
Abstract
Background
Generative artificial intelligence (AI) represents a potentially powerful, time-saving tool for grading student essays. However, little is known about how AI-generated essay scores compare to human instructor scores.
Objective
The purpose of this study was to compare the essay grading scores produced by AI with those of human instructors to explore similarities and differences.
Method
Eight human instructors and two versions of OpenAI's ChatGPT (3.5 and 4o) independently graded 186 deidentified student essays from an introductory psychology course using a detailed rubric. Scoring consistency was analyzed using Bland-Altman and regression analyses.
Results
AI scores for ChatGPT3.5 were, on average, higher than human scores, although average scores for ChatGPT 4o and human scores were more similar. Notably, AI grading for both versions was more lenient than human instructors at lower performance levels and stricter at higher levels, reflecting proportional bias.
Conclusion
Although AI may offer potential for supporting grading processes, the pattern of results suggests that AI and human instructors differ in how they score using the same rubric.
Teaching Implications
Results suggest that educators should be aware that AI grading of psychology writing assignments that require reflection or critical thinking may differ markedly from scores generated by human instructors.
Keywords
In the rapidly changing world of technology, educators must stay resilient and adaptable to capture the full potential of these technologies. Although some educators may be reluctant to embrace the use of artificial intelligence (AI) to lighten their workload, others may rely on AI with increasing frequency to accomplish tasks such as lesson preparation and assessment development (Yan et al., 2023). Recent AI innovations have demonstrated high potential to assist with some common instructor tasks in higher education (Oltz, 2023), including automating some aspects of important but time-consuming tasks such as grading (Yan et al., 2023). Educators facing time constraints or who wish to provide rapid feedback to students on writing assignments may find AI tools to be especially beneficial. However, research on the efficacy of using the latest developments of generative AI to grade essays has not yet been explored in depth.
The use of AI for scoring essays, for example, not only saves valuable time but may offer more standardized and fairer evaluations when compared to human graders. Human graders are susceptible to numerous errors and biases that may affect the way they evaluate students’ work, such as the halo effect (Malouff et al., 2013; Nisbett & Wilson, 1977), pressures to provide inflated grades (Cushman, 2003; Donaldson & Gray, 2012), and variables such as fatigue or even boredom (Erturk et al., 2022). To the extent that using AI for grading essays may mitigate some of these influences, its use could lead to scores that more accurately reflect the quality of work under consideration, which Sadler (2009) describes as being essential for maintaining grade integrity. On the other hand, AI is also prone to errors and biases, specifically associated with the data used to train the models (Eubanks, 2022). Additionally, human graders may focus on aspects such as creativity, originality, critical thinking, personal reflections, and depth of thought, which may be more challenging for AI systems to assess. This AI limitation could lead to an oversimplified evaluation of complex arguments or creative ideas, thereby leading AI to be less accurate in evaluating the quality of written work.
Whereas student use of AI systems such as OpenAI's ChatGPT (2023) to help author essays and complete their coursework has garnered much attention (e.g., Cotton et al., 2023), there has been less focus on how faculty may make effective use of AI. In response to the prompt of “What can ChatGPT do to support faculty in higher education,” the AI-generated text indicated that “ChatGPT can support faculty in higher education by automating routine tasks, assisting in content creation, and providing real-time student support, thereby enhancing teaching efficiency and personalized learning” (OpenAI, 2023). Given that faculty interest in automating feedback to students on the quality of their writing, specifically, stretches back more than 50 years to early work on computer evaluations of writing in Project Essay Grade (Page, 2003), the promise of using generative AI to assist in grading essays warrants attention. The focus of this study was to explore potential similarities and differences between AI and human graders in evaluating real, but deidentified, student essay submissions that were originally graded by human instructors and then evaluated by AI using the identical, detailed grading rubric. Thus, the question guiding this research was: will human instructor scores for student essays written for an introductory psychology essay be significantly different from AI generated scores when evaluating the same work?
Method
Participants
Human Instructors
Participants who comprised the human instructor sample included eight instructors who taught the same introductory psychology course at a military service academy during the fall semester of 2023. All instructors taught the lesson sequence in identical order and on the same dates. They also used the same essay prompt, grading rubric, and submission deadline.
