
Abstract
This study investigated the effect of a 12-session, implicit perceptual-motor training program on decision-making skills and visual search behavior of highly skilled junior female karate fighters (M age = 15.7 years, SD = 1.2). Eighteen participants were required to make (physical or verbal) reaction decisions to various attacks within different fighting scenarios. Fighters’ performance and eye movements were assessed before and after the intervention, and during acquisition through the use of video-based and on-mat decision-making tests. The video-based test revealed that following training, only the implicit perceptual-motor group (n = 6) improved their decision-making accuracy significantly compared to a matched motor training (placebo, n = 6) group and a control group (n = 6). Further, the implicit training group significantly changed their visual search behavior by focusing on fewer locations for longer durations. In addition, the session-by-session analysis showed no significant improvement in decision accuracy between training session 1 and all the other sessions, except the last one. Coaches should devote more practice time to implicit learning approaches during perceptual-motor training program to achieve significant decision-making improvements and more efficient visual search strategy with elite athletes.
Introduction
Decision-making skills are an important aspect of sport performance (Starkes & Ericsson, 2003). In combat sports, these skills are highly valued, as experts are required to read their opponents’ intentions to avoid being hit, as the time required for a defender to execute a move is short, once an opponent has initiated an attack (Fontani, Lodi, Felici, Migliorini, & Corradeschi, 2006). Consequently, anticipation is vital—as highlighted in the extant literature investigating time-sensitive interceptive actions (Roi & Bianchedi, 2008). In karate, Mori, Ohtani, and Imanaka (2002) investigated the decision-making performance of both expert and novice athletes using videotaped scenes of opponent’s offensive actions, which simulated the athletes’ view in real situations. The participants were asked to decide, as soon and as accurately as possible, whether the offensive action would come to the upper or the middle level of their bodies. Expert fighters were more accurate than their less skilled counterparts in predicting the direction of opponents’ offensive action. In addition, results highlighted the capacity of experts to predict the level of the attack at the onset of the move. This asset of combat experts has also been confirmed in French boxing (Ripoll, Kerlirzin, Stein, & Reine, 1995) and taekwondo (Milazzo, Rosnet, & Fournier, 2015).
The superiority of the experts in making quick and accurate decisions can be explained by their capacity to pick up earlier-occurring kinematic information from their opponents that forecasts the ensuing movement (for a review, see Abernethy, Farrow, Gorman, & Mann, 2012). In a meta-analysis, Mann, Williams, Ward, and Janelle (2007) found that experts use a more efficient visual search strategy involving fewer fixations of longer duration to less disparate areas of a display. Some exploratory studies have supported the existence of expert–novice differences in visual search behavior in combat sports such as karate (Williams & Elliott, 1999) and taekwondo (Lee, Kim, & Younghoon, 2010). For example, Ripoll et al. (1995) noted the use of a “visual pivot” among expert French boxers in order to diffuse attention according to the requirements of the task. Specifically, experts tended to maintain foveal vision on central regions of the opponent’s body, while simultaneously using peripheral vision to pick up information from the hand or foot regarding the initiation of an attack.
Over the last decade, a growing number of studies have shown that anticipatory skill can be improved by perceptual-motor training programs based on video simulation (see Farrow, 2014 for a review). The effectiveness of perceptual-motor training to improve decision time and/or decision accuracy has been shown across a large range of individual and collective sports (see Farrow, Chivers, Hardingham, & Sachse, 1998; Gorman & Farrow, 2009; Hopwood, Mann, Farrow, & Nielsen, 2011). Despite the interest from both coaches and researchers, only a small body of empirical work has examined whether the benefits of perceptual-motor training can be transferred to on-field sporting success (Hopwood et al., 2011). Moreover, the bulk of perceptual-motor literature has focused on lesser skilled performers with little consideration given to whether skilled performers can also benefit (e.g., Williams, Ward, & Chapman, 2002). An exception is Hopwood et al. (2011), who reported that on-field training combined with video-based interventions leads to improved decision-making performance of skilled cricketers in field-based tests compared to on-field training alone. Recently, Lorains, Ball, and MacMahon (2013a) also confirmed the successful transfer of learning from video-based training to real game performance with elite Australian football players.
A range of studies has compared the effectiveness of different methods of instruction used in perceptual-motor training in order to optimize the learner’s experience. That is why an implicit learning approach has been suggested to avoid the negative consequences of learning with instruction techniques (i.e., explicit learning), which leads to a form of “paralysis by analysis.” Specifically, researchers suggested that explicit learning leads to a reinvestment of effort toward more explicitly acquired knowledge under stressful conditions (Masters, 1992; Maxwell, Masters, & Eves, 1999; Smeeton, Williams, Hodges, & Ward, 2005). During video-based perceptual training, in order to encourage an explicit learning mode, the video sequence (i.e., the game sequence) is typically shown a second time. The full game sequence is therefore replayed so that the learner can judge the accuracy of his decision. In addition to this, between each video sequence, the coach can help the athlete make a connection between the information gleaned from observation of the action and the result of that action. For example, the coach can indicate to the player the positions of teammates on the screen or the different postures or positions of an opponent and thus lead him to associate with each position, a game sequence or “if-then” rules. The goal of this type of training sequence is to increase the quantity of declarative knowledge (i.e., knowing “what to do,” see McPherson, 1994) of the learners so that they can more readily understand the meaning of information picked up from the environment. Results show that explicit instructions favor rapid acquisition of conscious and verbalizable knowledge (see Smeeton et al., 2005).
In contrast, implicit motor learning is “the acquisition of a motor skill without the concurrent acquisition of explicit knowledge about the performance of that skill” (Maxwell, Masters, & Eves, 2000, p. 111). The goal of this approach is to minimize the accumulation of explicit knowledge and also the propensity of participants to reinvest knowledge during performance which could upset the automatic execution of decisions. During video-based perceptual training, to encourage an implicit learning mode, researchers have removed verbal instructions and just encourage participants to focus their attention on potential areas of interest that may anticipate the outcome of situations. For example, Smeeton et al. (2005) found that decision-making performance was more robust under anxiety-provoking conditions when participants used implicit perceptual training, compared to an explicit learning approach. In European handball, Abernethy, Schorer, Jackson, and Hagemann (2012) compared the efficiency of different perceptual training approaches for the improvement of anticipation using a goalkeeping task. Authors confirmed the superiority of decision-making performance in an implicit learning group under the stress situation to predict the direction of the shot in comparison to explicit and verbal cuing groups. In this sense, the implicit approach could be particularly recommended with skilled athletes who are frequently subjected to high pressure situations.
