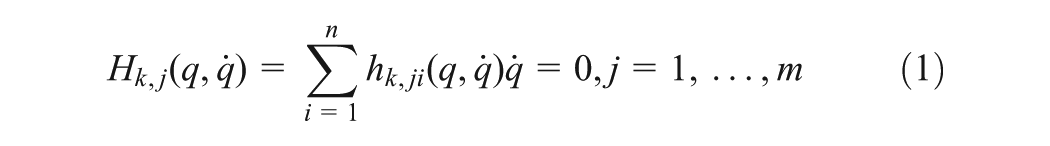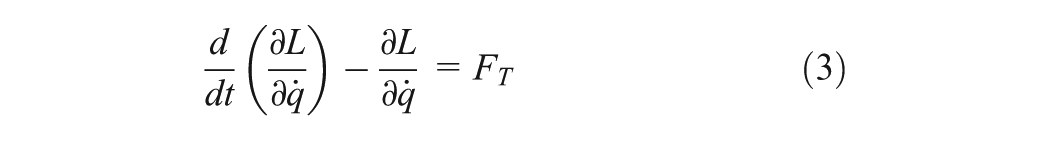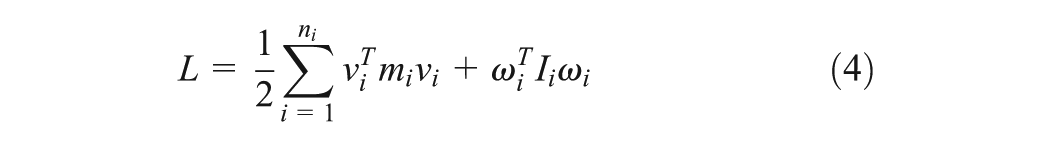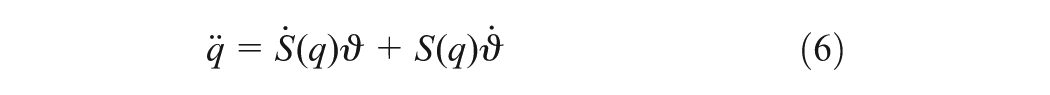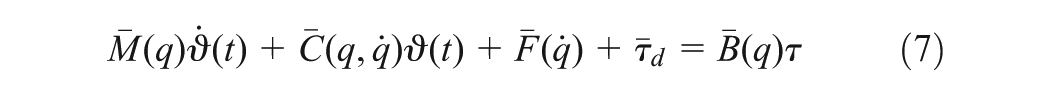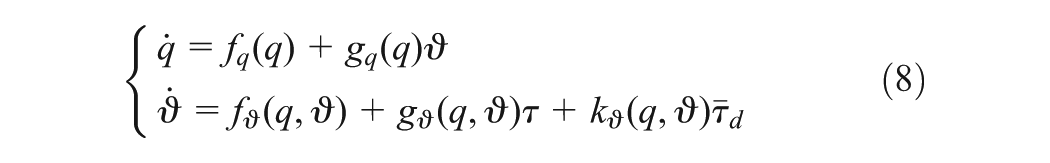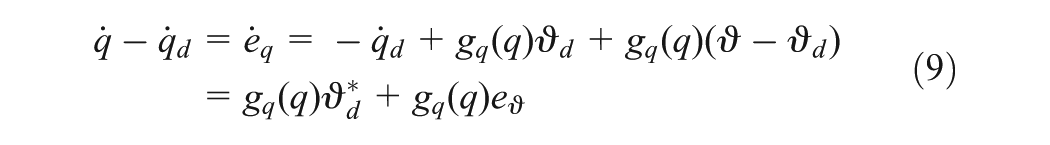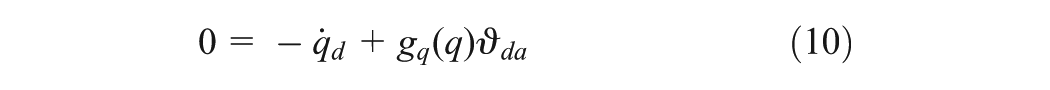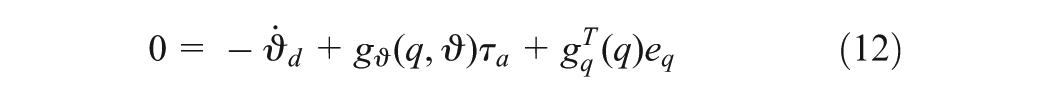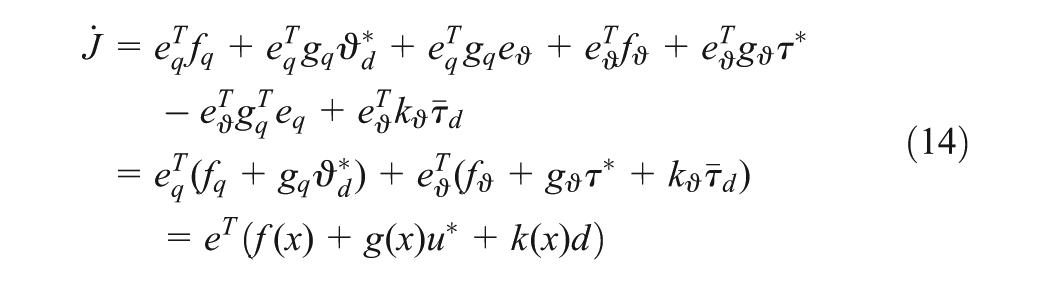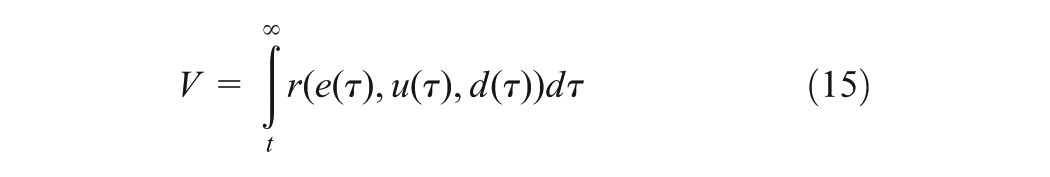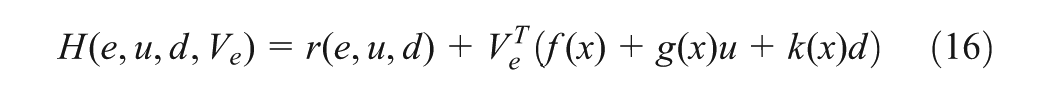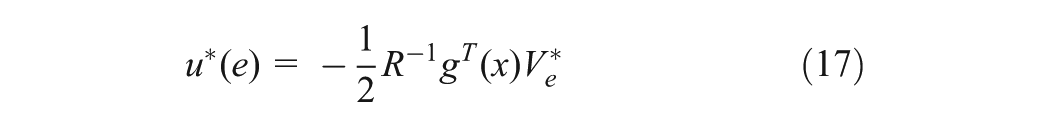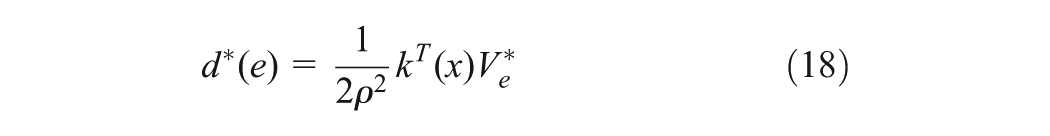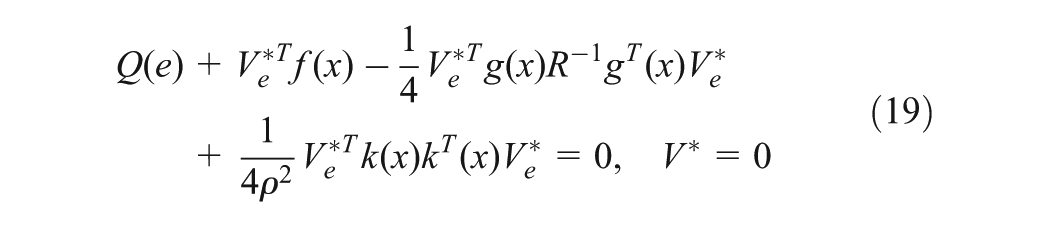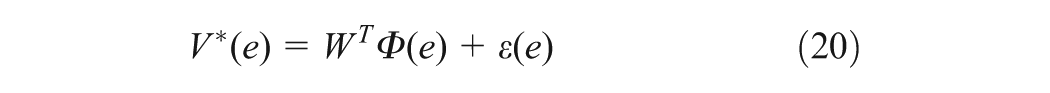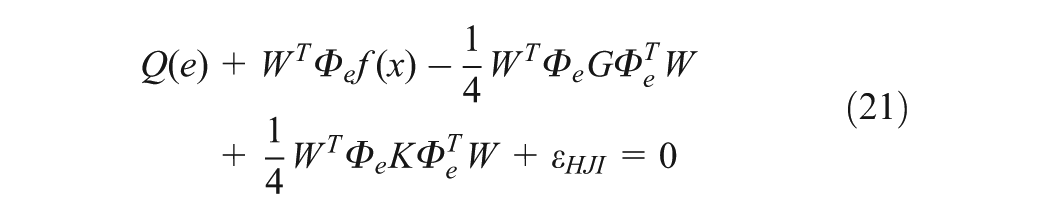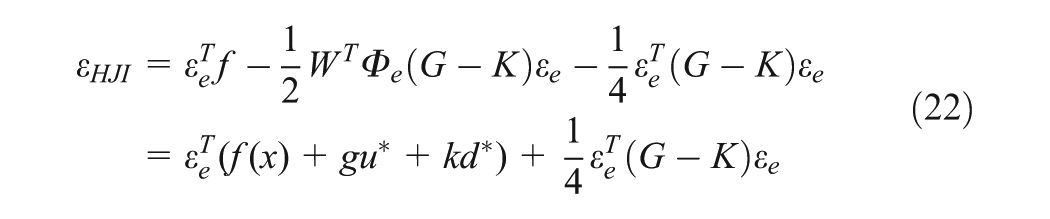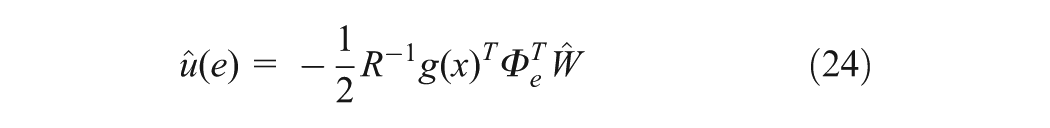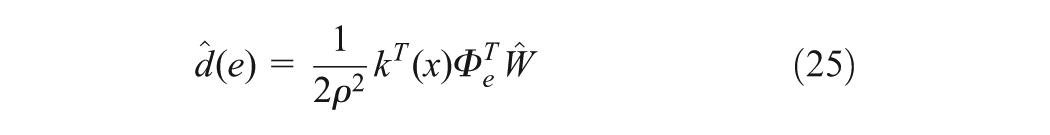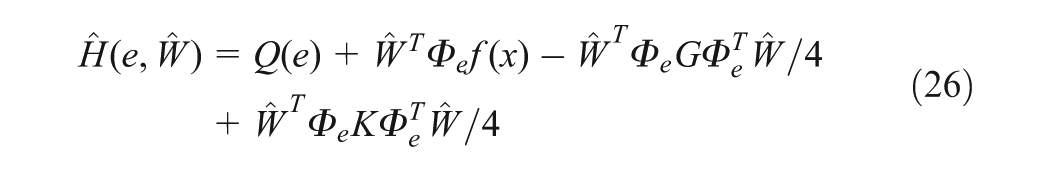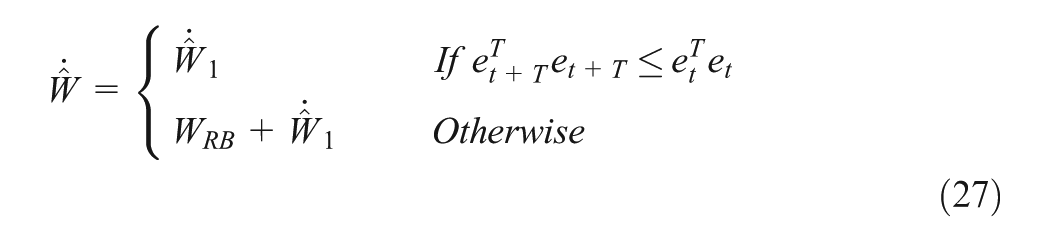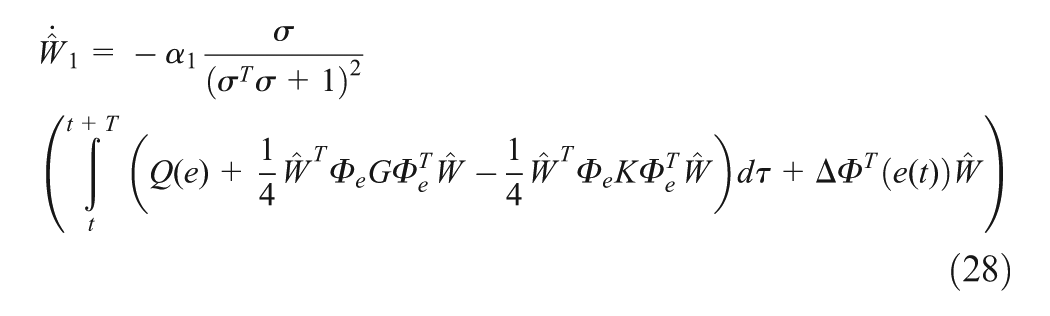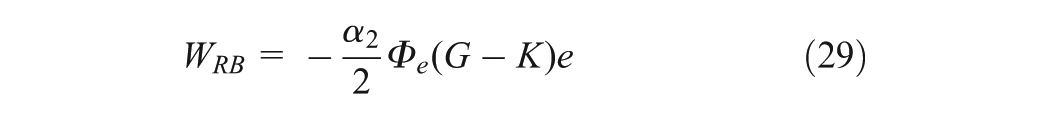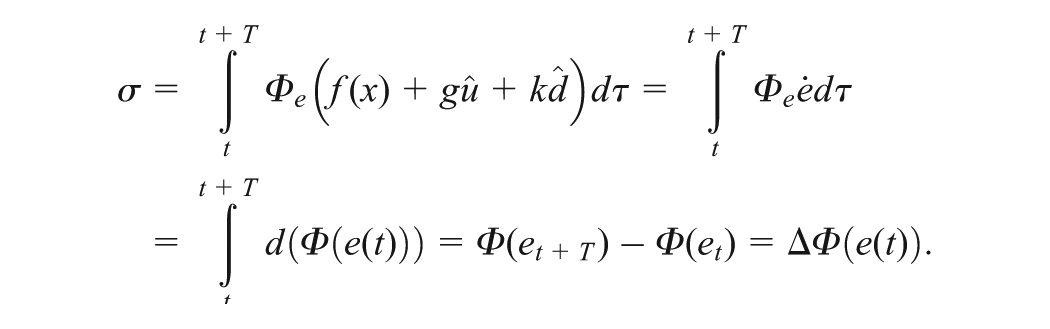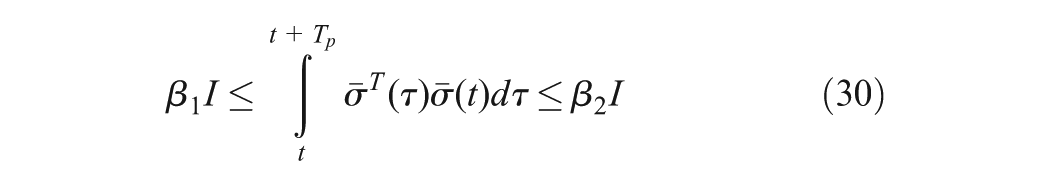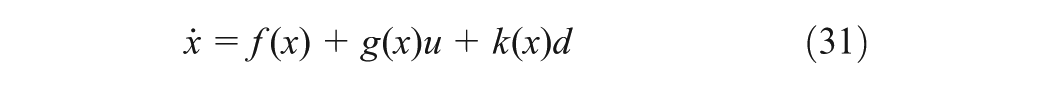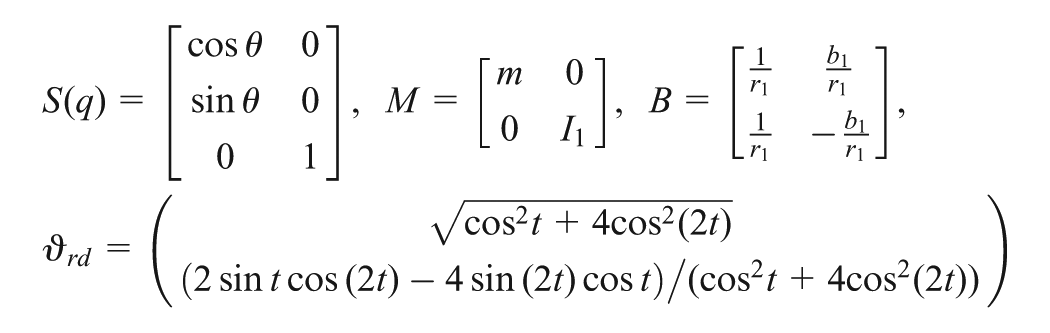This paper proposes a new method to design a reinforcement learning-based integrated kinematic and dynamic tracking control algorithm for a non-holonomic wheeled mobile robot without knowledge of the system’s drift tracking dynamics. The actor critic structure in the control scheme uses only one neural network to reduce computational cost and storage resources. A novel tuning law for a single neural network is designed to learn an online solution of a tracking Hamilton–Jacobi–Isaacs (HJI) equation. The HJI solution is used to approximate an H∞ optimal tracking performance index function and an intelligent tracking control law in the case of the worst disturbance. The laws guarantee closed-loop stability in real time. The convergence and stability of the overall system are proved by Lyapunov techniques. The simulation results on a non-linear system and wheeled mobile robot verify the effectiveness of the proposed controller.