AI Grading Systems
The AI grading systems used for this study included the free version of ChatGPT 3.5 released November 6, 2023 (OpenAI, 2023) and the newest, more advanced subscription model ChatGPT 4o released May 13, 2024 (OpenAI, 2024). ChatGPT 3.5 and 4o are generative AI models trained to produce text, or natural language. Both are capable of understanding text and images and can chat with the user about the topic of interest in response to user prompts. Open AI's ChatGPT models utilize a combination of pretrained models, human-labeled data, and reinforcement learning to enhance performance (OpenAI, 2023).
Materials and Procedure
To evaluate the consistency between generative AI essay scores and scores assigned by human instructors with disciplinary expertise, we evaluated 186 student essays from a required introductory-level psychology course using both methods. The essays were a convenience sample sourced from the total collection of 236 archived student papers that were written in response to the same essay prompt on the topic of close relationships and scored by instructors using a rigorous rubric. Instructors also met to calibrate their grading prior to scoring any essays. All essays were deidentified prior to being shared with the research team.
To evaluate each essay, we used a well-established and tested rubric that included five sections: introduction, analysis, reflection, application to future relationships, and writing/organization. The paper was scored on a 100-point scale with each of the independent sections weighted differently and evaluated based on the content that each student provided. The introduction (10 points) asked the students to provide a brief description of a close romantic relationship they had observed (positive or negative) and outline the supporting theories and concepts that they planned to use to discuss that relationship in the essay. The analysis section (25 points) instructed students to identify and discuss how various course concepts and theories could be utilized to explain the relationship examples provided. The reflection section (25 points) asked students to describe how the relationship examples they provided impacted their perspective on relationships. The application to future relationships section (25 points) asked them to apply the course concepts to a possible future relationship and explain how the lessons learned might be beneficial for that future relationship. The writing section was worth the remaining 15 points. The scoring rubric, which also contains brief descriptions of each section of the essay, is openly available (see Wetzler et al., 2024).
We used prompt engineering (Giray, 2023) to ensure that ChatGPT understood the task, as accurate, concise, and clear prompts tend to elicit better and more accurate generative output. Once we found the optimal solution for the prompt, we used it to score all papers. We used the following prompt: Instructions: Assume you are an instructor teaching a general psychology for leaders course to first year cadets at the U.S. Military Academy. Your students each wrote a paper, and you need to score it and provide feedback specifically using the rubric provided below. Provide section scores and the total score out of 100 using the rubric as a guideline for values and provide meaningful feedback to the writer.
The research team inputted the prompt into ChatGPT followed by the detailed grading rubric, which was then followed by a deidentified essay. To avoid direct comparisons among essays and prevent carryover, every essay was evaluated in a separate, independent chat session. Even though the essays were deidentified, we also set the data controls to prevent ChatGPT from retaining or training on any of the data or writing provided in the essays. Scores and feedback provided by each model of ChatGPT were recorded for comparison with instructor-generated scores. The Human Research Protection Program determined this study to qualify as exempt under 32CFR219.104(d)(4) due to the secondary analysis of existing data (control number CA-2024-77). We also obtained institutional approval to conduct the study. 1
Analytic Strategy
Planned analyses included first examining the data using descriptive statistics. The focal analyses also included one-way analyses of variance (ANOVAs) comparing instructor scores with AI scores on total scores, as well as section scores for the introduction, analysis quality, depth of reflection, demonstration of appropriate applications, and writing, for each model of ChatGPT. We also used a Bonferroni correction for multiple comparisons.
To further examine any observed differences, we conducted the multistep Bland-Altman analysis (Bland & Altman, 1986), designed specifically to compare two methods of measurement. The Bland-Altman analysis is commonly used in the medical field for evaluating whether a new measurement technique or device differs significantly from an existing method to aid in the determination of whether the new method might be used as a substitute or replacement. This type of analysis has recently been used to examine scoring patterns for human instructors versus AI in higher education research on grading exams of various types (e.g., Coskun & Alper, 2024). The Bland-Altman analyses allowed us to assess consistency between the scoring methods and visually depict the data patterns (see also Kaur & Stoltzfus, 2017). In the current study, human instructor scores were not assumed to be free from error or to represent true scores. Rather, instructor scores served as the benchmark for comparison as they reflect current standard practice in scoring essays. Therefore, some deviation of AI scores from human instructor scores was expected, though difference scores closer to zero would reflect better consistency between the two methods.
