
Abstract
We propose a new multiple imputation technique for imputing squares. Current methods yield either unbiased regression estimates or preserve data relations. No method, however, seems to deliver both, which limits researchers in the implementation of regression analysis in the presence of missing data. Besides, current methods only work under a missing completely at random (MCAR) mechanism. Our method for imputing squares uses a polynomial combination. The proposed method yields both unbiased regression estimates, while preserving the quadratic relations in the data for both missing at random and MCAR mechanisms.
Introduction
Multiple imputation (MI) is the method of choice for many incomplete data problems. MI incorporates the uncertainty about the missing data by creating
The most critical part of MI is specification of the imputation model. It is widely accepted that the imputation model should embrace all relations of scientific interest. Usually, this is done by incorporating the variables of interest as main factors. However, things become less clear if the scientific model contains nonlinear terms.
As an example, if we want to predict Y from X and its square
Von Hippel (2009) reviewed several approaches to imputing squares. The “transform, then impute” method calculates the squares and interactions in the incomplete data for the cases that have no missing values, and then imputes the derived variable like any other variable. The “impute, then transform” method imputes variables in their raw form, and then calculates the derived variable in the imputed data after imputation. These methods were compared to the passive imputation method (Van Buuren, Boshuizen, and Knook 1999), implemented in the mice package in R (Van Buuren and Groothuis-Oudshoorn 2011), and the ice command for Stata (Royston 2005).
Von Hippel (2009) advises to use the transform-then-impute method, which delivers acceptable regression estimates but heavily distorts the relationship between X and
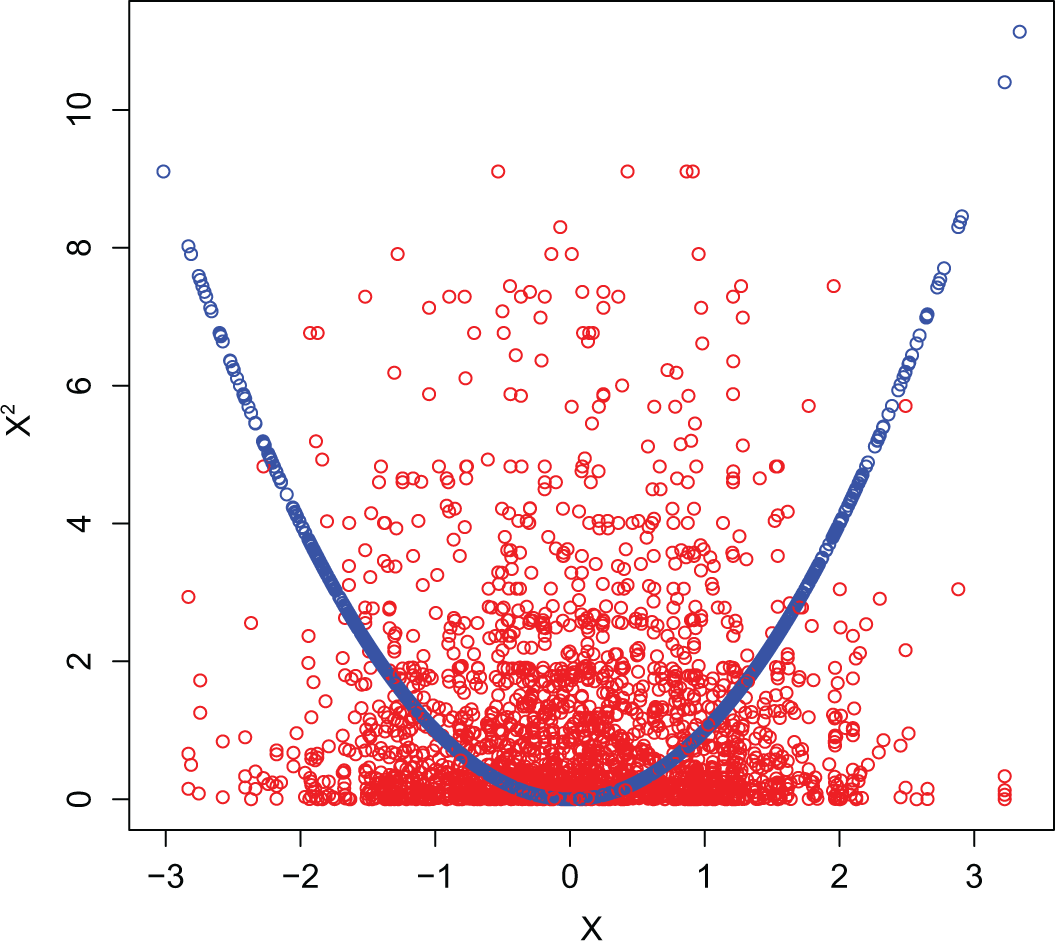
Transform-then-impute imputations. Observed (blue) and imputed values (red) for X and
We must note that Von Hippels conclusions are based on a missing completely at random (MCAR) mechanism (Seaman, Bartlett, and White 2012), where the missingness does not depend on the data, which is a limitation in practice. An imputation method would be more powerful if it yields acceptable inference under the missing at random (MAR) mechanism, where the missingness may depend on the data, but must not depend on the missing data itself.
Because existing methods for imputing squared terms are severely limited, we propose the polynomial combination approach, which yields unbiased regression estimates, while preserving the consistency between the imputed values, for MAR and MCAR mechanisms.
Method
Formulation of the Problem
The model of scientific interest is

