
Abstract
Previous research on imitation in L1 has shown that explicit instructions generally generate more robust convergence with the model talker than implicit instructions. However, this regularity has not gained sufficient empirical attention in L2 speech imitation. To address this gap, we examined English vowel duration variability as a cue to following voiced versus voiceless consonants (vowel clipping) in 28 Czech and 28 Polish L2 learners of English. Neither Czech nor Polish uses vowel clipping as a voicing cue in the L1. Participants completed three tasks: (1) baseline, (2) imitation, and (3) post-test. Our results confirmed convergence towards the model stimuli during imitation, but this effect diminished in the post-test. The critical manipulation involved the imitation task: half of the participants were explicitly instructed to imitate the model voice as accurately as possible (explicit imitation), whereas the other half performed a simple oral identification task (implicit imitation). Contrary to predictions based on L1 imitation studies, explicit instructions did not increase the magnitude of convergence in L2 learners in our study. Moreover, the results showed that the Czech and Polish participants exhibited comparable degrees of convergence with the native English model, thus replicating the null effect of instruction type across two language groups. We discuss the current results by offering two lines of reasoning as to why explicit instructions did not, in our study or more generally, lead to more imitation in L2 speech.
1 Introduction
The tendency to imitate others is a demonstrable element of human behaviour. People modify their language in interactions with others in pursuit of adaptations in different dimensions. Such adaptations have been found to occur not only for speech but also for written language (Adams et al., 2018) and sign language (Stamp et al., 2016). In spoken language, people imitate each other on multiple levels of linguistic organisation such as syntax, vocabulary, and morphology (as cited in Ulbrich, 2024). Phonetic imitation relates to the situation when an individual modifies phonetic properties of their speech to adapt to the phonetic properties of speech of an interlocutor or of the speech they are exposed to. Such adaptation is also referred to in the literature as accommodation (Giles et al., 1991; Pardo et al., 2022), alignment (Pickering & Garrod, 2004), convergence (M. Kim et al., 2011; Pardo et al., 2012; Pellegrino et al., 2024), or entrainment (Weise et al., 2020; Wynn & Borrie, 2022). Many experimental studies in noninteractive contexts (e.g., repeating or shadowing recorded words or longer stretches of speech in laboratory conditions) have shown that phonetic imitation occurs even if there is no physical interaction with an interlocutor. What is more, imitation is still observed when participants are not instructed to imitate or even when they are explicitly instructed not to imitate (Dufour & Nguyen, 2013; Goldinger, 1998; Shockley et al., 2004; Walker & Campbell-Kibler, 2015).
Shadowing is a remarkable demonstration of the permeating nature of imitation. In a typical shadowing task, participants are first asked to read aloud a list of test words (baseline condition). Next, they shadow (repeat as quickly as they can) the same words after the model talker. The results show that participants imitate phonetic properties of the speech provided by a model talker even though they are not told to do so (Mitterer & Ernestus, 2008; Mitterer & Müsseler, 2013; Pardo et al., 2017, 2018; Schertz & Johnson, 2022). The presence of imitation is evidenced by changes in the phonetic parameters of their speech when baseline productions are compared with shadowed productions. The direction of change is largely towards the properties of the model talker’s speech.
In the following sections, we review the studies that show that phonetic imitation is not restricted only to occurring in a native language (L1) but is also a widespread phenomenon in a non-native language (L2). Next, we define explicit and implicit imitation tasks and refer to previous studies to predict how the type of instructions (asking for imitation implicitly vs. explicitly) may influence the magnitude of observed imitation. Finally, we present the methodology of the current study, the tested phonetic parameter and the analysis, results, and discussion.
2 Phonetic Imitation in L2
The imitation of phonetic properties has also been attested in L2 (Gnevsheva et al., 2021; Hao & de Jong, 2016; Hashimoto et al., 2022, 2025; Hutchinson, 2022; Lewandowski & Nygaard, 2018; Trofimovich & Kennedy, 2014; Wagner et al., 2021). Imitation in L2 differs from imitation in L1 in that it operates on the interface of two phonological systems. One system is a target language system (model talker and native speaker), and the other system is frequently an amalgam of the target language system and the native language of imitators (the model talker’s language is L2 for imitators). Previous research has demonstrated that imitation in L1 is determined by the phonological relevance of the imitated detail (Kwon, 2019). For example, L1 Dutch speakers successfully imitated the presence/absence of prevoicing but did not imitate different durations of prevoicing due to the fact that Dutch differentiates /b, d, g/ from /p, t, k/ solely by the presence of voicing and the actual duration of prevoicing is irrelevant (Mitterer & Ernestus, 2008). Nielsen (2011) reported that lengthened Voice Onset Times (VOTs) rather than shortened VOTs for /p, t, k/ were more likely to be imitated in L1 English. It was interpreted as evidence that imitation in L1 is governed by the mechanism of contrast maintenance, because imitating shortened VOTs would have led to the switch into /b, d, g/ (but see also Nielsen & Scarborough, 2015; Schertz & Paquette-Smith, 2023).
Similarly, imitation in L2 appears to be shaped by the boundaries of phonological categories of the imitated language; however, here we have an additional factor of the imitators’ native phonological system. The two languages interact in shaping the imitators’ performance. The L2-category influence seems to be modulated by the degree to which L2 contrasts have been acquired and established. For example, Llompart and Reinisch (2019) tested the German learners’ imitation and perception of the English /ɛ/-/æ/ contrast. The results showed that the learners’ ability to imitate /ɛ/ and /æ/ was related to their perception of that contrast, showing a strong link between the degree of establishing the L2 contrast and the imitative performance. Similarly, Jia et al. (2006) reported that the imitation of American English vowels by native Mandarin speakers was fashioned by age of arrival (AoA), with younger AoA leading to more accurate imitations. As early AoA is linked with more successful L2 category formation, it indicates that imitation in this study was governed by how well L2 categories had been established. Chen et al. (2023) investigated the imitation of Thai tones by Thai-naïve Mandarin and Vietnamese participants. They found that imitation was influenced by perception, as shown by different perceptual assimilation types, pointing to L1 phonological and phonetic effects on L2 imitation.
Despite this, L2 imitators consistently show systematic adjustments of their productions towards the phonetic properties of the target language. Research has shown that L2 imitators converge with the model talker in phonologically highly relevant L2 phonetic properties both at the segmental and suprasegmental levels, such as VOTs in the voicing contrast in stops (Flege & Eefting, 1988; Hashimoto et al., 2022; Rojczyk, 2012; but see Wieczorek & Rojczyk, 2024, for the lack of convergence), vowel duration and quality (Hashimoto et al., 2025; Jiang & Kennison, 2022; Llompart & Reinisch, 2019; Rojczyk, 2013; Zając & Rojczyk, 2014), /r/ realisations (Ulbrich, 2024), and lexical tones (Chen et al., 2023; Hao, 2012; Hao & de Jong, 2016).
Interestingly, L2 speakers are also able to imitate phonetic detail that is allophonic in L2, such as t-glottalisation in English (Rojczyk et al., 2025; Šturm et al., 2022) and the lack of release burst in English stops (Rojczyk et al., 2013). Rojczyk and Rallo Fabra (2023) showed that L2 phonetic allophonic detail is even imitated by speakers who have no familiarity with the imitated language. In their study, Spanish–Catalan speakers imitated the rearticulation of geminates in Polish. Rearticulation manifests itself as two separate closures in a geminate rather than one long closure, which is typical for geminates in other languages. Rearticulation in Polish geminates is optional and largely speaker-dependent, as some speakers rearticulate more than others (Rojczyk & Porzuczek, 2019). Although in the baseline condition, L1 speakers of Polish produced more rearticulation (no rearticulation was found for Spanish–Catalan speakers in this condition), in the imitation task, both Polish and Spanish–Catalan speakers produced a high rate of rearticulation (more than 80% of the time).
All these studies suggest that L2 imitators may temporarily reproduce phonetic detail that is not reliably manifested in their baseline productions. In many cases, such detail is absent or weakly expressed prior to exposure, yet it emerges during imitation, indicating that learners are capable of producing phonetic features that are not consistently accessed in their spontaneous L2 speech. If it were, it would have emerged in their baseline condition productions. What is more, even L2 imitators with low proficiency or even no knowledge of the imitated language are able to reproduce, with different degrees, both phonologically critical and optional phonetic details in the L2. As a result, phonetic imitation is applied as a practical tool in L2 teaching by raising learners’ awareness of selected phonetic properties in L2 speech (Henderson & Rojczyk, 2023; Mora et al., 2013; Rojczyk, 2015).
3 Explicit Versus Implicit Phonetic Imitation
Although imitation in L2 is a widely attested phenomenon, very few L2 imitation studies have addressed the issue of how it is conditioned by instructions. This issue has gained much more interest in L1 imitation (Schertz, 2025; Schertz et al., 2023). Explicit imitation (also forced or conscious) is elicited by instructing the participants to actively imitate the model talker to sound like the speech they hear. Implicit imitation (also spontaneous or unconscious) is elicited in situations when participants’ attention is not directed to sounding like the speech they hear; instead, they are instructed to interact with an interlocutor or repeat the words they hear. Intuitively, explicit imitation should generate more convergence with a model talker, because the intended overtly stated target is the replication of phonetic features. Accordingly, participants have to identify what is salient in the delivered speech and manipulate their productions to consciously replicate the properties that they find salient (Schertz, 2025). In implicit imitation, on the contrary, the participants’ attention is not directed to the replication of phonetic features; therefore, there is no element of consciousness or purposefulness. Indeed, most of the L1 imitation studies have shown that explicit and instructed imitation yields more convergence (Clopper & Dossey, 2020; Dufour & Nguyen, 2013; Garnier et al., 2013; Sato et al., 2013; Schertz, 2025). No effect of explicit instruction on the magnitude of imitation was reported by Pardo et al. (2010).
Although the distinction between explicit and implicit imitation has gained observable interest in L1, the research on L2 imitation has paid very little attention to this issue. As explicit imitation relies on the identification of salient properties in the speech signal prior to replication, we may observe less advantage of explicit over implicit imitation in L2 due to the fact that the hierarchy of salience may differ in L1 and L2. In L2, the hierarchy of salience depends on how well phonological categories have been established, and it may not be as optimal as in L1 because of the interaction of L1 and L2 salience hierarchies. As shown by Gass et al. (2018), L2 learners may attend preferentially to features that are perceptually robust in L1, even when these features are not the most functionally relevant in L2. Conversely, phonetic cues that are crucial for contrast maintenance in L2 may remain relatively low in salience, because they are weakly represented or even absent in L1. Similar arguments have been made to cue weighting in L2 speech, where learners may rely disproportionately on certain cue dimensions, even when they are suboptimal for L2 phonological contrasts (Bohn, 1995). Applied to phonetic imitation, this suggests that explicit instructions may not always automatically guarantee a more successful approximation of native-like productions compared with implicit imitation. For explicit imitation to confer an advantage, learners must first identify which phonetic features are relevant targets for imitation.
To our knowledge, the only study that directly compared explicit and implicit imitation in L2 is that by Zając and Rojczyk (2014). The imitators were Polish learners of English (B2 proficiency level), who imitated English vowel clipping, which is vowel shortening before phonologically voiceless (fortis) consonants. Half of the imitators were instructed to wait until the recorded voice stopped producing the word and then read this word from the screen (implicit instructions). The other half were instructed to imitate the words they heard as faithfully as they could (explicit instructions). The results revealed that the different instructions received by the imitators did not have a significant effect on the magnitude of imitation, which stands in contrast to the results in most of the studies on L1 imitation. While the study by Zając and Rojczyk (2014) provides the only direct comparison of explicit and implicit imitation in L2 to date, the current study extends this work in three important aspects. First, implicit imitation is operationalised here using a task that nests speech production in a perceptual decision-making context and imposes additional cognitive load, thereby reducing intentional, expectation-driven imitation relative to repetition-based explicit paradigms. Second, our focus is on a contrastive cue (vowel duration as a cue to the voicing contrast) rather than on absolute temporal values. We achieve it by using normalised measures and ratio-based analyses to capture contrast adaptation. Third, by including learners from two L1 backgrounds that differ in the phonological use of vowel duration, we directly test whether L1 structure modulates L2 imitation.
Table 1 presents the review of L2 imitation studies together with the specific instructions provided to the participants. The ‘instruction type’ column is our classification of the specific instructions into the explicit/implicit categories.
L2 Imitation Studies With the Instructions Given to the Participants.