We then used regression analyses to predict difference scores from average scores for total scores and section scores, again with a Bonferroni correction. This approach allowed us to test for consistency in scoring at different ranges of the grading scale to determine whether there existed better consistency, for example, at the higher end of the grading scale than at the lower end, which would be indicative of proportional bias. Proportional bias occurs when the difference between the two methods changes or is inconsistent across the levels of measurement.
Due to the rapidly changing nature of generative AI and the release of newer versions of OpenAI's ChatGPT, the dataset included AI generated scores from two different AI models. We initially analyzed scores generated by ChatGPT 3.5, the free version. We subsequently generated scores with ChatGPT 4o, which was the newest available full model at the time of writing. We analyzed scores from each model separately.
Although not the focal part of the current study, we also reviewed the written comments generated by the AI models and conducted a text analysis of word count and tone using the Linguistic Inquiry and Word Count software (LIWC-22; Boyd et al., 2022). LIWC-22 is a text analysis program widely used in psychological research. The following variables were analyzed using the LIWC-22 dictionary, total word count, positive tone, negative tone, and an overall tone dimension. In addition, sample comments from the written feedback generated by ChatGPT for essays representing varying levels of quality (based on instructor scores) are openly available (see Wetzler et al., 2024). Both instructor and AI scores for the same essays are also included.
Results
