
Abstract
This article uses a multitheoretical approach to investigate the relationship between language use and opinion expression on Yelp. Using review metadata (e.g., star rating) to observe variation in reviewer feelings and motivations, we test for the strength of different message design logics: expressive logics, where language reflects a reviewer’s underlying opinion, and rhetorical logics, where language reflects a reviewer’s desire to make his or her opinion credible and acceptable to their audience. Results suggest that emotional language is motivated by expression as higher rated businesses are reviewed with more positive and fewer negative emotion terms. Rhetorical logics are associated with the use of abstract and self-focused language, with analysis suggesting this may result from the reviewer’s decision to write either narratively or formally.
Communication behavior is now observable to an unprecedented degree (Lazer et al., 2009). Because the vast majority of these observations are raw text (Rudder, 2014), research has increasingly focused on developing methods for analyzing these data (see Brook O’Donnell & Falk, 2015; Hopkins & King, 2010; Mehl & Gill, 2010). Less attention has been paid, however, to the theoretical study of textual production: the mechanisms and properties that observed discourse might reflect (Barnett, Wigand, Harrison, Woelfel, & Cohen, 1981; Brook O’Donnell & Falk, 2015; Lin, Margolin, & Lazer, 2016). Instead of systematically considering the possible ways a text may have been produced, research tends to assume a plausible theory consistent with a study’s aims. For example, research using sentiment analysis generally treats a text’s emotional content as a direct reflection of the speaker’s attitude (Himelboim, 2010; O’Connor, Balasubramanyan, Routledge, & Smith, 2010). Conversely, framing research typically evaluates differences in language use as choices in how to communicate rather than reflections of underlying intentions (Borah, 2014).
These assumptions distort analysis. If researchers assume that emotions expressed in discourse are authentic, they will be misled when it is used rhetorically (e.g., to provoke reactions in others). Similarly, if individuals use hostile or ideological frames because they view their opponents with hatred or disdain, their communication behavior is a symptom rather than a strategy (Borah, 2014). More broadly, failing to consider different processes of discourse bypasses the opportunity to use “big” text data to advance research into new domains.
This study aims to provide theoretical and methodological guidance for exploring different discourse processes by explicitly comparing them within a single dataset. We use the communication theoretic distinction between message design logics (O’Keefe, 1988)—expressive, conventional, and rhetorical—to make predictions for three kinds of discourse variables: emotion words, abstract language, and immediacy words. This approach, adapted from Monge and Contractor’s (2003) multitheoretic, multilevel (MTML) rationale for network study, provides a first step in distinguishing discourse production processes in real-world text.
Message Design Logics and the Challenge of Big Text Data
“Big” text data differ importantly from data used in prior communication research. Traditionally, text data were produced by unidentified individuals in controlled experiments (e.g., Hancock & Dunham, 2001) or surveys (e.g., Barnett et al., 1981; Rice & Danowski, 1993). In these contexts, topics, audiences, and incentives could either be manipulated or fixed in advance. When researchers gathered text from the messier real world, they were restricted to those produced by or within institutions (Lammers & Barbour, 2006), such as specific organizations (e.g., Kleinnijenhuis, van den Hooff, Utz, Vermeulen, & Huysman, 2010), fields (e.g., Doerfel & Barnett, 1999), or media (e.g., Corman, Kuhn, McPhee, & Dooley, 2002). While these institutions could not be controlled, they could be studied exhaustively through complementary means such as interviews or archival research. New media allows the observation of discourse produced by individuals in relatively uncontrolled settings (Himelboim, 2010). With these data, researchers can neither control why individuals are writing nor easily gather complementary, extratextual data about them. This uncertainty encourages researchers to assume that the text is produced via a plausible rationale without considering alternatives.
Monge and Contractor (2003) found a similar pattern in network research. Network scientists often assumed the network they observed was formed via a particular theoretical process when in fact multiple processes were plausible. In their MTML model, Monge and Contractor synthesized and catalogued the predictions made by different theories about how observed networks would form. They suggested that researchers should look for the signature of a theory, cases where the theory made a prediction that was distinct from those made by other theories. Identifying signatures of existing theories helped network researchers to identify dominant mechanisms (e.g., homophily) from rarer, more contingent ones (e.g., generalized exchange; Snijders, van de Bunt, & Steglich, 2010). The search for signatures also informed theory development by uncovering patterns not expected from known mechanisms.
We propose a similar multitheoretical approach to the study of observational text data. In particular, we suggest communication researchers should begin by exploring the textual signatures of different message design logics (Hart & Burks, 1972; O’Keefe, 1988). There are three basic design logics that govern the production of individuals’ statements. A message can be constructed expressively, meaning it reflects the underlying thoughts or feelings of the speaker; conventionally, meaning it is built in accordance with a set of rules appropriate to that situation or context; or rhetorically, meaning it is built in cognizance of feelings and rules but also with an awareness of the most persuasive way to present the message to achieve the speaker’s goal. A recent study reporting an association between the amount of anger in tweets sent throughout a county and the rate of heart disease in that county illustrates this difference (Eichstaedt et al., 2015). The implications of this correlation vary substantially depending on whether this observed anger reflects (a) self-expression: people feel (more or less) angry in some counties, (b) convention: people live in an environment where they are expected to sound (more or less) angry in some counties, or (c) rhetoric: people believe that to have their voice heeded, they must express (more or less) anger in some counties.
The difference between these logics is evident when considering their empirical implications for nontextual data. In an expressive logic, the discourse produced reflects the speaker as “an authentic being, . . . capable of imparting himself ‘as he really is’” (Hart & Burks, 1972, p. 76). The discursive signature of an expressive logic thus corresponds to an extratextual measure of the speaker’s self, such as physiological measures of their cognitive or emotional state (Brook O’Donnell & Falk, 2015). Conventional and rhetorical logics intervene between the speaker’s authentic state and their stated messages, as “sometimes the proposition expressed has nothing to do with one’s own actual salient beliefs” (O’Keefe, 1988, p. 86). The emphasis in these logics shifts to the speaker’s relationship to the audience. In conventional speech, this relationship is cooperative (O’Keefe, 1988). Speakers communicate by following the rules of a game and the audience infers the speaker’s intent within these rules. Rhetorical logics are extensions of conventional logics applied by speakers who have strategic incentives (O’Keefe, 1988). Rhetorical logics rely on, but also transform, conventions for strategic gain. Following the MTML rationale, we seek to first catalog and understand the extent to which well-theorized mechanisms are present in existing discourse.
The Current Study
The Setting: Online Review Sites
Online review sites have become increasingly prominent in commerce and research (Dellarocas, 2006; Li & Hitt, 2008; Walther & Jang, 2012). They are also an important site for competition between different message design logics. It is often assumed that the text of reviews is expressive. For example, the review “I’ve had excellent luck with the pizza from this place” 1 might be interpreted to reflect a positive experience. Yet reviews are also produced rhetorically, such as when an individual is paid to write a fraudulent review (Luca & Zervas, 2016; Ott, Choi, Cardie, & Hancock, 2011). Rhetorical practices also extend beyond fabrication through strategies such as framing (Entman, 1993) or self-presentation (Kacewicz, Pennebaker, Davis, Jeon, & Graesser, 2014).
Analytical Approach
We focus on expressive (emotional expression, Construal Level Theory) and rhetorical (self-presentation, rhetorical justification) mechanisms that prior work suggests should have signatures in reviews, and the dependent variables: emotion terms, linguistic abstraction, and words related to psychological immediacy—that characterize these signatures in other studies. We do not test conventional mechanisms in this article because of the difficulty associated with identifying the specific conventions reviewers are subject to (though we control for them statistically). To capture variation in logics, we focus on two kinds of review metadata—star rating and location. As we argue below, each of these should impact (a) how a reviewer thinks or feels about the object under review, altering the ideas they might express, and (b) the reviewer’s motivations relative to their audience, altering their rhetorical incentives.
