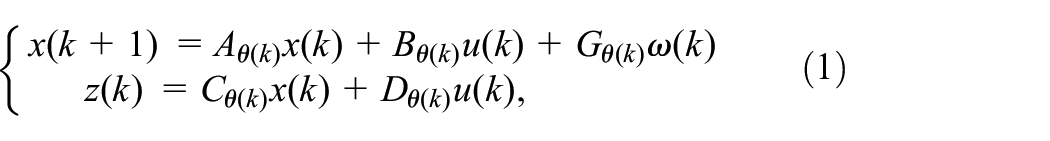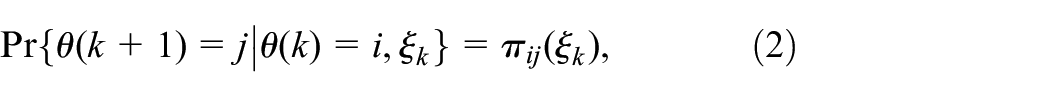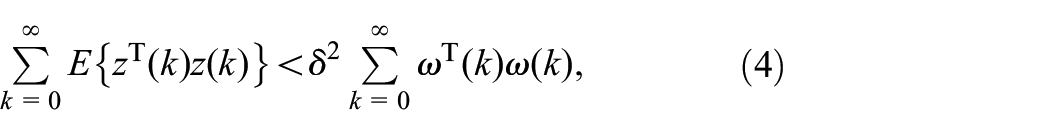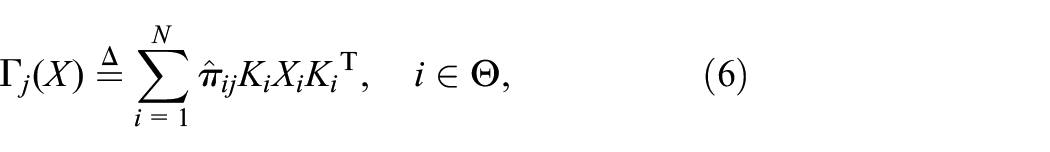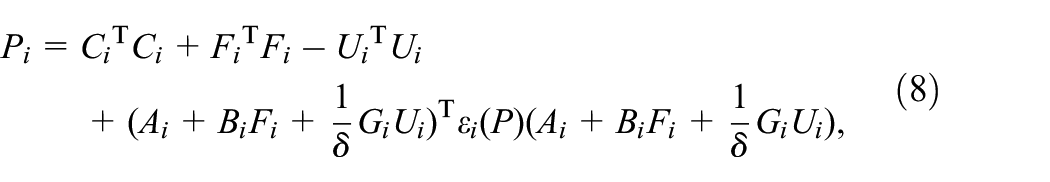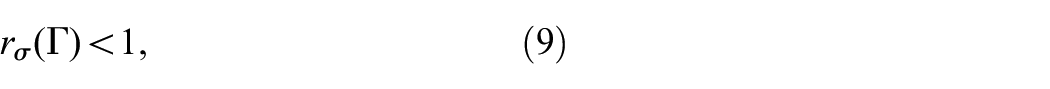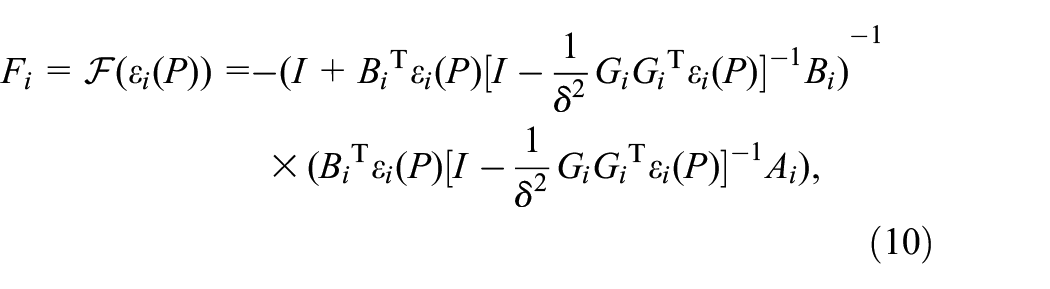