
Abstract
Causal inference approaches often emphasize binary treatments. But in many applications, the underlying constructs are continuous. In the potential outcomes framework, a continuous treatment can take on numerous values, each corresponding to a potential outcome that may be realized. In this setting, common estimands may be intractable because of a common issue in social research, particularly research on social inequality: the exposure is highly stratified by confounders. The authors show how to avoid drawing inferences about counterfactuals where data are unlikely to exist by carefully selecting the causal estimand. The authors adopt an additive shift estimand that adds a small, fixed amount to each unit’s income. This approach is preferable to population-average dose-response curves in settings in which some treatment values rarely occur in some subgroups. The authors also show how to estimate and summarize patterns of nonlinearity and effect heterogeneity with continuous treatments. As a motivating example, the authors consider the causal effect of parental income on college attendance, a setting in which the exposure is highly stratified by confounders (e.g., parental education). This approach applies to a wide range of possible treatment conditions in sociology.
Keywords
The widespread adoption of causal goals has unlocked new understandings in social research. Drawing inspiration from randomized controlled trials, many such studies begin by defining one treatment condition and one control condition. For example, people who completed a four-year college degree (a treatment condition) may not have completed that degree (a control condition). By studying the socioeconomic outcomes that would have resulted under each treatment assignment, scholars have gained new understandings of the causal role that college degrees can play in improving outcomes and breaking intergenerational cycles of disadvantage (Brand 2023; Brand and Xie 2010; Zhou 2024). As an example of an estimator in this framework, some researchers match treated units to comparable untreated units who serve as estimates for the counterfactual outcomes the treated units would have realized in the absence of treatment (Rosenbaum 2010; Stuart 2010).
Yet many causal inputs are continuous rather than binary. A child’s life chances might be shaped by the numeric value of their family’s income, their school’s student-teacher ratio, or their neighborhood’s homicide rate. Instead of two potential outcomes, each person has many: one for each value the numeric treatment could take (see Figure 1). Whether the treatment is truly continuous, with an infinite number of possible values, or discretely numeric, with a large but finite number of values, numeric treatments yield many potential outcomes. Just as randomized controlled trials motivated causal claims with binary treatments, an analogous (albeit rarely used) experimental design can motivate causal claims with continuous treatments. Imagine a cash transfer program in which the amount of cash transferred to recipients is drawn uniformly at random over some range. Researchers could measure each recipient’s outcome and then estimate a smooth curve to summarize the average response to various values of the treatment. This causal research goal, known as the average dose-response curve, is one example from a broad literature in statistics that generalizes causal inference from binary treatments to continuous exposures in both randomized and observational settings (Díaz and van der Laan 2013; Gill and Robins 2001; Hirano and Imbens 2004; Imai and Van Dyk 2004; Kennedy et al. 2017; Rothenhäusler and Yu 2019; Takatsu and Westling 2025).
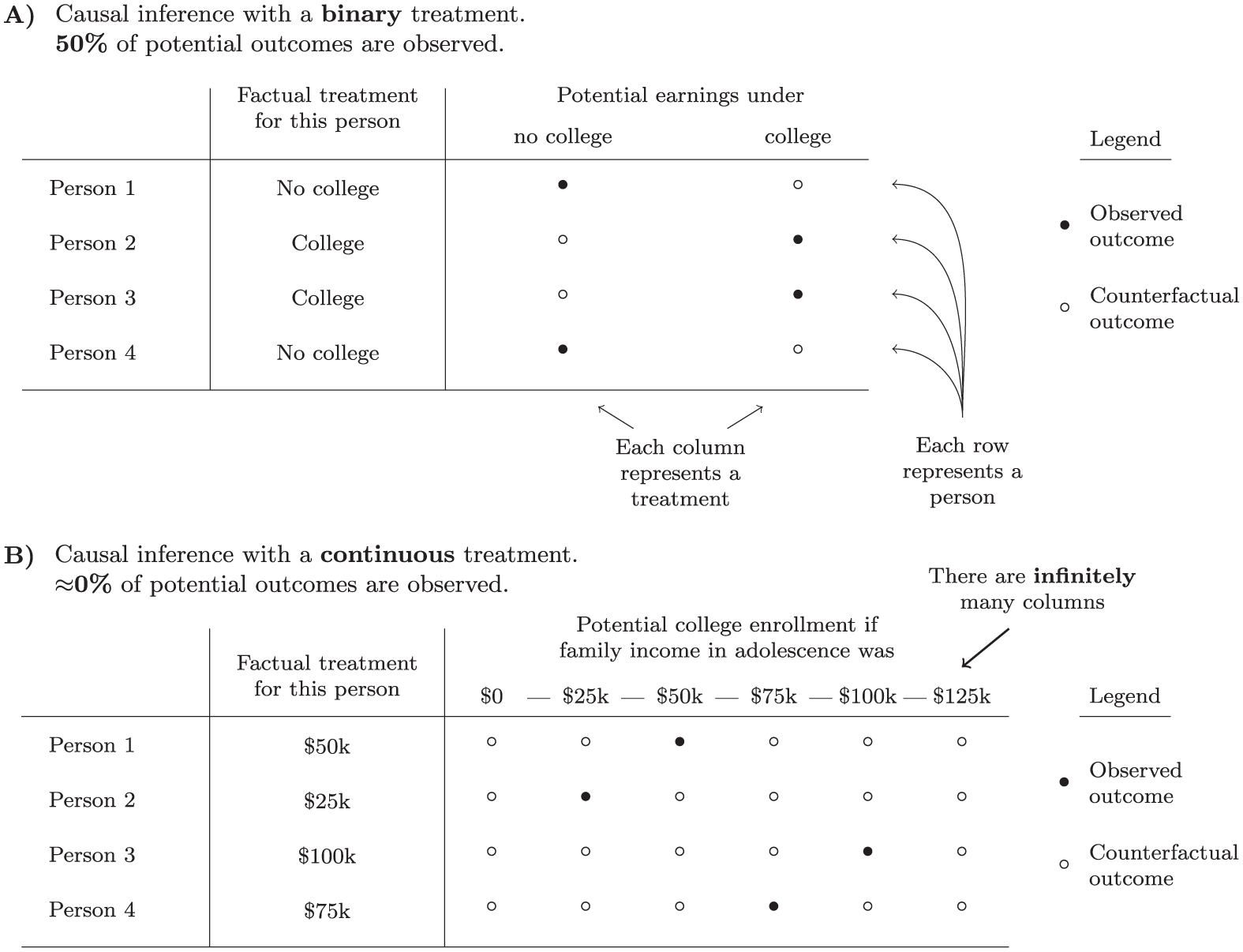
A continuous treatment creates infinite potential outcomes. (A) Causal inference with a binary treatment. Fifty percent of potential outcomes are observed. (B) Causal inference with a continuous treatment. Approximately 0 percent of potential outcomes are observed.
Our contribution is applied: we demonstrate how sociologists can apply causal approaches with continuous exposures. Although we draw heavily on existing statistical approaches, we argue that the population-average dose-response curve is often intractable for the types of questions commonly studied in sociology, where an input of interest (e.g., family income) is itself strongly shaped by measured confounders (e.g., parental education). We also demonstrate how two concepts, effect heterogeneity and nonlinearity, become empirically intertwined in settings in which measured confounders strongly shape treatment values. We show how a pivot to a different research goal, the additive shift estimand, avoids the problem of making counterfactual estimates far from the data. Our approach produces interpretable causal estimates even in settings in which measured confounders strongly influence treatment values.