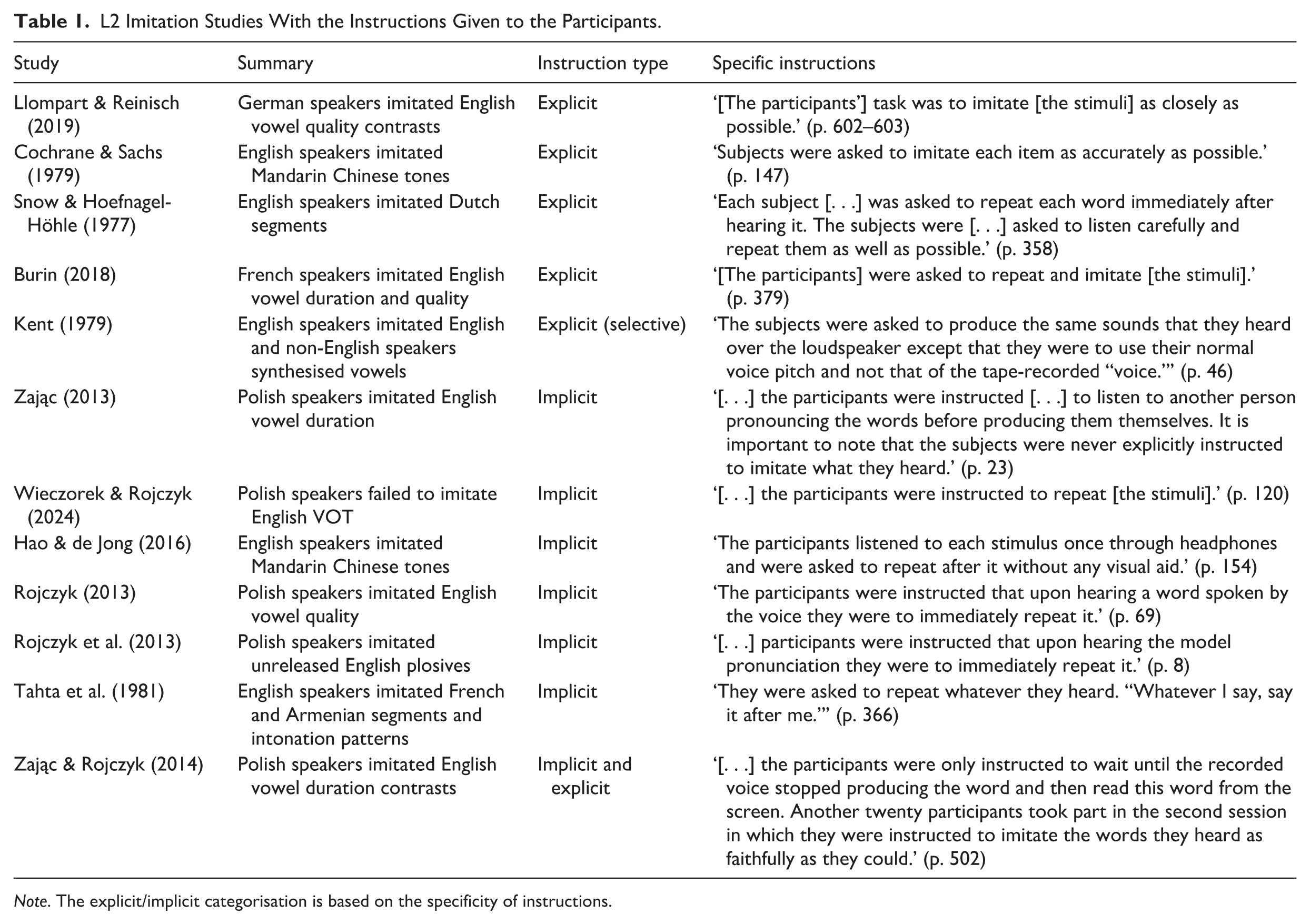
Note. The explicit/implicit categorisation is based on the specificity of instructions.
Although they did not directly tap into the explicit/implicit nature, some other L2 studies have attempted to test the strength of imitation in tasks that did not rely solely on immediate imitation. Rojczyk (2012) and Rojczyk et al. (2013) compared immediate imitation with distracted imitation (e.g., participants read a digit flashed on the screen between hearing a model voice and repeating the word). The results showed that distraction reduced the strength of imitation. Chen et al. (2023) tested the effect of memory load, expressed as the controlled time interval between hearing a word and starting to imitate. They found that imitations were generally more accurate under a low memory load. These three studies are taken as evidence that immediate L2 imitation may rely largely on the phonetic mode of speech processing, and any distraction increasing the memory load may force the imitators to resort to more phonological processing. The current study builds on this insight by introducing a different type of processing constraint. Rather than manipulating memory load through temporal delay, we impose cognitive load by embedding speech production within a perceptual decision-making task. This manipulation was intended to reduce access to a purely phonetic mode of imitation and to test whether explicit instructions to imitate confer an advantage compared with implicit conditions that limit phonetic processing resources.
Importantly, it should be noted that the term implicit imitation has been used somewhat broadly in the previous studies, often referring simply to the absence of explicit instructions to imitate, typically in repetition and shadowing tasks (see Table 1). In the present study, implicit imitation is operationalised more narrowly as imitation, which is both uninstructed and under increased cognitive load. By embedding stimuli within a two-alternative identification task, we aim to remove explicit imitation by taxing attentional and decision-making resources. We therefore treat implicit imitation here as a cognitively constrained form of imitation rather than merely the absence of explicit imitation instructions. We therefore take the position that simply omitting explicit imitation instructions – the methodology adopted by many previous studies reported in Table 1 – may not be sufficient to ensure a genuinely implicit mode of imitation. Participants engaged in repetition-based tasks may still infer an expectation to reproduce the auditory stimulus accurately, even in the absence of explicit instructions. For this reason, the present study introduces an additional manipulation, which is cognitive load evoked by an identification task, to reduce the likelihood of an expectation-based imitative strategy.
4 The Current Study
In the current study, we directly compare explicit and implicit phonetic imitation in L2. In the explicit condition, participants were asked to imitate the words they heard as faithfully as they could. In the implicit condition, we used a simple identification task in which the participants were asked to say which of the two words presented on the screen had been played to them. The identification task disguises the true purpose of the experiment and provides a degree of cognitive load (comparing and decision-making). Similar to memory load in Chen et al. (2023) and Schertz (2025), cognitive load in our study was expected to induce the participants into a strong implicit mode of imitation. Previous studies have shown that the increased cognitive load taxes the speech production resources (Huttunen et al., 2011; Lively et al., 1993; Mendoza & Carballo, 1998), so we expected to observe significantly reduced retention of phonetic detail in imitation in the implicit condition.
It should be acknowledged that the explicit and implicit conditions in the present study differ not only in the wording of the instructions but also in the structure of the task. Whereas the explicit condition relies on an immediate repetition task, the implicit condition employs speech production elicited by a word-identification paradigm. As a result, the present study does not aim to isolate the effect of verbal instructions alone; rather, it contrasts two instructional regimes that differ in task relevance and cognitive demands, with the goal of the more effective elicitation of a genuinely implicit mode of imitation.
The targeted phonetic detail was English vowel duration variability preceding fortis and lenis consonants. English vowels followed by lenis consonants are generally longer than the same vowels followed by fortis consonants (Hogan & Rozsypal, 1980; Peterson & Lehiste, 1960). This regularity in English is frequently referred to as vowel clipping or prefortis clipping (e.g., Ashby & Maidment, 2005; Broeders & Gussenhoven, 2025; Carley et al., 2025; Wells, 2008). We tested the imitation of this phonetic property by two groups of learners of English with Czech and Polish as L1. Unlike English, the two languages neutralise the voicing contrast in word-final positions (Jassem & Richter, 1989; Skarnitzl & Šturm, 2016). Although neither language exploits vowel duration as a cue to voicing, they diverge typologically; namely, Czech has a robust phonological contrast between short and long vowels, with pairs typically distinguished solely by duration (in the case of the high vowels, e.g., [ɪ] vs. [iː], the opposition involves both duration and quality; Skarnitzl et al., 2016, pp. 50–53). Polish, by contrast, lacks any phonological encoding of vowel duration (Rojczyk, 2019).
Accordingly, we compared one group of imitators whose L1 (Czech) uses vowel duration to signal phonological contrasts (in vowels) and another group whose L1 (Polish) does not. Given this cross-linguistic difference, we expected to observe better imitative performance by L1 Czech learners of English compared with L1 Polish learners of English, as Czech speakers are already sensitive to vowel duration as a cue to phonological contrasts.
Based on the discussion above, we formulated two main research questions:
In RQ1, by convergence to a cue to the voicing contrast, we do not mean convergence to individual vowel durations in isolation, but rather convergence to the relational duration pattern that distinguishes fortis and lenis codas in English. In this sense, imitation targets the contrastive use of duration (systematic lengthening of vowels before lenis consonants), rather than absolute durational values per se. Accordingly, convergence is not limited to sheer lengthening or shortening of vowels but is reflected in increased separation between fortis and lenis contexts, as captured by normalised vowel ratios. We predict that, following exposure, L2 participants will adjust their vowel durations to more closely match those of the native English model. This adjustment may be observed both globally, as a general shift across experiment stages (overall convergence to the model), and locally, on a word-by-word basis (synchrony with the model for individual lexical items). Czech learners might show greater convergence in vowel duration than Polish learners.
With respect to instruction type (explicit vs. implicit in RQ2), previous findings point to competing expectations. On one hand, research in L1 consistently shows that explicit instructions lead to greater convergence than implicit tasks (Clopper & Dossey, 2020; Dufour & Nguyen, 2013; Garnier et al., 2013; Sato et al., 2013; Schertz, 2025). If similar mechanisms apply in L2, explicit instructions should likewise enhance imitation by directing learners’ attention to relevant phonetic detail and by increasing their motivation to approximate native-like productions. These participants should therefore show greater shifts than those receiving implicit instructions. However, the explicit-instruction benefit seems to be attenuated in L2 (e.g., Zając & Rojczyk, 2014). Explicit imitation requires task-oriented identification of relevant phonetic properties prior to reproduction, yet this process may be compromised in L2 due to (a) the salience hierarchy in L2 may differ from that in L1, (b) phonological category formation in L2 may be incomplete or unstable, and (c) the L1–L2 interference may hinder access to phonetic detail relevant for imitation. Taken together, the existing evidence does not lead to an unequivocal prediction. Although explicit instructions may enhance imitation by increasing attention and motivation, this advantage may be limited in L2 imitation because of difficulty in identifying and prioritising relevant phonetic cues.
4.1 Participants
A total of 56 participants, consisting of 28 Czech individuals (18 female and 10 male) and 28 Polish individuals (22 female and 6 male), took part in the study. The mean ages were 20 for the Czech participants and 19.5 for the Polish participants. They were English department students at Charles University, Prague, and at the University of Silesia in Katowice. Prior to participating, all participants had self-declared their language proficiency level, with three Czechs and six Poles having a minimum proficiency level of B2 (Common European Framework of Reference for Languages [CEFR]), whereas the majority reported proficiency levels ranging from C1 (20 Czechs and 19 Poles) to even C2. The Czech participants received financial compensation for their participation, whereas the Polish participants received partial course credit. Before engaging in the study, all participants were required to complete an informed consent form and a questionnaire that gathered basic background information. None of the participants reported any speech or hearing deficits.
4.2 Procedure
Participants were randomly assigned to one of two instruction conditions: explicit versus implicit imitation. Each language group had half of the participants assigned to each condition.
The experiment consisted of three stages, with a short break between each stage. The entire experiment lasted approximately 12 min. To familiarise participants with the timing and experimental setup, they were initially presented with three training words at the beginning of the experiment. The following three stages occurred in the same order for all participants:
During the experiment, words appeared automatically in the centre of the screen for each task, with display durations varying as described above. In all cases, participants pronounced the target word. The key distinction in Stage 2 was the expectation that the explicit imitation group would converge more closely towards the particular model token than the implicit imitation group. The decision to use a word-identification paradigm was motivated by the aim to increase the functional contrast between explicit and implicit imitation beyond that achieved in earlier repetition-based studies. For example, Zając and Rojczyk (2014, p. 502) operationalised implicit imitation as ‘wait until the recorded voice stops producing the word and then read this word from the screen’. Although imitation was not explicitly requested, the task structure itself may have still promoted imitative behaviour by tacitly signalling that accurate reproduction of the heard stimulus was expected. By contrast, the identification task employed in the present study was designed to mitigate this effect by (a) shifting the participants’ focus away from reproduction and towards perceptual decision-making and (b) increasing the cognitive load, thus reducing the likelihood of expectation-based imitation.
