
Abstract
When systems evolve, the maintainability and the complexity of the system increase, resulting in the poor antidesign patterns or antipatterns in software maintenance. Refactoring is an operation used to improve the structure of an existing system by changing its internal structure without affecting its external behavior. Many studies revealed that refactoring is underused by software development team in industry due to its increased effort and lack of knowledge about existing approaches. Thus, a prioritized correction of antipatterns based on relevance of classes, analyzed development history, risk to refactor, minimized code changes, and maintainers context and preferences is needed for good refactoring recommendations. We propose an approach based on filtered relevant classes with generic linkage-based clustering and adapted nondominated sorting genetic algorithm III to find good refactoring recommendations, which maximize the software quality and reduce the refactoring effort. Our approach uses our own node centrality-based sub-graph isomorphism algorithm to dynamically understand the system with good accuracy prior to optimization. Our approach is evaluated on six open-source systems and the results have shown the effectiveness of our approach compared to the other existing ones.
Introduction
Software maintenance and evolution are two extreme ends for the success of a product in modern-day software development. The design and code to be optimized periodically in order to avoid any technical debt resulting from decaying of software artifacts such as classes, packages, requirement documents, etc. The decision is on part of the developer’s expertise, but the maintenance tasks when applied on software systems increase their complexity, which incurs a much deviation from its original design and structure. This may lead to poor design defects known as antipatterns.1,2 These antipatterns have negative effect on software quality attributes such as maintainability, flexibility, understandability, etc. 3
Refactoring is a widely used technique for improving software quality. Refactoring has been defined by Martin Fowler as the process of changing a software system in such a way it does not alter the external behavior of the code, yet it improves its internal structure. 4 Refactoring can be done mainly through the following steps: (1) identify the portions of code where there is a presence of antipatterns or code smells and (2) identify the good sequence of refactoring solutions. The first part is well covered in various literatures,3,5 but all these approaches are not interactive by putting the programmer into loop and purely metric based one. In the study by Mkaouer et al., 6 a high-dimensional search-based scalable approach is recommended, but the search space is still large to handle.
In this research work, we propose a novel interactive approach towards refactoring recommendations in which architecturally relevant classes are filtered and perform a cluster-based selection to prioritize the code smells according to criteria such as relevance, maintainer’s context and preferences, risk to refactor, minimized code changes, and analyzed version history. Thus, refactoring problem as a whole is considered as a multi-objective optimization one using generic linkage-based clustering selection to find good refactoring solutions. Our work is concentrated on the law of the vital few that is “only 20% code of code contains 80% of errors.” 7 We choose only the most relevant classes which are refactoring prone by considering historical information for urgent refactoring needs. We evaluated our approach on six medium- and large-scale open-source systems using existing related studies by Ouni et al. 3 and reported the effectiveness of our results.
The remainder of this paper is structured as follows: the upcoming section provides the challenges to refactoring recommendations, which is followed by a section that defines refactoring as a multi-objective optimization problem. A further section introduces a search-based approach to this problem using generic linkage-based clustering selection and adapted nondominated sorting genetic algorithm III (NSGA III) , which is followed by a section that describes the solution coding and fitness functions. The penultimate section explains the research questions, results and discussions and describes the related work, and the final section discusses conclusion, future work, and references.
Educational benefits
Design patterns and pattern-oriented software architecture is an important course in the domain of software engineering at postgraduate and doctoral level, but the students are not aware of the professional benefits of understanding this dynamic software. Also, they had a question how design patterns became antipatterns or code smells producing negative impact on the software quality and future maintenance. This research paper addresses these issues as how to prioritize antipatterns within the framework of interactive machine learning and graph algorithms to achieve high-quality software products. This work will provide a basis for further ongoing research and an enhanced course to become future entrepreneurs achieving good quality products.