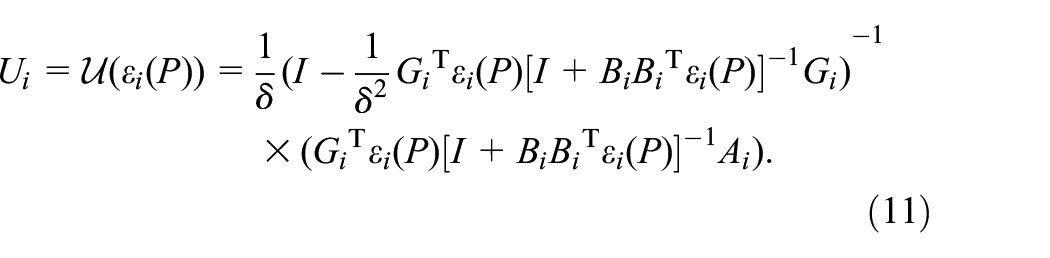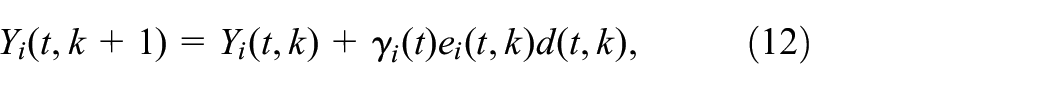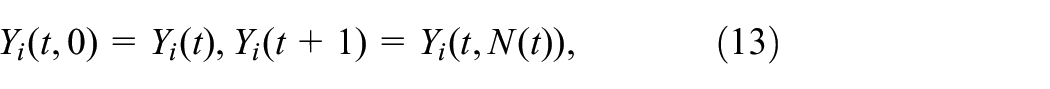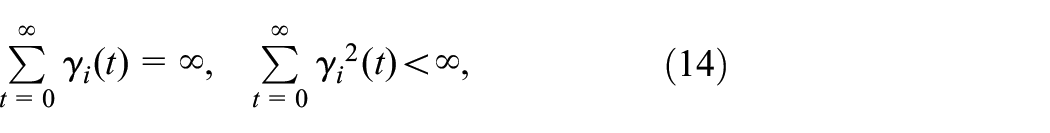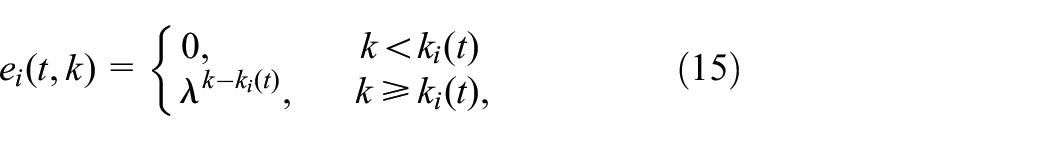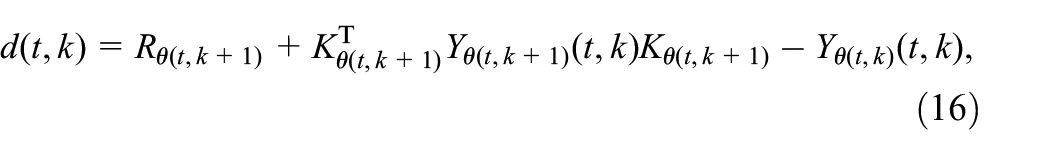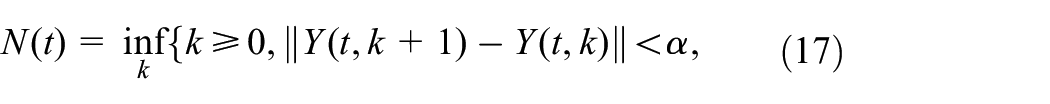