4.3 Stimuli
The set of stimuli used in each stage consisted of 48 words (24 targets and 24 fillers). However, the imitation task in the implicit imitation group included an additional set of displayed distractor words for the word-identification component (e.g., beat was shown on the screen in addition to the target seat). The target words for analysis, featuring a final obstruent in the coda of the monosyllable, are listed in Table 2. The stimuli are grouped into word pairs differing in the phonological voicing status of the final consonant: phonologically voiceless (fortis) on the left, for example, dock, note, versus phonologically voiced (lenis) on the right of each pair, for example, dog, node. The filler items comprised a variety of vowels and final consonants (including sonorants, e.g., tonne and cool) and started with a voiceless plosive. The aim was to provide a range of somewhat different yet similar words and ultimately distract attention from the targeted feature (vowel clipping) by maintaining a task focus on identification rather than phonetic form.
Stimuli Used for Vowel Duration Measurements (24 Words).
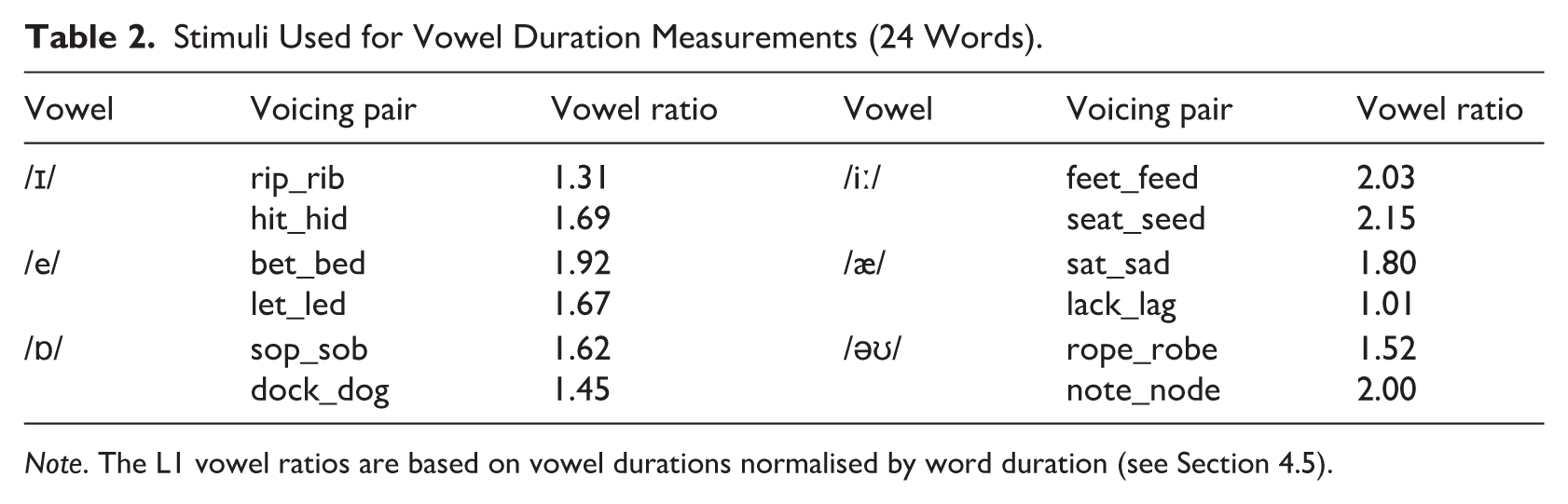
Note. The L1 vowel ratios are based on vowel durations normalised by word duration (see Section 4.5).
The words were read aloud in a randomised list by two male native British English speakers who spoke the standard variety of English. In the experiment, half of the words were spoken by one voice, whereas the other half were spoken by the other voice. To ensure that the baseline condition was suitable for the imitation tasks, we measured the duration of the vowel preceding the final consonant and expressed it as a percentage of word duration to obtain normalised values with respect to variations in tempo to facilitate comparison with the L2 data (cf. Section 4.5). The degree of vowel clipping was expressed as a ratio of the phonologically voiced (lenis) stimulus vowel to the phonologically voiceless (fortis) stimulus vowel, expecting vowel ratios exceeding the value of 1.0 for native speech. The results of these measurements are provided for each word pair in Table 2. Although the vowel ratios varied across pairs, the mean value was 1.68, indicating a robust fortis–lenis contrast (see Figure 1 for specific fortis–lenis differences). The low value in lack_lag can be exploited to see whether the L2 speakers, expected to produce a somewhat higher ratio in this case during the baseline reading, decrease towards the model after exposure, unlike in the other word pairs, where an increase is expected.
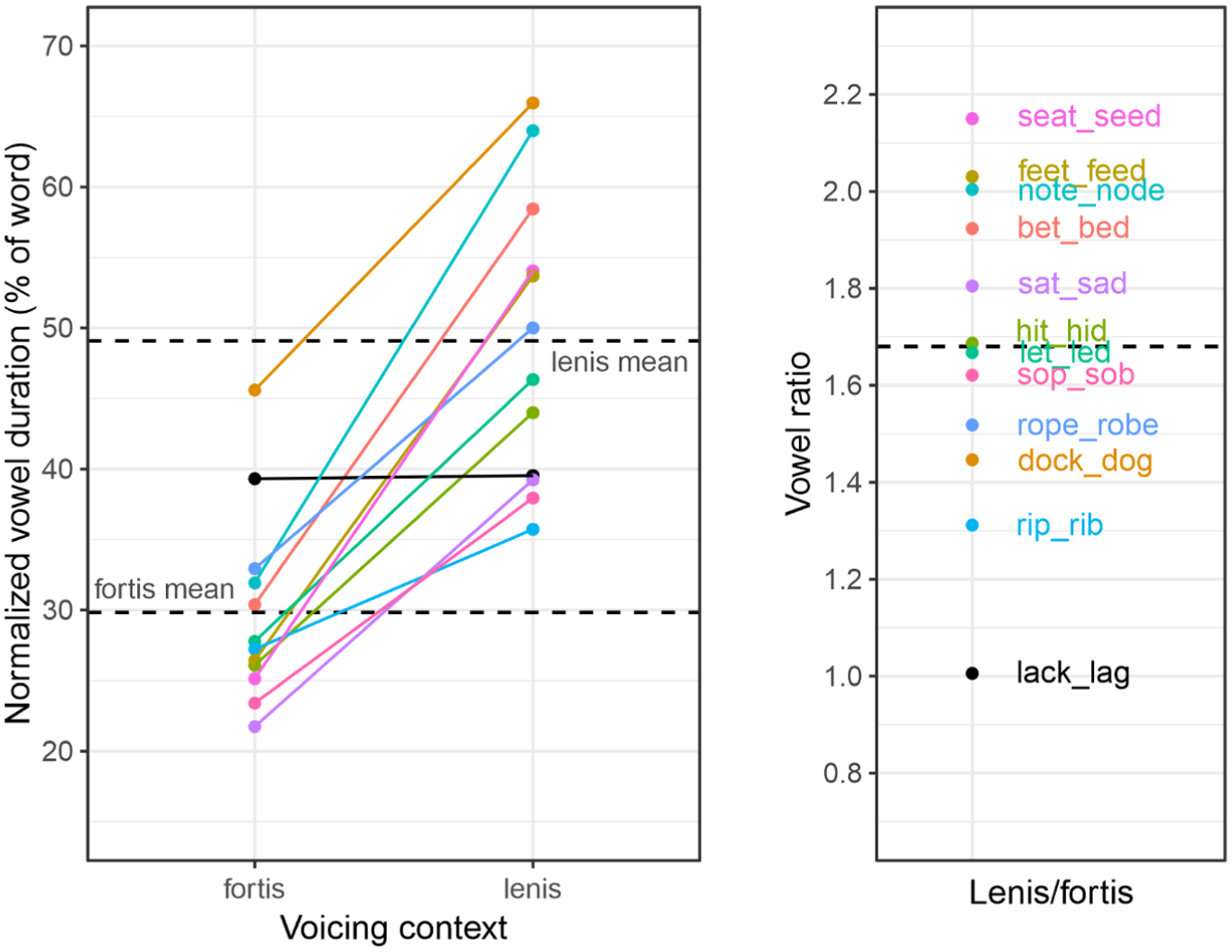
Normalised vowel duration (expressed as a percentage of word duration) before fortis and lenis codas in the 24 target stimuli words. The corresponding lenis/fortis vowel ratios are shown on the right. The dashed lines indicate the mean value for each category (fortis, lenis, and ratio).
4.4 Phonetic Segmentation and Acoustic Measurements
The acoustic parameters (vowel duration and word duration) were measured based on the waveform and spectrographic displays in Praat (Boersma & Weenink, 2022) in combination with the auditory assessment of the recordings. Word boundaries were automatically delineated through forced alignment using the Prague Labeller algorithm (Pollák et al., 2007) and were then manually adjusted, along with target segment intervals, according to standard measurement criteria (e.g., Lisker, 1978; Peterson & Lehiste, 1960). More specifically, vowel duration measurements were taken from the onset to the end of periodicity visible in the waveform, accompanied by a clear formant structure in the spectrogram (Figure 2). In cases where two neighbouring segments lacked a sharp boundary, for instance, between a liquid and the following vowel, the midpoint of a transition period was identified with the aid of both visual cues (formant pattern change) and auditory criteria. Virtually all final plosives were released, as shown in the figure. In the few cases that remained unreleased, the word-final plosive was delineated with a duration typical of the speaker and his or her tempo. A similar procedure was applied to the four words with initial lenis plosives. Their segmentation was straightforward when produced with prevoicing, but when devoiced, the duration of the closure – including the silent part – was set to 60–80 ms, depending on tempo and speaker behaviour in similar cases.
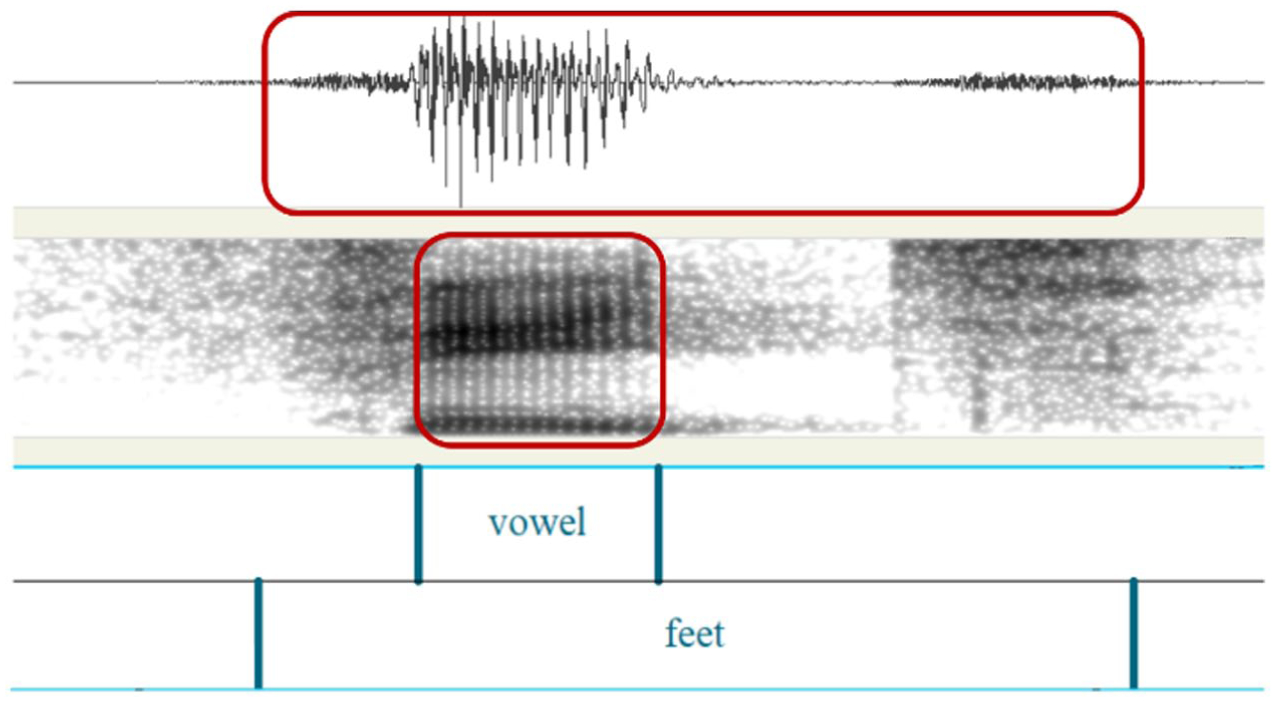
Example segmentation of a target stimulus, together with word boundaries (annotation tiers). Word duration and vowel duration are shown within the boxes on the waveform and spectrogram.
