
Abstract
Speech conveys rich paralinguistic information, notably the speaker’s emotional state. The acoustic expression of emotion, however, is subject to considerable variability shaped by factors such as speaker and listener gender, as well as broader cultural and linguistic contexts. This study investigates how four emotions - Happy, Sad, Angry, and Anxious - are perceived by 33 native Korean listeners. The stimuli consisted of low-pass filtered emotional utterances from ‘The Open AI Dataset Project (AI-Hub)’, which allowed for a focus on prosodic cues while removing semantic content. Results showed that recognition accuracy varied by both emotion and speaker gender: Happy was most consistently identified across all voices, while Angry was more accurately recognized in male speech and Sad in female speech. Perceived emotional intensity also differed by speaker gender: female speakers received higher intensity ratings for Happy than male speakers. In particular, female speakers’ Happy and Sad were perceived as more intense than their own Angry. These results are discussed in light of perceptual weighting of acoustic cues in emotion recognition, suggesting that gendered voice characteristics modulate how listeners extract emotional meaning from prosody alone.
Introduction
Speech communicates more than just linguistic messages; it also conveys paralinguistic information, such as the speaker’s emotional state. Both the transmission and perception of emotions are crucial in communication as they facilitate a deeper understanding and connection between individuals, going beyond the literal interpretation of words. For example, the tone of voice, facial expressions, and body language can alter the meaning of what’s being said, helping listeners interpret intent - whether it’s sarcasm, irritation, or sincerity. Additionally, emotions significantly reflect social norms and cultural expectations, shaping how people express themselves in various sociocultural contexts. Being able to recognize and interpret these cues is especially important in cross-cultural communication, where words alone often aren’t enough.
In the vocal domain, emotional state is expressed and perceived in three steps: encoding, transmission, and decoding (Scherer, 2003). Several acoustic cues are used to encode prosodic patterns conveying a speaker’s emotional state, and the variations in these cues have been shown to depend on the speaker’s gender. For instance, Scherer et al. (1991) found an interaction between emotion and speaker gender in English, with female speakers showing greater harmonic energy in the low-frequency range for anger, neutral, and joy, which reflects a steeper spectral tilt. They also noted gender differences in the lowest 5% of extracted fundamental frequency (F0) values, used as a speaker’s physiological baseline, with the largest difference observed in fear, followed by joy, neutral, sadness, and anger. Building on this, Biersack and Kempe (2005) explored how happiness is vocally expressed and perceived in Scottish English. Their study revealed that F0 range was a reliable cue for happiness only in female speakers. While listeners generally associated happiness with a higher F0, wider F0 range, faster speech rate, and reduced jitter, the only cue that consistently bridged reported and perceived happiness across genders was the first formant (F1), likely reflecting lip spreading during smiling. However, Biersack and Kempe (2005) reported the weak correlation between self-reported emotional states and listener judgments, challenging the assumption that vocal expressions directly reflect internal affect. Rather than accurately decoding speaker intent, listeners may rely on generalized acoustic patterns, especially those stereotypically linked to happiness, even when these do not align with the speaker’s true emotional state.
This tendency to over-rely on vocal cues may contribute to inconsistencies in emotion recognition. As a result, identification accuracy varies depending on the specific emotion, the speaker’s gender, and the listener’s gender. Some studies report high error rates for anger (e.g., Sauter et al., 2010, in British English), while others find anger to be among the most accurately identified emotions, second only to sadness (Sen et al., 2017, in Singaporean English; Coulombe et al., 2024, in Quebec French). Regarding speaker gender, Coulombe et al. (2024) observed that emotions were detected more accurately when produced by female speakers than by male speakers in Quebec French. Furthermore, Lausen and Schacht (2018) found that the effect of speaker gender on emotion recognition varied depending on both the emotion and the linguistic form of the stimulus. In their study of the emotion present in German, female speech was more accurately identified than male speech when listeners were presented with full sentences or affected bursts (e.g., simulated laughter or crying). In contrast, the emotion present in male speech was more accurately recognized when the stimuli consisted of words or pseudo-words. The authors suggest that this pattern may be due to the nature of pseudo-words, which strip away lexical meaning and compel listeners to rely solely on prosodic and acoustic cues. In such conditions, male speakers may have produced more salient or stereotypically marked acoustic features, making their emotional expressions easier to recognize. Similarly, Bonebright et al. (1996) reported an interaction between speaker gender and emotion: portrayals of anger and fear by male actors were more accurately identified than those by female actors, whereas portrayals of happiness by female actors were more accurately recognized than those by male actors. They also observed an interaction between listener gender and emotion, with female listeners outperforming male listeners in identifying fear, happiness, and sadness. Sen et al. (2017) likewise reported a female advantage, though only for recognizing happy and neutral voices in Singaporean English. Across studies, female listeners usually exhibit higher accuracy in recognizing emotions from facial and vocal cues, even under minimal stimulus conditions. This pattern may reflect females’ greater sensitivity to emotional cues, which some researchers attribute to either biological predispositions or socialized caregiving roles (Babchuk et al., 1985).
Emotion production and perception can vary significantly across languages and cultures. For example, Altrov (2013) found that Estonians and Russians residing in Estonia recognized emotions expressed by Estonian speakers more accurately than Russians living in Russia, across all tested emotions (joy, anger, sadness, and neutral attitude). Similarly, Laukka et al. (2016) demonstrated cultural variability in both expression and recognition of vocal emotions across five countries—Australia, India, Kenya, Singapore, and the USA. Thompson and Balkwill (2006) also compared prosodic features of emotional speech in English, German, Chinese, Tagalog, and Japanese, showing that English speakers expressed joy with higher mean F0 and F0 range than German and Japanese speakers.
