
Abstract
A growing number of social scientists use online genealogical data as an alternative digital census of historical populations to study past demographic dynamics. However, the non-representativeness of this data source requires the development of bias-adjusting methods to obtain accurate demographic estimates. We address this challenge by proposing an indirect estimation framework to investigate fertility trends in seven European countries and the United States of America for the historical period 1751–1910, integrating data from the big genealogical database FamiLinx with more conventional data sources. The proposed methods allow for the indirect estimation of the total fertility rate using the number of women aged 15–49 and children under age 5, while accounting for child mortality, age-specific fertility patterns, and biases. Our methodological approaches demonstrate that, when combined with reliable demographic data, online genealogical data can be fruitfully used to examine fertility patterns in countries and periods lacking well-functioning national civil registration systems.
Keywords
Introduction
The increasing availability of non-traditional data sources driven by the so-called ‘‘Data Revolution’’ (Alburez-Gutierrez et al. 2019; Cesare et al. 2018; Kashyap 2021) presents new opportunities to better understand demographic phenomena. Among these novel data sources, online genealogical data have gathered significant attention due to their unprecedented wealth of historical information about human societies (Alburez-Gutierrez et al. 2022; Colasurdo and Omenti 2024). Online genealogical data are scraped from websites, where users upload their own genealogical tree and insert individual-level demographic information about their ancestors, such as gender, birth and death dates, and countries. Online genealogies offer an unprecedented opportunity to examine population dynamics in historical periods and countries for which we lack ground-truth population data (Colasurdo and Omenti 2024; Stelter and Alburez-Gutierrez 2022). Nonetheless, as these data sources are not primarily designed for population studies, they are affected by several biases that hamper their usability for demographic research (Colasurdo and Omenti 2024). First, the bottom-up construction of the digital family trees amplifies the likelihood of omitting more distant ancestors. Second, the under-representation of various population subgroups, including women and children who died at an early age, and the over-representation of male individuals with higher socioeconomic status and better demographic conditions lead to a significant selection bias (Calderón-Bernal et al. 2025; Colasurdo and Omenti 2024; Hollingsworth and Hollingsworth 1976; Minardi et al. 2024, 2026; Stelter and Alburez-Gutierrez 2022). Third, an individual’s inclusion in the genealogy may be affected by the so-called ‘‘selective-remembering,’’ as the genealogist is more likely to include ancestors with a prominent role in their family history (Chong et al. 2022) and to omit relatives who dishonored the family (Zhao 2001). Fourth, the high percentage of missing values in common demographic variables, specifically birth and death dates and countries, makes only a small share of the profiles from online genealogies usable for demographic research (Colasurdo and Omenti 2024; Minardi et al. 2024). Additionally, online genealogies are built through a bottom-up approach as users begin the construction from the bottom of their family trees and trace their lineages backward, leading to the underestimation of childless individuals and the omission of more historically distant ancestors.
Due to these limitations, we cannot rely on online genealogical data alone to produce accurate population-level demographic indicators. As emphasized by Stelter and Alburez-Gutierrez (2022) and Colasurdo and Omenti (2024), the development of statistical methods, which account for these biases, is essential to enhance the reliability of demographic indicators derived from online genealogical data. Despite these limitations, the extensive historical coverage of such data can be leveraged beneficially in combination with more reliable but sparser historical data sources, such as censuses.
In this article, we address the challenge of estimating total fertility rates (TFR) from online genealogical data by extending an existing indirect estimation framework developed by Schmertmann and Hauer (2019) and by Hauer and Schmertmann (2020). Using the large-scale genealogical database FamiLinx as a case study, we adapt this framework, which permits both deterministic estimation through traditional indirect techniques and probabilistic estimation via Bayesian modeling, to the context of online genealogies. The original method relies on the number of children under age 5, the number of women aged 15–49, and child mortality, under the assumption that the ratio of children under age 5 to women of reproductive age (15–49) is accurate. As a consequence, this approach is not well-suited for TFR estimation in the context of online genealogies, where the age–sex structure of the online genealogical populations deviates substantially from that of the general population (Colasurdo and Omenti 2024). To address this issue, we refine this methodological framework to handle TFR estimation in situations, where the available population data are not representative and need to be combined with more reliable but sparser demographic sources.
Specifically, we produce annual
The proposed Bayesian model combines information on the number of children under age 5 and the number of women classified by maternal age group from two main data sources: a biased source with complete temporal and spatial coverage (e.g., online genealogical data) and a reliable source with more limited temporal availability (e.g., population censuses). The model also incorporates data on child mortality and standard age-specific fertility schedules, which do not need to coincide with the fertility schedules of the countries under analysis.
A Bayesian modeling framework is particularly well-suited in this setting, because it allows us to combine multiple data sources while accounting for their uncertainty (Bryant and Graham 2013). Additionally, in Bayesian modeling, the outcome of the analysis is a probability distribution around the demographic indicator, allowing us to quantify uncertainty and make probabilistic statements about its range of plausible values (Bijak and Bryant 2016).
Broadly speaking, the use of Bayesian methods for demographic estimation has gained traction in data-sparse contexts. Bayesian methods in demography have been developed to measure migration by combining social media data with more traditional sources (Alexander et al. 2020; Hsiao et al. 2024; Rampazzo et al. 2021), to generate subnational population estimates in contexts with limited data (Alexander and Alkema 2022), to reconstruct historical populations (Voutilainen et al. 2020; Wheldon et al. 2013), to obtain small-area population estimates from satellite imagery (Leasure et al. 2020; Linard et al. 2012), to estimate mortality in data-sparse contexts (Alexander and Alkema 2018; Alexander et al. 2017; Chong et al. 2022).
Most of the previous studies (Blanc 2024a, 2024b; Corti and Minardi 2026; Corti et al. 2024; Cozzani et al. 2023; Gay et al. 2025; Hsu et al. 2021; Minardi et al. 2024, 2026; Pojman et al. 2023), which relied on online genealogical data to study demographic outcomes in Europe and North America, often assumed that these data were representative of the general population or focused on highly selected sub-populations, such as male individuals who survived beyond the age of 30 (Colasurdo and Omenti 2024). The work by Chong et al. (2022) represented the first attempt to develop a Bayesian modeling framework to calibrate mortality rates from online genealogical data with estimates from more reliable data sources such as the Human Mortality Database. To the best of our knowledge, this study is the first to propose a method for correcting TFR estimates based on online genealogical data, thereby introducing a novel approach to fertility estimation in settings where reliable demographic data are limited and online genealogical data serve as a complementary source.
The remainder of the article is structured as follows. First, we provide a description of the big genealogical database FamiLinx. Second, we provide a more detailed explanation behind our methodological choices. Third, we describe the proposed extensions to the existing indirect estimation framework by Schmertmann and Hauer (2019) and Hauer and Schmertmann (2020). Fourth, we apply the proposed methods to examine the historical fertility patterns in seven European countries and the United States (US) during the historical period 1751–1910. Finally, the strengths and limitations of our study are discussed, along with potential directions for future research.
Data
The FamiLinx Database
This article relies primarily on FamiLinx, a database derived from publicly available online genealogies on the website geni.com. The database was curated by Kaplanis et al. (2018) that scraped over 86 million profiles from the digital trees on the website geni.com. This big genealogical database contains individual-level records about 86 million individuals and information about kinship ties for approximately 43 million of these profiles. Specifically, the data incorporate micro-level records containing information about essential demographic variables, namely birth and death dates and countries. Thus, this data source generates a sizable population of individuals with life courses unfolding across multiple centuries and countries.
Despite its massive size, this data set is subject to several limitations that hamper its usability for demographic research. Besides the biases reported in the introduction, this data source significantly over-represents individuals experiencing vital events, i.e., births and deaths, in western countries (Colasurdo and Omenti 2024), and displays a large amount of missing values in key demographic variables, i.e., birth and death dates and locations (see table A1 in the online supplement).
