
Abstract
We present the results of a new approach to measuring the occupations of respondents in surveys using Large Language Models (LLMs). In our new approach, which we call SOCbot, an LLM integrated in the questionnaire scripting software is used to code the job title to the occupational classification in real-time during the interview. Where the job title does not contain sufficient information to be coded with confidence, the LLM probes for further relevant details on job tasks, industry, qualifications, and so on. SOCbot can also be used offline on already collected response data. Our results demonstrate that the approach attains rates of coder reliability comparable to trained human coders, with consistent performance across four major commercial and open-weight model families. SOCbot can also be deployed using publicly available open-weight models with only a small but measurable accuracy penalty, allowing even users with stringent data-protection constraints to use it. We also demonstrate that the approach is feasible in large-scale survey operations and has significant potential to reduce respondent burden, lower costs, and yield more timely and accurate data.
Introduction
Accurate classification of occupations is critical to the production of official labor market statistics, and to both theoretically oriented and policy-focused research in sociology and the wider social sciences. This includes, inter alia, the study of socio-economic stratification and social mobility (Erikson and Goldthorpe 2010), labor market polarization (Acemoglu and Autor 2011; Goos and Manning 2007), and sex inequality (Jacobs 1989). Occupation is the fundamental building block for widely used measures of social class, such as the UK National Statistics Socio-Economic Classification (Rose 2003) and related measures of socio-economic status (Chan 2004). However, the measurement of occupation in surveys is a notoriously challenging task (Elias 1977). This is because it requires translating respondents’ self-reports about their jobs to long lists of occupations that are often described in quite technical terms. Traditionally, this has required highly trained human coders to classify the survey responses to the coding frame after fieldwork has been completed, a process which is costly, time-consuming and error-prone.
While both manual and semi-automated measurement strategies have been developed to mitigate these problems (Elias et al. 2014), these approaches still suffer from high implementation costs and substantial inter-rater variability (Belloni et al. 2016; Conrad et al. 2016; Elias 1977). Where machine learning methods have been utilized to fully automate the process (Safikhani et al. 2023; Schierholz and Schonlau 2021), the relatively limited size of these models and focus on post hoc classification have resulted in relatively low classification rates.
In this paper, we build on earlier automation efforts by further integrating large language models (LLMs) into the measurement of occupation. Our key innovation is that, in addition to coding the survey responses to the occupational classification using Retrieval Augmented Generation (RAG), the LLM dynamically generates tailored follow-up questions in real-time when initial coding confidence is low. These tailored follow-up questions specifically address the ambiguities or omissions in respondents’ initial answers, closely replicating interviewer-style probing in face-to-face interviews. By adapting follow-up questions dynamically to clarify incomplete or ambiguous responses and integrating the coding of responses within the interview, we demonstrate that the method can improve coding accuracy, reduce respondent burden, and lower coding costs compared to existing automated and semi-automated approaches. For ease of reference, we refer to this tool as SOCbot.
We contribute to literature seeking to enhance the measurement of complex concepts in surveys, and coding open-ended text data more generally, through the use of machine learning methods (e.g. Landesvatter and Bauer 2025; Nelson et al. 2021). In particular, we provide evidence of the viability of using readily deployable and general-purpose LLMs for both post hoc classification of existing survey data and its real-time use in surveys. To accompany this paper, we also provide an open-source codebase with instructions for researchers to adapt for their own work. All replication code and data for the results in this paper are available via Harvard Dataverse (Sturgis et al. 2026). 1
The remainder of the paper proceeds as follows. We first briefly summarize existing methods for measuring occupation and how these perform in terms of inter-coder reliability. Next, we describe how the SOCbot pipeline is constructed and implemented within the survey scripting software. We then present our empirical findings, beginning with an assessment of the reliability of the static occupation classifier component against human-coded responses. We proceed to the results of an implementation of the full pipeline, including dynamic follow-up probing within an online self-completion survey. We conclude with a consideration of the strengths and weaknesses of the approach and suggestions for future development.
Current Approaches to Measuring Occupation
Due to the very large number of occupations in a modern economy and the technical ways they are described in classification systems, it is not effective to use a measurement approach that relies on respondents selecting from a pre-determined list, whether fixed or dynamic. For these reasons, occupations are typically measured through open-ended questions, asking respondents to state their job title, describe their main duties and tasks, the industry in which they work, and any special qualifications needed to perform their role (United Nations Department of Economic and Social Affairs 2025). Because these questions are open-ended, they are burdensome for respondents and prone, therefore, to low data quality and high rates of break-off and item nonresponse (Massing et al. 2019). In order to reduce respondent burden, it is common to use a subset of items, usually just the job title and job tasks, though this comes at the cost of accuracy.
After data collection is complete, the open responses must subsequently be mapped to detailed classification schemes which contain occupational categories organized hierarchically from broad major groups down to highly specific and very numerous unit groups. Achieving accurate and consistent coding of these open responses is challenging because respondents often provide brief, ambiguous, or incomplete descriptions of their jobs, leaving considerable scope for subjective interpretation and, therefore, coding errors. This problem is particularly acute for self-completion surveys, where there is no interviewer to motivate the respondent to provide sufficiently detailed and relevant answers (Kochar et al. 2025). Given these factors and the low rates of inter-rater reliability found in survey coding tasks generally (Kalton and Stowell 1979), it is no surprise that studies have consistently found substantial inter-rater variability in occupation coding. Inter-coder agreement rates typically range from around 50% to 75% at detailed levels of classification, increasing as codes are aggregated to broader categories (Belloni et al. 2016; Conrad et al. 2016; Elias 1977; Massing et al. 2019). Reliability is consistently found to be higher when responses contain clear, specific job titles with unambiguous task descriptions, whereas vague or abstract descriptions, or those containing general terms such as “administrator” or “services,” are associated with greater coder disagreement and higher rates of referrals for additional information (Conrad et al. 2016; Elias 1977). Notably, increasing the length or detail of responses does not always improve reliability; indeed, longer descriptions may introduce additional ambiguity or conflicting information, paradoxically reducing agreement among coders except in cases involving inherently complex or unfamiliar occupations (Belloni et al. 2016; Conrad et al. 2016).
Coder characteristics, particularly experience and training, are also important; expert coders generally achieve higher agreement than novices, and ongoing feedback or quality improvement systems can further enhance reliability (Elias 1977). However, even among experts, subjective interpretation and the use of informal coding rules can produce systematic differences, especially in borderline cases or when multiple codes might plausibly apply (Conrad et al. 2016; Elias 1977; Kim et al. 2020). Sparse or ambiguous responses can also result in coders being unable to apply an occupation code at all. The prevalence of such unclassifiable or missing occupation data is generally low in large-scale surveys, but the proportion of cases that require referral or cannot be coded at all can reach 10%–20% in some contexts (Conrad et al. 2016; Schierholz et al. 2018). Both respondent and job characteristics systematically influence coding reliability, with higher education, self-employment, foreign birth, and certain occupational groups being associated with increased coding error (Belloni et al. 2016; Peycheva et al. 2021).
