
Abstract
Accurate energy forecasting is essential for grid stability, demand-side management, and efficient renewable integration. However, energy consumption data collected from smart meters may expose sensitive user information, thus raising privacy concerns. Federated Learning (FL) offers a privacy-preserving mechanism for collaborative model training without sharing raw data. However, conventional synchronous FL suffers from training delays caused by heterogeneous client availability and computational capabilities, while frequent exchange of model parameters can lead to communication overheads. To address these challenges, this paper proposes an asynchronous federated learning framework for energy forecasting that enables continuous global model updating without waiting for all clients to complete local training. We introduce a federated asynchronous adaptive aggregation mechanism, where client-specific learning rates are dynamically adjusted based on both update staleness and model performance contribution. A partial aggregation strategy is defined for a Long Short-Term Memory (LSTM) forecasting model that splits the local models’ layers, allowing clients to exchange only a subset of the weights with the server. The proposed solution is evaluated using real-world energy consumption data from multiple consumers. Experimental results demonstrate that the proposed asynchronous adaptive strategy outperforms the classic FedAvg approach and maintains prediction accuracy relative to personalised FedAvg, while reducing communication costs. Additionally, the proposed method outperforms the classic FedAsync algorithm across all client groups, with statistically significant improvements in most cases.
Keywords
1. Introduction
The necessity of accurate energy consumption forecasting has increased significantly with the evolution of modern power systems and the growing integration of distributed energy resources. The high penetration of renewable energy sources introduces variability and uncertainty in power generation, requiring more proactive grid management strategies and advanced operational planning. 1 In this context, demand response programs aim to better align electricity consumption with available generation resources. 2 However, their efficiency depends on consumers’ engagement and accurate energy forecasting at low-scale granularity. The integration of smart meters and Internet of Things (IoT) has facilitated this process by generating large volumes of high-resolution energy consumption data for providing detailed insights into consumer usage patterns and creating valuable datasets for training advanced forecasting models. 3 However, centralized forecasting architectures require the collection and storage of large volumes of fine-grained consumption data in a cloud data centre, which creates privacy and security concerns. 4 Smart meter data can reveal detailed information about household behaviour, occupancy patterns, and lifestyle habits, making citizens reluctant to centralised energy data storage. 5 In addition, the large volumes of monitored data contribute significantly to communication overhead, especially when the data exchanges with the centralised servers are frequent.
In this context, federated learning (FL) offers a promising solution by enabling collaborative model training across decentralised data sources while preserving data privacy. Thus, only the updated model weights are shared with the server for aggregation, and the raw energy consumption data remains stored locally.6,7 However, FL faces challenges including non-identical data distribution across clients, computational heterogeneity and synchronisation in training schemes. In the case of energy consumption, data on clients is non-IID (non-independent and identically distributed) because it can vary significantly due to personal user habits, external conditions, or differences in device configurations. 8 The number of available training samples can vary between clients, and it can negatively impact model convergence and performance. In some cases, a synchronous FL process can result in either unfair or slow global model updates. When participation is constrained by time limits, faster clients are favoured, while ensuring full participation requires waiting for slower clients, which delays model updating. 9 Also, communication costs remain challenging, as clients must repeatedly exchange high-dimensional model parameters, such as weights and gradients, during each training round. This issue becomes more pronounced when deep learning models, such as Long Short-Term Memory (LSTM), are used for load forecasting. Moreover, in the case of synchronous FL, the global model aggregation can only proceed after all participating clients have submitted their local updates. This dependency makes the training process depend on slower or intermittently available clients, introducing significant synchronisation delays. 10
To address these challenges, we propose an asynchronous FL framework that allows the global model to be continuously updated as soon as client updates are received, without requiring all clients to complete their local training. In this way, we address the delays caused by heterogeneous client availability and computational capabilities as we consider more relaxed synchronisation constraints. To ensure fairness and stability in the aggregation process, we introduce an adaptive aggregation mechanism in which each client’s update is weighed through a dynamically adjusted learning rate. This client-specific learning rate accounts for both the staleness of the update, reflecting the time elapsed since the client last synchronised with the global model and its contribution to global performance, evaluated on a server-side validation dataset. In this way, outdated or less beneficial updates will have a more limited influence on the global model, while more informative contributions are considered. Additionally, to address the communication overhead associated with frequent model parameter exchanges, we have defined a partial aggregation mechanism. Instead of transmitting the full set of model weights at each communication round, only selected layers of the LSTM forecasting model are transmitted. The main contributions can be summarised as follows: • Design and development of an asynchronous FL framework for energy load forecasting that accommodates client heterogeneity in terms of computational resources and availability, enabling continuous global model updates. • Design of a selective layer sharing mechanism for the LSTM forecasting model, where only weights from specific layers are shared and aggregated globally to reduce communication overhead. • Integration of a federated asynchronous adaptive aggregation mechanism that uses an adaptive learning rate specific to each client that is updated every round based on both staleness and contribution to the global model performance.
The rest of the paper is structured as follows: Section 2 presents the existing state of the art in FL for energy forecasting and partial aggregation mechanisms, Section 3 presents the proposed asynchronous FL system with partial global model aggregation with adaptive learning rate for each client, Section 4 presents the prediction results evaluated on real energy consumption data set, Section 5 discusses the findings and presents a comparative analysys, while Section 6 concludes the paper.
2. Related work
To contextualise the proposed approach, this section examines advances in energy consumption forecasting, reviews FL frameworks for distributed model training, and discusses synchronisation strategies in FL environments.
Energy consumption forecasting has evolved, transitioning from statistical methods, such as autoregressive models, to more advanced machine learning approaches capable of capturing nonlinear relationships in data. In Ref. 11 the authors use an Autoregressive Integrated Moving Average (ARIMA) model for time series forecasting of energy consumption across multiple energy sources, leveraging historical data to predict long-term future trends. With the growing availability of high-resolution time-series data, deep learning architectures, particularly recurrent models like LSTM12,13 and Gated Recurrent Unit (GRU), 14 have demonstrated the ability to model temporal dependencies and complex consumption patterns. In Ref. 15 the authors investigate peak electrical energy consumption forecasting using both traditional time series models and deep learning models, as well as hybrid combinations (ARIMA-LSTM and ARIMA-GRU), demonstrating that hybrid approaches achieve superior predictive performance. A comparative evaluation of Recurrent Neural Network (RNN)-based deep learning models for smart grid energy demand forecasting was conducted in Ref. 16, showing that GRU was the most effective due to higher performance metrics and better handling of long-term dependencies. More recently, transformer-based architectures have been adopted for energy consumption forecasting due to their capacity for explicit long-range dependency modelling, due to their self-attention mechanism. 17 Models such as the Temporal Fusion Transformer18,19 demonstrate improved performance on high-dimensional and long-horizon time-series tasks by effectively integrating multi-modal inputs, capturing complex temporal dependencies, enhanced forecasting accuracy, particularly in settings with heterogeneous data and limited training samples. However, these approaches often rely on centralised data collection, which raises concerns regarding data privacy, especially in the energy domain when dealing with consumption data from individual consumers. 20 While these approaches have demonstrated strong predictive performance, they mostly rely on centralised training that requires aggregating raw consumption data, generating privacy and security concerns for households’ energy consumers.