An important motion control problem for the system of wheeled mobile robots (WMRs) is the trajectory tracking. This problem has been extensively studied in past few decades. Generally, a variety of control algorithms for the trajectory tracking problem has been devoted in the form of adaptive control (Fierro and Lewis, 1998; Marvin et al., 2009; Mohareri et al., 2012) where the back-stepping techniques are used. The kinematic controllers are designed using the available models, and dynamic controllers are designed based on neural networks (NNs). They are considered indirect adaptive controllers. Besides, they do not minimize any long-term performance function and hence are not optimal. H∞ adaptive control for a WMR based on inverse optimality is proposed in Miyasato (2008) but it is an offline control scheme. A specific characteristic of the WMR models is that it can be presented as a non-linear system in a strict-feedback form, but until now, to the best knowledge of the authors, methods of tracking control for a WMR using this form are just considered in adaptive back-stepping (Chwa, 2010) or adaptive feedback linearization schemes (Khoshnam et al., 2011) without any optimality.
In the other direction, thanks to the abilities of online adaptive learning of reinforcement learning (RL) methods in optimal control, tracking control methods for WMRs have been studied. The adaptive critic structures in RL are exploited to learn discrete controllers (Lin and Yang, 2008; Zenon and Marcin, 2011) or a continuous controller without disturbance using the learned solution of the Hamilton–Jacobi–Bellman (HJB) equation (Luy, 2012). These controllers not