
Abstract
Objectives
Accurate triage of lumbar spine magnetic resonance imaging (MRI) referrals for sciatica is important for patient assessment, diagnosis and surgical planning. This study evaluates the accuracy and speed of large language models (LLMs) in automatically vetting lumbar spine MRI referrals from general practice.
Methods
Three LLMs (GPT-4, Claude Opus, Gemini) were tasked with assigning an outcome (Accept – Routine, Accept – Urgent, Reject) and flagging MRI contraindications for lumbar spine referrals. Three prompts of increasing detail, including clinical guidelines and training examples, were used. Two radiology registrars synthesised 120 referrals, vetted by two board-certified radiologists, with a third resolving disagreements. Performance was assessed using accuracy, precision, recall and F1 scores.
Results
Inter-rater agreement between radiologists was substantial for vetting outcome (Cohen's κ = 0.76) and contraindication detection (κ = 0.68). Claude Opus with the full prompt achieved the highest accuracy (0.86) for vetting outcomes. GPT-4 with the instruction-only prompt achieved the highest F1 score (0.88) for contraindication detection. LLMs completed the task substantially faster than radiologists (9.8 ± 1.0 vs 135.0 ± 45.0 min).
Conclusions
LLMs demonstrate promising performance in vetting radiological referrals for sciatica, particularly with detailed context. All models identified all urgent referrals, suggesting potential for prioritising vetting worklists and improving timeliness of care.
Keywords
Introduction
Timely and appropriate magnetic resonance imaging (MRI) is crucial for the effective management of spinal disorders, particularly for patients presenting with low back pain and suspected radiculopathy. However, the escalating demand for MRI examinations places significant strain on radiology services, potentially delaying access to this critical diagnostic tool.1,2 In the UK's National Health Service (NHS), all imaging requests, including MRI, undergo a vetting process by radiologists to ensure clinical justification and the selection of the most appropriate imaging modality. This process helps to avoid unnecessary investigations, optimise resource utilisation, and identify any contraindications.
While essential, the vetting process is time-consuming and, given the increasing workload pressures on radiologists, 3 can contribute to delays in patients receiving the necessary imaging. This is particularly relevant for spinal MRI, where prompt diagnosis can influence surgical planning and improve patient outcomes. Errors in vetting can result in inappropriate investigations or delays, impacting patient care and incurring unnecessary costs to health services. 4
Solutions that can streamline the vetting process without compromising accuracy are therefore highly desirable. Large Language Models (LLMs) have shown considerable promise in automating tasks involving text analysis, including concept extraction from medical documents.5,6 Crucially, these models can achieve high performance without extensive, task-specific training data. 7 Currently, the best-performing models are closed-source resources with controlled public access via online application programming interfaces (APIs). 8
This study focuses on lumbar spine MRI referrals from general practitioners (GPs) for low back pain, a common and increasingly frequent clinical scenario. At NHS Tayside, lumbar spine MRI examinations have increased significantly over the past decade, from just over 1500 to nearly 2500 studies annually (Figure 1). These referrals are typically vetted based solely on the text-based referral information, making them ideal for assessment by LLMs. The vetting radiologist determines whether the study is clinically indicated, assigns an urgency level (routine or urgent, based on the likelihood of nerve root compromise), or rejects the request if it is insufficiently justified. We aim to evaluate the performance of several widely available LLMs in automating the prioritisation and triage of GP-requested lumbar spine MRI referrals for low back pain, with a view to improving the efficiency of this crucial step in the patient pathway.
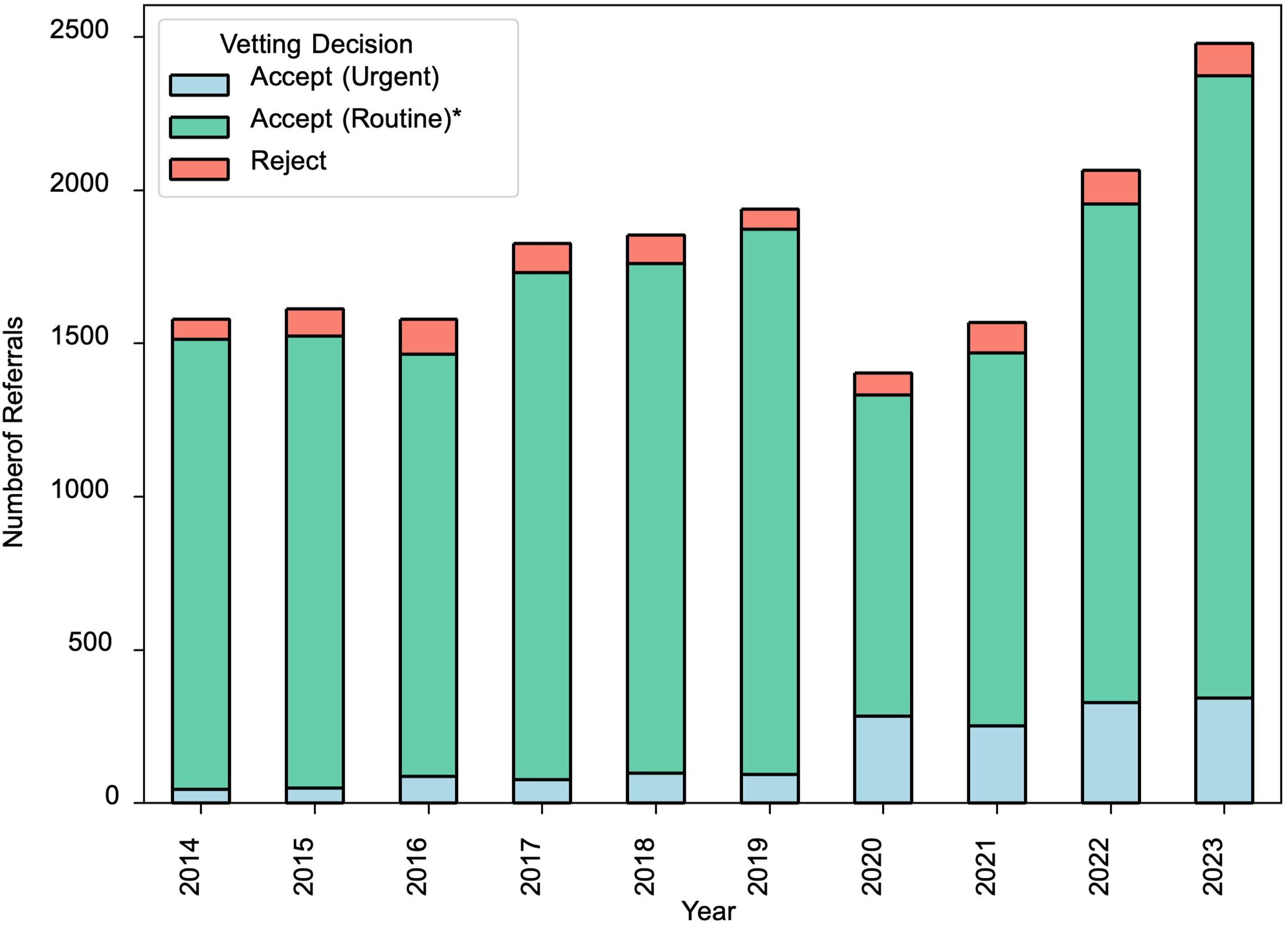
Total number of MRI lumbar spine electronic requests per year from GP and their corresponding vetting decision in the period 2014–2023 within NHS Tayside. *This study simplifies the vetting decision categories by grouping several options as ‘Accept (Routine)’; in practice there are additional Accept options at NHS Tayside including for ‘Medium’ urgency. NHS: National Health Service; MRI: magnetic resonance imaging; GP: general practitioner.
