
Abstract
Simplified user interfaces (SUIs) refer to a new design technique in technical communication that simplifies screenshots by removing irrelevant elements and highlighting only the essential information. While there is consensus on the benefits of signaling in multimedia learning, there is currently no empirical evidence on the effects of SUIs on user performance. This study reports an eye-tracking experiment that examined whether users can work more effectively and efficiently with a software tutorial containing SUIs instead of unedited pictures without signaling or pictures using conventional signaling techniques. The study also aimed to clarify whether SUIs draw user attention to relevant areas of a picture. Eye tracking and performance measures indicate that SUIs draw user attention successfully, but do not improve user performance compared to unedited screenshot in a tutorial scenario. The results contribute to the question of whether design principles of multimedia learning can be successfully transferred to action-oriented texts.
Introduction
Illustrations are an integral part of software documentation such as tutorials, online help systems, or user guides. The predominant type of illustration used in software documentation is screenshots, which provide realistic depictions of the user interface. Prior research has shown that for screenshots to effectively support software documentation users, they must use appropriate visual signaling techniques that draw user attention to the relevant areas, such as buttons or input fields that users are instructed to interact with inthe context of a certain task (Gellevij & van der Meij, 2002, 2004; Meng, 2019). Signaling techniques commonly used for this purpose are colored frames, arrows, or magnifiers that are added to or imposed on a screenshot.
In recent years, a new screenshot design technique, known as simplified user interface (SUI), has received considerable attention. Initially used primarily in marketing, screenshots using the SUI technique are now increasingly finding their way into technical communication (Bollen & Saremba, 2020, 2021) and are used in software tutorials, feature overviews, or quick tours. The SUI design technique is characterized by the simplification and reduction of a conventional screenshot to its essentials. All irrelevant text, symbols, and elements are removed or visually reduced to simple basic shapes (see Figure 1). Only content that serves as an orientation or is necessary for the task to be carried out at this point remains (Bollen & Saremba, 2020, 2021, p. 13 f.). The reduced content is intended to draw the user's attention to the essential information of the image, and everything else is hidden.
Nonsignaled screenshot (left), conventional signaling (middle), simplified user interface (right).
SUIs provide an alternative to commonly used signaling techniques for screenshots that visually highlight key areas of an image. While there is broad theoretical consensus and ample empirical evidence for the benefits of signaling in multimedia learning (Mayer, 2021) and some initial results for action-oriented texts (Meng, 2019), the situation is still different for SUIs. Despite the widespread use of this design technique, there is currently no empirical evidence on the effects of SUIs on user performance, for example, whether they help draw user attention to relevant information in a picture as intended and whether they support users of software tutorials to carry out tasks more effectively and efficiently. Moreover, whether using the SUI technique provides advantages over conventional signaling techniques has not yet been investigated. Shedding light on this issue is also important, as this can help practitioners decide whether the additional effort to create SUIs compared to using conventional signaling techniques is worthwhile.
The present eye-tracking study examined whether users can work more effectively and efficiently with a software tutorial containing SUIs instead of unedited pictures without signaling or pictures using conventional signaling techniques, such as colored frames. Moreover, this study seeks to clarify whether SUIs successfully draw user attention to relevant areas of a picture. The results should support practitioners in making evidence-based recommendations for the use of screenshots in action-oriented texts. This not only helps technical communicators use resources more efficiently in documentation and user assistance. On a theoretical level, this study contributes to the question of the extent to which well-known principles of multimedia learning, such as the signaling principle, can be successfully transferred to action-oriented texts.
Background and Prior Research
Multimedia Learning and Task Orientation
According to the Cognitive Theory of Multimedia Learning (CTML), multimedia instruction refers to presentations that use images and text to convey a message (Mayer, 2021, p. 4). The CTML examined multimedia instruction, particularly with a view to learning, and how multimedia instructions should be designed to foster learning in an optimal way. Theoretical models such as CTML attempt to explain cognitive processes in learning with the help of pictures and texts. The CTML is based on the premise that humans have a visual and a verbal information processing channel. Both have only a limited working memory capacity, which is why the cognitive load that is irrelevant to learning should be kept as low as possible. It has been well researched that a combination of text and images can foster learning, particularly for learners with little prior knowledge (Mayer, 2021; Mayer & Gallini, 1990). Other ways to keep the cognitive load during learning low may include removing irrelevant graphics or directing attention to relevant areas of a picture (Mayer, 2021, p. 143 ff., 166 ff.; Sung & Mayer, 2012, p. 1619). Mayer describes the latter in his signaling principle as part of the CTML. Attention can be drawn on a visual level by highlighting the relevant areas in color. This is also referred to as visual signaling and is discussed in more detail in a later subsection.
In contrast to learning materials, procedural texts such as software tutorials are generally not read solely for learning purposes. Rather, the focus is mostly on an action-oriented approach to reading in order to act or to learn how to act later (Carroll, 1990; Redish, 1989). The extent to which the design principles and underlying assumptions of the Cognitive Theory of Multimedia Learning can be transferred to action-oriented texts has not yet been fully researched. However, initial results indicate that, for example, the use of illustrations in action-oriented texts has a similar positive effect as in learning-oriented texts (Irrazabal et al., 2016; van Genuchten et al., 2014). For example, Irrazabal et al. (2016) demonstrated an advantage in using multimedia-prepared, action-oriented instruction texts. Participants were quicker to process instructional materials with illustrations or multimedia content than with pure text. In addition, they made fewer mistakes with the help of multimedia. Research on the specific effects of screenshots also confirms that action-oriented text benefits from multimedia. The results reported by van der Meij (1996) and Sweller and Chandler (1994) provide early evidence that procedural instructions containing screenshots can improve user performance (see Meng, 2019, for an overview). More recently, Meng (2023) found that study participants working through a software tutorial made fewer errors when the software tutorial included pictures that supported action steps within procedures compared to tutorials containing text only. However, whether and to what extent benefits from other design principles for multimedia learning proposed within CTML, such as the coherence or the signaling principle, carry over to action-oriented materials is still an open question.
Screenshots and Visual Signaling
Screenshots serve a variety of functions within tutorials, online help systems, or user guides (Gellevij & van der Meij, 2004; van der Meij & Gellevij, 1998). With the help of a screenshot, the user can locate and identify relevant controls or can collate a system status (Gellevij & van der Meij, 2004, p. 225). In addition, screenshots are assumed to help coordinate the switching of attention between the screen, software documentation and the use of the input device and thus counteract a split-attention effect (van der Meij, 2000, p. 295). For screenshots to support users effectively, their design has to support the intended function in an appropriate way, for example with respect to the area of the user interface shown and the size of the screenshot. A design quality that is of particular importance is the use of visual signaling (van der Meij, 2000, p. 296; van der Meij & Gellevij, 1998, p. 529). Visual signaling is often applied to screenshots to help users more easily identify the elements relevant to the action step to be performed. Designed techniques commonly used for visual signaling include arrows, frames, color highlights, or labels on the relevant area of the screenshot to direct the user's attention to it.
