
Abstract
This study investigates how word-initial /l/ and /n/ are phonetically realized in Mandarin Chinese as produced by speakers from three regions: Beijing (close to Standard Mandarin), Changsha (where Xiang, which contains /l/ but not /n/, is also spoken locally), and Meizhou (where Hakka, which contains both /l/ and /n/, is also spoken locally), focusing on acoustic cue use and phonological context effects. Using acoustic analysis and random forest classification, we analyzed five acoustic measures (F2–F1 spacing, F3 frequency, BW1, ΔA1, and A1–P0) and evaluated their contribution to distinguishing the two sounds. Results showed that speakers from different regions used distinct cue weighting strategies: Beijing Mandarin speakers relied more on spectral cues, Meizhou Mandarin speakers showed greater reliance on nasality-related cues, and Changsha Mandarin speakers combined both, with greater variability. Phonological context, including preceding nasals and following vowels, further modulated cue realization in region-specific ways. These findings demonstrate how native phonological background and phonological environment shape the phonetic implementation of a shared Mandarin contrast and illustrate the value of combining acoustic and classification-based approaches for modeling gradient phonetic variation.
1. Introduction
Phonological representations shape how speech sounds are realized in speech production and phonetic variation reflects the interaction between these representations and production mechanisms (Best & Tyler, 2007; J. E. Flege, 1995). In bilingual speech production, phonetic realization is influenced not only by the phonological system of the language (or dialect) being spoken but also by the phonological representations speakers bring from their native language (or dialect) (Amengual, 2024; J. E. Flege, 1995; Nagle et al., 2026). As a result, phonetic variation often reflects systematic influence from native-language phonological structure rather than articulatory difficulty alone (Amengual, 2024; Best & Tyler, 2007; Kogan & Tavares, 2024).
This study investigates how Mandarin word-initial /l/ and /n/ are produced by bilingual speakers whose native phonological systems differ in whether the /l–n/ contrast is phonemic, with a focus on how native-language phonological structure influences the realization of this contrast in Mandarin speech. This question is examined using Mandarin productions from speakers originating in Beijing, Changsha, and Meizhou.
Changsha Mandarin is spoken in a region where the local Chinese language, Xiang, contains only /l/. In contrast, Meizhou Mandarin is spoken in a region where Hakka Chinese maintains both /l/ and /n/ as phonemes. Speakers from Changsha and Meizhou typically acquire Mandarin as a second language through formal education and sustained daily use, and their Mandarin production often reflects features influenced by their native phonological systems (Chu et al., 2024; W. Zeng & Shea, 2025). Beijing Mandarin serves as a reference for comparison, as Mandarin spoken in this region closely aligns with Standard Mandarin and preserves the /l–n/ contrast (Duanmu, 2007; Norman, 1988).
Prior research has shown that native-language phonological structure shapes bilingual speech production (Best & Tyler, 2007; J. E. Flege, 1995; Scarborough, 2004). The present study extends this work by examining how the Mandarin /l–n/ contrast is implemented acoustically by bilingual speakers whose native languages differ in the phonemic status of this contrast. This sociolinguistic context provides a basis for examining how phonetic contrasts are preserved, reduced, or modified in the speech of bilinguals (Chang, 2012; Evans & Iverson, 2007). In particular, we tested how the /l–n/ contrast in Mandarin is shaped by the phonological structure of the native language and whether this effect varies across phonological environments. This study is informed by theoretical questions concerning cue integration, coarticulation, and the relationship between phonetic realization and phonological contrast. Our analysis focuses on the acoustic properties of /l/ and /n/ in Mandarin produced by speakers from different linguistic backgrounds. We examine how contrast maintenance is affected by native phonology and phonological context.
1.1. Native-Language Phonological Structure and Bilingual Speech Production
Research on bilingual and cross-language speech production has long demonstrated that phonetic realization in one language is shaped by the phonological structure of another language known to the speaker (Best & Tyler, 2007; J. M. Flege & Bohn, 2021). Such influence is not restricted to late second-language acquisition but is also observed in speakers who acquire multiple languages early and use them routinely within a shared sociolinguistic environment (Fowler et al., 2008), as in the case of Mandarin speakers from Changsha and Meizhou. As noted above, speakers from Changsha and Meizhou acquire Mandarin early through formal education, attain high functional proficiency, and use it routinely across communicative domains, while also maintaining a local language acquired in the home. Consequently, phonetic variation in their Mandarin speech is unlikely to reflect incomplete acquisition (Chang, 2012), given the early age of acquisition and sustained use of Mandarin, and is more plausibly interpreted as reflecting long-term interaction between phonological systems (Amengual, 2024).
Fowler et al. (2008) provide production evidence illustrating how phonetic realization can shift across languages when phonological contrasts are preserved. In their study of French–English bilinguals, voice onset time (VOT) values in each language were systematically shifted relative to monolingual norms: bilingual speakers produced French stops with longer VOTs than monolingual French speakers, and English stops with shorter VOTs than monolingual English speakers. At the same time, bilinguals reliably maintained distinct VOT distributions for English and French within speakers, rather than converging on a single intermediate category. Fowler et al. (2008) interpret this pattern as evidence that bilingual speech production reflects cross-language interaction at the level of phonetic realization by preserving phonological contrast. This distinction between contrast maintenance and phonetic implementation provides a useful framework for understanding patterns of cross-language phonetic influence (Best & Tyler, 2007; J. E. Flege, 1995).
More recent syntheses of the previous studies of early bilingualism elaborate this distinction. As reviewed by Amengual (2024), early bilinguals generally preserve language-specific phonological contrasts, but their productions often differ from monolingual norms in fine-grained phonetic detail, including the temporal and spectral properties used to realize those contrasts. From a sound change modeling perspective, Johnson and Babel (2024) argue that phonetic variation in cross-linguistically linked categories is shaped by the distribution of phonetic variability within each language and that such effects can arise even when the relevant categories remain contrastive in the target language. On this view, cross-linguistic influence reflects how language-specific patterns of variability and constraint modulate phonetic implementation in another language, without entailing category merger or loss of contrast.
The present study builds on this work by exploiting a comparison that has received little direct attention: Mandarin production as an acquired language variety across bilingual contexts that differ in whether the home language provides phonemic support for a target-language contrast. Specifically, speakers from Changsha and Meizhou differ in whether their native language encodes a phonemic contrast between /l/ and /n/. This design allows us to compare two routes to producing the same Mandarin contrast: implementation of a contrast that lacks phonemic support in the native inventory (Changsha/Xiang) versus implementation of a contrast that is already phonemically represented (Meizhou/Hakka). This comparison makes it possible to ask not only whether the Mandarin /l–n/ contrast is preserved, but whether its acoustic implementation converges on a Beijing Mandarin baseline or retains systematic influence from native phonological structure.
Evidence from earlier work suggests that even when contrasts are preserved, phonetic implementation may remain sensitive to a speaker’s broader phonological experience. Evidence from earlier work further suggests that early bilingualism does not entail uniform phonetic convergence with monolingual norms. Mack (1989), for example, examined English perception and production in early English–French bilinguals who acquired both languages before age eight and were English-dominant. While the bilingual speakers were monolingual-like in several respects, including discrimination and production of English /d–t/ and aspects of /l/ production, they also showed reliable differences from monolinguals in identification performance and in specific aspects of vowel and lateral production. Mack’s findings indicate that early bilinguals can achieve monolingual-like performance in one language for some components of the phonetic system by still exhibiting selective phonetic differences attributable to bilingual experience. In other words, preservation does not entail uniformity in phonetic realization, and early bilingual speech can reflect stable cross-language interaction even in the absence of overt merger or incomplete acquisition.
Together, this literature motivates an implementation-focused analysis of the Mandarin /l–n/ contrast in speakers from Beijing, Changsha, and MZ. By holding the target language and contrast constant when varying native phonological support, the present study isolates how differences in phonemic inventory shape the phonetic realization of a shared contrast in bilingual speech, including differences in how multiple acoustic cues are weighted and integrated in production.
1.2. /l/ and /n/ in Chinese Dialects
Across Chinese dialects, the phonological contrast and phonetic realization of /l/ and /n/ vary considerably (Cheng et al., 2022; Li et al., 2012; T. Zeng, 2020). These differences reflect both structural properties of segment inventories and the influence of coarticulatory patterns and language contact (Cheng et al., 2022; Recasens & Espinosa, 2007). In Northern varieties, such as Beijing Mandarin, the /l–n/ contrast is phonemically stable and acoustically well-maintained (Duanmu, 2007). In contrast, many Central and Southern dialects either merge these segments or preserve only one of them. For example, Xiang, spoken in Changsha, lacks /n/ in its consonant inventory and contains only /l/ (Ye, 2011; S. Zhou, 2005). Hakka, spoken in Meizhou, maintains both phonemes (Y. Chen & Wang, 2016) and is therefore expected to show more consistent preservation of the /l–n/ contrast in Mandarin production.
However, the presence of a phonemic contrast does not necessarily guarantee consistent phonetic realization. In Xiang, the phoneme /l/ shows considerable variation depending on the following vowel. S. Zhou (2013) reported that /l/ can surface as [n] (thus neutralizing /l/ and /n/), [ȵ], or [l̃] before high front vowels such as /i/ and /y/, particularly among older speakers. In other vowel contexts, /l/ tends to be realized canonically. This context-dependent variation likely arises from articulatory constraints. High front vowels require a raised tongue body and reduced oral space, which interferes with the lateral airflow necessary for producing /l/ (Recasens & Espinosa, 2007). As a result, the tongue-tip gesture may be weakened, causing the segment to shift toward nasal-like realizations. These articulatory tendencies are also reflected in acoustic patterns: high front vowels reduce the separation of formants such as F2 and F3 (Ladefoged & Johnson, 2015), increasing the spectral similarity between /l/ and /n/. This variation also appears to be influenced by age. Older speakers in Changsha are more likely to produce nasal-like variants of /l/, whereas younger speakers, possibly under greater influence from Standard Mandarin norms, more consistently produce canonical /l/ (S. Zhou, 2013). This age-based pattern may reflect dialectal change or differing degrees of exposure to Mandarin.
Findings from recent acoustic studies show that the phonological inventory alone does not predict phonetic outcomes. Cheng et al. (2022) examined how /l/ and /n/ are distinguished in Mandarin and Fuzhou Min Chinese to assess whether the contrast remains functional across dialects. Their findings showed that the two sounds were clearly differentiated in Mandarin but not in Fuzhou Min, where they appeared largely indistinct. This pattern suggested that the contrast between /l/ and /n/ may be undergoing merger or has already been lost in Fuzhou Min. Analysis also revealed low classification accuracy for the Fuzhou Min data, supporting the interpretation that speakers no longer reliably distinguish the two consonants in production. These findings highlight the importance of combining acoustic and statistical modeling to understand how phonetic contrasts may erode across dialects.
This pattern also has implications for Hakka. Although Hakka speakers in Meizhou maintain both /l/ and /n/ (Y. Chen & Wang, 2016), they are located near Min-speaking regions, where some dialects show reduced contrast or possible mergers between these segments (Cheng et al., 2022). Regional contact with such varieties may influence the phonetic strategies adopted by Hakka–Mandarin bilinguals, especially in contexts where Mandarin is acquired alongside or after a local variety. Therefore, even when the contrast is phonemically retained in Hakka, its phonetic realization in Mandarin may reflect broader regional norms and contact-driven patterns of acoustic cue integration.
As Mandarin is the standard language used in education and public life in China, speakers from all regions are expected to acquire it (Dreyer, 2003; M. Zhou & Sun, 2004). However, their Mandarin often reflects regional variations shaped by the phonological structure of their native language (W. Zeng & Shea, 2025). In this study, we examine the production of word-initial /l/ and /n/ in Mandarin spoken by speakers born in Beijing, Changsha, and Meizhou. Given the presence or absence of the /l–n/ contrast in their native languages (Lee & Zee, 2003; Ye, 2011; S. Zhou, 2013), we expect their Mandarin productions to differ in the degree of contrast preservation, particularly in phonological contexts that condition articulatory variation (Recasens & Espinosa, 2007; Schertz et al., 2015).
1.3. Acoustic Features of /l/ and /n/
Despite extensive research on the acoustic properties of /l/ and /n/ across languages, there is no consensus on which acoustic features consistently distinguish them (Barry, 2000; Cheng et al., 2022; Li et al., 2012). For example, studies report conflicting findings on duration: some find that syllable-initial /n/ tends to be longer than /l/ (Toft, 2002), whereas others show the reverse (Barry, 2000; Umeda, 1977). The duration of the consonant–vowel (CV) transition has also been found to be a relevant cue. In American English, /l/ typically exhibits a longer CV transition than /n/ (O’Connor et al., 1957). In the spectral domain, syllable-initial /l/ differs from /n/ due to lateral airflow, which results in distinct patterns of acoustic energy distribution (Dalston, 1975; Wayland, 2018).
In Chinese languages, the acoustic realization of word-initial /l/ and /n/ has received comparatively little attention. Much early work relied on impressionistic observations, but more recent studies have begun to use acoustic measurements to quantify these contrasts. For instance, Li et al. (2012) analyzed temporal and spectral cues in Nanjing Chinese and found that duration, F2, and F3 frequency helped distinguish /l/ and /n/. Cheng et al. (2022) compared the same segments in Mandarin and Fuzhou Min using six acoustic parameters including F2–F1 spacing, F3 frequency, the relative root mean square (RMS) amplitude, the change in amplitude of F1 (∆A1), the bandwidth of F1 (BW1), and the amplitude difference between the strongest harmonic in the F1 region and the stronger of the first or second harmonic (A1–P0). These features reliably distinguished /l/ and /n/ in Mandarin but not in Fuzhou Min, suggesting possible neutralization of the contrast in that variety.
