
Abstract
This study reports an experiment conducted to examine the contribution of non-native speech timing to the perception of foreign accent. Native English listeners rated utterances produced in English by speakers whose first language was English or Saudi Arabic, for the degree of perceived foreign accent. The utterances were acoustically modified to significantly reduce segmental and intonational information available to the listeners. The listeners were able to distinguish the native and non-native speaker groups in the acoustically degraded utterances. This suggests that the listeners were able to make use of temporal cues, in the absence of segmental and intonational information, to rate the utterances for the degree of foreign accent. To further investigate this, three temporal measures (articulation rate, durational ratio of unstressed to stressed vowels, utterance-final vowel lengthening) were calculated for each utterance to examine their contribution to the overall perception of foreign accent. Among these measures, articulation rate and, to a lesser extent, the durational ratio of unstressed to stressed vowels played a role in cueing the listeners’ perception of foreign accent. However, while the impact of articulation rate on listener ratings varied by speaker group, higher values of the ratio of unstressed to stressed vowel duration, reflecting lower degrees of vowel reduction, consistently predicted foreign accent ratings.
1 Introduction
Although foreign accent is a normal and common consequence of learning a language after early childhood, it can sometimes be detrimental to effective communication (e.g., Anderson-Hsieh & Koehler, 1988; Derwing & Munro, 2009; Gut, 2007; Munro & Derwing, 1995; Pérez-Ramón et al., 2022). A growing body of research has sought to ascertain the acoustic cues that underpin the perception of foreign accent (e.g., Anderson-Hsieh et al., 1992; Chan & Hall, 2019; De Mareüil & Vieru-Dimulescu, 2006; Gut, 2007; Magen, 1998; Munro, 1995; Trofimovich & Baker, 2006; Ulbrich & Mennen, 2016; Van Maastricht et al., 2021; Wayland, 1997). Finding the acoustic correlates of foreign accent is of practical importance to research in pronunciation learning and teaching, speech perception, speaker identification, and speech recognition and processing.
Early studies that examined how phonetic deviations from native norms can affect the degree of perceived foreign accent focused largely on the segmental level, which has influenced the development of second language speech theories and models (Ulbrich & Mennen, 2016), such as the Speech Learning Model (Flege & Bohn, 2021). Later studies have also sought to demonstrate the contribution of non-native prosody to the overall perception of foreign accent (e.g., De Mareüil & Vieru-Dimulescu, 2006; Munro, 1995; Trofimovich & Baker, 2006; Van Maastricht et al., 2021). For example, Munro (1995) found that native English listeners were able to detect foreign accentedness in the speech of Mandarin-speaking learners of English even after masking the content of the speech via low-pass filtering. A few studies have suggested that phonetic deviations from native norms at the prosodic level can have a higher impact on the perception of foreign accent than deviations at the segmental level (e.g., Anderson-Hsieh et al., 1992; Munro & Derwing, 1999). However, separating the effect of the two levels is extremely difficult as they interact in complex ways in their impact on the overall perception of foreign accent (Ulbrich & Mennen, 2016).
Among the various aspects of prosody, non-native stress-related timing has long been suggested to contribute significantly to the overall perception of foreign-accented English (Adams, 1979; Fokes & Bond, 1989; Taylor, 1981; Wenk, 1985). Recent studies have sought to ascertain the contribution of non-native speech timing to the overall perception of foreign accent (Kolly & Dellwo, 2014; Kolly et al., 2017; Ordin & Polyanskaya, 2015; Pellegrino et al., 2021; Polyanskaya et al., 2017; Polyanskaya & Ordin, 2019; Trofimovich & Baker, 2006; Van Maastricht et al., 2021; White & Mattys, 2007b). Their findings were mainly discussed from the perspective of cross-linguistic rhythmic classification. Although the nature of speech rhythm is still debated, there is a large consensus against the categorical classification of languages into rhythmic classes (e.g., Arvaniti, 2009; Bertinetto, 1989; Turk & Shattuck-Hufnagel, 2013; for detailed discussion see White & Malisz, 2020). The original evidence for rhythm classification came in part from perceptual studies demonstrating the ability of listeners to distinguish languages which belong to different rhythm classes (e.g., Ramus & Mehler, 1999). White et al. (2012) demonstrated that listeners use the specific durational timing cues available in the speech signal to differentiate between languages, and indeed between varieties of the same language, which is inconsistent with a putative set of consistent timing distinctions between rhythm classes. They found that English listeners were able to distinguish not only between English and Spanish but also between different English accents in content-masked speech, showing that durational contrast, speech rate, and utterance-final lengthening play a critical role in enabling listeners to make these distinctions.
Most previous studies which investigated non-native global timing have, as we shall see, focused on examining foreign-accented speech produced by learners whose native language is typically perceived as rhythmically distinct from the target language (e.g., English vs. French), and these studies have as a result often relied on the putative rhythm class dichotomy to explain patterns in L2 speech. This literature generally indicates a strong role of non-native global timing in the perception of foreign accent. However, two areas that need more attention are: (1) investigation of the contribution of specific aspects of timing patterns, such as utterance-final lengthening and stress-related vowel shortening/lengthening, to the overall percept of foreign accent and (2) inclusion of a wider variety of languages and cross-linguistic comparisons, including between languages typically perceived as rhythmically similar. The present study investigates the influence of global timing and of three timing measures known to vary cross-linguistically—namely, unstressed vowel shortening, articulation rate, and final-utterance lengthening—on the perception of foreign accent in Saudi Arabic-accented English, a variety that has not been previously examined.
1.1 Previous studies
Previous studies that have examined the contribution of global non-native timing patterns or cues to the perception of foreign accent vary greatly in the methods they used, and in the L2 populations and timing measures they examined. There are some commonalities among them, however. Studies typically used native listeners to judge accentedness or nativeness and attempted to neutralize the effect of spectral and intonational information on the listeners’ judgement. For example, in Trofimovich and Baker (2006), L1 English-speaking listeners were asked to rate six low-pass filtered utterances produced in English by L1 Korean learners of L2 English and by L1 English speaker controls, and found that the listeners were able to differentiate the speaker groups. Trofimovich and Baker (2006) also examined the relative contribution of specific timing measures—speech rate, pause frequency, pause duration, the ratio of unstressed to stressed syllable durations, and F0 peak alignment—to the perceived degree of foreign accent. Among these measures, only pause duration and speech rate were identified as reliable predictors of foreign accent perception.
Other studies have used resynthesized speech to examine the contribution of timing to the perception of foreign accent. Kolly and Dellwo (2014) showed that native German listeners were able to distinguish French-accented and English-accented German, under various listening conditions, in which the speech was significantly degraded in different ways but kept its temporal aspects: noise vocoded, monotone 1-bit requantized, and sasasa-speech resynthesized (replacing vowels with /a/ and consonants with /s/). In a subsequent study, Kolly et al. (2017) transplanted the segmental duration of French-accented and English-accented German onto native German utterances and asked native German listeners to identify whether the accent was that of a French or English native speaker. The listeners were able to distinguish the two foreign accents, to some extent, but the authors did not find a correlation between accent identification and any of a wide range of acoustic timing metrics (e.g., segmental pairwise variability indices and percentage of vocalic intervals). The authors suggested that the listeners may have relied on other unexamined temporal cues, such as utterance-final lengthening, to identify the accents.