According to the signaling principle proposed within the CTML, people learn better when cues are added to text (verbal signaling) or pictures (visual signaling) in multimedia materials that highlight the essential information (Mayer, 2021, p. 166). Ample empirical evidence exists which demonstrates that visual signaling fosters learning, and is especially effective for learners with low prior knowledge (Alpizar et al., 2020; Mayer, 2021). Regarding action-oriented texts, such as tutorials, there is only little research on the use of visual signaling. Evidence of a positive effect derives from the results of an eye-tracking experiment reported in Meng (2019). In this study, two tutorial versions were examined and compared, one with unedited, nonsignaled screenshots and the other one with screenshots using conventional signaling techniques. The results show a positive effect of signaled screenshots compared to unediteds creenshots in terms of errors made during the tutorial. Though these results provide a first hint that visual signaling effectively directs user attention and facilitates the identification of relevant content of a picture in action-oriented texts as well, more empirical research is needed in this area.
Simplified User Interfaces
Highlighting the relevant image content—as is done with conventional signaling techniques—is one variant. Screenshots using SUIs take a different approach: they follow the concept of less details and let everything that is irrelevant fade into the background. The highly reduced screenshots are also intended to help the user identify the essential information in the image more easily. Hence, SUIs can essentially be considered another design technique for visual signaling. Whereas conventional signaling controls attention through additional elements, SUIs achieve this through the reduction of irrelevant elements of a picture. The viewer’s focus is directed to relevant picture information because everything that is irrelevant is reduced to inconspicuous colors and shapes and thus fades into the background (see Figure 1).
From a practitioner's perspective, SUIs are claimed to have a number of advantages compared to conventional screenshots that directly depict the user interface (Boatman, 2020; Bollen & Saremba, 2020, p. 14). These advantages usually amount to time and cost savings with respect to content maintenance and localization. During the software lifecycle, changes to the user interface occur frequently. Due to new features or changes to user interface design, UI elements may be moved, renamed or new UI elements may be added, causing significant efforts to keep the images in the instructions up to date. This effort is largely eliminated with SUIs because elements that were modified during a software update might not have been displayed anyway. In a similar vein, SUIs can greatly reduce localization efforts, as much of the text is eliminated in SUIs. Therefore, SUIs can often be reused in different language versions of the documentation, and if necessary at all, only one image version needs to be maintained. SUIs also reduce effort and cost resulting from the need to create fictitious user data, as such data will only be needed if it is part of the relevant screenshot area that is not faded.
However, practitioners need to weigh these advantages against a significant disadvantage of SUIs compared to conventional screenshots: the creation effort. Disregarding the time necessary to prepare the UI, it takes one click to take a screenshot. For a SUI screenshot, the creation can be much more time-consuming. And even though commercial software exists that can automatically create SUIs from a screenshot, such as TechSmith Snagit, the process is still more effort than creating a simple screenshot and requires some prior knowledge in graphic design, for example, to make informed decisions regarding the design and the level of detail. Also, a lot of post-processing effort can be necessary, especially for complex and fine-grained screenshot content. Instead of having software create SUIs automatically, they can be created manually using any common graphics or image editing software. However, this requires even more time and expertise.
For practitioners to be able to make informed decisions about using SUIs in tutorials, online help systems, or user guides, it is important to understand how SUIs affect user performance. Bollen and Saremba (2020, p. 14) attribute SUI graphics to cause less cognitive load compared to unedited screenshots due to their hypothesized ability to direct attention and detail reduction. SUIs should therefore contribute to easier orientation and overall support user performance. These claims are plausible but have not yet been confirmed by empirical studies.
SUIs intend to direct user attention by creating a noticeable contrast between the relevant screenshot area which is maintained in full detail, and the irrelevant screenshot area which is backgrounded by reducing the level of detail. It is reasonable to assume that if this contrast is sufficient, it should facilitate the orientation of visual attention toward the relevant screenshot area. What is less clear is which effects the lack of detail in irrelevant screenshot areas has. A first question that arises in this context is whether reducing the amount of detail in irrelevant screenshot areas further facilitates the orientation process, that is, the identification of relevant information in a picture. According to the coherence principle of the CTML, leaving out irrelevant information reduces cognitive load (Mayer, 2021, p. 143). If this effect also applies to action-oriented information, it is possible that SUIs outperform not only screenshots without visual signaling, but also screenshots using conventional signaling techniques, in that they further facilitate orientation.
A second question is which effect the reduction of detail in irrelevant picture areas has on the coordination of attention between the documentation (e.g., a tutorial procedure containing SUIs) and the screen (i.e., the UI users are interacting with while working on the procedure). On the one hand, it is possible that SUIs facilitate coordination of attention since they reduce cognitive load, leaving more capacity for the coordination process. On the other hand, it is possible that the coordination process is hindered, since the lack of detail could make it more difficult for users to relate information from the screenshot to the actual user interface. For example, if a screenshot depicts only a small area of the UI, users need to localize and identify this area in the real user interface to which the screenshot refers. The lack of detail in SUIs could make this process more difficult, as suggested by research on line graphics in manuals showing that both too much but also too little detail negatively affects user performance (Alexander et al., 2016; Schumacher, 2007).
Research Questions
Although SUIs offer several advantages, there have been no systematic research attempts, especially with regard to their use in software documentation compared to conventional screenshots. Empirical evidence is required to determine whether the increased effort to create SUIs is worthwhile. Therefore, the main aim of this study was to determine whether SUIs are as effective or even more effective than screenshots using conventional signaling, which has already proven to be effective in a practical context (Meng, 2019) but requires much less effort to create. To address this question, two research questions were posed.
How well do SUIs support orientation compared to conventional screenshots with or without visual signaling?
The first question was intended to examine a person's orientation on a single, separate picture. The aim was to determine whether both visual signaling and detail reduction of SUIs help users to identify the information they look for, and if so, whether the SUIs provide an additional advantage over conventional signaling with respect to the identification of relevant picture information.
How effective are SUIs in supporting task execution compared to conventional screenshots with or without visual signaling?
Screenshots are primarily used in action-oriented contexts such as tutorials. In tutorials, screenshots complement text elements such as headings, action steps, and result statements that describe the tasks on which users are intended to work. Screenshots and text work together to instruct users on how to interact with software applications. The second question aimed to investigate the effectiveness of SUIs in a real-world application context.
Methods
To address these research questions, an eye-tracking study was designed. Data were collected through two short surveys and two experimental tasks on which participants worked using materials with SUIs, signaled screenshots, or conventional screenshots without visual signaling. The first experimental task (the orientation test) was intended to examine RQ1. Using individual pictures presented one after the other, the aim was to determine how participants managed to orient themselves and identify relevant information. Eye tracking is particularly useful for this task because it enables us to determine exactly when the area containing relevant information is reached. RQ2 was examined through the second experimental task (the tutorial test) which required participants to work through a software tutorial and execute the tutorial tasks. Eye tracking offers the opportunity to check how the various pictures in the tutorial are viewed and what effects they have on the reading process. In addition to the two experimental tasks, two questionnaires were administered. One questionnaire was presented at the beginning of the test session to collect demographical data and data on previous experience with image manipulation. A second questionnaire was presented after participants had completed the tutorial. The post-test questionnaire asked participants to rate aspects of the tutorial and the pictures it contained using four-point Likert scales.
