
Abstract
This research uses virtual reality (VR) to immerse human subjects in an active school shooting scenario in order to generate ecologically valid models of school shooter movement and behavior. Historically, data recovered from US school shootings has lacked the fidelity needed to model shooter movement; consequently, simulations of school shootings have had to rely on significant and unsupported assumptions about the movements of the shooter and/or victims. We asked human subjects to act as school shooters in a VR simulation. We then recorded their movements, observations, and actions. Our results show that participant shooters are statistically equivalent to historical incidents with respect to aggregate engagement metrics (shot rate, victim rate, and accuracy) across most scenarios. Moreover, empirical models trained on participant data reduced prediction error by at least 15.5% compared to heuristic baselines and 16.7% compared to models trained on pedestrian data. Overall, this work provides a reproducible framework for data-driven modeling of shooter movement, supporting controlled simulation-based evaluation of response strategies.
1. Introduction
Despite increased spending on school safety and preventive measures in the United States, school shootings have increased; among incidents involving at least one victim, more shootings occurred in the last decade (2016–2025) than in the previous five decades combined (1966–2015).1–3 Unfortunately, the effectiveness of preventive measures, such as the introduction of armed school security guards, has not been rigorously evaluated,4–6 largely because ecologically valid studies would require the simulation of a school shooting that could cause psychological distress to participants.7,8 In order to evaluate potential school shooting prevention measures, techniques must be developed that allow researchers to accurately simulate these traumatic events without harming human subjects. This paper argues that virtual reality (VR) can be used to safely simulate school shootings in order to model the behavior of shooters and capture data that reflects their behavior.
Our near-term goal is to generate data suitable for training a model that accurately predicts school shooter movements and behavior. We believe that an accurate model of the movements of a school shooter could be leveraged to evaluate or improve prevention measures or victim evacuation. Yet, modeling school shooter movements is difficult because, with one exception, data from prior shootings is too coarse to reconstruct the movements and actions of the shooter.9–11 Undaunted, agent-based modeling (ABM) has been used to simulate shooting incidents, often relying on critical yet unsupported assumptions about how a shooter will move in different situations. Common assumptions include the shooter remaining stationary, 12 moving randomly, 13 or consistently advancing toward the nearest civilian.14–17 The validity of these assumptions and their impact on the data collected from these simulations is unclear.
We intend to augment these agent-based models with data from human-subject studies conducted in VR. To this end, we asked university students and faculty to assume the role of a school shooter in a VR simulation. We then recorded their movements and actions. The resulting data include approximately 450 min of high-fidelity movement information of participants acting as a school shooter.
For a variety of reasons, we contend that our approach produces ecologically valid school shooter data. First, participants are given face-valid descriptions of the study and told that their goal is “to shoot as many people as possible.” We used surveys to confirm that participants understood these directions and were motivated to follow these directions. School shooters often express similar goals before initiating school shootings.9,18 Second, preliminary studies show that, despite being left to decide on their own how to act, participants take actions that qualitatively resemble shooter crime scripts developed by investigators to model shooter behavior: plan, enter the location, select the first target, fire, search for additional targets, fire, and repeat. 19 Although their movements vary, all of our subjects utilized a similar pattern of actions, switching between searching for targets and remaining in one location to fire on nearby targets of opportunity. In this paper, we further evaluate this hypothesis by comparing data collected from these human-subject studies to historical data collected from previous school shootings. We then compare a simple, empirical model of school shooter movements to previous approaches in terms of prediction error on unseen data. Finally, we evaluated how participants felt about the value of participating in this study.
This paper provides evidence that VR can be used to collect data capturing human behavior in rare, safety-critical scenarios under controlled conditions. We also demonstrate that the resulting data can be used to develop predictive models. This work is based on a paper presented at the 2025 Annual Modeling and Simulation Conference. 20 The data and models related to this work are available on GitHub (https://github.com/chrismcclurg/vr-shooter-data). The simulation environment is available upon request.
2. Related work
Our approach is motivated by research in ABM, where representing human behavior remains a central challenge; human trajectory modeling, which offers empirically grounded approaches to modeling individual decision-making; and VR, which provides both a source of empirical human behavior data and a means for validating behavioral models. These research areas are discussed in the following sections.
2.1. Agent-based modeling
Active shooting incidents have been studied with ABM, where researchers have examined how different modeling assumptions and interventions influence casualty outcomes. In ABM, individuals are represented as agents governed by rules or constraints, allowing population-level trends to be examined across many simulated trials. 21 Anklam et al, 13 e.g., looked at whether having individuals with concealed carry permits and/or an assigned resource officer would reduce casualties. In their model, the shooter agent randomly selects victims and when to change location until it encounters law enforcement or randomly commits suicide. Hayes and Hayes examined the impact of a proposed gun bill (Assault Weapons Ban of 2013) on school shootings.14,22 In this study, the modeled shooter followed a simple process of reloading, shooting the nearest individual, and moving toward the most recently targeted individual. Briggs and Kennedy studied whether people using unarmed resistance would reduce casualties. 12 Stewart used ABM to examine the impact of cognitive delay, response strategy, and police response time, with the shooter again targeting the closest person. 15 Lee et al. 16 evaluated the effectiveness of the Run. Hide. Fight. response strategy, with shooter behavior defined by proximity-based targeting within range, and later extended this work to an environment modeled after the Columbine High School library. 17 Across these studies, shooter behavior is specified through a small set of predefined decision rules.
Similar approaches have been applied to other risk-critical domains. Fire evacuation models commonly rely on heuristic decision rules (e.g., nearest-exit selection, shortest-path routing, and rule-based evacuation timing), often coupled to increasingly detailed physical or environmental dynamics.23–25 Similarly, Bae et al. 26 modeled city evacuation during a bombing by representing agents as traffic participants, assuming fixed congestion dynamics over road topology. Other studies model evacuation using agents with discrete action spaces, where actions are stochastic and probabilistically calibrated from survey data.27,28 Beyond evacuation, Malleson et al. 29 examined urban crime patterns using agents governed by the Physical conditions, Emotional states, Cognitive capabilities, and Social status (PECS) framework, which represents internal agent state while retaining prescriptive behavioral structure. In these domains, agent behavior is similarly defined through predefined heuristic, probabilistic, or conceptually structured decision rules.
Across both active shooter and broader risk modeling, a central challenge lies in how human decision-making is specified within agent-based systems. Kennedy identified three categories of decision-making models in ABM: (1) mathematical approaches based on simplified rules or functions, (2) conceptual frameworks that explicitly represent cognitive or emotional states, and (3) high-fidelity cognitive architectures. 30 Most existing models adopt mathematical or conceptual representations that favor interpretability and scalability over behavioral fidelity, reflecting practical constraints related to data availability and validation in high-risk domains. While heuristic-based ABMs may incorporate empirical calibration, the structure of the decision logic is typically defined a priori and held invariant. In contrast, our approach leverages VR to collect empirical trajectories from which decision-making policies are inferred directly, relaxing the assumption of predefined decision structure.
2.2. Human trajectory modeling
Human behavior representation is also central to the extensive literature on human trajectory modeling, which approaches decision-making implicitly through observed motion. In this setting, the positions of a target pedestrian are observed over time
Alahi et al. 36 introduced the Social-LSTM model, in which each pedestrian’s movement is represented by an individual LSTM. Information from neighboring pedestrians is shared in a pooling layer either through hidden states (S-LSTM) or coordinates (O-LSTM). Bartoli et al. 37 extended this model by including a “context-aware” pooling layer that accounts for the coordinates of static obstacles. Bisagno et al. 38 extended the S-LSTM model by first applying k-means clustering to the trajectories in a scene and then only pooling the hidden states of out-group trajectories with respect to a given trajectory. Pei et al. introduced a hand-crafted social affinity map (SAM) that divided the space around the target into bins. Neighboring pedestrians located within the same bin were then treated as a group and jointly influenced the target’s motion. 39 Other work used attention mechanisms to account for either static obstacles 40 or nontarget pedestrians41,42 in a scene, but these were often limited to high-resolution data. 40 Some researchers43–45 have used multichannel encoder–decoder architectures. Typical inputs included target position and/or velocity, static occupancy maps, and neighbor context encoded either as occupancy grids or relative motion. Pfeiffer et al. 44 combined velocity with explicit static maps and neighbor grids, while Xue et al. 43 replaced the static map with raw scene features. Finally, Shi et al. 45 avoided using grids, instead using a subnetwork based on the relative motion of a pedestrian’s neighbors. These types of models have demonstrated improved performance over S-LSTM on most benchmark scenes where direct comparisons were made.43,45
None of these previous models has been used to predict a shooter’s trajectory, nor have any been trained on data resembling a shooting event. The standard datasets for pedestrian movement prediction (ETH, 46 UCY 47 ) are based on the movements of crowds of homogeneous pedestrians (The ETH dataset admits that pedestrians that are “standing or strolling aimlessly” are ignored in order to remove nonhomogeneous data. 46 ). As a result, the models trained on these datasets produce socially compliant, smooth, and group-coherent38,39 trajectory predictions. School shootings, in contrast, involve a heterogeneous set of agents: bystanders who may run, freeze, or hide (without trajectory) and a shooter who is motivated to harm bystanders. Thus, previous models based on the movement of pedestrians are unlikely to generalize to shooter scenarios because of the difference in motivation of the agents. To capture this heterogeneity, we adopt a multichannel encoder–decoder architecture, which allows distinct input channels to account for different agent and environment states.43–45 Unlike previous work, our model explicitly encodes state information for neighboring pedestrians (e.g., alive or dead) by using dedicated channels. Finally, we avoid reliance on raw image data, which tends to overfit to scene-specific appearance features and generalizes poorly to visually distinct environments, especially in a simulation-to-reality domain shift.
