
Abstract
This paper describes agent-based models of epidemics dynamics, willingly simplified with the goal not to predict the evolution of the epidemics, but to explain the underlying mechanisms in an interactive way. They allow to compare screening prioritization strategies, and vaccination priority strategies, on a virtual population. The models are implemented in Netlogo in two simulators, published online at https://nausikaa.net/index.php/simulating-epidemics/ to let people experiment. This paper reports on model design, implementation, and experimentations. We have compared screening strategies to assess the epidemics versus control it by quarantining infectious people; and we have compared vaccinating older people with more risk factors, versus younger people with more social contacts.
Keywords
1. Introduction
The COVID-19 epidemic has now been lasting for over 2 years since the first case in late 2019. The only control strategy for the first year was general lockdowns, but was hard to maintain long term for economical and mental health reasons. In the second phase, when tests became available, the new strategy was to start large screening campaigns and to isolate only (detected) sick individuals. Vaccines had then become available in December 2020, and thus allowed to lift most constraining sanitary measures.
However, with the epidemic lasting longer than expected and its end being hard to predict, people are tiring out, sanitary measures are not always well accepted, trust goes down. 1 Fake news circulate with deadly consequences, 2 such as refusing or hesitating to get the vaccine.3,4 We believe that it is very important to inform the population and explain the mechanisms of the epidemics and the reasons behind all measures. 5 Besides, understanding constraints could improve their acceptability.
Computer simulation provides a useful tool in crisis management, by allowing to test various scenarios in silico. 6 This is particularly helpful to gain experience in between occurrences of crises, as well as to repeat and control precisely the scenarios to be tested, which is impossible in vivo; such real-life training could also be dangerous and put real human lives at stake. During the pandemic, computer simulation has been used in particular to predict the different waves of virus propagation, to compare various non-pharmaceutical interventions to slow down this propagation, 7 and to support government decisions in various countries (e.g., New Zealand, 8 the United Kingdom, 7 or Vietnam9,10 to cite a few). Such models are aimed at decision makers and are quite complex. But simulation is also a powerful tool to explore and understand complex mechanisms, in particular, during a stressful time such as this pandemic. 11 To this aim, simulators should be much simpler, to make their results easy to grasp for the general public. For instance, Taillandier and Adam 12 put the player in the mayor’s shoes, having to prepare their territory to face coastal flooding, but with simplified mechanics compared to a decision-support flood simulator.
In line with this approach, we claim that an interactive simulator is a good tool to explain mechanisms by letting users play a role and learn by exploring what-if scenarios. We have, therefore, designed two agent-based models allowing users to simulate various screening and vaccination strategies on a virtual population, and to compare these strategies in order to discover insight about their parameters. The first simulator, dedicated to screening, was designed in spring 2020 when testing kits became more widely available, to explain the priority allocation strategies. The second simulators, dedicated to vaccination, was designed in 2022 when vaccines had already been available for several months to compare the impact of various possible priority strategies. Both simulators are simple and interactive, since their goal is not to predict anything but to explain: users from the general population can play with them in order to understand the complex mechanisms behind the epidemics, and the reasons for the various sanitary measures. This work is part of a larger initiative aiming at answering questions from the general public about the COVID-19 epidemic, through interactive simulators along with explaining texts written by researchers from various disciplines. 11
This paper is structured as follows. We start with introducing useful background about screening, vaccination, and their challenges. We also survey some existing models to identify gaps in the literature, and state our goal. Our two models are presented separately since they make different initial assumptions, related to a different sanitary context: we start with the screening model design and experiments, and continue with the vaccination model design and experiments. Finally, we conclude the paper and discuss limitations and future prospects of this work.
2. Challenges of screening
This section introduces some useful background about screening, quality features of tests, and possible prioritization strategies for allocating a limited number of tests.
2.1. Lockdowns and screening
When lifting the lockdown after the first COVID-19 wave in spring 2020, the main goals of many countries around the world were to get back to a less restricted way of living while still maintaining the epidemic under control to avoid a “second wave..” Indeed, due to the low circulation of the virus during lockdown, herd immunity was still insufficient to prevent a rebound and new wave. For instance, it was estimated (by Pasteur Institute: https://www.pasteur.fr/fr/espace-presse/documents-presse/modelisation-indique-qu-entre-3-7-francais-ont-ete-infectes) that only 3% to 7% of the French population had been exposed to the virus (and was therefore immunized) when exiting the first French lockdown in May 2020. And as time has since proved, not only a second wave, but several more epidemic waves appeared, pushing some countries to enforce other lockdowns.
But the general lockdown is hard to maintain on the long term for both psychological and economic reasons, 13 and is hard to lift without creating a new wave since herd immunity does not develop during lockdown. One solution is to selectively isolate only sick individuals, but it is hard to implement efficiently. Indeed, COVID-19 incubation time is long (a week on average, but sometimes up to 20 days), so infected people have time to infect their contacts before they are detected and quarantined. Besides, the share of asymptomatic cases was still mostly unknown, but estimated to be around 30%, 14 meaning many infected people could unknowingly spread the virus among their contacts.
This implies that governments could not rely entirely on symptomatic displays to isolate infected people, but needed to test their population broadly by running large-scale screening campaigns. This is precisely the strategy recommended by the World Health Organization (WHO), as early as 16 March 2020 (https://www.who.int/dg/speeches/detail/who-director-general-s-opening-remarks-at-the-media-briefing-on-covid-19—16-march-2020): to test any suspicious case to confirm potentially infected individuals; to trace their contacts in order to identify chains of contamination; and isolate only (potentially) infectious people. But it took time to develop reliable tests and start this strategy.
2.2. Quality of tests
There exists different types of tests to detect the severe acute respiratory syndrome coronavirus 2 (SARS-CoV-2) virus responsible for COVID-19, in particular, PCR (polymerase chain reaction) tests, serological tests, antigenic tests, and auto-tests that one can realize at home. These tests have different levels of quality, depending on two factors:
Sensitivity of a test indicates the probability that the test is positive when the tested person is really sick. A 100% sensitive test applied to a sick individual will always return positive; therefore, a negative test gives absolute certainty that the tested individual is indeed not sick. In other words, there are no false negatives with a 100% sensitive test; so sensitivity is the proportion of true negatives.
Specificity of a test indicates the probability that the test is negative when the tested person is really not sick. A 100% specific test applied to a non-sick individual will always return negative; therefore, a positive test gives absolute certainty that the tested individual is indeed sick. In other words, there are no false positives with a 100% specific test, so specificity is the proportion of true positives.
However, it is impossible to design tests that are perfect on both criteria (or even on a single one). Screening tests always have an error margin. In particular, screening tests cannot be both highly specific and highly sensitive, so a compromise must be found between two opposites:
Very sensitive tests are more likely to be positive with sick individuals: this reduces the rate of false negatives, so prevents missing infected people who keep moving around instead of being quarantined.
Very specific tests are less likely to be positive when the individual is not sick: this reduces the rate of false positives, to prevent from quarantining healthy people.
The first screening tests designed for COVID-19 were relatively specific (in the range of 95% to 98% of true positives) but still little sensitive (sometimes up to 30% to 40% of false negatives). As a result, it was sometimes necessary to do a second test to confirm a negative test result.
2.3. Screening objectives
Time was needed to develop reliable quality tests and increase testing capacity. As a result, testing kits were rare at the start of the epidemic, forcing governments to prioritize who should be tested first to optimize the impact of the testing campaign. Even nowadays, when testing kits are widely available, and as new variants of the virus circulate very fast, the number of daily tests has exploded, posing a new issue of financing those tests. Some countries, therefore, again choose to restrict tests to some categories of people, for instance, the elderly who are more at risk of serious forms, or people with symptoms. Other countries require non-vaccinated people to pay for the tests, also to limit the number of tests performed. Screening tests actually pursue two main (partly contradictory) goals.
To control the epidemic, by spotting infected people and isolating them to break contamination chains.
To know the epidemic, i.e., evaluate as precisely as possible the total number of people infected at a given time, and deduce the actual case fatality rate.
These goals involve different screening strategies: to best control the epidemics, one should test in priority people who are more likely to carry the virus, but this leads to an over-estimation of the global circulation; to best know the epidemics, one should randomly test a representative sample of the global population, but this will lead to a large number of negative tests, failing to isolate many infected people. The best screening strategy is, therefore, not intuitive.
2.4. Screening prioritization strategies
Under the constraint that testing kits are in limited supply, governments want to prioritize wisely who should be tested, to reach both goals with the minimum amount of tests. For instance, France started testing late and slowly (https://www.usinenouvelle.com/article/en-retard-la-france-monte-en-puissance-pour-les-tests-de-diagnostic-du-covid-19.N945261): it took some time to design reliable tests, and the small number of such available tests was thus limited to healthcare workers and people at risk. Nowadays, tests are widely available and are the most cost-effective mitigating measure, 15 but some countries started restricting them again in order to limit the financial cost for society, for instance, by reserving them for elderly people, or by asking non-vaccinated individuals to pay for the tests. The following possible targeting strategies have different impacts on both goals stated above:
Random targeting consists in choosing randomly people who should be tested. This is a more representative sample of the population, and provides better knowledge of the current state of the epidemic. But when the incidence of the virus is very small (as it was after the first lockdown), the proportion of people infected is very low, so most tests will return negative. There is therefore a risk of “wasting” many tests, i.e., the chances of finding infected people to isolate them and control the epidemic are low.
A solution is to target suspicious cases (the symptomatic ones), but this strategy is insufficient to control the epidemic since it ignores all the (also contagious) asymptomatic cases. Besides, the sample is not representative of the general population, and the high proportion of positive tests in the sample might lead to overestimate the global circulation of the virus.
Another strategy consists in targeting people who work outside of home, since they are more likely to get infected and/or infect others. For instance, at the beginning of the epidemic, healthcare workers were tested in priority, since they were the most exposed to the virus; o reopen schools, there was also a focus on testing teachers, school workers, or children from the same class as an infected pupil. This strategy focuses on controlling the epidemic while allowing for economic activity, but it ignores contaminations that happen outside of work (shopping, leisure ...).
Finally a last interesting strategy consists in targeting high-risk people. Their profile is now better known, in particular elderly people or people with comorbidities. 16 The goal of this strategy is to detect infection soon and treat them early to prevent serious complications. But the results would then not be representative of the global circulation of the epidemic in the general population.
The choice is not intuitive, and we claim that simulation can help compare different strategies to draw interesting insight. Indeed, simulation allows to run the exact same scenario with only the parameters of the screening campaign varying, which is impossible in reality, and to compare estimations with the “real” epidemic curve, which can be known only in a simulation.
3. Challenges of vaccination
Vaccines became available in December 2020, and many different ones are now available. This section provides some useful background related to our model.