Ordin and Polyanskaya (2015) elicited L2 English utterances from L1 German-speaking learners of L2 English who were grouped into three proficiency levels: beginners, intermediate and advanced. These utterances were resynthesized using the sasasa-speech resynthesis approach. The resynthesized utterances were presented to L1 English-speaking listeners in a perceptual classification experiment. In addition, several timing metrics capturing vocalic and intervocalic durational variability, along with speech rate, were calculated for each utterance to determine their role in the classification process. Among these, only speech rate was found to influence classification significantly, with faster speech being more likely to be classified as produced by advanced L2 speakers. Polyanskaya et al. (2017) examined the independent contribution of speech rate and several speech timing metrics (operationalized as durational variability of vocalic, consonantal and syllabic speech intervals) to the degree of perceived foreign accent in the speech of L1 French-speaking learners of L2 English. In this case, durational variability played a significant role, where increased variability was associated with lower foreign accent ratings (i.e., sounding more L1-like). The authors attributed the difference between their findings and those of Ordin and Polyanskaya (2015) regarding the role of durational variability in the perception of foreign accent to either the nature of the stimuli or the L1 language background of the L2 speakers (German and French). Polyanskaya and Ordin (2019) replicated Polyanskaya et al. (2017) using resynthesized English utterances from L1 German- and French-speaking learners of L2 English. Segmental durational variability was found to play a greater role in cueing native English listeners’ perception of French-accented English (with lower durational variability) than it did for German-accented English (with higher durational variability). Similar findings were also reached by Pellegrino et al. (2021) for German-accented Italian, where both segmental duration and speech rate played a role in cueing the L1 Italian-speaking listeners’ ratings of nativeness. In contrast, Van Maastricht et al. (2021) used a similar resynthesis technique to Polyanskaya et al. (2017), but did not find rhythm (overall timing) to play a significant role in the perception of foreign accent in samples of speech produced by L1 Spanish-speaking learners of L2 Dutch but modified to have L1 Dutch durational variability, whereas faster speech rates were found to significantly reduce the degree of perceived foreign accent.
In sum, most prior studies of the role of durational variability in the perception of foreign accent have focused on language pairs traditionally described as rhythmically distinct. Speech rate is the factor most often observed to show a significant effect, but a potential role for other temporal cues, such as utterance-final lengthening, is also reported.
2 The current study
Saudi Najdi Arabic (referred to as Saudi Arabic hereafter) is the first language (L1) of the L2 English speakers examined in this study, and it exhibits several characteristics that may influence their production of English speech timing. Saudi Arabic has a relatively simple vowel inventory, consisting of three short vowels (/i/, /a/, /u/) and their long counterparts (/i:/, /a:/, /u:/), alongside two additional long vowels (/e:/, /o:/) (Algethami, 2023; Ingham, 1994). A robust phonemic vowel length contrast is maintained, with short vowels being approximately half the duration of their long counterparts (Algethami, 2023). This phonemic length distinction is not strictly tied to stress, as short vowels can occur in stressed syllables, but vowel length (quantity) remains a major determinant of syllable weight and, consequently, stress assignment. Heavier syllables, typically those with long vowels or closed codas, tend to attract stress in Arabic (Watson, 2011). This system of phonemic vowel length contrasts may have contributed to the typical perception of Arabic as a traditionally ‘stress-timed’ language (Ghazali et al., 2002). However, Saudi Arabic does not employ unstressed vowel shortening as extensively as English (Algethami & Hellmuth, 2024), and similar findings have been reported for Jordanian Arabic (De Jong & Zawaydeh, 2002).
Turning to consonants, Saudi Arabic exhibits some phonotactic complexity, allowing CC clusters in both onset and coda positions and -CCC- clusters word-medially (Ingham, 1994). Despite this complexity, Najdi Arabic’s simpler syllable structure overall, with a higher proportion of CV syllables relative to English, contributes to a relatively higher speaking rate in Najdi Arabic compared to British English (Algethami & Hellmuth, 2024). Another shared feature between Arabic varieties and English is the phenomenon of utterance-final lengthening, which has been documented in Lebanese Arabic (Kelly, 2021) and Jordanian Arabic (De Jong & Zawaydeh, 1999). While no systematic analysis of utterance-final lengthening in Najdi Arabic exists, it is expected to show similar lengthening of vowels occurring in utterance-final syllables.
These subtle phonological differences between Saudi Arabic and English led Algethami and Hellmuth (2024) to investigate the production of English speech rhythm by Saudi L2 learners, using timing metrics to measure vocalic and intervocalic durational variability. One of the key findings was that L1 Saudi-speaking learners of L2 English did not exhibit the same degree of unstressed vowel shortening as L1 English speakers. This difference in the degree of vowel reduction may contribute to the perception of foreign accent in the Saudi learners’ English speech, since unstressed vowel reduction is a hallmark of English stress (Cutler, 1986). In addition, the study highlighted differences in L2 production in the degree of utterance-final vowel lengthening, which, while present in Arabic, may differ from English in the details of its implementation and interaction with other prosodic features; for example, Jordanian Arabic is reported to exhibit a lesser degree of utterance-final lengthening than English (De Jong & Zawaydeh, 1999).
The current study builds on the findings of Algethami and Hellmuth (2024) by investigating whether a relative lack of unstressed vowel shortening contributes to perception, by native English listeners, of foreign accent in the speech of Saudi learners of English. This study also addresses a gap in research by examining the role of utterance-final lengthening as a cue for foreign accent perception. While utterance-final lengthening has been shown to play a significant role in signalling prosodic structure and differentiating native English accents (White et al., 2014), its role in L2 English speech perception remains largely underexplored. By focusing on specific timing measures (articulation rate, durational ratio of unstressed to stressed vowels, and utterance-final vowel lengthening), the study seeks to uncover how deviations in L2 timing patterns affect listeners’ judgements of foreign accent and to shed light on which temporal features are critical to the perception of foreign accent, especially in Arabic-accented English.
3 Method
3.1 Speakers and listeners
English speech samples were selected from a larger dataset collected to investigate the production of English speech rhythm by Saudi speakers whose first language (L1) is Arabic (Algethami & Hellmuth, 2024). The full dataset consisted of 180 recorded utterances: 10 English utterances produced by each of six L1 English speakers and 12 L1 Saudi-speaking learners of L2 English. For the current perception study, a subset of 36 utterances was used: four utterances produced by each of three native speakers and six non-native speakers. The decision to select a subset of the speakers was made to avoid the negative effect of listening fatigue as a result of listening to a large number of stimuli, since we also planned to present each utterance twice: acoustically modified (filtered) and natural unmodified (unfiltered) forms. The non-native speakers were male L2 speakers of English, who ranged in age from 19 to 32. Their only native language was Saudi Najdi Arabic, a colloquial variety of Arabic spoken in Saudi Arabia. They were recruited from the population of international Saudi students in the United Kingdom. Their length of residence in the United Kingdom ranged from 1 to 5 years. The native English group were all male native speakers of Standard Southern British English (SSBE) drawn from the student and staff community at the University of York and were in the age range of 20 to 40.
To obtain a representative sample of the speech data, the selection of the speakers in each group was based on their average %V scores (percentage of the total duration of vocalic intervals) in their production. The speakers with the highest, lowest, and nearest to the median scores were chosen. In case there was more than one score near the median, one of them was selected randomly. This was an attempt to ensure the listeners were presented with a wide range of timing variation to examine how these variations influence their judgement of foreign accent. The choice of %V, and not any other timing measure, as the criterion for selecting the speakers was for the following reasons. First, %V has been shown to be one of the more stable and reliable timing measures in capturing rhythmic language differences (Knight, 2011; White & Mattys, 2007a; Wiget et al., 2010). Second, %V quantifies the proportion of an utterance’s total duration that is occupied by vocalic intervals in a way that is inherently related to consonantal intervals, since the percentage of vocalic duration is calculated relative to the total utterance duration, which includes both vocalic and consonantal (intervocalic) intervals.