Methods
Below we describe the methodology of our prospective study including how we created the evaluation data, developed the LLM vetting pipeline, and the protocol we use for evaluation. Our methodology is also illustrated in Figure 2. All data supporting the findings of this study are available within the Supplemental Information. This study was reported in accordance with the Standards for Reporting of Diagnostic Accuracy Studies (STARD) guidelines.
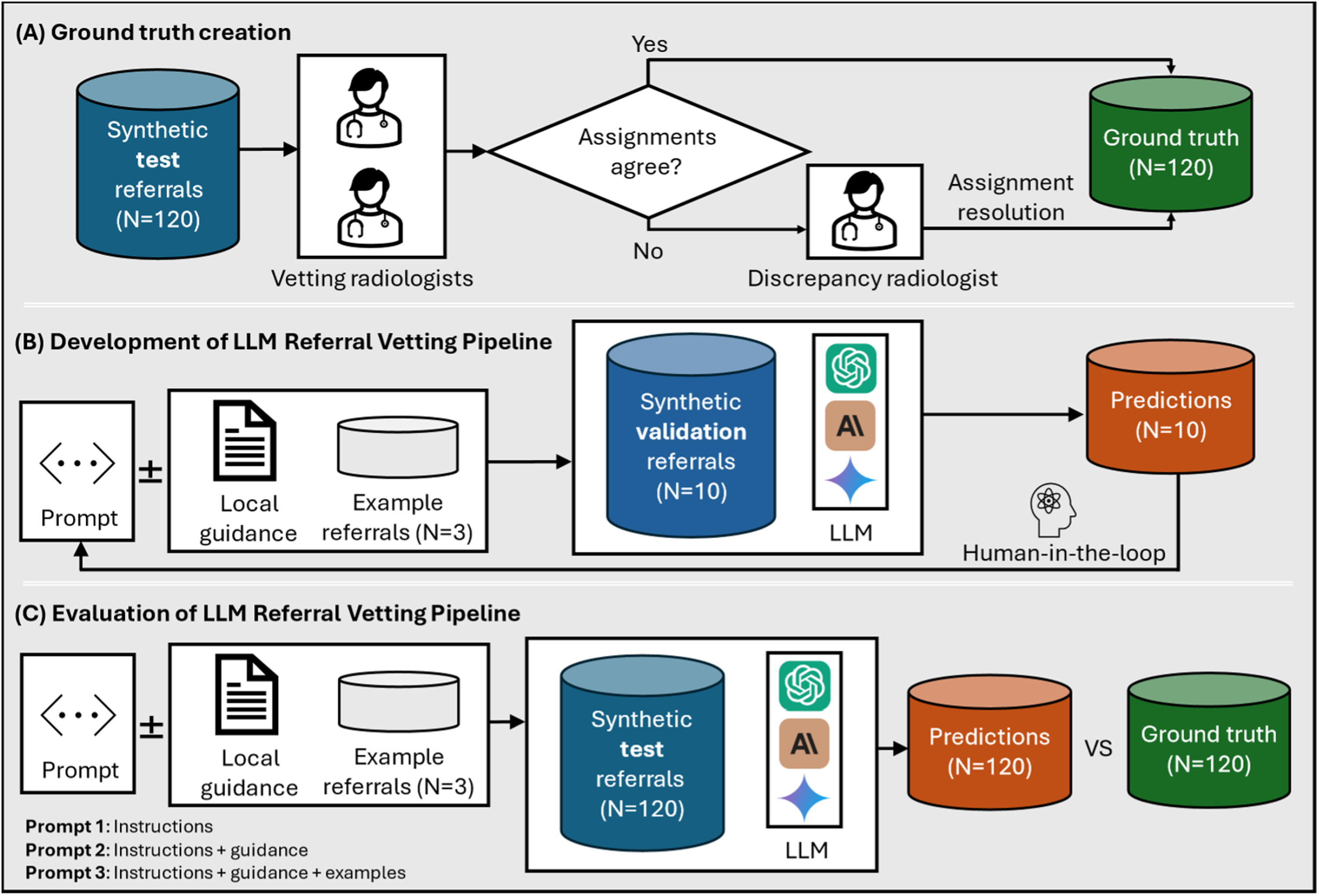
Study protocol. (A) Ground truth creation: Test referrals (N = 120) were synthesised by two radiology registrars and independently vetted by two board-certified vetting radiologists. In the case of discrepancy between outcomes, the case was reviewed by a third more experienced radiologist to obtain the final ground truth assignment. (B) Development of large language model (LLM) Referral Vetting Pipeline: A prompt was developed with the aid of a separate set of validation cases (N = 10). The raw prompt comprises task instructions, which may be supplemented by local clinical guidelines with or without 3 examples of referrals and their corresponding ground truth. The prompt together with each of the validation case was then provided to each of the LLMs, LLM outputs were inspected, and the prompt was adjusted until satisfactory results were achieved. Note that a single prompt was used for all models, and we avoided extensive tuning. (C) Evaluation of LLM Referral Vetting Pipeline: The prompt variants developed in step (B) were tested on the synthetic test referrals for each LLM. The LLM predictions were compared with the ground truth to obtain performance metrics.