Challenges to refactoring recommendations
Background and definitions
The idea of refactoring is to reorganize classes, variables, and methods to adapt to the changing requirements. Thus, the entire software system achieves various aspects of software quality such as maintainability, understandability,8,9 etc. Our approach has detected 12 kinds of bad smells such as Blob, Feature Envy, Spaghetti code, and anti-singleton, class data should be private, complex class, lazy class, long parameter list, message chain, refused parent bequest, data class, and Swiss army knife.10,11 In this approach, we attempt to correct those design defects termed as antipatterns1,2 that have a negative effect on software quality, which often leads to much bugs and failures.
In many real-life problems, there may be conflicting objectives with each other. Here, in this research work, we have to maximize the quality, minimize the refactoring effort, minimize the change score, and improve code correction ratio (CCR). To investigate a set of solutions, each of which satisfies the objectives at an acceptable level without being dominated by any other solution. So, the solutions were identified in the set of all feasible non-dominated solutions that is the pare-to optimal set. Identifying an optimal solution for conflicting objectives is practically impossible due to its size, so it will be worth to reduce the search space prior to genetic operations. For that purpose, we use generic linkage-based clustering adaptation to NSGA III algorithm. 12 Our objective is as follows: (a) improved software quality, (b) minimized code changes, (c) consistency with the analyzed version history, (d) the architectural relevance of the classes and their ranked prioritization, and (e) take into account the developer’s context and preferences.
Filtered cluster-based optimization perspective towards refactoring recommendation
An overview of the approach
The approach explores a large search space to gather good refactoring solutions to correct the detected antipatterns or bad smells. A generic linkage-based clustering optimization, that is, adapted NSGAIII, is used here to generate refactoring solutions. The general structure of our approach is sketched in Figure 1. Our approach first performs a class prioritization which is a three-step process: analyze different versions, according to the study by Girba et al.,
13
the classes that have been refactored frequently in the past are likely to be refactored in the near futureand analyze architecturally relevant classes from the current version; Then, a rank is calculated.
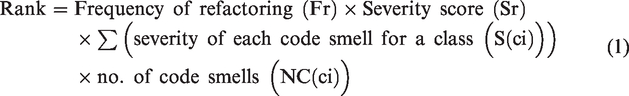

Proposed structure of the approach.
Refactoring process as a multi-objective problem
Quality
The quality objective fitness function can be evaluated by looking at the CCR, which is calculated using the ratio of the no. of antipatterns
1
to be removed from the system after refactoring to the total number of antipatterns observed in the system.

Code changes
To calculate the code changes score in the analyzed version history, we use the approach where each refactoring solution is considered as a set of n refactoring operations (ROs), a weight is assigned to each RO in the range [1--3].
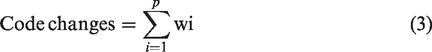
The java-based optimization frame work designed by our own easily calculates the value of the number of redirect method calls, field references, return types, and parameters of a method.
Consistency with the version history
The different stable versions of the input system have been analyzed. The classes which have been refactored at least once in the previous versions are recorded along with their frequency score value. For this purpose, we use Ref-finder 14 tool, and the current version of the system is analyzed with the organic tool (http://www.organic/). 15 To find out the antipattern detection, we use our own node centrality-based sub-graph isomorphism approach as described in the studies by Sreeji and Lakshmi.10,11 The classes that have not been refactored in the past are filtered out from this step. This process is conducted before the optimization is performed, and the rank score is given as input to the optimization framework.
Severity
Developers give different importance to different types of antipatterns because each of them has different impact on software quality. In this approach, we are considering 13 types of antipatterns and the highest score of 13 is given to Blob since it is most risky and affects a large number of classes as indicated in different literatures 3 and our observations10,11 (12 for feature envy, 11 for spaghetti code, and so on) depending upon the frequency of each type of antipattern. The value may vary from one system to another depending on the context. In this research work, the software developer context and preferences are taken into account for choosing the severity.