Research Questions and Hypotheses
Expressive Uses of Emotion
When emotional language reflects an expressive logic, the emotion words in the text reflect the true feelings of the writer. In Yelp, reviewer satisfaction is represented by the number of “stars” given to a business (more stars meaning greater satisfaction). While positive emotions are often associated with satisfaction (Pennebaker, 2011), negative emotions are associated with failed expectations. Thus, if reviewers express their emotions in the review text, star rating should be positively correlated with the use of positive emotion words and negatively correlated with the use of negative emotion words.
Importantly, this seemingly obvious relationship is not an empirical certainty in real-world statements. While research has established that positive and negative emotion words can accurately capture a speaker’s inner emotional states (for a review, see Pennebaker, 2011), these studies intentionally suppress the influence of conventional and rhetorical logics that might have interfered with this relationship. For example, a participant might be encouraged to write only for himself or herself (e.g., via a diary) or the researcher (see Mehl & Gill, 2010). These studies thus confirm that when an individual intends to express their emotions, he or she uses emotional words. However, they do not indicate whether actual uses of emotional language, in cases where many nonexpressive incentives are present, are primarily expressive. Yelp reviews offer the possibility of testing this proposition via the following expressive predictions:
Rhetorical Uses of Emotion: Self-Presentation
Rhetorical motivations may induce the writer to modify the emotional content of a message so that it is distinct from their true feelings. A well-known reason for this modified emotional content is offered by the theory of self-presentation (see S. W. Smith, Yoo, & Walther, 2008). Individuals use self-presentation strategies to achieve social goals such as to appear attractive to others or maintain a high status with their community (Kacewicz et al., 2014). Specifically, research suggests that people have incentives to present an overly positive image, as positive emotions are considered more socially facilitative and publicly appropriate (Bazarova, Taft, Choi, & Cosley, 2012; Turner, 2007). This leads to a tendency to express more positive emotion to others than one is privately feeling.
The motivation to self-present can vary across situations (see Walther, 1996). Individuals should be more motivated to engage in selective self-presentation when they believe that their audience is one in which their reputation is tracked and evaluated (Bazarova et al., 2012; Sommerfeld, Krambeck, & Milinski, 2008). In online review sites, this tracking and evaluation is performed largely through the text of reviews, such as seller feedback on eBay (Cabral, 2012). It follows that users manipulate this text to manage the impressions of others (see Ellison, Heino, & Gibbs, 2006). The consequences of earning a positive or negative reputation depend, however, on the individual’s relationship to the social community in which that reputation resides. People can afford to risk earning poorer reputations with audiences with which they share few social ties and/or little likelihood of future interaction (Burt, 2005; Coleman, 1988).
Social ties tend to cluster around their geographic home (Krackhardt, 1994; Preciado et al., 2011), even in virtual spaces (Huang, Shen, & Contractor, 2013). Thus, when individuals are writing about businesses located in their own geographic community, their reviews are more likely to be seen by people they know and to impact their neighbors. As such, self-presentation strategies are called for more when an individual is engaging in this more local social interaction for which they feel greater accountability (see Ellison, Hancock, & Toma, 2012; Lerner & Tetlock, 1999; Toma & Hancock, 2010). By contrast, when individuals write reviews for distant communities, they are ostensibly anonymous, and thus their incentives for self-presenting are lower (Anthony, Smith, & Williamson, 2009). Thus, the following hypothesis is proposed:
Expressive Uses of Abstraction and Immediacy: Construal Level Theory (CLT)
Neuroimaging has revealed that, beyond emotion, expression involves many subprocesses that can indicate why a particular message was produced (see Weber, Eden, Huskey, Mangus, & Falk, 2015). One of these subprocesses is how people think about current objects or life experiences in terms of psychological distance from the self.
CLT is a widely known theory of psychological distance that has been demonstrated to relate to language use (Trope & Liberman, 2010). CLT addresses the level of abstraction with which objects and experiences are conceptualized:
Moving from a concrete representation of an object to a more abstract representation involves retaining central features and omitting features that by the very act of abstraction are deemed incidental. For example, by moving from representing an object as a “cellular phone” to representing it as a “communication device.” (Trope & Liberman, 2010, p. 441)
A key tenet of CLT is that abstraction is associated with psychological distance. Distant objects are conceived of abstractly while close objects are conceived of more concretely (Trope & Liberman, 2010). For example, when anticipating a trip three months in the future (temporally distant), an individual may think about how the vacation will be enjoyable. When the trip is 1 week away (temporally proximate), he or she is likely to think about concrete items such as clothes to pack.
Construal is affected by social distance in addition to physical and temporal distance. When people are exposed to others who they perceive are socially similar, they achieve more concrete conceptual outlooks on ensuing tasks (Liviatan, Trope, & Liberman, 2008). When individuals feel a high level of power, they feel more social distance from others and produce more general and abstract categorizations (P. K. Smith & Trope, 2006). Social distance from an audience can also be important. Individuals focus more on the abstract features of a decision when giving advice to socially distant others (Kray & Gonzalez, 1999).
The conceptual differences predicted by CLT also modify word patterns. Magee, Milliken, and Lurie (2010) found that quotations from authority figures that were more focused on the future (rather than the present) contained a more abstract, less concrete language style. In an experiment by Fujita, Henderson, Eng, Trope, and Liberman (2006), individuals who viewed a video supposedly filmed at a distant location gave a more abstract description of the scene compared with those who viewed a video supposedly filmed nearby.
The social distance between a reviewer and a business should vary consistently with the reviewer’s relationship to the business’s location. Social identification with the local area as “home” can alter construal directly (Liberman & Förster, 2009). Local businesses are also more likely to be frequented by local people who the reviewer will consider similar (Christakis & Fowler, 2009). The reviewer’s location at the time of writing may have some impact, with some reviewers writing while physically at an establishment and others after they have returned home. Nonetheless, the systematic variance in social distance should persist because, according to CLT, variation in any distance has an impact (Katz & Byrne, 2013). Thus, we hypothesize the following:
Language patterns can also indicate construal through the use of immediacy words—language patterns that approximate the “here and now” (Cohn, Mehl, & Pennebaker, 2004). These words indicate where the speaker is focusing their attention. Immediate language expresses psychological closeness. High immediacy words, including first-person singular pronouns (self-references: I, me, my) and present-tense language, suggest that the speaker is focusing inward and on the self, rather than on the outside world (Pennebaker, 2011). This pattern is demonstrated in cases where people experience psychological distress. People facing distress reflect intensely on their current experiences and state of mind (Beck, 1967). Consistent with this tendency, suicidal writers show more self-focused communication patterns, including the increased use of self-references, than people who die of other causes (Stirman & Pennebaker, 2001). An increase in first-person singular pronouns can thus suggest where an individual’s attention is directed (e.g., inward and on the present; see Pennebaker, 2011). Therefore, if a review expresses the reviewer’s thoughts, text that contains more first-person singular pronouns suggests the reviewer is more focused on the self.
We predict that local patrons will feel more psychological closeness to the object of their review, and their writing style will reflect more verbal immediacy. If they write expressively, this will result in a higher rate of self-references in their reviews. Thus, we predict the following hypothesis 2 :
The valence of an experience can also impact construal. When people reflect on themselves and their own behavior, positive mood is associated with abstract construal (Labroo & Patrick, 2009). When reflecting on external circumstances and events, however, people are more likely to feel personally attached and closer to positive experiences because positive experiences often have an immersive effect of being present. Furthermore, negative experiences make people feel less personally and psychologically attached (see Carrera, Muñoz, Caballero, Fernández, & Albarracín, 2012). One way to cope with a negative experience, such as an unforeseen trauma, is to psychologically distance the self from the event. For example, Cohn et al. (2004) compared LiveJournal blogs before and after the terrorist attacks of September 11. Entries after 9/11 contained more psychological distancing (less immediacy) than before the attacks, suggesting psychological changes prompted by the need to manage the trauma.