Material
For the tutorial test, a short software tutorial for the image editing program GIMP (www.gimp.org) was created which contained several procedures supported by screenshots. The open-source software GIMP was chosen because participants could be expected to have little or no prior experience with it. Research has shown that pictures in learning materials are particularly helpful for novices (Kalyuga et al., 1998, 2000; Mayer, 2021). For the orientation test, five additional screenshots showing parts of the GIMP user interface were created to be presented individually to the participants. The screenshots were different from screenshots used in the tutorial. Three versions of the materials were produced for both the orientation and the tutorial test that differed only with respect to the type of picture used: SUIs, signaled screenshots using conventional signaling techniques (SIG), or nonsignaled screenshots (SCR). Both tests used a between-subjects design. Participants were assigned randomly to one of the three conditions and worked with the picture type during both experimental tests.
For creating the different picture types, screenshots were taken from the GIMP user interface using the Microsoft Windows Snipping Tool. To create the signaled screenshots, the raw screenshots were enhanced by adding red frames to relevant areas of the screenshot using Adobe InDesign. SUIs were created in Adobe Illustrator. The raw screenshot was placed in the background and then traced. Elements that were directly required for the action step supported by the screenshot remained in full detail. All text elements and symbols that were assumed to be irrelevant for the action steps but possibly useful for orientation were hidden by a gray box. Elements that were considered neither relevant to the action step nor to the orientation were completely removed. Materials for both tests can be downloaded from the OSF repository of this article at https://osf.io/3bhwv/?view_only=f5dea822b6f24cb3aadaf1f9bab92872.
Orientation Test
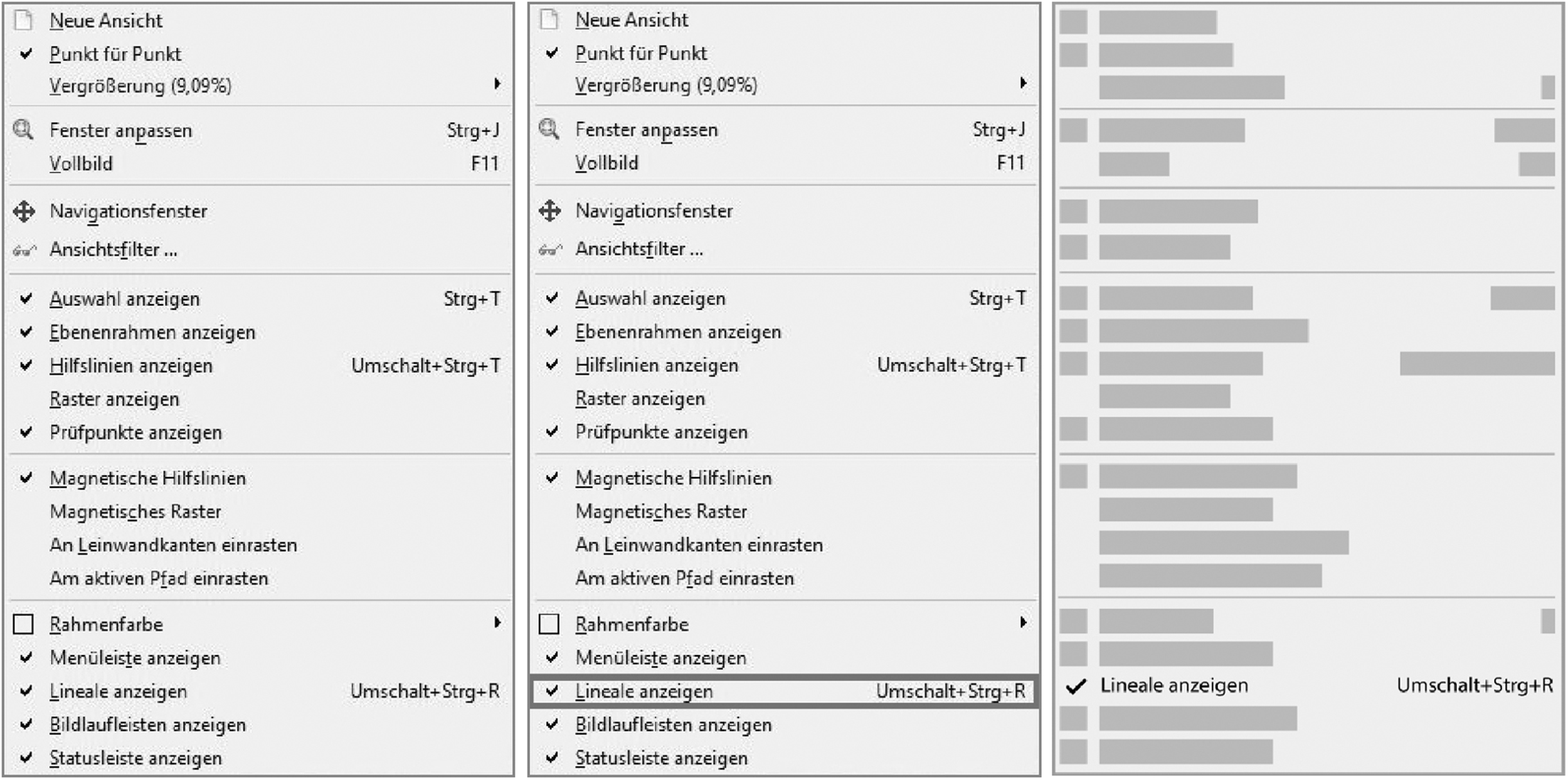
In the orientation test, participants were presented five individual pictures showing parts of the GIMP user interface, one after the other. For each picture, participants had to identify a specific parameter or value on these pictures as quickly as possible. Before a picture was displayed, a question was shown, which should then be answered using the picture. For example, a question was: “Which keyboard shortcut do you need for the action: Show rulers [‘Lineale anzeigen’ in German]?” When the participant pressed the spacebar, the picture (see Figure 1) was displayed on which the solution had to be found. The participant then had to orally express the solution as quickly as possible, but without a time limit. This was followed by the next question.
When selecting the images, care was taken to choose representations that were as different as possible. In the first image, a list menu was selected from which a specific key combination had to be found. In the second image, however, a window was shown with various setting options and controls, and in the third the entire user interface of the software. In task four, a list menu was again used, but in this case a more complex variant with a submenu. The last image again showed a window menu, but with an outline and other setting options. All questions and images were displayed in the same order for each participant.