4.5 Data Processing and Normalisation
The data were extracted from the annotated recordings and compiled into a table comprising 4,032 observations (24 target words * 3 stages * 56 speakers). However, due to mispronunciation of seven tokens, only 4,025 observations were ultimately included in the analysis. Outlying values were screened for potential artefacts and corrected, if necessary.
As depicted in Figure 3 on the left, raw vowel duration values displayed strong positive correlations with word duration. To account for these tempo differences, we normalised the raw values by dividing vowel duration by word duration and multiplying the result by 100. Such a procedure ensured that the resulting parameter captured the vocalic proportion relative to word duration (percentage of word duration). Figure 3 on the right confirms that the normalised parameter is indeed much less dependent on word duration.
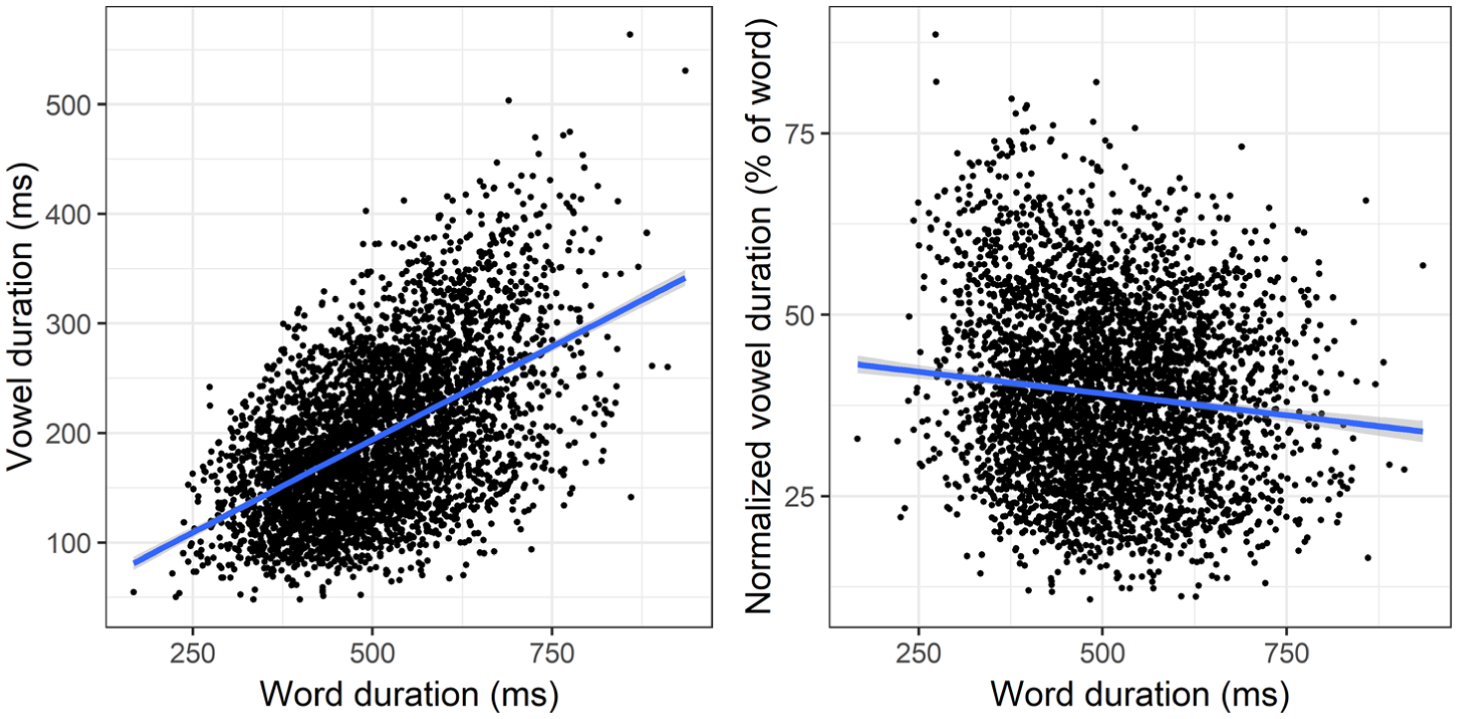
Effect of normalisation on vowel duration (raw values on the left and values normalised for word duration on the right).
Two sets of analyses were performed. In one, normalised vowel duration was analysed directly, comparing fortis and lenis contexts. However, given our focus on the voicing contrast, the dependent variable in the remaining analyses was a ratio of normalised vowel durations, where the lenis token (rib) was divided by the fortis token (rip), yielding a vowel ratio for each word pair. Values greater than 1.0 indicated a voicing contrast cued by duration, 1.0 suggested a lack of contrast, and values less than 1.0 indicated an incorrect contrast (i.e., a contrast in the opposite direction, with vowels before fortis consonants being longer than before lenis consonants).
4.6 Statistical Analysis
Three linear mixed effects (LME) models were constructed to assess the degree of convergence. In Model 1 and Model 2, the participants’ performance was compared across the three stages of the experiment, with the expectation that vowel durations would be adjusted after exposure to the native tokens (i.e., in the direction of the L1 values). Model 1 predicted normalised vowel duration for each word, whereas Model 2 predicted vowel ratios for each lenis/fortis word pair. Given that Czech and Polish speakers neutralise the voicing of final obstruents in their native language in favour of the voiceless member, participants were expected to lengthen the vowels before lenis codas rather than shorten the vowels before fortis codas. The following categorical predictors were used in both models as fixed effects, with treatment coding applied:
Model 3, in contrast, used the linear combination method, which tracks the synchrony between the L1 reference and L2 imitated values on an item-by-item basis (Clopper et al., 2024; Cohen Priva & Sanker, 2019; MacLeod, 2021). Specifically, each production in the imitation or follow-up stage is modelled as a function of the L2 speaker’s own baseline vowel ratio from the initial reading and the L1 speaker’s vowel ratio. Consequently, Model 3 lacked the Baseline level within
By contrast,
The random-effect components in all three models involved
The three LME models were fitted to the data using the lme4 package (Bates et al., 2015) in R (R Core Team, 2023). Model syntax is specified later when introducing the results. The evaluation of a predictor was conducted using likelihood-ratio tests (performed with the mixed() function of afex package; Singmann et al., 2025), comparing the full model to reduced models that lacked the predictor under consideration (the default sum-to-zero contrasts were replaced with treatment contrasts). Effect plots were also constructed with the afex package. LME model summaries are provided in the Appendix. Post hoc pairwise comparisons were performed using the emmeans package (Lenth, 2023), with the Bonferroni correction applied. All graphs were generated using the ggplot2 package (Wickham, 2009).
5 Results
In Section 5.1, we first describe the data before introducing the analyses of vowel durations (Model 1) and vowel ratios (Model 2) that evaluate the effect of instruction type on the degree of convergence (as overall shifts across experiment stages). Section 5.2 then presents data on variability across items and participants, which is important because the statistical models did not allow for including random slopes for
5.1 Durational Shifts Across Experiment Stages and Comparison With L1
5.1.1 General Description of the Data
Table 3 summarises the measures taken from the L1 stimuli and the three L2 stages of the experiment. Vowel durations before fortis codas were shorter in the native tokens than in the L2 baseline productions by a difference of 3% of the word’s duration (corresponding to 15 ms if the word is 500 ms long). Therefore, reductions in duration were expected in the L2 speech after exposure, but this seemed to occur only in the Polish group, especially for S2 (Imitation). In contrast, both language groups produced shorter vowels than the L1 models before lenis codas in the baseline condition: namely, a difference of more than 4% of the word’s duration (> 20 ms in a 500 ms word). Interestingly, the Czech participants seemed to lengthen their vowels during imitation to a larger degree than the Polish participants.
Mean Normalised Vowel Durations (Expressed as % of Word Duration) in Fortis and Lenis Contexts and Their Ratios for the Compared Speaker Groups and Experiment Stages.
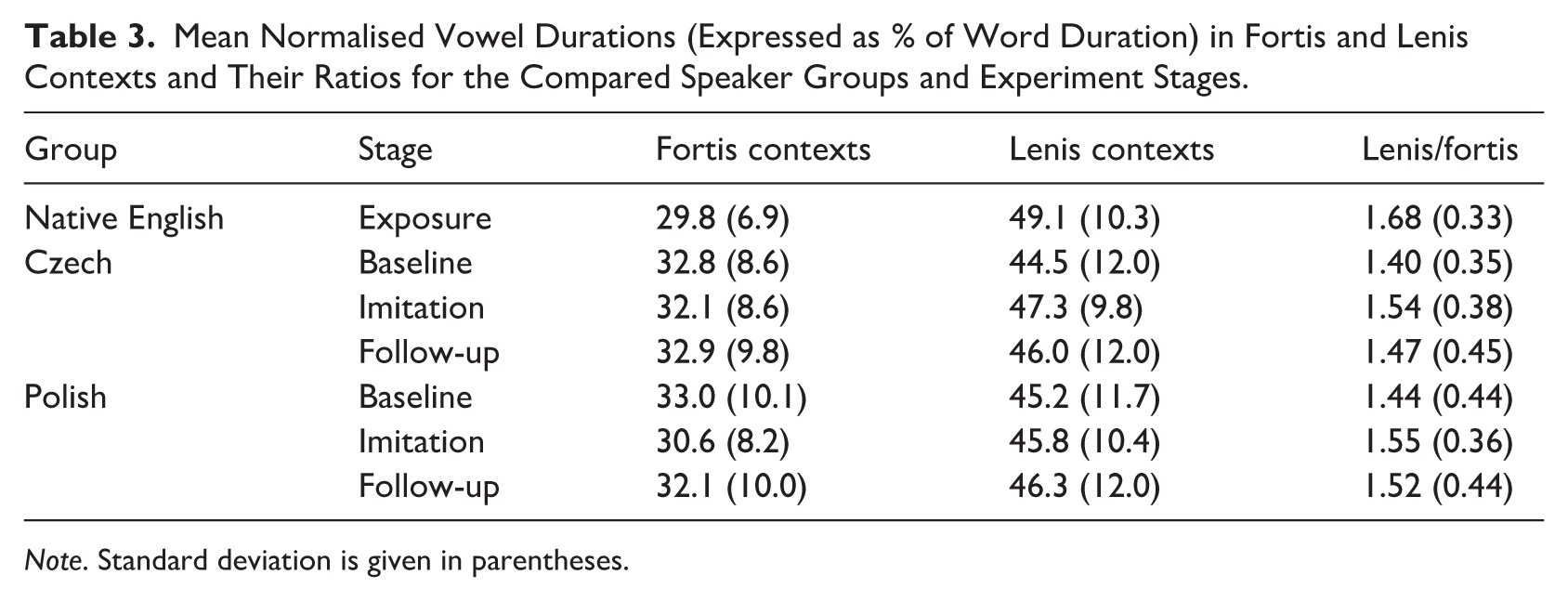
Note. Standard deviation is given in parentheses.
Although the contrast between fortis and lenis obstruents can be made more prominent by increasing vowel duration before lenis codas and/or by decreasing it before fortis codas, the analysis of vowel ratios captures both members of the voicing opposition at once. Table 3 shows that the initial L2 ratios were quite low and increased after exposure for both language groups, mirroring the higher values present in the native English stimuli. The distribution of the L2 ratios is shown in Figure 4, with a clear shift in S2 towards the L1 distribution.
