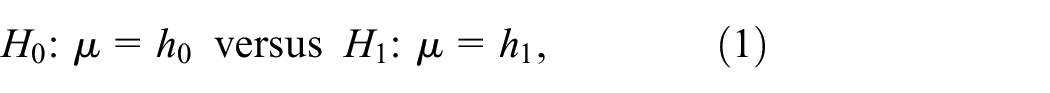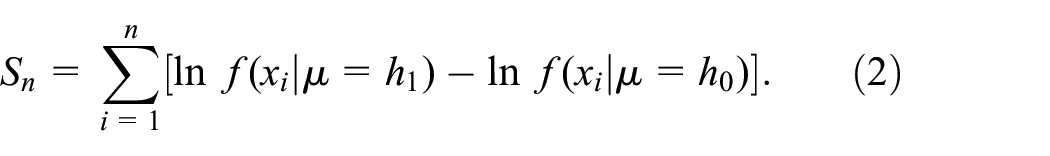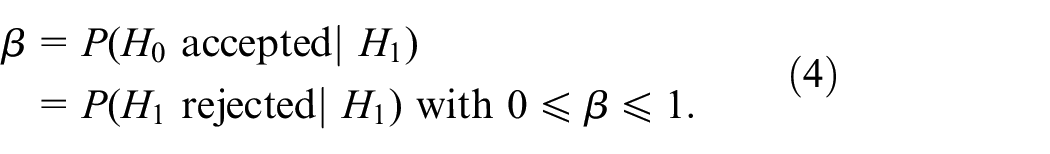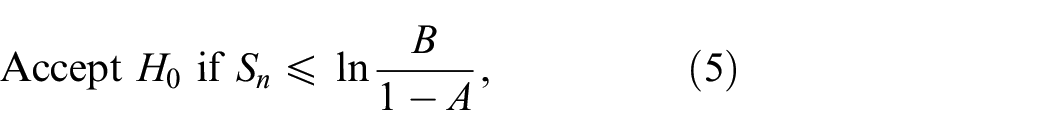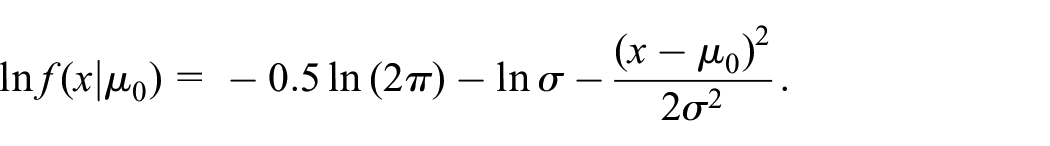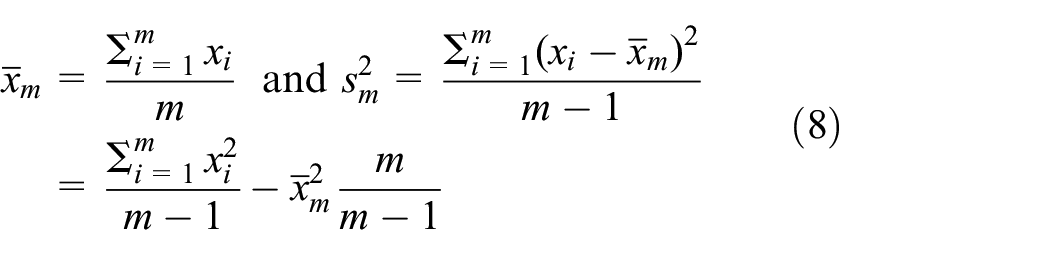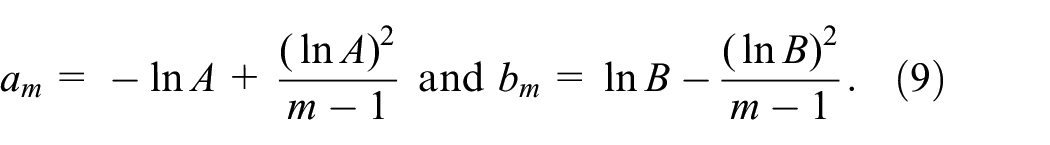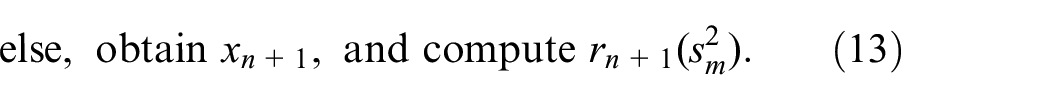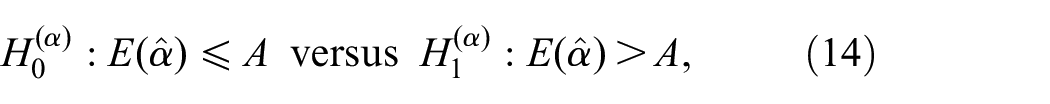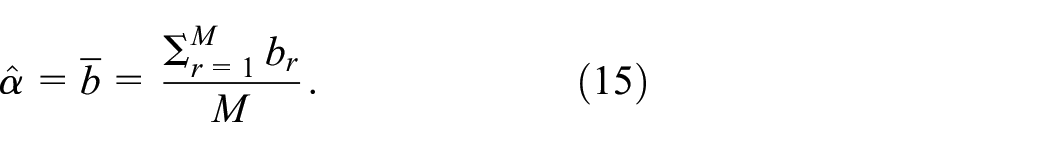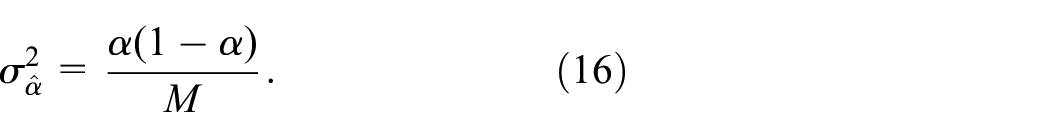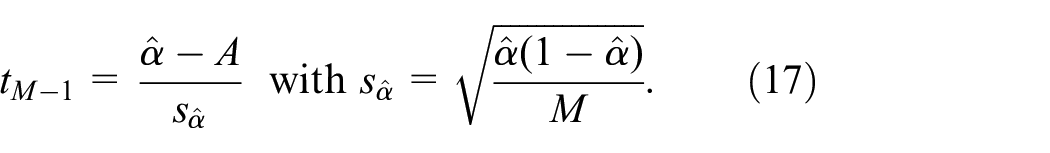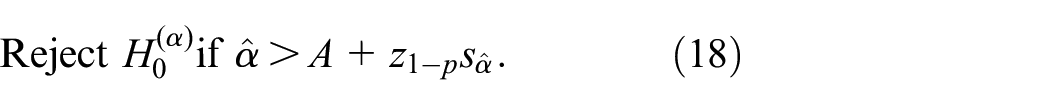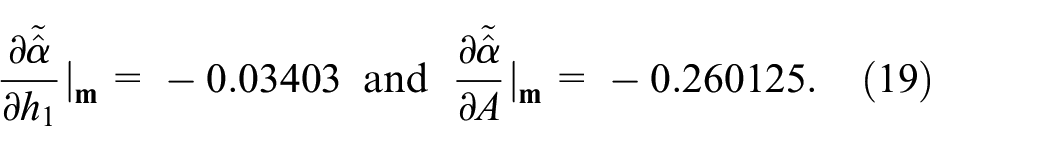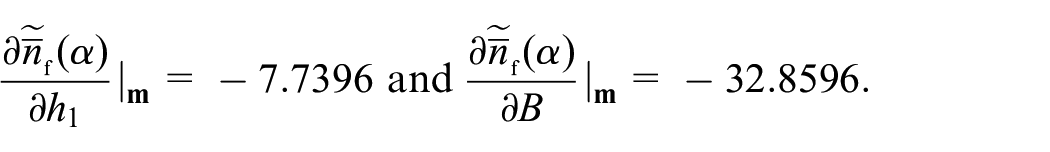Because computers (except for parallel computers) generate simulation outputs sequentially, we recommend sequential probability ratio tests (SPRTs) for the statistical analysis of these outputs. However, until now simulation analysts have ignored SPRTs. To change this situation, we review SPRTs for the simplest case; namely, the case of choosing between two hypothesized values for the mean simulation output. For this case, the classic SPRT of Wald (Wald A. Sequential tests of statistical hypotheses. Ann Math Stat 1945; 16: 117–186) allows general types of distribution, including normal distributions with known variances. A modification permits unknown variances that are estimated. Hall (Hall WJ. Some sequential analogs of Stein’s two-stage test. Biometrika 1962; 49: 367–378) developed a SPRT that assumes normal distributions with unknown variances estimated from a pilot sample. A modification uses a fully sequential variance estimator. In this paper, we quantify the performance of the various SPRTs, using several Monte Carlo experiments. In experiment #1, simulation outputs are normal. Whereas Wald’s SPRT with estimated variance gives too high error rates, Hall’s original and modified SPRTs are “conservative”; that is, the actual error rates are smaller than those prespecified (nominal). Furthermore, our experiment shows that the most efficient SPRT is Hall’s modified SPRT. In experiment #2, we estimate the robustness of these SPRTs for non-normal output. For these two experiments, we provide details on their design and analysis; these details may also be useful for simulation experiments in general.