During learning, explicit processes use working memory to identify and correct errors during the learning process so as to only store relevant information (Baddeley & Wilson, 1994). Typically, learners conceive and test hypotheses in a strategic, trial-and-error fashion. Masters and Poolton (2012) argued that implicit processes allow the encoding of new information without the involvement of verbal working memory. One method proposed by the authors to develop implicit learning is by removing outcome feedback (i.e., knowledge of results). Here, learners would be unable to test the relevance of decisions and the concomitant increase of explicit knowledge would be minimal. In this way, working memory is not involved, and the acquired knowledge remains unconscious and non-verbalizable (Kellogg, 1982). In combat sports, Milazzo, Fournier, and Farrow (2014) have shown significant improvements in perceptual skills with elite male karate fighters after a perceptual-motor training program without outcome feedback during learning. In that study, participants completed six video-based training sessions where they reacted to temporally occluded video footage of typical combat situations during which they had to mime, as rapidly and as accurately as possible, the action which they would have carried out in the observed situation. Results showed that participants who received “no-feedback” video-based perceptual training significantly enhanced their decision making relative to both control and motor training groups. Another method recommended by researchers to prevent the participant from consciously engaging in error-checking is the use of a secondary task (Masters & Poolton, 2012). For example, Masters (1992) successfully created implicit learning conditions by asking golf players to generate random letters during the execution of the putt. With the same success, Gorman and Farrow (2009) required basketball players to identify a high-pitched tone randomly inserted between several low-pitched tones during a video-based decision-making task.
Overall, to date, the effectiveness of implicit perceptual training to improve perceptual skills has been somewhat equivocal (e.g., Abernethy et al., 2012; Farrow & Abernethy, 2002; Gorman & Farrow, 2009; Jackson, 2003; Poulter, Jackson, Wann, & Berry, 2005). For example, Gorman and Farrow (2009) showed a statistically equivalent increase in decision accuracy for both explicit and implicit groups from pre- to post-test with skilled basketball players after a video-based training program. In football, Poulter et al. (2005) revealed a non-significant improvement in the implicit group during the very early stages of learning the perceptual-motor anticipation task of predicting ball direction of penalty kicks. Also, in a reanalysis of the data from Farrow and Abernethy’s (2002) study of implicit perceptual training, Jackson (2003) concluded that Farrow and Abernethy’s study provides no evidence that an implicit perceptual training paradigm improves anticipatory performance more than either an explicit learning paradigm or, indeed, an intervention involving mere observation of tennis matches. The lack of consensus should encourage researchers to continue investigating the effect of implicit learning during the acquisition of cognitive, perceptual, and motor skills. This is a key issue to be addressed in the current study.
In order to explain the demonstrated improvement of perceptual skills, it is assumed that after a perceptual-motor training program, players become more able to identify important postural cues using salient information from the relative motions of the body (Abernethy, Zawi, & Jackson, 2008). However, few studies have measured the effect of perceptual-motor training on visual search behavior. In one exception, Poulter et al. (2005) examined the effect of explicit and implicit instruction approaches on point-of-gaze in novice goalkeepers facing penalty kicks. Participants in the explicit learning group were given instructions about the relationship between postural cues and subsequent penalty kick direction, accompanied by still images to highlight key regions, whereas participants in the implicit learning group were given feedback after each trial in the form of knowledge of results. In addition, participants in the implicit group were told to estimate how fast the ball would travel after it had been kicked, based on information provided by the player prior to the occlusion point, thus ensuring that players did not generate hypotheses related to kick direction. From a theoretical perspective, the use of concurrent secondary tasks is supposed to prevent the accumulation of accessible task-relevant knowledge by overloading the working memory capacity (Masters, 1992). Findings showed that only the explicit perceptual-motor training program resulted in changes in eye movement, with novice football players spending a greater proportion of time looking in the direction of information-rich areas that corresponded to the instructions given to them during the acquisition phase (e.g., the legs). In contrast, Lorains, Panchuck, Ball, and MacMahon (2014) showed that an implicit learning intervention resulted in changes in eye movement behavior of expert football players. Specifically, it was demonstrated that, following a five-week video decision-making training program, the visual fixation duration of athletes became longer compared to those who had no video training. The differences of protocol designed in these studies, such as the mode of responses (oral vs. press button) or the level of expertise (novice vs. expert), could explain the differences in findings.
Unfortunately, because of the use of simplistic responses, such as button pressing (see Lorains et al., 2014) and verbal responses (see Poulter et al., 2005), both these studies failed to replicate closely the actions in the training environment to those in the performance environment (Broadbent, Causer, Williams, & Ford, 2015). However, to date, researchers highlighted the necessity to develop training protocols based on the same athletes’ response (i.e., fidelity of response) to those in a competitive situation to improve the transfer of learning from training to competition performance (see Broadbent et al., 2015; Pinder, Davids, Renshaw, & Araujo, 2011; Pluijms, Canal-Bruland, Kats, & Savelsbergh, 2013). Indeed, according to Gibson (1979), perception and action are functionally interdependent, and any experimental approach that manipulates one, may unintentionally alter the other. For example, Farrow and Abernethy (2003) showed that experts are more accurate in predicting the direction of an opponent’s service in situ under coupled (i.e., motor) rather than uncoupled (i.e., verbal) response-mode conditions. A recent meta-analysis of perceptual-cognitive skills studies showed that the closer the action completed in a simulated environment is to the current action required in a sport, the better are the advantages of the expert over the novice (see Travassos et al., 2013). However, in contrast, some researchers have found no difference between coupled and uncoupled responses in perceptual-cognitive skill studies (Ranganathan & Carlton, 2007; Williams, Janelle, & Davids, 2004).