Tutorial Test
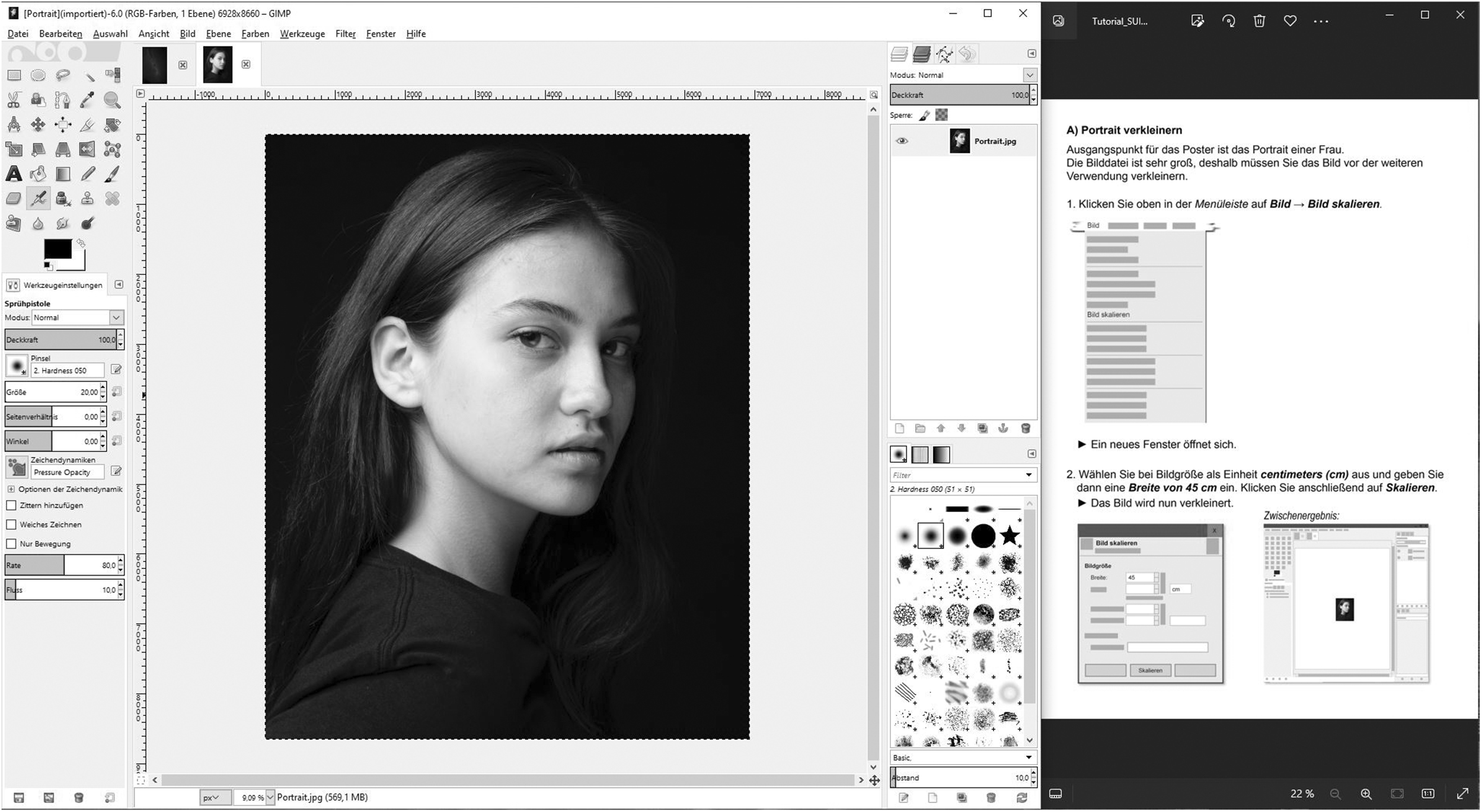
In the tutorial test, participants were asked to create a poster. To do this, two given photos should be combined and then edited using various functions and effects in GIMP. The tutorial consisted of 16 pages. The first page provided a welcome message, a task overview, as well as preview of the result. The second page showed main areas of the GIMP user interface and highlighted and named areas that were relevant to the tutorial.
The following 13 pages contained eight tasks (A–H) which formed the main part of the tutorial. The tutorial was completed by a page showing the final result again. The eight tutorial tasks consisted of a total of 43 action steps. Each task began with a heading expressing the task goal, followed by a brief summary of what should be done in that sequence (see Figure 2). The individual steps were numbered, each action step was followed by a result statement. In some places, information boxes were added which contained additional information, for example, to avoid errors. If action steps required participants to open a new menu or to search for a specific function, a screenshot was added to support the respective action step visually.

The three versions of the software tutorial (SCR: nonsignaled screenshot [left], SIG: conventional signaling [middle], SUI: simplified user interface [right]).
Procedure
Experimental sessions took place in the usability lab of Merseburg University of Applied Sciences. The session consisted of two short questionnaires and the two main tasks (orientation test, tutorial test), which were recorded using eye tracking. At the beginning of the session, the participant was welcomed and informed about the general procedure of the experiment, without going into the exact aim or specific content. A declaration of informed consent and data protection was signed and afterward, the participant was led to the workplace for the study.
The participants worked on a computer equipped with a 24-inch screen, a mouse, and a keyboard. For the eye-tracking recording, a RED 250mobile eye tracker (Sensomotoric Instruments, SMI) was attached to the bottom edge of the screen. The RED 250mobile is a video-based eye tracker, which operates in head-free mode. Both eyes were recorded simultaneously with a tracking rate of 120 Hz. The software SMI ExperimentCenter 3.7 was used to conduct the experiment and record the eye-tracking data. For data analysis, SMI BeGaze 3.7 was used.
The questionnaire starting the session asked participants for information on age, gender, degree program, and prior experience with image editing software in general and with GIMP, in particular. Afterward, participants were placed on an immobile chair in approximately 60 cm distance to the screen. They were instructed to move as little as possible during the experiment and to keep their eyes strictly on the screen at all times. Afterward, instructions on how to perform calibration of the eye tracker were given. The calibration was carried out as a 9-point calibration with subsequent validation. Deviations (X/Y) below 0.5 were accepted, for higher values, the process was repeated.
The eye-tracking recording started with the orientation test, where the participants had to follow the instructions on the screen. For the tutorial test, the screen was split. On the left part, the image editing software GIMP (2.8.18) was displayed, and on the right part the software tutorial (see Figure 3).
Positioning of tutorial and GIMP on the stimulus presentation monitor.
For the tutorial test, there was no time limit and participants were able to scroll through the tutorial backwards and forwards as necessary. After completing the tutorial, the eye-tracking recording was finished. In a final short questionnaire, the participants were asked to assess the difficulty of the tutorial and to evaluate the pictures regarding helpfulness and attractiveness. After answering the questions, the study was completed. At this point, participants were debriefed and possible questions were answered.
