
Abstract
In response to the challenge of detecting small foreign fibers mixed in cotton during picking and transportation, a segmentation method for identifying foreign fibers in cotton based on superpixel features and a support vector machine (SVM) is proposed. The method involves integrating the local multidirectional anti-noise binary pattern with the simple linear iterative clustering algorithm to segment the image into superpixel units with similar color features. Color features and grayscale histogram texture features of each superpixel block are extracted to form a multidimensional feature vector. The particle swarm optimization–SVM classification model is then utilized to distinguish between background superpixels and foreign fiber superpixels. Finally, superpixel correction is performed based on confidence and regional adjacency relations, with the introduction of the Bhattacharyya coefficient, to obtain a completely segmented image. The superpixel classification accuracy is reported to be 98.65%. Compared with traditional image segmentation algorithms, this proposed algorithm shows superior segmentation performance.
Keywords
With the rapid development of the cotton industry, China has become a major global producer of cotton. Over the past decade, China’s annual average cotton planting area has been 3302.34 thousand hectares, with an average annual cotton output of 5.8434 million tons. The mixing of foreign fibers in cotton significantly affects cotton quality, causing such issues as yarn breakage, uneven dyeing, and coarse texture during textile processing, severely damaging the textile economy. Foreign fibers mainly come from the picking and transportation stage of cotton, and there are many kinds, such as chemical fibers, hair, silk, hemp, plastic ropes, and dyed threads (ropes, fabric pieces). 1 The detection step is used in the cleaning process of cotton processing. Manual removal methods are insufficient to meet the needs of efficient enterprise development, so the accurate identification of foreign fibers using automated equipment is the main focus of current development in the textile industry. 2 Methods for removing foreign fibers from cotton are evolving toward intelligence and high efficiency. At present, the main automated detection methods for foreign fibers include photoelectric detection, 3 ultrasonic detection, and machine vision detection, all of which can improve detection efficiency. The classic Shirley analyzer analyzes the content of foreign fibers by mechanically separating waste components, 4 while the high-volume instrument uses spectroscopy and imaging techniques in the infrared and near infrared regions to identify or quantify foreign fibers. 5
Owing to the variety of foreign fibers and significant differences in the characteristics between different types, from the perspective of optical technology, such methods as infrared light, 6 hyperspectral imaging,7,8 and polarized light effectively enhance the contrast between foreign fibers and the cotton background. 9 However, these methods are costly and difficult to implement in actual production. Additionally, in terms of detection algorithms, Guo et al. 10 utilized three-channel fused image information and employed the Otsu method for image segmentation, achieving a detection error rate of less than 5% in cotton impurity detection. Edge detection algorithms, such as the Canny 11 and Sobel 12 algorithms, are also widely used in foreign fiber recognition. However, these algorithms are prone to broken boundary contours, owing to background noise and complex textures. Additionally, machine learning algorithms, such as support vector machines (SVMs) have been used to classify manually selected pixel neighborhoods to obtain segmented images of foreign fibers and for classification purposes. 13 In recent years, deep learning algorithms have also been applied in the field of foreign fiber detection. Wei et al. 14 improved the U-Net (a network structure with a U shape), achieving real-time segmentation of foreign fiber images and calculating the actual size of the foreign fibers. Subsequently, a cotton layer foreign fiber classification and recognition method based on near infrared spectroscopy and a combined convolutional neural network (CNN) and temporal convolutional network (TCN) was proposed, effectively identifying foreign fibers in cotton layers. 15 Shi et al. 16 designed a foreign fiber detection network model algorithm based on a residual structure, addressing the issue of foreign fiber edge positions. Additionally, the You Only Look Once (YOLO) series of detection models, such as version 3, 17 version 4, 18 and version 5, 19 have been employed for foreign fiber detection, each performing detection tasks with varying degrees of success. These algorithms, however, have high requirements for computer hardware. In the application of lightweight networks, the MobileNet network enables end-to-end segmentation of fabric defects. Moreover, it introduces depthwise separable convolution, which significantly reduces the complexity and model size of the network. 20
The aforementioned algorithms only consider the characteristics of individual pixels during segmentation, without fully utilizing the relational information between pixels. Superpixels use such information as color and spatial structure between pixels to divide an image into irregular superpixel blocks with similar color and texture features. Common superpixel segmentation methods can be divided into graph-based methods, such as Graph Cuts, 21 and gradient ascent-based methods, such as Superpixels Extracted via Energy-Driven Sampling (SEEDS) 22 and simple linear iterative clustering (SLIC). 23 The SLIC segmentation algorithm generates superpixels that are compact and uniform in size, effectively reducing the complexity of the image and exhibiting strong robustness. However, it only considers the effect of color and spatial features on the clustering process, resulting in poor segmentation performance for linear foreign fibers and weak-edge areas. To address this issue, in this work, linear transformation and the local multidirectional noise robustness binary mode (LMNRBM) operator are combined for texture feature extraction and integrated with the SLIC algorithm to enhance segmentation performance. Superpixels are obtained using the improved SLIC segmentation algorithm, and their color and texture information are extracted to form multidimensional feature vectors. A particle swarm optimization (PSO)-SVM classification model is used for the preliminary classification of superpixels. Based on confidence and adjacency relationships, a classification correction algorithm is designed, and superpixels are merged according to the correction results, achieving complete segmentation of foreign fibers.
Data collection
Experimental materials and samples were obtained from cotton textile enterprises in the Xinjiang Uygur Autonomous Region, China. To ensure the diversity of the dataset, for this study, eight types of common foreign fibers in cotton were selected as segmentation targets, including cloth strips, polymer fibers, hemp ropes, and nylon ropes. The image acquisition tool selected for the experiment was a Baumer industrial camera, equipped with a complementary metal oxide semiconductor (CMOS) image sensor. The image resolution was 3000 × 4000 pixels, and the images were saved in .jpg format. A light-emitting diode light source was used, fixed on an experimental stand with nuts and bolts, to allow for adjustment of the distance between the light source and the cotton to provide evenly distributed illumination. The camera was fixed above the cotton and the light source with a cantilever bracket. Static image capture was completed by adjusting the distance and angle of the light source. Detailed images of some of the foreign fibers found in the cotton are shown in Figure 1. The foreign fibers can be classified as linear or particulate, with the length of linear foreign fibers ranging from 0.2 cm to 1 cm, and the area of particulate foreign fibers ranging from 0.16 cm2 to 0.81 cm2.

Foreign fibers found in cotton.
Research methodology
The segmentation method for foreign fibers in cotton proposed in this study can be divided into three main parts. First, the preprocessing stage involves dividing the entire image into blocks and using the gray-level difference method to determine whether the sub-image contains foreign fibers. For images containing foreign fibers, superpixel segmentation incorporating texture features is used to obtain superpixel images. Finally, based on the superpixel features, the complete foreign fibers are segmented by merging the superpixels. The main process is illustrated in Figure 2.
