
Abstract
In June 2009, the Ricci v. DeStefano case was decided by five of the nine U.S. Supreme Court judges. This case impacts public-sector employers by expanding on the rule called a “strong basis in evidence.” Under this rule, a public-sector employer cannot engage in certain activities for the asserted purpose of avoiding or remedying unintentional disparate impact, unless the employer has a “strong basis in evidence” to believe it will be subject to disparate-impact liability. The evidence for this rule must be in place before a public-sector employer takes a race-conscious action to minimize adverse impact. This article critically evaluates the test validity discussion that occurred in the Ricci case; addresses topics relevant to the new rule not covered by the decision, such as the cutoff used, weights used, differentiating requirements of the rank-ordered list, and the rule of three; and describes guidelines for conducting a particular kind of study in an employment context, called a Croson Study, that can be used to gather a “strong basis in evidence.” This article identifies circumstances under which a Croson Study is needed, and how to do it that will allow public-sector employers to evaluate whether they may be justified—using the Supreme Court’s “strong-basis-in-evidence” rule—to institute race-conscious remedies under Title VII.
Background
When a public safety department (e.g., fire, police, sheriff, state patrol, corrections, fire marshal) needs to establish a promotional process, a risk begins for that public entity. If the promotional process ends up adversely impacting a minority group, minorities as a group, or women, a Title VII disparate-impact civil rights case could begin. If each practice, procedure, and test creating adverse impact used in the promotional process is job related to the satisfaction of a Court and no alternate employment practice is available that would suit the employer’s needs with less adverse impact, the public employer can successfully defend the suit, after spending a considerable amount of time and money on this project. But what if it is not that easy?
What practices, procedures, or tests typically used by public employers in public safety promotional processes are likely to adversely impact minorities or women?
Written tests
Weights assigned to written tests
Use of 70% cutoff score
Use of eligibility list in rank order
Rule of three.
When one or more of the above practices, procedures, or tests causes adverse impact and no Croson Study 1 has been conducted to provide the strong basis in evidence required from Ricci v. DeStefano, 2 the public employer has to rely upon the job-relatedness evidence from a validation study, hope the Court supports it, and hope the plaintiffs present no alternate employment practice that would suit the employer’s legitimate needs, as the Court sees it. Some public employers are choosing new practices (see Table 1). If the public employer has conducted a Croson Study (based on City of Richmond v. Croson, 1989a, discussed herein), perhaps under an attorney–client relationship to protect the results, and that study supported some limited remedial action, then other options become available to the public employer in addition to relying upon the validation study conducted. 3 Without a Croson Study, the public employer has more limitations, but still can take some positive steps to reduce unnecessary adverse impact in its exam plan.
Older Practices Versus Newer Practices.
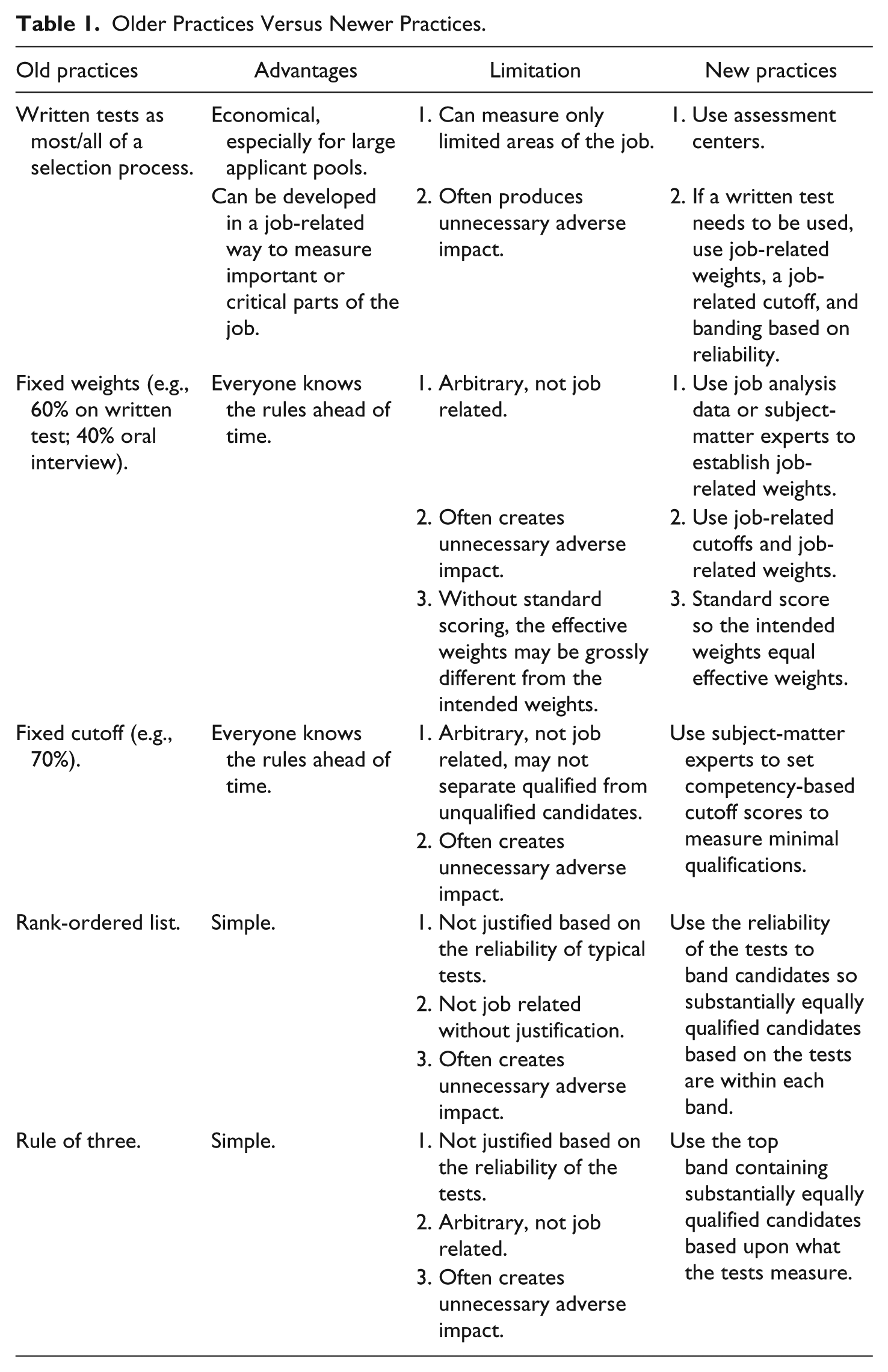
Once an employer is sued for employment discrimination under Title VII, the defense costs include long-term dedication of time by highly skilled human resource professionals, several attorneys, facilities to store documents, special computer equipment for scanning, substantial clerical support staff, computer staff, outside consultants, and, of course, nonbudgeted funds to pay all these staggering costs. What happens when a public employer loses a Title VII disparate-impact suit? Some typical remedies are paying back pay, paying for all plaintiffs’ litigation and discovery costs, and then there is injunctive relief. Monitoring (R. E. Biddle, 2002) may be ordered for a period of time. Changes may be imposed by a Court. Promotions may be delayed.
The end of June each year brings new decisions from the U.S. Supreme Court. Sometimes there is a decision that changes long-standing practices. For example, the 1964 Civil Rights Act did not include an express prohibition for employment practices or policies that produce an adverse impact on a group protected by the Act. However, in June 1971, the Supreme Court decided Griggs v. Duke Power Company (1971) and interpreted the 1964 Civil Rights Act to prohibit, in some cases, employers’ facially neutral practices that are discriminatory in operation if an employment practice operates to exclude minorities and cannot be shown to be related to job performance. A few years later, in June 1975, the U.S. Supreme Court supported its disparate-impact rule in Albemarle Paper Co. v. Moody (1975), stating that an employer’s burden is to demonstrate that practice has a manifest relationship to the employment in question when it has an adverse impact. In June 1982, the Supreme Court in Connecticut v. Teal (1982) held that even if the selection process as a whole showed no overall adverse impact, plaintiffs can still establish a prima facie case of disparate-impact discrimination if one of the practices, procedures, or tests adversely impacts a protected group. In June 1988, the Supreme Court in Watson v. Fort Worth Bank & Trust 4 supported the use of disparate-impact analyses for subjective as well as objective employment practices. Finally, in 1991, Congress passed the Civil Rights Act of 1991, 5 which included a provision codifying the prohibition of disparate-impact discrimination. The Ricci case, discussed in this article, further expands on the limitations public employers have with disparate-impact discrimination.
Summary of the Ricci Case
This case is an employment discrimination case under Title VII of the Civil Rights Act. It covers disparate-treatment (intentional) discrimination and disparate-impact (unintentional) discrimination. Disparate-treatment cases occur where an employer has treated a person less favorably than others because of a characteristic protected by Title VII (race, color, religion, sex, national origin). In a disparate-treatment case, the plaintiff must prove intent or motive.
By contrast, a disparate-impact case occurs when an employment practice, procedure, or test that is neutral on its face has a discriminatory impact on a certain group. A disparate-impact case under Title VII has three burdens: (a) plaintiffs must prove an employment practice has adverse impact against a group protected under the Act; (b) if shown, the burden shifts to the defendant to prove the practice causing the adverse impact is job related for the position in question and consistent with business necessity, usually done by means of a validation study (a term of art that specifies steps and procedures whereby a comparison is made between the job requirements and the measurements obtained through the testing process); and (c) if the practice causing the adverse impact is shown to be job related (valid), the burden then falls back onto plaintiffs to show that an alternative employment practice was available that could have been used (serving the employer’s legitimate interests) which would have less adverse impact. While this alternate employment practice burden had been defined in earlier Supreme Court cases, 6 it was codified by the 1991 Civil Rights Act.
