
Abstract
Background
Prior work on trust in multi-component systems has proposed two competing perspectives: system-wide trust (SWT) versus component-specific trust (CST). SWT argues that individuals view multiple agent teammates as interconnected parts of a single “system,” and thus trust in one agent spills over to others; CST, in contrast, argues that trust is evaluated on a component-by-component basis. However, existing studies have largely overlooked individual differences in these trust evaluation patterns.
Method
We conducted a lab study with 30 two-human-two-agent teams performing collaborative block-moving tasks. Teams completed 10 trials each under three agent reliability pairing conditions: perfect (both agents reliable), mixed (one reliable and one unreliable), and imperfect (both unreliable). After each trial, participants rated trust in each teammate and the team, while communication logs and task completion times were recorded. We first evaluated individual variability and classified participants based on how trust in one agent changed as a function of paired-agent reliability. Subsequently, we examined how these influenced communication behaviors and performance.
Results
We identified three distinct trust bias patterns: assimilation (trust becomes more similar across agents, consistent with SWT), no bias (trust remains independent across agents, consistent with CST), and contrast (trust becomes more differentiated between agents). These were associated with different communication strategies and reliance behaviors, which in turn affected team performance.
Conclusion
Trust in multi-agent HATs cannot be fully explained by SWT or CST alone but instead varies with how individuals comparatively evaluate autonomous agents.
Application
The findings provide a foundation for developing personalized trust bias mitigation.
Keywords
Introduction
With the increasing adoption of autonomous technologies across diverse domains, research on human–agent teams (HATs) has expanded from dyadic interactions to multi-agent collaborations to better reflect real-world complexity (Chung et al., 2026; Chung & Yang, 2026, 2026b; Guo et al., 2024; O’Neill et al., 2022). This shift highlights the need to understand how humans trust across multiple autonomous agents, as proper trust is essential for effective collaboration.
Two primary perspectives have been proposed to explain how operators form trust judgments in multiple automated or autonomous systems: system-wide trust (SWT) and component-specific trust (CST). SWT suggests that individuals view multiple systems as interconnected components of a single “system,” such that trust in one element can be influenced by the performance or reliability of others. Empirical work has often supported SWT, showing that unreliable elements can exert a pull-down effect on even perfectly reliable ones (e.g., Capiola et al., 2022, 2024). In contrast, CST proposes that trust is formed on a component-by-component basis, with each element evaluated independently based on its performance (Keller & Rice, 2009). While the majority of prior studies have supported SWT, some evidence indicates that operators with greater domain knowledge may be less susceptible to the SWT heuristic and exhibit CST (Lopez & Pak, 2020; Lyons et al., 2024).
In this study, we wish to offer a novel perspective to explain the seemingly mixed results. Human judgment is inherently comparative and can be shaped by cognitive biases (Mussweiler, 2003). Social judgment theory posits that people evaluate a target by referencing contextual cues and standards (Ledgerwood & Chaiken, 2007). Attention to similarities tends to produce an assimilation effect (the target is perceived as more similar to the reference), whereas attention to differences yields a contrast effect (the target is perceived as more different). Prior research further suggests that whether assimilation or contrast occurs depends on situational cues individuals attend to and individual dispositions (Bless & Burger, 2016; Mussweiler, 2003).
Despite this, research on trust biases in multi-agent HATs has not fully examined individual variability. While group-level patterns provide useful insights, individual differences may exist in whether each operator exhibits assimilation, contrast, or no discernible bias. Understanding how these patterns relate to team dynamics is crucial for designing personalized bias mitigation strategies and optimizing team performance. Accordingly, in this study, we adopt an exploratory approach to examine trust bias in multi-agent HATs with a focus on individual differences. We investigate three possible trust bias patterns: assimilation, no bias, and contrast.
We begin by reviewing relevant work on cognitive biases (assimilation and contrast effects) and extend this discussion to trust heuristics in multi-agent settings in HAT (SWT and CST). Subsequently, we review prior studies on the relationships between trust bias and performance.
Social Judgment Theory and Cognitive Biases: Assimilation and Contrast Effects
Human judgment inherently involves comparative processes in which individuals assess stimuli relative to their contextual surroundings (Ledgerwood & Chaiken, 2007; Mussweiler, 2003). According to social judgment theory, such comparative evaluations can lead to cognitive biases characterized by assimilation or contrast effects (Bless & Burger, 2016). The assimilation effect occurs when a target stimulus is perceived as more similar to the surrounding context than it objectively is. In contrast, the contrast effect arises when differences between the target and its context are amplified, leading to a perception of marked dissimilarity (Mussweiler et al., 2004).
Prior research has examined the information processing mechanisms underlying these effects. During a holistic evaluation of the similarity between a target and a reference standard, individuals draw upon a variety of accessible information such as situational cues, normative standards, and personal dispositions (Mussweiler, 2003). When they perceive that the available information emphasizes commonalities, a process of similarity testing is activated, selectively giving attention to features that indicate alignment between the target and its context. This process typically produces an assimilation effect. Conversely, when they perceive that the information underscores differences, dissimilarity testing predominates, which in turn promotes a contrast effect by accentuating the distinctiveness of the target.
A parallel line of inquiry has focused on factors that determine the magnitude and direction of these comparative influences. Although situational factors such as the availability and salience of contextual cues are undoubtedly significant (Mussweiler, 2007; Mussweiler & Damisch, 2008; Stapel et al., 1998), individual differences in information processing also play a critical role (Bless & Burger, 2016; Förster et al., 2008), which is a particular focus of this study. For instance, individuals who adopt a global processing style and place greater emphasis on identifying the relationship between a target and the group tend to attend more to the overall situational context (Oyserman & Lee, 2008). This global focus makes them more likely to evaluate a target relative to its surrounding stimuli, thereby exhibiting pronounced cognitive biases. Furthermore, these individuals may often rely on their preexisting assumptions and knowledge in information processing and evaluation. This will guide their selective attention toward cues that support either similarity or dissimilarity between the target and the contextual standard, which may result in assimilation or contrast bias, respectively.
Trust Bias in HAT: System-Wide Trust (SWT) and Component-Specific Trust (CST)
The abovementioned cognitive biases can be extended to explain human trust bias in HAT, particularly in multi-agent teaming situations where there are multiple agent teammates. In fact, an ongoing debate has emerged on whether humans adopt a heuristic strategy of viewing a set of agents holistically or assessing each agent individually (Keller & Rice, 2009; Lopez & Pak, 2020; Lyons et al., 2024). The former perspective is articulated in terms of System-Wide Trust (SWT), arguing that individuals view multiple agent teammates as interconnected parts of a single “system,” where trust in one can be affected by the performance or reliability of others. In most prior empirical studies supporting SWT, trust spillover has been observed, such that the presence of unreliable elements results in a pull-down effect on even the perfectly reliable element (e.g., Capiola et al., 2022, 2024; Foroughi et al., 2019). For example, Walliser et al. (2023) demonstrated that a single autonomous agent with 70% reliability led participants to rate lower trust in the other three agents with perfect reliability during a target identification task, and this effect was more pronounced when system accuracy and error attribution information were not provided. Similarly, Geels-Blair et al. (2013) found that when participants monitored eight gauges, each augmented by an automated aid, the presence of one aid with 70% reliability reduced compliance and reliance on the other aids, which actually exhibited 100% reliability. Applying the social judgment theory, this can be interpreted as the occurrence of assimilation bias, where a perfectly reliable element is depreciated under the assumption of similarity between the reliable and the unreliable elements.
In contrast, a few studies support the Component-Specific Trust (CST) perspective, which suggests that trust is evaluated on a component-by-component basis, with individuals assessing and trusting each element independently based on its performance (Keller & Rice, 2009). Unlike many studies that support SWT, several studies argue that operators with greater domain knowledge and more decision-making freedom may be less susceptible to trust bias (Lopez & Pak, 2020). For instance, Lyons et al. (2024) conducted a flight simulator study with experienced fighter pilots. In this study, pilots were tasked with monitoring four collaborative combat aircrafts (CCAs) and selecting one to perform targeting missions. Their results indicated that an error in one CCA reduced trust only in that specific CCA and did not significantly affect trust in the other CCAs. In terms of cognitive bias, this CST perspective can be interpreted as not resulting in any bias (i.e., no bias). Alternatively, if, during the evaluation process, operators focus more on the dissimilarity between different elements, they are prone to the contrast bias. In this situation, they will even rate their trust as significantly higher for the perfect agent if it is paired with an imperfect one compared to another perfect one, or significantly lower for the imperfect agent if it is paired with a perfect one compared to another imperfect one.
