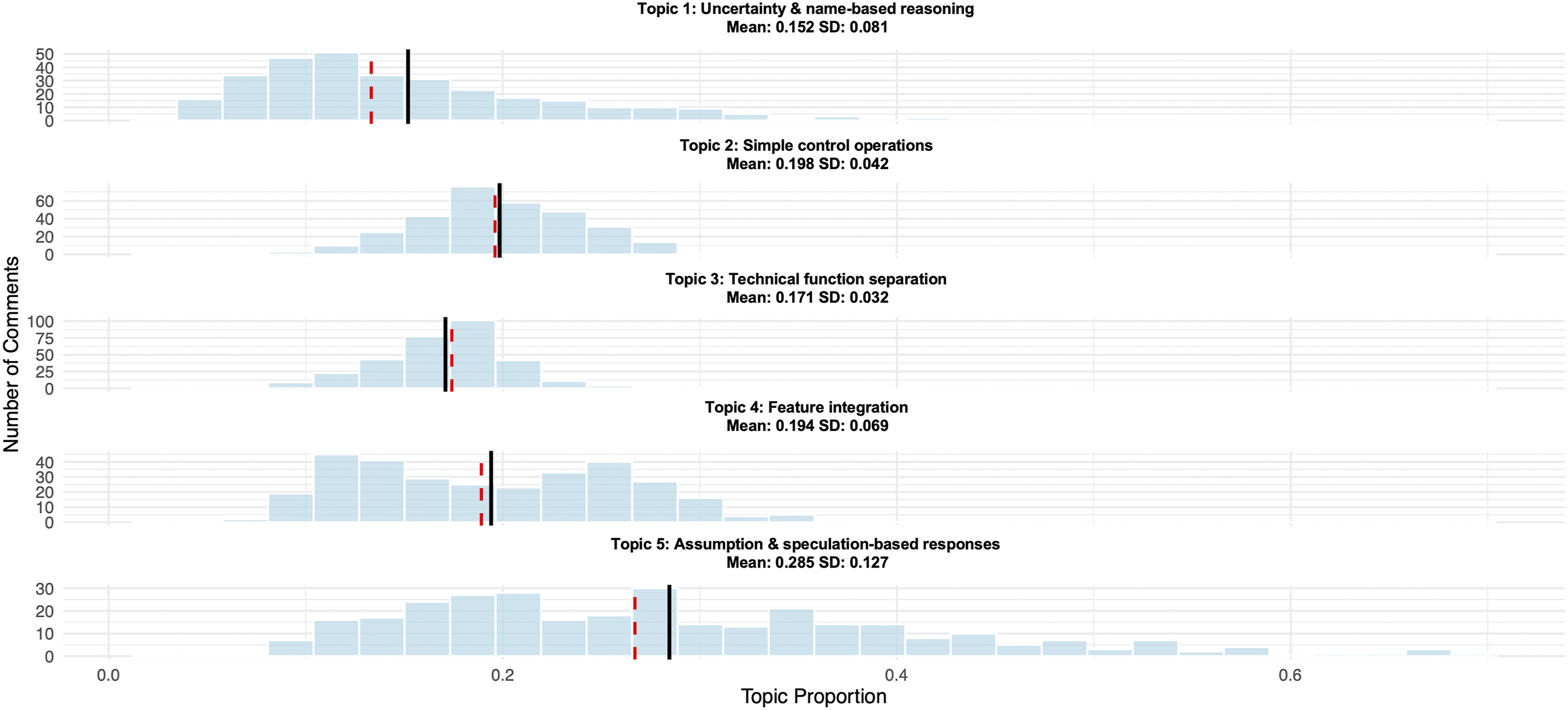
Topic 1 (Uncertainty & name-based reasoning) showed moderate prevalence (M = 0.15, SD = 0.08) with a right-skewed distribution. Most comments contained low proportions of this topic (10–15%), while some responses showed high proportions (up to 40%), indicating substantial individual variation in uncertainty-based reasoning.
Topic 2 (Simple control operations) demonstrated high prevalence (M = 0.2, SD = 0.04) with a narrow, bell-shaped distribution concentrated around 18–22%. This consistent pattern indicates uniform engagement with basic control concepts across participants. RAG-trained participants showed significantly lower engagement with this topic compared to PDF-trained participants (2.4% decrease, p = 0.04).
Topic 3 (Technical function separation) exhibited uniform distribution (M = 0.17, SD = 0.03) with the lowest variability across all topics. The narrow distribution indicates consistent engagement with functional decomposition concepts regardless of individual or training differences.