Disparate-impact liability can occur when adverse impact is shown of a practice, procedure, or test and that practice, procedure, or test is found to not be job related or properly validated, or, if valid, an alternate employment practice is shown to equally serve the employer’s legitimate interests with less adverse impact and the employer refused to adopt the alternate employment practice. 7
The plaintiffs in this case (17 Whites and 1 Hispanic) were likely to be selected from eligibility lists as fire lieutenants and captains in the New Haven Connecticut fire department. Ricci was one of the plaintiffs. The defendant was the City, represented by the mayor named in the suit—DeStefano. The employment practices challenged were the rejection of the rank-ordered eligibility lists created by the City for the lieutenant and captain ranks. Each list used a cutoff score of 70%, a written test weighted 60% plus an oral interview weighted 40%, scored in rank order, and a rule of three for the final appointments. The City discarded the lists because they did not like the racial composition of the list—not enough minorities were reachable for promotion with the lists.
Plaintiffs, who were White and near the top of the lieutenant and captain lists, proved that tossing out the test results just because not enough minorities were in the reachable part of the list was a race-based decision—hence disparate-treatment discrimination. The City defendant attempted to show that disparate-impact discrimination would occur if the two lists were authorized, because the lists adversely impacted minorities and the City presented some arguments that the two selection processes were not properly validated. However, the City asked its consultant not to provide a validation study and then made unsupported arguments against the job relatedness of the examinations. The City did not provide a validation study by the test developer nor any other expert. A validation study would have provided the framework for analysis to see whether the practices, procedures, and tests in the selection process were properly validated. The only relevant information before the Court was testimony from the test developer without a validation study and an evidence record that concentrated “in substantial part on the statements various witnesses made to the CSB.” 8 The White plaintiffs in this case wanted to support the selection process as valid so that they could have the selection process reinstated and used for their own promotions.
Clearly, there was neither professional review of the validity of the examinations nor any realistic challenge. There was, however, a judicial review conducted by the Federal District Court, the Second Circuit Court of Appeals, and the U.S. Supreme Court. The review was based on the limited evidence submitted to the courts. None of the courts conducted an independent review. Only the evidence submitted to the Federal District Court was considered.
The City defendants made some unsupported arguments against the job relatedness of the examinations, but their test developer, who had been paid to develop the selection process, testified that the selection process was valid (without providing a validation study). The evidence submitted to the Court from both sides supported the selection processes. The Court found that “there is no genuine dispute that the examinations were job related and consistent with business necessity” because there was no substantive challenge presented to the Court for review.
The City defendants made some arguments regarding alternate employment practices they should have used but provided no strong basis in evidence that a substantially equally valid, less discriminatory testing alternative was available that they refused to adopt. The Supreme Court has held in prior decisions that certain government actions to remedy past racial discrimination—actions that are themselves based on race—are constitutional only where there is a strong basis in evidence that the remedial actions were necessary (City of Richmond v. Croson, 1989a; Wygant v. Jackson Bd. of Ed., 1986). The Supreme Court stated that the evidence does not have to be a provable, actual violation.
The City defendants provided no strong basis in evidence of past disparate impact against minorities in prior selection processes, no strong basis in evidence that the at-issue selection processes were not valid, and no strong basis in evidence that alternate employment practices were indeed available. Arguments alone were not enough without a strong basis in evidence to support the arguments. The U.S. Supreme Court concluded that a race-based disparate-treatment action like the City’s in this case (tossing out the test results because they adversely impacted minorities) is impermissible under Title VII because the City did not demonstrate a strong basis in evidence that, had it not taken the action, it would have been liable under the disparate-impact statute. As a result, the City’s action in discarding the tests was a violation of Title VII.
The Supreme Court has identified in this decision a defense to disparate-treatment discrimination when a strong basis in evidence can be shown that disparate-impact discrimination would occur but not for the disparate-treatment discrimination. The evidence does not have to be a provable violation. This case provides guidance when the analysis and ultimate findings of these two types of discrimination conflict.
Reviewing the Disparate-Impact Burdens
The Ricci case is a so-called “reverse discrimination” race case because the plaintiffs were Whites. Most frequently, race cases have a minority group claiming discrimination. The burdens under Title VII are the same for minorities or Whites bringing a challenge under Title VII. Because Whites were the plaintiffs in this case and they wanted to support the selection process so they could be promoted, their role had a major impact on how the case developed and was presented. The City in this case wanted to show that it faced disparate-impact discrimination by authorizing the lists. If the City could have shown it faced disparate-impact discrimination, then its argument for tossing the lists was justified. The City faced three burdens for establishing disparate-impact discrimination. Each is discussed below.
The Adverse-Impact Burden
The City proved that the passing rates were lower for each minority group and minorities as a group compared with Whites on the lieutenant and captain lists. The passing rate for Whites on the lieutenant list was 58.1%. An 80% rule of thumb test is often used, along with other statistical tests, to see whether there is adverse impact. The 80% limit of the White rate here is 46.5% (58.1% × 80%). The passing rates for Blacks, Hispanics, and total minorities were all lower than the 80% limit (31.6%, 20%, and 26.5%, respectively). These differences were statistically significant as well. The passing rate for Whites on the captain list was 64%. The 80% limit here was 51.2%. The passing rates for Blacks, Hispanics, and total minorities were below this limit (37.5%, 37.5%, and 37.5%, respectively). These differences were not quite statistically significant. However, combining the lieutenant and captain list statistics showed Whites with a passing rate of 60.3%, setting the 80% limit at 48.2%. The passing rates for Blacks, Hispanics, and total minorities for the combined analysis were each lower than this limit (33.3%, 26.1%, and 30%, respectively), and these differences were statistically significant.
The Supreme Court acknowledged that the burden would shift in a disparate-impact case brought by minorities against the City and the City would be required to demonstrate the job relatedness of its tests. So the Supreme Court addressed the next burden. If the plaintiffs had been minorities rather than Whites, the minority plaintiffs probably would have performed statistical analyses on additional practices in the selection process, such as the weights used, the cutoff used, the use of rank-ordered scoring, and the rule of three, in an attempt to shift the burden of proof on these specific practices as well. The White plaintiffs in this case wanted to support these practices, not to attack them, so they did not challenge these practices. This unique situation led to the full exam process validity evidence to become a “hot potato” between parties with the test developer focusing only on the oral and written tests and no party providing a strong basis in evidence regarding the adverse impact and job relatedness of the 70% cutoff, weights used on the oral and written tests, use of a rank-ordered list, and rule of three. This lack of evidence played out in the Court’s very limited evidence record and related deliberation.
The Job-Relatedness (Validity) Burden
After the burden shifts in a disparate-impact case, the defendants have the burden to prove the employment practice causing the adverse impact is job related (valid) and has business necessity. In most Title VII cases, the defendant employer is motivated to demonstrate the job relatedness or validity of the employment practice in question. This is usually done by means of a validation study. Then minority plaintiffs, in typical Title VII disparate-impact cases, vigorously attempt to demonstrate the employment practice is not job related or valid. In this case, the City employer was the defendant but the City did not like the outcome of the testing process and attempted to cancel the process. In fact, the City made assertions that the exams at issue were not job related and consistent with business necessity, but provided no strong basis in evidence and these assertions were contradicted by the limited record. The City’s test developer provided testimony supporting the job relatedness of the tests it was contracted to develop. However, no independent validation study was conducted to evaluate the validity of the tests. Although many people involved in the case called for a validation study 9 to see whether all parts of the employment process were job related (valid), no validation study was submitted.
Courts can only review evidence the parties in the case submit to it. There is a process for this: An expert prepares a report about the validity of the practices, procedures, and tests used in the selection process (validation study). It is given to the other side for review. There is a deposition of the expert to ask details about the report. In court, there is direct testimony by the expert, cross-examination by the plaintiffs, and redirect. In this case, the plaintiffs, who usually would be motivated to show the employment practice was not job related (valid), were motivated to demonstrate the process was indeed job related so they could receive their promotions. This lack of professional review of the testing process allowed judicial review only of a very limited amount of information about the validity of the selection process, thus providing the crux of the decision as five conservative justices concluded the City’s race-based rejection of the test results did not satisfy the strong-basis-in-evidence standard. 10 Because no independent validation study was introduced demonstrating the flaws with the selection process, only positive aspects of the selection processes were presented through the testimony of the City’s test developer.
The evidence before the Court demonstrated the detailed steps taken to develop and administer the tests and the painstaking analyses of the questions asked the candidates to assure their relevance to the captain and lieutenant positions. The testimony showed that complaints with certain examination questions were fully addressed. This information is relevant to the validity of the selection processes for the jobs but not enough under any objective review of the Uniform Guidelines.
11
The City turned a blind eye to evidence supporting the exams’ validity.
12
“Content validity is demonstrated by data showing that the content of a selection procedure is representative of important aspects of performance of the job.”
13
Had the City desired to stop the process, it needed to demonstrate that part of the selection process was flawed under the accepted standards for demonstrating validation. The lack of job-relatedness evidence for the 70% cutoff score used, weights used on the oral and written tests, ranking process used on the lists, and rule of three was never presented. To present these data would require certifying an expert, having the expert review the process, having the expert prepare a report, deposing the expert, direct testimony of the expert before the Court, cross-examination of the expert before the Court, and redirect before the Court, so the Court could consider the evidence and the opinion of the expert from an impartial review of the processes. The arguments the City made showing why the exams might not be job related were not supported by the evidence produced by the City: [t]he City could be liable for disparate-impact discrimination only if the examinations were not job related and consistent with business necessity, or if there existed an equally valid, less-discriminatory alternative that served the City’s needs but that the City refused to adopt. §2000e–2(k)(1)(A), (C).