only overcome the drawbacks of the other methods such as the domain expert of fuzzy or existing controllers to generate a training sample for NNs, but also optimize utility functions, in contrast to the tracking error at the current time instant in the NN-based adaptive controllers. However, these methods have access to the known explicit model of WMR and ignored the disturbance, so they are not a type of robust adaptive control method.
To control a non-linear system, i.e. a WMR system with optimality related to disturbances using RL, the solutions of Hamilton–Jacobi–Isaacs (HJI) in the optimal control problem must be learned (Dierks and Jagannathan, 2010). The integral RL-based direct adaptive control algorithm for a class of general non-linear system has been studied in Vamvoudakis et al. (2011) to solve the HJI equation. The most favourable part of this algorithm is that NNs can be trained synchronously to approximate optimal control input and worst-case disturbance without knowledge of the system drift dynamics terms. However, it requires three NNs in the same structure – one for the critic and the others for actors. The number of neurons in the hidden layers should be at least (n+1)n/2, where n is number of state variables. In practical applications, e.g. robotics, the number of state variables measured from sensors for feedback may be relatively large. With three NNs, the number of NNs weights and the activation functions representing the elements in combination of the states will significantly increase. If applied directly, the algorithm to a non-linear system may lead to the computational complexity and resource consumption. In contrast, a method using a single online approximator (SOLA) in Dierks and Jagannathan (2010) to solve the HJI equation can reduce the number of NNs but, unfortunately, it is a type of model-based RL.