To address these limitations, FL has emerged as a distributed training paradigm that enables collaborative model development without sharing raw data. 21 LSTM models are often used for energy consumption predictions on historical monitored data in FL settings. In Ref. 5 the authors propose a FL-based approach for short-term residential load forecasts. Additionally, researchers propose combining an LSTM network with a multi-head self-attention mechanism to capture temporal dependencies and focus on the most relevant sensor features for energy demand prediction, whilst extending training to a decentralised learning setup. 22 This type of solution can address both communication overhead and privacy concerns by local training models and, eventually, clustering the users based on consumption patterns and similarities. 23 Federated Average (FedAvg) allows clients to perform several local updates before sending model parameters to the server, which uses computing a weighted average to update the global model. After training, each client sends the updated model weights back to the server. The server aggregates them by performing a weighted average.24,25 However, FedAvg may perform poorly in non-IID settings due to differences in client data distribution. Multiple algorithms are proposed to address this challenge, such as Federated Stochastic Variance Reduced Gradient (FedSVRG). 26 FedProx is an aggregation method based on FedAvg, which introduces a proximal term to stabilise training by preventing local models from diverging too far from the global one.27,28 Another improved version of FedAvg is Clipped Average Aggregation that applies clipping model updates to a predefined range before averaging. 29 To address privacy concerns regarding sharing weights, differential privacy methods are introduced where each client adds noise to its model updates before sending them to the server. 30 Additionally, some approaches use bio-inspired optimisation algorithms in the aggregation process to improve the convergence speed and performance of the federated model. 31
Despite its privacy-preserving benefits, FL introduces challenges in maintaining high prediction performance and ensuring fair model updates. 32 Model performance can degrade due to statistical heterogeneity across clients, leading to imbalanced and potentially unfair contributions, especially in non-IID settings where certain clients disproportionately influence the global model. 33 Additionally, in practical deployments, system heterogeneity and varying client availability introduce challenges related to delayed or stale updates. 34 Furthermore, communication constraints, such as limited bandwidth, intermittent connectivity, and transmission delays, can further impact training efficiency. 35 These challenges highlight the need for more adaptive training and aggregation mechanisms that can effectively address both data and system-level heterogeneity. In the synchronous FL, the central server distributes the global model to a selected subset of clients, waits for all of them to finish training locally, and then aggregates the updates received. 36 It can suffer from stability issues, particularly in the presence of heterogeneous client devices and unreliable communication. Clients can delay the entire training process, increasing the total convergence time. 37
In comparison, asynchronous FL provides several advantages by accommodating different clients, reducing idle times, and increasing fault tolerance.38,39 The asynchronous FL allows the server to aggregate model updates from clients as soon as they are received, without waiting for other clients to complete their training. Using this strategy, the server continuously updates the global model whenever it receives an update based on client contributions. This ensures the gradual integration of new updates while preserving stability. In addition, this mechanism enables devices and networks with heterogeneous capabilities to participate in the training process. 9 This type of strategy is mostly suited to energy forecasting environments where edge devices may have intermittent connectivity or differences in the complexity of the data. 40 However, asynchronous FL can have effects on the convergence and overall model accuracy, as the global model incorporates outdated or inconsistent local information. 41 Semi-asynchronous FL approaches have been investigated, highlighting the trade-off in improving training efficiency between synchronous (latency) and asynchronous approaches (accuracy).42,43 Partial weight training is a strategy adopted in FL to reduce communication overhead and enable personalisation, particularly in non-IID environments. 44 In this approach, only a subset of model layers is shared with the server for aggregation (feature extractor) and used for collaborative training. The rest of the layers remain local and are trained on each client to capture specific patterns. FedPA (Partial Aggregation Strategy) introduces an adaptive aggregation number per round, and only a subset of client models is used to update the global model. 45 This strategy integrates stale updates by adjusting weights based on staleness and data size, balancing convergence and efficiency. Other partial model aggregation mechanisms aggregate only lower layers of the neural network (the feature extractors), keeping upper layers (predictors) locally for personalisation. 46 This design has been shown to improve generalisation under non-IID data while significantly reducing transmission costs.
3. Asynchronous federated learning
We propose an asynchronous FL approach with partial weight aggregation for 24-hour energy consumption forecasting. The asynchronous mechanism aims to ensure fair participation amongst heterogeneous clients by updating the global model immediately upon receiving updates from individual clients. In addition, a partial weight aggregation method was implemented starting from the work presented in Ref. 30.