Adapted NSGAIII towards software refactoring
Algorithm 1: Pseudo code for adaptation of generic linkage-based clustering selection to NSGA III towards refactoring
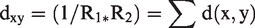

Algorithm 2: Pseudo code of adaptation to NSGA III 12 towards refactoring
Solution coding
The refactoring order is based on the position in the vector. First, create an empty vector for the current solution, then randomly select (1) a RO from the list of possible refactorings and (2) a set of code elements, and each of the RO suggested should satisfy a set of pre- and post-conditions. Apply the operation to an intermediate model and the process is repeated until we get a maximal solution of length (n).
Mutation and crossover applied to the individuals
A single-point cross-over and mutation performed by interchanging probabilistically the bit string position in the vector is shown as follows:
a. Crossover
Parent 1

Parent 2

⇓Cross-over
Child 1

Child 2

b. Mutation
Parent

Mutation ⇓
Child

Fitness function
After creating a solution S, the fitness is calculated, as for each filtered class here, we have conflicting objectives, so instead of giving equal weights, the problem should be solved multiple times with different weight combinations. A normalized weight vector is randomly generated for each solution during the selection phase at each generation. The simulation codes are programmed in java optimization frame work that helps to analyze java programs, metric calculation, and simulation of refactorings in Eclipse.
Results and discussions
Research questions
RQ1: To what extent the prior to optimization filtering of classes produces CCR, estimated effort to refactor, and rank score?
RQ2: To what extent the approach corrects the existing filtered out classes with antipatterns?
RQ3: How much of quality is gained after filtered and prioritized refactoring?
RQ4: How does the approach compared to the existing approach without prior filteration?
Experimental setup and systems studied
The approach is applied on six open-source projects which are large- and medium-sized ones such as GanttProject (www.ganttproject.biz), JFreeChart (http://www.JFreechart.org/), and JHotDraw (http://www.jhotdraw.org/). GanttProject is a cross-platform tool for project scheduling. JHotDraw is a GUI framework for drawing editors. ArgoUMLv0.6 and 0.3 is framework for modeling purposes. Xerces-J is a family of packages for parsing XML. Finally, JFreeChart is an open-source framework to create charts written in Java.
Result analysis
To answer RQ1 and RQ2, our method uses two performance metrics: CCR and estimated refactoring effort (ERE).
CCR is given in equation (1) and calculates the ratio of antipatterns corrected after refactoring over the total number of antipatterns observed in the system. After filtering at least once refactored classes between three consecutive versions, the architecturally relevant classes were found out. The CCR can be calculated and is shown in the Table 2. The proposed refactorings are applied using eclipse meta model, and the program behavior was observed. The ERE is calculated using the formula
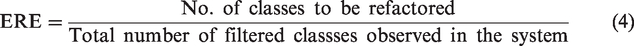
The results are shown in Table 1.
Performance Evaluation metrics for the systems studied.
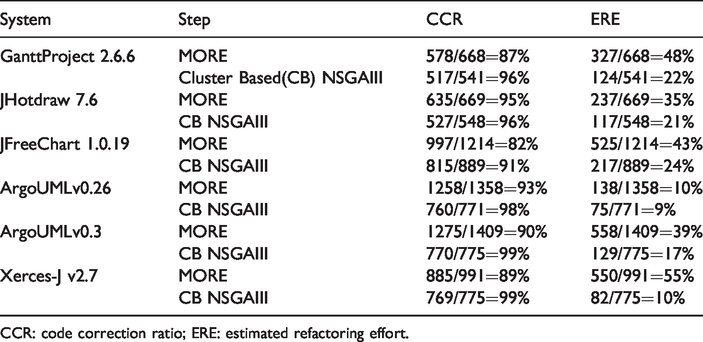
CCR: code correction ratio; ERE: estimated refactoring effort.
The statistical study of our approach uses 31 independent runs for each problem instance. The experiments are conducted using Wilcoxon rank sum test with 99% confidence level (α < 0.004) for CCR with p value <0.004 and 95% confidence value (α < 0.05) for ERE for the following algorithms: (1) MORE and (2) our approach. The results indicate that the new approach improves the CCR with minimized refactoring effort. Hence, our approach outperforms the other algorithms. RQ3: We use the QMOOD quality model as in the study by Ouni et al.
