
Abstract
Filled pauses are well known for their speaker specificity, yet cross-linguistic research has also shown language-specific trends in their distribution and phonetic quality. To examine the extent to which speakers acquire filled pauses as language- or speaker-specific phenomena, this study investigates the use of filled pauses in the context of adult simultaneous bilinguals. Making use of both distributional and acoustic data, this study analyzed UH, consisting of only a vowel component, and UM, with a vowel followed by [m], in the speech of 15 female speakers who were simultaneously bilingual in French and German. Speakers were found to use UM more frequently in German than in French, but only German-dominant speakers had a preference for UM in German. Formant and durational analyses showed that while speakers maintained distinct vowel qualities in their filled pauses in different languages, filled pauses in their weaker language exhibited a shift towards those in their dominant language. These results suggest that, despite high levels of variability between speakers, there is a significant role for language in the acquisition of filled pauses in simultaneous bilingual speakers, which is further shaped by the linguistic environment they grow up in.
Keywords
1 Introduction
The use of filled pauses (FPs), sounds like uh and um in English, in conversational speech is extremely common and reported cross-linguistically. Research in different languages shows that FPs, alongside other hesitation phenomena, serve as delays that facilitate listeners’ comprehension of upcoming information in their interlocutors’ speech (e.g., Bosker, Tjiong, Quené, Sanders, & de Jong, 2015; Corley & Hartsuiker, 2011; Corley, MacGregor, & Donaldson, 2007; Watanabe, Hirose, Den, & Minematsu, 2008). Despite the ubiquity of the presence and pragmatic impact of FPs, their patterns of production are far from universal, both between languages and between individuals. Language-to-language variability in the distribution and forms of FPs has a direct bearing on speakers who command multiple languages, though this area so far remains underexplored.
Building upon suggestions of language- and speaker-specificity found in the body of research conducted on FPs, the present study explores how these properties interact when they find intersection in bilingual speakers and the implications on the acquisition of such sounds. Specifically, this study focuses on the context of simultaneous bilinguals, who acquire more than one language from birth rather than sequentially (as in the case of sequential bilinguals), and looks at whether and how these speakers contrast their distribution and realization of FPs in different languages.
1.1 Language specificity
1.1.1 Relative distribution of FPs
Speakers of many languages make use of at least two types of FPs: UH, which consists solely of a vowel component (e.g., uh in English, euh in French), and UM, which has a vowel sound followed by a nasal, typically the bilabial [m] (e.g., um in English, ähm in German). Other forms and language-specific lexical items are commonly used in a manner similar to that of UH and UM (e.g., zhège in Mandarin Chinese, eto in Japanese, like in English), but whether they are subsumed under the term “filled pause” in research is variable. The focus in the present study is exclusively on UH and UM, which appear to be the most common types of FPs for speakers of many Indo-European languages.
Between these two FPs, speakers of the same language have been shown to generally maintain a preference for one over the other, and such tendency varies from one language to another. Dutch speakers, for example, have been repeatedly shown to strongly prefer UH over UM in different styles of speech (de Leeuw, 2007; Swerts, 1998). Nordic languages such as Norwegian, Danish, and Faroese follow a pattern similar to that in Dutch (Wieling et al., 2016). Conversely, German is an example of a language whose speakers typically use UM more frequently than UH (de Leeuw, 2007; Wieling et al., 2016). In some languages like English, studies based on a broad range of corpora have found both tendencies, though social factors such as gender, socioeconomic status, and age are also highly relevant, such that younger female speakers of higher socioeconomic status appear to be leading a rise in the use of UM relative to UH (Acton, 2011; de Leeuw, 2007; Tottie, 2011; Wieling et al., 2016).
Similar analysis of the relative distribution of UH and UM in non-Germanic languages is so far lacking. In French, for instance, the only systematic comparison came from the creators of the Nijmegen Corpus of Casual French (Torreira, Adda-Decker, & Ernestus, 2010), who reported 11,546 instances of UH and 4,391 of UM in the 36-hour conversational speech corpus. It thus appears that, with UH and UM at 72% and 28% of all FPs, respectively, French speakers tend to use UH far more frequently than UM.
1.1.2 Phonetic quality of FPs
Early impressionistic accounts also offer suggestions of language-specific tendencies in the vowels in FPs (Künzel, 1997; Levelt, 1983). Recent instrumental studies have confirmed systematic differences between languages and dialects in the vowel quality of their FPs (Candea, Vasilescu, & Adda-Decker, 2005; Gold, Ross, & Earnshaw, 2017). It has been suggested that FPs are linked to the specific articulatory settings of a language (Vasilescu & Adda-Decker, 2007), but any evidence for such connections remains circumstantial (Gick, Wilson, Koch, & Cook, 2004).
English speakers are most commonly said to use a schwa-like vowel [ə] (Maclay & Osgood, 1959; Shriberg, 1994, 2001), though vowel quality does vary widely between dialects, from a more backed, open vowel similar to [ʌ] in American English (Vasilescu & Adda-Decker, 2007) to a fronted [eː] in Scottish English (Cruttenden, 2001). Dialectal differences are also attested in Italian, where the FPs may be a central vowel for southern speakers or a front one for speakers from central Italy (Giannini, 2003). FPs by German speakers are similarly described to be central, close to [ə] or [ɐ] (Pätzold & Simpson, 1995). Languages like Hebrew, Russian, and Japanese predominantly make use of the mid to close front region for their FP vowel (Maekawa & Mori, 2015; Silber-Varod, Weiss, & Amir, 2015; Stepanova, 2007). The French UH is notable for having a rounded realization akin to [ø] or [œ] (Candea et al., 2005; Séguin, 2010).
In contrast to vowel quality, duration of FPs appears to be more resistant to language-specific tendencies. While there has been scarcely any empirical cross-language comparison of the temporal properties of FPs, they are consistently reported to be longer than lexical vowels of the same language (e.g., Shriberg 2001; Vasilescu & Adda-Decker, 2007). The vast majority of FPs are longer than 150 ms (Candea et al., 2005), and can easily range up to 500 ms or even longer (Rose, 2017). Unlike the duration of lexical vowels, which follows a sharp and heavily right-skewed distribution, the duration of FPs has been described as exhibiting a flat distribution (Vasilescu & Adda-Decker, 2007), indicating their malleability to lengthening.
Temporal comparisons between UH and UM remain few and far between. Unsurprisingly, UM is generally longer than UH, due to the nasal component (Moniz, Mata, & Viana, 2007; O’Connell & Kowal, 2005). However, if only the vocalic portion is taken into account, the corresponding part in UM may in fact be shorter and less variable than UH, at least in Standard Southern British English (SSBE) (Hughes, Wood, & Foulkes, 2016). Thus, there is evidence that durations of the vocalic and nasal components in UM can be decoupled, since either or both are available for lengthening (Shriberg, 1994).
1.2 Speaker specificity
Alongside language specificity, the striking display of speaker idiosyncrasy is another aspect of FPs that is constantly remarked on. Within a single language or dialect, speakers can vary widely in numerous aspects of their hesitation behavior, including the frequency of hesitation, the relative distribution of different hesitation phenomena, and the particular color of the sound they use (see, e.g., Braun & Rosin, 2015; de Leeuw, 2007; Goldman-Eisler, 1961; Hughes et al., 2016; Shriberg, 1994).
It is also claimed that individual speakers are consistent in their use of FPs. Künzel (1997) remarked that individual speakers “tend to be quite consistent in using ‘their’ respective personal variant of the hesitation sound, in particular with respect to the optional addition of a bilabial nasal consonant and the colour of the vocalic component [emphasis added]” (p. 51). The speaker’s tendency towards UH or UM and the phonetic quality of the vocalic component may thus be powerful sources of speaker specificity in FPs. Furthermore, speakers tend to adopt a similar vowel sound in both UH and UM and display similar degrees of variability within them (Hughes et al., 2016).
A number of factors contribute to the low within-speaker variability of FPs. As these utterances are often flanked by silence on at least one side (Grosjean & Deschamps, 1975; O’Connell & Kowal, 2005; Swerts 1998), they are less susceptible to coarticulatory effects and thus subject to less variation from surrounding contexts. Automaticity, or lack of awareness, in the production of FPs is another widely cited reason for their low within-speaker variability (Hughes et al., 2016; Jessen, 2008). Speakers are not expected to be able to exert much conscious control over the precise realization of FPs, which makes them less vulnerable to manipulation even in cases of voice disguise. However, the level of volition involved in the use of FPs is still a highly contended issue. Clark and Fox Tree (2002) claimed that speakers formulate FPs just as they do other words, as well as have control over the selection of UH or UM in order to achieve different signaling purposes. Currently, there is no evidence available of audience design (in the sense of Bell, 1984) in the use of FPs to demonstrate that speakers have the same level of intentional control over UH and UM as that over conventional words (Corley & Stewart, 2008; Finlayson, 2014; Finlayson & Corley, 2012).
With their high between-speaker variability and low within-speaker variability, the acoustic properties of FPs lend themselves cross-linguistically to strong discriminatory powers in forensic speaker comparison tasks (Cicres, 2014; Hughes et al., 2016). Similarly, the discriminatory potential of a speaker’s hesitation profile (i.e. the frequency and distribution of different hesitation phenomena) is harnessed in McDougall and Duckworth’s (2017) taxonomy of fluency features. Its recurrent employment in forensic casework (McDougall et al., 2018) substantiates the view that the usage pattern of hesitation phenomena, and among them FPs, is a strong carrier of speaker-specific information.
1.3 Hesitation phenomena in bilingual speakers
For speakers who orally command more than one language, the potential intersection of language- and speaker-specificity raises interesting questions about the properties of FPs demonstrated by these speakers in different languages. Analogous to how speakers have to mediate different forms as they acquire different sets of phonological and morphosyntactic norms, speakers may develop separate, language-specific forms and profiles of hesitation phenomena when they acquire two languages in which these forms and uses diverge. At the same time, speaker specificity may act as a countervailing force, prompting individuals to maintain the same behavior across languages. How these two possibilities interact and how they are manifested form the primary motivation for the present study.