Furthermore, these data exhibit various reporting errors, which may include improbable ages at death or unreasonable years of birth and death. Hence, before conducting any demographic analysis, a careful sample selection must be performed (Colasurdo and Omenti 2024). In addition, this data set is affected by passive registration. While in active registration systems, the data collection authority knows the status of the individual at all times, in passive registration systems, such as FamiLinx, only births and deaths are recorded (Colasurdo and Omenti 2024). Consequently, this data source lacks precise information about other essential life course events, including marriages and migrations. 1 Our analysis focuses on seven European countries (Denmark, England & Wales, Finland, France, Norway, Sweden, and the Netherlands) and the United States (US). 2 We have opted to select these countries for two major reasons. First, they are among the 20 countries with the highest number of births and deaths recorded in FamiLinx. Secondly, some of these countries are characterized by a long-standing tradition of well-functioning national civil registration systems that can be leveraged to inform the bias of demographic estimates calculated from online genealogical populations.
In order to create the country-specific analytical samples of online genealogical populations, we apply the following criteria:
The variables sex, birth and death years and countries must not be missing. The profile must have at least one parent or one child. This ensures that each individual belongs to a family network of size strictly greater than one. The birth year must not be greater than 1910. The earliest death year cannot be less than 1751. The age at death must fall between 0 and 110. The countries of birth and death of the profile must be the same.
We do not consider individuals born after 1910, since Kaplanis et al. (2018) omitted profiles that were still alive as of 2015 due to privacy-related concerns. Hence, we can only include individuals from birth cohorts that were almost surely extinct in 2015. The earliest year of analysis is 1751 since it represents the year in which accurate demographic data started to become available for at least one country, i.e., Sweden, among those included in the analysis.
3
Additionally, the age restriction enables to omit individuals with biologically implausible ages at death. We exclude migrants, defined in this study as individuals with distinct birth and death countries, due to the lack of information on the exact time of migration. Figure 1 displays the age–sex distributions of the genealogy-based populations in selected years and countries using population pyramids. The thick black lines indicate the true age–sex distribution when accurate population estimates are available. Overall, Figure 1 does not accentuate a clear convergence in the extent to which the age–sex distributions of online genealogical populations resemble the ones obtained from more reliable data sources.
4
The genealogy-based age–sex distributions for the US and Sweden seem to become more representative toward the end of the 19th century. On the contrary, in England & Wales the age–sex structure of the genealogical population appears to mirror the true one more closely at the beginning of the study period and to worsen in the 19th century. Nonetheless, a general tendency of genealogical data to under-represent women and children, albeit with distinct magnitudes, is evident across the entire historical period under examination for all countries.
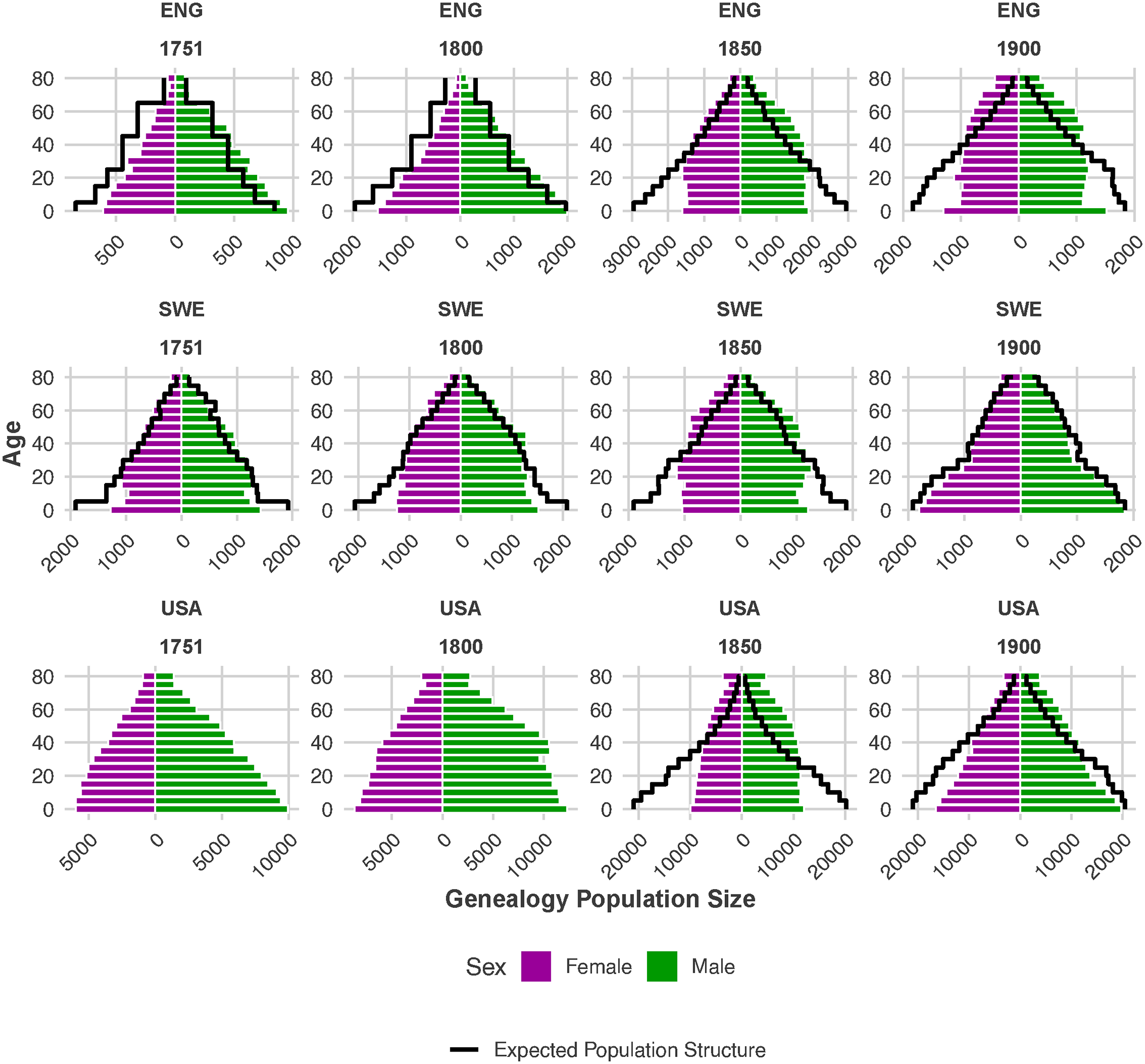
Genealogy-based and expected population counts by age and sex for selected calendar years in Sweden, England & Wales and the United States of America. The solid lines refer to the true age–sex distribution based on more reliable data sources. Bars on the left represent females, whereas bars on the right represent males.
Methodological Motivation and Background
Online genealogical data from FamiLinx pose significant challenges to the traditional calculation of the TFR. Traditionally, TFR is derived by summing age-specific fertility rates (ASFRs), where each ASFR is calculated as the number of births to women in a given age group divided by the number of women at risk of childbearing in that same age group. However, FamiLinx contains a high proportion of incomplete family trees and a substantial percentage of individuals with missing demographic information, including birth and death years and countries (Colasurdo and Omenti 2024). As a result, many individuals either lack a recorded mother or have a recorded mother with a missing birth year, making it difficult to determine the corresponding age at childbearing.
As shown in Figure 2, during the historical period 1751–1910, a substantial share of children under age 5 in the country-specific analytical samples from FamiLinx lacks information on maternal age.