The present study draws on findings from research on cue weighting, which has gained increasing attention in phonetics as a framework for understanding how speakers and listeners use acoustic cues to realize and perceive phonological contrasts. Cue weighting refers to how different acoustic dimensions are prioritized during speech perception and production, and this prioritization is shaped by language background, phonological structure, and cognitive factors (Clayards et al., 2008; Kong & Edwards, 2016; Schertz et al., 2015). For example, Clayards et al. (2008) showed that cue use adapts to variability in the input signal, whereas Kong and Edwards (2016) linked cue weighting to executive function in children. Schertz et al. (2015) demonstrated that individuals with different language learning experiences, such as bilinguals or second-language speakers, often weight acoustic cues differently from monolingual speakers.
Given that Mandarin is acquired across regions with different native phonological systems, the way speakers weight acoustic cues may differ based on their linguistic experience (Francis et al., 2008; Kong & Edwards, 2016; Schertz et al., 2015). Acoustic dimensions such as F2–F1 spacing, F3 frequency, and nasal-related amplitude measures may not contribute equally to the /l–n/ distinction across speakers (Cheng et al., 2022; Li et al., 2012). In regions where the /l–n/ contrast is absent or unstable, such as in many Xiang varieties, speakers may show reduced differentiation or rely on less typical cues when producing Mandarin (Y. Chen & Wang, 2016; Ye, 2011; S. Zhou, 2005). Conversely, in regions where the contrast is robust in both the local language and Mandarin, such as in Hakka-speaking areas like Meizhou, speakers may maintain clearer phonetic distinctions (Cheng et al., 2022; Feng, 2014). Cue integration strategies are therefore shaped not only by acoustic salience but also by phonological structure and the distribution of categories in a speaker’s native language (Escudero & Boersma, 2004; Francis et al., 2008). This study tests whether speakers from Beijing, Changsha, and Meizhou differ in how they prioritize acoustic cues in distinguishing /l/ and /n/ in Mandarin, reflecting the influence of their phonological backgrounds.
Random forest classification has been increasingly used in phonetic research to identify predictors of sound variation, particularly when multiple cues are involved (Dormann et al., 2013; Matsuki et al., 2016; Strobl et al., 2008), as is the case in the present study. For example, Villarreal et al. (2020) used random forest models to classify variants of nonprevocalic /r/ and medial /t/ based on a large set of acoustic features, and Strycharczuk et al. (2020) used the same method to detect dialect leveling in northern England. Tang et al. (2023) applied deep learning to assess lenition patterns in Argentinian Spanish using posterior probabilities of phonological features. These techniques can reveal which acoustic features most contribute to contrast realization, providing complementary evidence about the weight and variability of cues in speech.
1.4. The Current Study
This study investigated the phonetic variation of word-initial /l/ and /n/ in three regional varieties of Mandarin: Beijing, Changsha, and Meizhou. To examine these differences, we analyzed five acoustic measurements: F2–F1 spacing, F3 frequency, BW1, ∆A1, and A1–P0. These features have been shown in prior work to be informative for distinguishing lateral and nasal sounds in Mandarin and other languages (Cheng et al., 2022; Li et al., 2012; Wayland, 2018). They reflect both formant and spectral properties that capture differences in tongue positioning, nasal coupling, and energy distribution associated with /l/ and /n/. We also considered three phonological factors known to condition consonant realization: the preceding segment (S. Zhou, 2013), the following vowel (Y. Chen & Wang, 2016), and the presence or absence of a nasal coda (Cheng et al., 2022).
We addressed two main research questions. First, how do speakers of Beijing, Meizhou, and Changsha Mandarin phonetically realize the //l/–n/ contrast in word-initial position, and how do the acoustic cues used to distinguish these sounds vary by region? These questions target both the degree and pattern of phonetic differentiation across varieties. We analyze the five acoustic measures to evaluate how each cue contributes to distinguishing /l/ from /n/ in each group. Following prior work on dialect influence and cue weighting shaped by language experience (Clayards et al., 2008; Kong & Edwards, 2016; Schertz et al., 2015), we expected the clearest separation in Beijing Mandarin, with weaker differentiation in Meizhou and especially in Changsha Mandarin. Second, how do phonological factors affect the realization of these consonants across speaker groups? We expected /l/ to be more context-sensitive than /n/, particularly in Changsha Mandarin, where high front vowels and nasal codas have been shown to condition greater articulatory variability (Cheng et al., 2022; S. Zhou, 2013).
To address these questions, we used linear mixed-effects regression models to evaluate the effects of regional and phonological variables and random forest classification to assess cue importance and classification accuracy across groups. These methods allowed us to explore both between-group variation and the contributions of individual acoustic cues to phonetic contrast (Strycharczuk et al., 2020; Tang et al., 2023; Villarreal et al., 2020).
2. Method
2.1. Corpus
The corpus used in this study is a subset of the free Chinese Mandarin speech corpus provided by Beijing DataTang Technology Co., Ltd. The complete corpus comprises 200 hr of mobile recordings produced by 600 Chinese speakers from various dialectal regions in China. These recordings were conducted in a quiet indoor environment, and the transcription accuracy for each sentence was over 98%. The transcriptions were performed by trained native Mandarin speakers. For this study, we selected only recordings from speakers born in Beijing (BJ) City, Changsha (CS) City, and Meizhou (MZ) City.
2.2. Speakers
In the selected recordings, there were 46 Chinese speakers (23 males and 23 females) born in Beijing City, aged between 19 and 29 years old [M = 22.36 ± 2.24]. In addition, 37 speakers from Changsha City [M: 19; F: 18; Age: 20–25 years old, M = 20.55 ± 1.21] and 19 speakers from Meizhou City [M: 10; F: 9; Age: 20–25 years old, M = 23.42 ± 1.68] were also selected for the study.
To ensure that the selected speakers were representative of Beijing, Changsha, and Meizhou Mandarin, we applied strict inclusion criteria. Only participants who were born and raised in their respective cities and who reported Mandarin as their dominant language were included. To minimize potential variation introduced by exposure to other dialects, we excluded individuals who had lived outside their home city for an extended period before the age of 18. In addition, all participants had completed formal education primarily in Mandarin, ensuring consistency in their language use and phonetic exposure.
2.3. Tokens
For this study, we selected a total of 6,309 word tokens with word-initial /l/ and /n/ in BJ Mandarin, 5,053 in CS Mandarin, and 2,546 in MZ Mandarin (see sample words in Table 1). Table 2 specifies the number of word tokens based on various conditions, including word-initial consonant (/l/ vs. /n/), preceding segment (nasal vs. vowel), following vowel /i/ vs. other vowels), and coda (nasal vs. no coda), respectively. Due to the syllabic structure of Mandarin, the preceding segment could be either a nasal or a vowel in the preceding word, and the coda could be a nasal or absent in the same syllable as the word-initial consonants. As no word tokens used in the study were found with the following vowel [y], we grouped the following vowels as /i/ or other vowels (i.e., non-/i/).
Sample Word List.
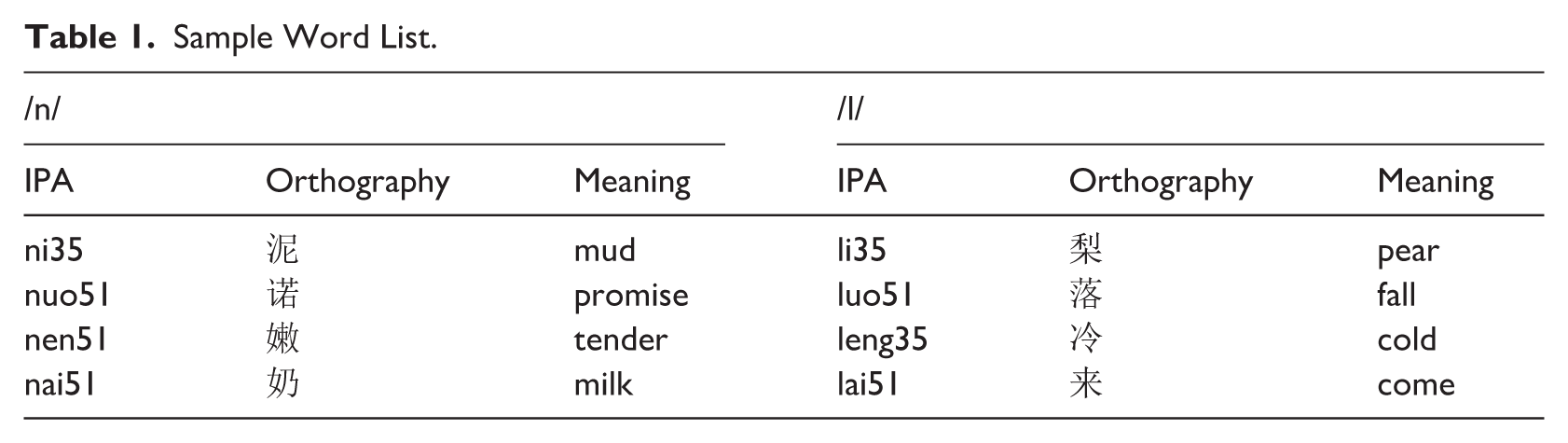
The Distribution of Word Tokens by Conditions.
Note. The three numbers from left to right represent BJ, CS, and MZ, respectively.
To ensure the dataset was well balanced across different phonetic environments, we carefully controlled the distribution of lexical items. The word list was designed to contain an equal representation of high-frequency and low-frequency words with word-initial /l/ and /n/ to capture a broad range of speech contexts. In addition, tokens were evenly distributed across different following vowel conditions and coda structures. The number of repetitions per token was also balanced across speakers to minimize the effect of individual variation in pronunciation.
2.4. Acoustic Measurements
To extract acoustic measurements of the word tokens, the study used the Montreal Forced Aligner (version 2.0) to automatically align the textgrids to the acoustic signals at the phone level with a customized phonemic pronunciation dictionary (McAuliffe et al., 2017). After the automatic alignment, the authors inspected the aligned annotations of the word tokens with the target sounds /l/ and /n/, and slightly adjusted the annotation boundaries based on the formant transition between the word-initial consonant and its following vowel. Specifically, the onset of each target word was marked at the beginning of the word-initial consonant, and the offset was determined based on the onset of the F1 transition into the following vowel (Cheng et al., 2022). Based on the findings of Cheng et al. (2022) and Li et al. (2012), five acoustic measurements, including F2–F1 spacing, F3, ∆A1, BW1, and A1–P0, were extracted using a customized Praat script (Styler, 2017).
The F2–F1 spacing, which refers to the difference in frequency between F2 and F1, and the F3 frequency were extracted at the midpoint of the word-initial /l/ and /n/. In addition, the BW1 of the vowel following /l/ or /n/ is also extracted at the 25% position of the vowel. The ∆A1 was computed as the amplitude difference between F1 at the midpoint of the consonant and at 25% into the following vowel. However, A1–P0 indicates the difference in amplitude between the strongest harmonic in the F1 region and the greater of the first two harmonics (Styler, 2017) and is commonly used as a measure of nasalization (M. Y. Chen, 1995, 1997).
2.5. Statistical Analysis
We performed linear mixed-effects regression models to examine how phonetic variation in word-initial /l/ and /n/ was influenced by regional and phonological factors. Each of the five acoustic measurements was modeled separately, with the measured values as dependent variables. The fixed effects in each model included word-initial consonant (/l/ vs. /n/; reference = /l/), birth city (Beijing, Changsha, and Meizhou; reference = Beijing), preceding segment (nasal vs. vowel; reference = nasal), following vowel (/i/ vs. other vowels; reference = /i/), and coda (nasal vs. no coda; reference = nasal), along with all two- and three-way interactions between word-initial consonant, birth city, and the phonological factors. Random intercepts by speaker and word were included to control for variability across individuals and lexical items. We used this intercepts-only structure to ensure model stability and convergence, consistent with recommendations to adopt parsimonious random-effects structures when the data do not support more complex alternatives (Matuschek et al., 2017). Categorical predictors were dummy-coded.
The linear mixed-effects models were fitted using the lmer function from the lme4 package in R (Bates et al., 2015; R Core Team, 2025). The syntax for the model formula was as follows:
acoustic measurements ~ word-initial consonant * birth city * (preceding segment + following vowel + coda) + (1 | speaker) + (1 | word)
Post hoc comparisons of interaction terms were conducted using the emmeans package, with p adjusted using the Holm correction method (Lenth & Piaskowski, 2017). The Holm method was selected because it controls the familywise error rate while maintaining greater statistical power.
2.6. Random Forest Classifiers
To investigate the acoustic distinction between the word-initial /l/ and /n/ in the three regional varieties of Mandarin, we developed a random forest classifier for each regional variety of Mandarin. The classifiers were trained to perform binary classification for /l/ and /n/ tokens. To accomplish this, data of tokens containing the word-initial /l/ and /n/ were divided into separate training and test sets for each regional variety of Mandarin. The training set, which comprised 75% of the total data, was utilized to train the random forest classifier, whereas the test set, which constituted 25% of the total data, was employed to assess the classification performance of the classifier. The distribution of /l/ and /n/ tokens in the training and test sets for each regional variety of Mandarin is presented in Table 3. Although there is a class imbalance between /l/ and /n/ tokens in the training and test sets, additional resampling was performed in tuning the parameters of the classifiers to reduce its effect on the classifier’s performance (Villarreal et al., 2020). Specifically, we compared three resampling methods: no resampling, downsampling of the majority class, and Synthetic Minority Oversampling Technique (SMOTE). The SMOTE was selected based on its superior classification performance across all three regional varieties of Mandarin.
The Distribution of Word Tokens in the Training and Test Set.