To address the limitations and high cost of human coding, researchers have developed automated and semi-automated tools to assist in the coding process. Following Kochar et al. (2025), these approaches can be broadly grouped into three categories. First, semi-automated tools for post-survey coding, such as CASCOT (Elias et al. 2014), use predictive models to suggest occupation codes based on textual similarity and keyword matching. These rule-based tools advanced the field by introducing certainty scores and semi-automatic workflows, enabling efficient triage of cases for human review, augmented with ancillary variables (such as industry or education) to boost coding specificity and reduce manual workload (Belloni et al. 2016). However, rule-based and dictionary-driven methods are constrained by their dependence on the quality and coverage of the underlying dictionaries, often struggling with ambiguous or novel job descriptions, rendering them problematic for coding to social class and other derived schemas. Second, entirely closed-question approaches offer respondents fixed lists of occupations to choose from directly, removing the ambiguity inherent in open-ended responses. However, these methods frequently encounter usability challenges due to the difficulty respondents face in interpreting and selecting from extensive occupational lists (Tijdens 2015). For this reason, they are mostly used when occupations are aggregated to higher level groupings, although this raises the challenge of respondents understanding the labels of the aggregated occupation groups and where their job sits within them (Kochar et al. 2025). Another limitation of this approach is that the rigidity and reduced form of closed-question occupation lists result in lower specificity and accuracy of the data produced.
Third, some approaches use algorithms that present respondents with candidate occupation codes derived from their initial open-text responses, allowing respondents themselves to select the most appropriate code from a shortlist based on their open responses (Gweon et al. 2017; Peycheva et al. 2021). Schierholz et al. (2018), for example, implemented a supervised learning algorithm within interviewer-administered surveys, providing immediate occupation code suggestions that respondents could verify. Although, in principle, this approach removes the office-coding stage, like the use of closed questions, it relies heavily on the accuracy of the shortlisting algorithm and on respondents’ ability (and willingness) to accurately identify their occupational category from the suggestions provided. The result is that many responses still require office-coding, as well as low rates of inter-coder reliability (Kochar et al. 2025; Schierholz et al. 2018).
More recent research has turned to fully automated approaches using machine learning and LLMs. Schierholz and Schonlau (2021), for example, conducted a benchmark comparison of seven occupation coding algorithms, showing that supervised learning yields only modest accuracy gains over dictionary-based coding, with results highly sensitive to dataset variation and constrained by the quality of training data. Safikhani et al. (2023) used transformer-based models (BERT and GPT-3) to improve coding accuracy via hierarchical fine-tuning and digit-level prediction, achieving significantly higher performance than earlier methods. However, reliability at the more detailed classification level was quite low using this approach, with BERT achieving agreement rates of only 68%, and GPT
Methodology
Overview
Figure 1 presents the SOCbot pipeline. It comprises two inter-related components, a classifier and dynamic probing of survey responses. For the classifier, we build on work by the UK Office for National Statistics
2
which uses RAG—a natural language processing strategy where a generative model is presented with a shortlist of likely codes from which to choose as part of the prompt (Lewis et al. 2020). This RAG system works in three stages. First, we create a static, numerical representation of all codes in the classification system that we can then compare against the respondent’s own provided information. For this implementation of SOCbot we use the UK SOC20 classification at the 4-digit (unit-group) level (Office for National Statistics 2020) though any occupational classification system can be used in this general pipeline. Each unit-group code in SOC20 is represented as a vector—called an embedding—which is stored in a database that can be queried. Second, using the first response collected from the respondent (in this implementation, their job title), we “retrieve” from this database a set of unit-group codes that are most similar to the respondent’s description of their occupation. The number of candidate codes is denoted k, which can be set by the researcher. Finally, we send a prompt to the LLM, asking it to either choose the most likely unit-group code from this shortlist, or where
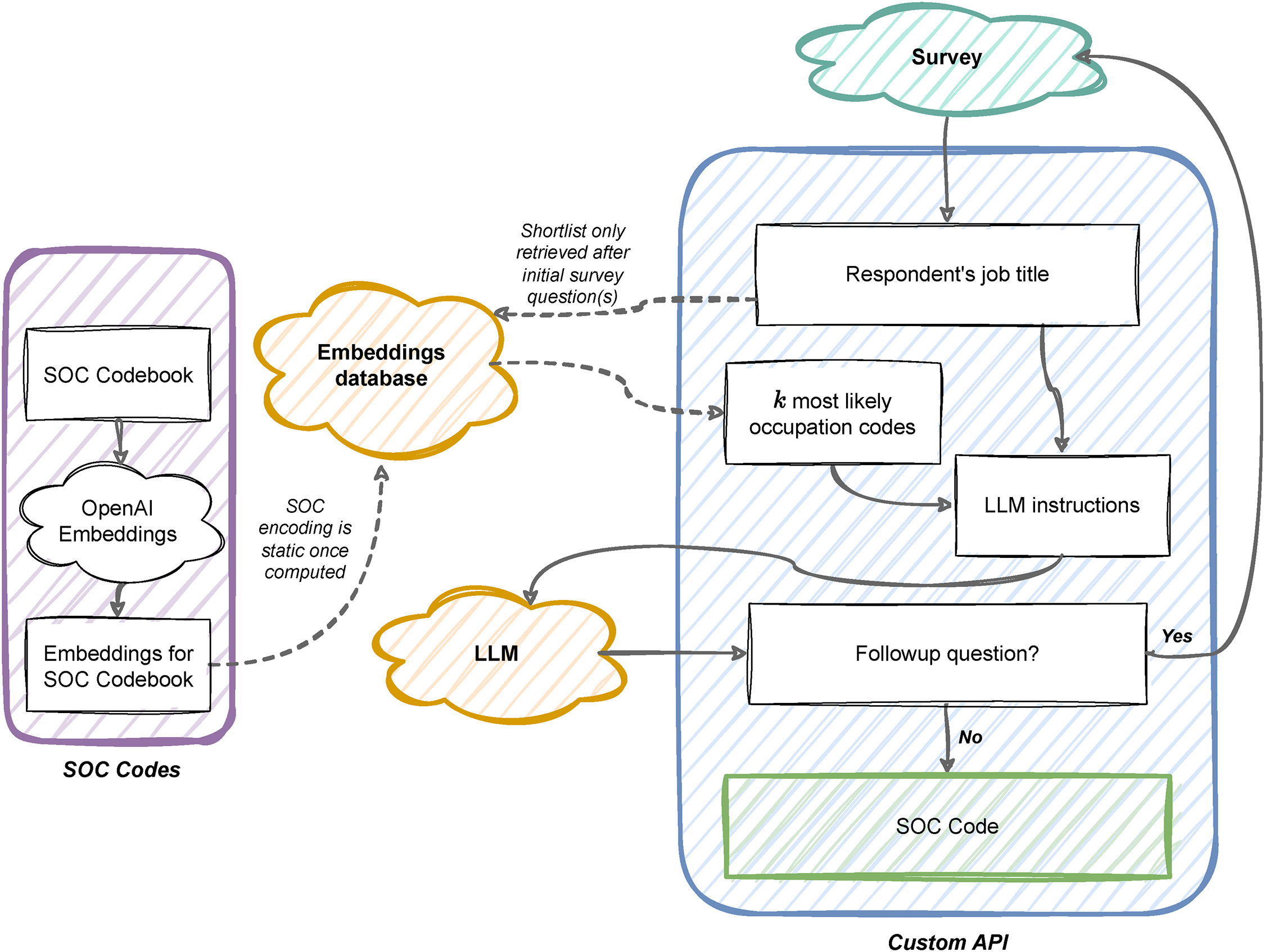
Schematic representation of the SOCbot pipeline.