14
The Alternate Employment Practices Burden
With the job relatedness shown for the City’s lieutenant and captain selection processes identified for judicial review–just the oral and written tests—not the 70% written cutoff score, fixed weights, rank-ordering process, nor rule of three, the burden would normally fall back on plaintiffs to demonstrate that an alternate employment practice was available to the City which it did not use, which would have served its legitimate needs with less adverse impact. As the White plaintiffs wanted to support the selection processes, the defendant City attempted to show alternate employment practices were available so it could toss the lists. The City, however, only produced arguments and not a strong basis in evidence. The Supreme Court stated that the City lacked a strong basis in evidence showing that a substantially equally valid, less discriminatory testing alternative was available that the City refused to adopt. The City used three arguments to no avail.
First, the City referred to testimony that a different weighted-score calculation would have allowed the City to consider Black candidates for then-open positions, but the City produced no evidence to show that the weighting actually used to create the lists was indeed arbitrary, or that the different weighting would be a substantially equally valid 15 way to determine whether candidates were qualified for promotions. Had plaintiffs been minorities motivated to prove the alternate weighting concept, plaintiffs would have provided evidence from subject-matter experts demonstrating that alternate weights, perhaps with job-related competency-based cutoff scores, would produce substantially equally qualified candidates with less adverse impact and produced this information prior to test administration. Making a change of weights after test administration using race as the reason, the Supreme Court states, could violate Title VII’s prohibition regarding race-based adjustment of test results. 16
Second, the City argued that it could have adopted a different interpretation of its charter provision that limited promotions to the highest scoring applicants, and that the interpretation would have produced less discriminatory results; but the Supreme Court stated the City’s approach would have violated Title VII’s prohibition of race-based adjustment of test results (because such practice would have been decided after the fact and instated solely to reduce the adverse impact). Had minorities been the plaintiffs in this case, motivated to provide a strong basis in evidence, testimony and other evidence would have been presented to demonstrate the psychometric properties and limitations of written tests and oral interviews. These are not perfectly reliable measurement tests. The observed scores from these tests are supposed to provide a proxy for measurement of different types of underlying ability that are supposed to be related to the job. Scores on these tests contain some amount of error. A statistic called “the reliability coefficient” on these tests quantifies this error. Plaintiffs would have demonstrated that differences in rank-ordered scores of a few points cannot be supported psychometrically—that substantially equally qualified candidates based upon what competencies are measured by the tests and how reliably the tests measure candidates cannot support very small differences in scores. Banding would have been presented as an alternate employment practice. The evidence would likely show that the reliability coefficients of the oral interview test and the written test are not perfectly reliable. The decision to band scores would have to be presented to the City prior to test administration to avoid the adjustment of scores after test administration for race reasons. The banding alternate employment practice could be done for psychometric reasons after testing administration revealed the reliability coefficients. The evidence would show that the banding alternative employment practice would reduce adverse impact and produce substantially equally qualified candidates.
Third, the City argued that it could have used an assessment center to evaluate candidates’ behavior in typical job tasks and the assessment center would have had less adverse impact than written exams. This argument did not aid the City, as it was contradicted by other statements in the record indicating that the City could not have used assessment centers for the exams at issue. The lead plaintiff in this case, Ricci, testified that “it would take several years . . . for the Department to develop an assessment-center protocol and the accompanying training materials.” 17 Had the plaintiffs been minorities and motivated to demonstrate there was an alternate employment practice that would serve the City’s legitimate needs with less adverse impact, plaintiffs would have introduced evidence of the feasibility of developing and administering an assessment center and evidence from other jurisdictions of the lesser adverse impact and improved job relatedness of this selection device. The U.S. Supreme Court stated that the strong-basis-in-evidence standard applies to this case, and the City could not create a genuine issue of fact based on a few stray (and contradictory) statements in the record. 18
Strong-Basis-in-Evidence Standard
In the Ricci case, the Supreme Court stated, We hold only that under Title VII, before an employer can engage in intentional discrimination for the asserted purpose of avoiding or remedying an unintentional disparate impact, the employer must have a strong basis in evidence to believe it will be subject to disparate-impact liability if it fails to take the race-conscious, discriminatory action.
19
The Court’s analysis begins with the premise that the City’s actions would violate the disparate-treatment provisions of Title VII unless there was some valid defense and reasons, All the evidence demonstrates that the City chose not to certify the examination results because of the statistical disparity based on race—i.e., how minority candidates had performed when compared to white candidates . . . Without some other justification, this express, race-based decision making violates Title VII’s command that employers cannot take adverse employment actions because of an individual’s race.
20
The Court clarified that the primary question being asked in the case was not whether that conduct was discriminatory but whether the City had a lawful justification for its race-based action: We consider, therefore, whether the purpose to avoid disparate-impact liability excuses what otherwise would be prohibited disparate-treatment discrimination . . . Our task is to provide guidance to employers and courts for situations when these two prohibitions could be in conflict absent a rule to reconcile them.
21
The Court continues and clarifies that “fear of litigation alone cannot justify an employer’s reliance on race to the detriment of individuals who passed the examinations and qualified for promotions”
22
and concludes by stating that race-based action like the City’s is impermissible under Title VII unless the employer can demonstrate a strong basis in evidence that, had it not taken the action, it would have been liable under the disparate-impact statute. The respondents, we further determine, cannot meet that threshold standard. As a result, the City’s action in discarding the tests was a violation of Title VII.
23
Had the City conducted a Croson Study for the at-issue jobs prior to the development of the selection processes, a strong basis in evidence may have been developed to support the City’s actions to toss out the test when the results showed adverse impact against minorities, and validity weaknesses were found. Obviously, however, this should be the last option a City would want to do—with or without the legal justification for doing so. Had the City conducted a Croson Study for the at-issue jobs prior to the development of the selection processes, the City may have been justified in implementing less extreme race-conscious remedies to identify substantially equally qualified candidates for the lists with less adverse impact, such as competency-based cutoff scores, weights less likely to adversely impact minorities that subject-matter experts say would produce substantially equally qualified candidates, banding based on the reliability of the tests to group substantially equally qualified candidates together, and so on.
In the public sector, there are often rules set up by a “merit system,” negotiation with a union, tradition, or some other situation. These rules influence the type of selection procedures to be administered and their use. Some examples include
a written test might be specified as required (rather than considering other options),
a 70% cutoff score might be required (rather than a competency-based cutoff score),
certain weights on tests might be required (rather than using job analysis data or having subject-matter experts establish the weights based on their opinions of relevance to the at-issue jobs, perhaps combined with a competency-based cutoff),
the rule of three might be required (rather than identifying those substantially equally qualified candidates based on the measurements of the tests),
a rank-ordered list might be required (rather than grouping candidates who are substantially equally qualified together), or
a rigid banding based on the same score might be required (rather than grouping substantially equally qualified candidates together).
These constraints are not necessarily geared to identifying the most qualified candidates based on competency. Indeed, different practices, procedures, and tests measure different competencies—each with varying levels of psychometric precision—and they should be put together and used with respect to how they relate to the job requirements (more so than just tradition). These constraints are set up so everyone knows the ground rules going into the selection process. The emphasis is on rules of control prior to the contest, rather than competency, a system more fair to candidates. If a public entity has any of these constraints, the Ricci case presents a blueprint of what is needed to establish a strong basis in evidence before making race-conscious remedies.
Often, a competency-based system can reduce unnecessary adverse impact against groups protected by Title VII compared with a selection system with rigid constraints. Tests such as assessment centers often create less adverse impact than traditional paper-and-pencil tests and can provide very qualified candidates. Assessment centers can measure important or critical parts of jobs not measurable with paper-and-pencil tests; however, the cost is usually higher, except when the number of candidates is small. Use of competency-based cutoff scores often provides more qualified candidates with less adverse impact than an arbitrary, fixed cutoff score, such as 70%. Using job analysis data or having subject-matter experts determine weights to be used by different parts of the selection process often gives much more flexibility to a public entity for obtaining very qualified candidates with less adverse impact than fixed weights not based on job analysis data or subject-matter expert opinions. Using a banding process to group substantially equally qualified candidates based on the reliability of the tests used in the selection process can provide many more competent candidates with less adverse impact than a fixed “rule of three.”
Any changes made after test administration for the sole purpose of lowering adverse impact, such as altering cutoff scores, alternate use of qualified weights, and so on, may invite challenges, because of Title VII’s prohibition against making race-based adjustment of test results. This is a special concern if the changes are outside of the “substantially equally valid” or “substantially equally qualified” doctrines or are not justified on the “strong-basis-in-evidence” standard. Ricci holds that these changes should be made, based on a strong basis in evidence, prior to the administration of the selection process, hence the need for a Croson Study prior to the implementation of a selection procedure: Title VII does not prohibit an employer from considering, before administering a test or practice, how to design that test or practice in order to provide a fair opportunity for all individuals, regardless of their race. And when, during the test-design stage, an employer invites comments to ensure the test is fair, that process can provide a common ground for open discussions toward that end. We hold only that, under Title VII, before an employer can engage in intentional discrimination for the asserted purpose of avoiding or remedying an unintentional disparate impact, the employer must have a strong basis in evidence to believe it will be subject to disparate-impact liability if it fails to take the race-conscious, discriminatory action.
24
Need for Croson Study Before Taking Remedial Action
The U.S. Supreme Court’s ruling in Croson and a related case, Wygant v. Jackson Bd. of Ed. (1986), established the basic principle that a governmental employer must provide a strong basis in evidence for its conclusion that remedial action is necessary before it takes the action. To support an affirmative action program that requires remedial action for minorities under strict scrutiny, there must exist a “strong basis in evidence” of past discrimination by the specific entity to support the conclusion that remedial action is necessary (City of Richmond v. Croson, 1989b). A generalized assertion that there has been past discrimination in an entire industry will not be enough to justify a race-conscious program under strict scrutiny (City of Richmond v. Croson, 1989c). Applying this rule has produced conflicting results (Donze, 2000). Croson did not provide guidance as to what amount and type of factual showing would provide a strong basis in evidence that discrimination existed in a particular industry (Alphran, 2003).