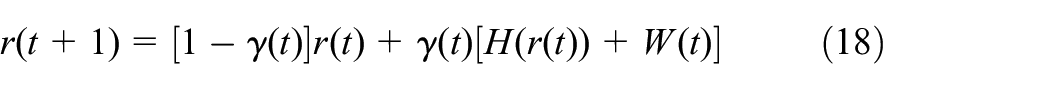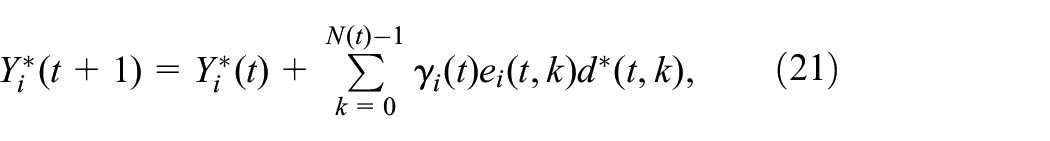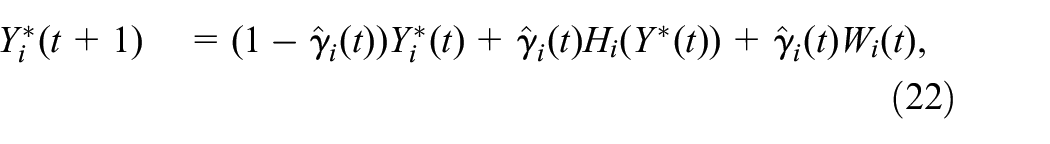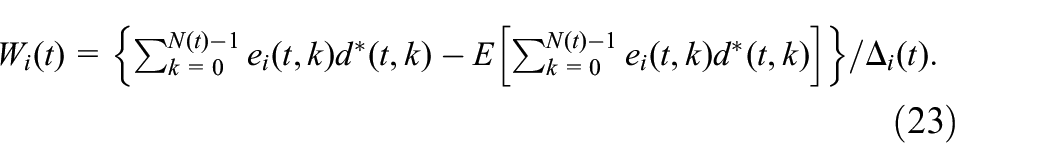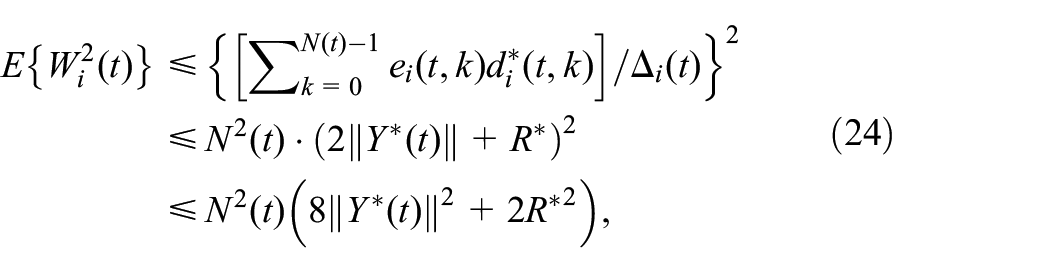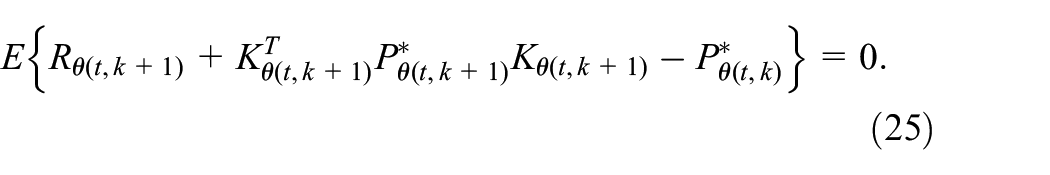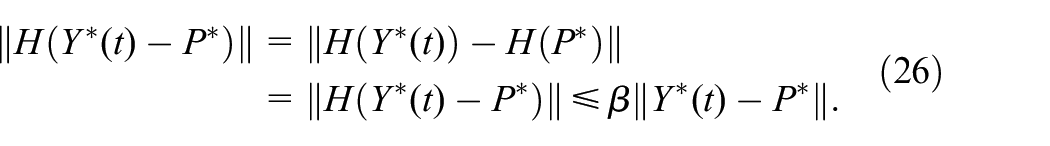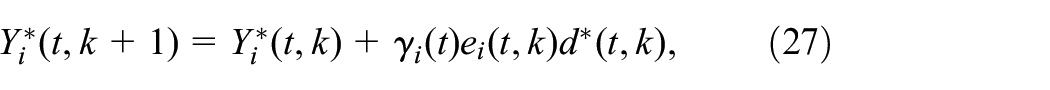