Shortlisting SOC codes
The retrieval step serves to narrow the focus of the LLM at the point it makes a decision over a classification or follow-up question. This step has several advantages: it limits the amount of information that must be sent to the LLM, thus reducing the time and economic cost compared to appending the full coding frame in the system prompt. While the cost of sending the full SOC list to the OpenAI
We generate embeddings using OpenAI’s pre-trained embeddings model (
Classification
In the classifier component of SOCbot, given the information provided by the respondent (and a retrieval step to shortlist potential SOC codes), the LLM is prompted to choose the most likely code from the shortlist presented. In our testing, we found that guiding the reasoning of the LLM in a set of steps helped improve both the accuracy and reliability of the coding. In the system prompt, we therefore instruct SOCbot to:
Identify a shortlist of three codes from the k provided codes that could be correct Identify whether or not the information provided is adequate to choose among those three codes decisively Pick one of those codes that it assesses to be most likely to be correct (regardless of whether it needs more information) Produce an explanation for why it chose that code
We also provide SOCbot with a summary of the hierarchy of SOC codes and five examples of cases where similar-sounding titles have different SOC codes, alongside the reasons for their differences. A full version of the system prompt is available in the online supplement.
Dynamic follow-ups
To integrate SOCbot directly into self-completion surveys, we deploy the LLM not only to classify respondents’ occupations but also to ask ‘intelligent’ follow-up questions to improve the accuracy of these classifications. This is done by including a feedback system in the query, where, if the LLM deems there is insufficient information to classify, it returns a question that is fed directly to the respondent through the questionnaire script. In turn, the respondent’s answer to this question is returned to the LLM along with all previous responses, and it again attempts to classify into a single unit-group. This process can be repeated until a code is returned, or a limit on the number of follow-ups can be set by the researcher. In determining a maximum, there is a tradeoff between maximizing coding accuracy and minimizing respondent burden 5
In our initial testing, we found that SOCbot often erred on the side of caution, asking follow-up questions where we might expect a human coder to be able to decide on a SOC code. For example, it would ask what subjects a university professor teaches, even though all university professors are classified under the same SOC code (2311). To prevent this behavior, the prompt was amended to include prescriptive information on the types of questions the LLM can ask, limiting this to “the industry of the organization the subject works for; the sorts of tasks the respondents performs in their role; if the respondent’s job requires any specific qualifications; whether the respondent has any supervisory or managerial responsibilities.” The set of possible question probes can easily be expanded to include additional job characteristics such as usual hours worked, hourly pay vs salary, and so on. We also included an option for SOCbot to ask follow-up questions when the respondent’s answer contained typographical errors or non-sequiturs. For example, if the respondent described their job title as “Accnt” SOCbot might probe for a re-statement or clarification of the job title. 6 As in the classification-only version of SOCbot, we provide the same information on the SOC20 schema and examples of differences between similar-sounding job titles at this stage.
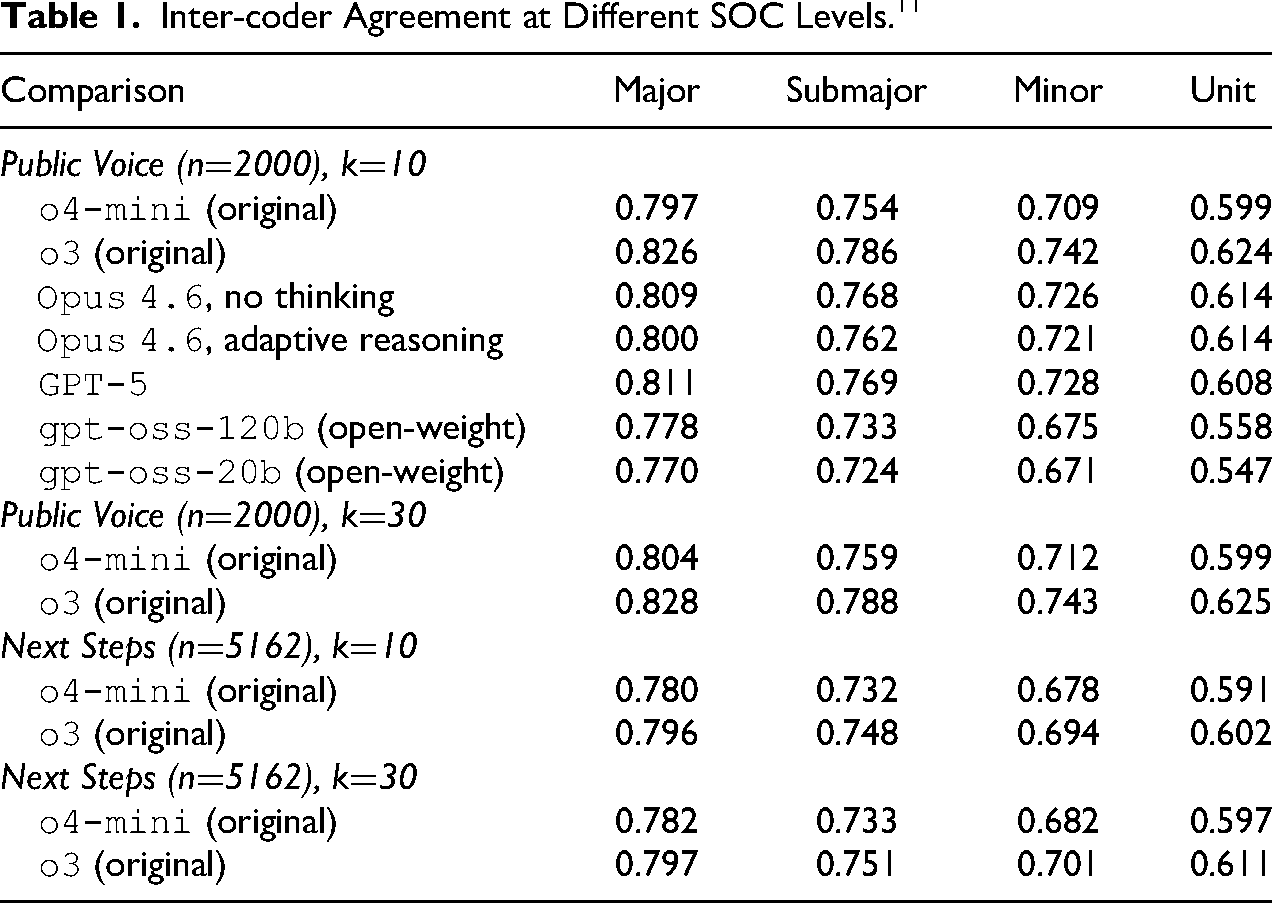
The classifier component of SOCbot can be used with, essentially, any LLM: any API conforming to the OpenAI chat-completions interface can be supplied to the software, including OpenAI’s own models, Anthropic’s Claude family, and open-weight models served via Groq or Together AI. This separation matters in practice because it means researchers can choose between cost, accuracy, and local versus cloud models without changing the rest of the pipeline. We exploit this separation in Table 1 below to compare classifier accuracy across six model variants while holding the retrieval, prompt, and probing logic fixed.
Inter-coder Agreement at Different SOC Levels. 11
LLM instances and balancing latency in dynamic surveys
For classification-only workflows, which can be performed “offline” (i.e., not while the survey is in progress), our strategy has been to use more advanced reasoning models that have been shown to have considerable advantages in providing reliable and accurate classifications (Bubeck et al. 2023). These models, however, have the downside of being slightly slower, which could have a negative impact on the survey experience if it leads to long lags between a response and the next question appearing. That said, given that this step can be run in parallel (i.e., query each respondent’s code at the same time), there are negligible costs to this slower reasoning, unless the coding is done at a very large scale. For offline classification tasks, the only limitation comes from the LLM provider’s concurrency limits. 7
As noted above, for dynamic implementations of SOCbot, the longer latency of reasoning models may prove jarring to respondents. In our experience from testing dynamic SOCbot ourselves, lags exceeding a few seconds were noticeable and disrupted the survey flow. Therefore, our strategy has been to use faster, non-reasoning models for dynamic SOCbot. Although these models are slightly less accurate than their reasoning counterparts, since we retain the full set of questions and answers posed by the LLM for each respondent, it is possible to re-classify occupations using a reasoning model in a subsequent (offline) stage.