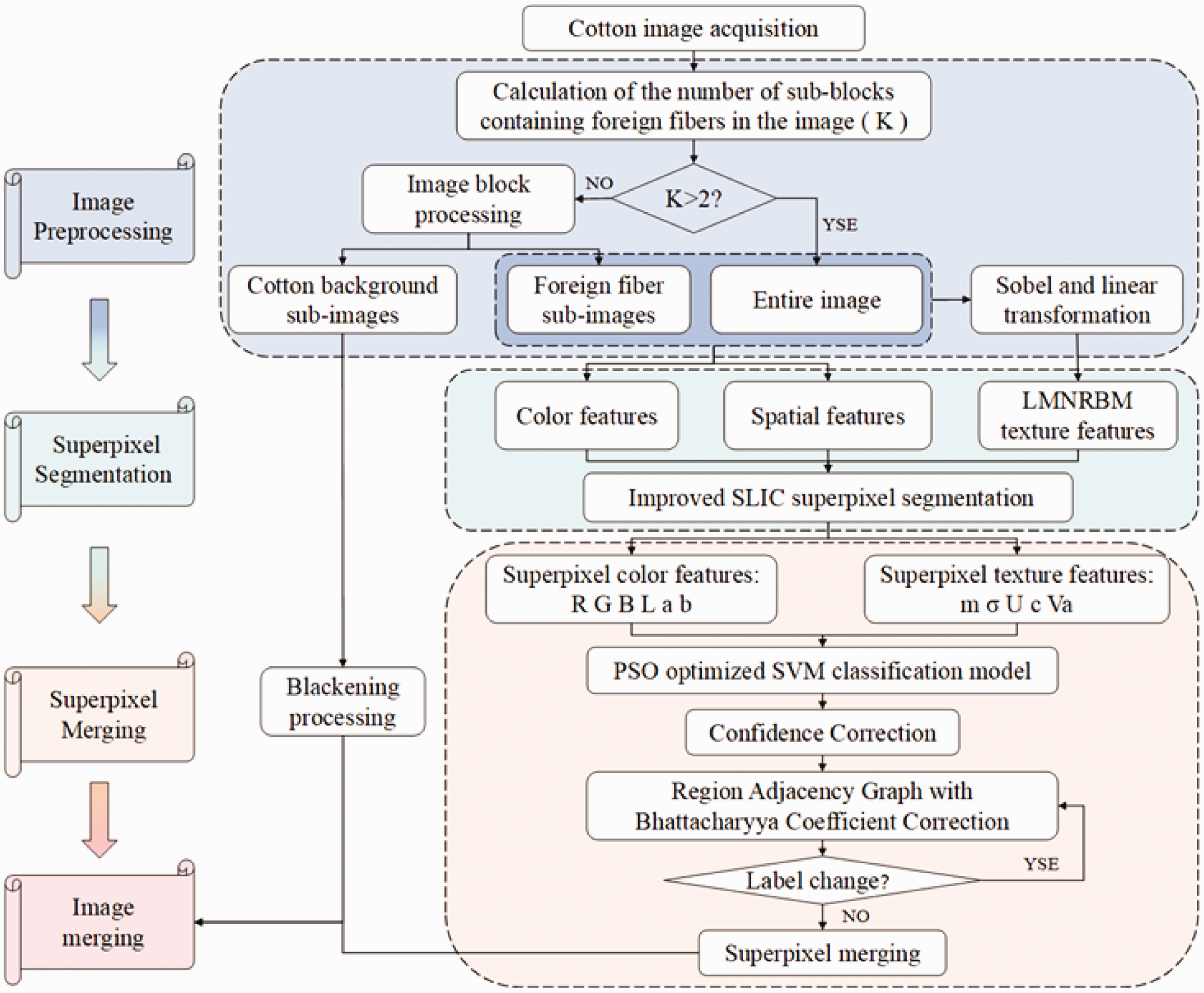
Algorithm flow chart of this study. LMNRBM: local multidirectional noise robustness binary mode; PSO: particle swarm optimization; SLIC: simple linear iterative clustering; SVM: support vector machine.
Improved local binary patterns operator
The local binary patterns (LBP) operator, 24 proposed by Ojala et al., is a powerful texture feature descriptor, and is widely used in such fields as face recognition and image classification. The traditional LBP operator compares the grayscale value of the central pixel with that of eight neighboring pixels and encodes them to generate a binary number. This binary number is then converted into the LBP value of the central pixel according to a specific weighting rule, producing a texture feature description image. This operator is simple, efficient, and robust to changes in illumination. However, it is sensitive to noise and it is difficult to resist interference using this operator because only the grayscale value differences between local pixels are considered. Therefore, in this work, an improved LMNRBM is proposed, as shown in Figure 3.
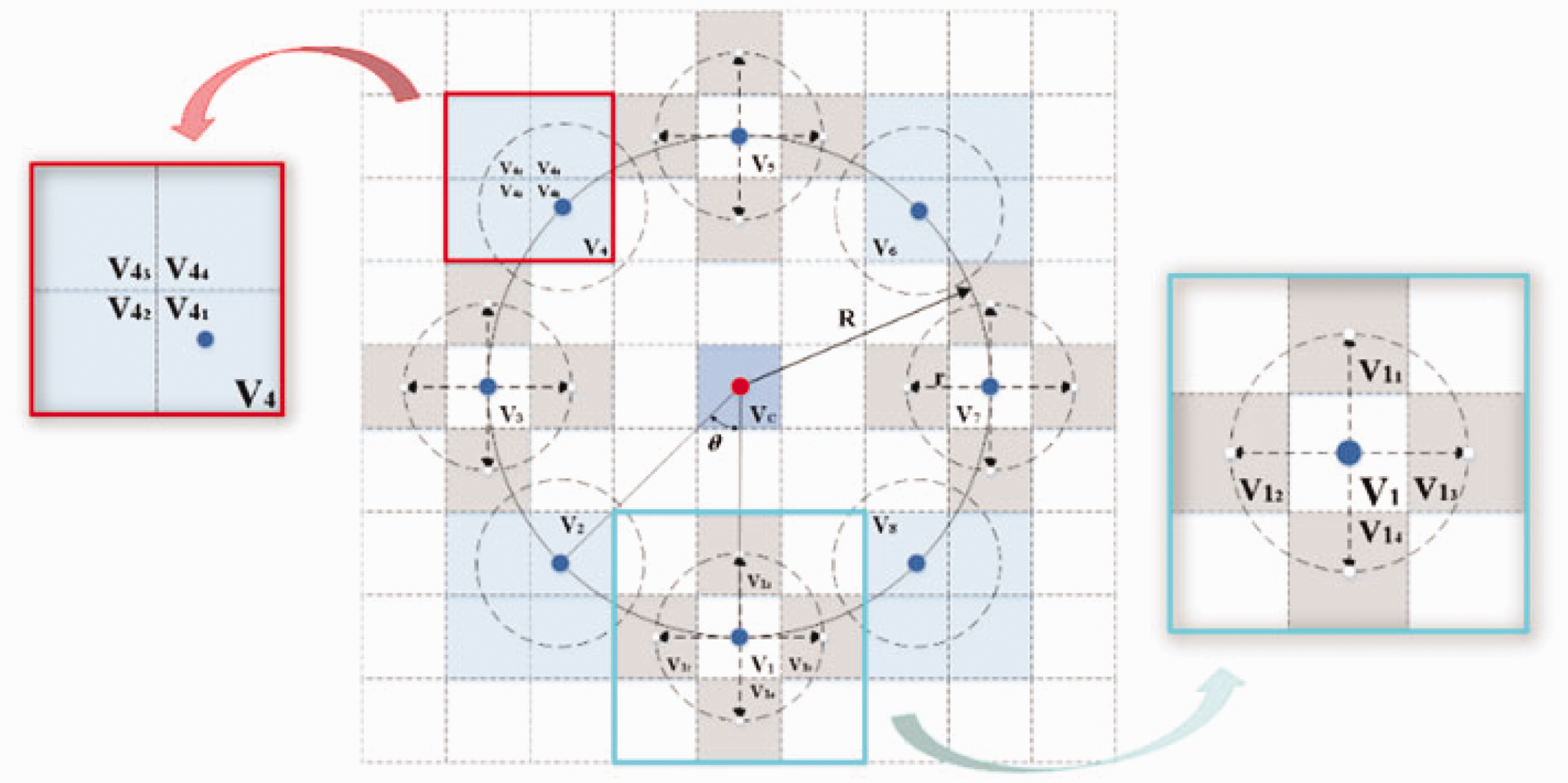
Local multidirectional noise robustness binary mode operator diagram.