While sequential probability ratio tests (SPRTs) are popular in application areas such as the testing of drugs on humans, they are virtually unknown in simulation. Indeed, testing drugs on humans should minimize the number of necessary observations, and SPRTs do so; that is, SPRTs are more efficient than classic tests such as the Student’s -test. In simulation, we should also strive for efficiency in the case where we need relatively much more computer time to obtain a single observation on the response (or output) of the given simulation model (this case is called “expensive simulation”). This need for efficient design and analysis of simulation experiments arises not only if we must choose between two hypothesized values for the mean simulation output (which is the focus of this paper), but also if we must choose among more than two simulated systems. Actually, the number of systems may be a given small number (e.g., 10), infinite (if continuous input variables define the system), or nearly infinite (if many discrete variables define the system). In these situations, we may try to estimate which system is optimal. This simulation optimization may use many statistical methods (see Kleijnen,1 pp.241–300). However, until now these methods have not used SPRTs.
We point out that—unlike classic tests—SPRTs do not have a favorite null-hypothesis ; that is, classic tests reject only if there is strong counter-evidence that supports the alternative hypothesis . In practice, there may be good reasons for formulating a favorite hypothesis; for example, in criminal law this hypothesis stipulates that the accused is not guilty, and in management the current system may be replaced only if there is strong evidence that the proposed new system is better. However, if management is considering two new systems, then there may be no favorite .
In mathematical statistics, it is well known that SPRTs are more effective in the sense that SPRTs control both the type-I or error probability—defined as rejected | )—and the type-II or error probability— accepted | ). However, SPRTs are not mentioned at all in the most popular simulation textbook; namely (Law2). Therefore, we provide a gentle introduction to SPRTs for the simulation community. We focus this review on random simulation, which includes discrete-event simulation (DES) and agent-based simulation (ABS); continuous simulation uses differential or difference equations, and is usually deterministic. Both deterministic simulation and random simulation may have inputs with unknown values, so probability density functions (PDFs) are used to “propagate uncertainty through the model”; this propagation is called risk analysis or uncertainty analysis. Whenever the simulation involves random inputs, the output (response) becomes random too.1
Mathematically speaking, the simulation output is a complicated implicit function of the inputs, including the pseudorandom number (PRN) stream determined by the PRN “seed” or initial value. This randomness implies that we must decide how many observations we want to obtain on the output, in order to obtain a “precise” estimate of the true output. To make such a decision, we should use statistical methods. The selection of these methods varies with the problem that we try to solve through the simulation model. In this paper, we focus on the simplest problem; namely, the simulation output is an estimate of the mean (say) for a given input combination. To illustrate this problem, we consider the following example (also see footnote 2).
Suppose management is interested in the following two system variants. System 1 is supposed to have a mean output = 100 (e.g., 100 pieces of throughput), and system 2 has a mean output that is 10% higher; so, : = 100 and : = 110. The simulation analysts build models of the two systems. Next the analysts must decide whether they have collected enough simulated observations to conclude whether or holds. The analysts may then apply a SPRT.
We claim that SPRTs may be useful in simulation, because most computer systems proceed sequentially. For example, a 1975 textbook on simulation (Kleijnen,3 pp.503–505) has already discussed the SPRT originally developed by Wald.4 A recent publication on SPRTs is the book on sequential statistics by Govindarajulu,5 which we shall use repeatedly in this paper. In the next sections we define Wald’s4 SPRT, Hall’s6 SPRT, and our simple heuristic modifications of these SPRTs. Hall6 (p.376) proposes similar modifications, stating: “No theoretical evaluation of these procedures has been possible.” Hall6 (Chapter 2) anticipates our modification of Wald’s SPRT. In this paper, we explain the dynamic behavior of these SPRTs. We also quantify the performance of these SPRTs, using several Monte Carlo (MC) experiments with prespecified nominal and error probabilities and prespecified distance between the parameter values in or . Note that we use the term MC for models that use PRNs, whereas we use the term simulation for dynamic models, which may be either random (so they are a type of MC) or deterministic. We carefully design these MC experiments including classic factorial designs and our modified central composite design (CCD) (instead of one-factor-at-a-time designs, which are often used in current simulation experiments), a carefully selected number of (macro)replications, and use of common random numbers (CRNs). Moreover, we analyze the experimental results through regression analysis that quantifies the interactions among experimental factors and the marginal effects of these factors; this analysis distinguishes between “per comparison” error rates and “familywise” error rates. (Our design and analysis may also be used in simulation experiments, in general.) 4
The seminal article by Wald4 assumes that the output (say) has an explicit probability density function (PDF) with a single parameter . This assumption holds for exponential distributions, normal (or Gaussian) distributions with known standard deviations, etc. Next, Hall6 assumes that the PDF is normal so , where in and in , and is unknown and is estimated from a pilot sample; in the rest of our paper we suppress the subscript if the context shows which random variable is meant. Wald4 (pp.132–133) and Hall6 (p.369) mention that the resulting SPRTs are conservative, that is, the actual error rates are smaller than the prespecified or “nominal” values (so, these values could have been realized with fewer observations than the SPRTs actually require). In this paper, we quantify the degree of conservativeness. Moreover, we investigate the robustness of these SPRTs; that is, we quantify the sensitivity of the SPRTs to non-normality if the analysts actually assume normality. In simulation practice, the output may indeed be non-normal.5 For example, Kleijnen1 (p.92) reports that the estimated average and the estimated 90% quantile of the output of a simulated queueing model (namely, a so-called M/M/1 model) are not normally distributed if the simulation run has only 1,000 simulated arrivals and the traffic rates are 0.5 and 0.9, respectively. In practice we often do not know which type of distribution the output has, so it is important to investigate the robustness of SPRTs.
We organize the rest of our paper as follows. In Section 2 we present details on Wald’s4 and Hall’s6 SPRTs, including simple modifications. In Section 3 we quantify the performance of these SPRTs in experiment #1, guaranteeing that the output is indeed normally distributed. In Section 3.1 we present details on the design of this experiment; in Section 3.2 we detail the analysis of the results of this experiment. This experiment suggests that Wald’s4 SPRT with estimated variance gives significantly high error rates, and that Hall’s6 SPRTs are conservative; the most efficient SPRT is the modified Hall6 SPRT. In Section 4 we detail experiment #2, which suggests that the SPRTs are robust. In Section 5 we present conclusions, and mention future research topics.