Participants
Forty-nine current or former students (28 female, 20 male, 1 nonbinary) participated in the experiment. The participants had diverse backgrounds from 20 different study programs. All participants were native or near-native speakers of German and had a normal (63%) or corrected to normal (37%) vision. The age range was between 18 and 40. The majority of participants (38) were between 20 and 30 years old, four were below 20 and another seven were between 31 and 40 years old. All participants were unaware of the purpose of the experiment and randomly assigned to one of the three conditions. Participants were paid 10 EUR for participation.
As described above, participants were asked to self-assess their previous experience with image editing in general and with GIMP, in particular, at the beginning of the session. On a scale from 0 (no experience) to 4 (very much experience) the participants showed a mean experience of 1.63 with image editing and 0.71 with GIMP (see Table 1). Overall, there is some experience with image editing in general, but hardly any experience with GIMP. Kruskal–Wallis tests revealed that there were no significant differences between the groups (prior experience with image editing: χ2 = 1.61, df = 2, p > 0.1; prior experience with GIMP: χ2 = 1.75, df = 2, p > 0.1).
Prior Experience With Image Editing and GIMP.

Dependent Variables
The main goal of the orientation test was to assess how effective screenshots in the three conditions enable the identification of the critical screenshot area (RQ1). For this purpose, we analyzed both the time and the number of fixations until the first fixation in the critical screenshot area depending on the respective task was made. The main goal of the tutorial test was to assess how effectively the three different screenshot types supported users in working through the tutorial tasks and in coordinating attention between tutorial and the GIMP user interface (RQ2). To address these questions, we analyzed performance measures and eye-tracking measures. Performance measures included the average time participants required to complete a tutorial task (time on tasks), and the proportion of tasks solved correctly (accuracy on tasks).
Eye-tracking measures were computed with reference to areas of interest (AOIs) which were added to the BeGaze screen recordings. First, AOIs were used to separate the screen area covered by the tutorial from the screen area covered by the GIMP software. Using these AOIs, we analyzed how much time participants spent reading tutorial information or interacting with the GIMP software, and how often they switched attention between the tutorial and GIMP. Within the tutorial AOI, the areas occupied by screenshots and the areas occupied by text segments were marked by AOIs as well. This way, it became possible to analyze how much time participants spent viewing the screenshots and how much time they viewed text elements, such as headings, action steps, or result descriptions.
Analysis
All statistical analyses were performed using R (R Core Team, 2023) and RStudio (R Studio Team, 2023). Before starting the analyses, all data (except for the accuracy on tasks) were checked and corrected for outliers. Data points more than 2.5 standard deviations away from the grand mean were regarded as outliers and removed from the data set. This affected between 1.5% and 4% of the data points. For all dependent variables, two types of analyses were performed: a one-way analysis of variance (ANOVA) of the factor “screenshot type” which—in case of a significant effect—was followed up by pairwise comparisons with Holm correction applied to p values. If assumptions of an ANOVA were not met with respect to normal distribution and homogeneity of variance, a Kruskal–Wallis test was used instead, followed up by a pairwise Dunn test, again with Holm adjustments. For these analyses, data were aggregated by participants across the five pictures (orientation test) or the eight tasks (tutorial test).
In addition, mixed-effects regression models were computed (Baayen et al., 2008; Brown, 2021; Winter, 2020) using the lme4 package (Bates et al., 2015). Mixed-effects models included “screenshot type” as fixed effect and “participants” and “tutorial task” as random effects, which means that these models can, unlike the ANOVAs, also capture systematic but uncontrolled influence of individual properties of the tutorial tasks on the dependent variable of interest. Mixed-effects modeling used default contrasts as specified in the lme4 package, which means that one condition served as the baseline against which the two other conditions were individually compared (Brehm & Alday, 2022). The condition serving as baseline was set individually for each analysis depending on the pattern visible in the means. ANOVAs and mixed-effects modeling led to nearly identical results. In what follows, we report the ANOVA or Kruskal–Wallis test results only, which readers are probably more familiar with. Data files and analysis scripts including both ANOVA/Kruskal–Wallis analyses and mixed-effects models can be downloaded from the OSF repository of this study at https://osf.io/3bhwv/?view_only=f5dea822b6f24cb3aadaf1f9bab92872.
Results
Orientation Test
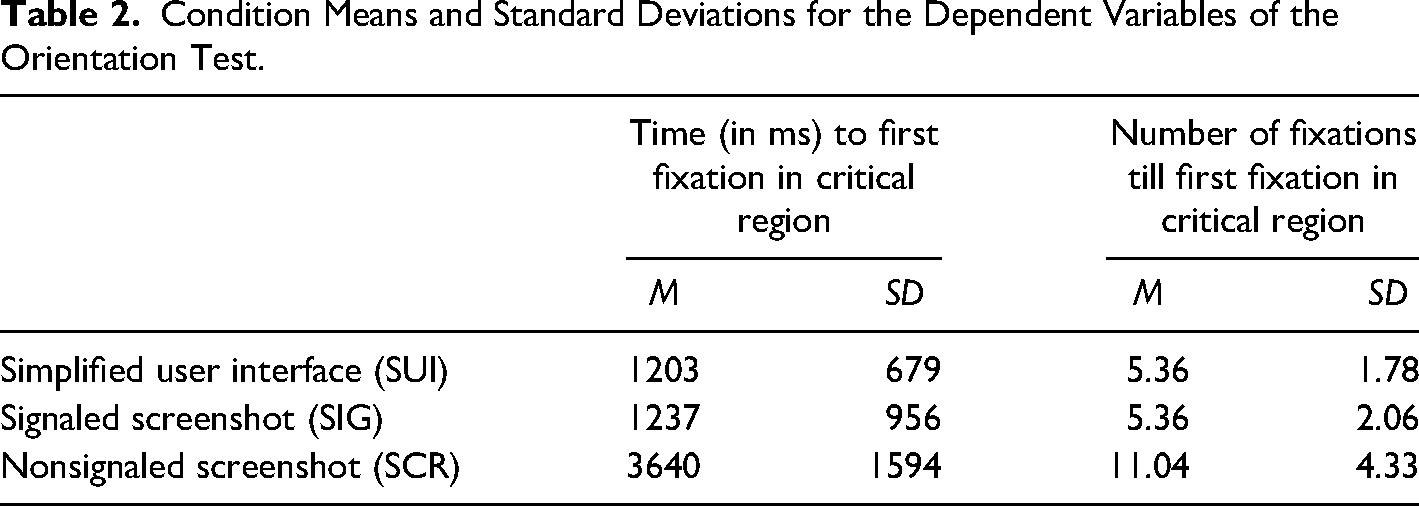
Condition means for the two dependent variables are shown in Table 2.
Condition Means and Standard Deviations for the Dependent Variables of the Orientation Test.
