
Abstract
This article explores how the analysis of inter-rater discourse can be used to support collective reflective practice in second language (L2) assessment. To demonstrate, a focused case of the discourse between two experienced language teachers as they negotiate assessment decisions on L2 written texts is presented. Of particular interest was the discourse surrounding the raters’ most divergent assessment decisions, which in this case were those relating to Task Achievement. Thematic analysis indicated that rater discourse predominantly focused on explicit objective factors, primarily the L2 texts and the rating scale; however, rater discourse also focused on more subjective, rater-centred factors. The discourse surrounding these rater-centred factors was often central to the identification and resolution of rating disagreements. The paper argues that the subjective dimension of language assessment needs to be more directly and systematically reflected upon in language teaching contexts and that analysis of rater discourse, especially discourse focused on points of disagreement between raters, provides a valuable mechanism to facilitate this.
Introduction
Facilitating the reliable assessment of second language (L2) writing is a real and universal issue faced by language teachers around the world (Hamp-Lyons, 2007; Trace et al., 2017). The assessment of L2 writing is problematic as even trained language teaching professionals using prescriptive rubrics typically do not rate L2 texts in a standard manner (Lindhardsen, 2018; Lumley, 2002; Winke and Lim, 2015). In part, these differences relate to external factors that are beyond the rater’s control; for example, rater background (Eckes, 2008), rater experience level (Cumming, 1990), and the rating scale being used (Barkaoui, 2010). However, central to assessment performance, and within the control of the rater, are the various subjective decisions that are made during the process. Lumley’s (2002) important work makes clear the problematic nature of rating L2 written texts. According to Lumley (2002), it can be difficult to get to the bottom of why raters make the decisions they do, as judgement often appears to be based on “. . . some complex and indefinable feeling [emphasis added] about the text, rather than the [rating] scale content” (2002: 263). Sobering as it may be that raters’ feelings influence their rating decisions, this observation aligns with what is already known about the importance of language teachers’ beliefs, defined here as consciously or unconsciously held propositions (Borg, 2001: 186). Simply, beliefs have a profound impact on how language teachers undertake their professional practice (Basturkmen, 2012; Borg, 2003; Farrell and Bennis, 2013; Richards, 1996).
Because difficult to define, subjective feelings play an important role in rater decision-making, it is important for raters to systematically reflect on their rating decisions. Finding ways to unpack and communicate the underlying reasons why individual raters make decisions is important as assessment of written work in language teaching contexts is often a collective endeavour undertaken by multiple teachers allocated to assessment teams. For this reason, establishing practical approaches applicable to professional settings that can facilitate collective reflection on how and why a teacher’s own assessment decisions may differ from those of their peers is likely to hold strong value. Drawing on the assertions of Farrell (2012), it is argued here that finding ways to help teachers collectively reflect on data about their rating processes will encourage collective rating decisions to be based more on evidence rather than feelings or impulse.
This paper presents an example of how inter-rater discourse and its analysis can be used to develop explicit frameworks that unpack rater decision-making and disagreement. The focused case presented here not only aims to provide a simple example of how such frameworks can be established, but also seeks to highlight the potential merit in facilitating a collective awareness of the sources of inter-rater disagreement in L2 written assessment.
Rater Decision-Making
The importance of raters’ decision-making has prompted long-standing calls for more research in this area (Connor-Linton, 1995; Hamp-Lyons, 2007; Weigle, 1994). However, to date, only a relatively small body of research exists that outlines the decision-making processes of L2 raters (Cumming et al., 2002; Gebril and Plakans, 2014; Lumley, 2002). These previous studies have used think-aloud protocols to elicit real-time data from individual raters engaged in the assessment of L2 writing, and have categorised the resultant decision-making processes. It is clear from this previous work that raters focus not only on the linguistic attributes of texts and the rating scale, but also on factors that are less strongly linked to these explicit reference points. For example, raters also consider their own biases, ponder institutional expectations, acknowledge gut impressions, empathise with the writer, and develop and alter their own rating criteria (Lindhardsen, 2018; Lumley, 2002). Although previous research provides insight into the decision-making by individuals during the rating process, it arguably casts little light on how such decision-making may proceed in collaboration with other raters.
In terms of research that specifically addresses the decision-making processes engaged when multiple raters collectively rate L2 texts, there is scant work in this important area (for a notable exception, see Lindhardsen, 2018). This gap in the literature is significant as the assessment of high-stakes writing is typically undertaken by multiple raters, and a key aspect of rater performance is the calibration of rating processes between multiple individuals (Trace et al., 2016). The negotiation of scores by multiple raters has been associated with reduced measures of bias, use of shared terminology, construction of shared meaning, and balance of attention to assessment criteria (Lindhardsen, 2018; Trace et al., 2017). Further, collaborative forms of assessment can promote thoughtful reflection and the reframing of previously held assumptions and beliefs (Nixon and McClay, 2007).