A group of 21 listeners whose first language was Southern British English participated in the perception experiment. They reported no speech or hearing problems. They were recruited from the student population at the University of York. Their age ranged from 20 to 45. Eleven of them were linguistics students, of whom three were postgraduates.
3.2 Speech stimuli
The four longest English sentences in the data set, counted in number of syllables, were selected to provide the perceptual stimuli for the current study. The choice of longer sentences was based on the assumption that listeners might find more rhythmic information in them than in shorter ones, which might, in turn, help them to make their judgements. The chosen sentences are:
The manager is the person in control of the city project.
It is against the law to bet on the outcome of the elections.
His parents gave him a present for solving the physics exercise.
The policemen used electric sticks to break up the demonstrators.
Some previous studies have reported that pauses in the speech of L2 speakers can contribute to the perception of foreign accent (e.g., Trofimovich & Baker, 2006). Therefore, all the utterances were checked auditorily to make sure that they did not contain any perceptible pauses. In case of uncertainty, the suspected pause was checked visually via the spectrogram display. A threshold of 100 ms was adopted to decide whether the suspected silence was a pause or not. The 100-ms threshold was adopted from Griffiths (1991), who suggested this durational cut-off point for pauses based on his review of previous studies on speech pauses. Only one utterance of the 36 had a perceptible pause longer than 100 ms. Thus, this utterance was deleted, reducing the number of utterances to 35.
Two versions of the 35 utterances were used in the perception experiment: unmodified (unfiltered, henceforth) and monotonized low-pass filtered (filtered, henceforth). The unfiltered version consisted of the 35 utterances without any acoustic modification. The monotonized low-pass filtered version consisted of the 35 utterances after acoustic modifications, which were applied to isolate the effect of durational information by reducing the influence of spectral and intonational cues on listeners’ judgements. The goal of these modifications was not to examine the effect of the absence of spectral or intonational information on foreign accent perception per se, but, rather, to ensure that the effect of durational information could be studied without being conflated with other acoustic properties. Both segmental and intonational information have been shown to play a significant role in the perception of foreign accent (e.g., Anderson-Hsieh et al., 1992; Van Els & De Bot, 1987), hence the decision to remove both segmental information (low-pass filter) and intonational information (monotonized F0). The unfiltered utterances were also included in the experiment to examine the relationship between ratings based on the full range of acoustic information (unfiltered) and those based primarily on durational information (filtered). This comparison allows us to assess whether or not listeners’ judgements of foreign accent in the modified utterances, which contained only timing information, pattern similarly to their judgements of the unfiltered utterances. In addition, the inclusion of the unfiltered utterances was necessary to establish the psychological reality of perceived foreign accent in the speech of the non-native speakers.
First, all the utterances were low-pass filtered at 300 Hz (i.e., all frequencies above 300 Hz were removed). Based on a survey of the literature on human language identification using filtered stimuli, Komatsu (2007) indicated that the usual cut-off frequency of low-pass filtering to remove segmental information in previous studies ranged from 600 to 300 Hz. For this reason, the 300 Hz cut-off frequency was chosen in the current study to ensure sufficient reduction of the segmental information. Second, intonation was monotonized by changing all the utterances’ F0 values to a constant value of 150 Hz. This resulted in a flattened pitch contour for all the utterances (Van Els & De Bot, 1987).
Low-pass filtering can also reduce information related to intensity, though only partially (Scherer et al., 1985). By looking at the spectrograms of the utterances in the current study after low-pass filtering and monotonization, it was clear that a large amount of information about intensity and intensity variability remained. Since intensity is a known correlate of stress in English (Fry, 1955), and because the focus of the current study is on temporal cues, it was preferable to reduce the effect of variability in intensity. To the best of our knowledge, none of the previous studies that have used low-pass filtering controlled variability in intensity, which could have contributed to listeners’ perception of differences between the native and non-native utterances (Pellegrino et al., 2021). In the current study, the intensity of the utterances was neutralized by changing the intensity values to a constant level of 75 dB. This procedure carried with it the consequence of amplifying the amplitude of low energy or silent intervals, such as the closure phase of stops. Thus, the output signal was similar to an alternation between monotone periodic and non-periodic noises, yielding a crude approximation of vocalic and consonantal intervals, respectively. All the acoustic modifications of the utterances were performed using bespoke scripts 1 run in Praat (Boersma & Weenink, 1992–2018). Figure 1 below presents a screenshot of the utterance It is against the law to bet on the outcome of the elections, as spoken by one of the non-native speakers, before and after modification. The spectrograms of filtered utterances were inspected visually in Praat to ensure that all the modifications were successful. In a pilot study, native English listeners, who were postgraduate students in Linguistics at the University of York, confirmed the unintelligibility of the filtered utterances; they were unable to identify the lexical content of any of the utterances after listening to the filtered speech.
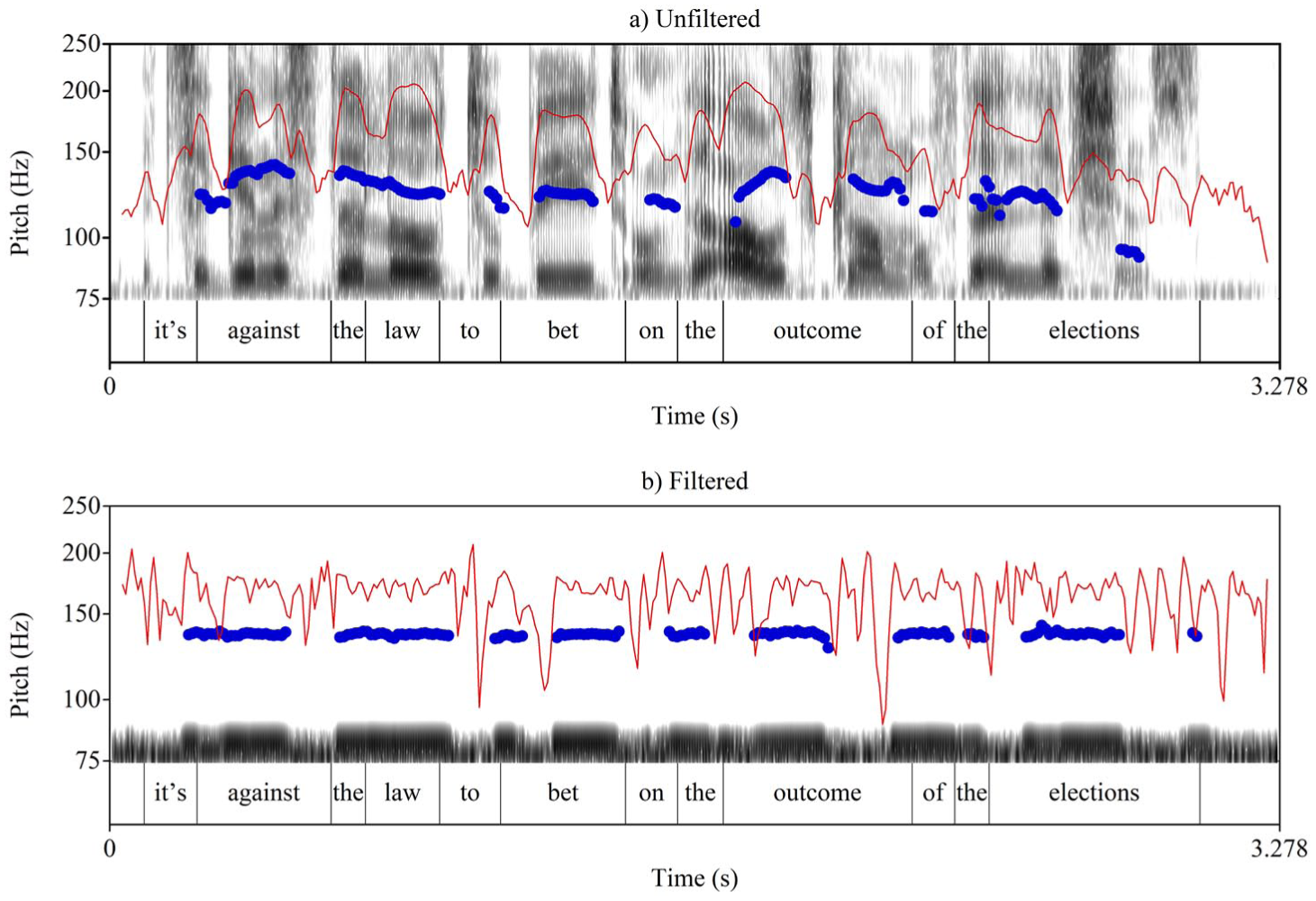
Sample non-native utterance of the sentence ‘It is against the law to bet on the outcome of the elections’ show (a) before and (b) after modification.