2.3. VR for data and validation
Virtual reality (VR) has been routinely validated as a tool for measuring and developing human decision-making in situations of risk. In fire evacuation, Arias et al. 48 found behavioral patterns (i.e., evacuation times and exit choices) to be comparable for both VR and physical experiments. In fire evacuation with robot assistance, Yin et al. 49 found similar outcomes and trust in the robot to be comparable in VR and physical experiments. Shipman et al. 50 studied a simulation of violent threat, demonstrating that psychological responses and key behavioral dependencies observed in VR were statistically indistinguishable from those measured in a corresponding physical experiment. Medical researchers have demonstrated that skill development in VR was comparable to real surgery training51–53 Qin et al. 54 demonstrated that VR-based combat trauma care training leads to significant improvements in trainee knowledge relative to pretraining baselines. Finally, Harris et al. 55 found the decision-making of individuals in military combat to be comparable for both VR and live-fire scenarios. This last example is particularly relevant to our work, because participants are given a gun and must make split-second decisions on when to shoot or not shoot.
The presented studies establish VR as a validated experimental instrument for measuring decision-making and behavioral dynamics in high-risk, time-critical scenarios. In the context of school shootings, continuous ground-truth movement data from real perpetrators is essentially unavailable, with only a single documented example known to the authors. 56 Accordingly, VR provides a rare and ethically feasible means of collecting ecologically valid, continuous behavioral data under controlled conditions. When individual real-world trajectories are unavailable, VR-derived behaviors are evaluated against aggregate statistics reported across historical incidents, which represents the level of validation available in this domain. Complementary work 57 has explored alternative modeling abstractions designed to support evaluation across multiple environments, trading geometric specificity for broader contextual coverage.
3. Human-subject experiment
We conducted three studies (S1, S2, and S3), which tasked human subjects in VR with acting like an active school shooter. The frequency of data collection was 1 Hz for S1 and 2 Hz for S2 and S3. All studies recorded the participant’s position and cumulative shots fired, but only S2 and S3 recorded the participant’s rotation, gaze direction, pupil diameter, cumulative reloads, and the position and visibility of other objects. For S1 and S2, data were written to a file at every timestep, whereas for S3, raw data were transferred over a User Datagram Protocol (UDP) socket to improve simulation performance and reduce subject nausea. Data was collected over three time periods: S1 in April 2023, S2 in September–October 2023, and S3 in October–December 2024. The total number of participants was 103, with 32, 39, and 32 participants in S1, S2, and S3, respectively. Data from participants who did not finish the simulation due to physical discomfort (6), psychological discomfort (3), or hardware error (4) was discarded.
3.1. Simulation environment
A virtual reproduction of Columbine High School served as the simulation environment, the site of the infamous 1999 school shooting in the United States. 9 Google Maps was used to measure the perimeter of the building using the built-in measuring tool, as shown in Figure 1(a). The newer renovations of the building were ignored in order to faithfully simulate the building at the time of the school shooting. Once the building perimeter was scaled, crime scene diagrams from the official report 9 were scaled to overlay on the building perimeter, resulting in a complete representation of the floor plans (except for rooms lacking crime scene diagrams). The floor plans were then used to create a computer-aided design (CAD) model in SolidWorks (Figure 1(b)). The CAD model was then imported into Unity. Unity’s asset store was used to obtain textures and objects such as doors, cars, and a detailed handgun for the environment. A comparison of the virtual environment to the physical environment in 1999 is depicted in Figures 1(c) and (d).
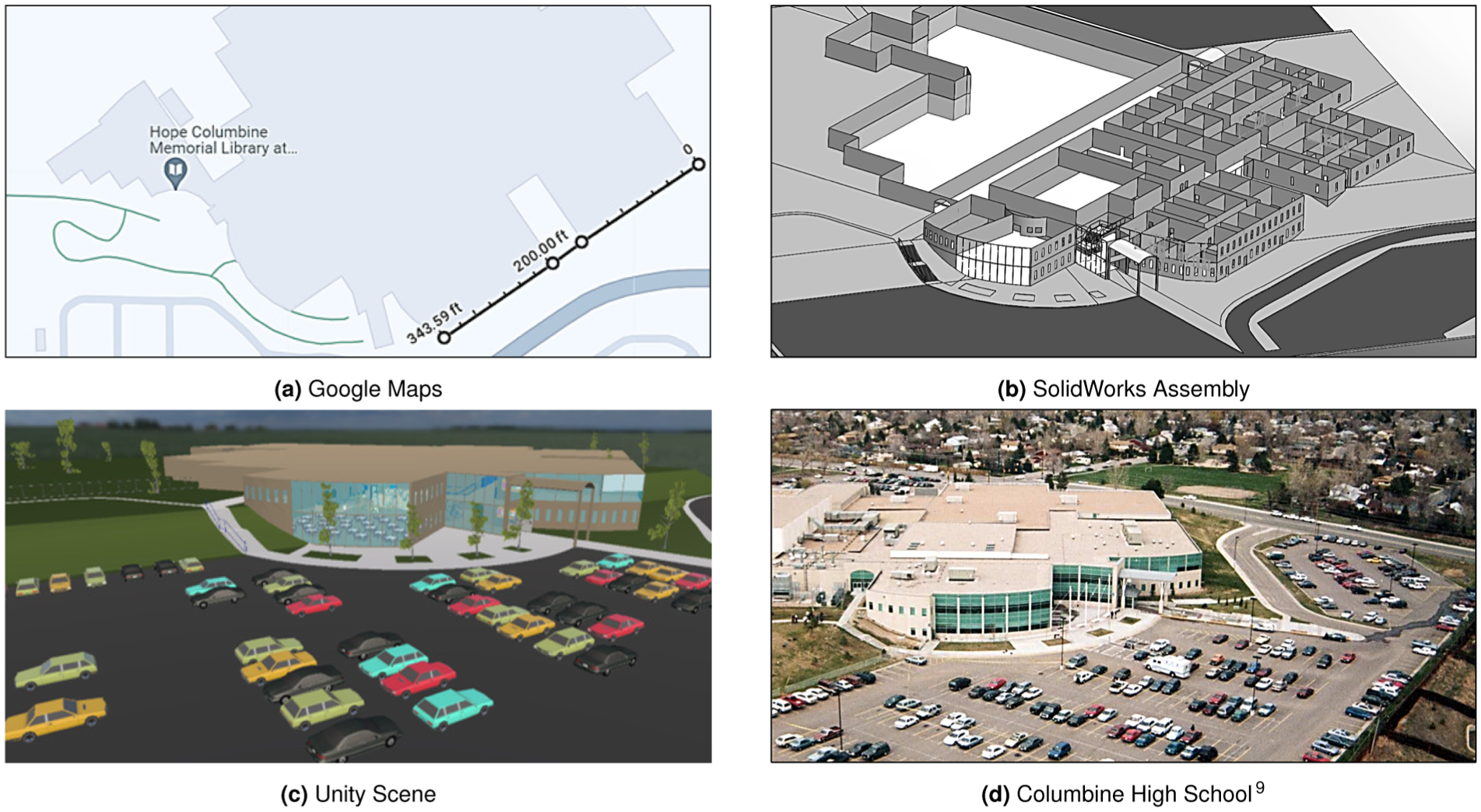
Steps (a–c) to make the simulation environment resemble the real environment (d) are depicted. (a) Google Maps. (b) SolidWorks Assembly. (c) Unity Scene. (d) Columbine High School. 9
3.2. Nonplayer characters as bystanders
The nonplayer characters (NPCs) were used to populate the environment with autonomously behaving students and teachers. These NPCs were controlled by finite state machines (FSM), a common practice for modeling evacuees.58–60 We designed the FSM to mimic the “Run. Hide. Fight” response recommended by the Department of Education. 61 Fighting is difficult to accurately simulate and seldom occurs during actual school shootings, so this option was disregarded. Figure 2 (right) depicts the implemented finite state machine. The default state of the NPC was relaxed. If triggered, the NPC would switch from the relaxed state to the alarmed state. From the alarmed state, the NPCs could either transition to the hiding or escaping states randomly. Our model includes the run–hide decision probability as a parameter, which we set to have the NPCs attempt to escape 25% of the time (see Appendix 5 for sensitivity analysis). While NPCs were in a given state (relaxed, alarmed, hiding, or escaping), they moved along a corresponding set of waypoints. This set of waypoints is color-coded on the left of Figure 2. The column of rectangles on the right side of the figure shows which animations correspond to a given state. By default, NPCs were either sitting, walking, or teaching. When triggered, the NPCs run (yellow, then orange or green). Once an NPC has reached either the end of a green or orange waypoint path, a crouch animation occurs.