Trust Bias and Performance
In HAT research, understanding trust bias is important as inappropriate trust bias can be detrimental to overall task performance (Parasuraman & Riley, 1997). For example, several studies have shown that the trust pull-down effect further degrades performance (e.g., response times and task accuracy) (e.g., Bean et al., 2011; Keller & Rice, 2009; Rice & Geels, 2010). In a study by Walliser et al. (2016), the presence of a UAV with 70% reliability led to significantly delayed responses for three other UAVs with 100% reliability. Due to the trust pull-down effect, operators monitored even the highly reliable UAVs more closely, diverting limited attentional resources to less critical tasks, and consequently exhibited poorer overall performance.
Accordingly, recent studies have begun evaluating various trust bias mitigation strategies aimed at reducing potential bias. Several strategies have been developed, including providing transparent information about agent reliability and offering training on how to correctly evaluate each agent independently (Beck et al., 2007; Rice & Geels, 2010; Walliser et al., 2016, 2023). Additionally, some approaches directly leverage the information processing mechanism underlying the assimilation bias by increasing the dissimilarity between elements, which is expected to discourage similarity testing (Mussweiler, 2003). For example, studies have examined whether designing automated elements with visually distinctive shapes, colors, and sizes can reduce trust assimilation behaviors (Bean et al., 2011; Ross, 2008). Similarly, a recent study on trust in smart home multi-component systems showed that people evaluate each component independently when each component is associated with an agent with a distinct voice, making the components highly distinguishable from one another (Lopez et al., 2023).
Despite existing research, research on the associations between distinct trust bias patterns and task performance remains largely underexplored. Although individual differences in information processing can significantly influence susceptibility to trust bias (Bless & Burger, 2016), most existing mitigation strategies assume a uniform bias pattern. Accounting for the individual differences is needed to design personalized mitigation strategies.
The Present Study
The present study takes an exploratory approach to examine individual variability in trust bias. We primarily aim to determine whether individual differences are significant and to further examine the distribution of individuals across distinct trust bias patterns.
To examine how operators evaluate multiple agents, we designed a multi-agent HAT scenario where two humans collaborated with two agents to complete block-moving tasks. Humans located target blocks and issued commands, while agents delivered them. The within-subjects design included three reliability pairings: perfect (both perfectly reliable, i.e., 100% reliability), mixed (one 100%, one 50%), and imperfect (both imperfect, i.e., 50% reliability). These pairings allow us to observe two trust bias types: (1) changes in ratings of a perfect agent based on its paired agent’s reliability and (2) changes in ratings of an imperfect agent based on its paired agent (Figure 1). For both, we aim to identify individual patterns, assess which pattern is more prevalent, and classify participants accordingly. We then examine how trust bias patterns affect teamwork, specifically, how they influence communication with agents of different reliability and team performance. Illustration of possible trust bias patterns in the evaluation of perfect and imperfect agents, depending on the reliability of the paired agent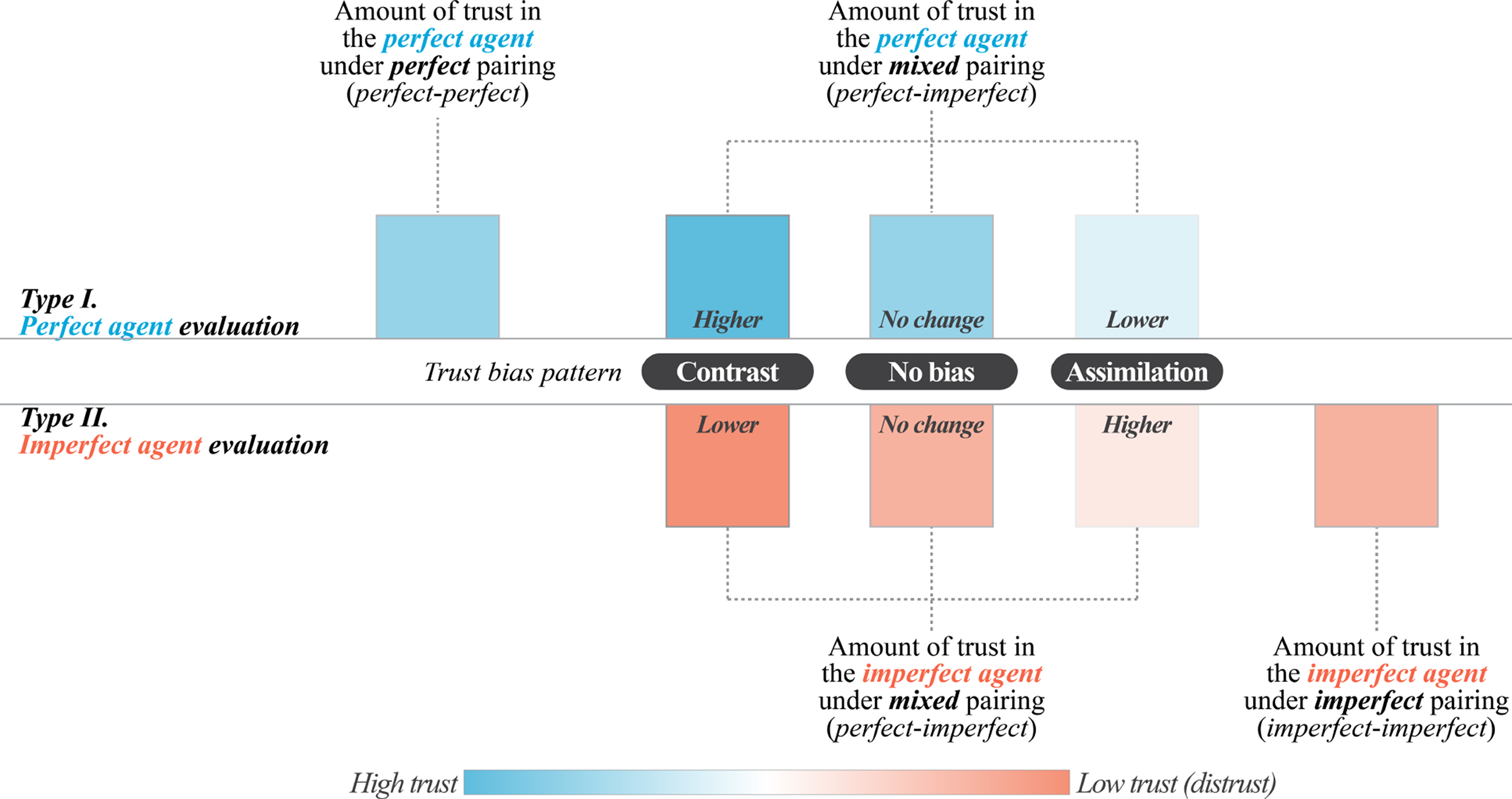
Regarding team composition, the study employed a two-human setup to better reflect realistic multi-human, multi-agent teaming contexts. In many real-world HAT environments, such as flight decks or factories operating UGVs, multiple operators collaboratively interact with several autonomous agents. In these environments, multiple agents are actively monitored and manipulated, and operators form evaluations of each agent through both direct and indirect experiences. Accordingly, this setup enabled us to examine trust bias toward agents under ecologically valid conditions. Additionally, this setup allows us to explore some analyses at the team level.
Method
Participants
A total of 60 participants with normal or corrected-to-normal vision and no color blindness (age: 21.6 ± 3.77 years) participated in this study. They were randomly assigned to teams of two. This research complied with the American Psychological Association Code of Ethics and was approved by the Institutional Review Board at the University of Michigan. Informed consent was obtained from each participant.