3
and its related attributes. These attributes are calculated using 11 low-level design metrics such as design size in classes, number of class hierarchies in a design, average no. of ancestors, data access metric, direct class coupling, cohesion among methods, measure of aggregation, functional abstraction, number of polymorphic methods, class interface size, and complexity in terms of number of methods. Let Q={q1, q2,q3,q4,q5,q6} are the quality attributes before filtration and prioritized correction plus optimization and QP={qp1,qp2,qp3,qp4,qp5,qp6}are the quality attributes after filtered prioritized correction. Assign a weight in between 0 and 1 for each of the attributes and find the weighted sum of the difference between these attributes. RQ4: Regarding the improvement in quality attributes, our approach has more improvement in QMOOD attributes such as flexibility and understandability. Figure 2 illustrates this fact. The graph is drawn for the QMOOD values for the six systems for both approaches. The quality gain values are normalized between 0 and 1 using min–max normalization. QMOOD quality attributes comparison over various systems.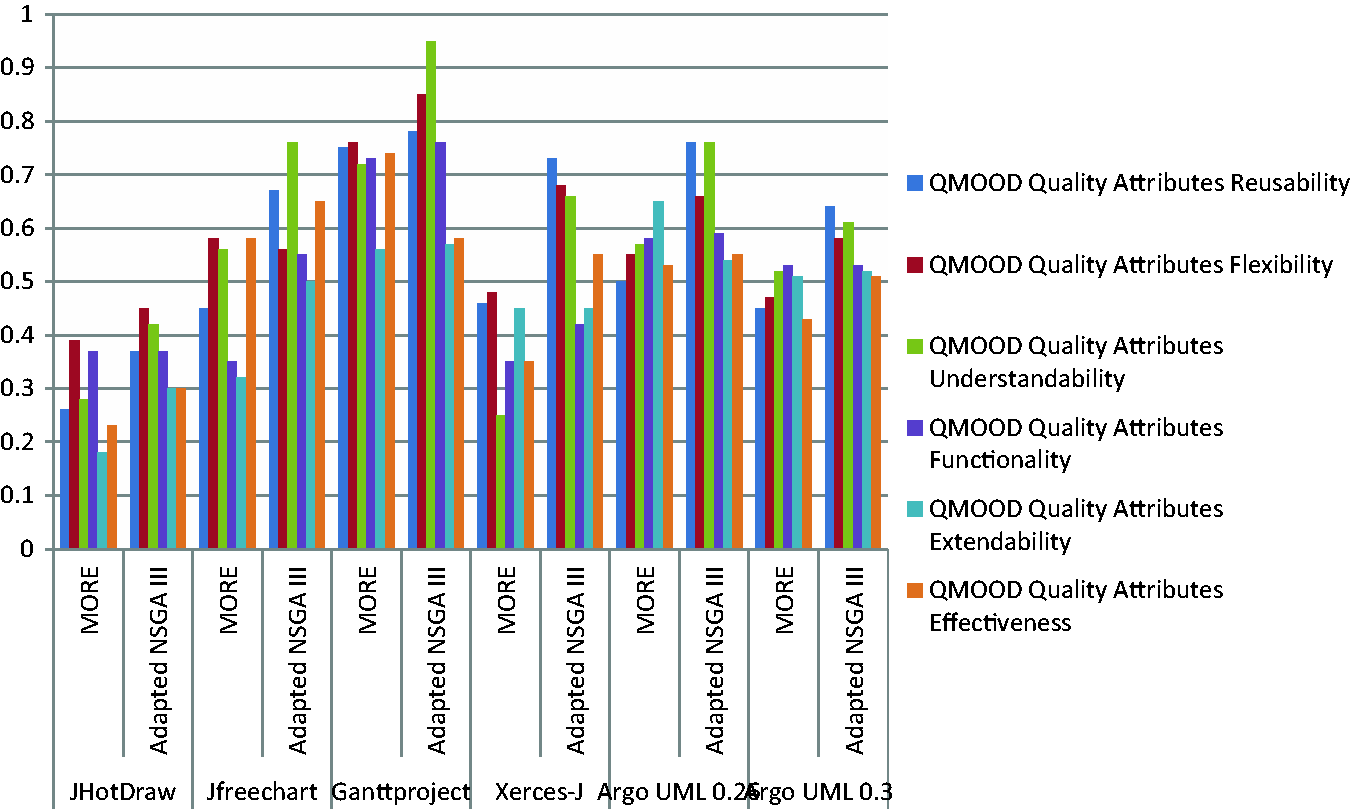
Parameter set-up and industrial case study
Our experimental approach uses different population sizes such as 90, 200, and 150 for 3, 5, and 8 objectives. The maximum number of generations used is 300, 400, and 600, respectively, for each of the objectives. Each algorithm is executed for 31 runs with different configurations and parameters, then the performance parameters such as CCR, ERE, computational time, the average Euclidean distance differentiating each reference point from its closest one that is termed as the IGD (inverted generational distance), and quality gain are