2. Overview of Wald’s and Hall’s sequential probability ratio tests
In this section we define Wald’s4 SPRT and Hall’s6 SPRT, plus simple modifications of these SPRTs. Moreover, we add some comments because these SPRTs differ from the classic test using -statistic and -values.
2.1. Wald’s SPRT
Wald4 assumes a sequence of independent and identically distributed (IID) observations on the random variable with the PDF , where and:
where and denote values specified by the users. An example is a normal PDF with mean and known variance. We use Greek lower-case letters to denote a parameter, which by definition has a value that is inferred from data such as (see the fundamental simulation textbook Zeigler et al. In a simulation context, may represent the output of simulation replication ; by definition, replications give IID observations. As is traditional, we use a “hat” to denote estimates (e.g., ) and a “bar” to denote sample averages (e.g., ). A list of abbreviations and major mathematical symbols with their definitions is given in Appendix 2.
By definition, the “probability ratio” (in the term “SPRT”)—also called the likelihood ratio (say) —of with is as follows:
It is convenient to apply the logarithmic transformation to this , which leads to the test statistic as follows:
Intuitively, we accept if is “low,” whereas we accept if is “high.” The classic error probabilities and (type-I and type-II error probabilities) are as follows:
The SPRT treats and similarly, whereas classic tests “favor”. An example of such a classic test is the -test (also see Equation (17) below). Classic tests control , whereas may be computed—given the sample size and the difference (also see Law,2 (pp.560–565)). We let and denote the nominal values prespecified for and , respectively. Then this SPRT has the following decision rule:
We implement various SPRTs in MATLAB software, using Govindarajulu5 (Section 6.2.1), but we correct some errors in this software for the SPRT due to Hall6 (p.369); see the next section. Actually, Wald’s SPRT is conservative: and (see Wald4 (pp.132–133) and Hall6 (p.369)). We shall estimate the magnitudes of and using the extensive MC experiment in Section 3.
To illustrate the computation of defined in Equation (2), we use the exponential PDF and the normal PDF (which we also use in later sections). The exponential PDF with parameter —which we denote by expo—is if ; else 0 (in Equation (1) we use the general symbol instead of the specific symbol ). To compute , we need the following:
The normal PDF is . Because Wald4 assumes that is known, this PDF gives the following:
We, however, either follow Hall6 and estimate through —the classic variance estimator with a fixed (pilot) sample size —or use the modified Hall6 SPRT with estimated sequentially through (see Section 2.2).
Now we illustrate the behavior of this SPRT, giving examples with the extreme (unrealistic) values = 0 and = 0, respectively. If = 0, then Equation (5) gives so is never accepted; that is, is always accepted so we never reject falsely. If = 0, then Equation (6) gives so is never accepted; that is, is always accepted so we never reject falsely.
Even though the SPRT does not have a favorite hypothesis, we may treat and differently because the consequences of erroneously rejecting or may be different in practice.7) We may then select different values for and . If , then the two boundaries defined in the right-hand sides of Equations (5) and (6) are not at equal distances from the origin, which is the point (0, 0) (see Figure 1, discussed next).
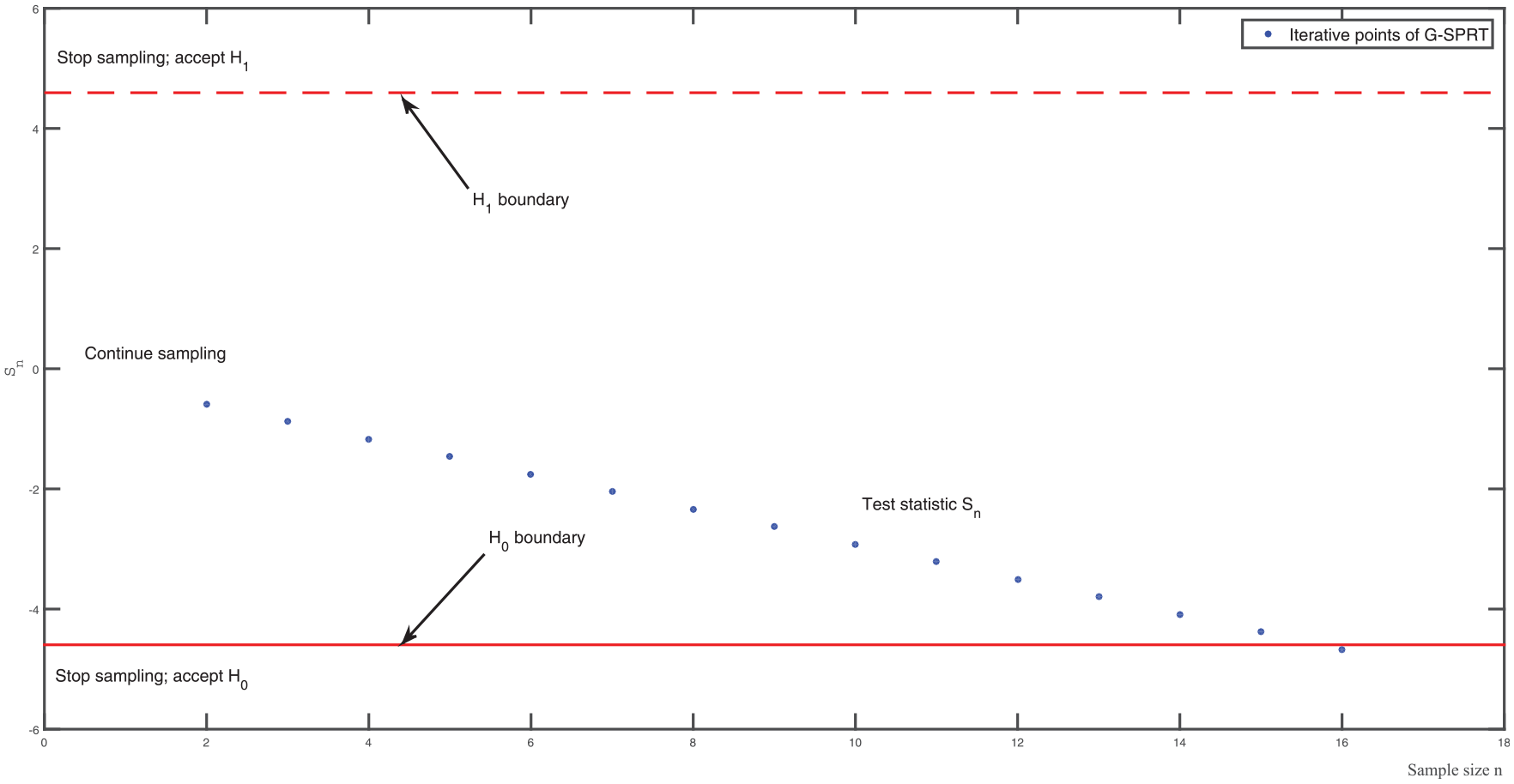
Example boundaries and sample path for Wald’s sequential probability ratio test with , , = 0, , .