To determine the classifiers that exhibit the most effective classification performance, a series of steps involving the tuning of hyperparameters was taken. These steps included additional resampling, determining the method of generating training/test subsets, selecting the number of variables tested at each node, specifying the node splitting rule, defining the minimum node size, and determining the number of trees used in training the classifiers. These procedures were carried out following the methodology outlined by Villarreal et al. (2020). To assess the performance of the classifiers, we employed the area under the ROC curve (AUC) multiplied by overall accuracy as the performance metric, following the methodology utilized by Villarreal et al. (2020). In addition, we reported overall accuracy and AUC as supplementary metrics to further evaluate the classifiers’ performance. Overall accuracy represents the ratio of correctly predicted observations to the total number of observations in the dataset, whereas AUC measures the model’s ability to distinguish between positive and negative classes. In this study, the reference labels used for evaluation were based on the target phonemes specified in the reading script, as all speech was produced by speakers reading aloud predetermined sentences. Although prior research (e.g., S. Zhou, 2013) has reported an ongoing /l–n/ merger in CS Mandarin, the classifier was trained and evaluated using these intended phoneme labels. As such, the performance metrics should be interpreted in light of this labeling criterion. The same acoustic measurements and phonological factors used in the regression analysis were employed as predictive variables during the training of the classifiers. The classifiers were trained using the ranger and caret packages in R (Kuhn, 2008; R Core Team, 2025; Wright & Ziegler, 2017).
Random forest classification was selected for its ability to capture nonlinear relationships between multiple acoustic cues, making it particularly well-suited for analyzing complex phonetic variation (Strycharczuk et al., 2020; Villarreal et al., 2020). Hyperparameter tuning was conducted to optimize classifier performance, reducing potential biases that could affect feature importance rankings (Probst et al., 2019). The classifier’s performance was evaluated using multiple metrics, including area under the receiver operating characteristic curve (AUC), overall accuracy, and variable importance scores. Variable importance scores were computed using an impurity-based measure from the random forest classifier (Biau & Scornet, 2015). The models used the extratrees split rule, which selects split points at random rather than based on optimal thresholds, introducing greater variability among trees and often improving generalization (Geurts et al., 2006). The importance scores reflect how much each variable reduces classification uncertainty across the forest, with higher scores indicating a greater contribution to accurate prediction (Liu & Zhao, 2017). Given that machine learning models provide statistical classification rather than phonetic perceptual validation, future research should compare classifier predictions with listener perception data to assess whether the acoustic features identified as significant correspond to those used in human speech processing (Villarreal et al., 2020; Voppel et al., 2023).
3. Results
3.1. Acoustic Measurements
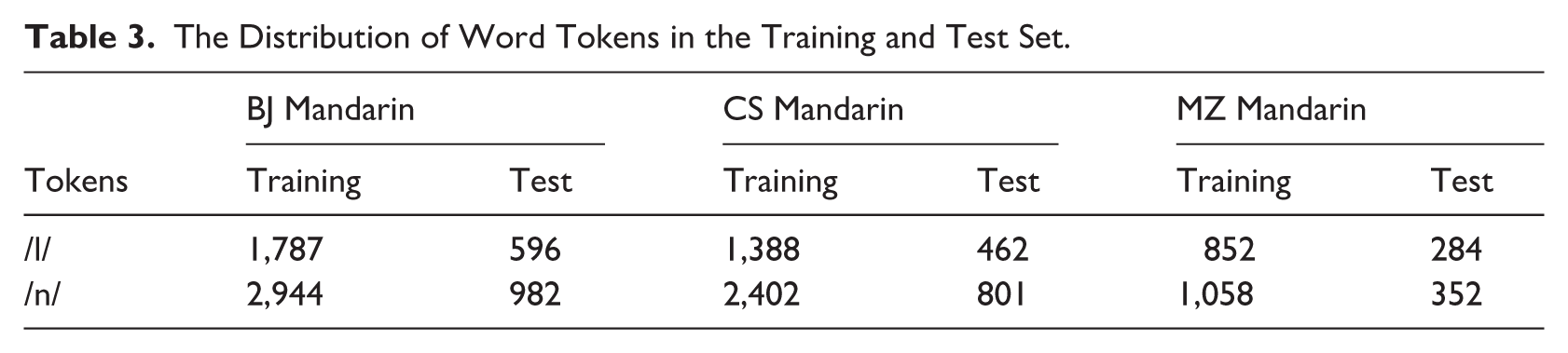
Table 4 summarizes the mean and standard deviation of the measured values of the acoustic measurements in BJ, CS, and MZ Mandarin.
Statistical Summary of the Acoustic Measurement of the Word-Initial Consonant [l] and [n] in the Three Regional Varieties of Mandarin.
Note. M = mean; SD = standard deviation.
3.1.1. F2–F1 Spacing
In BJ Mandarin, /l/ had significantly greater F2–F1 spacing than /n/, t(5546) = 2.01, p < .05. In CS Mandarin, this difference was even more pronounced, t(4297) = 6.77, p < .001. No significant difference was observed in MZ Mandarin.
Table A1 in the Appendix summarizes the fixed effect estimates of the linear mixed-effects models on F2–F1 spacing. The model revealed a significant main effect of the following vowel, F(1, 34.7) = 9.915, p < .01. Beyond these main effects, the model revealed several interaction effects indicating context- and region-specific modulation of the consonantal contrast. Significant interactions were found between word-initial consonant and birth city, F(2, 13,797.3) = 17.621, p < .001, word-initial consonant and preceding segment, F(1, 13,752.8) = 10.953, p < .001, and word-initial consonant and following vowel, F(1, 34.6) = 13.220, p < .001. Additional interactions were found between birth city and preceding segment, F(2, 13,776.6) = 3.000, p < .05, and a three-way interaction among word-initial consonant, birth city, and preceding segment, F(2, 13,784.6) = 3.308, p < .05, were significant.
For the interaction between word-initial consonant and birth city (see Figure 1A), F2–F1 spacing for /n/ was significantly lower in CS Mandarin than in BJ Mandarin (β = −129.68, SE = 41.70, z = −3.11, p < .05). Within CS Mandarin, F2–F1 spacing for /l/ was significantly higher than for /n/ (β = 152.82, SE = 50.80, z = 3.01, p = .037). For the interaction between word-initial consonant and preceding segment (see Figure 1B), /n/ had significantly lower F2–F1 spacing following a nasal than a vowel (β = −35.90, SE = 10.50, z = −3.42, p < .05).
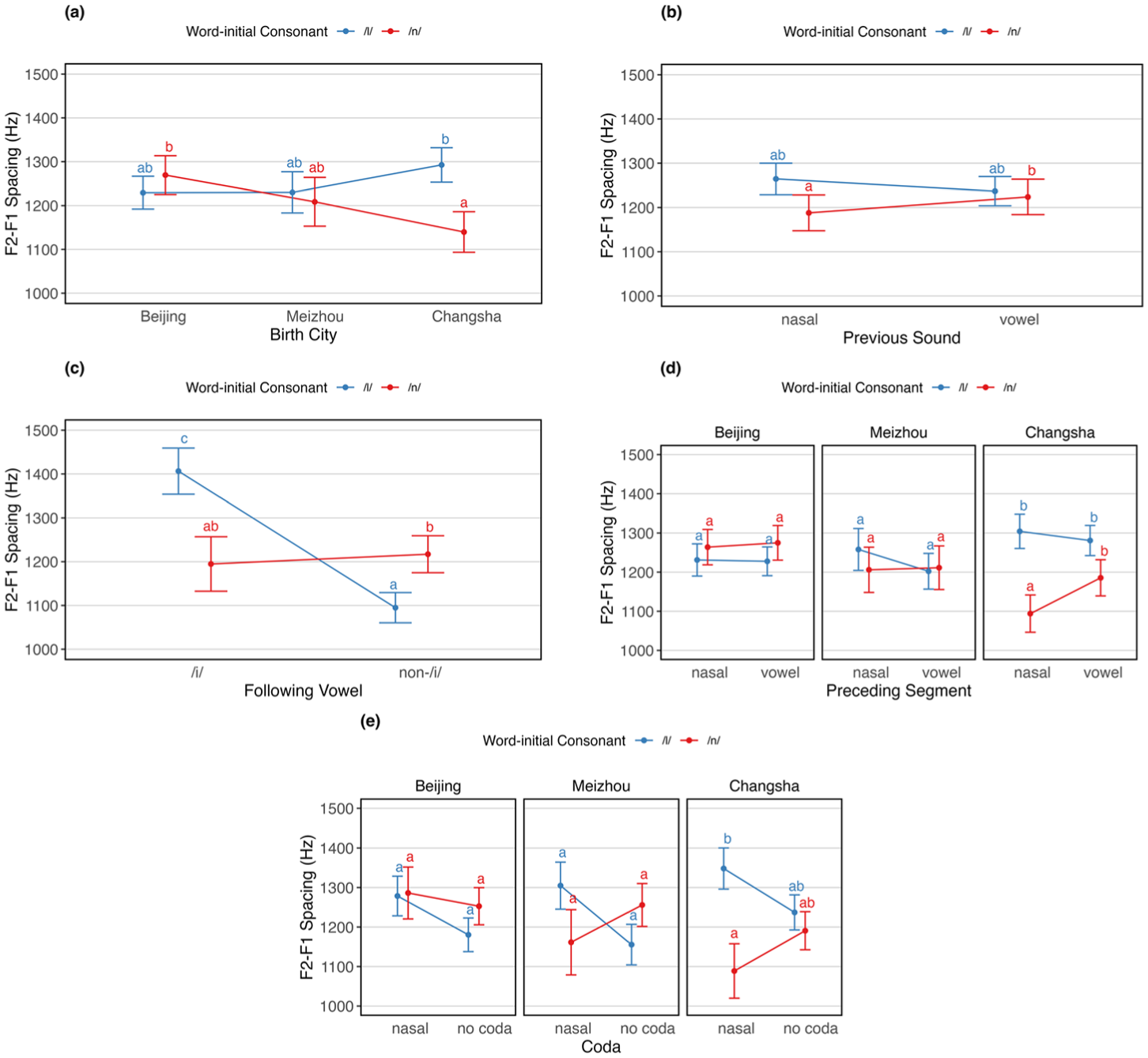
Estimated marginal means of F2–F1 spacing (in Hz) across different interaction conditions. Panel (A) shows F2–F1 spacing as a function of word-initial consonant and birth city. Panel (B) shows F2–F1 spacing as a function of word-initial consonant and preceding segment. Panel (C) shows F2–F1 spacing as a function of word-initial consonant and following vowel. Panel (D) shows F2–F1 spacing as a function of word-initial consonant and preceding segment, separated by birth city. Panel (E) shows F2–F1 spacing as a function of word-initial consonant and coda, separated by birth city.
For the interaction between word-initial consonant and following vowel (see Figure 1C), F2–F1 spacing for /l/ before /i/ was significantly higher than for /n/ before /i/ (β = 211.70, SE = 78.60, z = 2.69, p < .05), /l/ before non-/i/ vowels (β = 311.60, SE = 59.00, z = 5.28, p < .001), and /n/ before non-/i/ vowels (β = 189.40, SE = 64.00, z = 2.96, p < .05); in addition, F2–F1 spacing for /l/ before non-/i/ vowels was significantly lower than /n/ in the same context (β = −122.20, SE = 50.10, z = −2.44, p < .05).
For the three-way interaction between word-initial consonant, birth city, and preceding segment (see Figure 1D), effects were concentrated in CS Mandarin. In this variety, F2–F1 spacing for /l/ was significantly higher than for /n/ when the preceding segment was nasal (β = 210.29, SE = 55.50, z = 3.79, p < .001); F2–F1 spacing for /n/ was also significantly lower when preceded by a nasal compared with a vowel (β = −91.48, SE = 15.40, z = −5.93, p < .001) and significantly lower than /l/ in the nasal condition (β = −186.83, SE = 51.40, z = −3.64, p < .01).
For the three-way interaction between word-initial consonant, birth city, and coda (see Figure 1E), F2–F1 spacing for /l/ was significantly higher than /n/ in CS Mandarin when the coda was a nasal (β = 259.27, SE = 79.70, z = 3.25, p < .01). No other pairwise contrasts reached significance.
3.1.2. F3 Frequency
In MZ Mandarin, /l/ had significantly lower F3 frequency values than /n/, t(2540) = −2.75, p < .01. In CS Mandarin, /l/ had significantly higher F3 frequency values than /n/, t(4141) = 2.47, p < .05. No significant difference was found in BJ Mandarin.
Table A2 in the Appendix summarizes the fixed effect estimates of the linear mixed-effects models on F3 frequency. The results revealed significant main effects of birth city, F(2, 173.7) = 14.930, p < .001, preceding segment, F(1, 10,808.0) = 6.836, p < .01, and following vowel, F(1, 13.1) = 5.226, p < .05.
Significant interactions were observed between word-initial consonant and birth city, F(2, 13,720.9) = 3.590, p < .05, word-initial consonant and preceding segment, F(1, 11,021.4) = 10.959, p < .001, and word-initial consonant and following vowel, F(1, 13.1) = 6.363, p < .05. In addition, a significant interaction was found between birth city and following vowel, F(2, 13,829.7) = 3.445, p < .05.