From the aforementioned problems, there are three main contributions in the paper. The first involves the derivation of a tracking dynamics formed from a non-linear strict-feedback model of WMR the purpose of which is to design an integrated kinematic and dynamic control RL based-intelligent controller, i.e. the integrated kinematic and dynamic robust direct adaptive tracking controller with optimality without explicit knowledge of the system’s drift dynamics. The actor critic structure in the RL scheme uses only one NN for the critic law. Secondly, the last contribution is the tuning law for the critic NN so that solutions of the tracking HJI equation are learned, and optimality values of the tracking performance index function and the robust direct adaptive control law as well as the worst-case disturbance law are approximated without accessing the system’s drift dynamics. By Lyapunov techniques, the closed-loop system state and critic NN error are proved to be uniform ultimate bounds and system parameters show convergence to optimal target values asymptotically.
The paper is organized as follows. The next section provides the theoretical background of the WMR to establish the non-linear WMR system in the strict-feedback form and then the new tracking dynamics is derived. Then we design the integrated kinematic and dynamic robust direct adaptive tracking control scheme with optimality along with tuning law for the critic NN and give proof of stability and convergence. The results of simulation on the WMR verify the effectiveness of the proposed algorithm and conclusions are drawn.
Strict-feedback kinematic and dynamic model
A WMR with differentially driven wheels mounted on a driving axle can move and rotate on the horizontal plane thanks to two independent actuators. Torque from the actuators is transmitted to the left and the right wheels to drive the robot. The mass of the WMR including the mass of the platform without the wheels and the mass of the wheels is focused on a central point. The distance of the driven wheels is b1. The radius of each wheel is r1. The distance from the centre point to the driving axe is l. Without loss of generality, it can be assume that l=0. The WMR is considered a mechanical system with n generalized configuration variables q suffering m constraints (m<n) and represented by the equation as follows (Khoshnam et al., 2011)
where the number of holonomic and non-holonomic constrains are k and m−k, respectively. The constrains are independent of time and can be written as , where is a full-rank matrix. Assume that is also a full-rank matrix that is formed from a set of smooth and linearly independent vector fields in the null space of such that . Let be the velocity vector, which can be seen as the pseudo-control vector, and is important to form a strict-feedback non-linear system afterwards. The kinematic equation of WMR motion can be written as
To derive a dynamic equation of WMR, Lagrange formalism is used as follows
where is the vector of the generalized forces. The WMR moves on a plane so Lagrangian L only includes kinetic energy
where , , and are elements of the linear velocity, the rotation velocity, the mass and the moment of inertia, respectively. As a result, the dynamic model of the WMR is expressed as
where is the symmetric positive defined inertia matrix, is the centripetal and Coriolis matrix, is the surface friction and gravitational vector, denotes the bounded unknown disturbances including unstructured unmodelled dynamics, is the input transformation matrix, is the input torque vector and is the vector of constraint forces. Taking the time derivative of the kinematic model (2), one obtains
Substituting (2), (6) into (5) and multiplying both sides of the result by and note that , one obtains
where , , , , .
Definition 1. Letting , , , , .
The state space equation of WMR represented the non-linear system in the strict-feedback form is obtained by using kinematics and dynamics Equations (2) and (7)
The system (8) is assumed to be controllable and drift free with , a unique equilibrium point on a compact set . Let us view some following important properties.
Property 1. is a bounded asymmetric and positive definite matrix such that , where and are positive scalar constants.
Property 2. is bounded such that , where and are positive scalar constants.
Property 3. The disturbance is bounded such that , where is a positive scalar constant.
Property 4. is the system uncertainty dynamics term and .
Property 5. is bounded such that , where and are positive scalar constants.
Property 6. is bounded such that , where , the constant non-singular matrix, depends on the geometric parameter of the WMR, i.e. the radius of wheels and the robot frame width (Khoshnam et al., 2011), and according to Property 1, .
Property 7. is bounded such that and according to Property 1 .
Property 8., , and are non-linear smooth functions.
Definition 2. If a reference robot generates the bounded smooth trajectory vector that satisfies the constraint , where is the smooth velocity vector, the main objective for the robust adaptive tracking control problem for WMR is to design integrated kinematic and dynamic feedback control laws for the dynamic system (8) where contains the uncertainty terms and disturbance, such that when , then with . Furthermore, a defined tracking cost function related to (8) must be optimized.
To have tracking dynamics for designing integrated kinematic and dynamic feedback control law, some steps to change model (8) will be executed. The first equation in (8) is written as
where , is virtual control input such that with is an optimal tracking control input vector designed later, and , the feed-forward virtual control input, is the solution of the equation
Similarly, the last equation in (8) is written as
where is the tracking control input designed later such that and is a solution of the equation
Definition 3. Let , , , , , , , , , , .
Lemma 1. Consider the tracking dynamics of the WMR as follows
If the control law for (13) is designed, it can be the control law for (8), that means the control law for (13) and (8) is equivalent.
Proof. For (8), choosing the Lyapunov function candidate as and taking the derivative along with (9) and (11), one obtains
Comparing (14) and (13), it can be seen that the control law for (13) and (8) is equivalent.
This completes the proof.
Remark 1. If control law exists, it will be the integrated kinematic and dynamic control law as opposed to back-stepping control laws where kinematic and dynamic control inputs are separated.
Remark 2. represents system’s drift tracking dynamics and is the bounded unknown disturbance according to Property 3.
where , with is positive definite, i.e. and , , is the admissible control input that minimizes while tries to maximize (Dierks and Jagannathan, 2010; Vamvoudakis and Lewis, 2011), is a symmetric positive definite matrix, is the prescribed disturbance attenuation level, where is the minimum gain of for which the stability of closed-loop tracking system (13) is guaranteed (Van Der Shaft, 1992). Define the Hamiltonian of (15) associated with u and d as
where . There exists a minimum non-negative local smooth solution of (16) (Dierks and Jagannathan, 2010; Vamvoudakis et al., 2011). If is that solution and (13) is locally detectable, then the Nash equilibrium solutions in term of can be found by the stationary condition of (16), i.e. and
where . The tracking HJI equation is obtained by substituting (17) and (18) into (16):
Solutions HJI of (19) can be learned without explicit knowledge of the system’s drift dynamics by an integral RL-based PI algorithm where three NNs for the actor critic, which are the same structure, are required (Vamvoudakis et al., 2011). Using three NNs may lead to the computational complexity and resource consumption when applying for multivariable systems such as the WMR system defined earlier. Therefore, in this paper, the new actor critic scheme is proposed for the tracking problem using only one NN with the purpose of reducing the cost of computation and storage resources. The critic with the NN to approximate the optimal value function (15) is defined as
where is the activation function vector, N is the number of neurons in the hidden layer, is the NN approximation error and is the NN ideal weight vector. can be selected such that, and , and for fixed N, , where and are positive constants (Finlayson, 1990). Let us substitute (19), (20) into (16) to obtain the NN-based HJI equation
where , and is the residual error formed by the NN approximation error
when , converges uniformly to zero. For fixed , is bounded on a compact set (Vamvoudakis et al., 2011).
Fact 2. According to Properties 5 and 6, is bounded such that , and , with and are the largest and smallest eigenvalues of R, respectively.
Fact 3. According to Properties 7, K is bounded such that , , .
Assumption 1. The closed-loop tracking dynamics of WMR is bounded such that for the positive constant .
