
Abstract
Radical social movements are broadly engaged in, and dedicated to, promoting change in their social environment. In their corresponding efforts to call attention to various causes, communicate with like-minded groups, and mobilize support for their activities, radical social movements also produce an enormous amount of text. These texts, like radical social movements themselves, are often (i) densely connected and (ii) highly variable in advocated protest activities. Given a corpus of radical social movement texts, can one uncover the underlying network structure of the radical activist groups involved in this movement? If so, can one then also identify which groups (and which subnetworks) are more prone to radical versus mainstream protest activities? Using a large corpus of British radical environmentalist texts (1992–2003), we seek to answer these questions through a novel integration of network discovery and unsupervised topic modeling. In doing so, we apply classic network descriptives (e.g., centrality measures) and more modern statistical models (e.g., exponential random graph models) to carefully parse apart these questions. Our findings provide a number of revealing insights into the networks and nature of radical environmentalists and their texts.
Radical activist groups are of great interest to social movement scholars as well as sociologists and social scientists more generally. Indeed, these activist groups—which in some cases encompass leftist-oriented radical organizations such as Earth First! (EF!), the Earth Liberation Front (ELF), and the Anarchist Federation (AF), and in other cases encompass right-wing extremist groups such as the White Wolves, Aryan Nations, and Combat 18 (C18)—have now been extensively studied, especially within the contexts of advanced developed democracies in Europe, North America, and elsewhere (Blee and Creasap 2010; della Porta 1995; Downing 2001; Plows, Wall, and Doherty 2004; Wall 1999a). The use of illegal or controversial protest tactics by radical social movements—including (nonviolent) direct action, related forms of property sabotage, 1 protest camps, 2 and terrorism—has similarly garnered attention for such movements within the media and general public and among those concerned with domestic terrorism (Ackerman 2003; Chalecki 2002; Leader and Probst 2003; Sánchez-Cuenca and de la Calle 2009). These features have together led social scientists and social movements scholars to pursue a number of compelling studies of the life cycles, tactics, ideologies, and influences of radical activist groups (e.g., Blee and Creasap 2010; Foreman and Haywood 1993; Kitschelt 1986; Seel 1997; Wall 1999b).
Yet, extant research on radical social movements has also been limited by a paucity of data pertaining to the strategies, linkages, and agendas of these organizations. This deficiency is unsurprising. Many radical movements are short-lived or are highly volatile in their ideology, strategies, and membership (Smith and Damphousse 2009; Simi and Futrell 2015). The groups involved in these movements are also typically nonhierarchal in structure and anonymous in membership (Fitzgerald and Rodgers 2000; Joossee 2007), which limits researchers’ abilities to identify and compare membership structures and patterns across groups. By virtue of occupying the fringes of the society, the viewpoints of radicals, and the literature they produce, commonly fail to make it into mainstream media sources or public archives. Perhaps most notably, the ideology of radical activist groups, the illegal (or antigovernment) protest tactics that they often favor, and past countermovement efforts led by government actors have together given radical activist groups the incentives to conceal, obfuscate, and misrepresent their membership and ties with other radical groups as well as their favored tactics and ideologies (Plows et al. 2001, 2004; Simi and Futrell 2015). As a consequence of these tendencies, research on radical activism has been largely limited to qualitative case studies and small-N research. While these qualitative studies are insightful, we believe that a more systematic quantitative analysis of radical social movements could serve as a useful compliment to existing approaches.
Further, we contend that recent advances in automated content analysis, and social network analysis, 3 may together provide researchers with a means to do so. Regarding automated content analysis, we note that while radical groups are indeed guarded in membership, ideology, protest strategies, and collaborative efforts, they nevertheless communicate extensively with group members, potential recruits, and like-minded extremist groups through self-produced literature and periodicals (e.g., newsletters, websites, and magazines). For example, the U.S.-based Earth First! Journal has published approximately eight issues a year since 1981, whereas recent estimates by the Simon Wiesenthal Center (2008) have identified roughly 8,000 problematic hate/terrorist websites and related Internet postings. These texts are typically typeset and distributed by radical groups themselves and serve to discuss, organize, and promote the goals, concerns, tactics, and past and future activities of radical groups. We thus believe that a specific subset of automated content analysis techniques known as topic models, which allow one to systematically unpack a corpus of text documents by identifying words and phrases that commonly group together across documents, can help researchers to uncover the latent topics, or common themes, that arise across radical environmentalist texts. To the extent that these texts speak for radical groups, which they commonly profess to do, 4 the topics identified by topic modeling can be viewed as representing the ideology, tactics, and foci of radical groups themselves. As such, whereas the texts produced by radical groups offer a window into their activities and interests, topic models provide us with a means of systematically accessing this window.
Social network analysis (SNA) offers an additional, and complementary, suite of tools for the systematic study of radical groups. Indeed, group interaction, cohesion, and coordination have long been of interest to the social science community and lie at the heart of radical group behaviors. Over the last century, the development of methods and theories to both describe and predict such interaction has been largely developed under the umbrella of SNA. This theory includes formal mathematical models for describing complex relationships between entities (e.g., organizational coordination), and such methods have now been widely applied to studies of (radical) social movements (Ackland and O’Neil 2011; Caiani and Wagemann 2009; Hoffman and Bertels 2009; O’Callaghan et al. 2013; Saunders 2007b). For such movements, SNA offers researchers the ability to identify the ties that exist between and within various radical groups, allows scholars to quantify the centrality of various actors in a group network, and can potentially be used to shed light on the protest strategies that different networked group pairs choose to use with one another. However, while this technique has much potential for understanding radicalism, it has been employed rarely in this area of research due to the complexity of gathering high-quality network data for the covert actors described above. A key contribution of our article rests in the development of a means to overcome this limitation: We argue below, and show, that quantitative text analysis techniques can help to rectify data limitation challenges for social network analyses of covert groups.
Our article does so by combining topic modeling and SNA in novel ways—and at multiple stages of one’s analysis—so as to allow researchers to uncover the tactics and interactions of clandestine social movements and groups. In these respects, we develop a methodological “road map” for future scholars to use in their own applications and provide a number of important substantive insights into the networks and behaviors of contemporary radical leftist groups. Specifically, our proposed approach details how one can combine the use of co-occurrence counts, social network statistics, and structural topic models (STM) to extract an environmental group network—and the full set of protest strategies used within that network—from a corpus of self-produced (and often highly variable) radical environmentalist texts. We then show how to statistically associate one’s identified protest strategies with various subcomponents of the group network itself, which can be directly used in validation or hypothesis testing. In full, our approach enables us to explain why, when, and how radical groups may cooperate with one another in order to achieve their respective aims as well as the manners in which these groups choose to cooperate. To fully illustrate this approach, and the insights that arise from it, we apply our proposed methods to a novel corpus of radical UK environmentalist texts from the 1990s and 2000s, which yields a number of intriguing and theoretically consistent results.
Specifically, we extract a network of 143 UK leftist and environmentalist groups—with 134 co-occurrence relations between these groups—from our radical UK environmentalist texts. While regional UK environmentalist groups comprise the bulk of this network, centrality measures reveal that a small number of broader radical leftist (e.g., anarchist, antiglobalization, or worker’s rights) groups feature most prominently within our network’s connected component. This finding may help to explain the decline in the (UK) radical environmental protest movement during the late 1990s and early 2000s, as the centrality of nonenvironmentalist actors within our identified network suggests that the persistence of this network, and the groups therein, may have primarily rested on broader support for nonenvironmental leftist groups and views (e.g., anarchism) which was also waning during this time period. 5 Our analysis of these texts also identifies clear tactics of direct action, protest camps, international terror, and mass protest, and we find these tactics to be statistically associated with network group pairs and clusters in revealing manners that are also consistent with extant understandings of these groups. These findings help to validate our approach and suggest that systematic information on group ties, clusters, and shared strategies can be collected from radical group texts in an automated manner, thereby demonstrating how text and SNA can be combined to improve our understanding of covert groups.
This article proceeds as follows: We first cover a brief literature review of automated text and text-based networks, followed by a presentation of our sample of radical UK environmentalist texts, and describe how we extract a number of network and text analysis inputs from these raw texts. Next, we derive the complete network of radical groups from our radical environmentalist texts and discuss this network’s features. We then identify the group tactics, or protest strategies, 6 that underlie our radical environmentalist texts and examine how these strategies vary in relation to the radical activist groups found in our network’s connected component. Next to last, we discuss some novel ways to employ our automated text analysis of network discovery methods, and finally, we conclude with a discussion of our results and their implications.
Literature Review
In the following subsection, we discuss briefly the use of automated text models in sociology and the social sciences broadly and the use of text-based networks within these social science communities.
Automated Text Analysis
Recently, automated text methods have become a popular tool within sociology and the social sciences more broadly (see, e.g., Mohr and Bogdanov 2013; Roberts et al. 2014). Blei, Ng, and Jordan (2003) introduced Latent Dirichlet Allocation (LDA) models for text/topic modeling in machine learning—and recent developments in available software have begun to bring these methods to the forefront of both qualitative and quantitative analysis due to these methods’ scalability and flexibility (see, e.g., Roberts, Stewart, and Tingley 2015). This can be seen through the special issue in Poetic’s (Mohr and Bogdanov 2013) on topic models in cultural sciences and key work in political science such as that for unstructured survey responses (Roberts et al. 2014) or analyses of media (Grimmer 2012). This work has largely focused on using automated text methods for extracting central themes from big and small data. Important developments in calibration (e.g., Grimmer and Stewart 2013) and interpretation (Bonilla and Grimmer 2013; DiMaggio, Nag, and Blei 2013; Jockers and Mimno 2013; Marshall 2013; McFarland et al. 2013; Miller 2013; Mohr et al. 2013; Tangherlini and Leonard 2013) have similarly led to key insights and improvements in our understanding of social phenomena and a larger acceptance of these methods in practice within the social science communities. Finally, while the STMs methods discussed below have gained traction in political science, they have not yet been readily introduced to the sociological community which has primary focused on classic LDA methods. In the following sections, we employ a combination of automated text analysis and extraction methods, data cleaning, and STM to build and qualitatively assess automated network discovery methods from automated text models. Later, we discuss how to employ these methods to pull apart a complex multiplex network.
Text-Based Networks
Interest in building networks out of text has a rich history in sociology, extending from such classic works by Padgett and Ansell (1993), who built social/political networks from accounts of historical data of 1400s Italy. Other major examples include networks built out of ethnographic data such as group observation studies (e.g., Freeman and Webster 1994) and networks built from surveys, card sorts, and other methods (e.g., Marsden 1990; Romney, Weller, and Batchelder 1986). Citation networks are among the most famous form of text-based network analysis and have a rich literature in the bibliometric field. Examples in sociology include comparing the citation networks of North America and Europe via organizational journals (Üsdiken and Pasadeos 1995) or cocitation of biological science papers (Mullins et al. 1977). This work also draws heavily upon the exchange theory literature (e.g., Burris 2004). Other novel uses of text-based networks include Bearman and Stovel’s (2000) work on narrative networks, and Martin’s (2000) historical narrative work on the use of animals in stories and their relations to class division and labor. However, traditional methods for building networks out of text are labor-intensive and have the potential for coding effects (Marsden 1990; Romney et al. 1986). In response, more recent work in automated text analysis has been implemented by sociologists and social scientists, such as Adams and Light (2014) and Light (2016), work on understanding interdisciplinary networks in the medical community. In the field environmental sociology, Farrell (2016) has likewise employed automated topic models augmented with networks built out of affiliation networks, in a similar fashion, to the networks built for the subfield of corporate interlock networks (Mintz and Schwartz 1981). Also, in the area of environmental sociology, Farrell (2015) has explored environmental activist conflicts through automated text analysis and social networks.
Sample and Background
In implementing our proposed methodological approach, we focus on a single UK radical environmentalist publication, known as the Do or Die (DoD) magazine. In addition to the substantive justifications provided below, we chose to focus on this publication—as opposed to a broader collection of publications produced by different groups, across different countries, or over larger periods of time—in order to ensure that our underlying documents, networks, and identified groups were as comparable as possible. DoD was published semiannually during the years 1992 to 2003 by an anonymous collective of radical British environmentalists based, in large part, in Brighton, United Kingdom. At the time, the publication referred to itself as the voice of the UK EF! movement, although its editorial collective have since suggested that the publication was rather only a voice of the movement ( Earth First! Journal 2006 ). As stated by an editor, DoD more generally “pushed a green anarchist, direct action perspective […] gave publicity to sabotage and had a no compromise attitude [and was] largely aimed at a few hundred people in the UK eco scene,” although it was also widely read by more traditional anarchists and conservationists (Earth First! Journal 2006).
In a total of 10 issues, DoD was highly variable in structure and topics covered. Each issue had roughly 50–60 uncredited voluntary contributors, and the publication on the whole grew over time from a 20-page “zine” (issue 1) into a 343-page “massive book” (issue 10; Earth First! Journal 2006). Individual contributions (hereafter “stories”) included but were not limited to journalistic accounts of environmental protests in the United Kingdom or abroad; tutorials on sabotage, incarceration, or police interrogation; book reviews; and calls to arms over specific environmental crises. As is common across radical environmental zines, cartoons, images, and unstructured text were interspersed throughout these contributions. Ultimately, DoD ceased production in 2003 because its contributors wanted to pursue other activities, rather than for financial reasons ( Earth First! Journal 2006 ). With respect to the UK EF! movement that DoD sought to speak for, DoD’s editors note that, during its publication run, their preferred “green anarchist perspective went from being the minority to the majority perspective within EF! in the UK [which] resulted in lots of people dropping much of the non-violent pacifist ideology, moving more towards an anarchist position and supporting sabotage actions” (Earth First! Journal 2006).
