
Abstract
The voicing effect is among the most studied and robust of phonetic phenomena. Yet there remains a lack of consensus on why vowels preceding voiced obstruents should be longer than vowels preceding voiceless obstruents. In this paper we provide an analysis of the voicing effect in a corpus of natural speech, and using production data from a metronome-timed word repetition study. From this evidence, as well as the existing literature, we conclude that vowel duration differences follow from consonant duration differences. The characteristic voicing effect in English is largely limited to words of especially long duration, and preceding vowel duration does not reliably cue obstruent voicing under the following circumstances: when obstruent voicing or duration cues conflict; for lax or unstressed vowels; and for most conversational speech. We show that this behavior can be modeled using a competing-constraints framework, where all segments resist expanding or compressing past a preferred duration. Inherent segment elasticity determines the degree of resistance, but segment duration is ultimately determined by the interaction of these segmental constraints with constraints on the distribution of the lengthening force within the syllable, and how closely target durations are matched. This account of the voicing effect has a number of implications for phonological theory, especially the central role that the concept of prominence plays in the analysis of underlying features.
Keywords
1 Introduction
The terms “vowel lengthening” and “voicing effect” are used to refer to the empirical finding that vowels preceding voiced obstruents are longer than those preceding voiceless obstruents (e.g., Beguš, 2017; Braunschweiler, 1997; Chen, 1970; Coretta, 2019; Crowther & Mann, 1992; Crystal & House, 1982; de Jong, 1991, 2004; Denes, 1955; Derr & Massaro, 1980; Fischer & Ohde, 1990; Fitch, 1981; Fox & Terbeek, 1977; Hillenbrand et al., 1984; House, 1961; House & Fairbanks, 1953; Javkin, 1977; Klatt, 1973, 1976; Kluender et al., 1988; Ko, 2018; Krause, 1982; Kulikov, 2012; Laeufer, 1992; Lisker, 1974, 1978, 1986; Luce & Charles-Luce, 1985; Ohala, 1983; Peterson & Lehiste, 1960; Port, 1976; Port & Dalby, 1982; Raphael, 1972, 1975; Raphael et al., 1975; Sanker, 2019; Sharf, 1962; Smith, 2002; Sweet, 1880; Tanner et al., 2019; Umeda, 1975; Van Summers, 1987; Walsh & Parker, 1981). Voicing effects have been documented in a number of different languages. However, it is generally agreed that English (in many of its varieties) exhibits one of the strongest such effects, with vowels preceding voiced obstruents up to twice as long as their counterparts preceding voiceless obstruents (e.g., Chen, 1970; Harris & Umeda, 1974; Mack, 1982). English-speaking listeners also exhibit a robust categorical perception effect for final voicing based on preceding vowel duration alone (e.g., Crowther & Mann, 1992; Denes, 1955; Hillenbrand et al., 1984; Klatt, 1976; Raphael, 1972). Preceding vowel duration has, in fact, been described as the most reliable cue to voicing on final obstruents (Luce & Charles-Luce, 1985; Raphael, 1972; Raphael et al., 1975). Because stops are often unreleased in final position, it has also been suggested that a sound change has occurred (or is underway) in which the contrastive relationship between words like “bad” (bӕd) and “bat” (bӕt) has shifted away from the final obstruent itself, to be expressed in the duration of the preceding vowel (bӕˑt˺ vs. bӕt˺), at least in phrase-final position (e.g., Klatt, 1976).
In this paper, however, we will argue that the primary cue to obstruent voicing in coda position is the duration of the obstruent itself. Short obstruents are perceived as members of the phonologically voiced category, and long obstruents, as members of the voiceless. Because the long/short distinction is relative, preceding vowel duration, as an indicator of speaking rate, affects the perception of voicing. We find that the duration of the preceding vowel is better predicted by the following obstruent duration than by its voicing, and that “voicing effects” are the result of the negative correlation of voicing with segment length. We argue that the two phonological categories of stop are distinguished, not by their absolute durations, but by their inherent elasticity: the less elastic a segment, the more it resists both lengthening and shortening.
The paper is organized as follows. In the following section we provide background on the voicing effect and related phenomena. Section 3 contains a corpus study on American English. In Section 4, predictions of our hypothesis are tested using a variable-rate production task. In Section 5, we model the results using continuously violable constraints on duration at the segment and syllable levels. Our hypothesis is elaborated in Section 6, where we account for the perceptual side of the voicing effect. We summarize and conclude in Section 7, where we discuss the implications of the present work for theories of phonological contrast.
2 Background
Despite the large amount of research on the phenomenon, the underlying source of the voicing effect is unknown, with little consensus on what acoustic or articulatory properties give rise to the observed duration differences. Belasco (1958) and Delattre (1962) both argue that there is a tradeoff of effort between the vowel and consonant: strong (voiceless) consonants are accompanied by weak (shorter) vowels. However, Moreton (2004) and Schwartz (2010) argue essentially the opposite: that it is the spread of “fortisness” that shortens the preceding vowel. It has also been claimed that careful, and therefore slower (or simply earlier, see Klatt, 1976), movements of the vocal cords are required to avoid spontaneous voicing under reduced pressure (Halle & Stevens, 1967). However, clear evidence of differences in energy, effort, or precision between voiced and voiceless obstruents has not been forthcoming.
On the auditory side, Kluender et al. (1988) and also Jessen (2001) suggest that vowel lengthening is an enhancement effect, reinforcing the length differences of the obstruents, and thus the voicing contrast. Javkin (1977) posits that vowels are consistently perceived as longer before voiced obstruents because listeners mis-attribute glottal pulsing to the end of the vowel. However, there seems to be little evidence to support the latter hypothesis, and enhancement explanations are unable to account for why it is preceding vowel length, and not obstruent length, degree of voicing, presence of audible release, or aspiration that are used to enhance the contrastiveness of the obstruents themselves. More recently, Sanker (2020) has proposed an explanation based on the interaction between acoustics and articulation: a subset of the features in the vowel that are affected by the voicing of the following obstruent (spectral tilt, and intensity contour) also affect perception of vowel duration, presumably for unrelated articulatory reasons. Thus, in the presence of those cues, independent of the presence of a following obstruent, listeners perceive the vowel as being longer/shorter than some baseline duration. This proposal hinges on the source of the duration percept being independent of the voicing, which has not been established, since no articulatory explanation for why spectral tilt and intensity contour affect perceived duration has been proposed.
2.1 Production
The above hypotheses encounter more problems when the voicing effect is examined more closely. Voicing effects occur even when voiced obstruents are phonetically devoiced (Chen, 1970; Fox & Terbeek, 1977; Walsh & Parker, 1981), ruling out an active articulation-based source that relies on actual vocal fold vibration (although such a source may have been active at some previous time, and the pattern subsequently phonologized). A universal basis for the effect is called into question by the apparent absence of a lengthening effect in certain languages (Flege, 1979; Hillenbrand et al., 1984; Keating, 1979, 1985). 1 Even in English, with one of the most robust voicing effects measured, durational differences are not found in all contexts. Production studies typically consist of either word lists or brief sentences read by participants in a laboratory setting. In sentence contexts, the target words are often in utterance final position. Such words are also typically monosyllabic, which entails that the target vowel receives primary stress. When some or all of these factors are varied, the voicing effect can be significantly reduced, or disappear altogether: in phrase-medial position (vs. phrase-final) (Crystal & House, 1988; Luce & Charles-Luce, 1985; Smith, 2002; Umeda, 1975), 2 polysyllabic words (vs. monosyllabic) (Klatt, 1973; Port, 1981; Umeda, 1975), 3 lax vowels (vs. tense) (Crystal & House, 1988; Luce & Charles-Luce, 1985; Peterson & Lehiste, 1960), 4 unstressed vowels (vs. stressed vowels) (de Jong, 2004; Van Summers, 1987), 5 and fast speaking rates (vs. slow speaking rates) (Ko, 2018; Port, 1976; Smith, 2002). 6
2.2 Compensation
Obstruent duration differences mirror vowel duration differences: they are small or non-existent in the contexts in which vowel duration differences are small or non-existent (Crystal & House, 1982; Luce & Charles-Luce, 1985; Miller et al., 1986), 7 and they are large where large vowel duration differences are found, and in the opposite direction (e.g., Chen, 1970; Klatt, 1976; Luce & Charles-Luce, 1985; Miller & Volaitis, 1989; Umeda, 1975). 8 The inverse correlation between differences in obstruent duration and differences in preceding vowel duration was noted early on (Catford, 1977; Kozhevnikov & Chistovich, 1965). However, temporal compensation as an explanation for the voicing effect has been explicitly considered and rejected on a number of separate occasions (Braunschweiler, 1997; Chen, 1970; Keating, 1985). These rejections are largely based on the assumption that temporal compensation should be total, or near total, with the consequence that all syllables would have the same length. 9
Although syllable-level isochrony was originally hypothesized to apply in so-called “syllable-timed” languages like English (e.g., Pike, 1945), and to be the source of a number of apparently compensatory effects, it has become clear that uniform timing for syllables is not consistently enforced in English 10 or in any other language that has been investigated (see Krivokapić, 2020 for a review).
2.3 Competition
More recent work on temporal compensation is situated within Articulatory Phonology (AP), which does not assume isochrony at any level. This is appealing for “compensatory” phenomena that range widely in their degree (e.g.,Elert, 1965; Kavitskaya, 2002; H. Kim & Cole, 2005; Kristoffersen, 2000; Munhall et al., 1992). In AP, articulatory units of various sizes are modeled as harmonic oscillators with different characteristic frequencies (e.g., Browman & Goldstein, 1988, 1990; Nam & Saltzman, 2003; O’Dell & Nieminen, 1999; Saltzman et al., 2008). Phasing relationships between such articulatory units are modeled as oscillator coupling, in which the system settles at a characteristic frequency intermediate between the frequencies of the individual units. The same result can be derived from a competing constraints model in which none of the individual constraints on preferred frequencies can be perfectly satisfied, and a “compromise” frequency is adopted. Our model of the voicing effect is based on this approach. 11
2.4 Intrinsic duration
In our proposed model, it is preferred durations at the segment level that drive the voicing effect. We posit that something similar is at work in so-called prominence-based compensation, which occurs between two syllables of inherently different durations within the same word. Final lengthening associated with phrasal boundaries is typically strongest for the segment closest to the boundary, and extends only as far as the onset of the final syllable in most cases (Berkovits, 1993; Cambier-Langeveld, 1997; Campbell, 1992; Hofhuis et al., 1995; Port & Cummins, 1992; Turk & Shattuck-Hufnagel, 2007). However, Cambier-Langeveld (1997, 2000) show that, in Dutch, the penultimate syllable of the final word also sometimes experiences significant lengthening. This happens only when the final syllable is unstressed, or contains a schwa vowel (see also, Katsika, 2016; Turk & Shattuck-Hufnagel, 2007 for similar results).
In these studies, the characteristically shorter duration of unstressed vowels seems to prevent them from lengthening to a degree sufficient to satisfy the requirements of phrase-final lengthening. The voicing effect can be described in similar terms: lengthening (also often due to a phrase-final boundary) “shifts” to earlier segments (the vowel) when the final segment (the voiced obstruent) cannot be lengthened sufficiently. 12
2.5 Elasticity
Our model assigns a characteristic elasticity to each segment, which mediates the degree to which the segment resists pressures to lengthen or shorten from its preferred duration (see also Cambier-Langeveld, 2000; Miller, 1981). The concept of elasticity is related to the concept of spring stiffness in AP (e.g., Browman & Goldstein, 1986): a force of the same size will cause a greater perturbation to a spring with a smaller stiffness parameter, resulting in a longer duration. However, elasticity differs from spring stiffness in important ways: it applies to phonemes, which are not part of the inventory of timing units within AP, and not just to phonemes as a class, but to individual phonemes.
What is crucial in our model is that elasticity and duration determine the proportion of the syllable that each segment comprises (see Campbell, 1992). Our Expandability Hypothesis is defined in (1).
(1) The Expandability Hypothesis All segments have a characteristic elasticity that determines their resistance to lengthening Resistance to lengthening increases with increasing duration for all segments Lower elasticity equates with a more rapid increase in resistance Relative resistance determines the distribution of duration across the syllable
Modeling voiceless obstruents as high elasticity, and voiced obstruents, as low elasticity, we will show that the Expandibility Hypothesis parsimoniously accounts for the production data on the voicing effect, and is also, crucially, consistent with the existing perception data.
2.6 Perception
It turns out that vowel duration is not the only cue, and may not even be the main cue, to the voicing distinction in final obstruents. Wardrip-Fruin (1982) demonstrates that when preceding vowel duration conflicts with either formant transition cues, or actual vocal fold vibration, the latter dominates. Hogan and Rozsypal (1980) also report that, for certain voiceless-final words, lengthening the vowel does not change the percept to voiced, but produces no effect, or results in stimuli that sound unnatural. Revoile et al. (1982), using naturally produced stimuli, find that the identification of voiced stops is most strongly disrupted by removing vowel offset cues (see also Nittrouer, 2004; O’Kane, 1978), while the identification of voiceless stops is most strongly disrupted by removing the release burst. Similarly, Repp and Williams (1985) find that the addition of a release burst to otherwise ambiguous stimuli reduces voiced responses. Changes to vowel duration, on the contrary, have little effect on voicing perception in their study.
It is our hypothesis that the perception results are based primarily on obstruent duration. It was established quite early on that the perceptual boundary between the fricatives /s/ and /z/ in final position is dependent on both consonant and vowel duration (Denes, 1955); see also Raphael (1981) and Repp and Williams (1985). In fact, the literature on voicing in word-medial position standardly describes the perceptual boundary in terms of the ratio of closure duration to preceding vowel duration (e.g., Lisker, 1957; Port, 1979, 1981; Port & Dalby, 1982). The C/V ratio effectively normalizes stop duration relative to estimated speaking rate. This is exactly what we believe occurs in final position, with final lengthening accounting for the magnitude of the effect.