Equations (5) and (6) imply that the sample path of stops when crosses one of the two boundaries. Figure 1 gives an example in which the SPRT stops when crosses the lower boundary at the final sample size = 16; the SPRT then accepts . So, depends on the sample path of and the size of the continuation region between the two boundaries, which is determined by the prespecified values and . A larger value of and (e.g., 0.10 instead of 0.01) narrows this region, and thus tends to decrease . More specifically, as increases, the upper boundary decreases, so crosses this boundary more quickly and accepts ; that is, the SPRT gives a smaller . Furthermore, is determined by and (in and ); that is, as their distance increases, increases so tends to cross one of the two boundaries. We conjecture that the magnitudes of and remain the same as increases, but decreases; on the other hand, we conjecture that and decrease as increases, because it is easier for the SPRT to select the correct hypothesis. To investigate these conflicting conjectures, we use MC experiments (see Section 3). The sample path of stops after a finite sample size; namely, in the example. Theoretically, this path could continue for ever, but all our examples\ show that the sample path of —or a related statistic—terminates; i.e., is finite. We might also change the boundaries such that they include vertical stopping barriers at finite ends of the parallel horizontal lines.
2.2. Hall’s SPRT
Hall6 assumes an unknown in , and = 0 in and > 0 in . We point out that the assumption = 0 does not limit the generality of this SPRT; that is, if the observations of interest (say) have the mean , then the transformation has mean 0 where the users specify in their and ; that is, in their and in their , so in Hall’s6 and in Hall’s6. We shall use this transformation in Section 4.
To define Hall’s SPRT, we follow Govindarajulu5 (Section 6.2.6). So, we take a pilot sample of size with ≥ 2, and compute the classic sample average and sample variance:
where the last equality simplifies the computation of . To compute as increases, we use the update formula with . To compute , we use the sum of squares about the average , and the update formula with . These update formulas—plus references to alternative formulas—are presented in Kleijnen1992 (p.13). To improve the numerical accuracy of the variance estimate we might use the property that and with constant have the same variance; e.g., we may select .
Hall’s SPRT uses the following boundaries assuming a pilot sample of size with :
After observations with >, the test statistic is as follows:
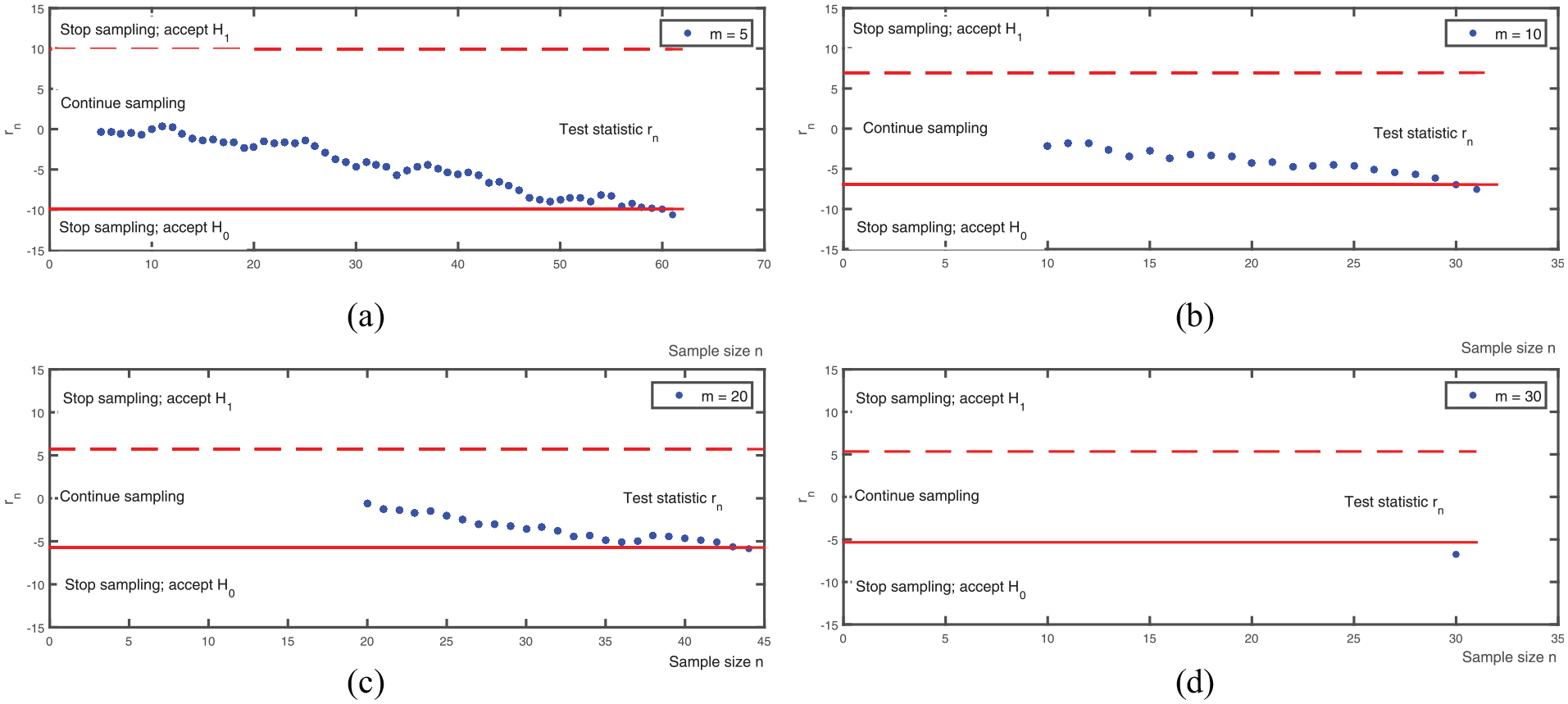
Hall’s SPRT has parallel boundaries (as Wald’s SPRT has), but as (pilot sample size) increases, these boundaries lie closer together so the continuation region gets smaller. For example, if , then if = 5, but if = 50; likewise, if = 5 and if = 50. Finally, if , then Equation (9) implies (analogous to Wald’s SPRT). Figure 2 displays results for 5, 10, 20, and 30. Its four plots demonstrate that a smaller results in a larger (longer sample path); for example, Figure 2(a) (with = 5) shows the largest , and Figure 2(d) ( = 30) shows that the sample path becomes a single point. This property holds because a larger gives not only more accurate estimators and in the test statistic defined in Equation (10), but also decreases the continuation region between the two boundaries so the sample path tends to hit one of the boundaries more quickly. However, if we select a “too big” value for , then no more observations are collected ( = ) and observations may be wasted. We conjecture that Hall’s SPRT requires a smaller than Wald’s SPRT does. To substantiate this conjecture, we shall conduct a MC experiment in Section 3.
Example boundaries and sample path of Hall’s sequential probability ratio test for with different pilot sample size , when = 0 and = 0.5, .
