
Abstract
This primer systematizes the emerging literature on causal inference using deep neural networks under the potential outcomes framework. It provides an intuitive introduction to building and optimizing custom deep learning models and shows how to adapt them to estimate/predict heterogeneous treatment effects. It also discusses ongoing work to extend causal inference to settings where confounding is nonlinear, time-varying, or encoded in text, networks, and images. To maximize accessibility, we also introduce prerequisite concepts from causal inference and deep learning. The primer differs from other treatments of deep learning and causal inference in its sharp focus on observational causal estimation, its extended exposition of key algorithms, and its detailed tutorials for implementing, training, and selecting among deep estimators in TensorFlow 2 and PyTorch.
Introduction
This primer aims to introduce social science readers to an exciting literature exploring how deep neural networks can be used to estimate causal effects. In recent years, both causal inference frameworks and deep learning have seen rapid adoption across science, industry, and medicine. Causal inference has a long tradition in the social sciences, and social scientists are increasingly exploring the use of machine learning (ML) for causal inference (Athey and Imbens, 2016; Wager and Athey, 2018; Chernozhukov et al., 2018). Nevertheless, deep learning remains conspicuously underutilized by social scientists compared to other ML approaches, both for causal inference and more generally.
The deep learning revolution has been spurred by the flexibility and expressiveness of these models. Neural networks are nearly nonparametric and can theoretically approximate any continuous function (Cybenko, 1989), making them well-suited for both classification and regression tasks. Furthermore, they can be configured with different architectures and objectives to learn from a variety of quantitative data as well as text, images, video, networks, and speech. These advantages allow them to learn vector “representations” of complex data with emergent properties. Simple examples of representation learning include the Word2Vec algorithm that discovers semantic relationships between words in texts, or face classification models that learn vectors describing facial features (Mikolov et al., 2013). More recently, generative models like DALL-E, Stable Diffusion, and ChatGPT have shown how life-like images and coherent text passages can be reconstructed from learned representations.
Here we explore the potential for leveraging these advantages to estimate causal effects. Causal inference frameworks are nonparametric, but the linear models traditionally used to estimate causal effects require strong parametric assumptions. In contrast, the nearly nonparametric nature of neural networks allows us to estimate smooth response surfaces that capture heterogeneous treatment effects for individual units with low bias.
1
The ability of these models to learn from complex data means we can extend causal inference to new settings where confounding is complicated, time-varying, or even encoded in texts, graphs, or images (see Box 1 for hypothetical examples). Lastly, given the right objectives, neural networks promise to learn deconfounded representations of data, presenting a new strategy for treatment modeling.
Example Scenarios for Causal Inference with Nontraditional Data
This primer synthesizes existing literature on deep causal estimators, but it is not a review; its goals are fundamentally pedagogical and prospective rather than retrospective. In the “Deep Learning Fundamentals” section, we introduce social scientists to the fundamental concepts of deep learning, as well as the basic workflow for building and training their own deep neural networks within a supervised learning framework. For readers unfamiliar with causal inference, the “Causal Identification and Estimation Strategies” section introduces the assumptions of causal identification and three fundamental estimation strategies within the selection on observables design: Matching, outcome modeling, and inverse propensity score weighting (IPW). ML models often perform poorly in both theory and practice when only one of these strategies is employed, so we also introduce the concept of double robustness.
The “Three Different Approaches to Deep Causal Estimation” section is the main body of the article. Here we introduce three distinct approaches to deep causal estimation---deep outcome modeling, balancing through representation learning, and double robustness with IPW---alongside four related deep learning models for the estimation of heterogeneous treatment effects: the S-learner, T-learner, Treatment Agnostic Regression Network (TARNet) and Dragonnet (Shalit, Johansson, and Sontag, 2017; Shi, Blei, and Veitch, 2019). Although this literature is rapidly evolving, these four models are sufficient to illustrate how traditional estimation strategies can be used in creative ways that leverage the key strengths of neural networks (i.e., deconfounding through representation learning, semiparametric inference). The “Confidence and Interpretation” section deals with the practical considerations of building confidence intervals and interpreting neural networks. These guidelines are concretized in the companion online tutorials, which show readers how to implement and interpret the models described in the “Three Different Approaches to Deep Causal Estimation” section in both TensorFlow 2 and PyTorch.
In the “Beyond Traditional Data: Text, Networks, Images, and Treatment over Time” section, we focus on the future of deep causal inference: estimators that can disentange counfounding relationships embedded within texts, images, graphs, or time-varying data. In the interest of clarity, we give hypothetical examples of the types of questions social scientists might answer with these models and briefly describe ongoing research on each of these modalities. For fuller treatments of some of these models, see the Online Appendix. We conclude with a discussion of how neural networks fit into the broader literature on ML for causal inference (the “Conclusion: Deep Causal Estimation in Context” section).
The primer makes multiple contributions. First, it is one of the first pieces in the sociological literature to introduce the fundamentals of deep learning not only at a conceptual level (e.g., backpropagation, representation learning) but at a practical one (e.g., validation, hyperparameter tuning). Our recommendations for training and interpreting neural networks are supported by heavily annotated tutorials that teach readers without prior familiarity with deep learning how to build their own custom models in TensorFlow 2 and PyTorch. Second, we use this foundation and select examples to build intuition on how the core strengths of deep learning can be leveraged for causal inference. Finally, we highlight future directions for this literature and argue why the future of causal estimation runs through deep learning.
Deep Learning Fundamentals
Artificial Neural Networks
Artificial neural networks (ANNs) are statistical models inspired by the human brain (Brand, Koch, and Xu, 2020; Goodfellow, Bengio, and Courville, 2016). In an ANN, each “neuron” in the network takes the weighted sum of its inputs (typically, the outputs of other neurons) and transforms them using a differentiable (or almost everywhere differentiable), nonlinear function (e.g. sigmoid, rectified linear unit). Neurons are arrayed in layers; an input layer takes in the raw data, and neurons in subsequent layers take the weighted sum of outputs in previous layers as input. An “output” layer contains a neuron for each of the predicted outcomes with transformation functions appropriate to those outcomes. For example, a regression network that predicts one real-valued outcome will have a single output neuron without a transformation function so that it produces a real number. A regression network without any hidden layers corresponds exactly to a generalized linear model (Figure 1A). When additional “hidden” layers are added between the input and output layers, the architecture is called a feed-forward network or multilayer perceptron (Figure 1B). A neural network with multiple hidden layers is called a “deep” network, hence the name “deep learning” (LeCun, Bengio, and Hinton, 2015). A neural network with a single, large enough hidden layer can theoretically approximate any continuous function (Cybenko, 1989).
Neural networks are trained to predict their outcomes by optimizing a loss function (also called an objective or cost function). During training, the backpropagation algorithm uses the chain rule from calculus to assign portions of the total error in the loss function to each neuron in the network. An optimizer, such as the stochastic gradient descent algorithm or the popular ADAM algorithm (Kingma and Ba, 2015), then moves each parameter in the opposite direction of this error gradient. Neural networks first rose to popularity in the 1980s but fell out of favor compared to other ML model families (e.g., support vector machines) due to their expense of training. By the late 2000s, improvements to backpropagation, advances in computing power (i.e., graphic cards), and access to larger datasets collectively enabled a deep learning revolution where ANNs began to significantly outperform other model families. Today, deep learning is the hegemonic ML approach in industries and fields other than social science.
Deep Learning in Practice
This section focuses on the practice of training neural networks within a supervised learning framework. While the principles behind supervised ML are universal, the workflow for neural networks differs substantially from other ML approaches (e.g., random forests, support vector machines) in practice. Figure 2 presents this workflow in four different parts: Set up, Training, Model Evaluation, and Interpretation. We delve into each of these topics in more detail below. Box 2 contains a basic introduction to supervised learning for unfamiliar readers.
Basic Introduction to Supervised Learning Deep learning algorithms have most commonly been adapted for causal inference using supervised machine learning, the most popular learning framework within the field.