3 A corpus study
In this section, we provide an in-depth analysis of the voicing effect in conversational speech, using data from the Buckeye Corpus (Pitt et al., 1997). Although the corpus is not balanced, it provides much more data, and a larger range of speaking rates and contexts than any single laboratory experiment. A corpus study allows us, first, to quantify the voicing effect in actual usage. Second, it allows us to probe more deeply into the factors that affect the realization of the effect. Conversational styles of speech are expected to exhibit considerable reduction in the realization of individual words, some component sounds of which may be entirely missing (e.g., Harris & Umeda, 1974; Johnson, 2004; Jurafsky et al., 1998). This reduction could neutralize small differences in duration that result from an underlying voicing effect. And previous studies with read scripts have shown a reduced voicing effect in comparison to single sentence or word list productions (Crystal & House, 1982, 1988). What we find is that there is an inconsistent effect of voicing that is dependent on the structure of our statistical model. For a simple model with no interactions, voicing is significant. However, when interactions are added to this model, the voicing effect fails to reach significance. However, the effect is found to participate in predicted interactions with speaking rate, phrase position, and frequency, exhibiting a dependence on absolute duration.
3.1 The data
The Buckeye Corpus consists of segmented and transcribed sound files. These are taken from interviews, each lasting about an hour, with 40 different speakers, all middle-class and Caucasian, who are also natives of central Ohio. Intertranscriber reliability of the phonetic symbols for stops and fricatives was reported for a sample of the Buckeye Corpus at 91.2% and 92.9%, respectively. For the unanimously transcribed subset of this sample, segmentation boundaries differed by an average of 16 ms. (Pitt et al., 2005). However, Raymond et al. (2002) report a difference in segmentation agreement for shorter versus longer phones: 73% of phones that were longer than average agreed within 20% of the average length of the two phones on either side of the segment boundary, whereas only 50% of phones that were shorter than average agreed within 20%. Shorter phones were thus proportionally less consistently transcribed than longer phones. In the absence of a consistent bias in the placement of the boundary, such errors could wash out a small voicing effect. Given that the voicing effect is expected to be larger for longer durations, however, this is unlikely to affect the outcome significantly. The segmentation of the vowel and final consonant are inherently negatively correlated; an error in which the vowel duration is longer will also produce an error in which the final obstruent is shorter. However, such ambiguity is more likely to arise with voiced than with voiceless stops. Thus, we would expect such errors to inflate any voicing effect.
From the Buckeye Corpus we extracted all monosyllabic words of the form (C)onsonant-(V)owel-(C)onsonant ending with one of the following obstruents: voiced (d,b,g,z,ʒ,v) or voiceless (t,p,k,s,ʃ,f). Consonant–vowel–consonant (CVC) words were selected because they were expected to show the largest voicing effect. Complex onsets were excluded to eliminate potential variability. No nasalized or rhotacized vowels were included, to be sure that each word had exactly three underlying segments. Only tokens that were both phonemically and phonetically CVCs were included. For example, tokens of “past” realized as [pæs], and tokens of “allowed” realized as [lâʊd] were both excluded. Because the transcription of the corpus is quasi-phonetic, we constructed a dictionary of citation forms to ensure that the phonological voicing category was correctly assigned to each word. Because there were no words ending in voiced dental fricatives, those ending in voiceless dental fricatives were also removed. The vowel /oȏɪ/ was also excluded for reasons of data sparsity. In all, 20.3% of the stops in the remaining data were transcribed as glottalized (tq), which could represent a glottal stop or unreleased stop with glottalization on the vowel, but less than 1% of those were underlyingly voiced, so all such tokens were removed from analysis. Affricates were excluded due to the possibility that they might straddle a word boundary.
In Figure 1, raw vowel durations for the set of CVC word tokens used in the following analyses are plotted as a function of the voicing feature of the final obstruent. If a voicing effect does exist in these data, it is masked by factors that affect vowel duration more strongly. The density plot on the right suggests that there is a very small effect of voicing at the longest durations. However, the actual counts given in the left panel show that there are never more voiced than voiceless tokens at any duration. This is due to the fact that there are considerably more word tokens with (phonemically) voiceless coda obstruents (over twice as many as voiced tokens, although there are more voiced than voiceless fricative tokens; see Appendix A). Vowels preceding voiceless obstruents have a slightly longer mode than those preceding voiced obstruents, and at the longer durations (above 175 ms.), the relative proportion of the voiced-preceding distribution is larger than the voiceless-preceding. For the most part, however, the two distributions are completely overlapped, showing no transparent voicing effect.
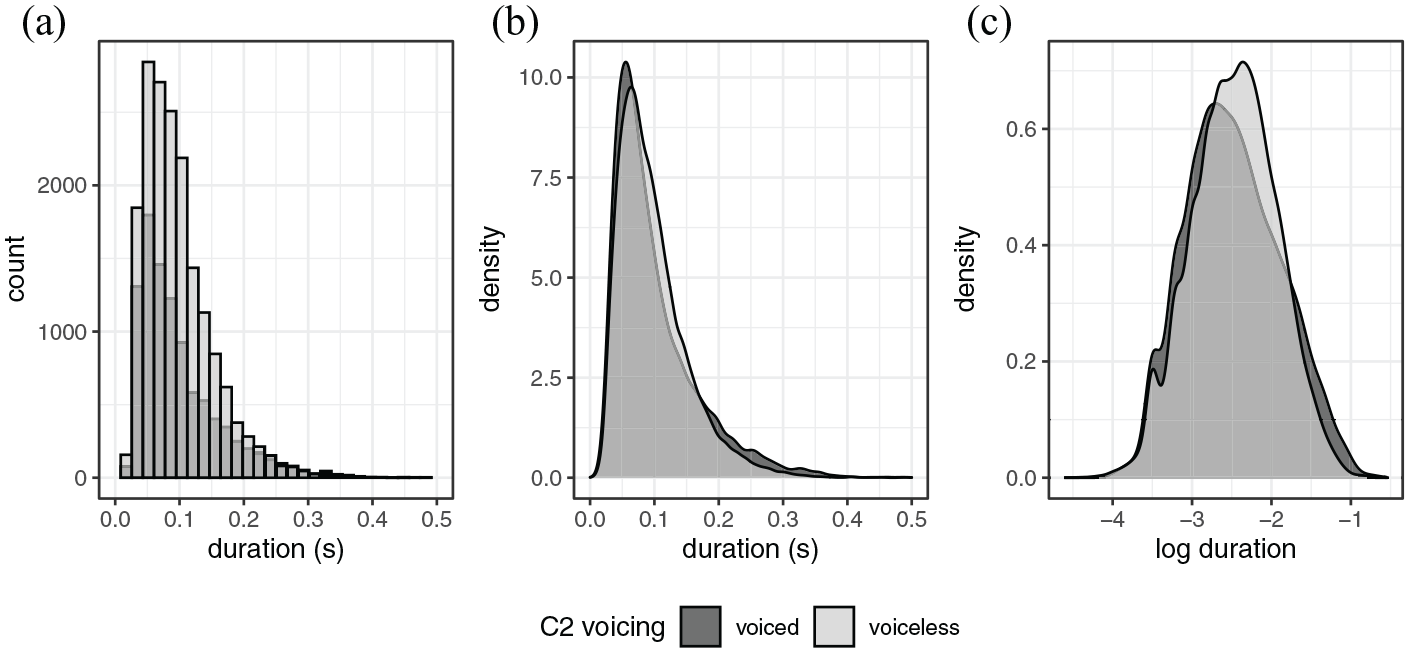
All CVC vowel durations: a) histogram b) density plot c) log duration density plot.
3.2 Model factors
The following factors, each of which is known to affect segment duration, are included in the statistical model of vowel duration. Because the analysis was limited to CVC words, stress and word length are not included:
INHERENT VOWEL CLASS: Tense and lax vowels in English are differentiated in part by duration. /ɪ, ɛ, ʊ, ᴧ/, all lax vowels, are reliably shorter than their tense counterparts (e.g., Klatt, 1976; Peterson & Lehiste, 1960; Stevens & House, 1963). Reduced or absent voicing effects have been reported for both unstressed and lax vowels which we interpret as a dependence of voicing on absolute duration (Crystal & House, 1982; de Jong, 2004; Umeda, 1975). To capture this phonetic length difference, Vowel Class is modeled as a factor with 2 levels: lax (ɪ, ɛ, ʊ, ᴧ, æ), and tense (all other vowels, namely, i,e,u,a,o,ɔ,aɪ,aʊ), coded as 1, and −1, respectively. Although vowel duration based on vowel quality is not actually binary, data sparsity for certain low-frequency vowels makes using vowel quality itself problematic as a finer-grained determiner of inherent duration.
VOWEL HEIGHT: Because high vowels tend to be shorter than low vowels, this can affect the realization of the voicing effect. Although there are potentially three possible height values, for ease of interpretability in the sum-coded model we use binary values for all discrete factors. Therefore.Vowel height is a factor with the levels: high (i,u,ɪ,ʊ), and non-high (all other vowels), coded as −1, and 1, respectively.
SPEAKING RATE: An estimate of speaking rate was calculated by counting the number of phones within the preceding 1 s of speech that includes the target word. Only the previous context was used since phrase-final tokens are included in the model. Speaking rate is modeled as a continuous variable.
WORD FREQUENCY: More frequently used words generally have shorter durations than less frequently used words, and both vowels and consonants within those words are affected (e.g., Fidelholtz, 1975; Fosler-Lussier & Morgan, 1999; Hooper, 1976; Jurafsky et al., 2001; Pluymaekers et al., 2005). Function words, generally the most frequent and the most contextually predictable words, are consistently shorter than content words (Bell et al., 2009; Umeda, 1975). Because the difference in frequency between content and function words is several orders of magnitude, Zipf scores,
PHRASAL POSITION: Prosodic boundaries have the effect of lengthening adjacent segments. The greater the number of nested phrases marked by the boundary, the greater the degree of lengthening, and the further its spread (Byrd & Saltzman, 2003; Fougeron & Keating, 1997; Oller, 1973; Wightman et al., 1992). Because the Buckeye Corpus is not annotated for syntactic boundaries, tokens were classified only as pre-pausal or non-pre-pausal, based on the end of a transcribed utterance. Pre-pausal position is expected to show the largest lengthening effects (see, e.g., Crystal & House, 1988; Klatt, 1975). The following tags in the Buckeye Corpus were used to identify a boundary: SIL (silence), E_TRANS (end of phonetic transcription), IVER (interviewer speaking), VOCNOISE (non-speech sound such as a cough, or laugh). Position is modeled as a factor with two levels: pre-pausal and non-pre-pausal, coded as 1 and −1, respectively.
PHONETIC VOICING: Phonetically voiced segments exhibit acoustic evidence of voicing, as transcribed by corpus annotators. Phonetic voicing is modeled as a 2-level factor: voiced, and voiceless, coded as 1 and −1, respectively. Phonetic voicing was included in the model because it was not known if there might be an effect of actual voicing above and beyond the effect of phonological voicing. We soon found that phonetic voicing did not differ appreciably from phonemic voicing, and it was dropped from the analyses. For the remainder of the paper, “voicing” will refer to phonological voicing.
PHONEMIC VOICING: Phonemic voicing refers to the category of the phoneme in the citation form of the word. Phonemic voicing is modeled as a 2-level factor: voiced, and voiceless, coded as 1 and −1, respectively.
OBSTRUENT TYPE: A 2-level factor: stop, or fricative, coded as 1 and −1, respectively.
3.3 Method
All statistics were performed using the lme4 package in R. Linear mixed effects models were run using the function lmer, fit by REML. The lmerTest function was used to obtain estimated p-values. All continuous numerical variables were log-transformed and mean-centered to approximate a normal distribution with a mean of zero. Following Tanner et al. (2019), we normalize by dividing by two standard deviations. Random intercepts for word and speaker were included in all models. Place of articulation of the final obstruent, although known to affect consonant duration, was too small of an effect to significantly improve model fit, and was therefore left out of the final model. Due to the asymmetric distribution of the data, it was not possible to used paired data in analyzing the voicing effect. All factors were sum-coded so that each individual factor was assessed at the mean value of all other factors. Three-way interactions were avoided for reasons of interpretability as well as model convergence.
3.4 Results
For each variable, the average value of its levels (if a factor), or of its range of values (if a continuous numerical variable) was the baseline for analysis. This allows us to conceptualize the results in a way that is similar to analysis of variance (ANOVA), where each effect is an adjustment to the average value for the model. For example, the effect of Vowel Class is determined by whether the average duration of the class of tense vowels is significantly different from the global vowel duration average, calculated over both tense and lax vowels.
We begin the analysis with a simple model of vowel duration, containing no interactions, but using random intercepts for word, speaker, and vowel quality (models with random slopes did not converge); see Table 1.
Results of the Following Linear Regression Model: Vowel Duration as a Function of Vowel Height (Non-High = 1), Vowel Length (Tense = 1), Speaking Rate, Voicing (Voiced = 1), Obstruent (Stop = 1), Phrase Postion (Final = 1), and Frequency (No Interactions Included).