3.1. Vaccination
The goal of vaccination is to provide people with some level of immunity against the virus, that will protect them from infection, and ultimately to create collective immunity at the level of the population to stop further propagation of the virus. The impact of the vaccination campaign can be measured on different indicators: the height of the epidemic peak (how many people are sick at the same time at the peak), the duration of the epidemic wave (how long it takes before nobody is sick anymore), the total number of people who got sick, the total number of serious cases, the number of people in hospitals, or the number of deaths. The efficiency of a vaccine can be defined on different terms, 17 such as reducing the risk of infection, the severity of the disease, or the duration of infectivity. A vaccine can have different levels of efficiency on these different aspects. It was initially hard to know exactly which factor was impacted by the vaccine: its effect on infection was tested by trials before release, but it was not clear if it was also effective on transmission, 18 on asymptomatic forms, 19 or on the risk of serious forms. Governments sometimes made simplified statements to encourage people to get the vaccine (https://www.liberation.fr/checknews/transmission-du-covid-19-les-autorites-ont-elles-menti-sur-lefficacite-du-vaccin-pour-justifier-les-pass-sanitaire-et-vaccinal-20221014_JEAR5KU73RFNTPRDWQCLHSNZQE/). The efficiency of the vaccine has also decreased against the new variants of the virus. 20
3.2. Individual vulnerability
Literature has shown that infections and serious forms are more frequent in people with risk factors, in particular those aged above 60 21 and/or having comorbidities (often associated with age) such as diabetes or chronic illnesses.22–24
Literature also shows that younger people have more contacts in average than older people. For instance, Ibuka et al. 25 studied influenza in Japan and showed difference in contact patterns based on age, gender, as well as during the week versus holiday. Bäacker 26 also studied the role of contacts with people of different age groups; they conclude that the case growth rate increases when there is more contacts with elderly people, but decreases with contacts among the same age group.
It is, therefore, important to model individual contacts and risk level in order to account for this individual variability, in particular when targeting who will be vaccinated in priority.
3.3. Vaccine prioritization strategies
Developed countries invested a lot of money to secure enough doses for their population, but the production and injection of millions of doses takes time. Furthermore, the immunity conferred by the vaccine only lasts for a few months, 27 so it is necessary to inject boosters regularly. As a result, governments are faced with a choice about who should be vaccinated first:
Vaccinating in priority people with comorbidities (elderly people or people with other health factors increasing their vulnerability), in order to protect them from serious forms of the illness.
Vaccinating in priority people with more contacts (such as health workers who are in contact with many sick or vulnerable people, teachers, or younger people who have more social contacts), in order to reduce the global transmission of the virus;
Vaccinating the population in random order.
Similar to screening, the optimal strategy is not intuitive since different strategies improve different indicators. One might reduce the number of serious forms but leave many younger people exposed, or reduce the total number of contaminations to prevent saturation of the healthcare system but take the risk of more serious forms among vulnerable people. Therefore, once again simulation could help in testing strategies by varying their parameters in isolation.
4. Agent-based simulation of epidemics
4.1. Advantage of simulation
One can see from the background above that finding the best (screening or vaccination) strategy on all accounts is not easy by using only intuition, but we claim that simulation can help. Computer simulation has many benefits in the context of the crisis management in general, and the current epidemic in particular.
The main measures against COVID-19 have been quarantine, contact tracing, screening, and isolation; there is no consensus on best practices, and countries differ in their approach, but a survey of medical publications 28 shows their efficiency, in particular when combined together. It is hard, however, to compare their efficiency in real life since their individual impact cannot be isolated. Indeed, in the real world, we can only compare between different countries applying different strategies, but they also differ on other regards: climate, culture, and so on, that all might influence virus spread, so it is impossible to isolate the precise impact of the strategy being evaluated.
On the contrary, in a simulation we control all parameters, so we can compare measures “in silico,” by running the exact same scenario several times. By varying only selected parameters (prioritization strategy, and so on), all other things being equal, we can evaluate their impact independently of all other factors, which is impossible in reality. Besides, in the real world, there is no way to assess the actual number of infected people (unless we could simultaneously test the entire country), so it is impossible to evaluate how good the curve estimated from the tests is compared to the “real” curve. On the contrary, in a simulation, we know the epidemiological status of all agents, so we can assess the real (simulated) epidemic curve, and compare it with estimations obtained from various screening strategies. Simulation is, therefore, a great tool to assess screening strategies on a virtual population.
4.2. Approaches to epidemics simulation
As a result, a lot of models of the COVID-19 epidemic have been published in the last 2 years. Current epidemic models mainly fall in two approaches.
Compartmental models divide the population in a number of epidemiological classes. The simplest ones (often shortened as SIR models) use only three compartments: susceptible (not yet infected so not immune), infected (and contagious), recovered (and immune). The hypothesis is that recovered individuals are then immune and cannot get infected again, which has proven wrong for COVID-19. Compartmental models of COVID-19 have often integrated more compartments, such as asymptomatic or hospitalized, in order to more precisely represent the dynamics. These models then rely on the mathematical resolution of differential equations to give a macroscopic view of the epidemic dynamics. It is therefore quite fast and scalable.
Agent-based models model each individual as an autonomous agent, to give a microscopic view of the situation. Agents are heterogeneous, initialized with different values of their attributes, such as age, gender, comorbidities, or social behavior. This allows to model the influence of individual decisions on the virus spread, such as a refusal to get vaccinated, or not respecting social distancing. These models are more complex to initialize as they require behavior data that is hard to get, and are less scalable since they require to compute the behavior of each individual agent. However, they are more precise, in particular, to study why a specific individual got infected.
Both approaches have their benefits and drawbacks depending on the goal and scale of the simulator.
4.3. Simulation for logistics
Mathematical models are mainly used to optimize or predict large-scale phenomena. For instance, Jerbi and Masmoudi 29 propose a discrete event simulation of a mass vaccination center in Sfax, Tunisia; their goal is not to explain the mechanisms of vaccination, but to improve performance of the vaccination center, in three scenarios of variable arrival flows; individual behavior is not modeled. Erkayman et al. 30 also propose a simulation of vaccine logistics during the COVID-19 pandemics. Their goal is to predict when herd immunity can be reached based on variable vaccine supply; without surprise, they find that higher supply leads to shorter delay of herd immunity. They do not model individual behavior or trust in the vaccine, which allows their model to scale well: they simulated the entire Turkish population with 83 million agents. However, their goal is to provide decision makers with predictions, rather than letting the general population interact and understand mechanisms.
Our goal being to explain the complex mechanisms behind the epidemics, rather than predicting its spread at the scale of a country, we chose an agent-based approach. We survey various existing agent-based models in the next paragraphs.
4.4. Simulations of interventions
In March 2020, Ferguson et al. 7 reported the results of an epidemiological model to inform policy-making in the United Kingdom and other countries, leading to general lockdown. At that time, in the absence of a vaccine, they assessed non-pharmaceutical interventions to reduce contacts in the population and therefore virus transmission, with two possible strategies: mitigation (slowing down the epidemic spread), versus suppression (completely stopping it). They showed that optimal mitigation policies might reduce the pressure on healthcare system by two-thirds and deaths by half, but might still result in hundreds of thousands of deaths and overwhelmed healthcare systems. So they suggested that where possible, countries should aim at suppressing rather than mitigating the epidemics, which would require a combination of several very constraining measures (quarantines, distancing, school closures) despite their negative side effects. Besides, they predict that such measures would need to be maintained indefinitely (or until a vaccine is found) to prevent a rebound as soon as they are relaxed. Not knowing if such suppression could be maintained on the long term, or how to reduce its social and economic costs, they also suggested intermittent measures: closely monitor the epidemic progression to relax measures when possible, but re-instantiate them when needed.
Other countries have also developed simulators to help policymakers. For instance, COMOKIT 10 is a framework composed of several realistic spatialized agent-based models of the epidemic and of various interventions, aiming at informing public health decisions made by the Vietnamese government. The models run on the GAMA platform. They can be fed from various data sources, provided by governments (census data, epidemiological data) or private actors (Facebook data, mobile phone data). They have been used to quickly compare potential strategies (lockdown at different scales, quarantines), and to suggest optimal timing or combination of multiple strategies. They have also been applied to towns in other countries, such as Nice in France. 31 The models offer a precise representation of the population and of contamination in closed spaces (shops, schools), although they neglect the role of transportation. They are very complex models aimed at guiding policymakers, rather than informing the general public.
Covasim 32 is an agent-based model of the epidemic that can be tailored to various local contexts (e.g., age distribution, daily contacts, epidemic progression in number of reported cases and deaths) and has actually been used in a number of countries. It allows to test several types of interventions: physical (e.g., lockdown), diagnostic (e.g., screening or contact tracing), or pharmaceutical (e.g., vaccination). However, it is targeted at researchers and policy makers rather than the general public, and as such is much more complex than our intended simulator. Moreover, testing strategies are expressed in terms of probabilities of testing people with or without symptoms, in/out of quarantine, or over a certain age; it does not include other interesting strategies such as random sampling or prioritizing essential workers.
4.5. Simulations of testing
Various models have specifically studied different screening strategies. For instance, Paltiel et al. 33 modeled several scenarios regarding the measures needed for a safe re-opening of US colleges. They modeled 5000 students, of whom 10 were infected at the start of the semester, and tested several epidemic scenarios (with reproductive number values between 1.5 and 3.5, a 0.05% fatality rate, and a 30% probability of showing symptoms when infected). They varied the following parameters of screening: frequency (every 1, 2, 3, or 7 days), sensitivity of tests (between 70% and 99%), specificity of tests (98% to 99.7%), and cost (US$10 to US$50 per test). They conclude that it is best to screen frequently (every 2 days) in addition to strict observance of sanitary measures to keep the reproduction number under 2.5. To limit costs, they also show that even a rapid, less expensive but poorly sensitive test (around 70%) is sufficient to control the number of infected students, who are isolated in a dedicated dormitory (within an 8 h delay). Of course this strategy is not applicable at the scale of a country (not enough medical staff to test the entire population every 2 days). The population of a college campus is also not representative of the general population, and in particular is younger so less exposed to serious forms.
Atkeson et al. 34 focus on the economic benefits of testing. They provide an SIR model of the US population with five age groups, working in various economic sectors. Their study shows that the economic benefits of rapid screening programs far exceed their costs, with a ratio between 4 and 15 (excluding the monetized value of lives saved) depending on the parameters of the screening. However, an interesting aspect of their study is that they consider a variable adherence to quarantine measures, depending on the probability to be a false positive: They conclude that tests used must be highly specific, or combined with a confirmatory test, in order to both reduce the cost of having healthy workers in quarantine, and decrease the number of people who break quarantine because they (wrongly) believe they are false positive.
To conclude, models that include testing as an intervention generally focus on controlling the epidemics: testing is part of the testing, tracing, and isolating strategy recommended by WHO. On the contrary, we want to compare testing strategies with respect to two different objectives: not only controlling the epidemics by appropriately isolating infected individuals, but also precisely estimating the current state of the epidemics (number of cases), which is useful to evaluate the impact of current measures and the necessity to adapt them.
4.6. Simulations of vaccination
Finally, other models focus on the impact of a vaccination campaign. This is relevant as vaccination poses a similar problem of prioritization for the allocation of a limited number of doses, but also an additional problem of compliance, or trust: some people might not want to get vaccinated, for various reasons. 35
For instance, Li and Giabbanelli 36 modeled a nation-wide vaccination campaign in the United States. They varied parameters such as vaccine efficacy or population compliance, and tested six scenarios combining a vaccination campaign with other interventions (distancing, and so on). Their results show that the vaccine significantly reduces infections, even with very low population compliance. However, they also show interesting counter-intuitive results: when compliance is very high, and since the older population is vaccinated first, the delay is longer for younger and more connected individuals to access the vaccine; as a result, the virus spreads more than if the compliance was lower. This also proves that the vaccine alone is not sufficient, and should be combined with other interventions to reduce the spread of the epidemics.