The present study sought to determine the effect of implicit perceptual-motor training on the decision-making skills and underlying gaze behavior of junior skilled female karate fighters. During video-based tests, participants either made physical (perception-action coupled responses) or verbal decisions (uncoupled responses) about various attacks in different fighting scenarios to determine the influence of perception-action coupling during implicit learning. It was first hypothesized that the implicit perceptual-motor training group would show equivalent or superior improvement in decision-making performance in post-test video testing compared with a motor training group (placebo) and control group. It was also hypothesized that there would be a significant improvement in decision accuracy for the implicit group only in the on-mat test, where it was predicted that participants would experience increased stress relative to the video-based tasks. Relatedly, if perceptual training was implicit in nature, the number of explicit rules accumulated during the training would not significantly increase over the intervention period. Based on the perceptual skills literature, it was hypothesized that a sufficient period of perceptual-motor training would result in changes in gaze behavior, highlighted by improvements in visual search strategy. These improvements would be supported by an increase in the mean of fixation duration and a decrease in the mean number of fixations.
Method
Participants
Eighteen highly skilled junior female athletes practicing karate who were part of the same training group in a national center volunteered to participate (implicit perceptual-motor training group: n = 6; motor training group: n = 6; control group: n = 6). Participants’ ages ranged from 14 to 18 years (M = 15.7, SD = 1.2) and all had fought at the international junior level. All athletes practiced karate for an average of 15 hours per week and competed for an average of eight years. The current research was a part of a larger training intervention during the regular season. Informed consent was obtained from the child and her guardian prior to participation; institutional ethical approval was also received.
Test and training film construction and presentation
The footage used during the video-based test and video-based training sessions presented sequences of international competitions filmed at fighter’s eye level, at a distance of 5 m from the center of the mat. This perspective provided vision of the two fighters at the same time. The film sequences were edited to produce 60 sequences for video-based decision-making tests and 360 sequences for video-based training sessions. Footage chosen for the respective test and training films was different to control for familiarity effects. All video sequences were edited by a national coach with customized video editing software (React). Each sequence was then submitted for the approval of two other international level coaches through the use of a Likert-type scale ranging from 1 to 3 (one point for each criteria: perspective, time of occlusion, and clarity of situation). Only those sequences that were rated above 2 by both coaches were included in the test or training films. Both testing and training sessions consisted of 30 sequences each separated by a 5-s inter-trial interval producing a total session time of 8 minutes. In the video sequences, the participant was required to place herself in the role of one of the two fighters. To avoid difficulties related to the identification of the participant with her persona (red or blue uniform), only the footage in which her persona was seen from behind or in profile was shown. Furthermore, the color associated with the participant’s persona was stated at the beginning of the sequence and did not change throughout the test or the training session. Then a fight sequence, which lasted between 4 seconds and 10 seconds, was played to the participant. The footage was then interrupted by a white frame at the moment the expert coach considered it appropriate for a decision to be made (Figure 1). This occlusion corresponded to one of the three following situations which were randomized in each test and training session: (1) after the beginning of an attack by the opponent, at the moment of the translation of the center of mass of the opponent forward, (2) during a move, at the moment when the opponent no longer has support from the floor when she is crossing her legs or at the moment of the second leaning of the forward leg on the floor, or (3) after a fake movement. To provide appropriate context, several actions were performed by both fighters on the screen just before the occlusion. In order to prevent the athletes from consciously verifying their decision accuracy, the result of an action sequence was not reported.
Schematic representation of a video sequence during video-based test and training session.
Test apparatus and procedure
Video-based decision-making test
Film was shown to the participants with a Sony KP44 PX2 video projector on a 3 × 2 m wall in order to recreate real viewing conditions as accurately as possible. Participants were positioned 2.50 m from the wall in a fighting stance (a ready-to-hit position) and hopping (on both legs) as is customary in shadow fighting—on which the test and training scenarios were based.
To examine the effect of perception-action coupling on the athletes’ decision-making skills, both coupled and uncoupled response conditions were used. The coupled condition required the athlete to mime the action, in as little time as possible, similar to the action she would have taken had she been in the fight situation shown at the moment of occlusion. In the uncoupled condition, participants had to say out loud, as soon as possible, the name of the action they would have chosen in the fight as soon as the screen was occluded. All participants watched a total of 60 sequences of fight in their test session (30 sequences in the coupled condition and 30 in the uncoupled condition). Each fighter completed all required trials for each response condition. Response conditions (coupled or uncoupled) were therefore blocked for each athlete but the order of presentation of the response conditions was counterbalanced across athletes.
Due to the sensitivity of the mobile eye-tracking system, the gaze behavior of participants was recorded only during the uncoupled condition. Before beginning, participants were given a brief introduction concerning the eye-tracking system (Mobile Eye, ASL, Bedford, MA), which they positioned on their heads. The Mobile Eye system is a head-mounted display which computes point-of-gaze and indicates the point-of-gaze by superimposing a positional crosshair on the video scene. This information is calculated with regard to a pre-calibrated nine-point grid overlaid onto the screen. Participants were asked to keep their heads stable and to move only their eyes during calibration, after which calibration accuracy was checked by asking the participants to fix their gaze on different objects in the task environment. Each session was filmed by a camera to record both the video projection of the fight situations and each of the participants’ responses.