Topic 4 (Feature integration) displayed a bimodal distribution (M = 0.19, SD = 0.07) with distinct peaks around 15% and 25% topic proportion. RAG-trained participants showed significantly higher engagement with this topic compared to PDF-trained participants (4.2% increase, p < .001). Participants showed substantial increases in integration reasoning following training (14.5% increase, p < .001). The bimodal pattern suggests the presence of two distinct subgroups with different levels of integration thinking, though the specific characteristics of these groups require further investigation.
Topic 5 (Assumption & speculation-based responses) showed the highest prevalence (M = 0.29, SD = 0.13) with the greatest variability. The wide distribution extending to 70% topic proportion indicates substantial individual differences in reliance on assumption-based reasoning when discussing automated driving systems.
Technology Acceptance for Learning Methods
The overall relationship between TAM constructs was tested by using a multi-group path analysis. This analysis tests the complete theoretical framework simultaneously and examines the critical mediating role of Attitude in the model (Figure 5). Multi-group path analysis of the Technology Acceptance Model for the PDF and RAG training groups. Rectangles represent the observed variables: PU (Perceived Usefulness), PEU (Perceived Ease of Use), AT (Attitude Toward Using), and BI (Behavioral Intention), with the mean score for each construct shown inside. The values on the arrows are the unstandardized regression coefficients (B), indicating the strength of the relationship between variables. Cyan arrows denote a positive relationship, while red arrows denote a negative one. The values inside the circular nodes indicate the residual variances for each variable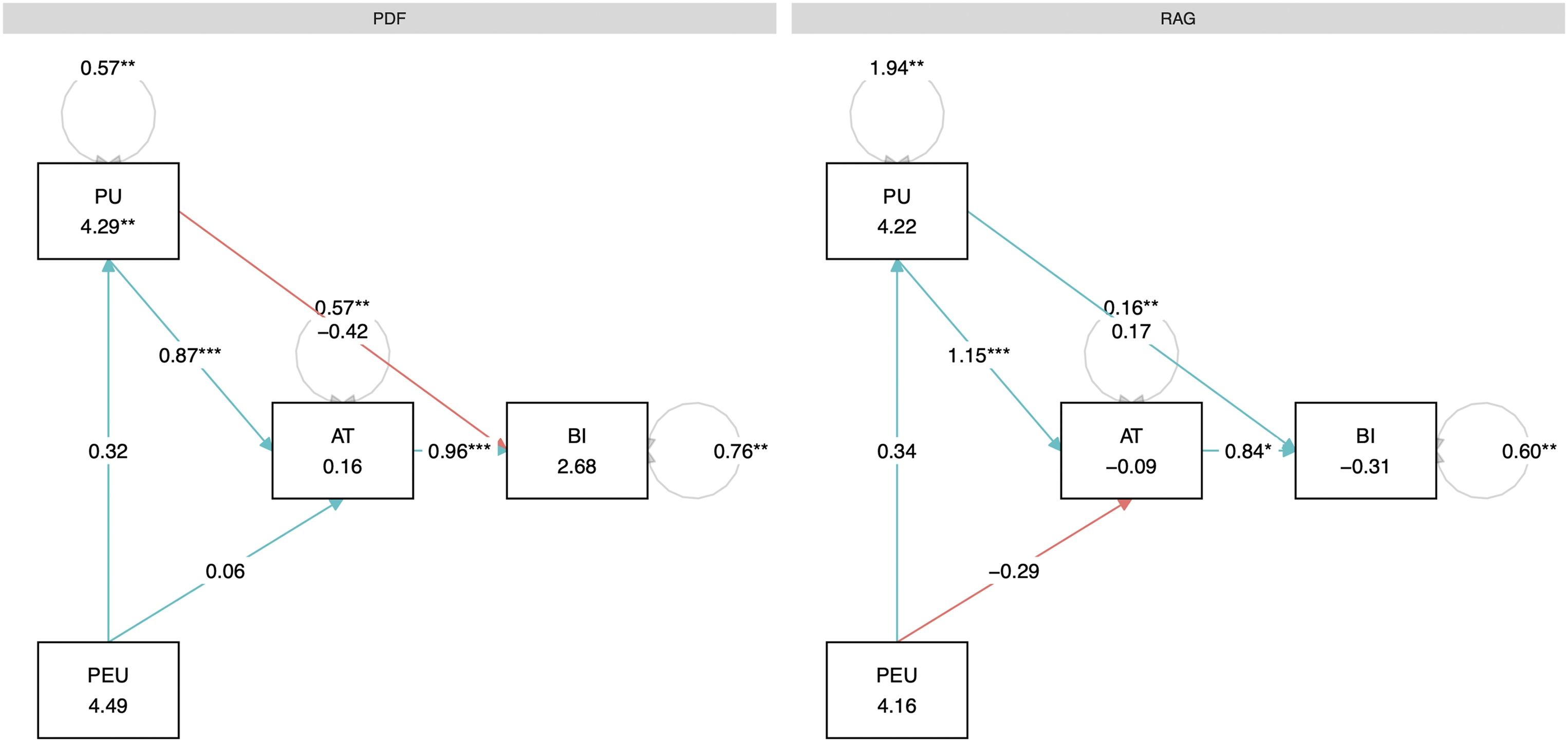
The multi-group path analysis showed excellent mode fit, χ 2 (2) = 0.39, p = .83, CFI = 1.00, TLI = 1.10, RMSEA = .00 (90% CI [.00, .27]), SRMR = .02. For both groups, Perceived Usefulness (PU) predicted Attitude (AT), which predicted Behavioral Intention (BI), while Perceived Ease of Use (PEU) was non-significant. Chi-square difference tests confirmed that the strengths of the key predictive paths within the TAM framework did not statistically differ between the PDF and RAG manual conditions. Constraining the path from Perceived Usefulness to Attitude to be equal across groups did not result in a significant change in model fit, Δχ 2 (1) = 1.33, p = .25. Similarly, constraining the path from Attitude to Behavioral Intention also did not result in a significant change in model fit, Δχ 2 (1) = 0.05, p = .82.