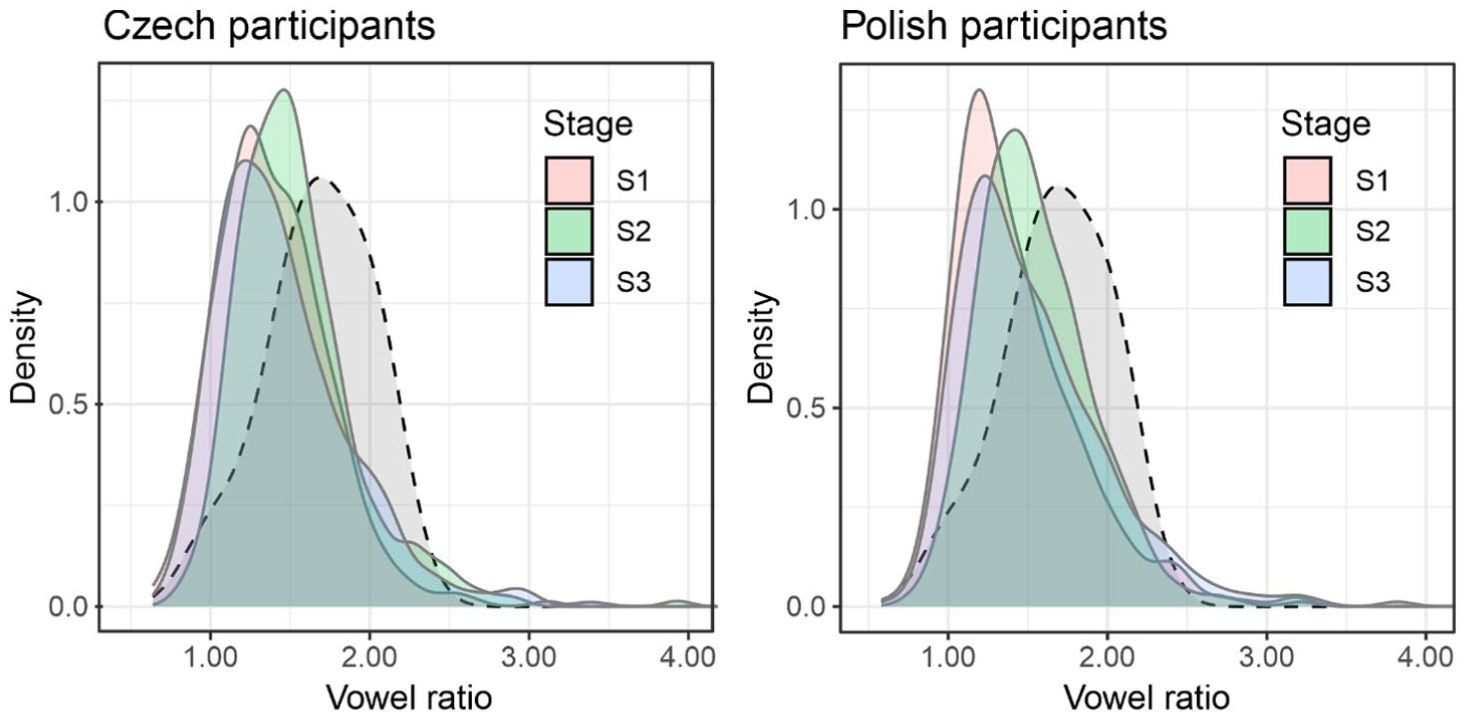
Density plots of normalised lenis/fortis vowel ratios across experiment stages (S1 = Baseline, S2 = Imitation, and S3 = Follow-up). The dashed line indicates the exposure values from the L1 English stimuli.
5.1.2 Model 1
This section introduces the statistical model predicting normalised vowel durations, specified with the following formula: L2 normalised vowel duration ~ Stage * Instructions * Language * Voicing context + (1| Participant) + (1| Word). Convergence is defined as a decrease in prefortis vowel durations (or an increase in prelenis durations) in the Imitation and possibly Follow-up stages. The effect of
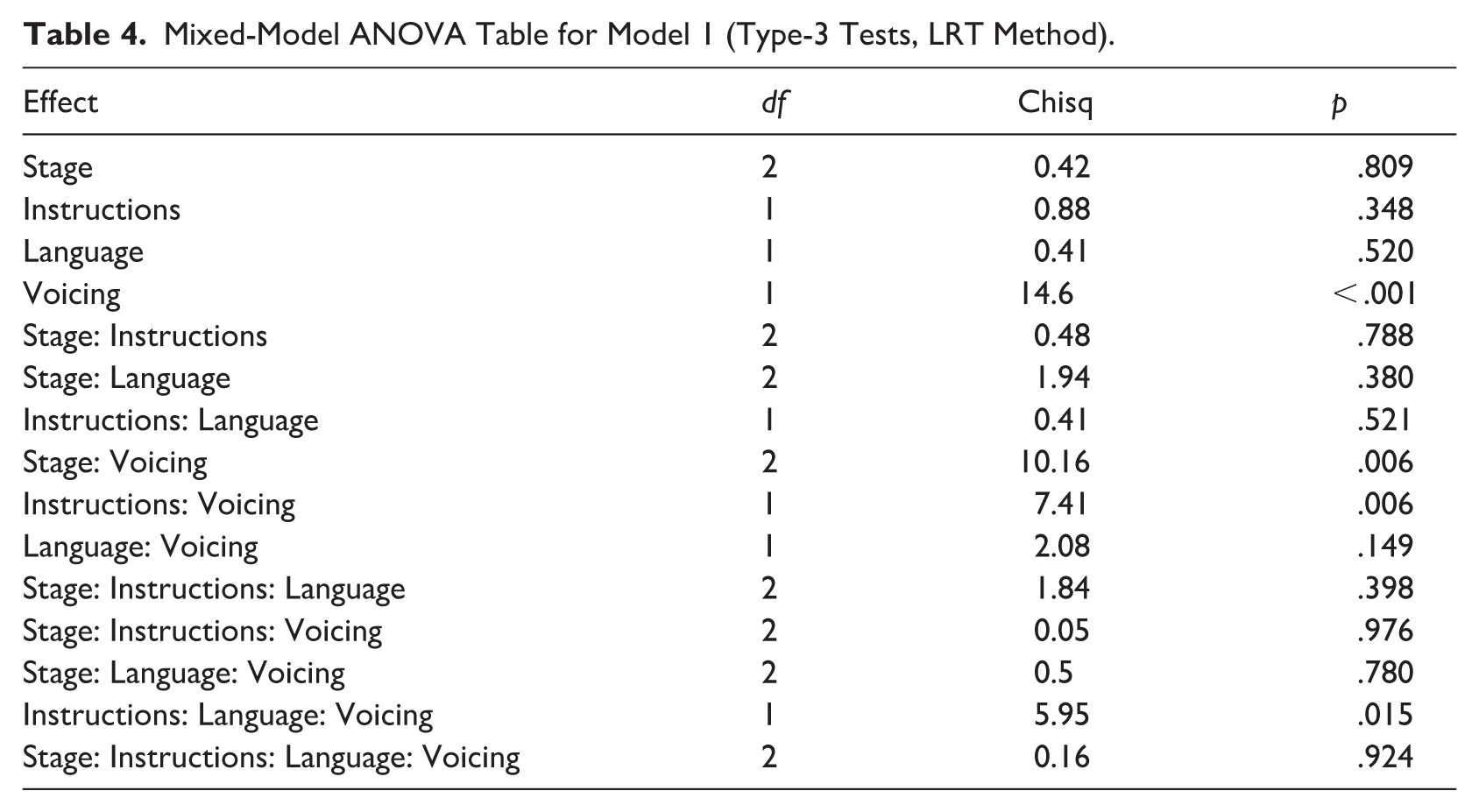
Table 4 summarises the likelihood ratio test (LRT) comparisons of the model with reduced models lacking one of the terms. There was a clear effect of
Mixed-Model ANOVA Table for Model 1 (Type-3 Tests, LRT Method).
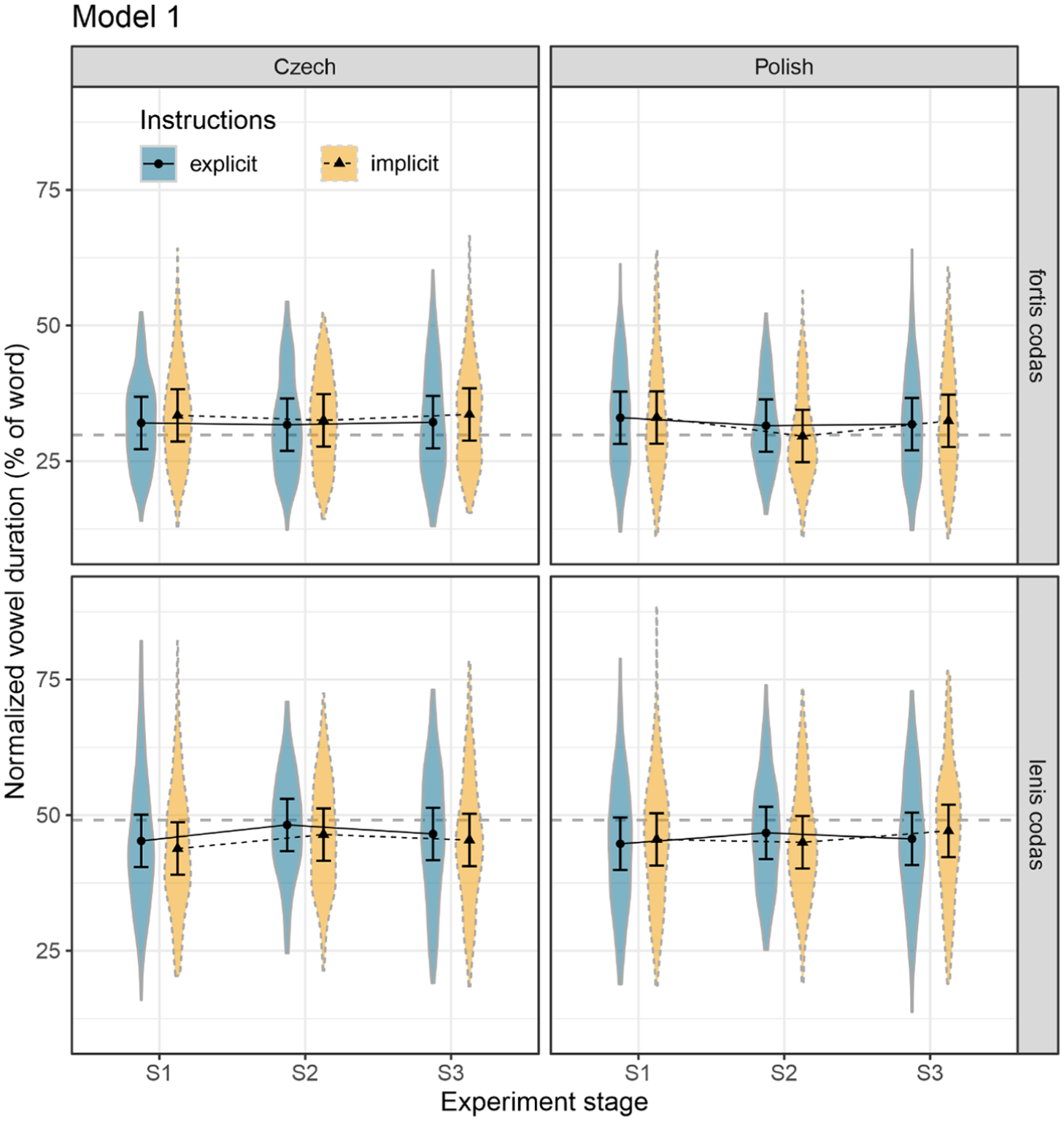
Effect plots of Model 1 predicting vowel durations as a function of
The Tukey post hoc comparisons revealed that vowel durations before fortis codas did not differ across stages for any group (p > .05), with one exception: Polish speakers in the implicit-instruction condition (upper right panel in Figure 5). In this group, vowels were significantly shorter in the Imitation stage compared with the Baseline on one hand (S1–S2 = 3.423, SE = 0.734, df = 3965, t-ratio = 4.7, p < .001) and the Follow-up on the other (S2–S3 = −2.809, SE = 0.734, df = 3965, t-ratio = −3.8, p < .001). The Baseline–Follow-up comparison was not significant (p = 1.0), indicating a return to Baseline values.
In contrast, vowels before lenis codas showed significant stage effects in all groups, although the pattern differed by language and instruction type (lower panels in Figure 5). Under explicit imitation instructions, both Czech and Polish speakers produced significantly longer vowels during imitation (Czech: S1–S2 = −2.932, SE = 0.733, df = 3965, t-ratio = −4.0, p < .001; Polish: S1–S2 = −1.997, SE = 0.732, df = 3965, t-ratio = −2.7, p = .019). In both groups, Follow-up values fell between S1 and S2 and did not differ significantly from either stage (p > .05), indicating that at least part of the exposure effect was retained in S3.