On-mat test
In this task, participants were required to make decisions and react to various attacks within different fight scenarios against a standardized expert opponent (National Coach and former international competitor). As is the case in karate competitions, the participants were required to “touch” their opponent quickly as possible without being hit. This test condition was included for two reasons. First, to provide a measure of transfer and second, to ascertain the influence of increased stress due to the possibility of being hit relative to the video-based testing conditions. It is argued that skills learned implicitly are more stress resistant (Masters, 1992). The sequences were the same as those shown during the training and the video test. Ten fight situations which consisted of two different moves by the opponent (i.e., a move on the right and a move on the left), two fake movements (i.e., a body feint and a kick feint), and six attacks based on six different karate techniques either aimed at the participant’s body or face, were chosen beforehand and known by the standardized expert opponent. Specifically, the six attacks were made of three punches, two of which were aimed at the body and one of which was aimed at the head; also three kicks, one of which was aimed at the body and two of which were aimed at the head. The fight situations were carried out in the same order and were the same for all participants. During the on-mat test, the two fighters came back to the same mat position between each sequence and stood face-to-face without moving for a few seconds at a distance of 2 m. Then, the experimenter issued a verbal command to inform the fighters of the beginning of the new fight sequence. The test was filmed on each occasion in order to analyze the decision times and the accuracy of each of the 10 decisions.
Verbalizable rules questionnaire
This task required participants to describe the key factors they considered when they made a decision during a fight. Specifically, verbalizable rules questionnaire consisted of pen-and-paper responses to the sole question, “Where do you focus your attention when making decisions during a fight?” With no time limit to answer, participants were asked to report explicit rules in the form of if-then statements. Examples of explicit rules reported included: “If my opponent attacks with the open side, then I defend with this move.”
Statements not referring to anticipatory cues or pattern-recognition principles of decision making in a fight were excluded, as, for instance: “I try to surprise my opponent to see how she reacts.” The questionnaire answers were scored by a specialist researcher in combat sport, by summing up the number of rules described by each participant (Masters, 1992). This method was used in the past to measure the success of an implicit learning intervention (Lam, Maxwell, & Masters, 2009; Poolton, Masters, & Maxwell, 2006). A large repertoire of verbalizable rules was taken as evidence of explicit knowledge development (Gorman, & Farrow, 2009).
Measures
Participants performed the same battery of tests twice, prior to a three-week training intervention (pre-test) and 24 hours after the completion of the training intervention (post-test). During pre- and post-test, participants performed the four tasks randomly: a video-based decision-making test in the coupled condition, a video-based decision-making test in the uncoupled condition, the on-mat test, and then the verbalizable rules questionnaire. Following the pre-test, participants were randomly divided into three groups—an implicit perceptual-motor training group, a motor training group, and a control group. No significant difference between the groups for each dependent variable was found at the start of the experiment (p < .05).
Training procedures
At the moment of this study, all athletes trained together in a national training center. As a consequence, all of them completed the same on-mat training program with the same national coach during the experimental intervention. Most of the time, the implicit perceptual-motor training and the motor training took place at the same time just before the second and last on-mat session of the day. Then, fighters from each group (i.e., control group included) completed the same on-mat training session.
Implicit perceptual-motor training group
Training was conducted over three weeks, at four sessions a week. In total, each athlete watched 360 sequences, that is to say, 95 minutes of video simulation or approximately 8 minutes per training session. The perceptual training sessions were similar to the video-based testing sessions but only in the coupled condition. So, fighters had to mime their decisions. To create implicit learning processes, no instruction about where participants should direct their attention was given during or after the training sessions. In addition, participants were required to respond to a concurrent secondary task by counting forward out aloud in two’s starting from zero (i.e., 0, 2, 4, 6… ). Each training session was filmed so as to allow the analysis of the decision accuracy in each scenario.
Motor training group
Participants were required to hit a dummy equipped with luminous targets (stimuli) placed on the head and on the chest. During the training, the aim was to hit the one or several targets illuminating randomly every 2 seconds, as quickly as possible. Each training session was completed individually and lasted for about 8 minutes. As it was the case in the implicit perceptual-motor training, the program consisted of 12 sessions of 30 sequences, conducted over three weeks, at four sessions per week. Participants were given information about the expected positive effects of this instrument on decision-making performance.
Control group
The control group completed each of the tests, and the same regular on-mat training program as experimental groups in order for all participants included in the study to have an equivalent amount of physical practice. The main goal of this group was to ascertain if any improvements in implicit perceptual-motor training may have arisen as a result of test familiarity.
Dependent measures
Decision accuracy
For video-based tests and on-mat tests, two national coaches selected the most appropriate decision for a participant in response to each fight situation. Decision-making accuracy was defined as whether or not the participant decided on the action selected by the coaches as most appropriate for that trial. A correct decision was awarded a score of one. A decision that was incorrect was awarded a score of zero. An overall percentage for decision making was then calculated and used for data analysis.
Gaze behavior
The mean number of visual fixations per sequence, the mean fixation duration per sequence, the total number of fixation locations per sequence, and the percentage viewing time on areas in the display were collected at a rate of 25 frames per second and subjected to a frame-by-frame analysis. As in previous research (e.g., Williams & Davids, 1998), a visual fixation was defined as the period of time (>100 ms) measured when the eye remains stationary within 1.5° of movement tolerance. Randomly selected trials (n = 30) were reanalyzed by the same experimenter and a second researcher, to assess the reliability of the pattern of gaze data. A high interclass correlation was found for intra- (r = .94) and inter- (r = .92) observer agreement (see Thomas, Nelson, & Silverman, 2005).
Mean fixation duration (ms) was the average of all the fixations that occurred during the test. Percentage viewing time was the percentage of time spent fixating any of the defined 17 fixation locations identified on the participant’s opponent. These locations included: front shoulder, rear shoulder, front arm, rear arm, front forearm, rear forearm, front hand, rear hand, trunk, pelvis, front thigh, rear thigh, front calf, rear calf, front foot, and rear foot. A category entitled “herself” was added to assess the visual fixations of the participant on the fighter who corresponded to her persona on screen. A further “unclassified” category was included to account for the fixations that did not fall within any of the areas already referred to.
Statistical analysis
Six athletes participated in 12 implicit video-based training sessions. However, due to injuries, one player did not complete the 12th perceptual training session. Therefore, this last training session was removed from all analyses. For the same reason, two participants failed to complete the on-mat post-test in both the implicit and motor training groups. Therefore, since these athletes were injured, they were removed from the on-mat test analyses.