Bilingual speakers generally differ in their use of hesitation phenomena and FPs according to the language they are speaking. In their second language (L2), speakers typically use more hesitation and FPs than in their first, or native, language (L1), as they are faced with higher cognitive load and greater planning difficulties (Fehringer & Fry, 2007; Guz, 2015; Rose, 2017). FPs and other hesitation phenomena also tend to be longer in L2 speech (Guz, 2015; Wiese, 1984), irrespective of articulation rate (Rose, 2017). Within L2 speakers, however, there is no straightforward relationship between those of lower or higher proficiency. Instead, they appear to make use of different strategies in communication, resulting in varying distributions and usage rates of different hesitation phenomena (Cenoz, 2000; Garcia-Amaya, 2015).
A main finding that has been repeatedly reported is the transfer of hesitation profiles from L1 to L2. Wiese (1984) demonstrated such behavior when his native English and German speakers spoke in the other language: While there was a significant increase in FPs and other hesitation phenomena, the ranking of hesitation categories in terms of relative frequency was maintained across languages. The same behavior has been found in speakers of language pairs with more dissimilar tendencies (Olynyk, d’Anglejan, & Sankoff, 1987), and is by no means limited to speakers of low or intermediate proficiency, extending to speakers with high proficiency or even balanced command of both languages (Fehringer & Fry, 2007; Wong & Papp, 2018). This also holds true on the level of individual speakers, where moderate to strong correlations found between the rates of each hesitation category produced by bilingual speakers in L1 and in L2 show that a speaker’s fluency behavior in L2 is, to a certain extent, reflective of their corresponding behavior in L1 (de Jong, Groenhout, Schoonen & Hulstijn, 2015), thus providing support for the argument that fluency behavior resides within the individual. Within the context of FPs alone, Rose (2017) observed the same tendency among highly proficient Japanese learners of English (the low proficiency group did almost completely turn away from polyphonemic FPs in L2 English, a divergence that Rose argued fits comfortably within the gamut of variation and as such may not be considered salient).
Transfer can also occur in the opposite direction—from L2 to L1—in the sense that forms and sounds commonly employed in the L2, but otherwise perceived as atypical of the L1, get adopted in L1 speech. For example, UH, but not UM, is generally regarded as an FP in Croatian, but when second-generation Croatians who grew up in Australia with English as their dominant L2 spoke in their L1, mixed with English code-switches, the use of UM outnumbered UH by five to one. The frequent use of UM provides evidence for the transfer of forms of hesitation phenomena from the dominant Australian English to the Croatian minority (Hlavac, 2011).
The hesitation profile of bilingual individuals is subject to shifting and redistribution. After being immersed in an environment where their L2 is dominant, the distribution of different hesitation phenomena may shift to more closely resemble that of native speakers of the dominant language (Möhle, 1984).
Taken together, these studies exemplify how the hesitation profile of bilingual speakers carries over from their stronger, more dominant language to their relatively weaker one. While these normally correspond to their L1 and L2, respectively, the case studies above on immigrant minorities and short-term immersion underscore the instrumental role of the dominant, or majority, language, even when it is the L2.
In terms of the vowel quality of FPs, acoustic research from a bilingual perspective is very limited. Findings so far suggest that L2 learners do not produce FPs with the same vowel quality as those of native speakers, though proficiency does appear to be an influential factor. While low-proficiency Japanese learners of English in Rose (2017) were unable to achieve the vowel height and backness in their English FPs, the FPs of the high-proficiency group were more similar to those of monolinguals, differing only in the dimension of height.
Effects of contact between languages on the production of FPs, akin to that observed in Hlavac (2011), are similarly found in the phonetic domain, as in the case of Spanish speakers residing in the northeastern United States: The more frequently they communicate in English with others, and the longer they have spent in the US, the more likely their FP vowel in Spanish is to deviate from the typical [e], towards a more centralized form as commonly used in English (Erker & Bruso, 2017). This provides support for the view that FPs may constitute a setting for change induced by language contact, in both quantitative and qualitative ways.
Furthermore, code-switching may influence the phonetic realization of FPs (cf. Hlavac, 2011, who found no such effect on the relative distribution of UH and UM). Spreafico’s (2016) examination of a single German-Italian-English trilingual suggested marked differences between his FPs within strictly monolingual portions of speech and those in the vicinity of points of code-switching: The former were well distinguished by language, whereas the latter drastically deviated from norms of the surrounding languages.
1.4 Simultaneous bilinguals
The research reviewed in the previous section suggests that, whether in terms of distribution or phonetic realization, there is generally some effect of language interference on FPs. However, most of this research concerns sequential bilinguals, speakers who acquire an L2 at a later stage than their L1. It remains the case that, to date, there has been an extremely limited amount of research on the FPs of simultaneous bilinguals, who acquire both languages from birth and, by nature, do not have an L1 and an L2 in the sequential sense.
The issue of hesitation behavior in simultaneous bilinguals remains one to be addressed empirically, as phonetic and phonological differences in the speech of sequential and simultaneous bilinguals (Guion, 2003) render it unclear to what extent conclusions drawn above regarding bilingual hesitation behavior apply to simultaneous bilinguals.
While studies on adult simultaneous bilinguals, which have largely focused on the production and perception of stops, concur that these speakers systematically maintain language-specific categories, they have also found evidence of phonetic influences from both languages to the other in their speech (Fowler, Sramko, Ostry, Rowland, & Hallé, 2008; Lein, Kupisch, & van de Weijer, 2016; Sundara & Polka, 2008; Sundara, Polka, & Baum, 2006). The speech of simultaneous bilinguals is thus distinct from that of monolinguals and other bilinguals. However, the extent and direction of cross-language influences in language-specific categories are likely variable. Simultaneous bilinguals in Fowler et al. (2008), for instance, produced stops in both languages with voice onset times (VOTs) intermediate between those produced by monolinguals, in contrast to the simultaneous bilinguals in Sundara et al. (2006) and Lein et al. (2016), whose VOTs exhibited different patterns with respect to monolinguals.
It has further been recognized that simultaneous bilinguals do not form a homogeneous group. Apart from order of acquisition, which distinguishes simultaneous from sequential bilinguals, distinction between two languages may arise within the functional and sociopolitical dimensions (Montrul, 2012), which contribute to determining the amount of input in each language different simultaneous bilinguals receive during acquisition. Discrepancies in early language exposure give rise to imbalance between the languages (Dupoux, Peperkamp, & Sebastián-Gallés, 2010; Kupisch, Barton, et al., 2014), and so it is often the case that one of the languages emerges as a dominant language.
The effects of having a more dominant language surface in the perception and production of both languages. In their dominant language, simultaneous bilinguals are found to behave similarly to monolinguals of the same language, while in their weaker language they tend to pattern with late learners (Dupoux et al., 2010; Kupisch, Barton, et al., 2014). Such effects, however, seem to be limited to the phonetic domain and do not readily extend to morphosyntactic domains (Kupisch, Lein, et al., 2014).
1.5 The present study
The main objective of the present study is to evaluate whether and how simultaneous bilinguals contrast the use and production of FPs in different languages. As they acquired both languages at the same time, did they acquire FPs as language-specific phenomena, or do their FPs lie strictly within a speaker-specific domain?
While the representation and usage of FPs are likely intertwined with other forms of hesitation phenomena (e.g., silent pause, lengthening, and other fillers), this study focuses only on a dichotomy between UH and UM, motivated by consistent language-specific tendencies in the literature. As such, changes and redistribution in other categories of hesitation phenomena across languages will not be reflected in the present analysis. The language- or speaker-specific possibilities of the broader hesitation profile among simultaneous bilinguals remain open to future investigation.
To investigate how simultaneous bilinguals make use of FPs in different languages, the present study analyzes speakers of French and German, two languages that exhibit marked differences in FPs.
The primary non-silent hesitation devices in French are said to be prolongation and UH (euh) (Grosjean & Deschamps, 1973). The treatment of UM is varied. In spite of some acknowledgment in the literature that UM (variably spelt euhm or hum) is in use (e.g., Dufour, 2010; Torreira et al., 2010), its use is still sometimes stigmatized as non-native or non-French (e.g., Frommer & Ishikawa, 1980; Temple, 2000). It is rarely the subject of investigation itself, and most empirical studies on FPs in French concern themselves only with UH. All this evidence combines to suggest that, in French, UM is strongly disfavored. The scant data available support this suggestion. By contrast, there is little dispute that both UH and UM (typically spelt äh and ähm) are regularly used in German. The literature reviewed above suggests that UM is generally more common than UH. The French UH vowel is described as front and rounded. In terms of vowel height, it has been found to be between [ø] and [œ] (Séguin, 2010). The German UH tends to be unrounded and central (Pätzold & Simpson, 1995). Thus, compared with the FP in French, the FP in German has a vowel that is typically more open and more back.
1.5.1 Predictions
Existing literature on hesitation of bilingual speakers clearly predicts their hesitation profile being transferred from one language to another, typically from the stronger, dominant language to the weaker language. In the case of simultaneous bilinguals, whose L1s are likely to be imbalanced, it can be hypothesized that:
(H1) The hesitation profile of the weaker language will closely resemble that of the dominant language. In other words, French-dominant simultaneous bilinguals will use more UH than UM, while German-dominant speakers will use more UM than UH.
In terms of the phonetic form of FPs, previous research suggests that simultaneous bilinguals are likely to maintain language-specific differences. At the same time, stemming from studies on language contact is the idea that the dominant language of the community would encroach on the minority or weaker language of the bilingual, reducing the distance between the forms. As such, the following hypotheses are formed:
(H2) Simultaneous bilinguals will maintain a phonetic difference in the vowel quality for FPs in French and German.