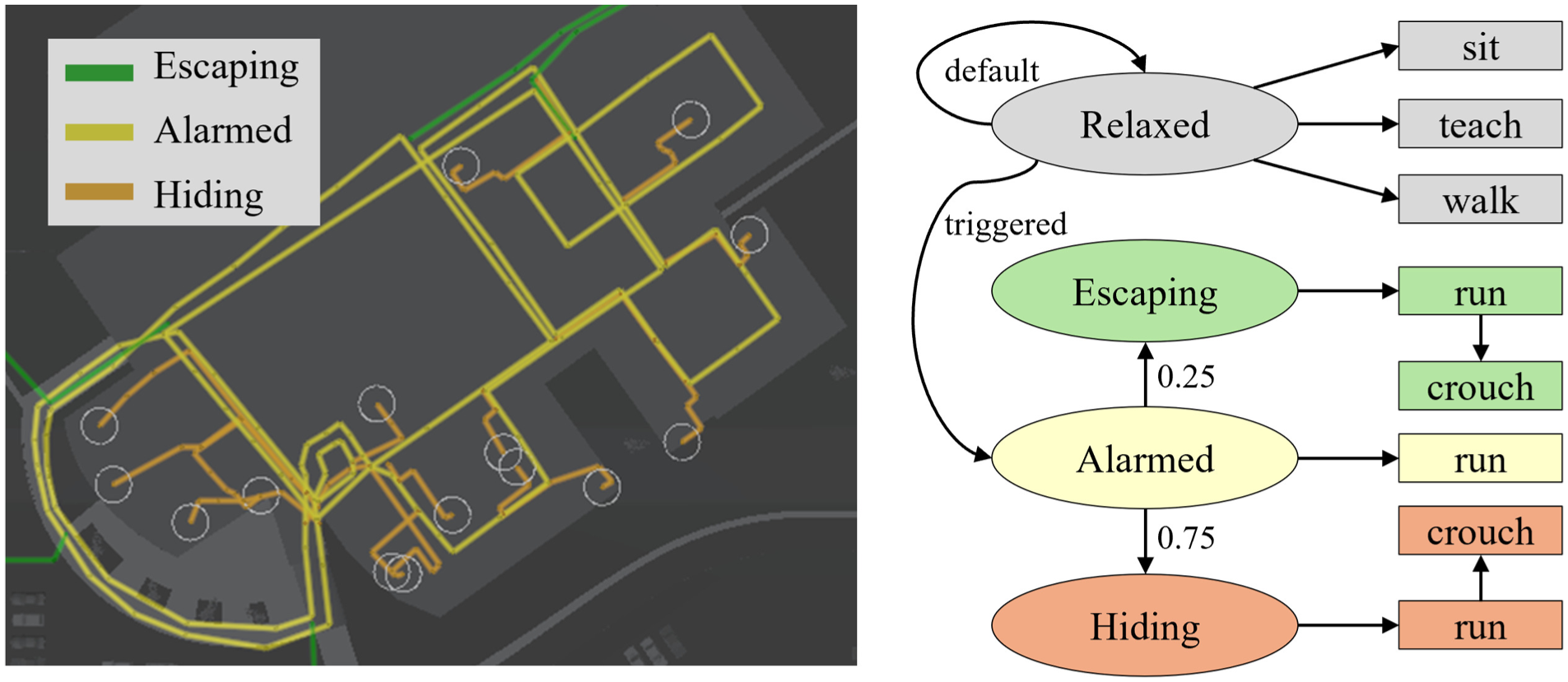
Each NPC is modeled as a finite state machine (right). The column of ovals describes the states and their transitions, whereas the column of rectangles describes the animation used by the NPC for that state. Within each state, the NPCs follow a specific waypoint system (left).
3.3. Hardware
An HTC Vive Pro headset was used, which compares favorably among other headsets in comfort, display quality, tracking system stability, and prescriptive glasses compatibility.62,63 Valve Index hand controllers were used. The right rear trigger was used to shoot the gun. While a two-handed gun controller was considered, we decided that a one-handed controller would better reflect the fact that 77.2% of mass shooters used handguns from 1966 to 2019. 64 Foot interfaces (Cybershoes) 65 were used to simulate embodied walking (Figure 3). The participants wore the shoes while sitting on a swivel chair, which allowed a full range of motion while remaining seated.

Participants were seated in a swivel chair with an HTC Vive headset. Cybershoes were strapped over shoes for locomotion. Valve Index controllers were strapped to hands for hand movements and shooting.
3.4. Participants
The experiments were conducted in a lab on the Pennsylvania State University campus. Poster and email advertisements were used to recruit subjects. The inclusion criteria for the study required participants to be male, at least 18 years of age, and not have previously experienced motion sickness while using a VR headset. Female participants were excluded because 98% of shooters between 1966 and 2019 were male. 64 Our target recruits generally matched the demographic characteristics of real school shooters—young male students. Participants were paid $15 in S1 and S2, while S3 paid $30 to attract more participants. Individuals were not permitted to participate more than once. The study was Institutional Review Board (IRB)-approved.
3.5. Procedure
Upon arrival at the lab, the participant was asked to complete a consent form. In S1, the experimenter read a fixed script describing the experiment and task. In S2 and S3, an NPC modeled after the experimenter explained the task. Next, a research assistant outfitted the subject with VR devices (Cybershoes, controllers, and a VR headset) and explained how to use the devices. Once participants entered the VR environment, they found themselves in a virtual environment modeled to closely resemble the real-world environment. The subjects were led to a training room by the NPC experimenter. In the training room, the participant practiced walking using the shoe interfaces and firing the gun at targets. The NPC experimenter explained how to shoot and reload the gun. The participant was allowed as much time as needed in the training room. After training, the participant exited the training room without a gun. The participant then arrived at an outdoor shed in order to study a map of the school environment. The map, shown in Figure 3(c), was in focus for exactly 1 min to reduce variability among participants in S2 and S3. In S1, participants could look at the map for as long as they wanted. In S2 and S3, the participant then toured the school. During the tour, the participant was shown the closest entrance, the cafe, the library, the auditorium, and the back entrance in that order. Once the tour was complete, the participant was given a handgun. The NPCs representing students then arrive at the school. This event marked the beginning of the experiment. Once the participant fired their first shot, the NPC bystanders reacted and the experiment continued for five more minutes. The different stages of the study are depicted in Figure 4.

The stages (a–f) of the simulation are depicted. (a) Receive instructions. (b) Practice aiming. (c) Study map. (d) Take tour. (e) Receive gun. (f) Be shooter.
4. Ecological validity of data
Having collected a large dataset on participant movements and actions across three studies (S1–S3), we now evaluate its suitability for modeling school shooter behavior. Specifically, we assess whether VR participants reproduce historically plausible aggregate engagement metrics and whether the resulting dataset improves trajectory prediction performance. To establish ecological validity, we compare participant shot rate, victim rate, and shot accuracy to historical school shooting data using the two one-sided tests (TOST) procedure to assess statistical equivalence. Because detailed real-world shooter trajectories and decision-level context are rarely available, this validation is intentionally limited to aggregate outcomes rather than fine-grained path or choice-point behavior.
4.1. Two one-sided tests
To evaluate the ecological validity of the collected data, we compared participant shooting statistics to measurements from historical school shootings. Using a database of school shootings spanning 1966–2023,
64
we extracted incidents with publicly reported durations, number of shots fired, and number of victims (see Table 1). For each outcome variable (shot rate, victim rate, and shot accuracy), we computed the experimental mean and 90% confidence interval (CI) and compared them to prespecified equivalence bounds (EB) based on the central 95% of the historical distribution (2.5th–97.5th percentiles). Equivalence was determined with a TOST,
66
which tests whether the mean lies entirely within the equivalence region. Unlike traditional
Historical data of US school shooting incidents.