Time to First Fixation in Critical Region
The grand mean time until participants made the first fixation in the critical screenshot area was 1940 ms (SD = 1569). A Kruskal–Wallis test indicated statistically significant differences across the three conditions (χ2 = 29.1, df = 2, p < .01). Pairwise comparisons confirmed that the mean times were faster for the conditions SUI and conventional signaling (SIG) compared to nonsignaled screenshots (SCR) (both p < .01). The difference between the means for SUI and SIG was not statistically significant.
Number of Fixations Till First Fixation in the Critical Region
The grand mean number of fixations until participants made the first fixation in the critical screenshot area was 7.14 (SD = 3.91). There were again significant differences between conditions, as revealed by a Kruskal–Wallis test (χ2 = 31.1, df = 2, p < .01). Pairwise comparisons showed that participants in condition SIG and SUI required fewer fixations to reach the critical screenshot area than participants in condition SCR (both p < .01). With this analysis as well, the difference between the means for SUI and SIG was not significant.
Tutorial Test
Performance Measures
Performance measures included accuracy on tasks and time on tasks. Condition means for the two dependent variables are provided in Table 3.
Condition Means and Standard Deviations for Performance Measures.

Accuracy on tasks was coded manually. To determine accuracy on tasks, we evaluated for each action step contained in a task whether the step was executed correctly or not. Execution of an action step was considered correct if it was executed as specified. Task execution was considered correct as well if participants reached the same result, but by using a different path, for example, by using the context menu instead of the main menu bar. Note also that the first attempt at executing an action (i.e., the first mouse click) was used for evaluation. Therefore, execution of an action step was also considered correct if participants later revised their initial attempt, possibly leading to errors later on, or if errors were solely due to errors made on previous steps. A task was scored as correct (coded 1) if all action steps it contained were executed correctly based on the criteria just described. If one or more steps were not executed correctly, the entire task was scored as incorrect (coded 0). Scoring was done by the first author of this paper. The proportion of tasks solved correctly was computed based on the assigned task scores. For the ANOVA-based analyses, proportions were aggregated by participants across tasks.
The time participants needed to execute a task was determined by manually annotating the screen recordings in BeGaze with time stamps. For each task, a time stamp was added to the first video frame displaying the tutorial task which participants were starting to work on. The time needed for a task was computed as the difference (in milliseconds) between the time stamp marking the beginning of the task and the time stamp marking the beginning of the next task (or for the last task: the time stamp indicating participants had completed the tutorial).
Accuracy on tasks. Across all conditions, the proportion of tasks solved correctly was 0.78 (SD = 0.42). Inspection of condition means revealed only small numeric differences, which were not significant, as indicated by a Kruskal–Wallis test (χ2 = 1.13, df = 2, p > .1). Similar results were obtained from an analysis which assessed performance accuracy not on the basis of tutorial tasks, but on the basis of individual action steps of the tutorial tasks. As expected, means resulting from this analysis were higher, but condition means did not differ significantly either.
Time on tasks. The average time participants across all conditions needed to complete a tutorial task was 100.6 s (SD = 51.4). When tutorials contained signaled screenshots, tasks were performed faster compared to tutorials with SUIs or nonsignaled screenshots. The ANOVA indicated that condition means differed significantly, F(2, 46) = 4.64, p < .05. Pairwise comparisons confirmed that participants in condition SIG were faster than participants in condition SUI and SCR (both p < .05), whereas the difference between SUI and SCR was not significant.
Eye-Tracking Measures
AOI-based eye-tracking measures are based on dwell time, which includes fixations and saccades. Condition means for all eye-tracking measures are provided in Table 4.
Condition Means and Standard Deviations for Eye-Tracking Measures.

Time in tutorial vs. Time in GIMP. Overall, participants spent 45.6 s (SD = 23.0) per task reading and processing tutorial information. As shown in Table 4, participants spent less time in the tutorial when using tutorials with signaled screenshots (SIG) or simplified screenshots (SUI), compared to participants using nonsignaled screenshots (SCR). The overall ANOVA indicated significant differences between condition means, F(2, 46) = 3.79, p < .05. Pairwise comparisons confirmed the difference between SCR and SIG (p < .05). However, the difference between SCR and SUI failed to reach significance (p > .1).
The mean time per task participants spent planning and executing actions in the GIMP software was 41.9 s (SD = 23.5). Participants spent less time interacting with GIMP when using tutorials with signaled screenshots (SIG), compared to tutorials containing simplified screenshots (SUI) or nonsignaled screenshots (SCR). The Kruskal–Wallis test indicated significant difference between condition means (χ2 = 7.3418, df = 2, p < .05). Pairwise comparisons confirmed the difference between SCR and SIG (p < .05). The difference between SUI and SIG was marginally significant (p = .56), whereas there was no difference between SCR and SUI.
Revisits to tutorials. The revisits measure reflects how often participants returned to the tutorial after having left it for the first time. Since all returns originated from the GIMP area, the measure can be used to assess how often participants shifted visual attention from the GIMP software back to the tutorial. Overall, the number of revisits to the tutorial per task across all participants and conditions was 19.0 (SD = 8.9). As shown in Table 4, differences between condition means were small. The ANOVA indicated that the differences were not significant, F(2, 46) = 0.57, p > .1.
Time in pictures vs. Time in text segments. The mean time participants spent for each task reading the text segments of the tutorial was 31.8 s (SD = 18.3). Inspection of the condition means suggested that participants spent less time reading text segments when using tutorials with signaled screenshots (SIG), compared to tutorials containing SUIs or nonsignaled screenshots (SCR). This impression was confirmed by an ANOVA indicating significant differences across condition means, F(2, 46) = 6.98, p < .01. Pairwise comparisons yielded significant differences between SIG and SUI as well as between SIG and SCR (both p < .01).
As can be expected, participants spent less time overall viewing the screenshots, with an overall mean time of 10.1 s (SD = 5.9). As confirmed by the ANOVA, differences between condition means were not statistically significant, F(2, 46) = 1.95, p > .1.