3.1. System architecture
Figure 1 presents the proposed asynchronous FL architecture incorporating the partial weight update strategy. The clients have access to their own private data and a local model (LSTM) split into a shared feature extractor and a local predictor. Each client requests the global model weights corresponding to its selected layers, initialises its local model, trains the entire model and sends only the updates for the shared layers (feature extractor), keeping the predictor layers private. The split of the model is controlled by selected layers, which indicate the layers that the client is willing to share for global aggregation. Async FL with adaptive aggregation architecture.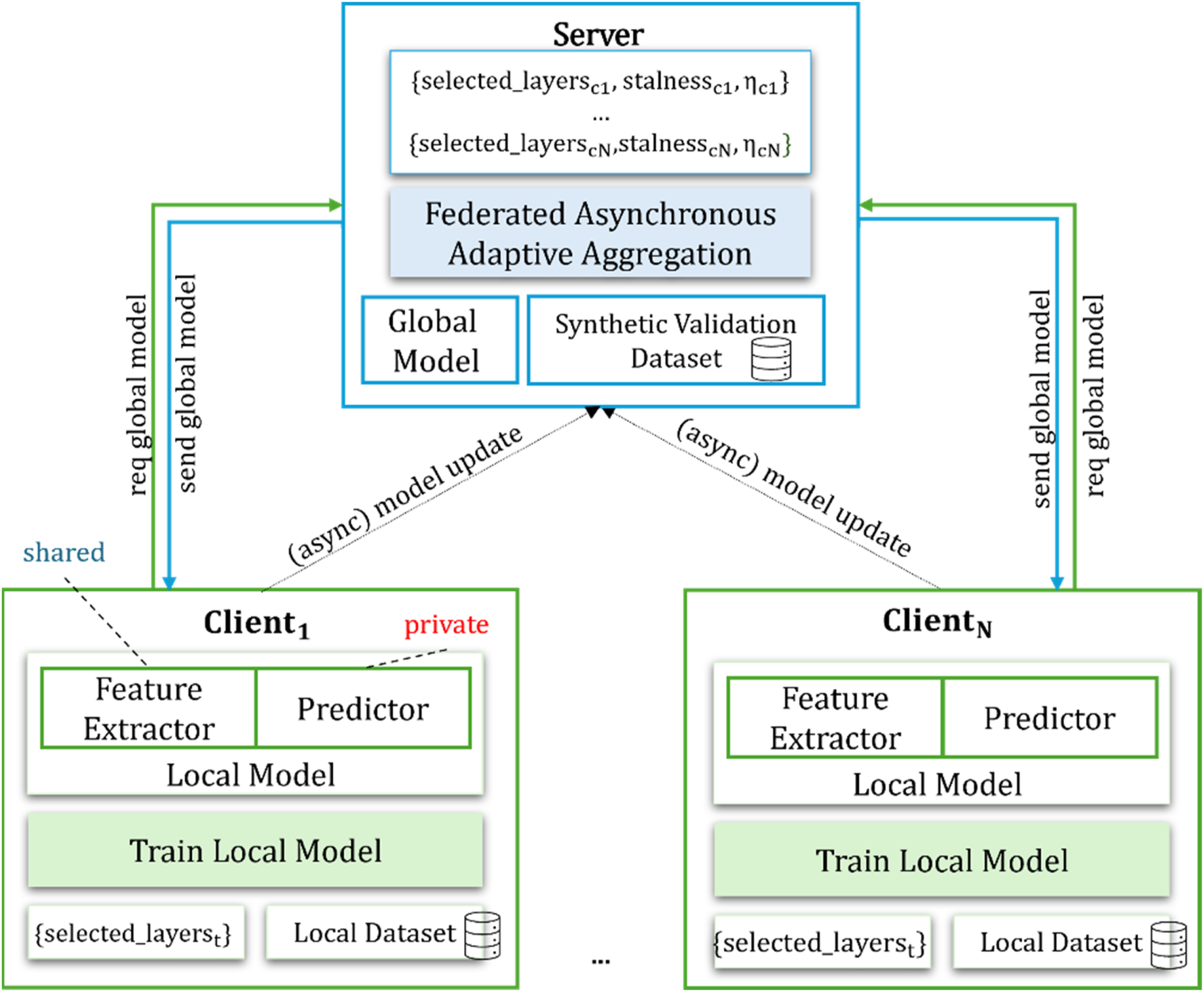
The server receives and aggregates updates asynchronously to the global model, considering the selected layers for each client and using the adaptive learning rate. The learning rate for each client is dynamically updated whenever the client sends a model update. The adjustment depends on two factors: (1) the performance of the client’s new weights on a server-side synthetic validation dataset and (2) the client’s staleness, a variable that quantifies the delay since the client’s last update. The synthetic validation dataset approximates the statistical characteristics of real energy consumption data. This dataset is generated by sampling from aggregated client statistics, ensuring that no individual user data is transmitted to the server. The clients compute summary statistics locally (e.g., mean, variance, hourly consumption distributions) over their private data and share only these aggregated metrics with the server. Using these statistics, the server samples values from distributions defined by client-provided means and variances to create realistic sequences. The synthetic dataset incorporates multiple usage patterns, including peak and off-peak hours, weekday and weekend variations, and seasonal trends, to provide a representative reference for model evaluation.
The flow of the asynchronous FL training process is presented in Figure 2. Firstly, the server initialises the global model. Before participating in a training round, the client must register with the server to initialise its learning rate. When a client wants to start a training process, it requests the part of the global model corresponding to its selected shared layers. The server initialises its staleness, and the client starts training the model locally on private data. After the weights are updated, it sends back to the server the ones from the shared layers, triggering the adaptive aggregation process. The server immediately updates the client’s learning rate and applies the received update to the global model. Lastly, the server increases the staleness for all the other clients. With such an asynchronous strategy, clients participate independently based on availability, requesting the latest global model at any time and performing local training. The server integrates the updates from the clients immediately, without waiting for other clients. Asynchronous FL with partial aggregation flow.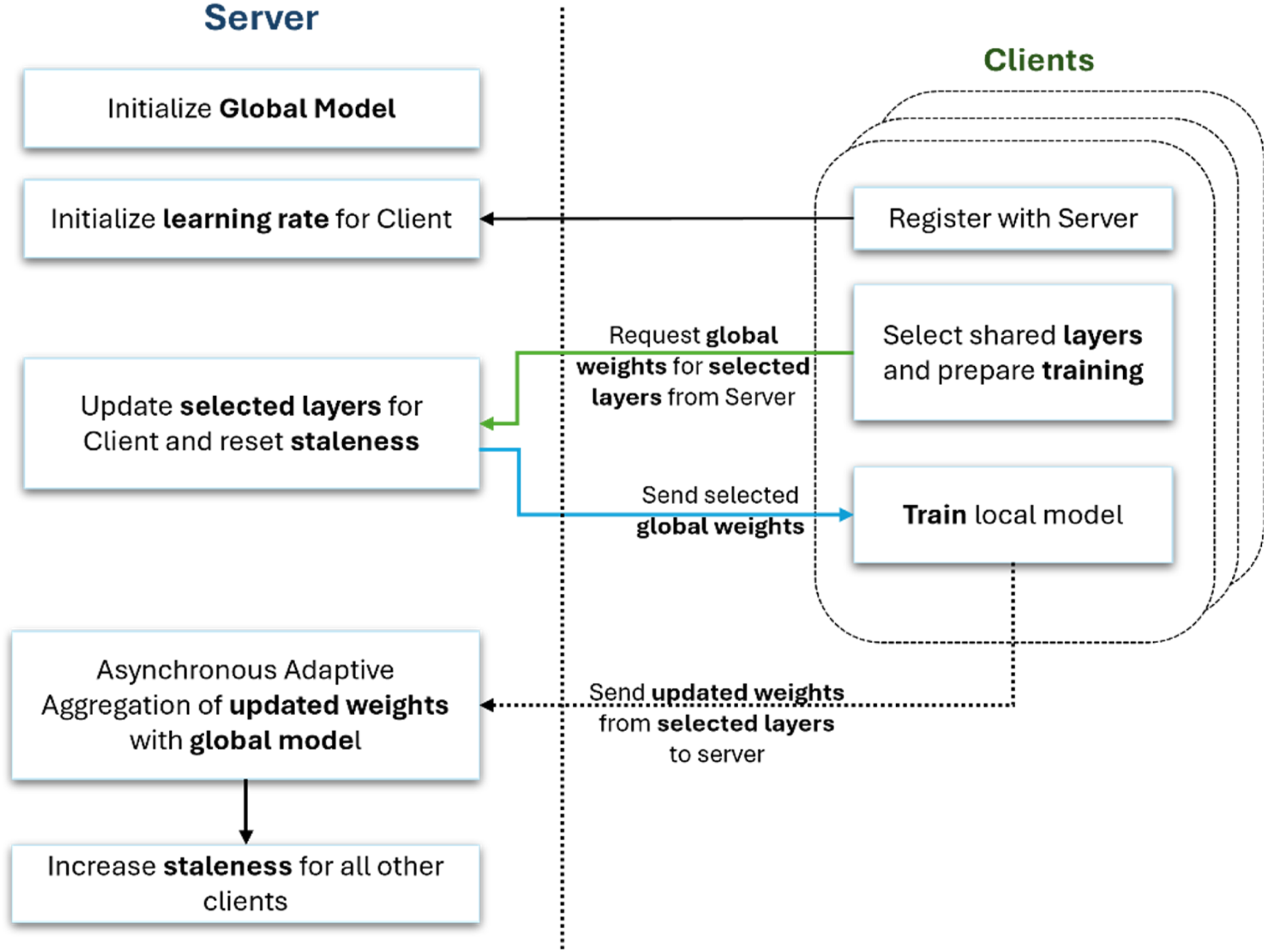
3.2. Asynchronous adaptive aggregation method
The aggregation method used for the proposed asynchronous FL system is described in Algorithm 1. The FedAsyncAdaptive function is executed each time a client c sends updates. The global model weights (line 3), as well as staleness and learning rate for each client, are stored on the server (line 4-5). The updated weights for this step are received from the client (line 6). Firstly, the delta loss between the global model and the received update is computed on the validation set of the server (line 9). Then, the learning rate for the client c is updated according to the loss delta and staleness of the client (line 10). The staleness for each client is increased when another client updates the model (lines 11-12). Lastly, the global model weights are updated and stored on the server (line 14).

3.3. Partial weight aggregation