Descriptive statistics, correlations, and one-way ANOVA results for scores generated by ChatGPT 3.5 and 4o are presented in Table 1. Results for ChatGPT 3.5 showed the AI scores to be significantly higher than the instructor scores for total scores, as were reflection scores and writing scores. Instructor scores were significantly higher than AI scores on the introduction. The mean difference between instructor (M = 83.81) and AI (M = 87.45) for the total scores was 3.64 points, with AI generated scores being more lenient on average. Results from the same analyses based on scores from ChatGPT 4o showed that, although mean total scores and reflection scores were not significantly different, scores on the introduction were significantly higher for instructors and scores generated by ChatGPT 4o were significantly higher for the writing section, similar to differences observed with ChatGPT 3.5. Interestingly, the analysis and application section scores were significantly lower for ChatGPT 4o than instructor scores, a pattern that was not observed with ChatGPT 3.5.
Means, Standard Deviations, and One-Way Analyses of Variance for Instructor, ChatGPT 3.5 and ChatGPT 4o.
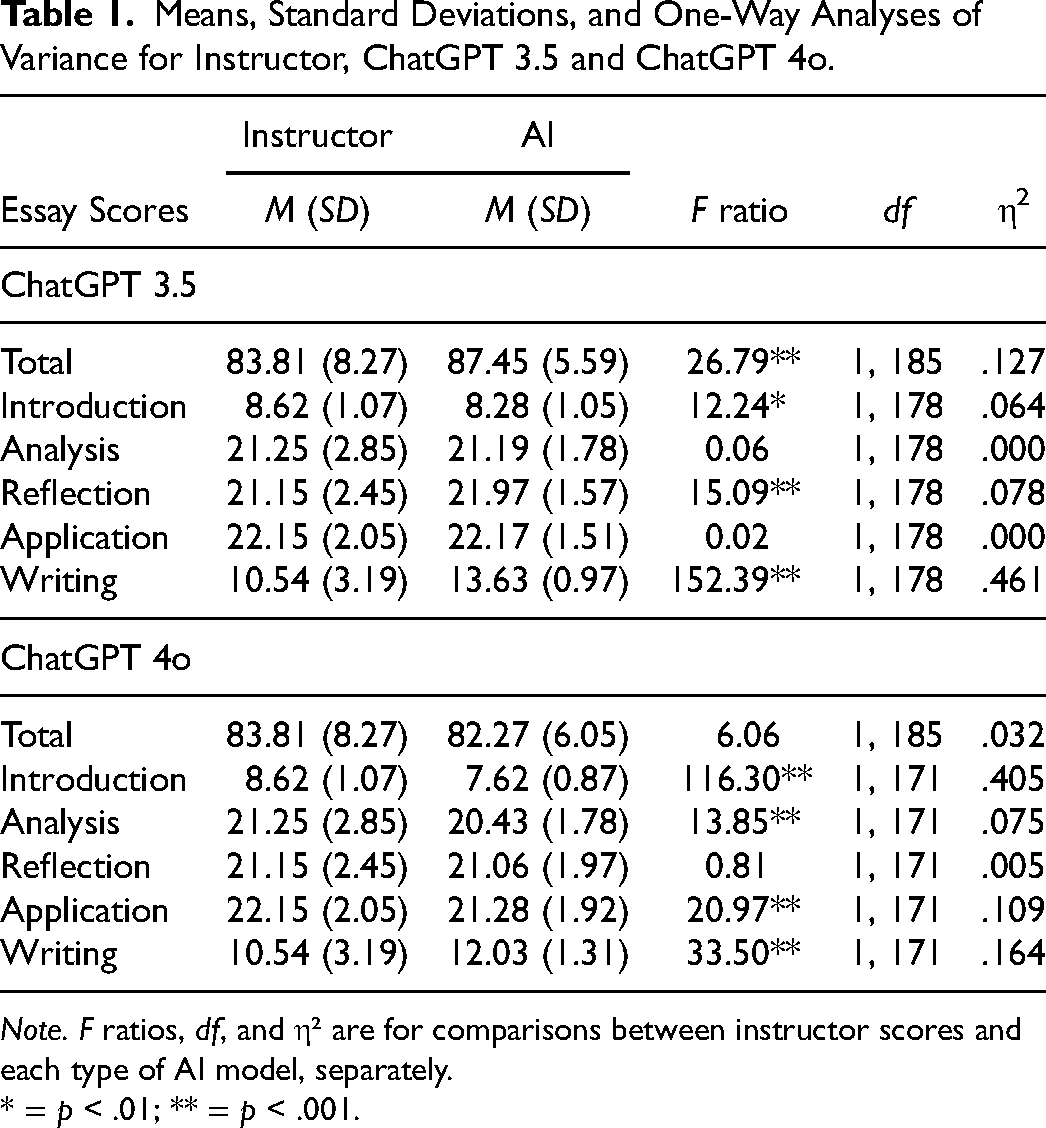
Note. F ratios, df, and η² are for comparisons between instructor scores and each type of AI model, separately.
* = p < .01; ** = p < .001.
The Bland-Altman analyses involved first computing the differences between instructor and AI generated scores for each variable, as well as computing the averages of the two. Difference scores were then tested using one-sample t-tests to determine whether they were significantly different from zero; zero difference would indicate perfect agreement. Difference scores for the total, introduction, reflection, and writing scores were all significantly