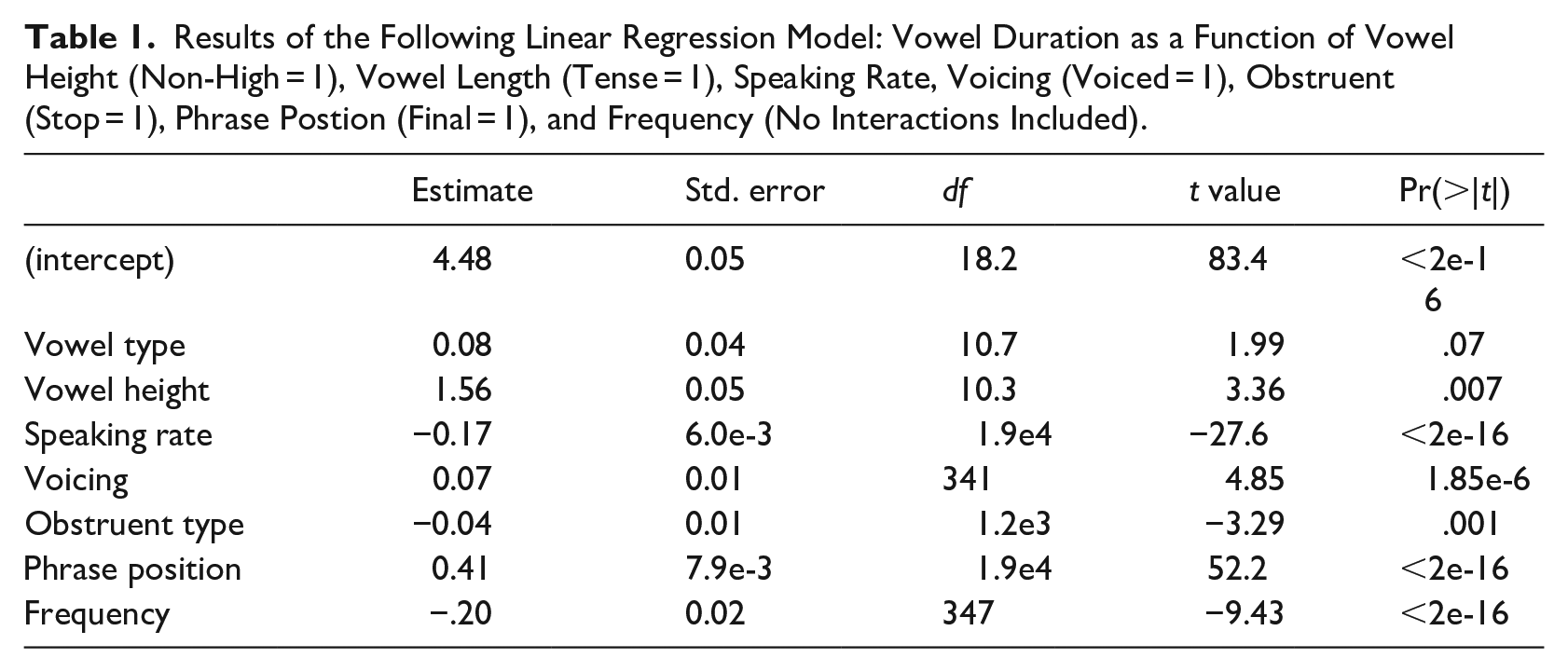
As expected, there was a significant main effect of speaking rate. Longer vowel durations were found at slower than average speaking rates. Word frequency also had the expected negative effect on vowel duration, such that words with higher than average frequency had shorter vowel durations. As predicted, high vowels were shorter than the average of high and low vowels. However, tense vowels were not significantly longer than the average of tense and lax vowels. Pre-pausal tokens were longer than phrase-medial. Voicing was also significant: vowels preceding voiced obstruents were longer than vowels preceding voiceless obstruents.
Our second model included interactions between voicing and speaking rate, voicing and frequency, voicing and vowel height, voicing and vowel length, and voicing and phrase-position. Frequency, speaking rate, and phrase-position remained significant, but voicing did not. See Table 2. The result was the same for a model including only pre-pausal tokens.
Results of the Following Linear Regression Model: Vowel Duration as a Function of Vowel Height (Non-High = 1), Vowel Length (Tense = 1), Speaking Rate, Voicing (Voiced = 1), Obstruent (Stop = 1), Phrase Postion (Final = 1), and Frequency, and the Interaction Between Voicing and Speaking Rate, Voicing and Frequency, Voicing and Vowel Height, Voicing and Vowel Class, and Voicing and Phrase-Position.
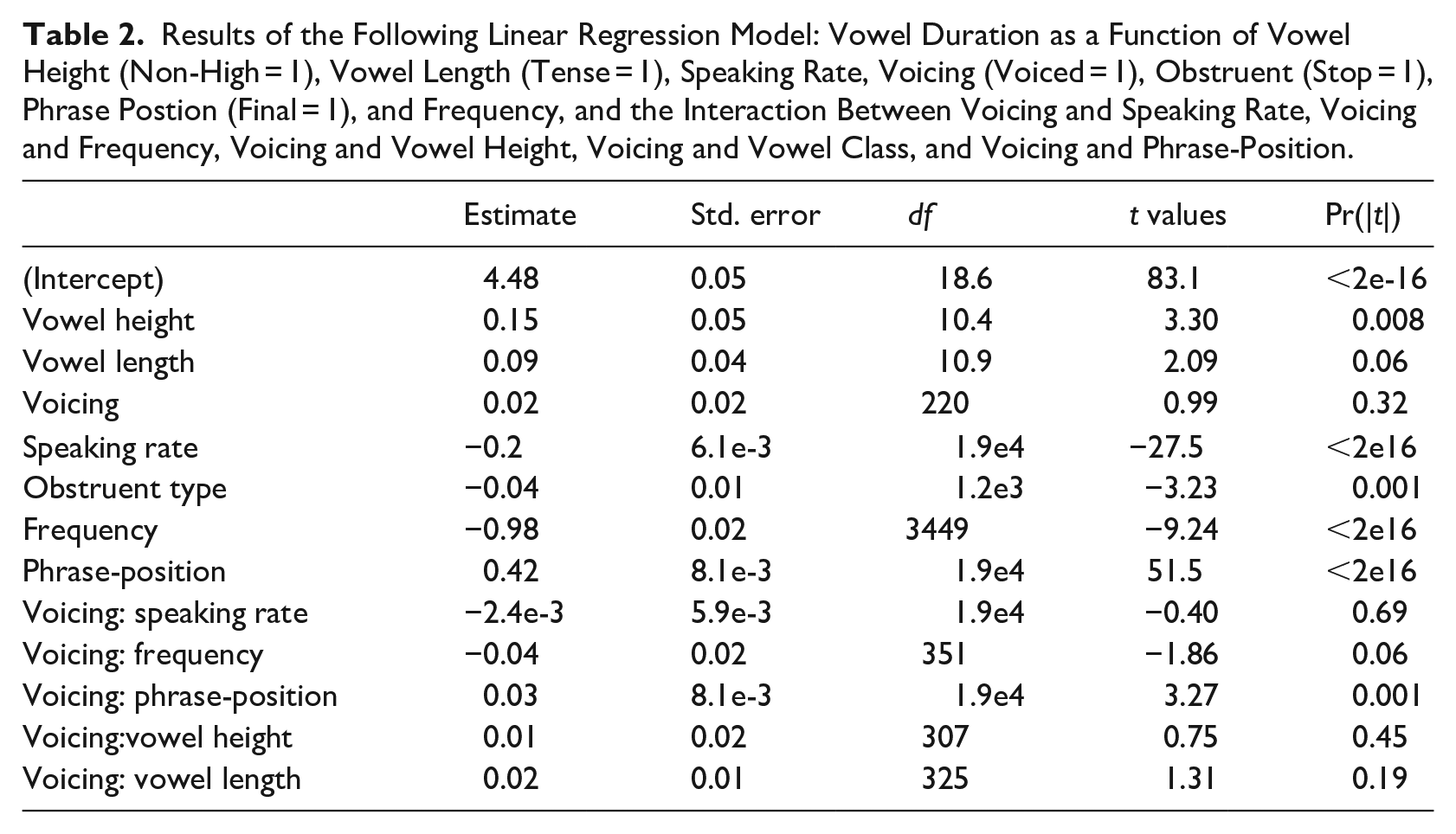
This is somewhat surprising, given that Tanner et al. (2019) report a voicing effect for phrase-final tokens in the Buckeye Corpus. However, they use a model that includes interactions between voicing and frequency, voicing and vowel type, voicing and obstruent type, and voicing and word class. They included random intercepts for speaker, word, and vowel quality, as well as random slopes for speaker by frequency, vowel type, obstruent type, word class, and by the interaction of voicing and obstruent type. Random slopes were also included for word by both speaking rate measures that they used. This model overfits our data and does not converge. We did find a significant interaction between voicing and phrase position, and a marginal interaction between voicing and frequency. Both factors increase the voicing effect, and both factors also increase the duration of the word. This suggests that the significant voicing effect in the simple model was driven by longer words. We posit that this effect, in turn, is driven by the difference in obstruent duration, which increases with increasing word duration.
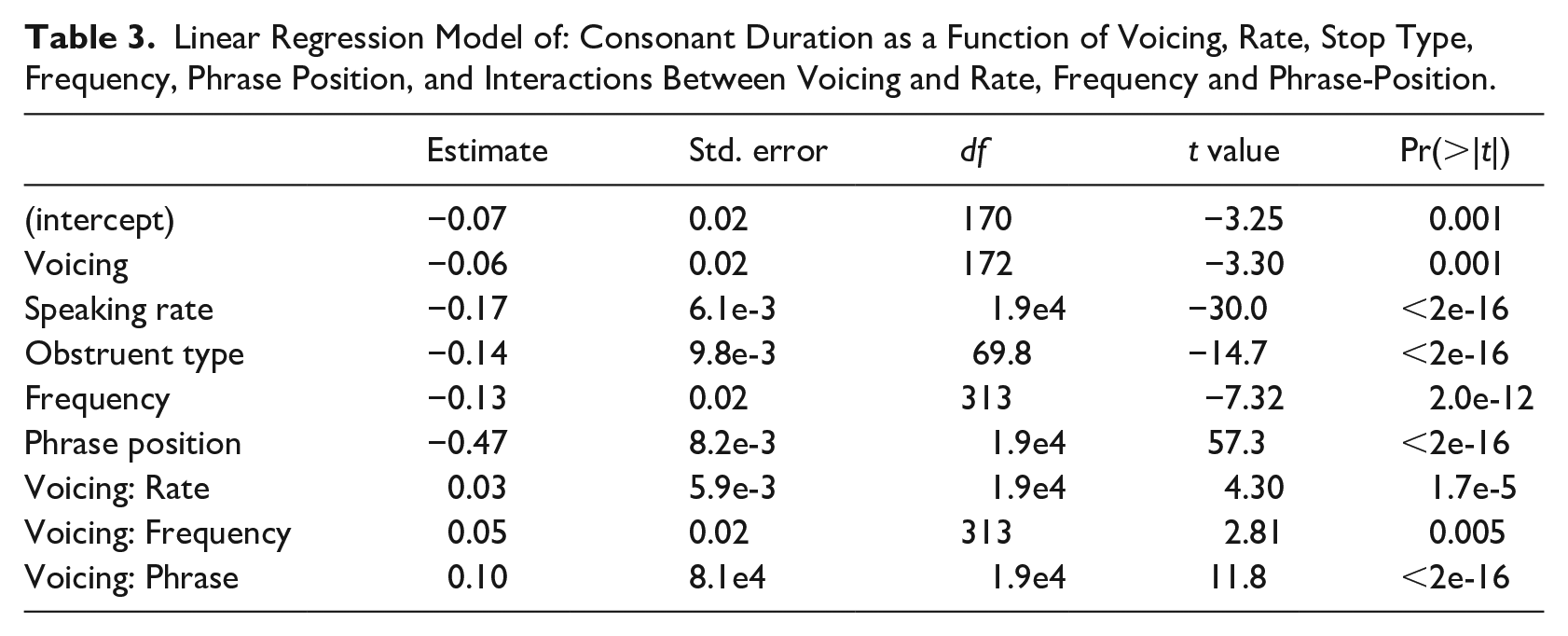
A regression model with obstruent duration as the dependent variable shows that voicing is significantly negatively correlated (see Table 3). Interactions between voicing, and rate, frequency, and phrase-position are all significant, indicating that the (negative) effect of voicing is reduced for fast rates, high frequency words, and non-pre-pausal position, as predicted. Although these results, in and of themselves, cannot prove the hypothesis that vowel duration differences arise from consonant duration differences, they are consistent with that hypothesis.
Linear Regression Model of: Consonant Duration as a Function of Voicing, Rate, Stop Type, Frequency, Phrase Position, and Interactions Between Voicing and Rate, Frequency and Phrase-Position.
3.5 Summary and discussion of corpus results
The corpus results show that voicing is a significant predictor in the simple model, but not in the model containing interactions, failing to replicate the finding of Tanner et al. (2019). We also see a dependence of the voicing factor on absolute durations in interaction terms with phrase-position and frequency. Consonant duration is also strongly (negatively) correlated with voicing and shows the same interactions for phrase-position and frequency, respectively. This is expected if the voicing effect is actually an effect of consonant duration, where the difference in obstruent duration between voiced and voiceless obstruents increases with increasing duration.
On the contrary, laboratory production studies find that there is a large and consistent voicing effect; vowels preceding voiced obstruents can be up to twice as long as vowels preceding voiceless obstruents (Chen, 1970; House, 1961; Luce & Charles-Luce, 1985; Mack, 1982; Peterson & Lehiste, 1960; Umeda, 1975). Similarly, voiceless stop closure durations can be from 25% to 50% longer than voiced stop closures (Chen, 1970; Luce, 1986). These discrepancies can be explained by the large difference in absolute durations between the corpus and the laboratory. Vowel durations in these studies are reported in the range of 175–300 ms (House, 1961; Luce & Charles-Luce, 1985; Mack, 1982; Peterson & Lehiste, 1960; Umeda, 1975), with voiceless stop closures ranging from 95 to 140 ms (Chen, 1970; Luce & Charles-Luce, 1985). For the vowel tokens in the Buckeye Corpus, on the contrary, durations this long are rare. Among the set of CVC words ending in voiced obstruents, less than 7% reach durations of 200 ms or above. Even restricting the sample to just characteristically longer vowels, only 13% of such tokens fall in this range. Median vowel duration over the complete set of CVC words used in this study is only 83 ms. Median vowel duration for just the voiced tokens is actually lower than that, at 75 ms. Similarly, only 9% of CVC-final voiceless stops reach durations of 100 ms or above in the Buckeye Corpus, while the median closure duration is 46 ms.
4 A production study
We take the corpus results, in conjunction with the production literature as a whole, to provide preliminary support for the Expandability Hypothesis. However, because paired data are not available in the corpus, our predictions must be confirmed in a setting where sources of variation can be controlled for. In this section, we report the results of a production experiment in which we asked native English speakers to repeat a series of CVC minimal pairs at varying rates. This allows us to directly compare the lengthening behavior of final voiced obstruents with that of final voiceless obstruents. The difference in obstruent duration can also be compared with the difference in vowel duration as a function of speaking rate. And we can test the hypothesis that consonant duration is not only negatively correlated with vowel duration, but a better predictor than voicing as well.