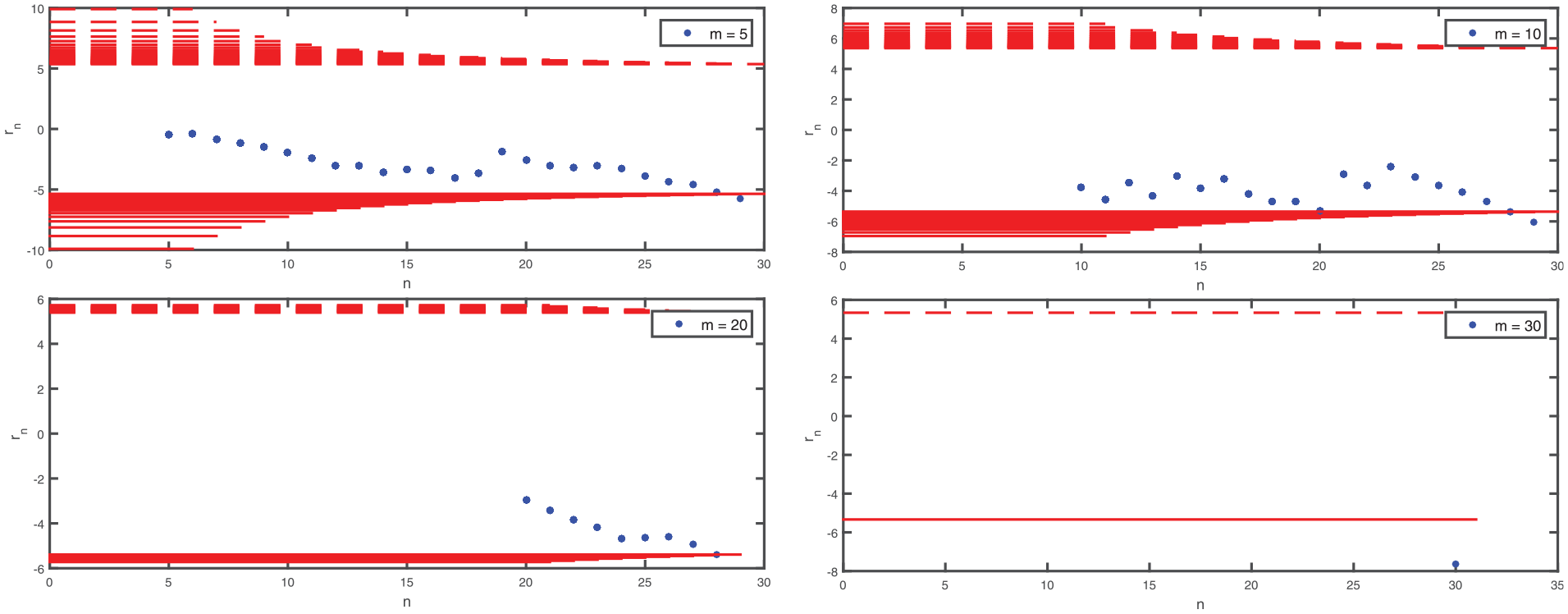
Hall’s6modified SPRT replaces with ; that is, this modification updates the estimated variance after each additional observation, and replaces in Equation (8) through Equation (12) by . The modified boundaries and become closer to zero as increases (whereas and are constants—given ). Let us assume that—in the modified test statistic —the expected values of and are constants (namely, and ), and let us ignore the nonlinearity of the transformation of and implied by . Then tends to increase as increases and (where is halfway between the hypothesized values of in and , respectively), so the modified SPRT tends to accept . On the other hand, tends to decrease as increases and , so our SPRT tends to accept . We illustrate this SPRT in Figure 3, where the boundaries and are the horizontal lines that lie closer to zero as increases (see the red lines).
Boundaries and sample path example for sequential probability ratio test with sequential estimator and pilot sample size , for with = 0, , . (Color online only.)
Comparing Figures 2 and 3 suggests that the modified SPRT gives results that are consistent with Hall’s original SPRT, for various . However, because this modified SPRT implies dynamic boundaries such that the continuation region tends to reduce as increases (but is random), this modified SPRT tends to require fewer observations than Hall’s original SPRT; for example, the plots show = 29 for the modified SPRT and = 61 for Hall’s original SPRT when = 5. To verify the results of this illustrative example, we use an extensive MC experiment in the next section.
3. Monte Carlo experiment #1: normal observations
In Section 3.1 we present details on the design of MC experiment #1: in Section 3.2 we detail the analysis of the results of this experiment. Because the design depends on the analysis that we plan to do, Section 3.1 also contains some analysis elements.
3.1. Experimental design
In this experiment we ensure that is indeed normally distributed. Whereas the preceding three figures displayed results for a single MC macroreplication, we now use = 1000 macroreplications; for example, to estimate , we use macroreplications with PRN-streams to sample from with the same and . We select these streams such that the outcomes of the macroreplications are IID; that is, we use non-overlapping streams. To evaluate these outcomes, we use the following two performance measures (criteria): (i) and , which denote the estimators of and ( is defined in Equation (15) below, and is defined analogously); (ii) , which denotes the final sample sizes averaged over the macroreplications. Our primary performance measures are and (defined in Equations (3) and (4), respectively). Obviously, our is unbiased: . In Section 1 we have already observed that Wald4 (pp.132–133) and Hall6 (p.369) mention that their SPRTs are conservative, so we test the following:
where the superscript distinguishes these hypotheses from and in Equation (1). We use MATLAB to program our MC experiments; MATLAB includes Wald’s and Hall’s original SPRTs (see Govindarajulu5 (Section 6.2)).
To compute , we sample from . We select = 0 because (without loss of generality) Hall’s SPRT assumes = 0 (see Section 2.2). Moreover, we—rather arbitrarily—select = 1; higher values for imply larger , which requires more computer time. Finally, we select where = 0 and is 0.5, 1, 2, and 3 so is 0.5, 1, 2, and 3; the higher is, the lower tends to be.
The macroreplications give IID Bernoulli outputs (say) where = 1 if macroreplication rejects and = 0 if it accepts . So, and . These values give the fraction (percentage) of the macroreplications that rejects :
Because has a Bernoulli distribution, has a binomial distribution with parameters and . This binomial distribution implies the following:
To select a value for , we assume that the SPRTs are not conservative so = . Then, Equation (16) implies ; for example, if = 0.10, then . The various SPRTs may give different values for and . For simplicity’s sake we select = 1000 for all combinations of , , , and SPRT. Please note that the formula for implies that it is easier to obtain a more “precise” estimate for closer to 1 than for closer to 0.5, where “precise” may be defined in an absolute sense () or a relative sense ().
Our hypotheses in Equation (14) require a one-sided test. Using a Gaussian approximation of the binomial distribution of , we obtain the following -statistic with degrees of freedom:
In general, the -statistic is known to be quite insensitive to non-normality. However, we do know that the Gaussian approximation is rougher as is closer to its extreme value 0; that is, is impossible in the binomial distribution but not in the Gaussian distribution. Actually, if the SPRT results in = 0 (so the denominator in Equation (17) becomes zero), then we need no refined mathematical statistics to reject . More generally, if , then we do not reject . If , then we reject only if , where denotes the quantile of the distribution and denotes the type-I error rate of the test (this rate is usually denoted by , but we have already defined differently in Equation (3)). Because = 1000, we replace with where denotes the standard normal . The combination of this reasoning with Equation (17) gives the following decision rule:
Now we discuss the choice of a value for in . We experiment not only with four values for (namely, 0.5, 1, 2, and 3; see above), but also with four values for and , respectively; namely, 0.01, 0.05, 0.10, and 0.20. Altogether we consider = 64 combinations of . For each combination we obtain a value for . If we rejected if , then we would expect “false alarms” (type-I errors); for example, if = 0.10, then we expect 6.4 false alarms. We use a simple—but conservative—solution based on Bonferroni’s inequality; this solution does not exceed a prespecified experimentwise or familywise error rate (say) (this is the analogue of and ); “familywise” and “per comparison” error rates are discussed by Kleijnen1 (p.98). So, in Equation (18) we replace with . We select = 0.20; such a relatively high -value is usual, because such a value reduces the loss of power caused by the conservative Bonferroni inequality. = 0.20 implies that we use Equation (18) with , so . To improve the precision of our comparisons—across various SPRTs, 64 combinations , and various distributions of —we use CRNs, as we explain in great detail in Appendix 3.