2
The goal of supervised learning is to teach a model a nonlinear function that transforms covariates/features As in traditional statistical analyses, the function is learned by optimizing the model’s parameters such that they minimize the error between its predictions Statistical learning theory articulates the central challenge of supervised learning as a balance between Diagnosing and addressing overfitting is a more challenging problem. In supervised learning, overfitting is diagnosed after training (but before testing) by assessing predictive performance in a reserved portion of the training set called the
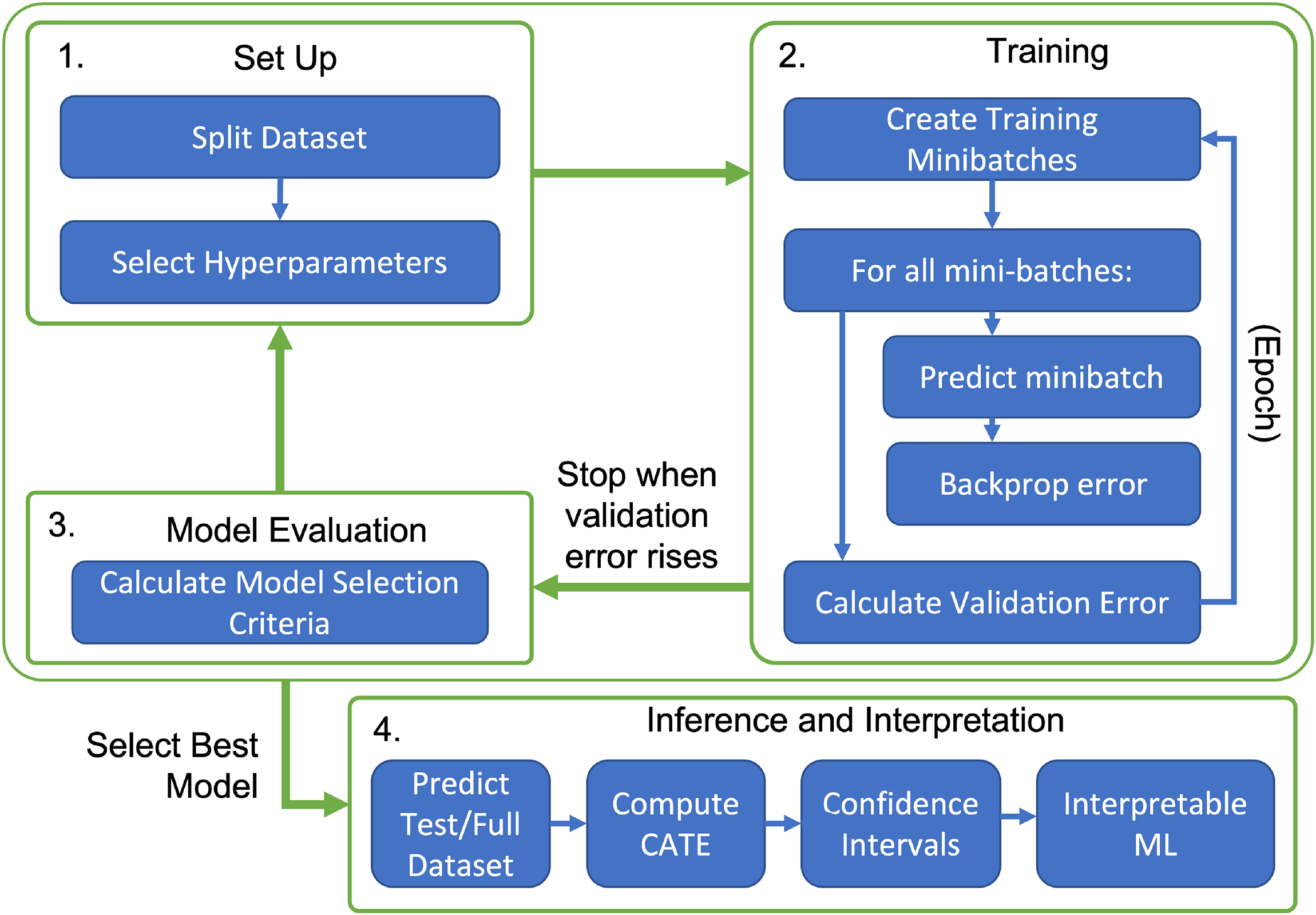
Supervised Deep Learning Workflow. (1) Set Up: The first step in training a deep learning model is splitting the data into a training set, validation set, and optionally a test set. Initial hyperparameters are then selected from a set of choices specified by the user. (2) Training: In each iteration of the training process (called an epoch), the training set is randomly divided into small minibatches For each minibatch, the network makes predictions for all units, and calculates the error gradients to be assigned to each neuron in the network based on those predictions. An optimizer then moves the network’s parameters in the opposite direction of the error gradient. After all minibatches have been trained (one epoch), error is calculated on the entire validation set. This whole process is repeated up until the validation error stops decreasing (to avoid overfitting). (3) Model Evaluation: A criterion (typically the validation error) is used to evaluate the performance of this hyperparameterization. New hyperparameters are then selected using a hyperparameter optimization algorithm (eg. Grid search, Bayesian hyperparameter optimization, genetic algorithms) and steps 1 and 2 are repeated. Once the hyperparameter optimization algorithm has completed its search, the “best” model is selected for inference. (4) Inference and interpretation: With a model selected, the analyst is now ready to apply it to their test data (or in the case of statistical inference, potentially the full dataset). Predictions of the outcomes and/or propensity score can then be used to compute the CATE (conditional average treatment effect) and calculate confidence intervals. Feature importance algorithms like SHapley Additive exPlanations (SHAP) or Integrated Gradients can also be used to interpret the CATE estimates.
Set Up and Hyperparameters
The first step in training a neural network, as in other types of supervised ML, is to split your dataset into training, validation, and testing datasets (Figure 2A). If the network is being used for statistical inference, as here, the testing dataset is optional, and inference may be conducted on just the validation set or the full dataset.
While the computational graph and loss function define a deep learning architecture (Box 3), actual implementations can vary significantly due to the choice of hyperparameters. In supervised ML, hyperparameters are parameters that are not learned automatically when training the model but must be specified by the analyst. In deep learning, architectural hyperparameters include the number of layers to use for each section of the computational graph, the number of neurons to use in each layer, and the activation functions to be used by neurons. While some basic rules of thumb apply (e.g., use fewer layers than neurons), these choices remain poorly understood theoretically
4
; decisions are generally made by comparing empirical performance on the validation set, a practice called hyperparameter tuning.
Reading Machine Learning Papers: Computational Graphs and Loss Functions Within the machine learning literature, novel algorithms are often presented in terms of their computational graph and loss function. A computational graph (not to be confused with a causal graph) uses arrows to depict the flow of data from the inputs of a neural network, through parameters, to the outputs. Layers of neurons or specialized sub-architectures are often generically abstracted as shapes. In our diagrams, we use rounded purple shapes to represent observables, orange rectangles for representation layers of the network, rounded white shapes for produced outputs, and textured rectangles for outcome modeling layers. Operations that are computed after prediction (i.e., for which an error gradient is not calculated) are shown with dashed lines (e.g., plug-in estimation of causal estimands). A: Generalized linear model (GLM) represented as a computational graph. Observable covariates Along with the architecture, the loss function of a neural network is the primary means for the analyst to dictate what types of representations a neural network learns and what types of outputs it produces. In multitask learning settings, we denote joint loss functions for an entire network as a weighted sum of the losses for constituent tasks and modules. These specific losses are weighted by hyperparameters. For example, we might weight the joint loss for a network that predicts outcomes and propensity scores as: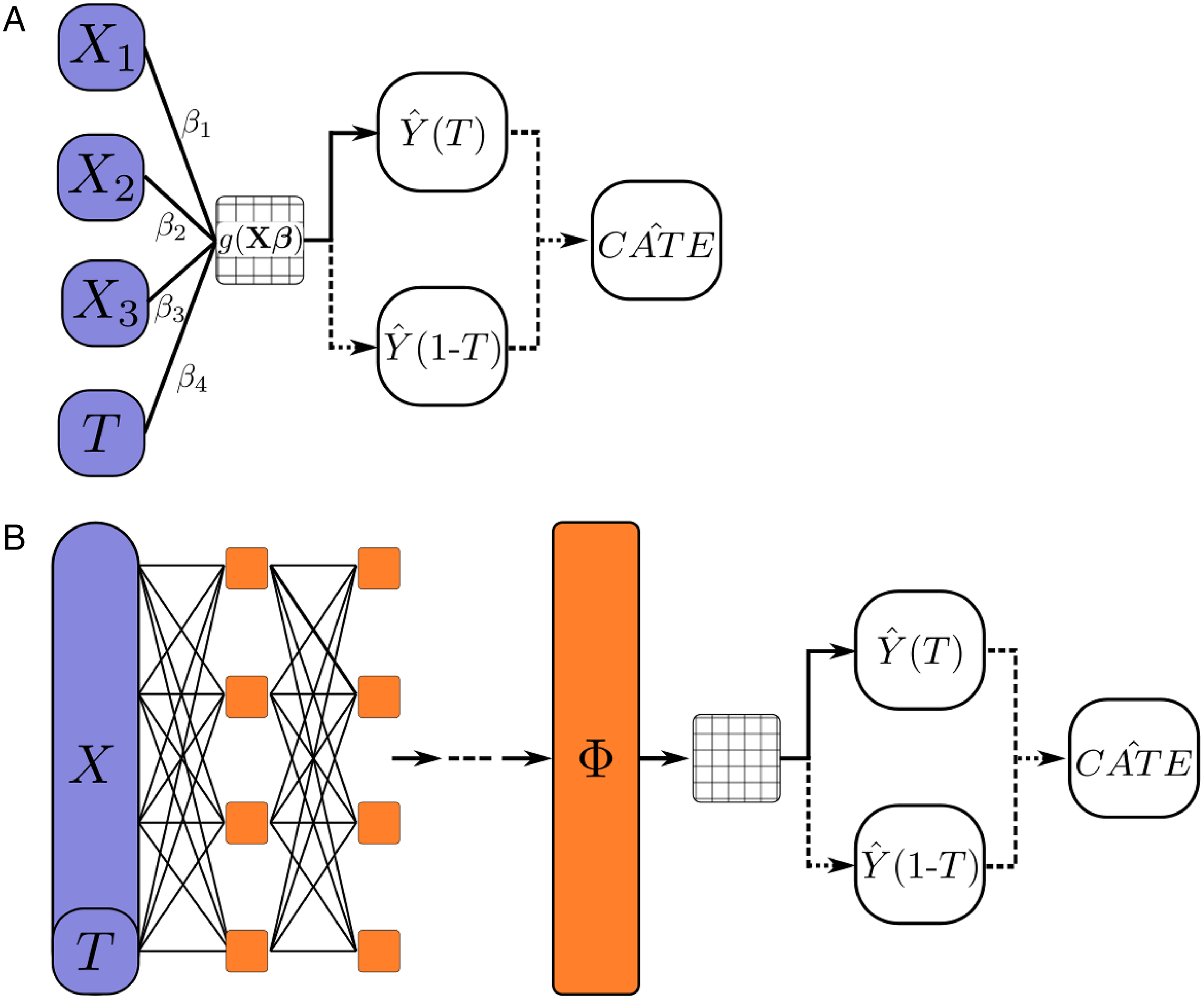
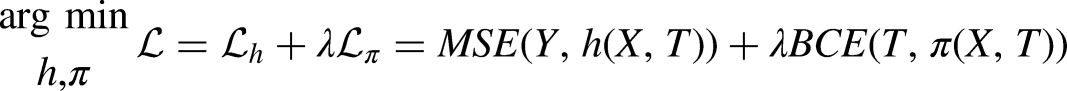
Training and Regularization
Neural networks are trained by repeatedly making predictions from the training set, calculating error gradients for each parameter, and backpropagating small fractions of those error gradients. (Figure 2 B). A full pass-through examples in the training set is called a training loop or epoch. At the beginning of each epoch, the training set is divided into mini-batches of 2 to 1024 units, randomly sampled without replacement. This practice not only aids in memory management, it also improves optimization. Using small random samples effectively introduces noise into the training process, making it less likely for the model to get stuck in local minima.
The size of mini-batches can be considered a hyperparameter. 5 Because a mini-batch of data is only a sample of a sample (the training dataset), the optimizer only adjusts weight parameters by a fraction of the error gradient (the learning rate) to avoid overfitting. The learning rate is also a hyperparameter, which typically varies between 0.0001 and 0.01.