What existing research makes clear and what language teaching professionals can draw from their own personal experience provide useful context for the current study. Importantly, despite strong efforts to make the assessment of L2 texts an objective process, it is, by necessity, always to some degree, a subjective matter. For instance, rating scales are reductionist in nature and never fully encompass and direct the decisions raters need to make. As Lumley (2002: 267) asserts, “[t]he rater, not the scale, lies at the centre of the [rating] process”. Further, it is clear that the assessment of a text requires sensitivity to factors external to that text; for example, determining the degree to which a text satisfies institutional or discipline specific expectations demands consideration of factors that are a step beyond the linguistic domain (Matthews and Wijeyewardene, 2018). Considering the rater-centred factors that are important to the rating process, it is not surprising that different raters approach rating in a variety of different ways, and often disagree about it (Crosthwaite et al., 2017; Yan, 2014).
In light of this, analyses unpacking the ways multiple raters reconcile their different rating decisions with one another are likely to be of value to the language teaching community.
The objectives of the current research were framed by the following two overarching research questions:
What themes emerge from the analysis of discourse between raters as they negotiate agreement on previously divergent rating decisions?
In what way can these themes, and their associated discourse, cast light on the way raters negotiate agreement on previously divergent rating decisions?
Methodology
This paper uses a case study approach (Merriam, 2001) to explore and describe a strongly focused corpus of discourse between two raters in order to provide basic information about their decision-making processes (Bogdan and Biklen, 1982). The focus of analysis is a subset of discourse gathered as part of a larger previously published research project that demanded strong levels of inter-rater reliability (Matthews and Wijeyewardene, 2018). The written texts used to elicit rater discourse in this study were compiled from an existing corpus of student L2 samples sourced from the public domain, written in response to the same writing task (Supplemental A – Writing task). These texts were written in response to task parameters aligned with the International English Language Testing System (IELTS) writing task two. Twenty texts were selected and adapted (when necessary) to ensure all were of a standard range of word length (between 250 and 350 words). The author selected texts that represented a range of performance level bands according to the IELTS rating scale (British Council, n.d.), which was the same rating scale used to assess the texts. The rating scale has four performance criteria (each with performance levels from one to nine); however, as explained in more detail below, the discourse surrounding the rating decisions on Task Assessment defined the scope of the case under investigation here.
Participants who rated the texts were two professionally acquainted, highly experienced English language teaching professionals who were recruited for the purposes of the research (pseudonyms: Bev and Christine). Each had over 30 years’ teaching experience and, at the time of the research, worked as language education professionals in the Australian higher education sector. Prior to rating the 20 texts, each was provided opportunities to use the rating scale to assess several texts, such that they were acquainted with the rating scale and its use.
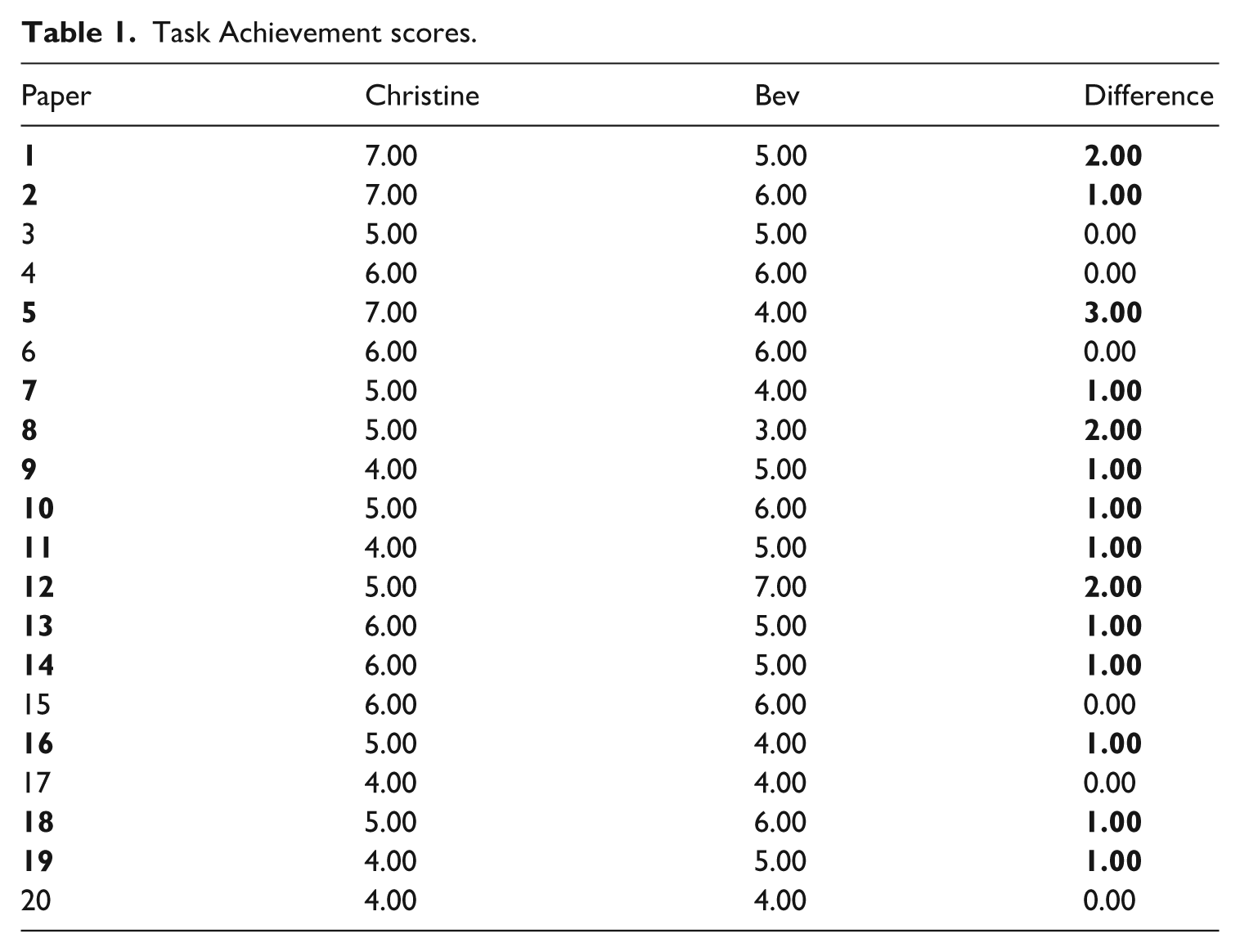