The LSTM model layers are divided into a shared feature extractor and a private predictor that remains on the client. 46 In addition, we developed this approach by enabling custom model splitting for each client; thus, each client can have a custom number of selected layers for the feature extractor and for the predictor, respectively. This enhances the personalisation of client training. The steps for local training and partial weight update on the server are described in Algorithm 2. The client c has its model weights from the previous training round (line 3) as well as a list of selected layers (4), which indicates how the model of the client is split for this training round. This function returns the feature extractor part of the updated weights to the server (line 5). Firstly, the client splits its previous round weights (line 7) and then requests the corresponding feature extractor weights from the server (line 8). In this step, the server stores the layers’ configuration of the client for this round. The client initialises its model with the weights composed of a global feature extractor and its own predictor (line 9) and then trains it on the local dataset (line 10). The updated weights are then split (line 11) into a feature extractor that is sent to the server (line 12) and a predictor that is kept private on the client. This supports both communication efficiency and client-level personalisation.

The weights are split based on the layers that are selected by the client to be shared. The split_layers function divides the weights into the feature extractor (weights that are in the selected layers list) and predictor (weights that are not in the list). This is achieved by traversing the model recursively. Thus, only a subset of the weights is shared with the server, minimising communication costs and enabling personalised training on clients. Additionally, this function is used when updating the shared part of the client model with the global model received from the server, ensuring that only globally aggregated layers are overwritten.
The split_layers function is further described in Algorithm 3, having as input the entire LSTM model and the selected_layers array (lines 2-4), and returning two sets of weights (line 9) representing the feature extractor (shared) and predictor weights (private). Firstly, the two arrays are initialised (line 7), and then the recursive function is called (line 8). The recursive function (lines 11-26) passes through the layers of the LSTM, and for each layer, it calls itself to build the two required arrays (lines 17-20). For the layers that have no sublayers, their corresponding weights are directly concatenated either to the feature extractor or to the predictor weights array (lines 21-26). This way, the weights are divided, and the clients can share with the server only the selected ones. A function with the reverted process is implemented to build the entire LSTM model by reuniting the feature extractor and predictor weights. This function is needed on both the client and server side.

4. Evaluation results
The consumers used for evaluation were selected from a real-world dataset that comprises time-series measurements of monitored energy over continuous periods for approximately 1000 prosumers, identified by unique IDs and having different energy scales. 31 For evaluation, only the energy consumption component was considered. The consumption data is recorded in kWh at 15-minute intervals and spans an approximate period of four years (2015–2018), offering a high temporal resolution for consumption patterns. It contains a timestamp indicating the date and time at which the measurement was taken and the active energy measured at that timestamp. A subset of 40 consumers was selected through a multi-stage filtering process. First, consumers with missing values were excluded. Second, we removed consumers who have strong temporal drift between the training and validation periods (e.g., near-zero consumption throughout the validation period), as well as those with a high proportion of zero readings. This ensured that only consumers with continuous and consistent measurements were used in the federated process. Finally, to ensure diversity in consumption behaviour and have a non-IID scenario, the average load profiles of the remaining candidates were analysed, and the clients were selected to reflect a wide range of distinct usage patterns.
The time series of each client was first normalised using a MinMaxScaler applied independently per client. The scaler parameters were fitted on the training set of each client’s data and then applied to the validation and test splits. The training samples were created using a sliding window approach. Specifically, for each client, input sequences of length 96 were constructed, corresponding to the past 24 hours of energy consumption at a 15-minute resolution. Each input window
Selected clients and simulation setup.