The nonconvex nature of most loss functions
6
mean that optimization often requires hundreds to potentially millions of epochs of training. Moreover, neural networks are highly susceptible to overfitting because it is easy to overparameterize them with excessive neurons/layers. To ward against overfitting, error metrics on the complete validation set are computed at the end of every epoch. In a regularization practice called “early stopping,” analysts usually stop training once validation metrics stop improving. Other common regularization techniques include weight decay (i.e.,
Dropout is a regularization technique in deep learning where certain nodes are randomly silenced from training during a given epoch (Srivastava et al., 2014). The general idea of dropout is to force two neurons in the same layer to learn different aspects of the covariate/feature space and reduce overfitting. Batch normalization is another regularization technique applied to a layer of neurons (Ioffe and Szegedy, 2015). By standardizing (i.e. z-scoring) the inputs to a layer on a per-batch basis and then rescaling them using trainable parameters, batch normalization smooths the optimization of the loss function. The addition and extent of each of these regularization techniques can be treated as hyperparameters.
Model Selection
(Tutorial 2  )
)
After the model has been trained, the analyst compares models assembled with different hyperparameterizations or initial parameter values (Figure 2C). Hyperparameterizations can be chosen using random search, an exhaustive grid search of all possible combinations, or strategic search algorithms like Bayesian hyperparameter optimization or evolutionary optimization (Snoek, Larochelle, and Adams, 2012). Validation loss metrics on the final epoch are commonly used for these comparisons.
Model selection for causal estimators is complicated by the fundamental problem of causal inference: we are not actually interested in the observed “factual” outcomes and propensity scores, but the CATE and ATE (average treatment effect). In the case of algorithms like Dragonnet where the validation loss explicitly targets a causal quantity, we use that as the model selection criterion. In cases where the algorithm is only trained for outcome modeling or propensity modeling, other solutions are needed. In the Online Appendix, we describe Johansson et al. (2020)’s proposal to use matching on a nearest neighbor approximation of the Precision in Estimated Heterogeneous Effects (PEHE), a measure of CATE bias, as an alternative model selection metric (Online Appendix A).
The development of more sophisticated methods for model selection of causal estimators through data simulation is an active area of research within this literature. 7 For example, Parikh et al. (2022) use deep generative models to approximate the data generating distribution under weak, nonparametric assumptions. Alaa and Van Der Schaar (2019) independently model each outcome and the propensity score before using influence functions to assess model error.
Representation Learning and Multitask Learning
One comparative advantage of deep learning over other ML approaches has been the ability of ANNs to encode and automatically compress informative features from complex data into flexible, relevant “representations” or “embeddings” that make downstream supervised learning tasks easier (Goodfellow, Bengio, and Courville, 2016; Bengio, 2013). While other ML approaches may also encode representations, they often require extensive preprocessing to create useful features for the algorithm (i.e., feature engineering). Through the lens of representation learning, a geometric interpretation of the role of each layer in a supervised neural network is to transform its inputs (either raw data or output of previous layers) into a typically lower (but possibly higher) dimensional vector space. As a means to share statistical power, encoded representations can also be jointly learned for two tasks at once in multitask learning.
The simplest example of a representation might be the final layer in a feed-forward network, where the early layers of the network can be understood as nonlinearly encoding the inputs into an array of latent linear features for the output neuron (Goodfellow, Bengio, and Courville, 2016) (Figure 1B). A famous example of representation learning is the use of neural networks for face detection. Examining the representations produced by each layer of these networks shows that each subsequent layer seems to capture increasingly abstract features of a face (first edges, then noses and eyes, and finally whole faces) (LeCun, Bengio, and Hinton, 2015). A more familiar example of representation learning to social scientists might be word vector models like Word2Vec (Mikolov et al., 2013). Word2Vec is a neural network with one hidden layer and one output layer where words that are semantically similar are closer together in the representation space created by the hidden layer of the network.
The novel contribution of deep learning to causal estimation is the proposal that a neural network can learn a function
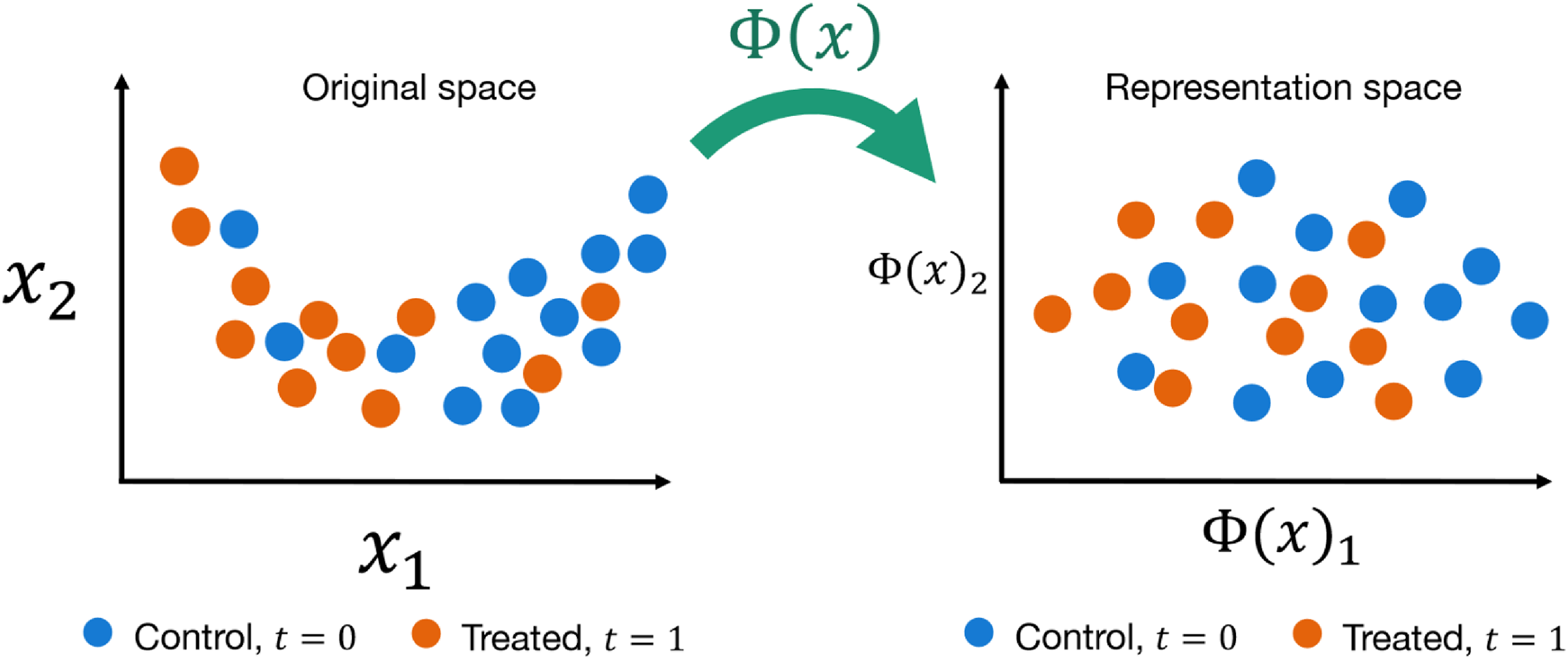
Balancing through representation learning. The promise of deep learning for causal inference is that a neural network encoding function
Causal Identification and Estimation Strategies
Identification of Causal Effects
The papers described in this primer are primarily framed within the Potential Outcomes causal framework (Neyman-Rubin causal model) (Rubin, 1974; Imbens and Rubin, 2015). This framework is concerned with identifying the “potential outcomes” of each unit Basic Introduction to Causal Inference Correlation does not equal causation, and causal inference is concerned with the identification of causal relationships between random variables. Many causal questions we would like to ask about social data (What is the causal effect of Randomized control trials (RCTs, also known as A/B testing in data science and industry applications) are usually understood to be the ideal approach to answering this type of question: each unit with covariates or features There are at least three different schools of causal inference that have been introduced in social statistics and econometrics (Rubin, 1974; Imbens and Rubin, 2015), epidemiology (Robins, 1986, 1987; Hernán and Robins, 2020), and computer science (Goldszmidt and Pearl, 1996; Pearl, 2009). The goal of these causal frameworks is to describe and correct for biases in data or