The rating proper was undertaken in two phases: individual rating and collective rating. Individual rating entailed each rater independently rating the 20 texts using the IELTS Task Achievement rating scale (Supplemental B – Rating scale for Task Achievement). During this individual rating phase, raters were asked not to communicate with one another regarding their rating processes or their rating decisions. After individually rating 20 texts in phase one, raters had assigned different numerical scores for Task Achievement to 14 of the 20 texts, with either a difference of one point (10 texts), two points (three texts), or three points (one text) (see Table 1). The 14 texts that yielded different individual rating decisions around Task Achievement defined the scope of the L2 texts that were used to elicit rater discourse in the second collective phase of rating. Task Achievement was the performance category that contained the most and largest discrepancies in text ratings and was, therefore, of particular interest. Evidently, raters had the strongest difference of opinion around Task Achievement. It was reasoned that analysis of the discourse around these differences of opinion would offer the strongest opportunities to explore the origins of difference in the raters’ feelings/beliefs about the rating process.
Task Achievement scores.
Phase two of the rating procedure – collective rating – involved multiple sessions, each facilitated by the author, during which time both raters were present. All 14 texts, which were individually rated differently by the two raters during the individual rating sessions, were again assessed in these sessions. During these collective rating sessions, raters were each provided a copy of the original text that they would collectively rate, their previous rating, and a copy of the rating scale. The sessions were designed to elicit discourse around the origin and resolution of disagreements about their divergent initial ratings. These sessions were standardised by way of a set protocol that was explained to the raters prior to each session (Supplemental C – Collective think-aloud protocol). During collective rating sessions, the raters were asked to continue discussing their respective rating decisions until a mutually agreed-upon score for each text had been negotiated. The raters were welcomed to engage whatever means required to establish a common score for each text. Raters were asked to articulate their thought processes and opinions as much as possible, and these were recorded, with prior written consent to do so received from both raters.
Data Collation and Thematic Analysis
The recorded sessions were transcribed and resulted in approximately 25,000 words of discourse directly relevant to the rating of Task Achievement. Thematic analysis of this discourse was undertaken following the prescriptions of Braun and Clarke (2006). An inductive data-driven approach to analysis was applied at the semantic level. Thus, surface-level or explicit meanings at the phrase, sentence, and group of sentences level were identified. Although the process of thematic analysis was not a linear process, and more recursive in nature, the following steps were undertaken while the entire breadth of the corpus was analysed multiple times:
An initial familiarisation of the data involving multiple readings of the corpus
The systematic generation of initial codes
The collation of codes into provisional themes
The review of themes and production of a thematic map
The definition and naming of themes (Braun and Clarke, 2006: 87)
Codes were created and merged until all relevant discourse could be categorised. The thematic analysis was facilitated with the qualitative data analysis software NVivo.
Results
In the following section, a broad overview of the main themes and the relationship between those themes evident in the discourse of raters is presented. Following this, vignettes will be presented from the discourse to highlight a specific instance of how subjective rater-centred factors played an important role in rater decision-making processes.
The codes that emerged were organised under four main themes: Text, Reading the rating scale, Rater-centred factors, and the Writer. A “map” showing the relationship between themes is presented in Figure 1. The themes could be categorised as those around more explicit factors (the Text and Reading the rating scale), and those around more subjective factors (Rater-centred factors and the Writer). Unsurprisingly, the most prevalent themes were those that focused on explicit factors – namely, the text and the rating scale (see Table 2). Discourse categorised as having a primary focus on the text could be further differentiated into two codes: Critiquing the text and Reading or interpreting the text. The distinction between these two codes can be broadly understood as the difference between text judgement and text interpretation (Cumming et al., 2002).
Themes that emerged from an analysis of discourse.