Scholarly accounts of the UK EF! movement largely support this latter contention. The UK EF! movement began in Spring of 1991 as a radical environmental advocacy group with the expressed goals of defending the environment, confronting those who threaten it, and promoting lifestyles that were in balance and harmony with nature (Purkis 1998:201). As such, the first UK EF! actions were heavily influenced by the previously established US EF! movement, as well as by the UK peace movement, and were initially directed toward blockades of the Dungeness nuclear power plant and the M. V. Singa Wilstream (a ship carrying tropical timber) on the Thames Estuary. These preliminary tactics of blockade then quickly evolved into larger scale efforts toward mass action, antiroads protests (in turn spurning new environmental movements and groups), and later into additional issue areas such as opposition to airport construction, genetics, and housing on greenfield sites (Wall 1999b). Furthermore, by the mid-1990s, these strategies of nonviolent direct action (NVDA) were increasingly observed alongside tactics of active sabotage, as both moderate and militant groups grew to coexist within the UK EF! during this period (Wall 1999b:88). The EF! movement and a variety of additional groups that have arisen from it—such as the oft-terrorist-labeled ELF—remain active to this day, albeit with considerably lesser prominence.
There is good reason to view the UK EF! and its DoD publication as embedded in a larger network of radical British groups and shared protest strategies. For example, Seel (1997:177) argues that the UK EF! culture “serves as an informal network from which more publicized protests spring. EF! is embedded in the same protest milieu as Reclaim the Streets, Corporate Watch, The Defiance Alliance, Road Alert!, The Land is Ours, and Justice? which prints Schnews.” He goes on to point out that [i]ndividuals often take part in several of these groups while being tied to none [and] EF! overlaps with these other disorganisations to such an extent that it is not really distinguishable from them. It is best understood […] as a way of linking activists within the green protest scene. (p. 177, emphasis added) [n]etworking brought with it the influence of the ideologies, issues foci, repertoires of action, strategies and articulations of existing green networks […], mass NVDA repertoires were derived from the peace and Australian rainforest movements. Repertoires of sabotage, in turn, were derived from animal liberation militants and to a lesser extent EF! (US) (Foreman and Haywood 1993). (Wall 1999b:90)
Acquiring the entire 10-issue corpus of DoD publications was a challenging task. Given the relative obscurity and somewhat dated nature of this publication, comprehensive records of DoD do not exist in machine readable form within any single library or repository. Fortunately, issues 5–10 and issue 1 are fully transcribed and archived in machine readable format on the now inactive, online archive “eco-action.org,” which was a website used primarily for documenting UK environmental activism during the 1990s (Eco-Action.org, Nd). The entries are stored in HTML at the story level (separately for each issue), and these individual stories were web-scraped for use in the analysis below. pdf images of the four remaining issues (issues 2–4)—as well as pdf images of the additional web-scraped issues mentioned above—were then obtained and downloaded from a second online archive of radical environmental activities known as the “Talon Conspiracy” (2014). These pdf-image files, which occasionally exhibit low image quality, 7 were then converted to machine readable text using optical character recognition (OCR) software.
Through the above approach, we obtained or created (i) pdf-image files of each DoD issue, (ii) OCR’d versions of each of these 10 issues (at the publication-page level) stored in txt and rtf formats, and (iii) cleaned web-scraped versions (in txt format and at the publication-story level) for issues 5–10 and 1. Given the higher quality of our web-scraped versions, we use these versions for issues 5–10 and 1 in our analysis below and then employ the OCR’d versions for the remaining issues (2–4). 8 Importantly, while our reliance on both OCR’d and web-scraped text for the creation of our final corpus may give rise to comparability issues, the fact that our OCR’d text corresponds to three early issues of DoD helps to minimize these concerns. Specifically, while the 10-issue DoD corpus is comprised of 1,565 total magazine pages, the subtotal for our three OCR’d issues amounts to only 136 pages. The remaining 1,429 pages are in web-scraped format, implying that only 8.7 percent of our final corpus was derived from OCR’d text.
Preprocessing
Our analysis requires that we create two intermediate input quantities from the text files described above: (i) a list of relevant (radical) UK environmental groups and (ii) a corpus of fully preprocessed text “documents.” The former is used for identifying the pairs of radical groups that co-occur within our text corpus and the underlying network of radical groups that arises from these co-occurrences. The latter is used for estimating the latent strategies that are discussed across our corpus and the variation in these latent strategies vis-à-vis our identified group network. We directly derive each intermediate input quantity from our text sample of DoD issues 1–10 and discuss each process in turn below, beginning first with our radical UK group list.
We used information contained within DoD itself to identify and construct our list of relevant UK groups. The final three to four pages of each DoD issue provide comprehensive contact information (e.g., names and addresses) for a wide range of radical leftist groups, typically separated by international and domestic (UK) groups as well as by group type (e.g., UK ecological direct action groups and other UK contacts). UK ecological direct action groups include regional EF! groups (e.g., Leeds EF!) as well as environmental protest groups focused on more specific environmental threats such as “Reclaim the Valleys,” an antimining protest movement in South Wales. The groups listed under “other UK contacts” ranged from radical bookshops (e.g., 56a Infoshop) to more traditional anarchist groups (e.g., AF) to left-wing UK organizations focused on nonenvironmental issues (e.g., Campaign Against Arms Trade). From these lists, we constructed a master list that included all UK ecological direct action groups and all other UK contact groups and then standardized our final group list to account for alternate spellings and capitalizations of each group name. Further below, we then use this UK environmental group list to identify the instances of proximate co-occurrence of each group pair within the DoD text, which is in turn used to construct our radical environmental group network. In this respect, our analytic framework follows past scholarship (e.g., Saunders 2007b) in analyzing our environmental group network through a relational approach—that allows the group interactions and behaviors within our texts to inform our network—rather than through a positional approach that defines our network based upon a (subjective) classification of our groups into specific issue areas (or categories) a priori.
The final list of 143 UK (environmental) groups and organizations—along with descriptions of each group or entity—is provided in Online Supplemental Materials. Importantly, while many of our 143 identified groups have historically advocated for issues that fall outside of the environmental arena (e.g., anarchism), we continue to characterize all 143 groups as (radical) environmental groups in our ensuing discussions, given that all groups in our sample were (i) at least tangentially involved in environmental issues and (ii) listed as key contacts, and frequently referenced within the texts, of a radical environmentalist publication. While we believe this to be most consistent with our relational approach, however, we do take care to note those instances where a specific group’s focus extended beyond radical environmentalism. Likewise, our final 143-group list also contains a number of UK groups whose tactics did not traditionally encompass radical environmental direct action. Rather than arbitrarily remove these potentially nonradical groups from our UK-group list ex post, we maintain these groups in our sample and use this variation (in known group strategies) to validate our protest strategy extraction methods below by assessing whether our unsupervised text analysis approach is indeed correctly identifying those groups that have been known to use, or not use, radical environmental direct action tactics.
We next turn to the second intermediate task mentioned above: the creation of a set of fully processed “documents.” Because the unsupervised topic modeling techniques used below require that we apply these methods to a collection of text documents, we must first define what a standard document should be for this stage of our text analysis. Based upon our substantive knowledge of the DoD corpus, as well as previous applications of topic models to social science texts, plausible document designations include each individual DoD issue, each individual page of text within our DoD sample, individual sentences or paragraphs, or each individual story entry within the corpus. Extant social science research has applied similar topic models to those used below to documents ranging in size from individual tweets (Barberá et al. 2014) to individual books (Blaydes, Grimmer, and McQueen 2015). Others have used more arbitrary text breaks to define documents such as page breaks, sentences, multisentence sequences, or paragraphs (Bagozzi and Schrodt 2012; Brown 2012; Chen et al. 2013). Hence, for the methods applied below, a great deal of flexibility can be afforded in defining one’s documents.
However, given that topic models are inherently designed to analyze large collections of text (Grimmer and Stewart 2013), the limited number of actual DoD issues (i.e., 10) precludes us from treating the individual DoD issues as our documents of interest. This limitation, and the broader formatting idiosyncrasies of DoD, accordingly made the designation of (comparable) documents for this corpus uncharacteristically difficult. To this point, recall that the individual contributions within DoD were often inherently unstructured and variable, with some entries following traditional paragraph form, others being more experimental and artistic in format, and still others following a simple bullet-point style. Moreover, the stories and pages within DoD often have text boxes arranged in different paragraph and column formats, with individual story entries ranging from 21,000+ words to 140 words (or less). Complicating this further was the fact that the OCR’d documents in our sample (issues 2–4), which were OCR’d at the page level, often lost information on paragraph breaks and story breaks whereas our web-scraped documents (issues 1 and 5–10) were archived at the story level, without complete information on page-breaks.
In light of these inconsistencies, the most defensible method for dividing the DoD corpus into text documents of comparable length is the use of multisentence sequences. Individual sentence-length documents were deemed far too short for identifying group co-occurrences or underlying mixtures of topics. By contrast, the use of consecutive sequences of sentences has past justification both in the estimation of underlying topics and in the identification of actors’ co-occurrences for the extraction of social networks from text (Bagozzi and Schrodt 2012; Chang, Boyd-Graber, and Blei 2009; Culotta, Bekkerman, and McCallum 2004; Davidov, Rappoport, and Koppel 2007). In essence, this approach entails that one link together nonoverlapping 9 series of n consecutive sentences, treating each resultant sentence sequence as an individual document. To do so, we start from the first DoD issue, and iterated through all 10 issues (in order), combining consecutive sentences by our designated n, and incrementally treating each subsequent n-sentence sequence as a new document. While somewhat arbitrary, this process helps immensely in ensuring that each document is of comparable size and content, as opposed to story-level breaks (which would entail documents ranging from approximately 100 words to others with over 20,000 words) or page-level breaks (which are equally arbitrary and likely too large for credible co-occurrences). As elaborated upon below, we specifically use text documents derived from 12-sentence sequences in our primary analysis but also explore 6- and 18-sentence sequences in order to ensure that our results are not overly sensitive to any single sentence sequence length.
Before constructing these sentence sequence documents, we first removed the aforementioned UK (and international) group contact lists from the final pages of each DoD issue. While we use these contacts for identifying our groups of interest, we wish to avoid treating this text as actual content text during either the extraction of group co-occurrence information or the topic modeling stages of our analysis, given that the contact lists included within DoD provide little to no surrounding content text aside from the listed names and contact information for each group. After dividing our remaining corpus into 12-sentence documents, we then processed each document’s text to remove all punctuation, numbers, and stopwords. The removal of these character sets is standard preprocessing for our intended topic model techniques (Bagozzi and Berliner 2017; Roberts et al. 2014). We then omitted sparse terms that did not occur in at least 1 percent of the documents in our corpus. Finally, and as is also common in topic modeling applications, all remaining words were converted to lower case, stemmed, and restructured into a document-term corpus before analysis. Altogether, these preprocessing steps created a corpus with 3,210 unique documents and 2,082 unique word stems. Further below, these preprocessed documents are used within topic models to discover the latent strategies that underlie the DoD corpus and to examine how these strategies vary in relation to our (separately derived) radical UK group network.
The tasks associated with extracting our radical group network, together with our topic model analysis, helped to inform our decision to use 12-sentence sequences as our primary document length. For our topic model analysis, the choice of 12-sentence sequences yielded a document length that was comparable to the shorter, and most common, stories and related text entries within the DoD corpus, while minimizing the aforementioned heterogeneity in story-length documents. The choice of 12-sentence sequences also allowed us to maximize the number, and validity, of our group co-occurrence indicator, which as mentioned above serves as the primary input for our radical group network. Here, the co-occurrence indicator reports whether or not a pair of groups from our final group list were each named within the same document in our corpus. As such, the length of a document directly affects our identified co-occurrences and is tied to an assumption of how proximate two groups must be in the text for us to consider them as co-occurring, and thus sharing a tie within our resultant network. The use of co-occurrences for building networks in this fashion is well established (Chang, Boyd-Graber, and Blei 2009; Culotta et al. 2004; Davidov et al. 2007), and using this literature as a guide, alongside information on the typical document length for our corpus, we believe 12-sentence sequences to be a reasonable balance between the identification of true co-occurrences and the avoidance of false co-occurrences.
Indeed, lowering this sentence sequence threshold by 50 percent to six-sentence sequences—which roughly corresponds to a paragraph’s length of English-language text—significantly reduces the number of identified co-occurrences and thus our identified network ties, potentially ensuring a substantial number of missed ties. Increasing the sentence sequence threshold by 50 percent, to 18-sentence sequences, instead increases the potential for false positives, as radical leftist groups that appear much further apart in the original DoD text will be considered as having a tie when they may in fact have been discussed in wholly separate contexts. We nevertheless explore networks constructed from 6- and 18-sentence documents in Online Supplemental Materials. The 6- and 18-sentence sequence results yield findings that are generally comparable to those obtained from our primary 12-sentence sequence documents, but which are also less coherent in terms of the underlying network identified and group clusters uncovered. These deficiencies are in line with the expectations outlined above, and further reinforce the choice of 12-sentence sequences as our primary documents within the analysis presented below, while also underscoring the more general stability of our network to sizable changes in sentence sequence length.