5
Although there is some variation across countries, these percentages consistently exceed
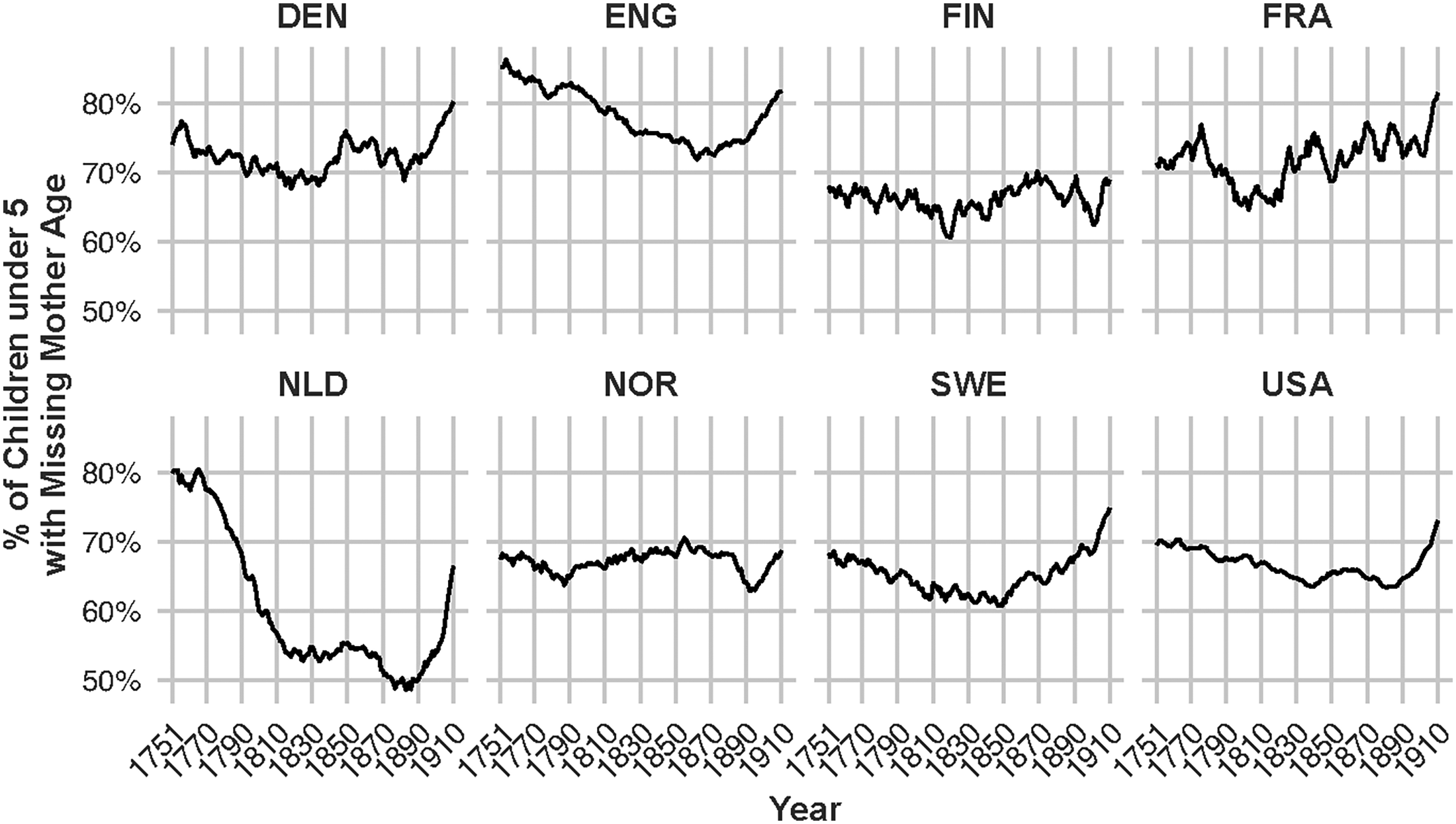
Percentage of children aged 0–4 in the selected FamiLinx sample who lack maternal age at birth. This includes both children without a recorded mother and those with a recorded mother whose age at childbirth is unavailable. In agreement with our initial assumption, only children, who were born and died in the same country, were included.
To overcome this issue, we build on the indirect estimation framework by Schmertmann and Hauer (2019) and Hauer and Schmertmann (2020), both of which enable the estimation of the TFR without requiring the birth counts classified by maternal ages. Specifically, these methods rely on the number of children under age 5 and the number of women aged 15–49 as an indirect means to obtain TFR estimates. A key assumption of these approaches is that the population pyramid derived from the data source of interest accurately mirrors the true population structure. In particular, the ratio of children under age 5 to women aged 15–49 should closely match the one observed in the general population of interest. Nevertheless, online genealogical data, such as FamiLinx, do not meet this assumption due to numerous types of biases, as previously displayed in Figure 1. To correct for these distortions, we integrate the number of children under age 5 and women aged 15–49 from FamiLinx with estimates from more trustworthy data sources.
An additional challenge is the limited availability of reliable historical demographic data, including TFR estimates and population counts by age and sex, across the entire historical period for most countries with the exception of Sweden and of England & Wales. To address this gap, we incorporate a bias-adjustment factor, which corrects the number of children under age 5 per woman aged 15–49 derived from FamiLinx based on more reliable sources when available. When these data are not available, biases are informed by patterns observed both in other countries with reliable population data of broader temporal coverage or in periods within the same country where reliable population data are available.
Overall, by combining the complete temporal coverage of online genealogical populations with more reliable but sparser historical demographic data, our proposed method provides annual TFR estimates for the historical period 1751–1910, while also extending the indirect estimation framework by Schmertmann and Hauer (2019) and Hauer and Schmertmann (2020) to contexts with limited availability of accurate population data.
Indirect Estimation and Extension to Adjust for Biases
In this section, we describe our proposed extension to the indirect method for the TFR estimation by Hauer and Schmertmann (2020). Our objective is to modify the original set of indirect TFR indicators by Hauer and Schmertmann (2020) to account for the fact that population pyramids extracted from online genealogical data are biased.
Background
Hauer and Schmertmann (2020) proposed to decompose the TFR as a product of three major factors. the ratio of children aged 0–4 ( a multiplier for the child survival a multiplier for the age distribution of mothers at childbearing
In this framework,
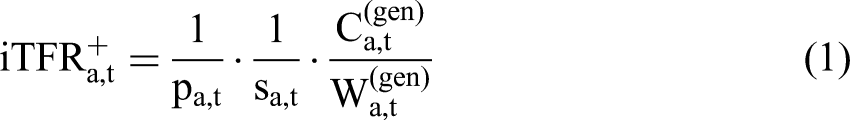
Hauer and Schmertmann (2020) have set
In general, the foundational assumption underlying Equation 1 is that the number of children under age 5, as observed in an age pyramid for country
Indirect Bias-Adjustment Multiplier
Online genealogies suffer from multiple biases that give rise to distorted population pyramids. To address this issue, we propose an extension to the decomposition in Equation 1 by introducing a bias-adjustment multiplier (
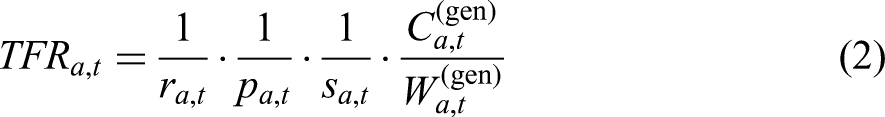
For countries with reliable historical population counts by age and sex available from certain year
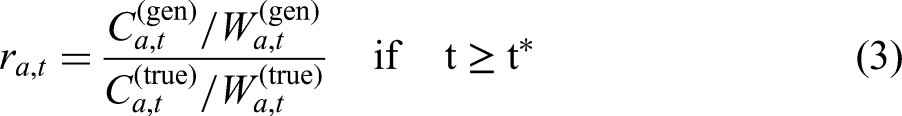
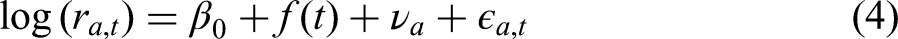
For each country with only partial availability of accurate population data, we fit the previous model using: (1) data from Sweden, the only country with complete and reliable time series of full age- and sex-specific population counts covering the entire study period, from the earliest available year (i.e., 1751) up to year
The predicted values of
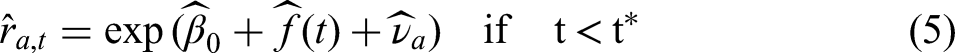
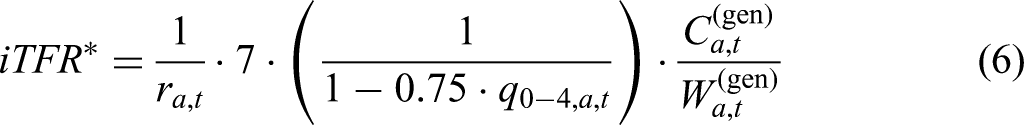
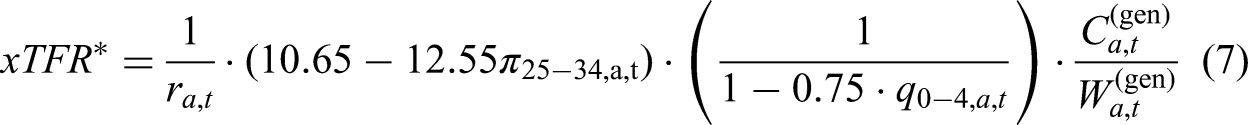
Bayesian Model
In this section, we describe the proposed Bayesian model, which extends the Bayesian modeling framework originally developed by Schmertmann and Hauer (2019) to allow for the indirect estimation of the TFR from non-representative populations. In comparison to the previous indirect estimation method, our proposed Bayesian model allows for uncertainty assessment around the TFR, which is essential in contexts with imperfect data, and for the coherent integration of multiple data sources.