Data synthesis and human vetting
Test data
Synthetic referrals for MRI lumbar spine were written by two radiology registrars (authors WC and HA). All referrals were created from the perspective of a GP referring a patient with low back pain. However, authors were encouraged to create a heterogeneous cohort with diversity in referral length, use of acronyms, level of detail, and clinical appropriateness. We requested that age and sex were included within the free text referral; in real-world referrals this information would typically be included, and if not then the patient's electronic health record would contain it in structured form.
Vetting was conducted by one board-certified musculoskeletal radiologist (author DS) and one board-certified neuroradiologist (author AKK) with 11 and 18 years of independent practice, respectively. Vetting radiologists were not involved in the synthetic data creation. Vetting radiologists were asked to assign an outcome for every synthetic referral, selecting either (a) Accept – Routine, (b) Accept -Urgent, or (c) Reject – [Reason]. A brief free-text justification was required if the referral was being rejected. Vetting radiologists were also required to complete a “Safety” column where MRI contraindications could be recorded (e.g., presence of pacemaker) independently of the clinical request. Each of the vetting radiologists was asked to record the time taken to complete the vetting of all synthetic referrals. The most senior board-certified musculoskeletal radiologist (author TBO) with 26 years’ experience reviewed and resolved all requests where there was disagreement between the vetting radiologists. The full ground truth is included with Supplemental Data 1.
Development data
An additional 13 referrals and corresponding ground truth were created by authors WC and HA for use in developing the algorithm. These referrals were not vetted by board-certified radiologists and were used for engineering a suitable prompt (N = 10) and for including an example of each vetting outcome class within the prompt (N = 3). These additional referrals were not included within the test set.
Development of large language model vetting pipeline
LLMs Used in our Experiments.
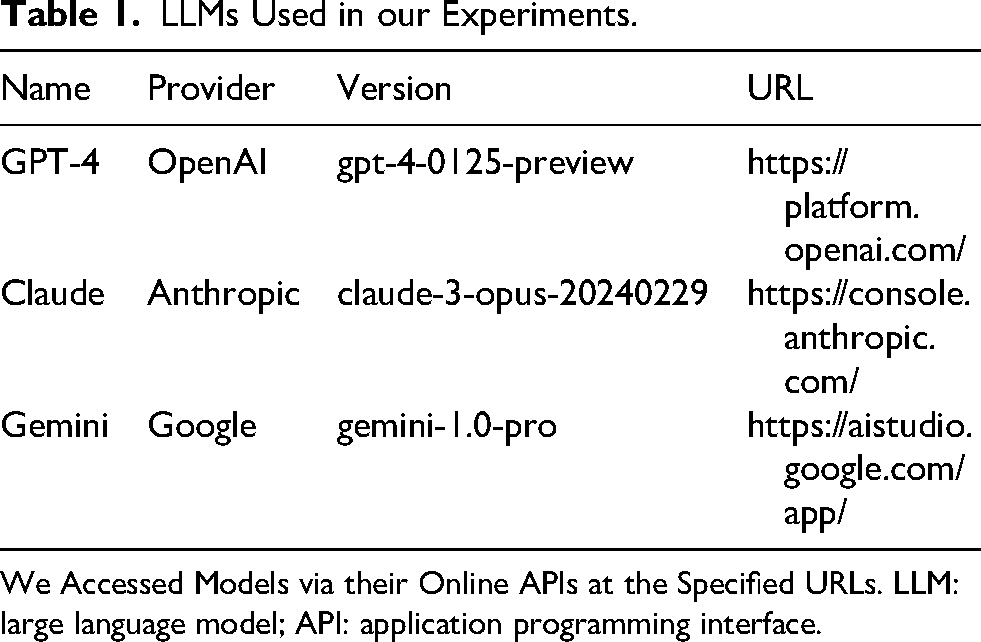
We Accessed Models via their Online APIs at the Specified URLs. LLM: large language model; API: application programming interface.