For the interaction between word-initial consonant and birth city (see Figure 2A), F3 frequency for /l/ in CS Mandarin was significantly higher than for /l/ (β = −180.35, SE = 31.30, z = −5.75, p < .001) and /n/ (β = −183.07, SE = 38.90, z = −4.71, p < .001) in BJ Mandarin, as well as for /l/ (β = −223.55, SE = 39.60, z = −5.64, p < .001) and /n/ (β = −224.90, SE = 49.30, z = −4.56, p < .001) in MZ Mandarin. The F3 for /n/ in CS Mandarin was also significantly higher than for /l/ (β = −137.15, SE = 46.60, z = −2.95, p < .05) and /n/ (β = −138.50, SE = 48.20, z = −2.88, p < .05) in MZ Mandarin. For the interaction between word-initial consonant and preceding segment (see Figure 2B), /n/ following a nasal had significantly lower F3 than when following a vowel (β = −58.03, SE = 10.80, z = −5.36, p < .001). For the interaction between word-initial consonant and following vowel (see Figure 2C), /l/ before /i/ had significantly higher F3 than before non-/i/ vowels (β = 107.75, SE = 27.10, z = 3.97, p < .001).
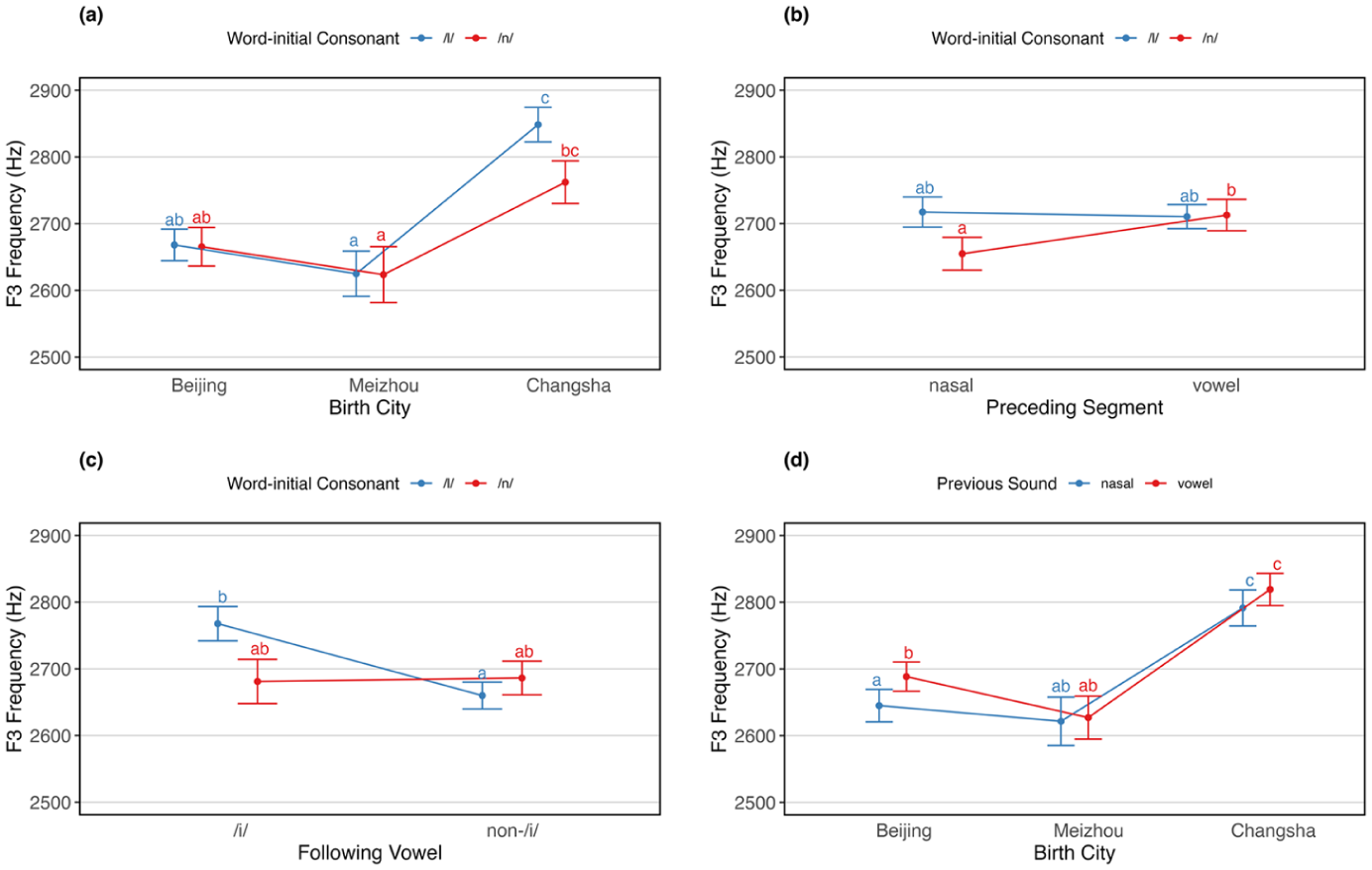
Estimated marginal means of F3 frequency (in Hz) across different interaction conditions. Panel (A) shows F3 frequency as a function of word-initial consonant and birth city. Panel (B) shows F3 frequency as a function of word-initial consonant and preceding segment. Panel (C) shows F3 frequency as a function of word-initial consonant and following vowel. Panel (D) shows F3 frequency as a function of the preceding segment and birth city.
Finally, for the interaction between preceding segment and birth city (see Figure 2D), F3 in BJ Mandarin was significantly lower following a nasal compared with a vowel (β = −43.50, SE = 13.50, z = −3.23, p < .05) and also lower following a nasal than following either a nasal (β = −146.40, SE = 33.90, z = −4.32, p < .001) or a vowel (β = −174.10, SE = 31.70, z = −5.50, p < .001) in CS Mandarin. Comparisons involving a preceding vowel in BJ Mandarin and both nasal (β = −102.90, SE = 32.20, z = −3.19, p < .05) and vowel (β = −130.60, SE = 29.70, z = −4.39, p < .001) contexts in CS Mandarin were also significant.
In addition, in MZ Mandarin, F3 was significantly lower following a nasal than both a nasal (β = −169.90, SE = 43.20, z = −3.93, p < .001) and a vowel (β = −197.60, SE = 41.50, z = −4.77, p < .001) in CS Mandarin; F3 following a vowel in MZ Mandarin was also significantly lower than after both a nasal (β = −164.40, SE = 40.00, z = −4.11, p < .001) and a vowel (β = −192.10, SE = 38.00, z = −5.06, p < .001) in CS Mandarin. No other pairwise comparisons were statistically significant.
3.1.3. Bandwidth of F1 (BW1)
Across all three varieties, BW1 robustly distinguished /l/ from /n/. /l/ had significantly higher BW1 values than /n/: BJ Mandarin, t(5223) = −8.82, p < .001, MZ Mandarin, t(2052) = −4.67, p < .001, and CS Mandarin, t(3843) = −4.99, p < .001.
Table A3 in the Appendix summarizes the fixed effect estimates of the linear mixed-effects model on BW1. The results revealed significant main effects of the preceding segment, F(1, 12,884.0) = 11.124, p < .001, and of the following vowel, F(1, 23.8) = 14.441, p < .001, with non-/i/ vowels associated with significantly higher bandwidth, β = 105.94, SE = 27.42, t(25.35) = 3.864, p < .001.
A significant main effect of word-initial consonant was also observed, F(1, 29.5) = 5.814, p < .05. Significant interaction effects were observed between birth city and following vowel, F(2, 13,865.6) = 3.744, p < .05, and a three-way interaction between word-initial consonant, birth city, and following vowel, F(2, 13,865.2) = 5.436, p < .01, indicating regional and contextual modulation of consonantal effects on BW1.
Post hoc comparisons for the interaction between following vowel and birth city (see Figure 3A) showed that BW1 was significantly lower for /i/ than non-/i/ vowels in BJ Mandarin (β = −98.70, SE = 21.7, z = −4.55, p < .001) and CS Mandarin (β = −82.80, SE = 22.2, z = −3.72, p < .01). The BW1 was significantly higher for non-/i/ vowels in BJ Mandarin than /i/ in MZ Mandarin (β = 86.30, SE = 30.2, z = 2.85, p < .05), and BW1 for /i/ in MZ Mandarin was significantly lower than for non-/i/ vowels in CS Mandarin (β = −106.10, SE = 30.8, z = −3.45, p < .01). For the three-way interaction between word-initial consonant, following vowel, and birth city (see Figure 3B), BW1 was significantly lower for /l/ before /i/ than before non-/i/ vowels in BJ Mandarin (β = −105.94, SE = 27.4, z = −3.86, p < .001), MZ Mandarin (β = −105.20, SE = 30.9, z = −3.41, p < .01), and CS Mandarin (β = −79.11, SE = 28.6, z = −2.77, p < .05). In the same cities, /l/ before /i/ also had significantly lower BW1 than /n/ before non-/i/ vowels (BJ Mandarin: β = −169.32, SE = 32.0, z = −5.30, p < .001; CS Mandarin: β = −141.57, SE = 33.5, z = −4.23, p < .001). Finally, /n/ before /i/ had lower BW1 than before non-/i/ vowels in BJ Mandarin (β = −91.53, SE = 33.7, z = −2.72, p < .05) and CS Mandarin (β = −86.55, SE = 34.1, z = −2.54, p < .05). Other comparisons were not statistically significant.
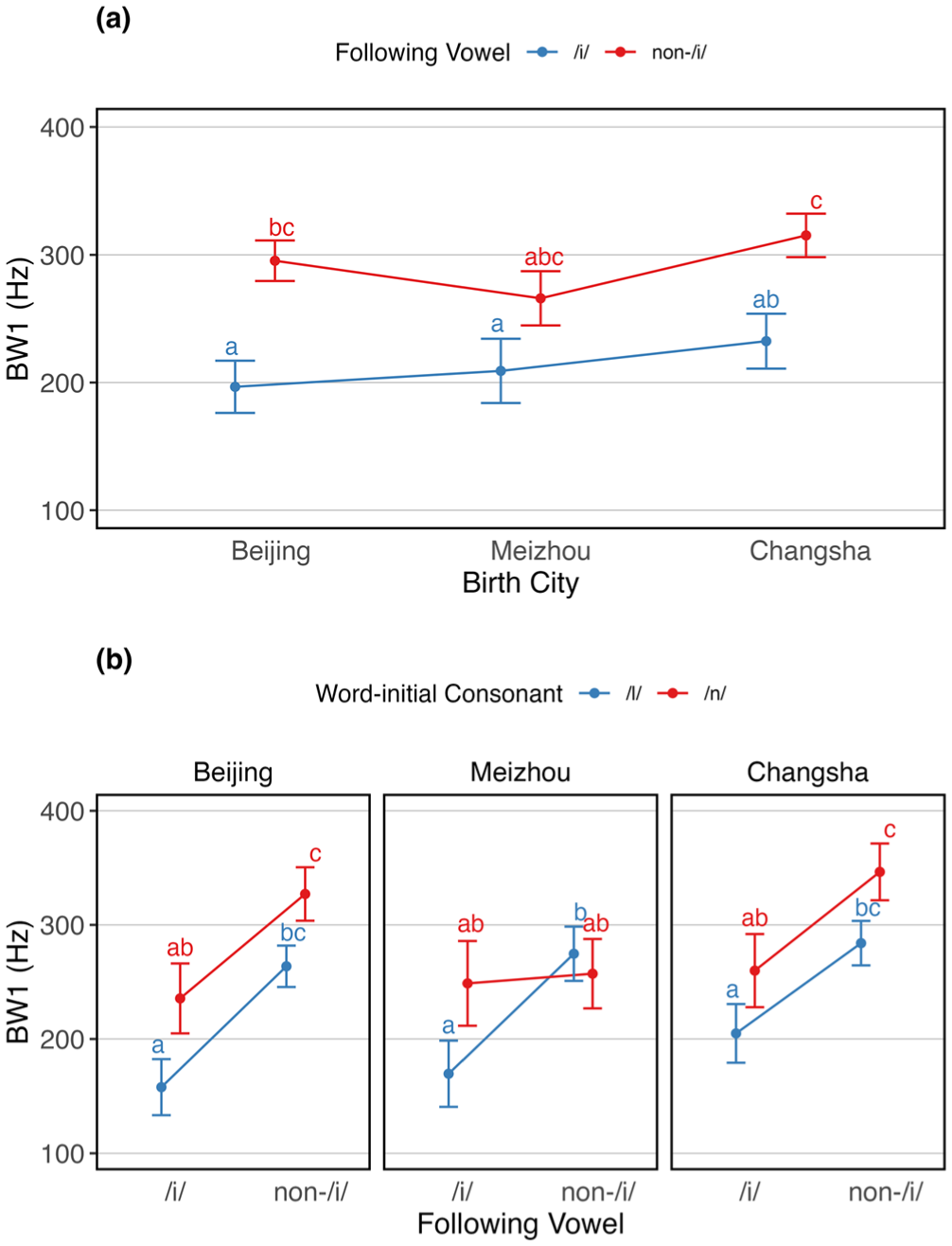
Estimated marginal means of BW1 (in Hz) across different interaction conditions. Panel (A) shows BW1 as a function of the following vowel and birth city. Panel (B) shows BW1 as a function of word-initial consonant and following vowel, separated by birth city.
3.1.4. Amplitude of F1 (∆A1)
In all varieties, /l/ had significantly higher ∆A1 values than /n/: BJ Mandarin, t(3855) = 14.71, p < .001, MZ Mandarin, t(2085) = 9.70, p < .001, and CS Mandarin, t(3304) = 13.99, p < .001.
Table A4 in the Appendix summarizes the fixed effect estimates of the linear mixed-effects model on ΔA1. The results revealed a significant main effect of preceding segment, F(1, 13,789.4) = 40.013, p < .001. Significant interactions were found between word-initial consonant and preceding segment, F(1, 13,805.1) = 41.127, p < .001, and between birth city and following vowel, F(2, 13,832.5) = 12.363, p < .001. No other interactions reached significance.