Data Model
Drawing inspiration from the modeling framework by Schmertmann and Hauer (2019), we propose a Bayesian hierarchical model to measure the TFR using the number of children under age 5 and the number of women aged 15–49, while accounting for child mortality, for standard age-specific fertility schedules and for the non-representativeness of online genealogical populations.
Specifically, we model simultaneously the number of children aged 0–4 (
We assume that both variables are generated from a Poisson distribution:
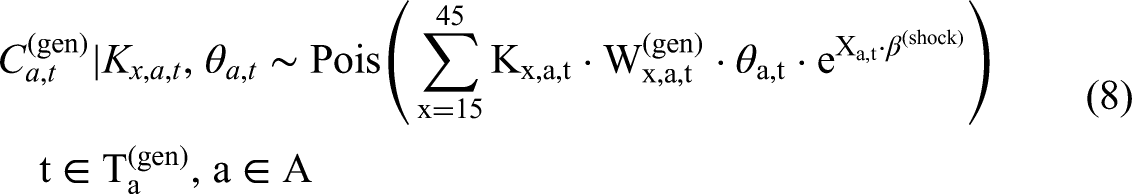
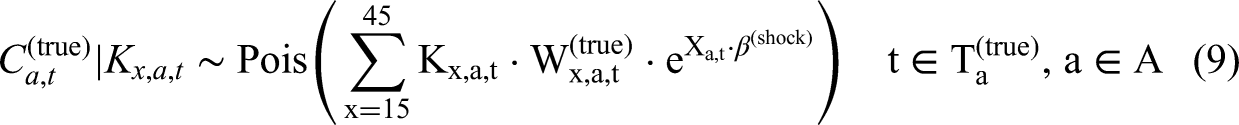
The term
Figure 3 displays a graphical summary of the proposed Bayesian modeling framework. An insightful description of the model parameters is provided in the following subsections.
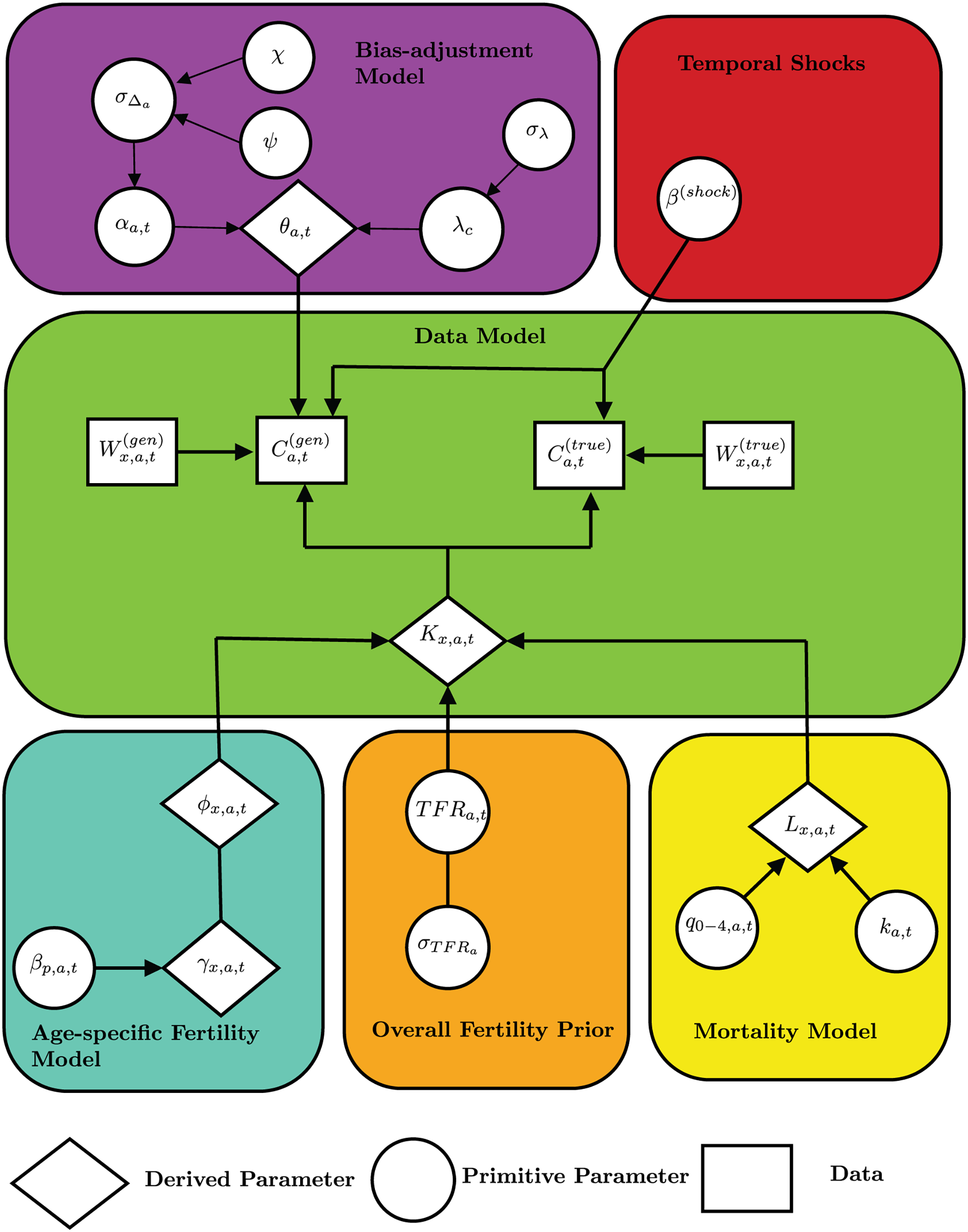
Graphical representation of the Bayesian modeling framework. Primitive parameters (circles) denote the fundamental parameters in a model that are directly assigned a prior probability distribution. Derived parameters (rhombus) are functions of primitive parameters and do not have prior probability distribution directly assigned to them. Input data are represented with rectangles.