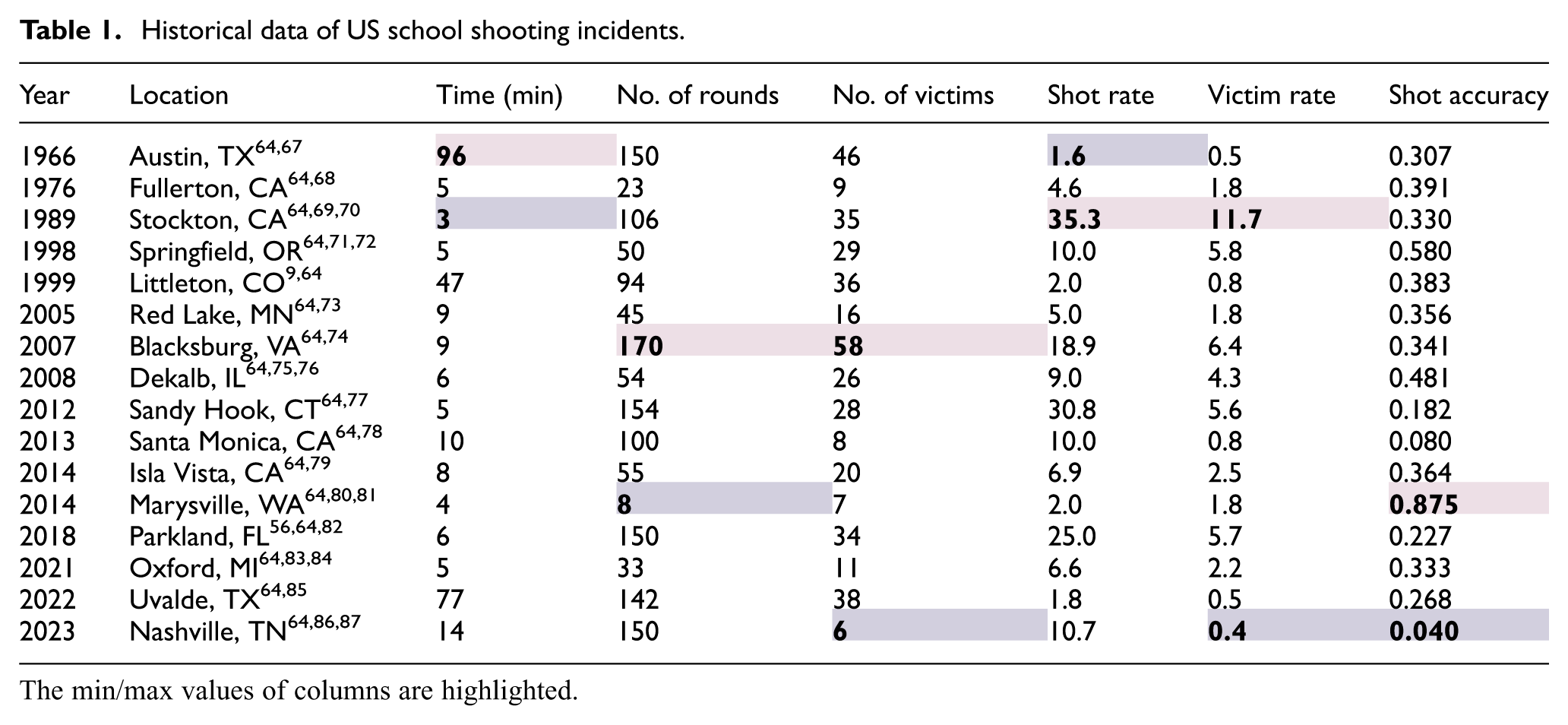
The min/max values of columns are highlighted.
As shown in Table 2, participant shot rate, victim rate, and shot accuracy were statistically equivalent to historical data under the prespecified bounds, with two exceptions: S1 shot rate exceeded the upper equivalence bound and S1 shot accuracy fell below the lower bound. Both deviations can be attributed to the absence of a reload requirement in S1. A reload action was implemented in S2 and S3, after which both measures fell within the EB. To assess the robustness of these findings, we conducted a sensitivity analysis by rerunning the TOST procedure with narrower EB. Specifically, we replaced the prespecified central 95% range (2.5th–97.5th percentiles) with the central 90% range (5th–95th percentiles), keeping all other parameters (sample sizes, standard errors, and
Results of two one-sided tests (TOST) comparing participant shooting statistics (shot rate, victim rate, and shot accuracy) from studies S1–S3 to historical school shooting data.
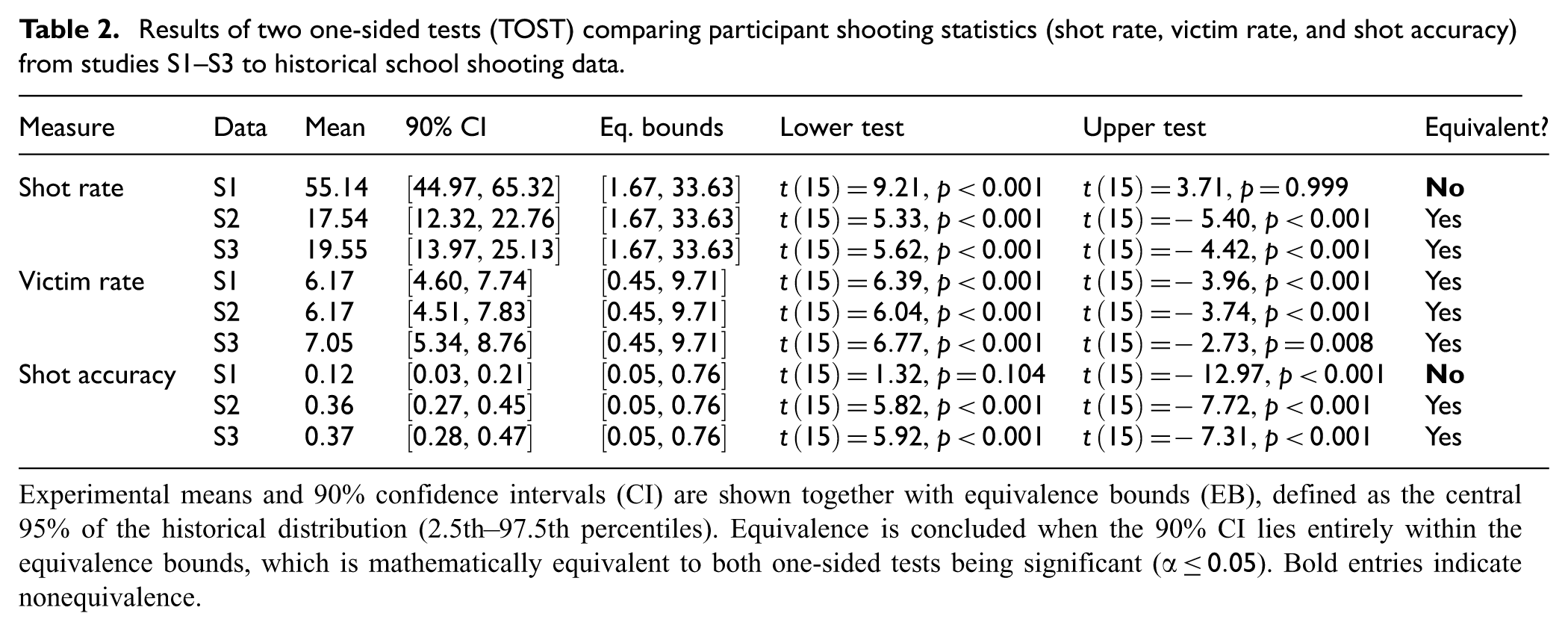
Experimental means and 90% confidence intervals (CI) are shown together with equivalence bounds (EB), defined as the central 95% of the historical distribution (2.5th–97.5th percentiles). Equivalence is concluded when the 90% CI lies entirely within the equivalence bounds, which is mathematically equivalent to both one-sided tests being significant (
5. Modeling shooter movements
This section evaluates shooter trajectory prediction. The goal is to predict, at every timestep, the next
5.1. Evaluations
We evaluated our data in three complementary ways. First, we trained a sequence-to-sequence LSTM trajectory prediction model on the participant data, providing a basic data-driven model of shooter dynamics, and compared its predictive accuracy to the heuristic-governed shooter trajectories commonly used in agent-based simulations.12,14–17 Second, we investigate the importance of data relevance by comparing model performance when trained on no data, nonrepresentative pedestrian data, and shooter-specific data. Finally, we compare multiple model architectures to examine whether additional architectural complexity provides measurable benefits once relevant data are available. Together, these analyses provide a comprehensive assessment of both the representativeness of our collected data and its utility for building models that accurately predict shooter movement.
5.2. Data
Our data sources included participants acting as shooters in VR, a real school shooting, and publicly available pedestrian crowd data. For the participant data, we used S2 and S3 for model training and testing because equivalence testing (section 4) showed that both were statistically equivalent with historical shooter data. In addition, only S2 and S3 included annotations of neighboring pedestrians and static objects, which are critical for more sophisticated models. This resulted in 60 participants and approximately 300 min of data sampled at 2 Hz. For the real shooter data, we extracted trajectories from a publicly available video animation of the Marjory Stoneman Douglas High School shooting. 56 This reconstruction, based on video surveillance, depicted the shooter and bystanders over time, relative to the school floor plan. We overlaid a Cartesian grid (scaled using Google Maps perimeter measurements) and discretized the animation into 300 frames. In each frame, we recorded the timestamp and positions of the shooter, bystanders, and doors using an interactive Python plotting script (see Figure 5). We then truncated the data to the longest uninterrupted segment and resampled it to 2 Hz using linear interpolation, yielding 192 s of data. For the pedestrian data, we used the ETH/UCY data, the standard benchmark for pedestrian trajectory prediction.36,46,47 It contains several hours of crowded urban and campus scenes with approximately 1500 annotated trajectories. For consistency, we resampled the data from 2.4 Hz to 2.0 Hz using linear interpolation.