Blocks World for Team (BW4T) Testbed
For this study, we used our re-created version of the BW4T testbed (Chung & Yang, 2025b). Using this web-based testbed, two humans (assigned player IDs 1 and 2) had to collaborate with two agents (denoted as players 3 and 4) to complete a block-moving task.
Experimental Task
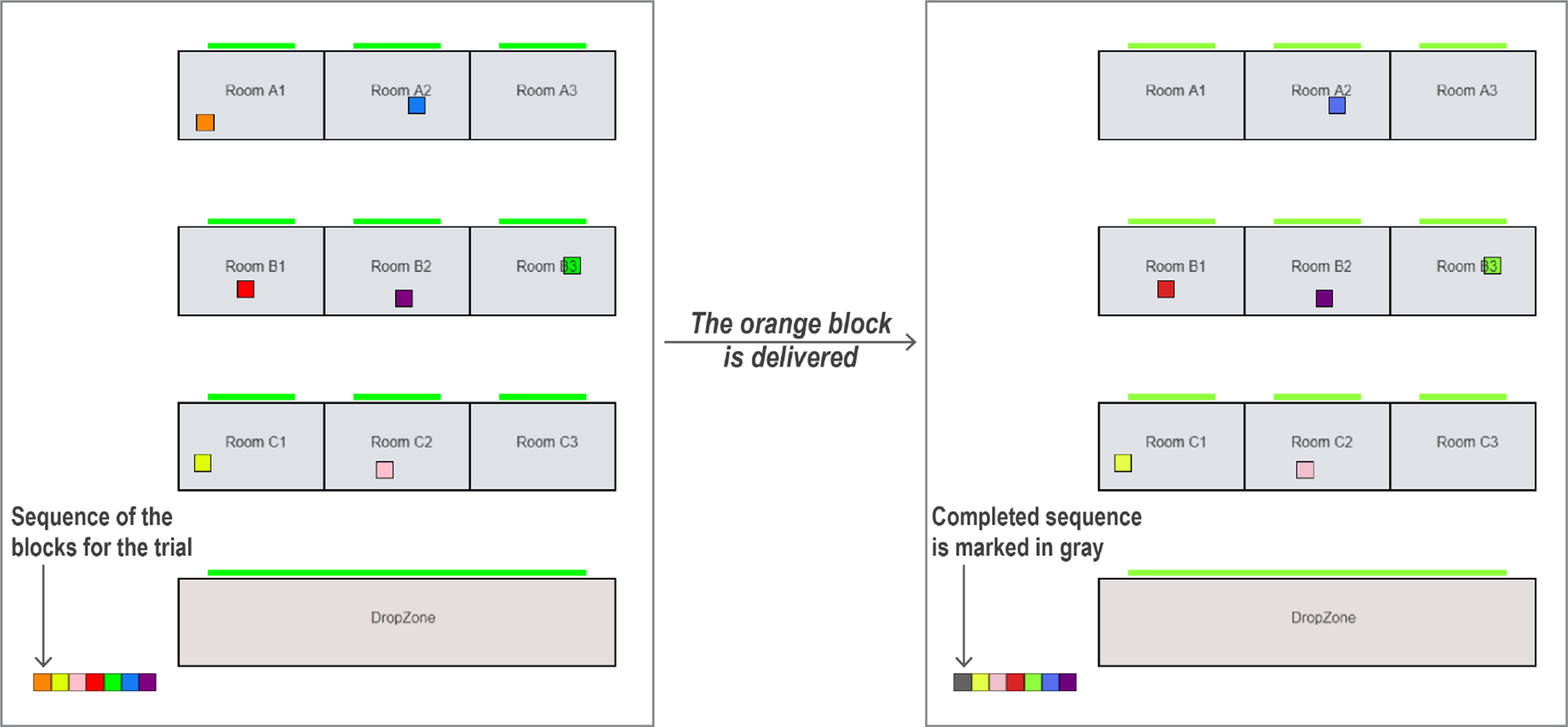
The task requires locating, delivering, and stacking seven colored blocks in the order shown on the screen (Figure 2). Blocks are randomly placed in nine rooms (Figure 3). Only players inside a room can see its blocks, and once occupied, other players cannot enter the room. Human players are tasked with searching the rooms, finding the correct blocks, and directing agent players to pick up and deliver them. BW4T testbed used in the study. The figure shows a screenshot from the perspective of one of the participants (Player 1) during the task. Player 1 is currently inside Room A2, and they see that Room A2 contains a blue block. Player 2 is inside Room B1, but Player 1 cannot see which blocks are inside Room B1. The red doors indicate that the rooms A2 and B1 are occupied. Player 1 issued a command to Player 3 to “Check Room A1,” and in response, Player 3 picked up an orange block from Room A1 and is currently en route to deliver it to the drop zone. The example illustrates the distribution of seven colored blocks across nine rooms in the trial shown in Figure 2. The trial begins with an orange target block located in Room A1 (see the left figure). Once it is delivered to the drop zone, the completed sequence is marked in gray (see the right figure), and Room A1 becomes empty. The next target block is a yellow block. Note that this example represents a single trial, and unique random configurations were assigned for each trial.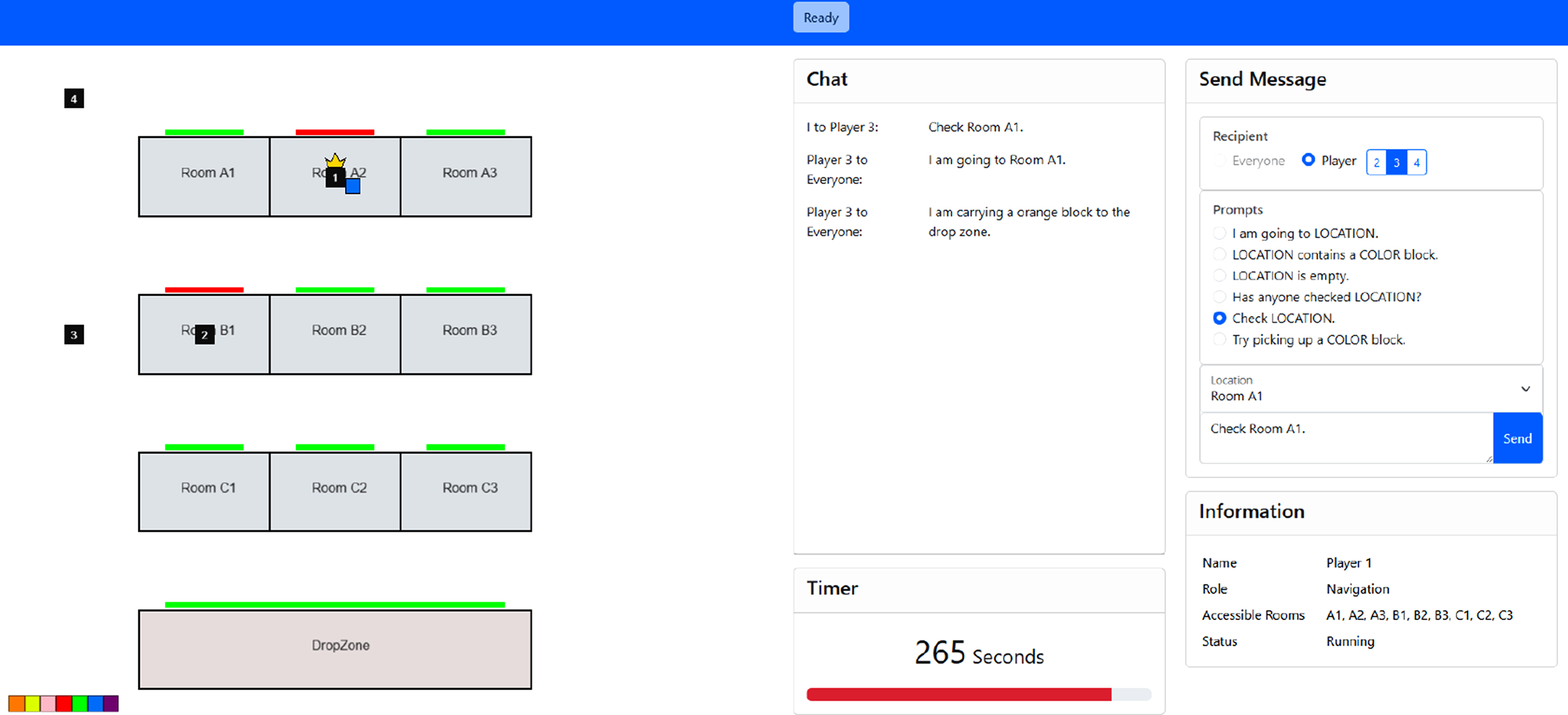
Communication
During the experiment, players communicated via a chat panel (Figure 2). Humans could message specific teammates by selecting their ID, typing freely or using templates to their human teammates, and sending fixed commands (“Check room [room id]” or “Try picking up a [color] block.”) to agents. Agents automatically broadcast their updates to all players, and all messages appeared in the chat inbox window.