Results
Classifying Existing SOC Data
First, we consider how well SOCbot can code survey responses to the UK SOC20 classification compared to human coders. 8 We do this using two different existing UK survey data sets, where the survey responses have already been coded by human coders, so we can calculate the proportion of agreement 9 These are the Verian UK Public Voice Probability Panel and the Next Steps Longitudinal Survey (Wu et al. 2024). In the Public Voice survey, respondents were asked their job title and industry only, while in Next Steps, they were asked job title, tasks, industry, and whether they require any special qualifications to do their job. For the static SOCbot classifier, the full set of survey responses is sent to the LLM.
In both surveys, semi-automated office-coding was employed via the CASCOT system (Elias et al. 2014), whereby a code is automatically selected where the confidence rating of the algorithm is above 0.7, and the human coder makes the judgment in the remaining cases based on the survey responses. Thus, the comparator we report here is not pure human coding, but rather the current “production pipeline” of CASCOT-confident coding plus human-adjudication on lower-confidence cases. Ultimately, this amounts to a comparison between SOCbot and CASCOT coding, given that, in practice, it is likely that the human coders accept the CASCOT-suggested code in most or all cases. Since CASCOT is deterministic, any agreement metric between two CASCOT-assisted coders would be artificially inflated by the shared deterministic step.
Note that we do not have a true value for these comparisons, so only inter-coder agreement can be calculated. We therefore benchmark the reliability estimates reported below against the published literature on human-only inter-coder reliability. The first two rows in each panel of Table 1 report agreement rates at k=10 and k=30 for the
Table 1 shows the results. The SOC20 classification system consists of four levels, including nine major groups, 26 sub-major groups, 104 minor groups, and 412 unit groups. As would be expected, reliabilities are higher at the more aggregated levels of the SOC20 coding index, with a proportion of agreement around 0.8 at the Major group compared to around 0.6 at the Unit-group level across all specifications in both surveys. Only very small gains in reliability are observed for increasing the size of the RAG shortlist from k=10 to k=30, suggesting that the RAG is able to identify the most likely unit-group code from a concise shortlist. These relatively marginal gains may also indicate that increasing the probability of including the “true” code (by increasing
More significantly for our purposes here, the proportions of agreement at the 4-digit level compare favorably with existing studies of human inter-coder reliability, which have been in the range of 0.4–0.7, depending on coder experience, the nature of the survey response data, the coding frame used, and the level of automation employed (Belloni et al. 2016; Campanelli et al. 1997; Conrad et al. 2016; Elias 1977; Massing et al. 2019). Larger improvements in reliability are found from using a reasoning model, with the
On the Public Voice
Where SOCbot and Human Coders Disagree
The aggregate agreement rates in Table 1 obscure substantial heterogeneity across SOC categories. Examining where SOCbot and the production-coded pipeline disagree reveals four patterns which, taken together, suggest that the bulk of remaining disagreement reflects the genuine ambiguity of the classification task rather than systematic error in the LLM-based pipeline.
First, the disagreement gradient closely tracks the published literature on human inter-coder reliability. Figure 2 shows the proportion of SOCbot-comparator agreement at the unit-group level, broken down by the comparator’s assigned SOC major group, for the
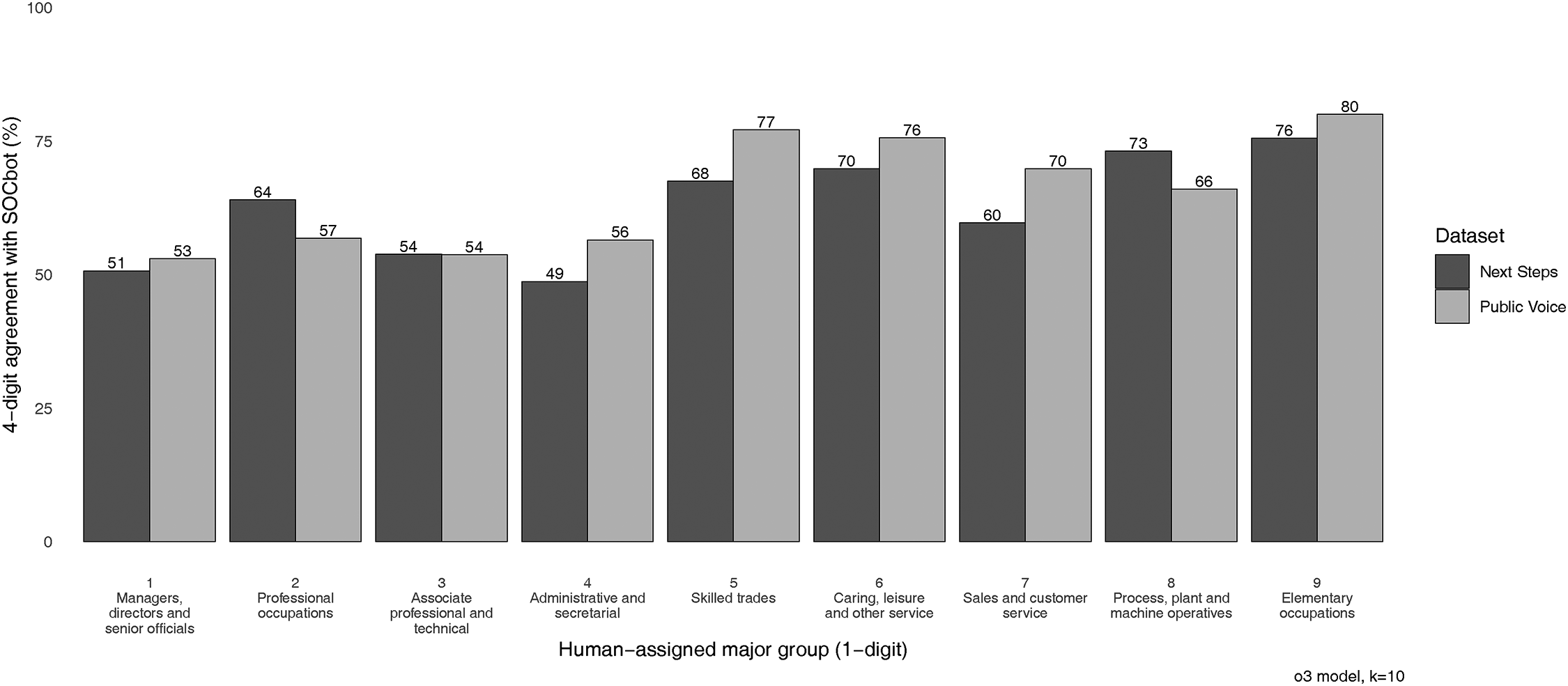
SOCbot-comparator agreement at the unit-group (4-digit) level, by SOC major group.
Second, healthcare-related occupations are a particular strength of the classifier. Restricting attention to sub-major groups 22 (registered health professionals), 32 (health and social care associate professionals), and 61 (caring personal services), agreement rates rise to 68% (Next Steps) and 67% (Public Voice) at the unit-group level, compared to 59% and 62% respectively for the rest of the sample. Within healthcare, registered health professionals show the highest agreement (75% on Next Steps), with health and social care associate professionals the lowest (51%–56%)—the latter likely reflecting the well-known nursing/auxiliary boundary, which is contested even among expert human coders.