These findings support the idea of an in-group advantage in emotion recognition: listeners are generally more accurate at identifying emotions expressed in their native language or familiar cultural context. In Thompson and Balkwill (2006), English listeners achieved the highest emotion recognition accuracy for English utterances and the lowest for Japanese and Chinese utterances. Importantly, this cultural effect extends beyond linguistic familiarity. Chung (1999), for instance, reported notable cross-cultural differences in the perception of positive emotions among Korean, American, and French listeners. Using a Korean television interview corpus featuring three female speakers expressing spontaneous emotions (happiness, sadness, and neutral states), the study found that while all listener groups broadly agreed on the emotional categories, their valence ratings differed. Korean and American listeners gave similar evaluations, whereas French listeners tended to interpret emotions more positively. Additionally, American listeners rated emotional intensity higher than Korean listeners, suggesting cultural variation in sensitivity to vocal affect. A supplementary written stimulus test revealed that Korean participants could not accurately infer emotions from text alone, indicating that their initial judgments were driven primarily by acoustic, not semantic, cues.
Given the influence of linguistic content on emotion perception, researchers have developed various methods to eliminate verbal content and isolate prosodic cues. These include randomly spliced speech (Teshigawara et al., 2007), reversed speech (Scherer et al., 1984), pitch inversion (Scherer et al., 1985), pseudo-sentences (Lausen & Schacht, 2018; Scherer et al., 1991), and speech in unfamiliar foreign languages (Bhatara et al., 2016). One widely used technique is low-pass filtering, which removes higher-frequency information from the signal (typically above 1 kHz) while preserving lower-frequency components essential for emotional perception (Knoll et al., 2009; Snel & Cullen, 2011, 2013). These retained features include pitch, stress, rhythm, and tempo, all of which are critical for conveying emotion. By focusing on these prosodic elements, listeners can attempt to identify emotions without being influenced by lexical content.
Building on this background, the present study investigates how vocal emotions are perceived in low-pass filtered Korean speech. Specifically, it addresses the following questions. (1) Does listener accuracy in emotion recognition vary as a function of emotion and/or speaker and listener gender? (2) Which acoustic features do listeners rely on when identifying speakers’ emotions, and do these acoustic cues differ as a function of speaker gender?
Despite extensive research on emotional prosody across languages, relatively little is known about how speaker gender shapes emotion perception in Korean, particularly when semantic information is removed. Most prior studies on Korean emotional speech have examined natural or semantically intact stimuli, making it difficult to determine the extent to which listeners’ judgments rely on prosodic versus lexical cues. Moreover, while gender differences in emotional expression have been relatively well documented in Western languages, especially for happy speech, cross-linguistic generalization remains unclear, as prosodic patterns and gender norms in vocal expression vary considerably across cultures. The present study addresses these gaps by examining how Korean listeners perceive emotions in low-pass filtered speech, a condition in which segmental and semantic information is largely unavailable and emotional cues are primarily conveyed through prosody. By isolating prosodic information, this study aims to clarify how speaker gender influences emotion perception and whether listener gender modulates recognition accuracy across different emotions.
Building on prior findings reporting a female listener advantage and gender-specific patterns in emotional expression, the present study tests explicit hypotheses regarding listener gender effects and speaker gender × emotion interactions. Specifically, we hypothesize that female listeners will show higher overall recognition accuracy than male listeners, even when segmental information is reduced and emotional cues are conveyed primarily through prosody. We further hypothesize an interaction among speaker gender, listener gender, and emotion, such that Happy will be more accurately recognized when produced by female speakers, whereas Angry and Anxious will be more accurately recognized when produced by male speakers (Bonebright et al., 1996; Sen et al., 2017). In addition, we expect female listeners to exhibit a particular advantage in recognizing Happy, Sad, and Anxious (Bonebright et al., 1996).
At the same time, given the scarcity of systematic, emotion-specific acoustic descriptions for sad, angry, and anxious speech as a function of speaker gender, the present study adopts an exploratory approach to identify which acoustic cues listeners rely on when decoding emotions from male and female speakers. Through this combined hypothesis-driven and exploratory framework, the study seeks to provide novel perceptual evidence on gender-dependent emotional prosody in Korean.
Methods
Stimuli
The stimuli were recordings of emotionally inflected utterances produced by native speakers of Korean, sourced from ‘The Open AI Dataset Project (AI-Hub, S. Korea)’ datasets. All data information can be accessed through ‘AI-Hub (https://www.aihub.or.kr)’, which provides a voice dataset categorized by various emotions and speech styles from 50 professional voice actors totaling 1,067 hours. The use of professionally trained voice actors was intended to ensure clear and controlled emotional expressions, rather than to model spontaneous emotional speech produced in everyday communication. The utterances were each produced to express different emotion types. Four emotions – Happy, Sad, Angry, and Anxious – were chosen based on prior research demonstrating their clear and distinct vocal patterns, which can be reliably recognized across various contexts (Ekman, 1992; Scherer, 2003). Among the four emotions examined, Anxious can be more difficult to define categorically than emotions such as Happy or Sad, given its conceptual and perceptual proximity to other negative affective states. Nevertheless, Anxious was included deliberately on theoretical and methodological grounds. While sadness and anxiety share negative valence, they differ systematically in arousal, with sadness typically associated with low arousal and anxiety with heightened arousal and tension (Feldman, 1995; Posner et al., 2005), a distinction that plays an important role in vocal emotion expression and perception. Moreover, anxiety generally represents a relatively subtle and less categorical emotional state compared to more prototypical emotions such as happiness, sad, or anger. Its inclusion therefore provides a useful test case for examining how listeners rely on acoustic cues, particularly under low-pass filtering conditions where segmental information is reduced. For each emotion category, different sentence stimuli were used, matched across speakers in terms of length and lexical similarity. Explicit emotion labels (e.g., angry) were excluded, while semantically related words (e.g., hate, vengeance) were preserved. The list of sentences is provided in Appendix A.