3.2. Analysis of the experiment
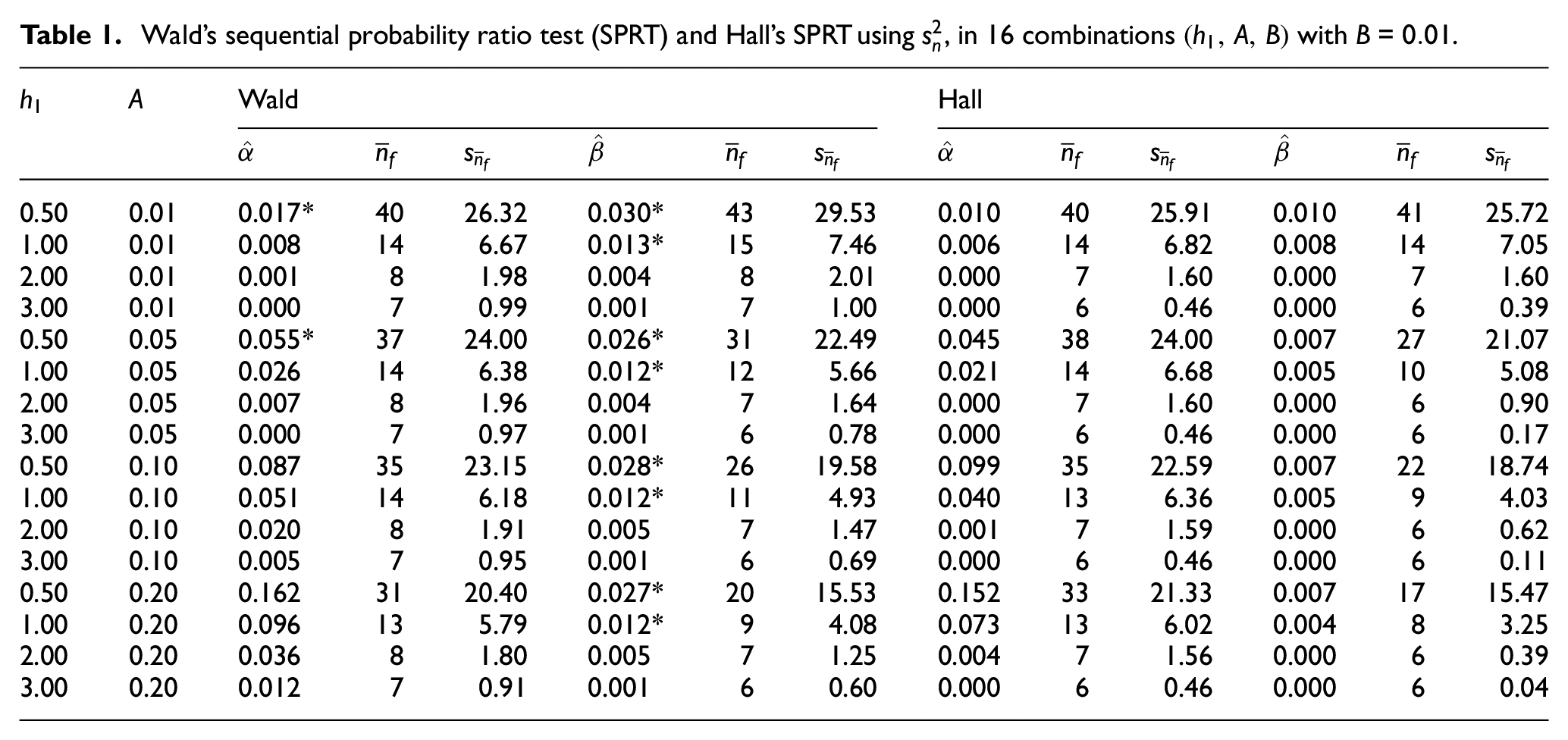
Table 1 displays results for Wald’s SPRT and Hall’s SPRTs—both modified so they use (we do not display results for the SPRTs that use , because these results are inferior)—and only 16 of the 64 combinations of —namely, the combinations in which is 0.01; the remaining 48 combinations in which is 0.05, 0.10, or 0.20 give similar results, so we display those results in Appendix 4 (actually, we shall see that the effect of on resembles the effect of on , and Table 1 does show all four values for ). Because of Equation (18), we reject if with ; to denote significantly high values in Table 1, we use an asterisk (*). Before we further comment on , we now discuss (which has its own and ; see the columns after in Table 1).
Wald’s sequential probability ratio test (SPRT) and Hall’s SPRT using , in 16 combinations with = .
Wald
Hall
0.50
0.01
0.017*
40
26.32
0.030*
43
29.53
0.010
40
25.91
0.010
41
25.72
1.00
0.01
0.008
14
6.67
0.013*
15
7.46
0.006
14
6.82
0.008
14
7.05
2.00
0.01
0.001
8
1.98
0.004
8
2.01
0.000
7
1.60
0.000
7
1.60
3.00
0.01
0.000
7
0.99
0.001
7
1.00
0.000
6
0.46
0.000
6
0.39
0.50
0.05
0.055*
37
24.00
0.026*
31
22.49
0.045
38
24.00
0.007
27
21.07
1.00
0.05
0.026
14
6.38
0.012*
12
5.66
0.021
14
6.68
0.005
10
5.08
2.00
0.05
0.007
8
1.96
0.004
7
1.64
0.000
7
1.60
0.000
6
0.90
3.00
0.05
0.000
7
0.97
0.001
6
0.78
0.000
6
0.46
0.000
6
0.17
0.50
0.10
0.087
35
23.15
0.028*
26
19.58
0.099
35
22.59
0.007
22
18.74
1.00
0.10
0.051
14
6.18
0.012*
11
4.93
0.040
13
6.36
0.005
9
4.03
2.00
0.10
0.020
8
1.91
0.005
7
1.47
0.001
7
1.59
0.000
6
0.62
3.00
0.10
0.005
7
0.95
0.001
6
0.69
0.000
6
0.46
0.000
6
0.11
0.50
0.20
0.162
31
20.40
0.027*
20
15.53
0.152
33
21.33
0.007
17
15.47
1.00
0.20
0.096
13
5.79
0.012*
9
4.08
0.073
13
6.02
0.004
8
3.25
2.00
0.20
0.036
8
1.80
0.005
7
1.25
0.004
7
1.56
0.000
6
0.39
3.00
0.20
0.012
7
0.91
0.001
6
0.60
0.000
6
0.46
0.000
6
0.04
Given the definition of in Equation (4), we compute through sampling from (instead of , which we used for ). The CRN implies that—instead of sampling —we sample , so and . Because = 0 in Equation (10), the test statistic increases with . Hence, the new is always higher than the old computed under . Our test for is the analogue of the test for in Equation (18). Because the SPRTs treat and similarly, we conjecture that and exhibit similar behavior. To test this conjecture, we use a second-degree polynomial regression model, as we shall explain below (in the paragraph containing Equation (19)).
Combining Table 1 and the table in Appendix 4 shows that either = 0.000 or = 0.000 in 92 of the 128 combinations (namely, 64 combinations for and 64 combinations for ). This value of 0.000 means that none of the = 1000 macroreplications cross the “wrong” boundary. Focusing on these 92 combinations, we try to discover whether specific values of , , or —or combinations of these values—give these extremely low or . We conclude that all combinations with = 0.000 or = 0.000 have a very large and a very small ; that is, combinations with imply that the SPRTs require only a small sample to make the correct decision.
Furthermore, several combinations in Table 1 and the table in Appendix 4 give a significantly high or for Wald’s modified SPRT, whereas Hall’s modified SPRT is conservative. This conclusion seems reasonable: after all, Hall’s SPRT is derived for the special case of a normal distribution with an unknown variance.
Now we test whether indeed and show similar behavior. For each of the two SPRTs, we first fit a second-degree polynomial with the explained regression variables (where the tilde denotes a regression estimate; denotes the estimate resulting from the MC experiment) and , respectively; the three explanatory variables are , , and . We present the (tedious) regression analysis in Appendix 5. This analysis uses the least squares (LS) criterion to fit these two polynomials to the = 64 combinations of . This fitting gives estimated coefficients for these polynomials and their standard deviations (or standard errors). So, we can test whether these estimated coefficients (or parameters) significantly differ from zero. We eliminate non-significant effects from the full polynomials, which gives the reduced polynomials. Finally, we use these reduced (simplified, parsimonious) polynomials to check whether the marginal effects of the explanatory variables are “understandable”; that is, do they have the correct signs? Therefore, we compute the marginal effects implied by the reduced polynomials, at the midpoint (or center) of our experimental area, :
So, a higher gives a lower , which makes sense because the SPRT can easily make the correct selection when the two hypothesized values are far apart. A higher gives a lower , which may be explained by the negative interaction between and in the reduced polynomial (again see Appendix 5).