Other studies are concerned with prioritizing the vaccines. Tatapudi et al. 37 simulate different prioritization strategies with a limited supply of vaccines, in a US urban region of 2.8 million residents. They show a limited impact of vaccination on reducing viral spread, mainly due to exponential contaminations before the start of vaccination, meaning that lots of adults were already immunized. Consequently, they suggest that vaccines should be distributed as fast as possible among all eligible adults after vaccinating the most vulnerable, to improve the speed of the vaccination campaign, rather than strictly respecting a priority schedule. The study by Yang et al. 38 compares age-related vaccination strategies in three countries; the authors find that vaccinating younger people first allows to reduce the number of infections, while vaccinating elderly people first reduces the number of deaths.
The results of both these studies are consistent with the findings of Li and Giabbanelli. 36 Besides, these studies also show the interest of simulation to reveal unexpected and unintended consequences of potential sanitary policies, that cannot be tested in real life.
4.7. Summary and goal
Not many models specifically focus on comparing various screening strategies to both evaluate and control an epidemic. This can be explained by the now wide availability of testing kits in developed countries, that allow to massively test the entire population. Nevertheless, such work is still important to explore screening strategies in countries where tests are not yet widely available, or to reduce the cost of screening, or for potential future epidemics. Such a model can also be extended to comparing the allocation of other limited resources, such as the vaccine doses.
In this paper, we present a model for comparing strategies of priority for the allocation of testing kits and of vaccine doses. Our model does not aim at predicting the exact evolution of the epidemics for deciders, but rather at explaining the mechanisms to the general public. It does so by letting users take on the role of public health deciders to select the parameters of a screening strategy or vaccination campaign, and observe the impact on the simulated population. The originality of our work is to target the general public and focus on explaining a complex phenomenon, unlike most models that are targeted at governments to help them make decisions.
5. Our model of screening strategies
This section describes our simple educational agent-based model of screening strategies.
5.1. Epidemiological model
Individuals in our population can be in one of five distinct states regarding the virus, as shown in Figure 1 below:
Susceptible: they have never been infected and are, therefore, not immune either;
In incubation: they have been infected but are not yet sick (it lasts 6 days on average);
Asymptomatic: they are sick but display no symptom. Only a test will reveal them (30% of patients below 65 years old, for an average of 21 days);
Symptomatic: they are sick and display symptoms (70% of patients below 65 years old, and 100% of older patients, for an average of 21 days);
Recovered: they are immune and cannot get infected again (this was a hypothesis of our model, at a time when this was unknown; 39 we now know that reinfection after recovery or vaccine has a lower risk but is still possible. 40

Evolution of epidemiological status of agents.
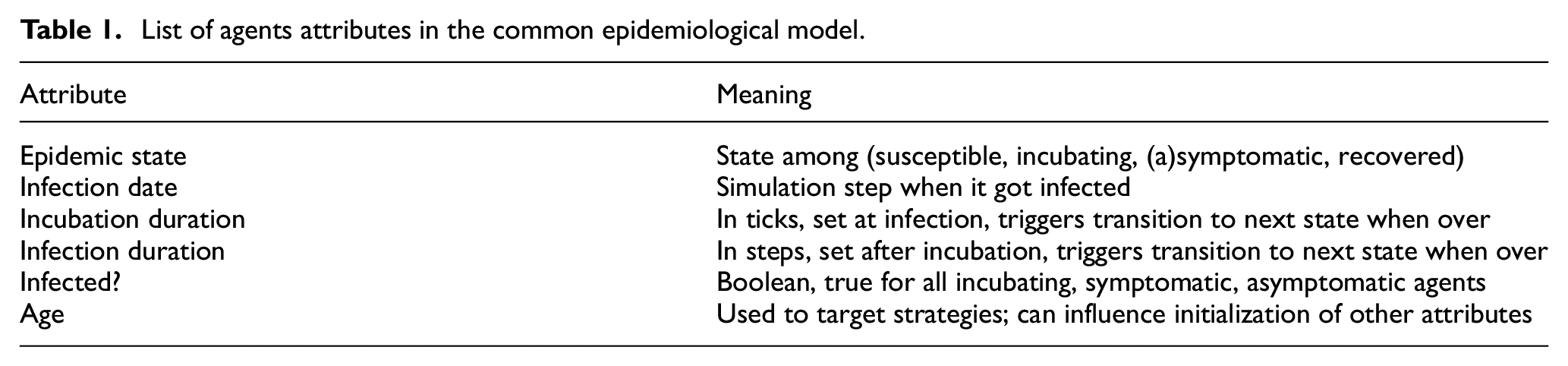
Table 1 summarizes the attributes of agents related to this epidemiological model. These attributes are common between our screening and our vaccination model.
List of agents attributes in the common epidemiological model.
5.2. Characteristics of the population
We have modeled a population of 2000 individuals, in order to keep the simulation fast enough and also allow clear visualization of the propagation. The environment is resized based on the population size, so that the density is around 10 agents per patch. Individuals are distributed in several age categories. This influences their sensitivity to the virus (older people have more risk to be symptomatic) as well as their mobility. For instance, 50% of people aged 20 to 65 have work outside their home (“essential” workers), whereas the rest stay at home (remote work, furloughed workers, family carers, and so on). In this screening model, people aged less than 20 and over 65 are considered homebound (by, respectively, remote schooling and retirement), as was the case at the time. The working population can work either from home or in presence. It is also considered that to reduce the spread of the virus, people who tested positive are put into quarantine and are completely isolated so they cannot transmit the virus. Table 2 summarizes additional agents attributes specific to this screening model.
List of additional agents attributes specific to screening model.

5.2.1. Movement and contacts
At each step of the simulation (representing a day), individuals (except those in quarantine or working from home) move around in the simulation world, with a reduced speed if they are symptomatic. The move is mostly random, but they try to avoid symptomatic agents. When moving, individuals can come into contact with one another. Infected people (in incubation, asymptomatic and symptomatic) are all contagious and can, therefore, transmit the virus to susceptible people they are in contact with. Individuals working from home do not move but they can be in contact with people passing by their home (deliveries, postal services, and so on). However, they have less contacts on average than people who have to work outside of home. Quarantined individuals have no contacts.
Of course this model is a simplification of reality, but it does reproduce the dynamics of virus propagation realistically enough. Indeed our focus is not on individual movements but on screening strategies and how well they can estimate and control this propagation.
5.3. Testing strategies
In our model, we simulate tests with both a sensitivity and specificity of 90%. It would be interesting to vary these two parameters in future work, to study their impact on the evaluation of the epidemic curve. Our goal is to find out how we can best use the tests available each day to reach the two main objectives of a massive testing campaign: to monitor the epidemic (optimize fit between estimated and “real” curve) and to control it (minimize the epidemic peak). The screening campaign has the following attributes:
The number of tests available each day. The testing strategy of the French government plans for 5 it is between 500 and 700 thousands tests per week (for a country of 70 million people), so equivalent to 2--3 tests per day in our 2000 agents simulated population.
The triggering time for testing, defined in terms of a threshold X for the proportion of symptomatic people: when more than X% of the population is symptomatic, the testing campaign starts.
The target population being tested, among: random sampling; symptomatic people; elderly/at-risk people; or people working outside of home.
5.4. Interactive simulator
Our simulator is implemented in Netlogo and playable online (Covprehension question 17: https://covprehension.org/en/2020/05/12/q17.html or a slightly updated version at: https://nausikaa.net/index.php/simulating-epidemics/). Figure 2 illustrates its online interface. The user plays the role of a public health decider with several goals:
To minimize the total number of tests used;
To minimize the spread of the epidemic, i.e., the total number of people infected;
To minimize the number of people quarantined for no reason, i.e., the number of false positive tests;
To estimate as closely as possible the “true” curve in order to precisely monitor the epidemic over time;
To reach these goals, the user can modify the parameters of the testing campaign as defined above;
The number of tests available each day (i.e., time necessary to test the entire target population);
The starting date of the testing campaign: immediately from the start of the epidemic, or later on;
The target population: in-person workers, elderly, random, symptomatic.
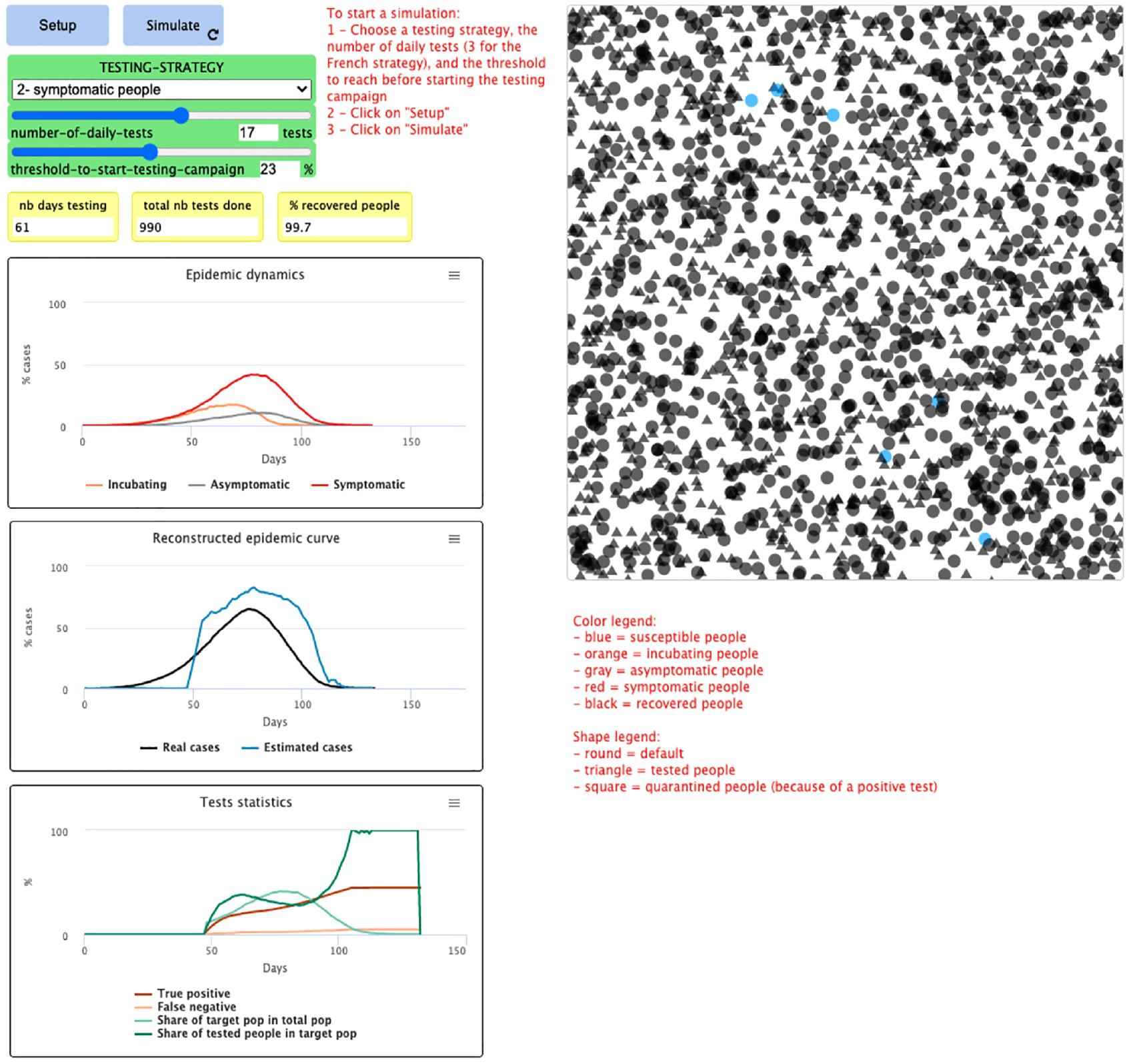
Interface of the online simulator.