3.3 Procedure
The perceptual experiment took place in a quiet room at the University of York. The listeners were tested individually, and each listening session lasted from 20 to 35 minutes. They were told that they would listen to a number of modified and unmodified English utterances, spoken by native and non-native English speakers, and rate each utterance on a six-point scale for the likelihood it was spoken by a native speaker. Before the start of the experiment, to familiarize the listeners with the task, they were offered the chance to listen to an example of a filtered utterance and its corresponding unfiltered utterance spoken by a number of native and non-native English speakers. This example utterance was not one of the four test utterances used in the current study. The utterances were played to the listeners over headphones using a personal laptop computer. They were presented using Praat ExperimentMFC (Multiple Forced Choice). In the main test, the filtered utterances were presented first, so that their identification would not be affected by the unfiltered ones.
The filtered utterances were presented in four blocks, and each block consisted of all tokens of a single target utterance produced by each of the nine selected speakers (three L1 and six L2; one block contained eight tokens due to exclusion of the token containing a pause). Within each block, the utterances were presented to the listeners in strictly random order, with a different randomization for each listener. The test item in each block was written on the screen, so the listeners would know which utterance they were listening to. In this way, they would rate each utterance according to how they expected it to sound. The listeners were asked to listen to each utterance as often as they wished, then to rate it by clicking on a number on the computer screen, on the following scale: (1) definitely spoken by a native speaker of English; (2) highly likely to be spoken by a native speaker of English; (3) possibly spoken by a native speaker of English; (4) possibly spoken with a foreign accent; (5) highly likely to be spoken with a foreign accent; (6) definitely spoken with a foreign accent. This scale did not contain a choice for ‘no decision’ because of the possibility that the listeners would end up choosing ‘no decision’ for most of the items due to the inherent difficulty of the listening task. The listeners were encouraged to use the full scale as much as possible when rating the utterances. Once they clicked a number and confirmed their rating by clicking OK on the screen, they were not able to change their responses. To make sure that they did not forget the scale or reverse it, the scale was written on a piece of paper placed next to the computer. In addition, a reminder of the scale, showing its two end points, was presented on the screen above the written utterance.
After rating the filtered stimuli, the listeners were presented with their corresponding unfiltered ones. The same procedure was followed as used for presenting the filtered stimuli, except for two differences. First, the utterances were not presented in written form on the screen. Second, a different wording was used for the scale. The listeners were asked to rate the utterances according to the following scale: (1) no foreign accent; (2) very slight foreign accent; (3) slight foreign accent; (4) moderate foreign accent; (5) strong foreign accent; (6) very strong foreign accent. The wording of the scale was changed for the unfiltered utterances because it was expected that the listeners, by relying on segmental information, would face no difficulty in separating the native speakers from the non-native ones if we used the same scale wording as used for the filtered utterances. To aid the comparison between the ratings of the filtered and unfiltered utterances, however, the same rating direction and number of levels were used.
3.4 Temporal measurements
Three temporal measures were calculated for each base stimulus utterance to find out whether they contributed to the listeners’ perception of foreign accent (see Table 1): durational ratio of unstressed to stressed vowels (USR), final vowel ratio (FVR) and articulation rate (AR).
Temporal Measurements.

Vowel identification and boundary delimitation were based on the presence of visible acoustic manifestations. Vowel-consonant boundaries were mainly delimited by the end of the pitch period preceding a break in the structure of the second vowel formant (F2), accompanied by a significant drop in the waveform amplitude, and consonant-vowel boundaries were delimited by the start of a pitch period concomitant with the beginning of the second vowel formant (White & Mattys, 2007a).
For AR, total raw sentence duration was divided by the number of syllables in the target utterance to calculate AR for each sentence. We counted canonical syllables in the target utterance (based on dictionary entry), rather than making a count of realized surface syllables in each individual utterance, as recent research found only minimal differences between canonical and surface syllable counts in their relationship to native English listeners’ perception of speech tempo (Plug et al., 2022). For USR, the mean duration of all unstressed vowels in an utterance was divided by the mean duration of all stressed vowels in the same utterance. For FVR, all vowel duration measurements were first normalized to control for variation in speaking rate across speakers and utterances. This was achieved by dividing each vowel duration by the average syllable duration of the sentence (calculated as total sentence duration divided by the number of syllables) (Kavanagh, 2012). The FVR was then calculated by dividing the normalized utterance-final vowel duration by the mean normalized vowel duration within the same utterance.
4 Results
4.1 Listeners’ ratings
Interclass correlations, using Cronbach’s alpha, showed high agreement between the listeners’ ratings of the filtered (.90) and unfiltered (.96) utterances. These scores indicate that listeners were highly consistent in their judgements of foreign accent. Figure 2 shows that utterances produced by L1 English speakers were rated as ‘no foreign accent’ near categorically when presented in unfiltered condition, but more variably when presented in filtered condition, with a few tokens rated as far in the opposite direction as response level 6 ‘Definitely spoken with a foreign accent’. In contrast, the utterances produced by the L2 English speakers were rated in unfiltered condition across almost the full range of response levels (though none are rated at level 1 ‘no foreign accent’). The L2 utterances also received ratings across all response levels in the filtered condition, and with a higher proportion of utterances rated as spoken with a foreign accent, that is, using response levels 4–6.