To construct our co-occurrence indicator, we iterate through every group pair included within our UK radical group list. For each pair (i), we query each 12-sentence document (d) to record whether (= 1) or not (= 0) group pair i co-occurred in document d. Importantly, for our documents d, we in this case use the unprocessed 12-sentence sequence documents, as opposed to the fully preprocessed documents discussed above, as decapitalization, stemming, and proper noun removal each undermine the appearance and identification of our target group names within our co-occurrence queries. 10 Furthermore, and immediately prior to implementing these co-occurrence queries, we applied a standardization routine to address typographical errors, and/or common variations, in the spellings of target groups within our unprocessed documents. This standardization approach first entailed that we identify and record each common (and plausible) group name variation, abbreviation, and misspelling, which was done through a manual review of the group contact lists provided in DoD issues 1–10. With this set of group name variations in hand, we implemented a processing script that individually standardized each group name within our unprocessed documents, while also incorporating unique features into some group names so as to ensure that groups with closely overlapping names were not incorrectly counted as (co-)occurring in instances when only a similarly named group was mentioned in a document.
With our group names standardized in this fashion, we are able to implement our co-occurrence queries in a manner that maximizes precision and recall. From the results of these queries, we construct a binary i by d matrix, where 1s denote co-occurrences between groups (rows) in particular documents (columns) and 0s denote the absence of a group-pair co-occurrence for a given document. A total of 44 groups in our 143-group master list co-occurred with another group at least once across all documents, with a mean, standard deviation, median, and maximum number of co-occurrences (per group) of 1.13, 2.52, 0.00, and 19.00, respectively. Accordingly, we define any group pair that exhibited at least one co-occurrence across all documents as having a “tie,” and use this classification for (i) constructing our group network and, later, (ii) assessing variation in latent protest strategies in relation to these network ties and clusters thereof.
Environmental Group Networks
Social network methods have a long history in the social sciences, dating back to the 1930s (Freeman 2004). Co-occurrence networks have been used effectively in the bioinformatics literature (e.g., Cohen et al. 2005), computer science and engineering (e.g., Matsuo and Ishizuka 2004), and the bibliometric literature (for a review, see King 1987). Social networks have been employed for related theoretical development in explaining social movements (e.g., Byrd and Jasny 2010) and in organizational (e.g., Burt 2000; Spiro, Almquist, and Butts 2016) activities. Further, one can represent a collection of individuals engaged in shared activity as single entity which engages in collaborative activities, for example, citation networks between blogs or disaster relief (e.g., see Almquist and Butts 2013; Almquist, Spiro, and Butts 2016). This work builds on this literature and extends it in several key dimensions. First, we directly incorporate text information to understand the diffusion of information, ideas, and activities which occur through these networks. Second, we explore the endogenous nature of the network and concepts which create these complex social interactions. Third, we empirically validate these measures in the policy relevant setting of modern environmental movements.
Here, we adopt the social network nomenclature of representing a network as a mathematical object known as a graph (G). A graph is defined by two sets,
The network literature is comprised of both theoretical and methodological insights. In the context of radical environmental group networks we are particularly interested in descriptive analysis (Almquist 2012; Wasserman and Faust 1994), metrics of power (also known as centrality indices, see Freeman 1979), and group analysis (i.e., community detection or clustering, see, e.g., Fortunato 2010; Mucha et al. 2010).
In the following subsections, we will outline the necessary literature and background for interpreting and using these statistics in our specific context. We will begin by carefully detailing the network of co-occurrence for our radical UK environmental groups, including visualization and basic descriptives. We will follow up the descriptive statistics with a node-level analysis of the individual actors and finish up with a group-level analysis of the network.
The Network and Descriptive Statistics
Typically network analysis begins by defining the bounds of the network and the relation of interest (Wasserman and Faust 1994). The group network analyzed in this article consists of 143 radical environmental groups identified in the text analysis portion of this research. The edge set is defined, as mentioned in the fourth section, by at least one co-occurrence between a

Network plot of the 12-sentence co-occurrence network. The left panel of the figure is the complete network including isolates, and the right panel of the figure is the largest connected component. Graph plotted using Fruchterman and Reingold’s force-directed placement algorithm.
This network is defined by 143 groups and 134 co-occurrence relations, providing a density of 0.00583.
11
Another important measure of the network is the degree distribution and the mean degree statistic, where degree of node v is number of ties connected to
Centrality
In SNA, the concept of node centrality is an important and classic area of study within the field (Freeman 1979). There exist within the social network literature a large set of centrality metrics and measures of power. We choose to focus on the four most popular (Freeman 1979; Wasserman and Faust 1994): degree, eigen, betweenness, and closeness centrality. Each captures a slightly different, but important aspect of node position within the network. Degree centrality is a straightforward measure of how connected a given individual actor is to all other actors in the network (Anderson, Butts, and Carley 1999). Eigen centrality (or eigenvector centrality) corresponds to the values of the first eigenvector of the adjacency matrix; this score is related to both Bonacich’s power centrality measure and page-rank and can be thought of as core–periphery measure (Anderson et al. 1999; Bonacich 1972). Betweenness is a (often normalized) measure of shortest path or geodesic distance between overall graph combinations; conceptually, a node with high-betweenness resides in a space with a large number of nonredundant shortest paths between other nodes. This can be interpreted as nodes which act as “bridges” or “boundary spanners” (Freeman 1977). The last centrality measure we consider is closeness which is another geodesic distance–based measure. Here we use the Freeman (1979) version which is defined for disconnected graphs and has largely the same properties as the classic closeness measure. We have tabulated the top-10 activist groups as ordered by degree in Table 1.
Top 10 Actors for Degree Centrality.a
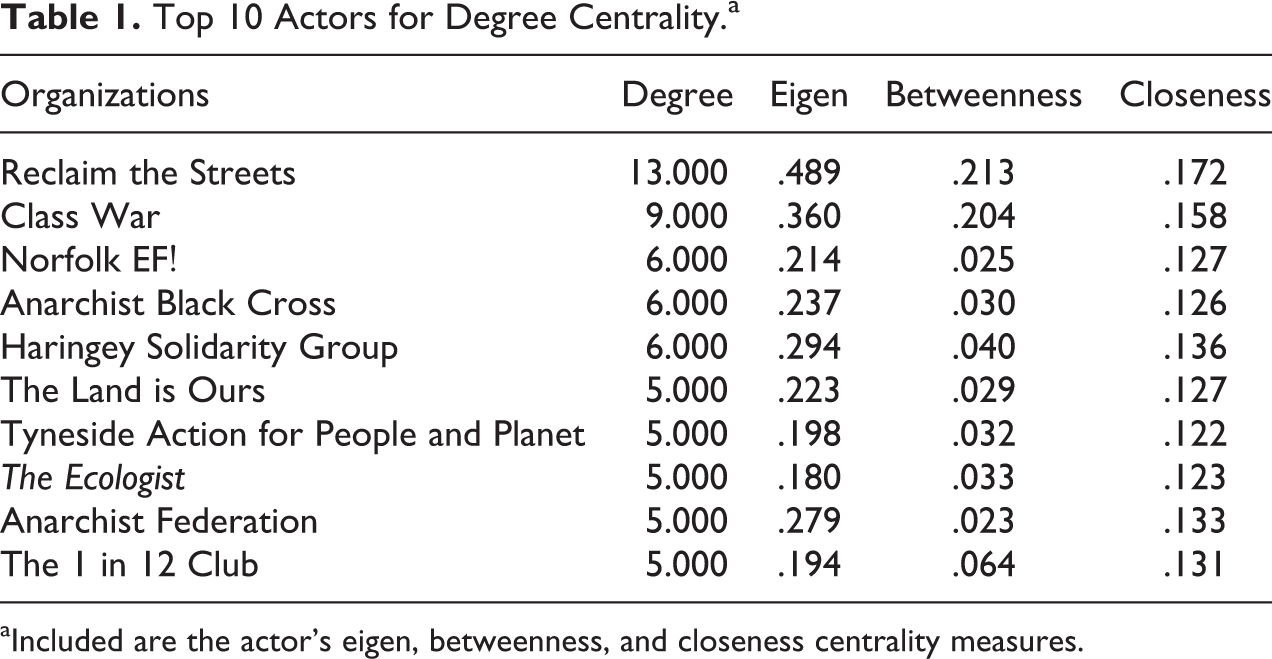
aIncluded are the actor’s eigen, betweenness, and closeness centrality measures.
Generally speaking, an activist group who is high on one measure of centrality is also high on the other measures of centrality. The lowest correlation is between betweenness and closeness which correlate at 0.56, and the highest correlation is between degree and eigen centrality at 0.95. The ranking of nodes is of course not perfectly aligned even in the case of degree and eigen centrality. Consider the Haringey Solidarity Group, which is tied for third with Norfolk EF! and Anarchist Black Cross in degree but is clearly ranked second in eigen centrality. In this case, the Haringey Solidarity Group’s high levels of centrality across both metrics are unsurprising, given this group’s long history, central London location, active participation in a wide array of crosscutting issue areas (including environmental sustainability, social justice, worker’s rights, and antifascism, among others) and media profile (including a website, very widely distributed newsletter, and Twitter account). Another illustrative case is that of AF which is tied for fourth rank with several other groups in degree, but would be ranked third in eigen centrality, 12 with each high-centrality measure perhaps owing to this AF’s uncharacteristically large membership size, reach, organizational development, and media presence.
The key finding of the centrality measures in Table 1 is that there are two groups—Reclaim the Streets and Class War—who very much stand out on all measures followed by several other groups who are highly active and then a separate set of groups with no collaboration at all. Like the cases of the Haringey Solidarity Group and AF discussed above, the centrality of Reclaim the Streets (and Class War) is consistent with extant knowledge of these groups. Reclaim the Streets was originally a UK-based antiroads NVDA group that grew out of the UK EF! movement and related protest camps but quickly established itself as a key actor within the (UK and international) antiglobalization movement (Chesters and Welsh 2011:67). The (international) scope of this group, its ties to the UK EF! movement and related UK direct action groups, and the frequent mass street protests that it led 13 all undoubtedly helped to establish Reclaim the Streets as a central actor within the radical UK environmentalist scene during the 1990s and early 2000s. Similarly, Class War is a UK anarchist group that rose to prominence in the early 1980s through a widely circulated self-produced newspaper, music records, and national conferences and later through its coordination of various actions and protests. Although Class War splintered into a number of regional groups during the late 1990s, its central role as an organizing and publicizing force for far left-activism during this period (and earlier) likely contributed to its high levels of centrality in our network. 14 That said, we need to follow up this node-level analysis with an attempt to better explain the larger macro dynamics of the network. We analyze this aspect of the network in the following section.
Clustering
There are numerous clustering (e.g., community finding) algorithms employed in SNA; however, the results of these various methods tend to be highly correlated (Anderson et al. 1999). We use a well-documented and accepted method of Hierarchical cluster analysis on a set of distances. Because social networks are binary arrays it makes sense to use Hamming distance (Butts and Carley 2005), which measures the minimum number of substitutions required to change one bit into the other bit (0 or 1) in the case of a graph. Further, we employ the Ward algorithm for finding these clusters (Butts and Carley 2005). In SNA, this is equivalent to finding the structural equivalence of a set of nodes in a given network (for more details, see Butts 2008). Because the isolates (nodes with no connections) automatically form their own equivalence classes, we do not include them in our analysis. In Figure 2, one can see the dendrogram plot from the clustering algorithm. Through visual inspection (and statistical analysis), we settle on three core groups (see Table 2).
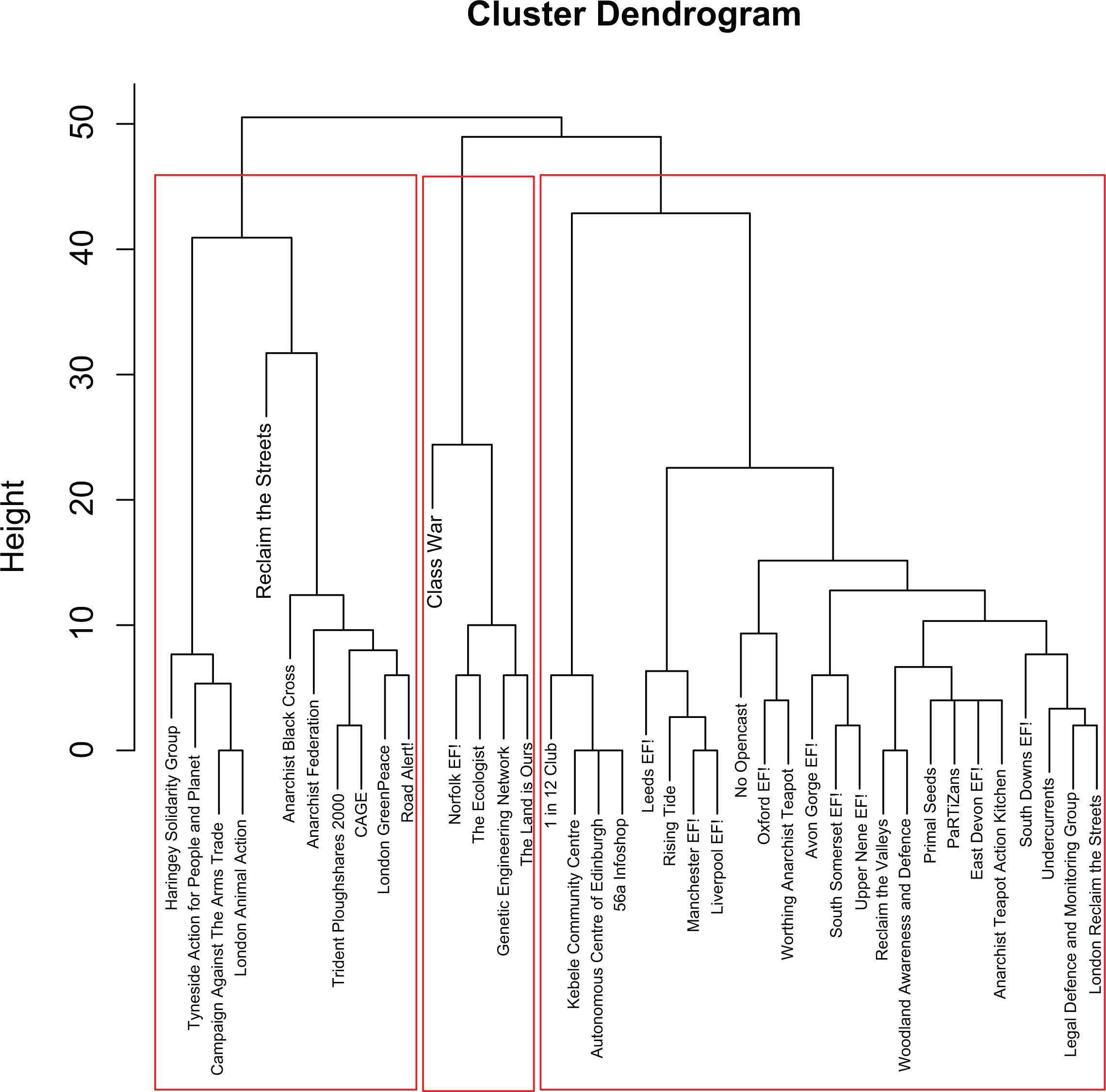
Dendrogram of the large cluster in the 12-sentence network. Computed using hamming distance with Ward’s D-decision criterion.