Causal Effects of a Continuous Treatment
When evaluating the causal effect of a continuous treatment
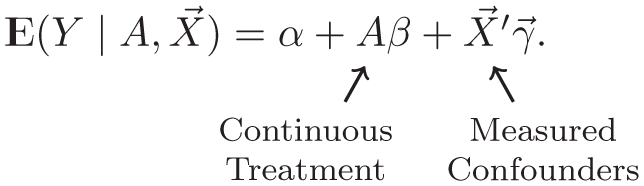
Researchers then interpret
From a statistical standpoint, this regression model can be interpreted as an estimator of a causal dose-response curve. Here we spell out the connection, which is useful for seeing additive ordinary least squares regression as a particular example within a broader class of possible estimators. For each unit
Three steps are implicit in the regression strategy. First is a causal identification step: the researcher must assume
In the additive ordinary least squares model of equation (1), the predicted conditional mean outcome for unit
Effect Heterogeneity and Nonlinearity: Why
Is an Inadequate Causal Estimand
The main problem with a
Scholars of causal inference widely agree that the same causal intervention is likely to have different average effects in distinct population subgroups (Brand, Zhou, and Xie 2023; Smith 2022; Xie 2013). Rather than simply asking whether a causal effect is large on average, we should also ask for whom the effect is largest. The search for effect heterogeneity has led to numerous advances. One example is evidence that completion of a four-year degree is most beneficial for graduates from the most disadvantaged social origins (Brand 2023; Brand and Xie 2010; Cheng et al. 2021; Hout 1988, 2012; Torche 2011). These findings have led to new insights in sociology and public policy, informing debates about how educational expansion can equalize opportunities across individuals from different backgrounds (Witteveen and Attewell 2020; Zhou 2019).
When the treatment is continuous, the concept of effect heterogeneity generalizes to two axes of variation: nonlinear effects of treatment
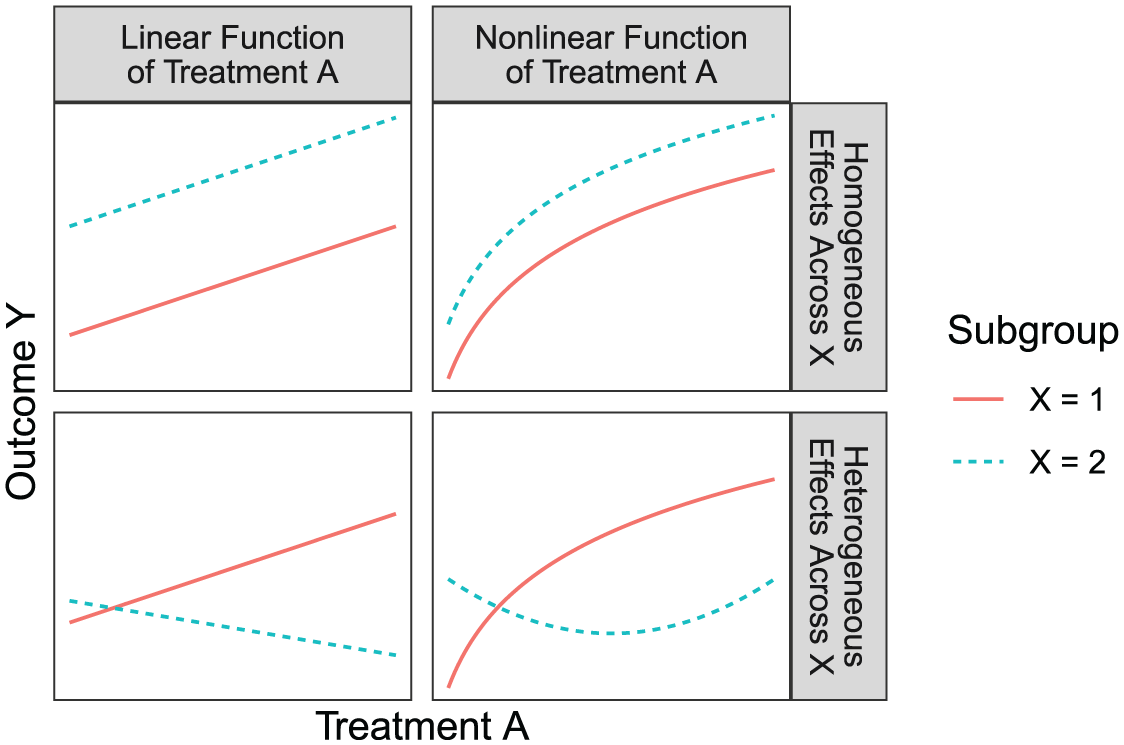
Nonlinear and heterogeneous effects are conceptually distinct.
Causal estimands in the potential outcomes approach are well defined regardless of whether effects are nonlinear, heterogeneous, or both. One can conceptualize the mean outcome,
The Extrapolation Problem
Nonlinearity and effect heterogeneity pose particular challenges in a setting common to sociological research: questions that require extrapolation beyond the support of the observed data. Under the assumptions of a linear model, such extrapolation appears straightforward; once those assumptions are relaxed, however, it may no longer be feasible. Figure 3 illustrates this through a hypothetical example in which two population subgroups (advantaged and disadvantaged) experience highly unequal exposure to a treatment variable.
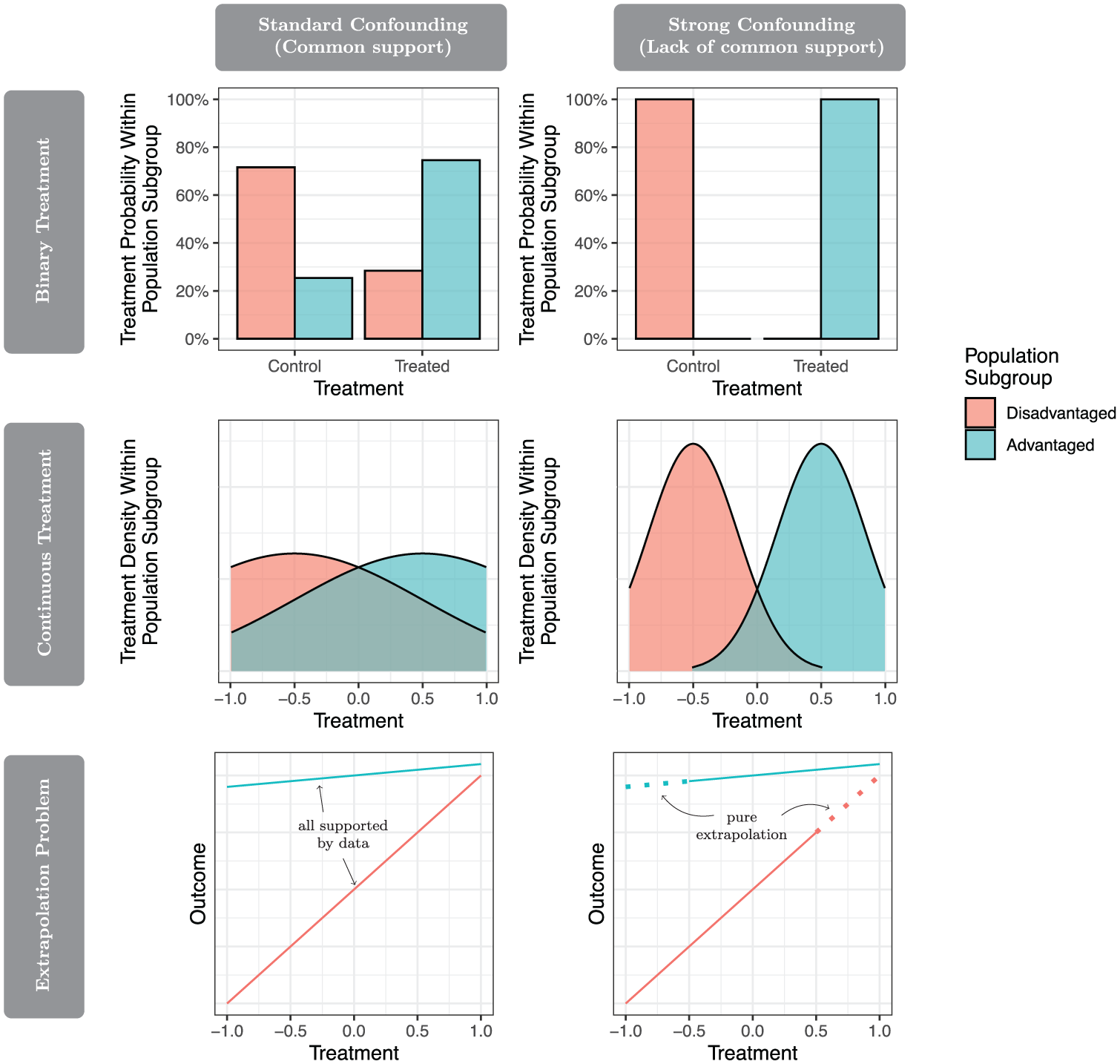
Strong confounding and the extrapolation problem.