(H3) FPs in the weaker language will shift towards the form in the dominant language. In other words, FPs in German produced by French-dominant speakers will shift towards their French FPs, while FPs in French produced by German-dominant speakers will shift towards their German ones.
With respect to the duration of FPs, while no systematic difference is expected between the two languages, speakers are predicted to show a difference between their dominant and weaker languages:
(H4) Akin to how L2 speakers produce longer hesitations, speakers are predicted to produce longer FPs in their weaker language.
2 Method
2.1 Speakers and materials
Data for the present study came from a subset of the HABLA (Hamburg Adult Bilingual LAnguage) Corpus (Kupisch, 2011; Kupisch, Barton, Bianchi, & Stangen, 2012) and comprised recordings from all female speakers who were simultaneously bilingual in French and German. 1 Male speakers were not included in this study in order to avoid reported effects of gender on the distribution of UH versus UM (Acton, 2011; Wieling et al., 2016), as such effects are not within the scope of this study.
Speakers were exposed to both French and German from birth and “used both languages actively with their parents at least until enrolment in school” (Kupisch et al., 2012, p. 169). On the basis of cloze test scores, self-assessment, as well as accentedness ratings by monolingual speakers, Kupisch et al. (2012) concluded that these speakers demonstrated higher proficiency in the majority language of their childhood environment and could thus be considered dominant in that language. Following their categorization, among the 15 chosen speakers (mean age: 31.7; range: 20–41), nine who spent their childhood and adolescence in France were classified as French-dominant, and the other six were classified as German-dominant.
All speakers were interviewed in both languages, with each interview conducted in a separate session by a monolingual or simultaneous bilingual speaker of the language. Most interviews lasted between 20 and 30 minutes. The interviewees only minimally code-switched to the other language, in some instances of proper nouns and place names, as well as short phrases on rare occasions. Speakers were thus considered to be speaking in “monolingual mode” (Grosjean, 2001), when they were arguably “most likely to produce monolingual-like speech” (Antoniou, Best, Tyler, & Kroos, 2010, p. 641).
2.2 Data extraction
To obtain each speaker’s FP profile, all instances of UH and UM were manually segmented in Praat (Boersma & Weenink, 2016) with the aid of the orthographic transcription accompanying the corpus. FPs found in the vicinity of any code-switching segments were not included to avoid potential instability (Spreafico, 2016). The boundaries for each token were determined with the visual aid of the waveform and the spectrogram. As the primary interest of the investigation lies in the quality of the vowels, only the vocalic portion of the FP was included in the case of UM.
For the acoustic-phonetic analysis, midpoint F1 to F3 frequencies of all FPs were extracted in Praat using the Burg algorithm for linear predictive coding, with the formant tracker set to search for 5 to 5.5 formants up to a maximum formant frequency of 5,000, 5,500 or 6,000 Hz. The precise formant settings were manually determined token by token, based on visual inspection of the spectrogram. No measurements were made for tokens that overlapped with speech by the interviewer or other noise events (e.g., bird chirping or door closing), and tokens for which no reliable measurements could be taken were excluded. Out of all segmented FPs (see Table 2 for full count), 110 FPs (10%) in German and 255 (15%) in French were excluded as a result. The duration of each FP (in the case of UM, the vocalic portion) was also recorded and log-transformed. For each acoustic variable, z-scores were calculated within each type of FP produced by each speaker for each language. Outliers in each set, with a z-score greater than 2 in any of the measurements, were excluded from subsequent statistical analyses; 772 FPs (358 UHs and 414 UMs) in German and 1,154 (888 UHs and 266 UMs) in French remained at this stage.
2.3 Statistical analysis
As the use of UH versus UM is a binary variable, a mixed-effects logistic regression model was used (via the lme4 package in R; Bates, Mächler, Bolker, & Walker, 2015; R Core Team, 2018) to evaluate the effect of different predictor variables on the distribution of FPs. The language spoken (German vs. French) and the sub-group to which the speaker belongs (German-dominant vs. French-dominant), as well as their interaction, were included as fixed effects. To account for potential effects of age on the distribution of FPs reported in Germanic languages (Wieling et al., 2016), the factor of age as a mean-centered continuous variable and its interaction with the other two factors were also included as fixed effects. By-speaker variation was modeled with random intercepts.
Each acoustic variable was then fitted with a separate linear mixed-effects model (also using the lme4 package). To evaluate the effect of language on formant frequencies within the different speaker groups, the type of FP (UH vs. UM), language and speaker group (German- vs. French-dominant) were included as fixed effects, along with their pairwise interactions, in the formant models. To assess how duration of the FP vowel varies between the speakers’ dominant and weaker languages, the factor of speaker group was substituted by the dominance of the language being spoken (dominant vs. weaker) in the durational model. The use of different factors for the durational model was driven by the nature of the corresponding hypothesis, where the relevant consideration was the status of a language being dominant or not, and not the identity of the dominant language. In all cases, random intercepts were included to model by-speaker variation. In addition, to account for variability in how speakers respond to a change from dominant to weaker language, and between different types of FP, random slopes were included to model effects of dominance-by-speaker and type-by-speaker variation.
Effect coding was adopted for all (binary) fixed factors in the above mixed-effects models, whereby one level received a code of −0.5 and the other a code of 0.5 (see Table 1), so that effects may be interpreted with respect to the unweighted group mean rather than with respect to a particular base level.
Correspondence of codes with levels in effect coding for mixed-effects models.

To find the best-fitting model for each acoustic variable, starting with an initial full model including all fixed-effect and random-effect terms, predictors were excluded one by one in a stepwise manner, and were only retained if their inclusion led to a significantly improved fit, as determined by a likelihood ratio test implemented using ANOVAs (α = .05). Only the best-fitting model for each acoustic measurement is reported, whereas full results of model comparisons are included in Appendix 1.
3 Results
3.1 Relative distribution of UH and UM
Table 2 reports the total number of FPs recorded in both languages, prior to any exclusion based on acoustic grounds. UH accounted for 531, or 48%, of all tokens in German, while UM contributed the other 52%. In French, the proportion of UH stood much higher at 78%, leaving the proportion of UM to be 22%. These figures align closely with previous findings that UH is strongly favored in French, while UM receives a modest preference in German. Figure 1 illustrates the relative distribution of UH and UM for each speaker by showing the proportion of UH used in the speech of each language. Any point above the 50% rule denotes the speaker’s preference for UH over UM, while any point below indicates the contrary. Figure 1 clearly shows that all speakers used more UH (and hence less UM) in French than in German.
Counts and percentages of UH and UM in German and French.

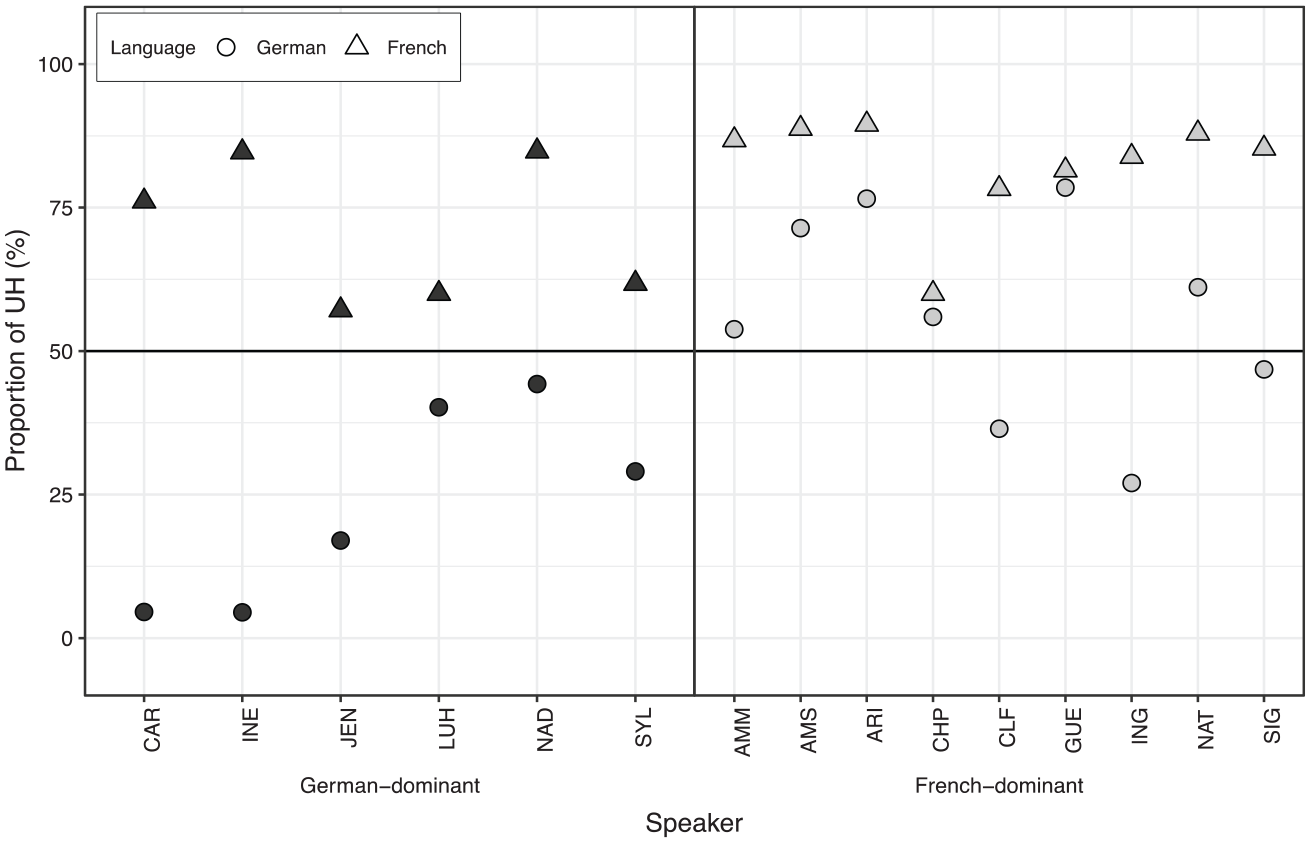
Proportions of UH (%) per speaker in German (circles) and French (triangles) (plotted using the ggplot2 package in R; Wickham, 2016). German-dominant speakers (black) are on the left and French-dominant speakers (grey) on the right. Horizontal rule at 50% to indicate the use of more UH than UM (above rule) or more UM than UH (below rule).