calculated for the two algorithms and for each open-source system. The scalability of NSGA III is illustrated in Mkaouer et al. 6 We compared the computational time and IGD for the algorithms such as high-dimensional NSGA III, 6 our adapted NSGA III, and multi-objective NSGA II (MORE). Our aim is to ensure the efficacy of our adapted approach. For that purpose, we asked five software engineers to use our approach on a medium-scale project, web based, and developed in java framework. Our approach is able to detect abstract factory, bridge and command design patterns with a total of 79 code smell instances out of 200 classes. They asked to perform the suggested refactorings and are able to fix 95% of code smells with minimized effort and improved quality. The recommended refactorings are consistent with their preferences and found to be useful.
Discussions
Table 2 shows the median IGD and CCR values of 31 independent runs for the three algorithms under comparison. For the three objective cases, the three algorithms perform almost same, but for higher number of objectives, MORE using NSGA II performs less. High-dimensional NSGA III 6 performs well for higher number of objectives, but our cluster-based NSGA III achieves much better results. This is due to its non-metric, graph-based antipattern detection and cluster-based selection to reduce the search space and finally the reference point-based selection for the next iteration. The CCR ratio increases with increased number of objectives.
The median IGD and CCR values of 31 independent runs for Mkauer et.al (NSGA III), Cluster based NSGA III and MORE using NSGA II.
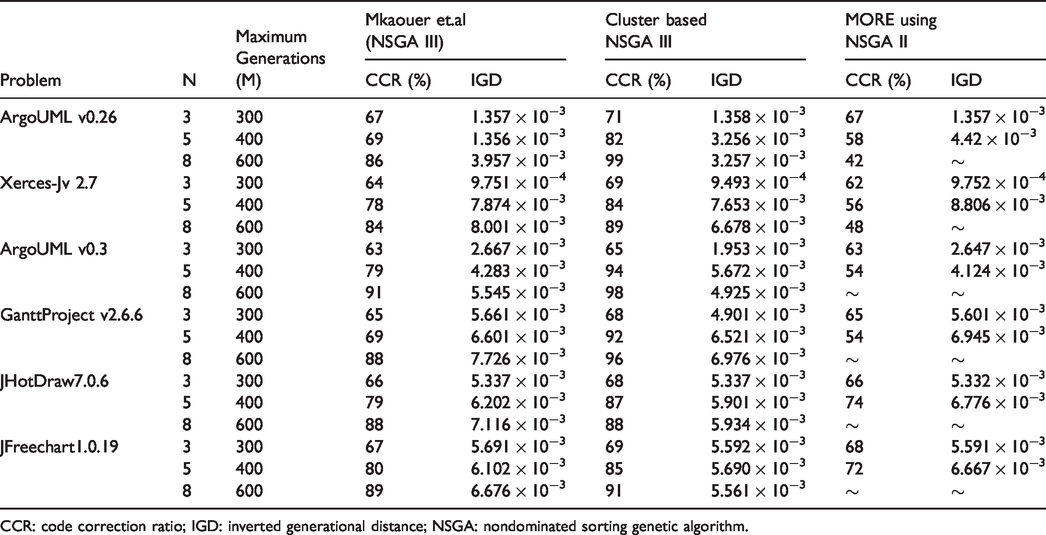
CCR: code correction ratio; IGD: inverted generational distance; NSGA: nondominated sorting genetic algorithm.