study design that would prevent one from making a true causal claim. If these biases are correctable and the causal effect can be uniquely expressed in terms of the distribution of observed data, then we say that the causal effect is identifiable (Kennedy, 2016). Only if a causal effect is identifiable can we use statistical tools to correct for biases and estimate the causal effect (e.g., inverse propensity score weighting, g-computation, deep learning). The algorithms presented in this paper focus on estimating causal effects primarily by correcting for confounding bias. Loosely speaking, a confounding covariate/feature is one that is correlated with both the treatment and the outcome, misleadingly suggesting that the treatment has a causal effect on the outcome, or obscuring a true causal relationship between the treatment and outcome. Often times, the confounder is a cause of the treatment and outcome. As an example of confounding bias, estimating the causal effect of attending college (treatment) on adult income (outcome) requires controlling for the fact that parental income may be a common cause of both college attendance and adult income. Applied Causal Inference Example: The Infant Health and Development Study To make this problem setting more concrete for readers unfamiliar with causal inference, consider simulations based on the 1985–1988 Infant Health and Development Study that are widely used as benchmarks within this literature. In this experiment, premature children were randomly assigned to intensive, high-quality childcare ( Hill (2011) turns this experimental data into an observational benchmark by re-simulating the outcome such that the covariates
The hypothetical confounding bias presented here can be adjusted for either through treatment modeling (e.g., inverse propensity score weighting, nonparametric, deep representation learning) to block the path 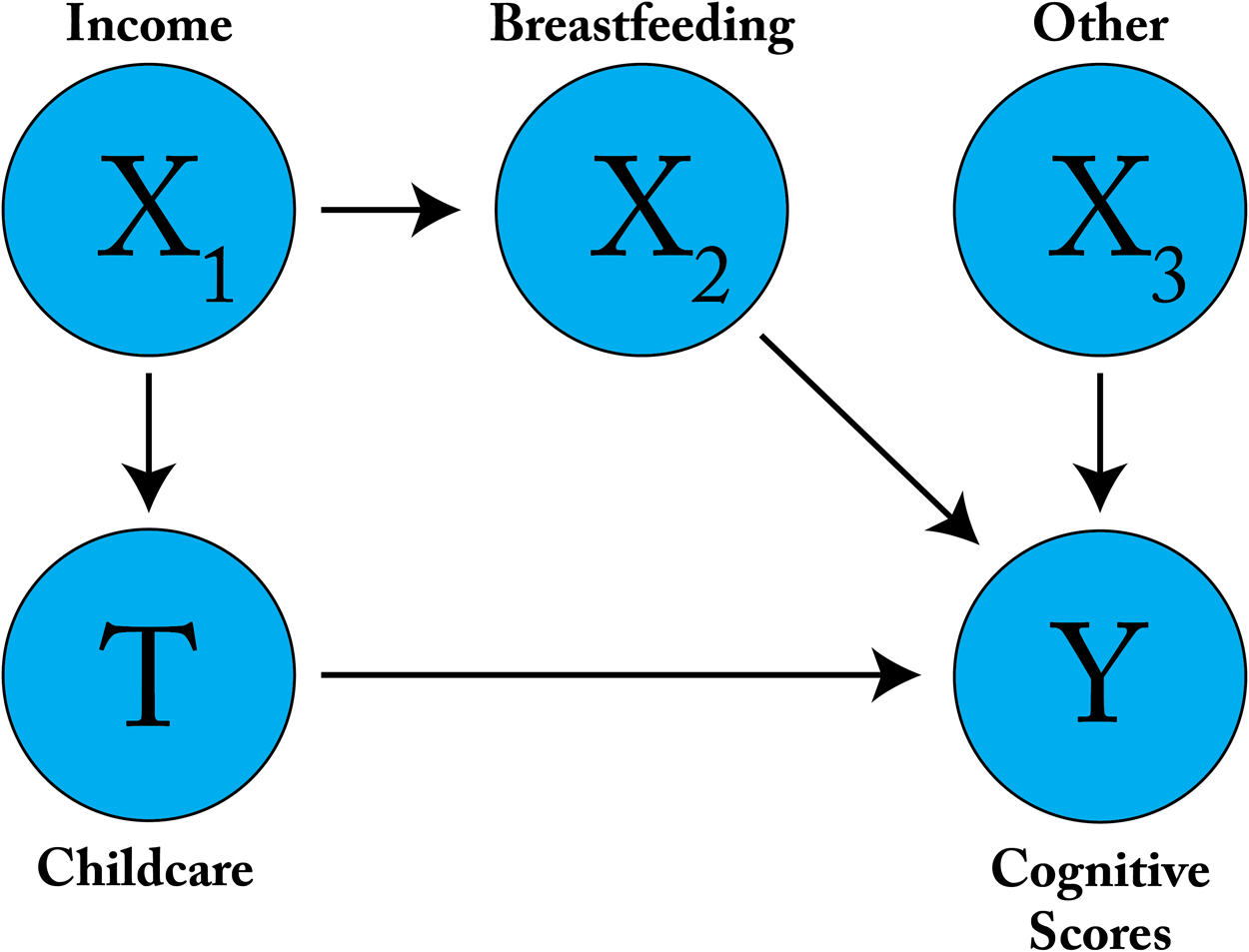
The ATE is defined as:
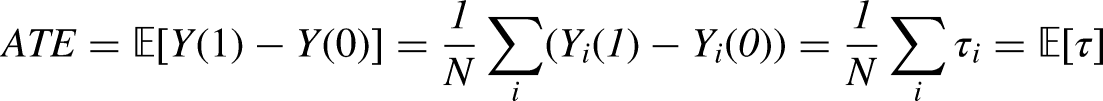
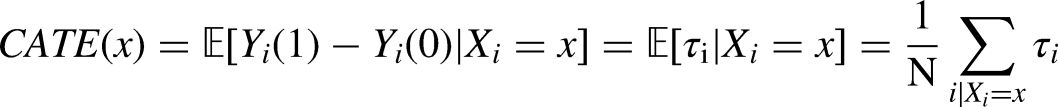
Within the ML literature on causal inference treated here, the primary strategy for causal identification is selection on observables. A challenge to identifying causal effects is the presence of confounding relationships between covariates associated with both the treatment and the outcome.
The key assumptions allowing the identification of causal effects in the presence of confounding are:
Conditional Ignorability/Exchangability The potential outcomes Other standard assumptions invoked to justify causal identification are: Consistency/Stable Unit Treatment Value Assumption (SUTVA). Consistency specifies that when a unit receives treatment, their observed outcome is exactly the corresponding potential outcome (and the same goes for the outcomes under the control condition). Moreover, the response of any unit does not vary with the treatment assignment to other units (i.e., no network or spillover effects), and the form/level of treatment is homogeneous and consistent across units (no multiple versions of the treatment). Note that this is an identification assumption, based on our understanding of the data-generating process, and independent of the model chosen for estimation. More formally, Overlap. For all An additional assumption sometimes invoked at the interface of identification and estimation using neural networks is: Invertability
For reference, we describe the full notation used within the primer in Box 6.
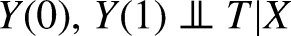
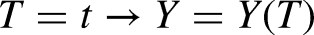
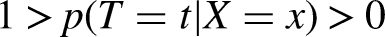
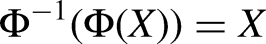
Notation for Causal Inference and Estimation
We use uppercase to denote general quantities (e.g., random variables) and lowercase to denote specific quantities for individual units (e.g., observed variable values).
Causal identification
Observed covariates/features: Potential outcomes: Treatment: Unobservable Individual Treatment Effect: Average treatment effect: Conditional average treatment effect: Predicted potential outcomes: Outcome modeling functions: Propensity score function: Representation functions: Loss functions: Loss abbreviations: Loss hyperparameters: Estimated CATE* for unit Estimated ATE: Precision in Estimated Heterogeneous Effects:
Deep learning estimation
Beyond the
Beyond being a metric for simulations with known counterfactuals, the
*Note that we use
Estimation of Causal Effects
Once a strategy for identifying causal effects from available data has been developed (arguably the harder and more important part of causal inference), statistical methods can be used to estimate causal effects by controlling for confounding bias, selection bias, and/or measurement error. There are two fundamental approaches to estimation: treatment modeling to control for correlations between the covariates
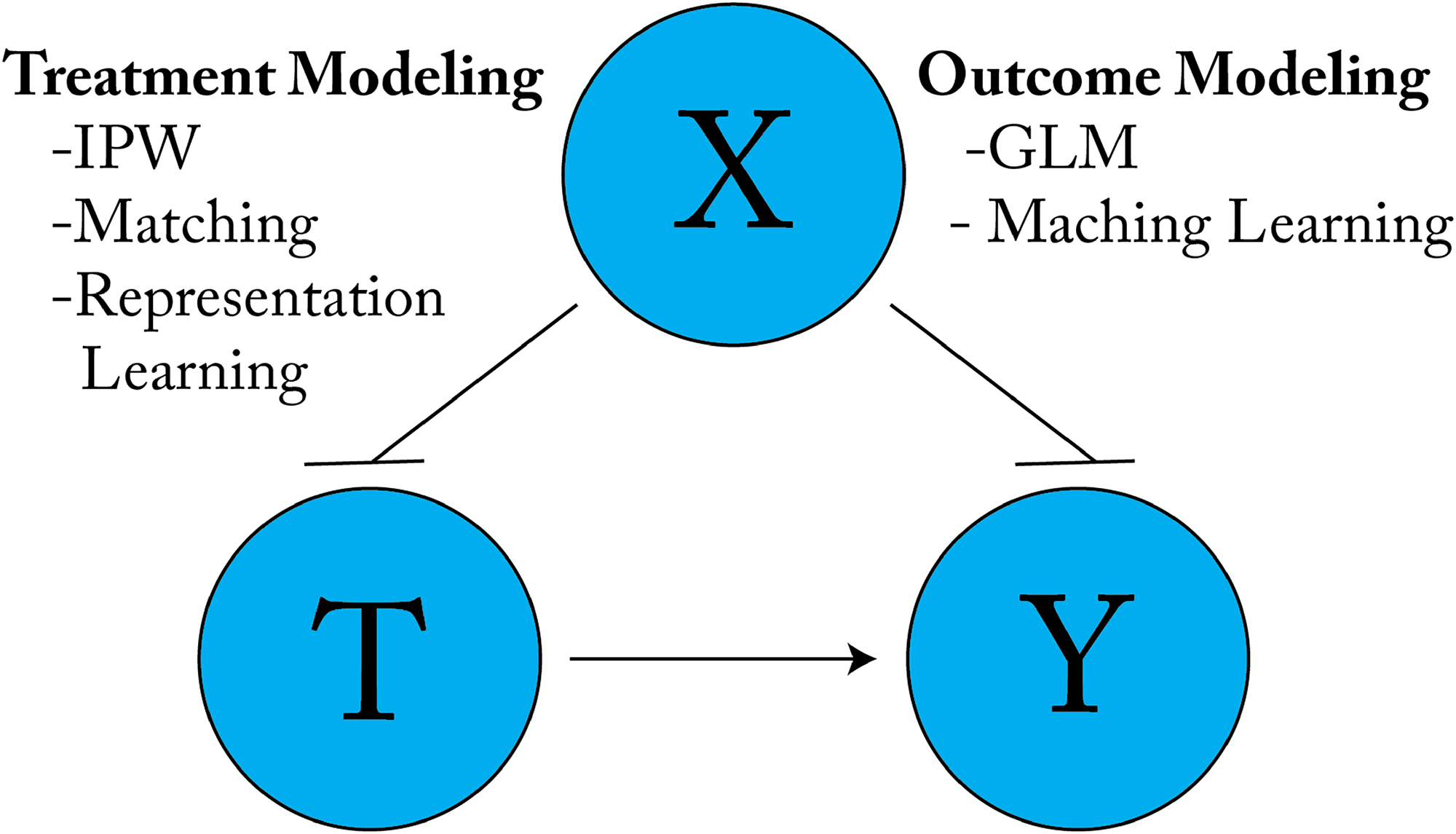
Two fundamental approaches to deconfounding. Blunted arrows indicate blocked causal paths. Treatment modeling approaches like inverse propensity weighting, balancing, and representation learning adjust for the association between the covariates
Outcome Modeling: Regression
Assuming the treatment effect is constant across covariates/features or the probability of treatment is constant across all covariates/features (both improbable assumptions), the simplest consistent approach to estimating the
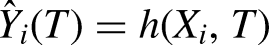
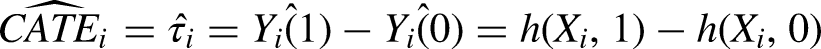
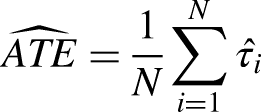
Treatment Modeling: Nonparametric Matching
A common treatment-modeling strategy is balancing the treated and control covariate distributions through matching. Matching requires the analyst to select a distance measure that captures the difference in observed covariate distributions between a treated and untreated unit (Austin, 2011). Units with treatment status
Treatment Modeling: IPW
Another common approach is IPW. In IPW, units are weighted on their inverse propensity to receive treatment. Without loss of generality, we call the propensity function
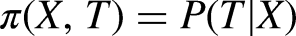
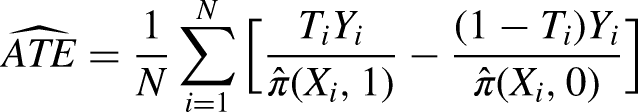
IPW weighting is attractive because if the propensity score
Double Robustness
Because different models make different assumptions, it is not uncommon to combine outcome modeling with propensity modeling or matching estimators to create doubly robust estimators. For example, one of the most widely used doubly robust estimators is the augmented-IPW estimator.