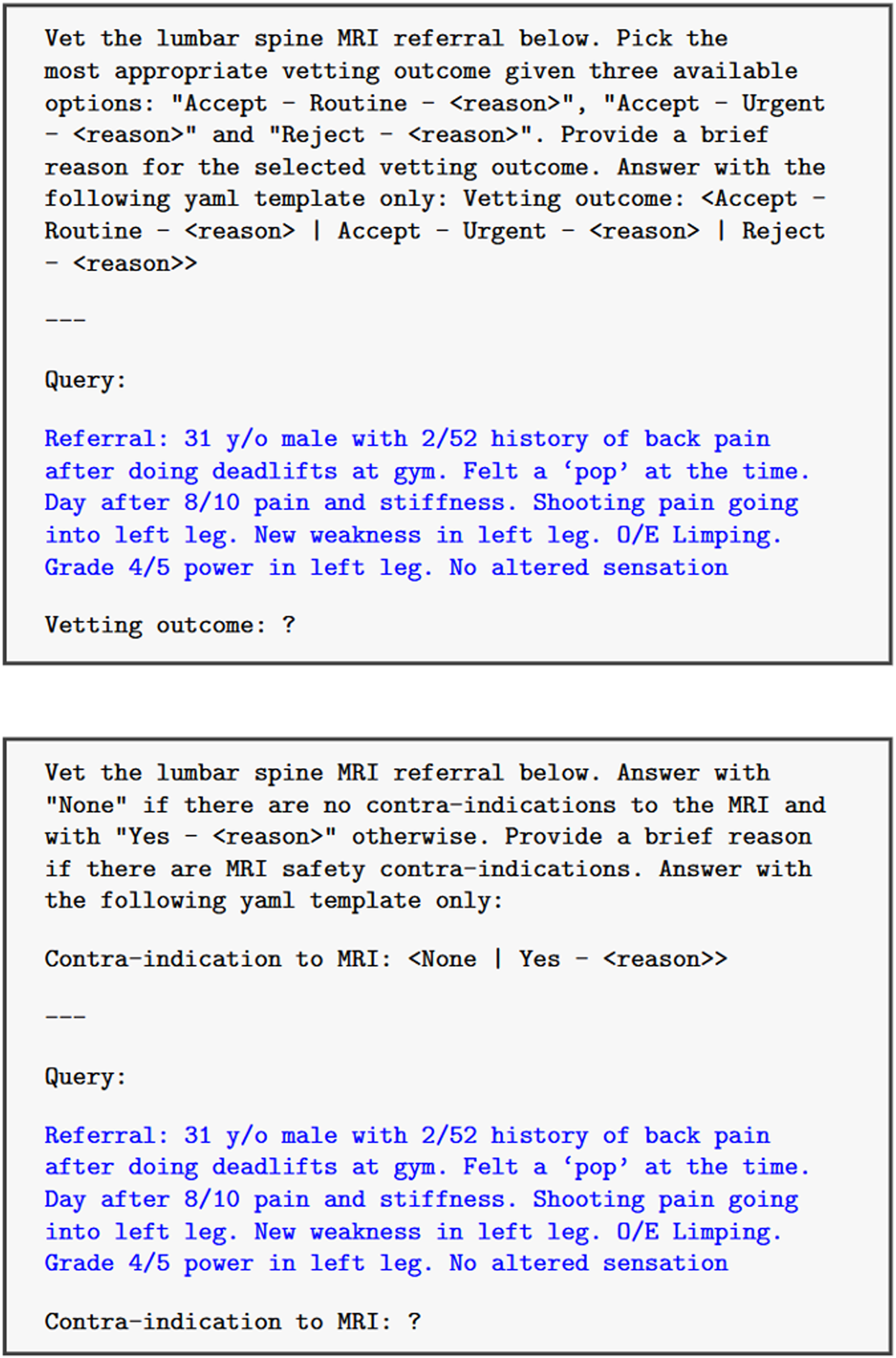
Instruction-only prompt (black text) for a sample referral (blue text) for outcome assignment task (top) and magnetic resonance imaging (MRI) scan contraindication task (bottom).
Evaluation protocol
We conducted a sample size calculation using a confidence level of 0.8, an alpha of 0.05, and an estimated proportion of 20% assigned “Reject” in the ground truth (inflated rejection rate compared to real data for more robust evaluation). This calculation yielded 105 as the minimum required number of referrals; we chose to create a slightly greater test set comprised of 120 referrals.
Continuous variables are reported as mean ± standard error of the mean. To assess model performance in the vetting task, we used accuracy as each class has equal importance and the distribution of classes is reasonably balanced. To assess model performance in the MRI contraindication task, we used recall, precision and F1 scores as this task has an imbalanced class distribution and identification of false negatives is particularly important. An F1 score is the harmonic mean of precision and recall.
We assessed the inter-rater agreement between the two radiologists using Cohen's Kappa to measure the degree of agreement between vetting decisions.
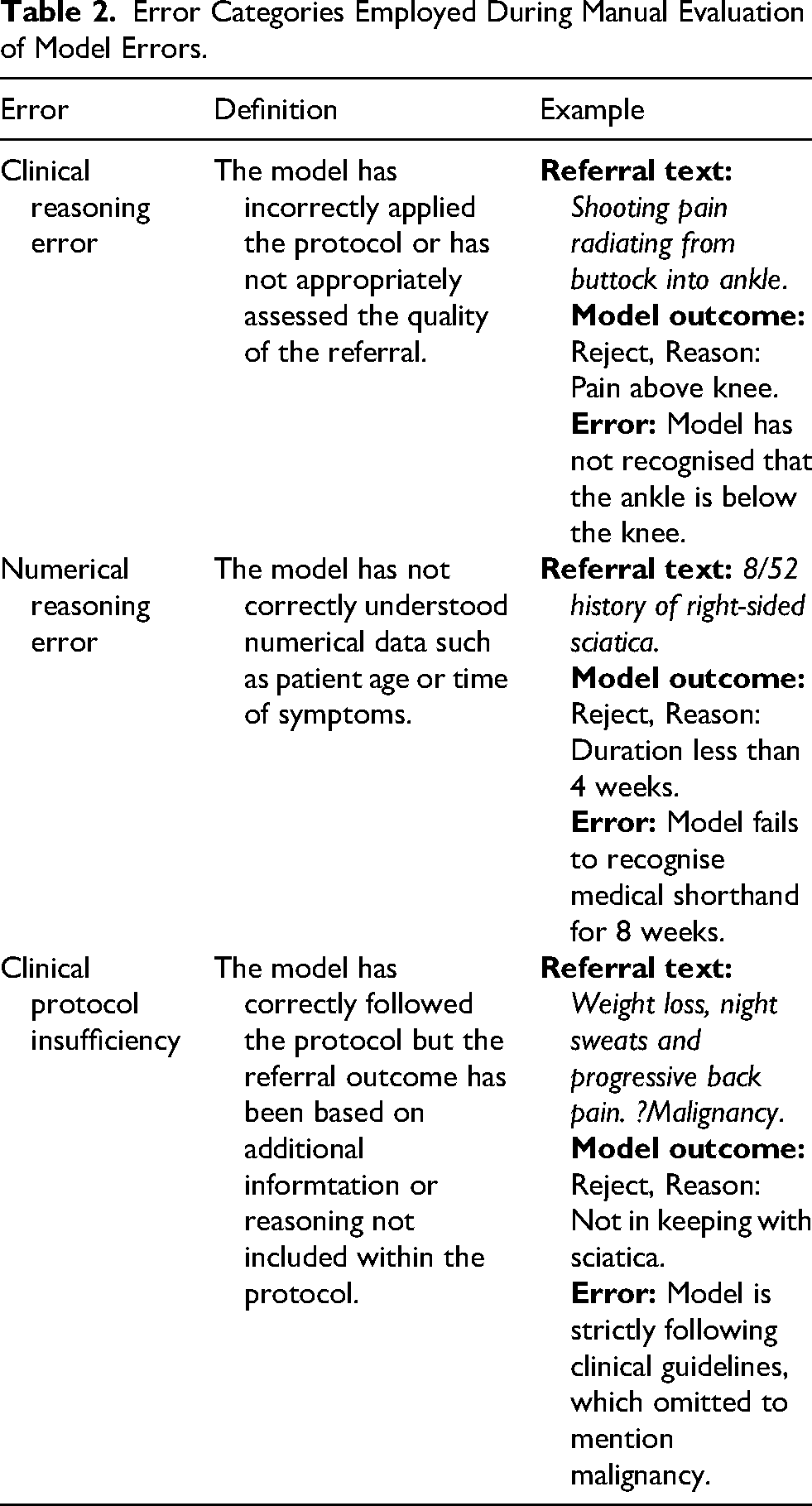
Manual analysis was undertaken by reviewing the justification given by all models provided with instruction and context which had incorrectly classified the outcome in the vetting task. Errors were classified as either a clinical reasoning error, a numerical reasoning error or secondary to protocol insufficiency as defined in Table 2. The assigning of all errors was determined by consensus review between authors WC, HA and HW.