If language is used expressively, then first-person singular pronouns should be used at a higher rate in the description of positive experiences. For example, Salovey (1992) induced participants into a positive, negative, or neutral mood and then had each person finish a sentence completion task with pronouns (e.g., I, she, or we). Those induced into a positive mood completed sentences with more first-person singular pronouns than those in the neutral mood (see also Silvia & Abele, 2002). We thus predict the following hypothesis:
Rhetorical Uses of Abstract and Immediate Language: Ambiguity and Justification
Expressive uses of abstraction and immediacy reflect how an individual conceives of an object. People may also choose to write reviews using abstract concepts or make more self-references because of their persuasive effects on an audience.
Abstraction can have rhetorical advantages by making it easier for the writer to escape the consequences of unpopular or controversial statements. More abstract, less concrete language creates greater opportunities for strategic ambiguity (Eisenberg, 1984), as vague, general claims are harder to evaluate and scrutinize (Margolin & Monge, 2013). For example, fraudulent scientific papers tend to have a more abstract writing style than legitimate papers (Markowitz & Hancock, 2016). Similarly, individuals concerned about their reputation on social media often make ambiguous statements to satisfy their audience (Marwick & boyd, 2011).
This argument suggests a prediction contrary to the prior argument for the expression of construal. CLT suggests that local reviewers will conceive of objects in more concrete terms. However, as local reviewers are more likely to be concerned about maintaining their reputations, they may also have a greater incentive to write abstractly. Thus, when reviewing a local object, individuals may edit their statements to be fuzzier or more abstract and thus more palatable to their local audience. Visiting reviewers, by contrast, should feel unimpeded to share their concrete evaluations expressively.
Local reviewers may also use language that appears vague, ambiguous, and abstract to outsiders but is well understood within their community (Margolin & Monge, 2013). For example, one reviewer wrote of a pizza restaurant in Lafayette, Indiana, “If you are from Lafayette, you don’t need to read this review . . . pizza is a thin crust Pizza King style pizza.” 3 This statement is conceptually abstract to outsiders (“Pizza King style”) but might be concrete to other locals. If individuals use community jargon in their reviews, their language may appear more abstract when it is not, because these reviews achieve specificity in a manner that is not recognized by standard coding dictionaries (Eisenstein et al., 2010). Thus, rhetorical logics predict the following hypothesis:
A related rhetorical motivation is the desire to justify nonnormative views (Hart & Burks, 1972). Individuals do not need to justify ideas that are already acceptable to a community (Green, Li, & Nohria, 2009). However, when statements are controversial or out of the norm, they require warrant and backing (Toulmin, 1958). “Extreme” reviews, or those whose star ratings deviate from the typical review, would thus be more likely to attract abstract writing. While a reviewer may write more concretely to reflect a positive experience, rhetorical logics suggest that as a rating increases toward either extreme, reviewers will muddle or “fuzz up” their claims (making them more abstract) so they are less controversial:
People can use first-person singular pronouns similarly. Claims about the self are harder for an audience to test than claims about the broader world. For example, it is harder to challenge the statement, “I called and was asked to hold. Two minutes went by and it was obvious I’d been forgotten about” 4 [1 star] than the statement, “The sushi here is decent, but the service is just too slow” 5 [2 stars]. The former refers to a now unobservable event in the past, something no one can challenge. The latter makes two testable claims that could be inconsistent with others’ experiences, casting doubt on the credibility of the reviewer.
Thus, self-references may justify opinions in a way that puts less credibility at risk. For example, Ott et al. (2011) found that, even though liars often use fewer self-references than truth-tellers (also Toma & Hancock, 2012), fraudulent hotel reviews contain more self-references than genuine reviews. Increased self-references may reflect a method to increase review credibility.
Local reviews should contain more self-references (H4), but for a different reason than predicted above. CLT suggests local reviewers perceive an object as psychologically closer to the self than visiting reviewers. Rhetorical logics suggest local reviewers reference the self to add credibility and defend their claims.
This rhetorical rationale leads to a different prediction when considering review valence. Reviewers should construe extremely positive reviews as close but extremely negative reviews as distant. Rhetorically, regardless of how the objects of review are viewed, both extremely high and extremely low-rated reviews should contain high rates of self-references to add defensibility:
Method
The Yelp Academic Dataset
We collected Yelp reviews from the Yelp Academic Dataset from 2014, which consists of information about businesses located near 30 major U.S. universities. Each review contains several attributes, and includes the review text and the user’s rating of the business on a 1-star (worst) to 5-star (best) rating. Other metadata, such as a nonidentifiable code for the specific reviewer as well as the city in which the business is located, are also provided. The city/town information provided by Yelp is very specific. Many towns contained very few businesses or reviews and were geographically very close to much larger cities or towns. Some locations are also nested within others. This inconsistency creates a challenge which we address in our operationalization of “local reviewers.”
Measures
Ratings
Each review is accompanied by a rating on a scale from 1 (a typically poor experience) to 5 (a typically great experience). No formal criteria or instructions are given by Yelp, so reviewers interpret these ratings for themselves.
Language analysis
Each review was analyzed with Linguistic Inquiry and Word Count (LIWC) software, an automated tool to calculate relative frequencies of words that reflect psychological categories (Pennebaker, Booth, & Francis, 2007). LIWC has become a primary means of automated text analysis in large datasets (Boyd & Pennebaker, 2015). Each LIWC category contains a dictionary of words that has been empirically validated to reflect that psychological dimension across different contexts (Pennebaker, 2011). Because LIWC relies on a standard dictionary that is independent of context, it does not account for slang or other domain-specific vocabulary that might also convey these dimensions. However, when data are drawn from a wide variety of locales for which the researchers lack detailed domain knowledge, LIWC’s dictionary ensures comparability across social communities (e.g., Coviello et al., 2014; Kramer, Guillory, & Hancock, 2014; Pennebaker, Chung, Frazee, Lavergne, & Beaver, 2014).
The text of each review was scored as a percentage of its words that match a particular language dimension. For example, the four-word phrase, “The best burger ever,” has one word that reflects positive affect (i.e., best), and it therefore receives a score of 25% for positive emotion terms. For transparency, we offer the following examples that are typical of Yelp reviews for the categories used in this study (words tapped by LIWC are italicized).
Positive emotion terms
“Food is priced well, tastes good, and the owner is really nice, fun to talk to him about Hawaii.”
Negative emotion terms
“The coffee is great but the service is so horrendous I am going back to Starbucks. The owner is so rude to her customers! PASS.”
Abstraction
Linguistic abstraction refers to the absence of concreteness or specificity of the words used. There are typically two approaches to operationalizing abstraction. The first considers the abstraction level of content words. For instance, the words evolution and mortal are more abstract than house and tiger because the mental images they induce are likely to be fuzzier (see Feng, Cai, Crossley, & McNamara, 2011; Paivio, 1991).
A second approach considers the rates of function words (Chung & Pennebaker, 2007). The use of articles (e.g., a, the) indicates the presence of concrete nouns, and the use of prepositions (e.g., over, under) indicates precise relationships. Quantifiers (e.g., any, every, more, less) express explicit differences between objects. Text that contains a high rate of articles, prepositions, and quantifiers is more concretely written than text with a low rate of articles, prepositions, and quantifiers (Larrimore, Jiang, Larrimore, Markowitz, & Gorski, 2011; Markowitz & Hancock, 2016).
Because our text is drawn from a particular domain (business reviews), we are unsure whether generic content dictionaries would appropriately capture abstraction. Function word use should be less sensitive to domains, however (Chung & Pennebaker, 2007; Pennebaker, 2011). Based on prior work (Larrimore et al., 2011; Markowitz & Hancock, 2016), we created an abstraction index that combines the standardized rates of articles, prepositions, and quantifiers into an index and multiplies that sum by −1. A higher score on this index suggests that a piece of text is more abstractly written compared with a piece of text with a low score on this index.