Post hoc pairwise comparisons for the interaction between word-initial consonant and preceding segment (see Figure 4) showed that ΔA1 was significantly higher for /l/ before vowel sounds than before nasal sounds (β = −2.65, SE = 0.35, z = −7.62, p < .001) and also significantly higher than for /n/ before both nasal (β = −3.64, SE = 1.17, z = −3.11, p < .01) and vowel sounds (β = 3.66, SE = 1.16, z = 3.16, p < .01). In contrast, post hoc comparisons for the interaction between following vowel and birth city revealed no statistically significant differences.
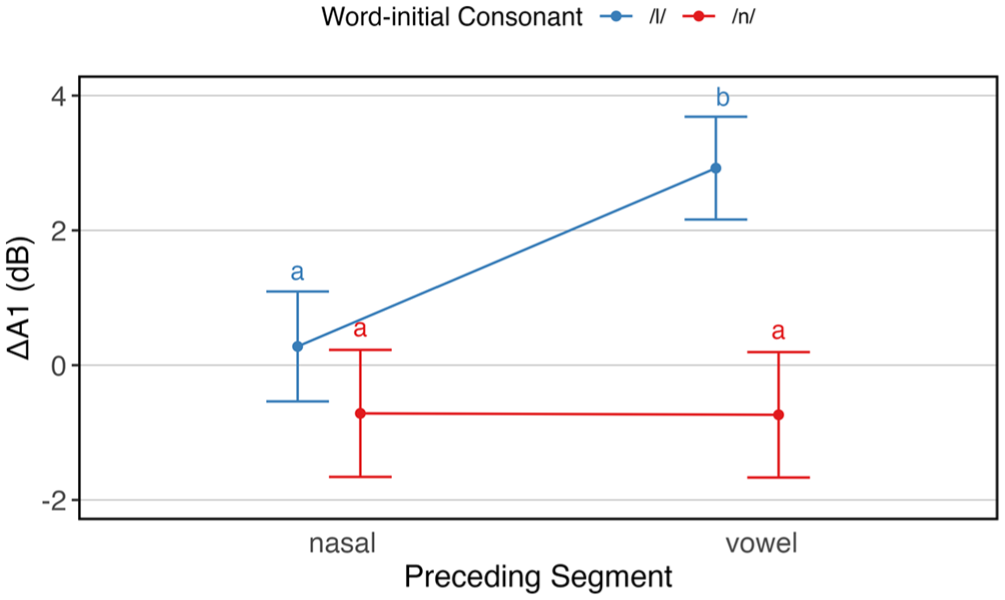
Estimated marginal means of ∆A1 (in dB) as a function of word-initial consonant and preceding segment.
3.1.5. A1–P0
In all varieties, /l/ had significantly higher A1–P0 values than /n/: BJ Mandarin, t(4737) = 16.04, p < .001, MZ Mandarin, t(2353) = 9.22, p < .001, and CS Mandarin, t(3886) = 12.32, p < .001.
Table A5 in the Appendix summarizes the fixed effect estimates of the linear mixed-effects model on A1–P0. The results revealed a significant main effect of word-initial consonant, F(1, 28.1) = 13.180, p < .01. There were also significant main effects of preceding segment, F(1, 13,304.1) = 25.091, p < .001, and following vowel, F(1, 24.6) = 30.304, p < .001. Significant two-way interactions were observed between word-initial consonant and birth city, F(2, 13,778) = 4.442, p < .05, word-initial consonant and preceding segment, F(1, 13,364.2) = 9.341, p < .01, and birth city and following vowel, F(2, 13,803.8) = 28.416, p < .001. In addition, significant three-way interactions were found between word-initial consonant, birth city, and following vowel, F(2, 13,803.5) = 6.303, p < .01, and between word-initial consonant, birth city, and coda, F(2, 13,757.8) = 4.057, p < .05.
For the interaction between word-initial consonant and birth city (see Figure 5A), A1–P0 was significantly higher for /l/ than /n/ in MZ Mandarin (β = 2.68, SE = 0.66, z = 4.08, p < .001) and BJ Mandarin (β = 1.81, SE = 0.54, z = 3.34, p < .05). For the interaction between word-initial consonant and preceding segment (see Figure 5B), A1–P0 was significantly higher for /l/ than /n/ before a nasal (β = 1.39, SE = 0.54, z = 2.58, p < .05), and for /l/ before a vowel compared with both /l/ before nasal sounds (β = −1.11, SE = 0.23, z = −4.83, p < .001) and /n/ before nasal sounds (β = −2.50, SE = 0.50, z = −4.95, p < .001). It was also higher for /l/ than /n/ before a vowel (β = 2.23, SE = 0.50, z = 4.51, p < .001). For the interaction between following vowel and birth city (see Figure 5C), A1–P0 was significantly lower before /i/ than before non-/i/ vowels in BJ Mandarin (β = −1.63, SE = 0.49, z = −3.33, p < .01), MZ Mandarin (β = −2.76, SE = 0.53, z = −5.25, p < .001), and CS Mandarin (β = −3.49, SE = 0.50, z = −6.99, p < .001). In addition, A1–P0 was significantly higher before non-/i/ vowels in MZ Mandarin than before /i/ in CS Mandarin (β = 2.75, SE = 0.93, z = 2.94, p < .05), and lower before /i/ in BJ Mandarin than before non-/i/ vowels in CS Mandarin (β = −3.16, SE = 0.79, z = −4.02, p < .001).
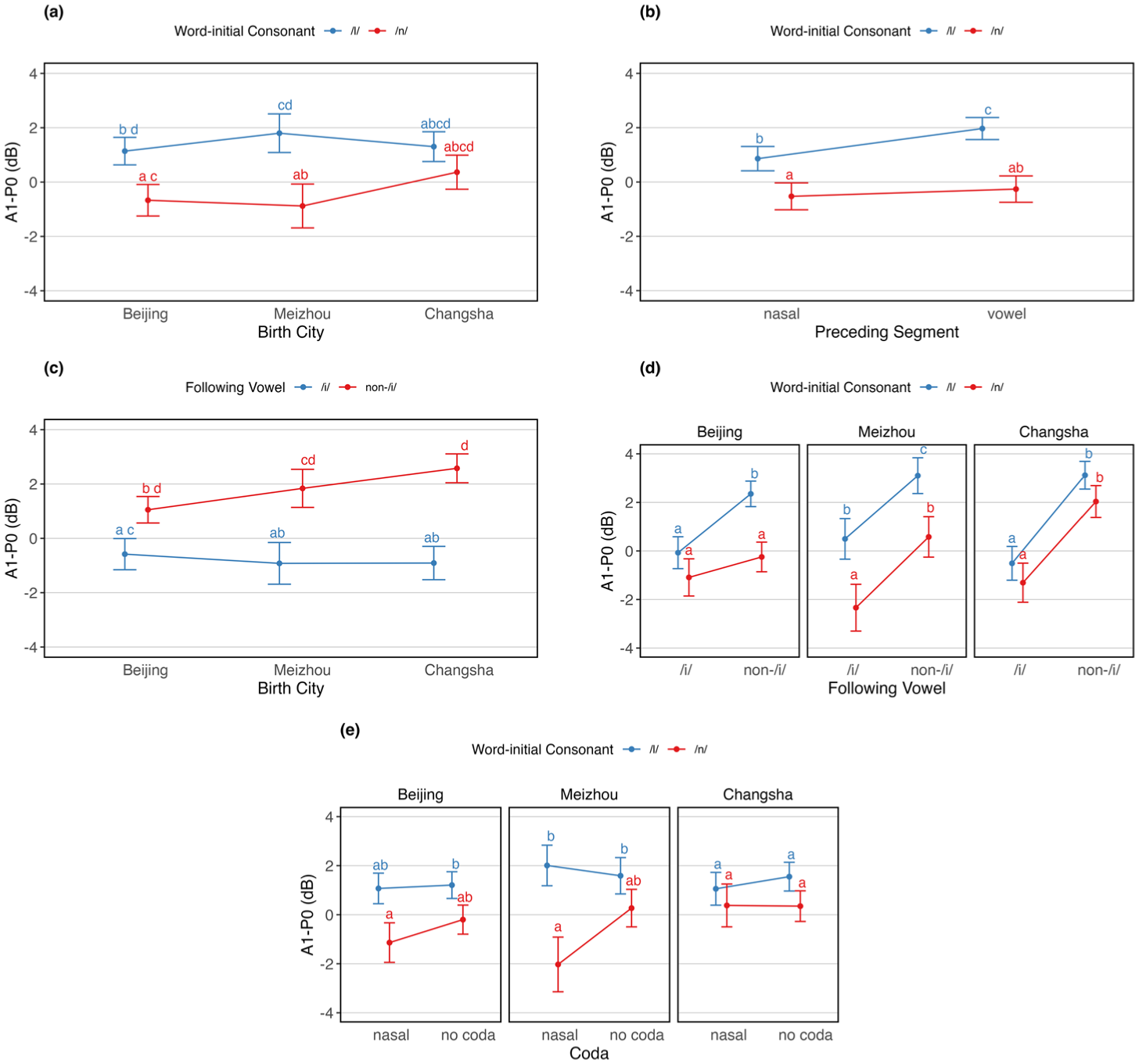
Estimated marginal means of A1–P0 (in dB) across different interaction conditions. Panel (A) shows A1–P0 as a function of word-initial consonant and birth city. Panel (B) shows A1–P0 as a function of word-initial consonant and preceding segment. Panel (C) shows A1–P0 as a function of the following vowel and birth city. Panel (D) shows A1–P0 as a function of word-initial consonant and following vowel, separated by birth city. Panel (E) shows A1–P0 as a function of word-initial consonant and coda, separated by birth city.
For the three-way interaction between word-initial consonant, following vowel, and birth city (see Figure 5D), A1–P0 was lower for /l/ before /i/ than before non-/i/ vowels in BJ Mandarin (β = −2.42, SE = 0.62, z = −3.88, p < .001), MZ Mandarin (β = −2.60, SE = 0.68, z = −3.82, p < .001), and CS Mandarin (β = −3.63, SE = 0.64, z = −5.65, p < .001). In MZ Mandarin, /l/ before /i/ also had higher A1–P0 than /n/ before /i/ (β = 2.83, SE = 0.95, z = 2.98, p < .01). Across all cities, /n/ before /i/ had lower A1–P0 than /l/ before non-/i/ (BJ Mandarin: β = −3.44, SE = 0.75, z = −4.59, p < .001; MZ Mandarin: β = −5.44, SE = 0.86, z = −6.29, p < .001; CS Mandarin: β = −4.43, SE = 0.78, z = −5.71, p < .001), and lower than /n/ before non-/i/ in MZ Mandarin (β = −2.92, SE = 0.80, z = −3.65, p < .01) and CS Mandarin (β = −3.34, SE = 0.76, z = −4.38, p < .001). For the three-way interaction between word-initial consonant, preceding segment, and birth city (see Figure 5E), A1–P0 was higher for /l/ than /n/ before a nasal coda in MZ Mandarin (β = 4.04, SE = 1.10, z = 3.68, p < .01) and lower for /n/ before a nasal coda than /l/ before no coda in BJ Mandarin (β = −2.35, SE = 0.81, z = −2.91, p < .05). In addition, /n/ before a nasal coda had significantly lower A1–P0 than /l/ before no coda in both MZ Mandarin (β = −3.62, SE = 1.03, z = −3.50, p < .01) and BJ Mandarin (β = −2.35, SE = 0.81, z = −2.91, p < .05). Other comparisons were not statistically significant.
3.1.6. Summary
Across the five acoustic measures, the statistical models revealed both shared and measure-specific patterns of variation (see Table 5). Word-initial consonant significantly affected BW1 and A1–P0, while birth city significantly influenced F2–F1 spacing and F3. The preceding segment showed a significant main effect for all measures except F2–F1 spacing, and the following vowel showed a significant main effect for all measures except ΔA1. Interaction effects frequently indicated regional modulation of the /l/–/n/ contrast, most prominently in CS Mandarin, with several three-way interactions involving word-initial consonant, birth city, and phonetic context.
Summary of Significant Main Effects and Interactions in the Linear Mixed-Effects Regression Models for the Five Acoustic Measures.