different from zero (ps < .01) for ChatGPT 3.5 generated scores, as were scores for the introduction, analysis, application, and writing sections for ChatGPT 4o (ps < .001). Next, we created graphs to depict the difference scores and average scores, including the mean and 95% confidence intervals showing the limits of agreement. All variables presented similar patterns for both ChatGPT 3.5 and 4o. Figure 1 shows the Bland-Altman graph for total scores for ChatGPT 4o and indicates very low agreement. Difference scores ranged from −27.00 to +25.75. In practical terms, these wide differences suggest that some essays that may have been scored quite low by human instructors were scored very high by AI and conversely that some essays scored high by instructors were scored very low by AI.
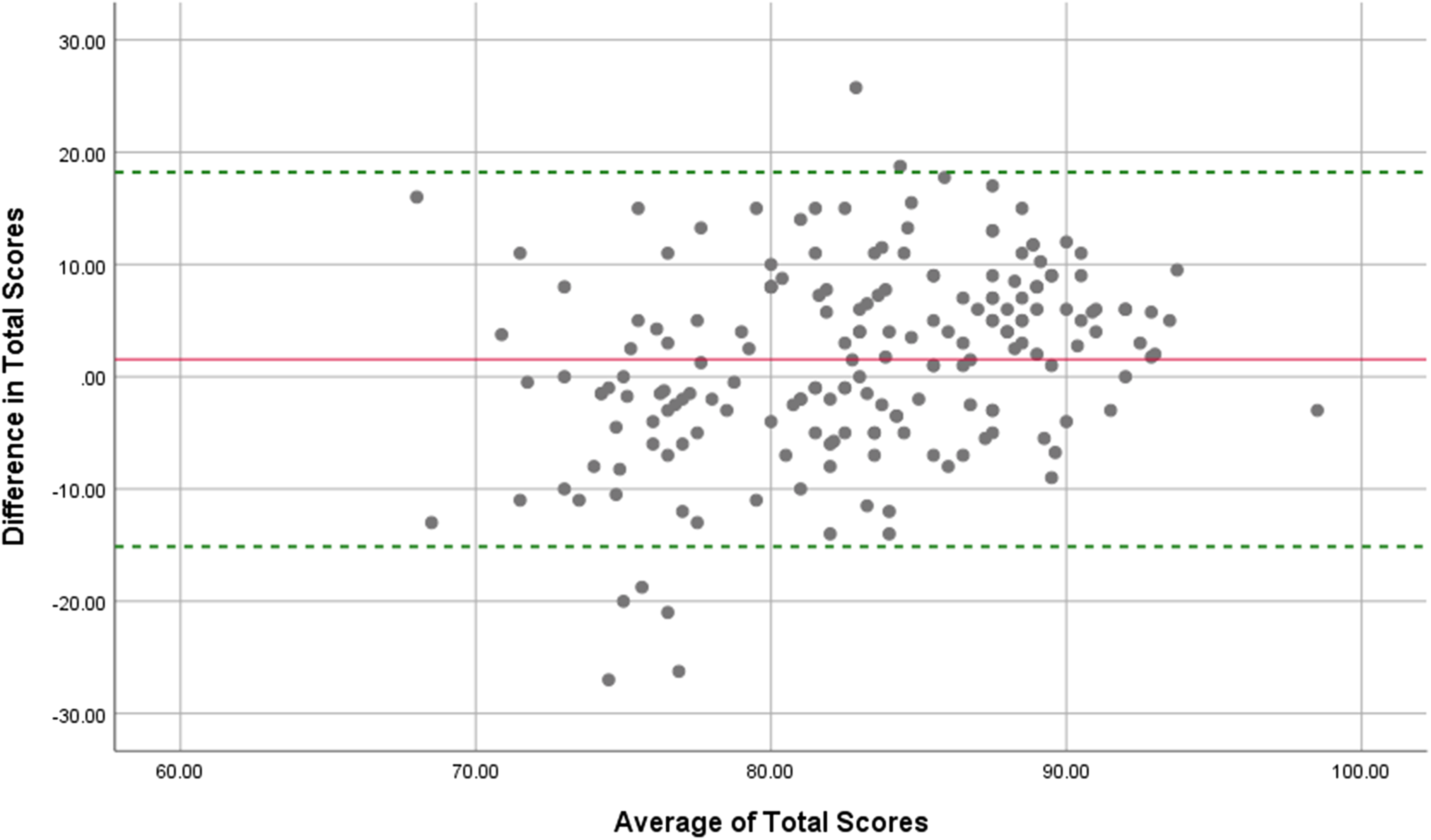
Bland-Altman graph for total scores with mean difference and 95% CI lines for ChatGPT 4o.
Figure 2 depicts the average difference in scores between human instructors and AI by quartiles for averaged total scores (i.e., the average of human instructor scores and ChatGPT 4o). For essays with averages in the bottom quartile, AI scored 3.97 points higher than human instructors. For the highest quartile, instructors provided scores that averaged 4.72 points higher than AI. This pattern suggests the presence of proportional bias, or inconsistencies in difference scores across the levels of measurement. To test for the presence of proportional bias, difference scores were predicted from average scores using regression analyses; results confirmed the presence of proportional bias for all but the introduction scores for ChatGPT 3.5 and for total, analysis, and writing scores for ChatGPT 4o. Results are presented in Table 2.