Error Categories Employed During Manual Evaluation of Model Errors.
Results
In this section, we report firstly the human inter-rater agreement and the final ground truth distribution, followed by the accuracy of the LLMs for our two tasks of vetting outcome assignment and MRI scan contraindication detection, and finally we compare the time and cost of different approaches.
Distribution of expert vetting assignments
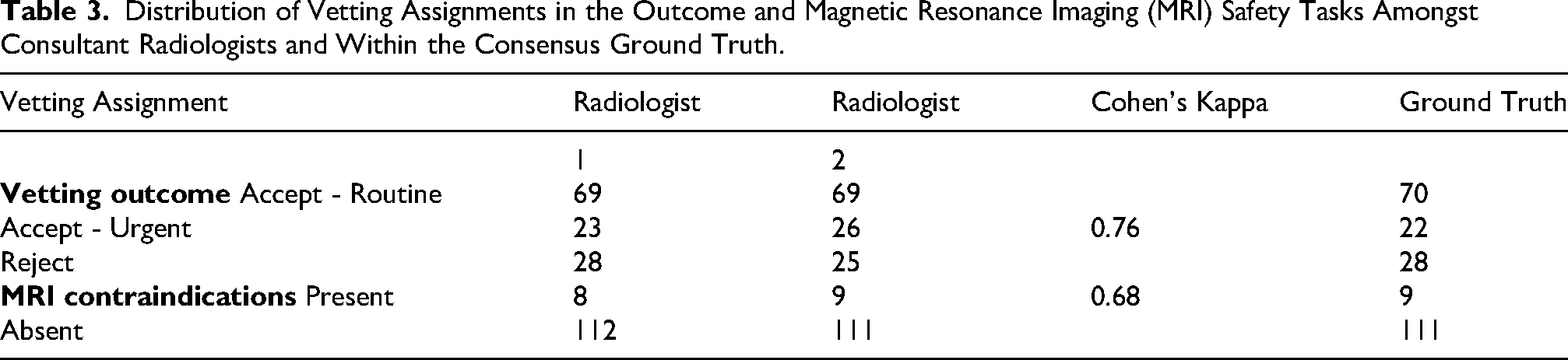
There was substantial agreement between the two vetting radiologists in both the vetting outcome (Cohen's Kappa: 0.76) and MRI contraindication detection (Cohen's Kappa: 0.68). Out of 120 synthetic referrals, the vetting radiologists agreed on the vetting outcome in 103 referrals and disagreed on 17 referrals. For MRI contraindication detection, the vetting radiologists agreed on 115 referrals and disagreed on 5. Following review, we obtained a dataset with ground truth label distribution as shown in the final column of Table 3.
Distribution of Vetting Assignments in the Outcome and Magnetic Resonance Imaging (MRI) Safety Tasks Amongst Consultant Radiologists and Within the Consensus Ground Truth.
Evaluation of vetting outcome assignment
Confusion matrices and accuracy for the vetting task are shown in Figure 4 and Table 4. Models provided with instruction and guidance or instruction, guidance and examples performed better than models given only instructions. Anthropic Claude Opus achieved the highest single model accuracy of 0.86 when given instructions, guidance and examples. No model receiving instructions, guidance and examples rejected any referral that radiologists had classified as urgent.

Confusion matrices of ground truth versus predicted assignments for the automatic referral vetting task for large language models (LLMs) with full context.
Vetting Outcome Task Results, Showing Accuracy of Models When Provided With Varying Levels of Context in the Prompt.