These goals are obviously not always compatible, and actions can have opposite effects on different goals, improving one at the cost of failing another. For instance, to best know the status of the epidemics, one could test every citizen but would fail to minimize the number of tests used; or one could randomly test people to get a representative picture of the situation, but would then “waste” many (negative) tests that fail to spot and isolate infected people. Managing the situation thus requires finding some compromise. We expect that playing with the simulator will help people understand the stakes behind the sanitary measures, and make them less subject to blindly believing disinformation. This will require future experiments of our simulator with users to test its actual impact.
In the following section, we describe the experiments that we ran by manually varying the different parameters (target population, number of tests per day, and starting date), and we compare how well they estimate the “real” curve, which the simulation allows to know.
6. Screening experiments
6.1. Inference of the epidemic curve
There are several ways to compute the estimated curve from the results of screening tests. The number of confirmed cases communicated every day by the authorities of different countries is a combination of test results and expertise of health professionals. But like any statistical estimation, these figures have error margins and potential biases. We believe that the general public should be aware that the “true” number of infected people is unknown and can only be approximated. It is one goal of our simulator to allow them to observe these variations and errors.
Indeed in our simulator we know the status of all of the agents, so we do know this “true” number of infected agents over time, which is impossible in reality. We can therefore compare the curve estimated using tests, with the “true” curve, in order to verify the correctness of the estimations obtained with different strategies. This is a great advantage of agent-based simulation, which will allow us to evaluate how well different computation methods do fit this real curve. We have actually tested two simplified estimation methods, described below: proportionality and predictive values.
6.1.1. Proportionality rule
First, we could intuitively use a simple cross multiplication: the number of positive tests among the total number of tests provides an estimation of the proportion of cases in the general population, by a proportionality rule. For instance, if we test 700,000 people and that 1000 of them are infected, this is a proportion of 0.14%, so we deduce that out of the 70 million residents of France, 100,000 are infected. But this simple proportionality rule does not work well in epidemiology, especially when the number of people tested is low, or when the prevalence of the epidemic (i.e., the total number of cases at a given time) is too low, as is the case at the beginning and at the end of an epidemic, or when tests are not entirely reliable.
6.1.2. Predictive values
Another method for estimating the total number of infected people is to compute the predictive values of the test, which depend on three elements: the prevalence of the epidemic, the rate of false positives (which is equal to
The positive predictive value (PPV) is also called precision. Its complement is the false discovery rate, i.e., the rate of false positives among the total of positive tests as follows:
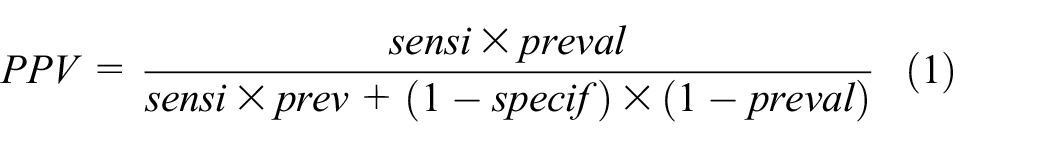
The negative predictive value (rate of true negatives in total negative tests) is the complement of the false omission rate (rate of false negatives upon total negative tests) as follows:
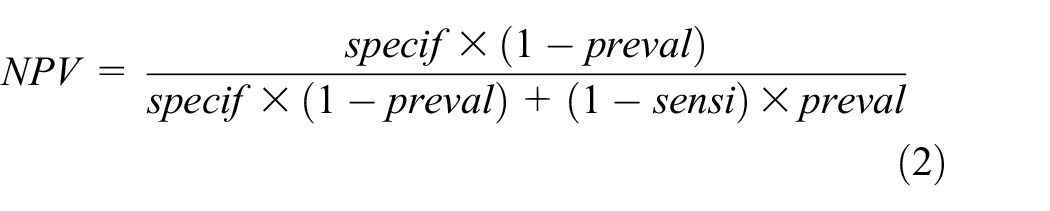
6.1.3. Experimental methodology
The following paragraphs describe our experiments on a simulated population of 2000 agents, exploring different scenarios by varying the different parameters of the screening campaign. Each scenario was run once, since the focus here is not on the exact aggregated epidemiological indicators, but on illustrating the difference between the real curve and its different estimations. The exact real curve (height and date of the peak) can vary slightly between two scenarios, due to the inherent randomness of the model (who meets who at each step), but the estimation error will always be similar. These scenarios can be reproduced with the online simulator.
6.2. Comparison of estimated cases for the different samples of population
In this scenario, we choose a daily number of tests equivalent to that of the French government (i.e., three tests for 2000 individuals) and start testing as soon as the first case appears (which has not been the case in France).
We compare the curves representing the number of cases estimated by the proportionality rule (in red), the number of cases estimated by computing the predictive values (in blue), and the “true” number of cases (in black), for each sampling strategy (testing priority among: random, elderly/at-risk, workers, symptomatic). Figure 3 summarizes the results.
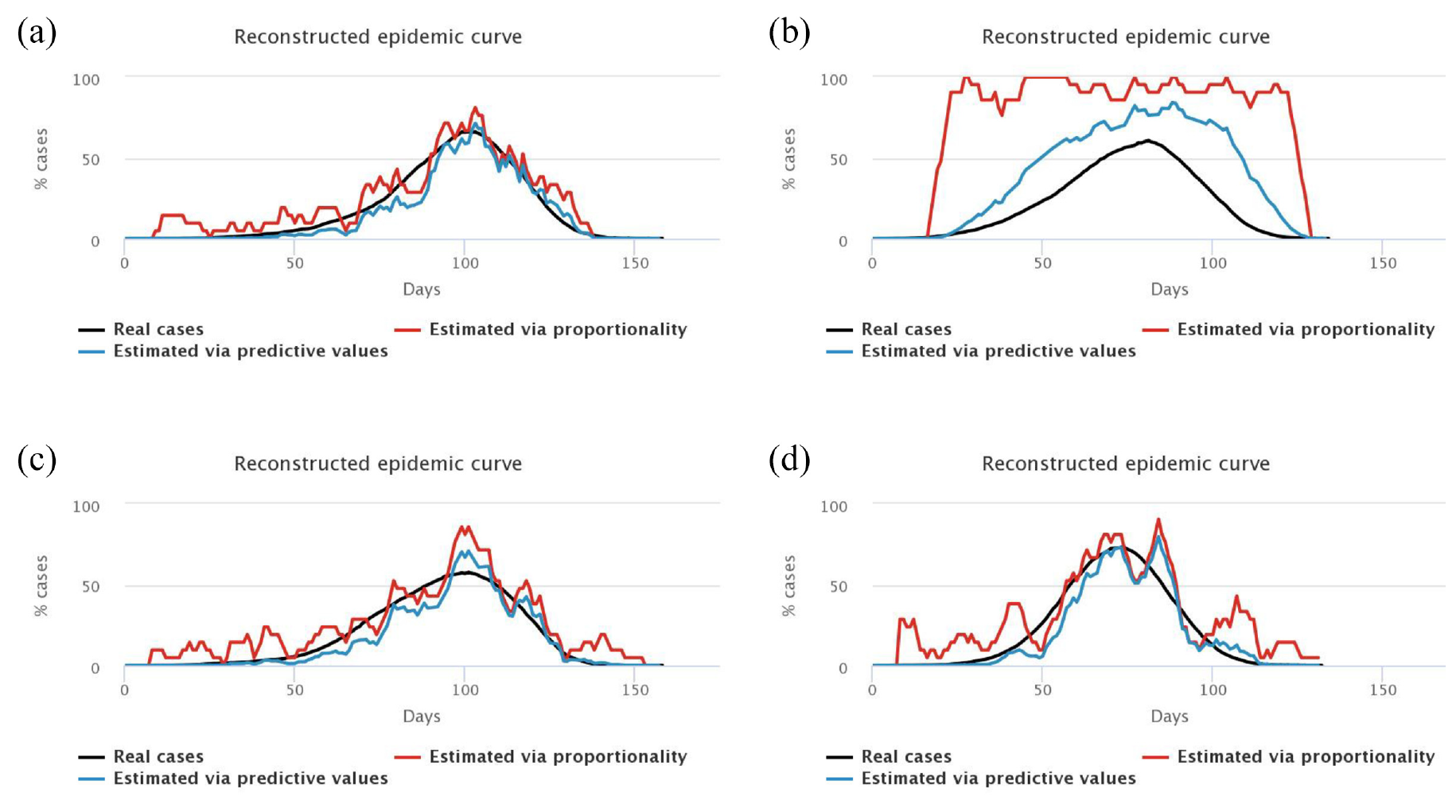
Experiment 1: 3 tests/2000, immediate start, different samples.
First, we note that the blue and red curves (estimated cases) vary a lot more than the black curves (“true” cases). Indeed, they depend on the number of positive tests each day, which varies greatly depending on who is tested. In general, we choose to “smooth” this estimation by computing the mean result of tests over several days (here, a mean over 7 days), but there is always a larger variability depending on who is tested each week. For example, a lot of negative tests may result in an estimation of a decreasing epidemic, which is not necessarily true (maybe we just tested non-infected people, which does not mean that no one is sick anymore).
We also note that the blue curves (with predictive values) are better estimators than the red curves (proportionality rule), especially at the beginning and at the end of the epidemic when the prevalence of the virus is low, and especially for symptomatic people, who are less representative of the total population.
Second, we find that the worst estimation happens when we only test symptomatic people (top right figure): since we only test symptomatic people, who therefore have a high probability of being infected by COVID-19, we obtain a high positivity rate of the tests, so we overestimate the “true” number of cases in the general population. Given that the tests we model are diagnostic ones, it is really not sound to extrapolate the number of cases in the general population from the tests performed on symptomatic people. The model confirms this. Such tests allow to control the epidemic by confirming and isolating infected people, but they do not allow to monitor its spread in the population.
6.3. Comparison of estimated cases with respect to the number of daily available tests
In a second experiment, we set the strategy to random sampling, and the beginning of the testing campaign as soon as the first case appears, and vary the number of daily tests from three tests per 2000 people (left), to six tests per 2000 people (middle), and finally nine tests per 2000 people (right). Figure 4 illustrates the resulting estimations of the epidemic curve, only with the predictive values method since it is better than the proportionality method.