The first row of Figure 3 considers a binary treatment. The panel on the left depicts standard confounding: the advantaged subgroup is assigned to treatment with a higher probability than the disadvantaged group, but a nonzero proportion of both groups is observed in the treatment and in the control condition. If the population subgroup were the only confounder, one could draw inferences by comparing across treatment conditions within population subgroups. The panel on the right shows the more difficult scenario of strong confounding: all units within the advantaged subgroup are treated, whereas all units within the disadvantaged subgroup are untreated. This setting is known as a lack of common support because the data cannot support causal inference: no one in the disadvantaged subgroup is exposed to treatment, and no one in the advantaged subgroup is exposed to the control.
A lack of common support poses similar risks when the treatment is continuous, yet it can be more difficult to recognize. With a binary treatment
Linear regression estimators appear deceptively simple in this setting (Figure 3, row 3). In the standard confounding setting on the left, one might summarize how the outcome responds to the continuous treatment by a linear regression estimated separately within each population subgroup. Although this approach assumes a line, at least the data provide evidence about that line across the full treatment distribution. In the strong confounding setting on the right, a researcher might similarly estimate linear regression models within each subgroup. The researcher might then predict counterfactual outcomes at any treatment value, even the treatment values that represent pure extrapolation.
Extrapolation is often a problem in empirical social research. We used linear regression here, but extrapolation can be a danger with any estimator when the target of inference is far from where the data exist. Researchers using a causal inference framework with binary treatments regularly take steps to avoid extrapolation (i.e., restrict to the region of common support). But with continuous treatments, the problem of common support is rarely discussed. One possible reason for this discrepancy is that studies with continuous treatments often begin by assuming a linear model. Under the assumptions of that model, any counterfactual can be predicted even if that prediction involves extrapolation. But if the true effects are nonlinear and heterogeneous, then extrapolated predictions are not credible. We avoid this problem by defining a causal estimand with minimal extrapolation before making any modeling assumptions.
Credible Counterfactuals: Additive Shift Estimands
With a binary treatment, a solution to the lack of common support is to restrict to a region of support, which entails a change to the target population. With a continuous treatment, an alternative approach is possible: in each population subgroup, restrict counterfactual predictions to the range of treatment values with nonzero density. We advocate a causal estimand that is easy to interpret and, in many settings, avoids the extrapolation problem by focusing on a carefully chosen counterfactual treatment value.
To fix ideas, we illustrate this estimand using our motivating example, in which the treatment is family income and the outcome is college enrollment. Suppose child
Formally, let
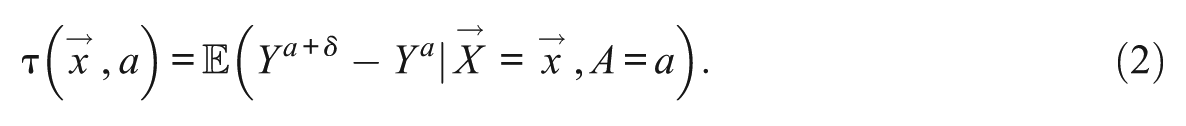
The key benefit of an additive shift estimand is that it does not involve highly unlikely counterfactuals (as long as
One could in theory use an additive shift estimand for grander questions, where the value of
Identification and Estimation for Additive Shift Estimands
Standard assumptions for causal identification in binary settings apply to the continuous setting (Gill and Robins 2001; Robins 1987). Adopting terminology and notation following the conventions in Hernán and Robins (2021), we first assume that potential outcomes are well defined so that for each unit
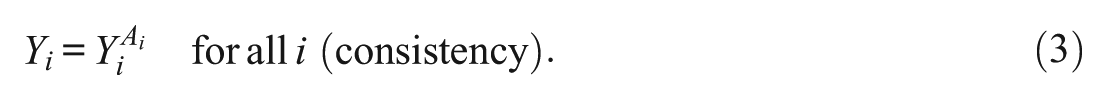
Considerations affecting the credibility of the consistency assumption are the same for both continuous and binary treatments. For example, in both cases, the assumption we defined above requires no interference such that unit
Second, we make a conditional exchangeability assumption defined for each unit
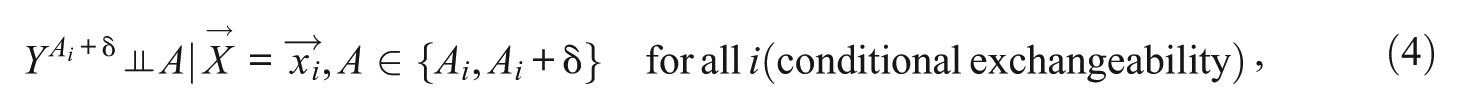
where in our example

In words, among units with treatment value
The conditional exchangeability assumption implicitly requires a positivity assumption,
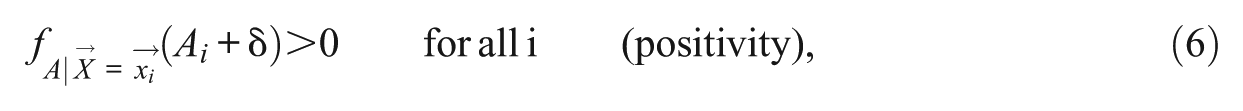
that the conditional density of treatment value
Finally, we assume a statistical model for the conditional mean outcome given the continuous treatment
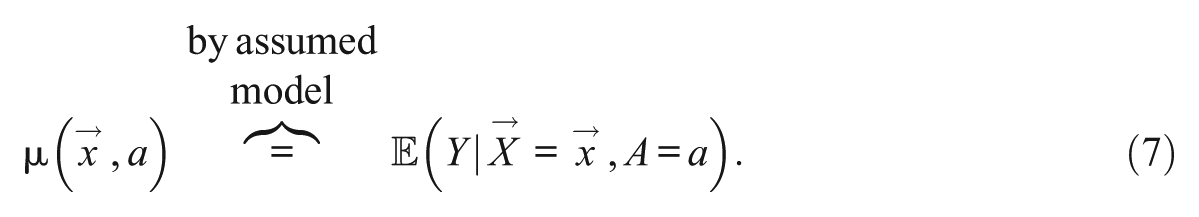
We then identify the additive shift estimand by a difference in conditional means under the incremented and nonincremented treatment values.
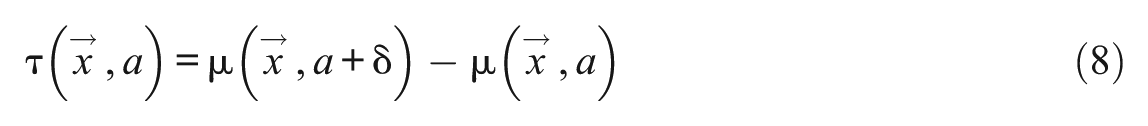
We may want to estimate the average value of the additive shift estimand within a subgroup
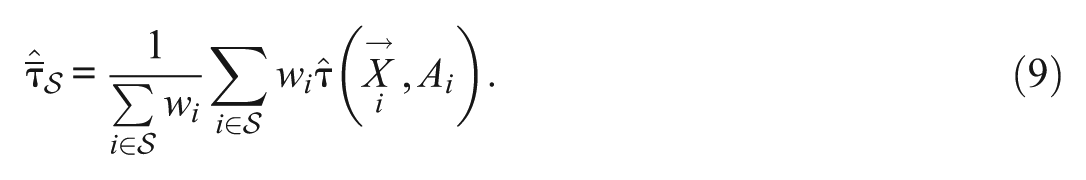
Because our procedure involves several steps (estimation and aggregation), we conduct statistical inference using a nonparametric bootstrap with 1,000 draws. We construct confidence intervals by a normal approximation using the point estimate and bootstrap estimate of the standard error.