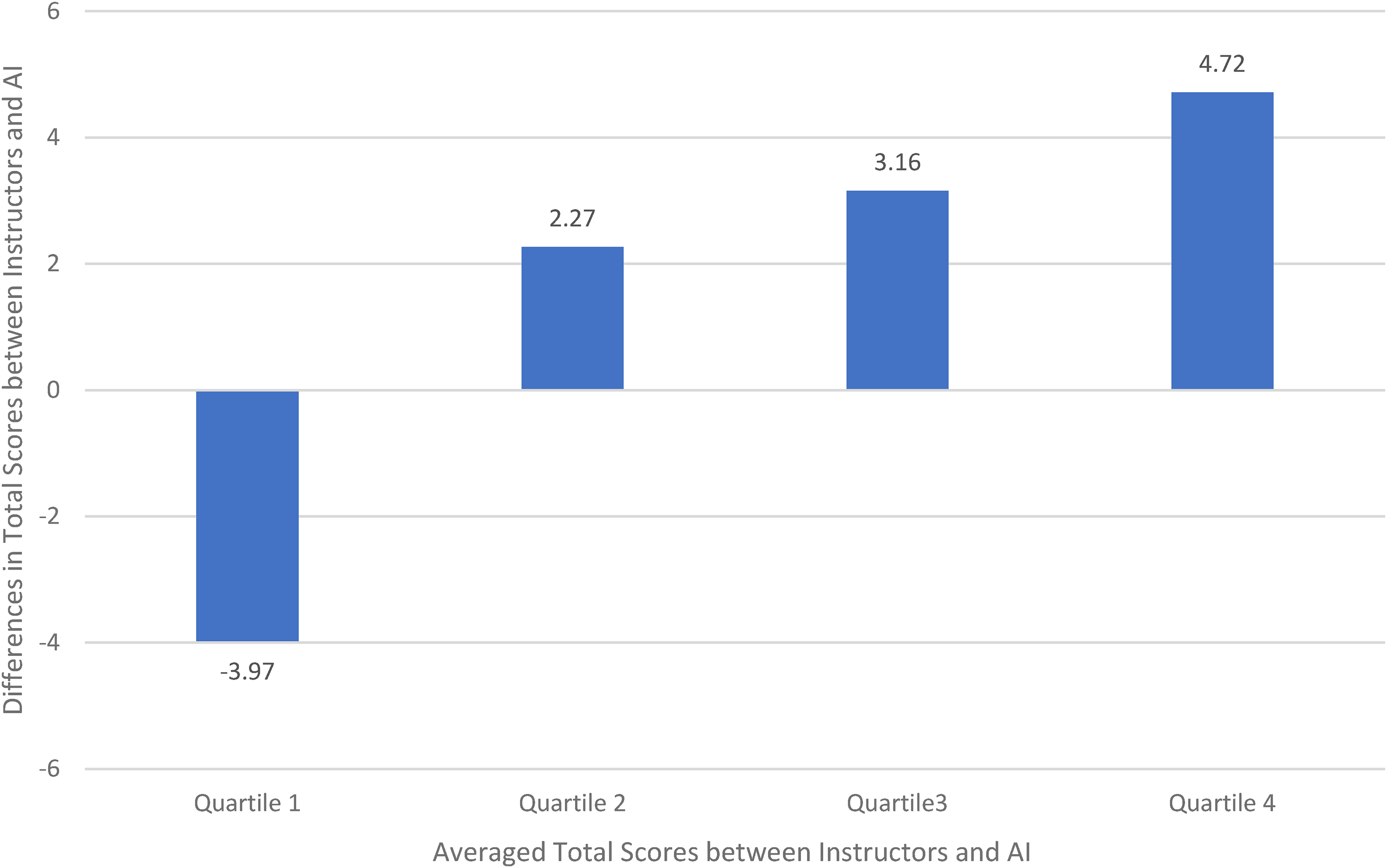
Total score differences between instructor and ChatGPT 4o by averaged score quartiles.
Linear Regressions Testing for Proportional Bias with ChatGPT 3.5 and ChatGPT 4o.