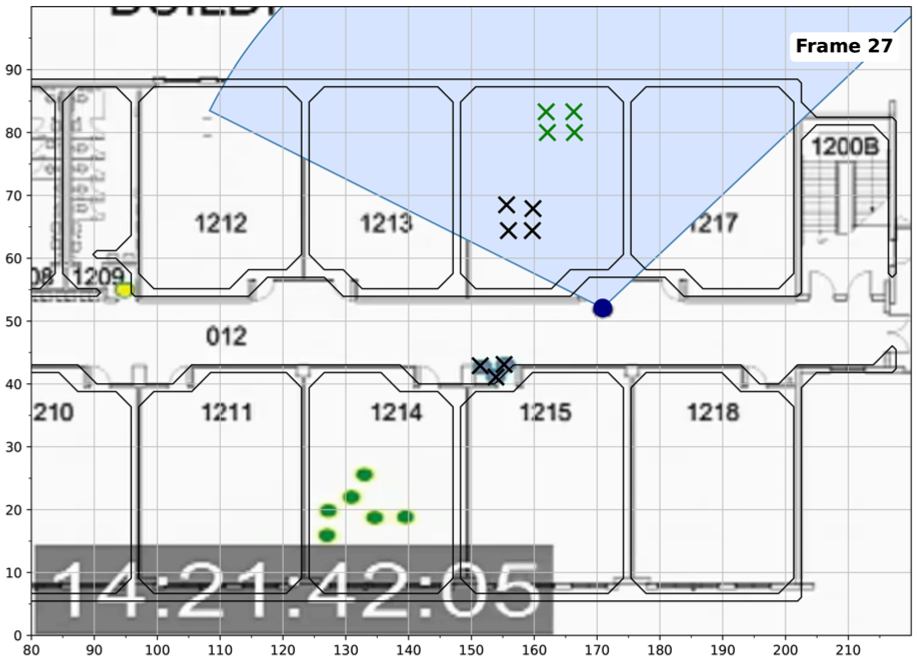
Positional data was extracted frame-by-frame from a video animation of the school shooting in Parkland, Florida. 56
5.3. Metrics
Based on previous work involving pedestrian trajectory prediction,
36
we used average path error (APE) and final path error (FPE) as quantitative metrics for comparing models. The APE measures the mean Euclidean distance over the entire predicted trajectory, whereas FPE measures the Euclidean distance at the final predicted timestep. Let
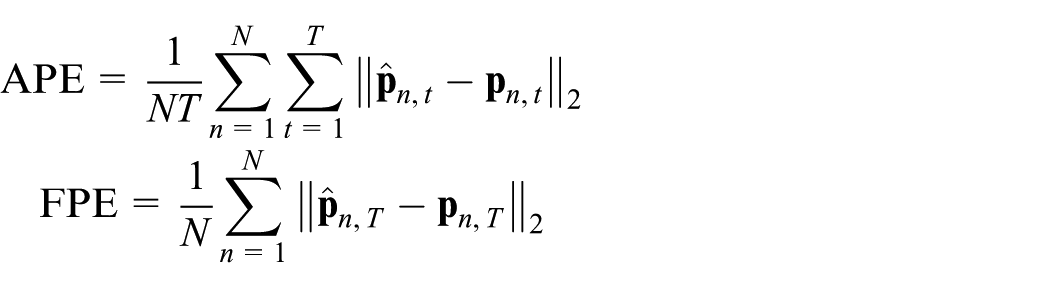
5.4. Procedure
All datasets were handled using the same evaluation pipeline. Participant data were randomly ordered by subject and divided by scene into five subsets. The real shooter data contained only one subject and thus formed a single subset. For the empirical models, we applied a leave-one-subset-out cross-validation scheme: in each split, four participant subsets (80%) were used for training and the remaining subset (20%) for testing. This process was repeated until each subset had served as the test set once. For models trained on nonrepresentative pedestrian data, we used the same five-fold structure for training but evaluated each model on the corresponding held-out participant subset, enabling direct cross-dataset comparison. Prediction errors were aggregated by subject, yielding one independent error value per subject for each model-horizon condition. Accordingly, the number of independent samples for statistical testing was equal to the number of participants (
5.5. Models
Several heuristics served as nonempirical baselines for comparison. The no-movement model and closest target (CT) model have been used previously in ABM,12,14–17 while the constant velocity (CV) approach is often used as a baseline in human trajectory prediction.36,46 Details for these baselines are provided in Appendix 3.
No movement (NM). The shooter remains stationary throughout the prediction horizon. 12
CT-f. The shooter moves toward the nearest alive person at a fixed speed, set to an empirically chosen constant.14–17
CT-a. The shooter moves toward the nearest alive person at an adaptive speed, computed as the mean velocity over a fixed window of preceding timesteps.
CV. The shooter continues moving with its current velocity, maintaining both speed and direction. 88
All our empirical models were based upon LSTM
35
network units for temporal encoding and decoding. An LSTM is a specialized recurrent neural network (RNN),
89
in which the recurrent cell maintains a hidden state
For empirical models, a single-channel LSTM encoder–decoder was used as the base model (BA-LSTM) for shooter trajectory prediction. This model, shown in Figure 6, consists of an LSTM encoder, an LSTM decoder, and a dense refinement stack of fully connected layers. The dense refinement stack was added to correct a severe underfitting seen in training to predict longer sequences. The model takes as inputs the sequence of previous 2D velocities, where it then predicts the future 2D velocities. Three other model architectures were considered: a three-channel LSTM encoder–decoder model called a “data-driven model” by its authors, 44 which we will refer to as DD-LSTM; a six-channel model that has been used to guide a shooter-distracting robot, 90 which we will refer to as RO-LSTM; finally, we present our model for predicting shooter trajectory, ST-LSTM, which incorporates some aspects of both RO-LSTM and DD-LSTM.
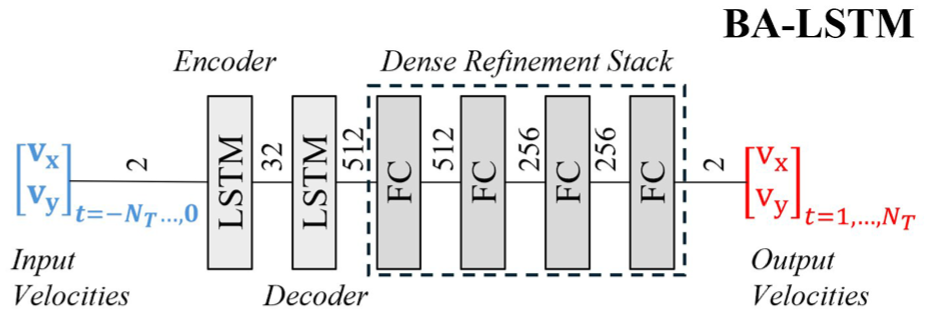
The base model used in this experiment, where the number of hidden units of each layer is annotated.
These other empirical models are shown in Figure 7. The DD-LSTM model (top-left) contains three input channels: 2D velocity, a static occupancy (
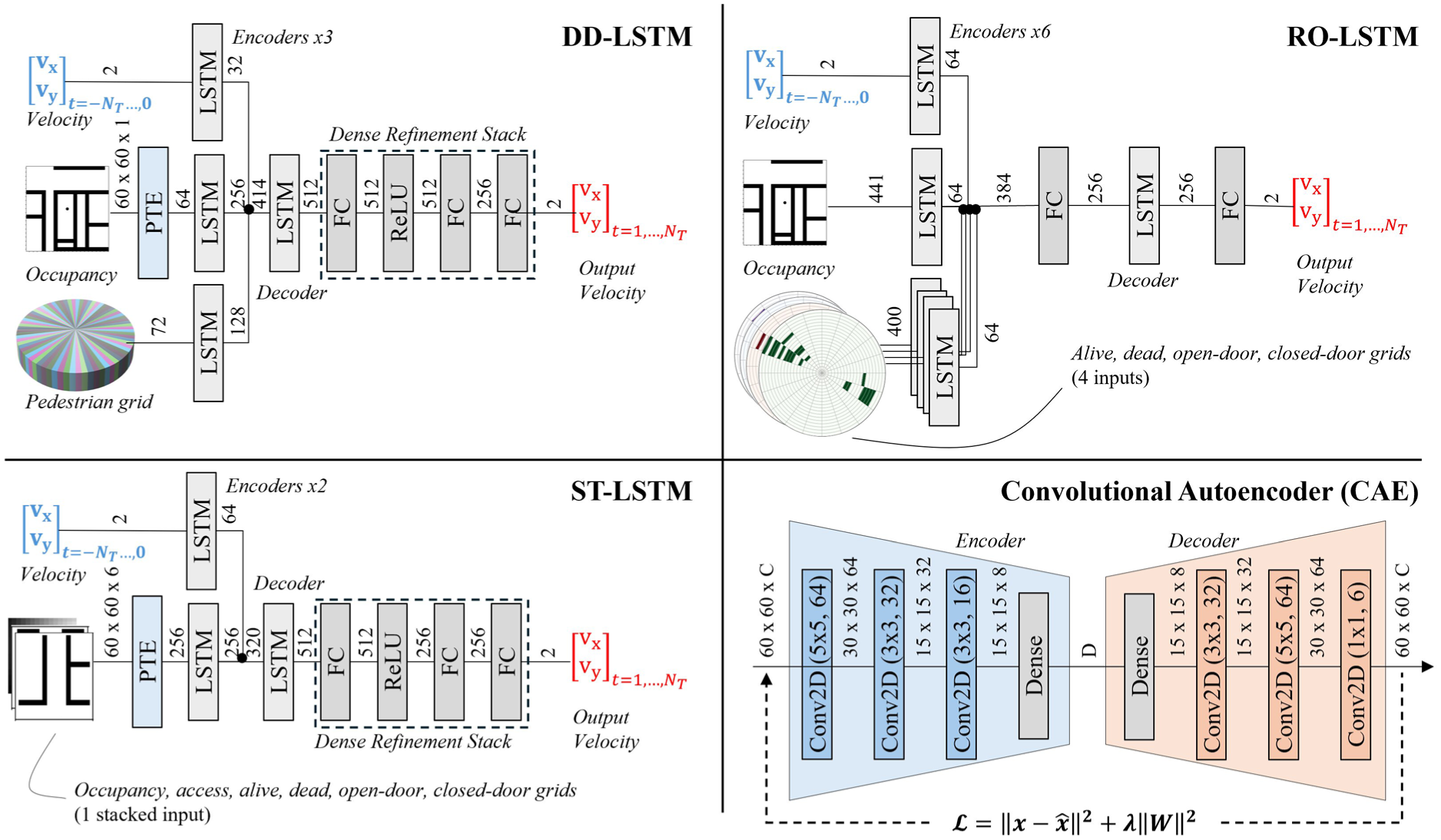
Comparison of architectures used in our STP analysis. Both DD-LSTM and ST-LSTM use a pretrained encoder (PTE) as a feature extractor. This PTE comes from the convolutional autoencoder (CAE) shown in the bottom-right. The training of the CAE uses reconstruction loss, which is depicted with the dashed arrow.