Construction of
The term
Following the parametrization of Schmertmann and Hauer (2019), the component
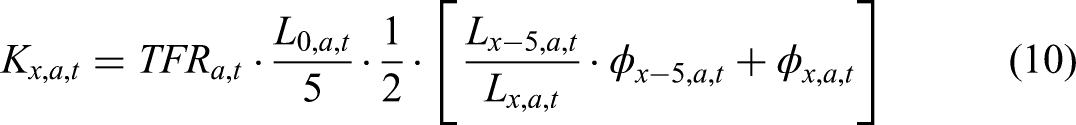
Model for Age-Specific Fertility
Following Schmertmann and Hauer (2019), to incorporate knowledge about the age-specific fertility patterns, we model the ratio of the share of lifetime fertility in an age group
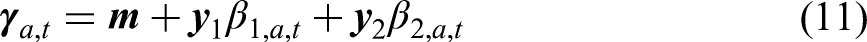
The terms
We place standard normal priors on the parameters

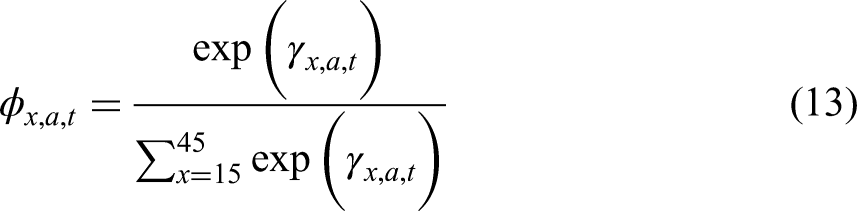
Prior and Model on Total Fertility Rates
We assign the parameters
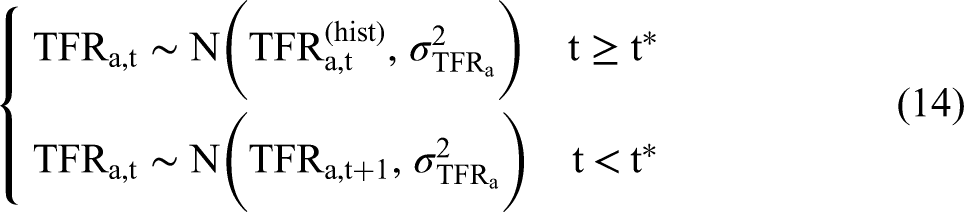
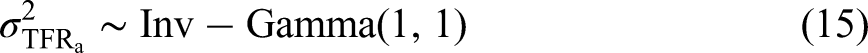
The practical implication of this choice is that the marginal posterior distribution of the TFR is mostly determined by the observed data rather than by the historical
Model and Priors for Age-Specific Mortality
The model for the term
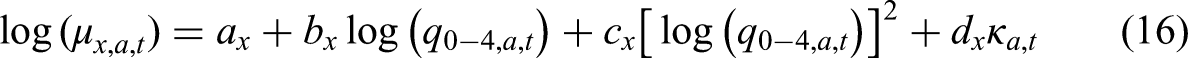
The model parameters
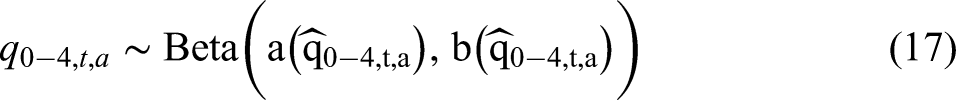
The parameters

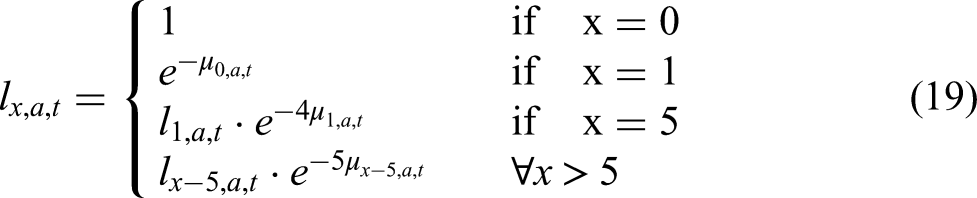
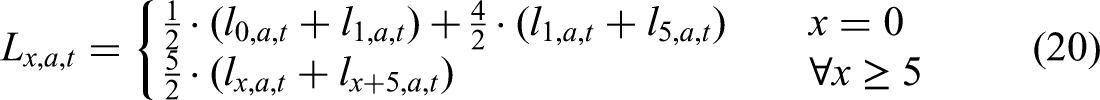
Model for the Bias-Adjustment Multiplier
The modeling framework by Schmertmann and Hauer (2019) relies on the assumption that the number of children under age 5 per women aged 15–49 or CWR observed in the sample closely reflects that of the general population. Nonetheless, this assumption is violated in online genealogical populations, where deviations from the age–sex distribution of the true population (Colasurdo and Omenti 2024) lead to implausible values for this ratio and, consequently, biased
To address this issue, we introduce a country- and year-specific multiplier
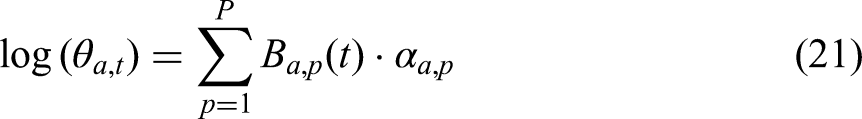
Similarly to Alexander and Alkema (2018), spline coefficients
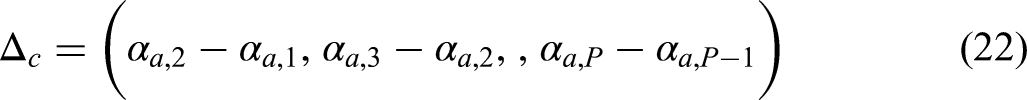


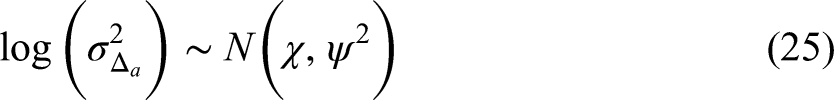
Effect of American Civil War
To account for the impact of temporal shocks on the expected number of children under age 5 per woman aged 15–49 due to the American Civil War (1861–1865), the mean of Model 8 also includes the term
Here, the term

Model Implementation
The model was implemented using the R statistical package
Since our ultimate objective is the estimation of the
Results
We present key findings on the evolution of the bias-adjustment multiplier over the years across countries and the TFR estimates based on the proposed methods. Furthermore, we compare the accuracy of the TFR estimates derived from our proposed methods with those obtained using the original modeling framework by Schmertmann and Hauer (2019), which do not incorporate any bias-adjustment.
TFR Estimates Across Countries
Figure 4 illustrates trends in the Bayesian TFR estimates
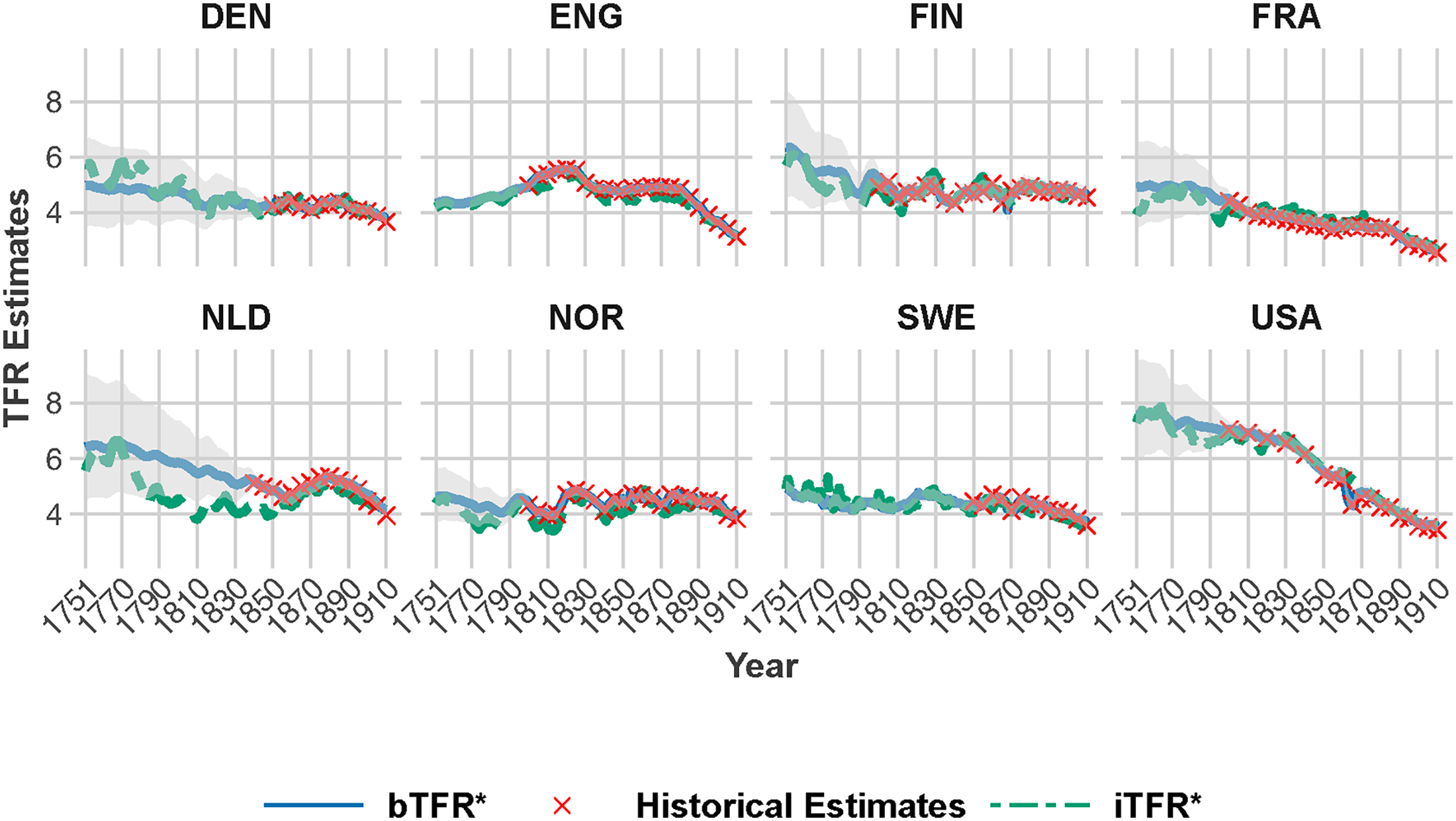
Model-based (solid lines) and indirect (dotted lines) TFR estimates against historical TFR estimates (star-shaped dots) for eight countries during the period 1751–1910.