The ideal weight vector (20) is unknown, thus is valued by
Then, the estimated control and disturbance laws become
The approximate Hamiltonian is obtained by substituting (23), (24) and (18) into (16)
Observing Equations (21) and (26), it is straightforward to see that should be tuned to minimize the subject error function related to . To design a tuning law for that does not depend on , the error function is chosen as , where with T>0 is a chosen sampling time. Then, the tuning law becomes . In addition, due to the approximation error during online learning, it is desired to design the tuning law of such thatit not only minimizes but also guarantees the stabilization of the system, concurrently. If more than one NN is used, the tuning law of the critic NN is responsible for minimizing , while the tuning laws of actor NNs guarantee the robust stability for the overall system. In our case, only one NN is used and thus both objectives must be intergraded into one, i.e.
where , , and
where
It will be shown in the proof of Theorem 1 that along with in (27) and the added term, , we will guarantee that the closed-loop system is uniform ultimately bounded (UUB; Lewis et al., 1999) when the behaviour of the overall system becomes unstable.
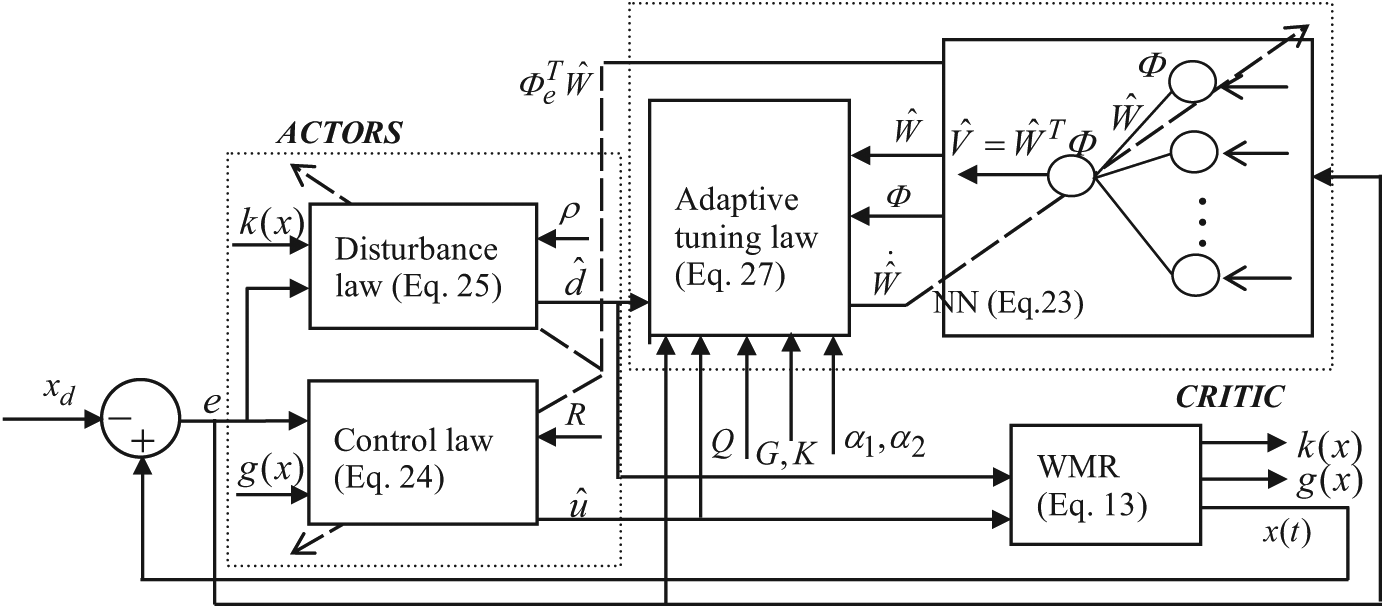
The proposed actor critic structure to learn and feedback control online is shown in Figure 1. It can be seen that the adaptive tuning law for the single NN in (27) is applied to update the NN weight such that the error function of approximate Hamiltonian in (26) is minimized and it does not involve the system’s drift dynamics, so the intelligent tracking control law defined previously can be obtained.
The proposed actor critic structure.
To guarantee the convergence of , the control inputs and disturbance must be fully explored by adding the noise probe to and . That means the Persistence of Excitation (PE) condition in the interval with , for all must be satisfied (Vamvoudakis et al., 2011)
where and are positive constants, and I is the identity matrix with the appropriate dimension.
Theorem 1. Let the tracking dynamics of WMR be given by (13) with the objective tracking HJI equation (19), critic NN be given by (20), the tuning law for critic be defined in (27) and the intelligent tracking control and disturbance laws to approximate the optimal tracking cost function (15) be defined in (24) and (25), is satisfied with the condition PE (30). Then, the closed-loop system state and the NN error are UUB with the limited number of hidden layer units. Furthermore, the approximation errors of control input and worst-case disturbance are bounded such that , for small positive constants , .
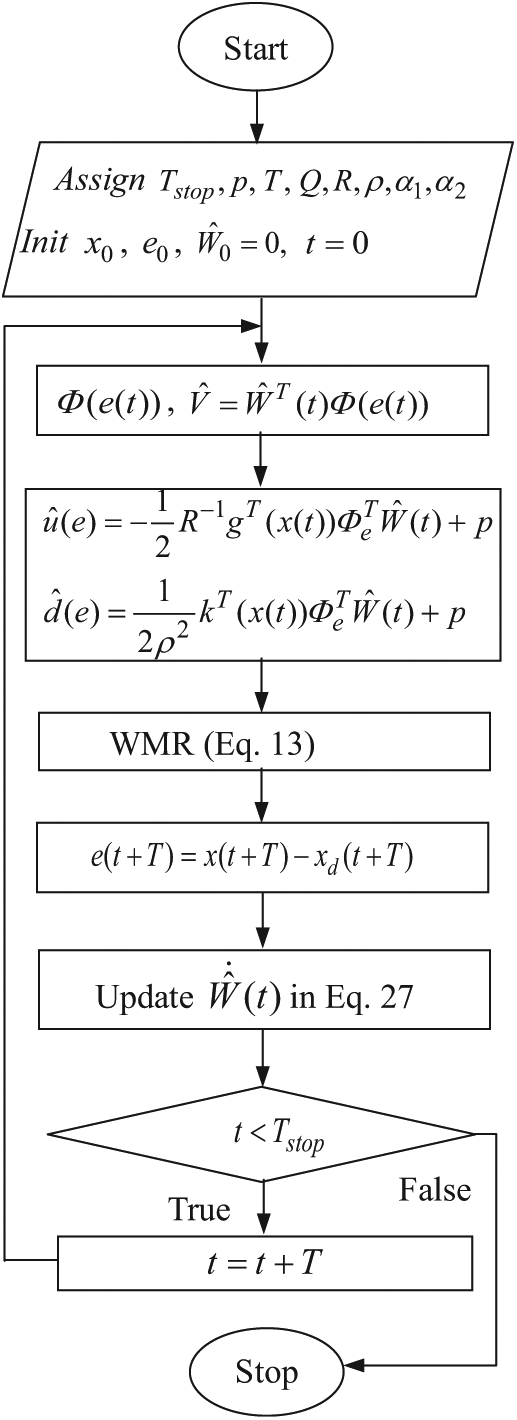
The proposed algorithm is represented by the block diagram in the Figure 2. is the time to stop the algorithm, p is the noise probe and the other parameters are mentioned before.