When we take the computational time (CPU time), which is the most crucial step in the evaluation process, cluster-based NSGA III performs well with reduced computational time since the number of classes in the solution space is further reduced due to filtration and clustering. Figure 3 illustrates this fact.
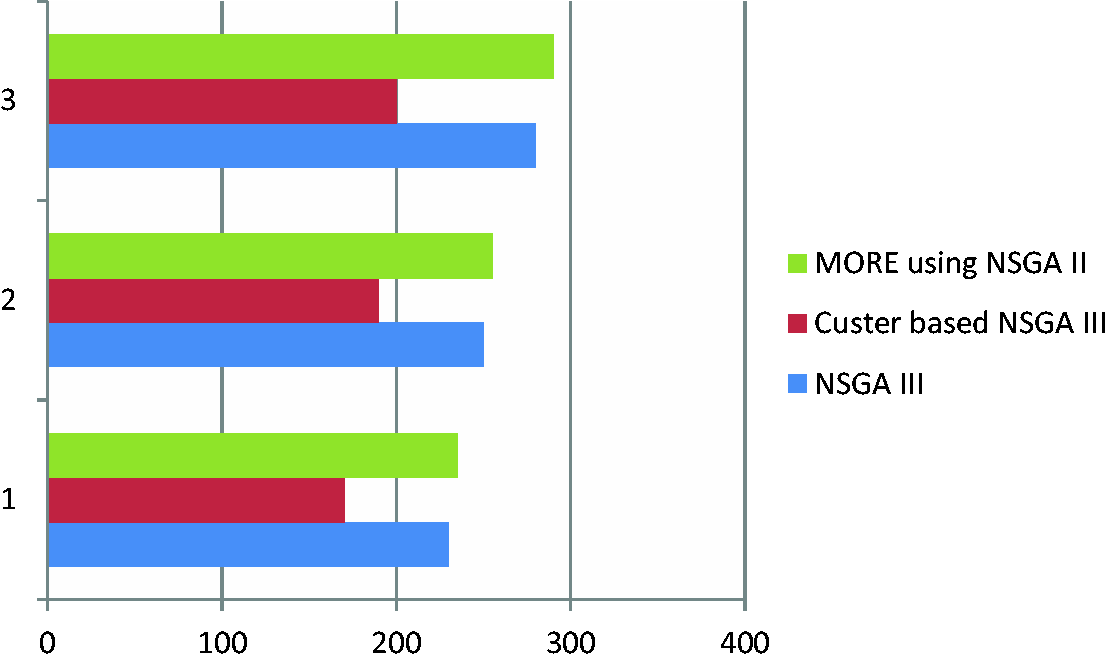
CPU time values of 31 independent runs of different algorithms studied.
Related work
Murphy-Hill et al. 16 conducted empirical studies to provide the support for refactoring. First, M Fowler8,9 coined the word refactoring as an effective approach to improve the design and to preserve the external behavior. Some of the major bottlenecks in adopting refactoring of industrial projects include deadline pressure, inadequate tool support, etc. This scenario demands an effective approach to the refactoring research community to help developers to attain good quality software without incurring much cost and effort. Search-based software engineering17–20 successfully adopted many different approaches to automate software engineering tasks such as refactoring.