The most probative type of evidence in government contracting cases is statistical data showing “gross statistical disparities between the proportion of minorities hired . . . and the proportion of minorities willing and able to do the work.” 25 In government contracting cases, this is often shown through the use of a disparity index, which is a comparison between the share of contracts awarded to minority contractors and the percentage of qualified, minority-owned firms in the local population that do such work. 26 In addition, while the combination of “convincing anecdotal and statistical evidence is potent,” 27 anecdotal evidence, by itself, will rarely suffice to justify a race-conscious remedy evaluated under strict scrutiny. 28 Specific analyses of underutilization for the at-issue jobs; past adverse impact for the practices, procedures, and tests used for the at-issue jobs; analysis of the job relatedness of prior selection procedures used for the at-issue jobs; and evaluation of alternate employment practices are needed. These things make up a Croson Study, but do they have to be facts ready to be proved in court? The strong-basis-in-evidence standard is not so restrictive, according to the Supreme Court, that it allows employers to act only when there is a provable, actual violation. 29
In the Ricci case, the U.S. Supreme Court stated that the City of New Haven’s race-based rejection of the test results only because of adverse impact against minorities cannot satisfy the strong-basis-in-evidence standard. 30 The racial adverse impact in this case was acknowledged by the city attorney and the head of human resources. There was no dispute that the City was faced with a prima facie case of disparate-impact liability. This information, alone, was not enough to cancel the eligibility lists. The problem for the City is that such a prima facie case—essentially, a threshold showing of a significant statistical disparity of test scores and nothing more—is far from a strong basis in evidence that the City would have been liable under Title VII had it certified the test results. The Court ruled that the City could be liable for disparate-impact discrimination only if the exams at issue were not job related and consistent with business necessity, or if there existed an equally valid, less discriminatory alternative that served the City’s needs but that the City refused to adopt. And, based on the record the parties developed through discovery, there was “no substantial basis in evidence that the test was deficient in either respect.” 31
The City made claims that the exams were not job related and consistent with business necessity but failed to produce any validation study supporting their claim. A validation study should have looked at the entire selection process and could have shown the parts that were valid and parts that were not, if there were any. Of particular interest is the fact that the city attorney asked the test developers to not provide the validation study already contemplated in the contract the test developer had with the City. 32 Several people asked the City’s Civil Service Board (CSB) to have a validation study conducted so that it could be determined if the test process was job related and consistent with business necessity. As a result of no validation study, the only evidence before the Court demonstrated that detailed steps were taken to develop and administer the tests and there were painstaking analyses of the questions asked to assure their relevance to the captain and lieutenant positions. The testimony also shows that complaints that certain examination questions were contradictory or did not specifically apply to firefighting practices in the City were fully addressed, and that the City turned a blind eye to evidence supporting the exams’ validity. 33 The City did not provide a strong basis in evidence that the exams were not job related to support its decision to toss out the test results.
The City made a few vain attempts at showing alternative selection procedures were available with less adverse impact. A strong basis in evidence was needed to support each of the City’s proposed alternate employment practices. The City asked for an opinion from a testing expert not involved in the selection process, but that testing expert did not review the selection procedures at issue before providing advice to the City. It is an inevitable conclusion that the City’s arguments would fail. The City referred to testimony that a different composite-score calculation would have allowed the City to consider Black candidates for then-open positions, but it produced no evidence to show that the weighting actually used was indeed arbitrary, or that different weighting would be a substantially equally valid way to determine whether candidates were qualified for promotions. The City argued that it could have adopted a different interpretation of its charter provision limiting promotions to the highest scoring applicants, and that the interpretation would have produced less discriminatory results; but the U.S. Supreme Court said the City’s approach would have violated Title VII’s prohibition of race-based adjustment of test results.
Here, banding was not a valid alternative for this reason: Had the City reviewed the exam results and then adopted banding to make the minority test scores appear higher, it would have violated Title VII’s prohibition of adjusting test results on the basis of race.
34
The City asserted that the use of an assessment center to evaluate candidates’ behavior in typical job tasks would have had less adverse impact than written exams, but this assertion was contradicted by other statements in the record indicating that the City could not have used assessment centers for the exams at issue, because it would have taken too long to develop. The City provided no strong basis in evidence that any alternate employment practice was available. 35 A Croson Study would have provided the strong basis in evidence the City needed.
What Is a Croson Study?
The U.S. Supreme Court in Croson and Wygant ruled that certain actions taken by governmental entities to remedy past racial discrimination—actions that are themselves based on race—are constitutional only when there is a “strong basis in evidence” that the actions taken for remedial purposes are necessary. A Croson Study is a way to gather the “strong basis in evidence” needed. In Ricci, the Court stated, The standard appropriately constrains employers’ discretion in making race-based decisions: It limits that discretion to cases in which there is a strong basis in evidence of disparate-impact liability, but it is not so restrictive that it allows employers to act only when there is a provable, actual violation.
36
A Croson Study is a practical and prudent vehicle for public employers to use to minimize the likelihood of losing a Title VII case or perhaps even being challenged.
A Croson Study is specific to the job classification or rank for which a promotional list is being considered. A Croson Study evaluates the utilization of minorities and women as well as the adverse impact and job relatedness of past practices, procedures, and tests used to select candidates during prior selection processes. The job-relatedness evaluation includes the assistance of subject-matter experts as well as outside experts who can provide information for alternative selection procedures. It is not enough to simply review prior statistics of practices, procedures, and tests (i.e., utilization analyses and adverse-impact analyses). The job relatedness of the practices, procedures, and tests used must also be addressed and some additional job-relatedness work might be necessary. The statistical and job-relatedness information is needed to establish a strong basis in evidence required to make temporary remedial or race-conscious or gender-conscious changes. Problems identified from a Croson Study do not have to reach the level required of proof in court. However, problems found from a Croson Study can be used as a blueprint for some change and as a basis for limited actions to substantially reduce the likelihood of losing a Title VII suit, or in the best case, avoiding the suit altogether. As the Court stated, Applying the strong-basis-in-evidence standard to Title VII gives effect to both the disparate-treatment and disparate-impact provisions, allowing violations of one in the name of compliance with the other only in certain, narrow circumstances. The standard leaves ample room for employers’ voluntary compliance efforts, which are essential to the statutory scheme and to Congress’s efforts to eradicate workplace discrimination.
37
See Table 2 for an outline of some typical practices, procedures, and tests covered in a Croson Study.
Under Ricci, How to Reduce Unnecessary Adverse Impact After Conducting a Croson Study.
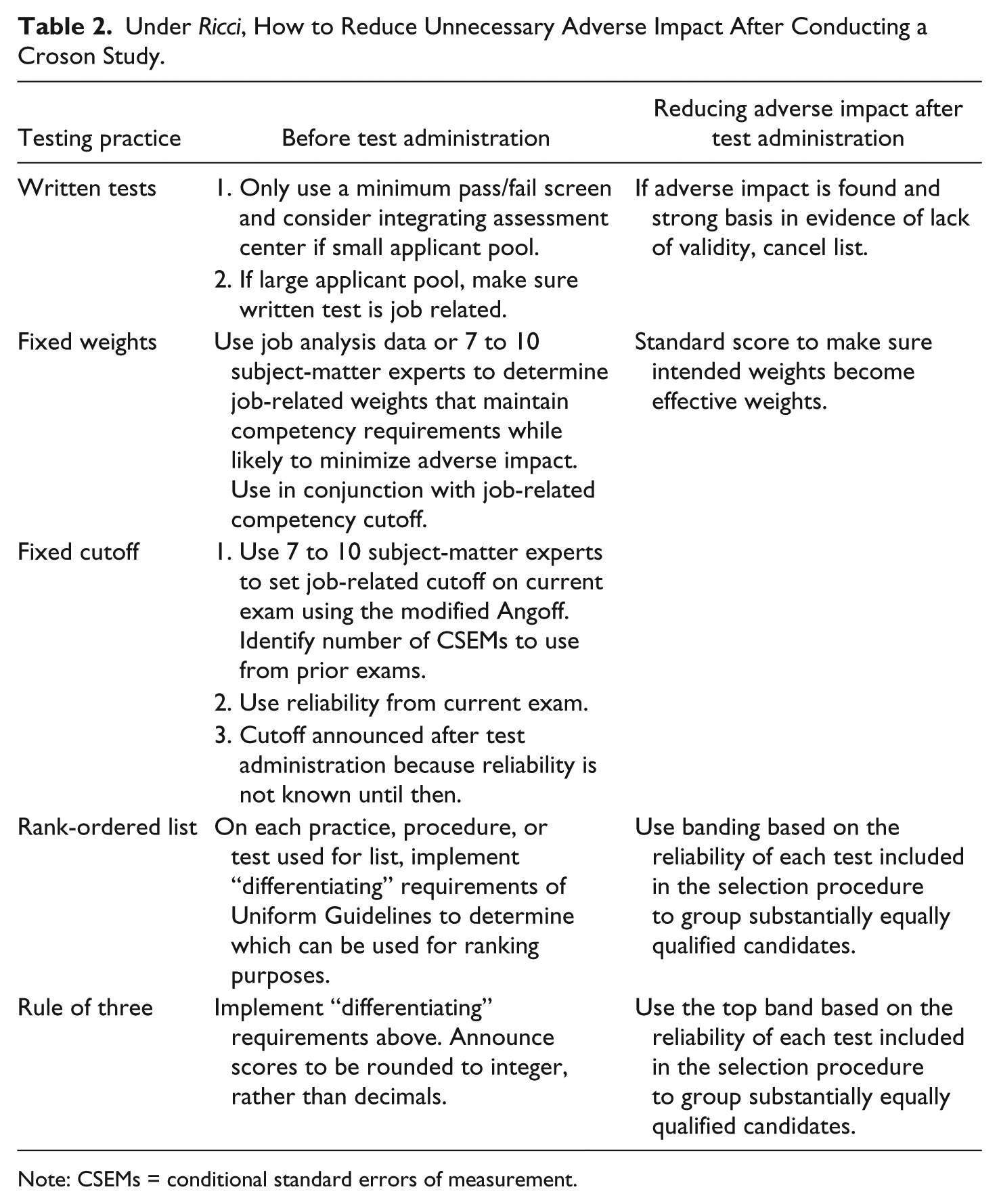
Note: CSEMs = conditional standard errors of measurement.