Names of Radical Environmental Groups Attached to Each Cluster Assigned by the Dendrogram Clustering Method.
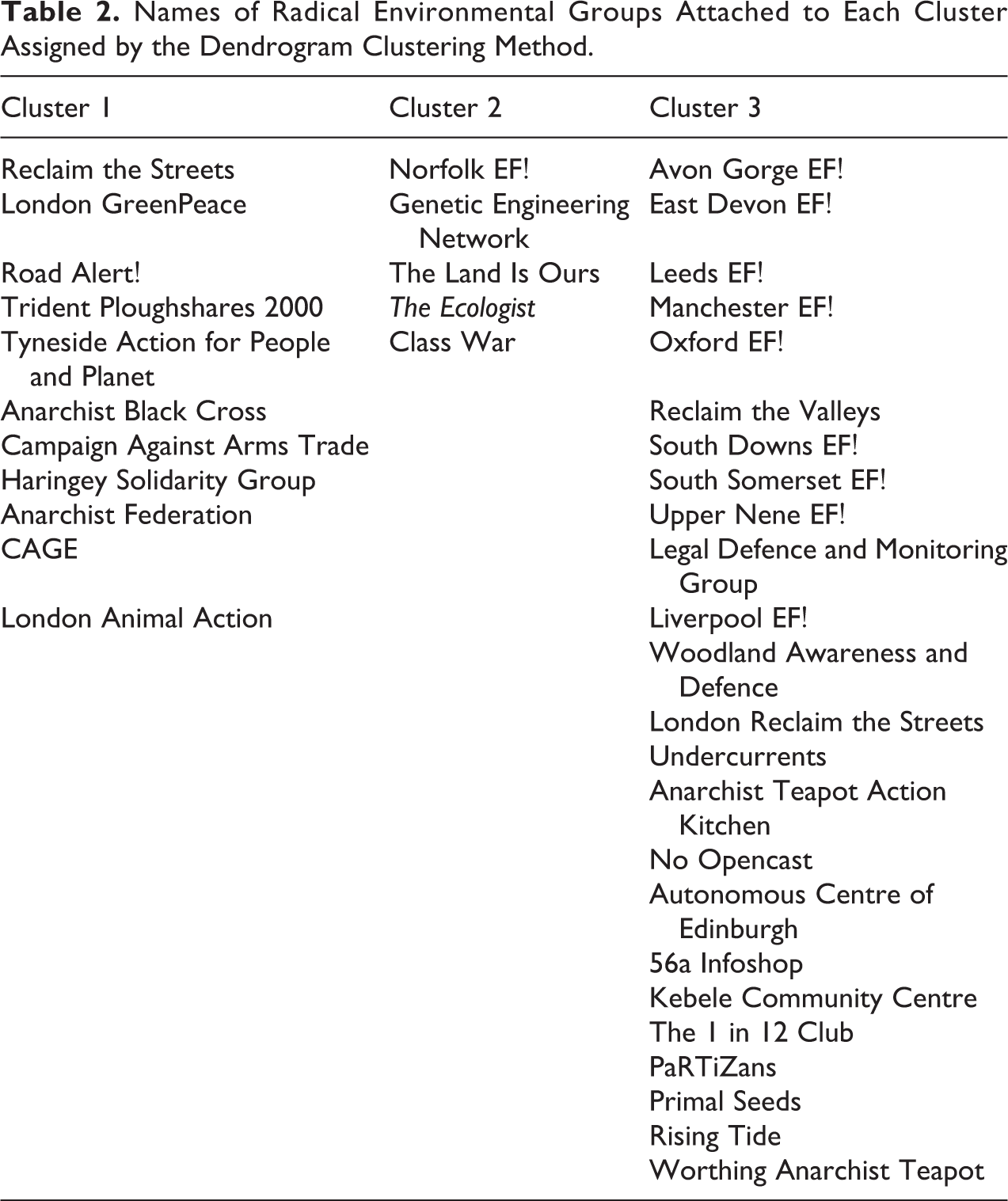
To better visualize these clusters, we replot the connected component network colored by the individual clusters in Figure 3. Based upon the individual characteristics of our connected component groups, the three identified clusters reveal a number of interesting and theoretically consistent patterns. We highlight a number of these patterns here and evaluate our contentions more explicitly within our Text Analysis section further below. Cluster 1 contains leftist environmentalist groups focused on a wide variety of issue areas, including antinuclear protest (Campaign Against Arms Trade; London GreenPeace; and Trident Ploughshares 2000), environmental direct action (Tyneside Action for People and Planet, London Animal Action), antiroads agendas (Reclaim the Streets, Road Alert!), and opposition to excessive government control (AF, Anarchist Black Cross, Haringey Solidarity Group, and CAGE). Notably absent from this cluster are any regional EF! groups or community centers. Given this variation, and the high-centrality measures of many of the groups included in cluster 1, we suspect that cluster 1 primarily identifies radical environmental and leftist groups that coordinate in omnibus street protests and direct actions. Indeed, a recent Reclaim the Streets protest included a workshop led by London Campaign Against Arms Trade and stalls hosted by Haringey Solidarity Group and Animal Rescue (Reclaim the Streets, Nd.c).
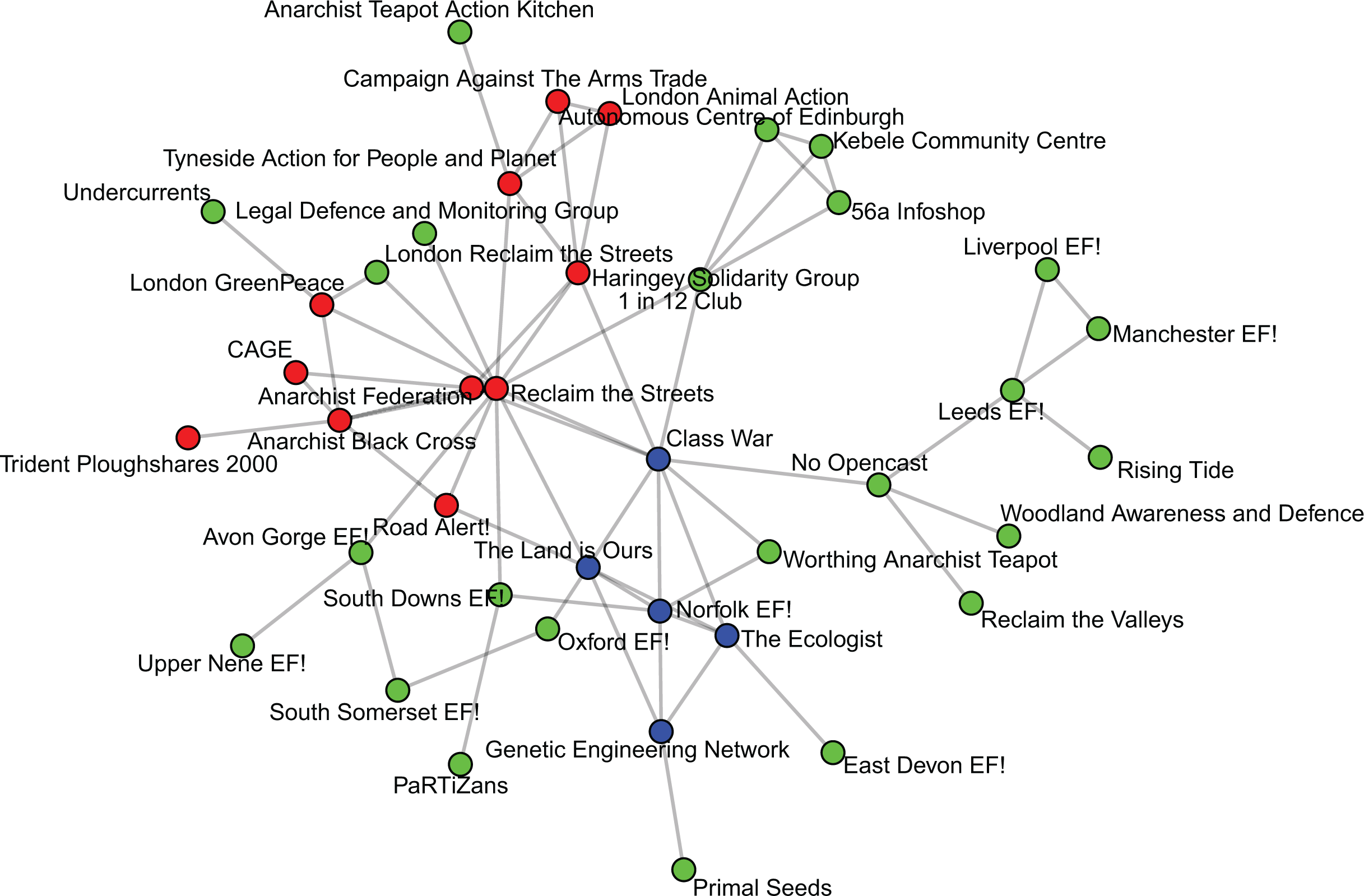
Network plot of the connected component of the 12-sentence network colored for cluster assignment.
Cluster 2 is smaller and more ambiguous. One can note that the groups contained in cluster 2 are generally environmental in nature and range from direct action-oriented groups (Norfolk EF!, The Land is Ours) to organizations primarily focused on information dissemination (The Ecologist, Genetic Engineering Network, and Class War). We therefore believe that this cluster identifies groups coordinating over ecotage and related direct action activities or coverage thereof. More generally, this cluster, as well as clusters 1 and 3, appears to incorporate groups arising from multiple (environmental) issue areas and/or ideologies. This is consistent with the levels of positional incoherence observed within positional blocks in past network analyses of European environmental groups and organizations (Diani 1995, 2002; Saunders 2007b:232-3) and underscores the utility of our relational approach.
Cluster 3 is the largest identified cluster and contains a majority of our regional EF! groups, several related groups known for occupation/camp-based protests (e.g., Reclaim the Valleys, No Opencast), and a large number of community/organizing centers, among others. Given the common usage of direct action tactics by a majority of these groups, as well as their frequent mutual participation in large-scale protest camps, we suspect that this cluster is identifying groups that coordinated together via these more targeted direct action activities as well as the venues where such activities were organized. An example of such behavior with respect to protest camps targeting opencast mining comes from DoD itself, which notes that “Leeds EF! took action in early 1995 targeting an opencast site in Yorkshire, and at about the same time, Welsh activists were setting up camps at Selar and Brynhenllys sites near Swansea. These actions, among others, led to an increasing alliance between EF!(ers) and the No Opencast campaign” (DoD 1998).
Radical Environmental Group Tactics
Our identified list of UK radical environmental groups, and group network clusters, includes some groups (e.g., The Ecologist) that neither engaged in nor advocated for acts of violence, sabotage, or property destruction, whereas others, including a number of our identified regional EF! groups, routinely did so. Hence, we next seek to discover the underlying protest tactics that are pursued by environmental groups within this network’s connected component and to evaluate whether these methods can accurately identify which groups actively pursued radical protest, and which did not, in an unsupervised fashion. To do so, we apply unsupervised topic models to our preprocessed text documents, so as to simultaneously (i) uncover the latent themes or “topics” that are discussed across documents and (ii) associate these topics with the group ties and clusters that we discussed above. Topic models allow one to recover the former quantity by treating one’s documents as a combination of multiple overlapping topics, each with a representative set of words. Latent topics are then estimated via a hierarchical model that treats each document as a mixture of underlying topics and returns the word distributions that are most strongly associated with each topic across all documents. Topic model extensions that incorporate predetermined network information have largely focused on conditioning topic estimation upon network structures (and documents) linked by authorship/recipient (e.g., McCallum, Corrada-Emmanuel, and Wang 2005) or citations (e.g., Chang and Blei 2009; Dietz, Bickel, and Scheffer 2007), although Chang et al. (2009) and Krafft et al. (2014) have developed more flexible network-oriented topic models that infer topic descriptions and their relationships from documents that are indexed by a network’s entities and/or entity pairs.