Polynomial Combination Method
Define the polynomial combination
Under the assumption that
The next step is to decompose Z into X and
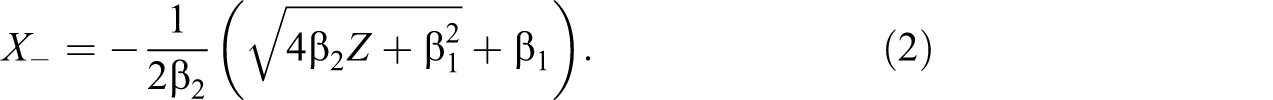

Given this assumption, for any given Z, we can take either
The choice between the roots is made by random sampling, conditional on Y, Z, and their interaction YZ. Let
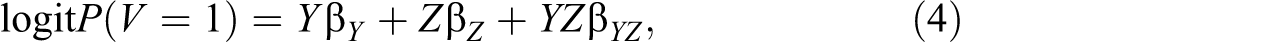
Imputation Algorithm
The procedure leads to the following algorithm for imputing squares:
Calculate
Use PMM to multiply impute
Estimate the pooled estimates
Calculate the polynomial combination
Multiply impute
Calculate roots
Calculate the abscissa at the parabolic minimum/maximum
Calculate
Impute
If
Calculate
The imputations
Results
To illustrate the polynomial combination method, we simulated and compared the performance of all methods discussed by Von Hippel (2009) against the polynomial combination method. Data were generated according to the model

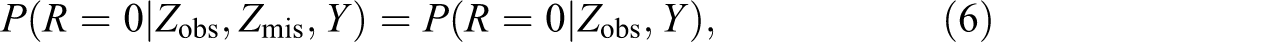

As an analysis, we used linear regression to see whether the population values could be estimated after imputation. We repeated the analyses 100 times.
The regression estimates after applying the polynomial combination imputation can be found in Table 1. The estimated coefficients of the imputed X and
Average Parameter Estimates for Different Imputation Methods Under Five Different Missingness Mechanisms Over 100 Imputed Data Sets (n = 10,000) With 50 Percent Missing Data.
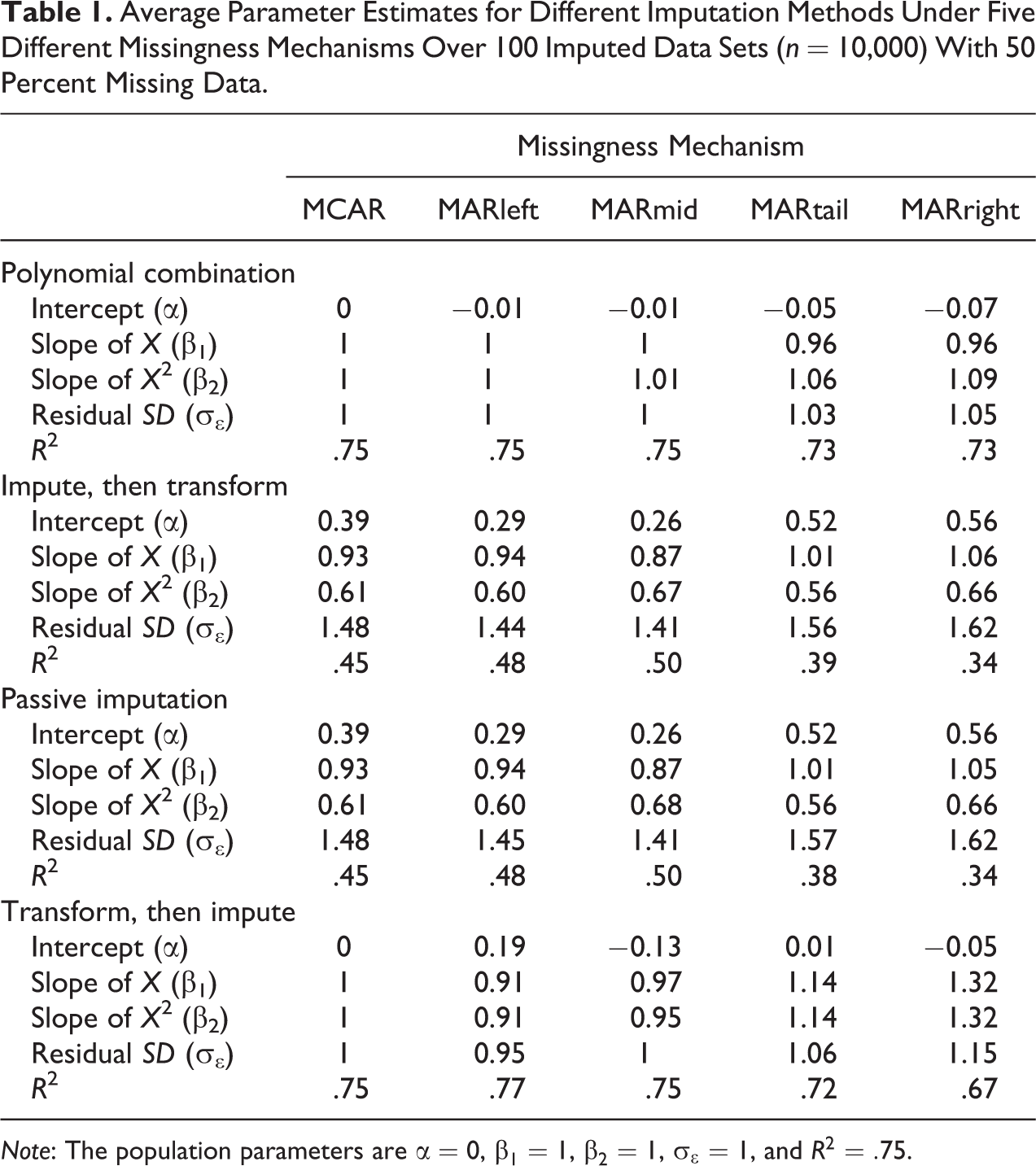
Note: The population parameters are
In contrast, Table 1 also displays the performance of the impute-then-transform method regression estimates under the same simulation conditions. The impute-then-transform method yields biased regression estimates, even under MCAR.
Table 1 also shows the performance of the passive imputation method. Passive imputation performance is similar to the problematic performance of the impute-then-transform method, as both methods calculate
Finally, the transform-then-impute method yields unbiased regression estimates, but only for MCAR. Although some estimates are retrieved, performance is severely impaired under the MAR assumption (see Table 1).
All in all, the polynomial combination method yields regression estimates that are both unbiased and preserve the data relation between X and