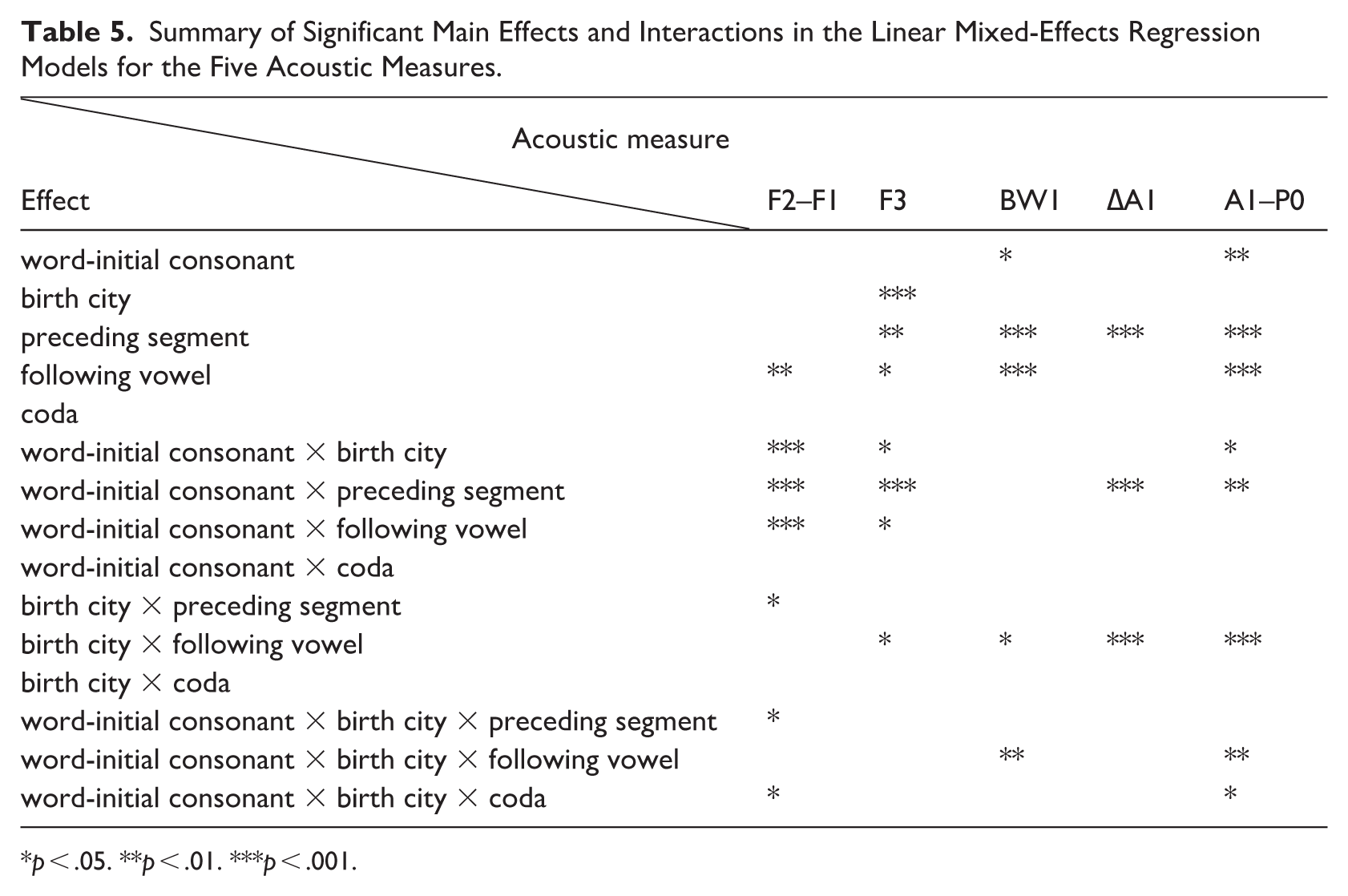
p < .05. **p < .01. ***p < .001.
3.2. Random Forest Classifiers
3.2.1. Performance
The analysis of the performance measures of three classifiers is presented in Table 6. Overall, the classifiers exhibited comparable performance across the three regional varieties of Mandarin, with only minor differences observed. Measures of overall accuracy, AUC, and class-level accuracy did not differ substantially across regions.
The Performance Results of the Word-Initial /l/–/n/ Classifier for BJ Mandarin, CS Mandarin, and MZ Mandarin.
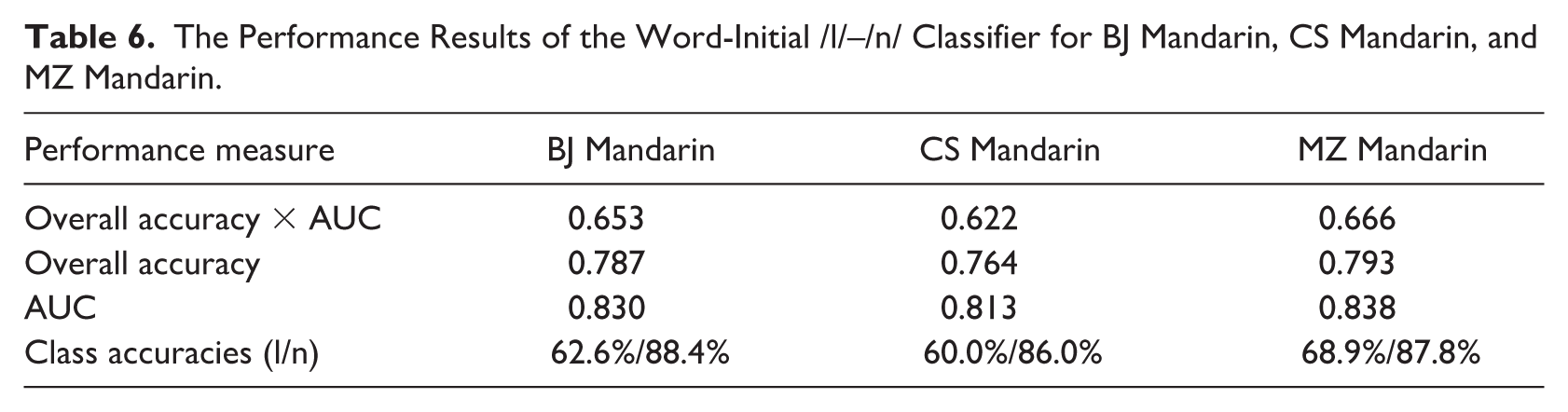
Across all three classifiers, /n/ tokens were classified with higher accuracy than /l/ tokens. Class-level accuracy for /l/ was highest in MZ Mandarin, followed by BJ Mandarin, and lowest in CS Mandarin, whereas classification accuracy for /n/ was the highest in MZ Mandarin, followed by BJ Mandarin, and the lowest in CS Mandarin.
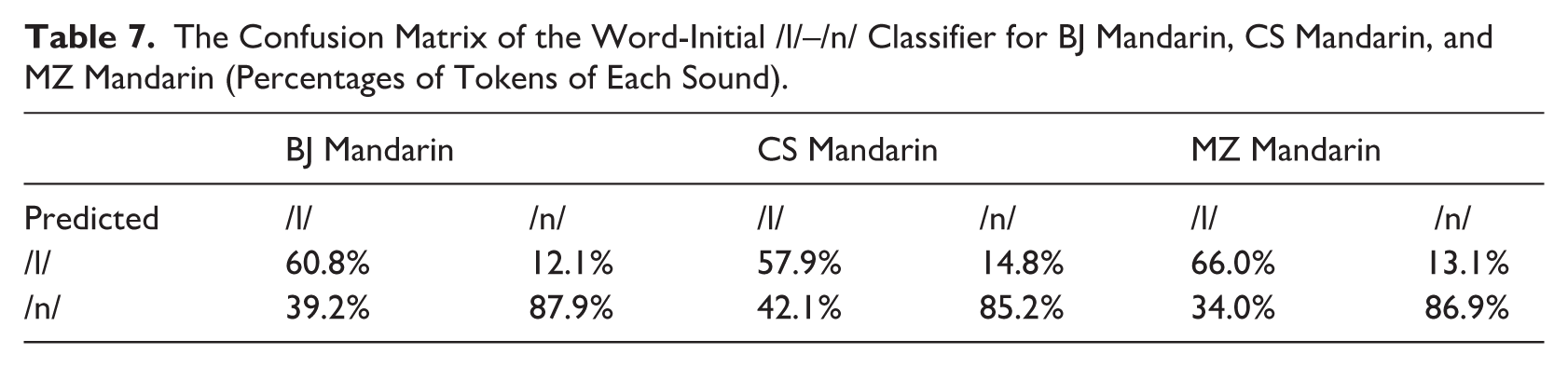
As shown in Table 7, all three classifiers achieved high prediction accuracies for /n/ tokens (BJ: 87.9%; CS: 85.2%; MZ: 86.9%), but comparatively lower accuracy for /l/ tokens (BJ: 60.8%; CS: 57.9%; MZ: 66.0%). This asymmetry in classification performance indicates that acoustic cues distinguishing /n/ are more consistently captured by the classifiers than those distinguishing /l/, particularly in BJ and CS Mandarin.
The Confusion Matrix of the Word-Initial /l/–/n/ Classifier for BJ Mandarin, CS Mandarin, and MZ Mandarin (Percentages of Tokens of Each Sound).
3.2.2. Variable Importance Scores
The relative importance of the acoustic measures and phonological factors is illustrated in Figure 6, with variable importance quantified using the Gini impurity index. The relative ranking of predictors differed across the three classifiers, indicating regional differences in how acoustic and phonological cues contributed to classification.
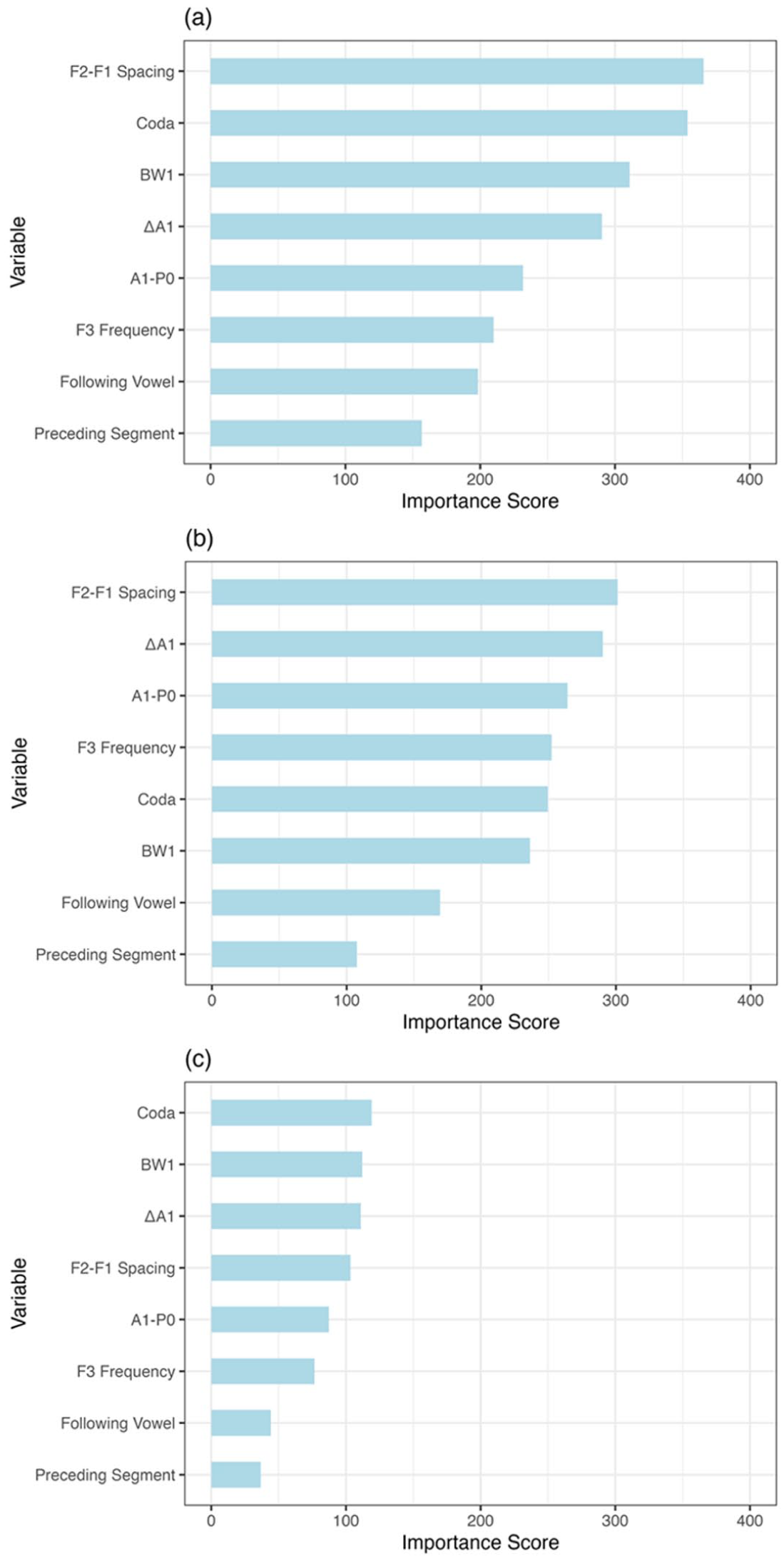
The importance score of acoustic measurements and phonological factors of the word-initial /l/–/n/ classifier for BJ Mandarin (A), CS Mandarin (B), and MZ Mandarin (C).
In both BJ and CS Mandarin, F2–F1 spacing ranked as the most important variable. In BJ Mandarin, this is notable given that F2–F1 spacing did not show a significant main effect of word-initial consonant in the linear model, suggesting that it may contribute to classification through complex interactions or nonlinear patterns captured by the random forest model. In BJ Mandarin, BW1 ranked third in importance, while in CS Mandarin, it ranked sixth. Other acoustic measurements followed the same sequence as in BJ and CS Mandarin but had a higher ranking in CS Mandarin. However, the ranking of these acoustic measurements differed in MZ Mandarin, with BW1 being the most important, followed by ∆A1, F2–F1 spacing, A1–P0, and F3 frequency in decreasing order of importance.
The least important phonological factors were identified as the preceding segment and the following vowel, as indicated by their low importance scores across the three regional varieties of Mandarin. However, the importance of the coda in classifiers varies between different regional varieties of Mandarin. In BJ Mandarin, coda was found to be the second most important variable, whereas in CS Mandarin, it ranked fifth in importance. However, in MZ Mandarin, it emerged as the most crucial variable.
3.2.3. Prediction Probabilities
Figure 7 displays the distribution of the probability of prediction of the classifiers as /l/ and /n/ for labeled /l/ and /n/ tokens, respectively, in the three regional varieties of Mandarin. The binary classification’s cutoff values demonstrate consistency among the three classifiers. Specifically, to predict /l/ tokens as /l/, the prediction probabilities were over 0.531, 0.529, and 0.522 in BJ, CS, and MZ Mandarin, respectively. Similarly, to predict /n/ tokens as /n/, their prediction probabilities were greater than 0.469, 0.471, and 0.478 in BJ, CS, and MZ.