Doubly robust estimation is especially important for causal estimation using ML. When using simple outcome plug-in estimators, bias is directly dependent on estimation error, which may be different for each potential outcome depending on the modeling strategy (Kennedy, 2020). ML estimation of the propensity score can also rely heavily on nonconfounding predictors, giving rise to extreme weights (Schnitzer, Lok, and Gruber, 2016). More generally, there are no asymptotic linearity guarantees for ML estimators which may converge at a slow rate, leading to misleading confidence intervals (Naimi, Mishler, and Kennedy, 2021; Zivich and Breskin, 2021). For these reasons, plug-in ML estimation often has poor empirical performance when not using double robust estimators (Benkeser et al., 2017; Kennedy, 2020; Zivich and Breskin, 2021).
The growth of ML for causal inference literature has thus been largely driven by the introduction of semiparametric frameworks. Semiparametric frameworks address these issues by using ML only to estimate the nuisance parameters (i.e., potential outcomes and propensity score) of influence functions for causal parameters like the ATE and CATE (Chernozhukov et al., 2018; Kennedy, 2016; Van der Laan and Rose, 2011). In these approaches, the estimation of causal parameters is only second order dependent on ML error, there is double-robustness against inconsistent estimation, and guarantees of fast convergence and asymptotically valid confidence intervals even if the ML models converge slowly (Benkeser et al., 2017; Kennedy, 2020; Naimi, Mishler, and Kennedy, 2021; Zivich and Breskin, 2021). We use the final algorithm introduced below, Dragonnet, as an opportunity to provide an intuitive introduction to semiparametric theory and how it can be used for doubly robust estimation (Shi, Blei, and Veitch, 2019).
Three Different Approaches to Deep Causal Estimation
The architectures proposed in the deep learning literature for causal estimation build upon the core idea discussed above. First, we introduce “S-Learners” and “T-Learners” to show how neural networks can be used to estimate nonlinearities in potential outcomes. Second, given the right objectives, a neural network can learn representations of the treated and control distributions that are deconfounded (Figure 3). This approach, which can be related theoretically to nonparametric matching, is illustrated by the foundational TARNet algorithm in the “Double Robustness with IPW” section (Shalit, Johansson, and Sontag, 2017). Finally, the ML for causal inference literature has been largely driven by the introduction of semiparametric frameworks that allow predictive ML models to be plugged-in to doubly robust estimation equations (Van der Laan and Rose, 2011; Chernozhukov et al., 2018, 2021). In the “Double Robustness with IPW” section, we introduce the concept of influence functions and the targeted maximum likelihood estimator to explain the Dragonnet algorithm. For clarity, the algorithms presented here all share a familial resemblence to the TARNet algorithm. However, we note that there are many other approaches to using deep learning for causal inference (e.g., the generative models described in Online Appendix).
Deep Outcome Modeling
S-Learners and T-Learners (Tutorial 1  )
)
Because at most one potential outcome is unobserved, it is not possible to apply supervised models to directly learn treatment effects. Across econometrics, biostatistics, and ML, a common approach to this challenge has been to instead use ML to model each potential outcome separately and use plug-in estimators for treatment effects (Chernozhukov et al., 2018; Van der Laan and Rose, 2011; Wager and Athey, 2018). As with linear models, a single neural model can be trained to learn both potential outcomes (S[ingle]-learner) (Figure 1B), or two independent models can be trained to learn each potential outcome (a “T-learner”) (Johansson et al., 2020) (Figure 5A). In both cases, the neural network estimators would be feed-forward networks tasked with minimizing the MSE in the prediction of observed outcomes. In a slight abuse of notation, the joint loss function for a T-learner can be written as:
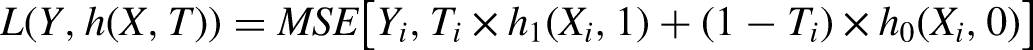
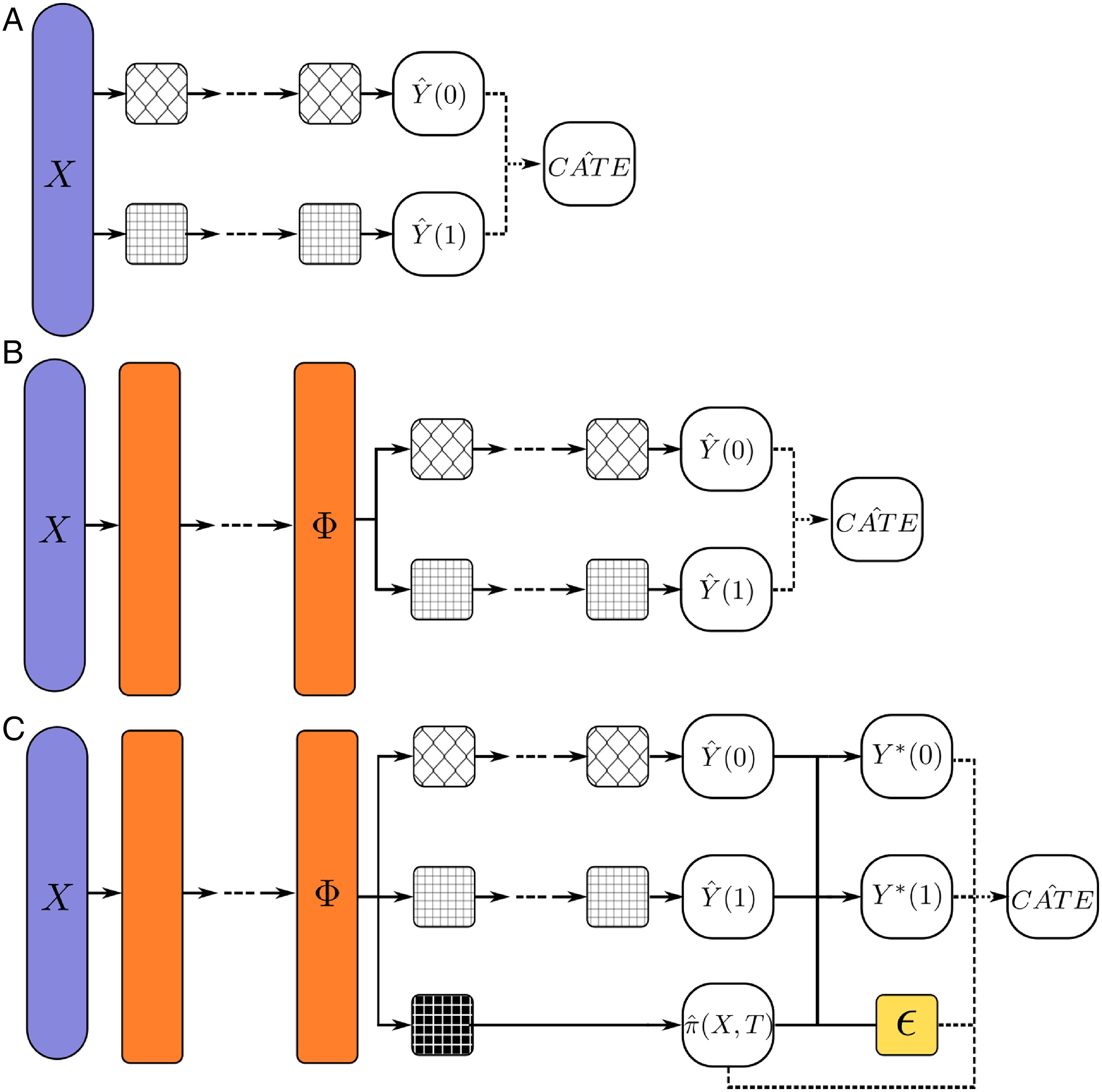
(A) T-learner. In a T-learner, separate feed-forward networks are used to model each outcome (rounded white boxes). We denote the function encoded by these outcome modelers
After training, inputting the same unit into both networks of a T-learner will produce predictions for both potential outcomes:
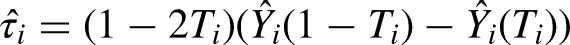
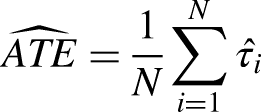
Balancing through Representation Learning
TARNet (Tutorial 1  )
)
Balancing is a treatment adjustment strategy that aims to deconfound treatment from the outcome by forcing the treated and control covariate distributions closer together (Johansson, Shalit, and Sontag, 2016). The novel contribution of deep learning to the selection of observables literature is the proposal that a neural network can transform the covariates into a representation space
To encourage a neural network to learn balanced representations, the seminal paper in this literature, Shalit, Johansson, and Sontag (2017), proposes a simple two-headed neural network called TARNet that extends the outcome modeling T-learner with shared representation layers (Figure 5B). Each head models a separate potential outcome: one head learns the function
The complete objective for the network is to fit the parameters of
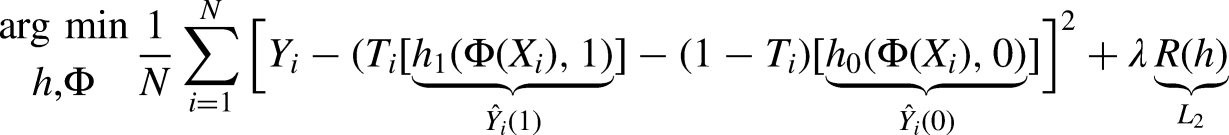
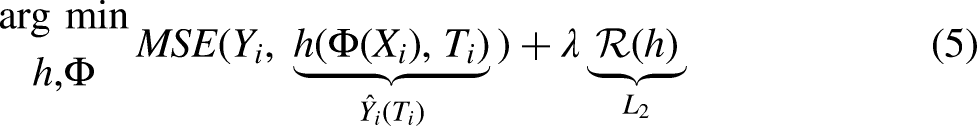
TARNet in Code
Below we show simple implementations of TARNet in Python TensorFlow 2 and Pytorch. For more explanation on this implementation and to run this code on the IHDP data, see the tutorials.