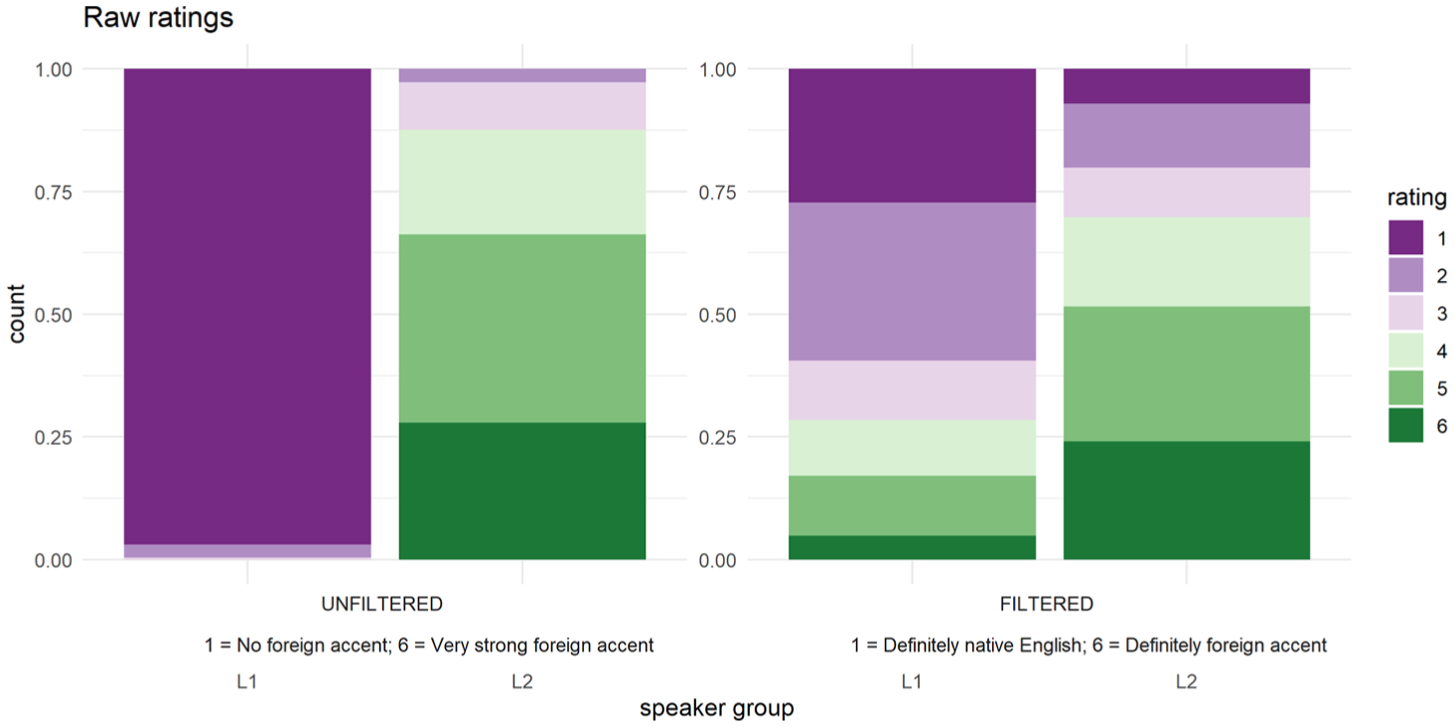
Listeners’ ratings of foreign accentedness by speaker group (L1/native and L2/non-native English speakers) and by stimulus presentation condition: unfiltered (left, where 1 = ‘no foreign accent’ and 6 = ‘very strong foreign accent’) and filtered (right, where 1 = ‘definitely spoken by a native speaker of English’ and 6 = ‘definitely spoken with a foreign accent’).
An ordinal logistic regression was run using the ordinal package in R (Christensen, 2026), to predict listener ratings as a function of speaker group (L1 or L2) and stimulus presentation condition (filtered or unfiltered), together with the interaction between them; the model also included the level of linguistic training of listeners (listeners who were either linguistics students, N = 12, or not), as an additional fixed factor, to control for potential effects of this difference between listeners in linguistic experience. The random effects structure included random intercepts for sentence, listener and speaker, with speaker nested within group. The model was treatment coded relative to ratings of unfiltered utterances produced by L1 speakers by listeners with no linguistic training (i.e., those without a graduate or undergraduate degree in a linguistics-related field).
The model predictions are visualized in Figure 3. The model showed a large main effect on ratings of both group (β = 7.6459; z = 11.986; p < .001) and condition (β = 4.7391; z = 12.231; p < .001), and also of the interaction between them (β = −5.4876; z = −13.526; p < .001). This confirms that ratings of L2 speech were significantly different from those of L1 speech across the board (with L1 speech always more likely to be rated at lower levels of the relevant scale than L2 speech), but that this effect is significantly modulated by listening condition (with a greater effect of filtered condition in pushing ratings higher up the scale for L1 speech than for L2 speech). There was no effect on ratings of listeners having linguistic training or not (β = −0.1923; z = −1.165; p = .244).
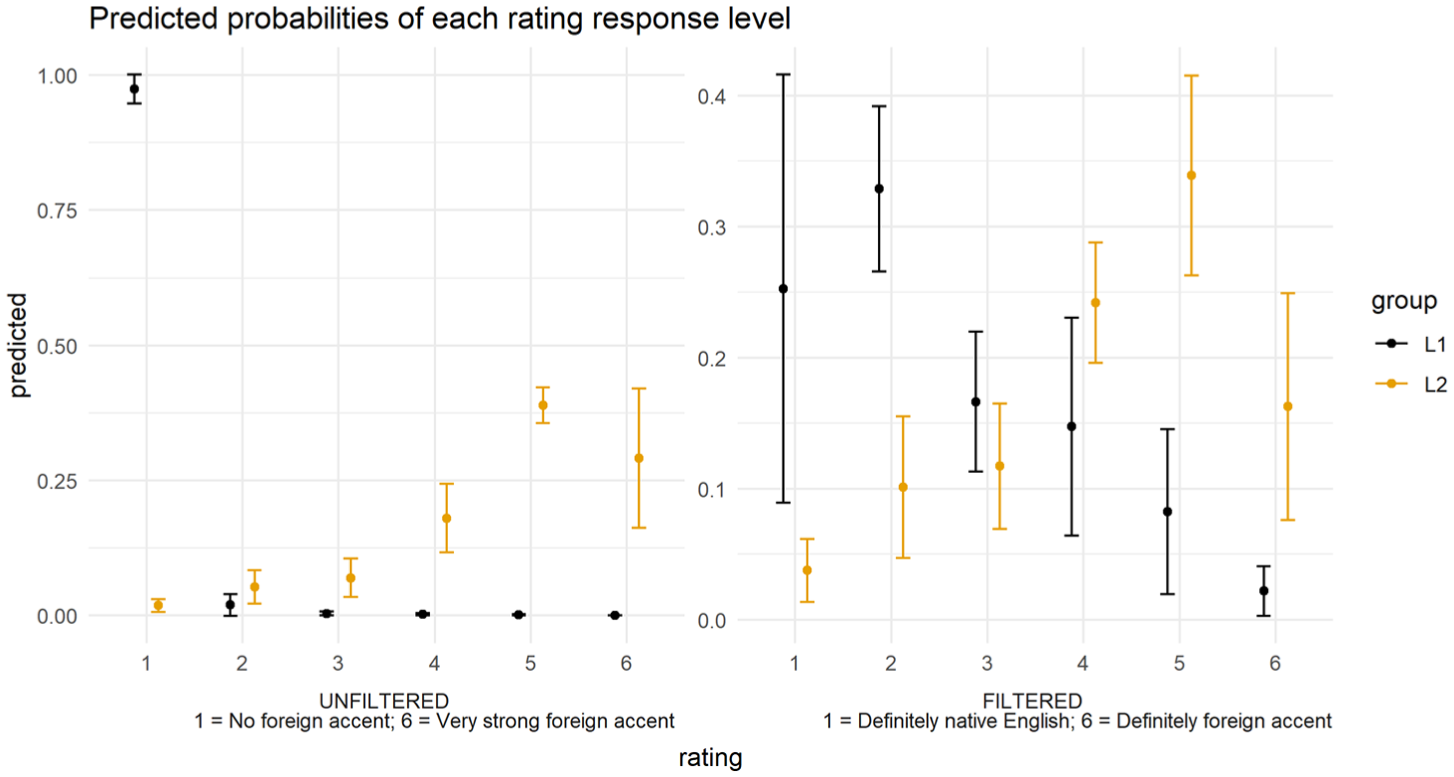
Predicted probabilities of each rating response level by speaker group (L1/L2) and by condition: unfiltered (left, where 1 = ‘no foreign accent’ and 6 = ‘very strong foreign accent’) and filtered (right, where 1 = ‘definitely spoken by a native speaker of English’ and 6 = ‘definitely spoken with a foreign accent’).
