
Abstract
The design of supervisory controllers to resolve any deadlock issue in automated manufacturing systems (AMSs) has attracted the efforts of many researchers. A great deal of work, which assumes that allocated resources do not fail, has been done, while only a few works pay attention to the existence of unreliable resources in AMSs. In this paper, we focus on the robust supervisory control for avoiding deadlocks in AMSs, each of which has one specified unreliable resource. We develop a robust supervisory control policy under which the system can continue producing without manual intervention in the face of the unreliable resource’s failure and recovery. Our policy consists of a modified Banker’s Algorithm and the available resource constraints. After proving the correctness of our policy, we show that there are more reachable states under our policy than the existing one. Therefore, our policy imposes less restrictive constraints on the system and is more permissive than the original one. Finally, an example is provided to illustrate our control policy’s advantage in permissiveness.
Introduction
Over the past two decades or so, practitioners and researchers from the manufacturing field recognized the need to develop supervisory control policies for automated manufacturing systems (AMSs). An AMS is usually a computer-integrated manufacturing system, i.e. a conglomeration of computer numerically controlled system. Supervisory control policies can be embedded in the software controller and implemented on the supervisory computers in the control hierarchy. An active area of supervisory control research has been the development of deadlock solution methods (Fanti and Zhou, 2004). There are a large number of research achievements for deadlock control problems (Chao et al., 2012; Chen et al., 2012; Hu et al., 2012; Huang et al., 2012; Jeng et al., 2002; Li et al., 2012; Liu et al., 2010; Nazeem and Reveliotis, 2012; Piroddi et al., 2008; Uzam, 2002; Wang et al., 2012; Wu and Zhou, 2001; Wu et al., 2008; Xing et al., 2011, 2012; Yue, 2011).
In most of the work, all the allocated resources are assumed to be reliable. However, inevitably, there are uncertainty factors such as an unreliable resource, which is prone to failure in an actual system. The common failures that may happen in AMSs include tool breakages, hydraulic failures, electrical failures, sensor failures, pneumatic failures, spindle failures and failures caused by parts going out of specification. When an AMS suffers a failure, none of the part instances, which are in processing on, or require in the future the failed resource, can be completed until the resource’s recovery. That is, some of the parts might be stalled. Much worse problems may arise, such as the stalled parts can block the production of other part types that do not need the failed resource. Compared with the scheduling problems, the deadlock and blocking problems in uncertain AMSs are not often focused (Chew et al., 2011; Hsieh, 2011). Consequently, it is a challenging area of research to consider robust supervisory deadlock control for AMSs with unreliable resources.
Wu and Zhou (2011) pioneer the concept of an ‘intelligent token Petri net’. They use this concept to model and control the reconfigurable AMSs with dynamic changes, and develop a supervisor for these systems to guarantee deadlock-free operations.
For an uncertain and non-deterministic discrete event system, Park (2012) presents necessary and sufficient conditions for the existence of a special robust and non-blocking supervisor.
Lawley et al. (Chew and Lawley, 2006; Chew et al., 2009, 2011; Lawley and Sulistyono, 2002; Wang et al., 2008, 2009) consider the robust supervisory control for a class of AMSs with unreliable resources. Each resource being discussed, which is actually a resource type, is a workstation. Specifically, a resource workstation contains a server or processor for processing parts and a couple of units of buffer space for storing parts. For a given resource, the number of its buffer space units is referred to its capacity. Resource ‘failure’ implies the failure of the server. When a resource fails, none of the waiting parts on the resource for processing can be processed and, thus, cannot proceed along their respective route until the resource is restored. Therefore, the failure of a resource may cause the buffer space to capacitate and propagate through blocking to stall other portions of the system. The supervisors proposed by Lawley et al. guarantee that, at all times, the system continues to produce part types that do not require failed resources.
For the same class of AMSs as researched by Lawley and Sulistyono (2002), this paper presents a robust supervisory control policy for deadlock avoidance. Our policy consists of an improved version of the Banker’s Algorithm and the available resource constraints. The policy is proved to be correct using the formal languages and automata theory.
The work in this paper is different from that of Wang et al. (2008); those researchers tried to improve the behavioural permissiveness of the supervisory controller by using the shared resources. Their policy is of the so-called ‘distributing’ type (Wang et al., 2009), while our policy belongs to the ‘absorbing’-type controllers. In fact, our policy is able to move all parts requiring the failed resource into the associated failure-dependent resources’ buffer spaces. Thus, the production of all the part types that do not require the failed resource is not affected at all.
Our work differs from the work of Hsieh (2007, 2011), which concentrated on the robustness analysis for flexible manufacturing systems, while our objective is to control the system so that the system can continue to produce part types not requiring the failed resource in the face of the unreliable resource’s failure and the failure recovery.
Unlike the mostly researched AMSs (Hsieh, 2011; Liu et al., 2010; Uzam, 2002; Wu and Zhou, 2011; Xing et al., 2009), in which each unit of each type of resource is able to process or store one part, every resource in our system is actually a resource type and consists of a server and several units of buffer space.
Moreover, our work differs from the work of Reveliotis (1999) and Chew et al. (2009) because we use no additional and external central buffers for temporarily storing parts, while central buffers are indispensable in their policies.
The main contribution of our work is as follows. In the modified Banker’s Algorithm of our policy, we carefully deal with the parts that have finished their current operation on the specified unreliable resource ru and do not need ru anymore. Therefore, our policy turns out to be more permissive than the existing one (Lawley and Sulistyono, 2002). Furthermore, we replace the original neighbourhood constraints by the available resource constraints. So our policy takes a more concise form.
The rest of this paper is organized as follows. Next we formally and precisely define the class of AMSs considered. Then, we propose the robust control policy to avoid deadlocks. We provide a performance comparison between our policy and the existing one, followed by the discussion. Finally, we conclude the paper.
Discrete event dynamic system model
This section is a brief presentation of some definitions and notations of the AMSs and their discrete event dynamic system models. For more details, please refer to Lawley and Sulistyono (2002).
The discrete event dynamic system model for this class of systems can be described as S = {R, C, P, ρ, Q, q0, Σ, ξ, δ}, where
R is the set of resources in the system with ru being the sole unreliable resource. We assume that ru is subject to failure and other resources are not subject to failure. For r∈R, C(r)≥1 is the capacity of r.