The block diagram of the algorithm.
Simulation results
To verify the proposed algorithm, two numerical simulations are offered. In the former, a non-linear system is learned and controlled by the proposed algorithm using one NN in comparison with another one using three NNs (Vamvoudakis et al., 2011). In the latter, the proposed algorithm is applied for the WMR.
Non-linear system
Consider the non-linear system with disturbance inputs, with a quadratic cost defined as in Vamvoudakis et al. (2011):
where and . We simulate in turn the non-linear system by the proposed algorithm using one NN and the algorithm in Vamvoudakis et al. (2011)using three NNs. To be comparable, the optimal tracking problem in the paper is transformed to the optimal control problem as Vamvoudakis et al. (2011), by defining the vector of tracking error as , where . In this case, the tracking dynamic Equation (13) is in the form of Equation (31).
In both algorithms, one selects , , , , , and Tstop=80 s. The optimal value function is , so the optimal inputs are and by theory. The NN activation function vectors are defined as and the weight vector of critic NNs are defined as for the algorithm using one NN and for one using three NNs. All initial values of weights are zeros. The other parameters for three NNs can be seen in Vamvoudakis et al. (2011).
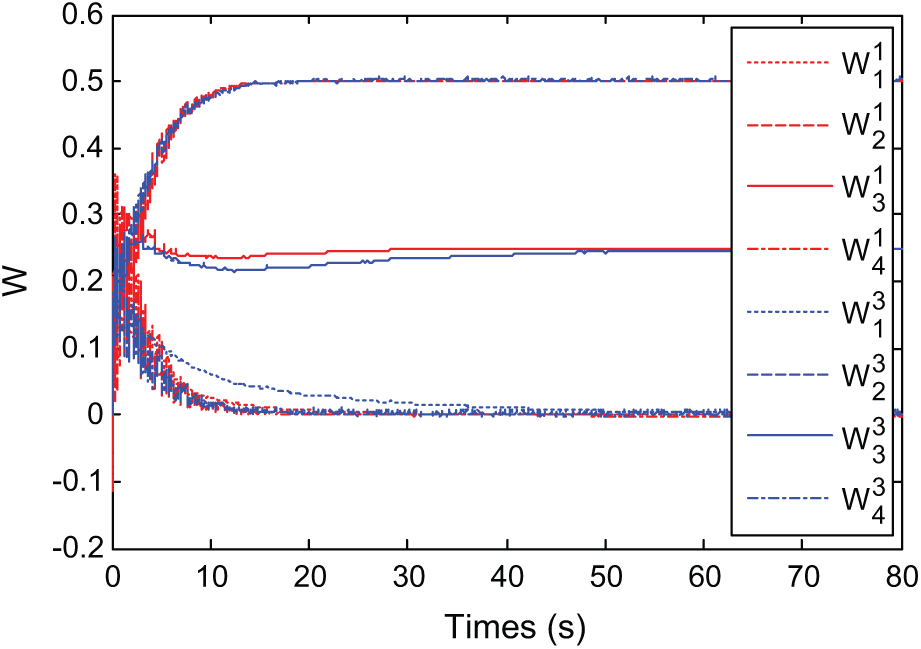
The convergence of critic parameters of both are shown in Figure 3. In the algorithm using one NN, all parameters converge at about 20 s with optimal values , while using three NNs, they converge slower, at about 50 s with optimal values . In addition, the parameters of the NNs for the actor and disturbance in the algorithm using three NNs also converged to the optimal approximate values (see Vamvoudakis et al., 2011, for more detail). Thus, using (24) and (25), both algorithms give similarly the optimal control inputs and the optimal disturbance inputs . However, it can be seen that using single NN, the proposed algorithm has reduced the complexity and resources, and given the convergence speed faster than the algorithm using three NNs.
Convergence of parameters of the critic neural networks (NNs) in algorithms using one and three NNs.
Wheeled mobile robot
Consider the WMR defined above. With the notation introduced before, state vectors and parameters of WMR are , , , and , , where and denote the value of the mass and the moment of inertia of the platform, motors and wheels, respectively. Note that with the designed robust adaptive control law, WMR parameters can change online in bounded domains. One assumes that the control torques applied to DC motor-mounted gearboxes are statically related to the voltage input by a constant so the electrical dynamics of the motors can be included in the general disturbance such that . If the WMR matrices and desired velocities of the reference robot are defined as ,
Then , and are identified by changing these parameters to the formulations in Definitions 1 and 3. The smooth desired eight-shaped trajectory is generated by and satisfied the constraint in Definition 2. The weight vector of critic NN is defined as , whose initial values are zeros. The adaptive gains are selected as and . The activation function vector of critic NN with 15 elements is chosen as One selects , and . The PE condition is applied by adding the noise to the control inputs and disturbance where generates random signals in the range [−1,1]. The desired position vector of the virtual robot is initial at . The initial position and velocities of WMR are , , respectively. The parameter T is chosen as and .