What Constitutes a Defensible Croson Study?
How defensible is a Croson Study? Ultimately, that depends on the extent to which the race-conscious remedies that are instated based on the Croson Study are exclusive versus inclusive. Race-conscious interventions that have the effect of being exclusive toward certain groups at the expense of being inclusive to others will be more highly scrutinized. After the landmark Adarand Constructors, Inc. v. Peña (1995) case, the U.S. Department of Justice authored a memorandum to general counsels 38 regarding the implications of the case relevant to the “narrowly tailored” and “strict scrutiny” requirements surrounding race-conscious remedies (such as those that might be justified based on a Croson Study). This memorandum included several evaluation criteria regarding the use of race-conscious remedies that are summarized below:
Before using race-conscious remedies, consider whether race-neutral alternatives could be used instead. This consideration should be obvious, but is nonetheless often overlooked by many well-meaning employers. Public- and private-sector employers should consider race-neutral measures before resorting to race-conscious action.
What is the scope of program (i.e., in what manner is race used)? Is the race-conscious remedy a hard, fixed number (e.g., a quota)? Is race used as a “plus factor,” or is it included in a static formula? Is it a soft or hard standard, variable, or fixed? Quota systems typically require judicial instatement and enforcement, whereas “plus” factors can sometimes be used with less scrutiny. For example, Justice O’Connor’s opinion for the Court in Croson criticized the scope of Richmond’s original 30% minority subcontracting requirement as a “rigid numerical quota.” In the U.S. Supreme Court case Gratz v. Bollinger (2003), the Court reviewed the University of Michigan’s affirmative action policies that used a strict “race = +20 points” program and ruled that race can be one of many factors considered by colleges when selecting their students, but cannot be used in such a strict formulaic manner.
What statistical evidence exists that substantiates possible discrimination? Evaluating this factor can include two types of statistical evidence: utilization analyses and classical adverse-impact evidence. Utilization analyses can be used to evaluate the group’s current representation in the workforce (e.g., their numbers in the at-issue position) to their availability in the relevant labor market (using either the qualified applicant flow data or census Equal Employment Opportunity [EEO] data). The two-tail exact binomial test can be used to evaluate whether the group is underutilized with a statistically significant finding constituting a threshold test (D. Biddle, 2006, pp. 22-24; R. E. Biddle, 1995, 1996) of possible discrimination. Classical disparate-impact evidence exists if the practices, procedures, and tests administered in the past have exhibited adverse impact and have not been validated.
The duration of the program. Race-conscious remedies should only be instated for a sufficient time period that is needed to remedy the ill effects of previous discrimination.
The extent to which the race-conscious remedy has an exclusionary effect on Whites or men. The most ideal race-conscious remedy is one that does not unnecessarily trammel the rights of any willing competitor to the process.
Weights in a Croson Study
Examining the weights used in prior selection processes to create a ranked list is one practice a Croson Study would evaluate. For example, a public safety department may have used a 60% weight assigned to the written test based on a collective bargaining agreement. The Croson Study may uncover that the 60% weight was negotiated but had no job-relatedness or validation support. The Croson Study might find that the 60% weight caused more adverse impact than lower weights subject-matter experts say could have been used that would have provided substantially equally qualified candidates, especially if a job-related competency-based cutoff was used first on the written test before weighting was applied.
One step that could be involved in a Croson Study is to gather data from 7 to 10 subject-matter experts for a midsized department regarding weights. These subject-matter experts would be provided information on what each test measures (e.g., a written test and an oral interview test) and each would be asked for independent opinions regarding the weights for each test that best represents the proper qualification mix necessary for the job. This effort could lead to, for example, a conclusion that the written test weight should have a weight of 30%, be used with a minimum competency cutoff score, and would provide substantially equally qualified candidates. In the Ricci case, the City demonstrated that weights of 30/70 would substantially reduce adverse impact but provided no evidence that the scores were substantially equally valid: Nor does the record contain any evidence that the 30/70 weighting would be an equally valid way to determine whether candidates possess the proper mix of job knowledge and situational skills to earn promotions . . . On this record, there is no basis to conclude that a 30/70 weighting was an equally valid alternative the City could have adopted.
39
Furthermore, they ruled that changing the weights for the sole purpose of reducing adverse impact would likely violate the race-norming prohibition of the 1991 Civil Rights Act: “Changing the weighting formula, moreover, could well have violated Title VII’s prohibition of altering test scores on the basis of race. See §2000e–2(l)” (italics added). 40
Clearly, a strong basis in evidence is needed to show that the different weighting options, perhaps with a job-related cutoff, would produce substantially equally qualified candidates. In the Ricci opinion, the Supreme Court explains its concerns before and after testing: Nor do we question an employer’s affirmative efforts to ensure that all groups have a fair opportunity to apply for promotions and to participate in the process by which promotions will be made. But once that process has been established and employers have made clear their selection criteria, they may not then invalidate the test results, thus upsetting an employee’s legitimate expectation not to be judged on the basis of race. Doing so, absent a strong basis in evidence of an impermissible disparate impact, amounts to the sort of racial preference that Congress has disclaimed, §2000e–2(j), and is antithetical to the notion of a workplace where individuals are guaranteed equal opportunity regardless of race. Title VII does not prohibit an employer from considering, before administering a test or practice, how to design that test or practice in order to provide a fair opportunity for all individuals, regardless of their race. (italics added)
41
An option from a Croson Study could be to use subject-matter expert opinions and data from prior exams (either given by that department, similar departments, or reported in the testing literature) and the currently proposed exam to develop weights that are likely to minimize adverse impact. Then set these weights ahead of time. Using a competency-based cutoff on the written test scores could sometimes allow the written test to be used as a pass–fail device rather than a ranking device. Using a job-related competency-based cutoff score on the written test could be used to make sure candidates had a minimum competency, then the rest of the selection process could be used to rank candidates, using factors that differentiate more between marginally successful and higher levels of job performance (ideally, ranking should be based on qualification factors that differentiate job performance rather than factors that are only needed at a minimum level for successful job performance—see further discussion later).
Also evaluated in a Croson Study is the practice of how the math was done on developing the weights prior to creating the ranked list. If the employer multiplied the raw score from the written test by 60% and the raw score from the oral interview score by 40% and then added these two scores together, it is very possible the effective weight for the written test could be 70% rather than the 60% advertised to the candidates, needlessly increasing adverse impact. Written test scores and oral interview scores may be normally distributed but they often come from different distributions. When we combine scores and desire to give them a certain intended weight, we need to consider each person’s score expressed as the deviation of his or her score from the mean score in each distribution in units of standard deviation. We have known about this concept since at least 1921 (http://www.merriam-webster.com/dictionary/standard+score; see also Francis, 2006). When we do not transform each candidate’s score into a score in relation to the standard deviation of that distribution, we do not know about the relative performance of the candidate compared with others on this test.
Raw scores on written tests and oral interview tests are usually quite different. A written test may have a mean of 55 with a standard deviation of 15 (i.e., 68% of the scores fall between 40 and 70, 95% of the scores fall between 25 and 85, and 99% of the scores fall between 10 and 100). An oral interview may have a mean of 84 and a standard deviation of 5 (i.e., 68% of the scores fall between 79 and 89, 95% of the scores fall between 74 and 94, and 99% of the scores fall between 69 and 99). Sometimes, oral interviewers will give a candidate a score of 69 as a “failure,” not using the whole distribution of failing scores.
A quick look at the mean raw score for the written and the mean raw score for the oral may detect a difference. If the standard deviations for the written and oral are different, almost certainly, the effective weights are not going to be the same as the intended weights. Standard scoring is the process used to make sure the intended weights become the effective weights. With standard scoring, the candidate’s raw score is subtracted from the mean score then divided by the standard deviation of the test. This conversion puts the candidate’s score in perspective with the distribution of scores. After each candidate’s score is converted to a standard score, the weights can be multiplied times the converted standard score to make sure the intended weight becomes the effective weight. This process was not completed by the City of New Haven, and the related impact led to the creation of a final list being issued where 43 of the 77 Lieutenants (56%) were out of their appropriate mathematical ranking (some as many as four positions out of their correct rank order) and 15 of the 41 Captains (37%) also being out of correct rank order. 42
Relative weight analysis (Johnson & Lebreton, 2004) can be used to evaluate the effective weights if raw scores have been used. Reanalyzing the raw score data in the Ricci case reveals that the actual effective weights of the lieutenant’s oral and written were 37.2% and 62.8%, respectively, and 38.2% and 61.8% for the captain’s oral and written, respectively.
Use of 70% Cutoff Score in a Croson Study
Another practice evaluated in a Croson Study is the cutoff score used in prior examinations for the rank. If a 70% cutoff score was used, the basis for its use may be a civil service rule, charter provision, or a provision negotiated with a union. If this cutoff is found to have had adverse impact on past exams for the rank and no job-relatedness data are available to support it, then the public employer may wish to use these facts to establish a strong basis in evidence and implement a cutoff score based on job-related competency (R. E. Biddle, 1993). In Footnote 16 of Justice Ginsburg’s dissenting opinion, she states, It appears that the line between a passing and failing score did not accurately differentiate between qualified and unqualified candidates. A number of fire-officer promotional exams have been invalidated on these bases. See, e.g., Guardians Assn., 630 F. 2d, at 105. (“When a cutoff score unrelated to job performance produces disparate racial results, Title VII is violated.”)