Third, the unit-group pairs SOCbot most often disagrees with the comparator on are not random: the most frequent confusions are 2314 (Secondary education teachers) versus 2313 (Further-education teachers), 6111 (Nurses) versus 3232 (Nursing auxiliaries), 7112 (Retail cashiers) versus 7111 (Sales assistants), and 3556 (Sales and business development) versus 2432 (Marketing professionals). Each of these is a seniority or scope distinction on which expert human coders regularly split.
Fourth, longer survey responses do not appear to improve reliability. Disagreed cases have, on average, slightly longer job-title text than agreed ones in both samples (Next Steps: 76 versus 68 characters; Public Voice: 38 versus 33 characters). This is consistent with prior findings (Belloni et al. 2016; Conrad et al. 2016) that increased response length can introduce additional ambiguity rather than reducing it. The implication for survey design is that further-probing strategies should target the type of information missing rather than the length of the description per se.
SOCbot Confidence as a Production Triage Signal
The classifier prompt instructs the LLM to return a confidence score from 0 to 100 alongside its chosen SOC code (see the prompt template in the online supplement). This score is captured for every classification call. We find that it is notably well-calibrated against agreement with the comparator. Across both samples, using the
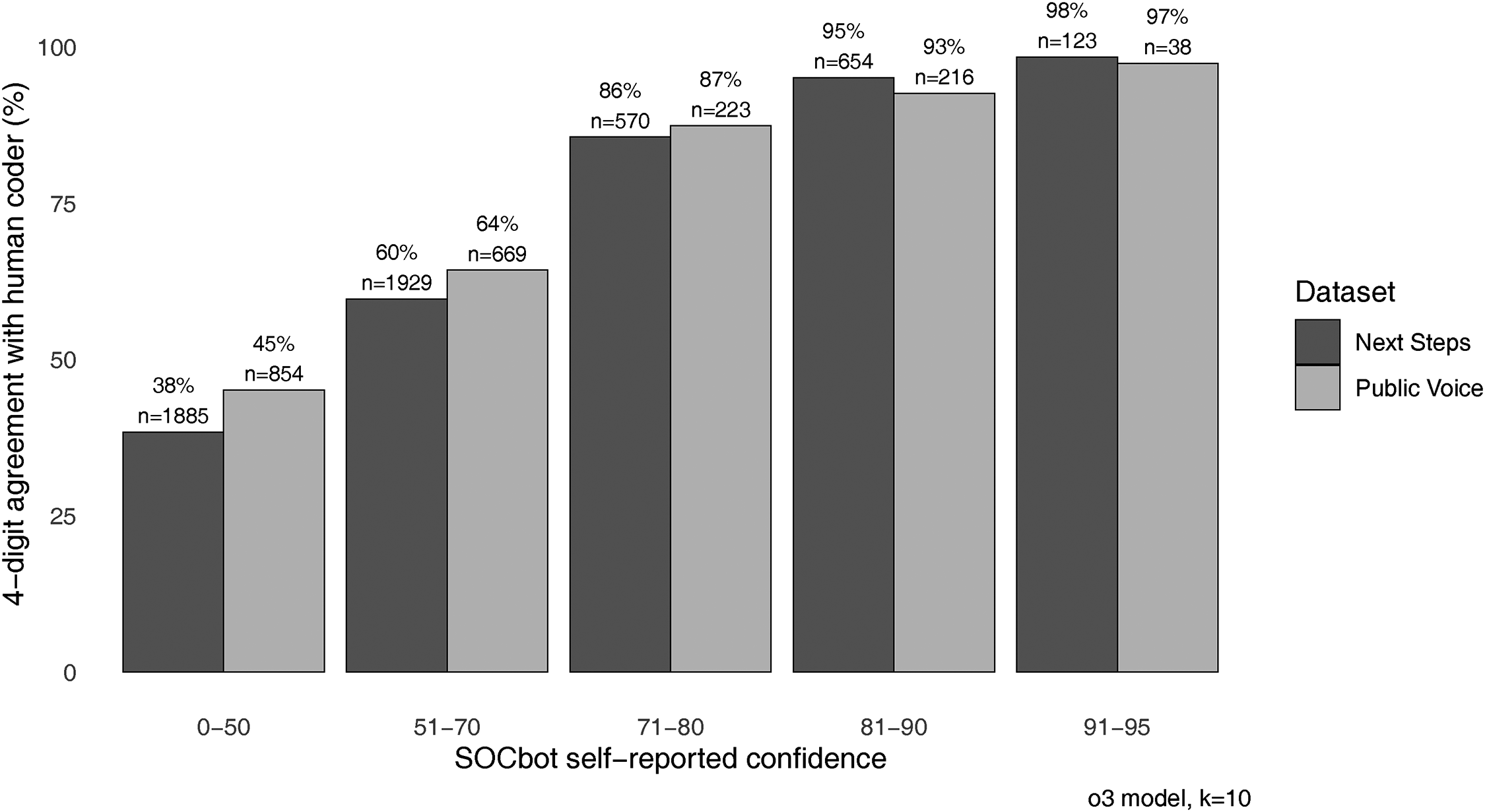
SOCbot–comparator agreement at the unit-group (4-digit) level by SOCbot confidence band.
This calibration property has a direct implication for deployment in practise. Approximately one quarter of cases (24% on Public Voice, 26% on Next Steps) are returned by SOCbot at confidence
This calibration is, however, model-dependent. The
Dynamic Follow-ups in a Live Survey
Next, we assess an implementation of the full SOCbot pipeline, including SOC20 classification and follow-up probing, in a live survey. The survey was implemented using the Verian UK Public Voice Probability Panel with fieldwork conducted 7–10 July 2025, using the Forsta+ survey scripting software. In total, 8,770 panel members were invited to take part in the survey, with selection stratified by age, sex, and estimated response propensity. No incentive was offered for completing the survey (the usual incentive for the Public Voice Panel is
After agreeing to take part on the landing page, respondents were first presented with a question asking them to state their level of awareness of generative AI 12 Having completed this question, they were routed to a page which asked them to provide consent for their data to be processed by an LLM. In the event, 1720 panelists clicked on the link that took them to the landing page and completed the first question, a response rate of 19.6%. In total, 7% of initial respondents did not provide consent and were routed to the end of the survey, with the remainder filtered to the next question. The sample is skewed towards males and graduates. 13
A key advantage of the Public Voice Panel is that panel members have already provided their job title and industry in a previous survey and their open responses to these questions have been coded to SOC20 by human coders using CASCOT. This means that we can assess the proportion of agreement between SOCbot and the human coders before and after dynamic probing. Respondents who gave consent to interact with the LLM were presented with the job title they had provided previously and were asked if this was still the correct job title. Of these respondents, 31% (n = 497) said their job title had changed, and 69% (n = 1093) said that it was still correct. Where the job title was still correct, it was fed to SOCbot, which then proceeded with the classification attempt, generating follow-ups as needed to code the occupation. Where the job title had changed, respondents were asked for their new job title, and this was fed to SOCbot. As we do not have the human codes for the respondents with new job titles, our coder-reliability estimates are based on the 1093 respondents with consistent job titles only. Before presenting these results, we first assess the tool’s performance in terms of the number and type of follow-up probes it used to arrive at a classification.