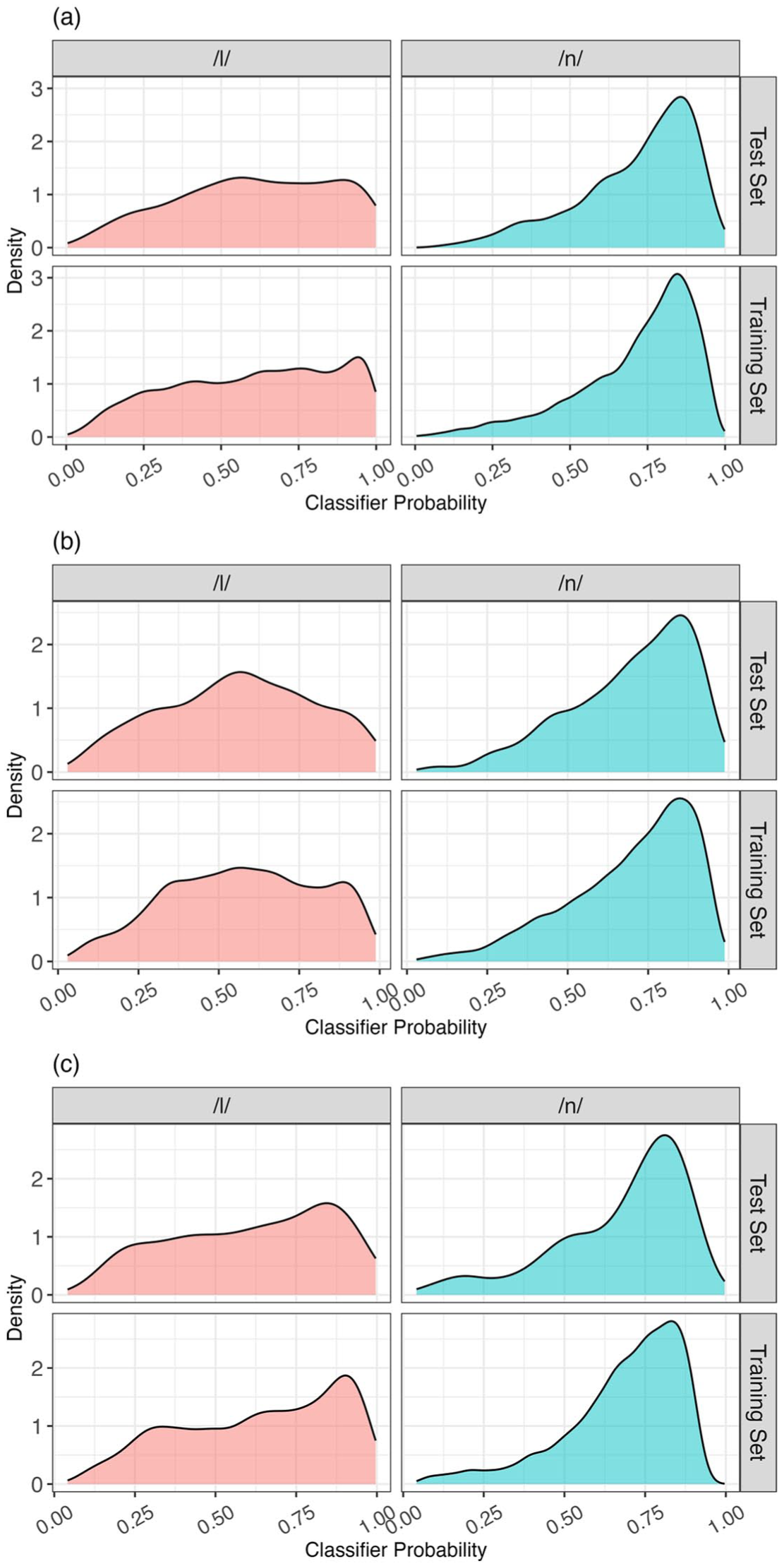
Distribution of classifier probabilities in the training and test set for the word-initial /l/–/n/ classifier in BJ Mandarin (A), CS Mandarin (B), and MZ Mandarin (C).
Mandarin, respectively. The distributions of classifier probabilities for the training and test sets exhibit comparable patterns across the three classifiers, with marked left-skewness observed in the distribution of probabilities for the /n/ tokens and mild left-skewness in the distribution of probabilities for the /l/ tokens in BJ and MZ Mandarin; the distribution of probabilities for the same tokens in CS Mandarin is nearly centered. Although more /n/ tokens were predicted correctly than /l/ tokens, it is important to note that the acoustic profiles of /l/ were considerably more diverse, particularly in CS Mandarin. This increased variability presents a greater challenge for classifier prediction accuracy.
The probabilities of the word-initial /l/ and /n/ in CS and MZ Mandarin, as generated by the BJ classifier, are illustrated in Figure 8. To determine the acoustic differences of the word-initial /l/ and /n/ between BJ Mandarin and CS/MZ Mandarin, we also used the classifier trained on the two consonants in BJ Mandarin to predict the probabilities of the two consonants in CS/MZ Mandarin. The accuracy of CS Mandarin was estimated to be 73.3%, with 51.9% and 85.6% accuracy for /l/ and /n/, respectively. The classifier’s accuracy for MZ Mandarin was 75.1%, with /l/ and /n/ having accuracies of 62.9% and 85.0%, respectively. The prediction results were also supported by the distributional patterns of /l/ and /n/ in CS/MZ Mandarin, as illustrated in Figure 8. The distributional patterns for the word-initial /n/ in both CS and MZ Mandarin were left-skewed, while the word-initial /l/ was evenly distributed in CS Mandarin and was slightly left-skewed in MZ Mandarin. The results suggest that the classifier trained on the two consonants in BJ Mandarin was more successful in predicting the /l/ and /n/ tokens in MZ Mandarin than in CS Mandarin. However, the /l/ tokens contained more phonetic variation, particularly in CS Mandarin, making it difficult for the classifier to make accurate predictions.
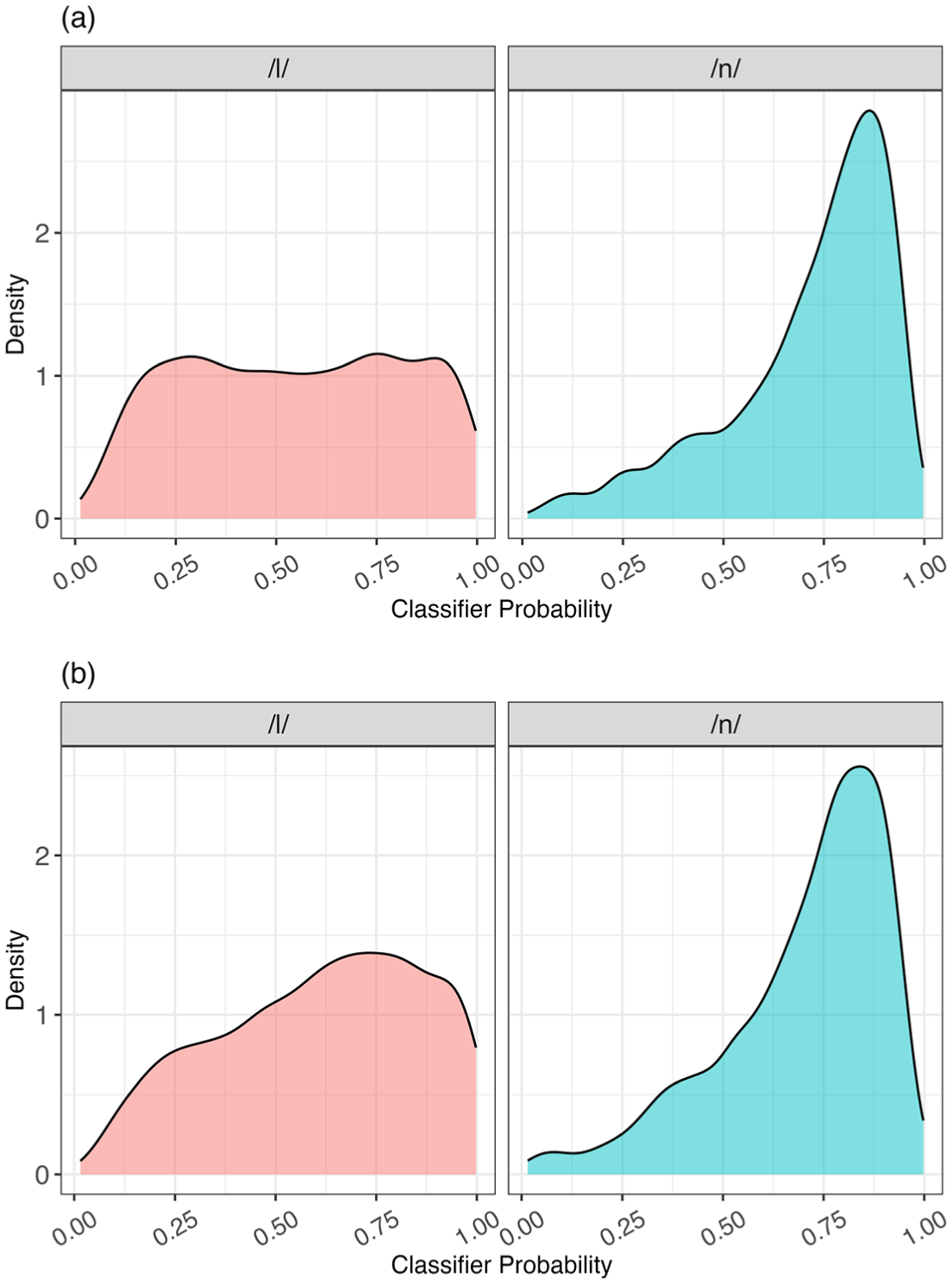
Distribution of classifier probabilities generated by the BJ Mandarin classifier for the word-initial /l/ and /n/ in CS Mandarin (A) and MZ Mandarin (B).
4. Discussion
The results revealed systematic differences in how Mandarin speakers from different regional backgrounds produce the word-initial /l–n/ contrast and how their realizations are shaped by both acoustic cue selection and phonological context. Rather than reflecting dialectal differentiation alone, the observed variation reflects how native-language phonological representations shape the phonetic implementation of a shared Mandarin contrast (Amengual, 2024; J. E. Flege, 1995). Variation was observed not only in the strength of the contrast but also in which cues were most informative, highlighting the role of dialect background and linguistic experience in shaping cue-weighting strategies. Contextual factors such as adjacent sounds and syllable structure further modulated the realization of /l/ and /n/, with greater variability observed in varieties with weaker phonological support for the contrast.
4.1. Phonetic Differentiation Between /l/ and /n/
The first research question addressed how Beijing, Meizhou, and Changsha Mandarin speakers phonetically differentiate word-initial /l/ and /n/, and how cue use differs across varieties. All three varieties showed statistically significant differences across multiple acoustic dimensions, indicating that the Mandarin /l–n/ contrast is preserved across groups, but the degree of separation and cue prioritization varied, reflecting distinct phonetic-level cue-weighting strategies.
Beijing (BJ) Mandarin speakers exhibited moderate differentiation between /l/ and /n/ in F2–F1 spacing and clear separation in BW1, ΔA1, and A1–P0. The F2–F1 spacing showed a significant interaction between word-initial consonant and birth city, and between word-initial consonant and following vowel. Although spectral cues like F2–F1 and F3 have been previously linked to place of articulation (Lee & Zee, 2003), F3 did not significantly distinguish /l/ from /n/ in BJ Mandarin. However, the random forest classifier still ranked F2–F1 and F3 as the most important predictors, suggesting these spectral features played a nonlinear role in differentiating the two sounds. The classifier trained on BJ data also yielded high prediction accuracy for /n/ and moderate for /l/, indicating relatively consistent cue use with limited phonetic variability for /n/ tokens.
In contrast, Meizhou (MZ) Mandarin exhibited a mixed pattern of cue differentiation. Although F2–F1 spacing did not significantly differentiate /l/ and /n/, F3 frequency did show a statistically significant difference, indicating that some spectral cues were effective in distinguishing the two word-initial consonants. Meanwhile, nasality-related cues (i.e., BW1, ΔA1, and A1–P0) demonstrated stronger separation, especially in environments involving high vowels and nasal codas. This profile reflects a cue-weighting system that leans toward nasality and glottal cues by still partially engaging spectral features (M. Y. Chen, 1995, 1997; Cheng et al., 2022). This pattern is likely influenced by contact with Min or Hakka dialects known for nasalization (Cheng et al., 2022; Ye, 2011). The random forest classifier ranked BW1 and ΔA1 as the most informative, and although prediction accuracy for /l/ was highest in this variety (66.0%), it remained substantially lower than for /n/, suggesting that /l/ tokens, while more regular than in other varieties, still showed variability.
Changsha (CS) Mandarin showed statistically significant differences across all five acoustic measures, including F2–F1 spacing, F3, BW1, ΔA1, and A1–P0. However, despite these differences, classifier accuracy for /l/ was the lowest (57.9%), suggesting greater phonetic variability rather than consistent contrast realization. The F2_F1 spacing and F3 were both significantly higher for /l/ than for /n/, with large interaction effects involving birth city and preceding sound. The ΔA1 and A1–P0 values were also clearly separated. Unlike BJ and MZ speakers, CS speakers exhibited a more balanced reliance on spectral and nasality cues, as reflected in a more evenly distributed importance ranking in the random forest model. This suggests a strategy of cue integration, potentially shaped by second language acquisition or compensatory learning (Schertz et al., 2015), especially because the Xiang dialect spoken in the region tends to neutralize the /l–n/ contrast (S. Zhou, 2013).