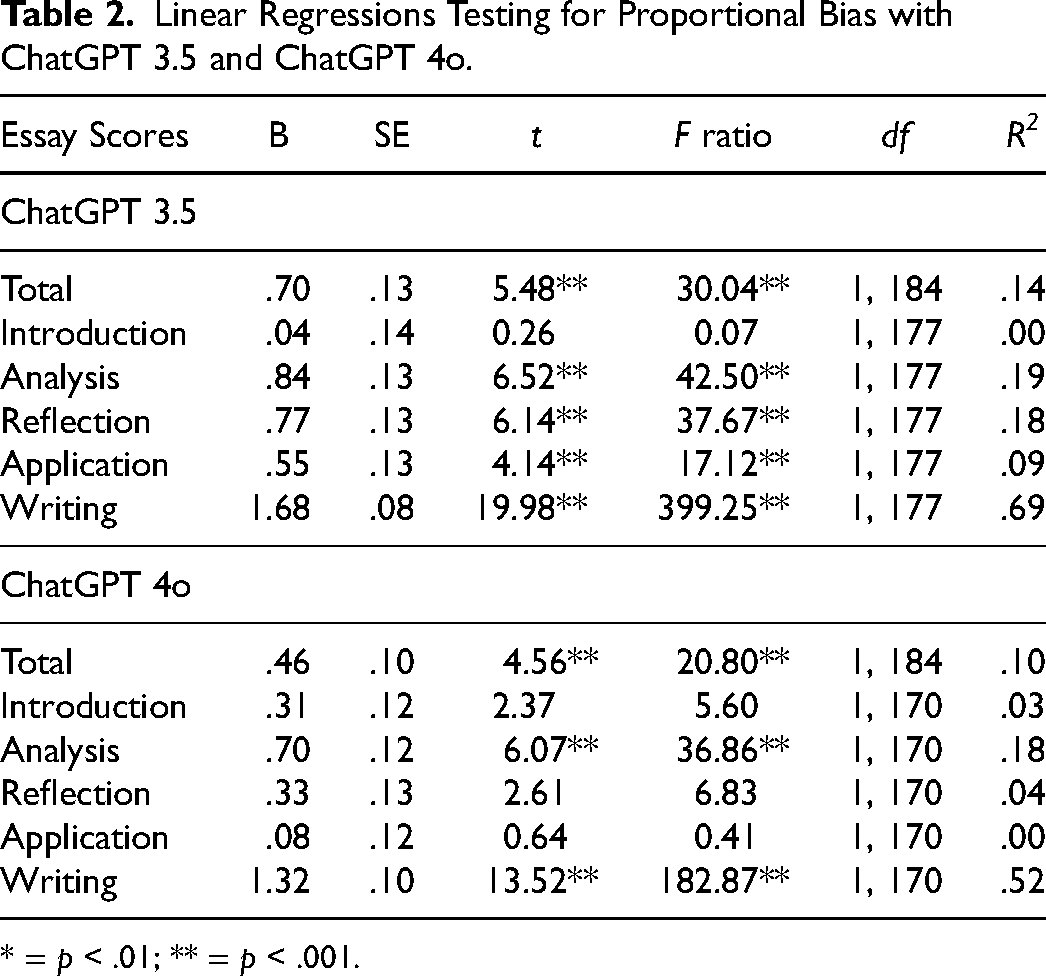
* = p < .01; ** = p < .001.
Results from the LIWC-22 text analysis indicated that written feedback from ChatGPT averaged 454.76 (SD = 60.67) words, indicating lengthy written feedback responses. The mean overall tone score was 74.97 (SD = 12.07), indicating that the general tone of the feedback was positive. The analysis also yielded higher positive tone scores (M = 3.84, SD = 0.93) than negative tone scores (M = 0.19, SD = 0.23) when considered separately. Although time elapsed for generating the AI scores plus written feedback was not recorded for every essay, time was recorded for a sample of ten essays and ranged from 18 to 32 s.
Discussion
This study evaluated differences between two methods of scoring student essays while using a standardized rubric: human instructors compared with generative AI, specifically OpenAI's ChatGPT models 3.5 and 4o. Results from the Bland-Altman analyses generally showed there to be low agreement between AI and instructor scoring, even when using the more advanced ChatGPT 4o model. Although this study only used one essay prompt and is limited in generalizability, the discovery of proportional bias in different directions at opposite ends of the grading scale merits discussion. AI-generated scores appeared to be more lenient for papers that were below average and stricter for above average papers when compared to grades from human instructors. The observed pattern may indicate a halo effect, with early judgments of essay quality affecting later judgments of quality by human instructors, or it may reflect the data that the AI models were trained on, which could have been essays with a restricted range. Alternatively, the pattern might reflect the tendency for human instructors to better appreciate the unique value of excellent essays or the specific problems associated with poorly constructed essays or arguments.
Indeed, AI systems and models have been known to have difficulty with certain types of human cognition, for example analogies and abstractions (Mitchell, 2021). Just as Lazarus et al. (2024) found that AI failed to account for individual differences in human anatomy when used to augment education for medical students, results from the present study suggest that ChatGPT may struggle to appreciate individual differences and the complexities of analyzing close relationships through the lens of psychology when scoring student essays. Nevertheless, scores in the middle of the measurement range also showed marked variability, with differences as great as ±20 points between instructor scores and AI. These findings suggest that agreement between human instructor scores and AI for this sample of student essays was not within reasonable limits, which is consistent with Coskun and Alper's (2024) findings of low consistency between human instructor and AI grading of traditional history exams.