Next we repeat our analysis for . The results in Appendix 5 suggest that and indeed respond in a similar way to , , and ; for example, the effect of on is , the effect of on is , and these two estimates do not differ significantly.
Finally, we examine (our secondary performance measure; see the text above Equation (14)). Table 1 clearly demonstrated that the modification accounting for unknown in Wald’s SPRT for gives significantly high or for many combinations . We therefore do not consider and its standard deviation for this modified SPRT; that is, we limit our regression analysis of to the modification of Hall’s SPRT. If more than one SPRT gave and and we are risk neutral instead of risk averse or risk seeking, then we would prefer the SPRT with the smallest . To analyze , we apply the same type of regression analysis as we applied for and (see the last part of Appendix 5). The resulting reduced polynomial gives the following.
So, a higher or decreases , because these factors have important negative first-order effects (namely, and ; again see Appendix 5).
We conclude the following:
Wald’s modified SPRT gives significantly high or for many combinations, whereas Hall’s modified SPRT is conservative;
and respond to , , and in similar ways;
if , , or increases, then of Hall’s modified SPRT decreases.
4. Experiment #2: non-normal observations
In MC experiment # 2 we sample observations that are not normally distributed, so that we can investigate whether the SPRTs are robust; that is, are the SPRTs “quite” insensitive to non-normality? There are infinitely many types of non-normal distributions, but we limit our experiment to the following three distribution types: (i) lognormal, (ii) gamma, and (iii) exponential. Now we detail our design and analysis for the lognormal distribution.
By definition, has a lognormal distribution with shape parameter and scale parameter —denoted as —if . The following relations are well known: and . Lognormal distributions may have various shapes; for example, if = 1, then these distributions are very skew so they are very non-normal. Samples from cannot be negative. For more details we refer to Law2 (pp.294–295).
In our MC experiment we use with = 0 and = 1; consequently, and . In Section 2.2 we saw that Hall6 assumes with = 0 in , so we apply the transformation with so = 0 (so we shift the lognormal to the left). Furthermore, the combination = 0 and = 1 implies that our shifted lognormal distribution with mean 0 has variance or standard deviation 2.17 approximately. Below Equation (14) we selected with = 0, = 1, and is 0.5, 1, 2, and 3; so, was 0.5, 1, 2, and 3. Now we select = 0 and with = 2.17 so is 1.09, 2.17, 4.34, and 6.51. Whatever values we select for and , the SPRT should guarantee ; we conjecture that a higher decreases (expected value of ), because it becomes easier for the SPRT to select or .
Furthermore, we compare for normal and lognormal distributions. To increase the precision of this comparison, we again use CRNs (in MC experiment #1, we used CRNs to compare combinations of , , , and SPRT). Now it is again easy to apply CRNs: when sampling from , the PRN-streams remain “synchronized” with sampling from (for details on “synchronization” we refer to Law2 (pp.592–598)): to sample from , we sample and compute and ; also see Appendix 6, which covers lognormal samples and normal samples while applying CRNs.
To design experiment #2, we use the results of our analysis of experiment #1. This analysis showed that a second-degree polynomial in the factors , , and is an adequate model of the reaction of or to these three factors. To fit such a polynomial, we now use a modified CCD. Classic CCDs are discussed by Kleijnen1 (pp.63–66). Compared with the design in MC experiment #1, a CCD saves computer time because it has fewer factor combinations (this design is detailed in Table 1 and Appendix 4). We modify the classic CCD such that it has only 14 combinations, which are specified in the first three columns of Table 2; we detail the classic CCD and our modified CCD in Appendix 7. Our modified CCD in MC experiment \#1 is a proper subset of the design in MC experiment \#1; e.g., combination 6 in Table 1 also occurs in Table 2 in the main text (because it combines the low axial point with the low intermediate values and in the design; again see Appendix 7), whereas combination 1 in Table 1 does not occur in Table 2 in the main text (because it combines the low axial points for all three factors; again see Appendix 7). The 14 combinations of our modified CCD are well spread over the experimental area, but they are sparser than the combinations and do not form a so-called balanced design.
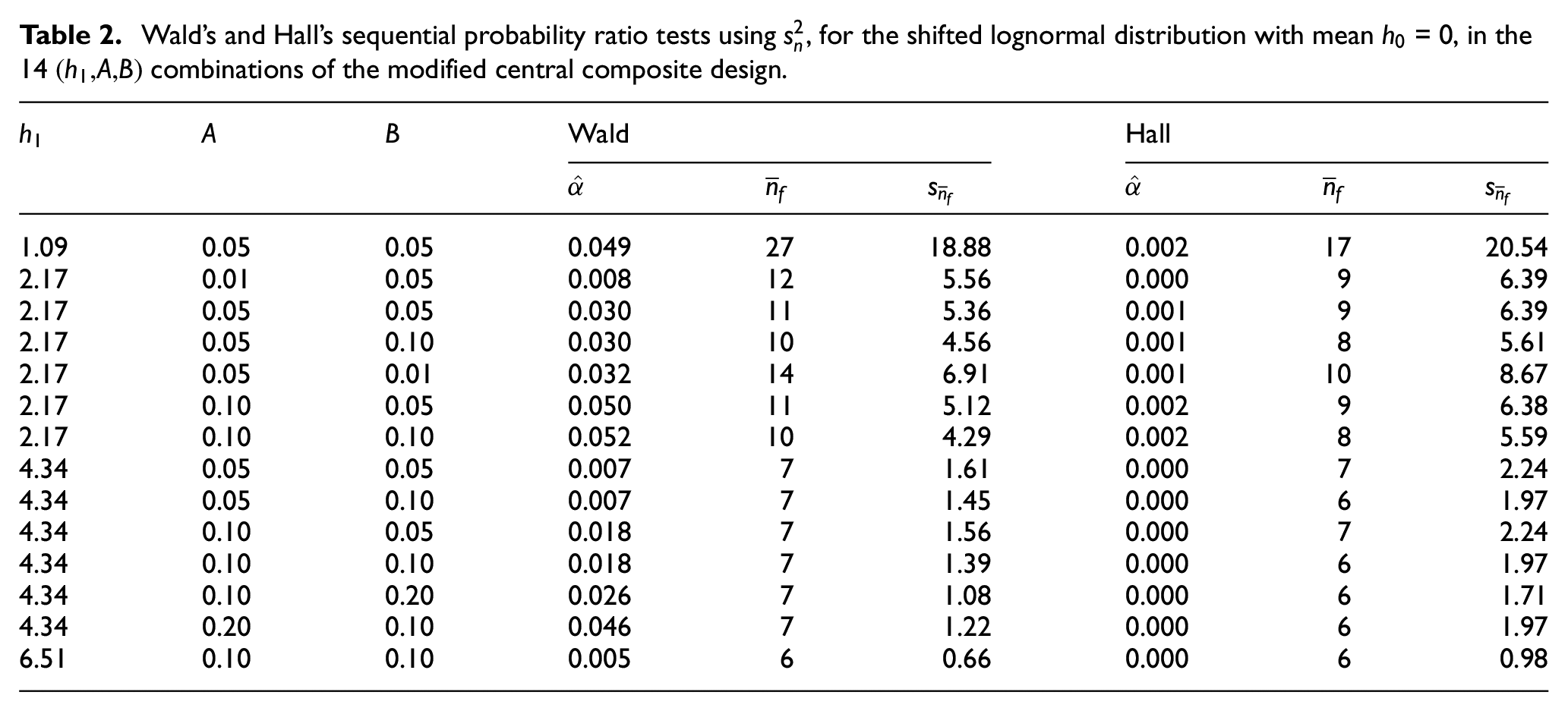
Wald’s and Hall’s sequential probability ratio tests using , for the shifted lognormal distribution with mean = 0, in the 14 combinations of the modified central composite design.