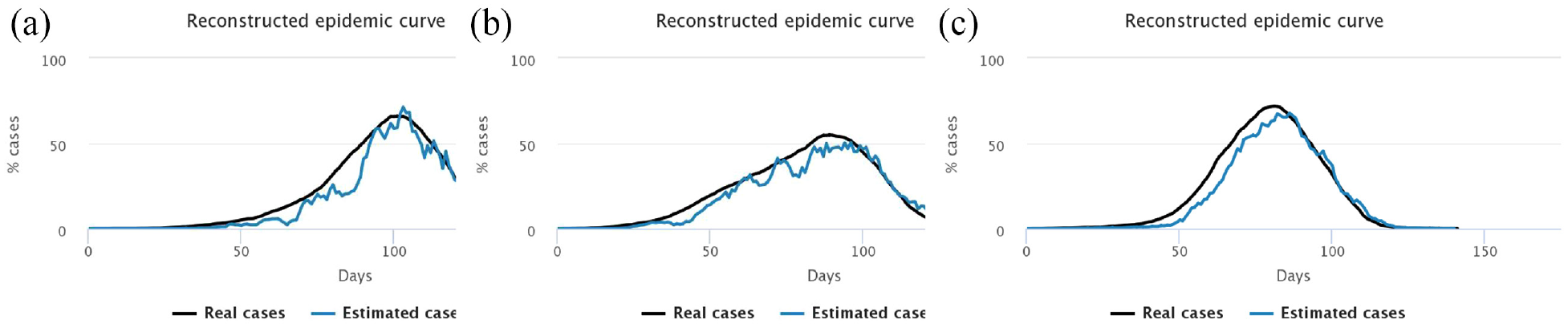
Experiment 2: immediate start, random sample, varying number of daily tests.
We notice that the higher the number of tests, the better the estimation of the number of cases in the general population. After an initial overestimation, when there are very few cases in the population and very little tests performed, the reconstructed curve follows rather precisely the actual epidemic curve, in particular around the peaking time, the key moment of the epidemic.
6.4. Comparison of estimated cases with respect to activation date of testing campaign
In this final experiment, we use the random sample again, and vary the starting date of the campaign as well as its intensity, in terms of the number of daily tests performed. The lower intensity, three tests/2000 people, corresponds to the initial strategy in France, when the number of available kits was still quite low. The objective of this experiment is to assess how well we can estimate the “real” epidemic curve, by either starting screening very early, or performing it at a very high intensity, or both. Figure 5 shows the results of the four different combinations of parameters.
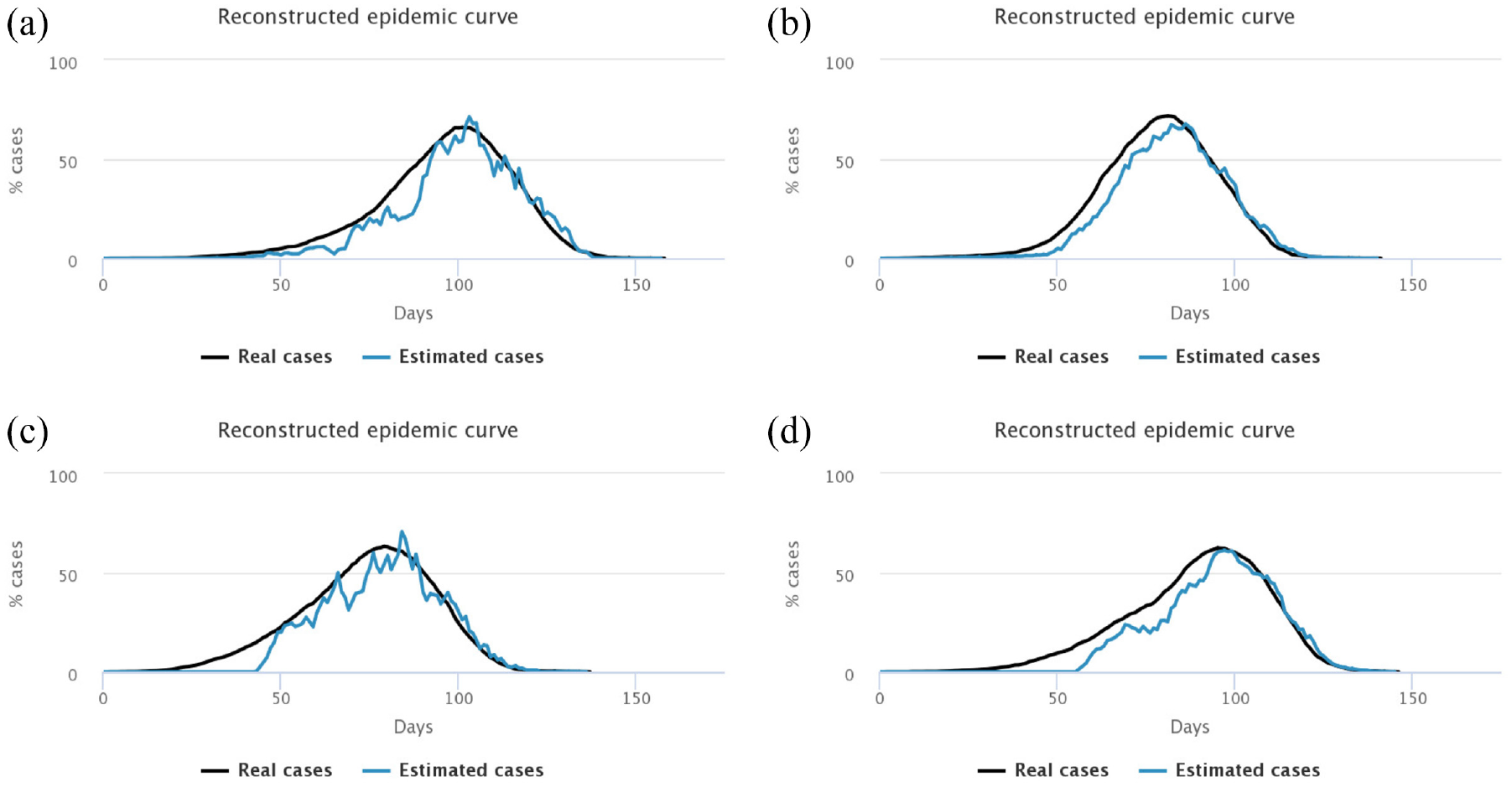
Experiment 3: random sample, varying starting date, and intensity of the testing campaign.
We notice that with a low screening intensity of three tests for 2000 people (first column), the reconstructed curve cannot capture the epidemic peak when screening started late (after 15% of infections, upper left).
Similarly, if the screening campaign starts late (15% people symptomatic, bottom figures), even increasing the number of tests to nine per 2000 people (bottom right), we notice that the peak identification is very uncertain, and cases are strongly overestimated after the peak. When screening starts immediately and intensively, this overestimation only happens when the number of cases is very low (top right). The conclusion is that if we wait too late to activate the testing campaign, the knowledge of the epidemic is strongly reduced, even if we ramp up the number of daily tests.
7. Our model of vaccination
In this section, we describe the updated vaccination model.
7.1. Modifications to the population model
The initial model was adapted to consider the new situation when the vaccine became available. In particular, we lifted the lockdown rules that are not enforced anymore: concretely, individuals are not considered to work or study from home anymore, but instead their mobility is now affected by other factors. Namely, all agents have two more attributes, randomly initialized based on their age:
Their risk factor, representing their probability to develop a serious form when contaminated. Since age is a known comorbidity for COVID-19, the risk factor attribute is set as proportional with age: most younger people have less risks to develop a serious form, even though some of them can have a high risk; and most older people have more risk to develop serious forms.
Their number of daily contacts, affecting the number of other agents that can contaminate them at each step. This number is initialized with a random individual part, plus a random part reversely proportional to age (as contacts usually decrease with age), and minus another random part proportional to the level of risk (as we assume people who know they are at risk will voluntarily limit their contacts from fear of being ill).
We also added new states to the epidemic model, set as boolean variables of the agents:
Serious form: when an agent is symptomatic it has a probability equal to its risk factor (or reduced if vaccinated) to develop a serious form. Serious forms last longer than other symptomatic forms.
Vaccinated: vaccinated agents have a lower probability (set by the vaccine efficiency parameter) to get infected, to contaminate others, and to develop a serious form when ill.
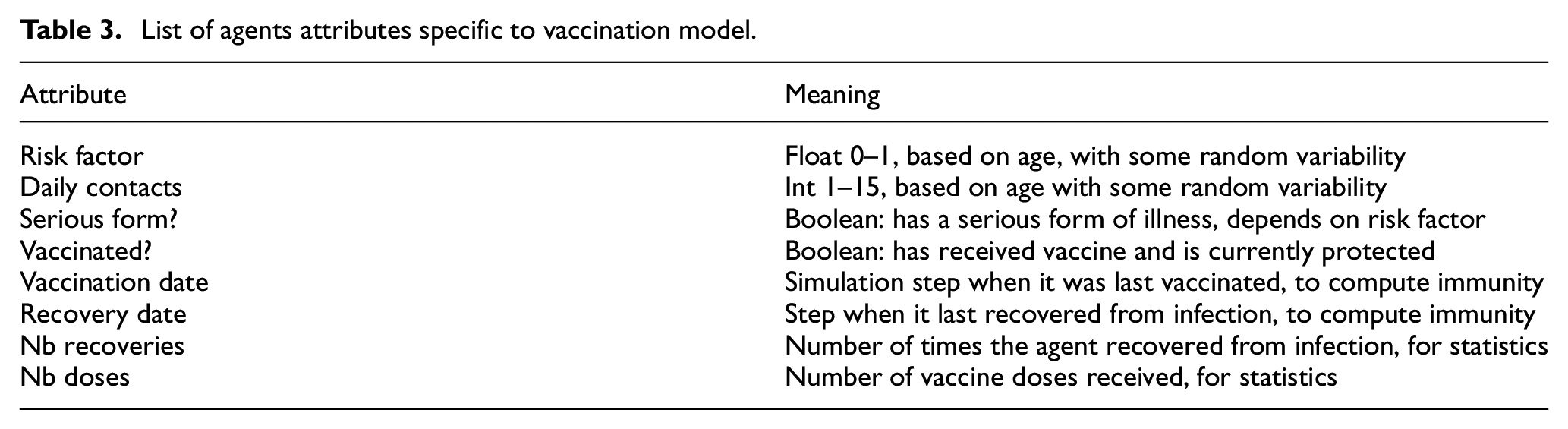
Finally, unlike the previous model and to account for new knowledge, we now consider that the immunity conferred by either vaccination or recovery is not permanent. We added two parameters for these two durations of immunity. Agents then return to the susceptible unvaccinated state, where they can be infected again, and considered for vaccination again. However for statistical purposes, we remember the number of recoveries and number of vaccine doses for each agent. Table 3 summarizes these new attributes (replacing those from Table 2).
List of agents attributes specific to vaccination model.
7.2. Modeling vaccination
The vaccination campaign has the following parameters:
Start of the vaccination campaign, in percentage of infected people in the population. Setting this to 0 allows to start vaccination immediately. In future work, we will also consider preventive vaccination campaigns and the resulting herd immunity (CovPrehension already offers a visualization of various levels of herd immunity: https://covprehension.org/en/2020/04/01/q8.html).