The logistic regression model, summarized in Table 3, found a significant interaction (z = −4.145, p < .0001) between language and speaker group. Figure 2, which displays the probabilities of using UH by each speaker group in both languages, further illustrates the interaction. German-dominant speakers not only used fewer UH than French-dominant speakers in general, but also exhibited a significantly greater shift away from UH (and towards UM) when the language spoken changed from French to German. In fact, all speakers favored the use of UH in French, and while the French-dominant speakers were divided in their preference for UH or UM in German, there was a clear divide for the German-dominant speakers, in that they favored the use of UM in German.
Summary of fixed effects in mixed-effects logistic regression model for UH versus UM.
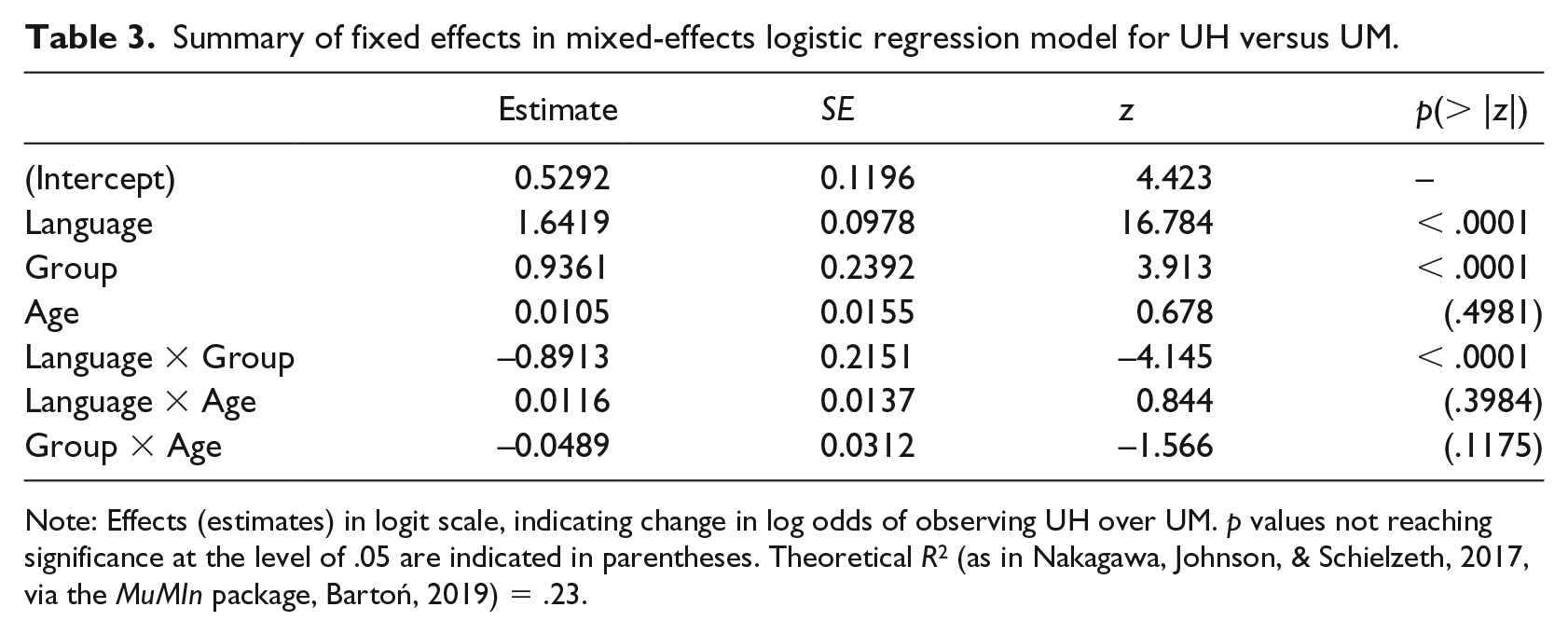
Note: Effects (estimates) in logit scale, indicating change in log odds of observing UH over UM. p values not reaching significance at the level of .05 are indicated in parentheses. Theoretical R2 (as in Nakagawa, Johnson, & Schielzeth, 2017, via the MuMIn package, Bartoń, 2019) = .23.
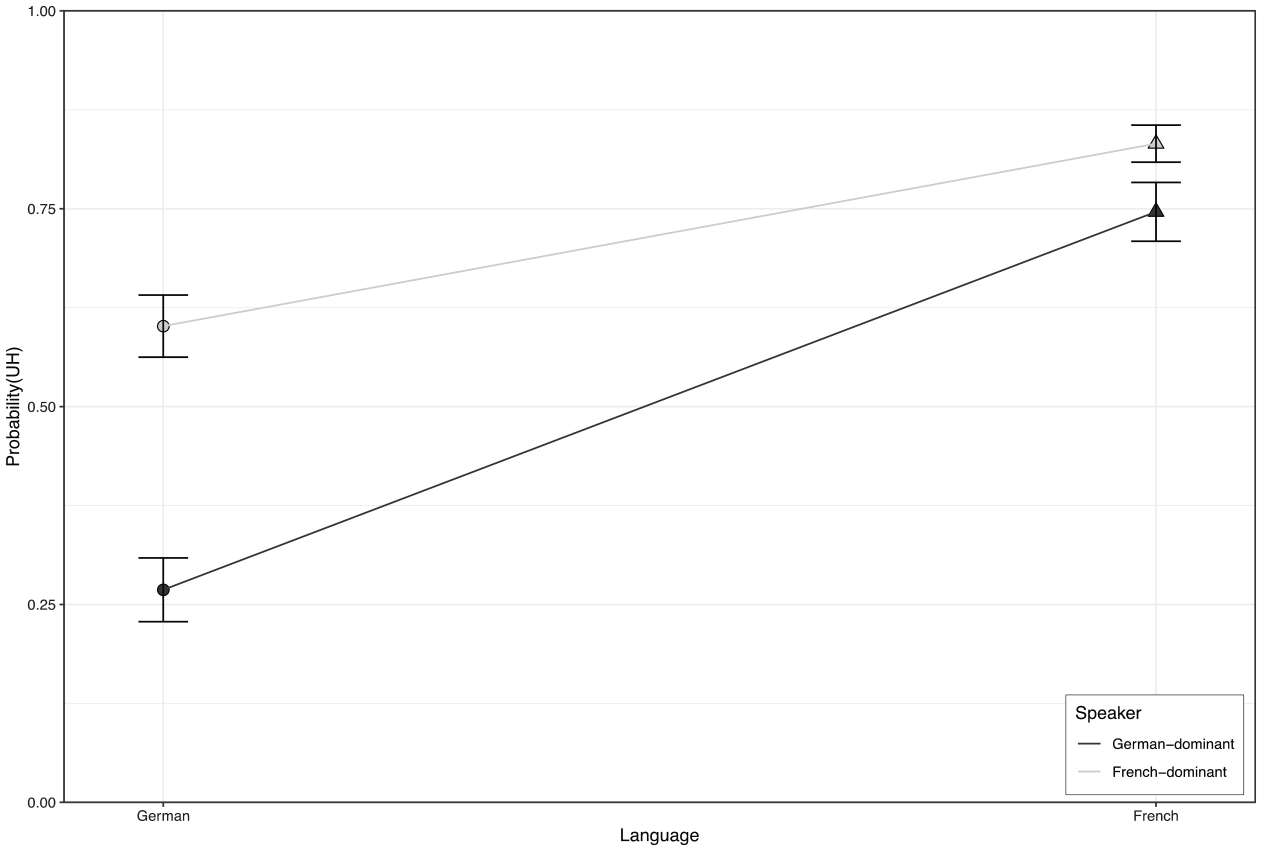
Probabilities of using UH (between UH and UM) by German-dominant (black) and French-dominant speakers (grey) in German and French. Error bars represent standard errors.
The point above further illustrates the extent of between-speaker variation within the same language. Even though all speakers use more UH than UM in French, there are differences in the degree of preference: The proportion of UH ranges from 57% to 89%. The range exhibited in German is even wider, going from an extreme preference for UM (5% UH/95% UM) to a strong preference for UH (79% UH/21% UM).
In the distributional model, age was not found to have a significant effect on the relative frequency of FPs, either on its own or in interaction with other predictors. The present data thus did not show a rise of UM in German similar to that reported in Wieling et al. (2016), which may be due to the small sample size here. The shift towards UM in Germanic languages, especially in English, as Wieling et al. (2016) pointed out, is a subtle one whose identification was only enabled by analyzing much larger corpora.
3.2 Phonetic quality of UH and UM
3.2.1 Formants
Figure 3 presents the distributions of midpoint F1–F3 for UH and UM in both languages, categorized by speaker group. In each case, the dominant language of the speaker group is shaded. Table 4 further summarizes the effects of predictors in the best-fitting models.