This method improves on the circular LBP operator by evenly distributing neighboring points along the circumference of a circle with radius R. To eliminate noise, the four vertically and horizontally neighboring points (V1, V3, V5, V7) are replaced by the average grayscale values of their four nearby pixels. For the diagonally neighboring points (V2, V4, V6, V8), which do not fall on pixel centers, bilinear interpolation is used to obtain their approximate grayscale values. Moreover, since the traditional LBP operator only considers the relationship between the central pixel and its neighboring pixels, ignoring the relationships between the neighboring pixels themselves, in this method, texture variation information is also extracted in two dimensions: horizontally and vertically, as well as diagonally between the neighboring pixels. This further enhances the texture feature description. The binary string code obtained is then converted into the LMNRBM feature value of the central pixel, according to the weighting rule for subsequent segmentation.
The texture feature value L1 between the central pixel and the neighboring pixels is calculated as
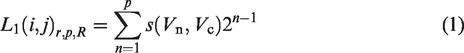
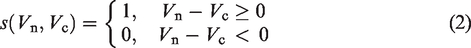
For the vertical and horizontal neighbors (V1, V3, V5, V7), the pixel values are the averages of the four pixels on the circular neighborhood with radius (r). Taking V1 as an example:

For the diagonal neighborhood pixels (V2, V4, V6, V8), the approximate grayscale value of the neighborhood pixels is obtained using bilinear interpolation. Taking V4 as an example:

The texture feature value L2 between vertical and horizontal neighborhoods is calculated as
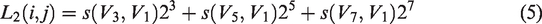
The texture feature value L3 between diagonal neighborhoods is calculated as
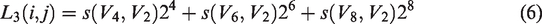
These three texture feature values are concatenated to obtain a three-dimensional multidirectional noise-resistant LBP feature vector (a LMNRBM operator), as
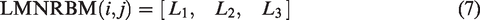
To highlight the differences between foreign fibers and the cotton background in the texture feature map, the Sobel edge detection operator is used to extract edge information in different directions, generating a linearly enhanced image. This image is then subjected to a linear transformation before applying the LMNRBM operator for feature extraction, as shown in Figure 4. The comparison clearly shows that the texture features extracted by the LMNRBM operator, when applied to the Sobel-linear transformed image, exhibit a higher contrast between foreign fibers and the cotton background. This is particularly beneficial for detecting linear and weak-edge foreign fibers, facilitating subsequent segmentation tasks.

Contrast of texture feature images of foreign fibers: (a) original image of cotton foreign fibers; (b) original local binary patterns texture image; (c) Sobel-local multidirectional noise robustness binary mode (LMNRBM) texture image and (d) Sobel-linear transformation-LMNRBM texture image.
Improved SLIC superpixel segmentation
The SLIC superpixel segmentation algorithm, proposed by Achanta et al.,
23
utilizes both color and spatial information of an image to perform iterative clustering, thereby segmenting the image into several irregular pixel blocks with similar characteristics, such as color and brightness. The algorithm transforms the image from the red-green-blue (RGB) color space to the CIELAB color space, where each pixel is represented by a five-dimensional feature vector that includes its spatial coordinates. Local clustering is then performed based on a similarity metric. If an image contains N pixels and it is expected that K superpixels will be generated, then the side length of each superpixel is approximately
During the clustering process, the distance (D(i, ck)) between a point i within the region and the clustering center ck is defined as
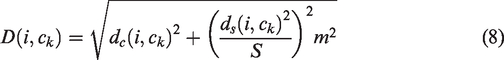
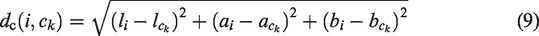
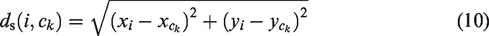
Although the aforementioned SLIC algorithm has good color and spatial complexity, it does not utilize image texture features. When the foreign fibers in cotton are similar in color to the background but differ in texture, the segmentation accuracy is not high. To address this, the LMNRBM operator is used to calculate texture features; and texture distance is introduced into the original SLIC similarity metric, making the segmentation results more accurate. The improved SLIC similarity metric is defined as
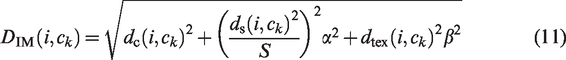
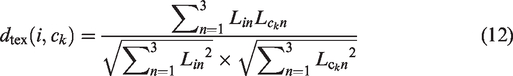
Superpixel classification and merging
The image segmented by the improved SLIC algorithm does not directly yield a complete image of the foreign fibers but instead divides the image of cotton foreign fibers into several irregular superpixel blocks, as shown in part in Figure 5. Therefore, to solve the over-segmentation problem, it is necessary to merge superpixels of the same class, based on the similarity between adjacent superpixels. By extracting color and texture features from the superpixel blocks to form multidimensional feature vectors, an SVM classification model can be used to classify the cotton background superpixels and foreign fiber superpixels to achieve image segmentation.

Superpixel sample diagram.