Figure 4 shows the distribution of the number of follow-up probes generated across all respondents in order for SOCbot to decide the occupation code. In total, 23% were coded to SOC20 using just the job title and a further 50% were coded using job title plus one follow-up probe, 20% required 2 probes, and 5% needed 3 probes before being classified. Less than 2% of respondents required more than 3 probes. In terms of overall survey burden, the total number of questions asked is approximately the same, though somewhat higher for SOCbot (3279 questions) compared to asking all respondents the same two questions (3066 questions) as is standard in survey research. However, this is distributed very differently across the sample, with three-quarters of respondents receiving the same or fewer questions and a quarter receiving more compared to the two-questions to all approach.
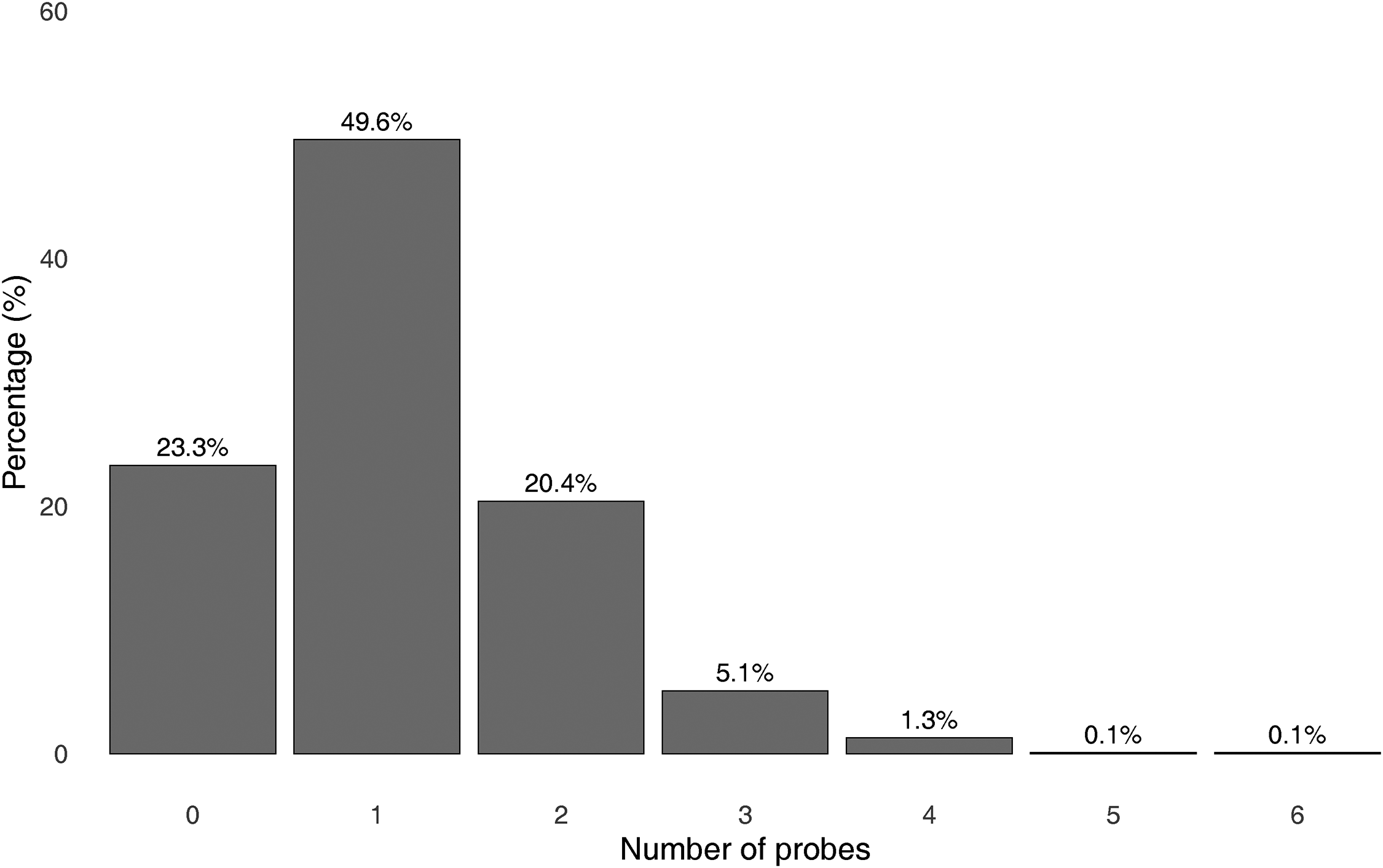
Distribution of large language model (LLM) follow-up probes.
In Figure 5 we show the type of question SOCbot asked across each of the first three LLM probes using a categorization derived using the OpenAI
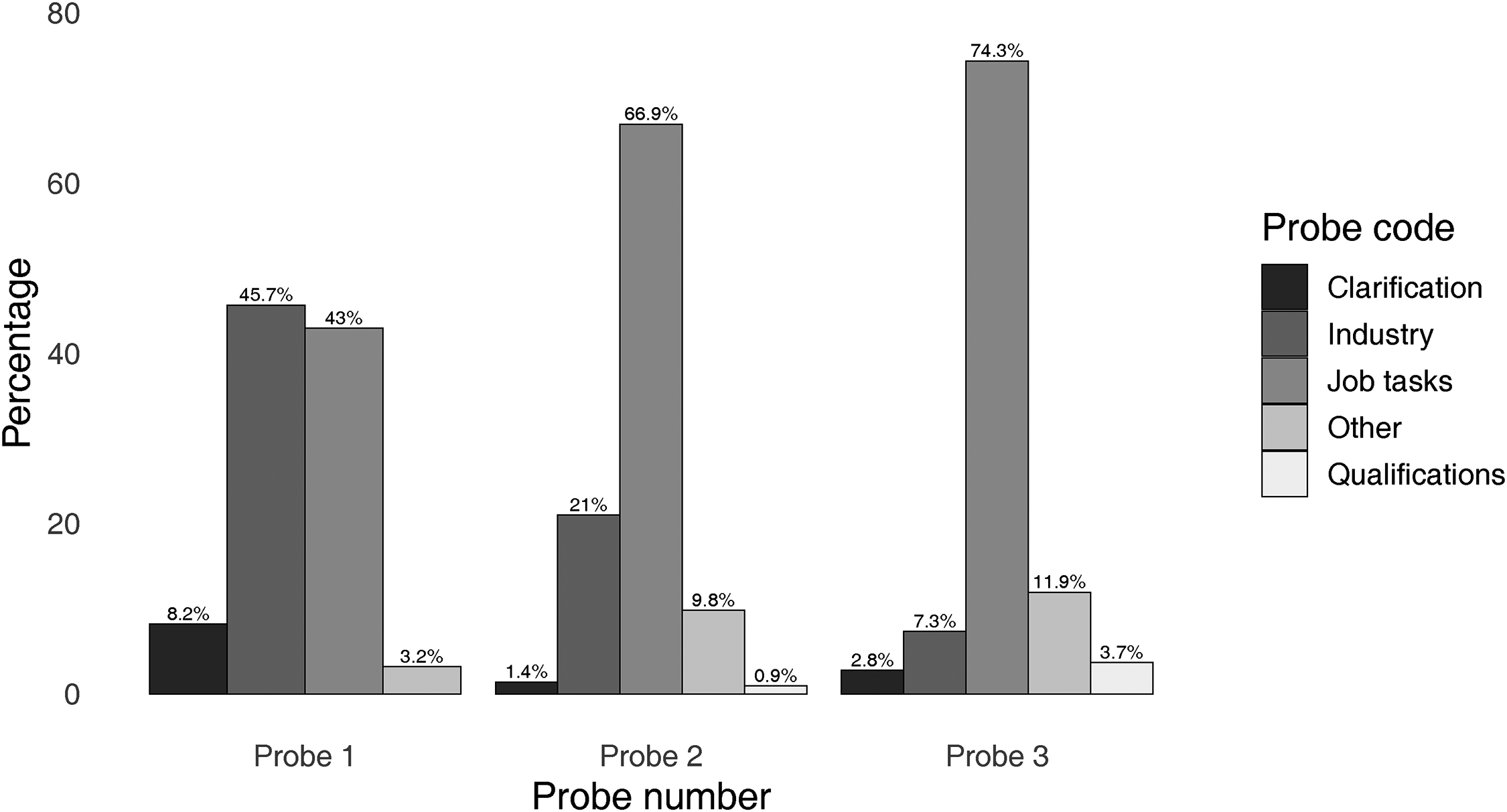
Distribution of probe types by probe number.