5.6. Implementation
All empirical models were trained and evaluated within a common implementation framework to ensure comparability across architectures. The DD-LSTM and RO-LSTM were adapted from their respective sources44,90 to use the same dense refinement stack as BA-LSTM (Figure 6). Across all models, encoder LSTM dropout, decoder LSTM dropout, and L2 regularization were drawn from shared search ranges, while all other optimization settings were held fixed. Specifically, the encoder LSTM dropout was selected from
To select hyperparameters that differed across model variants, we performed a focused grid search over encoder dropout, decoder dropout, and L2 regularization strength, while holding all remaining hyperparameters constant. Hyperparameters were selected based on validation loss using the same cross-validation splits employed for performance evaluation. The results from the grid search are provided in Appendix 4. Specifically, Table 8 gives the validation loss corresponding to each model and hyperparameter configuration. This strategy prioritizes controlled architectural comparison but does not exhaustively explore the full hyperparameter space for each baseline; as a result, some baselines may achieve improved performance under more extensive, model-specific tuning. Comparative results are therefore interpreted as indicative rather than optimal.
5.6.1. Empirical versus heuristic models
The first evaluation compared empirical and nonempirical approaches for predicting shooter trajectories. In ABM, researchers often rely on heuristics to approximate shooter movement. However, these heuristics can introduce systematic bias into population-level outcomes, as agent movements drive when and where encounters with victims or responders occur. This evaluation, therefore, assesses how using participant-derived data improves trajectory prediction accuracy over heuristic methods. The APE and FPE were used to quantify both overall path deviation and endpoint accuracy across conditions. In the results below, we report APE, whereas tabulated APE and FPE values are provided in Appendix 1.
The top row of Figure 8 depicts APE as a function of predictive model, comparing the empirical BA-LSTM to nonempirical baselines (NM, CT-f, CT-a, and CV) for predicting participant and real trajectories at 5 s, 10 s, and 20 s horizons. For participant trajectories, BA-LSTM reduced APE relative to NM, CT-f, CT-a, and CV by 30.8%, 48.0%, 35.6%, and 27.8% at 5 s; by 23.1%, 36.5%, 27.4%, and 28.0% at 10 s; and by 14.3%, 24.5%, 18.6%, and 32.4% at 20 s, with all differences statistically significant (
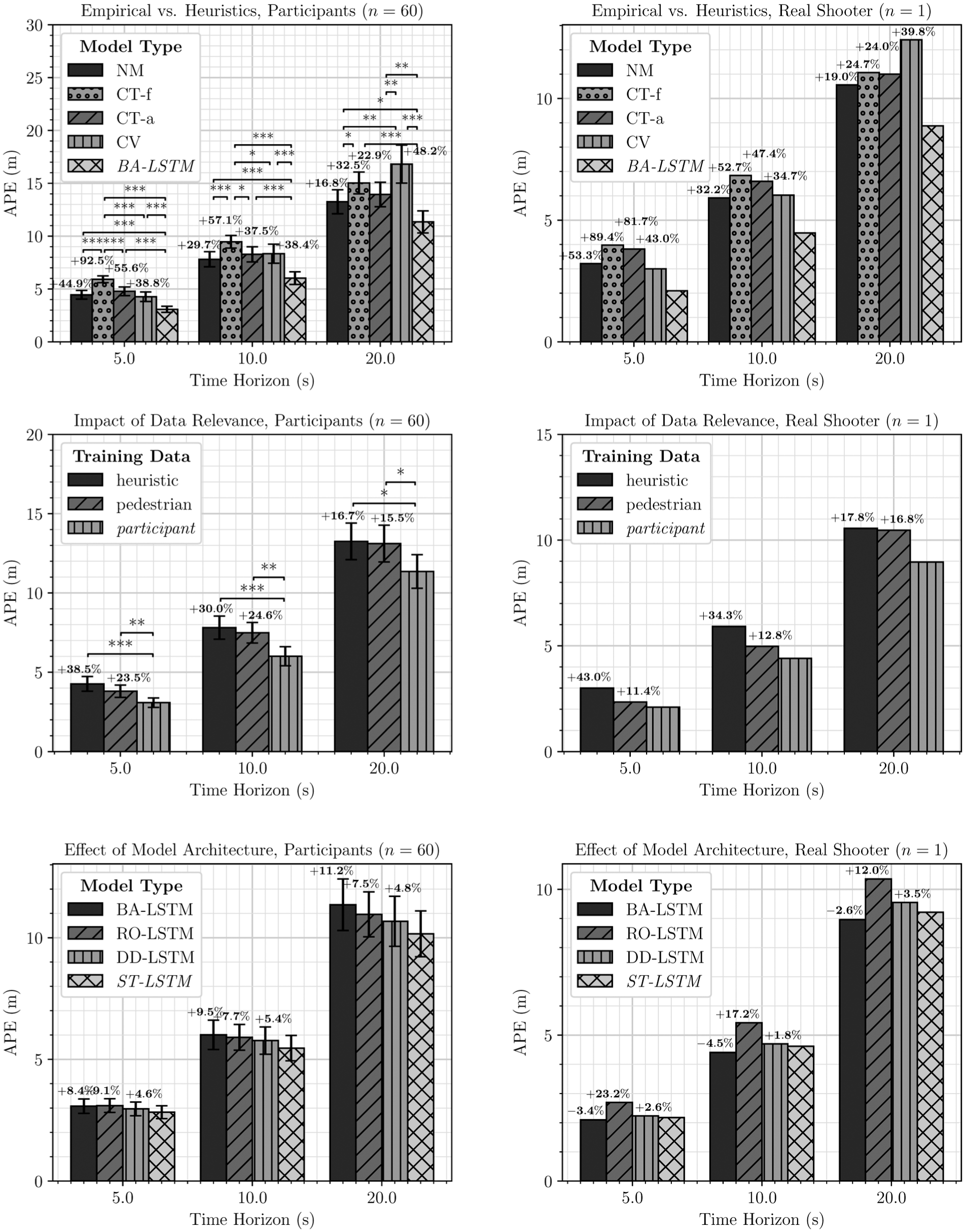
Comparison of APE across all three evaluations. In the case of predicting participant trajectories (left), asterisks indicate significance with Welch’s unequal-variance t-test: *
Pairwise Welch’s
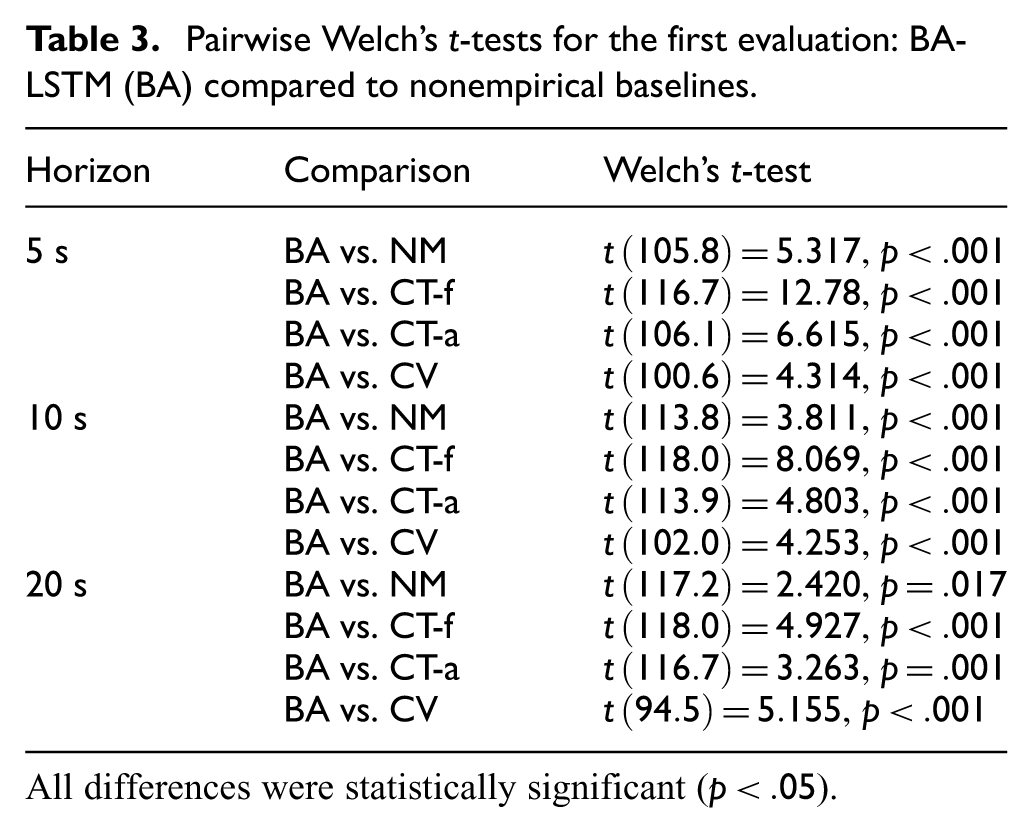
All differences were statistically significant (
5.6.2. Impact of data relevance
The second evaluation examined how prediction accuracy changes with different levels of data availability: no data, using the best-case of nonempirical heuristics; nonrepresentative data, training on pedestrians moving in crowds; and representative data, training on participants acting as school shooters in VR. While one might argue that motion models are domain-agnostic—that a single-channel encoder–decoder trained on kinematic inputs should generalize to any moving agent—this evaluation directly tests that assumption. By comparing prediction accuracy across these three levels of data availability, we quantify the benefit of using domain-specific shooter data over unrelated data or no data at all. The APE and FPE were used to quantify both overall path deviation and endpoint accuracy across conditions. In the results below, we report APE, whereas tabulated APE and FPE values are provided in Appendix 1.