For speech stimuli, utterances expressing four emotions were selected from the database, produced by eight speakers (four females and four males). Each emotional sentence was read aloud by two voice actors (one female and one male). A total of 48 recordings (four emotions × six sentences × two speakers) were included, as presented in Appendix A, comprising six utterances per emotion from both genders. Sentences deemed to most prototypically express the target emotions were first identified, and only those for which two native Korean speakers reached agreement were retained. Importantly, this selection process was completed prior to the perception experiment and independently of the acoustic analyses reported in the present study; no specific acoustic features were used as selection criteria. Each utterance lasted between 4 and 5 s to allow ample time for the perception of emotional cues.
Acoustic characteristics of the stimuli are provided in Appendix B. Overall production patterns show that Happy is characterized by the most pronounced acoustic cues, with gender-specific distinctions. In female speakers, Happy exhibits the highest median F0 (F0md), F0 range (F0rg), intensity range (Intrg), Jitter, Shimmer, and Speech Rate, along with the lowest median intensity (Intmd) and harmonics-to-noise ratio (HNR). Median values of F0 and intensity were used to reduce the influence of extreme upward shifts, which can disproportionately affect mean F0 and intensity values in emotional speech (Oh et al., 2023). These patterns suggest that Happy is produced with high pitch, wide pitch range, fast tempo, and increased vocal energy, reflecting heightened arousal and positive activation. Sad follows Happy in prominence, characterized by the lowest F0rg, Intrg, Jitter, and Speech Rate, implying monotonous speech with low energy and slower tempo. In contrast, Angry and Anxious in female speech did not consistently exhibit extreme values across the measured acoustic parameters, with most cues falling between those observed for Happy and Sad. In male speakers, Happy also shows the highest F0md, Intmd, and Intrg, and the lowest Jitter, indicating dynamic modulation of pitch and intensity. Sad and Anxious are expressed with less salient cues, whereas Angry stands out with the lowest F0md, F0rg, and HNR, and the highest Intmd, Jitter, and Shimmer, reflecting low pitch, limited variability, and rough voice quality.
The utterances were then edited using Praat software (Boersma & Weenink, 2026). They were then subjected to a low-pass filter with a cutoff frequency of 300 Hz and bandsmoothing at 100 Hz, which preserves F0 and jitter values (MacCallum et al., 2011). HNR at these frequencies was also analyzed to assess phonatory stability and breathiness (Meireles & Mixdorff, 2020; Patman et al., 2025). This filtering procedure attenuated segmental information while retaining the prosodic features relevant for emotion perception. Finally, amplitude and temporal smoothing were applied to reduce the perceptual salience of segment-specific cues supporting phonemic identification and enhance the clarity of suprasegmental features.
Participants
Thirty-three native speakers of Seoul Korean from two universities in Seoul participated in the experiment. There were 14 male and 19 female students with a mean age of 22.15 years (σ = 2.19). Eleven participants reported speaking an additional dialect of Korean (Jeolla-do, 4; Gyeonsang-do, 6; Chungcheong-do, 1), but 6 of those noted that their dialect usage was minimal. All the participants had studied English since middle school or earlier, and 18 had studied at least one additional foreign language (primarily Chinese (n = 12) and Japanese (n = 9). However, none had resided in a foreign country for more than 6 months. No one reported hearing difficulties.
Experimental Procedure and Measurements
Each participant was tested individually in a quiet research laboratory. They were seated in front of a computer screen and heard each utterance a single time over headphones (Sennheiser HD 590) at a fixed, comfortable listening level, presented with E-Prime 2 software. After hearing the utterance, participants were instructed to make two judgements in sequence. First, participants were asked to select the number on a keypad that corresponded to the position of one of four emojis displayed on the screen. The emojis were previously introduced as corresponding to Happy ( ), Sad (
), Sad ( ), Angry (
), Angry ( ), or Anxious (
), or Anxious ( ), and visual key was provided below the screen as a reminder. Once they chose an emoji, an eight-point rating scale appeared on the screen and the participants were asked to rate the intensity level of the speaker’s emotional vocal expression on a scale of 1 to 8 (where 1 = not intense at all, 8 = very intense).
), and visual key was provided below the screen as a reminder. Once they chose an emoji, an eight-point rating scale appeared on the screen and the participants were asked to rate the intensity level of the speaker’s emotional vocal expression on a scale of 1 to 8 (where 1 = not intense at all, 8 = very intense).
The 48 low-pass filtered utterances were divided into three blocks, with each block containing two utterances from each of the eight speakers. Stimuli were randomized within the block, but block order was not randomized. While the position of the emojis remained consistent for each participant, their order was counterbalanced across participants with eight different orders from a latin-square design. To familiarize participants with the experiment design, they were given practice trials consisting of eight utterances produced by the same speakers but using sentences not included in the main experiment. After a 500-millisecond (ms.) fixation cross, the auditory stimulus was presented once along with the four emotional emojis, and the subjects made the two judgements in sequence before moving automatically to the next trial. After each block, participants were given a self-paced break. The entire experiment including the practice trials and language background survey lasted approximately 20 min, and participants were compensated for their time.