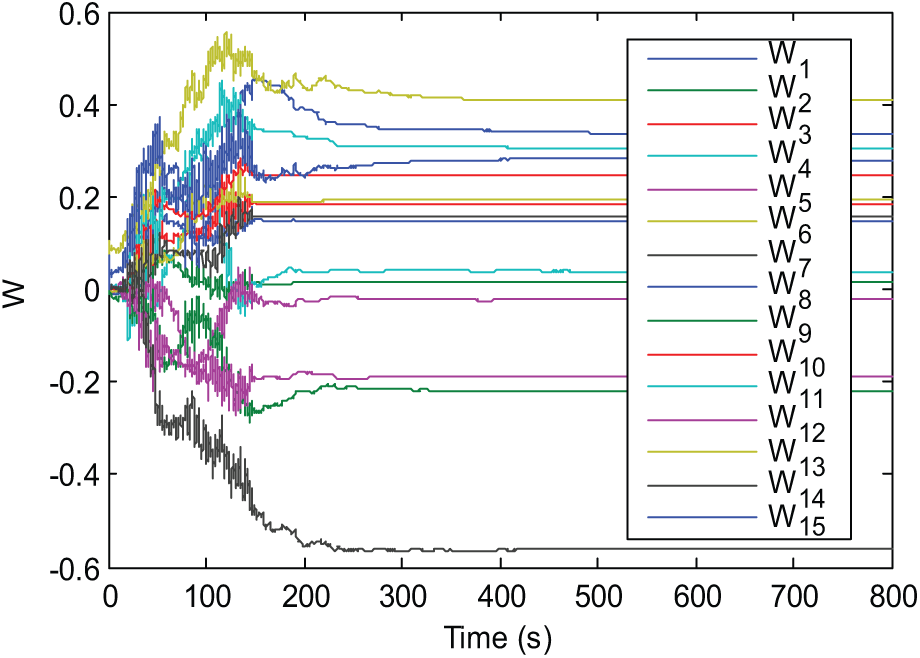
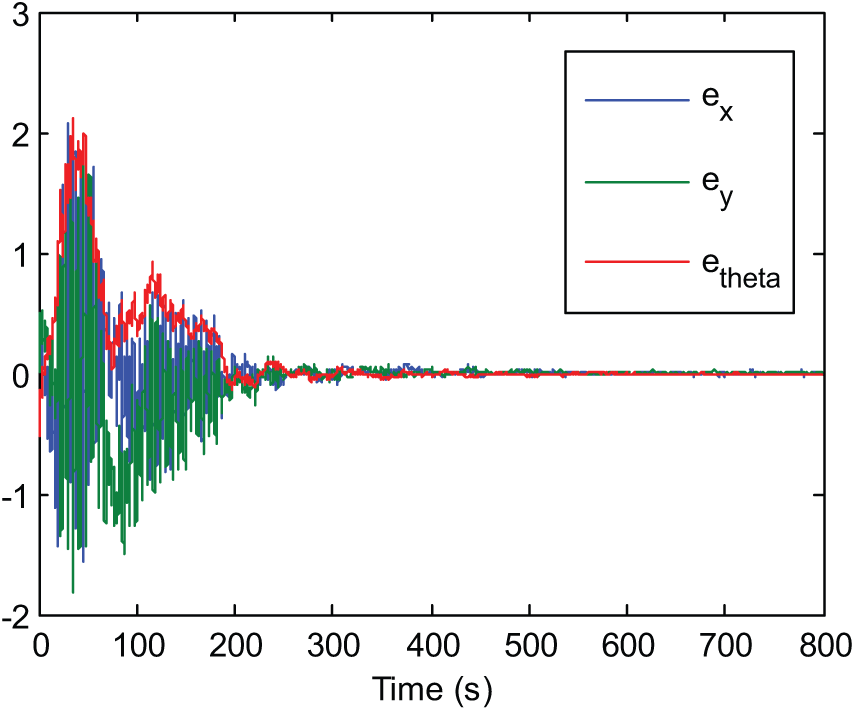
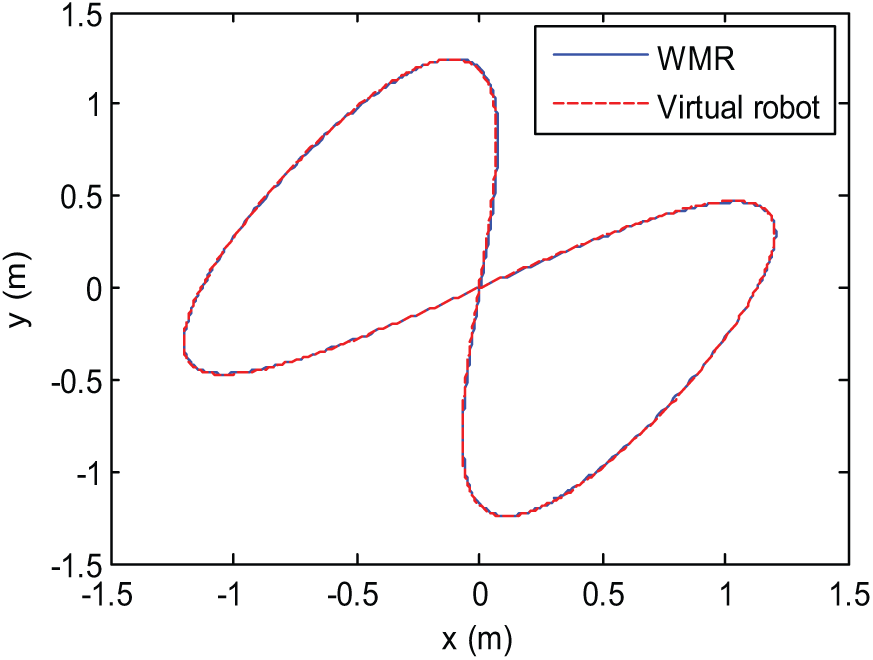
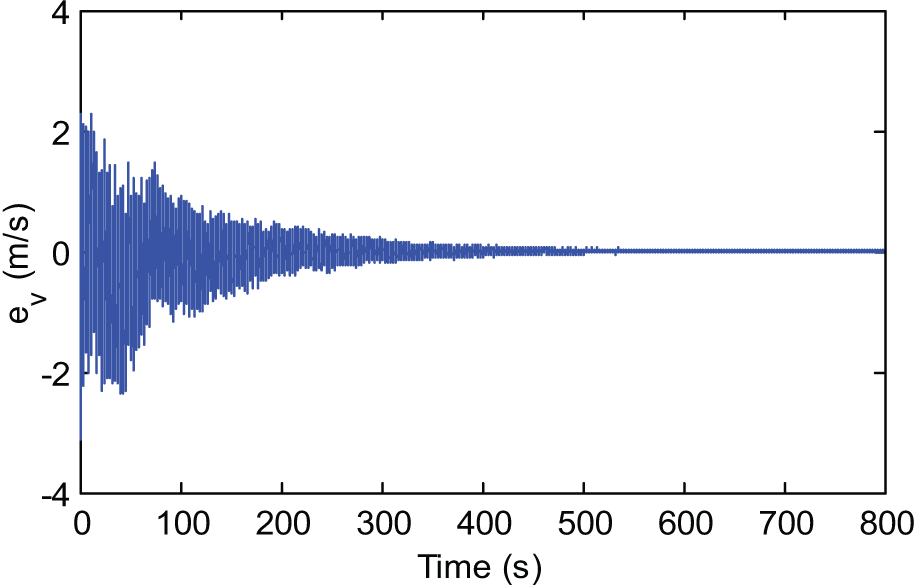
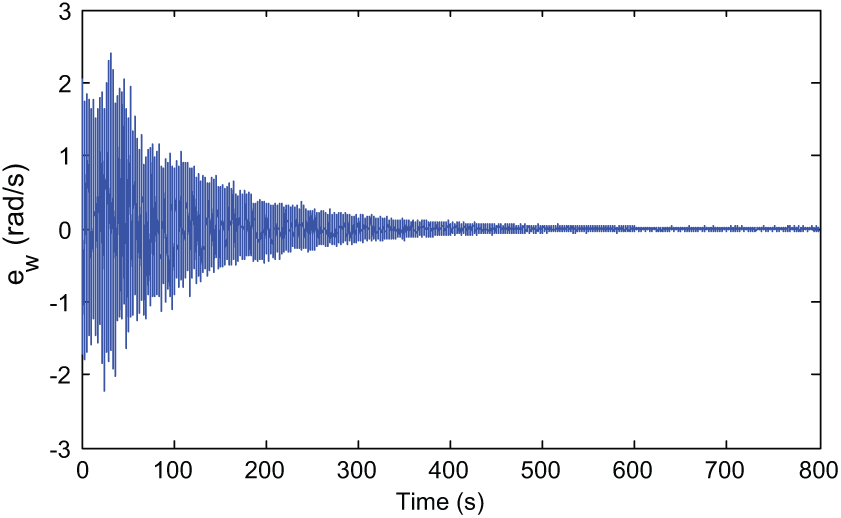
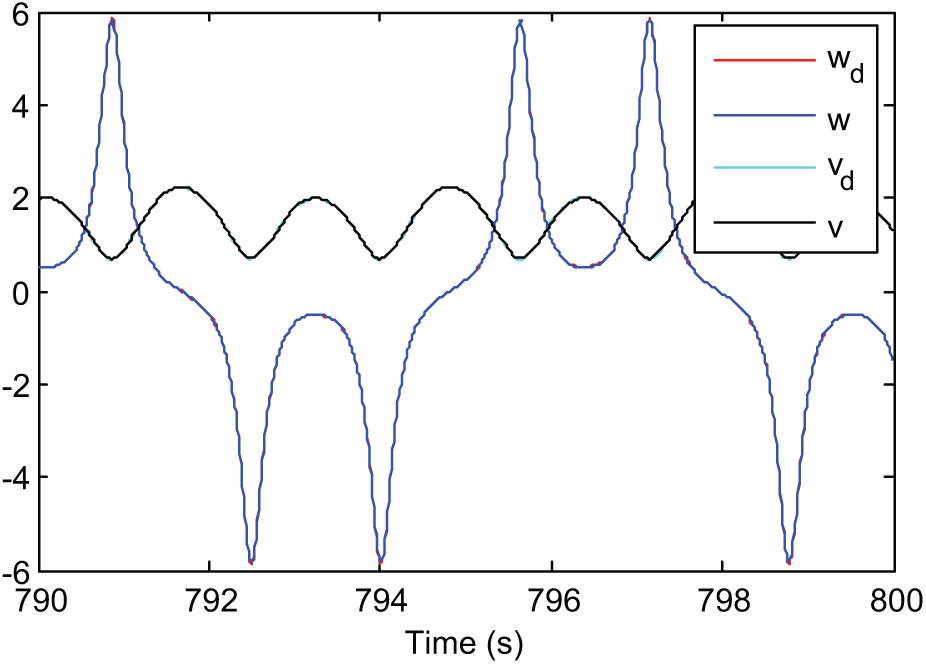
The convergence of critic parameters is shown in Figure 4. It can be seen that almost parameters converge after 300 s. The PE noise can be cancelled any time after that; here it is after 500 s. The evolution of the posture tracking errors during the simulation is presented in Figure 5. Although affected by input disturbances, the errors still converge closely to zero. Posture tracking of the WMR versus the reference robot by the designed robust direct adaptive controller is shown in Figure 6. The evolution of tracking errors between virtual control velocities and the WMR during simulation is shown in Figures 7 and 8, while Figure 9 represents the actual and virtual velocities.
Convergence of parameters of the critic neural network (NN).
Evolution of the posture tracking errors during simulation.
Posture of wheeled mobile robot (WMR) with input disturbances.
Evolution of the linear velocity tracking error.
Evolution of the rotation velocity tracking error.
Actual and virtual velocities with input disturbance.
Conclusion
The paper presents a new method for designing an integrated kinematic and dynamic intelligent tracking control algorithm for a WMR. The designed algorithm is a synchronous policy iteration using the actor critic structure with a single NN. Closed-loop dynamic tracking errors and critic parameters are proved to show UUB stability during the online learning. The optimal value function, the robust direct adaptive control input and worst-case disturbance are converged to the optimal approximate values.
Footnotes
Appendix A: proof
Funding
This research received no specific grant from any funding agency in the public, commercial, or not-for-profit sectors.
References
1.
Abu-KhalafMLewisFL (2005) Nearly optimal control laws for nonlinear systems with saturating actuators using a neural network HJB approach. Automatica41(5): 779–791.
2.
ChenBSUangHJTsengCS (1998) Robust tracking enhancement of robot systems including motor dynamics: a fuzzy-based dynamic game approach. IEEE Transactions on Fuzzy Systems6(4): 538–552.
3.
ChenHMaMWangH. (2009) Moving horizon H∞ tracking control of wheeled mobile robots with actuator saturation. IEEE Transactions on Control Systems Technology17(2): 449–457.
4.
ChwaD (2010) Tracking control of differential-drive wheeled mobile robots using a backstepping-like feedback linearization. IEEE Transactions on Systems, Man, and Cybernetics—Part A: Systems and Humans40(6): 1285–1295.
5.