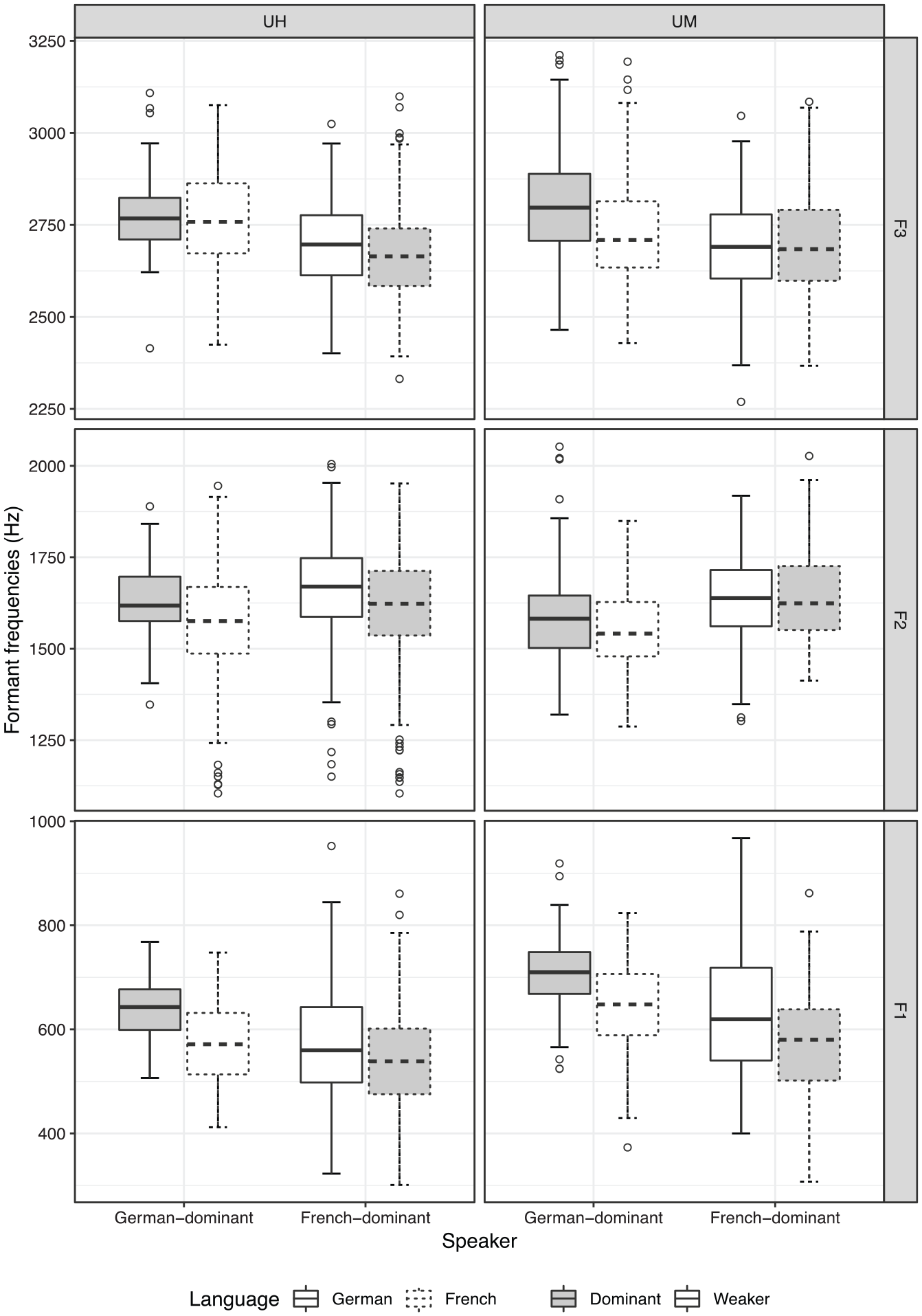
Boxplots of F1–F3 values (bottom to top, in Hz) from UH (left column) and the vocalic portion of UM (right column), produced by both German- and French-dominant speakers in German (solid line) and in French (dashed line). Values from the dominant language of the speaker group are shaded.
Summary of fixed effects in best-fitting linear mixed effects models of F1–F3.
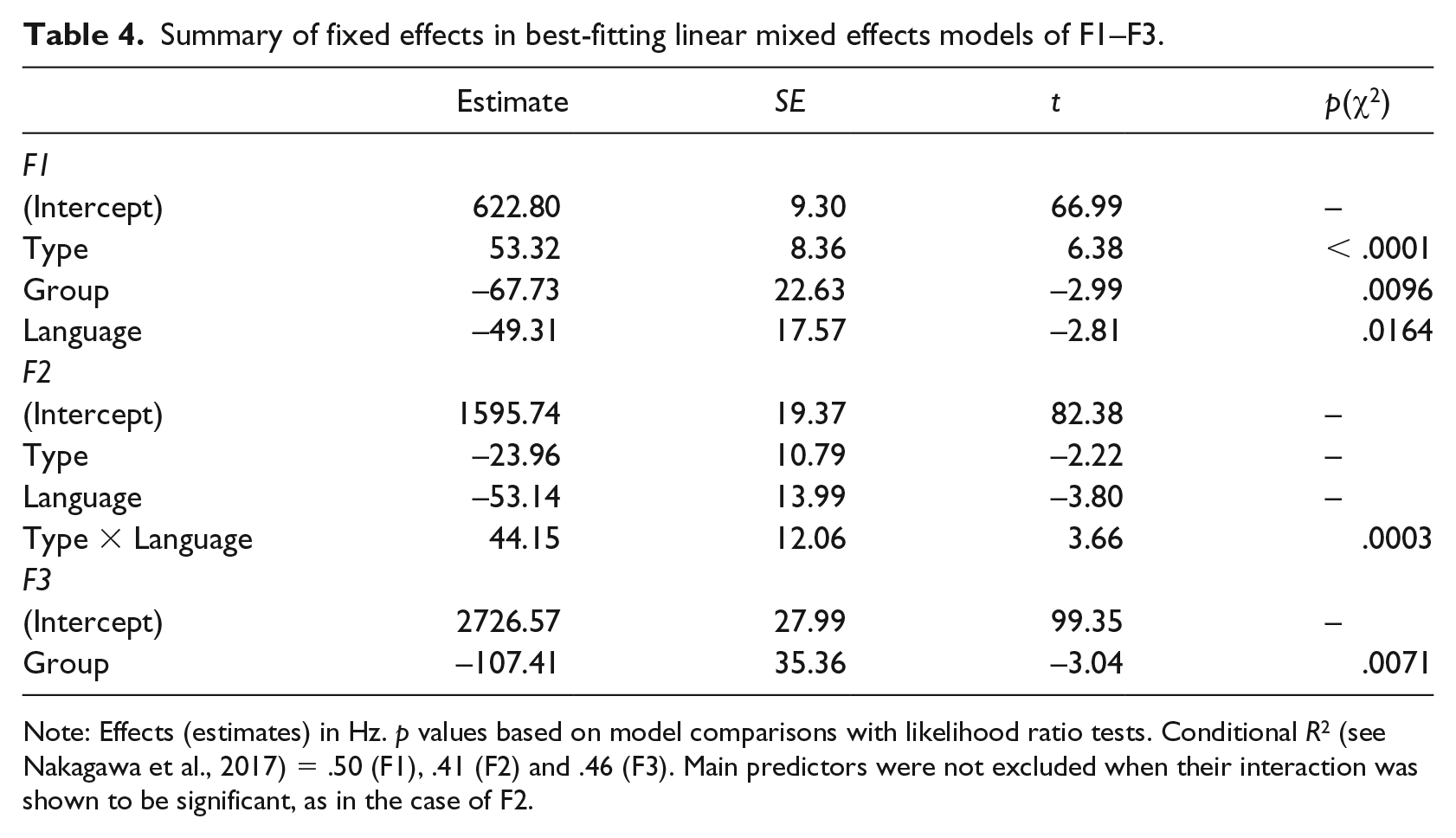
Note: Effects (estimates) in Hz. p values based on model comparisons with likelihood ratio tests. Conditional R2 (see Nakagawa et al., 2017) = .50 (F1), .41 (F2) and .46 (F3). Main predictors were not excluded when their interaction was shown to be significant, as in the case of F2.
When FPs in the dominant language are compared with those in the weaker language, two divergent trends in the formants can be discerned from Figure 3. For F1, FPs in German by German-dominant speakers had the highest median frequency while those in French by French-dominant speakers had the lowest. FPs in the weaker languages reported similar frequencies that were intermediate between those in the dominant languages. Therefore, FPs in German were realized with a higher F1 than those in French, and those by German-dominant speakers were higher than those by French-dominant speakers. These observations are supported by the best-fitting model, which found the effects of both language and group to be significant. The type of FP was also shown to be a significant predictor, with UM having a significantly higher F1 by around 50 Hz. The FPs further show considerable variability in F1. This is especially so for the French-dominant speakers, who made use of almost the full typical range of F1 in both UH and UM, with tokens reaching as low as 301 Hz and as high as 968 Hz.
A similar trend holds by and large for F3, though differences within the same speaker group were noticeably smaller. In particular, in the cases of UH by German-dominant speakers and UM by French-dominant speakers, the between-language differences in median F3 were lower than 10 Hz. The differences between languages did not reach significance, nor did those between the types of FP. Only the effect of group was found to be significant in the model fitted (see Table 4).
The reverse can be observed for F2. For both types of FP, those in the dominant languages had similar median F2, in between German by French-dominant speakers, with the highest F2, and French by German-dominant speakers, with the lowest F2. The best-fitting model found no significant effect of speaker group, but a significant interaction between language and type. Figure 4 illustrates this relationship, showing that while FPs in German generally had higher F2 than those in French (which reported very similar F2 for UH and UM), this effect was significantly stronger for UH by about 40 Hz.