Agent Characteristics
We developed the agents using a finite state machine so that they act based on predefined rules. Each agent is programmed to respond instantly to one of two specific commands from human players: “Check room [room id]” or “Try picking up a [color] block.”
In response to the “Check room [room id]” command, the agent visits the designated room, and if it contains a target-colored block, picks it up and delivers it. For the “Try picking up a [color] block” command, the agent searches all rooms in ascending room ID order until it finds and delivers a block of the requested color.
We allowed the agents to be set to different reliability levels. Upon receiving a command, they decide whether to act on it with a probability p, which denotes their reliability levels. Then, they initiate actions and broadcast any updates to all players. When an agent receives multiple commands, it handles them in the order they arrive.
Experimental Design
We manipulated the agent reliability pairing condition as a within-subjects variable with three levels: perfect (both have 100% reliability), mixed (one 100%, one 50%), and imperfect (both 50%). Each team completed three blocks (10 trials each), one per condition. The order of the reliability pairing conditions was counterbalanced across teams using a Latin square design, resulting in six unique order sets, with five teams (i.e., ten participants) randomly assigned to each set. In the mixed condition, the assignment order of the perfect and imperfect agents (i.e., player IDs) was also randomized across teams. Additionally, to reduce carryover effects, each trial featured a unique configuration of block order and locations, and the difficulty of these configurations was controlled to be similar through pilot simulations.
Measures
We collected the participants’ trust evaluations on each teammate and the team as a whole. Two types of trust ratings were collected: post-trial and post-condition. After every trial, participants filled out a paper-based survey rating their trust in their human teammate [play 1 or 2], agent 1 [player 3], agent 2 [player 4], and the team (on a scale of 0–100). The prompt asked: “How much do you trust that [referent] helps you achieve your goal?” Participants provided integer answers. Also, after each condition, participants filled out McAllister (1995)’s interpersonal trust scale for each teammate. They also completed the team trust survey by Costa and Anderson (2011). In order to identify individual trust bias patterns, we mainly focus on post-trial trust ratings in the two agents.
We also quantified the communication by counting the frequency of messages each human player sent to each recipient in every trial.
Additionally, task performance was evaluated by the time taken to complete each trial and the number of wrong blocks loaded into the drop zone (i.e., error). Task completion time was defined as the duration (in seconds) from the start of the trial to the successful placement of the final block in the sequence. Task error was defined as the number of incorrect blocks that were delivered and dropped off at the drop zone.
Experimental Procedure
Prior to the experiment, participants provided informed consent, completed a demographic survey, and received instructions.
Each participant performed individually on a separate desk with a partition. In order to get familiar with the interface and agent logic, they completed a practice session with four sample trials featuring agents with extreme reliability levels. It was emphasized before and after the practice that these examples are for illustration purposes only and do not reflect actual experimental reliability. Participants then completed three experimental blocks (30 trials total), followed by a debrief and compensation. The base compensation rate was $35 with a chance to earn a performance-based bonus up to $15.
Data Analyses and Results
In this study, we focus on identifying individual differences in trust bias patterns, as personalized bias mitigation strategies may be necessary to enhance team performance. Thus, rather than examining overall trends by aggregating data across individuals, we aim to understand trust bias at the individual level. To this end, we adopt an N-of-1 trials evaluation framework, a method widely used in medical research, gait analysis, and behavioral studies where the focus is on assessing the effect of an intervention or variable of interest on a specific individual (Nikles & Mitchell, 2015; McCallum et al., 2019). A key advantage of the N-of-1 approach is its ability to detect differential effects across individuals. This enables the development of personalized applications by defining target user groups and tailoring interventions, designs, or treatments. Since each participant provides multiple data points for each condition in the current experiment, the N-of-1 approach allows us to evaluate the effect of each condition at the individual level.
Following a similar approach used by Bequette et al. (2020), which investigated individual variability in the effects of a powered exoskeleton on physical and cognitive load, we first assessed whether the participant effect is statistically significant. Once confirmed, we analyzed each participant’s trust bias pattern for both bias types: evaluating a perfect agent and evaluating an imperfect agent. Specifically, for each participant, we examined whether there is a significant difference in trust ratings toward agents of the same reliability, depending on whether they were paired with a perfect or an imperfect agent. This is tested using a linear model. For individuals showing a significant difference, we further classified them based on the direction of the effect. As a result, each participant was assigned to one of three trust bias patterns for each type.
To mitigate the risk of false positives arising from 120 individual tests (60 participants × 2 bias types), we applied false discovery rate (FDR) correction to the p-values. Specifically, we used the Benjamini–Hochberg procedure (Benjamini & Hochberg, 1995) to adjust p-values for all trust bias classification tests.
Following the individual trust bias patterns assignment, we examined whether communication frequency and task completion time differ significantly across bias pattern groups, especially under the mixed pairing condition, using linear mixed model analyses.
Individual Differences in Trust Bias
Perfect Agent Evaluation
To evaluate the participant effect, we compared two linear mixed models. The baseline model fitted trust scores for the perfect agent with a fixed effect of pairing (paired with a perfect agent/paired with an imperfect agent) and included random intercepts for participant ID (i.e., random-intercept model). The alternative model extended this by also allowing the effect of pairing to vary by participant ID (i.e., random-intercept and random-slope model). The alternative model with random intercepts and slopes (AIC = 14,476, logLik = −7,231.9) significantly outperformed the baseline random-intercept model (AIC = 14,748, logLik = −7,370.1), χ2(2) = 276.41, p < .001. The result indicates that participants differed significantly in how pairing influenced their trust ratings.
Based on these findings, we further classified individuals into groups according to the significance and direction of the pairing effect. FDR-corrected p-values were evaluated at a significance level of α = 0.05. Three distinct trust bias patterns emerged.
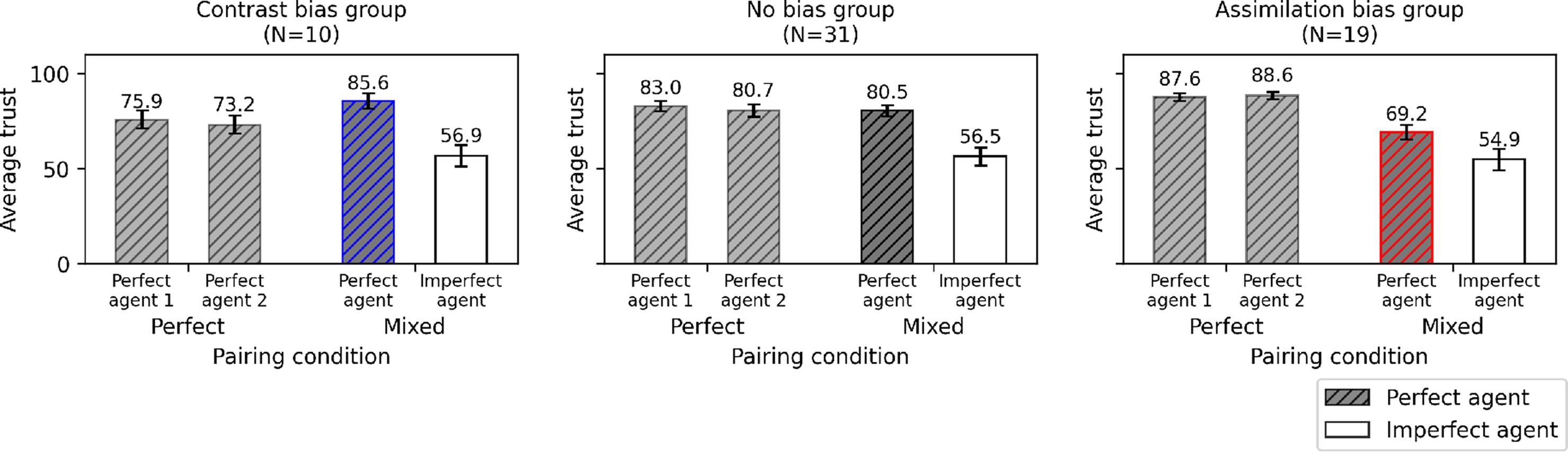
First, in the contrast bias group (N = 10), trust scores for the perfect agent were significantly higher when it was paired with an imperfect agent compared to when paired with another perfect agent, supporting the presence of a contrast effect. Second, in the no bias group (N = 31), trust scores for the perfect agent did not significantly differ based on the reliability of the paired agent, indicating no observable cognitive bias. Third, in the assimilation bias group (N = 19), trust scores for the perfect agent were significantly lower when paired with an imperfect agent compared to another perfect one, supporting a negative assimilation (i.e., horn effect).