Discussion
This study demonstrates that AI-powered interactive manuals can achieve comparable learning effectiveness to traditional PDF manuals while fostering more sophisticated reasoning patterns among participants. Both learning methods proved effective for ADAS knowledge acquisition, consistent with previous research demonstrating the viability of documentation-based learning approaches (Forster et al., 2019; McDonald et al., 2017). The absence of significant differences in quantitative mental model accuracy between PDF and RAG conditions confirms that interactive AI systems can maintain the established effectiveness of traditional manuals while offering benefits related to accessibility and usability.
One contribution of this research is demonstrating how STM can reveal meaningful differences in learning outcomes that traditional assessment methods may fail to capture. Multiple-choice accuracy and STM offer complementary perspectives on mental models: accuracy measures whether participants can identify correct answers, while STM captures the reasoning structures underlying those answers. Participants who achieve the same accuracy score may rely on fundamentally different mental models—one based on memorized control operations and another on integrated systems-level understanding. For instance, feature interaction accuracy did not differ significantly between conditions (RAG: 86.4%, SD = 10.4%; PDF: 81.7%, SD = 12.9%; t(19.14) = −0.94, p = .36, d = .40), limiting the sensitivity of multiple-choice assessment for distinguishing how participants reason about ADAS feature interactions. STM analysis quantified distinct reasoning patterns that demonstrate the qualitative advantages of interactive AI documentation. The most notable difference emerged in Topic 4 (Feature Integration), where RAG-trained participants showed more sophisticated systems-level thinking. RAG users developed mental models emphasizing how multiple ADAS features “work together” and operate “in conjunction,” while PDF users focused more on individual system functions and simple control operations (Topic 2). STM provided insights into how users conceptualize and reason about complex systems, revealing advantages of AI-augmented documentation that would otherwise remain hidden.
These qualitative advantages must be weighed against potential risks inherent in RAG systems. The “synthesis paradox” describes a tension in effective RAG: when AI produces coherent, well-cited summaries, users may trust the synthesis without critically evaluating source material (Lee, 2026). For ADAS training, users accepting AI-synthesized explanations without engaging underlying documentation may develop superficial mental models that fail under novel circumstances. Our implementation addressed this concern by displaying source citations with every response, showing users which sections of the owner’s manual informed each answer. This design encourages source engagement by making the connection between AI responses and authoritative documentation explicit and verifiable. Trust calibration—developing appropriate reliance that neither dismisses accurate information nor accepts responses uncritically—remains an important consideration for RAG-based learning systems.
Regarding the user perception component of RQ2, the multi-group path analysis confirmed that both learning methods follow similar psychological processes for user acceptance, with perceived usefulness serving as the primary driver of positive attitudes and behavioral intentions. The analysis revealed no significant differences in the strength of key relationships between groups; however, the absence of significant differences does not confirm equivalence. With a sample size of 38 participants, the multi-group path analysis had adequate power to detect medium-to-large effects in path differences but limited power for detecting small effects. Future research with larger samples could employ Bayes Factor analysis to more definitively distinguish between equivalent paths and insufficient statistical power. It is worth noting that the amount of information participants acquired in this study was relatively limited, covering only four ADAS features out of the 11 available. We expect that when the volume of learning materials increases, perceived usefulness and ease of use might change along with attitudes and intention to use different learning methods. Specifically, with larger volumes of information and learning content, the interactive aspects of RAG tools could become more beneficial due to their ability to summarize content, contextualize information, and customize responses to individual user needs.