Speed of the vaccination campaign, in number of daily doses available. The maximal value that can be selected is 30 doses per day for the 2000 agents population, which is equivalent to more than a million doses per day in a 70 million people country. As a comparison, in France (Source VaccinTracker: https://covidtracker.fr/vaccintracker/), the vaccination peak was reached in July 2021 (second dose) and again in December 2021—January 2022 (first booster) with about 700.000 doses per day, which would be closer to 20 vaccines per step in our simulation.
Target population that receives vaccine in priority, (“high risk,”“more contacts,” or “random”).
Vaccine efficiency was set to 90%, meaning that vaccinated agents have a probability reduced by 90%: to be infected when in contact with a sick person, to develop a serious form when infected and symptomatic, and to transmit the virus to their contacts when infected. To simplify, we consider that the vaccine efficiency is the same on all three values.
Duration of immunity conferred by the vaccine, after which the agent’s status is reset to unvaccinated.
If the proportion of sick agents in the population is above the selected threshold, the vaccination campaign can start. The target population for vaccination at each step is computed as follows. First, only agents that are not infected, and not currently immune (whether from vaccination or recovery) are considered as candidates. Then, the number of daily doses (parameter) provides the maximal number of agents that can be vaccinated at that step. Finally, this number of agents are selected among the candidates, in decreasing order of the value of the attribute corresponding to the selected strategy (daily contacts or risk factor), or randomly if so selected. This ensures that when the agents with the highest priority are already vaccinated, the following agents in order of priority can also access vaccination.
7.3. Vaccination strategies
We defined three vaccination strategies in our model:
Randomly targeting non-vaccinated, non-sick agents.
Higher risk first: targeting agents with the highest level of risk first, and then in decreasing order of risk. This is the most used strategy where elderly people or people with comorbidities are vaccinated first.
Higher contacts first: targeting agents with the most contacts first, and then in decreasing order of daily contacts. This is partly applied when vaccinating medical staff first since they are exposed to many sick or vulnerable people. We discussed above several simulations showing the efficiency of this strategy.
7.4. Interactive simulator
We implemented this new model in Netlogo (The model code and simulator are available online at: https://nausikaa.net/index.php/simulating-epidemics/). The interface (Figure 6) is similar to the previous simulator, but we have replaced the testing parameters with vaccination parameters. Our goal was to keep the interface simple enough, and not lose the user with too many different parameters. The fewer parameters there are, the easier it is to measure their individual impact. The user can select when to start the vaccination campaign, how many vaccines are available per day, the duration of immunity, and the target population. A number of graphs and monitors let them observe the results of their choices. We have also added two options:
One button allows to randomly introduce a sick individual, to simulate people arriving from the outside, who can possibly bring back the virus when the epidemic is locally controlled.
One switch allows to start/stop a lockdown: all agents stop moving until it is lifted. This provides an emergency reset when the situation gets out of control.
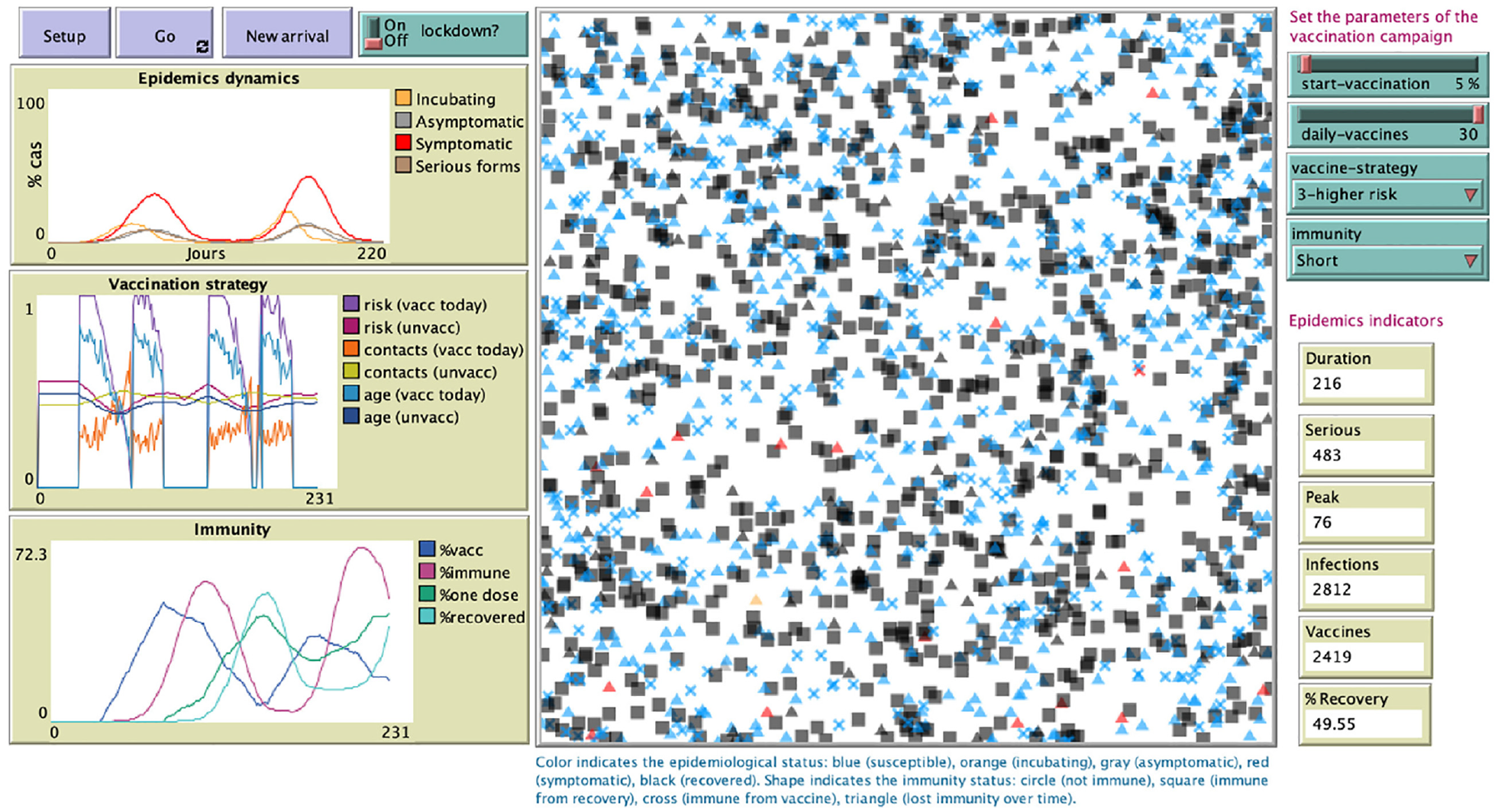
Screenshot of the online vaccination simulator.
8. Vaccination experiments
We conducted a number of experiments: first to test our model, and then to compare various parameters of the vaccination strategy.
8.1. Verifying the impact of attributes
8.1.1. Daily contacts
We first tracked infections by number of daily contacts. The “low contacts” category are agents with less than 4 daily contacts, while “high contacts” are agents with over 10 daily contacts. We tracked the percentage of agents in each category who got infected. Figure 7 shows that people with more contacts get infected first, and earlier than people with less contacts; but after a while, when the incidence rate is higher, even people with few contacts get infected as the virus has propagated to the whole population of agents. When vaccination is on, the incidence rate is lower, so the difference is even more visible.
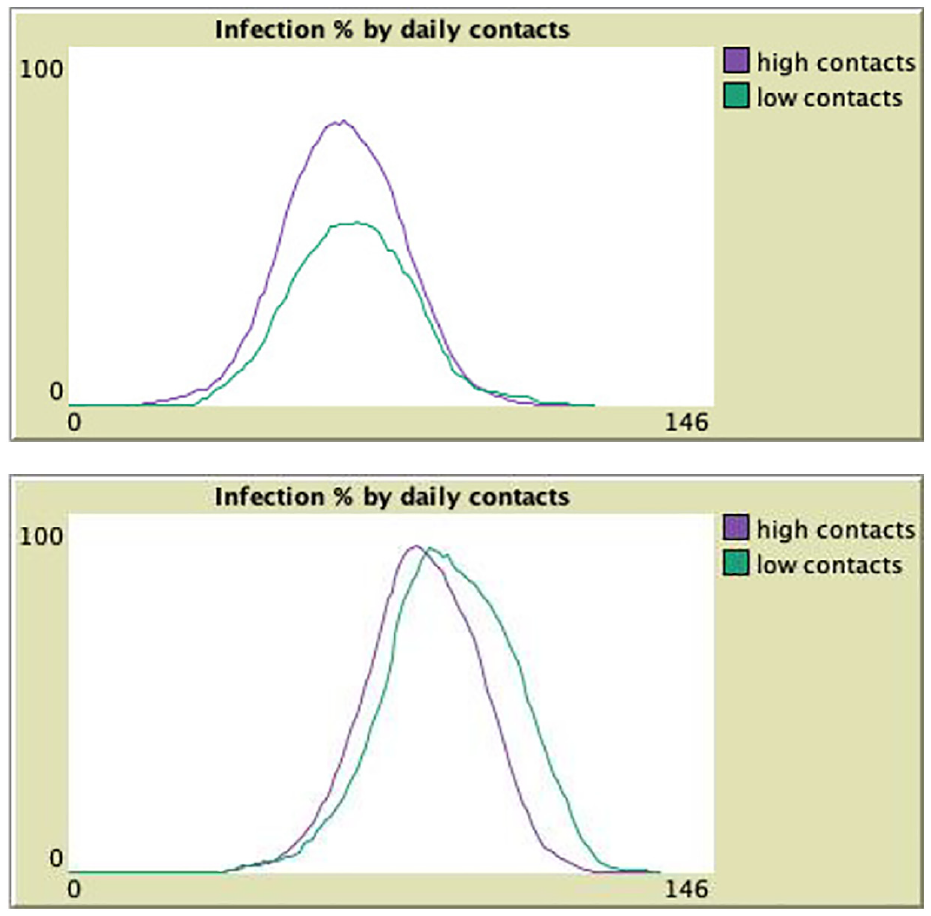
Infections by number of daily contacts: low incidence (top) or high incidence (bottom).
8.1.2. Risk factor
We then tracked infections and serious forms by individual risk factor. We considered as “high risk” agents with a risk over 0.75, and as “low risk” agents with a risk under 0.25. We then tracked the percentage of agents in each category who got infected, and who developed a serious form of the illness. Figure 8 reports the results. We can see that there are slightly more agents infected among the “high risk” category, but the main difference is in the proportion of serious forms: almost none among “low risk” agents, but many among “high risk” agents. This also reflects in the width of the peak: since serious forms last longer than other infections, the peak is larger (lasts more steps) among “high risk” than “low risk” agents.