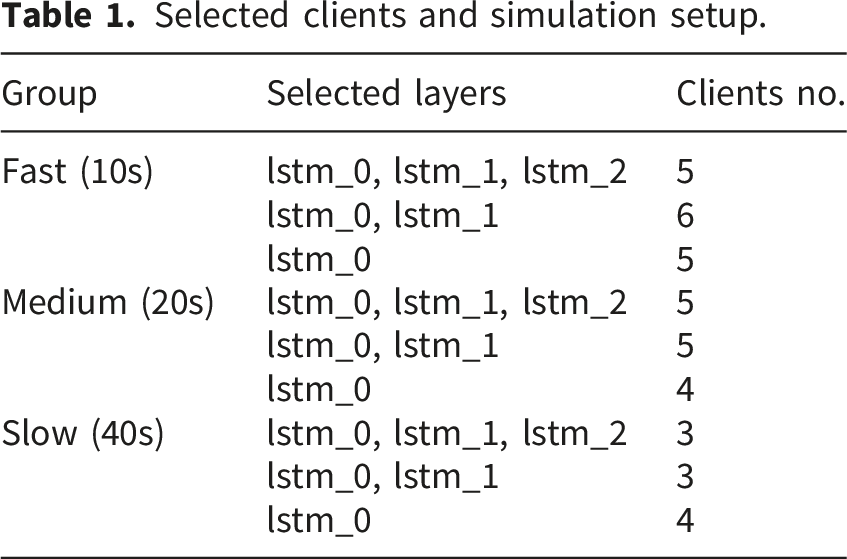
The simulation was run on a virtual time of 640 seconds, with each client participating according to its group. Figure 3 shows the staleness over the simulation period for each client group. Staleness measures the number of global model updates that occurred between a client’s request for the global model and its current update. Fast clients maintain low staleness, while slow clients are near the maximum for the entire duration of the simulation. Staleness over simulation time for each group.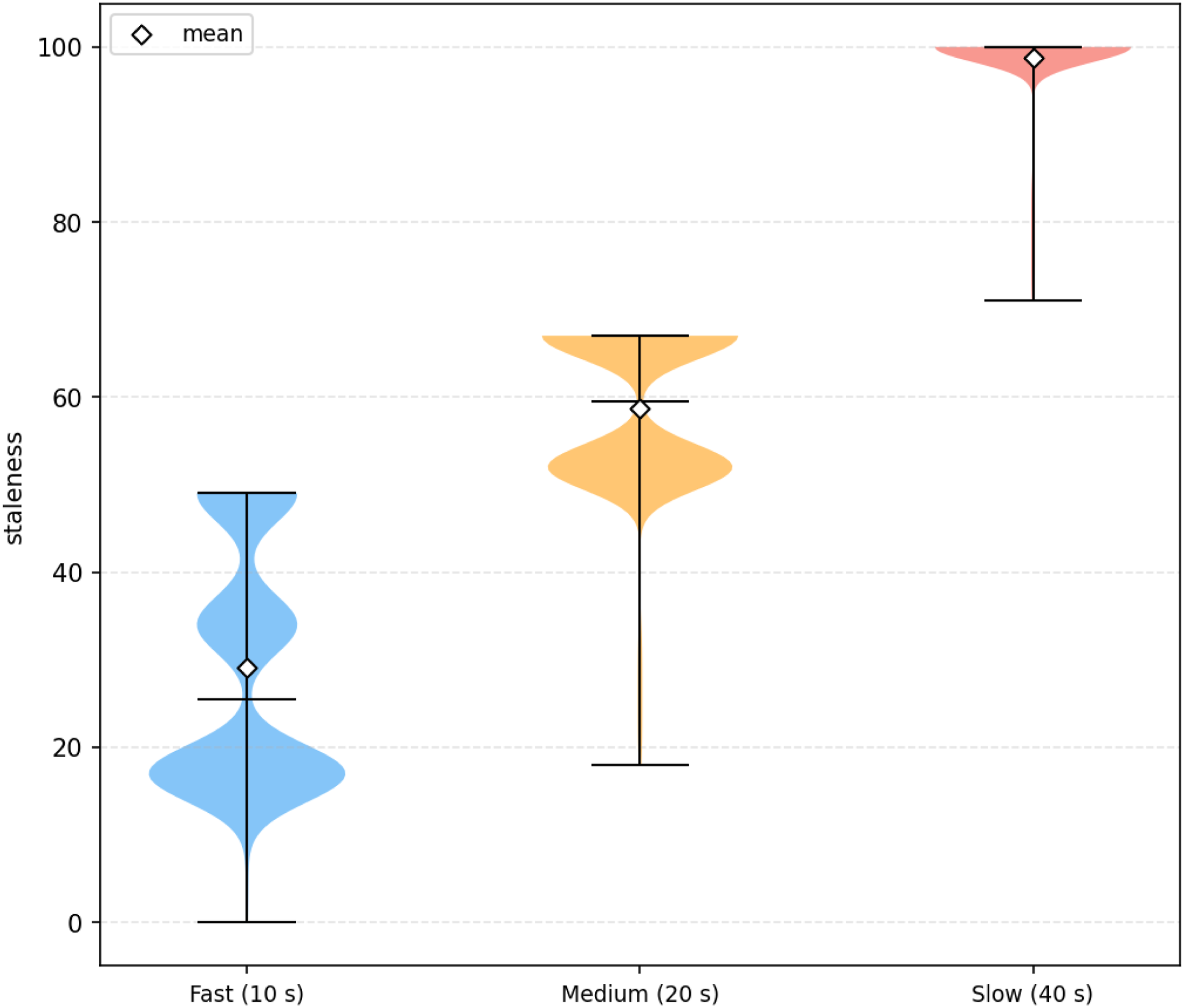
Figure 4 presents the evolution of the coefficient of determination (R2) and symmetric mean absolute percentage error (sMAPE) metrics during training for each local client round, averaged over groups, and the number of shared layers. The results are averaged within each group, with shaded regions indicating variability. Fast clients, which complete approximately 65 local training rounds within the simulation window, contribute most significantly to the global model. In this group, configurations sharing 2 layers achieve the best trade-off, with higher R2 and lower sMAPE compared to both more localised (1 layer) and fully shared (3 layers) setups. This suggests that partial sharing provides a balance between global model generalisation and local adaptation. For the Medium group (32 rounds), the configuration with 3 shared layers shows the most stable and strong performance. Slow clients (around 15 rounds) have slower convergence, with overall lower R2 and higher sMAPE across all configurations. This behaviour is expected, as their limited participation