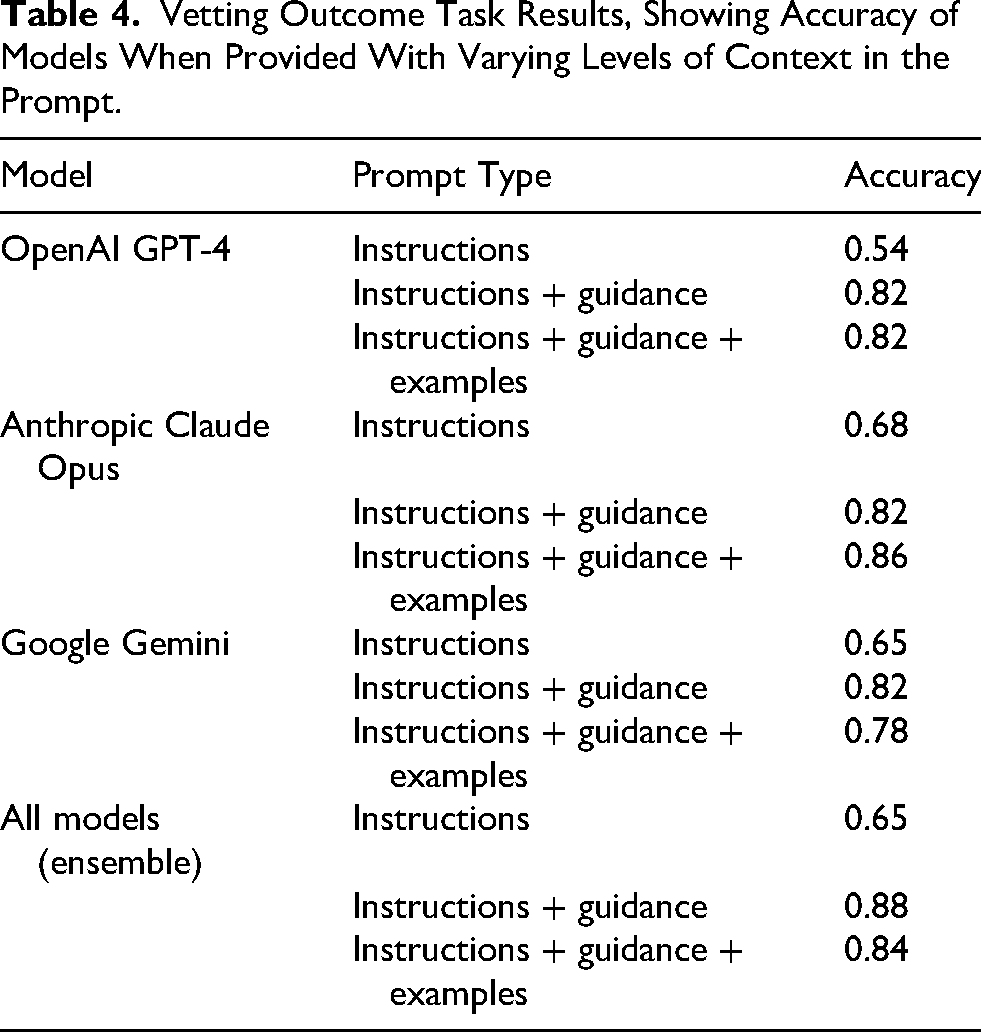
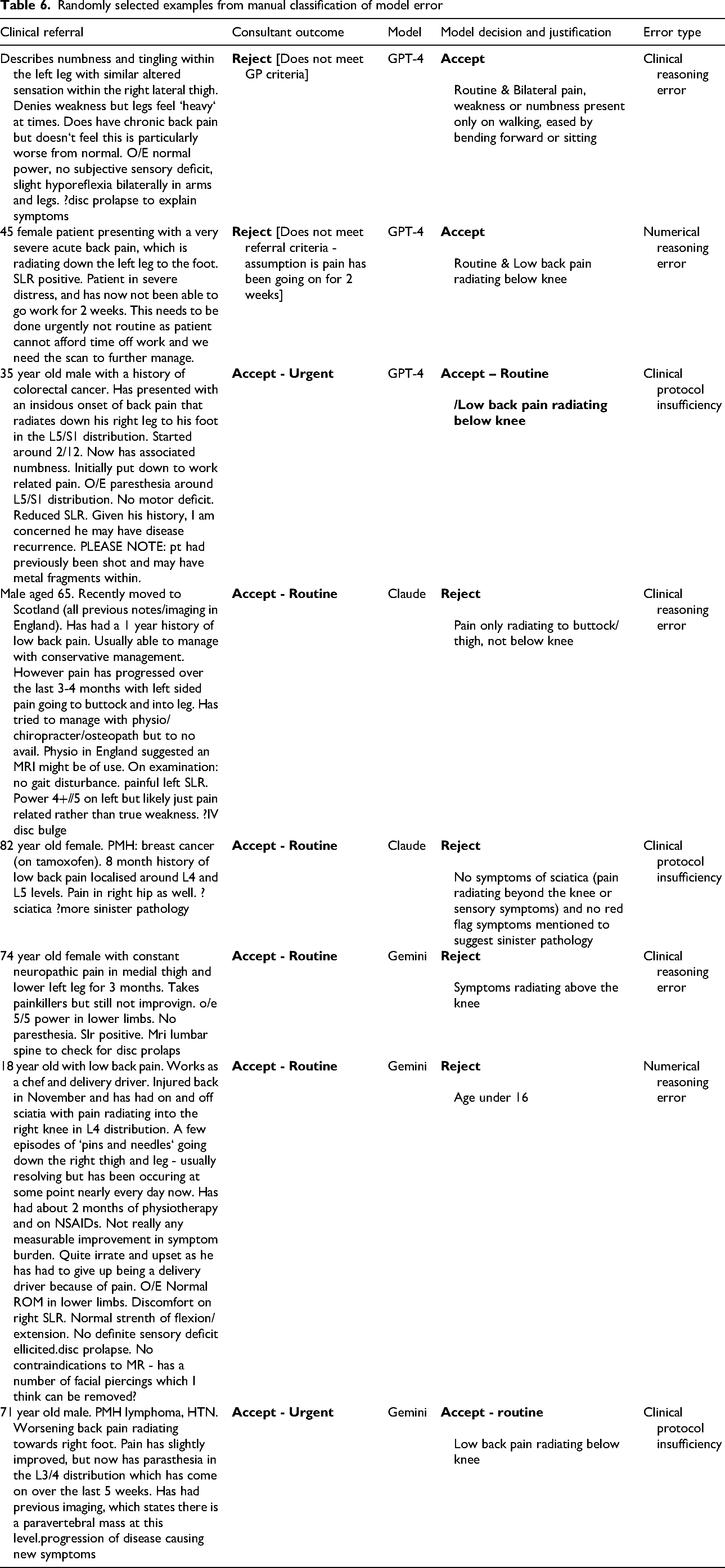
Table 5 presents the manual classification of model errors, with examples in Table 6. Google Gemini had 29 total errors, while Anthropic Claude Opus had 17. Open AI GPT-4 and Google Gemini most frequently made clinical reasoning errors (14 and 19 respectively), while Anthropic Claude Opus most commonly made clinical protocol insufficiency errors (9).