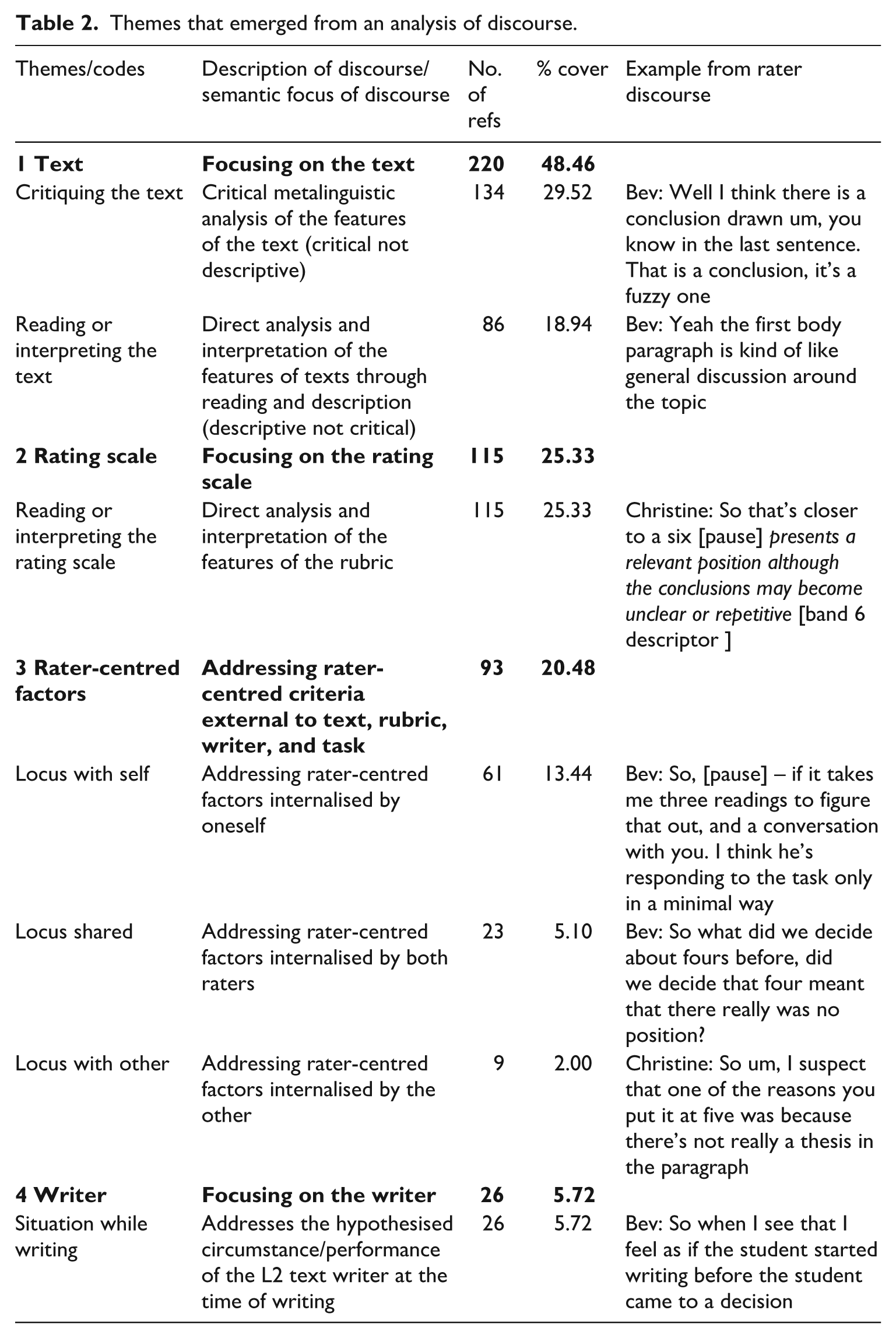
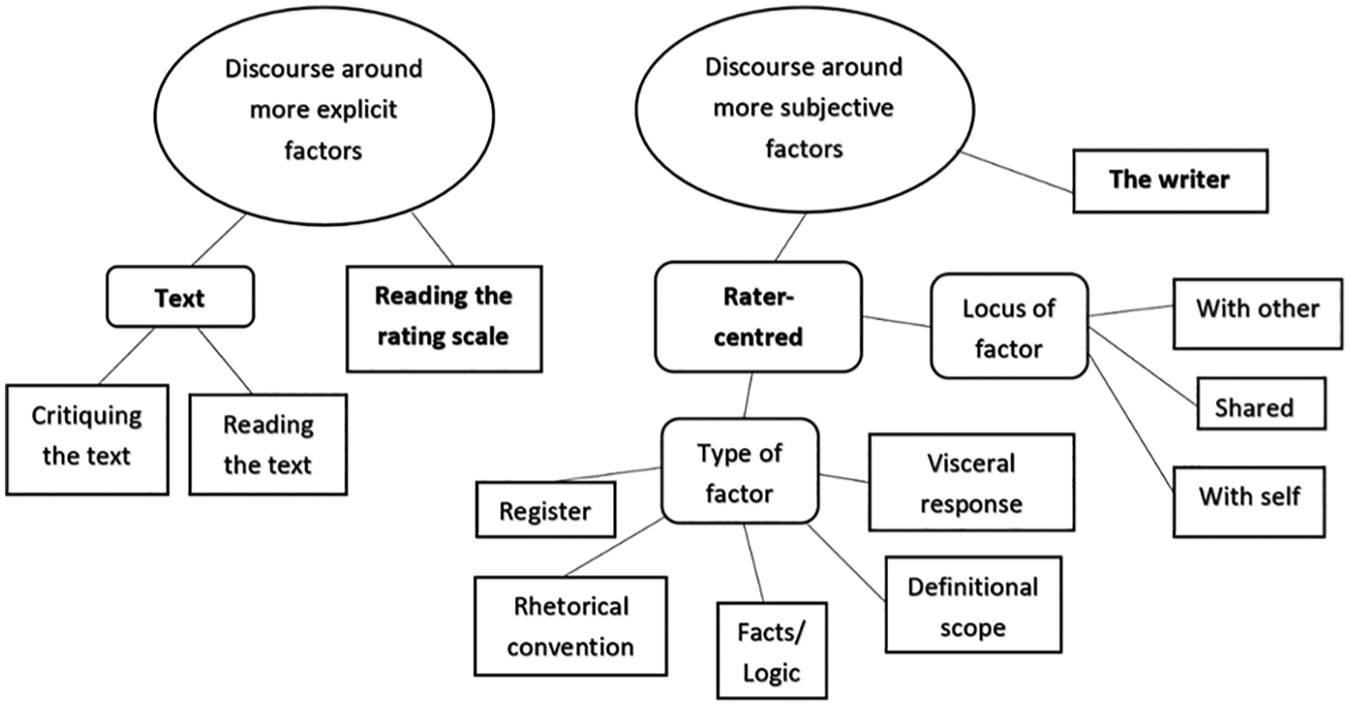
Thematic map showing the relationship between themes.
The next most common theme related to a focus on the rating scale, with one of the most salient features of this discourse being verbatim articulation of wording from the rating scale itself. Fundamentally, this theme entailed raters reading, recalling, and interpreting specific sections of the rating scale.
Approximately one fourth of the discourse focused on less explicit, more subjective factors. The least prevalent of these was discourse that focused on the writer – namely, the individual that was imagined by the rater as having written the L2 text (5.72%). This discourse was characterised by the hypothetical consideration of factors such as the writer’s time to complete the task, preparation prior to writing, and attitude while writing. Although only a small proportion of the total discourse, this is a clear example of the raters considering contextual factors beyond those explicitly represented by the text and the rating scale.
Approximately 20 per cent of the discourse focused on rater-centred factors. The diagnostic characteristic of this discourse was that it was espoused by raters as an influential factor on perceptions of text quality, but was largely external to the L2 text, the rating scale, the wording of the task, and the writer. Analysis of rater-centred factors could be mapped out in two directions. Firstly, rater-centred factors could be categorised based on the locus from where the factor emanated or resided. Put simply, this related to whether the discourse reflected the factor as the rater’s own belief (locus with self), the other rater’s belief (locus with other), or a shared belief (shared locus) (see Table 2). This categorisation was useful in tracking the dynamics of the discourse as a mutually -agreed-upon score for text was negotiated. For example, discourse characterised by rater-centred factors evolving from those with a locus with self to those with a shared locus appeared to play a role in establishing a communicable and mutually acceptable approach to aligning previously divergent scoring decisions.