leads to stale updates, which are frequently discarded or have reduced impact on the global aggregation. Although performance differences between sharing strategies are less pronounced in this group, configurations with more shared layers have a higher training performance. R2 and SMAPE during training by client group and shared layers.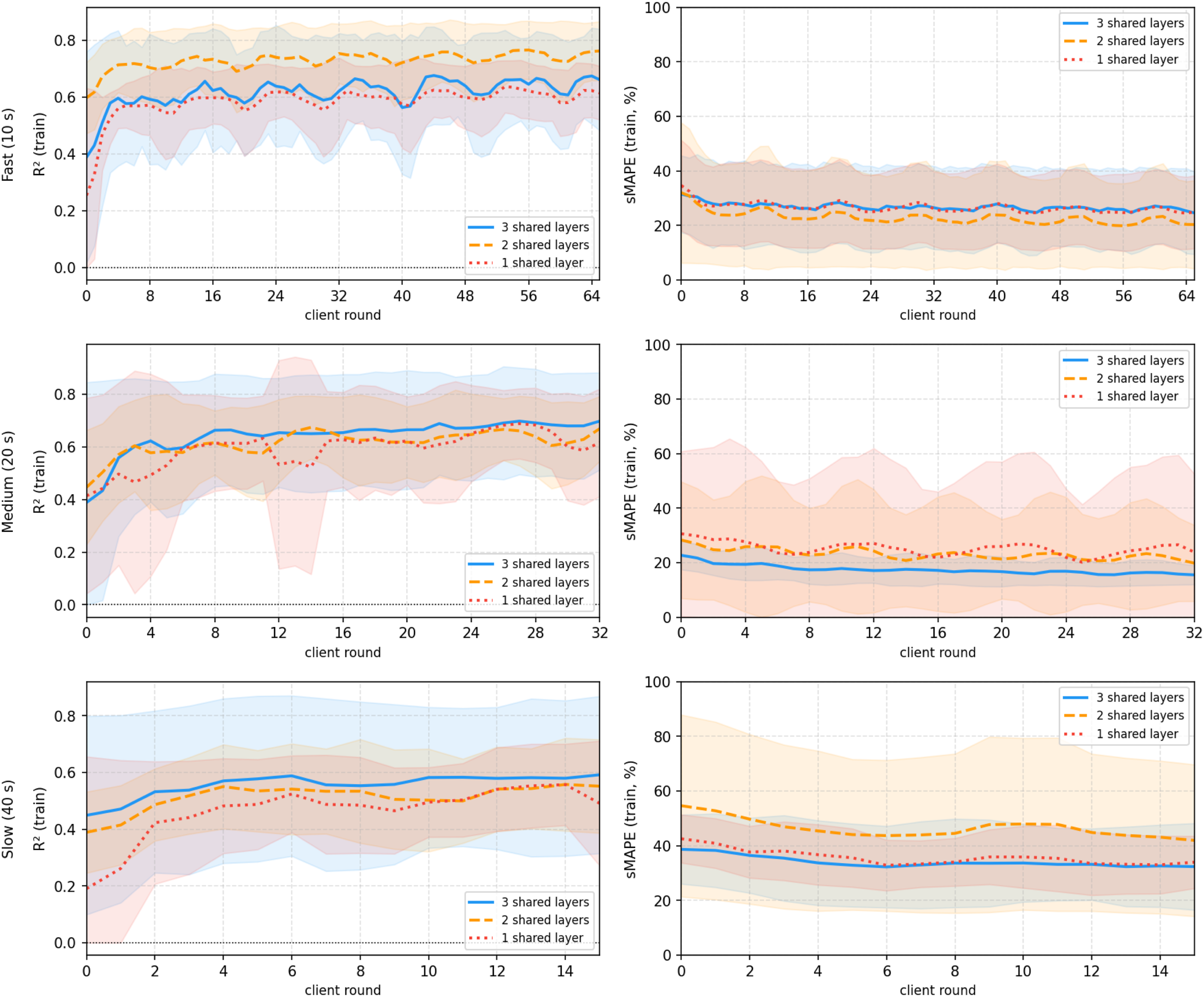
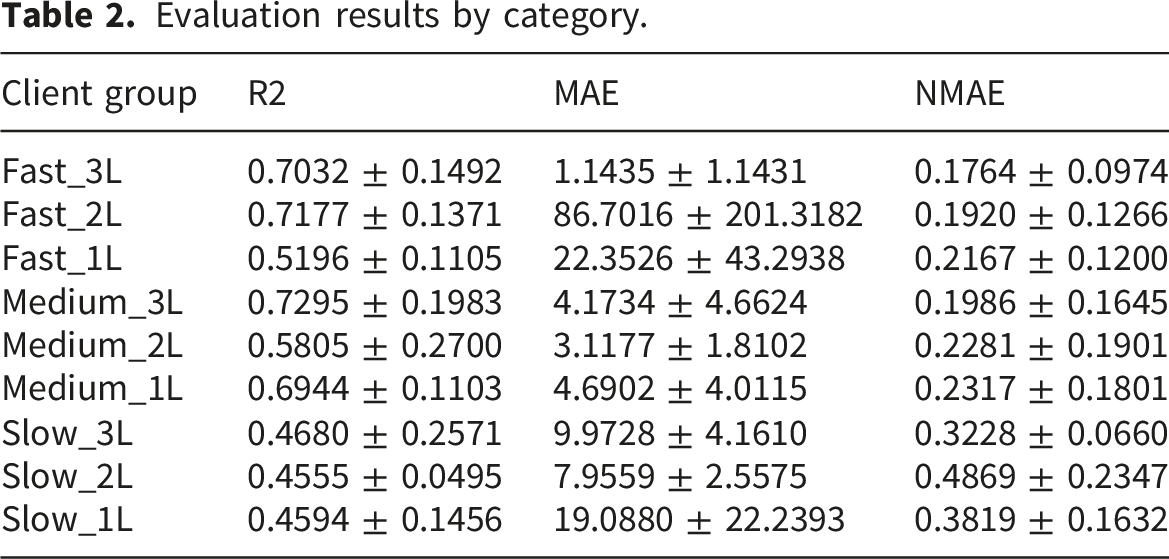
Evaluation results by category.
5. Discussion
We first compared the proposed solution against the FedAvg baseline method on the same datasets and model configuration. The classic FedAvg baseline trains a fully shared global model by aggregating all layers, including all LSTM layers and the dense layer, across clients. In addition, we compared the model with a Personalised FedAvg in which the aggregation is limited to the LSTM layers while keeping the dense layer client-specific, ensuring a fair comparison in non-IID settings. The client groups are the ones for the proposed asynchronous method, whilst the FedAvg methods were trained synchronously. The NMAE metric comparison is shown in Figure 5. FedAvg is consistently the worst across all nine groups, with a significant gap for fast clients. The difference is smaller in slow groups, for the clients who participated less during the asynchronous training. Personalised FedAvg shows similar performance for medium clients and a smaller gap for the fast ones, whilst in all three slow groups, Personalised FedAvg achieves lower NMAE than our solution. Additionally, we have compared our solution with a classic asynchronous FL method proposed by Xie et al. in (FedAsync).