Number and Type of Vetting Errors per Model After Human Evaluation of the Model Justifications.

Randomly selected examples from manual classification of model error
The ensemble approach achieved its highest accuracy (0.88) when models received instructions and guidance.
Evaluation of MRI scan contraindication detection
Models demonstrated variable performance in identifying MRI contraindications (Table 7). OpenAI GPT-4 achieved perfect precision (1.00) and the highest F1 score (0.88) with instruction-only prompts. Anthropic Claude Opus and Google Gemini both reached the highest recall (0.89) with instruction-only prompts.
Magnetic resonance imaging (MRI) contraindication Identification Task Results, Showing Recall, Precision and F1 Scores of Models When Provided with Varying Levels of Context in the Prompt.
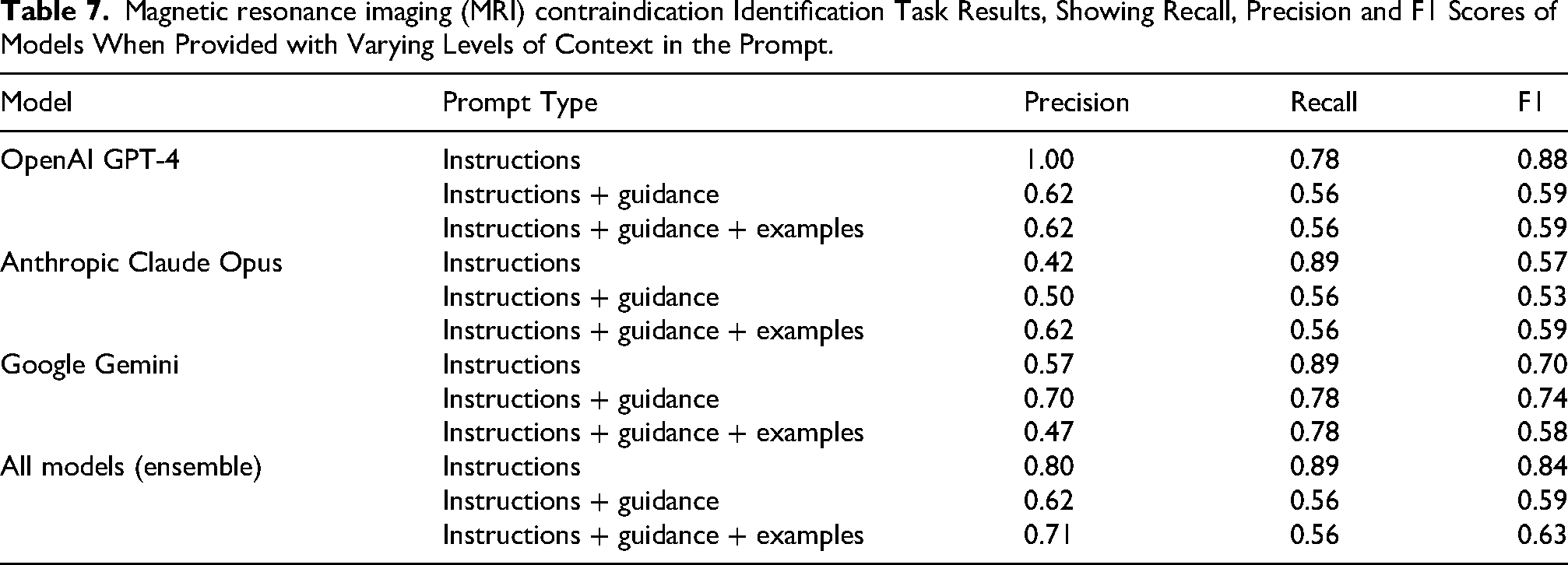
In general, models with basic instructions tended to outperform models with instructions plus guidance or instructions with guidance and examples. No single model achieved the highest scores in both recall and precision. The ensemble approach combining all models achieved an F1 score of 0.84 with instruction-only prompts, compared to lower scores of 0.59 and 0.63 with more complex prompting strategies.
Time and cost to vet
The mean length of referrals was 56.7 ± 2.2 words (range: 124 words). Consultant radiologists took 135.0 ± 45.0 min to vet all 120 referrals compared to an average LLM time of 9.8 ± 1.0 min (including vetting outcome task and MRI contraindication detection task). The combined time for both tasks was 8.8 min for Open AI, 14.2 min for Anthropic Claude Opus and 8.6 min for Google Gemini. The combined cost for both tasks was $2.90 for Open AI GPT-4, $5.30 for Anthropic Claude Opus and free for Google Gemini.
Discussion
This study explored the role of LLMs in the vetting of synthetic referrals for MRI lumbar spine studies for the clinical problem of low back pain. Three different LLMs were prompted, and supplied with different degrees of clinical context, to complete two separate tasks (a) vetting the appropriateness of the referral and assigning an outcome, and (b) identifying any MRI contraindications within the referral. LLM performance was assessed against ground truth created by experienced board certified subspecialist radiologists in the field of neuroradiology and musculoskeletal radiology.
As far as we are aware, this paper is the first to examine the performance of LLMs for comprehensive radiological vetting, not only for the core vetting task but also assessment of urgency and identification of any modality contraindications. A few other studies have examined the role of AI models in core radiology vetting.9,10 Rau et al. 11 specifically explored the use of LLMs for the related task of matching clinical referrals to appropriate imaging modalities, reporting improved performance when information from the American College of Radiology (ACR) appropriateness criteria 12 was provided as context; our study evaluates a similar idea of providing MRI scan referral guidelines as context. The use of LLMs in screening for safety concerns in radiology has also been suggested, 13 but not widely researched.