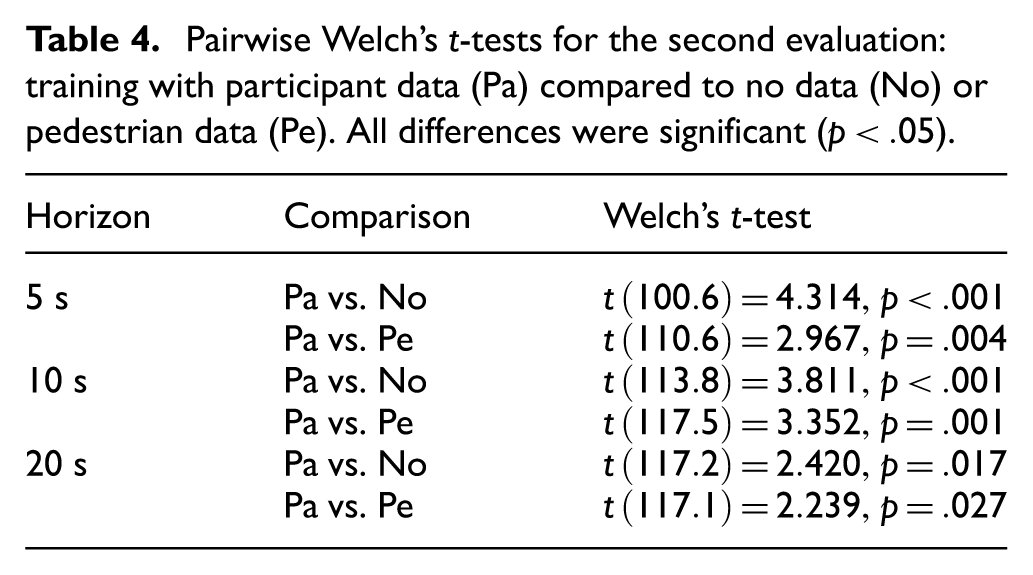
The middle row of Figure 8 shows APE as a function of training data availability (no data, nonrepresentative pedestrian data, and representative participant data) for predicting participant and real trajectories at 5 s, 10 s, and 20 s horizons. For participant trajectories, representative training reduced APE relative to no training data (i.e., the best nonempirical baseline) and pedestrian (ETH/UCY) training data by 27.8% and 19.0% at 5 s, by 23.1% and 19.7% at 10 s, and by 14.3% and 13.4% at 20 s, with all differences statistically significant (
Pairwise Welch’s
5.6.3. Effect of model architecture
The third evaluation compared trajectory prediction accuracy across model architectures of increasing complexity: a kinematic-only, single-channel model (BA-LSTM); a model incorporating static and pedestrian occupancy grids (DD-LSTM); an extension with separate grids for alive and dead pedestrians (RO-LSTM); and a hybrid model that combines the most effective features of the others (ST-LSTM). All models exhibited convergence during training, suggesting that they successfully learned the task. This evaluation assessed whether trajectory prediction benefits from greater architectural sophistication. The APE and FPE were used to quantify both overall path deviation and endpoint accuracy across conditions. In the results below, we report APE, whereas tabulated APE and FPE values are provided in Appendix 1.
The bottom row of Figure 8 shows APE as a function of predictive model, comparing empirical architectures (BA-LSTM, RO-LSTM, DD-LSTM, ST-LSTM) for predicting participant and real trajectories at 5 s, 10 s, and 20 s horizons. For participant trajectories, ST-LSTM reduced APE relative to BA-LSTM, RO-LSTM, and DD-LSTM by 7.7%, 8.3%, and 4.4% at 5 s; by 8.7%, 7.1%, and 5.1% at 10 s; and by 10.1%, 7.0%, and 4.6% at 20 s, although none of these differences were statistically significant (
Pairwise Welch’s
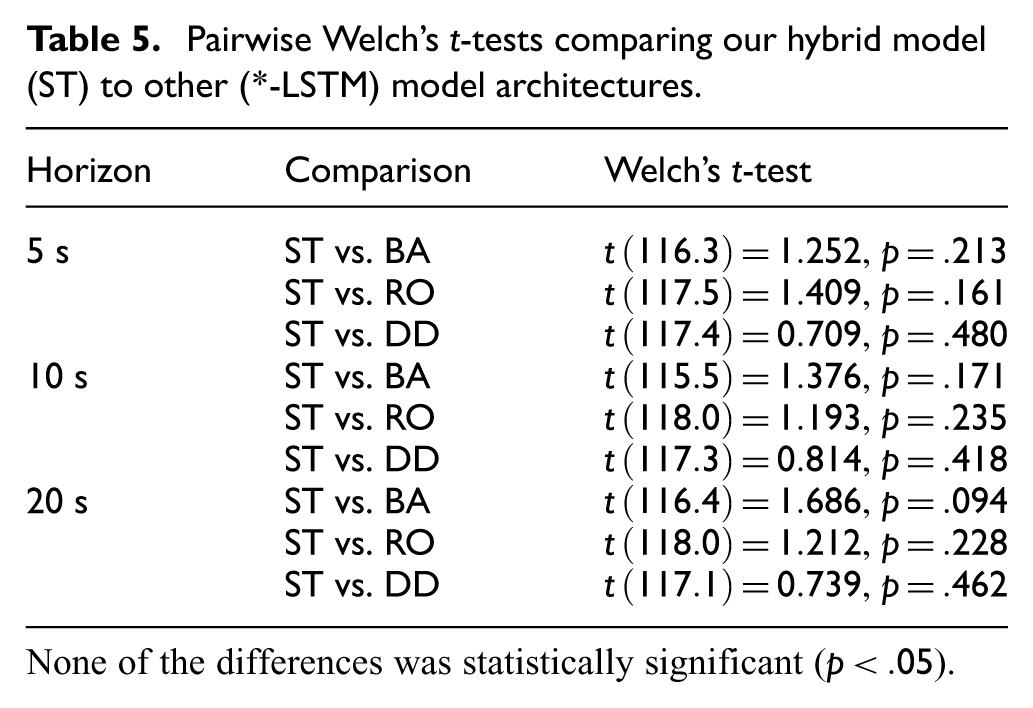
None of the differences was statistically significant (
6. Discussion
Several trends emerge from our results. First, nonempirical heuristics that assume how a shooter moves performed significantly worse than our baseline empirical model trained with participant data, highlighting clear improvements over prior approaches. Second, training the empirical model with nonrepresentative pedestrian data (ETH/UCY) also yielded significantly worse performance than training with participant data, demonstrating that shooter movement models are not domain-agnostic. Finally, while the hybrid ST-LSTM slightly outperformed other models in predicting participant trajectories, the differences were not statistically significant, and results were mixed when applied to real shooter data. Notably, the single-channel BA-LSTM remained competitive across all comparisons of predicting the real trajectory. Altogether, these results suggest that improving the availability of relevant data has a greater impact on predictive accuracy than introducing new architectures. This finding reinforces recent trends in machine learning, showing that data-centric approaches—such as correcting labels or augmenting training sets—often outperform model-centric efforts like hyperparameter tuning. 91 Our findings also align with recent data-quality research emphasizing informativeness and representativeness as critical dimensions of trustworthy machine-learning datasets. 92 For the active shooter modeling task, task-aligned participant data provided greater performance gains than more complex model architectures. These results further support data-centric machine learning and demonstrate that VR offers a practical and more ethical avenue for collecting high-fidelity human behavior data in safety-critical contexts.