It is essential that educators be aware that this pattern of differences is possible in AI generated essay scores, and that raw scores generated by AI models may not evidence grade integrity (Sadler, 2009). AI leniency at the lower end of the scale may be especially problematic in that the scores may falsely certify that a student has met the requirements at a satisfactory level or has a base level of knowledge that they have not demonstrated. If instructors relied solely on the AI-generated scores, then they might miss opportunities to provide developmental feedback to low-performing students and fail to acknowledge excellence for high-performing students. Both types of missed opportunities could undermine student motivation in learning and send false signals regarding students’ capabilities and demonstrated skills. Shu and Lam (2011) discuss how success and failure feedback affect students’ motivation differently, depending on whether they are motivated to approach positive outcomes or avoid negative outcomes. A low-performing student desiring to avoid a failing grade might be motivated to repeat the same (poor) performance if falsely told via an AI-generated score that the essay was better than it truly was, whereas a high-performing student who desires to approach a positive outcome may become confused about what constitutes excellence or disillusioned when their superior performance goes unrecognized as such by AI.
The findings from the text analysis of the written feedback offers some promise for the notion that AI may be useful for augmenting the essay-grading process and saving time. Receiving several paragraphs of detailed and generally positive AI-generated feedback on an essay during formative assessments of writing could be quite helpful to both students and instructors, especially because it can be done so quickly with AI. The written feedback might be useful for identifying elements of the assignment that may be missing entirely and for explaining why certain aspects of the writing were poorly organized or unclear. Certainly, the speed of generating AI written feedback may be encouraging for instructors who wish to provide timely, detailed feedback but who have large quantities of essays to evaluate. More comprehensive studies of the quality of written comments that generative AI can produce are needed.
From a broader perspective, the use of AI to assist in evaluating student essays merits consideration of how students might perceive the utility and fairness of this practice. For example, some students may favor the idea of AI scoring their work, based on the notion that it would be fairer and less prone to error than a human instructor. Other students may be uncomfortable with or even troubled by the notion of AI evaluating their work, especially in a discipline specifically focused on human behavior and mental processes. Given that the essays in the current study asked students to reflect on positive and negative aspects of close relationships, students’ motivation to provide deep-level reflections, analyses, and applications may be reduced if there is no anticipation that a human instructor might read and respond to the content. Results from Tossell et al.'s (2024) recent study on students’ perceptions of the use of AI in grading in an engineering course showed that students preferred the combination of an instructor and AI, as opposed to either one alone, with the instructor providing oversight of the AI.
Findings from the current study contribute to the understanding of AI's potential and limitations in academic assessment, but the study is not without limitations. The study only included essays from one introductory-level psychology course and one essay prompt, which limits generalizability. Additionally, AI's performance is influenced by its design, making it susceptible to its own form of biases, especially if the training data used to develop the AI system is not representative or is biased in other ways (Eubanks, 2022). This could lead to unfair grading outcomes for certain groups of students (i.e., students with different linguistic, cultural, or educational backgrounds), which was not tested in the current study. Future research also may address strategies for attenuating potential biases in training samples as well as methods for refining AI performance, such as improving the prompt engineering and specifically training the AI system on essays that represent varying levels of performance. Also, the prompt engineering could include a cautionary statement about proportional bias as a possible means of mitigation. Last, although human instructors were used as the standard of comparison in the current study, it is important to reiterate that they, too, are susceptible to a variety of biases and errors.
Conclusion
Although generative AI could theoretically be useful as an augmentation to human instructor essay grading in some circumstances, results from the current study suggest that there was a low level of agreement between the two methods. Scores generated by both ChatGPT 3.5 and 4o showed large discrepancies with instructor scores and in opposite directions at the upper and lower ranges of student performance.
Footnotes
Availability of Data and Material
The datasets for this study are not publicly available because they belong to the U.S. Military Academy and cannot be released without authorization. Requests to access the datasets should be directed to the author at elizabeth.wetzler@westpoint.edu.
Declaration of Conflicting Interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Disclaimer
The views expressed herein are those of the authors and do not reflect the position of the U.S. Military Academy, the Department of the Army, or the Department of Defense.
Ethics Approval
This research was approved by the Institutional Review Board at the U.S. Military Academy with project control number: CA-2024–77. This research has not been previously published and is not under consideration at any other journal.
Funding
The authors received no financial support for the research, authorship, and/or publication of this article.