P is the set of part types produced by the system with each part type Pj∈P represented as an ordered product route Pj = <Pj1, Pj2, …, Pj, |Pj| >, where Pjk is the kth part type stage of Pj, k = 1, 2, …, |Pj|. Let pjk represent an actual instance of Pjk. Each pjk occupies one unit of buffer space of the resource ρ(Pjk), where ρ(Pjk) is the resource required by Pjk. For r∈R, let Ω(r) = {Pjk: ρ(Pjk) = r}, and this notation can be extended to a set, i.e. if R1⊆R, then Ω(R1)=∪r∈R1Ω(r).
Q is the set of system states, and Q ∍ q = (svu, yjk, xjk, j = 1, 2, …, |P|, k = 1, 2, …, |Pj|) is a state, where svu shows the status of the unreliable resource ru (0 if failed, 1 otherwise), xjk (yjk) is the number of the parts that are on the resource ρ(Pjk) and have (have not) finished their current operation Pjk. q0 is the initial state in which no resource is allocated and ru is operational.
Σ=Σ c ∪Σ u is the set of all events. Σ c = {αjk: j = 1, 2, …, |P|, k = 1, 2, …, (|Pj|+1)} is the set of controllable events with αjk (k ≤ |Pj|) representing allocating a unit of buffer space at resource ρ(Pjk) to a pjk, and αj, (|Pj|+1) representing that a finished part of type Pj leaves the system. Σ u = Σu1∪Σu2 is the set of uncontrollable events with Σu1 = {βjk: j = 1, 2, …, |P|, k = 1, 2, …, |Pj|} where βjk represents the completion of service for part type stage Pjk, and Σu2 = {κu, ηu} where κu and ηu represents the failure and the recovery of ru, respectively.
ξ: Q → 2Σ is the event enabling function. For q∈Q, ξ(q) is the set of enabled events under q, as defined as follows. a) ∀r∈R, ∀Pj1∈Ω(r), if C(r)−∑Pjk∈Ω(r) (yjk+xjk)>0, then αj1∈ξ(q); b) ∀ri∈R (if i = u, then svu = 1 is additionally needed), ∀Pjk∈Ω(ri), if yjk>0, then βjk∈ξ(q); c) if svu = 1 and ∃Pjk∈Ω(ru) such that yjk>0, then κu∈ξ(q); d) if svu = 0, then ηu∈ξ(q), and for ∀Pjk∈Ω(ru), βjk∉ξ(q); e) ∀r∈R, ∀Pjk∈Ω(r) with 1 < k≤ |Pj|, if xj, k-1>0, and C(r)−∑Pjk∈Ω(r) (yjk+xjk)>0, then αjk∈ξ(q); f) if
δ : Q×Σ→Q is the state transition function. δ(q, π) is defined only for π∈ξ(q). Let
Let L(S) = {σ : σ∈Σ* and δ(q0, σ) is defined} be the language generated by S, and let Q r (q0) = {q : σ∈L(S), q = δ(q0, σ)} denote the set of states reachable from the initial state q0.
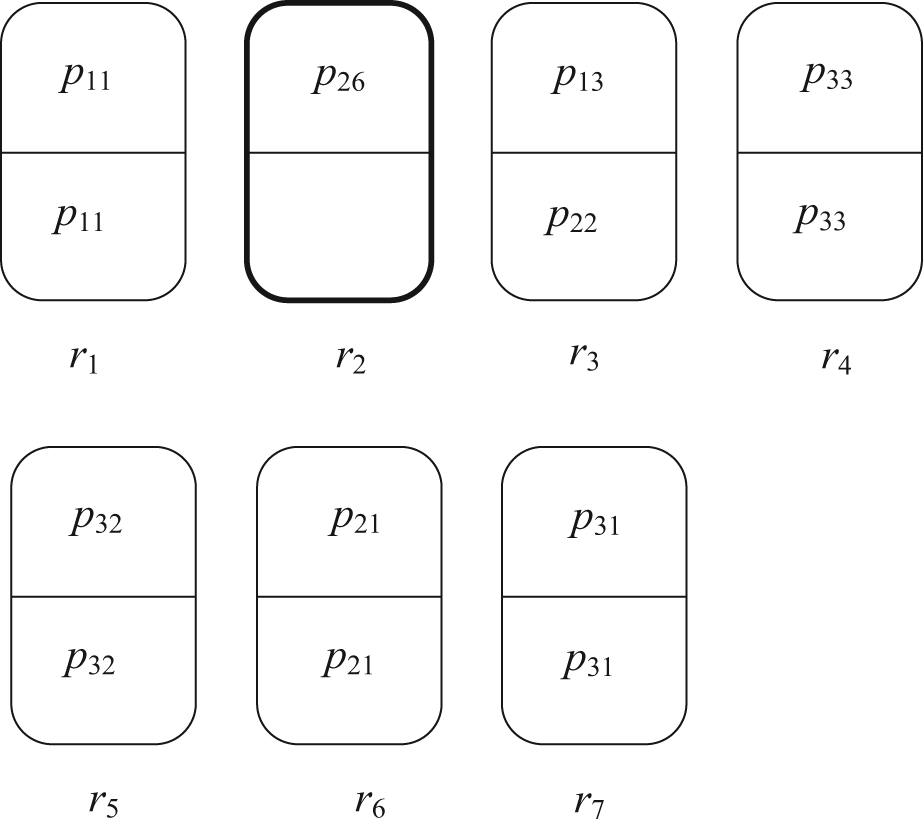
A state of an automated manufacturing system.
Consider the system state shown in Figure 1. There are part instances such as double p11 on the resource r1 with x11+y11 = 2, and a single p26 with x26+y26 = 1. Note that the information about the exact number of yjk or xjk, and the status of the unreliable resource is not presented in Figure 1. However, for the state as shown in Figure 1, we designate that all the parts have finished their current operations, that is, yjk = 0, j = 1, 2, 3, k = 1, 2, …, |Pj|.
A supervisory control policy△ for S is a function △:Q→ 2Σ, with △(q) = {π∈Σ : π is permitted to occur by the policy △ at the state q}. A policy △ cannot prohibit the uncontrollable events, i.e. Σ u ∩ξ(q)⊆△(q).