Results
Accuracy of Emotion Identification in Filtered Speech
To examine the accuracy of emotion identification in filtered speech, a generalized linear mixed-effects model was fitted to assess the effects of Emotion, Speaker Gender, Listener Gender, and their interactions on Accuracy, with Participant and Item included as random intercepts. 1 The analysis revealed significant main effects of Emotion (χ 2 (9, 33) = 33.86, p < .001) and Speaker Gender (χ 2 (5, 33) = 11.67, p = 0.04) on Accuracy, whereas Listener Gender showed no significant effect. Additionally, a significant interaction emerged between Emotion and Speaker Gender (χ 2 (3, 33) = 9.09, p = 0.028), indicating that the effect of Emotion on perceptual accuracy varied depending on the speakers’ gender. However, no significant interactions were found between Speaker Gender and Listener Gender, Listener Gender and Emotion, or the three-way interaction among Emotion, Speaker Gender, and Listener Gender. Given that Listener Gender and its interactions were not significant in the initial analysis, we proceeded with a reduced model including only Speaker Gender, Emotion, and their interaction as fixed effects. 2 A model comparison using the Likelihood Ratio Test confirmed that the reduced model did not result in a significant loss of explanatory power relative to the full model (χ2 (8, 33) = 9.92, p = 0.27). Therefore, all subsequent analyses were conducted using this simplified model.
Figure 1 illustrates that participants achieved high accuracy for Happy and low accuracy for Anxious. For Sad and Angry, however, accuracy differed by Speaker Gender: participants were more accurate in perceiving Sad produced by female speakers (ranking second only to Happy) and Angry produced by male speakers (also following Happy). Predicted probability of response accuracy across emotions and speaker genders in filtered speech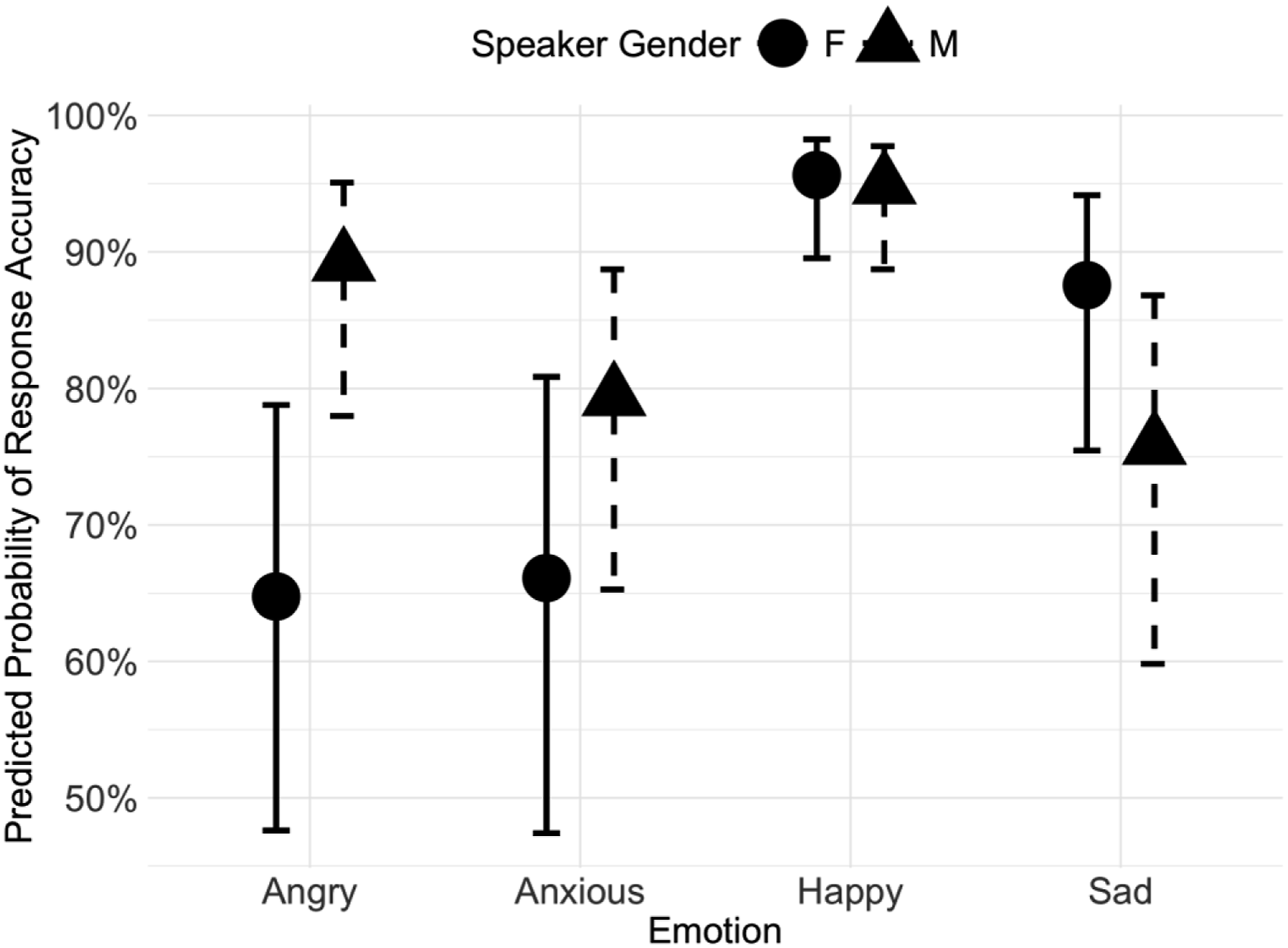
A post-hoc pairwise test using the Tukey HSD revealed that for female speakers, significant differences in accuracy were found between Angry and Happy (E = −2.4, SE = 0.6, p = 0.0003) and between Anxious and Happy (E = −2.41, SE = 0.6, p = 0.0003). For male speakers, significant differences in accuracy were observed between Anxious and Happy (E = −1.74, SE = 0.59, p = 0.017) and between Happy and Sad (E = 2.1, SE = 0.6, p = 0.003). These findings suggest that for female speakers, emotions such as Happy and Sad were easier to recognize, while in male speakers, emotions such as Happy and Angry were more accurately identified.