The first task we instructed models to perform was predicting a vetting outcome for the clinical referral. In general, models provided with referral guidelines in the context performed well. Importantly, no model which was provided with instruction, local guidance and examples rejected a referral which was vetted as urgent. Interestingly, there appeared to be little benefit in the addition of in-context examples to the model prompt. It may have been that the number of examples was too few to capture the diversity of referral data, and in particular the provided examples may have been too simple to help with more complex referrals. By contrast, Agarwal et al. 14 demonstrated that in-context many shot learning, where hundreds or thousands of examples are included within the prompt, had improved performance across generative and discriminative tasks including translation, sentiment analysis and classification. Currently, the size of the context window determines how much data can be included within the prompt and as context windows expand there will be greater scope for testing the performance of models with many shot in-context learning. We improved performance for this task by simple ensembling of model predictions; ensembling is a common technique in standard machine learning but appears underutilised in the recent LLM literature. However, recently Yang et al. 15 reported an improved performance in medical question-answer tasks when they created an ensemble of LLMs.
The second task we instructed models to perform was identifying an MRI contraindication within the clinical referral. Although MRI does not involve the use of ionising radiation, it is not a risk-free modality and is associated with hazards such as ferromagnetic missile effect, radiofrequency burns and implant heating. 16 Unlike in the vetting outcome task, addition of context with guidance and with or without examples appeared to attenuate the performance of the models. A likely reason for this is that vetting radiologists picked up additional general safety concerns beyond the specific MRI contraindications in the guidelines, for instance presence of skin piercings; this may be more consistent with the LLMs’ training data.
In terms of clinical application, although autonomous vetting is unlikely in the immediate future without clinical oversight, LLMs demonstrated significant efficiency advantages over consultant radiologists when processing the referrals. This suggests potential roles in clinical workflow optimisation, including: prioritising urgent cases to reduce delays for critical patients, providing safety verification to identify contraindications or erroneously rejected referrals, and supporting clinicians in adhering to guideline-based decision-making for appropriate resource utilisation. Notably, Anthropic Claude Opus’ strict protocol adherence revealed inconsistencies in local guidance, particularly regarding patients with confirmed or suspected malignancy (see Table 6). In these instances, radiologists often pragmatically expedited cases outside formal guidelines rather than awaiting secondary care referrals that might delay diagnosis of potential malignancies.
Limitations
Our study had a number of limitations. Firstly, our experiment is not fully reflective of current clinical practice at NHS [INSTITUTION] as there are more options for vetting referrals than the Accept (Routine), Accept (Urgent) and Reject options used in this study. These additional options include more variations of ‘Accept’ (e.g., assigning a ‘moderate’ priority or if the patient requires follow-up imaging) which were condensed to allow for a more straightforward study design. Additionally, our study considered only the text referral rather than capturing all the patient data available to radiologists for vetting. Whilst the process of vetting lumbar spine MRI is usually based on the text referral, there may be occasions when review of other available data would be appropriate. For instance, the patient's previous imaging might be reviewed in the context of recent surgery. Multimodal approaches are however being assessed, in particular in the field of image analysis, 17 although this is still at an early stage; we highlight this as future research. Finally, in this study, we used synthetic data, however the sensitivity of patients’ healthcare data raises important questions concerning the safeguarding of data during practical deployment. Future research might investigate locally run LLMs which would avoid sharing of patient data with third parties. 18
Conclusion
Our study demonstrates that contemporary LLMs show promise in evaluating MRI lumbar spine referrals when provided with appropriate clinical context. Notably, all models correctly identified urgent cases, indicating potential utility in prioritising clinical workflows. The speed and cost-effectiveness of LLM-assisted triage could enhance efficiency in spinal imaging pathways, potentially reducing delays for patients requiring prompt specialist assessment and intervention.
Supplemental Material
sj-docx-1-scm-10.1177_00369330261441582 - Supplemental material for Evaluation of large language models with clinical guidance for vetting outpatient magnetic resonance imaging lumbar spine referrals
Supplemental material, sj-docx-1-scm-10.1177_00369330261441582 for Evaluation of large language models with clinical guidance for vetting outpatient magnetic resonance imaging lumbar spine referrals by William Clackett, Hatim Alsusa, Hannah Watson, Antanas Kascenas, David Scott, Avinash K Kanodia, Oliver T Barry and Alison Q O’Neil in Scottish Medical Journal
Supplemental Material
sj-docx-2-scm-10.1177_00369330261441582 - Supplemental material for Evaluation of large language models with clinical guidance for vetting outpatient magnetic resonance imaging lumbar spine referrals
Supplemental material, sj-docx-2-scm-10.1177_00369330261441582 for Evaluation of large language models with clinical guidance for vetting outpatient magnetic resonance imaging lumbar spine referrals by William Clackett, Hatim Alsusa, Hannah Watson, Antanas Kascenas, David Scott, Avinash K Kanodia, Oliver T Barry and Alison Q O’Neil in Scottish Medical Journal
Footnotes
Ethics approval
Ethical review was considered but not deemed necessary due to the use of synthetic data within this study.
Consent
No consent was required.
Authors’ contributions
William Clackett and Hatim Alsusa developed the test synthetic data. Hannah Watson developed the validation synthetic data. William Clackett and Antanas Kascenas developed the prompt. Oliver T Barry, Avinash K Kanodia and David Scott created the ground truth. William Clackett, Hatim Alsusa and Hannah Watson carried out manual evaluation of model outputs. Antanas Kascenas and Alison Q O’Neil carried out quantitative assessment of model outputs.
Funding
The authors received no financial support for the research, authorship, and/or publication of this article.
Declaration of conflicting interests
The authors declared the following potential conflicts of interest with respect to the research, authorship, and/or publication of this article: Author William Clackett was a previous employee of Canon Medical Research Europe and currently has a consultancy agreement with Canon Medical Research Europe. Author William Clackett controlled the data in this study. The following authors analysed the data: William Clackett, Hatim Alsusa, Antanas Kascenas, Hannah Watson and Alison O’Neil. Authors Hannah Watson, Antanas Kascenas and Alison O'Neil are current employees of Canon Medical Research Europe within their artificial intelligence research team. None of these employees have fiduciary duty to Canon Medical Research Europe.
Data,materials and/or code availability
All data generated or analysed during this study are included in this published article and its supplemental information files.
Supplemental material
Supplemental material for this article is available online.
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.