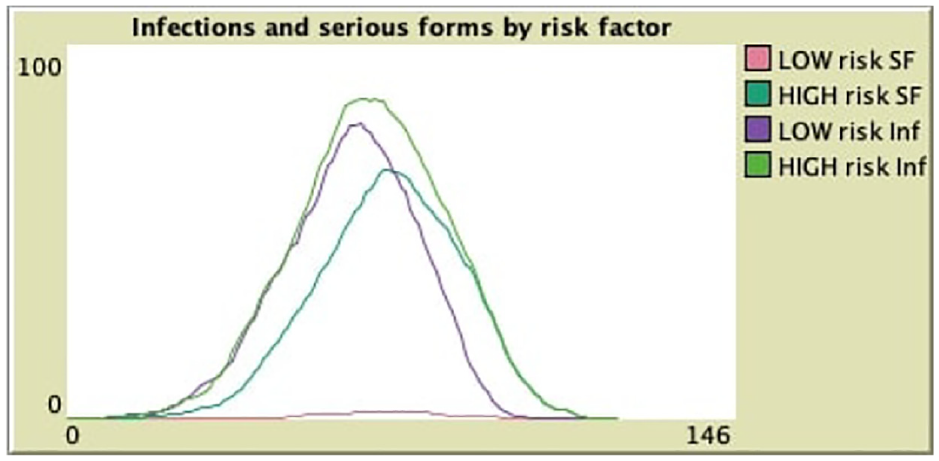
Infections and serious forms per risk category.
8.2. Verifying the vaccinations targets
Figure 9 illustrates how the mean values of relevant attributes (daily contacts, risk factor, and age) evolve over the vaccination campaign. We averaged those three values in the group of agents that were the most recently vaccinated (at the previous step) as well as among the agents not yet vaccinated.
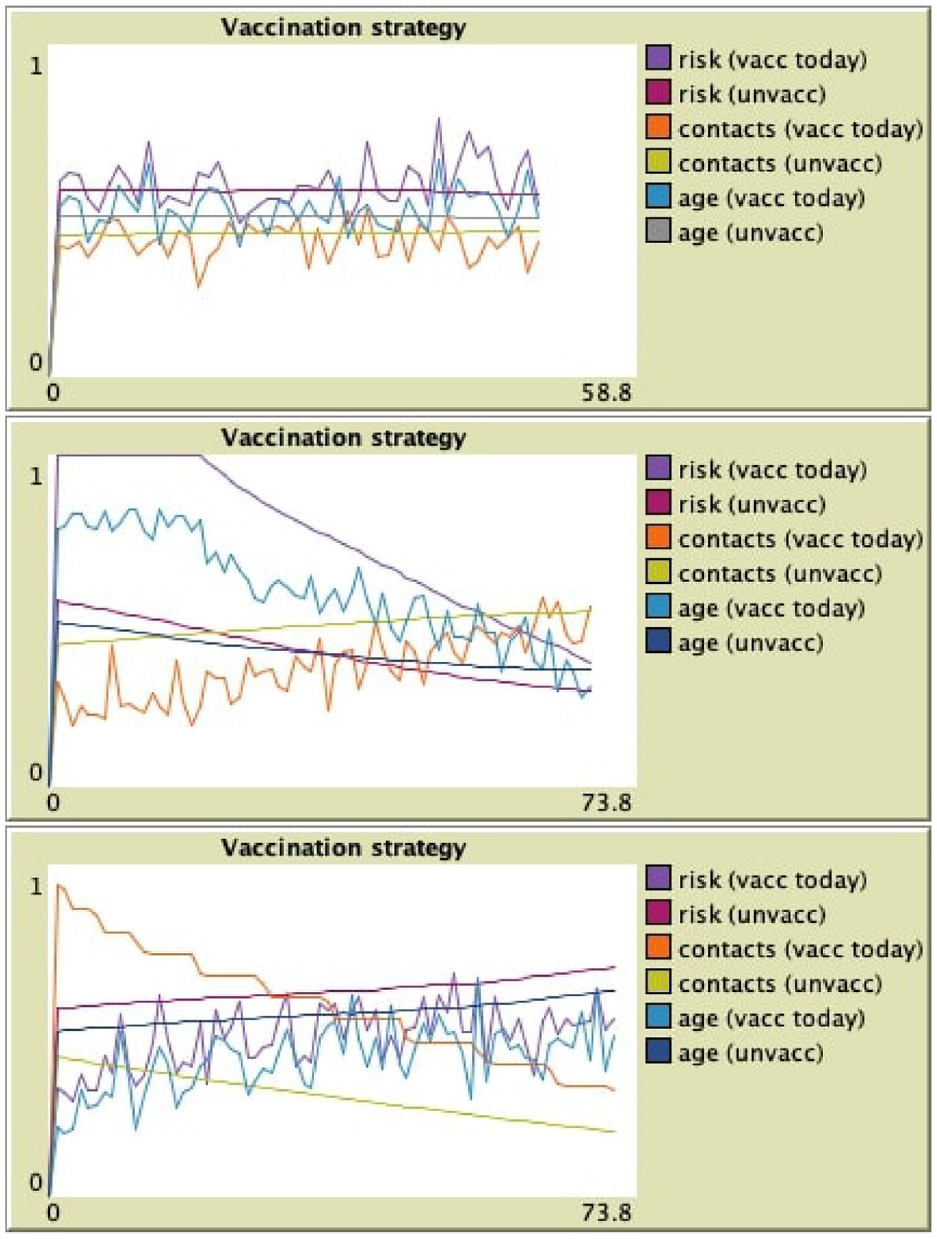
Vaccination targeting: random (top), risk first (middle), and contacts first (bottom).
8.2.1. Risk first
One can see that with risk-first strategy (middle), the average risk factor of just vaccinated agents is stable at 1 (the maximum value) for an amount of time, requested to vaccinate all high-risk agents. It then decreases as agents selected to receive vaccination have a lower and lower risk. In the mean time, the level of risk of agents not vaccinated yet (and therefore still exposed to the virus) decreases. The average age also goes down as it is linked with a higher risk.
8.2.2. Contacts first
When selecting agents with more contacts to be vaccinated first (bottom), one can observe that the average number of daily contacts decreases among agents just vaccinated and not yet vaccinated. This means that the agents having more contacts, and more probability to get infected and/or to infect others, are already protected by the vaccine. We can observe that in that case the average age of vaccinated agents increases with time: since a younger age is linked to more contacts, younger people are vaccinated first.
8.2.3. Randomly
The baseline is provided when vaccinating agents in random order (top). In that case, we can see that the average values of attributes is oscillating around the mean value in the global population.
8.3. Comparing durations of immunity
In the following experiment, we set the duration of immunity provided by the vaccine, or by recovering from the illness, to 40 steps. We started without vaccination, and observed four successive waves of the epidemics. We then started vaccinating with the risk-first strategy, and observed three subsequent waves, but much lower than the previous ones. We manually stopped the simulation, since the stop condition that no agent is infected anymore cannot be reached with such a short immunity duration. Figure 10 shows the epidemic dynamics with its seven waves, as well as the immunity of the agents. We can observe that the rate of agents currently immune from the vaccine or from recovery goes in waves; the rate of agents having received at least one dose increases but they lose their immunity after a while.
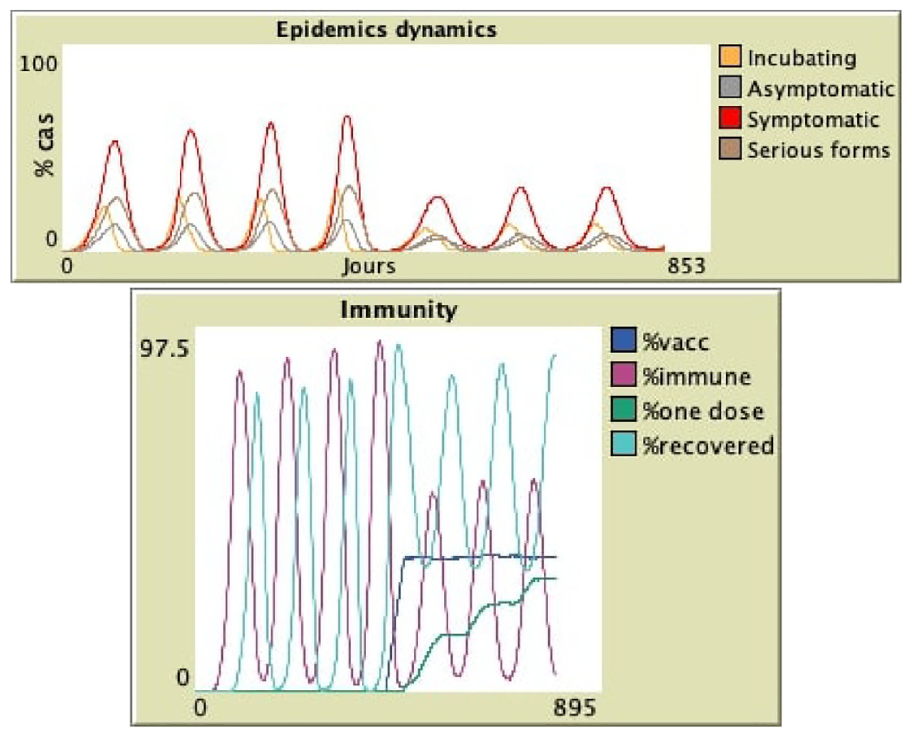
Epidemic dynamics and immunity of agents: seven waves created with a shorter immunity duration (40 steps), vaccinating risk-first after four waves.
This immunity duration of 40 steps is very short, but in a closed environment with no agents arriving from the outside, it is required to observe such waves. Another option to create such waves with a longer immunity duration is to introduce new infected agents in the simulation when the population of agents has become susceptible again. This is what happens in real life, when people start traveling again: even when the epidemic is locally controlled, new individuals can arrive and bring back the virus, which restarts another epidemic wave; this phenomenon has been witnessed over and over again since the end of the first general lockdown. The “visitor” button in the interface lets the user add new infected agents whenever wanted to reproduce such waves. One could also extend the model to automatically randomly introduce such visitors from time to time.
8.4. Exhaustively comparing vaccination strategies
8.4.1. Experimental setting
Contrary to the previous simulations, where we wanted to visualize one particular run of a scenario, we now want to exhaustively compare vaccination strategies. The model has some inherent randomness, in particular in the agents’ movements and contacts, as well as the locations of the first infection and of the vaccinated agents. To smooth out that randomness, we run each configuration 20 times, which is sufficient to stabilize the outputs. We ran experiments varying some parameters (targeting strategy and timing) of the vaccination campaign. In all experiments, we have set the vaccine efficiency to 0.9 and immunity duration to permanent (in order to avoid infinite waves and ensure that simulations stop). The simulation stops when no more agent is infectious. For each configuration, we logged the average final values over 20 runs of five indicators that evaluate the efficiency of the campaign:
Duration of the simulation, i.e., how long it took to control the epidemic;
Serious: number of serious forms, i.e., how many agents got seriously ill;
Peak: epidemic peak as the maximal number of daily new infections;
Infected: total number of agents infected;
Vaccines: total number of vaccines injected.
The results are summarized in the tables below.