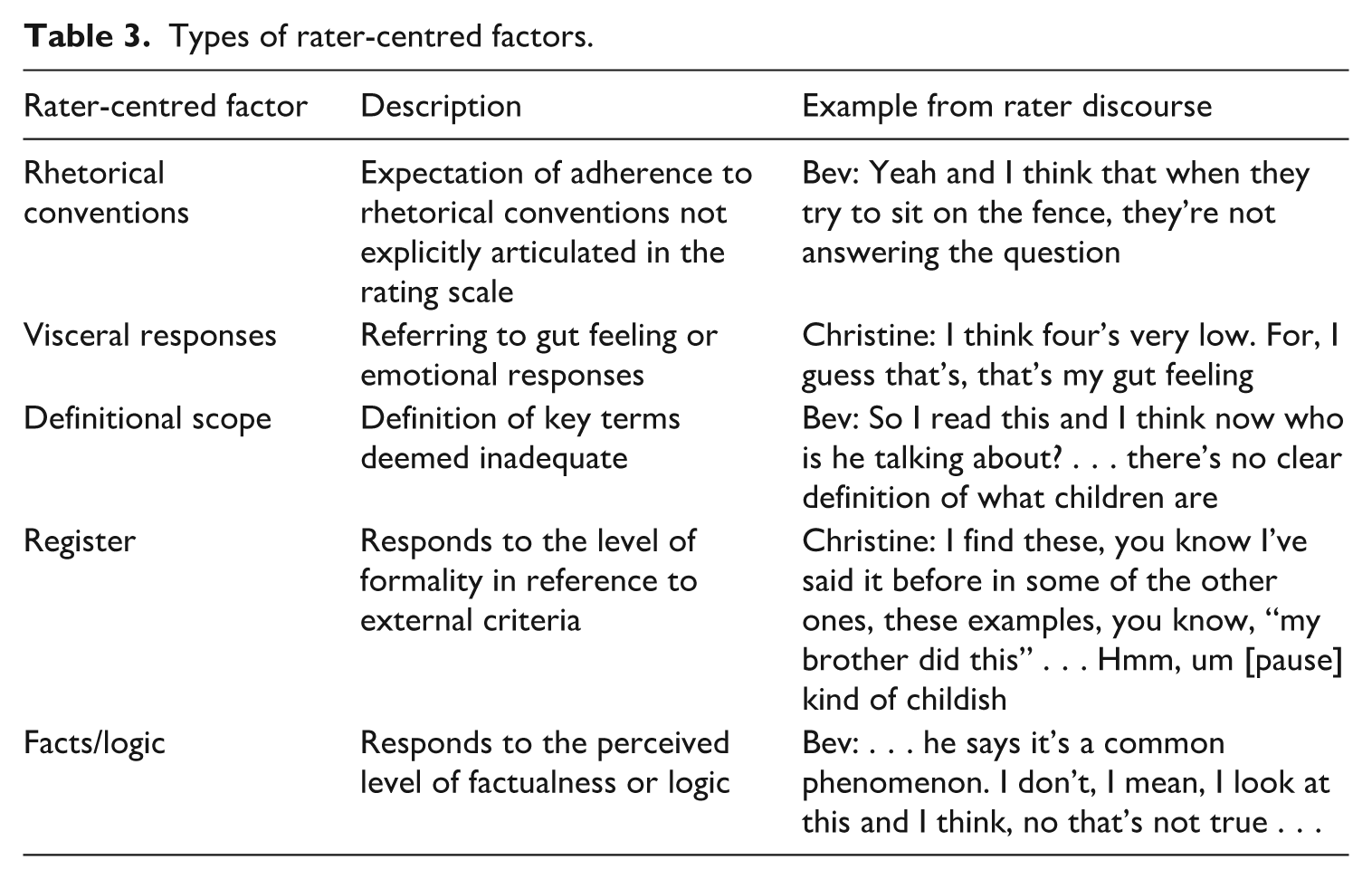
Further, rater-centred factors could be categorised in terms of the type or substance of the rater-centred factor itself. The readily identifiable types of rater-centred factors are presented in Table 3. These factors are of interest as they speak to the importance of raters’ beliefs in rater decision-making and also align well with the indefinable feelings alluded to by Lumley (2002) (specific example provided in the following section).
Types of rater-centred factors.
Towards a Shared Locus of Rater-Centred Rhetorical Conventions
The vignettes below present an illustrative example of how one rater-centred factor, rhetorical conventions, was prominent in the collective rating. In what follows, we can see how differences in raters’ expectations about the rhetorical conventions writers applied in the texts influenced their rating decisions. The vignettes begin with the negotiation of the score on text five, which was the text with the largest discrepancy in rating (Bev, four and Christine, seven). The vignettes are presented in order of their occurrence in the rater discourse, and italicised text indicates direct references to the language of the rating scale.
Early in the discourse addressing text five, it became clear that Bev believed that text five did not express an opinion, thus precluding it from reaching level five on the rating scale. At this early stage, the locus of this opinion was clearly with Bev:
Okay well I started at seven because I thought it was, for Task Achievement, I thought it was quite well set out.
Okay, so what’s the main idea? What’s the main claim? . . . I don’t think he is expressing an opinion.
Hmm.
What is he saying? I just think he’s talking around the topic. He’s got ideas, some of, most of which are on topic. But I don’t think there is any clear position there.
Hmm. Okay. (Transcript from text five)
Christine acknowledges Bev’s position, but the locus of this opinion is still with Bev. Christine offers an alternative perspective to rationalise a level-five rating:
Hmm, well if we follow what Bev says, five says expresses a position [level-five descriptor] and Bev says [the writer] doesn’t express a position.
Hmm.
Or it’s not clear, or but the development is not always clear and there’s no conclusions drawn. Presents some main ideas but these are limited and not sufficiently developed [level-five descriptor] Yeah, okay. I think, I just feel, that’s right okay there’s not, there’s not a clear thesis, it doesn’t get repeated clearly in the conclusion but there are some very clear main ideas. (Transcript from text five)
In the ensuing discussion, Bev presents some rhetorical conventions that she feels are pre-requisite for the text to express a clear position:
See I think this person does not have a thesis statement, either in the introduction or the conclusion but he has thought of a few sub-topics that are suitable for body paragraphs [pause]. I think this person has not planned an overall argument. (Transcript from text five)
Bev’s belief was that a text should articulate an explicit position on one side of an argument in order for it to express an opinion. Conversely, Christine’s belief was that a position could be non-commital providing this fence sitting was clearly expressed throughout the piece:
Yeah well I think a lack of a thesis statement in both the introduction and the conclusion. You know I read this and I cannot say in my own words what is this student’s position. . . . I cannot say. I can see he’s got some ideas that are relevant.