To demonstrate the index in practice, consider two pieces of text describing loan requests in a peer-to-peer lending network: (A) “It was tough getting my finances back together and I was relying on my credit card” and (B) “I need a loan to pay off my credit card debt.” Text B is more specific and concrete than Text A, and this is reflected in the abstraction index. Text A contains a lower rate of articles (0 words = 0%) than Text B (one word = 9.09% of the total word count), indicating a reduced presence of concrete nouns, and contains fewer prepositions (Text A: one word = 6.25%; Text B : two words = 18.18%), suggesting that A specifies fewer specific relationships between its referents than B. Neither text has any quantifiers (Text A: 0 words = 0%, Text B: 0 words = 0%). When combined, A will be scored as more abstract than B. 6
First-person singular pronouns
These include references to the self. For example, “I feel ill whenever I eat here. I noticed I tend to review the places I love and not the places I hate. This was the first spot I thought of under the ‘hate’ category” (1-star).
Local reviewer
The local reviewer category is designed to capture whether the business being reviewed is in the “home” local area of the reviewer. While in these anonymized data we do not have the reviewer’s address, we can observe the locales of the businesses for which they typically write their reviews. As mentioned above, the challenge is that the raw business locations provided by Yelp are at inconsistent levels. Some businesses are given generic cities (e.g., Albany, NY; Amherst, MA) and others small, adjacent communities (e.g., Watervliet, NY) or more specific neighborhoods within those broader cities (e.g., North Amherst, MA).
As the goal of capturing location is to identify meaningful differences in the reviewer’s conception of the object or their audience, we combined reviews into “local areas” that included all named locations that were adjacent to or subsumed by another location in our data. This process left us with 26 distinct, noncontiguous local areas. We then checked whether these 26 areas were meaningfully coherent and distinct. Research indicates that people spend the majority of their daily time within one hour of home (see Marchetti, 1994; Schafer & Victor, 2000). Examination of the distances between the businesses and the local areas to which they were assigned indicated that our local areas capture distinct communities. First, we observe that 77% of businesses reviewed were assigned to their original location (i.e., were not reassigned to an adjoining location). An additional 14% (91% cumulative) were assigned to a local area that was 5 miles or fewer from their original location with an additional 8% (99%) cumulative were within 11 miles. The remaining 1% were assigned to local areas no further than 23 miles from their original location. At the same time, no distinct local areas were this close to one another, with only three (out of 325) pairs of local areas even within one hour of one another according to Google Maps navigation (Los Angeles, CA-Claremont, CA = 36 minutes; Palo Alto-Berkeley = 50 minutes; Boston, MA-Providence, RI = 55 minutes). This method thus separates objects of review into those that are well within an individual’s egocentric area of identification and interaction from those that are outside of this area (Liberman & Förster, 2009).
To assign specific local areas to reviewers, we examine the frequency with which they review businesses in an area. Specifically, if 75% or more of a reviewer’s reviews are written about businesses in a particular local area, we consider this local area to be the reviewer’s home area (see explanation below). Each individual review where the business reviewed is in the reviewer’s home area was dummy-coded as a local review.
Threshold Selection and Robustness Checks
As is often the case with datasets of real-world behavior, our data require us to make a number of choices regarding thresholds for measurement (González-Bailón, 2013). The full dataset also brings substantial statistical power, as it contains over 300,000 reviews to perform our analyses. However, our goal is not to understand or characterize Yelp reviews in particular but to understand general processes of discourse production that extend across platforms. For this, the full bulk of Yelp data is not needed, because it does not afford observable variation in important dimensions for the specific message design logics in which we are interested. To test for these logics, we substantially subset our data to those cases where each theoretical mechanism would reasonably be expected to have an observable influence. In other words, we ask the following question: With these criteria for inclusion in our dataset, if this mechanism were to have a strong influence, should we expect to see that influence within this set of cases, and if it were to have a weak influence, should we expect to see little or no effect?
Focal dataset
The primary logic of our analysis is based on within-reviewer differences: how reviewers’ language changes for good experiences versus bad experiences, and local businesses versus distant businesses. We are also interested in reviewers who have enough investment in their reputation on Yelp to be subject to reputational concerns (Anthony et al., 2009). Thus, we restrict the dataset to reviews by individuals who have written at least 10 reviews including at least one local review and one visiting review and then set the threshold for local reviews at 75%. These decisions should give us reasonable precision for identifying local reviewers, as each local reviewer must have written at least eight reviews within one area, and no more than 25% of their reviews in all other areas, to be considered local. Importantly, because our data do not comprise all Yelp reviews, but only those from specific areas provided by Yelp, lower thresholds carry the risk that the reviewer’s true home is unobserved. For example, an individual could write five reviews in New York, three in Los Angeles, two in Houston, and six in Denver (which is not included in the academic dataset). A 50% threshold would mark this person as a New Yorker, when it is more likely they do not clearly identify with a particular community. While setting the threshold at 75% does not eliminate such cases, it makes them much less likely, because the observed data would show a clear tendency for one location.
Robustness check datasets
Based on the preceding rationale, we expect that if expressive and rhetorical logics meaningfully influence language choices in reviews, there should be significant differences observable in the focal dataset. We thus report analyses of our focal dataset in detail. Nonetheless it is possible that these decisions, though reasonable, lead to misleading conclusions. We also run each of our analyses at the following levels—five or more reviews (rather than 10), 50% local threshold and 90% local threshold, and reviews with 50 or more words—and summarize the main findings from these robustness checks.
Models
As our data contain multiple levels with repeat observations at several levels (reviewers, businesses, local areas), we implement multilevel modeling using the lme4 package (Version 1.1-10) in R. Each model contains a random intercept for reviewer, business, and local area. We apply these random effects because specific reviewers, businesses, and local areas appear numerous times in our data and might have specific effects that influence the results.
Results
Descriptive statistics for the focal dataset are provided in Table 1. Bivariate correlations for each variable of interest are provided in Table 2.
Focal Dataset Descriptive Information.
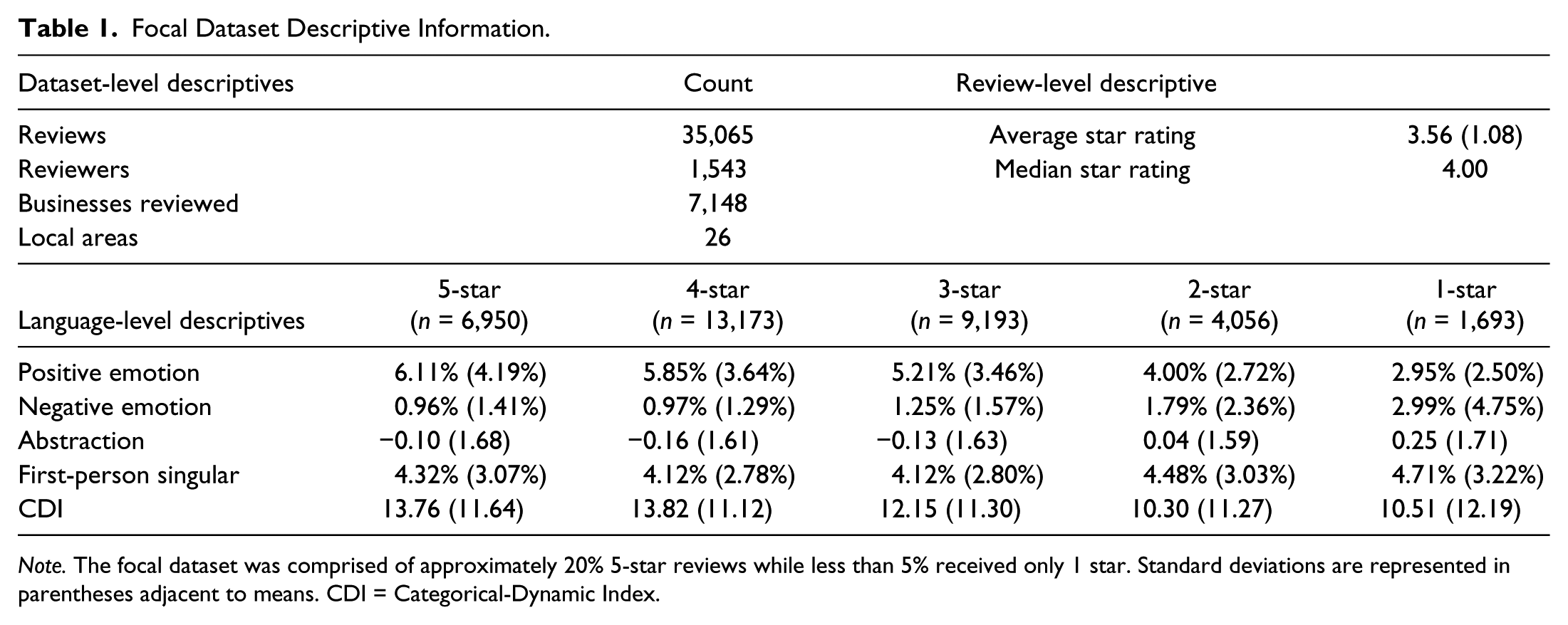
Note. The focal dataset was comprised of approximately 20% 5-star reviews while less than 5% received only 1 star. Standard deviations are represented in parentheses adjacent to means. CDI = Categorical-Dynamic Index.