4.2 The relationship between temporal measures and the ratings
Three temporal measures (AR, USR and FVR, see Table 1) were calculated for all L1 and L2 utterances. Table 2 presents means and standard deviations for all measures by group and Figure 4 visualizes the spread of values in individual utterances for each measure by group.
Mean and Standard Deviation of AR, USR and FVR by Group.

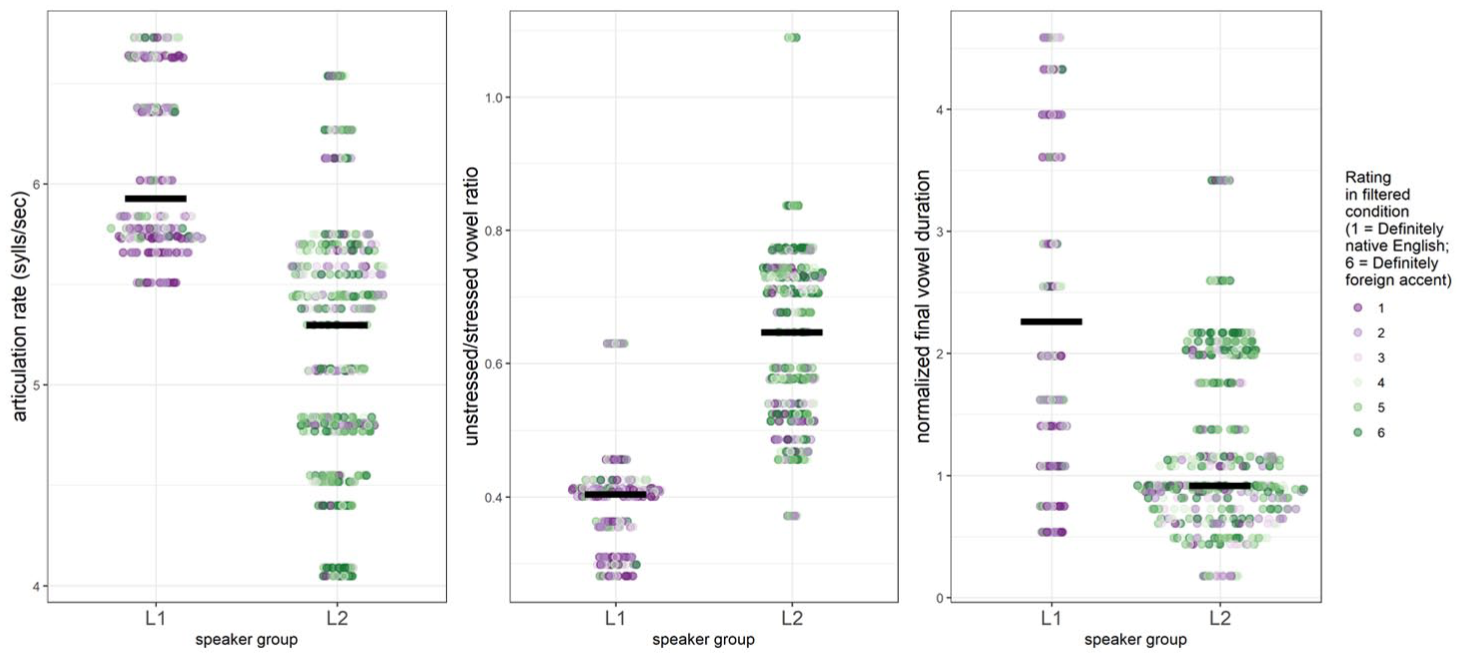
AR, USR and FVR values, by speaker group (L1/L2): the median is indicated by a black horizontal bar; each point represents the value of the temporal measure for one utterance, using colour to visualize how that utterance was rated in filtered condition (where 1 = ‘definitely spoken by a native speaker of English’ and 6 = ‘definitely spoken with a foreign accent’).
The calculated temporal measures for each utterance were submitted to a series of linear mixed-effects models (one model for each measure), with speaker group as a fixed factor (treatment coded with the L1 speaker group as reference level), and random intercepts for speaker and sentence. The results show a significant difference between the two speaker groups for all three temporal measures. For articulation rate (AR) as a group the L2 English speakers produced significantly slower speech (fewer syllables per second) (β = −0.877, SE = .28, t = −3.09, p = .0175), though it is clear that there is wide variation in speech rate across the L2 utterances, with at least some falling in the same range of AR as those produced by the L1 English speakers. For USR, the L2 speaker group produced a significantly smaller durational difference (i.e., larger ratio) between unstressed and stressed vowels (β = 0.251, SE = .06, t = 4.09, p = .0046). As expected, this indicates that the L2 English speakers did not shorten unstressed vowels to the same extent as the L1 English speakers did. Finally, results for FVR indicated that while both speaker groups exhibited utterance-final lengthening, the magnitude of this lengthening was significantly greater for the L1 English speakers than for the L2 English speakers (β = −1.15, SE = .303, t = −3.816, p = .006).
To confirm which of these observed differences in temporal measures (if any) contribute to listeners’ ratings, a further ordinal logistic regression was run. This model was run on the data for filtered L2 speech only to find out how the calculated measures contribute to the perception of foreign accent in Arabic-accented English utterances which have been modified to retain only temporal cues. The model predicts listener ratings with the three temporal measures (AR, USR and FVR) as fixed factors, with random intercepts for sentence, listener and speaker. The AR, USR and FVR factors were centred and scaled. Of the three temporal measures, only AR significantly influenced listener ratings of the filtered L2 utterances (β = −0.43085; z = −3.742; p = .000183), with lower AR (fewer sylls/s) predicting higher rating response levels (more ‘foreign’). The influence of USR approached significance (β = 0.19223; z = 1.851; p = .06424), with USR values closer to 1 (indicating minimal vowel reduction) tending to co-occur with higher rating response levels (more ‘foreign’). There was no effect of FVR (β = 0.07215; z = 0.685; p = .49362). Figure 5 visualizes the predicted probabilities of each rating response level in the model by unscaled values of AR and USR (back-transformed for ease of interpretation).