Hmm I think the student’s sitting on the fence.
Yeah.
. . . I think the student . . ..
. . . Yeah and I think that when they try to sit on the fence, they’re not answering the question.
Christine ultimately agrees to assign a rating of level four to text five based on the arguments put forward by Bev, but this decision was made with some reservation. At that point, it seems apparent that Christine has changed her rating decision mainly due to Bev’s strong belief about the correctness of that decision (locus of decision with the other):
Um – well I’m, I can understand Bev’s arguments are quite persuasive. I can understand why she is saying that, so I’ll come down to a four and I’ll agree with her – although part of me, you know.
You’re not happy are you?
Well, ah I just, yeah, maybe it’s just you know it’s my gut feeling and sometimes your gut feeling’s not right. I just felt that.
Sometimes it is.
[laugh]
But I can understand Bev’s arguments so I’ll agree to a four. (Transcript from text five)
A mutually agreed distinction between levels four and five became clearer as a result of internalisation of rhetorical expectations. In evidence of this, in relation to text 11, Christine articulated the expectations put forward by Bev earlier in the rating process:
Hmm yeah, you thought six, I though five.
. . . So um, I suspect that one of the reasons you put it at five was because there’s not really a thesis . . ..
Yep, yep.
. . . in the paragraph, the first paragraph and I can see that now, um comes up in the conclusion. (Transcript from text 13)
Christine also began applying the rater-centred rhetorical conventions articulated earlier by Bev to reconcile rating decisions:
Yeah, yeah [pause] okay I’m prepared to go down [pause] I’m prepared to go down. So, yep and I guess the main reason um yes their thesis doesn’t occur in the beginning, this is what I need to look out for . . .. (Transcript from text 13)
Towards the end of the sessions, both raters had a clear sense of how the rater-centred rhetorical conventions related to performance levels three, four, five, and six on the rating scale. Discourse drawn from later sessions suggested that the raters shared these rhetorical expectations. An explicit example of this was when Bev notated the rating scale with a descriptor of the rhetorical expectations applied to distinguish level five and level six. It is important to note that the language of the notation was different from that of the wording of the relevant section of the rating scale. This was a rater-centred factor that had been explicitly applied by both raters, and thus had a shared locus:
But because it doesn’t have the thesis, um, we’ve been saying the task only, addresses the task only partially [level-five descriptor].
Hmm.
That’s kind of one of the, um, criteria we’ve been using I think.
Hmm.
In this task for Task Achievement. Um [pause] yeah so [pause] for that reason, I would come down to a five. Um [pause].
Yeah I’m noting on, um, under Task Achievement number six “thesis must be in the introduction and consistently maintained all the way through” to warrant a six [notates rating scale]. (Transcript from text 14)
Discussion
The results showed that although collective rater discourse predominantly revolved around explicit factors such as the L2 text and the rating scale, discourse also centred on more subjective factors. These subjective factors, such as different expectations from the raters around application of rhetorical devices, were influential on rater decision-making. This example shows that in order to understand the factors important to the rating process, we need to be cognisant of both explicit factors as well as those that are more subjective. To ignore these subjective factors, or perhaps to dismiss them as sporadic confounds of assessment, would appear to risk portraying an inauthentic picture of the rating process.
The impact of subjective factors on rater decision-making observed here echoes the findings of Lumley (2002), where raters’ judgments circled back to a “. . . complex and indefinable feeling about the text” (p.263). According to Lumley (2002), when individual raters verbalised their explanations of score allocation, it offered little insight into the underlying rater decision-making processes. The current study’s methodology, which entailed two raters resolving divergent rating opinions, appears to yield richer insight in this regard. Problematising discrepancies in rating decisions between multiple raters and having them articulate the underlying reasons they have rated a text in a particular way is a useful mechanism to make indefinable feelings about texts far more explicit.
The process modelled in this paper has a number of broadly applicable implications for both the practice and underlying theoretical foundation of L2 assessment. The most obvious practical implication of this approach is its capacity to initiate, or perhaps further enhance, reflective practice around assessment in professional contexts. With subjective factors, effectively feelings or beliefs, having a real impact on rating decisions, it is important to establish opportunities for members of rating teams to articulate their feelings or beliefs around real rating decisions. As was shown in the current research, there was much to be learnt about the beliefs of the raters by problematising their rating decisions.
Another practical implication of this collective reflective approach is in rubric development and repair. Raters’ discussions around their ratings for a group of candidates can be used to pinpoint areas in a rating scale that need to be tightened or further explained. This approach could help not only in the initial development of rating scales but also in their ongoing maintenance. For example, the case presented here captured an instance of the raters annotating the existing rating scale with their own elaborations in an effort to make the rating process more robust. Application of the collective reflective process outlined in this paper will offer similar opportunities for the systematic improvement of rating scales in a variety of assessment contexts.