The trends in the
Furthermore, at the beginning of the study period, although none of the countries had yet undergone their fertility transition, they exhibited different fertility levels. In the European countries, the average number of children ranged between 4 and 6, whereas in the US, it exceeded 7. This finding aligns with previous studies, which attributed the higher fertility levels of the US to factors such as the greater land availability and earlier ages at marriage in comparison to European countries (Lee 2002).
The trends in the bias-adjusted indirect estimate
Bias-Adjustment Estimates
Figure 5 illustrates the evolution of the Bayesian bias-adjustment multiplier
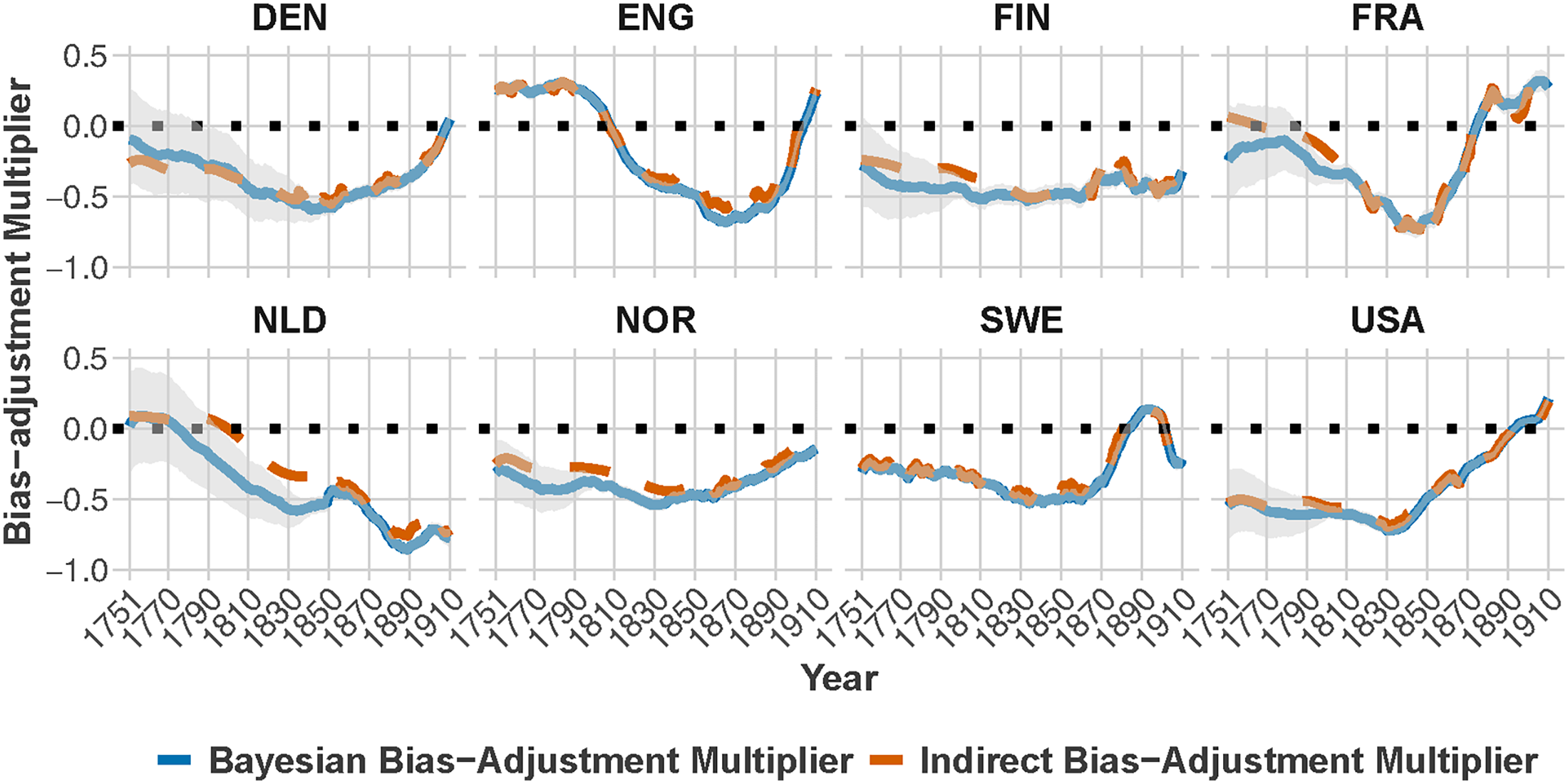
Median posterior estimates for the bias-adjustment multiplier
Figure 5 reveals no consistent patterns in the evolution of the bias-adjustment multiplier during the period 1751–1910 across countries. For instance, in England & Wales we observe a U-shaped trend, with positive values at the beginning and at the end of the period, but negative values in between. Similar patterns are observed in France and Denmark, although their median estimates for the bias-adjustment multiplier remain negative throughout the historical period. This implies that at the beginning of the study period the fertility of these countries is either overestimated (England & Wales) or slightly underestimated (Denmark and France).
In the Netherlands, we observe a decline in the multiplier during the entire period, implying that the underestimation of the genealogy-based expected number of children under age 5 per woman aged 15–49 worsens over time. In Sweden and the US, genealogy-based CWRs are severely underestimated until the mid-19th century. However, this underestimation becomes progressively less severe as the 20th century unfolds, though a renewed underestimation appears in Sweden in the early 1900s. Norway and Finland exhibit a consistent underestimation of genealogy-based CWRs throughout the historical period. Additionally, in periods, where reliable data on population structure is lacking, countries display wider credible intervals. As more reliable data becomes available for a country, the size of its credible intervals narrows. Broadly speaking, these findings highlight that the non-representativeness of online genealogical data is not only time-dependent but also varies considerably across countries. Similar patterns are observed if we consider the predicted and observed indirect bias-adjustment multiplier estimates
Bayesian Model Validation and Accuracy of TFR Estimates
The performance of the Bayesian model was evaluated through a series of out-of-sample validation exercises. We constructed test datasets consisting of the most recent “true” counts of children under age 5 from the final 20 and 30 years of the considered historical period. Accordingly, the training datasets included all the “true” counts of children under age 5 up to the years 1890 and 1880, respectively. In these validation exercises, only the “true” counts of children under age 5 from the final 20 and 30 years are withheld from the model. All other sources of information were retained for the entire historical period, including the historical values of the TFR and child mortality probabilities, which are used as inputs to the TFR prior distribution and the log-quadratic mortality submodel, as well as the information derived from FamiLinx on the number of children under age 5 and the number of women classified by maternal age group.