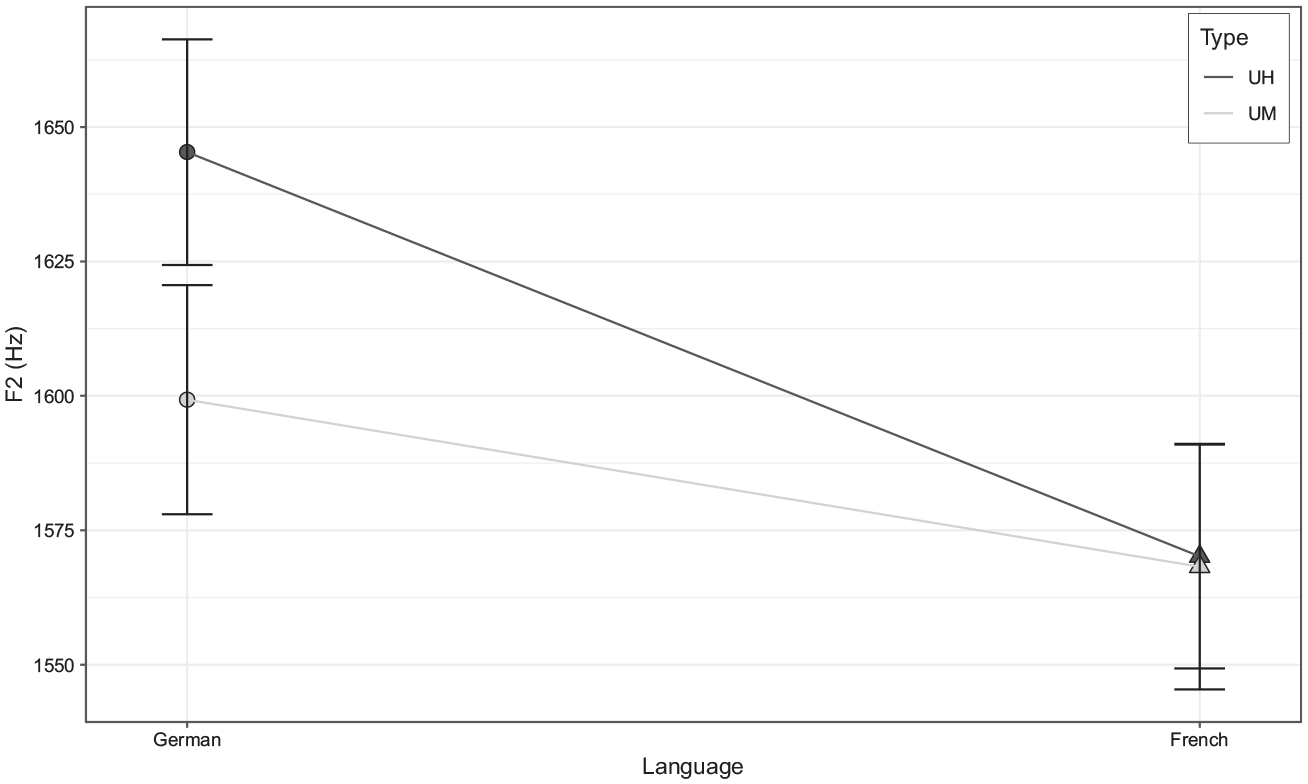
Plot showing the effect of interaction between language and type of FP on vocalic F2. Error bars indicate standard errors.
Considerable variability in vowel quality was found between different speakers. Figure 5 shows, as an illustration, speakers with the most extreme F1 and F2 frequencies in the UM vowel in both German and French. Mean F1 had a range of about 200 Hz (c. 480–680 Hz) in French, and spanned an even greater range approaching 250 Hz (c. 520–760 Hz) in German. In both languages, mean F2 frequencies displayed a range of almost 400 Hz (c. 1450–1840 Hz). The extent of variability in mean F1 observed here is comparable to that reported for SSBE speakers, with an even wider spread of mean F2 (Hughes et al., 2016). Between-speaker variability in FPs was observed not only within a single language, but also in the direction and magnitude of shift between different languages. Some speakers, such as CAR and GUE, realized UM with lowered F1 and F2 when speaking in French, while some others, such as AMM and ARI, demonstrated a shift in the opposite direction. Figure 5 further shows varying degrees of internal consistency within individual speakers. SYL used vowels that covered a large area of the vowel plane, especially in French, while speakers such as CAR and SIG displayed very low variability along the dimensions of F1 and F2, respectively.
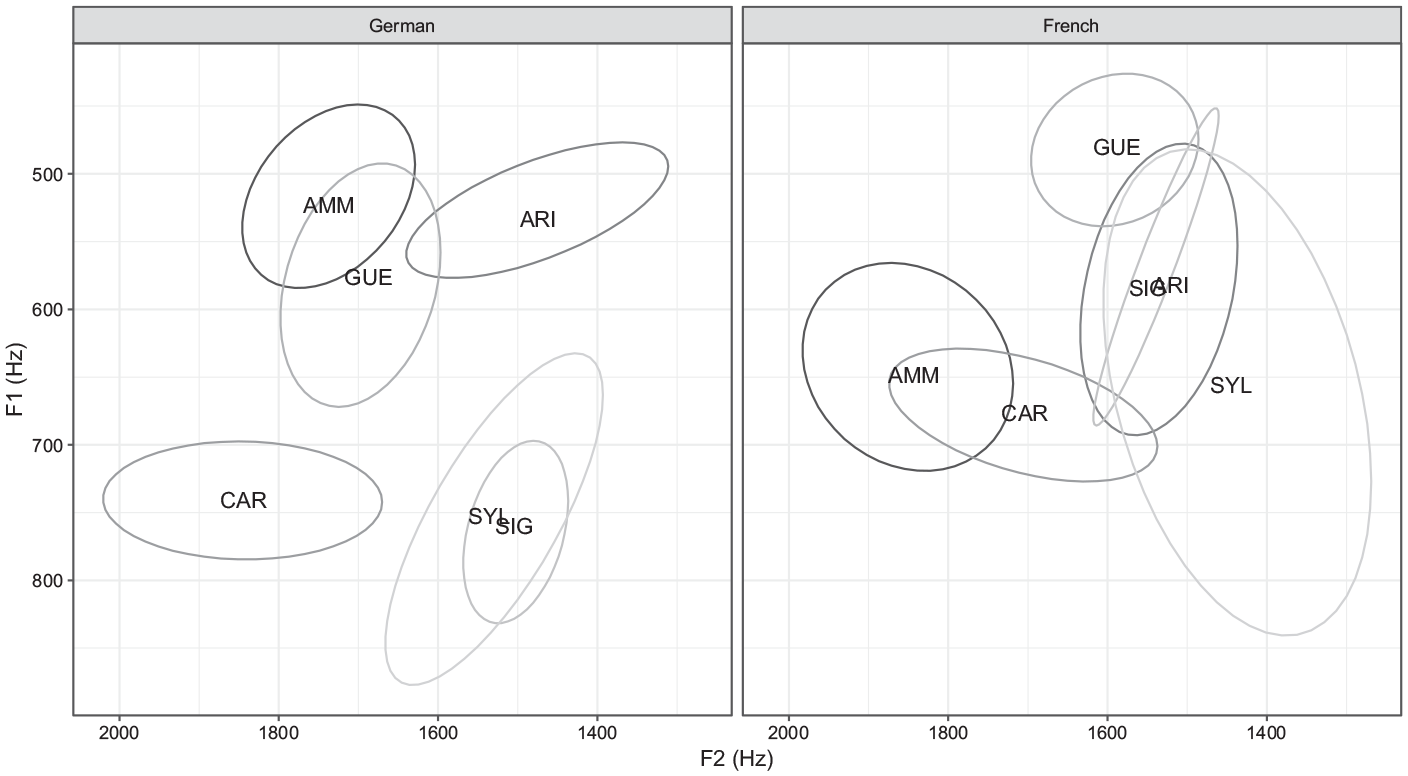
Ellipses showing mean formant frequencies ±1 SD of the vocalic portion of UM in German (left panel) and French (right panel) for six speakers with the maximum and minimum mean F1 and F2 values in either language.
3.2.2 Duration
Figure 6 presents durations of the vowels in UH and UM in both languages, categorized by speaker group. The dominant language of the speaker group is shaded, as in Figure 3. Table 5 provides a summary of the fixed effects in the best-fitting model.
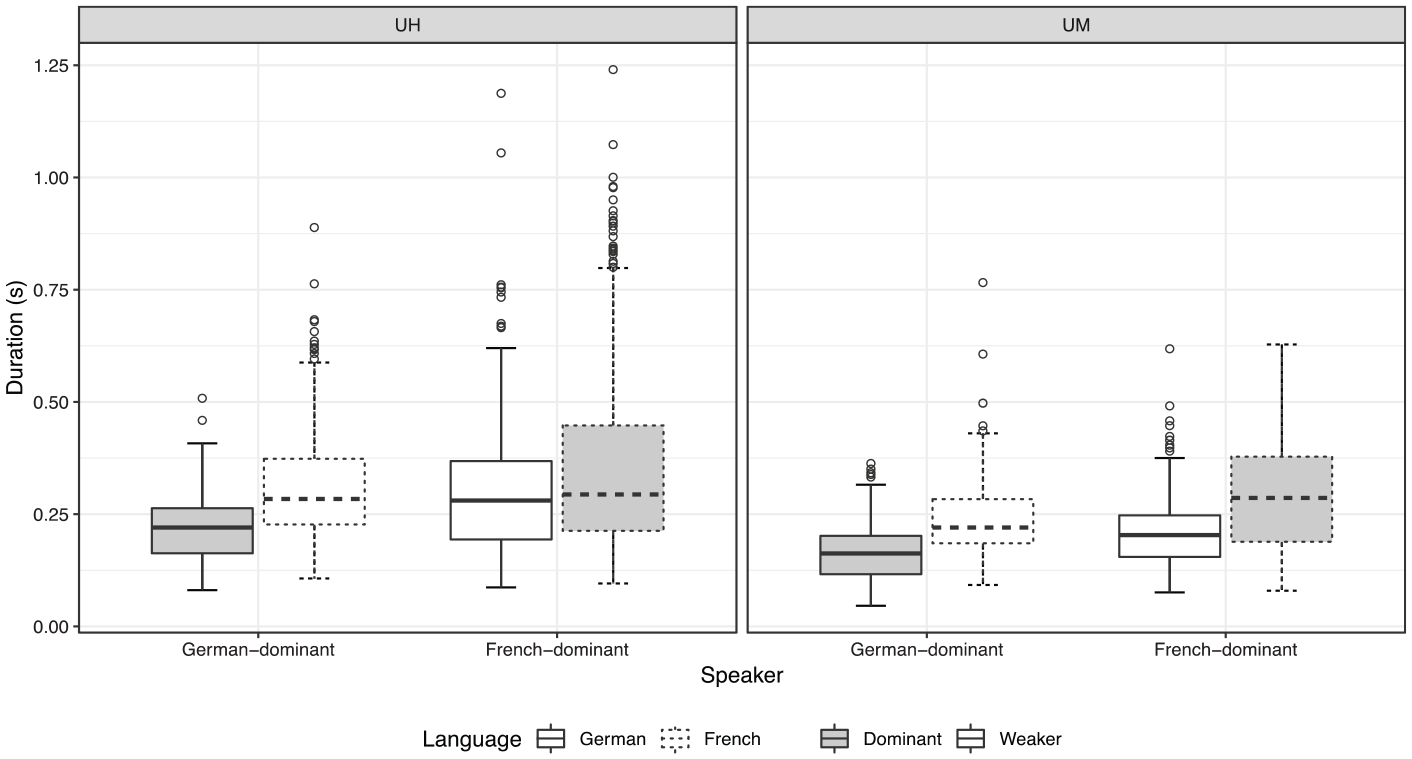
Boxplots of vocalic durations (in s) of UH (left panel) and UM (right panel) in German (solid line) and French (dashed line) by German-dominant and French-dominant speakers. Durations from the dominant language of each group are shaded.
