
Abstract

1. Introduction
We thank the editor for the opportunity to engage in scholarly dialogue, and we are grateful to the commentators for their insightful and constructive critiques. We agree in many ways with our colleagues. Conceptually, we agree with Hutter’s observation (this volume, pp. 58–63) that our use of the term collective action events is restrictive and more restrictive than current usage of the term in sociology. As we continue this project, we are interested in expanding CASM to include a wider range of action forms, such as Internet activism and collective petitioning. Operationally, Oliver’s comment that humans are imperfect at identifying protests absolutely resonates with our experience in having research assistants code training and validation data. We spent a great deal of time training our human coders and improving our coding rules for constructing the second-stage training data and the validation data set, but despite high intercoder reliability, there were always ambiguous “edge” cases. Here, we believe that conducting out-of-sample validation plays a crucial role in assessing the extent to which an automated approach minimizes the blurriness of what constitutes an event. We also appreciate Oliver’s helpful comments (this volume, pp. 63–68) about how to incrementally improve the China data. We have explored several of these areas, and results (e.g., on keyword set size) can be seen in the Appendix. 1 Methodologically, we agree with Steinert-Threlkeld (this volume, pp. 68–75) on the value of image data as well as multimodal data. Finally, all three commentaries encourage us to expand CASM to cover more characteristics (which Hutter refers to as “subdimensions”) of collective action events—for example, size, action form, claims/issues, targets, organizers, and violence. We wholeheartedly agree, and we are actively pursuing this area now.
Another commonality between the three commentaries is the idea that more data—more subdimensions of events (Hutter), more modes of data (Steinert-Threlkeld), more media sources (Oliver)—will improve our ability to correctly identify events. More data can absolutely improve our understanding of events, but it may harm the precision and recall of event detection when automated systems of event identification are used to integrate these data. We want to spend the main portion of this rejoinder discussing the challenges of more data in machine classification of events. Additional methodological work is needed to effectively incorporate additional dimensions and sources of data for automated methods of event identification.
Hutter writes that measuring more subdimensions of protest events—for example, action form, claims/issues, targets, organizers—can increase precision of event identification by reducing duplication and minimizing false positives. Steinert-Threlkeld notes that using multimodel data is one way of overcoming the limited diversity of events that can be detected in images. Steinert-Threlkeld recommends using text and image data, as we have done, as well as adding in metadata such as screen names, biographic descriptions, and image captions to expand the diversity of events identified through social media.
Currently, we group posts located in the same county 2 and on the same date into one collective action event. The location either comes from geolocation metadata or the text of the post. The date is taken from the post’s metadata. Now, imagine that we add two more subdimensions: target and protest size. Suppose we identify the target from the text of the post and identify protest size from the image because, as Steinert-Threlkeld notes, image data increase the precision of measuring crowd size. It is easy to imagine how adding these two additional subdimensions would improve event identification. For example, we might see that some posts made on the same day in the same county are about a large-scale protest targeting a polluting factory and other posts are about a medium-sized protest targeting a government bureau. In this case, by adding the target and protest size subdimensions to protest location and date, we improve the precision and recall of event identification. 3
However, to incorporate the target and protest size subdimension, or any subdimension for that matter, we would have to extract subdimension information from the text, image, or metadata. And, as with any classification system (especially machine-based), there will be missing data (some posts will not contain information about target or protest size) and incorrect classification (the target or protest size will be incorrectly identified). As more subdimensions are added for event identification, missing data can lead to underreporting the number of events, and error in coding subdimensions can lead to overreporting the number of events and misattribution of posts to events. These problems are especially significant if we use exact matching methods, as in our article.
2. Missingness
If we use exact matching on
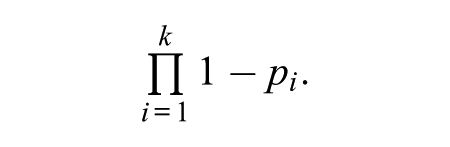
Imagine a simple case where we can code 80 percent of posts on each subdimension
Of course, this scenario may be too extreme. In practice, we would develop methods to utilize posts with missing subdimensions. For example, we may require matching only on a set of subdimensions smaller than
3. Error in Subdimension Coding
Even if we do not have the problem of missing subdimensions, some subdimensions may be incorrectly classified. Suppose again that each post in
More generally, imagine that
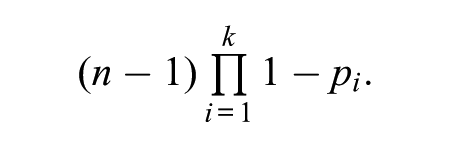
Assuming we have four subdimensions and the
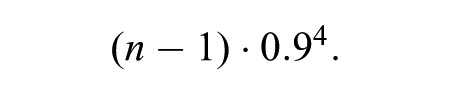
This number increases with the number of total posts (
Errors in subdimension coding could also misattribute posts to the wrong event, which has implications for our understanding of the characteristics of protest events. Continuing with our previous example, in which post
The relative probability that incorrect subdimension coding would lead to misattribution as opposed to generation of events that do not exist depends on the number of values (or levels) any subdimension takes on (which may decrease
More broadly, the problems of missingness and incorrect classification may also hinder attempts to merge events from different sources. Oliver writes that “the ideal would be to develop protocols that allow events collected in different ways from different sources to be merged.” If such protocols were automated, the same problems of underestimation due to missingness and overestimation and misattribution due to incorrect classification would be present. Because of missingness in one source or another, only a subset of events would be identified through merging. If there are similar errors in coding subdimensions in two data sets being merged, these errors could lead to overestimation in the number of events or misattribution of posts to events. As Schrodt (2015:6) notes, in automated event coding systems, “as the number of sources (and hence texts) increases, we see diminishing returns on the likelihood of a correct coding, but a linear increase in the number of incorrectly coded events.”
We illustrate why more data does not automatically improve event grouping (or de-duplication) in machine coding. Hutter’s suggested remedy of adding more subdimensions and Oliver’s recommendation of a protocol for merging events would work well with human coding, but the scale of data we are working with does not allow us to extract subdimensions of events and merge events with other protest event data sets entirely by hand. Potential solutions include moving away from exact matching and deterministic algorithms to probabilistic algorithms, such as probabilistic record linkage and their extensions in large-scale data settings (Enamorado, Fifield, and Imai 2019; Fellegi and Sunter 1969; Xiao et al. 2011). In our article, we rely on two subdimensions—location and date—to group posts to an event because we do not yet have a highly reliable way of coding additional subdimensions. Similarly, the relatively smaller number of levels we use for location is driven by considerations of precision in coding this subdimension. Using more fine-grained levels for location (e.g., township, village, landmarks) meant more missing data and errors in coding. We experimented with different grouping methods and found that relying on two subdimensions generated the best results under our current exact matching methods. Looking forward, more work is needed to expand CASM to include more action forms; more accurately extract subdimensions of events from text, image, and other multimodal data; and develop methods to better utilize additional subdimensions to improve the precision and recall of event identification and merge different protest event data sets.
Footnotes
Notes
Author Biographies
The author biographies can be found on page 57 of this volume.