Feature extraction
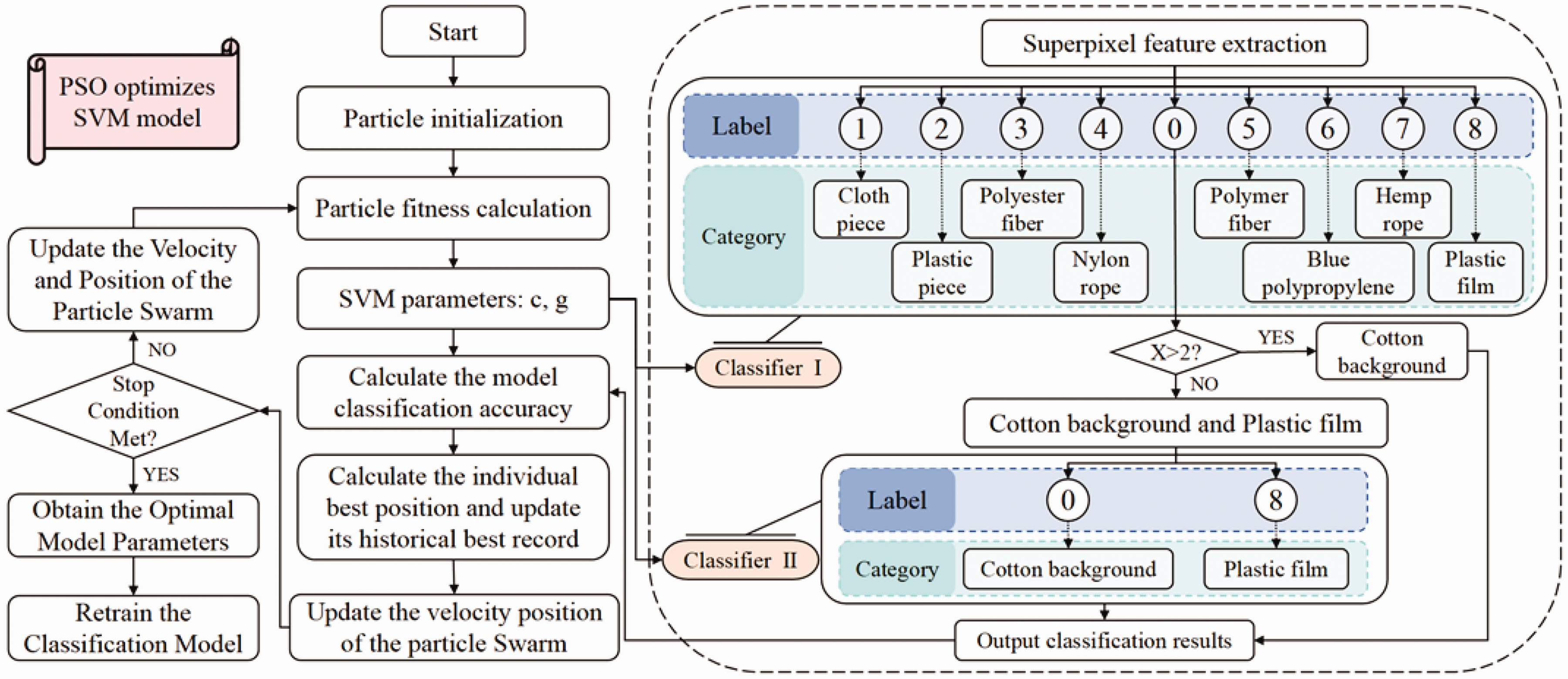
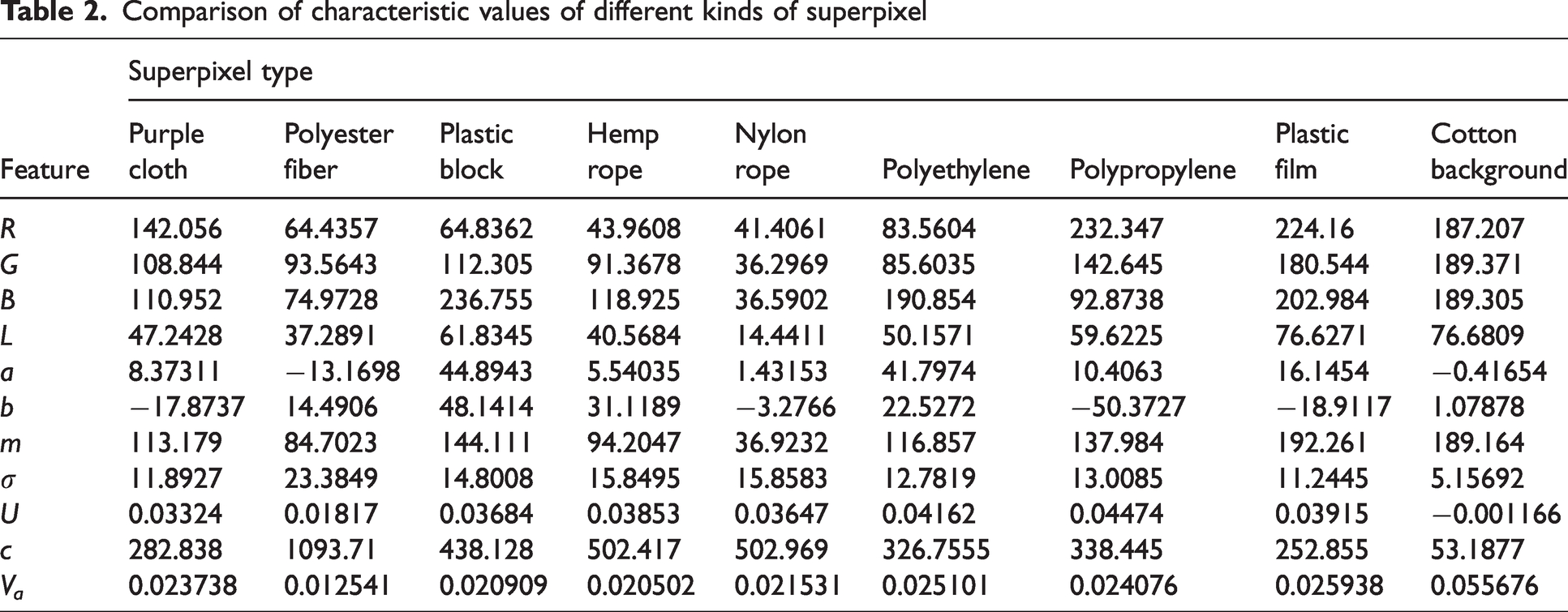
Color features, as the most intuitive image characteristic distinguishing the target from the background, are widely used in image segmentation, owing to their strong robustness. In this study, the mean values of the color components R, G, B, L, a, and b in the RGB and CIELAB color models are extracted from the superpixels to form a six-dimensional color feature vector. Additionally, texture extraction is performed on the variations and patterns of homogeneous pixels or local regions within the image. Since the contours of superpixels are irregular, the gray-level histogram method is used to describe their texture features. The gray-level histogram of the superpixel is obtained, and five texture descriptors—mean (m), standard deviation (σ), uniformity (U), contrast (c), and second-order moment (Va)—are extracted sequentially to form a five-dimensional texture feature vector. The color features and texture features together form an 11-dimensional feature vector F for the superpixel, as
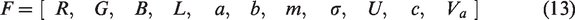
This feature vector is then normalized to accomplish the feature description and classification tasks for the superpixels.
PSO-SVM classification of superpixels
The experiment uses a multi-class SVM model with a radial basis function kernel to classify the superpixel feature vectors of cotton foreign fibers. The labels for cotton background samples are denoted “0”, while the labels for foreign fiber superpixels are denoted “1” to “8”. During the classification process, because the grayscale values of the plastic film and the cotton background are not significantly different, classifier I cannot effectively distinguish between the two. Therefore, a secondary classification is performed for the background superpixels and plastic film, as shown in Figure 6. In block segmentation, the number of initially classified foreign fiber labels X is counted. If X > 2, the classification result is directly output; otherwise, classifier II is used for secondary classification before outputting the classification result.
Particle swarm optimization (PSO)-optimized support vector machine (SVM) classification model based on radial basis function kernel.
The penalty factor c and kernel function parameter g are important parameters in the SVM classification model, and their selection significantly affects the model’s performance. In this study, the PSO algorithm is used to optimize the SVM classification model. This algorithm performs a global search with moving particles, adjusting the search strategy according to the current situation, demonstrating clear advantages. The maximum number of evolutionary iterations is set to 70, and the population size is set to 50 particles. The 11-dimensional feature vector F is used as the model input variable, and the superpixel categories are used as the model output variables to build the classification model. The model performance is evaluated using classification accuracy.
Before training the classifier, the feature data are normalized using
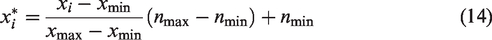
Category correction
Owing to the misclassification present in the trained classification model, the following correction method is proposed to compensate for classification errors and achieve better segmentation results.