The state transition function under the control of a policy △ is δ△ :Q×Σ→Q, where for q∈Q and π∈Σ, if δ(q, π) is defined and π∈△(q), then δ△(q, π) = δ(q, π); otherwise δ△(q, π) is not defined. Similarly, δ△ can be extended to Q×Σ* in the usual way.
The language generated by S under △ is L(△/S) = {σ∈Σ* : δ△(q0, σ) is defined}. Let Q r (△, q0) = {q∈Q: q = δ△(q0, σ), and σ∈L(△/S)} denote the set of all states reachable from q0 under △.
Robust supervisory control
Let S = {R, C, P, ρ, Q, q0, Σ, ξ, δ} be an AMS. We want to design a robust supervisory control policy for S. To make it easy to understand our policy, we first depict a fairly simple AMS with one of its block states.
The AMS shown in Figure 2 has resources r1, r2 and r3, each having a single unit of buffer space, and r2 is unreliable. One circle stands for one buffer space unit and the spanners for the servers, one resource with one server. Three types of parts have to be processed with processing routes <r1, r2>, <r2, r1> and <r3, r1, r3>. In the state as shown in Figure 2, a part p11 and a part p12 are in process on the servers of r1 and r2, respectively. Then the sate is a ‘bad’ one because, if r2 fails at this time, not only the parts p11 and p12 are stalled, but also the production of parts of type <r3, r1, r3>, which does not need the failed resource, is blocked. Therefore, our policy must discard such ‘bad’ states like the one shown in Figure 2.
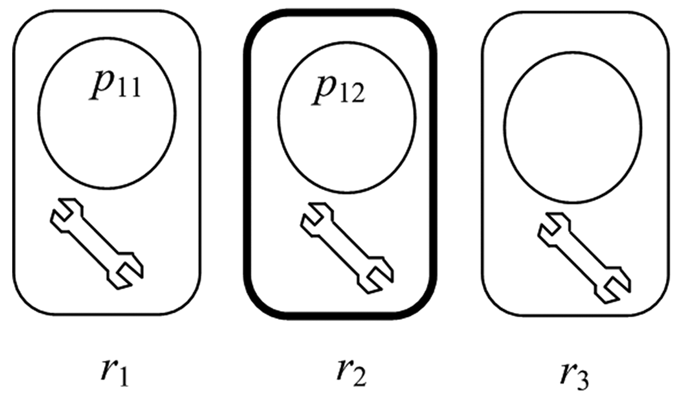
Another automated manufacturing system with a ‘bad’ state.
Formal definition of robust supervisory control policy
The following definition of a robust supervisory control policy △ is essentially the same to that in Lawley and Sulistyono (2002).
For q∈Qr(△, q0) such that svu = 1, then ∀π∈Σ\Σu2, ∀n∈
For q∈Qr(△, q0) such that svu = 1, if κu∈ξ(q), let δ△(q, κu) = qg, then ∀π∈Σ\(ψ∪Σu2), ∀n∈
For q∈Qr(△, q0) such that svu = 0, then ∀π∈Σ\(ψ∪Σu2), ∀n∈
For q∈Qr(△, q0) such that svu = 0, let δ△(q, ηu) = qh, then ∀π∈Σ\Σu2, ∀n∈
Obviously, Qr(△, q0)⊆Qr(q0). Generally, we hope that the limitation of △ to the system would be as small as possible. That is, |Qr(△, q0)|, the cardinality of the set Qr(△, q0), should be as large as possible.
Furthermore, let us give some remarks on the term ‘robust’ in Definition 2. It is accepted that the unreliable resource’s failure can disable the production of some part types. However, a ‘robust’ supervisory control policy can prevent the failure from propagating to stall other part types whose production does not need the failed resource. That is, under the control of a ‘robust’ supervisory control policy, and with the unreliable resource alternating between failed and operational, the system can continue producing any part type that does not require the currently failed resource without any manual intervention.
Partitioning the set of part type stages
First of all, we classify the resources of an AMS as Lawley and Sulistyono (2002) did.
For the AMS shown in Figure 1, we have that ru = r2, FD = {r1, r2, r6} and ND = {r3, r4, r5, r7}.
Let ℙ denote the set of all part type stages in the system. For Pjk∈ℙ, j = 1, 2, …, |P|, k = 1, 2, …, |Pj|, let RTjk = {ρ(Pjl) : l = k, k+1, …, |Pj|}, and let PFD = {Pjk : ru∈RTjk}. As a consequence, there is a partition of ℙ
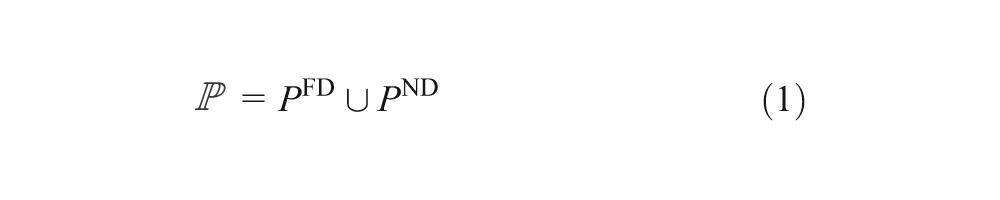
And
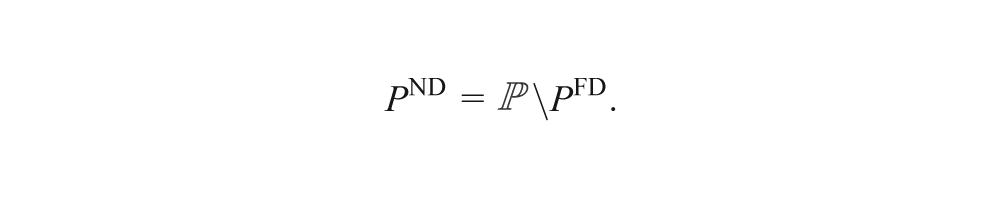
For the system as shown in Figure 1, PFD = {P11, P12, P21, P22, P23, P24, P25, P26}, PND = {P13, P14, P31, P32, P33, P34}.