Several observations from this study point to the potential for further enhancement of RAG-based documentation systems. To isolate the core conversational capabilities of the RAG system, we disabled two key features of the RAG tool: knowledge graph showing relationships between topics and contents, and a self-testing feature that allows users to take quizzes on selected features to assess their understanding. Activating these features could enhance both learning effectiveness and user acceptance of the learning method. Post-study survey feedback revealed specific user needs that align with the RAG tool’s capabilities. Participants requested an overview of available contents similar to a table of contents, which could be fulfilled through knowledge graph or concept map features. PDF group participants noted difficulties in quickly navigating the manual, which interactive knowledge graphs could address by allowing users to visualize available features and navigate to specific content through direct interaction.
During the study, we observed variability in RAG tool usage patterns between participants. While some participants fully utilized the system with diverse questions and customized responses for better understanding, others struggled to formulate appropriate queries. This suggests that the tool’s usefulness depends partly on users’ familiarity with generative AI, indicating that future development should focus on making the tool more proactive in guiding users toward their learning goals. Additionally, effective AI systems require not only technical sophistication but also mechanisms to detect and overcome miscommunication between users and AI systems (Cros Vila & Sturm, 2025). To better understand the effectiveness of RAG-based tools, future research should collect usage logs, including types of questions asked, system responses to each query, and the number of conversational turns required. This study used fixed learning duration for both groups, but several RAG participants completed their learning process before the allocated 20 min, suggesting that learning time could serve as a dependent variable or be tracked within fixed durations to provide additional insights into learning effectiveness.
Future implementations of RAG-based documentation systems would benefit from systematic evaluation frameworks. The RAGAS (Retrieval-Augmented Generation Assessment) framework (Es et al., 2024) provides structured evaluation through metrics including faithfulness (whether responses accurately reflect retrieved content), context relevance (whether retrieval identifies appropriate segments), and answer relevance (whether responses address the user’s question). Applying such frameworks during system development could help optimize retrieval parameters and validate response quality before deployment in safety-critical domains.
Several limitations should be considered when interpreting these findings. First, this study tested a single RAG system developed for one vehicle manufacturer’s documentation; generalizability to other RAG implementations, vehicle types, and documentation styles remains to be established. Second, the user interface design likely influenced how participants interacted with the RAG system—the simple text-based interface prioritized accessibility but may not represent optimal designs for all user populations. Third, this study examined immediate learning outcomes; whether RAG-trained users maintain their systems-level understanding over time or transfer it to real-world ADAS use requires longitudinal investigation. Finally, while we assessed knowledge acquisition, this study did not measure participants’ willingness to engage with manuals outside experimental contexts. Research on whether AI-based systems increase voluntary engagement with technical documentation would address an important antecedent to the learning outcomes examined here.
Conclusion
This study addressed two key research questions about AI-powered interactive manuals for ADAS education. Regarding the first question of how AI-powered interactive manuals compare to traditional static manuals in supporting drivers’ understanding, our findings demonstrate that both approaches achieve comparable quantitative learning effectiveness. This confirms that AI-augmented documentation maintains the established effectiveness of traditional manual-based learning approaches. For the second research question about qualitative differences in reasoning patterns and user perceptions, STM revealed distinct cognitive approaches despite similar quantitative outcomes. RAG-trained participants developed significantly more sophisticated systems-level thinking, emphasizing feature integration and coordination between multiple ADAS systems. This is particularly valuable for safety-critical systems where understanding system interactions is essential for appropriate use. TAM analysis showed that both methods operate through similar psychological mechanisms, with perceived usefulness driving user acceptance in both cases.
The research makes several key contributions to the field. First, it establishes that AI-augmented documentation can serve as an effective enhancement to traditional learning, maintaining proven educational effectiveness while providing qualitative improvements. Second, it demonstrates the methodological value of STM for detecting meaningful differences in learning outcomes that conventional multiple-choice assessments cannot capture. Third, it provides empirical evidence that interactive AI systems guide users toward more sophisticated mental models of complex automated systems, particularly in developing systems-level integration thinking.
For future research, longitudinal studies examining how different documentation approaches influence long-term retention and real-world system use would provide valuable insights into the practical benefits of AI-augmented technical documentation.
As vehicle automation continues to evolve in complexity, the need for effective driver education approaches becomes increasingly important. This research provides evidence that AI-powered interactive documentation can meet this challenge while building upon the established foundation of effective traditional learning methods.
Keypoints
• AI-augmented interactive manuals achieve comparable learning effectiveness to traditional documentation while fostering superior systems-level thinking in complex technical domains • RAG-based interactive systems guide users toward integrated understanding of feature interactions rather than isolated system functions • Structural topic modeling reveals qualitative differences in reasoning patterns that conventional multiple-choice assessments cannot detect • Both traditional and AI-augmented documentation operate through similar psychological acceptance mechanisms, with perceived usefulness driving user adoption.
Footnotes
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This study was supported by the Toyota Collaborative Safety Research Center.
Declaration of Conflicting Interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.