Overall, these patterns support the use of cue weighting to explain how different dialect groups maintain phonetic differentiation (Schertz et al., 2015). Rather than relying on a fixed cue set, speakers distribute production resources in ways that reflect their linguistic environment (Cheng et al., 2022; Clayards et al., 2008; Kong & Edwards, 2016; McMurray & Jongman, 2011). BJ speakers emphasize canonical spectral cues; MZ speakers prioritize nasality-related cues; and CS speakers attempt to integrate both sets of cues, but their /l/ productions are more variable, possibly reflecting influence from dialect merger (Ye, 2011; S. Zhou, 2013). The acoustic and classification analyses align in showing that /n/ is more stable across dialects, whereas /l/ exhibits more variability, especially in CS Mandarin.
4.2. Effects of Phonological Context
The second research question focused on how phonological context influences the realization of /l/ and /n/ and how these effects differ by region. The linear mixed-effects models revealed complex interactions among these variables, shaped by dialect background.
Preceding nasals significantly reduced F2–F1 spacing and F3 for /n/ across varieties, consistent with increased nasal coarticulation. For /l/, preceding nasals led to reduced ΔA1 and A1–P0, indicating greater nasal coupling. These effects were most prominent in CS Mandarin, where coarticulatory sensitivity was highest. Random forest classification accuracy also dropped in nasal contexts, especially for /l/ in CS Mandarin, confirming that phonetic cues are weakened by overlap with preceding nasals. This supports findings from prior work showing that lateral consonants are highly sensitive to coarticulatory influences (Recasens & Espinosa, 2007).
The following vowel quality affected all acoustic measures except ΔA1. High front vowels like /i/ raised F2–F1 and F3 while lowering BW1 and A1–P0, reflecting tongue fronting and reduced nasalization. These effects were most prominent in BJ and CS Mandarin, though context-cue interactions differed. For example, in BJ Mandarin, F2–F1 spacing remained a dominant cue for distinguishing /l/ even before /i/, whereas in CS Mandarin, nasality-related cues such as A1–P0 gained relative importance in the same context. This suggests a dynamic cue reweighting depending on both phonological environment and dialect background.
Coda effects were more limited but evident in specific interactions. In CS and MZ Mandarin, nasal codas lowered F2–F1 spacing and A1–P0 for /n/, reducing contrastive salience. These patterns align with known nasal assimilation processes in Xiang and Hakka dialects (S. Zhou, 2013). In BJ Mandarin, these effects were weaker, suggesting tighter articulatory targets. Classifier performance in coda-influenced environments showed more variability in MZ and CS Mandarin, indicating that coda effects complicate cue stability.
Three-way interactions involving word-initial consonant, birth city, and phonological context (e.g., coda or preceding segment) revealed that cue stability is modulated by dialect-specific articulatory and perceptual norms. The BJ Mandarin showed the least contextual modulation, supporting the idea of a more rigid cue hierarchy shaped by exposure to Standard Mandarin norms (Y. Chen & Wang, 2016; Lee & Zee, 2003). In contrast, CS and MZ speakers showed flexible cue use, adjusting reliance on spectral or nasal dimensions based on local segmental environments, consistent with findings from dialect contact and adaptive cue weighting studies (Kong & Edwards, 2016; Schertz et al., 2015; S. Zhou, 2013).
Together, these results show that phonological context interacts with dialect background to shape cue salience and distribution. Coarticulatory and vowel-driven effects reduce cue distinctiveness, and the degree of compensation varies by variety. These findings underscore the adaptive nature of the phonetic realization of the word-initial consonants /l/ and /n/ across regional varieties of Mandarin.
4.3. Implications and Future Directions
The findings demonstrate that Mandarin speakers of different varieties produce the word-initial consonants /l/ and /n/ through flexible phonetic cue-weighting strategies shaped by both dialect background and phonological context. Rather than relying on a fixed set of cues, speakers distribute attention across spectral and nasality-related dimensions in ways that reflect their linguistic environment and articulatory constraints. The BJ speakers generally exhibit stable use of spectral cues, whereas MZ and CS speakers show greater reliance on nasal and glottal cues, especially in contexts that weaken contrastive clarity. These differences are amplified by coarticulatory effects, such as preceding nasals and high front vowels, which dynamically modulate cue salience (Manuel, 1990; Recasens & Espinosa, 2007). Classification models further reveal that cue importance shifts across both varieties and contexts, supporting models of adaptive cue reweighting in speech production (Clayards et al., 2008; McMurray & Jongman, 2011; Toscano & McMurray, 2010).
Future work should examine whether the cue patterns observed in production align with perceptual sensitivity across varieties (Kong & Edwards, 2016; Schertz et al., 2015). Testing how listeners from different regional backgrounds attend to these cues can help clarify the relationship between production and perception (Clayards et al., 2008; McMurray & Jongman, 2011). Longitudinal studies may also reveal how exposure to standard Mandarin influences cue weighting over time (Chang, 2012; Evans & Iverson, 2007). Finally, incorporating sociolinguistic factors such as age, education, and mobility could offer a fuller picture of how phonetic contrast is maintained and adapted in a changing linguistic landscape (Munson et al., 2006; Thomas & Reaser, 2004).
5. Conclusion
This study examined the phonetic realization of word-initial /l/ and /n/ in three regional varieties of Mandarin: Beijing (BJ) Mandarin, Meizhou (MZ) Mandarin, and Changsha (CS) Mandarin, using five acoustic measures and random forest classification. When all speaker groups maintained some degree of phonetic contrast between /l/ and /n/, the acoustic cues employed and their relative weighting varied systematically across varieties. BJ Mandarin speakers relied most consistently on spectral cues, particularly F2–F1 spacing. MZ Mandarin speakers placed greater emphasis on nasality-related cues such as ΔA1 and A1–P0. CS Mandarin speakers used a more evenly distributed set of cues, indicating a flexible integration strategy.
Phonological context also affected the realization of these two word-initial consonants, with stronger contextual modulation observed in MZ and CS Mandarin. Preceding nasals, high front vowels, and nasal codas each altered acoustic patterns in ways that interacted with dialect background. In particular, CS Mandarin showed greater articulatory variability in response to context, likely reflecting both the absence of a native /l–n/ distinction and adaptive speech patterns shaped by dialect exposure.
The use of random forest modeling added a quantitative layer to the analysis by identifying the most informative acoustic predictors and revealing variation in cue salience across varieties. These findings highlight that phonetic realization in Mandarin is not uniform but reflects systematic variation linked to regional dialect background, cue-weighting strategies, and contextual sensitivity. Mandarin should therefore be viewed not as a single standard but as a collection of regionally shaped phonetic systems.
Footnotes
Appendix
Summary of the Fixed Effects of the Linear Mixed-Effects Model on A1–P0.
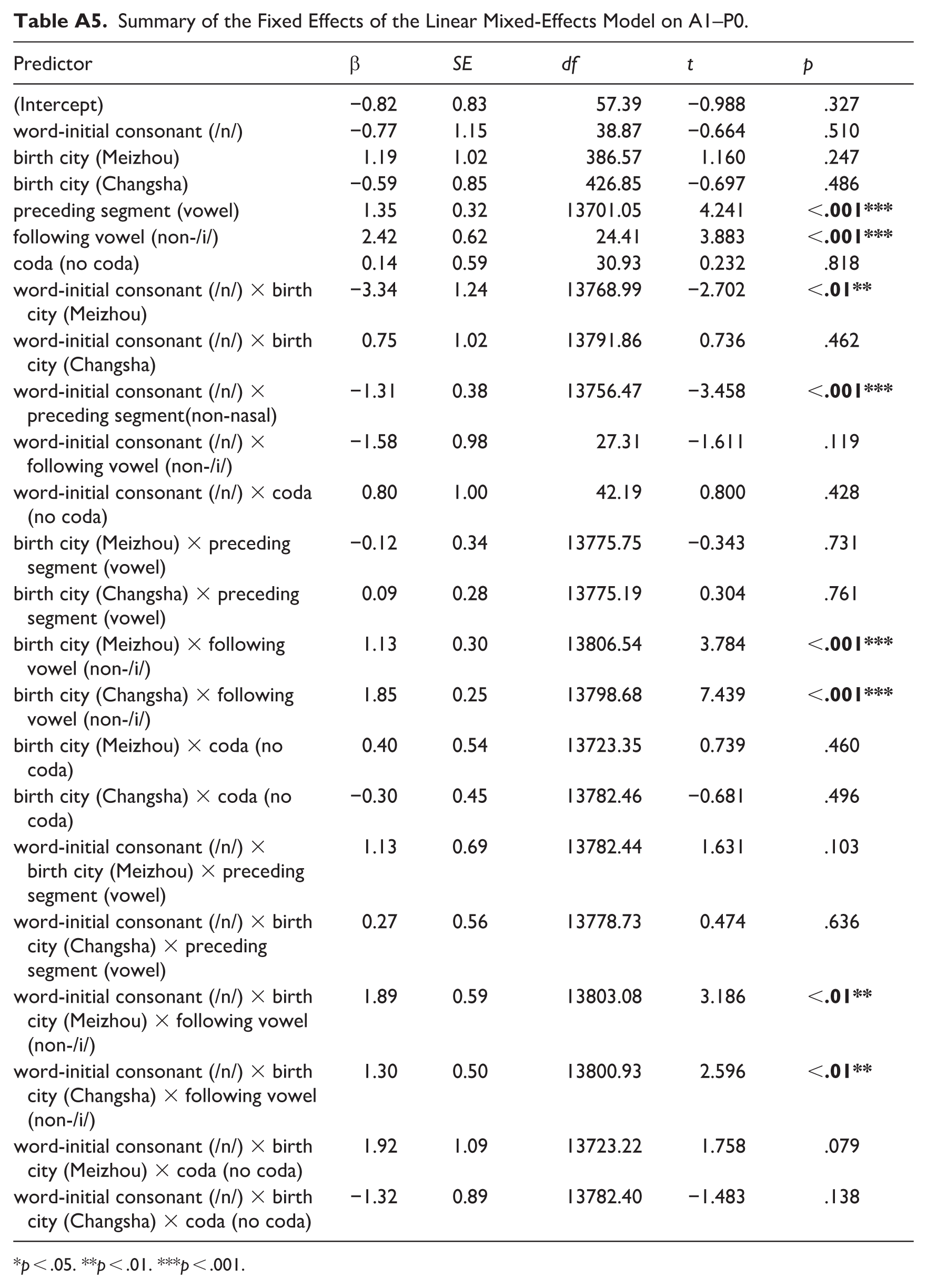
| Predictor | β | SE | df | t | p |
|---|---|---|---|---|---|
| (Intercept) | −0.82 | 0.83 | 57.39 | −0.988 | .327 |
| word-initial consonant (/n/) | −0.77 | 1.15 | 38.87 | −0.664 | .510 |
| birth city (Meizhou) | 1.19 | 1.02 | 386.57 | 1.160 | .247 |
| birth city (Changsha) | −0.59 | 0.85 | 426.85 | −0.697 | .486 |
| preceding segment (vowel) | 1.35 | 0.32 | 13701.05 | 4.241 |
|
| following vowel (non-/i/) | 2.42 | 0.62 | 24.41 | 3.883 |
|
| coda (no coda) | 0.14 | 0.59 | 30.93 | 0.232 | .818 |
| word-initial consonant (/n/) × birth city (Meizhou) | −3.34 | 1.24 | 13768.99 | −2.702 |
|
| word-initial consonant (/n/) × birth city (Changsha) | 0.75 | 1.02 | 13791.86 | 0.736 | .462 |
| word-initial consonant (/n/) × preceding segment(non-nasal) | −1.31 | 0.38 | 13756.47 | −3.458 |
|
| word-initial consonant (/n/) × following vowel (non-/i/) | −1.58 | 0.98 | 27.31 | −1.611 | .119 |
| word-initial consonant (/n/) × coda (no coda) | 0.80 | 1.00 | 42.19 | 0.800 | .428 |
| birth city (Meizhou) × preceding segment (vowel) | −0.12 | 0.34 | 13775.75 | −0.343 | .731 |
| birth city (Changsha) × preceding segment (vowel) | 0.09 | 0.28 | 13775.19 | 0.304 | .761 |
| birth city (Meizhou) × following vowel (non-/i/) | 1.13 | 0.30 | 13806.54 | 3.784 |
|
| birth city (Changsha) × following vowel (non-/i/) | 1.85 | 0.25 | 13798.68 | 7.439 |
|
| birth city (Meizhou) × coda (no coda) | 0.40 | 0.54 | 13723.35 | 0.739 | .460 |
| birth city (Changsha) × coda (no coda) | −0.30 | 0.45 | 13782.46 | −0.681 | .496 |
| word-initial consonant (/n/) × birth city (Meizhou) × preceding segment (vowel) | 1.13 | 0.69 | 13782.44 | 1.631 | .103 |
| word-initial consonant (/n/) × birth city (Changsha) × preceding segment (vowel) | 0.27 | 0.56 | 13778.73 | 0.474 | .636 |
| word-initial consonant (/n/) × birth city (Meizhou) × following vowel (non-/i/) | 1.89 | 0.59 | 13803.08 | 3.186 |
|
| word-initial consonant (/n/) × birth city (Changsha) × following vowel (non-/i/) | 1.30 | 0.50 | 13800.93 | 2.596 |
|
| word-initial consonant (/n/) × birth city (Meizhou) × coda (no coda) | 1.92 | 1.09 | 13723.22 | 1.758 | .079 |
| word-initial consonant (/n/) × birth city (Changsha) × coda (no coda) | −1.32 | 0.89 | 13782.40 | −1.483 | .138 |
p < .05. **p < .01. ***p < .001.
Funding
The authors received no financial support for the research, authorship, and/or publication of this article.
Declaration of Conflicting Interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Data Availability Statement
The data presented in this study are available upon request.