Going a step further, there is a partition for PFD
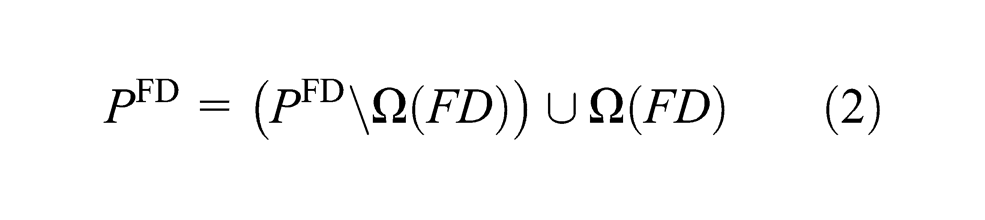
since ∀r∈FD, Ω(r)⊆PFD.
In order to go one more step further in partition the set of part type stages, we need the following definition.
For example, recall that the sole unreliable resource is r2 in the AMS shown in Figure 1, so we have that Θ = {P12, P26}. Evidently, Θ⊆Ω(ru), and hence,
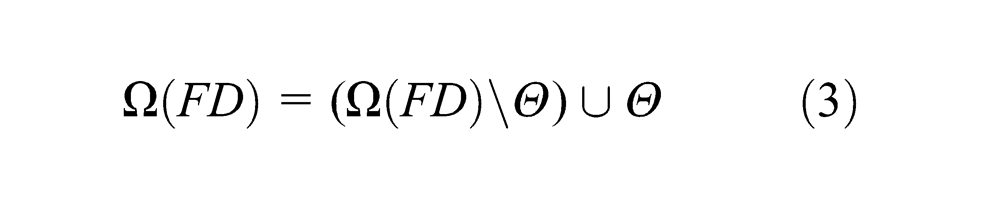
From (1), (2) and (3), we have

where ℙ1 = PND, ℙ2 = (PFD\Ω(FD)), ℙ3 = (Ω(FD)\Θ) and ℙ4 = Θ. It is trivial that ℙm∩ℙn = ∅, m≠n.
For the AMS shown in Figure 1, we have ℙ1 = {P13, P14, P31}, ℙ2 = {P22, P25}, ℙ3 = {P11, P24, P23, P21} and ℙ4 = {P12, P26}.
For q∈Q, let d(q) = {Pjk: xjk+yjk>0}. Namely, d(q) is the set of part type stages represented in q. In order to prepare for the modified Banker’s Algorithm (MBA) that will be presented in the next subsection, we partition the set d(q) as follows
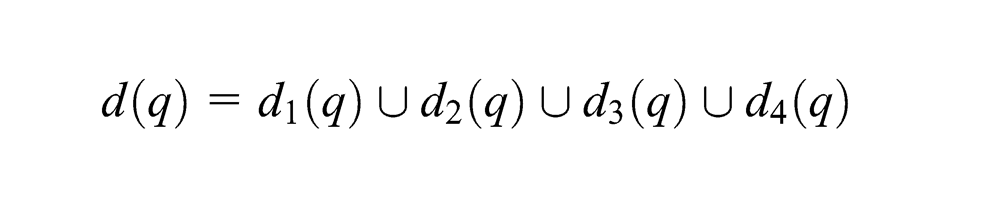
where d1(q) = d(q) ∩ℙ1, d2(q) = d(q) ∩ℙ2, d3(q)=(ℙ3∪ℙ4)\d4(q), d4(q) = {Pjk: Pjk∈ℙ4∧xjk>0}. It is also trivial that dm(q) ∩dn(q)=∅, m≠n.
Clearly, even if ru fails, it is still possible for the xjk part instances of type Pjk∈d4(q), which has completed their operation on ru, to be finished and driven out of the system.
For example, for the system state shown in Figure 1, recall that x26 = 1, then we have that d1(q) = {P13, P33, P32, P31}, d2(q) = {P22}, d3(q) = {P11, P21}, d4(q) = {P26}.
Modified Banker’s Algorithm
In order to increase the policy flexibility of the existing supervisory controller, we modify the Banker’s Algorithm (BA) in Lawley and Sulistyono (2002). Let us first briefly review BA. For a state q, BA tries to move all parts of all part type stages in ΛLS(q) = d1(q)∪d2(q) so that the following two things finally hold: 1) all part instances of type Pjk∈d1(q) can be driven out of the system; 2) every part instance of type Pjk∈d2(q) can be advanced into the first-met failure-dependent resource in its remaining route.
Our MBA is then outlined. Taking a state q, MBA acts as follows. 1) Try to move all parts of type Pjk∈d1(q) to completion; 2) try to advance every part of type Pjk∈d2(q) into the first-met failure-dependent resource in its remaining route; 3) try to drive the parts of type Pjk∈d4(q), which have finished their services on ru and still remain at ru, to completion; and 4) keep other parts where they currently are.
To summarize, for a state q, MBA tries to search for an ordering of all the part type stages in the set Λ1(q) = d1(q)∪d2(q)∪d4(q) such that all parts can be placed in proper locations by following this ordering. If this part type stage ordering is possible, MBA accepts q and returns (Accept, qe), where qe is the resulting state computed by MBA on q. Otherwise, MBA rejects q and returns (Reject, qe).
Now, we want to explain and highlight the differences between BA and MBA. MBA pays more attention to the parts that have finished their current operation on the specified unreliable resource ru and do not need ru anymore. Unlike BA, which just keeps these parts on ru, MBA tries to move these parts to completion and out of the system. Furthermore, after its execution on a state q, MBA outputs the resulting state qe, which will be used later by the available resource constraints. However, BA does not output its resulting state since the resulting state is useless.
In the following description of Algorithm MBA, for ri∈R, i = 1, 2, …, |R|, AVAILABLE[i] records the number of available buffer space units of the resource ri. For ri∈R and a part type stage Pjk, NEED[ j][k][i]=1 (or 0) records that a part pjk does (does not) require the resource ri in order that pjk can reach the proper location.
Algorithm MBA
INPUT: An AMS S = {R, C, P, ρ, Q, q0, Σ, ξ, δ} and a state q.
OUTPUT: MBA(q)∈{Accept, Reject} ×Q.