Decision accuracy of the video-based decision-making tests was analyzed using a 3 × 2 × 2 (Group × Test × Response condition) factorial analysis of variance (ANOVA) with repeated measures on the last two factors. Relevant significant interactions were followed up by a series of fully repeated-measures 2 × 2 (Test × Response condition) analyses of variance conducted separately for each group. The results of the verbal rules questionnaire were assessed to determine the number of rules reported by each participant. A 3 × 2 (Group × Test) mixed-design ANOVA with repeated measures on the last factor was used to analyze the results. Separate 3 × 2 (Group × Test) ANOVAs with repeated measures on the last factor were conducted on the mean number of visual fixations, the mean fixation duration, the total number of fixation locations per trial, and the percentage viewing time on each areas pre-selected. Finally, decision accuracy of the video-based training sessions were analyzed separately only for the implicit perceptual-motor training group using 1 × 11 (Group × Test) mixed-design ANOVA tests with repeated measures on the last factor. For all analyses, significance was achieved when p ≤ .05 and effect sizes stated as partial eta squared. Any significant results were followed up with post-hoc analyses, adjusted where appropriate using the Bonferroni correction factor.
Results
Video-based performance
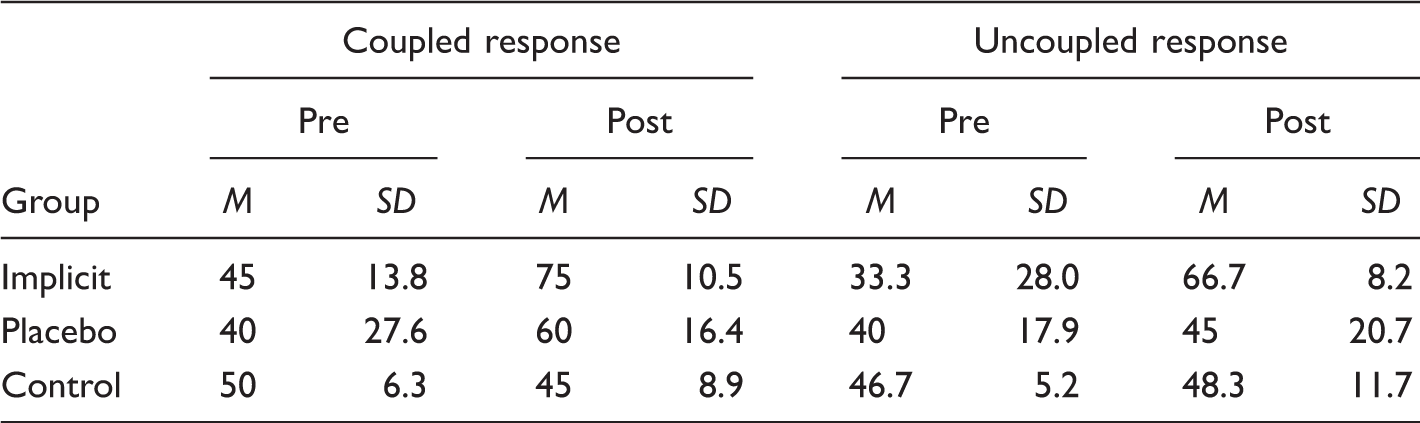
Results from the 3 × 2 × 2 (Group × Test × Response condition) factorial ANOVA showed a significant effect of time of testing, F(1, 60) = 15.25, p < .01, η2 = 0.20, and a significant Group × Test interaction, F(2, 60) = 5.48, p < .01, η2 = 0.15. A post-hoc test with Bonferroni correction highlighted a significant improvement in the decision accuracy for implicit perceptual-motor training group in both coupled and uncoupled response conditions, compared to the motor training group and control group.
Mean decision accuracy (%; with SD) on video-based tests per group across times of testing and mode of response conditions.
Gaze behavior data
Mean fixation duration
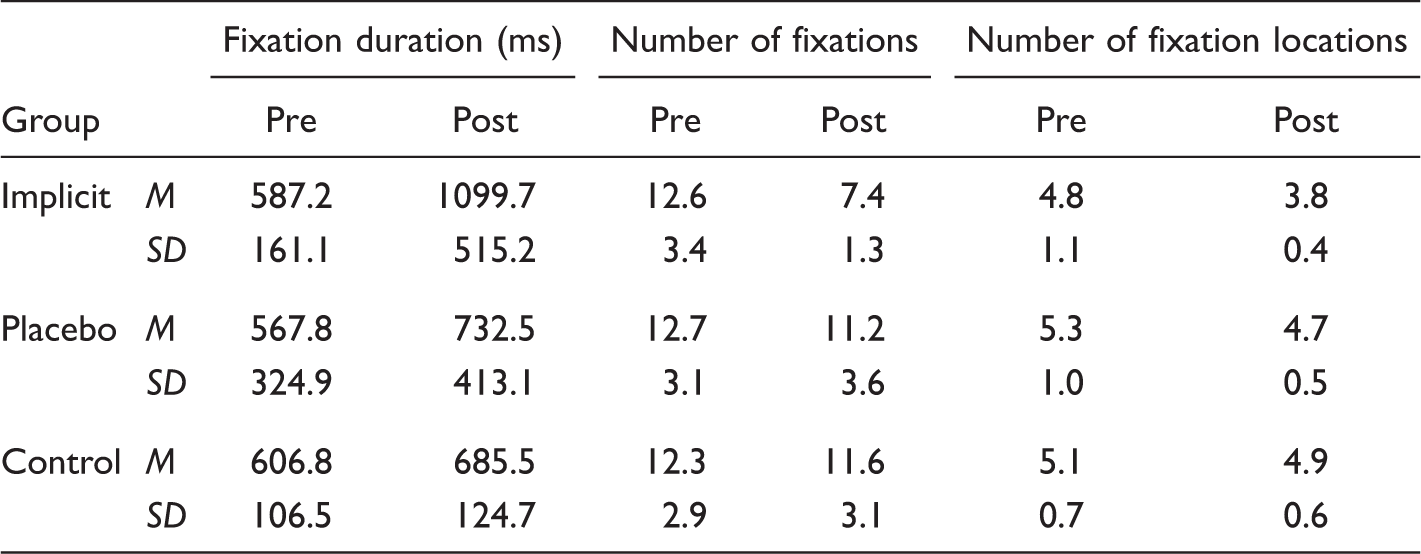
Fixation duration (with SD), number of fixations, and number of fixation locations and (SD) per group across time of testing.