Many of the search-based approaches use metric-based objective functions to find an optimal refactoring sequence. 3 The researchers used QMOOD quality model and attained minimal improvement in quality factors such as understandability and flexibility. Seng et al. 21 proposed a mono objective optimization approach, which uses a genetic algorithm to maximize a weighted sum of several quality factors such as cohesion, complexity, etc, but the approach needs a human intervention to decide whether a suggested refactoring can be applied or not. Recently, Ouni et al. 3 introduced a search-based approach using NSGA II, which, in addition to the quality fitness function, semantic fitness, and code smell objective function, is also considered. The approach is able to fix 84% of code smells and introduce an average of six design patterns. But the approach suggests an offline refactoring suggestions which is tedious and time-consuming process. Also, the approach fails to assess the ERE in urgent refactoring needs.
There are very few research works going on towards the prioritization and correction of antipatterns when software community needs urgent refactoring treatments. R Marinescu8,22 developed the InFusion tool and defined the severity index as severity is computed by measuring how many times the value of a chosen metric exceeds a given threshold considering size, encapsulation, complexity, coupling, and cohesion metrics. Other facts such as change history, the context, and the characteristics of the smell are also considered to prioritize and manage antipatterns. Arcelli et al. 23 proposed a tool called JCodeOdor to filter and prioritize code smells. The approach defined an index called code smell harmfulness to approximate how harmful does each code smell with the help of metrics and threshold computation. Arcoverde et al. 24 evaluated different heuristics such as change density and error density to prioritize the antipatterns and help maintainers with automatically ranking the code anomalies which are more harmful. Steidl and Eder 25 proposed a prioritization mechanism for maintainability defects such as code clones and long methods that are easy to refactor. Palomba et al. 26 proposed approaches which uses the parameter development version history of various applications to identify the code smells in the current version. Tsantalis et al. 27 described a search-based approach for identifying the good refactoring solutions based on historical information. In the study by Ouni et al., 3 a search-based approach for identifying the good refactoring solutions based on chemical reaction optimization was described and good CCR was achieved, and no attempt is made to assess the quality and reduce the refactoring effort. Choudhary and Singh 28 proposed an approach to minimize the refactoring based on historical, relevance, and code smell information, but the three-step filtration process filters out much of the relevant classes, and the design quality is not checked. Mkaouer et al. 6 proposed the study on the scalability of the NSGA III algorithm for 15 different low-level design metrics and claimed as the first study using NSGA III. The approach uses static metric analyzers to detect the antipatterns, and no attempt is made to improve the refactoring effort.
The above works did not taken into account the developer context and preferences, and none of the works made an attempt to estimate the refactoring effort and reducing the search space. Also, they rely upon the static metric analyzer for the detection of antipatterns and found such relevant code smells to be missing. Our approach is a novel one which combines the benefits of graph algorithms for the detection of more antipatterns and design patterns instead of simple metrics, and we employed a filtered and cluster-based adapted NSGA III approach with reduced computational effort, more quality gain, and minimized refactoring effort to reduce the technical debt.
Conclusion and future work
Our approach performs the filtration of relevant and at least once refactored classes, prioritizes them, and then finds out the normalized rank score. The highest ranked classes are then optimized using generic linkage-based clustering and NSGA III multi-objective optimization. The approach achieves high-quality gain, reduced refactoring effort, and improved CCR than MORE using NSGA II 3 and high-dimensional NSGA III. 6 Our approach applied on six open-source systems written in java programming language, and the computational effort also becomes less since there are only relevant classes that are considered for optimization.
Our approach has two parts, one for dynamic recommendation of design patterns by using the concept of antidesign patterns. For this, we used a combined technique of graph algorithm and metric analyzer implemented by our own program. The second part uses filtered search-based optimization. Also, a semantic fitness function can also be incorporated to better achieve the refactoring meaningfulness.
Footnotes
Declaration of Conflicting Interests:
The author(s) declared no potential conflicts of interest with respect to the research, author- ship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.