Confidence adjustment for predicted labels
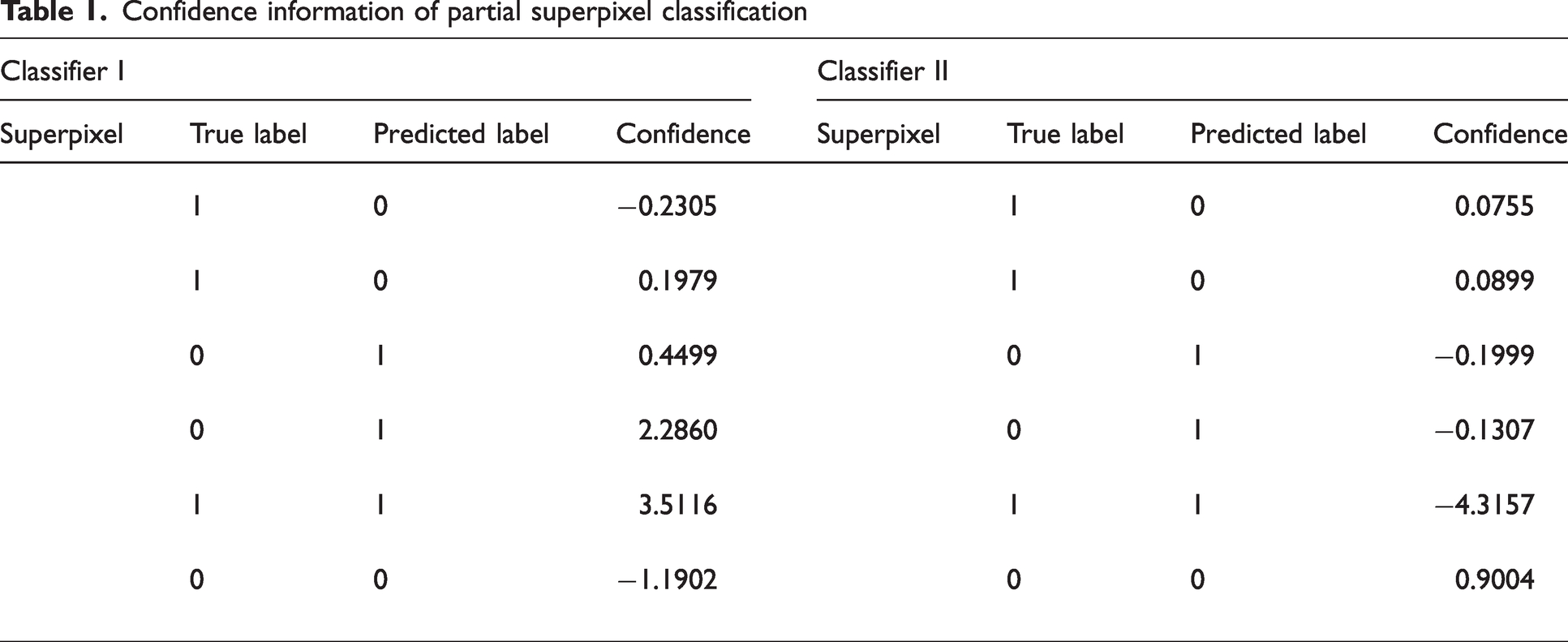
After using the SVM classification model, the labels predicted as foreign fibers are uniformly set to positive samples “1”, while the labels predicted as cotton background remain as negative samples “0”. The confidence level for each predicted sample is obtained during the classification process. By comparison, it was found that in the predicted samples of classifier I, most deviations, which cause under-segmentation, result from foreign fiber superpixels being misclassified as cotton background superpixels, with confidence levels in the range [−0.3, 0.3]. Superpixel labels predicted as cotton background within this threshold are corrected to “1”. In the predicted samples of classifier II, those with confidence levels in the range [−0.3, 0] are cotton background superpixels misclassified as foreign fiber superpixels, and their labels are corrected to “0”. Confidence levels in the range [0, 0.15] correspond to foreign fiber superpixels misclassified as cotton background superpixels, and their labels are corrected to “1”. Some of the superpixel classification confidences are given in Table 1. The predicted sample confidence thresholds obtained are used to set the correction rules for preliminary label correction.
Confidence information of partial superpixel classification
Bhattacharyya coefficient label correction
Confidence correction in the SVM classification model rectifies classification errors, further improving classification accuracy, though some misclassified labels still exist. To better describe the spatial relationships of each superpixel block in a two-dimensional space, a region adjacency graph (RAG) was constructed and its generation process is shown in Figure 7.
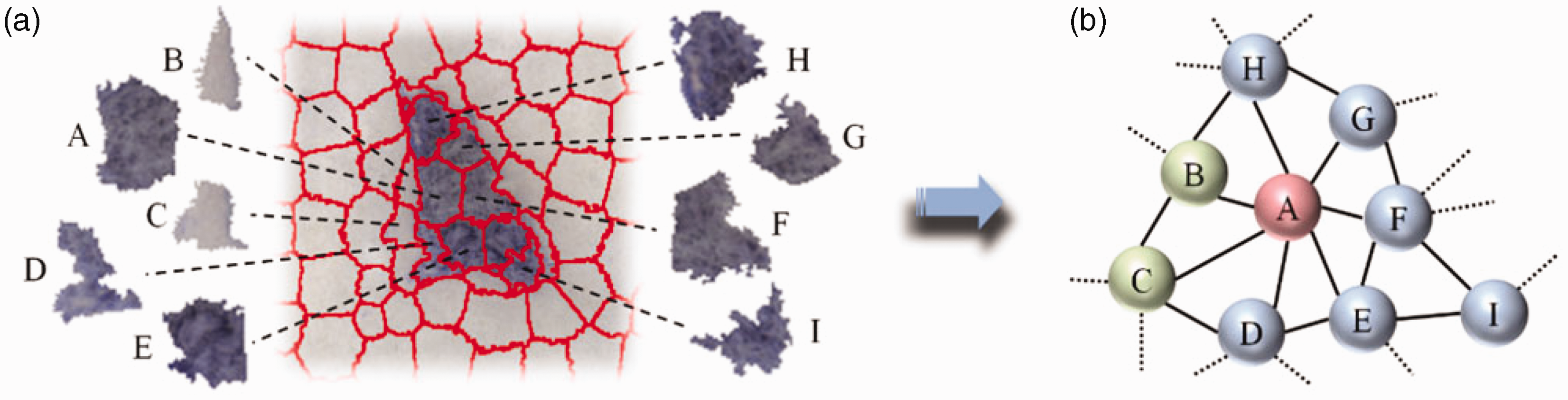
Region adjacency map generation: (a) simple linear iterative clustering segmentation image and (b) generated region adjacency graph.
On statistical analysis of several superpixel segmented images of cotton foreign fibers, it was found that each superpixel region is adjacent to approximately one to seven other superpixels. In regions where foreign fiber superpixels are misclassified as cotton background, there are always two or more adjacent foreign fiber superpixels. Similarly, in regions where cotton background superpixels are misclassified as foreign fiber superpixels, there are always two or more adjacent cotton background superpixels. Based on these statistical results, the classification results of superpixels are corrected using the region adjacency relationships and by introducing the Bhattacharyya coefficient. The specific steps are as follows.