Correlations Between Independent and Dependent Variables (N = 35,065).
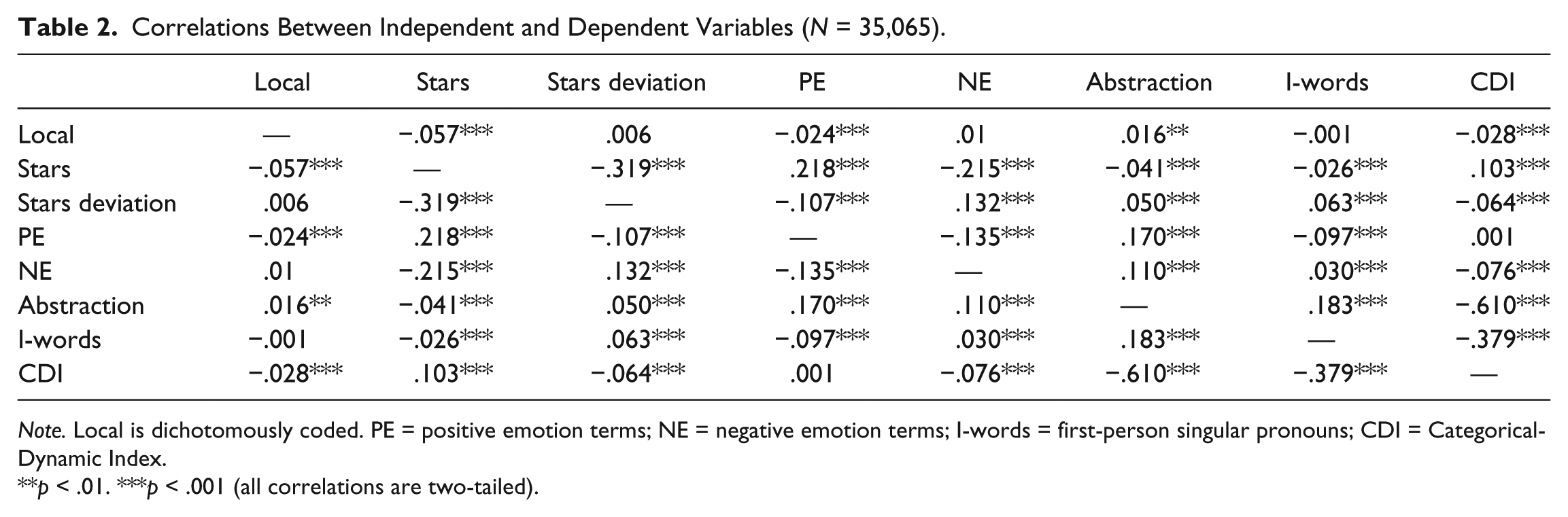
Note. Local is dichotomously coded. PE = positive emotion terms; NE = negative emotion terms; I-words = first-person singular pronouns; CDI = Categorical-Dynamic Index.
p < .01. ***p < .001 (all correlations are two-tailed).
Hypothesis Tests
Results for emotion variables can be observed in Table 3, with abstraction and immediacy findings displayed in Table 4. A general summary of our findings with their corresponding empirical and theoretical motivations can be found in Table 5.
Regressions on Use of Emotional Language.
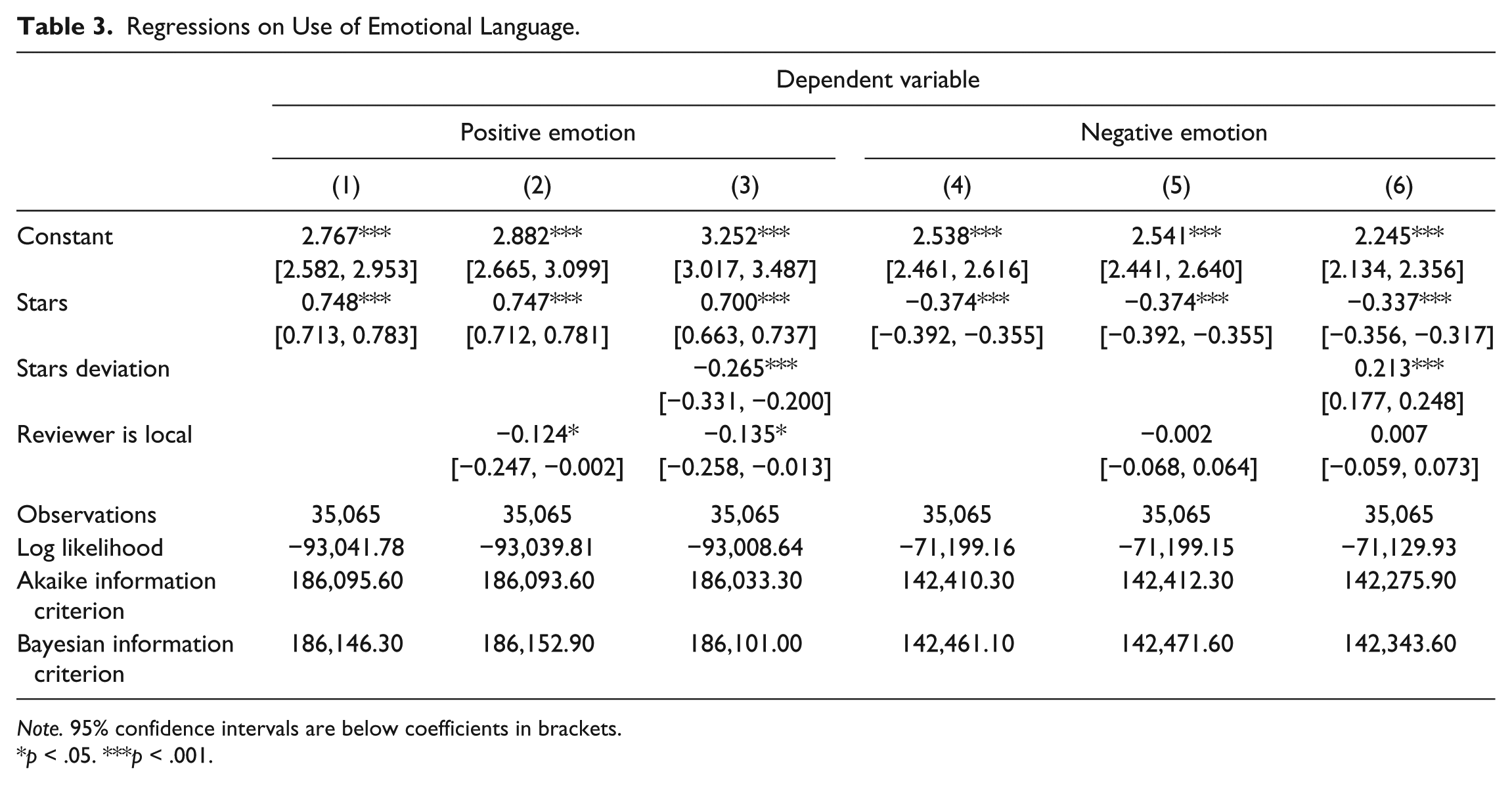
Note. 95% confidence intervals are below coefficients in brackets.
p < .05. ***p < .001.