Connections to Literature in Statistics
An additive shift estimand is one example of a broader class of estimands known as modified treatment policies, in which the counterfactual treatment value may depend on both pretreatment variables and the factual treatment value. An example is the causal effect of reducing the factual duration of a surgery by five minutes (Haneuse and Rotnitzky 2013). A modified treatment policy is conceptually distinct from a stochastic estimand, in which the counterfactual treatment value depends on pretreatment variables but not on the realized treatment value (Díaz Muñoz and van der Laan 2012). However, the two have many similarities. For example, a stochastic intervention assignment rule can be defined so that only realistic treatment values are assigned (Moore et al. 2012; Van der Laan and Petersen 2007), which is also our goal with additive shift estimands. A stochastic intervention can also be defined so that the statistical estimand is identical to that of a modified treatment policy (Haneuse and Rotnitzky 2013; Young, Hernán, and Robins 2014). For example, the modified treatment policy “increase the treatment value
Additive shift estimands are a discrete version of the incremental causal effects studied by Rothenhäusler and Yu (2019), in which the estimand is the rate of change in the outcome per an infinitesimal increment to each unit’s treatment. Incremental causal effects are thus defined as the average value of a derivative, and are identified by statistical estimands equivalent to average partial effects that are already common in social science (Long 1997; Powell, Stock, and Stoker 1989; Wooldridge 2005). Yet estimands defined in terms of derivatives may be difficult to convey to broader audiences, such as the public and policymakers. We therefore choose to study the causal effect of discrete additive shifts that may be easier to interpret.
Our estimator of an additive shift estimand is equivalent to a common practice for interpreting nonlinear models through predicted values: predict under a factual value, predict after incrementing a chosen predictor, and summarize the differences. This procedure is the same as one might use in noncausal settings to summarize a logistic regression model by predicted probabilities under a discrete change (Hanmer and Ozan Kalkan 2013; King, Tomz, and Wittenberg 2000; Long and Mustillo 2021; Mize 2019; Mize, Doan, and Long 2019). But an additive shift estimand differs from a marginal effect because it involves an explicitly causal goal: the causal effect of increasing a particular treatment variable by a given amount.
We focus on outcome modeling, but an alternative strategy is to build a statistical model for the conditional treatment density
Summary: Why Use Additive Shift Estimands
Linear regression models such as equation (1) are by far the most common approach to continuous treatment variables in the social sciences. Yet the specification of these models raises immediate concerns. First, how should one conceptualize the summary coefficient
Empirical Example: Effect of Parental Income on College Enrollment
We demonstrate causal identification assumptions and estimation approaches through an empirical illustration of the causal effect of parental income on college enrollment. Family income is a powerful indicator of socioeconomic advantage. Children from high-income families are more likely to enroll in and complete college (Acemoglu and Pischke 2001; Bailey and Dynarski 2011; Belley and Lochner 2007; Bloome, Dyer, and Zhou 2018; Voss, Hout, and George 2024) and earn more as adults (Chetty et al. 2014). In addition to descriptively marking life chances, family income may also cause life chances. Income enables parents to purchase goods that facilitate children’s success in school, such as nutritious food, medical care, academic enrichment activities, and homes in neighborhoods with high-quality schools (Bloome et al. 2018; Duncan and Murnane 2011; Farkas 2018; Kornrich 2016; Kornrich and Furstenberg 2013; Reardon 2011; Schneider, Hastings, and LaBriola 2018; Voss et al. 2024). Increasing income inequality has also meant growing class gaps in investments that affect children’s education (Reardon 2011). Among college enrollees, low-income students often lack economic resources and face barriers to completion (Goldrick-Rab et al. 2016; Houle 2014; Jack 2019; Regan 2020). Whereas prior causal work on the effect of family income has focused on the problem of unmeasured confounding (Elwert and Pfeffer 2022; Mayer 1997), we focus on the more tractable problem of measured confounding and show how additive shift estimands can yield improved estimates.
Data
We analyze data from the National Longitudinal Survey of Youth 1997 cohort (NLSY97). The NLSY97 began with a probability sample of U.S. youths 12 to 17 years of age in 1997 followed across repeated interviews through 2019. From the original sample of 8,984 respondents, we make several sample restrictions. We first restrict to the 6,588 youth with valid reports of our treatment variable: total gross household income in 1996 as reported in the 1997 survey wave when respondents were ages 12 to 17. We adjust to 2022 dollars using the Consumer Price Index and bottom-code at $10,000. The NLSY97 top-codes 1996 family incomes at the top 2 percent ($449,299 in 2022 dollars). We restrict to the 6,455 respondents with incomes below this survey-enforced top code, because the data are uninformative about the effects of income changes above this value. We measure enrollment as any report of enrollment in any college up to age 21. We restrict to the 6,357 respondents who either reported college enrollment before age 21 or were observed at ages 19 to 21 but reported no college enrollment.
We measure three confounding variables: race, parents’ education, and wealth. Race is categorized as Hispanic, non-Hispanic Black, and non-Hispanic White or other, as coded in the 1997 survey. We refer to these categories as Hispanic, Black, and White or other. Parents’ education is measured as no parent completed college, one parent completed college, or two parents completed college. We constructed this variable from reports by the residential mother and father in 1997. The variable implicitly indicates family structure; a child with only one residential parent is always coded as either no parent completed college or one parent completed college. We chose this simple operationalization because we treat family structure as influencing children’s education insofar as it shapes whether children have access to one or more parents who understand the higher education system, and insofar as households with two college-educated adults are likely to have higher incomes. Wealth is the log household net worth reported by the parent in 1997, adjusted to 2022 dollars and bottom-coded at $10,000. Our models also include indicators for whether wealth before bottom-coding was (1) negative or (2) between $ 0 and $10,000.
Adjusting for only three confounding variables simplifies our methodological illustration. In this setting, our causal identifying assumptions (see the section “Identification and Estimation for Additive Shift Estimands”) are likely to be violated to some degree. Yet our main claim is that positivity violations are serious and require a change in how researchers define their estimand. These positivity violations would be even more severe if our confounder set included a richer set of variables that might shape family income. We thus take our analysis using three confounding variables as a conservative illustration of a problem that is likely to be even more serious in applications with a larger set of confounders.
Hypotheses
Additive shift estimands enable us to generate hypotheses about heterogeneous effects, analogous to those generated for binary treatments. In our setting, we expect nonlinear effects of family income. Because of diminishing returns, a fixed increase in income may be less consequential for youth in families with already high incomes. We therefore expect differences in treatment effects across subpopulations defined by the baseline treatment value.
Hypothesis 1: An increase in family income would more strongly affect college enrollment among youth with low parental income.
We also expect effect heterogeneity by selected confounders. By a logic similar to that in hypothesis 1, a small increase in family income may be more consequential for youth in families with lower wealth.
Hypothesis 2: An increase in family income would more strongly affect college enrollment among youth with low parental wealth.
Finally, parental education is a key, if not the most important, factor affecting children’s educational attainment. The overwhelming majority of youth whose parents hold bachelor’s degrees enroll in postsecondary education (Chen et al. 2017). College-educated parents support and advise their children in college selection, preparation, application, and financial aid processes, whereas less educated parents have limited resources to help their children navigate higher education (Hout and Janus 2011). More educated parents also spend an increasingly large amount of time on developmental activities that cultivate educational achievement (Lareau 2003). Youth with more educated parents, who have a very high likelihood of college enrollment, could therefore be less sensitive to incremental increases in family income. By contrast, for children who might otherwise not attend college because of low parental education, an increase in parental income could be more consequential for attaining higher levels of education.
Hypothesis 3: An increase in family income would more strongly affect college enrollment among youth whose parents did not complete college.
Identification and Estimation
In our empirical example, our consistency assumption is that each child’s college enrollment equals the enrollment they would realize if hypothetically exposed to an intervention to set their family income to the value that actually occurred for that child (
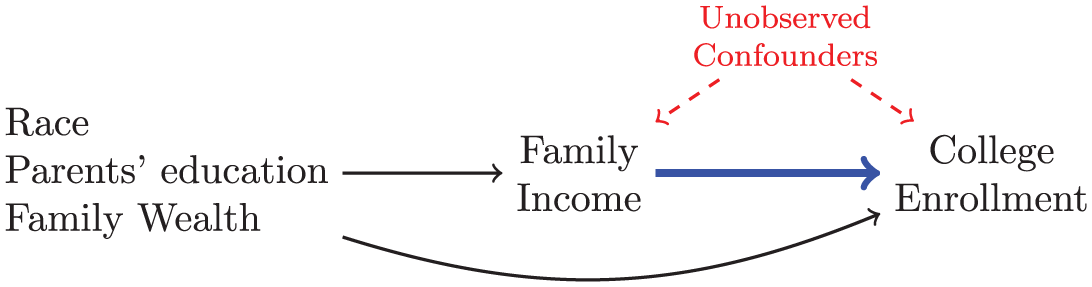
Causal assumptions in a directed acyclic graph.