Polynomial combination imputation. Observed (blue) and imputed values (red) for X and
We also looked at the mean and covariance matrix as reproduced by the imputed data and compared it to the population values. The mean and covariance matrix of 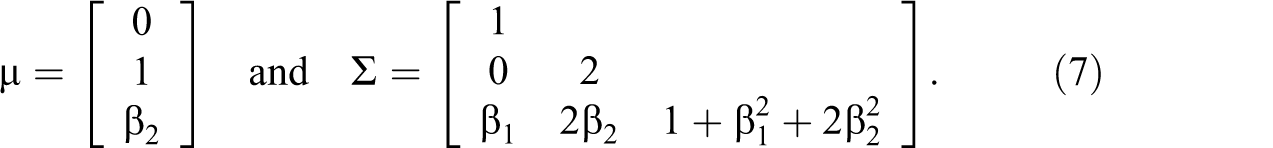
A set of k mean values can be pooled to a single residual mean value with

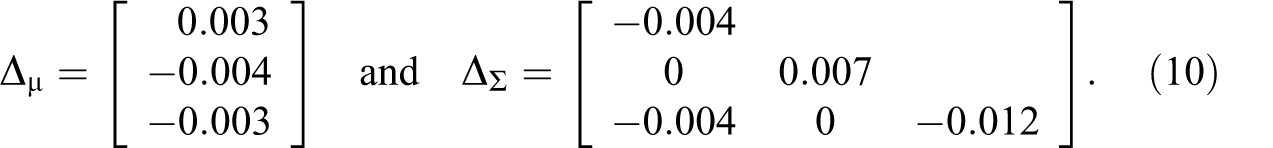
The results in equation (10) suggest that the mean and covariance matrix in the population data are accurately preserved in the imputed data. Given that only normal imputations that preserve the mean and covariance matrix from the population data can yield unbiased imputations, we can now confidently say that the polynomial combination method yields unbiased regression estimates and delivers transformed variable imputations that are consistent with each other.
All computations in this study have been carried out in R and all imputations are generated with the mice package in R (Van Buuren and Groothuis-Oudshoorn 2011) with m = 5 multiple imputions. A mice.impute.quadratic routine that implements the polynomial combination method is available in mice.
Conclusion
The polynomial combination method as developed here provides unbiased estimates for problems where incomplete X and
We note that the simulation conditions used are rather harsh. For example, 50 percent of X is missing and some missingness mechanisms severely limit the amount of usable predictive information, especially right-tailed MAR missingness. Also, note that imputations are based on just one covariate. In real-life data sets, conditions for imputing the data are often much better. Yet, also for simpler incomplete data problems, the polynomial combination method yields the best possible inferences even though the difference with the results from other methods may be smaller.
We limited our calculations and analyses to squares, which are essentially interactions between two identical variables. Interactions between different variables remain best imputed using the transform-then-impute method. The polynomial combination method can be generalized to more complex nonlinear combinations. We expect that the proposed method also applies to problems in which the scientifically interesting model contains multiple versions or transformations of X, such as interactions between different variables, higher degree polynomial equations and perhaps even splines, which are essentially piecewise polynomials. Exploring such applications of the polynomial combination method is subject to future work.
Footnotes
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.