38
In this approach, each model update is weighted by a staleness discount, the clients share all model layers, and the update quality is not considered in the weight. For evaluation, we used the same virtual clock, and uploading intervals defined by the client group (fast, medium and slow). The results show that our solution achieves lower NMAE than the classic FedAsync baseline across all client groups, with reductions ranging from 0.13 to 0.22 NMAE across different groups. NMAE comparison with personalised FedAvg, FedAvg and classic Async FL by client group.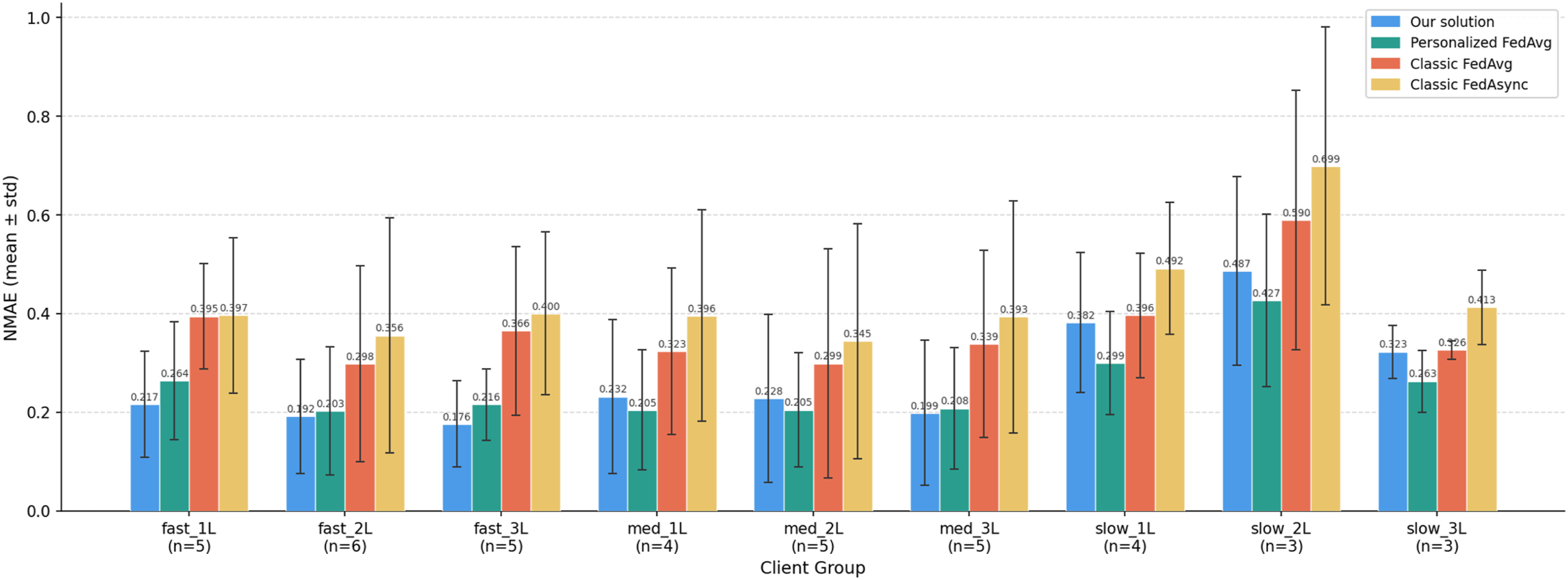
Paired t-test results for NMAE: Our solution vs FedAvg and personalised FedAvg.
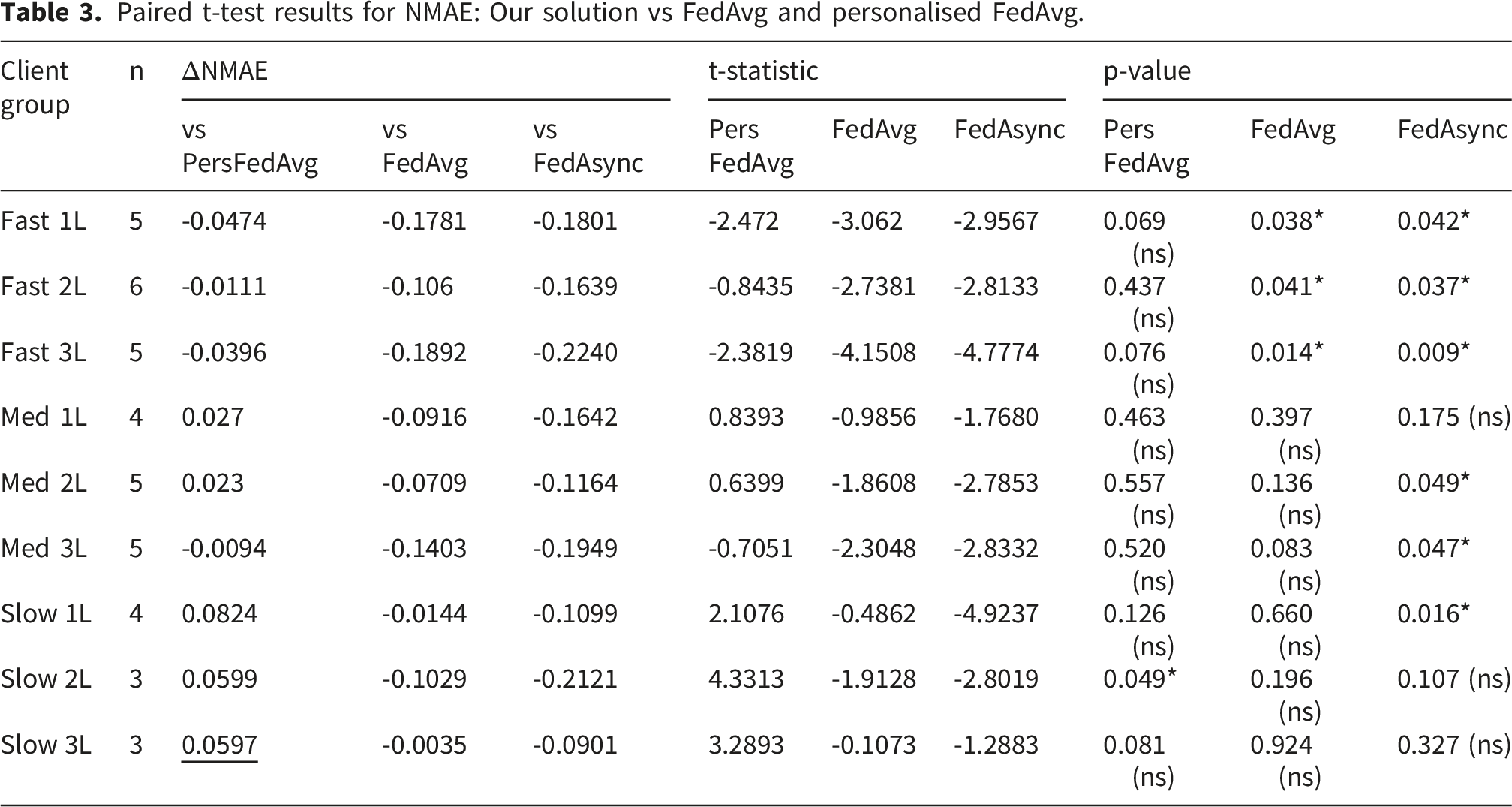
Figure 6 shows the impact on communication of each shared layer configuration and the full model. For our solution, the sizes of the updates sent to the server were measured during the simulation and are represented in kilobytes. The Dense Layers are the part of the model that are never shared with the server for our solution. For classic FedAvg and FedAsync, the full model (∼530 KB) is uploaded, whilst for the personalised version, only the LSTM layers are shared (∼500 KB). In comparison with the two methods, our approach reduced communication overhead from ∼500 KB to ∼450 KB, and even to ∼260 KB, depending on the number of layers selected by the clients. Moreover, when larger models are used, the impact on communication can be even more significant, as they usually contain layers with a higher number of parameters. This reduction in communication overhead improves scalability, as its benefits become more significant in large-scale deployments with many clients and frequent updates. In such settings, lower communication costs improve overall efficiency, while the asynchronous mechanism reduces the impact of delayed updates. Moreover, data heterogeneity increases as the number of clients grows, further motivating the advantage of personalisation in adapting the model to specific clients. Communication overhead per round by shared layers configuration.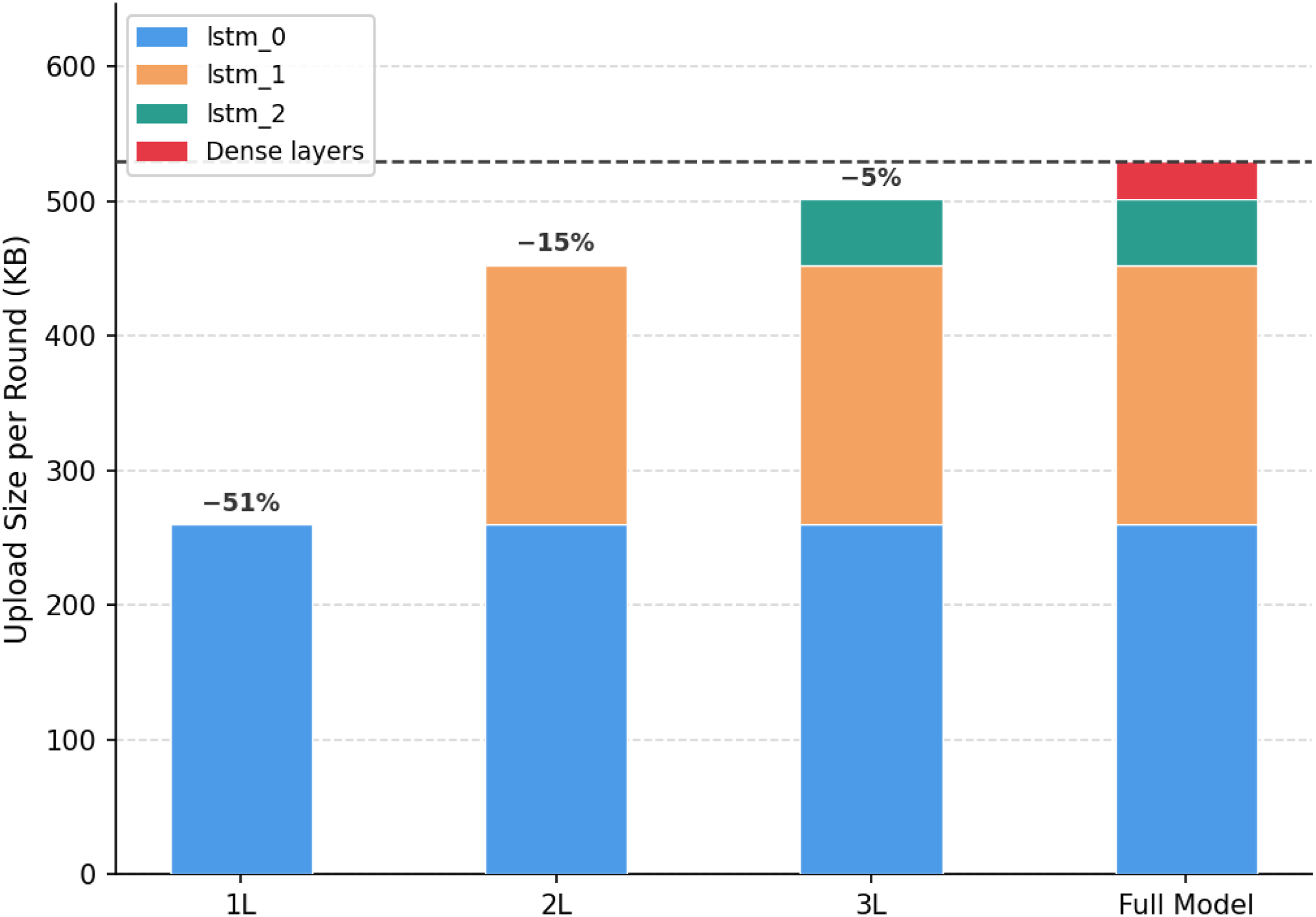
6. Conclusion