Figure 4 displays participant-level slopes for the effect of pairing within each classified group. Figure 5 further illustrates the average trust scores aggregated by group, reflecting the identified trust bias patterns. Individual slopes illustrating differences in trust scores for the perfect agent across pairing conditions. Participants are classified into three groups based on their identified trust bias patterns: the contrast bias group, no bias group, and assimilation bias group. In all graphs, a point with a circle marker represents the average trust rating when the perfect agent was paired with another perfect agent (i.e., perfect pairing condition), while a point with an X marker represents the rating when paired with an imperfect agent (i.e., mixed pairing condition). The first group (contrast bias) showed increased trust in the mixed condition, highlighted in blue, whereas the third group (assimilation bias) showed decreased trust in the mixed condition, highlighted in red. Average trust scores for each agent in the perfect and mixed pairing conditions, grouped by trust bias pattern. Bars with a gray hatched pattern represent trust scores for the perfect agent. Consistent with the color highlights in Figure 4, the contrast bias group showed an average increase in trust toward the perfect agent in the mixed condition, highlighted in blue, while the assimilation bias group showed an average decrease, highlighted in red.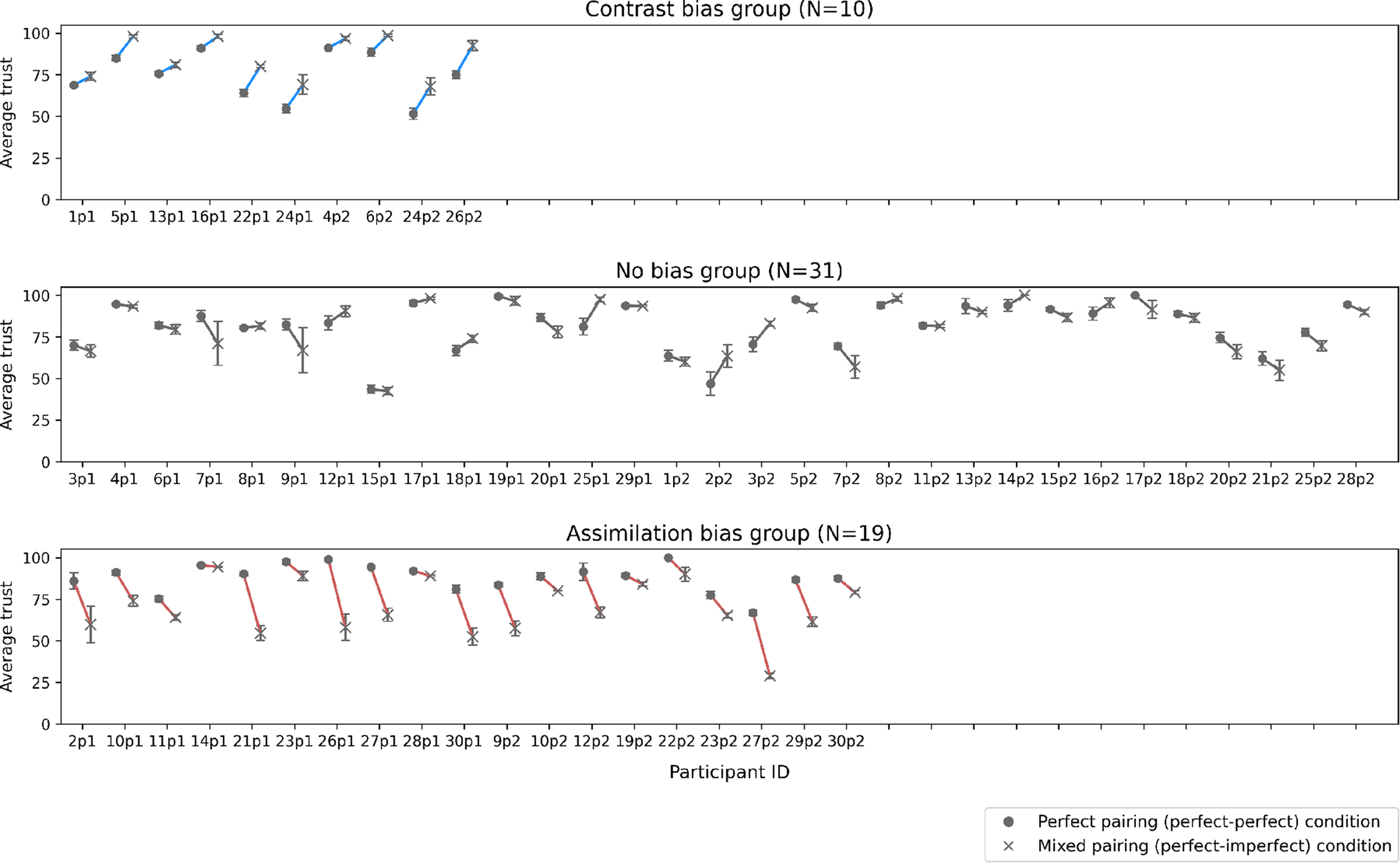
Imperfect Agent Evaluation
Similarly, the baseline random-intercept model and the alternative random-intercept and random-slope model for the pairing model were compared to evaluate the participant effect. For both models, trust scores for the imperfect agent were fitted with a fixed effect of pairing (paired with a perfect agent/paired with an imperfect agent). The result showed that the alternative random-intercept and random-slope model (AIC = 15,373, logLik = −7,680.5) significantly outperformed the baseline random-intercept model (AIC = 15,717, logLik = −7,854.5), χ2(2) = 348.1, p < .001. In other words, participants differed significantly in how pairing influenced their trust ratings in the imperfect agent.
We further classified individuals into groups according to the significance and direction of the pairing effect. FDR-corrected p-values were evaluated at a significance level of α = 0.05. Again, three distinct trust bias patterns emerged.