We first estimate a statistical model for the conditional outcome mean
To produce the predictions, we consider two candidate statistical models. The first focuses on effect heterogeneity: we specify a logistic regression model that assumes the log-odds of college enrollment are linearly related to log income, but includes interactions between treatment

The second statistical model we consider focuses on nonlinearity: we specify a generalized additive model in which the log-odds of college enrollment are an additive (no interactions) function of parental income

We estimate the term
The models above have distinct motivating goals: equation (10) is designed to flexibly discover effect heterogeneity while assuming a particular parametric form of nonlinearity, whereas equation (11) is designed to flexibly discover nonlinear treatment effects while assuming no interactions. Although it is theoretically possible to estimate a more complex model that incorporates both effect heterogeneity and nonlinearity, such a model would involve a large number of parameters and potentially imprecise estimation because of the available sample size. Appendix A illustrates this problem in one simple simulated setting, and Appendix B shows that a flexible machine learning estimator (a random forest) produces estimates that are high variance. We therefore focus on models that learn either additive nonlinearity or heterogeneous parameterized effects. As additional evidence to support this choice, our empirical setting is one where the treatment values (income) are strongly determined by the confounders (race, wealth, parental education). In the “General Discussion” section, we will show that in settings in which treatment assignments are strongly confounded it may be possible to model data equally well with statistical models motivated by nonlinearity or by effect heterogeneity (Figure 8). In our empirical setting, this is true: we find very similar empirical estimates by either approach (Figure C1).
A key benefit of our approach is apparent when one compares equations (10) and (11) to the simple additive regression model we describe in equation (1). The simple regression model summarizes the entire distribution of causal effects by a single coefficient
Results
Our results suggest the probability of college enrollment increases substantially over the family income distribution: fewer than one in three students at the bottom decile of the income distribution enroll in college by age 21, whereas more than three in four of those at the top decile of the distribution enroll (see Figure 5). The gap in the probability of college enrollment is sizable even for small differences in family income. For each child, the predicted probability of college enrollment is 3.1 percentage points (95 percent confidence interval = 2.8 percent to 3.4 percent) higher than the predicted probability for a hypothetical child with an income $10,000 lower.
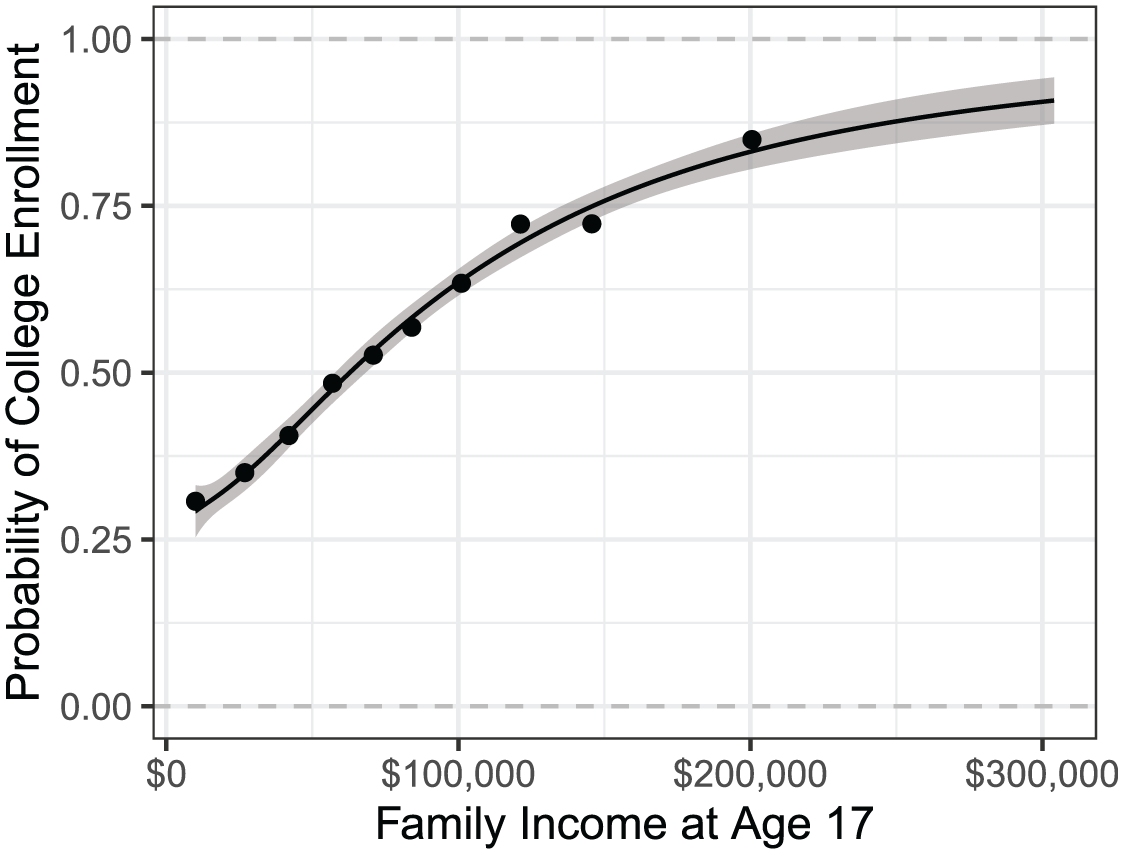
Descriptive result: family income strongly predicts college enrollment.
The results reported in Figure 5 represent a descriptive pattern. Next, we consider a causal effect estimate of the relationship between family income and children’s educational attainment. To produce a single average effect estimate, we first estimate the additive shift estimand
We now turn to how the probability of college enrollment changes as a function of family income within population subgroups, taking a particular set of confounder values. Figure 6 shows these curves as estimated by the interactive logistic regression model and the generalized additive model. Similar to the unadjusted descriptive curve in Figure 5, the estimated curve within nearly every subpopulation shows an upward trend: the probability of college enrollment increases with family income. Results suggest nonlinear patterns across family income, supporting hypothesis 1, and effect heterogeneity by family wealth, supporting hypothesis 2. Additionally, the curves are flatter among the subgroups that correspond to children from families in which two parents completed college, indicating that college enrollment is less responsive to family income in these families, supporting hypothesis 3.