4.1 Methodology
4.1.1 Participants
All participants were undergraduate students at The Ohio State University who were given course credit for completing the experiment. A total of 45 participants were run; of this group, 11 were excluded from analysis for the following reasons: they reported hearing issues (3); they reported learning a language other than English before the age of 7 (7); or they did not learn English until after the age of 7 (1). In many cases, participants produced “dose” and “doze” tokens that were difficult to disambiguate. Two such participants were removed due to their productions of final s and z being practically identical. Five participants were removed for either failing to vary their speaking rate significantly across trials, or varying only inter-word pause duration rather than word duration. An additional participant was removed due to adopting a sing-song (high-low) prosody to the word repetition. This left data from 26 participants (a total of 5,049 tokens): 17 female, and 9 male, with an average age of 20.
4.1.2 Procedure
Participants were seated in front of a computer monitor inside a sound-attenuated booth. Continuous audio was recorded from a desktop microphone using the sound editing software Audacity. 13 Participants were instructed that they would be asked to speak into the microphone in response to prompts on the computer screen. The entire experiment took less than an hour to complete.
The experiment began with a practice block to acclimate participants to the experimental task, and the different repetition rates involved. Prior to the start of the practice block, participants were given the following instructions: A + sign will appear on the screen. It will be black to begin with, then will change to red, and keep alternating. Your job is to repeat the word on the screen every time + changes color. Try to use the entire time that the + does NOT change color to say the word. Keep going until the flashing stops. Press any key when you are ready to practice with the word “lab.”
For the first trial, participants saw the following text: “Here’s the fastest speed.” The word “lab” appeared 1.5 s later. The word stayed on the screen as the “+” immediately appeared and began to change color. Color changes occurred 8 times. At the end of the 8 cycles, a new trial began. For each new trial, participants were alerted to the change with the following text: “A little slower.” The same word then appeared 2 s later. There were five different rates, corresponding to the time it took for the plus sign to change from black to red: 350, 550, 750, 950, and 1,150 ms. The slowest and fastest rates were chosen to be as extreme as possible while still being within the ability of participants to match. 14
At the end of the practice session participants were told that they could begin the experiment whenever they were ready. The experimental trials were identical to the practice except that the rates went in order from slowest to fastest. Participants were presented with the following text: “You will begin with the SLOWEST speed, and the flashing will become faster.” Subsequently, each rate change was signaled with: “The speaking rate will now speed up a bit.” Trials were blocked by word, such that participants experienced all rates before beginning with a new word. At the end of a given block, participants were alerted that “The next item will now appear on the screen,” with a pause of 2 s before the word appeared. Word order was randomized across participants, but the order of rate presentation was fixed. Each word/rate pair was presented once.
The minimal pairs reported in this paper (feet/feed, thief/thieve, lobe/lope, and doze/dose) were chosen to vary across vowel quality (o or i), consonant manner (stop or fricative), and final consonant place (coronal or labial). Differences in part of speech and morphological complexity were largely unavoidable in constructing CVC minimal pairs, but those factors are not expected to show interactions with speaking rate. No effort was made to balance word frequency, beyond the avoidance of archaic forms, for the same reason. While higher frequency words would be expected to be somewhat shorter across the board, there was no reason to believe that speaking rate would affect the individual segments differently. Nevertheless, it is possible that such differences across a given minimal pair might obscure vowel length differences due to coda voicing.
4.2 Data selection and annotation
Each participant produced approximately 8 tokens of each word at each rate. To avoid edge effects, and fluctuations in rate, a single representative token from the center of the group was selected and measured. Because each token was surrounded by other tokens at the same repetition rate, it was possible to segment both the closure and the release interval for each stop. Occasionally, at the fastest rates, final stops did not have a clear release. In those cases, the end of the stop was set to the end of the voicing bar (for voiced stops), or the point at which the amplitude returned to background levels (for the voiceless stop). Background level was estimated by the amount of noise visible during the gaps between successive words.
The most ambiguous cases involved the segmentation of the sonorant /l/ from the following /o/ vowel, given a large degree of coarticulation. At faster rates, the point at which the release of the final /d/ became the initial fricative of the following token of “feed” could also be hard to determine. This was also true of the final /v/ and the initial /θ/ in “thieve” sequences. Measurement variability is likely to be highest in those contexts. Note, however, that any measurement errors for these kinds of tokens will only introduce error for one of the measured variables. For “lo,” the vowel duration will be affected by where the segment boundary is placed, but not the final p/b. For “

Closure duration, VOT, and Total duration (TDur) for final stops as a function of repetition rate (decreasing from left to right). Means and standard error bars.
The data for the first two word pairs (feet/feed, thief/thieve) were randomly assigned to three undergraduate research assistants for annotation. One of the authors and two of the RAs then re-measured a subset of the data produced by the other two annotators. Discrepancies between any two raters were discussed as a group to establish shared criteria for ambiguous tokens. The two RAs then individually reviewed their previous measurements and made adjustments where their original segmentation did not meet the discussed criteria. The same two RAs each also re-measured half the data of the third RA who had left the lab at that point. The second set of words (lobe/lope, doze/dose) were measured later, by an additional two RAs. Measurement verification was conducted in the same way. It was stressed that the most important criterion was consistency. As a final check, 2% of all tokens from each annotator were re-measured by the first author, selected in pairs in order to assess the discrepancy in the measured voicing effect. In terms of absolute durations, vowel measurements differed by an average of 12 ms, and total consonant durations differed by an average of 21 ms. The difference in vowel duration between voiced and voiceless minimal pairs differed by 13 ms, and the difference in total consonant duration by 30 ms. However, because the durations were sometimes longer than the first author’s measurements, and sometimes shorter, the actual effect of discrepancies in this sample of data were much smaller: 6 ms shorter for vowel duration; 12 ms shorter for total consonant duration, a vowel duration difference that was 3.6 ms smaller, and a consonant duration difference that was 15 ms larger.
Occasionally the voiced stops and fricatives at the slower repetition rates were produced with a final epenthetic schwa. There were 29 such tokens. Any words with final schwa were removed from the analysis. Praat (Boersma & Weenink, 2009) was used for segmentation and annotation.
4.3 Results
In Figure 2, final consonant durations for the stop-final words are plotted as a function of repetition rate (shown as a number between 1 and 5, where 5 is the fastest rate, and 1 the slowest). Voiced and voiceless tokens are plotted separately, and three different duration measures are given: closure (black), VOT (light gray), and the sum of the two (TDur: dark gray). Closure duration for final voiced stops varied relatively little across repetition rates. However, most stops were also produced with a period of aspiration (VOT). Voiced stops show a clear increase in total duration as rate decreases, but one that appears to plateau at the slowest rates. For voiceless stops, closure duration increases steadily, patterning very closely with VOT. Because both duration measures show a dependence on rate, total duration was used as the dependent variable for testing the Expandability Hypothesis.
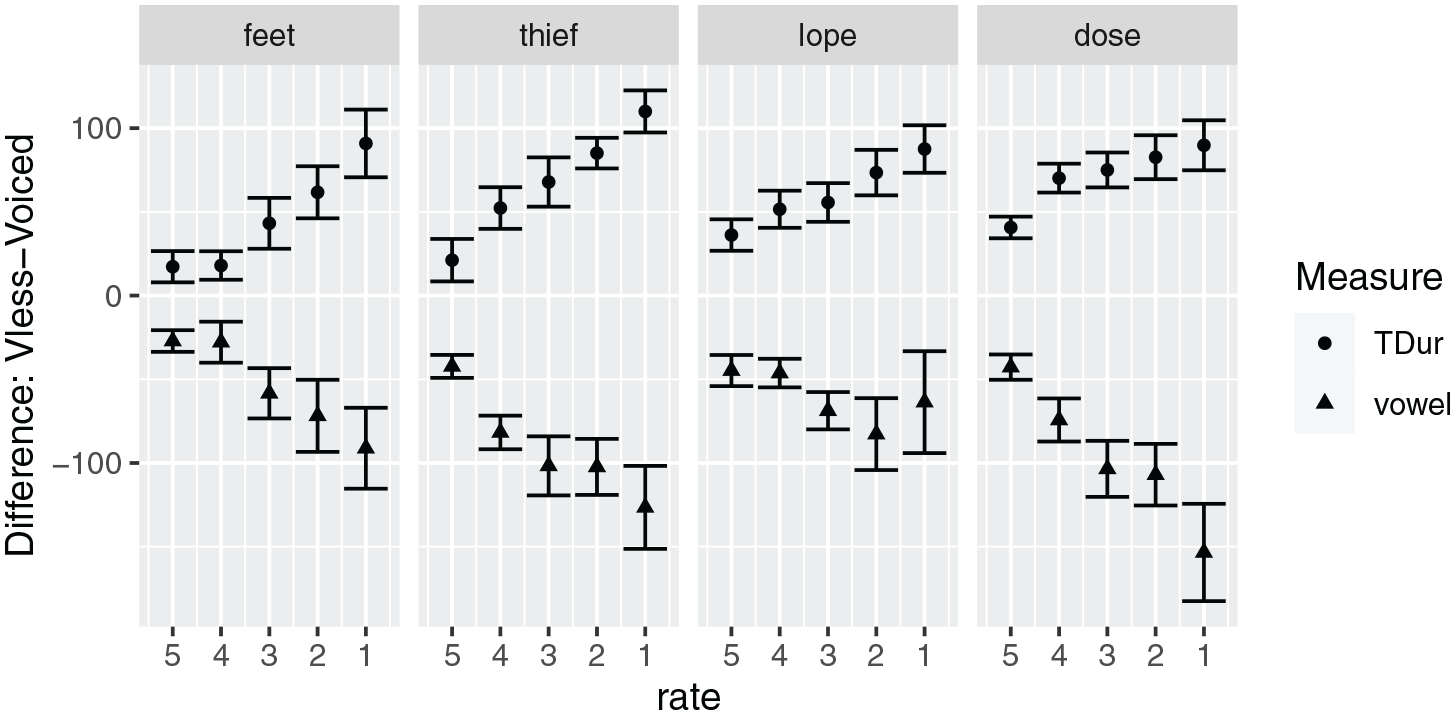
Figure 3 provides duration data for the full set of words, both vowel duration (triangles), and total obstruent duration (filled circles). Visual inspection shows that larger vowel durations were reached by the voiced member of each minimal pair, while larger obstruent durations were reached by the voiceless member. There is also a larger difference between consonant and vowel durations for voiced-final tokens across all repetition rates, and that difference increases with decreasing repetition rate.
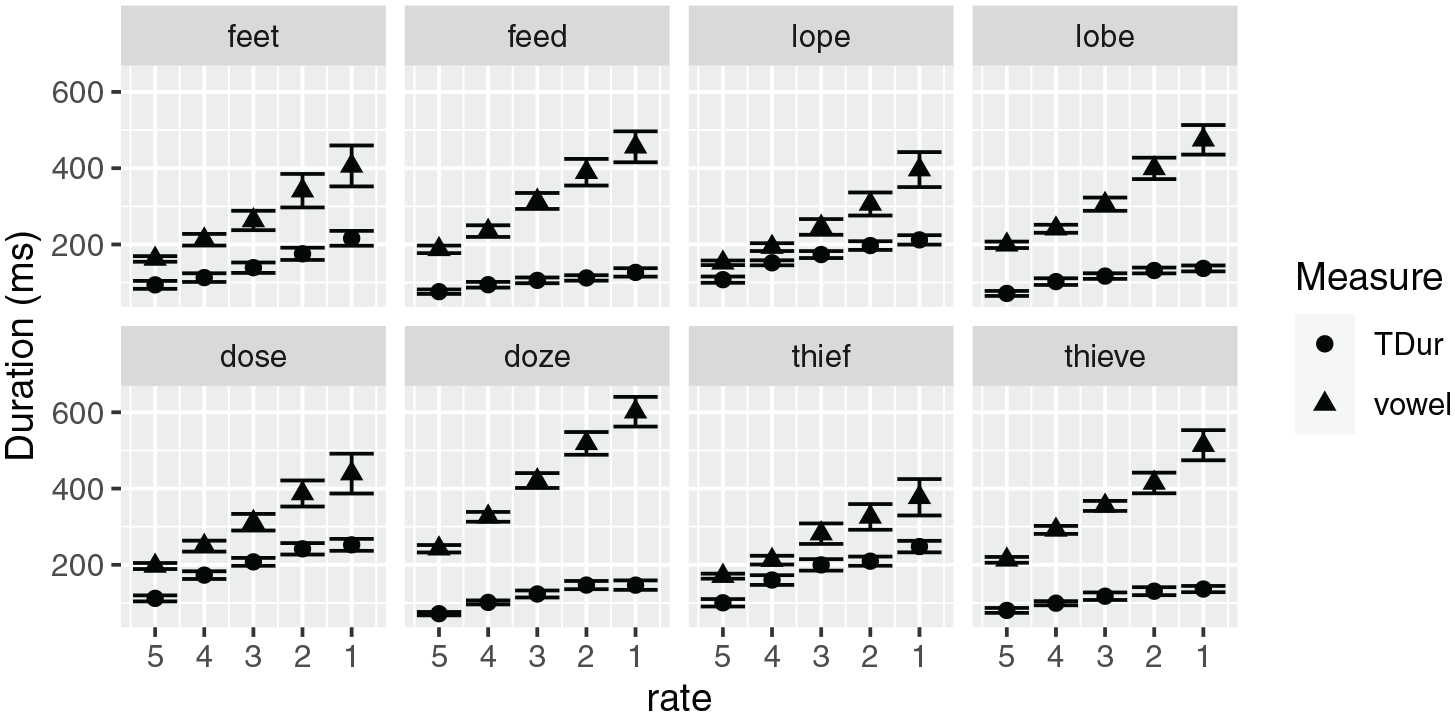
Total consonant duration and preceding vowel duration, as a function of repetition rate. Means and standard error bars.