DierksTJagannathanS (2010) Optimal control of affine nonlinear continuous-time systems using an online Hamilton–Jacobi–Isaacs formulation. In: 49th IEEE Proceedings of the CDC2010 (pp. 3048–3053).
6.
FierroRLewisFL (1998) Control of a nonholonomic mobile robot using neural networks. IEEE Transactions on Neural Networks4: 589–600.
7.
FinlaysonBA (1990) The Method of Weighted Residuals and Variational Principles. New York: Academic Press.
8.
HornikKStinchcombeMWhiteH (1990) Universal approximation of an unknown mapping and its derivatives using multilayer feedforward networks. Neural Networks3: 551–560.
9.
KhoshnamSAlirezaMSAhmadrezT (2011) Adaptive feedback linearizing control of nonholonomic wheeled mobile robots in presence of parametric and nonparametric uncertainties. Robotics and Computer-Integrated Manufacturing27(1): 194–204.
10.
LewisFLJagannathanSYesildirekA (1999) Neural Network Control of Robot Manipulators and Nonlinear Systems. London: Taylor & Francis.
11.
LinWSYangPC (2008) Adaptive critic motion control design of autonomous wheeled mobile robot by dual heuristic programming. Automatica44: 2716–2723.
12.
LuyNT (2012) Reinforcement learning-based optimal tracking control for wheeled mobile robot. In: Proceeding of the IEEE International Conference on Cyber Technology in Automation, Control, and Intelligent Systems, pp. 371–376.
13.
LuyNTThanhNDThanhNT. (2010) Robust reinforcement learning-based tracking control for wheeled mobile robot. In IEEE Proceedings of the ICCAE2010, Vol. 1, pp. 171–176.
14.
MarvinKBSimonGFLiberatoC (2009) Dual adaptive dynamic control of mobile robots using neural networks. IEEE Transactions on Systems, Man, and Cybernetics—part b: Cybernetics39(1): 129–141.
15.
MiyasatoY (2008) Adaptive H∞ control of nonholonomic mobile robot based on inverse optimality. In: Proceedings of the American Control Conference, Seattle, WA, pp. 3524–3529.
16.
MohareriODhaouadiRRadAB (2012) Indirect adaptive tracking control of a nonholonomic mobile robot via neural networks. Neurocomputing88: 54–66.
17.
VamvoudakisKGLewisFL (2010) Online actor critic algorithm to solve the continuous-time infinite horizon optimal control problem. Automatica46: 878–888.
VamvoudakisKGVrabieDLewisFL (2011) Online learning algorithm for zero-sum games with integral reinforcement learning. Journal of Artificial Intelligence and Soft Computing Research1(4): 315–332.
20.
Van Der ShaftAJ (1992) L2-gain analysis of nonlinear systems and nonlinear state feedback H∞ control. IEEE Transactions on Automatic Control37(6): 770–784.
21.
VrabieDPastravanuOLewisFL. (2009) Adaptive optimal control for continuous-time linear systems based on policy iteration. Automatica45(2): 477–484.
22.
ZenonHMarcinS (2011) Discrete neural dynamic programming in wheeled mobile robot control. Communications in Nonlinear Science & Numerical Simulation16. 2355–2362.