Regressions on Use of Abstract and Immediate Language.
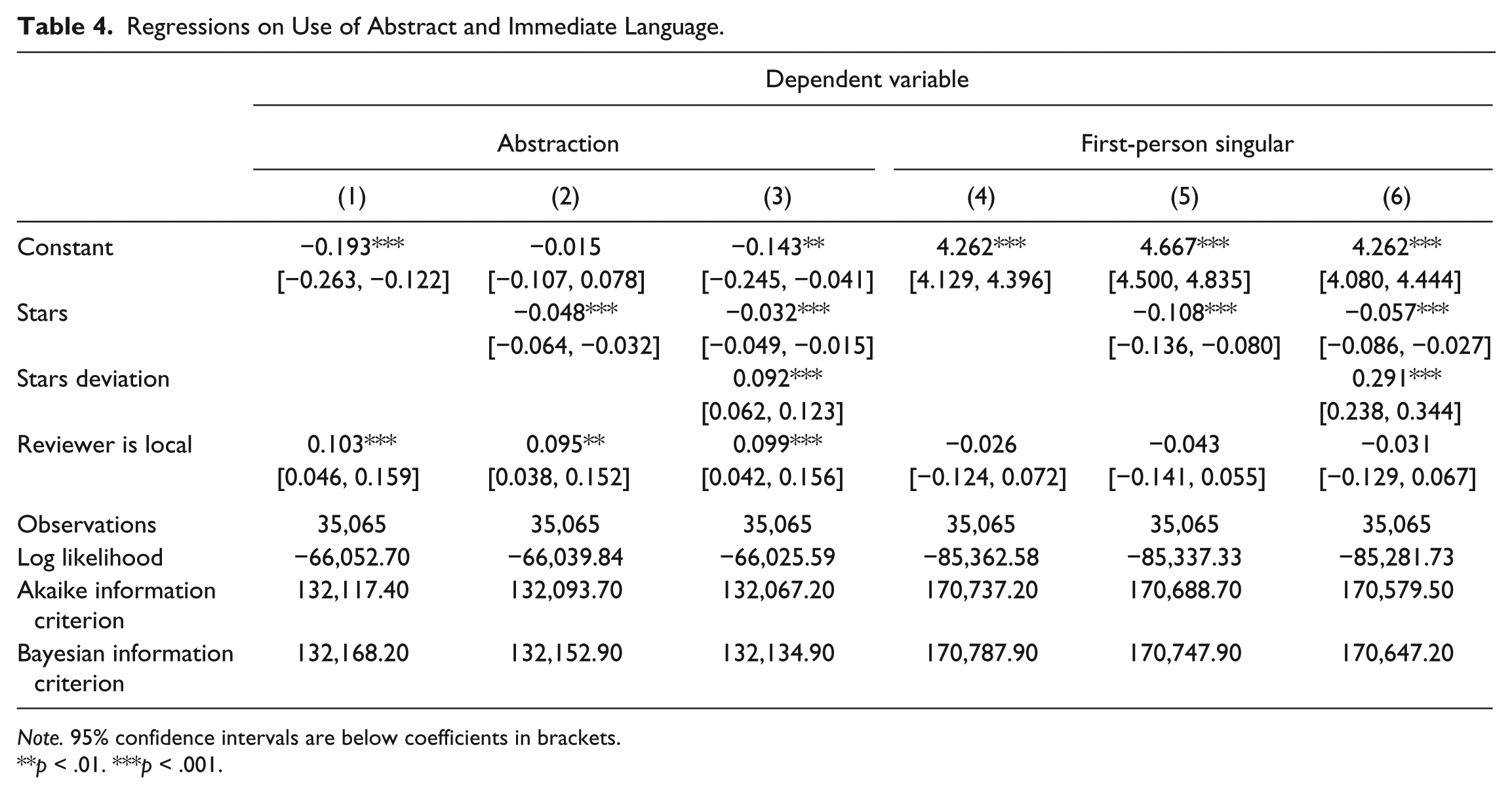
Note. 95% confidence intervals are below coefficients in brackets.
**p < .01. ***p < .001.
Summary of Hypotheses and Results.
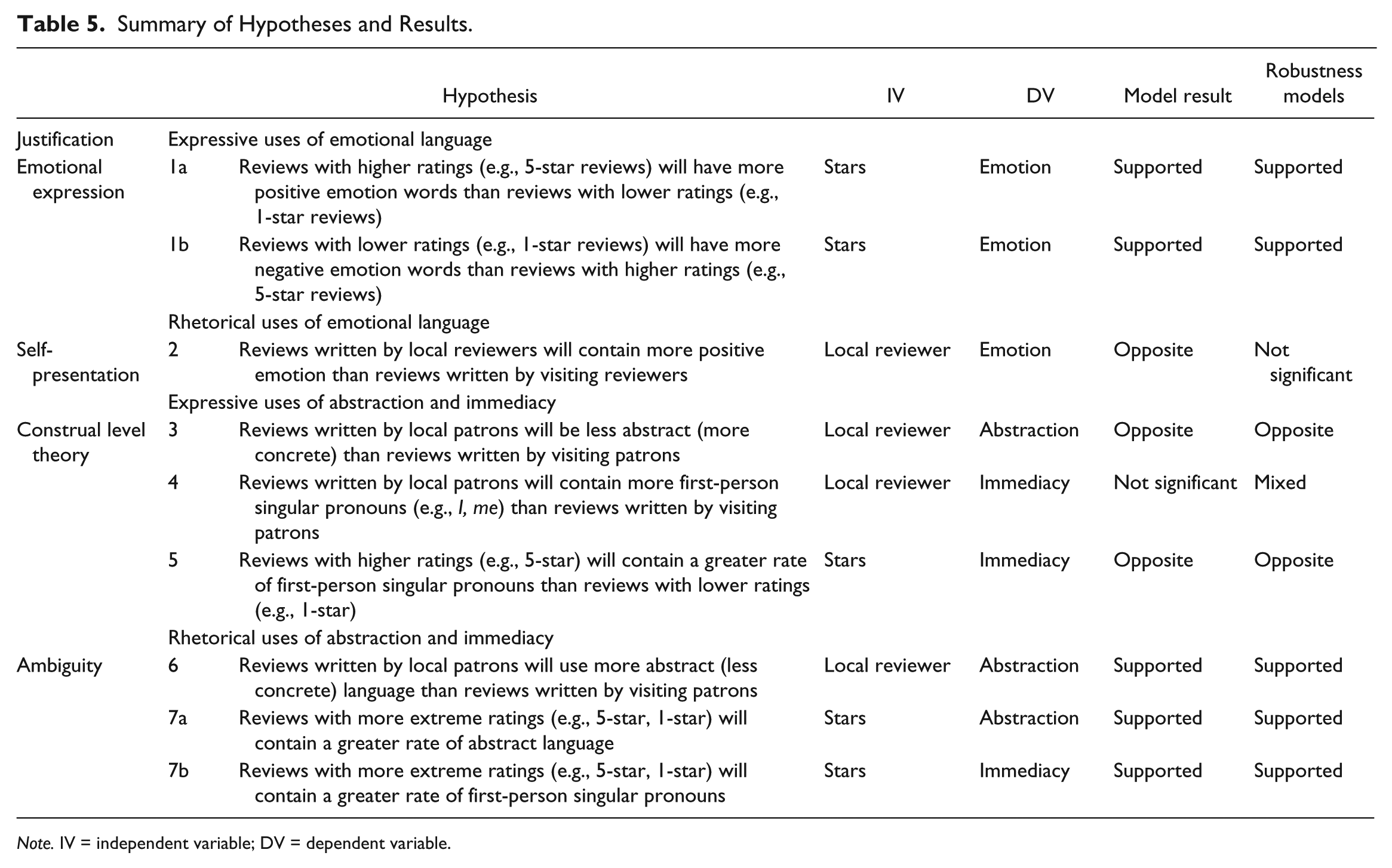
Note. IV = independent variable; DV = dependent variable.