Under implicit imitation instructions, the two language groups diverged. Czech participants again showed increased prelenis durations immediately after exposure (S1–S2 = −2.574, SE = 0.732, df = 3965, t-ratio = −3.5, p = .001), with no significant differences involving S3. Polish speakers, by contrast, did not show a significant change from Baseline to Imitation but increased vowel duration between Imitation and Follow-up (S2–S3 = −2.095, SE = 0.732, df = 3965, t-ratio = −2.9, p = .013). Neither S2 nor S3 differed significantly from S1. Thus, the maximal benefit of exposure appeared immediately for Czech participants but only at Follow-up for Polish participants. It must be stressed, though, that pairwise comparisons of
5.1.3 Model 2
This section introduces the statistical model predicting vowel ratios in lenis/fortis word pairs, specified with the following formula: L2 vowel ratio ~ Stage * Instructions * Language + (1| Participant) + (1| Word pair). Convergence was defined as an increase in vowel ratios in the Imitation and possibly Follow-up stages. The effect of instruction type on the degree of convergence will emerge as a significant interaction between
Table 5 summarises the LRT comparisons of the model with reduced models lacking one of the terms. The analysis identified
Mixed-Model ANOVA Table for Model 2 (Type-3 Tests, LRT Method).

Predictions from the model are shown in Figure 6. Given the absence of significant interactions, we report post hoc tests for
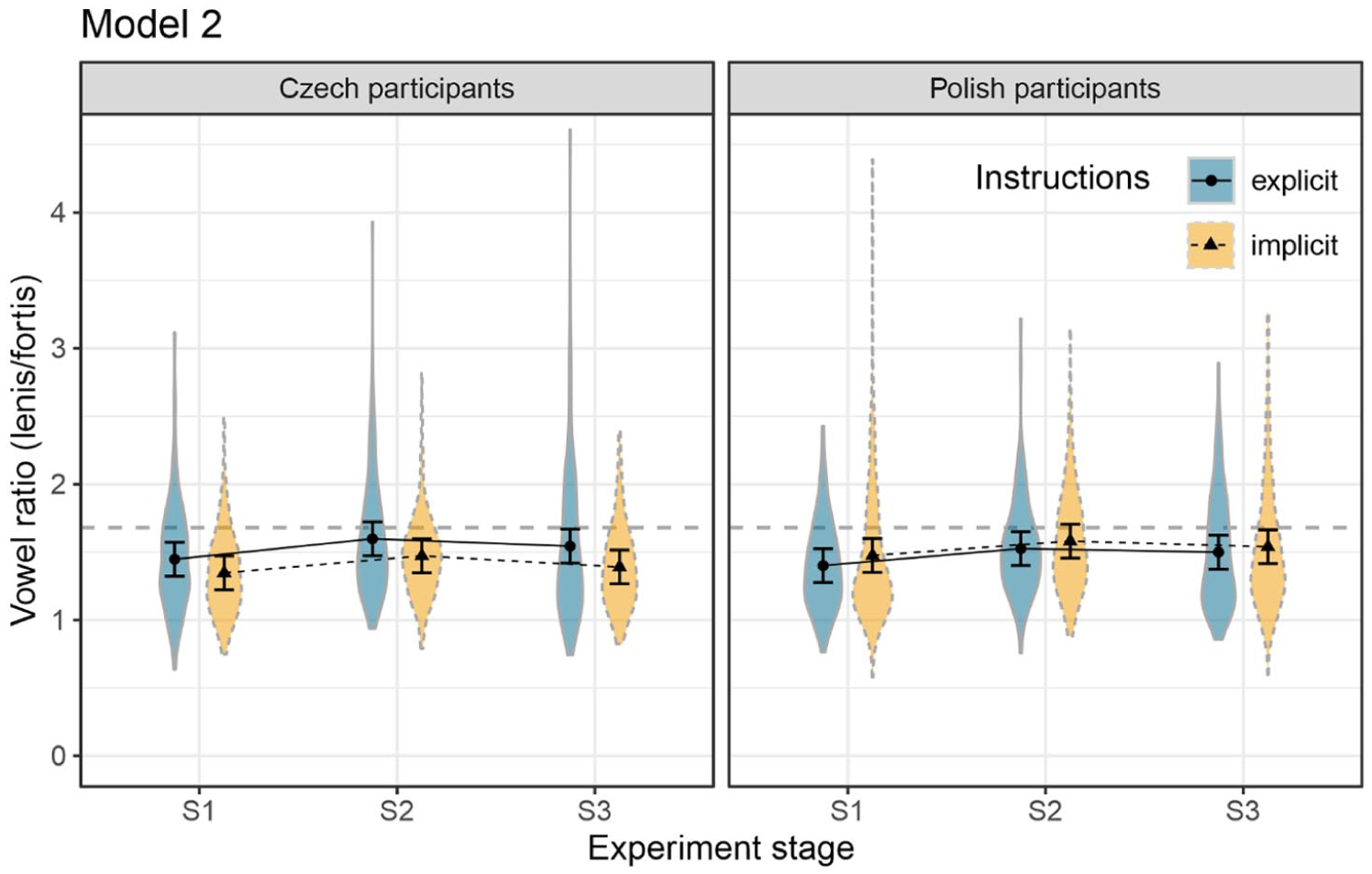
Effect plots of Model 2 predicting lenis/fortis vowel ratios as a function of
5.2 Individual Variation
The convergence effect cannot be considered uniform across participants or items. Because random slopes for
Figure 7 illustrates that although each word pair exhibited different behaviour, vowel ratios consistently shifted towards the L1 speaker values (dashed line). Specifically, L2 vowel ratios increased in S2 (and decreased again in S3) when the L1 model was higher (e.g., note–node and seat–seed), but decreased when the L1 model was lower (in lack–lag and dock–dog). The degree of convergence also tended to be greater when the gap between L1 and L2 speakers was larger. Finally, in cases where instruction type made a difference, Czech participants tended to produce higher ratios under explicit instructions (blue line above yellow), whereas Polish participants showed the opposite pattern (blue line below yellow).
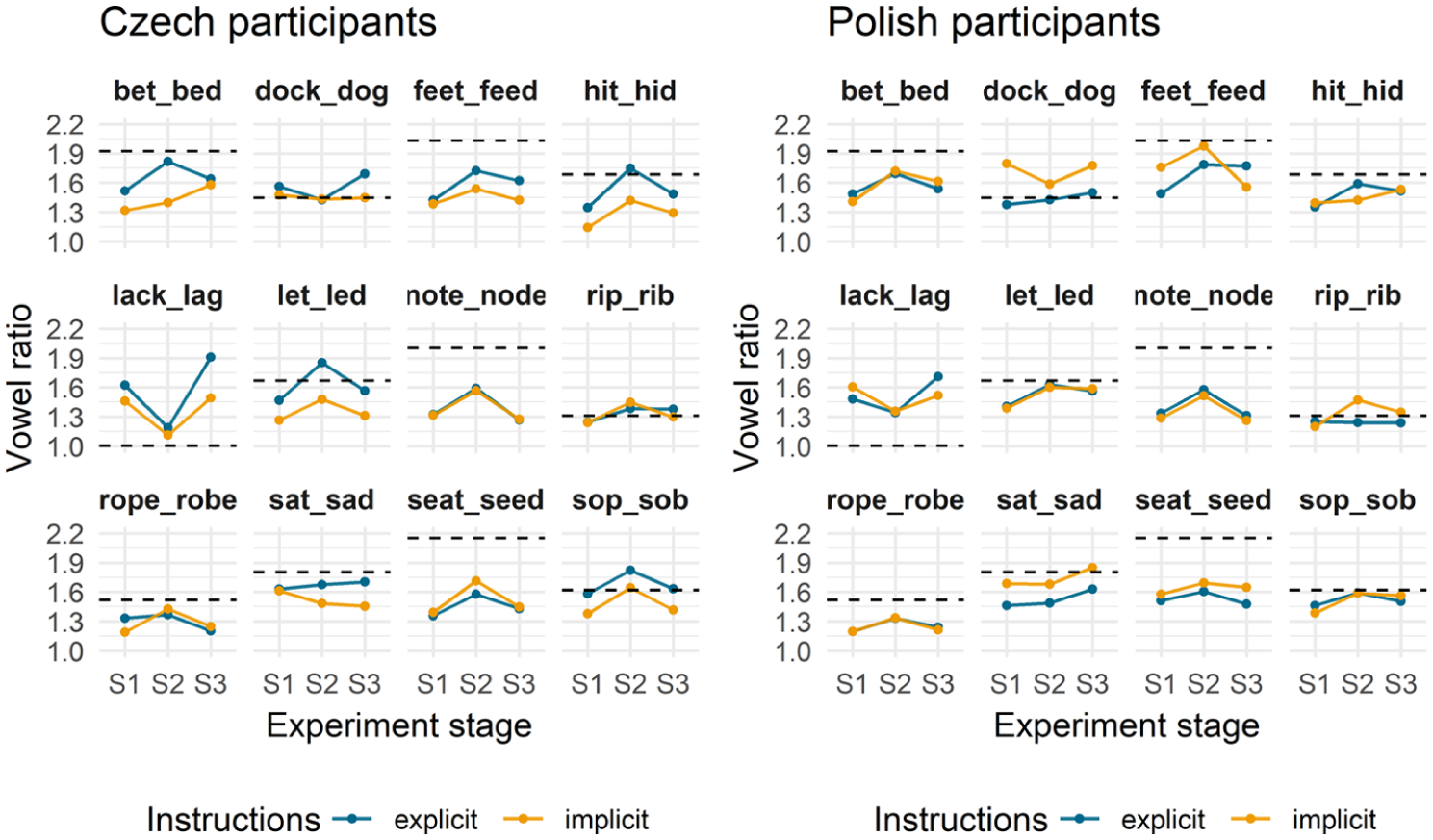
Convergence patterns by
Speaker differences are shown in Figure 8. Participants with mean baseline vowel ratios above the dashed line (representing the mean of the L1 speaker values) generally produced lower values in S2, indicating convergence, with only one exception (this speaker increased the ratios despite already having sufficient contrast in S1). Most participants, however, began with ratios below the reference line and increased their values in S2 towards the higher L1 targets. Although some speakers maintained these increased ratios in S3, others reverted towards their S1 values.
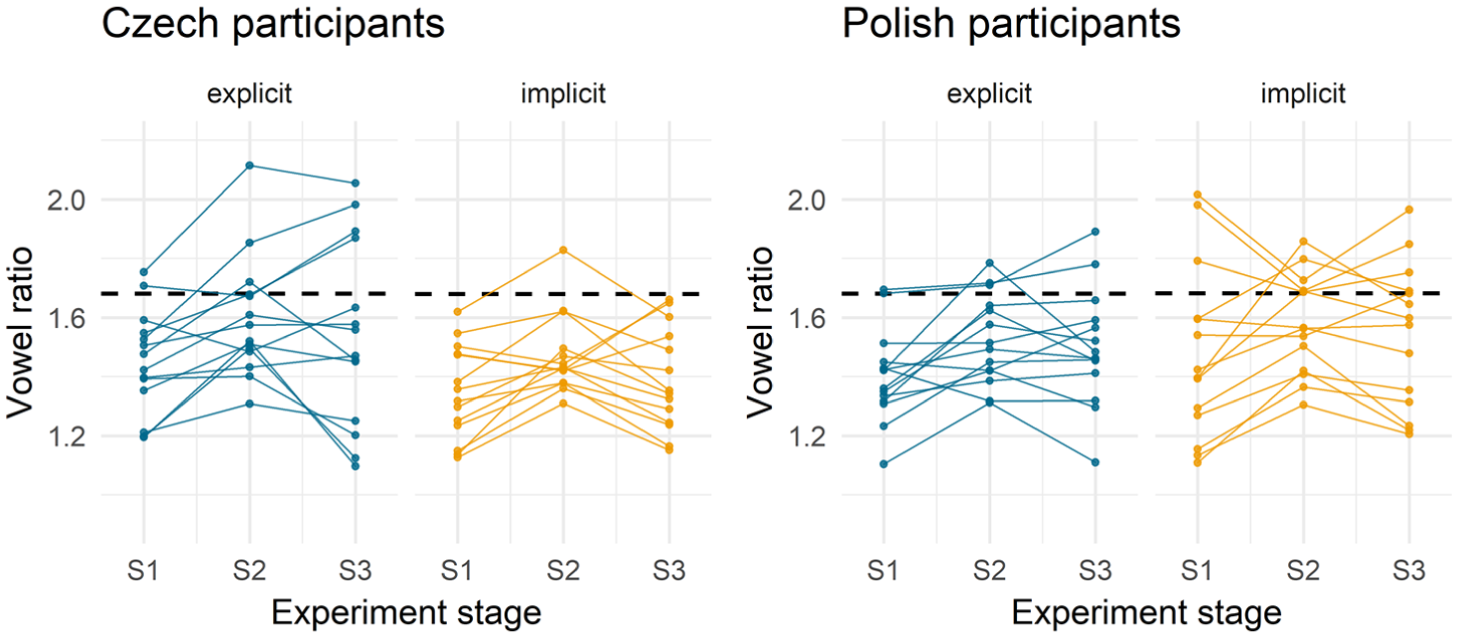
Convergence patterns by
Regarding the experimental conditions, the two language groups showed comparable baselines under explicit imitation instructions, but a different range of values under implicit imitation instructions. Moreover, in the explicit condition, a few individual speakers contributed to a wider range of values in S2 and S3 for Czech participants than for Polish participants.