While the above models provide useful methods for discovering latent topics from networked documents, they each generally require that one’s documents be fully indexed with relevant network information. This is unsurprising, as a primary goal of these models is to recover latent topics from networked texts. However, for the DoD corpus, the vast majority of our (12-sentence sequence) documents are not associated with specific network entities, entity pairs, or clusters. Indeed, only a small proportion of these documents contains relevant network information, which effectively precludes us from using the models discussed above to extract topic-based information concerning our network’s underlying strategies and tactics. This is for two interrelated reasons. First, subsetting out only network-associated documents from our corpus for use in the above models would leave us with a sample size that is far too small for tractable topic model estimation. Second, subsetting our sample to only these network-associated documents would also sacrifice the wealth of information that is contained in our nonnetwork-associated documents. While these latter documents do not contain information directly associated with our network’s features, they do contain extensive information pertaining to the latent topics underlying our corpus on the whole and thus help us to obtain more accurate estimates of our topics of interest.
Accordingly, we favor a more recently developed approach for the incorporation of external document-level information and structure into unsupervised topic model analyses known as the structural topic model (STM Roberts et al. 2014). The STM estimates latent topics in a similar hierarchical manner to that of the general discussion provided earlier, while also incorporating document-level information via external covariates into one’s prior distributions for document topics or topic words. In this manner, one can use the STM to not only identify a set of shared latent topics across a corpus but also to evaluate potential relationships between document-level covariates and the prevalence of a given topic within and across documents. As such, the STM has been effectively used to estimate the effects of survey–respondent characteristics upon variation in respondents’ open-ended responses (Roberts et al. 2014) as well as the effects of country-level characteristics (e.g., regime type) upon the topical attention of U.S. State Department Country Reports on Human Rights Practices (Bagozzi and Berliner 2017). For our application, the STM’s advantages intuitively lie in its ability to incorporate structural network information—namely, group tie presence and cluster member presence—as binary predictors of variation in attention toward different radical protest strategies and tactics across documents. This, in turn, allows us to estimate a set of topics across all documents and then to evaluate whether the presence of a given group tie (or cluster member) significantly increases the attention dedicated to a given topic. 15 When it does, we interpret this as evidence for shared strategies or tactics between groups within our network.
We specifically model our 12-sentence sequence document corpus as a function of the aforementioned external covariates using the stm version 1.1.3 R package (Roberts et al. 2015). As is the case for most unsupervised topic models, we must explicitly choose the number of topics to be estimated within the STM. Roberts et al. (2015) note that “[t]here is no right answer to the appropriate number of topics. […] For small corpora (a few hundred to a few thousand) 5-20 topics is a good place to start.” As our corpus contains 3,210 documents, we rely on the above suggestions—as well as on the topics identified in similar analyses of international social texts (e.g., Bagozzi and Berliner 2017)—to select a topic number of 15 for our primary STM analysis. We further validate our choice of a 15-topic model both qualitatively and quantitatively in Online Supplemental Materials. In brief, we first show qualitatively in our Online Appendix that the topwords from our final 15-topic STM (after addressing the multimodality issues discussed below) are similar, but more relevant and interpretable than those identified in comparably estimated 10- and 20-topic models. Second, and in keeping with the topic number selection routines employed by Bagozzi and Berliner (2017), we then quantitatively derive aggregate exclusivity and semantic coherence metrics for each of our 10-, 15-, and 20-topic models so as to compare the performance of each candidate model more objectively. In this context, exclusivity quantifies how exclusive one’s topwords are to each topic based upon a word’s relative probabilities of association across topics, while semantic coherence measures the relative co-occurrence of our topics’ topwords across our corpus and thus provides a sense of how internally consistent the topics are within each candidate model (Roberts et al. 2014). As discussed in our Online Appendix, we find that our 15-topic STM exhibits the best joint performance along both semantic coherence and exclusivity dimensions of comparison, whereas the 10- and 20-topic STMs perform noticeably on at least one of these two metrics. We interpret these findings as further evidence in support of our choice of a 15-topic STM within our primary analysis.
Finally, in order to address multimodality concerns in the estimation of our final 15-topic model, we follow Roberts et al. (2014) and estimate a set of 50 separate 15-topic STMs, while employing different starting parameters for each initialization, 16 and store exclusivity and semantic coherence metrics for each model. We select a single model from this set of 50 models that maximizes the coherence and exclusivity of our topic word vectors. Using the results of this model, we examine the sets of 20 topwords that best characterize each identified latent topic. After establishing the semantic meaning of our 15 identified latent topics according to these topwords, we then derive a series of postestimation quantities that allow us to examine how topical prevalence varies in relation to group ties and group clusters.
Topics
This section discusses the topics that we identify as underlying the DoD corpus. Recall that our STM identifies the 15 topics that best characterize our preprocessed 12-sentence sequence documents. Each topic represents an underlying word distribution, wherein each word in our corpus is given a posterior probability of assignment to that topic. For these word vectors, and consistent with Roberts et al. (2014), we derive the words most associated with each topic according to frequency exclusivity scoring metrics, which ensures that our reported topwords correspond to the word stems that are both most frequently assigned to a given topic and most exclusive in their assignment to that topic. It is up to us to substantively interpret the meaning of each topic based upon these probabilistic word assignments. To do so, we draw upon the 20 most frequent and exclusive words for each topic and present our 15 topics of interest—including our labels for each topic, the topic’s (stemmed) topwords, and the topic’s reference number—in Figure 4.

Topwords for 15-topic model.
By and large, the 15 topics identified by the STM appear to correspond to meaningful constructs. We group the 15 identified topics into three general categories for discussion: “ideology,” “tactics,” and “general discourse.” Ideology represents the largest of these topic groupings and includes topics 2–4, 6, 8, 12, and 15. In line with our earlier discussions of the overarching goals of the DoD publication Earth First! Journal 2006 , topic 2 is labeled Group Identity Debates and exhibits topwords pertaining to the ever-changing environmental perspectives and overarching goals of the UK EF! movement and debates therein. Topic 4 is labeled Eco-Literature and encompasses topwords pertaining to the publication and dissemination of radical environmentalist viewpoints. The remaining ideology-based topics clearly identify ideological issues that environmentalists and radical leftists are either for (topic 6: Species Conservation; topic 8: Land Conservation; and topic 12: Sustainable Societies) or against (topic 3: Neo-Colonialism; topic 15: Anti-Capitalism). We take the identification of these highly plausible ideological topics as evidence to suggest that our STM is performing as expected for the corpus as hand.
The next grouping of topics is of most interest to our analysis and encompasses a number of radical protest tactics and strategies. In full, we identify four topics in Figure 4 that appear to pertain to such tactics: topic 9: Violent Protest; topic 10: Direct Action/Ecotage; topic 11: Occupation/Camps; and topic 13: International Terror. The Violent Protest topic encompasses topwords related to mass protest (“crowd,” “march,” “demonstr,” and “banner”) as well as to the potential violent consequences of such activities (“polic,” “arrest,” “cop,” “smash,” and “riot”). Direct action/ecotage contains both “direct” and “action” in its topwords in addition to “sabitag,” “act,” and “target.” The occupation/camps topic appears to relate primarily to tactics involving the semipermanent occupation of areas for protest or obstruction and includes words related to the strategy of occupation itself (“camp,” “evict,” “climb,” and “squat”) and words related to the areas that were typically targeted by this strategy in the UK during this time period (“road,” “quarri,” “twyford,” “tunnel,” and “tarmac”). Finally, international terror captures illegal international activities (“bomb,” “murder,” and “kill”) involving environmental and/or leftist radicals (“black,” “panther,” “shepherd,” and “ship”) and their aftermath (“prison,” “sentenc,” “jail,” “fbi,” and “trial”). As such, our documents and STM approach have together identified four fairly coherent, yet largely distinct, tactics used by radical environmental (and leftist) groups.
In addition, four of the latent topics in Figure 4 appear to relate to more general (environmental) media discourse. Topic 1 is fairly ambiguous and is labeled Inspirational Language. It contains a range of topwords that we suspect are intended to communicate optimism (“great,” “strong,” and “left”) and inclusiveness (“mani,” “togeth,” and “join”). Topic 5: News and Culture encompasses current events that are likely of general interest to DoD’s UK environmentalist readership, including family-related issues (“men,” “women,” and “school”), sports (“footbal,” “game,” and “team”), and legal/terrorism updates (“terrorist,” “intellig,” and “court”). Topics 7 and 14 are labeled General Concern and Admonishments and appear to, respectively, voice (i) overarching environmental concerns for the survival of the planet and (ii) criticisms of those that do not support the (radical) environmentalist viewpoint. While we remove stopwords during preprocessing, topic 14 in particular seems to contain a large number of words that could be considered stopwords. We refrain from removing these additional stopwords in a post hoc fashion, given that they are not included in the primary English-language stopwords list that is commonly used in STM analyses (e.g., Bagozzi and Berliner 2017; Roberts et al. 2015, 2014). Finally, while we rely on the topwords to define our topics above, note that we also use the STM to identify a sample of 10 highly representative documents for each topic, and have used these sample documents to qualitatively guide our topic labeling efforts.
Shared Group Tactics
Focusing on the four tactic-based topics discussed above, we next evaluate whether these topics vary systematically in relation to the presence or absence of specific group ties and whether such variation is consistent with our extant theoretical expectations. To do so, we make use of our group-pair STM covariates—which indicate whether (or not) a connected group pair co-occurs within a given document—and specifically estimate the effect of a 0-to-1 change in each group pair’s presence in a document on that document’s attention to each tactic-based topic. We highlight and discuss a selection of our specific findings in this regard below, before summarizing our more general findings for all connected component group pairs in the identified network.
Figure 5 presents three sets of estimated effects—which correspond to three specific group pairs—to illustrate our findings pertaining to the association of particular groups with certain tactics and variation therein. Turning first to the pairing of Oxford EF! and Class War in Figure 5, we find that this group pair is positively associated with the use of violent protest tactics, but not significantly associated with tactics of direct action/ecotage, occupation/camps, or international terror. While we held no prior expectations for the shared tactics involving a pairing of Oxford EF! and Class War, these findings our intuitive. As alluded to above, Class War is a long-running anarchist movement that, among other activities, was known for its coordination and coverage of large-scale violent protests and riots during the 1980s and 1990s 17 Hence, in terms of its ties to an ecological direct action group such as Oxford EF!, it’s likely that such ties would encompass coordination on tactics of violent protest as opposed to the more explicitly environmental direct action and protest-camp activities that regional UK EF! groups are more commonly known to participate in.

Estimated associations between tactics and group ties.
By contrast, we find in Figure 5 that the Avon Gorge EF! and South Somerset EF! group pair is not significantly related to tactics of violent protest nor to tactics of direct action/ecotage or international terror. However, our findings for the Avon Gorge EF! and South Somerset EF! groups do suggest that these two groups are more likely to be jointly associated with tactics of occupation/camps-based protests: The co-occurrence of these two groups in a given document is estimated by our STM to be associated with a roughly 40 percent increase in attention to occupation/camps-type tactics. While EF! groups are most commonly viewed as coordinating over direct action and ecotage-type tactics, our finding in this case is again unsurprising. Indeed, one of the UK EF! movements’ longest running campaigns during the 1990s was its use of occupation camps to protest the Somerset-based Whatley Quarry, which most notably involved the two regional EF! groups examined here (DoD 1996; Schnews 1995). As such, this result suggests that our tactic-based findings do indeed correspond to actual strategies of coordination between specific groups, rather than to more arbitrary overlapping associations of the individual (and unique) tactics associated with pairs of co-occurring groups within the DoD text.
Recall that some groups within our UK radical environmental groups list (and group network clusters) are generally known to not partake in radical protest strategies. We next seek to evaluate whether our proposed approach correctly identifies such groups as nonradical, even when one examines the ties between nonradical groups and more radical groups within an assigned group cluster. One such case is The Ecologist, a mainstream UK environmental journal that was nevertheless listed as a key UK-group contact within some issues of DoD and was earlier assigned to cluster 2 alongside more violent and radical groups such as Class War. The third subfigure in Figure 5 accordingly examines the associations of the Class War and The Ecologist group pair with each of our four identified protest tactics. As one would expect, we find in this case that the Class War and The Ecologist group pairing is not significantly associated with any of the four identified protest tactics. This implies that, within DoD, these two groups are not associated along radical protest dimensions and that our proposed method is capable of avoiding false positives with respect to the association of radical protest strategies with specific (nonradical) group pairs.
The final subfigure in Figure 5 highlights a group pair—that of Reclaim the Streets and London GreenPeace—that is positively associated with the direct action/ecotage tactic. This finding is understandable, given the extensive ties between these two groups 18 and the direct action agenda of London GreenPeace during the period under analysis. Moreover, whereas Reclaim the Streets is most commonly characterized as pursuing large-scale nonviolent protests and “street parties,” evidence suggests that these events are often cover or magnets for ecotage-oriented tactics as was widely observed during Reclaim the Street’s guerilla gardening actions in Parliament Square on May Day 2000, as well as, for example, “during the 1996 Reclaim the Streets Party on the M41 (urban freeway) in West London, [wherein] the skirts of giant pantomime dames on stilts were used as cover for activists using pneumatic drills to break up the road” (Plows et al. 2004:205). Therefore, in sum, our Figure 5 findings highlight the useful information that can be extracted from our network using STMs and associated co-occurrence information. While these findings are far from definitive, extant theory suggests that they are consistent with our understanding of past UK environmental group behaviors, thereby highlighting and validating the utility of this approach.