H1a
H1a predicted that as review star rating increases, the rate of positive emotion terms in the review text would increase as well. As shown in Table 3, column 1 (tested in isolation) and column 2 (with covariates included), the result is statistically significant at the p < .001 level. The estimates suggest that a 1-star review would contain about 3.6% positive emotion terms, with each increase in star adding about 0.75% (B = 0.747). In our focal dataset, the average length of a review was 138 words, suggesting that an incremental increase in star rating adds approximately one positive emotion word to the review. Overall, this result was very robust, as it was statistically significant in each model regardless of thresholds for local reviewer (50% or 90%), number of reviews (5 or 10), or number of words in the reviews (at least 1 or at least 50), and holds when controlling for stars deviation (column 3). Together, H1a is supported.
H1b
H1b predicted that as review star rating increases, the rate of negative emotion terms in the review text would decrease. As shown in Table 3, column 4 (tested in isolation) and column 5 (when covariates included), the result is statistically significant at the p < .001 level. The estimates suggest that a 1-star review would contain about 2.2% negative emotion terms, with each increase in star removing less than 0.4% (B = −0.374). This suggests that based on the average length of a Yelp review from our database, half of one negative emotion term would decrease as star rating increases. This result was very robust, as it was statistically significant in each model regardless of thresholds for local reviewer, number of reviews, or number of words in the reviews, and holds when controlling for stars deviation (column 6). Thus, H1b is supported.
H2
H2 predicted that for businesses rated with the same number of stars, reviewers would use more positive emotion terms when writing about businesses in their home area relative to a visiting locale. As shown in Table 3, column 2, the result is not in the predicted direction (B = −0.124) and statistically significant (p < .05). That is, when writing about businesses in their local community versus a nonlocal community, reviewers used an average of 0.12% fewer positive emotion terms. Considering the length of an average Yelp review from our sample, local reviewers use close to one fewer positive emotion term per five reviews than visiting reviewers. This result is not robust, however, as it is not significant in any of our other models. Thus, H2 is not supported.
H3 and H6
H3 predicted that reviewers would communicate with a less abstract (more concrete) style when writing about local businesses while H6 predicted that reviewers would communicate with a more abstract (less concrete) style when writing about local businesses. As shown in Table 4, column 1 (and consistently in columns 2 and 3 where stars are included as a covariate), the result is consistent with H6 (B = 0.103, p < .001). This suggests that, on average, a local business review contains approximately one fewer article, preposition, and quantifier per seven reviews compared with a visiting business review. This result was very robust, as it was statistically significant in each model regardless of thresholds for local reviewer, number of reviews, or number of words in the reviews. We thus find support for H6 and no support for H3.
H4
H4 predicted that reviewers will use more first-person singular pronouns when writing about local businesses. As shown in Table 4, column 4 (and consistently in columns 5 and 6 where stars are included as a covariate), the result is not statistically significant. Inspection of the robustness check models suggests a slightly more complicated pattern. In models with the local threshold, at 90% the negative coefficient was significant (p < .05). Thus, there is some evidence that locale influences first-person singular pronoun use, nonetheless, in no cases were results consistent with H4, which is not supported.
H5
H5 predicted that reviewers will use more first-person singular pronouns when writing about businesses to which they assigned a higher star rating. A shown in Table 4, column 5 (and also column 6), the coefficient is in the opposite predicted direction and significant (B = −0.108, p < .001). On average, more highly rated reviews contain approximately one fewer self-reference (e.g., I, me, my) for every seven reviews. This result was very robust, as it was statistically significant in each robustness check model except one (where only five reviews were required and no minimum word limit was required). Thus, the pattern appears consistent but contradicts H5, which is not supported.
H7a
H7a predicted that reviewers will use a more abstract style when writing about businesses to which they assigned a more extreme rating. To test this hypothesis, we include both a term for stars and a term for stars deviation, the number of stars that a particular review’s rating is above or below the average for that business. H7a is supported if there is a significant, positive relationship between stars deviation and abstraction. As shown in Table 4, column 3, the stars coefficient is significant and negative (B = −0.032, p < .001) and stars-deviation coefficient is positive (B = 0.092, p < .001). This result was very robust as it holds in each robustness check model. Thus, H7a is supported.
H7b
H7b predicted that reviewers will use more first-person singular pronouns when writing about businesses to which they assigned a more extreme rating. H7b is supported if there is a significant, positive relationship between stars deviation and the use of self-references. As shown in Table 4, column 6, the stars coefficient is significant and negative (B = −0.057, p < .001) and stars-deviation coefficient is positive (B = 0.291, p < .001). This result was very robust as it holds in each robustness check model. Thus, H7b is supported.
Post Hoc Analysis
An advantage of the multitheoretical approach is its ability to identify specific cases that appear to contradict established theories and thus require further attention. Contrary to predictions derived from CLT, we observe that first-person singular pronouns decline as stars increase (Table 4, column 5). This effect is reduced, but not eliminated, by the inclusion of the rhetorical effect for extreme reviews (Table 4, column 6). We also observe that stars have a similar, negative relationship for the use of abstraction (Table 4, columns 2 and 3). This suggests that, contrary to the logic of CLT, which suggests that objects at greater psychological distance should be associated with both more abstraction and fewer self-references, abstraction and self-references are positively correlated, which examination of the bivariate correlation confirms (r = .18, p < .001). Having identified this anomaly, we now inspect the raw text of the reviews to see if other theoretical processes, beyond those we have considered, are leading abstract writing style to be joined to self-references in the production of text.
We began our investigation by identifying cases where such processes would likely be visible to the naked eye. We constructed several relevant categories of review: reviews that were high (top 15%) in both abstraction and self-references, those that were low (bottom 15%) in both abstraction and self-references, and those that were high in one category and low in the other. 7 We then inspected the texts in each of these groups to see if any pattern or intuition emerged regarding how or why abstraction and self-references were joined.
Our observations lead us to hypothesize that their co-occurrence may be caused by reviewers’ choosing or avoiding narratives. Specifically, we observe that many of the reviews that score high on both categories take the form of informally depicted stories. For example,
I learnt a lesson. I had dismissed this place, merely because their food is not very nice. One Saturday morning, having entered the realm of the unwell, I had to leave S&S (for the last time, odious place). I had still not eaten nor had coffee, so I ducked in here in desperation. They looked after me very well. They saw I was none too lively and it seemed mere humane hospitality to them. Bless them. [4-stars]
8
Similarly, we observe that many reviews that score low on both abstraction and self-references are written in a more formal, analytical style such as
Pagliacci is good for a slice on the go. They usually have a few different varieties available for by-the-slice action, ranging from the fancy to the unhealthy. All seem to be in the $2.50 range, which is quite reasonable if you’re going for a quick meal. I personally enjoy the double pepperoni. Sometimes you just need some grease. The crust is great—soft inside and crunchy on the outside—and it feels like a classic pairing with tasty-but-simple cheese and sauce. The pepperoni can get greasy, but it’s delicious. [4-stars]
9
Rather than telling a personal story, this reviewer provides a more formal, analytical description of the typical experience at the restaurant.
Having observed this pattern, we considered available theories that might explain this difference. This distinction between narratives and analytical descriptions has both a theoretical and methodological background. Theoretically, the difference can be interpreted as one of “genre” (Yates & Orlikowski, 1992) or “register” (Biber & Jones, 2005). Yates and Orlikowski (1992) defined a genre as “a typified communicative action invoked in response to a recurrent situation” (p. 301). Genres are deployed for rhetorical reasons, to meet the needs of a situation, but carry with them rules, or conventions, for their execution. Similarly, registers are “varieties of language that are defined by their situational (i.e. non-linguistic) characteristics . . . e.g., conversation, spontaneous speeches, newspaper editorials, academic prose” (Biber & Jones, 2005, pp. 164-165). Typically, genres and registers are not considered individual-level choices. Rather, they are given by the norms of a situation. However, one of the unique features of online communication is the speaker’s freedom to define the institutional nature of the forum (Marwick & boyd, 2011). Thus, while restaurant reviews written for a newspaper might be required to provide a formal description, Yelpers are free to choose whether to write formally or tell a story.