5.3 A Linear Combination Model: Evaluation of Synchrony
A new approach to modelling conversational interaction data or shadowing data is the linear combination method (see Section 4.6 for details). This model is suited for examining the item-by-item tracking of the L1 stimuli values by participants. Model 3 was specified with the following formula: L2 vowel ratio_z ~ Baseline_z + Model_z * Stage * Instructions * Language + (1 + Model_z| Participant) + (1| Word pair). Unlike previously, the
Table 6 summarises the statistical significance of predictors and interactions using LRT comparisons of the model with reduced models lacking one of the terms (the model summary is provided in the Appendix). The only significant interaction term was
Mixed-Model ANOVA Table for Model 3 (Type-3 Tests, LRT Method).
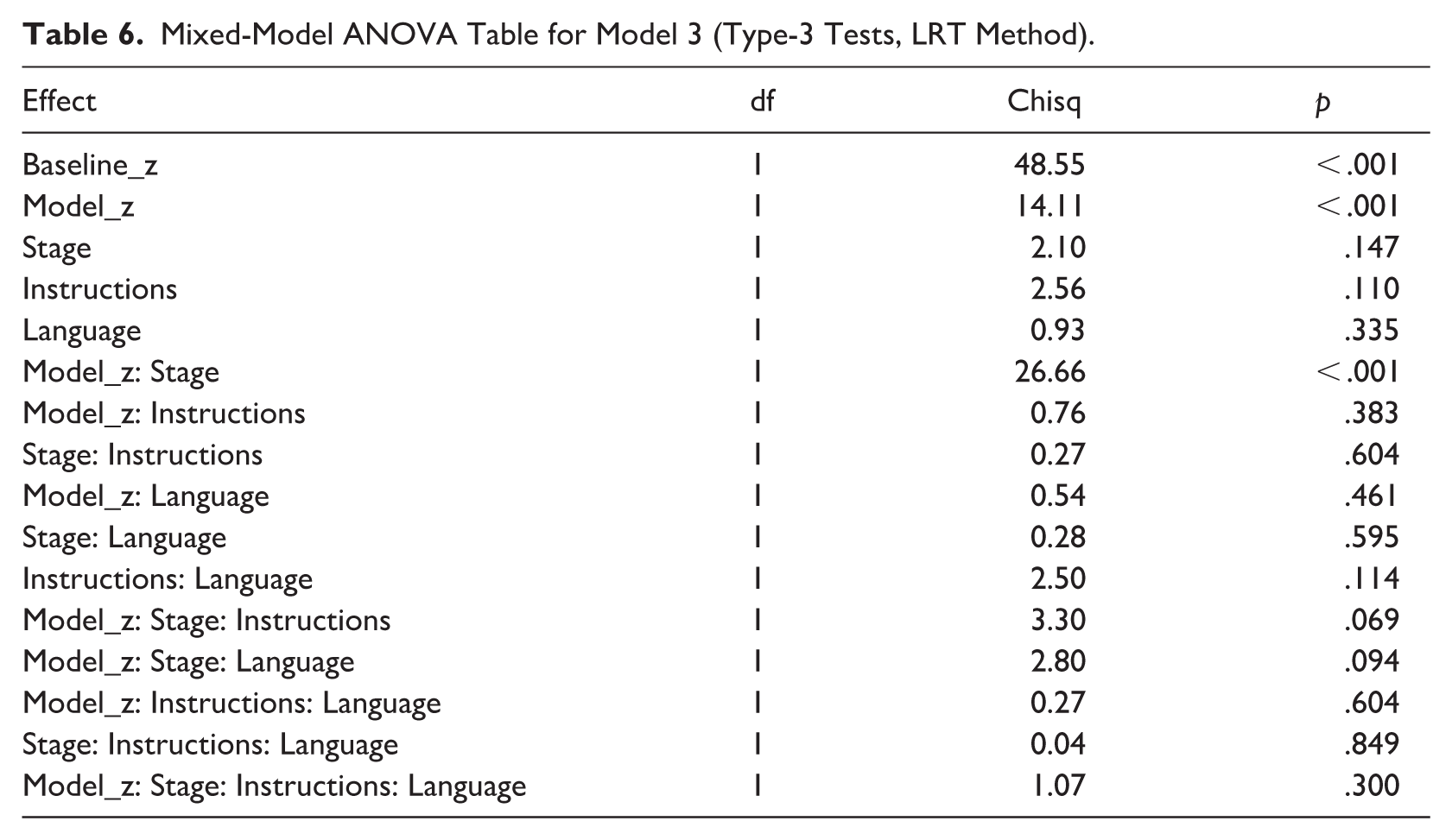
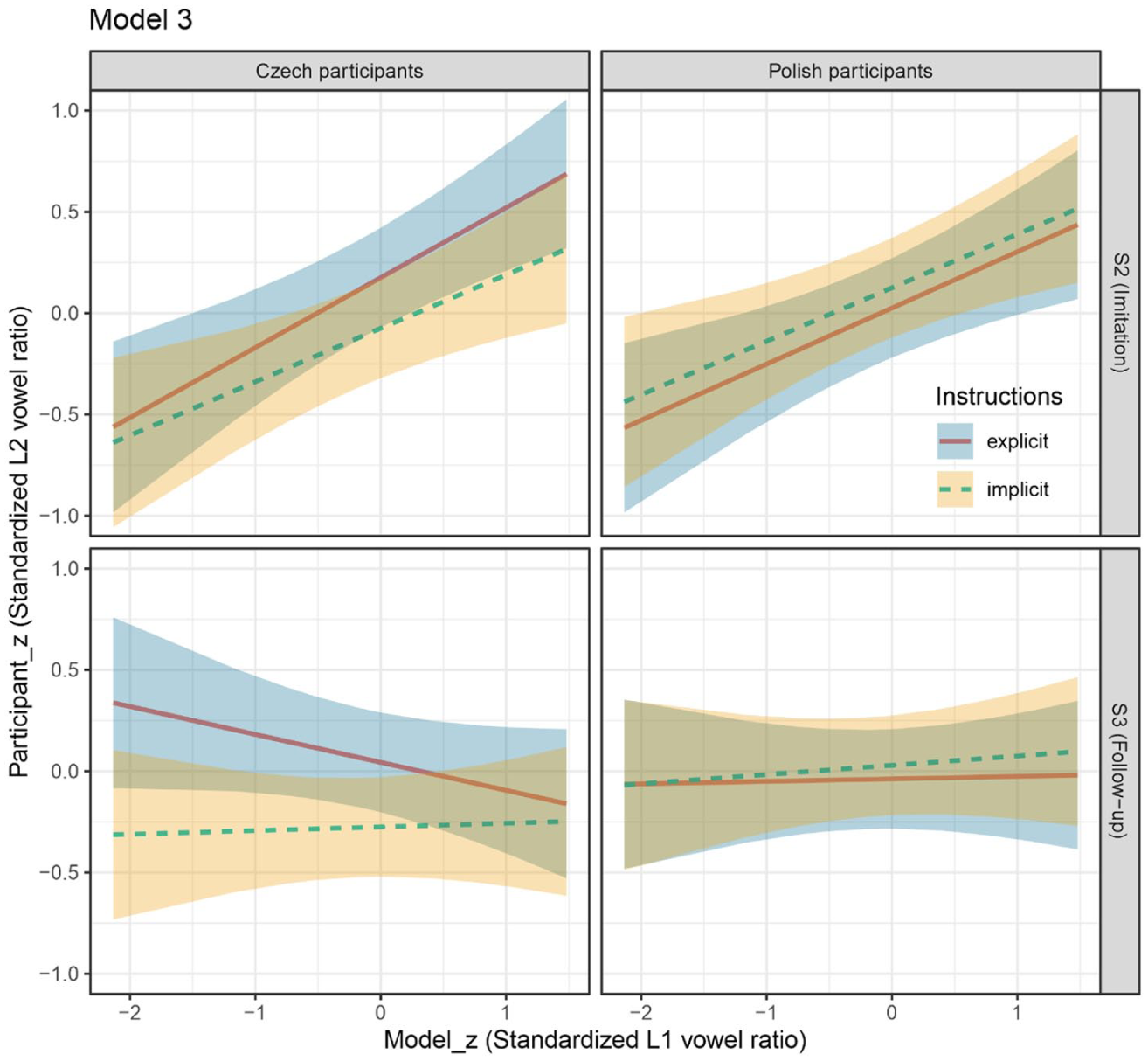
Effect plots from Model 3 (a linear combination model), showing L2 vowel ratios as a function of L1 exposure values, separately for the two imitation conditions and stages, with variables standardised to z-scores. Positive slopes indicate synchrony with the model speaker.
6 Discussion
The experiments in this study focused on how the type of instructions given to second-language learners affects their imitative performance in the target language. Half of our participants imitated native English models explicitly, with a focus on accuracy, whereas the other half did so implicitly, through employing a decoy task (a word-identification task). Both Polish and Czech learners of English were found to converge to the native English models, with comparable degrees of convergence. The type of instructions used in the experiments did not significantly affect the degree of convergence. This has significant consequences for the studies of L2 imitation.
6.1 Imitation of Voicing Contrast Cued by Vowel Duration
As neither Polish nor Czech uses vowel duration as a determining cue to signal the voicing status of the following coda consonant (Jassem & Richter, 1989; Keating, 1985; Sobkowiak, 2008), native speakers of these languages were expected to underappreciate this cue in their baseline English productions (initial word reading in Stage 1). After being exposed to native English speech, which displayed overall greater vowel ratios in lenis/fortis word pairs, the participants were expected to increase their ratios in the imitation stage (Stage 2). Accordingly, both Polish and Czech speakers significantly increased the ratios in this stage, displaying convergent behaviour towards the model values for the voicing contrast concerned. The same finding was observed when issues associated with distance metrics, such as the Starting Distance Bias (Clopper et al., 2024; MacLeod, 2021), were accounted for. The magnitude of the imitative effect was not lasting, however, as the distances increased in the follow-up reading task (Stage 3) relative to Stage 2, with the L2 learners’ ratios falling between those observed in Stage 1 and Stage 2.
The significant baseline-to-imitation improvement in the realisation of the voicing contrast was largely accompanied by the lengthening of vowels in prelenis contexts rather than by shortening them in prefortis contexts. In the latter case, the participants’ vowels were consistently longer than those of the models across the stages, with the exception of Polish speakers under one condition (see below). Conversely, both groups readily converged to the models’ longer vowels preceding lenis codas, particularly in Stage 2 in the explicit condition. One reason for this finding may lie in the initial (baseline) participant-to-model distance, which was, regardless of direction, greater for words with lenis codas than for words with fortis codas. Greater initial distance may positively affect the magnitude of convergence between speakers (Nycz & Mooney, 2017), as a natural consequence of there being a greater gap to be potentially bridged, making the feature of interest possibly more salient to the imitators. The results of some studies support the idea that lengthening of a feature may be somewhat more prone to being imitated than its shortening in specific phonological contexts. For example, Nielsen (2011) found artificially lengthened VOTs – but not shortened ones – to be imitated, due to different phonological consequences for the two directions of VOT adjustments. Similarly, although Schertz et al. (2023) observed both shortening and lengthening of VOT, it was the latter that was more pronounced, as speakers may resist excessive shortening to preserve phonological contrasts.