Step 1: Initialization
Г=d1(q) ∪d2(q) ∪d4(q) ;
qe = q;
For (Pjk∈Г) ∧ (ri∈R)
NEED[ j][k][i]=0;
For (Pjk∈d1(q)) ∧ (ri∈RTj, k+1) ∧ (ρ(Pjk) ≠ri)
NEED[ j][k][i]=1;
For (Pjk∈d4(q)) ∧ (ri∈RTj, k+1)
NEED[ j][k][i]=1;
For (Pjk∈d2(q)) ∧ (ri∈{ρ(Pj, k+l) : l = 1, 2, …, c}, where c is the minimal value such that ρ(Pj, k+c)∈FD) ∧ (ρ(Pjk) ≠ri)
NEED[ j][k][i]=1;
For all ri∈R
AVAILABLE[i]=rc(q, ri); /*rc(q, ri) is the number of remaining buffer space units at ri in q. */
Step 2: Main body
Begin
While (Г≠∅)
Find Pjk∈Г such that NEED[j][k][] <=AVAILABLE[]
If (no such Pjk) exits, return (Reject, qe);
Else
If (Pjk∈d1(q)){
Advance all parts of type Pjk to completion, and reach a new state qn ;
AVAILABLE[i]=AVAILABLE[i]+xjk+yjk, where ρ(Pjk)==ri;
}End If
If (Pjk∈d2(q)){
Advance all parts of type Pjk to the first-met failure-dependent resource rw in their remaining route, and reach a new state qn ;
AVAILABLE[i]=AVAILABLE[i]+xjk+yjk, where ρ(Pjk)==ri;
AVAILABLE[w]=AVAILABLE[w]−xjk−yjk ;
If (AVAILABLE[w] < 0) exits, return (Reject, qe);
}End If
If (Pjk∈d4(q)){
Advance the parts which have finished their current operations and of type Pjk to completion, and reach a new state qn ;
AVAILABLE[i]=AVAILABLE[i]+xjk, where ρ(Pjk)==ri;
}End If
qe = qn;
Г=Г\{Pjk} ;
End Else
End While
If (Г==∅), exits, return (Accept, qe);
End
In the rest of the paper, we will also use qe = MBA(q) if only the relation between the output and input states is considered.
Lemma 1 is trivial and its proof is omitted.
For example, let us consider that MBA takes the state q shown in Figure 1 as input. Then, MBA acts as follows. 1) Move the p22 from r3 to r2; 2) unload the finished unit p26 from the system; 3) advance the double p33, double p32 and double p31 to completion and unload them; 4) advance the p13 to completion and unload it. Therefore, the ordering of all stages in the set Λ1(q), which is computed by MBA, is <P22, P26, P33, P32, P31, P13>. So we have MBA(q)=(Accept, qe) and qe∈QT, where qe is the state with a single p23, double p11 and double p21 located in the buffer space of r2, r1 and r6, respectively.
Robust supervisory control policy
We first propose the available resource constraints (ARC). ARC requires that for q∈Qr(q0), there are at least (|FD|−1) resources of FD such that any of them has at least one available buffer space unit. That is, any two resources in FD totally have at least one remaining buffer space unit in q. Formally, ARC consists of the following (|FD|×(|FD|−1))/2 inequalities.

For example, please reconsider the state q shown in Figure 1. It is easy to check to know that q fails to satisfy ARC since rc(q, r1)+rc(q, r6)=0.
Let S = {R, C, P, ρ, Q, q0, Σ, ξ, δ} be an AMS. Our robust supervisory control policy for S is a function △1 : Q→ 2Σ such that for a state q∈Q and an event π∈Σ, it follows that: 1) if π∈Σ u , then π∈△1(q); and 2) otherwise(π∈Σ c ), π∈△1(q) if and only if q1 = δ(q, π) is defined, MBA(q1)=(Accept, qe), and qe satisfies ARC.
In order to prove the correctness of △1, we first need the following lemma.
If σ = ε (empty string), then q = q0 and MBA(q) = q0. It is clear that q0∈QT, so MBA accepts q according to the sufficient condition in Lemma 1. Additionally, we have that q0 satisfies ARC. Thus, the conclusion follows when |σ|=0.
Suppose that the conclusion follows when |σ|=n≥0. If |σ|=n+1, let σ = σ1π, π∈Σ. Since q = δ△1(q0, σ) = δ△1(q0, σ1π) is defined, we get that q′∈Qr(△1, q0) and q = δ△1(q′, π) is defined, where q′=δ△1(q0, σ1). From inductive hypothesis, we have MBA(q′)=(Accept, q′ e ) and q′ e satisfies ARC since |σ1|=n. We get that π∈△1(q′) since δ△1(q′, π) is defined. Now, we consider three cases of π∈Σ=Σ c ∪Σu1∪Σu2.
Case 1: π∈Σ c . According to the depiction of △1, we have MBA(q)=(Accept, qe) and qe satisfies ARC since π∈△1(q′) and π∈Σ c .
Case 2: π∈Σu1. It is evident that MBA(q)=(Accept, qe) and qe satisfies ARC since MBA(q′)=(Accept, q′ e ) and q′ e satisfies ARC. To see this, we have that ∀r∈R, rc(qe, r)≥rc(q′ e , r).
Case 3: π∈Σu2. It is also clear that MBA(q)=(Accept, qe) and qe satisfies ARC since MBA(q′)=(Accept, q′ e ) and q′ e satisfies ARC. To see this, we have that ∀r∈R, rc(qe, r) = rc(q′ e , r).
In summary, when |σ|=n+1, we have MBA(q)=(Accept, qe) and qe satisfies ARC, where q∈Qr(△1, q0) and q = δ△1(q0, σ).