In this paper, we propose an asynchronous FL solution with an adaptive aggregation mechanism and partial model sharing for energy consumption forecasting. This solution addresses the identified limitations of synchronous FL, including training delays caused by client heterogeneity and high communication overhead. Moreover, using a client-specific adaptive learning rate, it addresses challenges commonly associated with asynchronous approaches, such as update staleness and fairness across clients. The adaptive mechanism assigns dynamic learning rates to clients based on both update staleness and the performance of each client’s update measured on the server’s synthetic validation data. In addition, the partial aggregation approach, tailored for LSTM-based models, allows clients to selectively share only a subset of model layers, reducing communication overhead. The experimental results on real-world energy consumption data show that the proposed asynchronous strategy achieves comparable predictive performance with the standard FedAvg baseline across most client groups, with statistically significant improvements observed for fast clients. Compared to Personalised FedAvg, the proposed approach performs similarly for fast and medium clients, while having a lower predictive performance for slow clients, which is justified by their reduced participation in the asynchronous training process. In addition, the proposed solution outperforms a baseline asynchronous federated method in terms of prediction accuracy, with statistically significant improvements observed for most of the groups. The partial aggregation mechanism reduces the amount of transmitted data per training round, lowering the communication cost of a full model update to smaller updates depending on the number of shared layers, while maintaining the prediction accuracy. Future work includes evaluating the proposed asynchronous FL framework on larger-scale settings involving more clients with different computational capabilities and larger models. This would provide better insights into the impact on prediction performance, the reduction in communication costs, and the trade-off between them.
Footnotes
Ethical considerations
This article does not contain any studies with human or animal participants.
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported by the project “Romanian Hub for Artificial Intelligence-HRIA”, Smart Growth, Digitization and Financial Instruments Program, MySMIS no. 334906.
Declaration of conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.