The models fitted to each training set were then used to predict the true number of children under age 5 in the corresponding test set. Rather than comparing the predicted and observed true number of children under age 5, we opted to conduct the comparison in terms of the CWR. This transformation constrains the outcome to a narrower range, facilitating more stable and interpretable comparisons than those based on raw counts.
For the left-out observations, we calculated the absolute relative error defined by
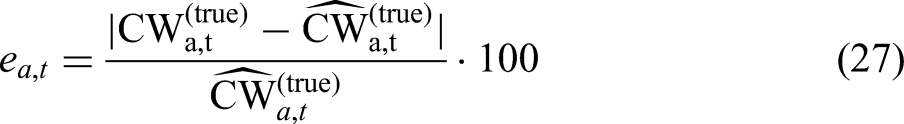
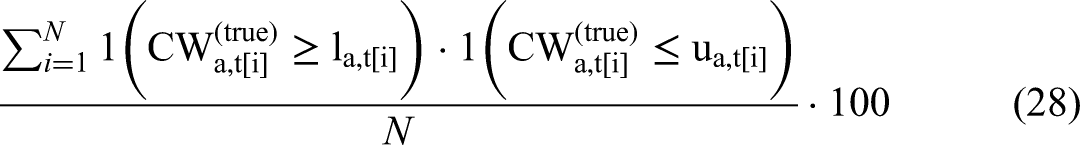
Panel A of Table 1 reveals that the MAREs are around
Model validation results and accuracy of TFR estimates.
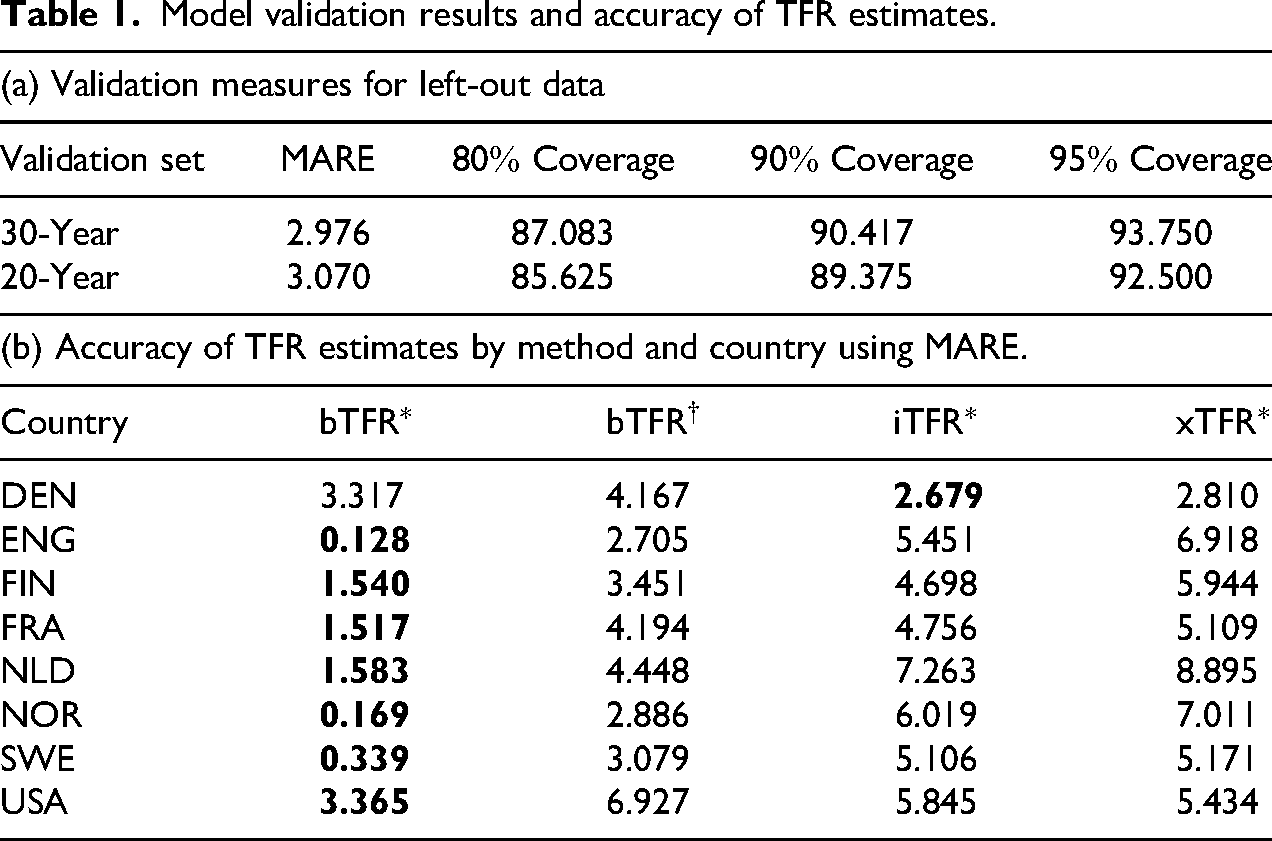
In addition, we assessed how accurately the posterior TFR estimates from our proposed Bayesian model reproduce reliable historical TFR values. We compared its performance with that of the proposed indirect estimation indicators and with the posterior estimates from an alternative Bayesian model that relies exclusively on accurate population data and does not incorporate FamiLinx. This alternative model is structurally similar to the proposed Bayesian model but excludes the bias-adjustment component. The median posterior estimate from this restricted specification is denoted by
Panel B of Table 1 reports the MAREs for the different TFR estimation methods by country. Overall, the proposed Bayesian model combining FamiLinx data with reliable population data achieves the lowest MARE. In particular, the TFR estimates from the proposed model provide the highest accuracy for most of the countries, apart from Denmark, where the TFR estimates from the indirect estimation method align more closely with the historical benchmarks. In addition, across all countries examined, the proposed Bayesian framework, which integrates online genealogical data with more reliable conventional sources, produces more accurate TFR estimates than the corresponding model that excludes the genealogical data from FamiLinx.
We further assessed the robustness of the proposed model through a series of sensitivity analyses, reported in the online supplement. These include prior-to-posterior comparisons for the TFR and the bias-adjustment multiplier, posterior predictive checks for the CWR, sensitivity to the exclusion of countries with reliable population data throughout the full historical period, sensitivity to alternative age-specific fertility schedules used in the singular value decomposition, sensitivity to the choice of the prior distributions for the variance parameters, and an examination of posterior correlations between the TFR and bias-adjustment parameters.
Conclusion
Limitations
Our study is not free from caveats. First, the proposed methods are limited to estimating the TFR and do not allow for the calculation of other fertility measures such as the cohort fertility rate (CFR) and the mean age at childbearing (MAB). While the TFR is widely used due to its availability across countries and time periods, multiple studies (Bongaarts and Feeney 2000, 2010; Sobotka and Lutz 2010) have highlighted the susceptibility of this indicator to tempo distortions. Temporary declines in the TFR may not reflect an actual decrease in fertility but rather delays in childbearing in response to external shocks, such as wars, economic crises, or pandemics. Hence, the availability of additional fertility indicators would certainly provide a richer understanding of the fertility patterns experienced by the countries included in the analysis during the historical period 1751–1910.
Second, our study assumes constant child mortality in cases where reliable historical estimates are unavailable. Nonetheless, pre-transitional populations displayed high and fluctuating child mortality rates due to the widespread prevalence of infectious diseases, poor sanitary conditions, and the recurrent occurrence of pandemics and famines (Omran 1998; Pozzi and Fariñas Ramiro 2015).
Third, the absence of socio-economic variables limits the depth of our analysis. Crucial factors such as education, wealth, occupation, and social class, which are known to have influenced fertility behaviors in historical populations in Europe and the US (Dribe et al. 2014), are not available in FamiLinx. As a consequence, we are unable to examine how fertility transitions varied across different social classes or to investigate mechanisms driving the diffusion of birth control methods.