Figure 2 presents confusion matrices for vocal emotions expressed by male and female speakers. As previously noted, Happy was the most accurately recognized emotion for both male and female speakers, with 93.9% and 94.4%, respectively. Among male speakers, Sad was the most challenging emotion to identify, with a response accuracy of only 67.7%, following Anxious (75.8%) and Angry (84.8%). In contrast, for female speakers, Sad was the second most accurately recognized emotion, with a response accuracy of 83.8%. Participants demonstrated greater difficulty recognizing Anxious and Angry in female speech, achieving accuracies of only 64.1% and 63.1%, respectively. Interestingly, participants showed notable confusion between Sad and Anxious for both male and female speakers. For male speakers, Sad was frequently misinterpreted as Anxious (22.7%) while Anxious was misinterpreted as Sad (17.7%). Similarly, for female speakers, Anxious was highly confused with Sad, with a confusion rate of 30.3%. Confusion matrices for vocal emotions expressed by (a) male and (b) female speakers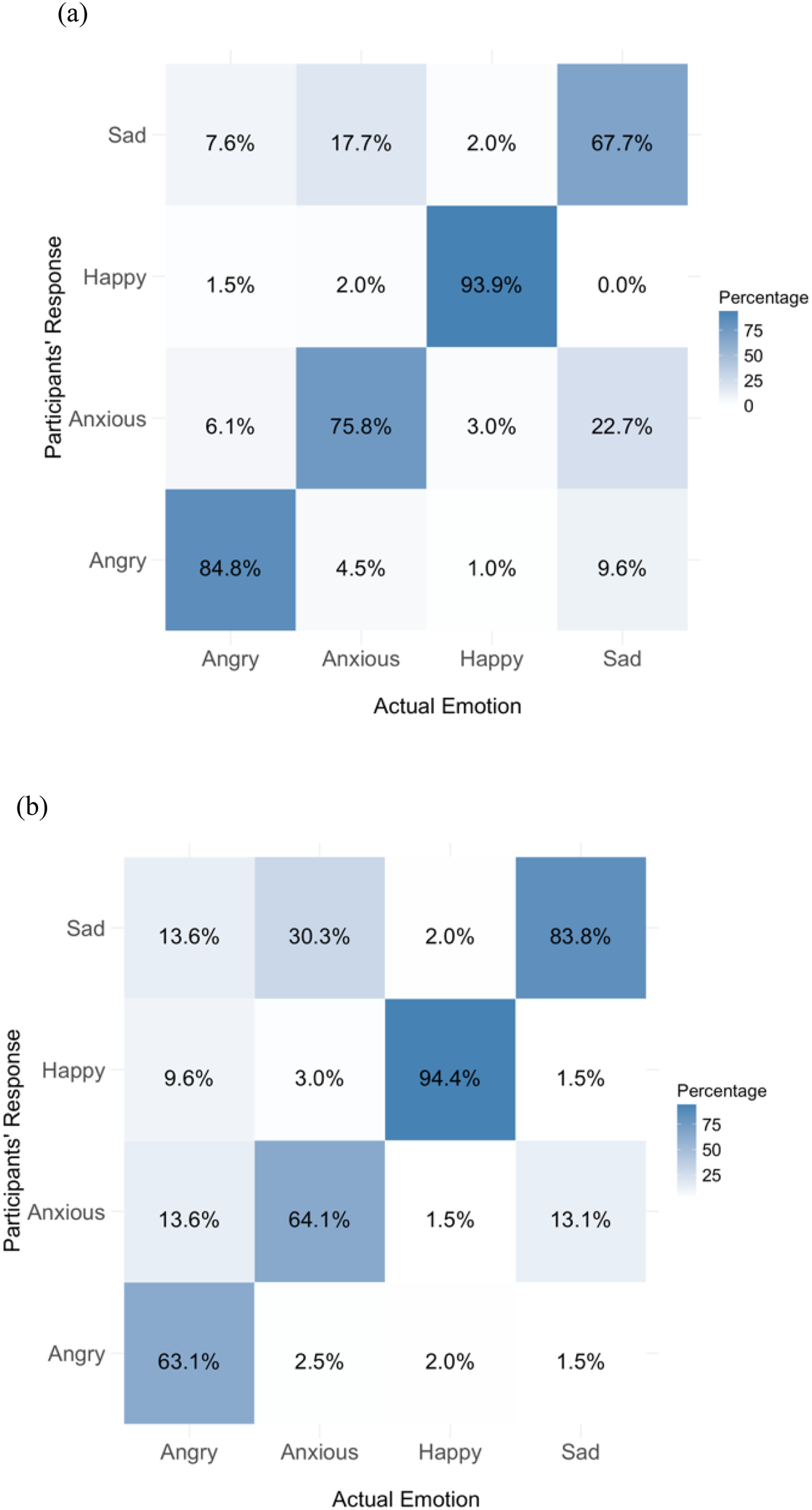
Perceived Emotional Intensity
Given the observed patterns of emotion misidentification – particularly between acoustically similar emotions such as Sad and Anxious – analyzing perceived emotional intensity was essential to determine whether it contributed to recognition accuracy. Participants rated the strength of each emotion on an 8-point scale. A linear mixed-effects model was conducted with Emotion, Speaker Gender, and their interaction as fixed effects, and Participant and Item as random intercepts. The results showed a significant main effect of Emotion on perceived intensity (χ2(3, 33) = 8.84, p = 0.03), but no significant main effect of Speaker Gender. However, there was a significant interaction between Emotion and Speaker Gender (χ2(3, 33) = 18.76, p < 0.001), indicating that the perceived intensity of emotions differed depending on the speaker’s gender.