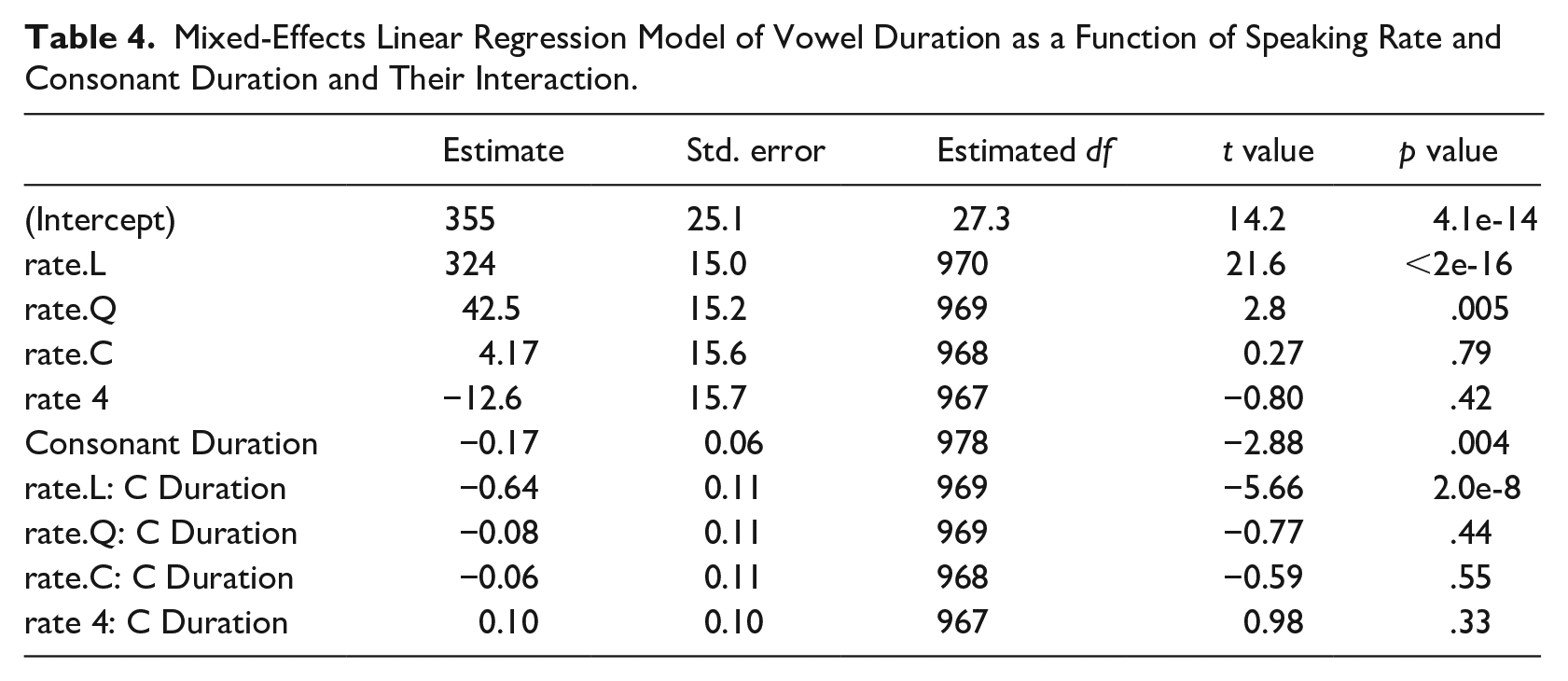
A linear mixed-effects model was fit to the vowel duration data as a function of repetition rate and consonant duration. Consonant duration was treated as a continuous variable, and repetition rate, as an ordinal variable. Random intercepts for participant and word were included. Random slopes were not used as they caused the model to fail to converge, or led to singularity. As expected, a significant (linear and quadratic) effect of speaking rate was found (vowels were longer at slower speaking rates). There was also a main effect of consonant duration; vowels were longer when the coda consonant was shorter. The interaction between rate and consonant duration also reached significance; the negative effect of consonant duration was strongest at the slowest rates (see Table 4).
Mixed-Effects Linear Regression Model of Vowel Duration as a Function of Speaking Rate and Consonant Duration and Their Interaction.
A separate model of vowel duration as a function of rate and voicing behaves very similarly. As before, random intercepts were used for participant and word, but random slopes were not used as they caused the model to fail to converge, or led to singularity. Main effects of (linear) rate and voicing are found (reference level is Voiceless), as well as an interaction between voicing and rate such that the positive effect of voicing is strongest at slower rates.
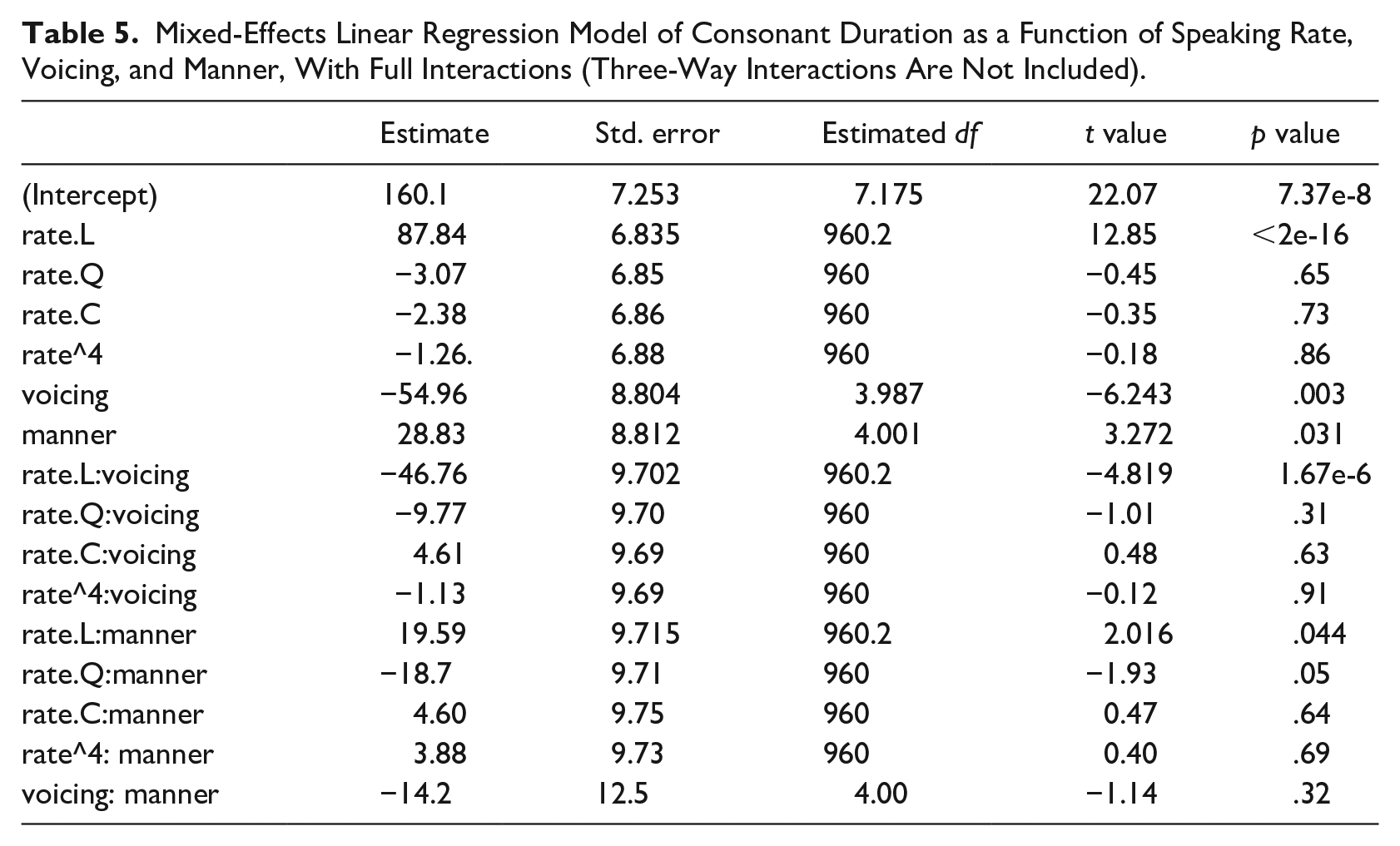
The model of consonant duration as a function of voicing confirms the interpretation that the “voicing” effect is driven by consonant duration (see Table 5). Random intercepts for participant and word were included. Random slopes were not used as they caused the model to fail to converge, or led to singularity. A fully crossed rate, voicing, and manner model produced significant main effects of speaking rate (linear), voicing, and manner. Fricatives were significantly longer than stops (reference level is Stops). A significant interaction between rate (linear) and voicing was also found, indicating, as expected, that differences in duration between voiced and voiceless consonants increased with decreasing repetition rate. An interaction between manner and rate (linear) also reached significance: the difference in duration between fricatives and stops was even larger at slower rates.
Mixed-Effects Linear Regression Model of Consonant Duration as a Function of Speaking Rate, Voicing, and Manner, With Full Interactions (Three-Way Interactions Are Not Included).
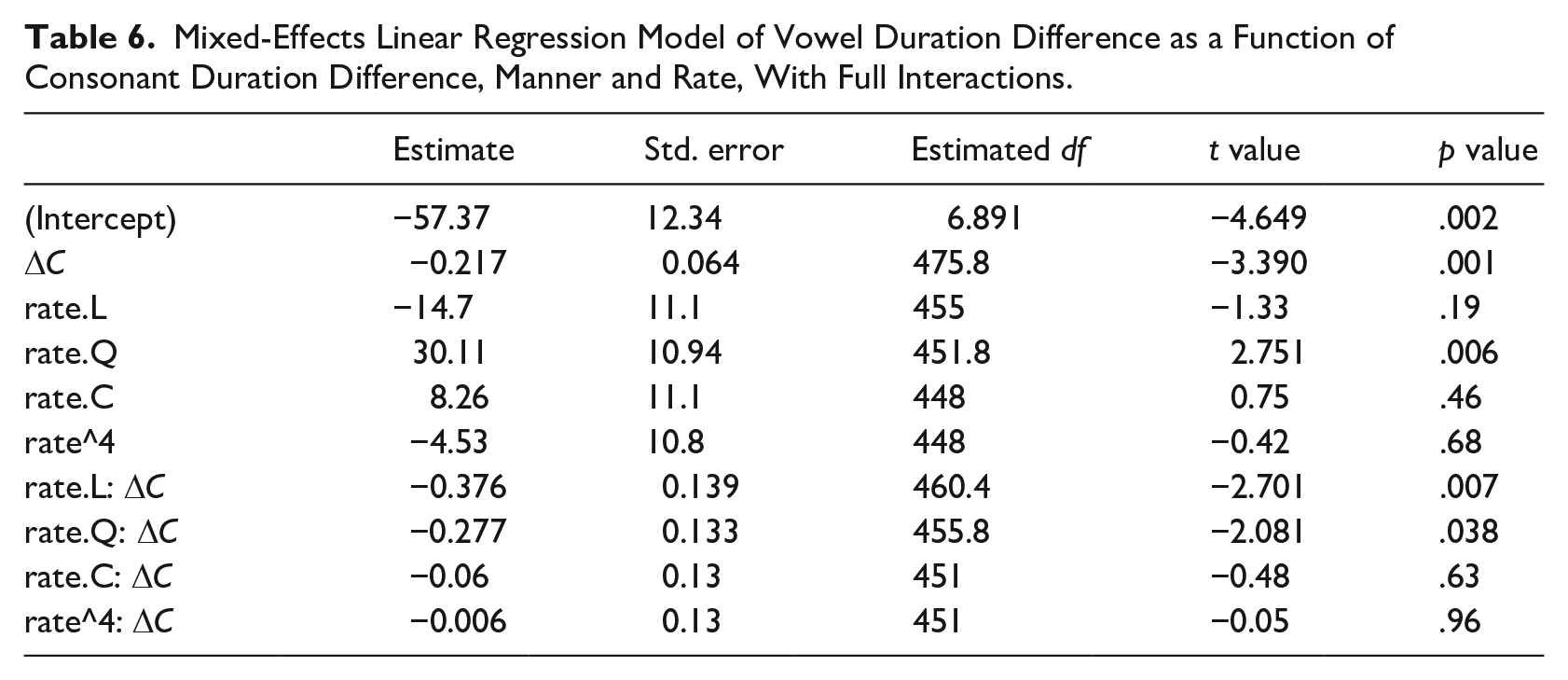
A final analysis of the paired duration differences confirms the negative correlation between the difference in duration of voiceless and voiced consonants, and the difference in duration of their preceding vowels. Random intercepts for participant and word were included. Random slopes were excluded as they caused the model to fail to converge, or led to singularity. Adding manner to the model also resulted in singularity. The final model of ∆
Mixed-Effects Linear Regression Model of Vowel Duration Difference as a Function of Consonant Duration Difference, Manner and Rate, With Full Interactions.
4.4 Discussion
These results strongly support the Expandability Hypothesis. First, we confirm the predicted difference in lengthening between voiced and voiceless consonants in coda position, paralleling what has been repeatedly found in initial and medial position (Miller & Baer, 1983; Miller & Volaitis, 1989; Port, 1976, 1981; Volaitis & Miller, 1992). There is a difference in consonant durations at all rates, 15 and there is also a large difference in the slopes of the duration curves. The difference in consonant duration increases with decreasing rate, as does the vowel duration difference. Pairing consonant duration differences with vowel duration differences at each speaking rate shows that the strength of the voicing effect is significantly correlated with the size of the consonant duration difference, something that cannot be captured with a binary voicing feature. The significant interaction between rate and consonant duration (vowels), and between rate and voicing (consonants), is precisely what is predicted if vowel duration differences derive from consonant duration differences. In fact, absolute vowel duration differences and consonant duration differences are very close. Rhyme (VC) durations were significantly different between voiceless and voiced, but not large, at 26 ms. For stops, the rhyme duration difference was only 2.8 ms. These results probably overestimate the degree to which vowel and consonant duration are traded off, given that the experimental task is highly unnatural, and likely to bias more toward uniform syllable duration than natural speech contexts.