Double Robustness with IPW
Rather than applying losses directly to the representation function, IPW methods estimate propensity scores from representations using the function
Dragonnet (Tutorial 3  / Tutorial 4
/ Tutorial 4  )
)
A trivial extension to TARNet is to add a third head to predict the propensity score. This third head could use multiple neural network layers or just a single neuron, as proposed in Dragonnet (Figure 5C) (Shi, Blei, and Veitch, 2019). Dragonnet uses this additional head to develop a training procedure called Targeted Regularization for semiparametric causal estimation, inspired by TMLE (Van der Laan and Rose, 2011).
With three heads, the basic loss function for this network looks like:
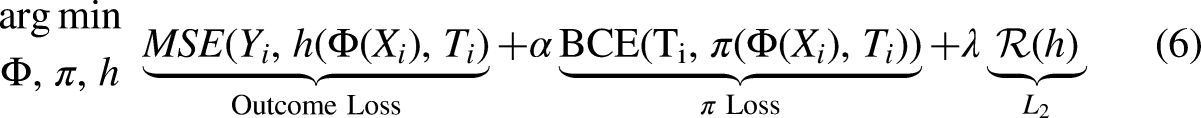
Below, we explore how the authors add a second loss on top of this one to allow for semiparametric estimation.
Semiparametric Theory of Causal Inference
In recent years, semiparametric theory has emerged as a dominant theoretical framework for applying ML algorithms, including neural networks, to causal estimation (Chernozhukov et al., 2018, 2021, 2022; Farrell, Liang, and Misra, 2021; Kennedy, 2016; Nie and Wager, 2021; Van der Laan and Rose, 2011; Wager and Athey, 2018). The great appeal of these frameworks is that they allow for ML algorithms to be plugged-in for nonlinear estimates of outcomes and propensity score, while still providing attractive statistical guarantees (e.g., consistency, efficiency, asymptotically valid confidence intervals).
At a very intuitive level, semiparametric causal estimation is focused on estimating a target parameter
Regardless of
To sharpen the likelihood’s focus on
The EIC for the ATE is,
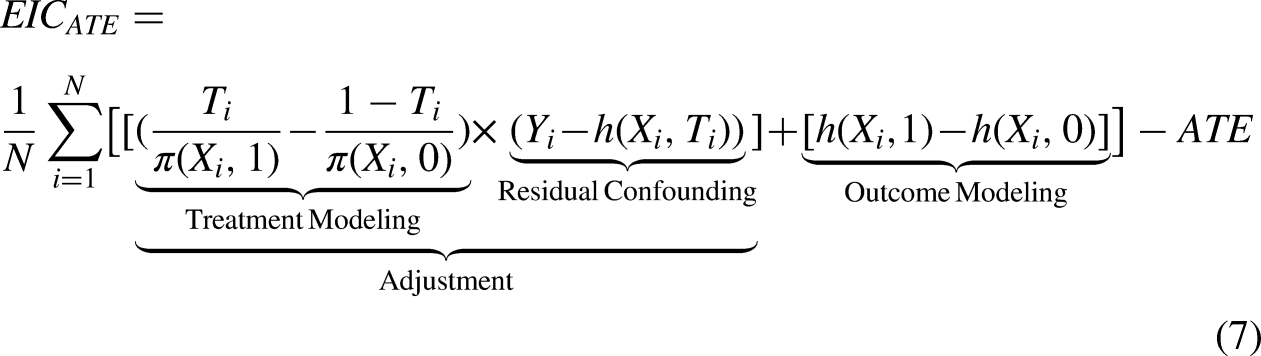
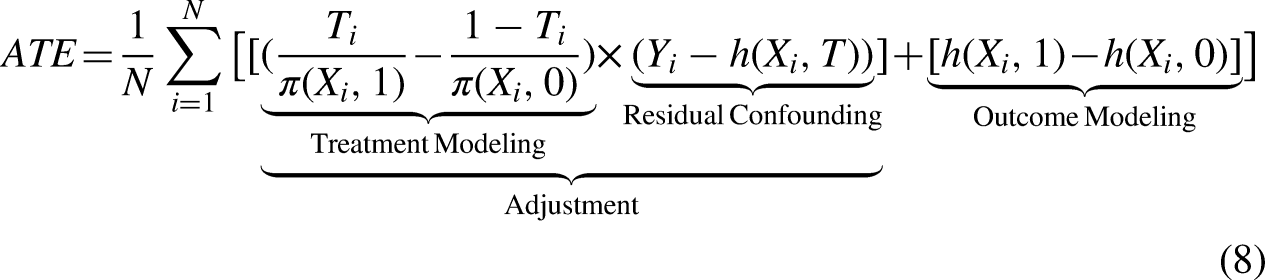
From TMLE to Targeted Regularization
Targeted Regularization (TarReg) is closely modeled after Targeted Maximum Likelihood Estimation (TMLE) (Van der Laan and Rose, 2011). TMLE is an iterative procedure where a nuisance parameter
Fit Fit Plug-in Plug-in
Targeted Regularization takes TMLE and adapts it for a neural network loss function. The main difference is that steps 1 and 2 above are done concurrently by Dragonnet, and that the loss functions for the first three steps are combined into a single loss applied to the whole network at the end of each batch. It requires adding a single free parameter to the Dragonnet network for
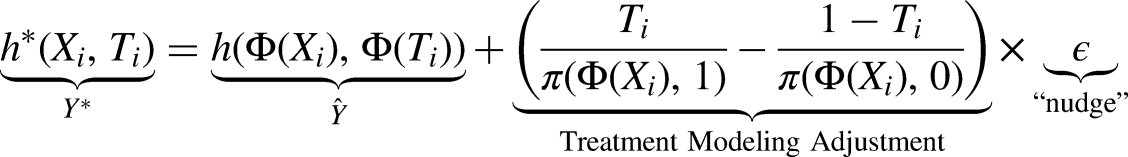
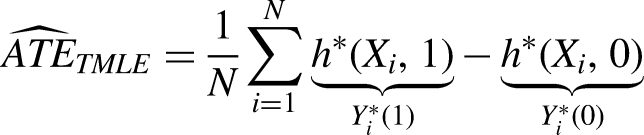
At a very intuitive level, Targeted Regularization is appealing because it introduces a loss function to TARNet that explicitly encourages the network to learn the mean of the treatment effect distribution, and not just the outcome distribution. The Targeted Regularization procedure proceeds as follows:
In each epoch:
Use Dragonnet to predict Calculate the standard ML loss for the network using a hyperparameter
Compute Calculate the targeted regularization loss: Combine and minimize the losses from 1 and 2 using a hyperparameter
Step 3 of Targeted Regularization is exactly equivalent to minimizing the EIC up to a constant
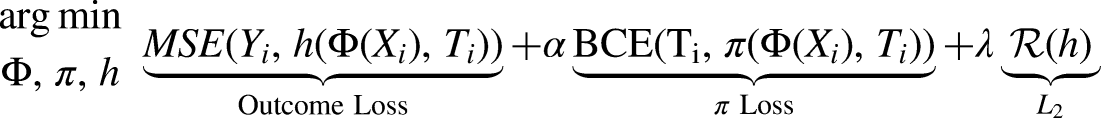
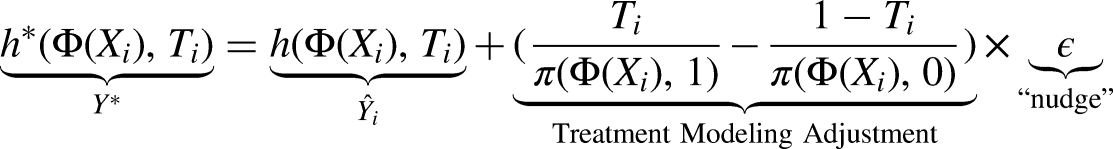
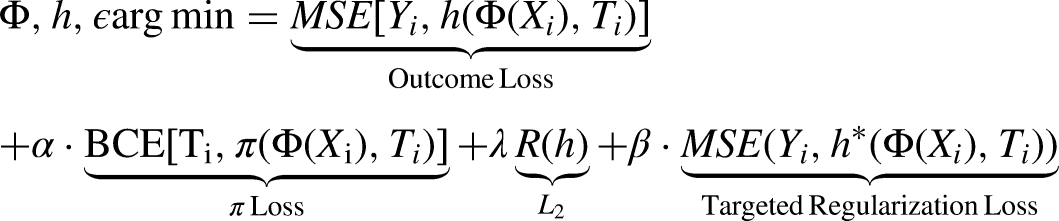
At the end of training, we can thus estimate the targeted regularization estimate of the ATE
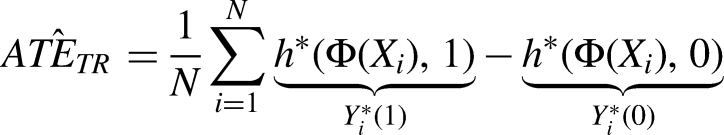
Confidence and Interpretation
In this section, we move from theory to practice and treat best practices for building confidence intervals and interpreting heterogeneous treatment effects. Both of these topics are active areas of development, not only within the causal inference literature but across ML research. Here we specifically focus on recommendations that can be easily implemented by analysts.