6.1. Subjective responses
To further assess the trustworthiness of the data, we examined participant feedback on their experience. Across the three studies, participants rated statements on a 1–5 scale (least to most true). On average, they reported moderate immersion in the environment (
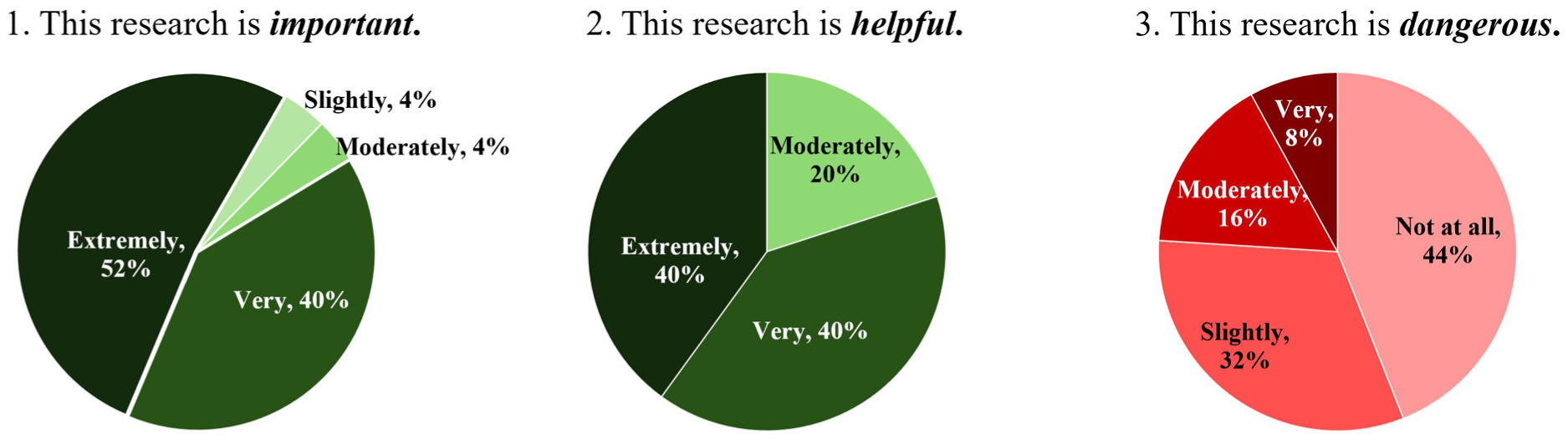
Study 3 (S3) surveyed participants’ experiences and impressions (
6.2. Ethical considerations
Because this study involved simulated violence and potentially distressing scenarios, steps were taken to minimize potential negative impacts on participants. The study protocol was reviewed and approved by the authors’ IRB, which classified the research as minimal risk under US federal guidelines (45 C.F.R. § 46.102). 93 The experiment was designed to be fully face-valid and nondeceptive: participants were informed at recruitment, during consent, and through in-experiment instructions that the task involved shooting NPCs in a virtual environment. Participants were advised that they could withdraw at any time without penalty and still receive full compensation, and experimenters were trained to monitor for visible signs of distress and to terminate the session if necessary. Following participation, individuals completed postexperiment questionnaires assessing perceived danger and emotional discomfort, with a strong majority (76%) of respondents rating the study as no more than slightly dangerous. All participants were also provided with contact information for university mental health services in case distress arose after leaving the laboratory; consistent with the IRB’s determination of minimal risk, no structured psychological debriefing or longitudinal monitoring for delayed distress was required or implemented beyond these safeguards. Participant data were handled in accordance with an IRB-approved protocol requiring deidentification and access control: identifiable information was collected only for compensation purposes and stored separately from experimental data, no master list linking participant identities to behavioral records was created, and the publicly released dataset consists of anonymized, abstracted coordinate trajectories from a simulated environment labeled only with arbitrary participant identifiers (e.g., P00 and P01) and containing no direct or indirect identifiers, demographic information, or link to real-world identities. Prior to release, data were stored on institutionally managed systems with access restricted to authorized research personnel. Although the goal of this work is to support the evaluation of defensive interventions, we recognize that any model predicting behavior in violent scenarios could, in principle, be repurposed for harmful purposes; to reduce this risk, we limit public release to anonymized trajectories in a simulated environment and do not provide recommendations, optimization strategies, or guidance for real-world actions.
6.3. Limitations
A few limitations of this work should be noted. Participants were not real school shooters, and access to such individuals is effectively impossible, as most perpetrators either die during their attack or serve long prison sentences. Accordingly, this study does not attempt to reproduce or model the internal psychological states of real shooters, particularly given the lack of a clear or consistent psychological profile across cases. 64 In addition, the absence of ground-truth trajectory data from real-world school shootings precludes direct validation of individual movement paths. Despite this, the experimental task was designed to be face valid with respect to the assumed proximate objective of maximizing casualties. Under this framing, participant movement trajectories are treated as approximations of behavior consistent with task instructions. Postexperiment surveys (section 6) confirmed that participants understood the task and took it seriously, and observed behavioral metrics were consistent with aggregate patterns reported in historical school shooting data, providing contextual support for interpreting results.
This study did not explicitly assess participants’ prior familiarity with the Columbine shooting or its associated narratives, which represents a potential source of unobserved bias. Participants were drawn from a college-aged population (
Certain participant characteristics warrant clarification. While participants engaged in simulated violence as instructed, without personal intent to harm real individuals, the participant pool was not selected to be stress-free or psychologically neutral. A strong majority (70%) reported ongoing life stressors, and a substantial portion (60%) reported prior involvement in physical fights, reflecting heterogeneity in stress and conflict exposure. These factors do not approximate perpetrator psychology or confer violent intent, but they indicate that observed behaviors arose from real individuals making goal-directed decisions under nontrivial cognitive and emotional demands rather than from an artificially neutral participant pool.
The NPC behavior in the present study is intentionally simplified and does not capture higher-order responses such as panic, freezing, herding, or barricading, all of which may influence real-world dynamics during violent emergencies. The NPCs are therefore modeled as a controlled representation of bystander availability and exposure rather than as a comprehensive behavioral simulation. This abstraction enables tractable analysis and avoids introducing additional unvalidated behavioral assumptions, while still supporting sensitivity analysis of key parameters (Appendix 5).
Finally, all VR data used to train the models were collected in a single school environment, which limits the ability to make strong claims about generalization across arbitrary environmental layouts. Although the learned continuous trajectory prediction model was evaluated on a real shooter from a different, unseen environment, broader claims about environment generality would require empirical data collected across multiple school layouts. While we acknowledge that collecting training data from a single school layout limits claims of generalization across arbitrary environment layouts, we view this work as an important step toward the goal of creating better active shooter simulations. Reproducibility across active shooters, the focus of this paper, may allow us to create active shooter models that generalize across environments if environment-independent patterns can be found or if the framework can be used to collect seed data in other environments. But this cannot all happen in a single paper. The evaluations presented in this paper support consistency at the level of aggregate behavioral patterns, but do not imply environment or path-level generalization. Follow-on work has begun to explore alternative modeling abstractions in order to facilitate evaluation across multiple environments. 57
7. Conclusion
Evaluating school shooting preventive measures requires an accurate and reproducible simulation. This paper presents a method for using human-subject experiments conducted in VR to generate data for modeling shooter movements. Virtual reality offers a means of immersing participants in stressful or emotionally charged situations without risk of harm, but the ecological validity of such data has remained an open question. Our results provide evidence that participant behavior in VR meaningfully reflects the behavior of real school shooters. Participants demonstrated similar behavioral tendencies to those observed in historical shootings. Moreover, empirical models trained with participant data significantly outperformed both heuristic baselines and models trained with nonrepresentative pedestrian data. Finally, survey responses indicated strong endorsement from participants, with the majority rating the study as very to extremely important, very to extremely helpful, and no more than slightly dangerous. Altogether, we believe that this research will contribute to the efforts of the ABM community to simulate school shootings by providing informative and representative data grounded in the behavior of human subjects.
In future work, we plan to extend this research in several directions. The participant dataset will be used to inform agent-based models of active shooter incidents, enabling the discovery of new, emergent population-level trends. We will also repeat the experimental procedure in our virtual environment to generate training data for models of victims and first responders. Importantly, we plan to replicate the data collection protocol across multiple school layouts to explicitly examine how building layout variations influence learned movement patterns and model generalization. In addition, we will use the procedure to systematically evaluate the effectiveness of various security measures on shooter outcomes, building on prior work deploying shooter-mitigating robots in schools. 90 Beyond school shooting scenarios, our methodology for collecting ecologically valid, context-specific behavioral data offers a template for other domains where domain-agnostic movement models are inadequate or where representative datasets are scarce. Together, these extensions will enable formal validation of agent-based models and rigorous benchmarking of intervention strategies across systematically varied simulation conditions—including facility layouts, agent behaviors, and mitigation strategies—supporting reproducible, data-driven evaluation of school safety policies and other high-risk scenarios.
Footnotes
Appendix 1
Appendix 2
Appendix 3
Appendix 4
Appendix 5
Appendix 6
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This material is based upon work supported by the National Science Foundation under grant no. IIS-2045146. Any opinions, findings, and conclusions or recommendations expressed in this material are those of the author(s) and do not necessarily reflect the views of the National Science Foundation. Portions of this paper were edited and refined with assistance from generative AI. The authors reviewed and take responsibility for all content.
Declaration of conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.