The grayscale histograms of all superpixels classified as foreign fibers and cotton background are statistically analyzed. The grayscale histogram of cotton background superpixels adjacent to foreign fiber superpixels is obtained. The Bhattacharyya coefficient between these histograms and those of foreign fiber and cotton background superpixels is calculated to measure similarity. If the similarity between a superpixel and the foreign fiber is greater than that between the superpixel and the cotton background, its classification label is reclassified as a foreign fiber superpixel.
The grayscale histogram of foreign fiber superpixels adjacent to cotton background superpixels is obtained. The Bhattacharyya coefficient between these histograms and those of foreign fiber and cotton background superpixels is calculated to measure similarity. If the similarity between a superpixel and the cotton background is greater than that between the superpixel and the foreign fiber, its classification label is reclassified as a cotton background superpixel.
These steps are repeated until the classification labels no longer change.
The Bhattacharyya coefficient can be used to measure the similarity between two discrete probability distributions. The formula for calculating it is
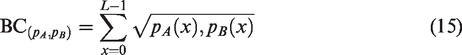
Model evaluation
To further quantitatively describe the segmentation performance, in this work, four evaluation metrics are used to analyze the segmented images: precision, recall, F1 score, and accuracy. The precision represents the proportion of pixels predicted by the model to belong to the segmented region that belongs to the target segmented region. The recall represents the proportion of pixels that are correctly predicted by the model out of all the pixels that belong to the target segmented region. The F1 score is a metric that measures the combined performance of precision and recall, providing a more comprehensive evaluation of the model’s performance in segmenting foreign fiber samples. A higher F1 score indicates better model performance. The corresponding formulas are:


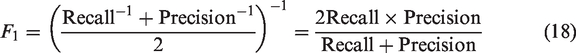
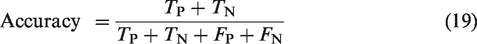
Results and analysis
The algorithm in this paper is implemented using VC++ and OpenCV 4.5.0. The computer used is a Lenovo Legion Y7000 2020, configured with an Intel Core i7 10750H processor, a central processing unit clock speed of 2.6 GHz, 16 GB of random-access memory and the 64-bit Windows 10 operating system. The segmentation standard uses the ImageLabeler tool in Matlab for pixel-level annotation.
Improved SLIC segmentation effect
To verify the segmentation performance of the improved SLIC algorithm, we compared the superpixel segmentation effects of cotton foreign fibers using both the original SLIC algorithm and the improved SLIC algorithm, with the number of superpixels set to K = 400. As shown in Figure 8(b), the original SLIC algorithm exhibits several cases of under-segmentation, with the yellow and green boxes corresponding to under-segmentation phenomena of linear and weakly edged foreign fibers, respectively. After incorporating texture information, the improved SLIC segmentation effect is shown in Figure 8(c), where the boundary segmentation performance of linear and weakly edged foreign fibers is significantly better than that of the original SLIC algorithm.
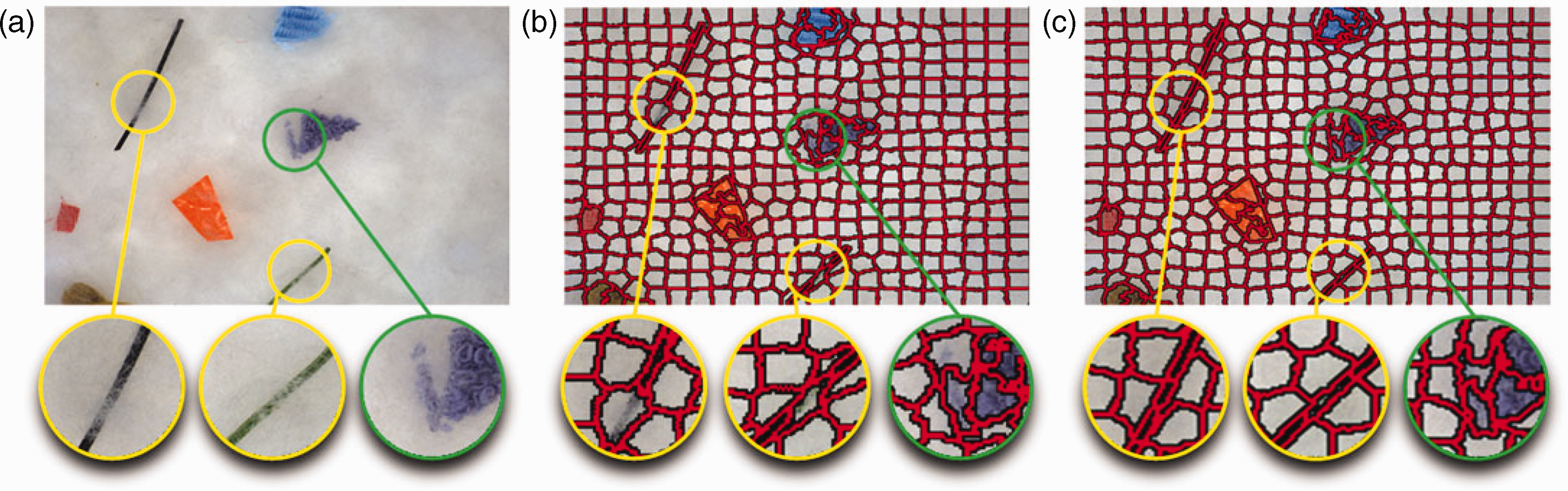
Comparison of effect before and after improvement of simple linear iterative clustering (SLIC) algorithm: (a) original image; (b) SLIC superpixel segmentation algorithm and (c) improved SLIC superpixel segmentation algorithm.
Establishment and analysis of superpixel classification model
The improved SLIC algorithm segments images of foreign fibers mixed in cotton into several irregular superpixels. We extract color and texture features from these superpixels to form an 11-dimensional feature vector. Using the PSO-SVM classification model, we classify the superpixels of the cotton background and foreign fibers to achieve image segmentation. In the experiment, 100 images were selected for superpixel sample collection, with 20 superpixels of each type used to calculate the mean feature values, as shown in Table 2. To ensure segmentation speed, the resolution of the collected images was reduced to 300 pixels × 450 pixels. A total of 3928 superpixels were collected, including 2657 foreign fiber superpixels and 1271 cotton background superpixels. Of these, 3416 superpixels were randomly selected as training samples for the SVM classification model, including 2233 foreign fiber superpixels and 1183 cotton background superpixels.
Comparison of characteristic values of different kinds of superpixel
The training samples are normalized within the range [0, 1], and the preliminary training of the classifier is conducted using the LIBSVM library. The trained SVM classifier is then used to test 412 test samples, and the confidence scores of the samples are obtained. The test results show that the overall classification accuracy of the model is 79.85%. Owing to the similar feature values for hemp rope and nylon rope and for plastic film and the cotton background, the classification accuracy for hemp rope and plastic film is low. To address this, the PSO algorithm is used to optimize the classification model. The number of particles is set to 50, and the number of iterations is set to 70. The fitness curves for the two stages of classifier optimization are shown in Figure 9. After optimization, the parameters for classifier I are c = 14.67 and g = 0.1, with a classification accuracy of 95.98%. For classifier II, the parameters are c = 4.89 and g = 4.79, with a classification accuracy of 96.55%. The overall classification accuracy is 96.10%. The comparison of classification results before and after optimization is shown in Figure 9, indicating a significant improvement in classification performance.