Post hoc comparisons using Tukey HSD test revealed that female speakers were rated significantly higher in intensity for Happy compared to male speakers (E = 1.21, p = 0.0345). Within the same gender, female speakers exhibited significantly higher perceived intensity for Happy speech compared to Angry (E = −1.97, p < 0.0001), while no significant differences were observed between Happy and Sad, or between Happy and Anxious. In addition, Sad produced by female speakers was rated significantly more intense than Angry (E = −1.44, p = 0.0058). Anxious showed no significant intensity differences relative to the other emotions. In contrast, male speakers’ emotional intensity was perceived as similar across emotions. Overall, emotional intensity ratings differed by speaker gender and emotion, with systematic differences observed only for female speakers.
Acoustic Cues for Emotion Identification From Speech
To examine which acoustic features contribute most to participants’ ability to accurately recognize emotions in filtered speech, a Random Forest classification model was applied separately for each emotion category (Happy, Anxious, Angry, and Sad) and speaker gender. The Random Forest model was chosen because of its robust handling of high-dimensional data and ability to identify the relative importance of predictor variables (Breiman, 2001).
The dependent variable was Accuracy (1 for correct and 0 for incorrect responses), while the independent variables comprised a range of acoustic features, including pitch-related features (e.g., F0md and F0rg), intensity features (e.g., Intmd and Intrg), voice quality features (e.g., Shimmer, Jitter, and HNR) and speech rate. A Random Forest classifier with 500 trees was trained separately for each emotion. For each model, the Mean Decrease in Gini Index (MDG) was calculated to determine the importance of each feature and was normalized for comparison between genders ((each feature’s Normalized MDG) = (each feature’s MDG)/(the sum of MDGs across all features)). When a feature is used to split a node, it contributes to a decrease in Gini Index (i.e., impurity reduction). Features that consistently result in a larger reduction in Gini Index are considered more important because they contribute more to the model’s predictive accuracy. Namely, a larger decrease in Gini index indicates a greater contribution of that feature to the model’s ability to predict accurate responses. Given the relatively small sample size, the random forest analyses are intended as exploratory tools to identify potential acoustic cues that listeners may rely on when decoding emotions, rather than as inferential or predictive models. Accordingly, the feature importance patterns should be interpreted with caution and as indicative rather than definitive.
Figure 3 illustrates the acoustic features that listeners relied on when identifying a speaker’s emotion from low-pass filtered speech. As can be seen in Figure 3(a), the perception of Happy in male speech primarily depended upon pitch (e.g., higher F0md) as well as intensity and its dynamics (e.g., higher Intmd and wider Intrg). In contrast, the perception of Happy in female speech appeared to rely upon a broader range of acoustic features, including voice quality (e.g., higher Jitter), pitch dynamics (e.g., higher F0rg) and intensity (e.g., lower Intmd). This aligns with the acoustic characteristics of Happy, where all acoustic features exhibit either the highest or lowest values compared to other emotions, possibly making Happy easier to identify. This use of multiple prosodic cues indicates that Happy was characterized by systematic shifts in both central tendency and variability across several acoustic dimensions, including pitch, intensity, and voice quality, in both genders. Speech Rate, although fastest in Happy, was not a primary cue in either gender’s speech. Feature importance for the perception of emotional speech from male (M) and female (F) speakers as determined using random forest analysis: influential acoustic features for (a) Happy speech; (b) Anxious speech; (c) Angry speech; (d) Sad speech. Higher Mean Decrease in Gini (MDG) values reflect greater predictive importance of the acoustic feature in classifying emotions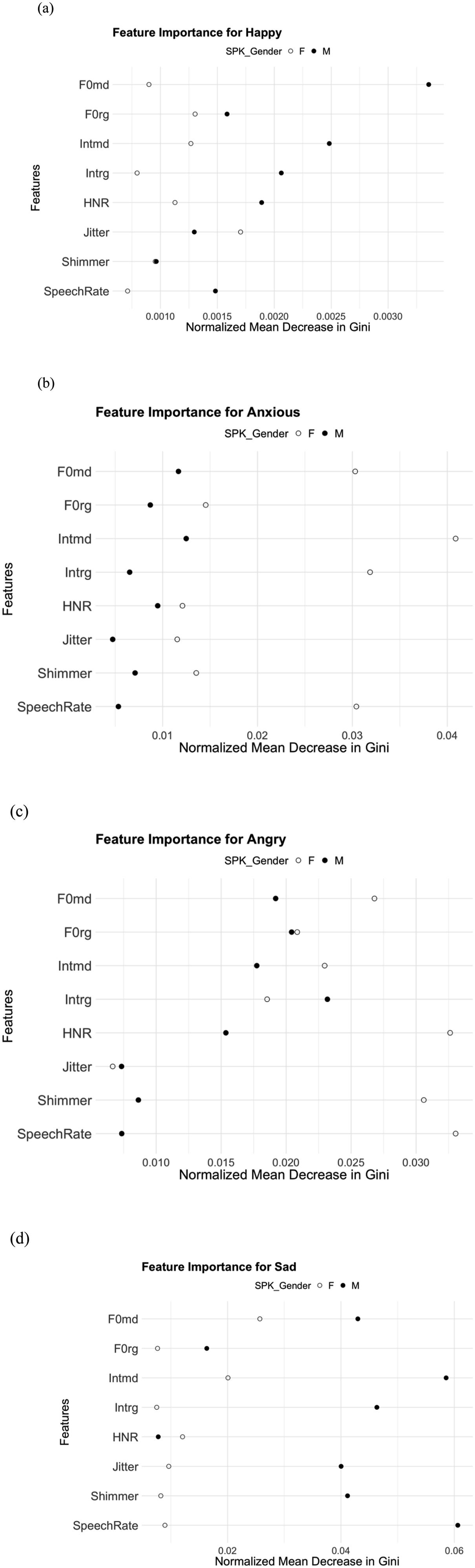