More generally, we find that a very large number of the group pairs within the connected component of our network are significantly and associated with the direct action/ecotage topic, though we do not report each figure here to save space. This frequent association with direct action/ecotage is in line with extant studies and theory, as direct action and ecotage–type strategies are by and large the primary tactic used by the UK EF! groups examined here. At the same time, we find that a much smaller number of our overall connected component group pairs are significantly associated with either violent protest or occupation/camps. Furthermore, virtually no group pairs were significantly and positively associated with the international terror topic. Given our focus on UK rather than international extremist groups, and the predominately nonterrorist designations of the radical leftist groups in our sample, this latter null finding is reassuring. Nevertheless, an examination of whether international (environmental) extremist groups (which are also listed in the appendices to DoD publication) exhibit similar patterns of (non)association with these four tactics would make for an interesting future extension of the present analysis.
Cluster Tactics
We next evaluate the extent to which our three connected component network clusters exhibit similar variation vis-à-vis the identified protest-strategy topics. These estimated effects, again with 95 percent confidence intervals, appear in Figure 6. Beginning first with cluster 1, we find in Figure 6 that the connected component groups included within this cluster are significantly more likely to be associated with tactics of violent protest and direct action/ecotage but are no more or less likely to be associated with the radical protest tactics of occupation/camps or international terror. The former findings suggest an increase in topical attention of roughly 5–10 percent per document and is highly consistent with our expectations. As discussed above, the groups included within cluster 1 tend to have high centrality within our overall network, are often located in the London area, each share a history of joint participation in large-scale omnibus protests and can be generally thought of as being involved in a diverse cross-section of radical leftist issues and concerns (e.g., Reclaim the Streets, Nd.c). We hence anticipated that these groups had been clustered together based upon their frequent coordination over (violent) protest and direction action campaigns but not international terrorism or protest-camp activities—which is confirmed in Figure 6. This accordingly suggests that our clustering strategy is revealing at least some commonly shared group tactics.
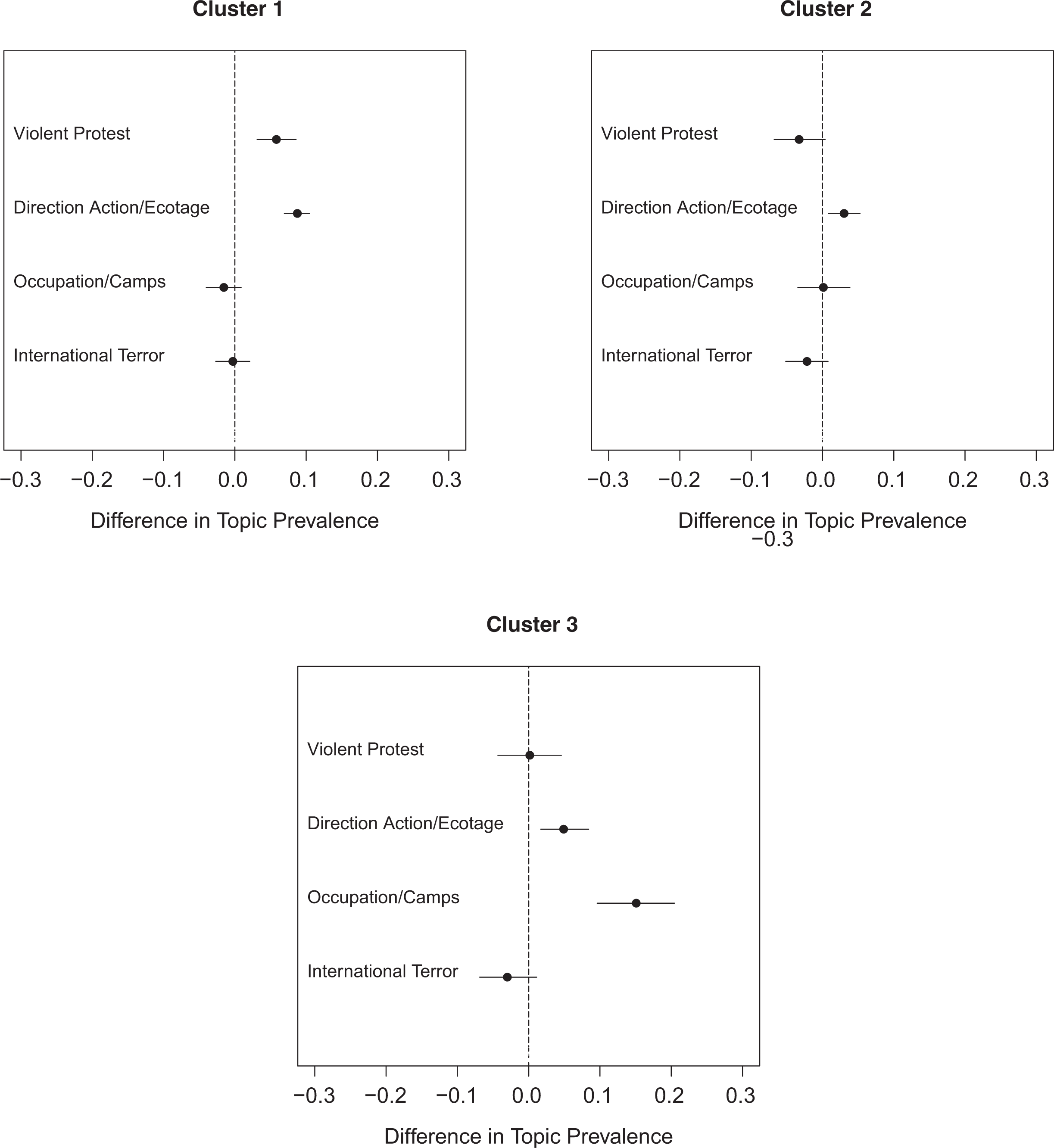
Estimated associations between tactics and clusters.
Our findings for cluster 2 reinforce these conclusions. Recall that, while virtually all groups in cluster 2 are environmentalist in nature, some are direct action-oriented groups (Norfolk EF!, The Land is Ours), while others are predominately focused on reporting and disseminating information on environmentalism and environmental protest (The Ecologist, Genetic Engineering Network, and Class War). We therefore did not expect the groups in Cluster 2 to uniformly be partaking in violent protest activities but rather anticipated that the active groups in cluster 2 (Norfolk EF! and The Land is Ours) would orient this cluster’s tactics toward the strategies most commonly used by these two groups, specifically direct action/ecotage. In Figure 6, we indeed find that cluster 2 is significantly more likely to be associated with the direct action/ecotage topic (though the effect size is small in magnitude), but is perhaps less likely to be associated with violent protest, and is no more or less likely to be associated with occupation/camps or international terror. These findings are consistent with our expectations, assuming that The Ecologist, Genetic Engineering Network, and Class War are primarily reporting on and publicizing these direct action strategies and tactics, rather than actively participating in them.
In contrast to clusters 1 and 2, cluster 3 exhibits a positive and significant association with the occupation/camps topic. Specifically, when discussions pertaining to cluster 3’s groups appear in DoD’s text, we see a nearly 20 percent increase in a document’s attention to occupation/camps. Similar to clusters 1 and 2, we also find a positive and significant association between cluster 3 and attention toward our direct action/ecotage topic. At the same time, we find no significant association for international terror or violent protest. Taken together, these findings are consistent with our expectations: This cluster encompasses a large number of regional EF! groups alongside several protest camp–oriented groups that often coordinate with EF! within protest camps or direct actions. A number of anarchist bookstores and community organizing centers, which often serve as organizing venues for EF! and related group activates, also appear in this cluster. We therefore expected that cluster 3’s shared tactics would largely fall within the protest camps– and direct action/ecotage–type tactics, as these are the activities that cluster 3’s groups are most often and likely to coordinate on—which is indeed the case in Figure 6. Hence, these findings further demonstrate that our combined network and text analysis strategy is able to uncover useful and theoretically consistent information with respect to radical protest tactics and strategies.
The results presented in Figure 6 also reveal a number of novel theoretical insights that together help to sharpen our understandings of social and environmental movements in the United Kingdom. For instance, while we find above that both clusters 1 and 2 are positively associated with our direct action/ecotage topic, we find that cluster 2 is marginally less likely to coordinate on violent protest, whereas cluster 1 is significantly more likely than not to coordinate on violent protest. This divergence, alongside the observed absence of regional EF! groups in cluster 1 (and the presence of these groups in cluster 1) potentially identifies a split in the UK environmental movement at this time, with one subset eschewing violent tactics and another subset embracing violence. While a schism among the specific groups identified here, to our knowledge, has not been identified in past literature, our findings in these regards are consistent with accounts of broader tensions in protest tactics among radical environmental groups in the United Kingdom at this time 19 as well as with characterizations of the UK EF! movement as being “resolutely” nonviolent (Saunders 2007a:112). In these respects, our findings of a positive association with violent protest for cluster 1, but a potentially negative association with this topic for cluster 2, may also suggest that the broader radical leftist and anarchist groups in our sample—which happen to be among the most central groups in our identified network—have a uniquely violence-inducing effect on environmental groups’ protest strategies (i.e., in the case of cluster 1), though further research is needed to fully evaluate this claim.
Network Discovery/Classification via Topic Models
A common problem in network analysis is that of network discovery or network classification of a given relation (see e.g., Wasserman and Faust 1994). This is especially a problem in the case of networks derived from text, such as co-occurrence networks. The methods employed in this article can be used for a two-fold analysis of this issue. First, the topic models can be engaged so as to allow for a qualitative understanding of the co-occurrence relationships (e.g., coordination or communication over direct action or media campaign). Second, these models can be employed as classifiers (here we use classifier in the manner computer scientists refer to the term, for a review, see Vapnik and Vapnik 1998, where a classifier is a method to identify categorical items of interest) to select out relations of interest. Say, for example, that we want to compare networks which exclusively represent the direct action/ecotage relation and/or networks which exclusively represent the eco-literature shared knowledge network relation. To demonstrate how this could be accomplished, we provide two different classification techniques. We derive a network based on the classification of a given relation by its statistical significance (direct action/ecotage), and we also derive a network based on the magnitude of the effect size (eco-literature). In the following subsections, we first describe the classification of each network. We follow these descriptions with a comparison of the two resulting networks. Lastly, we conclude with a statistical analysis of each network and a brief discussion of our substantive findings.
Classification by Statistical Significance
To identify which co-occurring groups in our sample exhibited direct action/ecotage–oriented relation, we iterated through each group pair in our co-occurrence sample and extracted from our primary STM model the mean estimates and bootstrapped 90 percent confidence intervals for the effect of each group pair’s presence in a document upon each topic’s prevalence. We then classified a group pair as a direct action/ecotage group pair based upon whether (= 1) or not (= 0) that group–group had a positive and statistically significant association with our direct action/ecotage topic. This exercise identified 20 of our 67 total group pairs as direct action/ecotage-oriented pairs. We then chose to limit the bounds of the network to only those actors who were actively engaged (i.e., had a relation in the larger co-occurrence network). Overall, this resulted in a network with a density of 0.021 and we visualize this with a standard network plot in Figure 7.
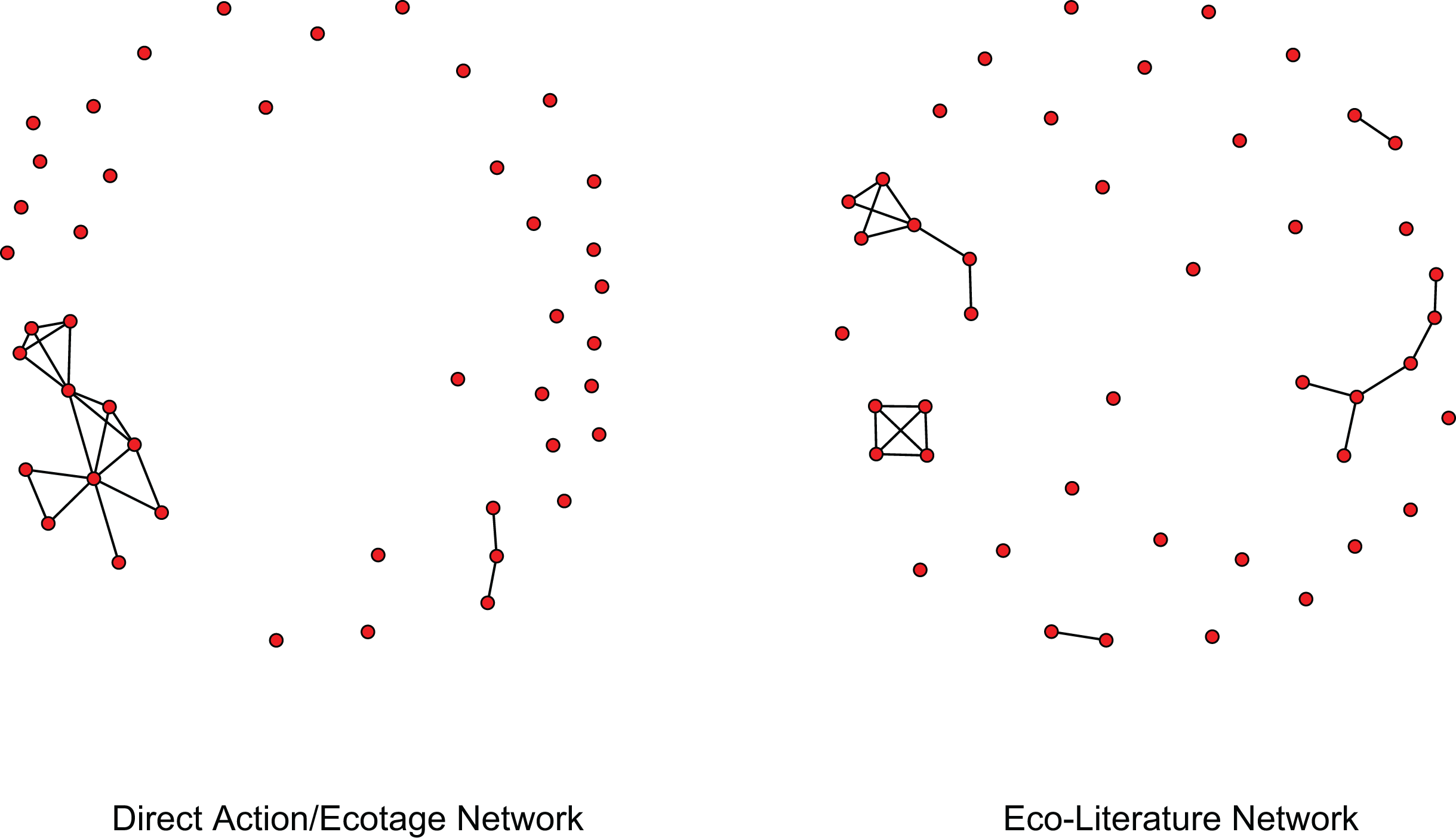
Direct action/ecotage-classified network and eco-literature-classified network plotted based on Fruchterman and Reingold’s force-directed placement algorithm (Butts 2008).