43
If a Croson Study finds that the 70% cutoff score has created unnecessary adverse impact in the past and is not supported by any job-relatedness or validation data, then a strong basis in evidence is available to the public employer to make a change. The fact that a city charter, merit system, or even state law specifies the use of a 70% rule is not enough to justify it. The U.S. Supreme Court warns against this: “A state court’s prohibition of banding, as a matter of municipal law under the charter, may not eliminate banding as a valid alternative under Title VII. See 42 U. S. C. §2000e–7.” 44 Not using a competency-based minimum score can needlessly increase adverse impact. In other situations, using a competency-based cutoff may actually increase adverse impact, although in such situations the adverse impact would be justified because the cutoff score represents the competency levels necessary for success.
If an employer desires to determine a job-related, competency-based cutoff score, the steps are quite straightforward. One such process (known as the “modified Angoff technique”) can be completed by convening a panel of 7 to 10 qualified subject-matter experts to rate every item on the test with respect to the percentage of minimally acceptable candidates who would likely answer the question correctly. These ratings are then averaged in a “critical score” that is reduced by deducting 1, 2, or 3 conditional standard errors of measurement (CSEMs) after the test is administered and the reliability becomes known. 45
The classical standard error of measurement (just “SEM”) is calculated using the standard deviation and reliability of the test (
The SEM varies across the range of candidate proficiencies. Individual candidate score levels on any specific test have different degrees of measurement error. The SEM as well as individual score level estimates are typically reported and commonly referred to as CSEMs. 46 The CSEM gives the estimate of reliability (error estimate) at each score point. The SEM is considered a test-level statistic and the CSEM is considered a score-level statistic. Both can be used to compute a confidence band around a score to determine a score range in which the true score probably lies. Unlike the SEM, the CSEM takes into account the variation in measurement accuracy across the score scale into consideration. That is why the CSEM can offer a more precise error band around any one individual score.
Section 2000e-2(l) of Title VII specifies, It shall be an unlawful employment practice for a respondent, in connection with the selection or referral of applicants or candidates for employment or promotion, to adjust the scores of, . . . or otherwise alter the results of, employment related tests on the basis of race, color, religion, sex, or national origin.
Therefore, it might be prudent to determine whether to use 1, 2, or 3 CSEMs to adjust the critical score before test use. To properly determine the CSEMs, the test must first be administered, but then the predetermined number of CSEMs can be deducted to arrive at the final cutoff for the test (there are, however, some methods for determining the CSEM prior to administration—see discussion later).
While predetermining the number of CSEMs to use for the final adjustment may lower risk, determining the number to use after the test has been given is a risk if the decision is based solely upon race. Lowering a validated cutoff score by 1, 2, or 3 CSEMs to reduce adverse impact (as well as factoring in other relevant factors) is merely accounting for the lack of reliability of the test (using 1, 2, or 3 CSEMs as confidence intervals [CIs] for including true scores); it does not alter the results or use different cutoff scores for different groups, but merely uses the existing results in a different way. It is unclear how a conservative Supreme Court would view using race as one factor. Therefore, it would be safer to make the decision prior to test administration but there are some advantages and risks associated with waiting until after test administration to decide on the number of CSEMs to use.
There are several case examples where this process has been supported (i.e., reducing cutoff scores within substantially equally qualified ranges to reduce adverse impact). Perhaps the first example is given in the U.S. Supreme Court case, U.S. v. South Carolina (1977/1978). In the South Carolina case, the Court permitted the consideration of five statistical and human factors when choosing whether to deduct 1, 2, or 3 SEMs:
The size of the SEM. Large SEMs indicate low test reliability and/or high levels of variance in the applicant pool.
The possibility of sampling error in the study (this relates to the number of subject-matter experts who served on the cutoff development panel). Panels with only a few Job Experts raise concern based on this factor, especially if there are a large number of incumbents in the workforce.
The consistency of the results (internal comparisons of the panel results). Panels that included biased Job Experts raise concern here (only if they were not removed based on interrated reliability and/or being extreme outliers).
The supply and demand for incumbents in the target position (pertaining to the demand for workers needed in the workforce).
The racial composition of the workforce/levels of adverse impact on each of the cutoff options should be considered.
Deducting SEMs or CSEMs in this fashion preemptively addresses concerns or attacks that plaintiff groups may bring by arguing that lower cutoff scores are within the range of the “substantially equally valid” requirement of the Uniform Guidelines (Section 3B) and the third burden (“alternate employment practices”) discussed in the 1991 Civil Rights Act. Without deducting CSEMs, employers could find themselves wide open to alternate employment practice arguments brought by enforcement agencies or plaintiff groups. Furthermore, if the critical score has statistically significant adverse impact and 1 CSEM below does not, the employer is faced with a situation where two cutoff options that are substantially equally valid result in very different liability outcomes (one is enforceable under Title VII, the other is not).
A more recent example occurred in Isabel v. City of Memphis (2005) where the City of Memphis used a written test for the sergeant promotional process. The City had negotiated to use a 70% cutoff for the test, which had disparate impact against Blacks, and the Court ruled that the cutoff score was invalid, stating, “To validate a cutoff score, the inference must be drawn that the cutoff score measures minimal qualifications.” The district court found that the cutoff score was “nothing more than an arbitrary decision and did not measure minimal qualifications.” Given this context, the Court supported lowering the (arbitrary) 70% cutoff score to reduce adverse impact.
Use of List in Rank Order in a Croson Study
Another area investigated in a Croson Study is how the prior lists have been used. If the lists have been used in strict rank order, then an investigation is made using a distribution type of adverse-impact analysis
47
to see whether the rank-order process itself adversely impacted any groups protected by Title VII. If so, then the investigation continues to the job-relatedness support to see the reasons for using the list in rank order. It is not enough to provide job-relatedness data using content validity to support a rank-ordered list with adverse impact. The employer must provide evidence that the test measures those aspects of performance which differentiate among levels of job performance. The Uniform Guidelines (1978, Section 14C9) state, Where a selection procedure supported solely or primarily by content validity is used to rank job candidates, the selection procedure should measure those aspects of performance which differentiate among levels of job performance. (italics added)
This concept has been deliberated in several court cases. For example, in Guardians v. Civil Service Commission of New York (1980), the Court ruled that the scores were “too bunched” to be used in rank order. The Court remarked, Rank-ordering satisfies a felt need for objectivity, but it does not necessarily select better job performers. In some circumstances the virtues of objectivity may justify the inherent artificiality of the substantively deficient distinctions being made. But when test scores have a disparate racial impact, an employer violates Title VII if he uses them in ways that lack significant relationship to job performance.
The Court ruled that rank ordering was only permissible when a demonstration could be made of “such substantial test validity that it is reasonable to expect one- or two-point differences in scores to reflect differences in job performance.” Even though the Court approved the validity of the test itself, it viewed the evidence required to use the test as a separate and distinct issue: “Our prior conclusion that the test itself may have had enough validity to be used does not, therefore, lead to approval of using its results for rank-ordered selections.”
In a similar case, Vulcan Pioneers v. NJ Department of Civil Service (1985), the Court ruled that the tests were not appropriate for ranking because subject-matter experts were not even asked whether the knowledges, skills, and abilities were appropriate for ranking; rather, they were asked to indicate whether the knowledges, skills, and abilities ought to be “qualifying” . . . several knowledges, skills, and abilities, such as knot-tying or first aid, appear to be abilities common to all experienced firefighters, and as to which only a very insignificant range of performance ought to have been possible.
The Court also noted that the reliability of the examinations was poor and that the test placed a premium on test-taking ability rather than the relevant knowledges, skills, and abilities required for the job.
In Ricci, the differentiating evidence required to demonstrate the job relatedness of the rank-ordered lists was not addressed by the Supreme Court majority. 48 The plaintiffs did not attack this process because the top scorers on the lists were the plaintiffs. Not surprisingly, the City did not criticize their own rank-ordered process either. However, the validation report would have, but, alas, the City chose not to ask for the validation report!
When lists are used in a strict rank-ordered way, they can needlessly increase adverse impact. The reliability of tests and consistency of measurement used in personnel selection are not perfect. Anyone who has taken a typing test knows that you may score 45 words a minute, but 5 min later, if you take the test again, you may score 43 words a minute or 48 words a minute, but you are unlikely to score exactly 45 words a minute again. If we repeat this process with many candidates, we will find the reliability of the test. There are other ways to find reliability, but reporting the reliability of tests is a requirement of the Uniform Guidelines, whenever it is feasible. 49
It is very common in test scoring programs to produce different types of reliability calculations. The reliability can be used to establish the reasonable range with which candidates are likely to obtain their true score. This range reflects the error of measurement for the test and can be used to group scores so that substantially equally qualified candidates are banded together based on the test or tests used.
A Croson Study could evaluate the distribution of scores of prior exams to see whether the rank-order process contributed to adverse impact. If so, the Croson Study would evaluate the justification for the use of the test in a rank-ordered way to see whether there is differentiating job-relatedness support that adequately addresses the Uniform Guidelines requirements. Moreover, the Croson Study would evaluate whether the reliability of the tests has been addressed in how the rank-ordered list had been used. If there are problems in this area, the Croson Study can be used to establish the strong basis in evidence needed to make changes to help the public employer reduce unnecessary adverse impact and more properly use these selection tools, relying on the reliability of the test to group scores of substantially equally qualified candidates.
It is important that the decision to band is set up prior to the next test administration. Changes in the scoring process after test administration may place the public entity at a major risk. The Supreme Court has stated that banding would not be an option after the fact (if it was used solely to reduce adverse impact), but should rather be decided in advance as a practice the employer will adopt: “Had the City reviewed the exam results and then adopted banding to make the minority test scores appear higher, it would have violated Title VII’s prohibition of adjusting test results on the basis of race. §2000e–2(l).” 50 If adverse impact is shown with the rank-ordered process after test administration, adequately addressing the differentiating validity requirements is the only hope of success in court.