For Anxious, as illustrated in Figure 3(b), intensity- and pitch-related measures were the most important cues for identifying this emotion in both male and female speech. For male speakers, listeners primarily relied on intensity (e.g., higher Intmd), followed by pitch (e.g., higher F0md). Similarly, for female speakers, listeners focused on intensity measures (e.g., higher Intmd and smaller Intrg) and pitch (e.g., higher F0md). These findings suggest that greater intensity (with reduced variability for females) and higher pitch were the key acoustic features used by listeners to detect Anxious in both male and female speech. Interestingly, Speech Rate was also an influential feature in identifying Anxious in female speech, though the reason for this is unclear, given that Speech Rate of female Anxious was moderate – neither extremely fast nor slow. A possible explanation is that listeners may expect Anxious to be a combination of fast and slow elements: rapidly produced intervals due to nervous emotional state, interspersed with slower segments resulting from hesitations or pauses, ultimately leading to a moderate overall speech rate.
Figure 3(c) demonstrates that the perception of Angry depended on a large number of features for both genders. Listeners relied heavily on vocal intensity (e.g., smaller Intrg and higher Intmd), pitch (e.g. lower F0rg and F0md) and voice quality (e.g. lower HNR) for male speech, while for female speech, they focused on speech rate (e.g. moderate Speech Rate), voice quality (e.g., lower HNR and higher Shimmer), pitch (e.g. lower F0md and F0rg), and intensity (e.g. moderate Intmd and higher Intrg). Lower pitch, minimal tonal variation, greater intensity, increased roughness or harshness, and a faster speech rate all correspond to the typical characteristics expected in angry emotional states. Interestingly, all acoustic features except Jitter were influential cues for detecting Angry in female speech. This may be because the acoustic measures of female Angry, except for F0md, were not extremely high or low compared to other emotions, leading listeners to rely on a combination of multiple features. This could explain why listeners rated female Angry as less strongly expressed compared to Happy and Sad.
For Sad, as shown in Figure 3(d), the perception of Sad relied on a smaller set of highly diagnostic features, with a more pronounced variation depending on speaker gender. For male speech, listeners primarily relied on speech rate (e.g., slower Speech Rate) and intensity (e.g., lower Intmd). For female speech, pitch (e.g. lower F0md) and intensity (e.g. higher Intmd) emerged as the most salient cues. Interestingly, many acoustic characteristics were not used as primary cues for Sad, such as F0rg, Intrg, Jitter, Shimmer, and Speech Rate in female speech, and F0rg in male speech, despite these features exhibiting extremely high or low values in Sad compared to other emotions in each gender’s speech. This suggests that, among the various distinct acoustic characteristics of Sad, a select few play a much more significant role in the recognition of Sad – such as extended segmental duration and reduced intensity in male speech, and lower pitch and intensity in female speech.
Key Acoustic Features in Perceptual Identification of Emotion by Speaker Gender

Discussion and Conclusion
This study examined how Korean listeners perceive four emotions (Happy, Sad, Angry, and Anxious) in low-pass filtered speech, revealing clear effects of speaker gender on both acoustic realization and perceptual accuracy. Happy emerged as the most reliably recognized emotion across genders, while Angry and Sad showed gender-specific recognition patterns, and Anxious was frequently confused with Sad.
Happy was the most easily recognized emotion overall. Acoustically, it was characterized by elevated pitch and high variability in both pitch and intensity. Among male speakers, Happy speech also exhibited greater loudness, more modal phonation, and a moderate speech rate, whereas among female speakers it involved higher pitch, lower loudness, greater variability in both pitch and intensity, faster tempo, and slightly degraded voice quality. Together, these features suggest that Happy speech is acoustically rich and dynamic, marked by heightened expressiveness and redundancy. This multiplicity of cues likely enhanced perceptual robustness which allowed listeners to identify happiness even when parts of the acoustic signal were degraded by filtering. The Random Forest model indicated that emotion recognition relied on a distributed combination of prosodic parameters rather than a single dominant feature, consistent with earlier findings by Banse and Scherer (1996) and Juslin and Laukka (2003). Notably, breathier voice quality, indexed by reduced HNR and increased jitter, served as a perceptual cue only for female Happy. This supports Xu et al. (2013), who reported that breathier female voices are often perceived as happier, possibly because breathiness resembles a smile’s acoustic correlates and signals appeasement or affiliative intent (Morton, 1977).