Therefore, through mathematical induction, we have that, if a state q∈Qr(△1, q0), then MBA(q)=(Accept, qe) and qe satisfies ARC. ▪
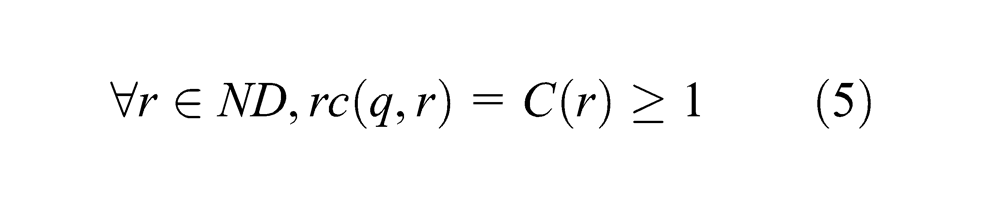
If ∀r∈R\ND = FD, rc(q, r)≥1, then let σ = ε, and q1 = δ△1(q, σ) = δ△1(q, ε) = q. Otherwise, consider the set of resources {r : r∈FD and rc(q, r)=0}. Since q satisfies ARC, the set FD contains at most one resource that does not have any remaining buffer space unit in q. Thus, let s1 be the only failure-dependent resource that has no free buffer space unit in q, and we have
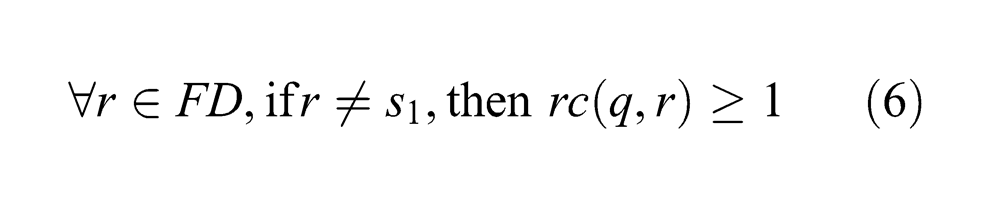
Take at random a part pjk represented in q at s1. From (5) and (6), we have that pjk can be allocated enough resources to be driven from the system, making s1 get one empty buffer space unit. Let the corresponding event sequence of the above procedure be σ1, then σ1∈(Σ c ∪Σu1)*. Furthermore, it is evident that the execution of σ1 never requires a violation of △1. Thus, δ△1(q, σ1) is defined. Let δ△1(q, σ1) = q1. We then have ∀r∈R, rc(q1, r)≥1. ▪
∀q∈Qr(△1, q0) such that svu = 1, from Lemma 7, we get that ∀π∈Σ\Σu2, ∀n∈
∀q∈Qr(△1, q0) such that svu = 1, if κu∈ξ(q), then κu∈△1(q). Let δ△1(q, κu) = qg, then qg∈Qr(△1, q0) and svu = 0. From Lemma 8, we have that ∀π∈Σ\(ψ∪Σu2), ∀n∈
∀q∈Qr(△1, q0) such that svu = 0, from Lemma 8, we get that ∀π∈Σ\(ψ∪Σu2), ∀n∈
∀q∈Qr(△1, q0) such that svu = 0, let δ△1(q, ηu) = qh. Then qh∈Qr(△1, q0) and svu = 1. From Lemma 7, we have that ∀π∈Σ\Σu2, ∀n∈
By Definition 2, the above 1)–4) imply that △1 is a robust supervisory control policy to avoid deadlocks. ▪
Policy performance comparison
In this section, we compare the performance of our policy △1 with that of the policy △LS (Lawley and Sulistyono, 2002).
The control policy △LS is made up of BA and the neighbourhood constraints (NHC). That is, for π∈Σ c , π∈△LS(q) if and only if q1 = δ(q, π) is defined, BA accepts q1 and q1 satisfies NHC. Here, we need briefly to review NHC.
For r∈FD, let NH(r)=Ω(r)∪{Pjk : ∃c>0 such that Pj, k+c∈Ω(r), and ∀d∈[0, c), ρ(Pj, k+d) ∉FD}. For r∈FD and NH(r), let Z(r)=∑Pjk∈NH(r) (xjk+yjk). Let NHC1 = {Z(r) ≤C(r): r∈FD }, NHC2 = {Z(rg)+Z(rh) < C(rg)+C(rh) : rg, rh∈FD }, and NHC=NHC1∪NHC2. A state q is said to satisfy NHC if and only if q satisfies every inequality in the set NHC.
In the following, we first prove Qr(△LS, q0) ⊆Qr(△1, q0). Then, we propose an algorithm based on the breadth-first research to generate the reachable state space for a control policy. Finally, we illustrate that △1 is more permissive than △LS.
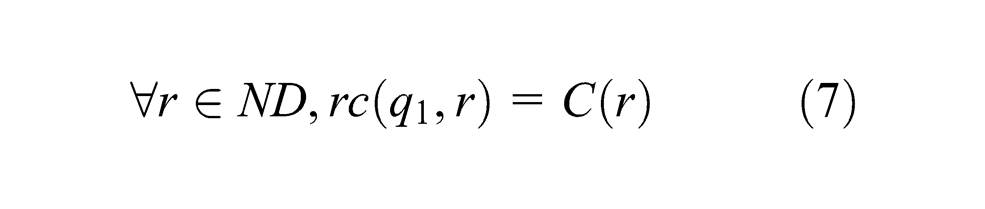
Taking the state q as input, MBA acts the following two steps.