Mean number of fixations
A significant effect of test was found, F(1, 15) = 10.95; p < .05, η2 = 0.42. A post-hoc test with Bonferroni correction showed a significant decrease in the mean number of fixations per trial for implicit perceptual-motor training group, between the pre-test (M = 12.6, SD = 3.4) and the post-test (M = 7.4, SD = 1.3) compared to the motor training group (M pre-test = 12.7, SD = 3.1; M post-test = 11.2, SD = 3.6) and control group (M pre-test = 12.3, SD = 2.9; M post-test = 11.6, SD = 3.1) (Table 2).
Mean number of fixation locations
Despite the biggest decrease in the number of fixation locations for the implicit training group from pre-test (M = 4.8, SD = 1.1) to post-test (M = 3.8, SD = 0.4) compared to the motor training group (M pre-test = 5.3, SD = 1.0; M post-test = 4.7, SD = 0.5) and the control group (M pre-test = 5.1, SD = 0.7; M post-test = 4.9, SD = 0.6), results from ANOVA showed no significant main effects or interactions for the mean number of fixation locations (p < .05) (Table 2).
Percentage viewing time
Mean percentage of viewing time on each area in the display per group across time of testing.

Note. U: unclassified; Hs: herself; T: torso; P: pelvis; H: Head; Far: Front Arm; FrT: Front thigh; FrS: Front shoulder; ReT: Rear thigh; Ffo, Front forearm.
On-mat performance
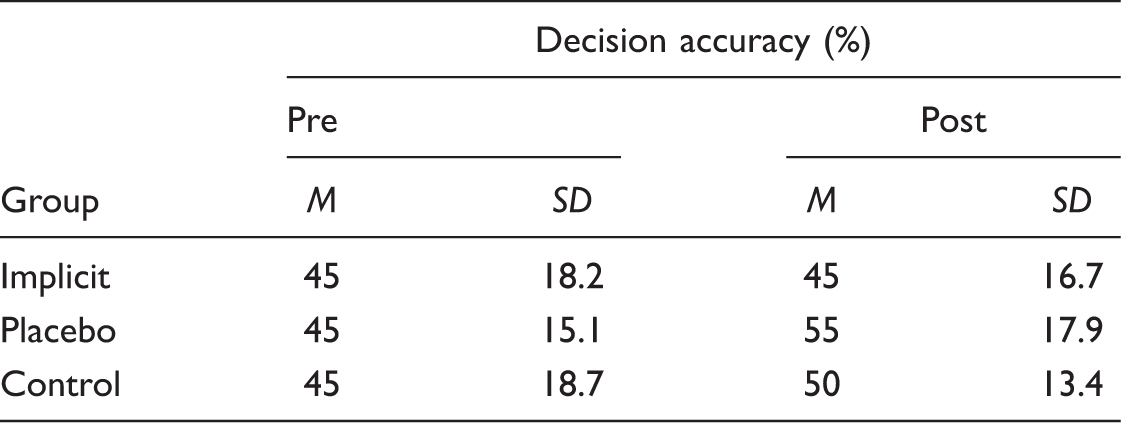
Decision accuracy (%, with SD) on on-mat test per group across time of testing.
Verbalizable rules test
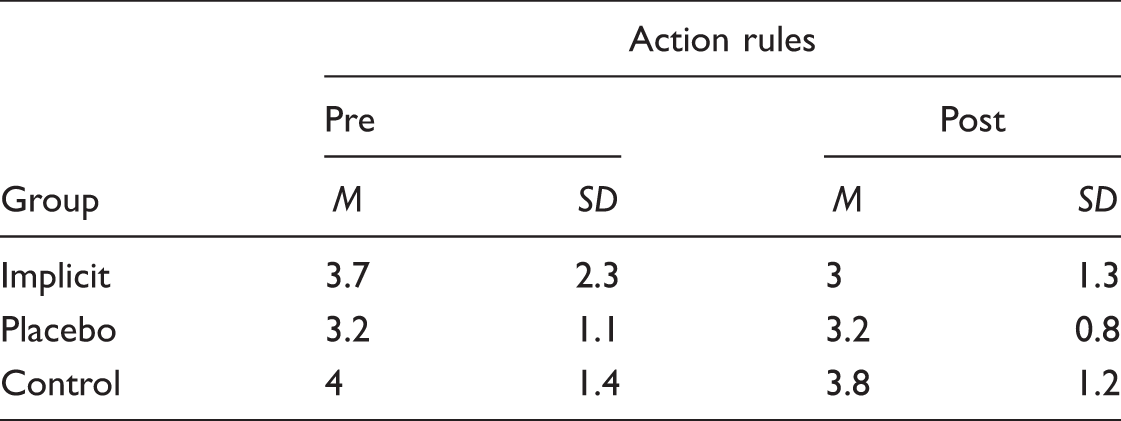
Mean number of action rules (with SD) per group across time of testing.
Training session performance
Analysis of decision accuracy for the implicit perceptual-motor training group from the first to the last training session revealed a significant main effect on training outcomes, F(10, 50) = 2.03, p < .05, η2 = 0.29. This showed that a general improvement in decision-making performance occurred for the experimental group from the 1st to the 11th training session during the intervention period (Figure 2). Bonferroni corrected post-hoc analyses demonstrated no significant improvements in decision accuracy (p > .05) between the 1st training session and each other session before the last one.