Assessing Confidence
(Tutorial 4  )
)
In this paper, we feature Dragonnet over other approaches because of its attractive statistical properties. Because the Targeted Regularization procedure in Dragonnet is essentially a variant of TMLE, an asymptotically valid standard error can be calculated as the sample corrected variance of the EIC
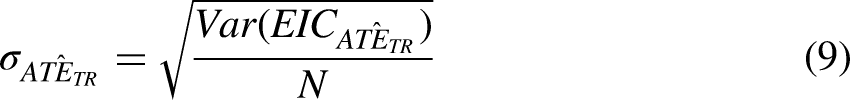
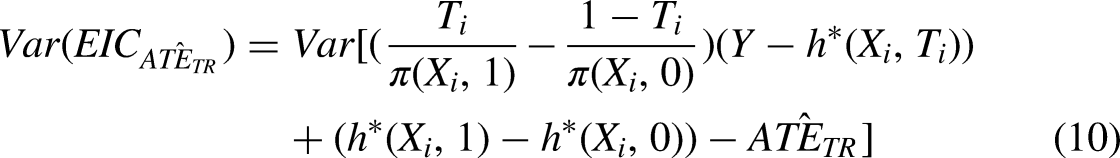
In Tutorial 4, we show how
Interpretation
(Tutorial 4  )
)
A lack of interpretability has been a barrier to the adoption of ML methods like neural networks and random forests in social science settings. However, the literature on post hoc interpretability techniques has matured considerably over the past five years, and several techniques for identifying important features/covariates such as permutation importance, LIME scores, SHapley Additive exPlanations (SHAP) scores, Individual Conditional Expectation plots etc. are in widespread usage today (Altmann et al., 2010; Goldstein et al., 2015; Lundberg and Lee, 2017; Ribeiro, Singh, and Guestrin, 2016). For a broad and accessible treatment of interpreting ML models see Molnar (2022).
Building on criteria used to evaluate other explainable AI methods, Crabbé et al. (2022) note four desirable properties of a feature importance technique for the interpretation of deep causal estimators: Sensitivity, completeness, linearity, and implementation invariance (Sundararajan, Taly, and Yan, 2017). A method that is sensitive can distinguish between features that are simply predictive of the outcome, and those that actually influence CATE heterogeneity. A method that is complete identifies all features that, together, explain all effect heterogeneity compared to a baseline. A linear method is one where the feature importance scores additively describe the prediction. Lastly, the approach should be agnostic to both the model architecture (e.g., TARNet, Dragonnet) and different architectural hyperparameterizations (i.e., invariant to implementation). Of the feature importance methods surveyed, they identify two that manifest all four of these qualities: SHAP scores, and integrated gradients.
SHAP scores have emerged as one of the most popular methods for evaluating ML models in recent years (Lundberg and Lee, 2017). SHAP is what is called a “local” interpretability method: it provides feature importance estimates for each individual datum. Theoretically, SHAP frames feature importance estimation as a cooperative (game-theoretic) game between covariates to predict a specific outcome. Under the hood, the algorithm exhaustively compares all possible “coalitions” of covariates and their ability to predict the outcome (win the game). Predictions from this powerset of coalitions are used to calculate the additive marginal contributions of each feature in prediction using Shapley values. The disadvantage of SHAP is that, even with computational tricks, calculating scores for every unit can become computationally intractable in high-dimensional datasets. SHAP scores are interpreted in comparison to a causal baseline of the ATE.
Because of the computational expense of SHAP scores, Crabbé et al. (2022) also recommend another local-interpretability method called “Integrated Gradients” (Sundararajan, Taly, and Yan, 2017). Intuitively, this algorithm draws a straight-line, linear path in feature space between the target input (individual unit) and a baseline (i.e., a hypothetical unit who is exactly average on all covariates). A feature importance score can then be constructed by calculating the gradient in prediction error along this path with respect to the feature of interest. Note that SHAP scores can also be understood theoretically within the path framework. From this perspective, coalitions are paths in which each feature is turned on sequentially, and the SHAP score is the expectation across these paths. This interpretation leads to a gradient-based algorithm for calculating SHAP scores specifically for neural networks, which is also in the SHAP package. In practice, we recommend that analysts experiment with both integrated gradients and SHAP scores.
What’s in the tutorials?
To move from theory to empirics, the online tutorials show how to implement many of the ideas presented throughout this primer. The tutorials are hosted in notebooks in the Google Colaboratory environment. When users open a Colab notebook, Google immediately provides a free virtual machine with standard Python ML packages available. This means that readers need not install anything on their own computers to experiment with these models. The tutorials are written in the Python programming language and provide examples in both TensorFlow2 and Pytorch, the two most popular deep learning frameworks. We note that both TensorFlow2 and Pytorch have implementations in R. However, we strongly recommend that readers interested in getting into deep learning work in Python, which has a much richer ecosystem of third-party packages for ML.
Currently there are five tutorials:
 Tutorial 1 introduces S-learners, and T-learners before TARNet as a way to get familiar with building custom TensorFlow models.
Tutorial 1 introduces S-learners, and T-learners before TARNet as a way to get familiar with building custom TensorFlow models. Tutorial 2 focuses on causal inference metrics and hyperparameter optimization. Because we do not observe counterfactual outcomes, it’s not obvious how to optimize supervised learning models for causal inference. This tutorial introduces some metrics for evaluating model performance. In the first part, you learn how to assess performance on these metrics in Tensorboard. In the second part, we hack Keras Tuner to do hyperparameter optimization for TARNet, and discuss considerations for training models as estimators rather than predictors.
Tutorial 2 focuses on causal inference metrics and hyperparameter optimization. Because we do not observe counterfactual outcomes, it’s not obvious how to optimize supervised learning models for causal inference. This tutorial introduces some metrics for evaluating model performance. In the first part, you learn how to assess performance on these metrics in Tensorboard. In the second part, we hack Keras Tuner to do hyperparameter optimization for TARNet, and discuss considerations for training models as estimators rather than predictors. Tutorial 3 highlights the semiparametric extension to TARNet featured in Shi, Blei, and Veitch (2019). We add treatment modeling to our TARNet model, and build an augmented inverse propensity score estimator. We then briefly describe the algorithm for Targeted Maximum Likelihood Estimation to introduce and build a Dragonnet with Shi et al.’s Targeted Regularization.
Tutorial 3 highlights the semiparametric extension to TARNet featured in Shi, Blei, and Veitch (2019). We add treatment modeling to our TARNet model, and build an augmented inverse propensity score estimator. We then briefly describe the algorithm for Targeted Maximum Likelihood Estimation to introduce and build a Dragonnet with Shi et al.’s Targeted Regularization. Tutorial 4 reimplements Dragonnet in Pytorch and shows how to calculate asymptotically valid confidence intervals for the ATE. We also interpret the features contributing to different heterogeneous CATEs using Integrated Gradients and SHAP scores. This tutorial is a good tutorial if you also just want to learn how to interpret SHAP scores, independent of the context of causal inference.
Tutorial 4 reimplements Dragonnet in Pytorch and shows how to calculate asymptotically valid confidence intervals for the ATE. We also interpret the features contributing to different heterogeneous CATEs using Integrated Gradients and SHAP scores. This tutorial is a good tutorial if you also just want to learn how to interpret SHAP scores, independent of the context of causal inference. Tutorial 5 features the Counterfactual Regression Network (CFRNet) and propensity-weighted CFRNet in Shalit, Johansson, and Sontag (2017); Johansson et al. (2018, 2020) (see Online Appendix). This approach relies on integral probability metrics to bind the counterfactual prediction loss and force the treated and control distributions closer together. The weighted variant adds adaptive propensity-based weights that provide a consistency guarantee, relax overlap assumptions, and ideally reduce bias.
Tutorial 5 features the Counterfactual Regression Network (CFRNet) and propensity-weighted CFRNet in Shalit, Johansson, and Sontag (2017); Johansson et al. (2018, 2020) (see Online Appendix). This approach relies on integral probability metrics to bind the counterfactual prediction loss and force the treated and control distributions closer together. The weighted variant adds adaptive propensity-based weights that provide a consistency guarantee, relax overlap assumptions, and ideally reduce bias.
Beyond Traditional Data: Text, Networks, Images, and Treatment over Time
As exciting as neural networks are for heterogeneous treatment effect estimation from quantitative data, a great promise of deep causal estimation is inference when treatments, confounders, and mediators are encoded in high-dimensional data (e.g., text, images, social networks, speech, and video) or are time-varying. This is a strong advantage of neural networks over other ML approaches, which do not generalize competitively to nonquantitative data. In these scenarios, multitask objectives and tailored architectures can be used to learn representations that are simultaneously rich, capture information about causal quantities, and disentangle their relationships. Moreover, the inherent flexibility of neural networks means that, in many cases, the TARNet-style models presented above can serve as the foundations to inference on text and graphs with some architectural modifications, additional losses, and new identification assumptions.
This literature is rapidly evolving, so readers should treat this section of the primer as fundamentally prospective. To maintain accessibility, our primary goal here is to introduce readers to hypothetical scenarios where they might perform causal inference on text, network, or image data. Second, we selectively review contemporary, theoretically motivated literature on deep causal estimation in these settings. The identification assumptions for different data types differ substantially, so we generally leave those to the interested reader. Finally, we briefly discuss approaches for dealing with time-varying confounding. We also take this section as an opportunity to introduce Graph Neural Networks (GNNs) and the Transformer architecture, now used in most contemporary deep learning models to learn from complex data (Box 8).
Graph Neural Networks and Transformers The most intuitive understanding of how graph neural networks work is as a message-passing system (Gilmer et al., 2017). We use one of the first GNN papers, the Graph Convolutional Network as an example (Kipf and Welling, 2017). In this interpretation, each node has a message that it passes to its neighbors through a graph convolution operation. In the first layer of a GNN this message would consist of the node’s covariates/features. In consecutive layers of the network, these messages are actually representations of the node produced by the previous layer. During graph convolution, each node multiplies incoming messages by its own set of weights and combines these weighted inputs using an aggregation function (e.g., summation). By the As of 2023, Transformers and GNNs, specifically GATs, are roughly equivalent architectures. From the graph perspective, words in sentences are akin to nodes in networks, with their relative positions to each other being analogous to their structural positions in the graph. Transformers improved on previous sequential approaches to text analysis (i.e. recurrent neural networks) by having each word (or representation of a word) receive messages from not just adjacent words, but all words heterogeneously. Attention mechanisms throughout the architecture allow each layer of a transformer to attend to words or aggregated representation heterogeneously. Architectures such as BERT or GPT stack transformer layers to create models with hundreds of millions to hundreds of billions of parameters. These models are expensive to train, both computationally and with respect to data, so they are often pretrained on enormous datasets and then “fine-tuned” (lightly re-trained) with smaller datasets for specific tasks or to align with certain goals.