Previous evidence of phonetic convergence related to the voicing contrast cued by vowel duration by L2 learners has not been conclusive. Zając (2013) observed Polish learners of English to notably modify the contrast only in the case of one word pair (bit-bid) out of four word pairs. The results, however, were somewhat obscured by expressing vowel durations in absolute terms. Analysing absolute durations does not take into account potentially variable speech rates of both the participants and the model speakers, which may render across-the-task comparisons inconclusive. In a similar study by Zając and Rojczyk (2014), Polish learners of English were found to exhibit accurate realisation of the voicing contrast. This, however, was observed in both the baseline task and the imitation task, which made it difficult to determine the extent of convergence to the model speaker. The current study, therefore, provided clarity on the issue by considering vowel duration in relative terms (as lenis/fortis vowel duration ratios); in addition, by accounting for across-the-task changes in speech tempo (vowel normalisation to word duration), as well as by incorporating more up-to-date statistical modelling.
Our results point to the participants’ diminished performance in the realisation of the contrast in the follow-up stage, which mimicked the baseline stage (in both S1 and S3, the participants were asked to read the words). Even though the participants were advanced learners of English, the contrast proved to be an unstable feature in their pronunciation, particularly for the Czech speakers. In Stage 3, once the learners had to rely only on the written representations of the stimuli and on what little auditory traces they retained from Stage 2, they tended to revert to their native (non-English) pronunciation habits, which was especially clear in the analysis of synchrony. This is in line with the results of Paquette-Smith et al. (2022), who exposed Canadian-English participants to lengthened VOTs in both a shadowing task and a delayed-imitation task. While their participants successfully imitated this acoustic parameter during shadowing (immediate imitation), they failed to do so with a delay (but see Nielsen, 2014). The persistence of the imitative effect can also be selective, as was found by Zellou et al. (2013), where English speakers were asked to imitate tokens with acoustically manipulated degrees of vowel nasality, a noncontrastive feature in English. The participants were found to imitate both increased and decreased levels of nasality, but only the latter quality persisted in their productions in the postshadowing task.
The inclusion of two groups of second-language learners, native Polish and native Czech learners of English, was intended to account for potential variability stemming from different linguistic backgrounds, particularly in the way vowel duration is used to signal phonological contrasts. In other words, we aimed to investigate how different L1 backgrounds modulate imitative performance in L2. The fact that Czech uses vowel duration contrastively, while Polish does not, tentatively suggests that the Czech participants might be able to better manipulate vowel duration in English, despite the different phonological nature of the two contrasts. However, the Czech speakers did not ostensibly excel at either their baseline or imitative performance relative to the Polish participants. In other words, the lenis/fortis vowel duration ratios across the three stages were realised comparably in the two language groups, showing that our results are cross-linguistically consistent.
The only discernible difference in the participants’ performance concerned which words – those ending with lenis or fortis consonants – contributed most to the increased lenis/fortis ratios in the imitation stage. The Polish speakers, besides increasing prelenis vowel durations (in the explicit condition only), also shortened the prefortis durations (particularly in the implicit condition), virtually matching the models’ prefortis durations in Stage 2. Conversely, the Czech speakers consistently lengthened their prelenis durations in Stage 2, but they failed to shorten their prefortis durations. It is possible that the native habit of Czech speakers to use intrinsic vowel length differentiation interfered with their realisation of the English contrast (see, e.g., Flege & Bohn, 2021). In particular, the L2 vowels preceding fortis codas may have undergone perceptual assimilation to the established reference ‘short’ vowel duration based on Czech, which would have made them resistant to further shortening. However, the L2 vowels before lenis codas may have been assimilated to a different, ‘long’ category, thus producing longer durations in response to the stimuli. In contrast, Polish speakers, not being constrained by the phonological opposition of short and long vowels in their native language, may have had more freedom in terms of the direction of vowel durational shifts.
6.2 Effect of Task Focus and Instruction Type
Before interpreting the absence of task and instruction effects, it is important to reiterate that the present comparison involves two imitation regimes that differ in task structure as well as in instructional focus, rather than isolating verbal instructions alone. The current experiment investigated how the task focus and type of instructions given to second-language learners in two experimental conditions affect their imitative performance. We hypothesised that the learners who were asked to imitate the native models’ speech as accurately as possible (the explicit imitation condition) would exhibit a greater degree of convergence than those who were supposed to pronounce the words as a way of signalling their choice in a word-identification task (the implicit imitation condition). Contrary to our predictions, both groups of L2 learners imitated the voicing contrast to comparable extents in the explicit and implicit versions of Stage 2. This finding was robust, confirmed in all three statistical models.
Most research on the impact of instruction type on imitative performance in L1 suggests that explicit instructions should elicit a greater degree of phonetic imitation. For example, Dufour and Nguyen (2013) showed that although phonetic convergence occurs even during shadowing without explicit imitation instructions, convergence was significantly greater when participants were explicitly instructed to imitate the model talker’s pronunciation. With regard to imitation in the context of L2 learners, studies have generally provided evidence for imitation without accounting for the explicit–implicit instructional contrast (but see Zając & Rojczyk, 2014, for no effect of instruction). The expectation that explicit instructions should yield a greater degree of convergence is based on the assumption that L2 learners’ motivation to sound more native-like should surface in the context of explicit instructions, where the accuracy of imitation is the target. At the same time, this expectation presupposes that learners are able to identify successfully which phonetic properties are relevant for faithful reproduction, a condition that may not be fully met in L2. Being thus instructed, they might be expected to capitalise on the opportunity to improve their pronunciation skills by attentively following the patterns of native model speakers. In contrast, while some convergence is to be expected in implicit conditions, it should be of lesser magnitude when the learners’ attention is diverted away from imitation goals and redirected to the correct identification of the target words appearing in pairs on the screen. Our results, however, do not provide evidence for this reasoning, and we offer two approaches to explaining this.
The first approach assumes an unexpectedly high degree of convergence in the word-identification task in Stage 2. The implicit nature of the task and its higher cognitive load did little to either impede the learners’ attunement to the auditory dimension of the stimuli or to prevent them from satisfactory reproduction of the voicing contrast of the model speakers. One reason for this may lie in the participants’ potential proclivity for the adaptation to durational aspects of sounds. It is not uncommon for L2 learners to rely excessively on duration when contrasting vowel qualities, as a way of compensating for their lack of sensitivity for quality nuances between their L1 and L2 vowels (Bohn, 1995). At the same time, vowel duration lends itself better to imitation than spectral characteristics, even when participants show greater perceptual weight to the latter (D. Kim & Clayards, 2019). It may thus be speculated that, despite the participants’ attention being diverted, the durational contrast was robust enough for them to successfully replicate it.
Our participants may have been additionally aided in their satisfactory reproduction of the voicing contrast by their implicit knowledge of it, as they manifested a certain degree of the contrast already in the baseline stage. Hearing a stimulus, even without consciously attending to its phonetic features in the implicit condition, may have been sufficient to activate their not fully established representations of the contrastive feature concerned. Another possibility is that, having already been exposed to the written representations of the stimuli in Stage 1, the learners may have considered Stage 2, regardless of its nature, as an opportunity to correct their non-native pronunciation over Stage 1. In this vein, they would be prone to attend to the model speakers’ pronunciation features more than would typically be expected in a word-identification task.
The second approach assumes that the participants’ performance in the explicit version of Stage 2, although significantly better than their baseline performance, did not reflect their full imitative potential, given that the participant-to-model distances were not entirely bridged. This may be linked to the fact that, even though our participants were instructed to imitate the model speakers as accurately as they could, they were not told what particular phonetic or phonological features they should attend to. Schertz et al. (2023: 4) observe that ‘successful explicit imitation requires [. . .] also qualitative decisions about what to pay attention to, because the choice of which features are relevant (identification) will differ based on the imitative goal’. In line with this reasoning, our participants, not having been cued specifically to the voicing contrast, were free to decide what was relevant in the stimuli and what was not. This freedom may have led to the participants’ various degrees of attention being distributed across different speech dimensions, be they phonological or indexical in nature, which may have obscured the true benefit of the explicit instruction provided. This points to the potential importance of considering various degrees of explicitness of the instructions in ascertaining their effect, with and without the participants’ attention being directed towards the specific features of interest.
What may also have limited the participants’ imitative performance in Stage 2, despite being given explicit instructions to imitate, was the potential effect of orthographic input on their pronunciation. Although they were advanced learners of English, for the sake of not imposing additional cognitive load on them, the participants had access to orthographic forms of the stimuli in all three stages. At the same time, as the impact of orthography on pronunciation in the second language seems uncontested (see Hayes-Harb & Barrios, 2021 for a review), our participants, having seen the words in the baseline stage – and, perhaps more importantly, in the imitation stage – may have been affected by the provision of orthographic input. More specifically, the fact of seeing a given word right before listening to it (and imitating it) made it unequivocal what the word was, and it may have activated their preexisting idea of how the word should be pronounced prior to imitation. This idea could be expected to reflect their baseline production of a given word, that is, one that would at least partly exhibit their native (non-English) pronunciation habits. In consequence, with such a preconceived idea established, the incoming acoustic layer of the stimulus of the model speaker may have had a limited effect on how the word would ultimately be produced. We speculate that if the effect of orthography indeed attenuated the performance of our participants, this effect would not be as strong in the implicit condition, where the learners were preoccupied with a word-identification task and not with getting ready to produce accurate speech productions. It may be worthy of investigation how specific types of instruction interact with the presence versus absence of orthographic input in future studies on phonetic imitation among L2 learners.
6.3 Conclusion
The current study contributes to our understanding of phonetic imitation, specifically in the context of second-language speech. Previous research has shown that speakers display a greater degree of phonetic convergence when they are explicitly instructed to imitate other speakers. A similar tendency was expected in the case of second-language learners imitating native speakers of the target language. Our study offers strong evidence regarding the imitation of the temporal voicing parameters by accounting for variable speech rates between L2 learners and the native model speaker, as well as by considering L2 learners from different linguistic backgrounds. In the imitation stage, native Polish and Czech learners of English exhibited comparable degrees of convergence, as evidenced by their increased (and more native-like) vowel duration lenis/fortis ratios, showing their temporary improvement in manipulating duration to cue the voicing status of the following consonant, a characteristic virtually absent in their respective native languages. Contrary to our predictions, however, regardless of whether the participants were asked to imitate the models as accurately as they could (in the explicit condition) or whether they were to say which word they heard in the word-identification task (in the implicit condition), the two conditions were associated with similar degrees of imitative performance.
The most likely reason for the absence of difference across the two conditions lies in the specific speech dimension considered, that is, vowel duration, cueing the voicing status of the following coda consonants. The learners’ general overreliance on durational aspects of speech sounds, or their already acquired – albeit limited – implicit knowledge of the voicing contrast concerned, may have overridden the increased cognitive load imposed in the implicit condition. Alternatively, the explicit condition may not have been explicit enough, by not cueing the participants’ attention to the dimension of interest, which may have prevented the participants from reaching their full imitative potential. It may also be the case that orthography, known to affect pronunciation in L2, may have attenuated their performance in the imitation stage.
Although the study did not find support for the role of instructions in L2 speech imitation, the idea should not be abandoned. Future research may need to consider varying degrees of instructional explicitness – and possibly implicitness – to capture their potentially more intricate effects. For now, our findings suggest that studies of L2 imitation are broadly comparable regardless of the specific nature of the instructions to imitate.
Footnotes
Appendix
Model summaries for the three LME models. In Models 1 and 2, the intercept equals the combination of reference levels (S1 and explicit imitation and Czech participants, and in Model 1, fortis codas). In Model 3, it equals the combination of reference levels (S2 and explicit imitation and Czech participants) by holding Baseline_z and Model_z at 0.
Ethical Considerations
Research approved by the Ethics Committee of the University of Silesia. Certificate of Ethical Acceptability of Research Involving Humans KEUS297/10.2022. Project title: How is phonetic imitation conditioned by instructions? Explicit versus implicit imitation.
Consent to Participate
The collected informed consent was written.
Author Contributions
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: Research supported by the National Science Centre, Poland, grant Phonetic imitation in a native and non-native language (UMO-2019/35/B/HS2/02767) to the first author and by the funds granted under the Research Excellence Initiative of the University of Silesia in Katowice. The work was supported by the European Regional Development Fund-Project ‘Creativity and Adaptability as Conditions of the Success of Europe in an Interrelated World’ (No. CZ.02.1.01/0.0/0.0/16_019/0000734).
Declaration of Conflicting Interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Data Availability Statement
Supplemental Material
Supplemental material for this article is available online.