Mean decision accuracy performance expressed in % error per video training session for perceptual-motor training group.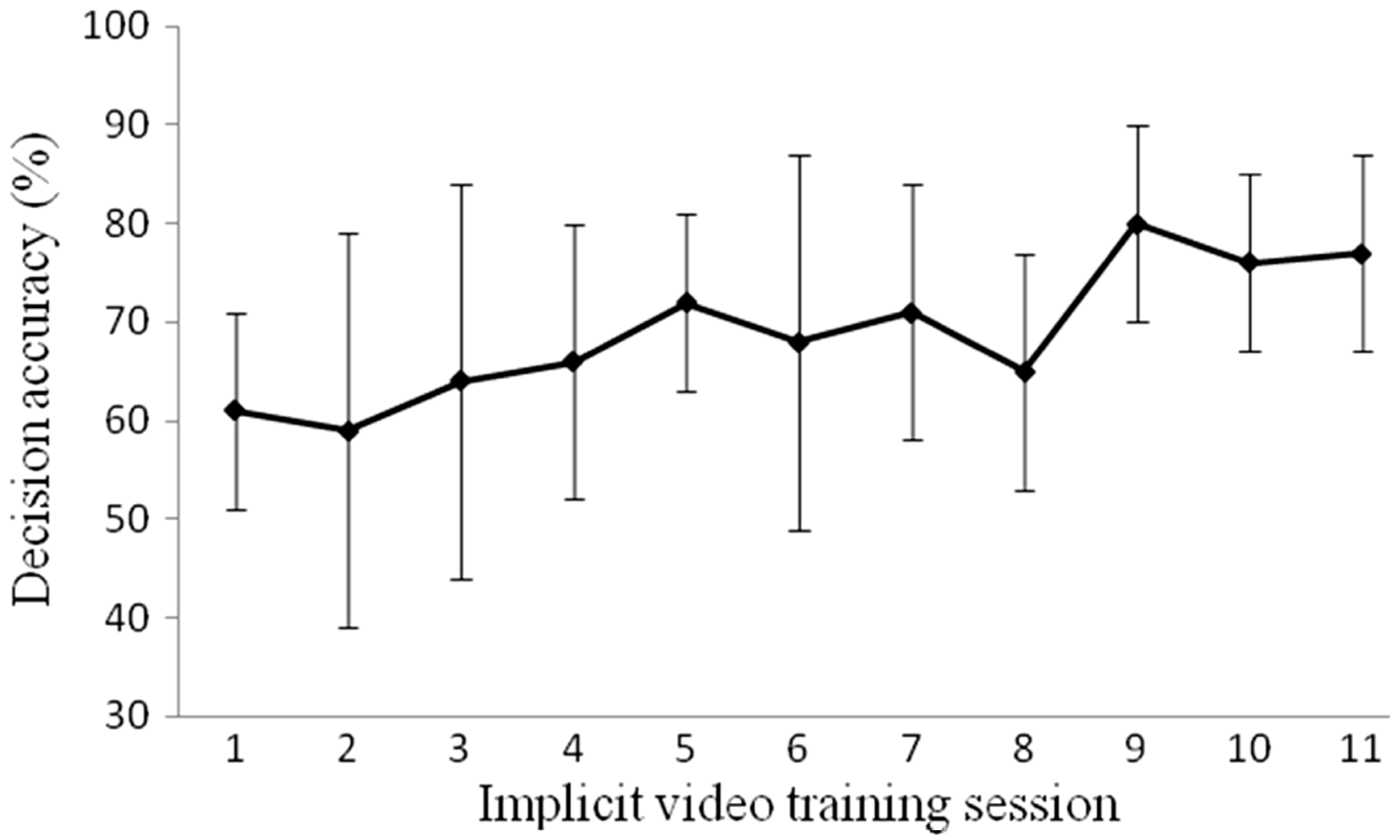
Discussion
The primary aim of this study was to evaluate the effectiveness of an implicit video-based perceptual training program compared to a motor training program to enhance the decision-making skills of highly skilled junior female karate fighters. The study also assessed the relative effects of 12 implicit video-based training sessions on gaze behavior. It was hypothesized that the implementation of the implicit perceptual-motor training program would improve decision-making performance as shown by an increase in decision accuracy without explicit information accrual during video-based training and video and on-mat testing situations. Finally, it was predicted that a sufficient period of practice in video-based simulation would result in strategic changes in gaze behavior.
The data from the video-based training showed that the accuracy of the implicit group significantly increased after three weeks of training. In addition, results demonstrated that there were no significant differences in the total verbalizable knowledge articulated by the participants between the beginning and the end of the training intervention, suggesting that improvement of performance was a case of implicit learning. These findings are consistent with other perceptual training studies (e.g., Farrow & Abernethy, 2002; Smeeton et al., 2005). This suggests that the acquisition of implicit task-specific knowledge during training enabled participants in the perceptual training group to identify and interpret environmental cues to better understand the situations presented. The improvement of performance during training is likely to be mediated by the high level of expertise of participants in the current study (see also Smeeton et al., 2005). Indeed, expert fighters would possess a degree of structured declarative knowledge that might act to support further knowledge acquisition, without the need for explicit instruction (Chase & Ericsson, 1982; Smeeton et al., 2005). According to Ericsson and Kintsch (1995), experts appear to be able to increase storage capacity and efficacy of information processing in short-term working memory through the establishment of retrieval structures in a specific memory structure, the so-called long-term working memory. We can assume that during the perceptual-motor training program, the high frequency use of implicit task-specific knowledge enabled the development of retrieval structures in long-term working memory promoting effective responses to familiar situations and to deal with new situations (Zoudji, Thon, & Debû, 2010). In addition, similar to the mechanisms involved in short-term priming repetition protocol, it is possible that the first fight situations presented in video clips were stored and tagged in Long Term Memory and then were efficiently retrieved, thanks to retrieval structures when the same type of situation presents itself anew (Ericsson, 2004; Zoudji et al., 2010).
The session-by-session analysis of decision accuracy is a relatively unique contribution to extant literature in perceptual-motor training. The present results indicated no significant improvement between the first training session and subsequent sessions (except the last session). These results suggest that when using an implicit training approach, sufficient time is necessary (the observation of 330 fight sequences in the current study) before a significant improvement can be observed. Indeed, implicit training leads athletes to find solutions to problems by themselves, which explains why the progression in performance may be slower but also why implicit learning may show greatest resistance to performance loss over the extended retention period (Abernethy et al., 2012). The progressive change in performance measured during the perceptual training program suggests that this is a meaningful improvement rather than a result of increased test familiarity or habituation, as it is supported by the observation of rapid improvements in first trials with implicit reaction time protocols. This result could also be explained by the use of concurrent secondary tasks which tend to limit performance enhancement with regard to the primary task (Poulter et al., 2005).