Post-Test Ratings
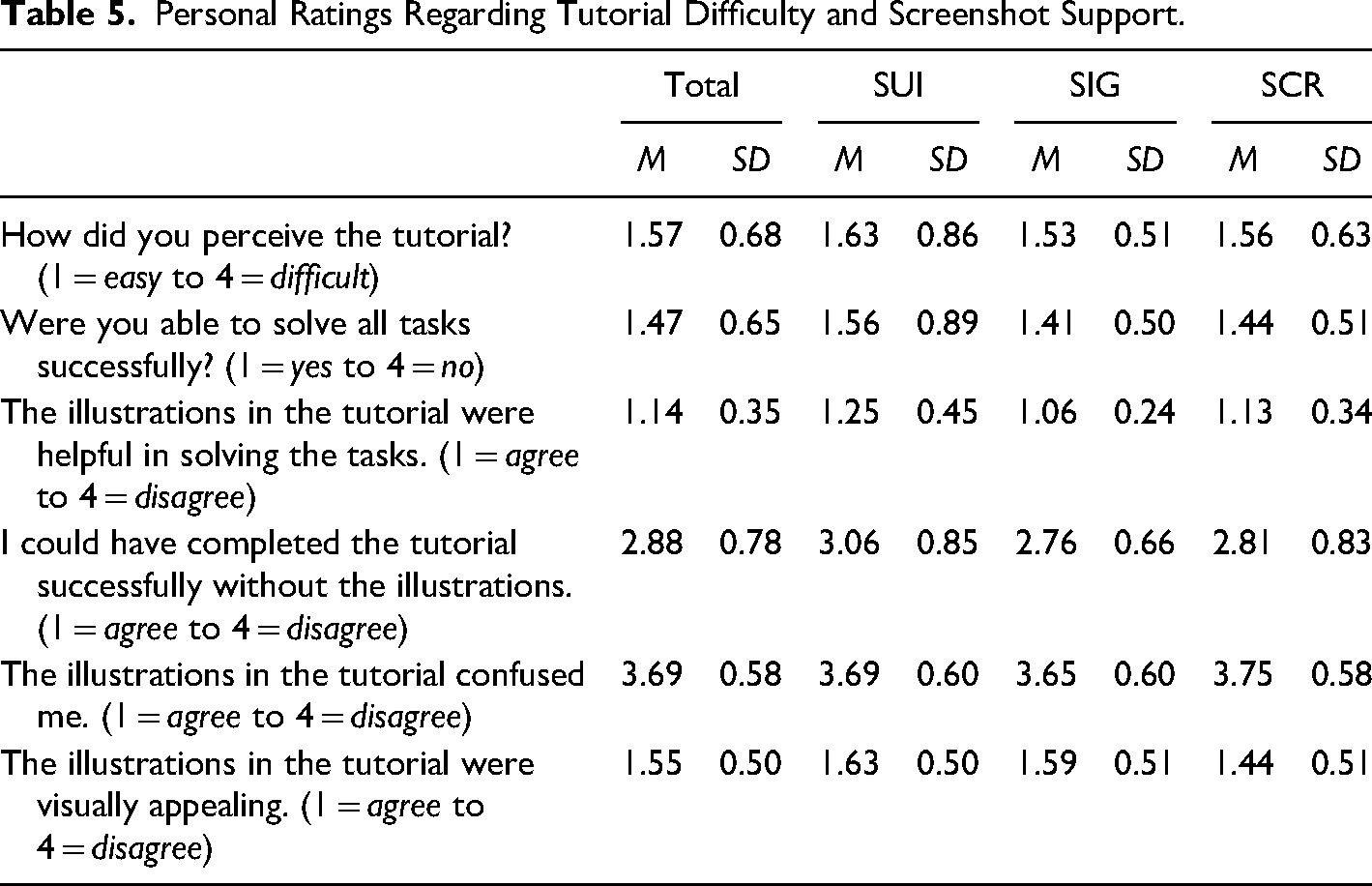
In order to supplement the quantitative results of eye tracking, the participants’ subjective impression of the tutorial and the types of images it contained was also recorded. A personal assessment should also be used to analyze how difficult the tutorial was and how helpful the illustrations were perceived. The results (see Table 5) show that the type of illustration makes no difference to the personal evaluation. All participants found the tutorial to be rather easy and easy to solve. Regardless of their design, the illustrations were perceived to be helpful and visually appealing. There were no differences between conditions, as indicated by Kruskal–Wallis tests applied to the ratings for each question.
Personal Ratings Regarding Tutorial Difficulty and Screenshot Support.
Discussion
SUIs have been proposed as a new variant of visual signaling. The design technique is becoming increasingly popular because it promises to improve the effectiveness of screenshots and at the same time can help reduce the costs of maintaining and localizing screenshots. However, to date, no empirical research has been conducted on SUIs. The present study presented an experiment intended to test the effectiveness of SUIs in comparison to unedited screenshots without visual signaling and screenshots using conventional signaling techniques. An orientation test was carried out to test whether SUIs help find critical image areas more quickly. The tutorial test examined the effectiveness of the graphics in a realistic usage scenario.
Main Findings and Conclusions
The orientation test carried out at the beginning of the study was intended to analyze the three types of screenshots (SUI, SIG, and SCR) separately from an additional verbal description as in the tutorial. The results of the orientation test showed that SUIs enabled participants to identify a relevant area in the image faster and with fewer fixations compared to nonsignaled screenshots, leading to a very robust effect. This finding confirms the main assumption that motivates the design technique used by SUIs. The contrast between the relevant area that is displayed in full detail and the irrelevant area that is shown with reduced detail and faded into the background is an appropriate signaling technique and efficiently directs visual attention to relevant information, as intended.
The orientation test also revealed that conventional signaling (i.e., red frames, as in the study's materials) achieved an effect that was similarly robust. Participants identified critical picture elements faster and required fewer fixations with both SUIs and signaled screenshots than nonsignaled screenshots, but there was no difference between the two groups. Therefore, regarding RQ1, we conclude that SUIs successfully direct the visual attention of users to critical picture information. However, the reduced level of detail in irrelevant screenshot areas did not facilitate orientation beyond that. SUIs are an effective means of signalization, but with respect to facilitating orientation and identification of relevant information in a picture, there is no apparent advantage of the SUI technique compared to the effects accomplished via conventional signaling. Taken together, these findings provide further evidence for the supportive and immediate effects of visual signaling in general.
Whereas the orientation test presented pictures in isolation, the tutorial test examined the effectiveness of the different screenshot types in an action-oriented usage scenario. The supportive effects of visual signaling were evident in the context of working through a software tutorial as well, but turned out to be dependent on the signalization technique used. No differences were found among the three groups in terms of task completion accuracy. The proportion of tasks solved correctly did not differ across conditions, suggesting that participants were equally successful in completing the tutorials regardless of the screenshot type used and whether or not they were supported by signalization. Differences between groups emerged for time on tasks. We found that participants completed the tutorial tasks faster when working with tutorials that contained pictures with conventional signaling, compared to participants using nonsignaled images and SUIs, leading to a robust effect. The use of nonsignaled screenshots or SUIs did not lead to significant differences. Hence, the performance measures confirm that using conventional signaling improves user performance, whereas no such effect occurs when using SUIs.
The results obtained here for the performance measures are consistent with those reported by Meng (2019), but it should be noted that visual signaling led to different effect patterns in both studies. While the current study observed faster task completion but no difference regarding the accuracy on tasks between the groups working with tutorials containing signaled vs. nonsignaled screenshots, Meng (2019) found that visual signaling increased accuracy on tasks, but the time participants required to complete the tasks did not differ significantly between groups. The different effect patterns are possibly due to differences in the complexity of the tasks that the participants had to solve. Note that in the study presented here, the accuracy on tasks was quite high across all conditions. Participants were able to complete the tasks successfully most of the time, even if they were not supported by visual signaling, although more effort and time were required in this case. Accuracy on tasks was significantly lower in Meng (2019) if no signaling was available, suggesting that, for at least some of the tasks, visual signaling was essential to avoid errors.