5 The expandability hypothesis: modeling the corpus data
The corpus and production study results, combined with the previous research summarized in Section, strongly suggest that final obstruent duration trades off against preceding vowel duration, and that the size of the resulting voicing effect depends on absolute duration. To account for both of these properties, in addition to the fact that apparent compensation is not “perfect” (cf., Chen, 1970; Keating, 1985; Port & Dalby, 1982), we propose a competition-based model where tradeoffs in duration arise, not from isochrony, but from pressures to meet certain duration targets, none of which can be fully satisfied.
5.1 A competing constraints model of the voicing effect
In this section we model the voicing effect as the outcome of a competition between duration targets at the segment level which conflict with final-targeted lengthening. Each segment possesses an inherent elasticity which is implemented as the weighting factor on a constraint that acts to keep the segment at its preferred duration. Constraints are implemented as Normal probability distributions. Each distribution assigns the highest probability to its preferred duration (the mean of the distribution), and smoothly decreasing probabilities for durations both longer and shorter than that mean. The variance of the distribution controls how quickly the probability decreases. 16 The smaller the variance, the more rapid the decrease, and the greater the resistance to deviations from the mean. Its variance thus acts effectively as a weighting factor for each constraint. This means that, all else being equal, a segment with a broader probability distribution will be lengthened or shortened more than a segment with a narrower probability distribution. Variance thus also maps to segment elasticity. Constraint “competition” in this model is realized through maximization of the joint probability function over all constraints. This function exhibits the desired behavior: one constraint may be “violated” to a greater degree (a decrease in probability) if this allows another, more highly weighted constraint to be less “violated” (a greater increase in probability).
The results reported here are for VC syllables. The three segment-level constraints for the voicing effect model are shown graphically in Figure 4. Voiced and voiceless obstruent constraints are given the same mean value in these simulations, differing only in their variance. In the absence of a lengthening force it is assumed that segments default to their preferred durations.
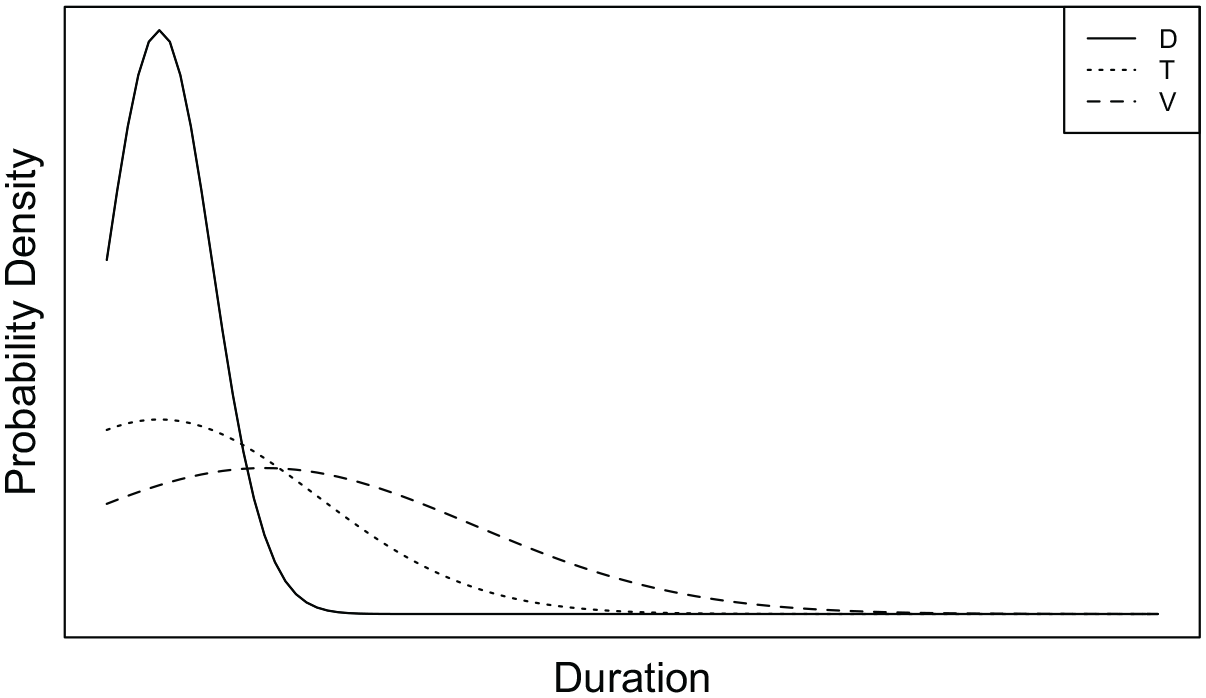
Probability densities for: voiced obstruent (solid); voiceless obstruent (thick solid); and vowel (dashed).
A nonzero lengthening force generates target durations for consonant and vowel. To model final lengthening, this force is not distributed equally, but is biased toward the segment closest to the prosodic boundary (the consonant in this case). Furthermore, lengthening under applied force is calculated proportionally. In other words, the same force applied to consonant and vowel will lengthen each the same relative amount, but not by the same amount in absolute terms. The variable
For a given force value, the model conducts a brute force search for the durations of the coda consonant (D or T), vowel (V), and alpha value (
Figure 5 shows the result of running the model for a set of force values ranging between 0 and 10 (x-axis). On the y-axis, vowel duration, consonant duration, and syllable duration (V + C) are plotted for both voiced (black) and voiceless (gray) syllables. Each point on the graph corresponds to a VC word (V0 = µV; C0 = µC), after the given lengthening has been applied to the segments. For example, for a lengthening force of 3, and a voiced-final syllable, the optimal vowel duration is 420 ms, and the optimal voiced obstruent duration is 90 ms, for a total syllable duration of 510 ms. For a voiceless-final syllable, on the contrary, the optimal vowel duration is 350 ms, and the optimal voiceless obstruent duration is 125 ms (for a syllable duration of 475 ms). Both sets of points are shown as filled circles in Figure 4. The vowel, like each obstruent type, prefers the mean duration of its probability distribution (150 ms in this case). It is forced to lengthen due to the pressures of the other constraints. Because the voiced obstruent constraint is more highly weighted than the voiceless obstruent constraint (smaller variance), it does not shift as far from its preferred duration (at 50 ms). Therefore, the vowel is forced to lengthen more when it co-occurs with a voiced obstruent than with a voiceless obstruent.
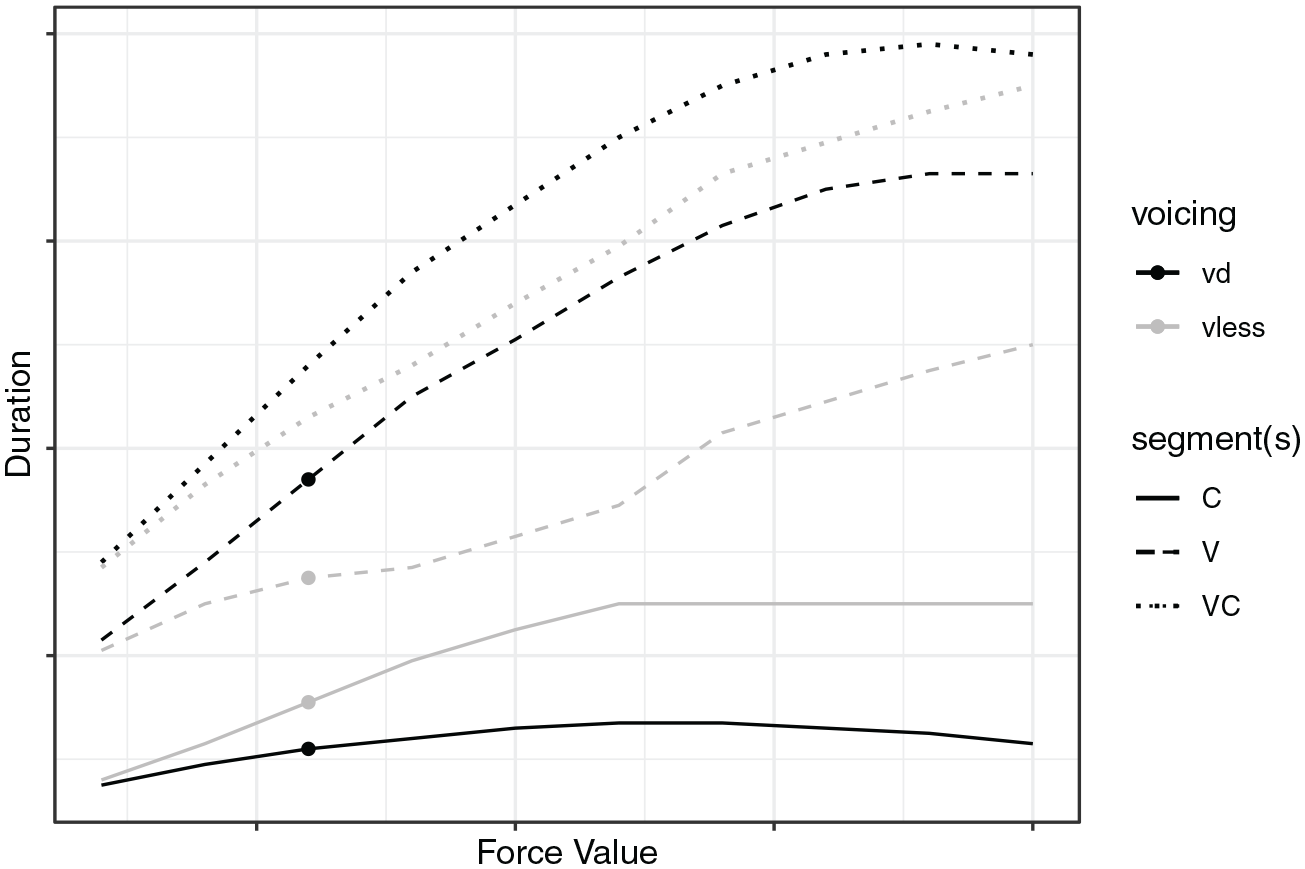
Behavior of the competing constraints model of segment duration as a function of lengthening force.
At shorter target syllable durations, voiced and voiceless obstruents (black and gray solid lines, respectively) are more or less identical in duration; preceding vowel durations (black and gray dashed lines) are also identical within the same range. As target syllable duration continues to increase, the consonant durations start to diverge. Because of its much smaller variance, the voiced obstruent not only resists lengthening more strongly than the voiceless, but that resistance also grows faster, leading to smaller and smaller increases in duration. As a result, either the vowel must lengthen more, or the divergence from the target vowel duration must increase, or both. Here the vowel duration difference continues to increase with increasing duration, meaning that the magnitude of the voicing effect increases as well. This is true up to the point at which the vowel duration of the voiced stop hits an effective maximum value.
Syllables closed by voiced obstruents also appear to be longer than those closed by voiceless obstruents (cf. Luce & Charles-Luce, 1985). There are two model features that produce this result. First, more of the force, on average, is distributed to the coda than the nucleus. Second, the translation from force to length is given as a proportion of preferred segment duration. In other words, instead of distributing syllable length over the vowel and consonant, the same amount of force is assumed to affect lengthening in the two segments relative to their default durations (see Campbell, 1992 for a similar approach). Greater lengthening applied to the coda consonant will be diverted in larger amounts to the vowel in the voiced case, due to the high weight of the voiced consonant constraint, whereas more of that lengthening will stay with the voiceless coda, due to the lower weight of its associated constraint. This interaction is what allows the vowel preceding the voiced coda to lengthen additionally relative to the vowel preceding the voiceless coda.
For comparison we created a baseline model that determines the length of the vowel preceding the voiced obstruent as a fixed percentage (30%) of the length of the vowel preceding the voiceless obstruent. Both segments also lengthen as the lengthening force increases, by a fixed percentage of their current durations at each step (10%). The resulting vowel duration functions look somewhat similar to the vowel duration functions in the competing constraints model, at least at the low end (see Figure 6). This simple model, however, does not allow interactions between vowel duration and consonant duration. Therefore, an apparent connection between the two would have to be due to chance.
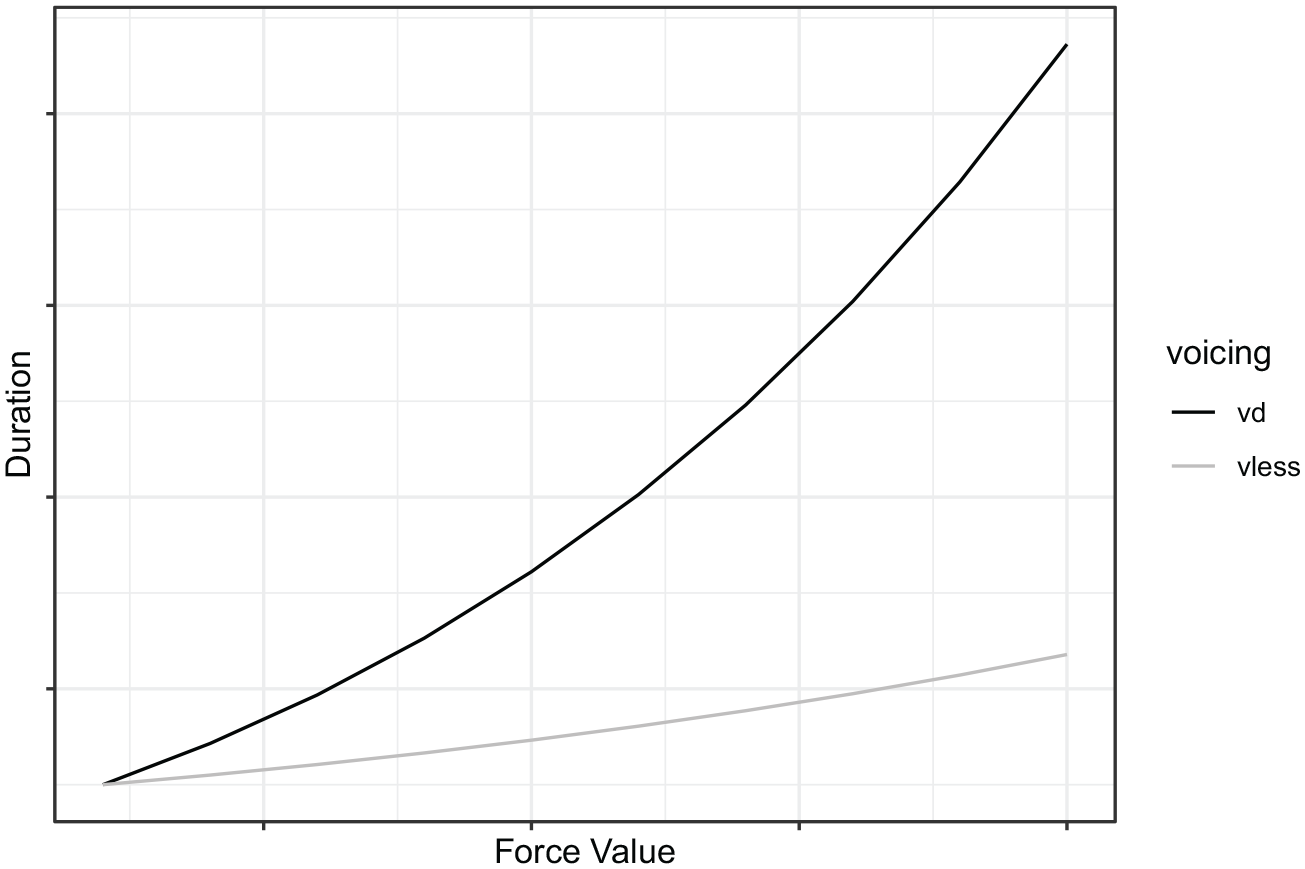
Baseline percentage increase model.