Rule of Three in a Croson Study
Another practice that could be evaluated in a Croson Study is the practice of how top candidates are certified to an appointing authority for final appointment. The appointment certification procedure called “the rule of three” used by a public employer may adversely impact groups protected by Title VII. Any practice, procedure, or test that causes adverse impact on a group protected by Title VII in a hiring or promotion process is subject to a disparate-impact discrimination challenge. If an adverse-impact analysis of the rank-ordered distribution of scores shows adverse impact throughout the appointing potential part of the list, the chances are very good that the rule of three will have adverse impact (as it selects three people at a time from the rank-ordered lists). If the Croson Study finds that the practice of the rule of three has adversely impacted a group or groups protected by Title VII, then the job relatedness of the rule of three needs to be demonstrated. This will be hard to do when the psychometrics of a written test and oral interview will almost never be reliable enough to justify strict rank order in groups of just three candidates.
For example, in the Ricci case, using the known standard deviations of each test, typical reliability estimates of .90 for the written test (internal consistency) and .60 for the interview (interrater reliability), and the correlations between these two tests (rs = .35 and .40 for the lieutenants and captains, respectively), the composite reliability of the two combined measures can be estimated (rs = .84 and .85 for the lieutenants and captains, respectively). This value can be used with the standard deviation of scores on each list to compute a standard error of difference (SED) that can be used to band applicants who are deemed substantially equally qualified. Multiplying the SED in this example by 1.96 provides a 95% CI that applicants who are within a 9.12 point spread (for the Lieutenants list) and 9.06 point spread (for the Captains) possess scores that are statistically indistinguishable. In other words, score differences within the broader extremes of this range can be considered the product of measurement error with these tests rather than reliably different ability levels. With these ranges of substantially equally qualified candidates, sometimes there might be two substantially equally qualified candidates for the appointing authority to consider and other times there may be nine or more. It is unlikely that there always will be three. The reliability of the test is used to establish the measurement range of the test. The number of substantially equally qualified candidates will vary throughout the range of scores. Isn’t that what a job-related selection procedure should be doing—basing the grouping of candidates according to how their competency levels may reliably differ?
Remember that the Supreme Court has stated that banding would not be an option after the fact if the sole reason is race based. The process needs to be set up before test administration begins. “Had the City reviewed the exam results and then adopted banding to make the minority test scores appear higher, it would have violated Title VII’s prohibition of adjusting test results on the basis of race. §2000e–2(l).” 51 If a public entity performs a Croson Study, evaluates the rule of three as a part of that study, and finds adverse impact in the past, it is likely to happen again. Changing to a banding process after test administration will probably be too late, according to the Supreme Court, if the reason is race based. But stating, before test administration, that banding will be used based on the reliability of the tests involved in making the list, rather than the rule of three, is making adjustments on the basis of the test reliability, not race. Banding should be done based on the measurement properties of the tests involved and not based on an artificial number of three candidates at a time. The Croson Study can help act as the change agent to avoid disparate-impact discrimination liability. However, once adverse impact is shown on a current list with the rule of three, it is probably too late (see discussion on this specific topic later).
An inherent conflict exists between a Civil Service requirement that the selection process be job related and a requirement to use a rule of three. In the 1971 Griggs case, we learned from the Supreme Court that the rule of three is a practice covered under Title VII: “Under the Act, practices, procedures, or tests neutral on their face, and even neutral in terms of intent, cannot be maintained if they operate to ‘freeze’ the status quo of prior discriminatory employment practices.” The City charter of New Haven established a merit system. The merit system requires the use of job-related exams: When the City of New Haven undertook to fill vacant lieutenant and captain positions in its fire department (Department), the promotion and hiring process was governed by the city charter, in addition to federal and state law. The charter establishes a merit system. That system requires the City to fill vacancies in the classified civil service ranks with the most qualified individuals, as determined by job-related examinations. (italics added)
52
The Griggs case, quoted above, tells us that “examinations” must be interpreted as “practices, procedures, or tests.” The City’s merit system states the requirement to use the rule of three: After each examination, the New Haven Civil Service Board (CSB) certifies a ranked list of applicants who passed the test. Under the charter’s “rule of three,” the relevant hiring authority must fill each vacancy by choosing one candidate from the top three scorers on the list.
53
Perhaps the conflict between being required to use job-related practices and also being required to use the rule of three has been anticipated when the Supreme Court in Ricci issued a clear warning to the public sector that relying upon a state court’s prohibition of banding may not be enough: “A state court’s prohibition of banding, as a matter of municipal law under the charter, may not eliminate banding as a valid alternative under Title VII. See 42 U. S. C. §2000e–7.” 54
Nothing in this subchapter shall be deemed to exempt or relieve any person from any liability, duty, penalty, or punishment provided by any present or future law of any State or political subdivision of a State, other than any such law which purports to require or permit the doing of any act which would be an unlawful employment practice under this subchapter. (42 U. S. C. §2000e–7)
A Croson Study can gather the data regarding adverse impact of the rule of three and crystallize the issue for public-sector management to address before required to by a court. With a Croson Study completed, more options are available to the public employer.
What a Validation Study Would Cover
No validation study was presented to the City by the test developer. No validation study was presented to the City by any outside independent expert. No validation study was made available to any party in this case. No validation study was presented to the Federal District Court in this case. No validation study was available for review by the Second Circuit Court of Appeals in this case. No validation study was available for the U.S. Supreme Court to review in this case. Plaintiffs in typical disparate-impact cases would hope a validation study would find problems with the selection process. Plaintiffs in this case, mostly Whites near the top of the eligibility lists, wanted the selection procedure to be supported so they could be promoted; therefore, they had no interest in finding problems with the selection process. Defendants in typical disparate-impact cases want a validation study to provide the basis of support for their selection process. Defendants in this case used arguments (without supporting evidence) to criticize their own selection process but, at the same time, used actions (such as having their consultant testify in total support of the selection process, not providing any evidence to support their self criticisms, and not providing the validation study already part of the City’s contract with the test developer) to support their own selection processes. Perhaps the City knew the plaintiffs in this case would not want to do anything but support the selection process as well.
What is missing is a validation study of the entire selection process, so a professional review of the validity could be impartially conducted to represent all candidates competing for the lieutenant and captain positions. The Uniform Guidelines (1978) would usually be used for the outline of requirements for a validation study as it contains nine reporting requirements.
55
Under the Uniform Guidelines, many details of the selection process would be reported in a validation study—much more than presented to the courts and considered for judicial review in this case. Below are two sections from the validation reporting requirements of the Uniform Guidelines (41 CFR 60-3.15C) that would have been addressed if a validation study had been conducted in Ricci: (6) Alternative procedures investigated. The alternative selection procedures investigated and available evidence of their impact should be identified (essential). The scope, method, and findings of the investigation,
56
and the conclusions reached in light of the findings, should be fully described (essential). (italics added) (7) Uses and applications. The methods considered for use of the selection procedure (e.g., as a screening device with a cutoff score, for grouping or ranking, or combined with other procedures in a battery) and available evidence of their impact should be described (essential). This description should include the rationale for choosing the method for operational use, and the evidence of the validity and utility of the procedure as it is to be used (essential).
57
The purpose for which the procedure is to be used (e.g., hiring, transfer, promotion) should be described (essential). If the selection procedure is used with a cutoff score, the user should describe the way in which normal expectations of proficiency within the work force were determined and the way in which the cutoff score was determined (essential).
58
In addition, if the selection procedure is to be used for ranking, the user should specify the evidence showing that a higher score on the selection procedure is likely to result in better job performance. (italics added)
59
Much information was unavailable for judicial review because no validation study was presented to any court in this case. The City claimed flaws with the selection process but provided no strong basis in evidence to support its claims. However, the City did have its testing consultant testify. It is no shock that claims without evidence were not supported in a judicial review. Rather, the City, knowingly and deliberately, turned a blind eye to obtaining a validation study and had its testing consultant testify in support of the selection processes. The plaintiffs, in this case mostly Whites who would have been promoted but not for discarding the lists, had no motivation to do anything but support the validity of the very process being challenged. This environment was not ripe for an objective review of the validity based on the actions of both sides supporting the process. 60
Current Implications for Organizational Practice—Applying the Ricci Standard to Common Testing Situations
We have prepared some examples of how employers can address real employment situations. These examples consider the (a) Ricci admonishment regarding changes after a selection process has been administered absent a “strong basis in evidence” that not acting will cause a disparate-impact situation, (b) “Prohibition of discriminatory use of test scores” in Title VII’s Section 2000e-2(l), and (c) alternate employment practices in Title VII’s Section 2000e-2(k)(1)(A)(ii) (and related doctrine codified in the Guidelines, Sections 3B, 5G, 14B[5] and [6], and 14C[8] and [9] with respect to “alternate use with less adverse impact”). Each example will be discussed in the context of the employers in situations with and without a strong basis in evidence (i.e., evidence that the test(s) used were not sufficiently valid) as well as before or after the test administration.
Changing weights: For purposes of this discussion, the process of changing weights means changing from union-negotiated or arbitrary weights to a set of job-related weights based on job analysis data or ratings from a panel of subject-matter experts. Because developing test weights based on job research results in weights that accurately reflect job requirements, such a process is actually more likely to produce a more qualified applicant list than union-negotiated or arbitrary weights, and may produce more or less adverse impact.
Changing weights before test administration with or without a strong basis in evidence: This practice is acceptable, even if adverse impact was a motivating factor behind starting the process to research and identify the actual job-related weights (based on the “alternate employment practice” requirement of the 1991 Civil Rights Act and the “substantially equally valid” doctrine of the Guidelines). For example, an employer, in an attempt to maximize the validity of the process and reduce undesirable adverse impact, may conduct research and determine that assessment centers are an effective means at reducing adverse impact while measuring competencies that are typically untapped by written tests, and decide to include an assessment center as part of the overall weighted testing process. Another example would be an employer that uses a written test and an assessment center (weighted arbitrarily 50%/50%), and decides to conduct a study to reweigh the tests according to their relevant importance to the job. Yet another example would be using the written test with a validated cutoff score as a pass/fail device only (especially if it only measures abilities needed at a baseline level rather than differentiating abilities), and then weighting the assessment center 100% (especially if it measured differentiating abilities).