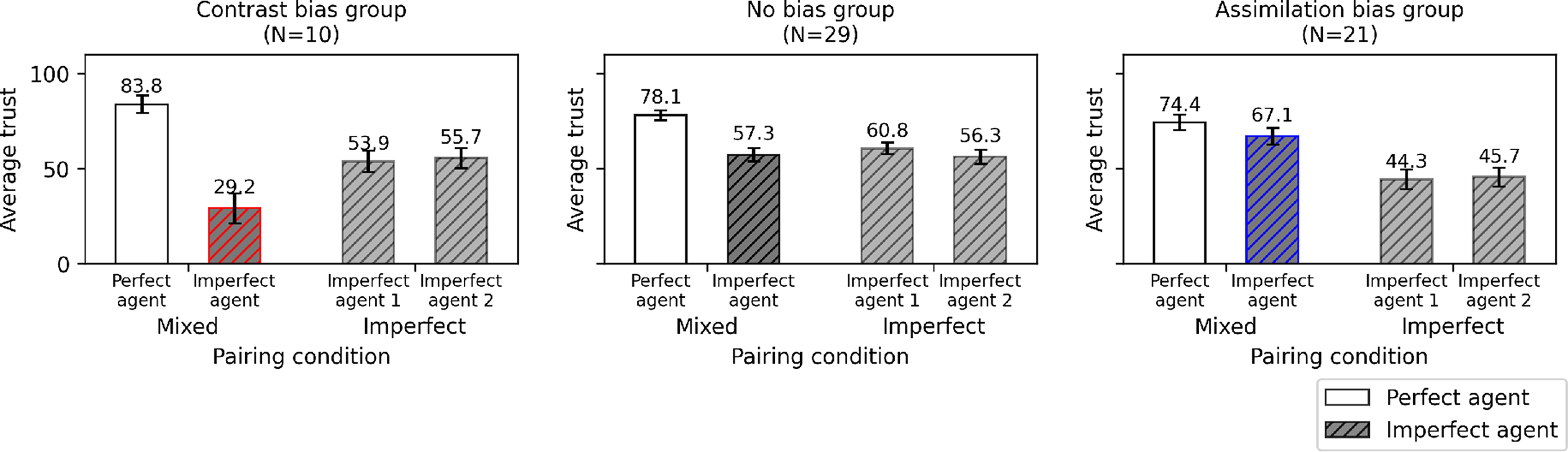
First, in the contrast bias group (N = 10), trust scores for the imperfect agent were significantly lower when it was paired with a perfect agent compared to when paired with another imperfect agent, supporting the presence of a contrast effect. Second, in the no bias group (N = 29), trust scores for the imperfect agent did not significantly differ based on the reliability of the paired agent, indicating no observable cognitive bias. Third, in the assimilation bias group (N = 21), trust scores for the imperfect agent were significantly higher when paired with a perfect agent compared to another imperfect one, supporting a positive assimilation (i.e., halo effect).
Figure 6 displays participant-level slopes for the effect of pairing, and Figure 7 shows the average trust scores aggregated by group. Individual slopes illustrating differences in trust scores for the imperfect agent across pairing conditions. Participants are classified into three groups based on their identified trust bias patterns: the contrast bias group, no bias group, and assimilation bias group. In all graphs, a point with a circle marker represents the average trust rating when the imperfect agent was paired with another imperfect agent (i.e., imperfect pairing condition), while a point with an X marker represents the rating when paired with a perfect agent (i.e., mixed pairing condition). The first group (contrast bias) showed decreased trust in the mixed condition, highlighted in red, whereas the third group (assimilation bias) showed increased trust in the mixed condition, highlighted in blue. Average trust scores for each agent in the mixed and imperfect pairing conditions, grouped by trust bias pattern. Bars with a gray hatched pattern represent trust scores for the imperfect agent. Consistent with the color highlights in Figure 6, the contrast bias group showed an average decrease in trust toward the imperfect agent in the mixed condition, highlighted in red, while the assimilation bias group showed an average increase, highlighted in blue.
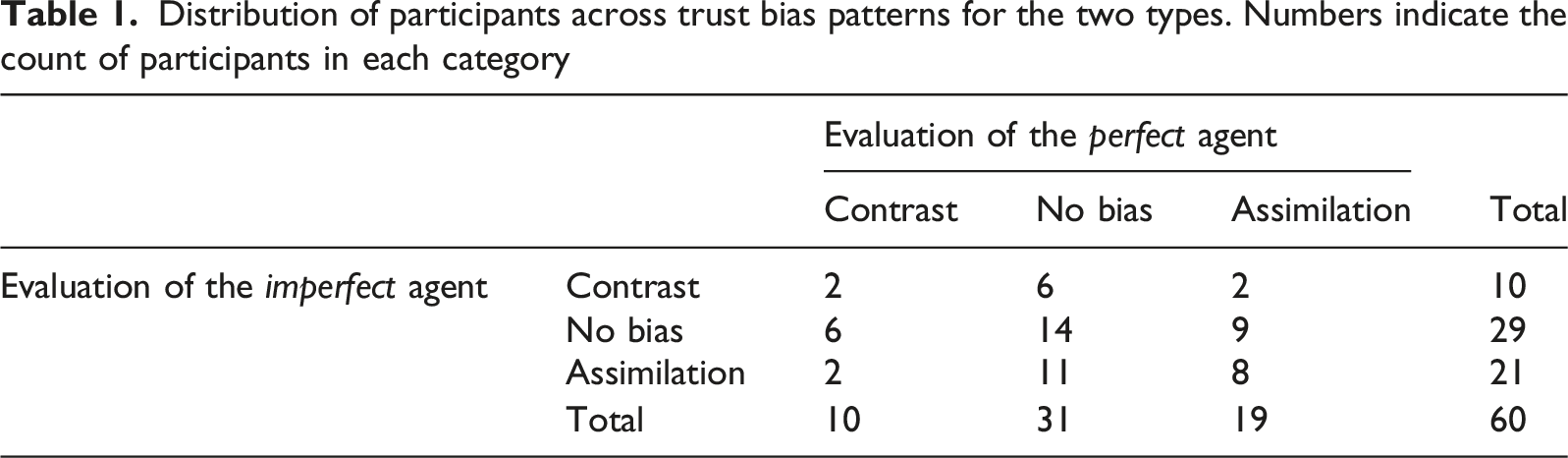
Distribution of participants across trust bias patterns for the two types. Numbers indicate the count of participants in each category
Effects of Trust Bias on Communication and Team Performance
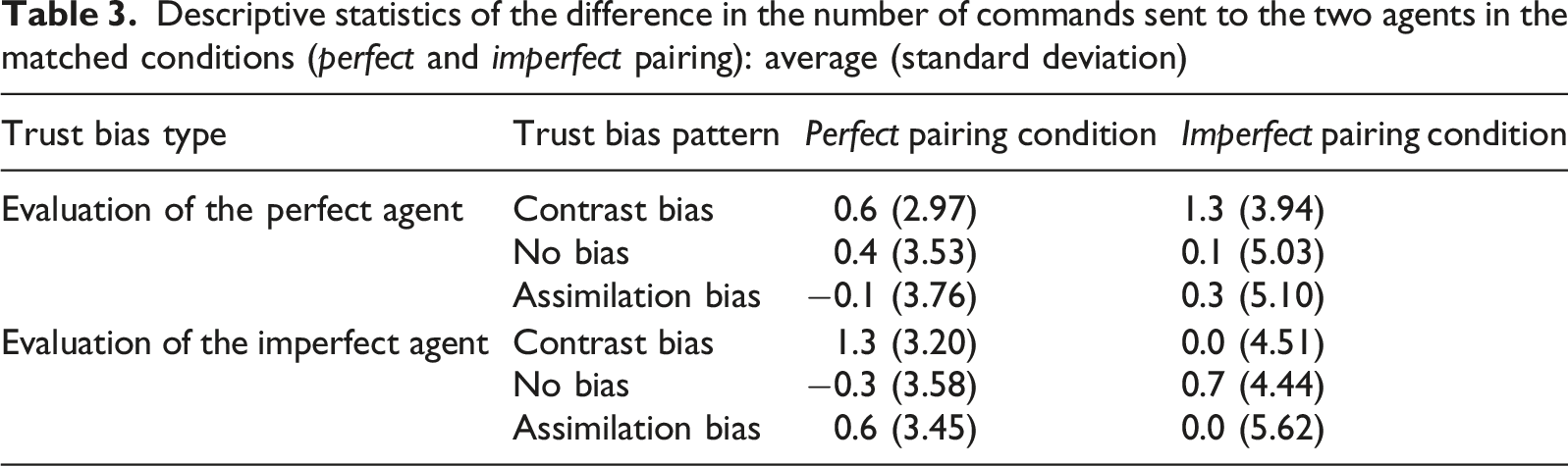
Based on the results above, each individual was assigned two types of trust bias patterns: one for evaluating the perfect agent and the other for evaluating the imperfect agent. Subsequently, we conducted linear mixed model analyses to examine whether the identified trust bias patterns were associated with distinct communication behaviors and performance outcomes. Since differences in communication and performance driven by trust bias are most evident when the two agents have different levels of reliability (i.e., the mixed condition), we focused our primary analyses on this condition. For the matched conditions (i.e., the perfect and imperfect conditions), we conducted the same analyses to confirm that when the two agents have the same reliability, they are perceived as similar and do not produce significant behavioral differences across trust bias patterns.