A closer inspection of viewing times using AOI-related eye-tracking measures revealed that signaled screenshots sped up processing the tutorial, and in particular, reading the text elements. SUI screenshots also showed a tendency toward more efficient processing of tutorial information, but the effect was less robust and no advantage was observed with respect to reading times for text elements between SUIs and nonsignaled screenshots. A clear difference emerged regarding the time participants spent interacting with the GIMP software. Participants required less time to interact with GIMP when working with tutorials containing signaled screenshots compared to SUIs and nonsignaled screenshots.
Taken together, we tentatively conclude that SUIs show at least a tendency toward facilitating the processing of the tutorials (i.e., reading the text elements and integrating information from the text with information from the pictures) compared to nonsignaled screenshots, although the effect was less robust compared to the effect elicited by images using conventional signaling. Given that SUIs facilitate orientation in pictures and identification of relevant information, this tendency is not surprising. The somewhat smaller effect found for SUIs with respect to the time spent in the tutorial could be due to specifics of the materials used in the tutorial test. The screenshots in the tutorial were rather small and low-contrast, which may have reduced the actual advantage of better orientation through the reduction of detail in the SUIs. Additional color highlights, such as red frames, as used in the SIG condition, stand out more clearly and, therefore, are probably more effective in this specific context.
We also conclude that SUIs do not, in contrast to signaled screenshots, facilitate interactions with GIMP. Hence, SUIs facilitate the identification of relevant information in a picture, but do not seem to be particularly effective when it comes to coordinating attention between the tutorial and the GIMP user interface, particularly when applying tutorial information to GIMP. A possible explanation is that the reduction of detail in irrelevant screenshot areas of SUIs removes information that could be useful in relating information from screenshots to the actual GIMP user interface. In other words, SUIs remove information that is irrelevant in the context of a certain action that the SUI supports, but this same information would be relevant and helpful for the user to locate the window or menu that the SUI depicts in the actual GIMP user interface, which at least partially cancels out the advantages they provide in terms of the faster identification of relevant screenshot information.
Evidence supporting this explanation arises from additional correlation analyses (using Spearman's rank correlation test), which we planned and conducted post hoc. These correlation analyses checked for associations between experience with GIMP that we collected through the pre-test questionnaire and the time participants spent in the GIMP software. No significant correlation was observed for participants working with nonsignaled or signaled screenshots. For participants working with SUI screenshots, a negative correlation was observed: the higher the experience with GIMP, the less time was spent interacting with GIMP in the course of tutorial execution (Spearman’s ρ = −0.574, p < .05). Hence, the greater familiarity with GIMP and the GIMP user interface may have made it easier for experienced users to relate information from the SUIs to the actual user interface because they were less dependent on details that were missing in the SUIs. Due to the small sample size, this result should be regarded as a hint, and the conclusion is tentative.
In summary, the combined results of the orientation and tutorial tests confirm that screenshots using conventional signaling techniques effectively support users in identifying relevant information in a picture and enable more efficient user performance when using such screenshots in a tutorial. The results for SUIs were mixed. SUIs also facilitate the identification of relevant information in a picture and effectively direct user attention. On the other hand, when used in an action-oriented context, such as a tutorial, SUIs provide no clear advantage in comparison to nonsignaled screenshots. However, SUIs may enable more efficient performance for users who already have some familiarity with the respective application.
In this study, an image editing program was used, with which the participants had little or no prior experience. Learners’ prior knowledge can significantly influence the effective use of pictures in learning materials. Novices, in particular, often benefit from pictures, but adding pictures has no or even a negative effect on the performance of experts (Kalyuga et al., 1998; Mayer & Gallini, 1990). Thus, it can be assumed that the participants in the present study fundamentally benefited from the use of the images, regardless of their design. This was reflected in the participants’ personal ratings of the tutorial and screenshots. Regardless of the type of screenshot used, responses showed that the participants considered the illustrations helpful in solving the tasks. Responses also showed that the participants believed that they would not have been able to complete the tutorial without screenshots.
Limitations and Suggestions for Future Research
The present study represents a first approach to closing the research gap on the effectiveness of using SUIs in technical documentation. However, further research is needed to address the limitations of the current study.
The software tutorial examined in this study was perceived as easy by the participants. In previous research, screenshots have been shown to be especially useful for complex tasks (Sweller & Chandler, 1994). This could explain why our study did not detect advantages for SUIs in terms of accuracy on tasks and time on tasks. Further research should address this question and examine the effectiveness of SUIs in more complex tasks. Moreover, as discussed, it is possible that the effectiveness of SUIs when used in a tutorial depends on the size and complexity of the images as well as on the ratio between relevant and irrelevant screenshot areas. To effectively support orientation and enable efficient coordination of attention between tutorial and user interface, SUIs may need to be sufficiently large for the contrast between relevant and irrelevant areas to stand out clearly enough. Future research is necessary to verify whether these suggestions are correct.
Research should also examine the impact of design features on the effectiveness of SUIs, particularly regarding information that needs to remain in the irrelevant screenshot area, because it is important to locate and identify elements depicted by a screenshot (such as windows, menus, or a certain working area) in the actual user interface. Finally, research is needed to determine the effects of using SUIs in other usage contexts, in particular usage contexts that are less action-oriented, such as a guided tour that introduces new features, as well as the effectiveness of SUIs when used on mobile devices, such as tablets or smartphones.
A more general limitation of this study relates to its low statistical power. The term “power” in this context refers to the probability that a study can detect an effect of interest (Cohen, 1992). Power for a given study design can be determined using tools such as G*Power (Faul et al., 2007) or the pwr package for R (Champely et al., 2017). As pointed out by an anonymous reviewer, with 49 participants randomly assigned to the three groups, the probability of an ANOVA F-test to detect an effect of screenshot type is below the level of 0.8 which is generally regarded acceptable (Cohen, 1992). On the other hand, it should be noted that in order to significantly increase power to detect small and moderate effects, a number of study participants would be required that easily exceeds available capacities for data collection and analysis. Research following up on the results of this study should optimize the balance between power implications of the planned study design and the number of study participants that can be tested with reasonable effort. In general, power analysis should receive more attention by technical communication researchers.
The findings of the current study add to the evidence suggesting that visual signaling not only fosters learning from multimedia instruction but also supports users in an action-oriented usage scenario. If confirmed by future studies, further research is needed to examine the possible boundary conditions, such as the level of user expertise and prior experience. Moreover, it is desirable to address the effects of other design principles proposed by the CTML in scenarios in which the primary goal is not learning but carrying out actions. In addition to principles intended to reduce cognitive load irrelevant to learning or carrying out actions, such as the signaling principle or the coherence principle, such research should also consider principles intended to enhance deeper and more intensive processing of information from multimedia instruction (see Irrazabal & Burin, 2021, for example). The current study emphasizes the important role that the eye-tracking method can play in such research.
Footnotes
Declaration of Conflicting Interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The authors received no financial support for the research, authorship, and/or publication of this article.