Summary of fixed effects in the best-fitting linear mixed effects model of log-duration.
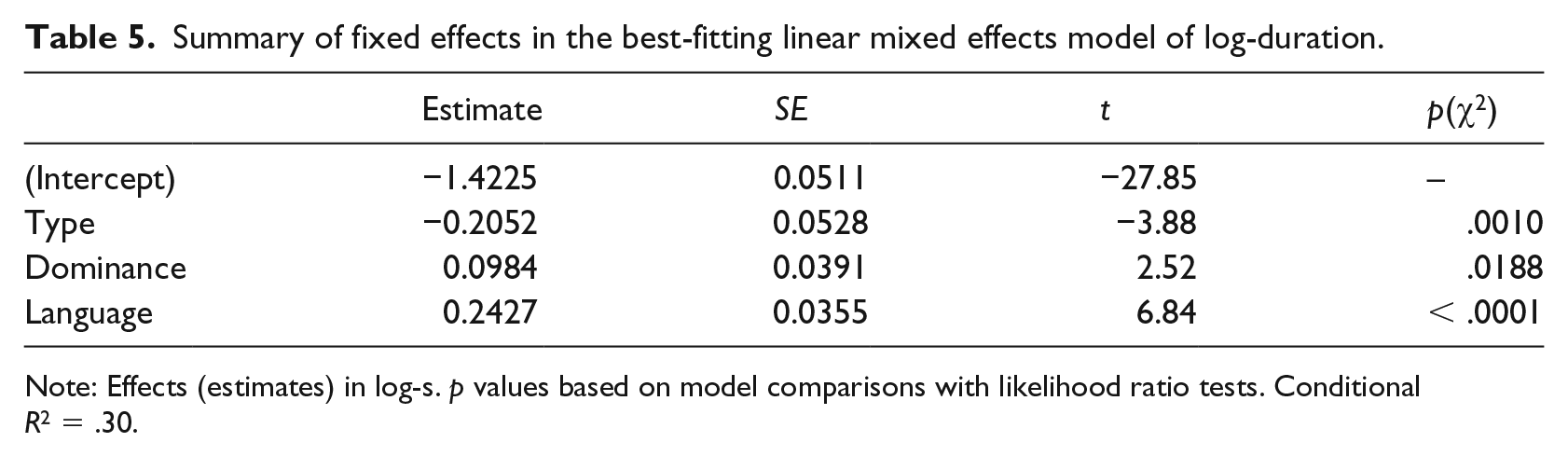
Note: Effects (estimates) in log-s. p values based on model comparisons with likelihood ratio tests. Conditional R2 = .30.
Figure 6 clearly indicates that both German-dominant and French-dominant speakers produced longer FPs in French than in German, meaning only German-dominant speakers produced longer FPs in their weaker language. This would suggest that language itself, but not the dominance of the language, was the main predictor of FP duration. The significantly longer duration of FPs in French was indeed confirmed in the best-fitting model. Although the final model obtained also reveals a much smaller but significant effect of dominance, this should be considered in light of its interaction with language, which reached close to significance during fitting (p = .0920, see Appendix 1). These results are suggestive of the idea that, consistent with the observation made in Figure 6, the effect of simultaneous bilinguals producing longer FPs in their weaker language is primarily constrained to the German-dominant speakers.
The duration model further showed the vocalic portion in UM to be significantly shorter than UH. Most instances of UM had a vocalic duration of below 0.3 s, whereas UH displayed a considerably larger range, many tokens of which were longer than 0.75 s and went up to as long as 1.25 s.
4 Discussion
The present study set out to explore how FPs are manifested in the speech of simultaneous bilingual speakers. In this section, the predictions made above on the basis of previous research are discussed in turn.
The hypothesis (H1) that the hesitation profile of the weaker language would resemble that of the dominant language was partially supported. Only the French-dominant speakers maintained an overall French-like preference for UH in both languages, even though they did shift away from UH and towards UM in German. The German-dominant speakers, on the other hand, exhibited monolingual-like profiles in both languages. That their profile in the dominant language was not mirrored in the weaker language distinguishes them not only from the French-dominant simultaneous bilinguals but also from highly proficient sequential bilinguals. These findings contrast with other scenarios involving sequential bilinguals reported above, where transfer is common from the more dominant language (L1, or the majority language of the community) to the weaker language (L2, or the minority language) (Fehringer & Fry, 2007; Hlavac, 2011). If such transfer had indeed taken place for the German-dominant speakers, the degree of influence from German would likely have been minimal, as some of the most committed users of UM in German (CAR and INE) were also among the most frequent UH users in French. These results thus suggest that, between the two groups, the dominant language exerts its influence differentially.
Turning to the acoustic-phonetic elements of the FPs, those in the dominant languages indicate that they are in line with existing accounts of their phonetic quality. In the dimension of vowel heights, higher F1 in German indicates it to have the more open vowel of the two languages. Similar to findings reported in Candea et al. (2005), the magnitude of the differences in F2 between the two languages was very small, which may be due to the countervailing acoustic consequences of different articulatory gestures. Compared with the centralized FP in German, the more fronted position canonically associated with FPs in French would lead to higher F2. At the same time, lip protrusion from rounding in the French vowel would lengthen the vocal tract and consequently lower F2 (and F3). The extent to which the two opposing effects offset each other is likely idiosyncratic to the speaker, depending on the precise gesture adopted. A comparison of F3 suggests that a distinction in roundedness between the FPs in French and German may indeed be found, whereby the lower F3 produced by the French-dominant speakers points to a more rounded vowel. The cumulative evidence is thus consistent with previous data of FPs from monolingual speakers, although a direct comparison with monolinguals in the future would be helpful in establishing the degree of similarity between FPs acquired by simultaneous bilinguals and monolinguals.
Additionally, an overall difference in height was found between UH and UM, with the latter being slightly more open. While the distinction could be due to coarticulatory effects from the following [m] in UM, which would cause additional resonances in the region of F1 and thereby possibly raising it, this possibility remains an unlikely scenario. The vocalic portion in UM has a relatively long duration, when compared with lexical vowels in spontaneous speech, and previous studies in French or on FPs suggest that anticipatory coarticulation from a following nasal generally does not set in until well after the midpoint of the vowel (Delvaux, Demolin, Harmegnies, & Soquet, 2008; Hughes et al., 2016). The reason for the difference is thus not entirely clear. As there is much variability in F1, especially for UM, the issue of phonetic quality in FPs warrants future investigation with larger sets of speakers.
A cross-language comparison of FPs finds support for both hypotheses (H2) and (H3). FPs in French were less open than those in German. At the same time, German-dominant speakers produced more open FPs in French, their weaker language, than their French-dominant counterparts. A similar trend (in the opposite direction) was found in German, demonstrating the pulling influence of the dominant language on the weaker language.
On the face of it, data on F2 alone suggest a shift of FPs in the weaker language away from rather than towards the dominant language. However, as explained above, the articulatory gestures that characterize the typical FPs in French offer competing acoustic cues. When F2 is evaluated in conjunction with F3, the findings here are consistent with the German-dominant speakers adopting a higher degree of rounding in their French FPs than in their German FPs, and vice versa for the French-dominant speakers. This would mean that speakers were indeed using different sets of vowels in FPs of different languages. There is nevertheless evidence from F3, in a similar manner to F1, that the dominant language has an effect on how speakers make use of different gestures in their weaker language.
The best-fitting mixed effects model for (log-)duration provides only limited support for the hypothesis (H4). While the model suggests that FPs are significantly longer in the weaker language, the effect of dominance on duration has a very small magnitude and remains overshadowed by much stronger effects of FP type and language. It thus appears that the type of FP and the language spoken, rather than the dominance of such language, form the main driving factors of duration in the vocalic portion of FPs. Indeed, as Figure 6 clearly shows, longer instances of UH are far more frequent in French. The tendency for French UH and UM to be considerably longer than their German counterparts is in line with the general penchant of French speakers to elongate word-final vowels, which Grosjean & Deschamps (1975) attributed to the open syllable structure of the language. The possibility of coupling between lengthening and FPs (see Clark & Fox Tree, 2002) is substantiated by the stark contrast between the purely vocalic UH and the vowel-nasal UM. Consistent with Hughes et al.’s (2016) finding in SSBE, UH is longer than the vocalic portion of UM in both French and German. While there seems to be a clear ceiling for the vowel in UM, potentially due to the presence of the subsequent nasal, which can also contribute to lengthening (Hughes et al., 2016; Shriberg, 1994), the entirety of UH is available for lengthening.