Communication
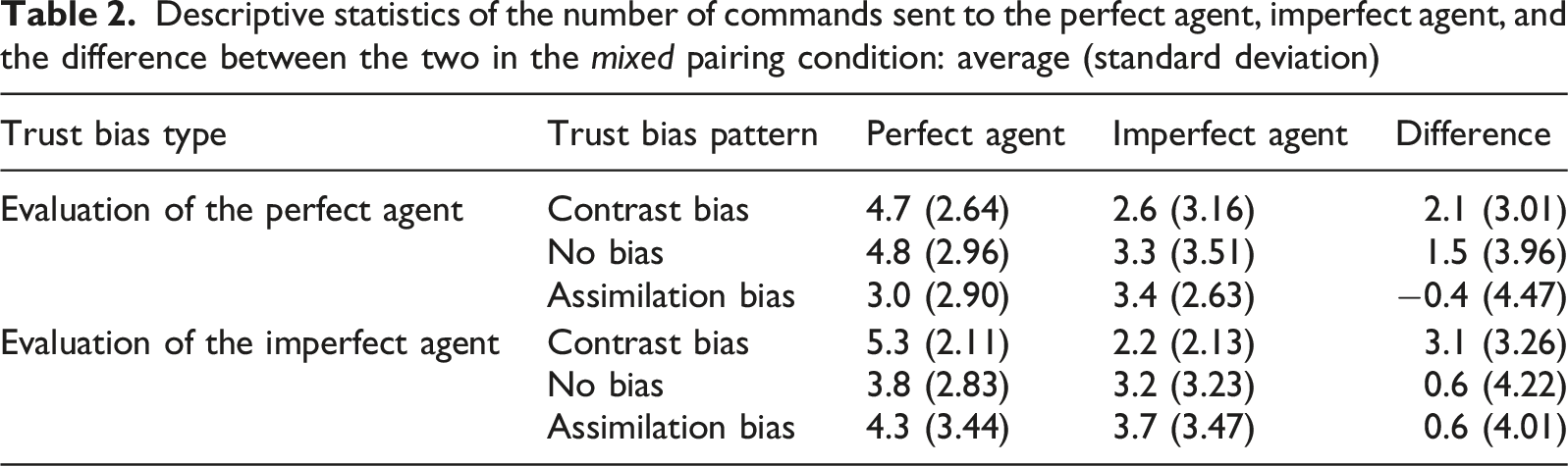
Descriptive statistics of the number of commands sent to the perfect agent, imperfect agent, and the difference between the two in the mixed pairing condition: average (standard deviation)
For each participant and trial, we first calculated the difference in the number of commands sent to the perfect agent and the imperfect agent by subtracting the latter from the former. Then, we fitted a linear mixed-effects model with this difference as the dependent variable, the trust bias pattern as a fixed effect, and participant ID as a random intercept to account for repeated measures. The analysis was conducted twice: once using the trust bias pattern when evaluating the perfect agent, and once using the pattern when evaluating the imperfect agent.
For the mixed condition, concerning the trust bias pattern based on evaluations of the perfect agent, it revealed a significant main effect (F(2, 57) = 3.21, p = .048). Pairwise comparisons using Tukey-adjusted estimated marginal means showed that the assimilation bias group exhibited a smaller difference value compared to the contrast bias (p = .092) and the no bias group (p = .080).
Regarding the trust bias pattern based on evaluations of the imperfect agent, the main effect was significant (F(2, 57) = 3.16, p = .050). The contrast bias group exhibited the largest difference compared to the no bias (p = .067) and assimilation bias (p = .073) groups.
Descriptive statistics of the difference in the number of commands sent to the two agents in the matched conditions (perfect and imperfect pairing): average (standard deviation)
Team Performance
Descriptive statistics of the task completion time (seconds) by the pairing condition: average (standard deviation)
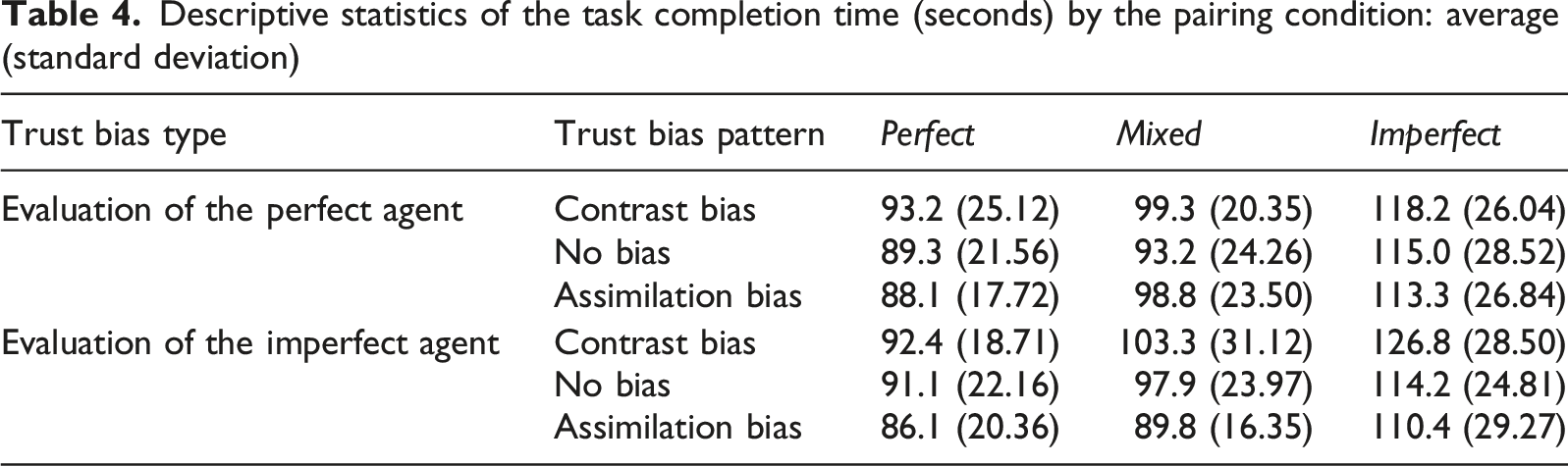
As the team performance measures (task completion time and task error) are team-level measures, we modeled them using linear mixed-effects models with fixed effects representing the distribution of trust bias patterns within each team. For each team, we first calculated how many of the two human teammates were assigned to each trust bias group. We then fitted the performance measures using the number of human teammates exhibiting assimilation bias and the number of teammates showing no bias as fixed effects, with team ID included as a random effect. The number of teammates in the contrast bias group was not included. This was because the sum of these three variables always equals two, which would create a multicollinearity problem. Accordingly, the two most prevalent groups were included. Similar to the analysis of communication frequency, this analysis was conducted for each trust bias type under each reliability pairing condition.
Estimation of Fixed-Effects Parameters on Task Completion Time

Discussion
Individual Variability in Trust Bias
The key finding of this study is that individuals exhibit different trust bias patterns when evaluating one agent in the presence of another in multi-agent HATs. Perspectives from prior studies on trust in multi-component systems (i.e., SWT and CST) cannot fully explain trust in multi-agent HATs on their own. Specifically, trust can become more similar (i.e., assimilation bias), remain unaffected by paired-agent reliability (i.e., no bias), or become more differentiated (i.e., contrast bias). It should be noted that the trust bias pattern itself does not directly indicate calibrated trust. Rather, it reflects individuals’ tendency for their trust in one agent to be influenced by the presence of another agent when working with multiple agents in a team.
The distribution of participants across the trust bias patterns (Table 1) supports the presence of individual variability. These findings have important implications for the widely discussed pull-down effect in prior literature (Geels-Blair et al., 2013).