8.4.2. Varying the strategy
In this first experiment, we set the vaccination to start at a threshold of 5% infected agents, with 30 daily vaccines. We then varied the strategy among the three possible targets. Table 4 shows the resulting average indicators. We can see that vaccinating high-contacts first leads to more serious forms, since older people with less contacts and more risk factors are not vaccinated early, and are therefore not protected against serious forms. Random vaccination is slightly better on that aspect, while high-risk prioritization is much more efficient with the number of serious forms divided by 2. Starting vaccination that late (already 5% infected) does not allow the contacts-first strategy to be efficient. In the next experiment, we also compare these strategies with different starting timings.
Comparing three strategies in terms of five indicators.

8.4.3. Vaccinating high-risk first
In the next experiment, we set the strategy and varied its timing, i.e., the start and intensity (number of daily doses) of the vaccination campaign. Table 5 shows the results for the “risk first” strategy. We can observe that vaccinating the most vulnerable people very early (before any agent is infected, so a preventive campaign) is very effective against serious forms. With the start at time 0 and 30 daily doses, the number of serious cases is as low as 19.7 in average over 2000 agents. This is also due to the much lower number of infections. This is in favor of injecting a vaccine booster to the highest-risk people before the epidemic season starts.
Risk-first vaccination, impact of early/late start and speed of vaccination on epidemic peak and serious forms.
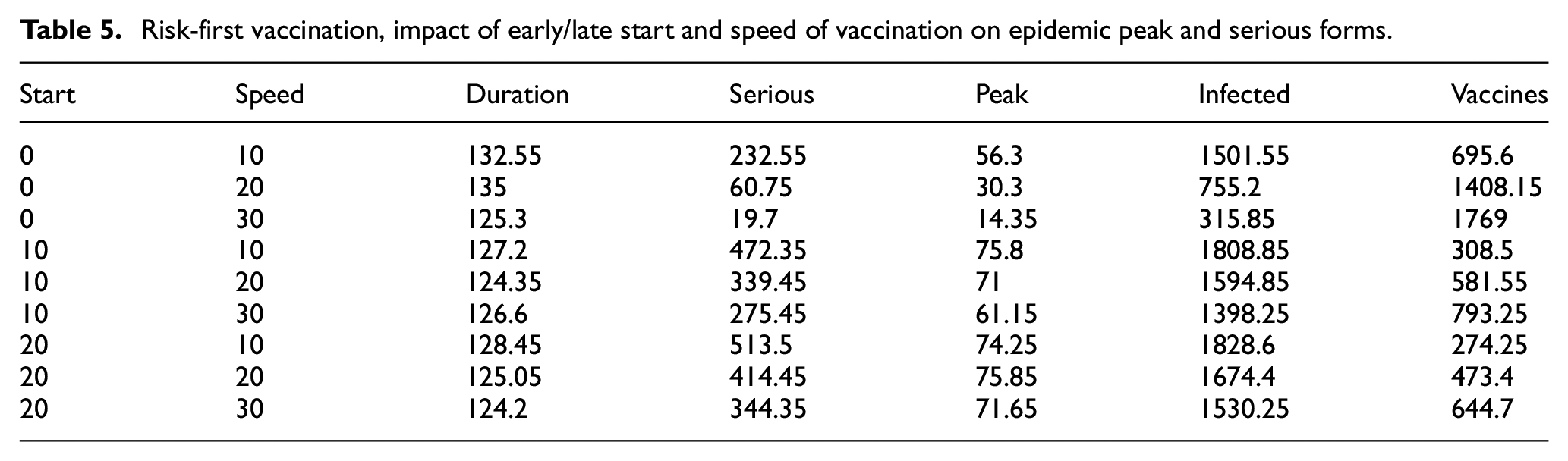
When starting later, the number of serious forms is much higher since many people would have been infected before the vaccination starts. This can be seen through the higher values of the total number of infections, and the subsequently lower number of vaccines injected (since recovered agents are already immune and not considered for vaccination).
8.4.4. Contacts first
The results for the “more contacts first” (Table 6) strategy show that the number of serious forms is much higher with that strategy. It also shows again that when starting vaccination very early and fast, the epidemic can be contained to a very low level (with an epidemic peak of only 8.8 new daily infections). The difference in total number of infections is flagrant when starting immediately and increasing speed: this shows how fast the epidemic can spread, so that going from 10 to 30 daily doses makes an enormous difference. This difference is less obvious when starting too late, since high-contacts agents are already infected, as shown by the much lower number of vaccines. So this strategy can only be efficient if high-contacts people are vaccinated before the epidemic starts, in order to prevent them from propagating the virus.
Contacts-first vaccination, impact of early/late start and speed of vaccination on epidemic peak and serious forms.
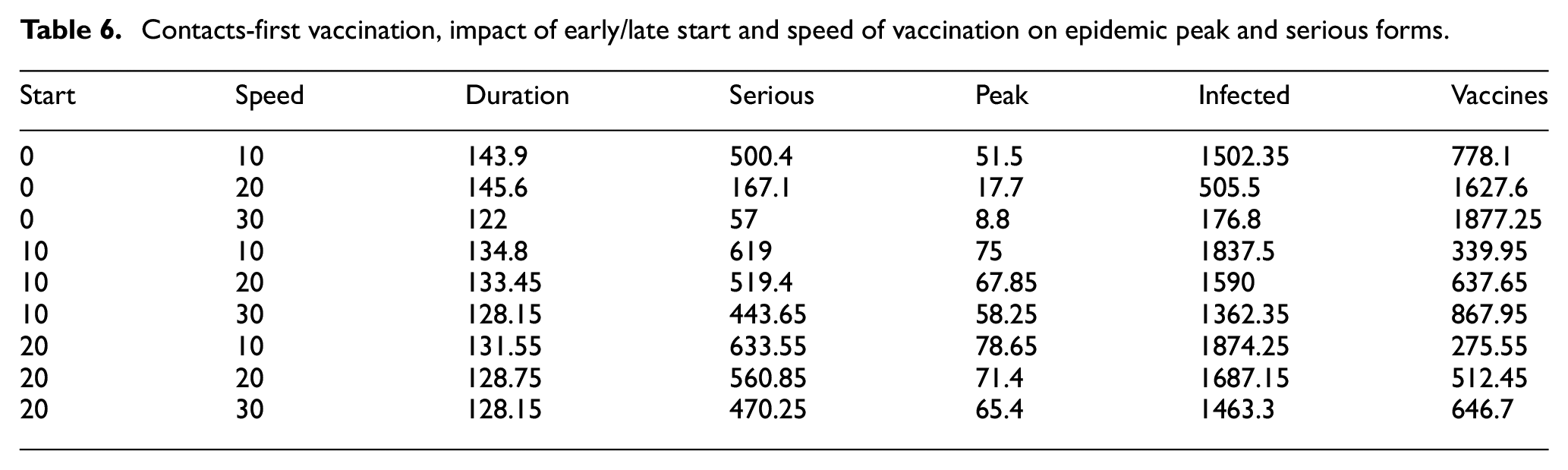
8.5. Limitations and discussion
In this model, we consider individual differences in risk and daily contacts when vaccinating agents. We made a number of simplifications. In particular, even though we take into account the number of daily contacts of each agent, we do not specify who these contacts are. In our model, they are selected among the agents located closer to the agent, whatever their attributes; in reality contacts happen mostly within age groups. Second, we do vaccinate agents in the order of priority set by the strategy, but we did not implement any age limitation (even infants can be vaccinated) or exclusion. In reality, some people cannot receive the vaccine because they are too young or have health problems incompatible with the vaccine; so other people are vaccinated in part to develop a herd immunity that will protect people who cannot be vaccinated. Besides, the number of vaccinations per day is linearly distributed in our model, while in reality vaccine demands happened in waves rather than as a stable flow.
In our simulator, we have set the efficiency of the vaccine to 90%, and assumed it to be the same on all parameters (infection, transmission, risk of serious forms). It is not exactly the case in reality, it does not decrease at the same rate over time, and it also depends on the variants; future experiments could vary that efficiency to observe effects. Another interesting extension is to consider preventive vaccination; if the virus becomes endemic, vaccination can happen before a contamination wave even starts, allowing to build herd immunity in advance. At the moment, our simulator only allows to start vaccination after the first case, but this scenario could be added to explain the role of vaccines in a more general context than just COVID-19.
Another limitation concerns the role of trust: we assumed here that agents eligible to vaccination will receive the vaccine in order of priority. In fact, this is not necessarily true, some people might not want to receive the vaccine because they do not trust it, in particular if they believe it is dangerous or not efficient. In other work, we are interested in how trust evolves and influences the speed of the vaccination campaign. 41 Trust can have a long-term influence on vaccination decisions and public health, as well as more generally on risk perception; 42 it is therefore very important to preserve.
Finally, the literature proves that no sanitary intervention should work in isolation, but should be combined to improve their efficiency. However, in the interest of simplicity of use, we have limited the number of parameters and outputs in each simulator. As a result, we have not tested the combination of several sanitary measures (for instance screening and vaccination). Other simulators of other interventions (lockdown, contact tracing) are available on CovPrehension. Different simulators allow to test measures in isolation and understand their individual impact, which is never possible in real life.
9. Conclusion
9.1. Summary
In this work, we have provided a simple model of the propagation of COVID-19 in a population. This model was implemented in two simulators, one for screening and one for vaccination. Both simulators are available online, in French and English, so that people can play with them; their source code is also available. In the interest of simplicity of use, we have limited the number of parameters and outputs in each simulator, so each one focuses on a different aspect.
In the first simulator, we have integrated different screening strategies to both control and evaluate the epidemic curve. The model is based on figures available for France but is easily adaptable to other countries. It is willingly simplified, in order to provide an interactive simulator to explain to the general public the mechanisms of the epidemics and how the count of infected people is estimated every day. Besides, we have also used our simulator to compare different computation methods to estimate the epidemic curve, and different screening parameters. In other work, 43 we have used an optimization algorithm to prove the required properties of a successful screening campaign, which fit the successful strategy of South Korea at the start of the epidemic.
In the second simulator, we have integrated several vaccination strategies to either limit the total number of cases by targeting people with more contacts, or limit the number of serious forms by targeting people with risk factors. Consistently with other works, we find that vaccinating younger people very early on can provide a better herd immunity to limit the total number of cases. However, we also show that when starting vaccination later or when the immunity duration is shorter, it is important to rather vaccinate older people who have more risks factors, to reduce the number of serious forms.
9.2. Future prospects
We believe that providing the population with scientific facts and explanations is key to improve the acceptability of sanitary measures (e.g., necessity of regular self-tests for children at school, vaccination, and so on) and protect them from fake news. Even though our simulator is already available online, we have not yet surveyed the users to assess its impact. Participatory or interactive simulation has been long known to help learning, by providing a first-person point of view on the modeled phenomena. 44 We have not evaluated the impact of these two specific simulators on users via surveys, but we did so for previous works with positive results, for instance when teaching risk management to students 42 or evaluating risk communication during floods. 12 Future experiments will be set up with users of different profiles to prove our claim that changing role (playing the role of a health decider), actually interacting with parameters to test what-if scenarios, and getting feedback about one’s choices, can provide a welcome feeling of control and a better understanding and acceptance of this difficult situation.
Footnotes
Acknowledgements
We would like to thank to the CovPrehension collective for their insight and help about design and testing of the screening model, as well as publication and translation of the original blog post.
Funding
This research received no specific grant from any funding agency in the public, commercial, or not-for-profit sectors.