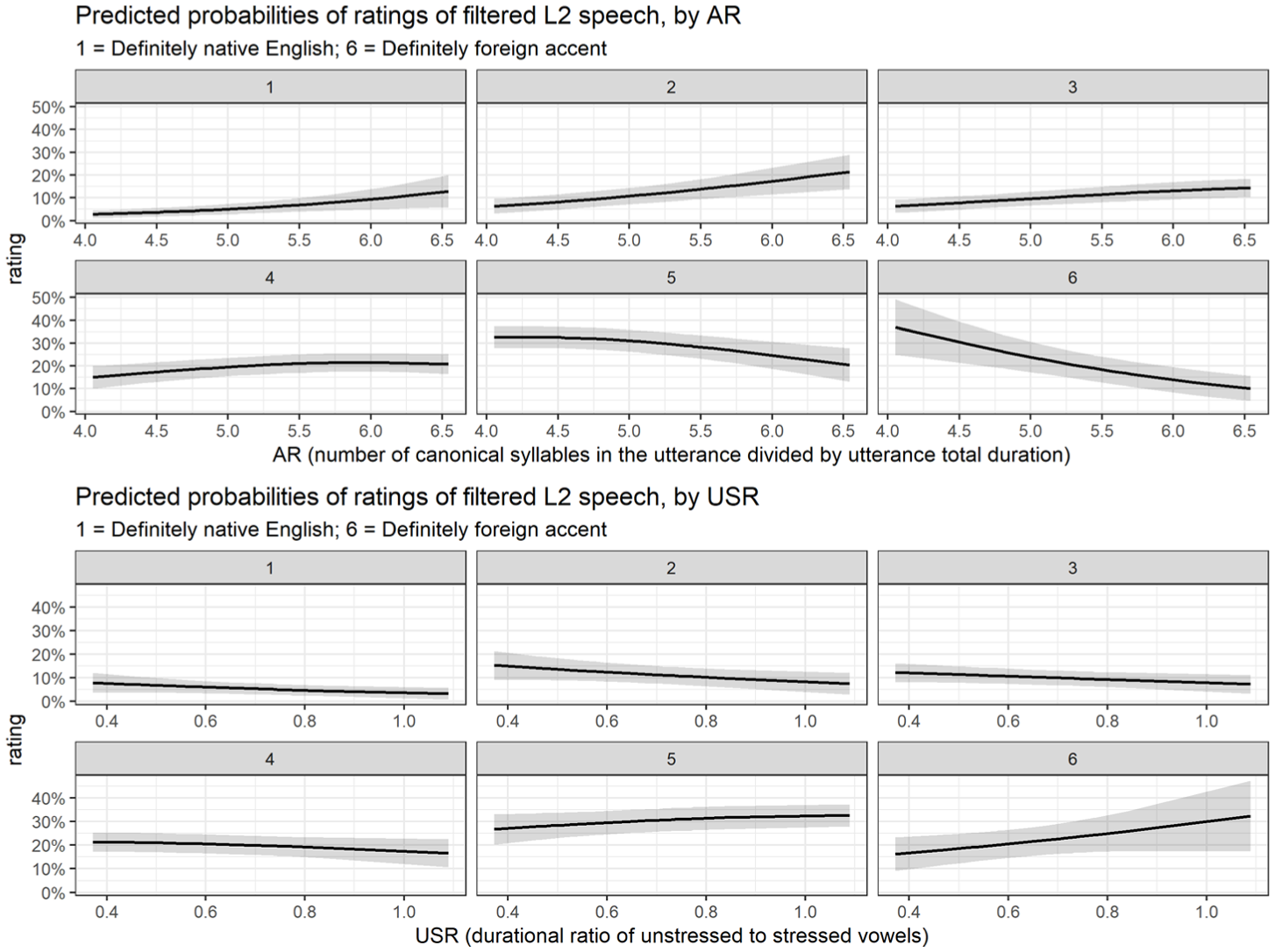
Predicted probabilities of each rating response level of filtered L2 speech by values of AR (upper panel) and USR (lower panel), where 1 = ‘definitely spoken by a native speaker of English’ and 6 = ‘definitely spoken with a foreign accent’.
So, in filtered L2 speech, slower AR (fewer syllables per second) predicts higher ratings (more ‘foreign’) and higher USR (less vowel reduction) tends to attract higher ratings (more ‘foreign’).
We then ran a final pair of models to compare the effect on ratings of the AR and USR properties of L2 versus L1 filtered utterances, to explore whether listeners’ ratings differ in their sensitivity to AR or to USR when presented with L1 versus L2 speech. Each model was run on the data for filtered speech from all speakers to predict listener ratings with speaker group as a fixed factor (treatment coded with L1 speakers as reference level), in interaction with either AR (in the first model) or USR (in the second model) as fixed factors, and with random intercepts for sentence, listener and speaker, with speaker nested within group. The AR and USR factors were again centred and scaled. The AR*group model reveals a main effect of both group (β = 2.1746; z = 5.869; p < .001) and of AR (β = 0.6795; z = 3.215; p = .0013), and significant interaction between them (β = −1.1797; z = −5.15; p < .001). The USR*group model also reveals a main effect of group (β = 1.2181; z = 2.759; p = .0058) and of USR (β = 0.5231; z = 2.045; p = .0408), but no interaction (β = −0.2958; z = 0.2789; p = .2888). Figure 6 visualizes the predicted probabilities of each rating response level in the two models by group and by unscaled values of AR and USR (back-transformed for ease of interpretation).
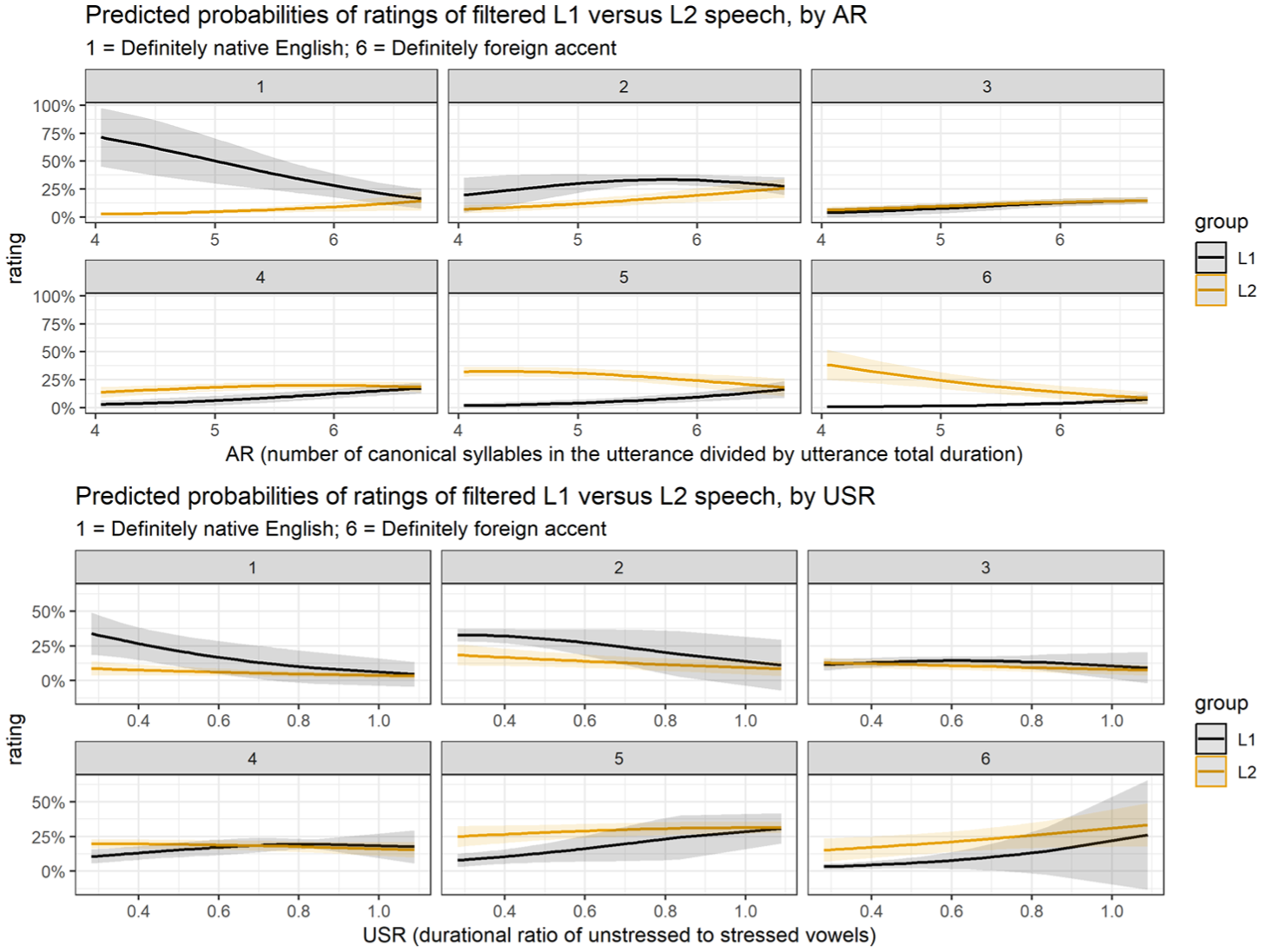
Predicted probabilities of each rating response level of filtered speech by group and by AR (upper panel) and by group and USR (lower panel); in both panels 1 = ‘definitely spoken by a native speaker of English’ and 6 = ‘definitely spoken with a foreign accent’.