Wald
Hall
1.09
0.05
0.05
0.049
27
18.88
0.002
17
20.54
2.17
0.01
0.05
0.008
12
5.56
0.000
9
6.39
2.17
0.05
0.05
0.030
11
5.36
0.001
9
6.39
2.17
0.05
0.10
0.030
10
4.56
0.001
8
5.61
2.17
0.05
0.01
0.032
14
6.91
0.001
10
8.67
2.17
0.10
0.05
0.050
11
5.12
0.002
9
6.38
2.17
0.10
0.10
0.052
10
4.29
0.002
8
5.59
4.34
0.05
0.05
0.007
7
1.61
0.000
7
2.24
4.34
0.05
0.10
0.007
7
1.45
0.000
6
1.97
4.34
0.10
0.05
0.018
7
1.56
0.000
7
2.24
4.34
0.10
0.10
0.018
7
1.39
0.000
6
1.97
4.34
0.10
0.20
0.026
7
1.08
0.000
6
1.71
4.34
0.20
0.10
0.046
7
1.22
0.000
6
1.97
6.51
0.10
0.10
0.005
6
0.66
0.000
6
0.98
Our analysis of experiment #1 showed that and give similar results, so in experiment #2 we estimate only (not ); that is, we sample only from a distribution with mean = 0 (not ). We again use = 1000 macroreplications. Table 2 shows that (i) both SPRTs give in all combinations, and (ii) Wald’s modified SPRT (using ) often requires a higher . Hall’s modified SPRT (using instead of ) gives = 0.000 if ≥ 4.34 and if = 0.01. Cursory inspection of this table suggests that does respond to ; to quantify this response function we again apply regression analysis (see Appendix 8). The design and analysis of our experiments with the other two non-normal distributions (namely, gamma and exponential) are detailed in Appendixes 9 and 10. In Appendix 11 we investigate whether a normalizing transformation of may reduce . We focus on the simplest normalizing transformation; namely, the logarithmic transformation. Our MC experiment \#3 shows that this transformation does not decrease ; neither does it decrease .
Altogether, experiment #2 gives the following results, where “Wald” and “Hall” mean Wald’s and Hall’s modified SPRTs using , respectively.
Lognormal: (i) both Wald and Hall give in all 14 combinations of (, , ), and (ii) Wald often requires a higher . (See Table 2.)
Gamma: (i) both Wald and Hall give in all 14 combinations, and (ii) Wald requires a smaller than Hall does. (See Appendix 9.)
Exponential: (i) both Wald and Hall give in all 14 combinations, (ii) Wald requires a smaller than Hall does, and (iii) Wald’s non-modified SPRT for exponential distributions gives in all 14 combinations and requires a smaller than Wald’s modified SPRT in 13 of the 14 combinations. (See Appendix 10.)
We conclude that the SPRTs give in all 14 combinations of (, , )—so the SPRTs are “conservative”—even if the distribution is non-normal—so the SPRTs are “robust.” Our explanation is that Hall’s test statistic (defined in Equation (10)) resembles the classic -statistic, which is quite insensitive to non-normality. Wald’s test statistic (see Equation (2)) is a sum of random variables, so the central limit theorem (CLT) applies. Which SPRT requires a smaller is not so clear; if we assume an exponential PDF, then Wald’s non-modified SPRT requires a smaller . However, our experiment #1 with a normal PDF showed that Wald’s modified SPRT gives significantly high for many combinations (whereas Hall’s modified SPRT is conservative)—which seems to contradict our conclusions based on experiment #2. Altogether, we recommend Hall’s modified SPRT—pending further research.
5. Conclusions and future research
For the testing of two hypothesized values of a mean output, we reviewed Wald’s4 and Hall’s6 original SPRTs, and two simple modifications. For these SPRTs we used plots to illustrate both the boundaries—which define their continuation areas—and possible sample paths of their test statistics.
We designed our MC experiment #1 such that the output is guaranteed to be normally distributed. This experiment showed that Wald’s SPRT modified for unknown output variance may give significantly high (estimated type-I error rate) or (estimated type-II error rate) for some factor combinations in the experiment. However, if we modify Hall’s SPRT to get a sequential estimator of the output variance, then the resulting SPRT is conservative; that is, this SPRT gives significantly low or . Furthermore, our regression analysis of MC experiment #1 showed that and exhibit similar reactions to (difference between the hypothesized value in hypothesis and in ), (prespecified nominal ), and (nominal ). Finally, (final sample size of the SPRT) decreases for increasing , , or .
Our MC experiment #2 used three types of non-normal distributions; namely, lognormal, gamma, and exponential distributions. This experiment showed that the SPRTs are quite robust; that is, and remain below and . Our explanation was that Hall’s test statistic resembles the classic -statistic; Wald’s test statistic uses a sum of IID variables so the CLT applies.
We hope that in the near future other researchers will repeat and extend our research—possibly applying our methodology for the design and analysis of MC experiments with SPRTs. Finally, we hope to investigate SPRTs for more than a single mean output.
Supplemental Material
sj-pdf-1-sim-10.1177_0037549720954916 – Supplemental material for Sequential probability ratio tests: conservative and robust
Supplemental material, sj-pdf-1-sim-10.1177_0037549720954916 for Sequential probability ratio tests: conservative and robust by Jack PC Kleijnen and Wen Shi in SIMULATION
Footnotes
Acknowledgements
We thank Ruud Brekelmans (Tilburg University) for helping us solve the problem of avoiding overlap among PRN-streams when applying CRNs. We thank three anonymous referees for their comments that helped us to clarify some issues and improve our presentation.
Funding
The work of Wen Shi was partially supported by the National Natural Sciences Foundation of China (Grant Nos. 71971219, 71790615, and 71991463).
ORCID iD
Wen Shi
Author biographies
Jack PC Kleijnen is Emeritus Professor of “Simulation and Information Systems” at Tilburg University (TiU), where he is still an active member of both the Department of Management and the Operations Research Group of the Center for Economic Research (CentER) in the Tilburg School of Economics and Management (TiSEM). He is also an active author and reviewer for many international journals. His email address is kleijnen@tilburguniversity.edu.
Wen Shi is a Professor in Business School at Central South University. He holds a PhD in management science and engineering from Huazhong University of Science and Technology. His research focuses on simulation modeling, simulation experiment design and analysis, and supply chain management. His email address is shi3wen@163.com.
References
1.
KleijnenJPC. Design and analysis of simulation experiments. 2nd ed.New York: Springer US, 2015.
2.
LawAM. Simulation modeling and analysis. 6th ed.Boston, MA: McGraw-Hill, 2015.
3.
KleijnenJPC. Statistical techniques in simulation: Part II. New York: Dekker, 1975.
4.
WaldA. Sequential tests of statistical hypotheses. Ann Math Stat1945; 16: 117–186.
5.
GovindarajuluZ. Sequential statistics. Singapore: World Scientific, 2014.
6.
HallWJ. Some sequential analogs of Stein’s two-stage test. Biometrika1962; 49: 367–378.
7.
ZeiglerBPPraehoferHKimTG. Theory of modeling and simulation: Integrating discrete event and continuous complex dynamic systems. San Diego, CA: Academic Press, 2000.
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.