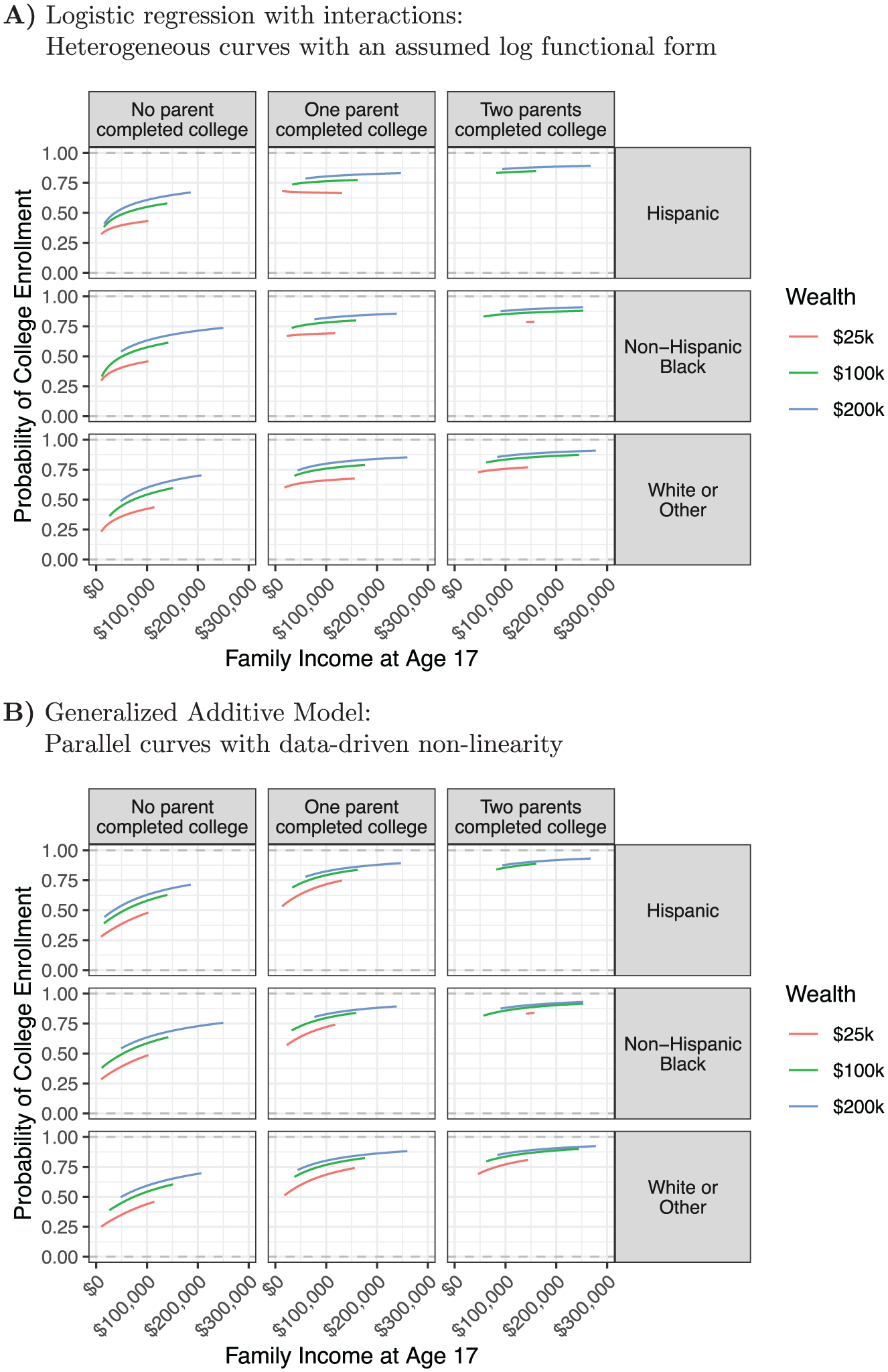
Models for causal estimation: family income effects on college enrollment are nonlinear and heterogeneous. (A) Logistic regression with interactions: Heterogeneous curves with an assumed log functional form. (B) Generalized additive model: Parallel curves with data-driven non-linearity.
Comparing across modeling approaches, Figure 6 shows remarkably similar curves estimated by either approach: interactive logistic regressions or generalized additive models. This similarity may be surprising: the first model assumes the log-odds of college enrollment are an interactive function of confounders and log family income, whereas the second model assumes the log-odds of college enrollment are an additive function of confounders and a data-driven smooth function of family income. The models seem, in theory, quite different. Nevertheless, their implications are very similar. Figure C1 further confirms this similarity by showing that the estimated value of the additive shift estimand for each unit tends to be similar under both approaches. We suspect the near equivalence of the estimates arises because of strong confounding. With strong confounding, models that focus on effect heterogeneity and models that focus on additive nonlinearity (here on the logit scale) can have very similar empirical implications (see Figure 8 in the “Discussion” section). It is also possible that the log functional form closely approximates the true pattern of nonlinearity. Alternatively, our sample size may be too small for the flexible smooth functions to learn a more complex pattern.
Using the modeled curves in Figure 6, we next produce aggregate estimates that summarize the additive shift estimand for population subgroups: how the probability of college enrollment changes, on average, for a $10,000 increase in family income over a particular set of units (see Figure 7). Because the results are very similar under both modeling approaches (columns), we discuss them together. The first row of Figure 7 reports estimates by terciles of family income. Consistent with hypothesis 1, the average causal effect in the bottom tercile of family income is more than three times larger than in the top tercile. In support of hypothesis 2, the average causal effect is approximately twice as large in the bottom tercile of family wealth compared with the top tercile. In support of hypothesis 3, income is more consequential for children’s college enrollment when parents do not hold college degrees. All three conclusions are the same under either modeling approach, with nearly identical estimates.
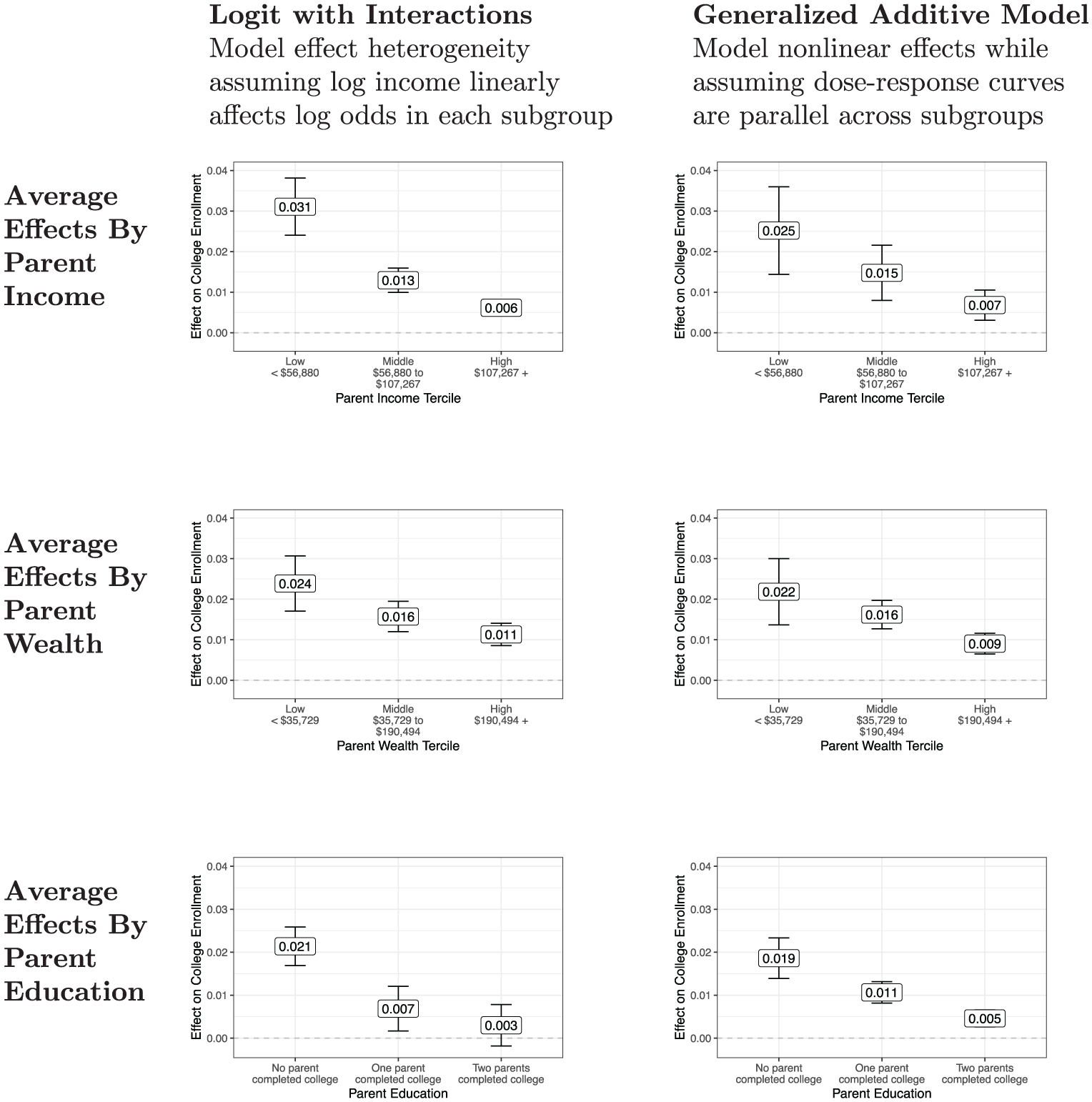
Models for heterogeneous effect estimation: family income effects differ across population subgroups.