Classification by Magnitude of the Effect Size
We followed a similar approach in classifying our group pairs as groups exhibiting ties through our eco-literature topic. Employing the same topic-indexed mean estimates discussed above, we considered a group pair to be an eco-literature pair, if the presence of that group pair in a given document (relative to its absence) was estimated by our primary STM model to exert a positive substantive effect of at least 0.20 (corresponding to at least a 20 percent increase in the prevalence of a chosen topic) with our eco-literature topic. This approach identified 20 group pairs of our 67 total group pairs as being eco-literature–coordinating group pairs. We then chose to limit the bounds of the network to only those actors who were actively engaged (i.e., had a relation in the larger co-occurrence network). Again, we can visualize this with a standard network plot in Figure 7.
Comparison Direct Action/Ecotage Network to Eco-Literature Network
The resulting networks are quite different even though their density is the same. The graph correlation (given graphs G and H, then
Statistical analysis of Direct Action/Ecotage Network and Eco-Literature Network
Here, we consider probabilistic models of social networks fit by maximum likelihood estimation (MLE). These models are derived from exponential random family models and have thus been referred to as exponential random-family graph models (ERGM). The probability model is typically written as, using the notation of Almquist and Butts (2014, forthcoming),
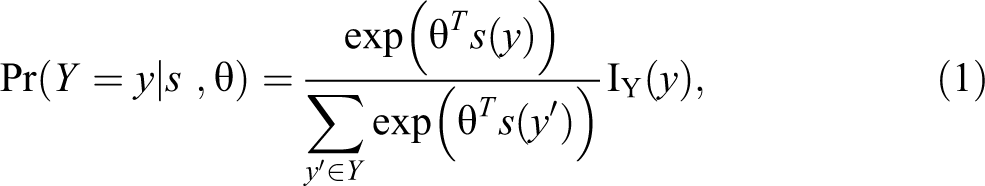
where
Cosine similarity metric
This metric, which corresponds to a cosine similarity measure for the group pairs in our sample, allows us to control for the overall topical similarity of each group pair (i, j) within our ERGM. To create this measure, we must first recover a vector of group (rather than group pair) specific topic measures as input quantities. We do so by extracting a set of group-specific occurrence measures in a similar fashion to the manner in which we extracted our group-pair co-occurrence indicators from our 12-sentence sequence documents. We then estimate a new 15 STM that included these group-specific document occurrence indicators rather than our group co-occurrence indicators. The topics obtained from this modified STM are virtually identical to those discussed above and appear in Online Supplemental Materials. With these group-occurrence STM estimates in hand, we use our STM model’s posterior probabilities of topical assignment to classify our 12-sentence sequence documents based upon their most “dominant topic” (
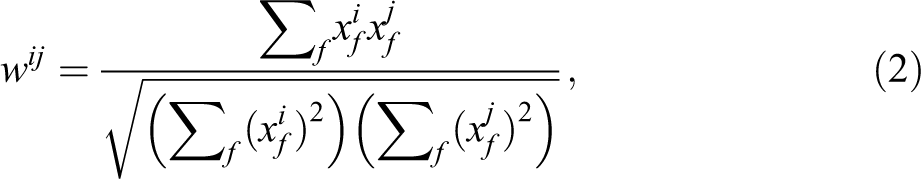
where values range from 0 to 1, with lower values denoting groups that never co-occur in documents of the same dominant topic, and groups equal to 1 correspond to groups that only co-occur in documents of the same topic. As mentioned above, we use this measure as an edge covariate in our ERG model below so as to control for overall topic similarity between groups.
Analysis of direct action/ecotage network
In line with the typical ERGM (and larger statistical model literature), we begin with an edge model (or random graph model; Bayesian information criterion; BIC = 200.69) and then extend it to encompass more complex effects, such as edgewise-shared partners (a measure of clustering, Hunter and Handcock 2012, BIC = 197.42), and then follow up by controlling for topic similarity through our cosine similarity metric. Here, we follow Hunter and Handcock (2012) and use the geometrically weighted edgewise-shared partner distribution (GWESP)—a reparameterization of a statistic of Robins et al. (2007)—which is an alternative approach to counting triangles and can be interpreted as a measure of clustering. It can be considered in comparison or as an alternative measure to the census of triangles or the clustering coefficient for a graph (Hunter and Handcock 2012). Handcock et al. (2008) has implemented a parametric form of the GWESP statistic and the entire model is fit as a curved exponential family via MCMC-MLE, with convergence assessed using the Raftery and Lewis diagnostic (Handcock et al. 2008). We find that the lowest BIC score at this point is in the model which includes the cosine similarity metric with a BIC of 150.14 (see Table 3). We then follow Hunter, Goodreau, and Handcock’s (2012) advice and examine the goodness-of-fit statistics (Figure 8) and find that on all metrics we seem to be doing quite well. We do notice that we could do a bit better on two-edgewise-shared partners and degree of 2 and 3 actors statistics, and this can be managed by adding in terms for two-edgewise-shared partners, degree 2, and degree 3; however, this lowers the BIC score and so we choose to interpret the original full model. The model is composed of an edge statistic (baseline interaction effect), a GWESP term (clustering/triadic closure), and the cosine similarity term (the metric of topic level relation). In Table 3, the baseline log odds of a relation is quite low at
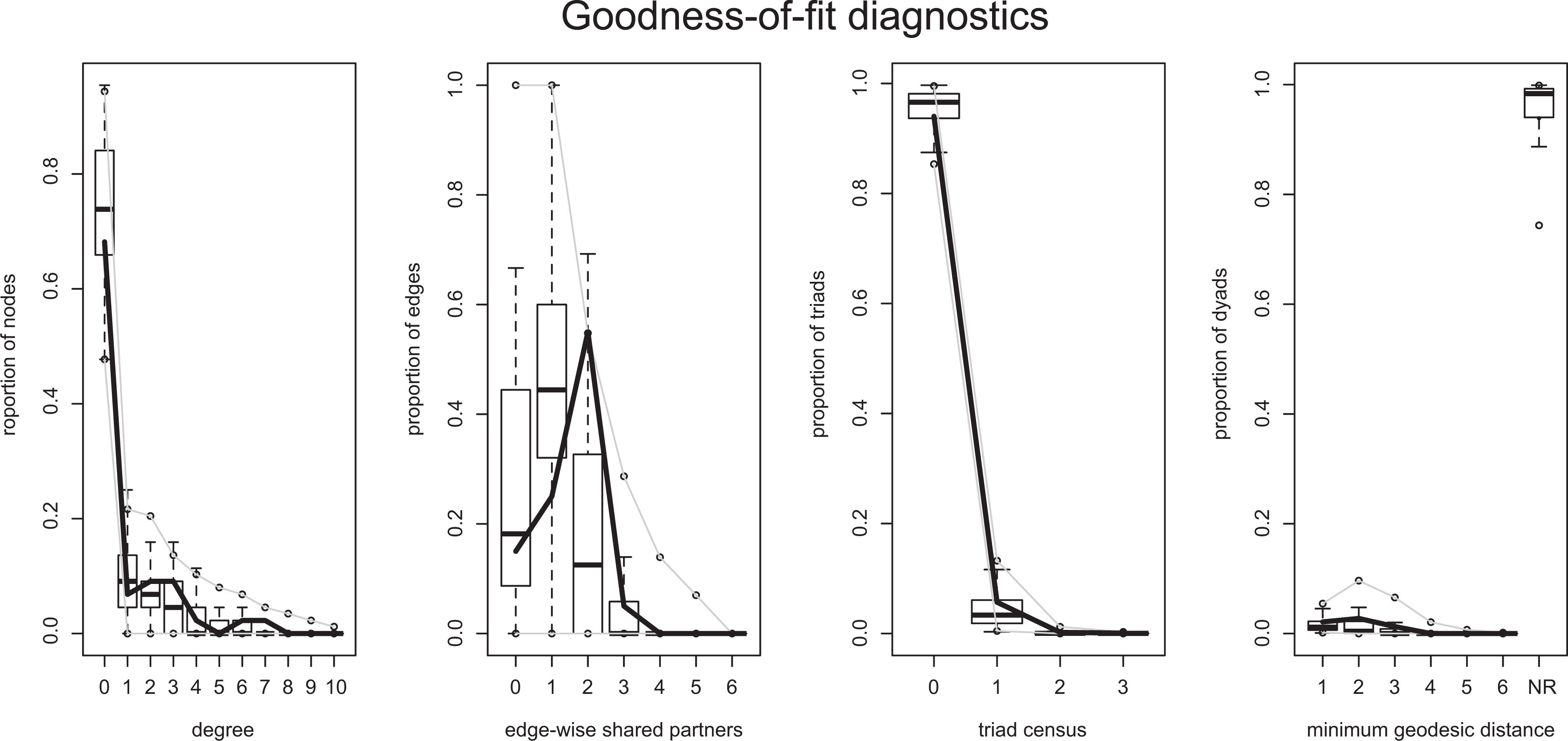
Direct action/ecotage-classified network goodness-of-fit plot based on Hunter et al. (2012).
Output for ERG Model From Statnet (Handcock et al. 2008) for the Direct Action/Ecotage-classified Network.
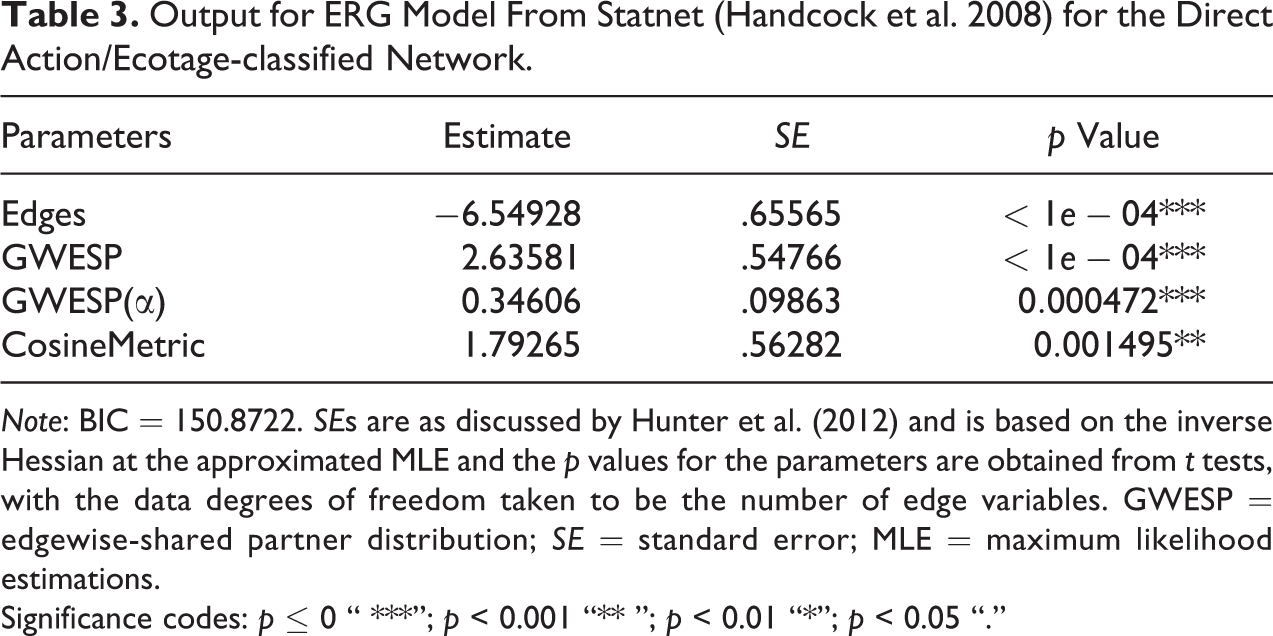
Note: BIC = 150.8722. SEs are as discussed by Hunter et al. (2012) and is based on the inverse Hessian at the approximated MLE and the p values for the parameters are obtained from t tests, with the data degrees of freedom taken to be the number of edge variables. GWESP = edgewise-shared partner distribution; SE = standard error; MLE = maximum likelihood estimations.