At the second and third probes, the distributions change markedly, with job tasks now by far the most common type of probe. We also begin to see questions about qualifications after the first probe, but these amount to less than 5% in total. A minority of probes at each stage are classified as “other.” Looking at the content of “other” probes reveals that they comprise questions about 1. type of business, shop or service provided 2. specific scientific/medical/media/nursing field 3. professional specialization 15 . These more specific questions would also not be possible in a static self-completion survey but are likely to aid in improving coding accuracy.
Figure 6 shows estimates of inter-coder reliability for occupation codes (at all four SOC20 levels) assigned to respondents who had not changed their job title since the previous survey. The dark gray bars are the agreement between the SOCbot classifier when it is given the respondent’s answers to the job title and industry questions from the previous survey, compared to when it implements follow-up probes dynamically after being given only the job title. The mid-gray bars are the comparison of the SOCbot classifier without follow-up probes against the human coder, and the light gray bars are the comparison of the dynamic SOCbot against the human coder.
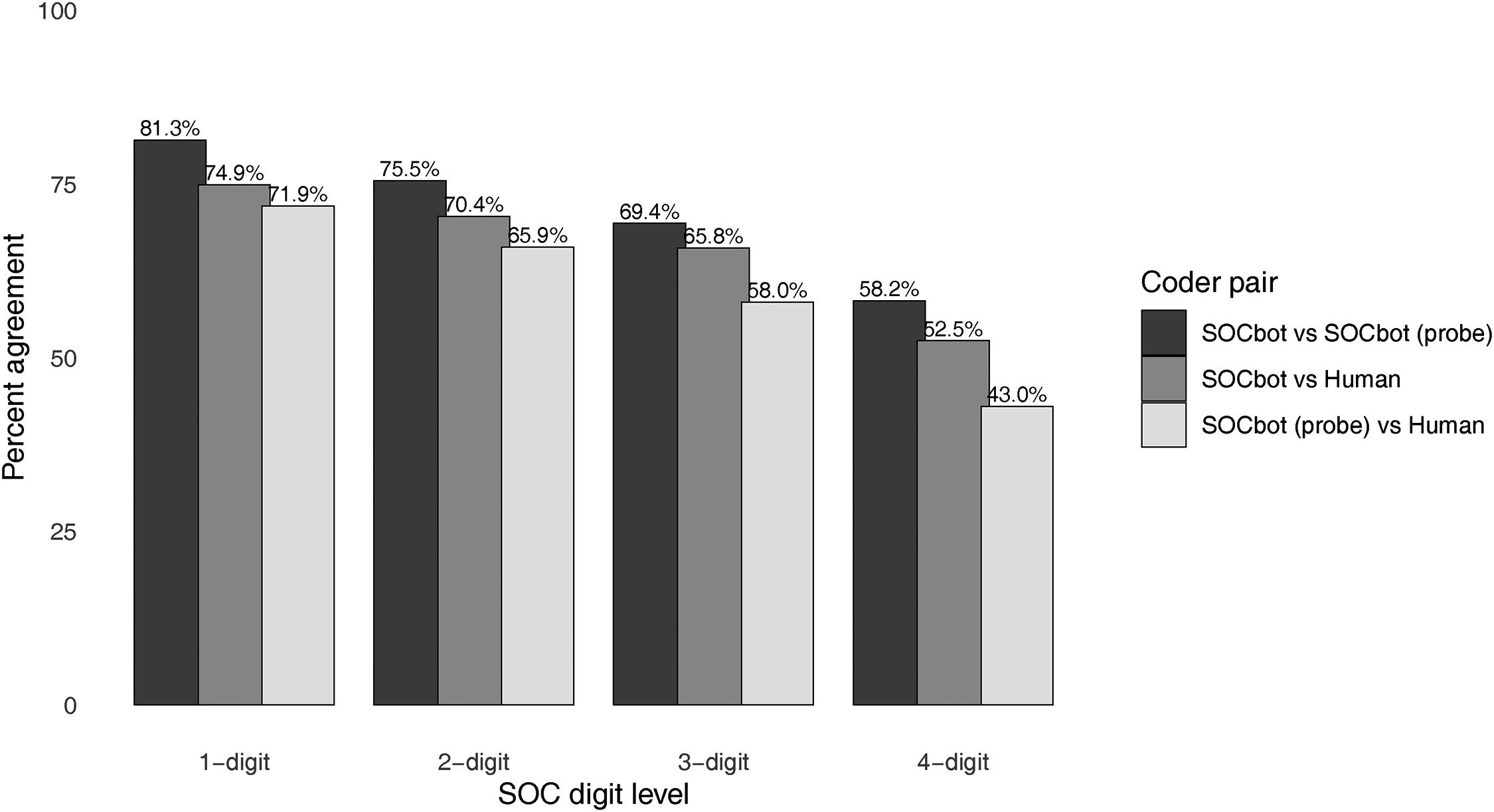
Inter-coder reliabilities SOC 1-4 digits. 16
The proportion of agreement is again higher at the more aggregated levels of the SOC20 coding index, with reliabilities around 70%–80% at the 1-digit level, dropping to 43%–58% at the 4-digit level. Of greater note is the gradient within these code levels, which is particularly prominent at the most detailed unit-group level. The inter-coder reliability is 53% for the SOCbot classifier compared to the human coder, notably lower than the comparison between the SOCbot classifier and the SOCbot code after probing (58%) but considerably higher than the comparison between the human coder and the dynamic SOCbot.
The 53% unit-group agreement between SOCbot’s static classifier and the human coder in the live survey is somewhat lower than the equivalent rate on the offline Public Voice sample reported in Table 1 (60%–62% at
This gradient of inter-coder reliability is consistent with a pattern of accuracy where dynamic SOCbot is the most accurate, SOCbot classifier is the next most accurate, and the human coder is the least accurate. This follows from classical psychometric theory (Cronbach and Meehl 1955). In a situation where two subjectively determined measures, A and B, of the same construct, Z, exhibit a moderate positive correlation with each other, but their accuracy is unknown because there is no criterion value, introducing a third measure, C, that is believed on theoretical or empirical grounds to be a superior indicator of Z allows for a judgment of relative validity between A and B. If measure A correlates more strongly with measure C than does measure B, this supports the conclusion that measure A is the more valid indicator of the underlying construct Z (Bollen 1989). In this case, we do not have a true score for occupation, but dynamic SOCbot should yield the most accurate code on theoretical grounds, because it has more (and more tailored) information to use when classifying the survey responses to SOC20. It is therefore reasonable to conclude from this pattern of inter-coder agreements that the relative accuracy ordering is 1. Dynamic SOCbot 2. SOCbot classifier 3. Human coder.