For Angry and Sad, recognition accuracy differed by speaker gender. Angry was more accurately perceived in male speech, while Sad was more accurately recognized in female speech. Emotional intensity ratings provided partial support for this pattern, in that, within female speakers, Sad was judged as more intense than Angry. These findings suggest a gendered pattern of emotional expression and perception: male voices emphasize energy and dominance through cues such as loudness and roughness, whereas female voices highlight emotional sensitivity and warmth through cues such as pitch modulation and breathiness. The acoustic data support this: for male speakers, Angry speech was marked by greater loudness, faster rate, and rougher phonation, which likely increased perceptual salience; for female speakers, Sad speech was characterized by higher mean intensity, more stable phonation, and reduced variability, cues that may have made it easier to identify. In contrast, Sad in male speech and Angry in female speech showed less distinctive acoustic signatures, possibly explaining their lower recognition rates.
These asymmetries reflect not only acoustic differences but also socialized patterns of emotion expression. According to Social Role Theory (Eagly, 1987; Eagly & Wood, 2016; Eagly et al., 2000), historical divisions of labor between men and women have produced enduring gender roles associated with dominance and agency in men, and nurturance and restraint in women. In many cultures, anger aligns with masculine-coded traits such as assertiveness and control, while sadness aligns with feminine-coded traits such as empathy and emotional openness (Brody & Hall, 1993; Fischer & Jansz, 1995). Our findings are consistent with this pattern: male anger and female sadness were both acoustically and perceptually salient, which may reflect culturally influenced tendencies in emotional expression and perception.
The Korean context provides additional insight into these gendered effects. Despite rapid industrialization, South Korea continues to exhibit substantial gender inequality, ranking 101st out of 146 countries in the 2025 Global Gender Gap Report (World Economic Forum, 2025). Traditional Confucian values, which emphasize male authority and female modesty, have long shaped emotional norms. Common sayings such as “A man should cry only three times” and “A woman should never raise her voice” encapsulate enduring expectations that men suppress sadness while women restrain anger. These cultural scripts help explain why Sad was least accurately detected in male speech and Angry in female speech, even when lexical information was absent. The persistence of such perceptual asymmetries in filtered speech suggests that cultural norms may subtly influence the way listeners interpret vocal emotion cues.
Listeners frequently confused Anxious with Sad, particularly in female speech, despite distinct primary acoustic characteristics. Both emotions exhibited relatively high mid-intensity values (Intmd), which may have contributed to their perceptual overlap. Some stimuli may also have contained subtle traces of indignation or heightened vocal effort, leading listeners to interpret both emotions as similarly “tense.” These findings suggest that, when deprived of semantic content, listeners rely on global prosodic patterns rather than specific acoustic cues. For male speech, explaining the confusion between Anxious and Sad is less straightforward, as their acoustic profiles diverged. Prior studies point to other relevant cues, such as spectral tilt measures (e.g., H1–H2, H1–A3), that may distinguish between breathier and more modal voice qualities (Cai & Xu, 2023; Wang et al., 2024). Future research should therefore incorporate spectral parameters to more fully characterize the acoustic overlap between sadness and anxiety.
Regarding listener gender, no significant differences in recognition accuracy were observed, in contrast to previous studies reporting a female advantage (Lausen & Schacht, 2018; Sen et al., 2017; Wang et al., 2024). One plausible explanation is methodological: the use of low-pass filtered speech restricted both male and female listeners to the same set of acoustic cues, thereby minimizing potential gender differences in cue weighting. Alternatively, sociocultural changes in education and communication practices may have equalized perceptual sensitivity across genders. The presence of a strong speaker gender effect alongside the absence of a listener gender effect suggests that the socialization of expressive behavior may be more pronounced than that of perceptual sensitivity in contemporary Korean society. Expressive tendencies appear closely tied to social role expectations, whereas perceptual abilities may be shaped through shared communicative experience and exposure.
A few limitations should be noted. First, the imbalance in emotional valence categories, three negative emotions and one positive, may have introduced perceptual bias. Overlap among negative emotions could have increased listener confusion, reducing overall accuracy for those categories. Second, the number of speakers and trials was relatively small. Specifically, each set of stimuli per emotion was produced by a single male and a single female speaker, limiting the ability to assess within-emotion variability. While similar sample sizes have been used in prior research (e.g., Sauter et al., 2010; Scherer et al., 1991), larger speaker pools and a greater number of trials would improve generalizability and allow for individual-level analyses of emotional expression (Dor et al., 2025; Fan et al., 2025). Future studies should employ larger and more balanced speaker pools and include additional measures - such as spectral tilt or formant-based cues - to better understand the acoustic dimensions that drive emotional perception.
Supplemental Material
Supplemental Material - How Speaker Gender Shapes Emotion Perception: Prosodic Cues in Low-Pass Filtered Korean Speech
Supplemental Material for How Speaker Gender Shapes Emotion Perception: Prosodic Cues in Low-Pass Filtered Korean Speech by Dayeon Yoon, and Grace Eunhae Oh in Psychological Reports.
Footnotes
Ethical Approval
This study received ethical approval from the Konkuk University IRB (KKUIRB-202509-HR-117) on September 8, 2025.
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: The Ministry of Education of the Republic of Korea and the National Research Foundation of Korea (NRF-2023S1A5C2A02095124).
Declaration of Conflicting Interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Data Availability Statement
Due to privacy and consent restrictions related to audio recordings, the data are not publicly available but may be available from the corresponding author upon reasonable request.
Supplemental Material
Supplemental material for this article is available online.
Notes
Author Biographies
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.