The effect of articulation rate on listener ratings is modulated by speaker group but is best interpreted considering the spread of AR values produced by each group (Figure 4). The L2 speech displays a wide range of AR values: slower AR (fewer sylls/s) predicts a higher rating (more ‘foreign’) and faster AR (more sylls/s) predicts a lower rating (more ‘English-like’). In contrast, in L1 speech, observed AR values clustered at faster rates only (5.5 sylls/s or higher): the model offers a predicted probability of lower (more ‘English-like’) response levels 1 and 2 ratings of L1 speech at slower AR rates, but with low confidence (indicated by wide confidence intervals) due to the lack of observed data points from the L1 speaker group at slow AR values; the probability of higher (more ‘foreign’) ratings of L1 speech at response levels 3–6 is consistently low, showing only a weak relationship with AR for this speaker group. We thus interpret the significant AR*Group interaction as confirmation of the role of AR in perception of foreign accent for L2 speech (as seen in the L2 only model), whereas AR values do not vary enough in L1 speech to play a significant role in how those utterances are perceived. This suggests that other temporal factors may play a role, and the results of the USR*group model offer an explanation. There is a main effect of USR on listener ratings, but no interaction with group; higher USR (less vowel reduction) always predicts a higher rating (more ‘foreign’), and lower USR (more vowel reduction) always predicts a lower rating (more ‘English-like’). There is a main effect of group because USR rates differ in L1 versus L2 speech, but the effect of USR variation on listener ratings is consistent across groups.
5 Discussion
The objective of the current study was twofold. First, it sought to examine the role non-native timing plays in cueing native listeners’ perception of foreign accent in Arabic-accented English. Second, it examined the relative contribution of unstressed vowel shortening, utterance-final vowel lengthening and AR to the overall percept of foreign accent. Utterances produced by L1 English speakers and by L1 Arabic-speaking learners of L2 English were acoustically modified to significantly reduce segmental and intonational information and then presented to L1 English-speaking listeners for foreign accentedness rating. The L1 English listeners were able to distinguish the L1 and L2 modified utterances despite the spectrally and intonationally degraded speech. This demonstrates that deviations from the L1-like timing patterns alone can play a significant role in cueing listeners’ perception of foreign accentedness in Arabic-accented English. The results corroborate the results of recent studies which have demonstrated the important role that global non-native timing plays in the perception of nativeness and foreign accent (Kolly & Dellwo, 2014; Kolly et al., 2017; Pellegrino et al., 2021; Polyanskaya et al., 2017; Polyanskaya & Ordin, 2019; Van Maastricht et al., 2021). Most previous studies, which examined the effect of overall non-native timing on the perception of foreign accent, focused on speakers whose L1 and L2 have been traditionally described as rhythmically distinct (e.g., English vs. French), and concluded that L1 influence plays a major role in the production of L2 speakers and thus in turn on the degree of perceived foreign accent in their speech. The current study adds to the existing evidence for the salience of non-native timing to the percept of foreign accent, by examining L2 speakers whose L1 (Arabic) differed from English in a number of timing patterns, even though the two languages are traditionally described as rhythmically similar (Algethami & Hellmuth, 2024). It would therefore be more informative for L2 speech theories and models to discuss and explain L2 global speech timing in terms of specific cross-language durational patterns, such as vowel reduction, rather than appealing to putative rhythm classes (‘stress-timing’ vs. ‘syllable-timing’).
In line with prior evidence that L2 speakers of English usually speak at a lower speaking rate than L1 speakers (Munro & Derwing, 1998), the current study found a significant difference between the L1 and L2 groups in the AR of their productions. However, the spread of AR values in the L2 utterances varied widely, and as a result, overlapped with the spread of AR values in L1 utterances. This wide variation may be an artefact of the scripted speech task used to elicit the production data in the current study, and/or of the relatively advanced reading proficiency of the L2 speakers, coupled with the observation that L2 speakers generally speak at a slower rate than native speakers (e.g., Munro & Derwing, 1998) due to the cognitive demands of second language processing. The spread of AR values in the productions of L2 groups no doubt underpins the observed significant effect of AR in influencing the listeners’ ratings of the degree of foreign accent in filtered L2 speech. As previous studies have clearly demonstrated the significant role of AR in cueing listeners’ perception of foreign accent in segmentally masked speech (e.g., Munro, 1995; Polyanskaya & Ordin, 2019; Trofimovich & Baker, 2006; Van Maastricht et al., 2021), future L2 research should continue to take speaking rate into consideration as a factor that listeners may resort to in their judgement of nativeness, though with the caveat that it may also interact with other timing cues.
FVR did not contribute to the overall perception of foreign accent in Arabic-accented English despite a significant difference between the L1 and L2 groups in their production of FVR. It is difficult to interpret this finding in terms of L1 influence on these L2 speakers, as there are, to our knowledge, no studies yet of the extent to which utterance-final vowels are lengthened in Saudi Arabic varieties. Given the fact that utterance-final lengthening can affect listeners’ categorization of languages and accents (White et al., 2014), future research is recommended to take prosodic lengthening effects into consideration.
The durational ratio of unstressed to stressed vowels (USR) was found to differ significantly between the L1 and L2 utterances, but USR showed only a tendency to contribute to the perception of foreign accent in Arabic-accented English, in a model of L2 filtered speech. Algethami and Hellmuth (2024) previously demonstrated that Saudi L2 speakers do not reduce unstressed vowels in their L2 English and attributed this pattern in production to the influence of their L1. The results of the current study point to the potential effects of USR on perceived L2 accent, and a consistent effect of USR on predicted ratings of L1 versus L2 speech was indeed observed. It has long been suggested that L2 learners of English typically face persistent difficulty in producing English rhythm, of which unstressed vowel reduction is a key characteristic (e.g., Adams, 1979; Fokes & Bond, 1989; Taylor, 1981). The results of the current study contrast with those of Trofimovich and Baker (2006), in which the durational ratio of unstressed to stressed syllables was not shown to be a significant predictor of foreign accented in the speech of L1 Korean-speaking learners of L2 English. This difference in findings could be a result of a key difference in methods between the two studies; Trofimovich and Baker (2006) examined the duration of syllables and the current study examined the duration of vowels. White et al. (2012) suggested that English listeners may not utilize the durational variation of whole syllables, as the timing effects that listeners usually attend to are not ‘evenly distributed over whole syllables’ (p.677). This may explain why the stress-related timing measure examined by Trofimovich and Baker (2006) was not predictive of foreign accent in Korean-accented English.
Overall, the results of the current study provide novel evidence of the important role that timing plays in the perception of foreign accent. The current study extends the conclusion reached by White et al. (2012) for L1 speech into the context of L2 speech and shows that listeners are able to exploit any timing cues available to them. Unstressed vowel shortening was found to be a consistent cue to the degree of foreign accent in ratings of filtered L1 and L2 speech in which only temporal information was available, in a context where overlapping speaking rates in the L1 versus L2 utterances resulted in somewhat indirect cues from AR. The current study is limited to the three timing measures it examined, and future research may explore other timing measures and examine their relative contribution to the overall percept of foreign accent. The findings of the current study demonstrate, for the first time, how speech timing and temporal variation between stressed and unstressed vowels specifically contribute to the perception of the degree of foreign accent in the speech of L1 Arabic speakers of L2 English.