Step 1: MBA executes the same as BA does. The state q1 is reached again. Moreover, the remaining part type stages in Λ1 constitute d4(q). We have
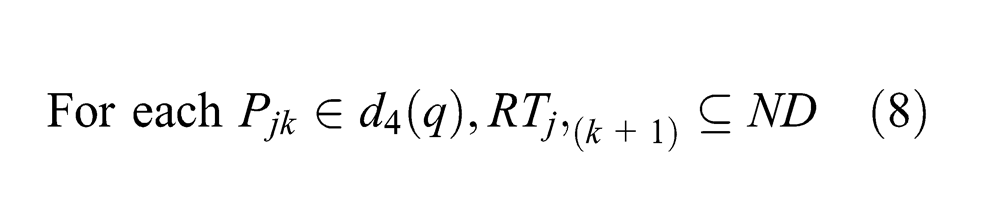
Step 2: MBA continues from q1. Because of (7) and (8), all parts of all types Pjk∈d4(q) that have finished their current operations are driven out of the system. Let q2 be the resulting state, and it is clear that q2∈QT. Thus, MBA accepts q by the sufficient condition in Lemma 1. ▪
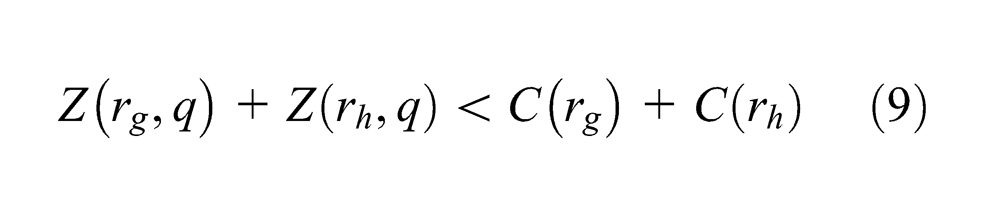
where Z(rg, q)=∑Pjk∈NH(rg) (xjk+yjk) and Z(rh, q)=∑Pjk∈NH(rh) (xjk+yjk). Since qe = MBA(q), according to the execution of MBA, it follows that, for ∀r∈FD
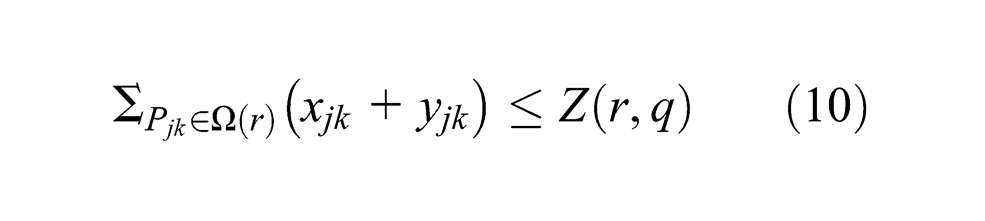
where ∑Pjk∈Ω(r) (xjk+yjk) corresponds to qe. Moreover, at the state qe, for ∀r∈FD,
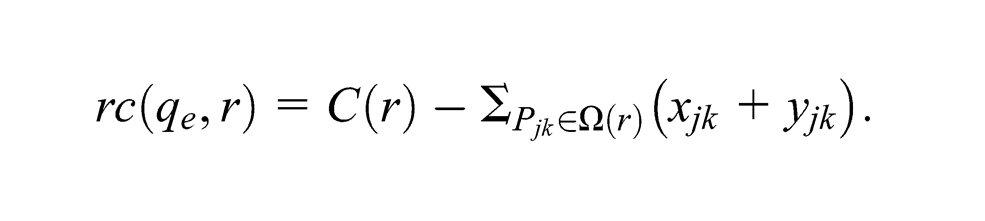
Then
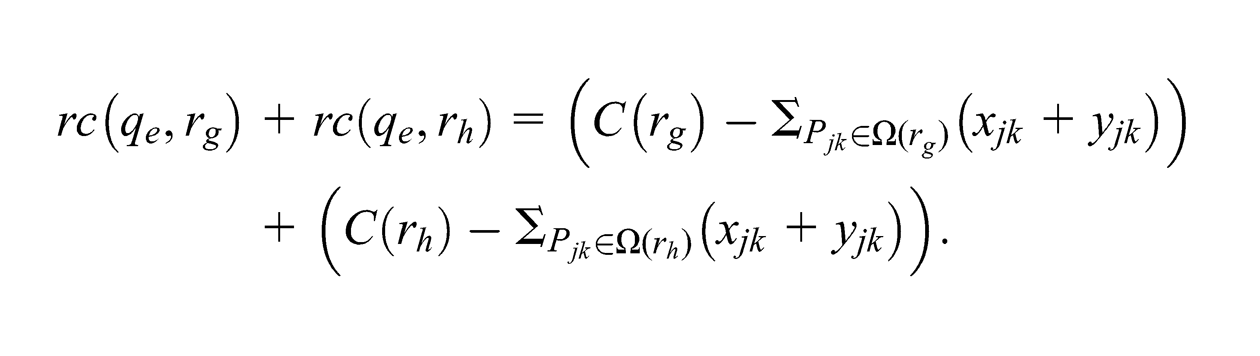
From (10), we have
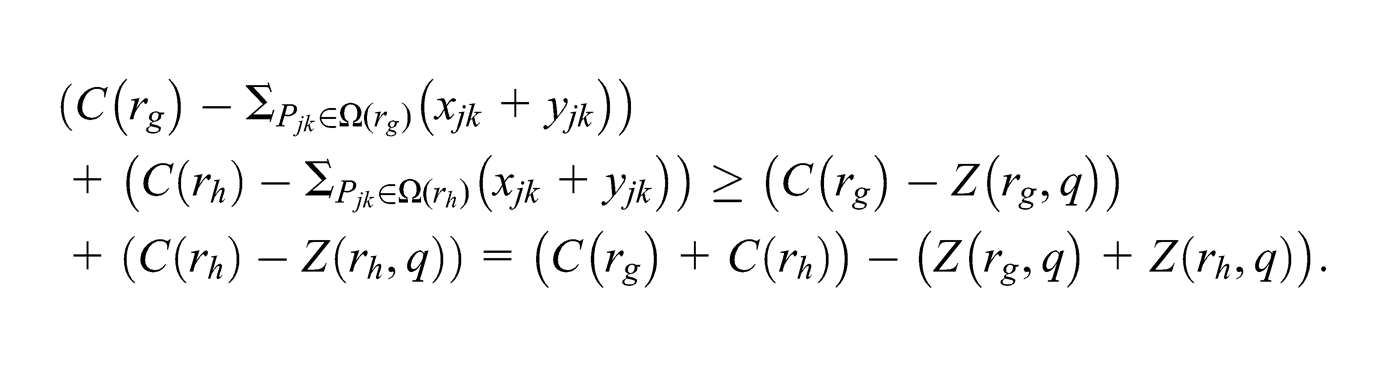
Furthermore, from (9),

To summarize, we have that,
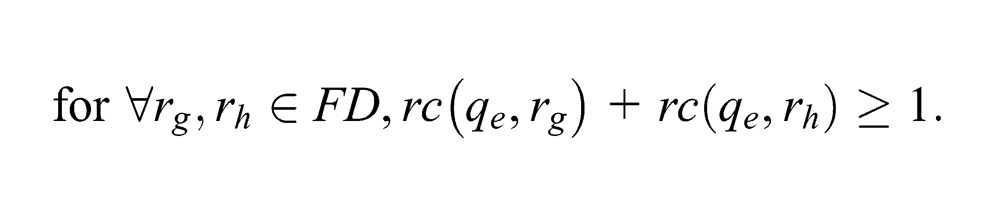
Hence, qe satisfies ARC. ▪
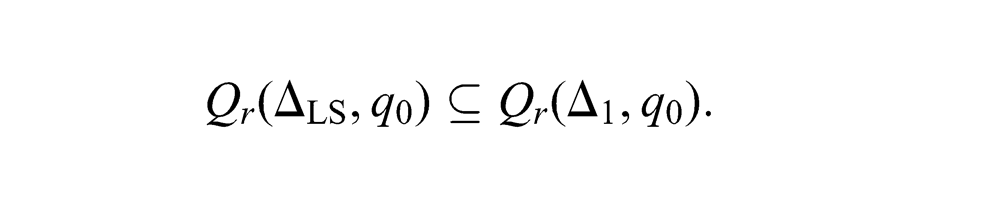
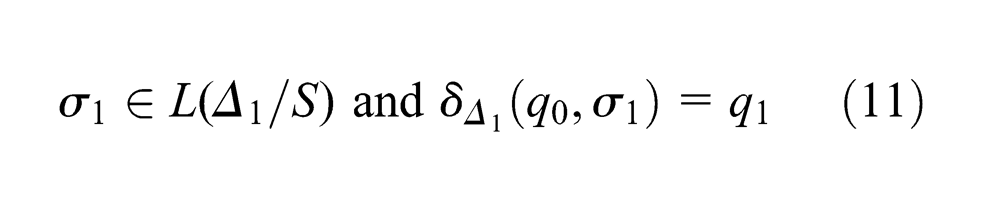
Since δ△LS(q1, π) = q is defined, π∈△LS(q1). So it follows that BA accepts q and q satisfies NHC. By Lemma 9, BA accepts q implies that MBA accepts q. Let MBA(q)=(Accept, q2). By Lemma 10, q satisfies NHC2 and MBA(q)=(Accept, q2) imply that q2 satisfies ARC. Thus, we have that π∈△1(q1) and δ△1(q1, π) = q. Combining δ△1(q1, π) = q with (11), we get δ△1(q0, σ1π) = δ△1(q0, σ) = q, σ∈L(△1 /S). Hence, it follows by induction that q∈Qr(△1, q0) and Qr(△LS, q0) ⊆Qr(△1, q0). ▪
We design the following algorithm, Algorithm ES, which is based on the breadth-first search, to get all reachable states from the initial state under a policy.
Algorithm ES
INPUT: An AMS S = {R, C, P, ρ, Q, q0, Σ, ξ, δ}, and a supervisory control policy △.
OUTPUT: Qr(△, q0).
Step 1: Initialization
Qr(△, q0)=∅;
QUEUE=NULL (empty queue);
enqueue(QUEUE, q0);
Qr(△, q0) = {q0} ∪Qr(△, q0);
Step 2: Main body
Begin
While (QUEUE !=NULL)
q = dequeue(QUEUE); /* Return the element at the front of the queue and remove it from the queue. */
For (each event π∈△(q) ∩ξ(q))
q1 = δ(q, π)
If (q1∉Qr(△, q0))
Qr(△, q0) = {q1} ∪Qr(△, q0);
enqueue(QUEUE, q1);
End If
End For
End While
End
Furthermore, we have tried over 100 system instances. We have found that our policy △1 achieves about 40% improvement in the number of the reachable states over △LS on average.
From Theorem 2. we know that Qr(△LS, q0) is a subset of Qr(△1, q0). Now we use an example to show that Qr(△LS, q0) is a proper subset of Qr(△1, q0), that is, there are states which are in Qr(△1, q0), but not in Qr(△LS, q0).