As a proof of concept, the competition model does quite well at capturing the critical behaviors that motivated our re-analysis of the voicing effect in English, and without a directly compensatory mechanism. The model can also capture the interaction between the voicing effect and vowel length, using a lower elasticity parameter for inherently shorter vowels. 18 Reducing the variance of the vowel probability distribution, but keeping all other parameters the same, results in a smaller duration difference between the paired preceding-voiced/preceding-voiceless vowels, and much less of a difference in syllable duration between the two. Both obstruents are also longer in the short vowel model. Nevertheless, the difference in duration between the obstruents is comparable for both types of syllable (see Appendix B). Qualitatively, this behavior is consistent with the finding that the voicing effect is significantly reduced in preceding vowels that are inherently short (Crystal & House, 1982; de Jong, 2004; Umeda, 1975). Because very few studies on the voicing effect report final obstruent durations, it remains to be seen whether this prediction is borne out. Note that the baseline model cannot capture the difference between long and short vowels. Starting the model with a lower vowel duration leads to less lengthening before voiced stops, but also to less lengthening, as a function of force, before voiceless stops. Therefore, the size of the voicing effect is almost identical for the two types of syllable.
The lengthening force in our model is treated as an independent variable derived from various sources, such as speaking rate, and final lengthening. For the largest durations/strongest forces, a robust voicing effect is found both in laboratory speech, (e.g., House, 1961; Luce & Charles-Luce, 1985; Mack, 1982; Peterson & Lehiste, 1960; Umeda, 1975), and in phrase-final position. A particularly large final lengthening effect in English (e.g., Delattre, 1966), we conjecture, may be largely responsible for the particularly large voicing effect in this language.
6 Further tests of the expandability hypothesis
In the previous sections we have shown that vowel duration is better predicted by coda duration than by coda voicing. The implication being that the correlation between obstruent duration and voicing is the source of the apparent voicing effect. It has also been demonstrated that a model of competing durational constraints can qualitatively capture the duration trade-offs between consonant and vowel duration. However, the Expandability Hypothesis, in and of itself, does not explain the ability of listeners to reliably use vowel duration to predict post-vocalic obstruent voicing. In this section we will show that not only is the Expandability Hypothesis consistent with the perception literature, it is confirmed by certain results. For the remainder of the paper we will focus on word-final stops because there are often very limited cues to stops in final position, and it is primarily for stops that preceding vowel duration has been characterized as a contrastive cue.
6.1 Perception of voicing in final position
A review of the perception literature in Section 2.6 has shown that other cues to the voicing contrast are likely to be stronger than preceding vowel duration, and categorical perception results may only be possible with highly impoverished stimuli. Meanwhile, categorical perception results have been obtained by varying obstruent duration alone (e.g., Denes, 1955). Based on these results, we hypothesize that listeners are using stop duration itself as the cue to voicing when final stops are both voiceless and unaspirated. Vowel duration factors into the classification decision insofar as it provides information about stop duration indirectly, as a measure of speaking rate. 19 In essence, the listener’s task is to decide whether what they are hearing is a voiced stop spoken slowly or a voiceless stop spoken quickly. Shorter vowel durations, which comprise the majority of the corpus data, correspond to speaking rates at which voiced and voiceless stop durations are not significantly different from one another. In this range, vowel duration is ineffective as a cue to voicing. Only as speaking rate slows to the point where the voiced and voiceless expansion trajectories begin to diverge, does vowel duration become predictive.
The competition model of Section 4 is used to illustrate this hypothesis (see Figure 7). The duration of the voiceless stop (gray solid line) gradually diverges from the duration of its voiced counterpart (black solid line), as the lengthening force increases. This divergence is mirrored in the preceding vowel duration (gray dashed line—preceding voiceless stop; black dashed line—preceding voiced stop). If the listener is exposed to a relatively short vowel (Figure 7(a): horizontal gray line), their expectation for the duration of the upcoming stop will be roughly the same whether it is voiced or voiceless (vertical difference between the lower open circles). An observed stop duration (lower dotted line) that falls close enough to both expected values is assumed to be acceptable for either member of the pair, and will not be sufficient to distinguish between the two in the absence of other cues.
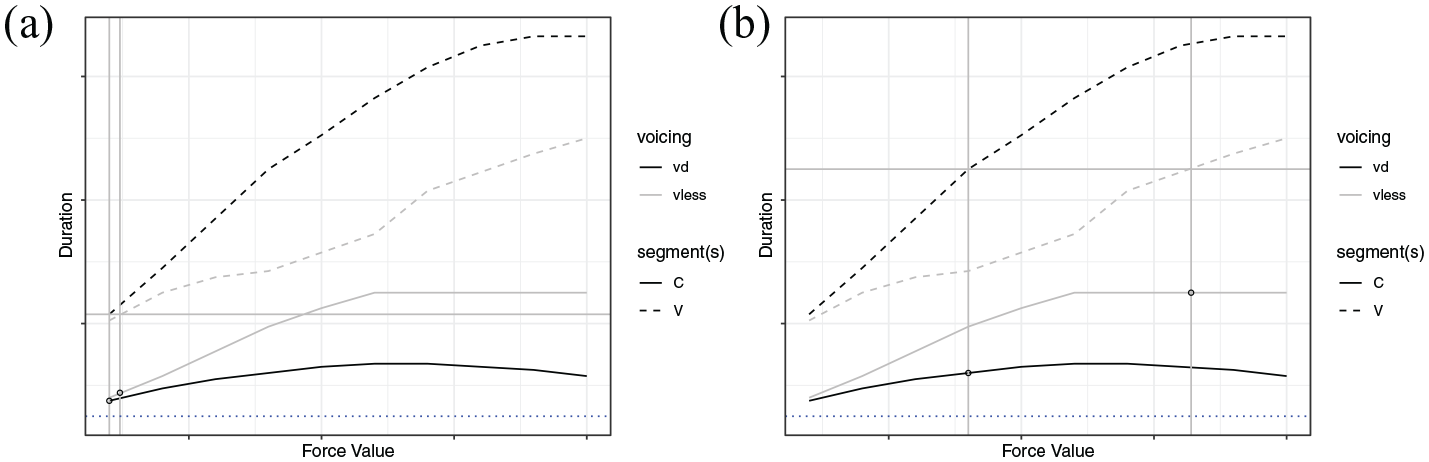
Competition simulation: Observed vowel duration is marked by the horizontal gray line in both figures. Vertical solid lines intersect expected lengthening force, and expected stop duration. Left line: voiced stop coda; Right line: voiceless stop coda. The lower dotted line indicates the actual duration of the following stop. (a) Short vowel token. (b) Long vowel token.
For a longer vowel, on the contrary, there is a larger difference in the expected durations of the voiced and voiceless stops. See Figure 7(b). The same observed stop duration (lower dotted line) now falls significantly below both expected values. In a two-alternative forced choice task we predict that this stimulus should sound more like a voiced than a voiceless stop. In general, an ambiguous final stop of fixed duration should sound more and more like a voiced stop as vowel duration increases. We assume that the category cross-over point from voiceless to voiced falls where the stimulus is significantly shorter than expected for a voiceless stop at that rate. After that, the likelihood of a voiced stop continues to increase (cf. Massaro & Cohen, 1983).
The foregoing can thus explain the increase in voiced responses with increasing vowel duration. However, given that we hypothesize that shorter vowels should not provide any cues to the voicing contrast, we would expect, all else being equal, that listeners would be at chance in identifying tokens in the short half of the continuum. Here it is the nature of the actual experimental stimuli that may bias perception strongly toward the voiceless stop. In the first place, ambiguous tokens are, by definition, phonetically voiceless. Depending on how exactly such stimuli were created, they may retain other cues to the original speech token from which they were generated, such as an F1 offset that is more consistent with a voiceless, than a voiced, stop. The synthetic stimuli used in Denes (1955), for example, were based on originally voiceless tokens. Whereas Repp and Williams (1985), using naturally produced stimuli, found a large perceptual difference between continua generated from an originally voiced stop (lab), versus an originally voiceless stop (lap). Voiced responses were about 40% higher for the former across all but the two longest vowel durations.
We therefore posit that the categorical perception results are due, first, to a default voiceless percept, based on residual cues that are more consistent with the voiceless member of the contrast, and second, to unusually long vowel durations. At the longest vowel durations (vanishingly rare in the speech corpus), we posit that the expected duration of a voiceless stop is so long that its likelihood approaches zero. For such extreme tokens, selection/perception of the voiced alternative may occur prior to actually hearing the final segment. However, it appears that the addition of a period of strong aspiration at the end of the stop is sufficient to switch the percept to voiceless. 20 Listeners may also be able to reliably select the voiced member of a minimal pair when final stops are entirely removed. We suspect that this is only possible in an explicit comparison task where listeners must label one token as voiced, and one as voiceless. In such a a task it is likely that listeners assume a uniform speech rate, leading them to attribute a somewhat longer vowel duration to the effect of a following voiced stop.
Additional support for this account of voicing perception comes from studies of the voicing contrast in initial position. It has been consistently found that the perceptual VOT boundary is longer than the boundary estimated from production data (e.g., Miller et al., 1986; Miller & Volaitis, 1989; Volaitis & Miller, 1992). However, the two boundaries coincide when naturally produced, unedited stimuli are used in the perception task. Nagao and de Jong (2007) suggest that the mismatch may arise from the fact that the stimuli typically used in perception experiments are artificially impoverished. In other words, the edited tokens are so ambiguous that they can only be confidently classified at very long VOT, or very slow speaking rates. The consistency in the reported perceptual cross-over point across experiments on word-final stops may be explained by the same artificiality. For voiceless closures with no audible release, the duration of the coda stop is indeterminate. Listeners may therefore assume a duration that is plausible given their language experience and consistent with experimental variables such as the inter-stimulus interval. It is therefore likely to be relatively stable across experiments involving native speakers of English.
6.2 Predictions
Our explanation of the perception results generates a number of testable hypotheses. For one, we predict that a change in the perception of voicing should lead to a change in the perception of speaking rate (greater force = slower speaking rate). During the course of vowel production, it is assumed that a hypothesis about both speaking rate and following segment duration is generated by the listener. In the absence of any information about the duration of the following stop (silent and unreleased), we posit that listeners will infer a duration that is consistent with those hypotheses. For a particularly long vowel, an expectation for a following phonologically voiced stop should lead listeners to infer the expected duration for a voiced obstruent, and the lengthening force associated with that duration (as depicted in Figure 7(a) and 7(b): the intercepts of the leftmost vertical line with the voiced obstruent duration curve and the x-axis, respectively). In the case where that lengthening force comes from differences in speaking rate, they are predicting the associated rate for each token. However, if listeners subsequently experience unambiguous release or aspiration cues, then we hypothesize that there should be a noticeable correction to both the perceived stop class and the perceived speaking rate. The voiceless stop should indicate that the speaking rate is actually slower than previously supposed (represented by the x-intercept of the rightmost vertical line in Figure 7(b)). 21 Sanker (2019) has shown that the judgment of whether a vowel is “long” or “short” depends not only on the duration of the vowel, but on whether it is followed by a voiced or a voiceless obstruent. For vowels preceding voiced obstruents, longer durations are required to elicit a “long” response. Although she did not report obstruent duration, we interpret her results as deriving from the expectation for a specific vowel duration given the unambiguous obstruent duration and its voicing. Vowels shorter than this expected value would be perceived as “short,” and vowels longer than this value would be perceived as “long.”
The Expandability Hypothesis also predicts that it should be possible to find apparent compensation with segments other than immediately preceding or following vowels, as long as they are more expandable than voiced obstruents. This is corroborated to a certain extent. A difference in nasal duration preceding voiced versus voiceless stops has been found both for monosyllabic words of the form “dens/dense” (Beddor, 2009; Port & Cummins, 1992; Raphael et al., 1975), and polysyllabic words of the form “cantor/candor” (Vatikiotis-Bateson, 1984). Furthermore, Raphael et al. (1975) find that both vowel and nasal duration affect perception of voicing on final stops. In an eye-tracking study by Beddor et al. (2013), participants heard CVND words (such as “bend”), CVNT words (such as “bent”), and
An additional corollary of our account of the voicing effect is that actual voicing, or any feature other than length, is not required for a “voicing” effect to arise. In fact, active phonetic voicing cannot be a requirement when the strongest effect is seen in English pre-pausally, where final voiced obstruents are likely to undergo devoicing. Given our hypothesis, however, it should be possible to find a “voicing” effect involving segments that have low elasticity for a reason not related to historic voicing. Some evidence for this comes from Beguš (2017), who finds that stop duration correlates negatively with preceding vowel duration not just for voiced and voiceless stops in Georgian, but for ejectives as well, with ejectives intermediate between voiced and voiceless stops in terms of both consonant duration and preceding vowel duration.