Assimilation bias was common for both perfect (19 of 60 participants) and imperfect agent (21 of 60 participants) evaluations, aligning with prior findings of a population-level trend of the pull-down effect. However, the present study highlights the need to also consider the remaining participants: many exhibited no bias, and about 16.7% showed contrast bias. Taken together, this exploratory study suggests that caution is warranted before assuming that most human operators generalize trust across system components.
As discussed earlier, the participant effect can be explained by the consequences of humans’ selective comparative evaluation (Bless & Burger, 2016; Mussweiler, 2003). When evaluating a target, people tend to activate comparison by relating the characteristics of the target to features of a reference. In this process, some individuals do not engage in an exhaustive comparative test using all accessible information to make judgments. Instead, they undergo selective hypothesis testing depending on whether they focus on the similar or dissimilar characteristics between the target and the reference. In our study, individuals who did not engage in such selective comparative evaluation can be interpreted as belonging to the no bias group, while those who did engage and focused more on similarities between the two agents represent the assimilation bias group. Conversely, those who focused more on dissimilar performance between the two agents fall into the contrast bias group.
In the context of the current study, the presence of all three trust bias groups is plausible. Agents were clearly distinct from human teammates, which may have led some participants to view them as a single group and evaluate them similarly (assimilation bias). However, at the same time, it was emphasized throughout the instruction phase that the reliability of the two agents might differ. We believe that those who focused more on such potential reliability differences may have perceived greater differences between the two (contrast bias). Lastly, those not influenced strongly by either cue showed no bias.
Trust Bias, Communication Behaviors, and Team Performance
We observed a clear alignment between trust and communication behavior. Under the mixed pairing condition, participants in the contrast bias mostly directed commands to the perfectly reliable agent, while those with assimilation bias distributed commands more evenly to the two agents.
Interestingly, this tendency was further associated with team performance. The number of teammates exhibiting assimilation bias was positively associated with team performance. In other words, among the two human teammates, teams with more teammates showing assimilation bias when evaluating the imperfect agent completed the task faster.
The key takeaway from the associations between trust bias, communication behaviors, and team performance is that individual trust bias patterns shape humans’ teamwork strategies in HATs, particularly regarding how they comparatively evaluate agents and decide how to utilize each agent within a multi-agent setup. How each pattern influences agent utilization and, ultimately, team performance should be carefully examined within the specific task and environment context. The specific finding in this study that the assimilation bias group completed the task faster serves only as one example of how trust bias can shape teamwork dynamics. It should not be interpreted as suggesting that this pattern is inherently preferable or recommended. Rather, our analyses suggest that such findings can help explain what may have constituted an effective strategy for utilizing agents within this particular experimental context.
In this study, the optimal strategy was to effectively use both agents. Even if the imperfect one only had a 50% reliability, keep sending them commands was more efficient than relying solely on the perfect agent. The level of trust that individuals with assimilation bias had in the imperfect agent might be interpreted as the optimal amount of trust needed to arrive at the best task delegation strategy in the mixed condition. Indeed, under the mixed condition, the trust bias pattern had a significant effect on individual trust in the imperfect agent based on a linear mixed-effects model with trust bias as a fixed effect and participant ID as a random effect (F(2, 57) = 11.76, p < .001). The assimilation bias group showed the highest average trust score (67.1), which was significantly higher than both the no bias group (average score = 57.3, p = .001) and the contrast bias group (average score = 29.2, p < .001) (Figure 7).
These findings highlight that the consequences of trust biases are context-dependent, and thus, customized mitigation strategies are needed. Most prior work has focused on reducing the pull-down effect (e.g., Beck et al., 2007; Johnson et al., 2023; Walliser et al., 2023), but key questions remain: Does everyone show this effect? Is it always detrimental to performance? What level of trust is optimal for each agent? Without such insights, one-size-fits-all solutions may not optimize team performance. Accordingly, based on this study, future research could focus on developing and implementing personalized trust bias mitigation strategies aimed at achieving properly calibrated trust for all. For example, in more safety-critical tasks, any trust bias that leads to excessive trust in an imperfect agent should be avoided, whether it arises from assimilation bias caused by the presence of a highly reliable paired agent or from contrast bias caused by comparison with an even less reliable agent.
In addition, regarding task error, no significant effects were observed. We noticed a very low likelihood of teams making wrong block loading errors. Errors could most likely occur when participants issued a command to an imperfect agent to pick up a specific color block. However, as instructing an agent to search all rooms for a potentially incorrect target would lead to substantial delays, participants, in most cases, instead issued a more targeted command (i.e., directing the agent to a specific room) after identifying the location of the correct block. As a result, task errors were extremely rare: out of 900 total trials across the entire experiment, 92.3% (n = 831) contained no errors, and only 5.2% (n = 47) contained a single error. This limited variability made it difficult to examine team performance from the perspective of error-related outcomes. Future studies could address this limitation by adopting more diverse task designs and communication structures in which task errors are more likely and play a consequential role. Such designs would enable a clearer examination of potential trade-offs between faster task completion driven by assimilation bias and increased error risk and would help identify the optimal trust bias configuration for different task environments.
Limitations and Future Research
We acknowledge several limitations that point to future research directions. First, while individual variability in trust bias was observed, further work should examine the personal factors underlying these differences (Chung & Yang, 2025a). Cultural orientation (e.g., individualism vs. collectivism) may shape how individuals evaluate one teammate relative to others (Oyserman & Lee, 2008), and perceptions of agency or human-likeness may also influence trust bias (Kulms & Kopp, 2019).
Second, this study did not explicitly explore team-level trust bias, specifically, how pairing humans with similar or different bias patterns affects each other and overall team dynamics. While our analyses revealed that the number of teammates exhibiting assimilation bias was associated with team performance, further investigation is needed to determine optimal team assignments. Future studies could more directly examine these through controlled recruitment and systematic team assignment based on trust bias profiles. In addition, in studies with larger team sizes involving more than two humans, it would be valuable to examine whether the improvement in task performance scales proportionally with the number of teammates exhibiting assimilation bias, or whether this effect eventually diminishes or reverses.
Third, while the two-human setup enabled the study of trust bias in a more naturalistic multi-human multi-agent HAT, social and behavioral confounds inherent to multi-human teams (e.g., peer influence and unequal division of labor) were not strictly controlled. In future work, a Wizard-of-Oz approach could be employed to regulate key teamwork variables, such as communication frequency and task allocation, allowing for more rigorous exploration of trust bias effects with minimized confounds.
Lastly, future studies should investigate a broader range of agent reliability levels to systematically model trust bias as a function of reliability differences among all the agents.
Conclusion
The current study took an exploratory approach in examining trust bias patterns (assimilation, no bias, and contrast) when participants evaluated one agent in the presence of another within a multi-agent HAT. We found significant individual variability and reported the distribution of the trust bias patterns: while all three patterns were present, assimilation bias was more common than contrast bias. We also examined how these patterns affected communication strategies and team performance in the mixed condition. This study underscores the importance of considering individual variability in trust bias, which is essential for developing effective personalized mitigation strategies.
Key Points
• This study explores individual variability in trust bias when evaluating one agent in the presence of another in multi-agent human-agent teams (HATs). • Individuals exhibit different trust bias patterns, which can be classified into three groups: assimilation bias (trust becoming more similar), no bias (trust unaffected by the paired-agent reliability), and contrast bias (trust becoming more differentiated). • Individual trust bias is associated with distinct communication strategies, especially under pairing conditions in which the agents have different reliability levels, aligning with participants’ differing trust bias patterns. For example, individuals exhibiting contrast bias communicated significantly more with the perfect agent than with the imperfect one when the two were paired together, reflecting their tendency to perceive the agents’ reliability more distinctly and place greater trust in the perfect agent. • Individual trust bias, in turn, influences team performance, as it shapes teamwork strategies regarding how team members comparatively evaluate and utilize each agent within a multi-agent setup. • When evaluating trust bias and developing mitigation strategies in multi-agent HATs, individual variability should be considered.
Footnotes
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work is partially supported by the National Science Foundation under Grant No. 2045009, the Air Force Office of Scientific Research under Grant No. FA9550-23-1-0044, and the University of Michigan Rackham Predoctoral Fellowship awarded to the first author.
Declaration of Conflicting Interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.