Changing weights after test administration without a strong basis in evidence: This practice would not be defensible post Ricci.
Changing weights after test administration with a strong basis in evidence: The Supreme Court ruled in Ricci that “changing the weighting formula, moreover, could well have violated Title VII’s prohibition of altering test scores on the basis of race. See §2000e–2(l)” (italics added). 61 Their key caveat to this statement was, “On this record, there is no basis to conclude that a 30/70 weighting was an equally valid alternative the City could have adopted” (italics added). 62 If, however, the City presented a set of weights (based on job analysis data or qualified subject-matter expert opinions) that were in fact substantially equally valid—or perhaps even more valid—than the original set used by the City, but reduced adverse impact, they might have been accepted. For example, if the City used job analysis data or subject-matter expert opinions to determine that a 50%/50% weighting scheme was substantially equally valid (or even more valid) than the 60%/40% weights that were used, and the job-related set reduced adverse impact, such a weighting scheme could have been adopted. However, merely suggesting alternative weights without also demonstrating that they were substantially equally valid to sufficiently address the “alternate employment practice” requirement of the 1991 Civil Rights Act and the “substantially equally valid” doctrine of the Guidelines would obviously not be acceptable, as they were rejected in the Ricci case.
Lowering cutoffs: Because cutoffs split the entire applicant group into two halves (passing and failing), they should be set in a way that maximizes the differentiation between the qualified versus unqualified applicants. The most effective cutoff scores have the highest levels of decision consistency reliability—a type of reliability that evaluates how consistently the test classifies “qualified” and “nonqualified” or those who pass the test versus those who fail. Cutoffs that are set too high will screen out too many applicants who are actually qualified. Cutoffs that are set too low obviously have the opposite effect—They will screen in too many unqualified applicants. Cutoffs that are accurately set using a job-related process like the Angoff method are likely to have higher levels of decision consistency reliability than arbitrary cutoffs. Even if a cutoff is set using a job-related method like the Angoff technique, the test used to measure applicant qualification levels along the continuum of scores will have a certain degree of score consistency (reliability) with respect to measuring the same. As discussed earlier, accounting for this lack of perfect measurement can be done by reducing the cutoff score by 1 to 3 CSEMs. Also discussed below is the possibility of lowering cutoffs without respect to the consideration of such measurement error.
Lowering cutoffs before test administration without a strong basis in evidence: Although this example implies lowering cutoffs in a way that is not based on the psychometric properties of the test (e.g., without considering the reliability or CSEM), it is likely defensible because it was done before the administration of the test. However, lowering cutoffs without respect to the psychometric properties of the test (or the ability continuum inherent within the score distribution) may possibly result in setting a standard that is below the qualification levels needed for the job. It is recommended to use the psychometric properties of the test and a job-related cutoff procedure.
Lowering cutoffs before test administration with a strong basis in evidence: If an employer determines a job-related cutoff before the test is given and desires to account for the measurement error of the test, they can defensibly lower the cutoff using CSEMs and determine the exact number (either 1, 2, or 3) beforehand. Most CSEM methods require postadministration statistics for computation. However, the Lord-Keats method can be used for estimating CSEMs before a test has been administered, 63 although it is more advisable to simply state up front whether 1, 2, or 3 CSEMs will be deducted and then use the most accurate CSEM computations after test administration.
Lowering cutoffs after test administration with a strong basis in evidence: If an employer administers a test that is used with an arbitrary cutoff, and they subsequently determine that neither the test nor the cutoff score is sufficiently valid (establishing a strong basis in evidence), lowering the cutoff score to reduce or eliminate adverse impact may be permissible. In fact, the Court ruled in Ricci that having a strong basis in evidence may even justify a more severe action—retracting the test results altogether. Lowering the cutoff score with consideration of the psychometric properties of the test would be helpful to support this situation, as would knowing the test score level associated with the minimum levels needed for the job (e.g., a cutoff score set using the modified Angoff technique).
Lowering cutoffs after test administration without a strong basis in evidence: Provided that the employer lowers the cutoff based on the psychometric limitations of the test, lowering the cutoff by 1 to 3 CSEMs may be permissible based on the “alternate employment practice” requirement of the 1991 Civil Rights Act and the “substantially equally valid” doctrine of the Guidelines. It should be noted here that the race-norming prohibition of the 1991 Civil Rights Act (§2000e–2[l]) expressly states that using different cutoff scores for different groups is prohibited; however, this should be differentiated from lowering a cutoff score, which is applied to all test takers in the distribution, within a range that is within the substantially equally valid confines. If the employer arbitrarily lowers the cutoff for race reasons only without a strong basis in evidence, this practice would not be supported post Ricci.
Banding: As discussed above, test score banding is widely practiced in the testing field and has been endorsed far more times than denied in litigation settings (see Aguinis, 2004). However, if banding is adopted after a test has been administered for the sole purpose of reducing adverse impact, the foundations laid down in Ricci apply as follows.
Banding before test administration with or without a strong basis in evidence: Before a test is administered, employers can predetermine to use banding, even though the span of the bands can only be determined after the test(s) have been administered (because the psychometric properties of the tests cannot be known until afterward).
Banding after test administration without a strong basis in evidence: This practice is not permissible after Ricci.
Banding after test administration with a strong basis in evidence: Provided that this process is based on the psychometric properties of the test(s) involved, banding using 1 to 3 SEDs (D. Biddle, 2008; see also D. Biddle, Kuang, & Higgins, 2007) may be permissible based on the “alternate employment practice” requirement of the 1991 Civil Rights Act and the “substantially equally valid” doctrine of the Guidelines.
Conclusion
What can be learned from Ricci? Perhaps the key lesson is that public employers, before implementing any race-conscious remedies, should perform a Croson Study. Throwing out the results of a list because the results adversely impact a group protected by Title VII of the Civil Rights Act needs to be justified with a strong basis in evidence. It is not enough to feel a selection process is not job related enough to withstand a court challenge. A Croson Study is needed to establish a strong basis in evidence for its conclusion that remedial action is necessary. Discussions with the employer’s attorney on how this process can be done would be prudent.
Public employers with constraints on the type of test (e.g., written test is required), how tests are used (e.g., rank order, rule of three, weights designated ahead of time rather than using job analysis data or by subject-matter experts, 70% cutoff scores specified by “merit system” rules, negotiation, or tradition rather than based upon competency), will most likely continue unnecessary adverse impact, unless they take some action such as conducting a Croson Study. Public employers may be continuing this adverse impact knowingly when there is another option. An option is to conduct a Croson Study, perhaps under attorney–client privilege, to see whether race- or gender-conscious remedies may be appropriate on a limited basis for a limited time in some situations. Revised selection procedures can be developed that focus on the type of practice, procedure, or test to identify competent applicants, with weights designated by job analysis data or subject-matter experts and competency-based cutoffs set by subject-matter experts. A Croson Study can provide a strong basis in evidence to provide more flexibility regarding the type of test, the weights to be used, and the cutoff, and alternate selection procedures can be developed and administered that can substantially reduce unnecessary adverse impact while selecting qualified candidates.
Finally, if evaluating alternate employment practices, make sure to compile evidence, not just rhetoric, to support the position that the alternate employment practice (such as banding, a different set of weights, a different cutoff score, another test such as the use of an assessment center) will provide substantially equally qualified candidates with less adverse impact. Make sure to do a Croson Study to see whether race-conscious remedies are appropriate on a limited basis for a limited period of time.
Questions for the Future
What will happen if the City of New Haven uses this challenged selection process, then minorities sue under Title VII, adverse impact is shown against minorities, and the validity of the lieutenant and captain selection processes is subjected to a professional review? All the practices, procedures, and tests used for the lieutenant and captain lists will be subject to review. The weights used were not subjected to a professional review in Ricci. The cutoff score used was not subjected to a professional review in Ricci. The rank-order process was not subjected to a professional review in Ricci. The rule of three was not subjected to a professional review in Ricci.
These practices would have been covered in a validation study. For some reason, which one can only guess, the City asked the testing consultant not to provide a validation study. The City made some arguments against the job relatedness of the examinations without providing supporting evidence and had its testing consultant testified as to the job relatedness of the oral and written tests, not how they were used. The plaintiffs in this case wanted to support the validity of the examinations, so they made no substantive criticisms. Therefore, the true validity of the practices, procedures, and tests used in these selection processes has never been subjected to a professional review. Neither the Federal District Court, the Second Circuit Court of Appeals, nor the U.S. Supreme Court had before it an objective professional validity review of the practices, procedures, and tests used in these selection procedures. A suit involving minorities would certainly focus on the adverse impact and job relatedness of the weights used, cutoff used, use of rank order without reliability considerations, use of raw scores rather than standard scores, and the use of the rule of three.
Sometime in the near future, an employer will find a substantially equally valid alternative employment practice with less adverse impact after a selection process has been administered and will want to resolve the apparent conflict regarding Title VII two sections, 2000e-2(l) and 2000e-2(k)(1)(A)(ii). Section 2000e-2(l) 64 is the section dealing with the “Prohibition of discriminatory use of test scores.” Section 2000e-2(k)(1)(A)(ii) 65 deals with the “Burden of proof in disparate-impact cases,” specifically the “alternate employment practice” provision. Research needs to be conducted on these two sections of Title VII along with the Uniform Guidelines interpretation of the alternate employment practices application (see Section 60.3B) 66 to crystallize potential conflict concerns and ask the question of how there can be a reconciliation.
Footnotes
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.