In principle, any apparent temporal compensation phenomenon could be modeled using the competing constraints framework (see Section 4.1). All else being equal, we might also predict that an appreciable difference in consonant duration should lead to a complementary difference in preceding vowel duration in monosyllabic words. However, it may prove difficult to isolate elasticity-based effects from other factors that affect syllable duration. For example, vowels in monosyllables closed by nasals have been found to be as long, or longer, than vowels in monosyllables closed by voiced obstruents in English (e.g., Crystal & House, 1988; House & Fairbanks, 1953; Peterson & Lehiste, 1960; Umeda, 1975), which is the opposite of what one would expect for a sonorous segment like a nasal. However, both Crystal and House (1988) and Klatt (1975) report nasal durations that are comparable to those for voiced stops. Thus, it may be the case that nasals (and possibly other sonorants) are not as elastic as might have been expected. Another possibility is that the phasing relationship between vowel and coda may be different in the case where the two gestures can overlap significantly without masking. Thus vowels may be measured as longer, and nasals, as shorter, if there is significantly more coarticulation than occurs with other consonants. If this is correct, then the vowel should be acoustically highly nasalized when the nasal is short, reflecting the true length of the nasal. Note that this would be consistent with the results for
There is also evidence that may argue against the Expandability Hypothesis. It has been found that vowels preceding voiced fricatives are longer than vowels preceding voiced stops, while vowels preceding voiceless fricatives are somewhat longer than those preceding voiceless stops (Peterson & Lehiste, 1960; Umeda, 1975).
22
Furthermore, the voicing effect has been reported to be larger for fricatives than for stops (e.g., House, 1961; House & Fairbanks, 1953). Although our production experiment was not designed to explicitly test fricatives against stops, our results are in line with these findings. In our data, vowel durations were longest before voiced fricatives, and a larger voicing effect was found for fricatives than stops (91 ms, vs. 56 ms ∆
Production differences by voicing for each minimal pair.
The Expandability Hypothesis as developed here was designed for consistency with an already very large experimental literature, thus many of its predictions are actually postdictions. Nevertheless, we have offered a number of speculations that can, in principle, be tested. Among these are the hypothesis that longer vowels in CVN words are highly nasalized, and that less nasalization in VNC sequences is correlated with longer VN durations. The competing constraints model also offers the hypothesis that significant differences in obstruent duration can occur without apparent compensation on vowels that are inherently short (see Appendix B). Additional predictions about differences in effect size across final, medial, and initial position cannot be entirely determined by comparing across heterogeneous studies, but require carefully controlled experimentation to assess. More detailed information about gestural coordination between vowels and specific following consonants is also needed to fine-tune model predictions.
7 Summary and conclusion
In much modern work, the voicing effect tends to be described in simplified terms, as a regular, quasi-universal, phonetically driven phenomenon. In English, preceding vowel duration is often said to play a contrastive role for word-final stops (e.g., Klatt, 1976). Yet vowel duration differences can be quite small in continuous speech, in polysyllabic words, across a syllable boundary, and phrase-medially (e.g., Umeda, 1975). In addition, lax, unstressed, or otherwise inherently short vowels show little to no voicing effect even in laboratory speech (e.g., Peterson & Lehiste, 1960).
In production studies that manipulate speaking rate it has been shown that voiceless obstruents, in both word-initial pre-stressed (VOT, e.g., Miller & Volaitis, 1989), and word-medial post-stress (closure duration, e.g., Port, 1976) position, are longer than voiced, with that difference increasing as speaking rate decreases. We extended that finding to coda position, demonstrating that the difference in vowel duration increased in step with the inverse duration difference for obstruents. 23 Using paired data, we were able to show that the magnitude of the “voicing” effect depended on obstruent duration across the board, while voicing was only significant at the slower rates (i.e., when it was significantly correlated with duration). And obstruent duration itself has been shown to affect voicing perception in final position (Denes, 1955; Raphael, 1981; Repp & Williams, 1985), just as it does in word-medial position (Port & Dalby, 1982).
This body of results argues against preceding vowel duration as a primary cue to the voiced/voiceless contrast in English. Indeed, it strongly suggests that vowel duration affects the perception of obstruent duration, not voicing itself. We have offered a proposal that fits a large range of experimental findings. Namely, that the voicing effect in English is the result of the inherently low elasticity of voiced obstruents, and that segment durations, in general, are determined by the components of the Expandability Hypothesis, reproduced below.
(2) The Expandability Hypothesis All segments have a characteristic elasticity that determines their resistance to lengthening Resistance to lengthening increases with increasing duration for all segments Lower elasticity equates with a more rapid increase in resistance Relative resistance determines the distribution of duration across the syllable.
The inverse correlation between obstruent duration and vowel duration, and its dependence on speaking rate, are attributed to a type of compensatory effect (see also Campbell, 1992; Massaro & Cohen, 1983), but not one based on syllable isochrony. Our competing constraints model of segment timing allows for “imperfect compensation,” which appears to be the rule in language generally, rather than the exception (e.g., Browman & Goldstein, 1988; Krivokapić, 2020).
This model provides a proof of concept for deriving the voicing effect from a set of general-purpose timing constraints. The fact that the voicing effect is larger in fricatives than in stops cannot be explained under our account without allowing for differences in one or more parameter values. However, we still cover much more empirical ground than explanations of the voicing effect that are based on actual vocal fold vibration, or articulatory effort. It is also worth noting that competing explanations (described in Section 2) have not attempted to explain this difference between stops and fricatives (and most don’t even mention it). Whereas, we are able to unify the treatment of the contrast across word and syllable position, and draw connections between effects based on differences of consonant elasticity, and those based on differences of vowel elasticity. Our explanation for the voicing effect also has ramifications for theories of contrastive features.
7.1 Contrast and allophony
Throughout this paper the relevant obstruent contrast in American English has been referred to as one of voicing. This is in spite of the fact that it is precisely because phonetic voicing is often absent from “voiced” stops that preceding vowel duration can be discussed as a possible cue to contrast. Clearly, the presence or absence of vocal fold vibration is not always necessary, or even sufficient, for phoneme identification. In order for the contrast to be described as one of voicing, it is necessary to treat the phonological voicing feature as distinct from the phonetic feature of the same name. The first is transformed to the second via a series of allophonic rules. For example, in absolute initial position the /-voice/ stop becomes [+spread glottis], while the /+voice/ stop may become [-voice]. In final position, a /-long/ vowel preceding a /+voice/ stop becomes [+long].
However, we have seen that apparent vowel lengthening varies considerably as a function of speaking rate, sentence and word position, stress, and other factors (e.g., Crystal & House, 1988; Umeda, 1975). Most importantly, longer vowels correlate with shorter consonants, and voiced obstruents tend, cross-linguistically, to be shorter than their voiceless counterparts. The apparent physiological difficulty of maintaining the necessary conditions for voicing over extended closure periods has been proposed as an explanation for this tendency (e.g., Ohala, 1983, 2011). Nevertheless, it is possible, by virtue of greater articulatory effort, to maintain voicing if desirable, at least up to a point. Partial, or total, devoicing is also a possible outcome. Therefore, we expect the duration differences between voiced and voiceless obstruents to be language specific. The fact that “voiced” stops in English are now frequently devoiced means that the observed duration differences are no longer the direct result of physiological constraints, but of what has become an underlyingly specified property of the segment. The fact that the difference in behavior between voiced and voiceless obstruents is only observable at long durations means that the specification is not for absolute duration, but for something that quantifies resistance to lengthening. The large voicing effect in English, we argue, is due to the voiced segment being pushed well beyond its preferred duration. Our claim is that vowel duration differences emerge directly from these elasticity differences. Therefore, we also conclude that vowel duration is not a feature that is specified in English, either at the phonological or phonetic level.
Although categorical perception effects have been demonstrated for the vowel duration cue, this is not particularly noteworthy, given that the number of acoustic cues to the contrast that listeners are able to exploit has been shown to be quite large. Duration and intensity of voicing, aspiration, and F0 contour, length of vowel formant transitions with respect to steady state duration (Fitch, 1981), F1 offset frequency (Crowther & Mann, 1992), speed of jaw lowering, and jaw offset position (Van Summers, 1987) all differ consistently between the two stop types in final position. In medial post-stress position, consistent differences have also been found in the timing of vocalic voice offset, and the signal decay time (Lisker, 1986), which should apply to final position as well. Furthermore, it is well known that cues can be “traded off” with one another. That is, while a long enough closure duration can cue a “voiceless” stop on its own, a shorter closure in tandem with a shortened vowel can also do so (e.g., Bailey & Summerfield, 1980; Fitch, 1981; Klatt, 1976; Kohler, 1979, 1984; Lisker, 1986; Malécot, 1968; Van Summers, 1987). Yet absolute vowel duration, and not closure duration or formant transition information, is frequently characterized as a phonological “voicing” feature, even though the latter two cues have been shown to influence perception to the same, or an even greater, degree. This may be due, in large part, to the privileging of “prominent” contexts in phonological theory.
7.2 Prominence
While the phonetic realization of underlyingly contrastive features is assumed to vary by context, the most prominent environment, usually initial pre-stress position, is assumed to most faithfully reflect those features. Not only that, but features are said to be enhanced, or more strongly signaled, in such contexts (e.g., Kingston & Diehl, 1994). Conversely, observed enhancement is taken to indicate features that are “controlled,” or underlyingly specified, as opposed to being supplied by context-sensitive rules (e.g., Ohala, 1981). Enhancement can be realized as an increase in acoustic amplitude, an increase in size of articulatory gestures, and/or an increase in gestural, and thus, segmental, duration (e.g., Beckman et al., 2013). In addition to making individual features more salient, enhancement is also assumed to be a mechanism for increasing discriminability between the members of a phonemic contrast (e.g., Cho, 2016; Cho & Jun, 2000; de Jong, 1995). For the above reasons, slower than normal speaking rate is considered to be an enhancement mechanism that should lead to lengthening, but only of contrastively specified features (e.g., Solé, 2007).
Underspecification theory applied to laryngeal contrasts typically makes use of the following privative features: [spread glottis], [voice], and [constricted glottis] (e.g., Iverson & Salmons, 1995; C.-W. Kim, 1970). This system yields three possible two-way contrast systems, one for each of the features, with the second member always unspecified. The phonetically voiceless stops in French and Thai fail to lengthen significantly with decreased speaking rate, and are therefore taken to be unspecified for laryngeal features, while the phonetically short lag/voiced stops in English are the unspecified member of the contrast 24 (Beckman et al., 2013; Kessinger & Blumstein, 1997).
In the same vein, an observed interaction between a given phonetic cue, and any variable that affects duration, is taken to indicate that the cue is an inherent part of the contrast. It has been argued that vowel duration is purposefully manipulated by speakers to enhance the laryngeal contrast of the following obstruent, based on the following set of results: that the effect of stress is smaller for voiceless-preceding vowels than for voiced-preceding vowels in English (de Jong, 2004); that /-long/ voiced-preceding vowels lengthen less than they would otherwise, in order to avoid overlapping with /+long/ voiceless-preceding vowels, and preserve an existing long versus short vowel distinction in German (Braunschweiler, 1997); that vowel duration differences preceding voiced versus voiceless segments are greater for long vowels than for short vowels in English (Peterson & Lehiste, 1960); that the difference in duration between the stressed vowel in a monosyllabic word and the same vowel in a bisyllabic word is larger (by percentage) for syllables closed by voiced stops than those closed by voiceless stops (Crowther & Mann, 1992; de Jong, 1991; Klatt, 1973; Raphael, 1975; Smith, 2002; Van Summers, 1987); that the vowel shortening effect of affixation is greater (both absolutely, and proportionally) for a voiced-final stem than for a voiceless final (Lehiste, 1972).
In this paper, however, we have conceptualized stress, prosodic boundary marking, and speaking rate simply as external forces which, among others, can act to lengthen segments. Under our account, all segments are subject to such lengthening and shortening pressures. How much lengthening or shortening actually occurs, however, is governed by the interactions of all such constraints, some of which are more highly weighted than others. The apparently asymmetric effects on voiced versus voiceless syllables do not need to be explained as the result of speaker effort to avoid phonetic ambiguity, or to maintain a specific range of phonetic values. They follow directly from these two premises: that the voicing effect derives from differences in segment elasticity; and that the resulting differences in duration increase with increasing duration. Characterizing the voicing effect as a consequence of on-line timing adjustments (to which multiple factors can contribute) is therefore more parsimonious, and more explanatorily adequate, than the hypothesis that there is both a grammatical rule of vowel lengthening, and a set of deliberate adjustments made to preserve the output of that rule. Note that this analysis requires elasticity to be underlyingly specified. This is not the same, however, as an underlying specification for an abstract voice feature. In the first place, all segments are assumed to have their own characteristic elasticity. Furthermore, a specification of this kind is necessary for independent reasons: to account for the differing degrees to which segments respond to changes in speaking rate. Finally, relative duration values within a word cannot be derived from a /voice/ feature, or even a long/short duration feature, as they depend on potentially complex interactions between all the segments within a word.
If “prominent” contexts (such as slow speaking rate) do not actually enhance contrastive features, then the realization of the features in such contexts should not necessarily be taken as underlying. Doing so, in fact, requires potentially extensive transformations to arrive at the more frequent, non-prominent contexts of normal speech. If we reverse this relation, then very slow hyper-articulated speech is the exception, rather than the rule, and intense aspiration and especially long durations are derived from features that are more typical of the contrast in general. Large differences in preceding vowel duration are, almost exclusively, the product of atypical speech and therefore, in our view, should be considered the least central to the “voicing” contrast, not the most. This flipped view of contrast offers an intriguing avenue for future research.
Footnotes
Appendix A
Appendix B
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This research was partially supported by an OSU Targeted Ideas in Excellence grant. Thank you to Jessica Jelinger, Hannah Young, Nohyong Kim, Evan Nelson, Joseph Conley, Micaella Bruton, Rachel Meyer, Andrew Duffy, Maddie Bloomquist, and Margot Hare for their assistance in data collection and preparation.