Although the scale of this investigation was modest, and this can be seen as a limitation, this attribute also makes the model presented here relevant and feasible for busy language teaching contexts. It is possible for teachers to individually, and then collectively, rate common samples of student work, and then openly discuss their different ratings. This discourse can be recorded and retrospectively analysed. Such collective reflective practice is likely to be useful for teacher training and professional development. Facilitating articulation and reflection around teachers’ beliefs helps teachers become more aware of the impact of these beliefs in their practice (Farrell and Ives, 2015), and the approach of individual and collective rating presented in this paper provides a simple model to achieve this goal.
Building upon, discussing, and critiquing the themes presented here, especially by way of action research embedded within practitioners’ own language teaching contexts, is likely to be valuable and empowering (Edwards and Burns, 2016). The themes articulated in the present research may or may not relate to those that are found in analyses of collective rater discourse in other contexts. Indeed, considering that some of the factors that influence rating decisions are subjective, it is likely that each assessment context will have its own particular set of themes dependent upon factors such as the individual raters involved, the task in question, and so forth. Systematic effort applied towards making clear the context-specific factors that impose an influence on rater decision-making, especially those that are rater-centred, will likely push those factors toward a shared locus. This, in turn, is suggested as being useful in enhancing the reliability and validity of assessment procedures generally.
In terms of informing the theory of practice, bringing practitioners’ attention to the role of subjective factors in the rating process may provide impetus for the consideration of alternative paradigms in assessment. As Moss and Schultz (2001) describe, conventional paradigms of assessment emphasise the primacy of consensus, and view disagreement as a problem that needs to be overcome. Moss and Schultz (2001) go on to assert that in the context of assessment, “. . . dissensus is an essential natural resource that should be acknowledged and nurtured along side the search for consensus or agreement” (p.65). In line with these assertions, Lindhardsen (2018) presents the case of communal writing assessment (CWA), where assessment between co-raters is conceived of as an interpretative transaction within which disagreements between raters are acknowledged and built into the rating process. The approach to assessment described by Lindhardsen (2018) takes a step away from the conventional psychometric paradigm of assessment, which views rater disagreement as a manifestation of an error in measurement. Drawing on the work of Moss and Schultz (2001), Lindhardsen (2018) espouses hermeneutic values in the rating process, which promote differences in rater beliefs as an opportunity for the negotiation of meaning and, thus, a source of validation of the scoring process. Of course, the degree to which such interpretative or hermeneutic values are applicable, or indeed palatable, to any given assessment context will certainly vary. However, the position put forward here is that as subjective rater-centred factors are likely to always be an important consideration in assessment practice, it is preferable to establish an open and explicit dialogue around them. It is important to establish a shared professional culture that views rater difference as an important and valuable resource that demands systematic reflection to ensure valid assessment procedures.
As alluded to previously, a key limitation of the current study was the small scale of the investigation. However, what was intended here was the exploratory analysis of a highly focused case – a well-defined corpus of rater discourse – that would present basic information about it. There is inadequate research around rater decision-making, especially research that investigates interaction between multiple raters, and, thus, another goal of the current study is to encourage further research in this space. The intention here was to present a small-scale model that could be feasibly applied in authentic professional language teaching contexts. Future replication studies are encouraged, especially those undertaken by practising teachers that have identified existing issues or problems in the current operation of their assessment practices. Longitudinal interventions looking at the influence of regular collective reflection on rating procedures and inter-rater reliability would also yield impactful data.
Conclusion
This exploratory study investigated a case of rater discourse focused upon instances where raters had divergent opinions about the assessment of L2 written texts. The findings indicate that rater discourse predominantly focused on explicit factors like the L2 text and the rating scale, but approximately a quarter of the discourse focused on more subjective rater-centred factors. Thematic analysis enabled categorisations of these rater-centred factors in terms of the type of factor (register, rhetorical convention, facts/logic, definitional scope, visceral response) and locus of the factor (with self, shared, with other). The illustration of how different rater beliefs around a rater-centred factor (rhetorical convention) influenced decision-making is a concrete example of the impact of subjectivity on assessment. Although this study involves a relatively small corpus involving just two raters, the study does succeed in providing a simple and accessible model that can facilitate collective reflective practice in assessment. Subjectivity and difference of opinions should be considered standard features of language assessment. Seeing these differences of opinion as valuable opportunities to improve the validity of collective assessment procedures is recommended.
Supplemental Material
sj-pdf-1-rel-10.1177_0033688220977373 – Supplemental material for Using Inter-Rater Discourse to Trace the Origins of Disagreement: Towards Collective Reflective Practice in L2 Assessment
Supplemental material, sj-pdf-1-rel-10.1177_0033688220977373 for Using Inter-Rater Discourse to Trace the Origins of Disagreement: Towards Collective Reflective Practice in L2 Assessment by Joshua Matthews in RELC Journal
Footnotes
Declaration of Conflicting Interests
The author has no conflicts of interest to declare.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This project was supported by a research grant obtained from the Association for Academic Language and Learning (AALL).
Supplemental Material
Supplemental material for this article is available online.
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.