Taken in totality, the findings from the simultaneous bilinguals in the present study demonstrate, in the case of FPs, a complex interplay between language- and speaker-specificity.
Speaker idiosyncrasy is evidenced by the wide range of variation exhibited within the same language. The extent of variability in this relatively small sample already closely approximates the full gamut expected from existing descriptions, both in the distribution and in the quality of FPs (de Leeuw, 2007; Pätzold & Simpson, 1995). These results lend support to the view that FPs are useful features for discriminating between speakers, as well as raise the degree of shift between the two languages as an additional source of speaker-specific information.
At the same time, these speakers exemplify that, between the two languages, no strong correspondence of FP profiles was observed on an individual level. The high use of UH in French suggests that language still plays an overarching role in determining a speaker’s hesitation profile. The German-dominant speakers in particular, who all used relatively more UH in French but more UM in German, provide strong support for this notion. The role of language manifests itself in the acoustic-phonetic domain as well, with evidence from findings in both vowel height and duration. (While results from F2 and F3 are not inconsistent with an overall difference between German and French, further investigation using articulatory data is needed to ascertain the differences in backness and roundedness of the vowels.)
Contrary to the high cross-language within-speaker consistency of rates of hesitation phenomena found in de Jong et al. (2015) and Fehringer and Fry (2007), the results here indicate that, in developing their hesitation behavior, simultaneous bilinguals may behave differently from intermediate or advanced sequential bilinguals in the earlier studies. Findings from both the distribution and realization of FPs point to the suggestion that, exposed to and having acquired two languages at the same time, the simultaneous bilinguals here do not develop a single system of hesitation behavior specific to each individual; rather, they develop language-specific categories of FPs. The ability of simultaneous bilinguals to maintain language-specific sound categories is supported by Guion (2003), who found that simultaneous Ecuadorian Quichua–Spanish bilinguals stood out from other sequential bilinguals in their ability to maintain a difference between Quichua /ɪ/ and Spanish /i/.
On the other hand, there are also other differences between the present study and the aforementioned studies. The present study did not examine the actual rates of FPs, as a single category, alongside other hesitation categories, but instead focuses on the relative usage of only FPs with respect to each other. As Fehringer and Fry (2007) noted, the pair of languages in their study, English and German, largely make use of the same hesitation phenomena, while French speakers are expected to adopt different strategies. With regard to FPs specifically, French speakers are noted for their preference for UH over UM, a tendency also reflected in the French speech of the simultaneous bilinguals here. Future research into the frequencies of UH and UM within the broader scheme of hesitation phenomena may provide further insights into how the hesitation behavior of simultaneous bilinguals aligns in both languages.
Both sets of data further suggest that the influence of language on the production of FPs in simultaneous bilinguals is mediated by whether the language is dominant for the speaker in question. Between the German-dominant and French-dominant speakers, however, there are indications of disparity in the degree of influence of dominance. As pointed out above, the French-dominant speakers all maintained a preference for UH in German. Similarly, the vowel duration of the French-dominant speakers’ FPs in German retained a distribution more akin to that in their French than that of the German-dominant speakers.
A possible reason for the divergent behavior between the two groups lies in the input they received. In a study conducted on an almost identical set of speakers from the same corpus, Lein et al. (2016) found that French-dominant simultaneous bilinguals were less successful in producing German-like VOT than German-dominant bilinguals were in producing French-like VOT. The authors suggested that this might be due to the greater amount of time spent in France during the childhood of simultaneous bilinguals from Germany. As a consequence, the German-dominant speakers would on the whole receive more input in their weaker language earlier in their process of acquisition. Findings in the present study are comparable to those in Lein et al. (2016), in the sense that the French-dominant simultaneous bilinguals were less “successful” in producing German-like forms of FPs than German-dominant bilinguals were in producing French-like forms of FPs. Since speakers receive input in the form of fine-grained phonetic details as well as conversational norms, among other things, the difference in the background of these speakers may then contribute to the varying use and form of FPs in their adulthood. Nevertheless, for the German-dominant bilinguals, there is some evidence of transfer from German to French in the formant data, which suggests that the influence of the dominant language may surface in the phonetic domain in a manner different from the selection of FPs.
5 Conclusion
This study has provided an investigation into the use and realization of FPs by simultaneous bilingual speakers. Both distributional and acoustic data demonstrate that FPs in the two simultaneously acquired languages are not one and the same, but maintain language-specific properties. At the same time, the speech community in which the speakers grow up also has a significant influence on the production of FPs. Furthermore, systematic differences in the frequency and acoustics between UH and UM show that, notwithstanding the level of planning involved in these utterances, speakers do make differential use of them. They highlight the importance of considering both types of FP when examining hesitation phenomena, especially when considering their phonetic colors, as well as treating them prima facie as different entities. The nature of the data, however, offers only a circumstantial glimpse into the nature and representation of FPs in simultaneous bilingual speakers. The findings here thus call for more research into the use of FPs by simultaneous bilinguals from different perspectives, so that the existing picture of our understanding of FPs can continue to be enriched.
Research Data
HABLA_HES_full – Supplemental material for Between Äh(m) and Euh(m): The Distribution and Realization of Filled Pauses in the Speech of German-French Simultaneous Bilinguals
HABLA_HES_full for Between Äh(m) and Euh(m): The Distribution and Realization of Filled Pauses in the Speech of German-French Simultaneous Bilinguals by Justin J. H. Lo in Language and Speech
Footnotes
Appendix
p values in stepwise exclusion of predictors in fitting linear mixed effects models.
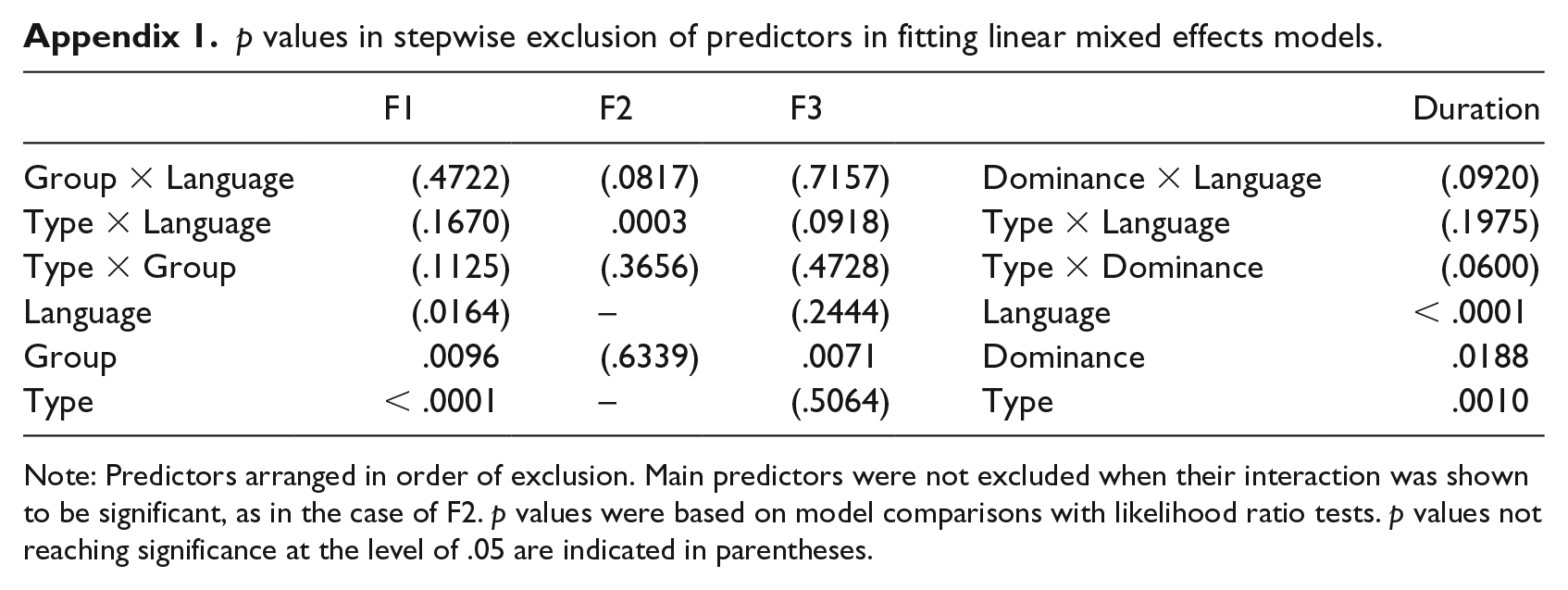
| F1 | F2 | F3 | Duration | ||
|---|---|---|---|---|---|
| Group × Language | (.4722) | (.0817) | (.7157) | Dominance × Language | (.0920) |
| Type × Language | (.1670) | .0003 | (.0918) | Type × Language | (.1975) |
| Type × Group | (.1125) | (.3656) | (.4728) | Type × Dominance | (.0600) |
| Language | (.0164) | – | (.2444) | Language | < .0001 |
| Group | .0096 | (.6339) | .0071 | Dominance | .0188 |
| Type | < .0001 | – | (.5064) | Type | .0010 |
Note: Predictors arranged in order of exclusion. Main predictors were not excluded when their interaction was shown to be significant, as in the case of F2. p values were based on model comparisons with likelihood ratio tests. p values not reaching significance at the level of .05 are indicated in parentheses.
Acknowledgements
I am most grateful to Paul Foulkes and Vincent Hughes for their invaluable guidance and valuable comments on early drafts. Thanks also to two anonymous reviewers for their helpful comments and suggestions.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.
Notes
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.