Consistent with previous work (e.g., Smeeton et al., 2005), analysis of video-based decision accuracy from pre- to post-intervention revealed a significant increase for the implicit perceptual-motor training group only. In addition, it is important to note that means were higher in the coupled condition relative to the uncoupled condition. This is consistent with previous research (see Farrow & Abernethy, 2003; Farrow, Abernethy, & Jackson, 2005). According to Fitts and Posner model (1967), experts acquired through extensive practice and more proceduralized and automated skills (autonomous phase). As a result, the nature of the verbalized response condition may disrupt the automated functioning of decisions (Farrow & Abernethy, 2003). Interestingly, there was an unexpected increase in the decision accuracy of the motor training group from pre-test to the post-test in the coupled response mode. This improvement can be explained by the use of interactive motor training as a placebo task, which may have created a level of expectancy that is commensurate with that experienced by the implicit perceptual-motor group.
Analyses of gaze behavior demonstrated that there was a significant change in the mean fixation duration and number of fixations for the implicit group from the pre- to post-test while percentage viewing time did not reveal any significant effects. It appears that participants in the implicit perceptual-motor training group used fewer fixations of longer duration than the athletes in both the motor training and control groups. This is consistent with previous research demonstrating that expert fighters have less exhaustive visual search strategies relative to novices (Ripoll et al., 1995; Piras, Pierantozzi, & Squatrito, 2014). These findings suggested that perceptual-motor training can increase the visual search efficiency. Further, the results highlight that improvements in decision accuracy are likely to be a result of a more refined ability in perceptual-motor training group to pick up subtle postural cues and to ignore irrelevant sources of information (Goldstone, 1998). As suggested by Williams and Elliott (1999), reduced search rate appears to be an effective strategy for making decisions because the saccadic eye movements that separate each visual fixation, which are inactive periods of information processing, are less numerous. Recently, Lorains et al. (2014) have confirmed the modification of point-of-gaze with elite football players after the implementation of a video-based training program without the use of explicit instructions. However, the present results contrast with those of Poulter et al. (2005) who did not find any changes in gaze behavior after an implicit perceptual-motor training of only 96 trials. This difference may be due to the respective length of the interventions.
In general, it appears that participants in all groups were rarely focused on peripheral areas such as the feet, the hands, or the calves. On the contrary, the majority of visual fixations were directed to central areas of the opponent’s body such as the torso and the pelvis. The torso-pelvis region is an important information cue for it indicates the opponent’s intention. As reported for experts in karate (Williams & Elliott, 1999) and French boxing (Ripoll et al., 1995), all athletes in this study appeared to use an effective “visual pivot” strategy to maintain point-of-gaze on upper central body regions while simultaneously scanning front peripheral cues such as the front shoulder and the front thigh. In addition, in line with previous research in fencing (Hagemann, Schorer, Canal-Bruland, Lotz, & Strauss, 2010), participants spent long periods fixating on “unclassified” areas on screen, which corresponded, in general, to fixations which were near the opponent’s body. These data highlight the use of a second “visual pivot” by experts and confirm the combined use of foveal vision to undertake a comprehensive analysis of the situation, and of peripheral vision to pick up the relative movement pattern (Williams et al., 2004). For elite athletes, it may be that each specific information source is less important than the relative motions between these areas (Abernethy, Gill, Parks, & Packer, 2001; Savelsbergh, Williams, Van der Kamp, & Ward, 2002; Ward, Williams, & Bennett, 2002). It is also interesting to note that participants in both groups spent at least 40% of total fixation time looking at the participant who corresponded to her persona on screen. This result could explain the improvement of decision accuracy in the current study in light of observational learning framework (Bandura, 1969). Indeed, according to Bandura (1969), an individual acquires information about that situation and about the consequences of specific actions in that situation through observation of another’s behavior in a particular situation. In the present experiment, several actions performed by both fighters were presented in each video sequence just before the occlusion. So, it is possible that participants have reproduced relevant decisions made by their persona on screen before the occlusion in previous sequences during later presentations of the same type of fight sequences at the moment of occlusion.
The present experiment demonstrated the efficacy of implicit perceptual-motor training to enhance the perceptual skills and decision-making performance of skilled karate fighters. The results suggest that skilled fighters used more effective visual strategies (reduced search rate) to make accurate decisions after a period of implicit training. Coaches should devote more practice time to implicit learning approaches to achieve significant improvements. However, the lack of significant differences between the implicit perceptual-motor, the motor, and the control groups in the on-mat test highlighted some limitations in the current study. First, because of some demonstrations of transfer success in perceptual training situations, it is possible that a larger sample size would yield further performance differences in transfer test, although additional statistical analysis did not show the presence of outliers (see Gabbett, Rubinoff, Thorburn, & Farrow, 2007; Williams et al., 2002). Second, it is possible that we did not provide enough perceptual learning re-coupled with the action to transfer the anticipatory skills acquired during training back to the field to ensure the significant improvements of performance. For example, it is essential for fighters to keep a proper distance from an opponent, to prevent the opponent from making attacks, and to score during a match (Mori et al., 2002). However, the viewing perspective chosen for the video simulation sequences provided at least visual information about the distance between both fighters on the screen.
In future research, it would be worthwhile to study the influence of the fighting distance on the participants’ visual search strategies and determine whether foveal or peripheral vision is used more heavily depending on whether the opponent is far or near (see also Hristovski, Davids, Araujo, & Button, 2006). It should be noted that the on-mat situation puts at stake the fighters’ physical well-being. Thus, the fear of getting hurt in this kind of test may have influenced the results obtained. We assume that the development of notational analysis methods in real game situations, such as the works of Lorains, Ball, and MacMahon (2013b) will be a good way to improve the effectiveness of assessing decision-making performance.