Consider two more states named q′ and q″, which are described as follows. In comparison with the state q that is shown in Figure 1, q′ has only one p21 in r6 and has an additional completed part instance p12 staying in r2. The difference between q′ and q″ is that q″ has no part instance p26 staying in r2. We have that q′∉Qr(△LS, q0) and q″∉Qr(△LS, q0). To see this, we note that q′ is rejected by BA, NHC1 and NHC2, and q″ is accepted by BA, but is rejected by NHC2. Nevertheless, both q′ and q″ are accepted by MBA, and both of the states MBA(q′) and MBA(q″) satisfy ARC. Moreover, it is easy to verify that both q′ and q″ are in Qr(△1, q0).
Discussion
We address how to improve the policy flexibility for the robust supervisor in AMSs each with a specified unreliable resource. Our policy has advantages over the original one in permissiveness. However, both our policy and the original one have the following two limitations. First, it can only handle the systems each with a single unreliable resource; however, a real system might have more than one unreliable resource. Second, the inherent drawback of all the Banker’s Algorithms makes it impossible to get a general optimal control policy.
The aforementioned limitations may lead to some open issues. Using the underlying idea in this paper and the associated existing policies in literature, it is possible to extend the policy proposed here to obtain robust supervisory controllers with more permissiveness for AMSs with multiple unreliable resources. However, it seems to be rather difficult for the policy’s extension to the systems where each part type may require multiple unreliable resources due to the combinatory nature of such systems. As far as the control optimality is concerned, there is a lack of generally accepted robust supervisory control policies with optimal deadlock avoidance even for a simple class of AMSs. Another open issue is as follows. Though our policy can guarantee the robust deadlock-free operation of the AMSs, the performance measures or indexes such as the maximal production level or the minimal makespan cannot be guaranteed until a suitable scheduling algorithm is proposed.
Conclusion
In this paper, we proposed a robust supervisory control policy for deadlock avoidance in a class of AMSs each with one specified unreliable resource. Specifically, our policy consists of a modified version of the well-known Banker’s Algorithm, and the available resource constraints. In comparison with the original one, our policy imposes less restrictive constraint on the system and is more concise. Moreover, it is the most important that evidence shows that our policy achieves a great improvement in the permissiveness of the policy.
Footnotes
Acknowledgements
The authors would like to thank the editor and all anonymous reviewers for their thoughtful comments and suggestions that greatly helped in improving the presentation and technical quality of this paper.
Funding
This work is supported by the National Natural Science Foundation of China under grants 50975224 and 60774083, China Postdoctoral Science Foundation funded project under grant 2013M532064 and the Natural Science Foundation of Fujian Province of China under grants 2013J05105 and 2010J01354.