As a second approach to summarize effect heterogeneity, Table 1 stratifies the population by the estimated conditional average treatment effect of a hypothetical additional $10,000 and summarizes the outcome, treatment, and covariates of these subpopulations. In the subgroup with the smallest effect, a $10,000 increase in family income would change the probability of college enrollment by between −3 and +1 percentage points. These are advantaged children with a median factual family income of about $138,000, median wealth of about $221,000, and 84 percent have at least one parent holding a four-year college degree. Notably, the lack of a causal effect in this advantaged subgroup cannot be interpreted as simply a ceiling effect: about 79 percent of the subgroup enrolled in college, so there is room for college enrollment to rise by up to 21 percentage points. Yet a $10,000 boost to family income raises the probability by only about 1 percentage point at most. The subgroup for whom the hypothetical income boost would be most consequential has notably large effects: a $10,000 increase in family income would increase the probability of college enrollment between +2 and +13 percentage points. These are disadvantaged children with a median family income of about $25,000, median wealth of $10,000 (the bottom code we enforced on this measure), and 97 percent of whom have no parent who holds a four-year college degree. Partitioning the sample by the estimated effect size and summarizing confounders reinforces our conclusions: a small increase in family income is most consequential for disadvantaged population subgroups.
Subgroup Characteristics by Estimated Effects of Family Income.
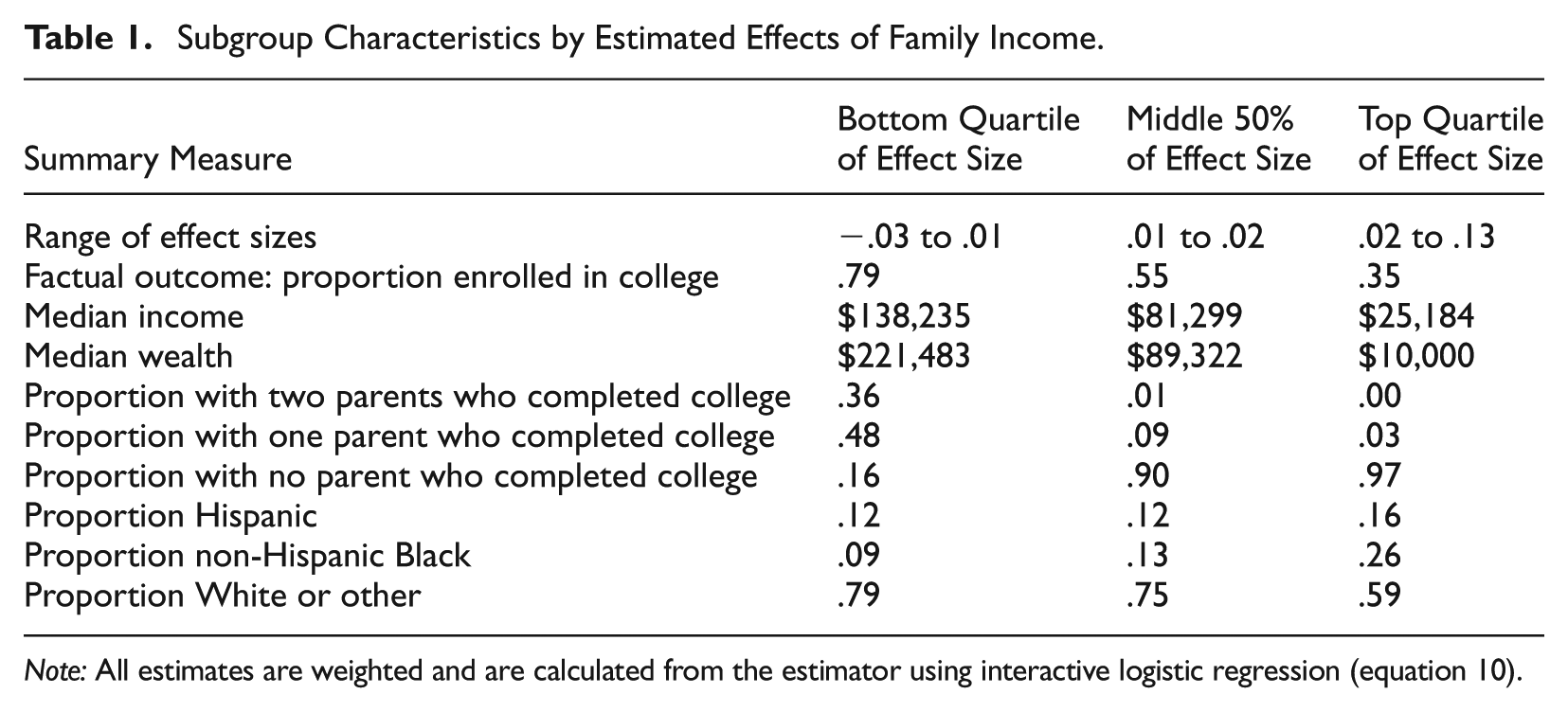
Note: All estimates are weighted and are calculated from the estimator using interactive logistic regression (equation 10).
Empirical Illustration Discussion
Our empirical illustration offers insights into an important question for social stratification research and policy: for whom does family income most strongly affect educational attainment? Researchers have extensively documented that material conditions during early childhood predict later-life outcomes (Chetty et al. 2014; Duncan, Kalil, and Ziol-Guest 2018; Duncan et al. 1998; Heckman 2006). Instead of focusing on whether income matters, we used additive shift estimands to address questions about income’s nonlinear and heterogeneous effects. We find that small differences in family income are most consequential for college enrollment among low-income families, low-wealth families, and families in which neither parent completed college.
Our empirical results raise new questions about the connection between family economic inequality and children’s educational inequality. The current period is marked by both rising income inequality (Piketty and Saez 2003) and stalled educational expansion (Voss et al. 2024). If college enrollment is especially responsive to changes in family income at upper-income values, then a rising upper tail of the income distribution could reshape who enrolls in college. But our result suggests college enrollment is especially responsive to income at lower income values. Thus, inequality in college enrollment may be more responsive to changes in economic inequality at the bottom of the distribution. Future work should explore this connection.
Heterogeneous effects of family income also point toward a new set of priorities for causal identification strategies that complement existing priorities. Past scholarship has often prioritized designs with strong internal validity. For example, Dynarski (2003, Table 2) showed that a financial transfer averaging $6,700 per year increased college enrollment by 18 percentage points by analyzing changes in a Social Security program to support the college costs of children with a deceased parent. This evidence has strong internal validity but speaks to only one subpopulation: individuals with a deceased parent who were eligible for the program. As another example, Manoli and Turner (2018) use kinks in the earned income tax credit (EITC) to show that a $1,000 transfer increases the probability of college enrollment by 1.3 percentage points among those whose family income is $12,780, but with no effect at a different kink point where family income is $40,964 (for a similar design, see Dahl and Lochner 2012). Studies such as these, which prioritize internal validity, will always hold an essential place in research on the effect of family income. But if the effect of family income is heterogeneous, their implications are bound to the subpopulations to which they speak. We took a different path by prioritizing external validity, seeking to summarize effects over the entire population. These two research strategies are complementary. Future research should use both econometric designs with strong internal validity and selection-on-observables designs, which, although weaker in terms of internal validity, can better explore the distribution of effect sizes across the population.
General Discussion
Causal questions involving continuous treatment variables are, in many ways, analogous to those involving binary treatment variables, but they invite qualitatively distinct considerations. With many potential outcomes for each unit, there are many possible causal estimands, some of which are more tractable than others. We demonstrated how additive shift estimands enable credible inferences that avoid extrapolation and support the exploration of effect variation across the population.