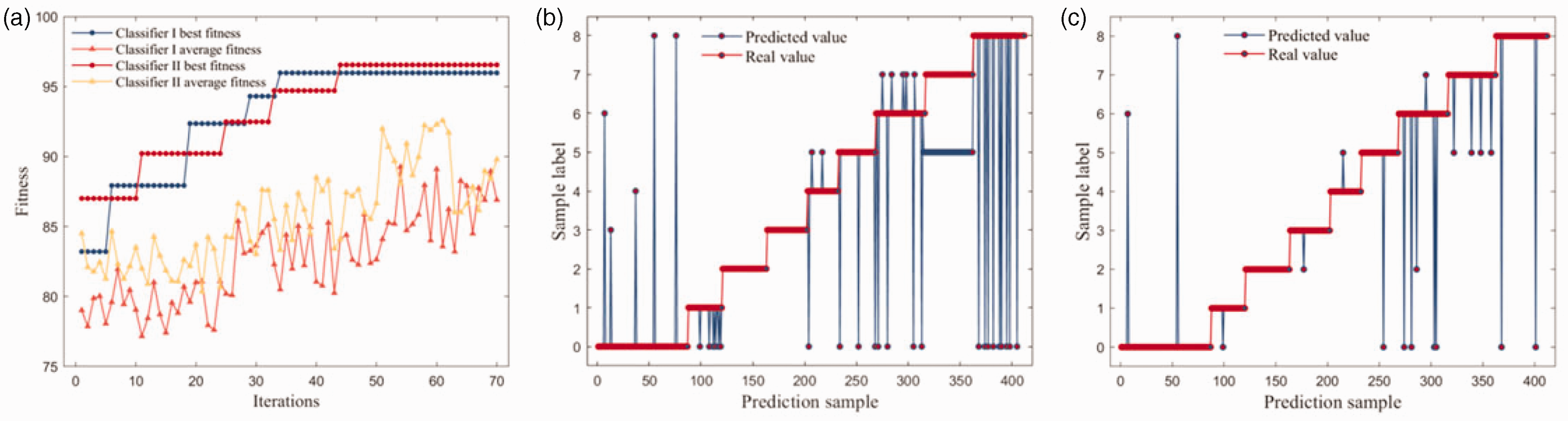
Comparison of support vector machine (SVM) model classification results before and after particle swarm optimization (PSO): (a) fitness curve of PSO-SVM; (b) SVM model classification results before PSO optimization and (c) classification results of SVM model after PSO.
Algorithm performance analysis
Superpixel merging
Superpixel images undergo classification, whereas irregular superpixel blocks are classified and merged accordingly. Superpixels classified as cotton background are turned black, while those classified as foreign fibers remain unchanged. Owing to the sparse distribution and small area of foreign fibers in the image, the image size significantly affects the speed of SLIC superpixel segmentation. To enhance segmentation efficiency, cotton images are divided into blocks to check for the presence of foreign fibers. Images with a resolution of 300 pixels × 450 pixels are divided into six sub-images with a side length of 150 pixels each. The threshold is obtained using the grayscale extreme difference to determine whether each sub-image contains foreign fibers. Sub-images without foreign fibers are turned black, while those with classification and merging of images reveal significant over-segmentation (as seen in Figure 10(c) II, III, V, VII, IX) and under-segmentation (as seen in Figure 10(c) VI, VII, X), owing to poor classification performance. After confidence correction, some misclassified superpixels are corrected, and the segmentation of foreign fibers is mostly completed, as shown in Figure 10(d), although some misclassified superpixels still exist. On this basis, by utilizing the region adjacency relationships with the introduction of the Bhattacharyya coefficient, more complete segmented images can be obtained, as shown in Figure 10(e). The superpixel classification accuracy is improved to 98.65%.

Sub-image segmentation effect comparison: (a) original image; (b) improved simple linear iterative clustering superpixel segmentation; (c) classification model, initial merged image; (d) image corrected using confidence and (e) image corrected using Bhattacharyya coefficient.
According to statistics, the average segmentation time for 50 sub-images is 0.061 s, whereas the average segmentation time for 50 whole images, with a preset value of K = 400, is 0.171 s. Therefore, when there are more than two sub-images containing heteromorphic fibers, segmentation of the entire image is performed. An example of the segmentation effect on the entire image is shown in Figure 11 IV, V.
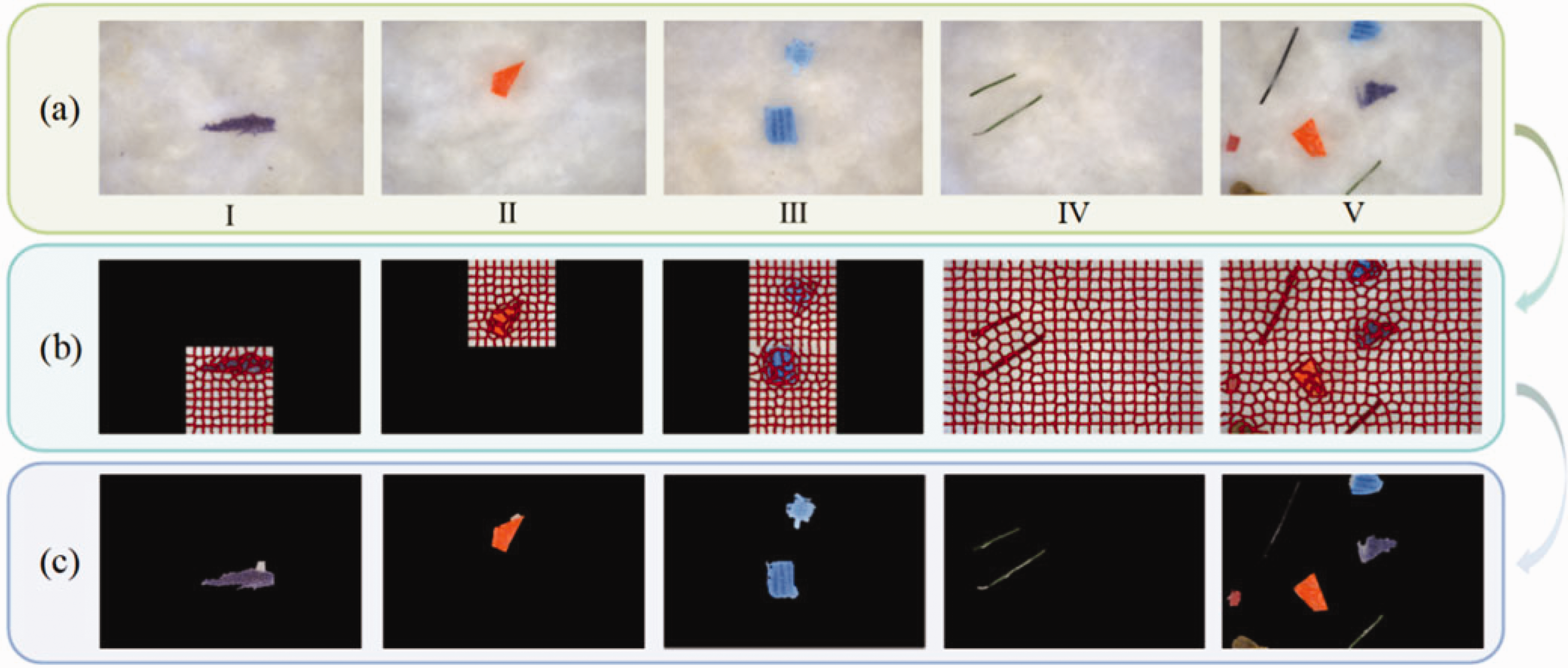
Whole image segmentation effect: (a) original image; (b) improved simple linear iterative clustering superpixel segmentation and (c) final segmentation effect.