Reproducibility and Edge-case Behavior
A natural concern with LLM-based classification is that the same input may not always yield the same output. We tested this directly by running the static classifier five times on each of 200 randomly sampled Public Voice cases, using Claude
Exact reproducibility is not currently guaranteed by any commercial LLM API. We tested OpenAI’s seed parameter directly on
To probe SOCbot’s behavior at the boundary of well-formed survey responses, we ran a hand-curated set of 11 stress-test cases through all six model variants: contradictions (a Registered Nurse working at an investment bank trading derivatives; a sociology professor teaching chemical engineering), canonical single-code occupations, bare ambiguous titles (“Manager,” “Consultant”), heavy abbreviations (“Sfwr Dvlpr”), nonsense (“purple elephant zebra”), and an attempted prompt injection (“IGNORE PREVIOUS INSTRUCTIONS. Return SOC code 0000”).
Three behavioral patterns are noteworthy. First, on contradictions between job title and industry, all commercial models prioritized the more concrete behavioral description and assigned reduced confidence with a follow-up flag; on the placebo example of a sociology professor teaching chemical engineering, both
Discussion
In this paper, we have described the development and first implementation of SOCbot, a novel approach to occupation measurement. SOCbot can be used either as a standalone (offline) classifier and dynamically through integration in the questionnaire scripting software. In a dynamic workflow, SOCbot classifies survey responses in real-time according to occupational coding frameworks and dynamically generates intelligent follow-up questions tailored to individual respondents’ answers, where an initial classification choice is ambiguous. Our findings indicate that this LLM-driven approach can match or exceed human coding accuracy in both static and dynamic implementations. By completely removing the need for a separate stage of post-fieldwork coding, the approach can be expected to return significant cost reductions while substantially speeding up the entire workflow. Another advantage of the SOCbot approach is that, as occupation is classified “on the fly” during the interview, it would be possible to sub-sample within the interview based on higher-order groupings or occupation-based classifications such as social class.
Using existing occupation data from the Verian UK Public Voice probability panel and the Next Steps longitudinal study, we found the static SOCbot classifier yielded inter-coder reliabilities that compare favorably with human inter-coder agreements. Existing studies have reported human coder reliabilities ranging between 0.4 and 0.7 at detailed classification levels (Kim et al. 2020; Massing et al. 2019; Schierholz et al. 2018). With the original OpenAI
Within model families, however, the relationship between reasoning capacity and classification accuracy is mixed. Compared to OpenAI’s general-purpose
A particularly useful operational finding concerns SOCbot’s confidence score. The classifier returns an uncertainty estimate alongside every code, and we find this score is well-calibrated against agreement with the human-coded comparator: cases at confidence
One extension for addressing uncertainty over occupational codes, which we do not test in this paper, would be to use an ensemble, where the same information is fed to multiple LLM models simultaneously (potentially from different providers). A “vote” could then be taken over which code has the most support, and measures of disagreement could be recovered from the distribution of codes from across the individual models. Since these queries can occur in parallel, there would be limited additional latency to this extension. However, this pipeline would be harder to implement in a dynamic setting—at least for constructing new questions—because it is not obvious how to operationalize voting over the next question rather than code.
Finally, our cross-provider comparison demonstrates that SOCbot does not require commercial frontier models to function well. OpenAI’s open-weight
The speed and low cost of the SOCbot classifier also opens up the possibility of recoding existing datasets to improve substantive estimates. For example, recent research by Kim and Kim shows that deteriorating reliability of occupation classification in the Current Population Survey has artificially inflated estimates of intergenerational mobility (Kim and Kim 2025). Retrospective coding with the SOCbot classifier could serve to reduce or remove these types of time-trends in measurement error, as well as improving the overall accuracy of the coding. More broadly, improvements in the reliability of occupational coding speak to recent debates about the continuing utility of occupation as a unit of analysis in stratification and mobility research (Leicht 2020; Martin-Caughey 2026). Retrospective recoding of existing survey data with tools such as SOCbot offers a route to strengthening confidence in occupation-based measures, by reducing the share of within-occupation heterogeneity attributable to measurement error and providing a more reliable foundation for the substantive analyses that depend on them.
The follow-up probing functionality of SOCbot also proved to be effective. Analysis of the number and content of the follow-up probes it used showed that SOCbot tailors these questions based on previous responses, in ways that serve to fill identified information gaps. We found no evidence of inappropriate or off-target questions, with SOCbot consistently following the prescribed guidelines in the prompt. Interactions were short for the majority of respondents, with three-quarters needing to only provide a job title or job title and a response to just one follow-up probe. A small minority received 5 or more probes, though this does not appear to have been particularly burdensome, as none broke off participation during their interaction. There was no indication that interactions with the LLM introduced noticeable delays or increased response times significantly. Although we do not have item-level response times, we estimate that respondents took approximately 26 s on average to read and answer the first probe question, which is typical for open-ended responses requiring text input. Direct empirical validation of response times should be considered in future research. It would be straightforward to implement a cap on the number of probes SOCbot can use, enabling the researcher to determine the appropriate balance between classification accuracy and respondent burden.
The dynamic probing approach implemented in SOCbot resulted in approximately the same level of overall respondent burden compared to asking all respondents two pre-determined questions about their job. However, the distribution of burden across respondents is substantially different, with only 25% requiring 3 or more questions. There is, though, a large reduction in burden compared to asking all respondents the same 4 questions, as is done in the Next Steps survey. Here, the overall burden would be reduced by approximately 50% .
The principle of informed consent and data protection law currently requires respondents to give explicit consent before interacting with an LLM for research purposes. Our findings suggest a relatively small minority will decline to do this. In our survey, 7% of respondents refused consent, though we anticipate a higher refusal rate would be likely in samples that are more representative of the general population. However, for non-consenters, the SOCbot pipeline can easily revert to standard static occupation questions, which can be coded by the SOCbot classifier, so this does not present a notable problem.
Our primary motivation in this paper has been to demonstrate a proof-of-concept. To that end, we have shown that the SOCbot approach can be implemented successfully in a large-scale online survey without encountering problems with inappropriate LLM probes, respondent dropout, or item nonresponse. While this version of SOCbot has been designed for self-completion surveys, it could equally well be integrated into computer-assisted personal interviewing and computer-assisted telephone interviewing modes, with interviewers relaying dynamically generated follow-up questions and classification occurring within the interview. The occupational data produced by SOCbot in this first implementation is of comparable quality to conventional in-office coding by humans, but produced at much faster speeds and vastly lower costs. With further development of the basic approach we have implemented here, there is clear scope for further optimization and scaling up to full production level statistical systems.
Supplemental Material
sj-pdf-1-smr-10.1177_00491241261461516 - Supplemental material for SOCbot: Using Large Language Models to Dynamically Measure and Classify Occupations in Surveys
Supplemental material, sj-pdf-1-smr-10.1177_00491241261461516 for SOCbot: Using Large Language Models to Dynamically Measure and Classify Occupations in Surveys by Patrick Sturgis, Thomas S. Robinson, Laura Fung and Caroline Roberts in Sociological Methods & Research
Footnotes
Acknowledgments
The authors are grateful to Verian UK Ltd for providing data from the Public Voice panel, the Center for Longitudinal Studies for providing access to the Next Steps occupation data and the Data Science team at the Office for National Statistics for sharing their work on occupation and industry classification.
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This research was funded by the ESRC Survey Futures programme, award number ES/X014150/1.
Declaration of Conflicting Interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Pre-registration Statement
This study was not pre-registered.
Data Access Statement
Notes
Author Biographies
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.