Significance codes: p ≤ 0 “ ***”; p < 0.001 “** ”; p < 0.01 “*”; p < 0.05 “.”
Analysis of eco-literature network
Again, in the typical fashion, we begin with a random graph model and then extend it to encompass more complex effects, such as edgewise-shared partners (a measure of clustering, Hunter and Handcock 2012) and then extend this by controlling for topic similarity through our cosine similarity metric. The GWESP statistic can be interpreted as before. Because the clustering in this network appears to be more localized than the direct action/ecotage network, we also employ a statistic for local triangles conditioned on the larger co-occurrence network (Schweinberger and Handcock 2015). We again follow the model building/initial hypotheses testing formulation through BIC selection criterion (following the logic of Almquist and Butts [2014]). We find that the lowest BIC score at this point is in the full model (BIC scores: 200.68, 255.6126, 251.2582, and 151.388). We then follow Hunter and Handcock’s (2012) advice and look at goodness-of-fit statistics (Figure 9) to find that our models perform commensurately along all metrics examined. We do notice that we could do a bit better on two-edgewise-shared partners and degrees of 2 and 3 actors statistics and this can be managed by adding in terms for two-edgewise-shared partners, degree 2, and degree 3; however, this lowers the BIC score and so we choose to interpret the original full model. The model is composed of an edge statistic (baseline interaction effect), a GWESP term (clustering/triadic closure), the cosine similarity term (the metric of topic level relation), and a statistic for local triangles (LocalTriangle). In Table 4, the baseline log odds of a relation is quite low at
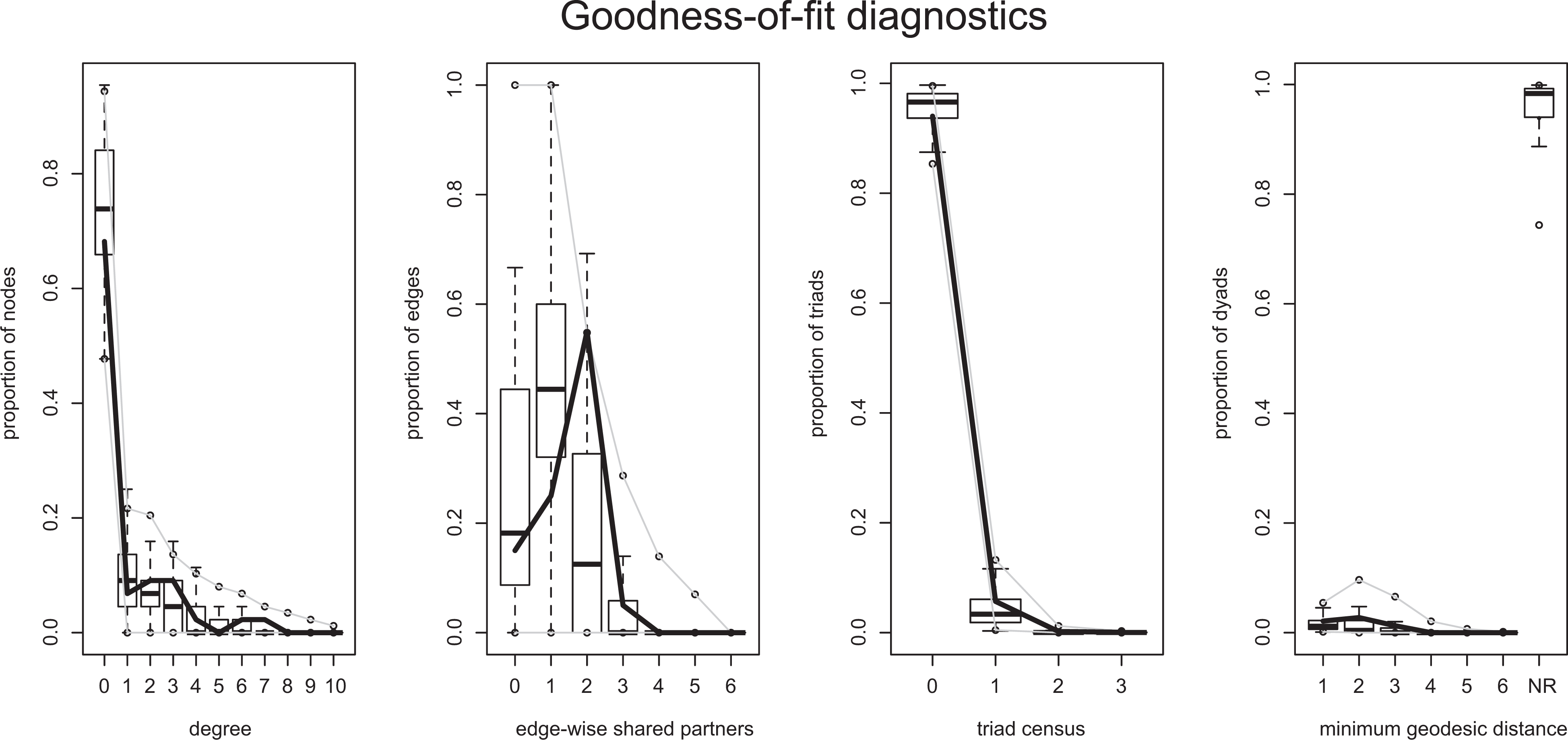
Eco-literature-classified network goodness-of-fit plot based on Hunter et al. (2012).
Table Output for ERG Model From Statnet (Handcock et al. 2008) for the Eco-literature-classified Network.
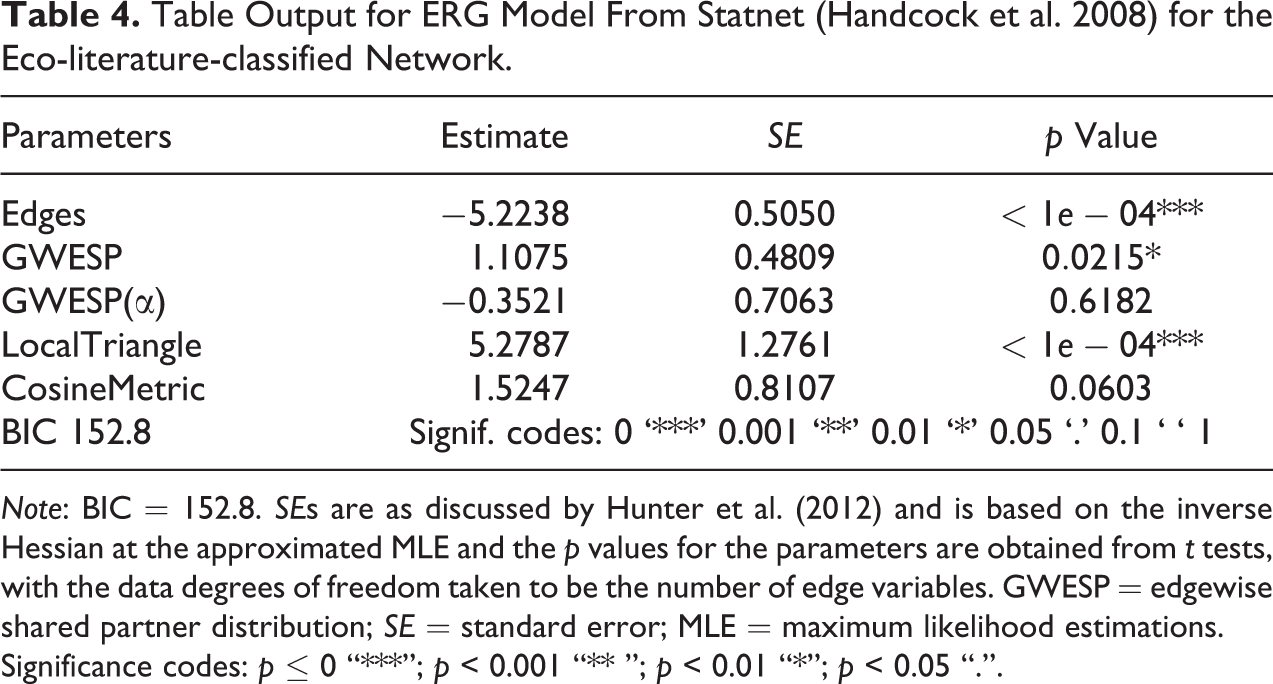
Note: BIC = 152.8. SEs are as discussed by Hunter et al. (2012) and is based on the inverse Hessian at the approximated MLE and the p values for the parameters are obtained from t tests, with the data degrees of freedom taken to be the number of edge variables. GWESP = edgewise shared partner distribution; SE = standard error; MLE = maximum likelihood estimations.
Significance codes: p ≤ 0 “***”; p < 0.001 “** ”; p < 0.01 “*”; p < 0.05 “.”.
Discussion and Summary of Topic Based Network Classification
We have found that it is possible to use our favored topic model approaches to carefully classify subnetworks from the core co-occurrence network for further analysis and comparison. These methods not only provide for a better qualitative understanding of a given edge without direct human coding but also allow for the identification of salient subnetworks within the larger network without the aid of human coders. Further, we can individually analyze these networks to uncover distinct substantive findings. For example, in doing so above, we found that the direct action/ecotage network can be largely explained through edgewise shared partner clustering and topic similarity, whereas the eco-literature network requires the extra information of local clustering in order to model it correctly. This suggests that there are distinct local groups within the eco-literature network, whereas the direct action/ecotage network appears to be much more cohesive. The latter finding lends support to past anecdotes of high inbreeding among radical environmental groups in the United Kingdom—which previously noted that insufficient data on radical UK environmental groups limited systematic conclusions in these regards (Saunders 2007b:237)—as well as to findings concerning the tendencies of subversive and radical groups to disproportionately seek out closer and/or more like-minded collaborators when coordinating on potentially illegal or violent actions (Almquist and Bagozzi 2016). These findings also fit within our larger network and topic model analysis, which demonstrated distinct subgroups within the more mainstream groups as compared to the more subversive groups in the network. Hence, altogether, we find that this is a strong and clever technique for improving our understanding of networks and subnetworks through topic models and modern text analysis approaches.
Summary
This article presents a suite of tools for the automated discovery of radical activist group networks and tactics from raw unstructured text and applies these methods to a collection of radical UK environmentalist publications. While radical groups are often covert in their networks, membership, and tactics, they produce a great deal of text during their efforts to publicize their concerns, communicate with like-minded groups, and mobilize support for their activities. The advent of the World Wide Web, along with more recent advancements in automated text analysis and SNA tools, enables scholars to take advantage of these self-produced texts in novel ways. As we show, such methods not only allow one to uncover detailed network information from unstructured environmentalist texts but can also identify the underlying tactics that are discussed in these texts and help to pair these tactics with one’s uncovered network. In these respects, our findings contribute to the growing body of research that has sought to apply SNA tools to environmental advocacy groups (e.g., Ansell 2003; Ackland and O’Neil 2011; Saunders 2007b) and radical social movements (Almquist and Bagozzi 2016; Caiani and Wagemann 2009; O’Callaghan et al. 2013). Furthermore, our UK environmental group application provides scholars with a detailed guide for implementing these techniques and offers a number of insights into the network and tactics of radical leftist and environmentalist groups within the UK.
Specifically, we find that the UK environmental movement of the 1990s and early 2000s, while most commonly associated with the UK EF! organization, is actually embedded within a larger network of radical leftist groups and venues. Surprisingly, the most central members of this network share close ties to the EF! movement, but primarily advocate for a more general set of leftist ideals, including opposition to globalization, the promotion of worker’s rights, and anarchism. This is consistent with characterizations of leftist global social movements’ increasing de-environmentalization, and subsequent reorientation toward social justice and economic issues during the late 1990s and onward (Buttel and Gould 2004). With respect to the UK specifically, scholars have often noted the decline of environmental protest in the UK during the late 1990s (Rootes 2000:49), which was shortly followed by the demise of the DoD publication itself. We believe that the highly central, but nonenvironmentalist, radical leftist groups that we identify—and variation in support for their respective movements and causes—may help to explain this decline. Additional research, however, is needed to fully explore this possibility. Lastly, we also find sound evidence to suggest that UK leftist groups pursue a range of coherent protest tactics and that these tactics vary considerably depending on the group pairs and clusters that one examines within the larger network. It is hoped that this variation will accordingly offer a new avenue for future theoretical tests concerning the timing, circumstances, and dynamics by which radical groups choose to favor one protest tactic over another.
Supplemental Material
Supplemental_Appendix - Using Radical Environmentalist Texts to Uncover Network Structure and Network Features
Supplemental_Appendix for Using Radical Environmentalist Texts to Uncover Network Structure and Network Features by Iddo Tavory, Zack W. Almquist and Benjamin E. Bagozzi in Sociological Methods & Research
Footnotes
Authors’ Note
Author list is composed in alphabetic order to denote equal authorship. All data and code are made available and can be found at doi:10.7910/DVN/PNK7AB, Harvard Dataverse, V1.
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported in part by an ARO YIP #W911NF-14-1-0577.
Supplemental Material
Supplementary material for this article is available online
Notes
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.