Effect Heterogeneity and Nonlinearity: Exploring Variation That May Be Difficult to Disentangle
We emphasized two conceptual axes of variation: effect heterogeneity and nonlinearity. Effect heterogeneity is analogous to the questions asked with binary treatments: the effect of a treatment
Figure 8 considers a hypothetical sample divided into three subgroups by confounder values
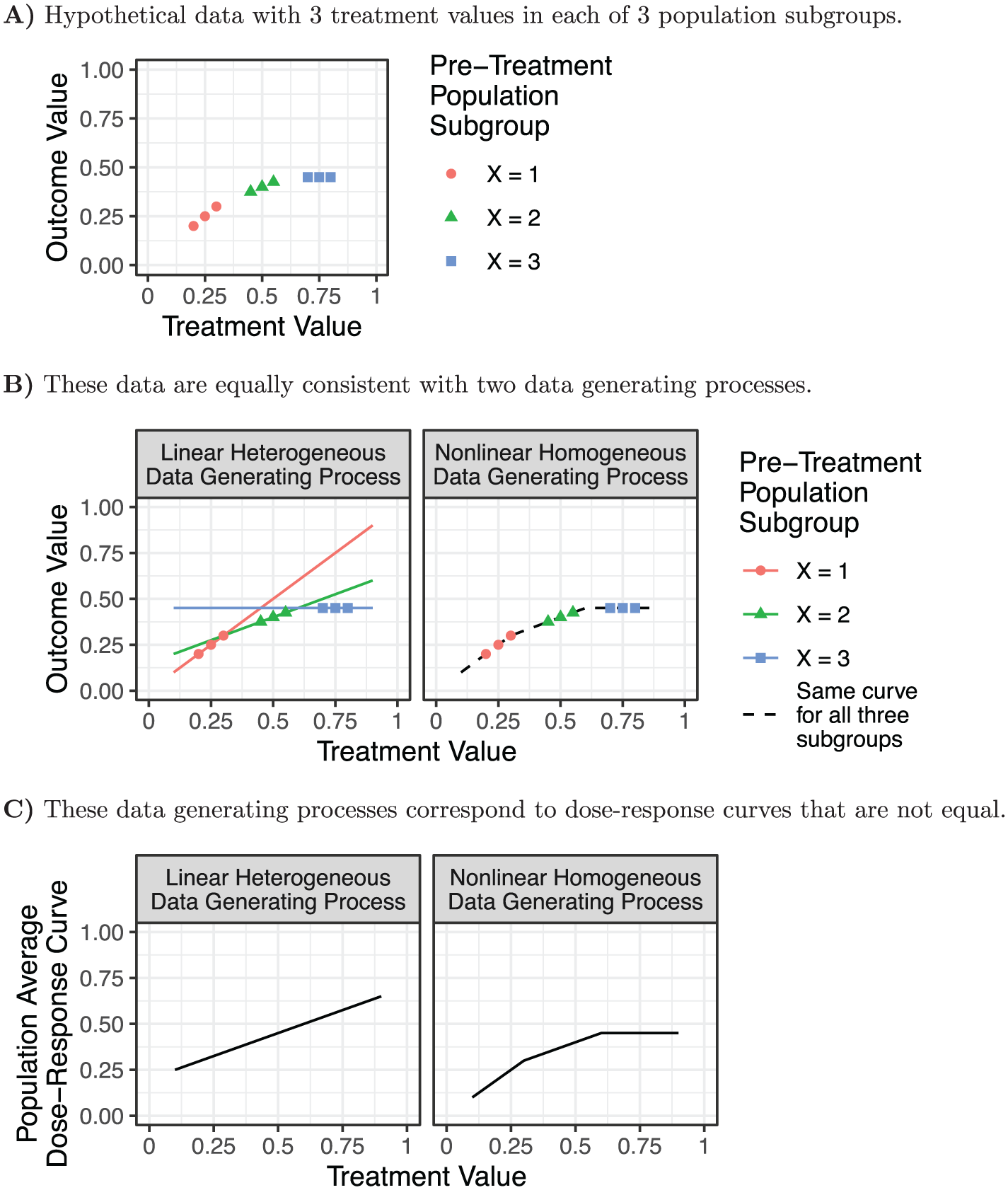
Nonlinearity and effect heterogeneity: empirical equivalence under strong confounding. (A) Hypothetical data with three treatment values in each of three population subgroups. (B) These data are equally consistent with two data-generating processes. (C) These data-generating processes correspond to dose-response curves that are not equal.
This illustration is an extreme case, but there may be many social science settings in which treatments are strongly determined by confounders. In these settings, it may be empirically challenging to adjudicate between nonlinearity and effect heterogeneity. The resulting shape of an estimated population-average dose-response curve may depend on modeling assumptions that are not easy to test empirically. Rather than engaging in these debates with limited data, researchers who adopt additive shift estimands can study an estimand that does not require a choice between models equally consistent with the observed data.
Conclusions
Social scientists routinely work with exposures that are at least theoretically continuous: income, wealth, parental work hours, minutes spent reading per day, neighborhood crime rates, and so on. For researchers interested in causal inference who might otherwise dichotomize these treatments, our approach offers an alternative strategy that allows the direct study of exposures in their continuous form. Because many of these exposures are themselves strongly shaped by other stratification processes, we suspect that many such applications will benefit from additive shift estimands that remain well defined in the presence of strong measured confounding. This framework can support future efforts to uncover not only whether numeric treatments have large effects, but also for whom and under what conditions.
Footnotes
Appendix A: Simulation: Heterogeneous Nonlinearity Can Be Difficult to Estimate
Effect heterogeneity and nonlinearity are distinct concepts that can coexist (see Figure 2). Consequently, researchers may seek an estimator that can estimate a nonlinear response curve that is also heterogeneous across population subgroups. However, estimation of patterns that are both nonlinear and heterogeneous can be statistically challenging. In small to moderate samples, one may prefer an estimator that focuses on either heterogeneity (as in equation 10) or additive nonlinearity (as in equation 11). This section presents a simulation illustrating the estimation difficulties in a specific setting.
Figure A1 illustrates a setting with five population subgroups labeled
The simulation shows several results. As expected, when the true DGP is additive, the additive nonlinear estimator has better performance (lower error) than the interactive nonlinear estimator. What may be more surprising is that, even in a truly interactive DGP, the additive estimator performs better at smaller sample sizes. Only at larger sample sizes (
Appendix B: Simulation: Forests Can Produce High-Variance Estimates
The main text focuses on models that assume global or local smoothness, including parametric logistic regression and generalized additive models. These approaches model the response surface as a function in which the outcome
Figure B1 presents the simulation and results. We consider two DGPs. In both DGPs, a treatment variable
As shown in Figure B1, the logistic regression produces a very accurate response surface estimate in the DGP where it is correctly specified and a less accurate response surface estimate in the DGP where it is incorrectly specified. The forest estimators consistently adapt to the response surface to produce a reasonably close fit, and the forests outperform logistic regression in terms of predicting conditional means in the DGP where the logistic regression is misspecified. Yet, in both DGPs, the logistic regression produces more accurate estimates of additive shift estimands. The reason is that the forest estimators produce locally bumpy response surfaces, and these local bumps result in additive shift estimands that are either highly positive or highly negative across the distribution of the treatment. Thus, although the forest estimators produce estimates of conditional means with adequately low variance and outperform logistic regression in predicting conditional means in one setting, they are inferior to logistic regression for the goal of estimating additive shift estimands in both settings.
These results are based on only one simulation, and the relative performance of forest versus logistic regression estimators is likely to vary across settings depending on the available data and the extent to which nonlinear and heterogeneous effects may be poorly captured by logistic regression. Yet this simulation serves as a cautionary note that estimators such as forests, which produce locally bumpy rather than locally smooth response surfaces, may be poor estimators of additive shift estimands.
Appendix C: Comparison of Estimators for Additive Shift Estimands
Figure C1 depicts the estimated value of the additive shift estimand for each unit under both estimation approaches considered in the main text. The figure shows that the estimates are substantively similar regardless of whether we use the interactive logistic regression or the generalized additive model specification.
Appendix D: Causal Identification Proof
Our causal identification is standard, but we provide the proof below for completeness.
In the proof, (12) is our causal estimand, (13) is by linearity of expectation, (14) is by conditional exchangeability, and (15) is by consistency. The final line is our empirical estimand, which we estimate by predicting the two quantities using our outcome model.
Acknowledgements
We thank the Inequality Data Science Lab at the University of California, Los Angeles, and Florencia Torche for helpful discussions and feedback relevant to this project, as well as seminar participants at the New York University Department of Sociology, University of Pennsylvania Department of Sociology, University of Washington Center for Statistics in the Social Sciences, Linköping University Institute for Analytical Sociology, and the annual meetings of the American Sociological Association and the Population Association of America.
Authors’ Note
We did not use artificial intelligence tools to facilitate writing this article; we did use artificial intelligence tools to check our human-written replication package for coding errors.
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: Research reported in this article was supported by the National Science Foundation under award 2104607 and by the Eunice Kennedy Shriver National Institute of Child Health and Human Development of the National Institutes of Health under award P2CHD041022.
Declaration of Conflicting Interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.