Pennebaker et al. (2014) observed writing style differences between genres in college applications. They measure the distinction using the Categorical-Dynamic Index (CDI). This measure evaluates text along a continuum, which on the high end is formal and analytical (the categorical end of the CDI) and on the low end that is more free-flowing and less formal (the dynamic end of the CDI). The more dynamic a piece text, the more it is associated with a more narrative style of explication (see Pennebaker et al., 2014, for the CDI formula). In the examples above, the first, more narrative review receives a lower, more dynamic CDI score (−2.89) when compared with the second, more categorical and formal review (33.30).
Our inspection of the text thus leads us to a testable hypothesis that might explain the otherwise anomalous co-occurrence of abstraction and self-references: a dynamic, narrative writing style. We first test whether our independent variables predict this choice. We predict CDI scores based on the location of the reviewer, stars, and the extremity of the stars in the rating. We find a clear effect for all three variables. First, local reviewers show a significant tendency to use a less categorical, more dynamic style (B = −0.840, p < .001), indicating that they are more likely to write narratively. Second, we find that categorical language increases with stars, as the stars coefficient is positive (B = 0.923, p < .001), but decreases with extremity (B = −0.545, p < .001). Thus, consistent with the rhetorical rational provided for H7a and H7b, extreme reviews are more likely to be couched in a more narrative writing style and thus more difficult to challenge. However, we also see that the willingness to write categorically increases as the review becomes more positive.
Next, we predict both the level of abstraction and the level of first-person singular pronouns in reviews based on both our hypothesized variables and the CDI as a covariate. Results show that, contrary to the results for H6, local reviewers are no longer more linguistically abstract once their choice to write narratively or analytically is accounted for (B = 0.022, p = .17). Similarly, local reviewers are now less likely to use first-person singular pronouns, once their choice to write narratively or analytically is accounted for (B = −0.105, p < .05). At the same time, consistent with the predictions of CLT, stars are now positively associated with self-references (B = 0.029, p < .05), though the coefficient is very small.
Taken together, these results suggest that rhetorical choices occur in a reviewer’s selection of genre or register, rather than in their selection of specific words. Local reviewers, and reviewers with extreme ratings, often tell stories rather than provide formal assessments. Controlling for this genre-level choice, however, there is some evidence of typical CLT effects.
Discussion
Review and Implications of Findings
Our results help to advance the theoretical understanding of the mechanisms that produce real-world text. First, we find support for the presence of both expressive and rhetorical design logics in Yelp reviews, with each operating on the production of a different language feature. Expressive logics were dominant in the production of emotion terms. More highly rated businesses were described with more positive emotion and less negative emotion. Rhetorical logics appeared to operate more strongly on the use of an abstract writing style and self-references. Local reviews, where reviewers have more reputation at risk, and extreme reviews, where reviewers are more likely to draw skepticism or criticism, were written with a more abstract, less specific style. More extreme reviews also contained more self-references, suggesting claims that are harder to challenge. There was little evidence that linguistic choices directly reflected construal in the observed discourse. These results do not suggest that these more muted mechanisms do not operate but rather that, in the production of discourse in this context, they are drowned out by competing theoretical processes.
The results also reveal interesting findings about how these more dominant logics may work. First, our results indicate that expressiveness is not equal across these emotional categories. Inspection of the regression coefficients indicates that the use of positive emotion words varies almost twice as much with star ratings (B = 0.748 in Table 3, column 1) as the use of negative emotion words (B = −0.374 in Table 3, column 3). In other words, the use of positive emotion words appears to be more sensitive to the speaker’s underlying feelings. As we discuss below, this may be an important topic for further research.
Results of the post hoc analysis also suggest the possible need for a shift in the theoretical understanding of these logics. In the approach taken at the start of this article, rhetorical logics are assumed to act after conceptualization through self-editing. The post hoc analysis suggests, however, that rhetorical logics may act more strongly earlier in the process, when individuals choose to write with a particular style (story, formal description, argument). Specifically, we find that local reviewers, and reviewers writing extreme views, are more likely to use language in a manner consistent with narrative or storytelling (indicated by lower CDI scores). Controlling for this tendency, local reviewers are indistinguishable from visiting reviewers in terms of abstraction. This theoretical model suggests that rhetorical and expressive logics may both operate but at different levels, with rhetorical motivations influencing genre choice and expressive logics influencing word choice. Future work might focus specifically on more complex models of discourse production, including relationships between multiple LIWC dimensions, using path analysis. 10
Limitations and Future Directions
By design, this study focuses exclusively on theoretically expected associations between a small set of variables in textual data observed in a messy, real-world setting. Its strength lies in its ability to untangle the influences that operate in real-world discourse, but its weakness is that it can only go so far in identifying and isolating mechanisms. Below we delineate the main limitations of the study and describe how we hope our theoretical approach can help to engender complementary research to address them.
First, now that the most important effects observable in real-world data have been identified, controlled studies could go much further to measure and manipulate emotions, construal, and sensitivities to audiences. For example, a more precise measure of emotions to be expressed could be obtained using functional magnetic resonsance imaging and other physiological measures of emotion, which could then be compared with word choice and review ratings (Brook O’Donnell & Falk, 2015). Such research might investigate how sensitive the use of positive or negative emotion words is to a reviewer’s underlying feelings.
Experimenters may also choose to more precisely manipulate self-presentational concerns to see what prompts shifts in choices for genre or language. An important limitation of the current study is that “localness” may only weakly capture the social community to which the reviewer feels most accountable. Reputational concerns could be manipulated directly, however. For example, subjects could be asked to write reviews that would vary in whether the reviews were shown to friends. These reviews could be evaluated in terms of genre (narrative vs. analytical) as well as the specific word choices. Construal could also be manipulated in terms of hypothetical distance, the probability with which an individual anticipates an experience. This manipulation may be less likely to be confounded with self-presentational concerns and may provide insight into how construal affects discourse.
A second limitation concerns the small effect sizes resulting in the limited change in language use we observe at the review level. For example, with each incremental star rating increase, there would be approximately one positive emotion term added to a review. Conversely, negative emotion terms decrease by approximately half of one word with a reduced star rating as well. While the scale of these changes is consistent with manipulations in many priming and framing studies (Aarts & Dijksterhuis, 2003; Greene, McDaniel, Buksa, & Ravizza, 1993; Schuldt, 2013), it is likely that on the individual review level these sentiment changes are unnoticeable to the average Yelp user—a trend that has been acknowledged in prior large-scale experiments evaluating discourse patterns (Coviello et al., 2014; Kramer et al., 2014). Changes for other effects were even smaller (approximately one word in every five to 10 reviews).
This is an important limitation for certain applied uses of this research for understanding review sites. Our interest in this research, however, is less in the effects of these changes on Yelpers per se, but on the kinds of theoretical conclusions that researchers might draw from textual data. In that sense, statistically significant patterns in large textual datasets, and the relative strength between them, are the relevant research subject, not just patterns that are influential on or detectable by humans.
Another limitation is the restrictiveness of Yelp, particularly its subject matter. We use Yelp because review metadata allow us to observe variation in important extratextual variables that are more difficult to measure in typical social media. Considering a broader array of review sites, such as Airbnb or similar sites where users rate one another’s personal property or services, may afford a greater opportunity to observe certain theoretical dynamics. For example, the effects of self-presentation, which is primarily activated in interpersonal domains where communication is dyadic and face-saving techniques are important, may be easier to observe in this setting (Brown & Levinson, 1987). We encourage future research to explore dynamics of the online sharing economy in a systematic manner.
Conclusion
This study has provided an example of a multitheoretical approach to studying observable text data. Its aim was to encourage further research on the mechanisms through which discourse is produced, that is, the processes that stand between the text that researchers observe and the underlying thoughts, feelings, and other attributes of the text’s authors. The results of the study indicate that while some aspects of this process are already well understood, others merit, and hopefully will draw, further interest.
Footnotes
Declaration of Conflicting Interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This material is based upon work that is supported by the National Institute of Food and Agriculture, U.S. Department of Agriculture, Hatch under 1004600.