Fourth, migration data are not available in FamiLinx, preventing us from examining fertility differentials between native and migrant women. Especially, in the context of the US, previous research (Dribe et al. 2014; Hacker 2003) has shown distinctive fertility trends between migrants and natives during the US fertility transition.
Fifth, the anonymity of the records in FamiLinx poses another constraint, as it prevents us from linking these data with other micro-level sources such as censuses and parish records. The employment of statistical matching techniques, which could enhance the richness of FamiLinx by integrating additional micro-level socio-economic information, is not feasible.
Sixth, the proposed indirect estimation framework does not allow us to estimate the TFRs when reliable historical benchmarks are unavailable. The incorporation of the bias-adjustment multiplier requires at least some reliable demographic data over part of the historical period in order to examine long-term fertility trends. Without these benchmarks, online genealogical data alone are insufficient to produce reliable annual TFR estimates.
Despite these limitations, we believe that our study represents an important step in advancing statistical methods for the estimation of demographic indicators in data-sparse settings, as well as in advancing fertility estimation in historical populations using a novel non-traditional data source in combination with more reliable data.
Discussion of the Results
The spread of technology has furnished population scientists with an unprecedented wealth of data sources, significantly enriching the demographic research landscape (Kashyap 2021). This surge has led to a growing body of literature in demographic research relying on digital data. Although the majority of studies in digital demography have focused on contemporary populations, we believe that historical demography stands in a unique position to benefit from these novel data streams. The digitization of traditional data sources such as parish records and censuses, alongside the development of platforms where users from different parts of the world can share their family history, offers much promise for the examination of demographic processes in the past at a more global scale. In this article, our focus is on data derived from digital genealogical trees, generated by a transnational network of genealogy enthusiasts dedicated to reconstructing their family history. As they contain demographic information about individuals whose life courses unfolded in the last 400 years across different countries, these repositories provide an unprecedented opportunity to study population dynamics in the past. Nonetheless, as pointed out by Colasurdo and Omenti (2024), this data source presents several pitfalls, which hamper its employment in demographic research, including the under-representation of various subgroups such as women and children as well as issues related to the accuracy of the reported demographic information.
In response to these challenges, this article proposes a methodological framework to obtain accurate TFR estimates from data that are inherently defective. Our proposed methods combine data from online genealogical populations with more traditional data sources in order to obtain TFR estimates in various historical populations. Specifically, we added a bias-adjustment multiplier to the modeling framework developed by Schmertmann and Hauer (2019) and the indirect TFR estimation method by Hauer and Schmertmann (2020) to incorporate information about the extent to which the number of children under age 5 per woman aged 15–49 is under- or over-estimated in online genealogical data.
The results suggest that the incorporation of a bias-adjustment parameter into the Bayesian modeling framework by Schmertmann and Hauer (2019) produces plausible annual TFR estimates that cover historical periods when most of the countries in our analysis lacked national well-functioning civil registration systems. The inclusion of a bias-adjustment factor into the TFR decomposition by Hauer and Schmertmann (2020) has also led to indirect TFR estimates, which closely align with historical TFR estimates. However, the proposed indirect estimation method under-performs in comparison to the Bayesian model in most countries. While the proposed indirect TFR estimation approach is straightforward and does not require a complex modeling procedure, unlike the proposed Bayesian model, it lacks the capability of accounting for uncertainties arising from different data sources and does not provide credible intervals. In contexts where accurate population data are only partially available, probabilistic demographic estimates, which usually come with a range of plausible values, certainly provide researchers with a more realistic and informative picture about fertility patterns.
Broadly speaking, online genealogical data are inherently biased and noisy. Consequently, relying solely on large genealogical databases such as FamiLinx to estimate overall fertility indicators for historical populations would lead to misleading results. By explicitly modeling the bias in populations derived from online genealogies, we are able to reconstruct annual time series of TFR estimates for multiple European countries and the United States over the period 1751–1910. The proposed model, which integrates online genealogical population data with more reliable historical sources, yields TFR estimates with higher accuracy and finer temporal resolution than a model that relies exclusively on reliable historical data.
While the article uses online genealogies to analyze fertility dynamics in historical populations, we argue that the proposed methodological framework has considerable potential for application in other historical and contemporary data-sparse settings. In particular, it is well suited to contexts where civil registration systems are incomplete, large-scale population surveys are available but infrequent, and non-traditional data sources can be leveraged to improve the temporal and spatial resolution of the TFR estimates.
In contemporary settings, potential applications include low- and middle-income countries in which fertility measurement relies primarily on infrequent household surveys. For instance, in Sub-Saharan Africa, genealogical reconstructions available through platforms, such as FamilySearch, could be combined with large-scale population surveys, including the Demographic and Health Surveys and Multiple Indicator Cluster Surveys, to improve the temporal resolution of fertility estimates between survey waves. In historical contexts, this framework could be applied to reconstruct TFR estimates at finer geographical scales by combining population reconstructions from local parish or genealogical records with higher-quality sources, such as historical population censuses. In both settings, the proposed methodological framework enables the integration of rich but biased information with sparse reliable data, yielding a more granular and informative time series of TFR estimates.
From a methodological viewpoint, conditional on the availability of data on the number of children under age 5 classified by maternal age group, an interesting extension of the proposed model would involve jointly modeling these counts from both a biased data source and a more reliable one. This approach could enable the estimation of fertility indicators beyond the TFR.
From a broad perspective, we have proposed a novel extension to the existing indirect estimation framework by Schmertmann and Hauer (2019) and by Hauer and Schmertmann (2020) to allow for the reconstruction of fertility patterns in eight countries during the historical period 1751–1910, when the availability of reliable population data is limited for most countries. The proposed extensions allow us to combine online genealogical data with other historical data sources, whose information was included either through the incorporation of a bias-adjustment statistical model within the Bayesian modeling framework or through the incorporation of a bias-adjustment factor within the indirect estimation method. To conclude, this research article sheds new light on the potential of Bayesian and indirect estimation methods to investigate historical fertility patterns in countries and historical periods with imperfect demographic data.
Supplemental Material
sj-pdf-1-smr-10.1177_00491241261463559 - Supplemental material for Bayesian Indirect Estimation of Historical Fertility in Europe and US Using Online Genealogical Data
Supplemental material, sj-pdf-1-smr-10.1177_00491241261463559 for Bayesian Indirect Estimation of Historical Fertility in Europe and US Using Online Genealogical Data by Riccardo Omenti, Monica Alexander and Nicola Barban in Sociological Methods & Research
Supplemental Material
sj-pdf-2-smr-10.1177_00491241261463559 - Supplemental material for Bayesian Indirect Estimation of Historical Fertility in Europe and US Using Online Genealogical Data
Supplemental material, sj-pdf-2-smr-10.1177_00491241261463559 for Bayesian Indirect Estimation of Historical Fertility in Europe and US Using Online Genealogical Data by Riccardo Omenti, Monica Alexander and Nicola Barban in Sociological Methods & Research
Footnotes
Acknowledgments
An earlier version of this article was presented at the 2024 Population Association of America Conference, the 2023 British Society for Population Studies Conference, the 15th Conference of Young Demographers, the Formal Demography Working Group Seminar Series, the Max Planck Institute for Demographic Research Seminar Series, and the Quetelet 2023 Seminar. The authors thank the participants at these events for their valuable comments and feedback. They also gratefully acknowledge Jakub Bijak, Ridhi Kashyap and Rebecca Johnson for their helpful suggestions on an earlier version of the paper. We used the large language model GPT-5.5 to assist with grammatical and typographical editing of the manuscript. All edits generated by ChatGPT were carefully reviewed by the authors.
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: Riccardo Omenti and Nicola Barban received funding from the European Research Council under the European Union’s Horizon 2020 research and innovation program (Grant Agreement 865356).
Declaration of Conflicting Interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Preregistration statement
This study was not preregistered because it relies on publicly available data that already existed before the study was begun.
Code Availability Statement
Data Availability Statement
All the data needed for the study are publicly available and deposited in the permanent repository available at this link https://zenodo.org/records/20423970 (Omenti, 2026).
Material Availability Statement
Supplemental Material
Supplemental material for this article is available online.
Notes
Author Biographies
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.