Causal Inference from Text
In recent years, an interdisciplinary community across both social science and computer science has coalesced around causal inference from text (see Keith, Jensen, and O’Connor (2020) and Feder et al. (2021) for exhaustive reviews). Broadly speaking, texts may capture information about any causal quantity (treatments, outcomes, confounders, mediators) we might be interested in. For example, in an exit-polling experiment, analysts might want to measure toxicity (
The ability of neural networks to automatically extract features makes them particularly suited for the last scenario when both treatment information and confounding covariates are encoded in text. In many cases, we may not have explicitly identified, quantified, or labeled all of the confounders in text (e.g., subject matter and tone of emails), but we would still like to control for them. Pryzant et al. (2021),Veitch, Sridhar, and Blei (2020), and Gui and Veitch (2022) address this problem by prepending Transformer-layers (Box 8) for reading text to the beginning of TARNet or Dragonnet. Veitch, Sridhar, and Blei (2020) demonstrate the viability of this approach on a Science of Science question testing the causal effect of equations on getting papers accepted to computer science conferences. Pryzant et al. (2021); Gui and Veitch (2022) explore the more complicated scenario in which the treatment is not explicitly known (e.g., equations in papers, gender of authors), but is instead externally perceived upon reading (e.g., politeness/rudeness of an email or toxicity of a social media post). In these models, an additional loss function is also added for learning text representations concurrently with the causal inference losses discussed above.
Causal Inference from Networks
A smaller literature has leveraged relational data for causal inference in two distinct scenarios. In the first traditional selection on the observable setting, we wish to control for information about unobserved confounding inferable from homophilous ties. For example, age or gender might be unmeasured in our data, but we might expect people to develop friendship ties with those of the same gender identity or age cohort.
This scenario suggests estimation strategies similar to those when confounders are encoded in text. Much like Transformer layers can be prepended to TARNet-style estimators to learn from text, GNNs (an analog of the Transformer) can be preprended to learn from graphs. Guo, Li, and Liu (2020) provides a first pass at this problem by adding GNN layers to CFRNet Shalit, Johansson, and Sontag (2017) (Box 8). Veitch, Wang, and Blei (2019) instead adapt Dragonnet in a semiparametric framework to allow for consistent estimates of the treatment and outcome, assuming the network representation encodes significant information about confounders.
The second, more challenging scenario is estimating the causal effect of social influence on outcomes from observational data. For example, Cristali and Veitch (2022) introduce the problem of measuring the effects of vaccination (
Causal Inference from Images
While ideas from causal inference have been leveraged extensively to improve image classification, to our knowledge there are no papers that explore causal inference where treatments, confounders, mediators, or predictors are encoded in images. 12 That being said, some scenarios proposed for causal text analysis should apply here as well. For example, consider the conjoint experiment on the electability of politicians’ faces by Todorov et al. (2005) where both the treatment (e.g. incumbency of a politician) and potential latent confounders (e.g., party, age, gender, race) are encoded in an image. In this setting, a TARNet-like model adapted to learn and condition on image representations could improve treatment effect estimation by controlling for confounders such as the politician’s age. Causal inference on images is an area ripe for exploration, and we hope to see more work here in the future.
Causal Inference from Time-varying Data
One natural extension of deep causal estimation is to scenarios where treatments are administered over time and confounding may be time-varying. While “g-methods” developed by Robins et al. for estimating effects with time-varying treatments and confounding have existed for decades, the statistical assumptions encoded in these models are quite strong (Robins, 1994; Robins and Hernán, 2008; Robins, Hernan, and Brumback, 2000). Due to their reliance on generalized linear models to define the “structural” component, they assume that the outcome is a linear function of all covariates and treatment. Second, for identification, they make strong assumptions about which previous timesteps confound the current one. Third, they require different coefficients to be estimated at each time steps. Transformers (Box 8) and RNNs, a simpler model for sequential data (Online Appendix), should be able to capture long-term dependencies and nonlinearities in ways that marginal structural models and g-computation cannot.
Several papers have begun to explore these possibilities in the context of personalized medicine. Lim, Alaa, and van der Schaar (2018) build a marginal structural model using a RNN, and Bica et al. (2020) extend this framework with an additional loss to more explicitly deal with time varying confounding by forcing the model to “unlearn” information about the previous time steps. Melnychuk, Frauen, and Feuerriegel (2022) go one step further by adapting Bica et al. (2020)’s approach with a transformer. Inspired by longitudinal targeted maximum likelihood, Frauen et al. (2022) add a semiparametric targeting layer to their RNN to create a g-computation algorithm that is doubly robust and asymptotically efficient. Li et al. (2021) instead propose an RNN framework for g-computation that allows for dynamic treatment regimes. All of these papers use simulations of tumor growth dynamics, naturalistic simulations based on vital signs from intensive care unit visits, or datasets on the response of back pain to physical therapy.
Conclusion: Deep Causal Estimation in Context
In this primer, we introduce social scientists to the emerging ML literature on deep learning for causal inference. To set the stage, we first provide both an intuitive introduction to fundamental deep learning concepts like representation and multitask learning, as well as practical guidelines for training neural networks. In the main body of the article, we show how ML researchers have adapted core treatment and outcome modeling strategies to leverage the particular strengths of neural networks for heterogeneous treatment effect estimation. We follow with a discussion on inference (e.g., model selection, confidence intervals, interpretation), and close with a prospective look at algorithms for inference from text, social networks, images, and time-varying data.
Deep learning is not the only potential tool for heterogeneous treatment effect inference, and there are robust literatures exploring the usage of other methods in both the econometrics and biostatistics communities (Van der Laan and Rose, 2011; Chernozhukov et al., 2018; Wager and Athey, 2018). While these literatures are certainly more mature, below we discuss reasons why we think the use gap between neural networks and other ML methods will continue to narrow, a change that we must prepare for.
First, neural networks are better at modeling nonlinear heterogeneity (e.g., in treatment responses) than other ML methods. In extensive simulations, Curth et al. (2021) found that when the data-generating process for treatment heterogeneity includes exponential relationships, neural networks outperformed random forests, but tree-based methods are robust when the data-generating process is built on linear functions. Neural networks were also consistently better at predicting outlier treatment effects than forests. These differences result from how the two methods model functions. While neural networks can approximate any continuous function with enough neurons, random forests must build nonlinear or nonorthogonal decision boundaries using piecewise functions and average predictions. Consistent with these differences, Curth et al. (2021) also find that neural networks do better when variables are constructed as continuous covariates, and vice versa when they are dichotomized.
From a statistical perspective, the rise of semiparametric and double ML frameworks has also narrowed the gap between neural networks and other types of ML in terms of theoretical guarantees. For example, the TMLE-inspired Dragonnet algorithm featured here is unbiased, plausibly consistent, and converges to the target estimand at a fast rate of
Third, folk beliefs about the data-hungriness and uninterpretability of neural networks are overstated. Neural networks are data-hungry when over-parameterized or learning from high-dimensional data like images, but we show in the tutorials that modest-sized (hundreds of neurons), well-regularized neural networks can successfully infer heterogeneous treatment effects in a naturalistic simulation of quantitative data with less than 800 units. In the “Confidence and Interpretation” section, we also highlight the considerable progress in ML interpretability over the past five years, much of which has been on model-agnostic approaches that benefit all black-box algorithms equally. 13
In our opinion, the most pressing limitation of current deep learning approaches is the difficulty of optimizing neural networks. Theoretically, this stems from (a) the complexity of the loss functions which are often nonconvex, and (b) the ease of over-parameterizing these models to fit these functions. If neural networks are to be used as statistical estimators, statistical guarantees must be backed by optimization guarantees and/or more rigorous methods for model selection. Outside of statistical estimation, this limitation has largely been addressed through empirical testing on test data and strategic model selection. Within the statistical estimation context, this gap will likely need to be addressed by simulation-based sensitivity analyses and, in the short term, comparisons to other model families.
Moreover, there has been a lack of mature tools and empirical applications of these models. A major goal of this primer, and the tutorials in particular, is to synthesize the theoretical literature, practical training and interpretation guidelines, and annotated code in one place so that social scientists can start using these models. Deep learning frameworks like TensorFlow and Pytorch are becoming more accessible every year, but we note that canned Python packages like Uber’s causalML exist for interested readers who just want to experiment with a few of these models (Chen et al., 2020).
Despite current limitations, we believe the future of causal estimation runs through deep learning. As causal inference ventures into new settings, the flexibility of neural networks will become essential for learning from text, graph, image, video, and speech data. For time-varying settings, we believe the ability of neural networks to model nonlinearities and long-range temporal dependencies will ultimately lead to solutions with net weaker assumptions than current approaches. Overall, we are optimistic and excited to see where deep causal estimation heads over the next few years.
Supplemental Material
sj-pdf-1-smr-10.1177_00491241241234866 - Supplemental material for A Primer on Deep Learning for Causal Inference
Supplemental material, sj-pdf-1-smr-10.1177_00491241241234866 for A Primer on Deep Learning for Causal Inference by Bernard J. Koch, Tim Sainburg, Pablo Geraldo Bastías, Song Jiang, Yizhou Sun, and Jacob G. Foster in Sociological Methods & Research
Footnotes
Declaration of Conflicting Interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The authors received no financial support for the research, authorship and/or publication of this article.
Data Availability Statement
The tutorials use the IHDP naturalistic simulation introduced in Hill (2011) as an example. The 25 covariates/features for the 747 units (139 treated) in the dataset were taken from an experiment, but Hill simulated the outcomes to create known counterfactuals. The data are available from Fredrik Johansson’s website ![]() .
.
Supplemental Material
Supplemental material for this article is available online.
Notes
Author Biographies
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.