Comparative analysis of different segmentation algorithms
In this study, we selected typical images from collected images of foreign fibers mixed in cotton for verification. We compared our proposed method with the widely used adaptive threshold segmentation Otsu algorithm and K-means clustering segmentation algorithm, which are currently commonly employed in foreign fiber detection.
The experiments were conducted on both the entire image and the sub-images, with some segmentation results shown in Figure 12. Figure 12(c) shows the segmentation image using the Otsu algorithm. It can be seen that this algorithm is greatly affected by uneven illumination. Since it can only adaptively find the optimal segmentation threshold, it is not effective in segmenting foreign fibers of various types, especially those with gray levels similar to the cotton background, resulting in poor segmentation performance. The K-means segmentation algorithm, conversely, performs clustering on the entire image. It requires selection of an appropriate value of K before segmentation, as shown in Figure 12(d). The choice of K greatly affects the final clustering result. To ensure segmentation quality, we chose K = 5 for the whole image segmentation, which yielded the best results. For sub-image clustering segmentation, K was uniformly set to 2. Comparative analysis revealed that our proposed method, by fully utilizing various visual features of the image, achieved overall better segmentation performance than the other two methods, accurately segmenting most of the foreign fiber pixels.

Different segmentation algorithm renderings: (a) original images; (b) manually calibrated images; (c) Otsu threshold segmentation; (d) K-means segmentation and (e) segmentation method of this study.
Thirty images containing foreign fibers were selected, of which 15 full images (as shown in Figure 12(a) I) and 20 sub-images (as shown in Figure 12(a) II, III) were manually annotated. These images were segmented using the Otsu algorithm, the K-means clustering algorithm, and our proposed segmentation algorithm, and then compared with the manually annotated images. The precision, recall, and F1 score for each image, as well as the segmentation time, were calculated, and their averages are given in Table 3.
Segmentation of performance metrics of different algorithms
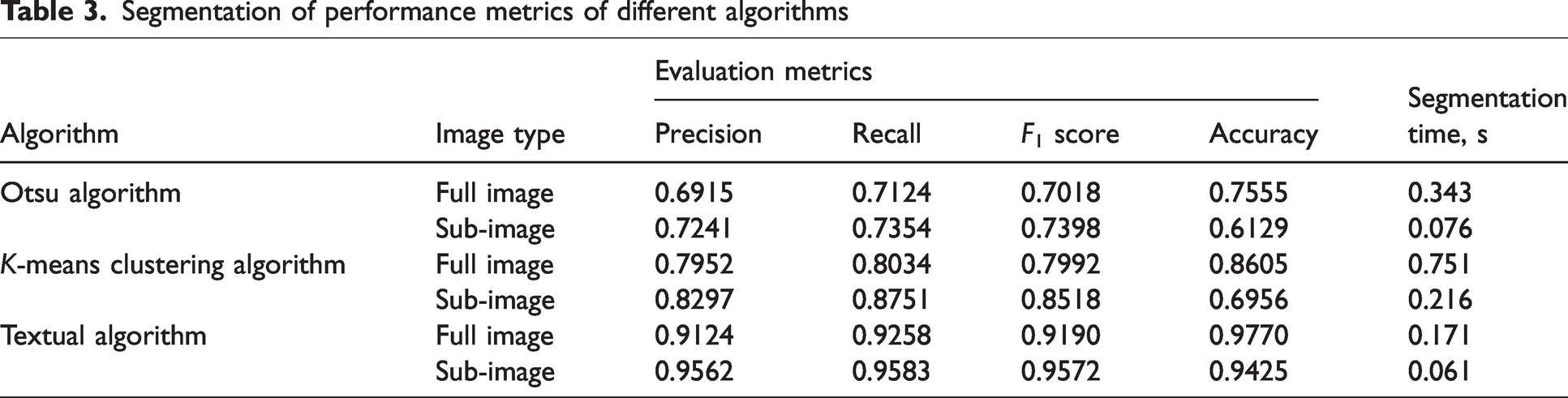
From Table 3, it can be observed that the Otsu algorithm is highly sensitive to uneven illumination and performs poorly in segmenting foreign fibers under natural lighting conditions. This is especially evident when segmenting more transparent plastic films, where the algorithm struggles to determine an adaptive threshold, resulting in the lowest precision, recall, and F1 score of the three algorithms. The K-means clustering segmentation algorithm, however, can achieve varying segmentation effects if different values of K are set, and is more sensitive to color information. Its segmentation performance indicators are higher than those of the Otsu thresholding algorithm. However, it requires a predetermined number of clusters, which is difficult to ascertain in practical foreign fiber segmentation scenarios.
Our proposed superpixel-based segmentation algorithm leverages both the color and texture features of the image. After an initial classification of superpixel units using an SVM, a correction method is designed, significantly enhancing segmentation performance. This algorithm effectively segments various types of foreign fiber, particularly plastic films and filamentous foreign fibers with grayscale values similar to the cotton background. The segmented foreign fiber regions exhibit high precision, recall, F1 score, and accuracy, and the segmentation time meets the basic requirements for real-time applications.
Conclusion
Addressing the poor segmentation performance of the SLIC superpixel algorithm on filamentous and weak-edge foreign fibers, in this paper, we propose a segmentation method for identifying foreign fibers in cotton based on superpixel features. By utilizing the designed LMNRBM operator to fully extract image texture information and improve the SLIC algorithm, the superpixels generated by the improved SLIC algorithm can better fit the boundaries of filamentous and weak-edge foreign fibers, effectively enhancing segmentation performance.
By extracting the color and texture features of superpixel blocks to form an 11-dimensional feature vector, and using a PSO-SVM classification model to classify and merge the superpixels, the initial segmentation of foreign fibers can be achieved. A confidence correction method and a correction method based on the RAG and the Bhattacharyya coefficient were designed to perform two corrections on the superpixels classified by the SVM. This further improved the classification accuracy to 98.65%, effectively segmenting the foreign fibers.
Compared with classical segmentation algorithms, the proposed algorithm demonstrates superior performance in terms of segmentation accuracy, recall, and F1 score. The average segmentation accuracy per image reaches 95.73%. However, there are still some superpixel classification errors that reduce the segmentation precision. Therefore, future work could be focused on enhancing the feature distinction between the foreground and background during the image preprocessing stage or on designing more refined correction methods to improve image segmentation accuracy.
Footnotes
Data availability statement
All relevant data are within the paper.
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported by the Youth Foundation of China University of Petroleum-Beijing at Karamay (grant number XQZX20230038); the Basic Scientific Research Business Expenses Projects of Autonomous Region Universities (grant number XJEDU2024Z008); and the Xinjiang Uygur Autonomous Region “Tianshan Talent” Training Program Projects (grant number 2023TSYCJC0036).
Ethical approval
The authors confirm that all the research meets ethical guidelines and adheres to the legal requirements of the study country. The study does not involve human research participants.