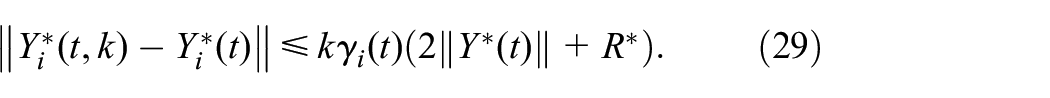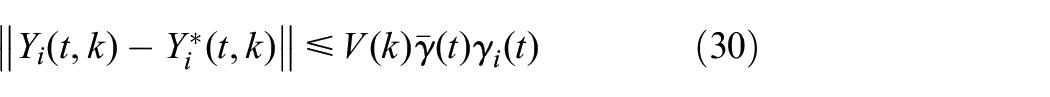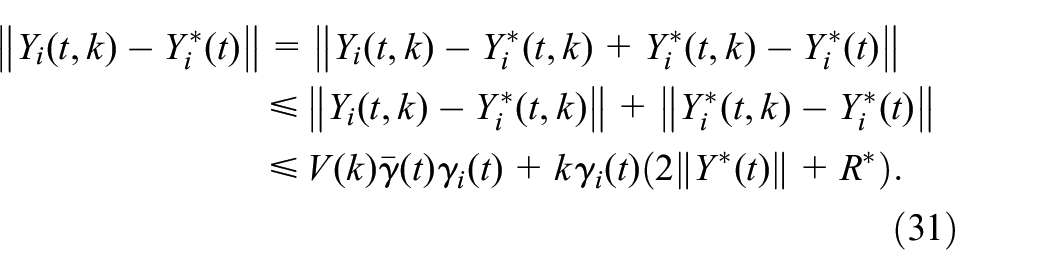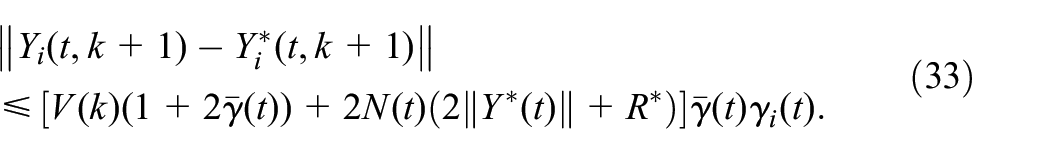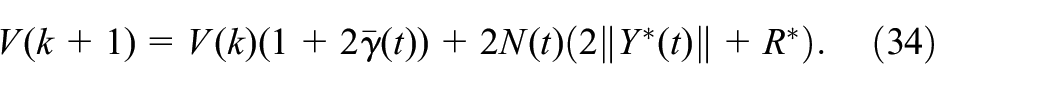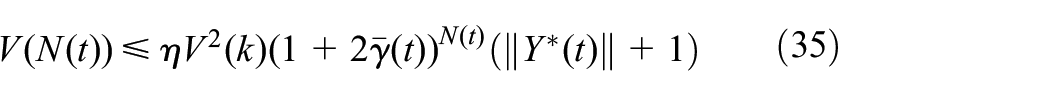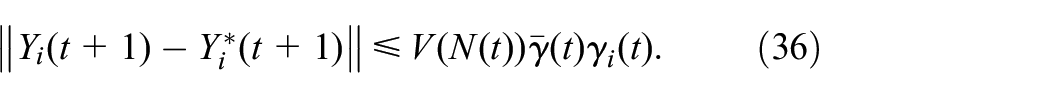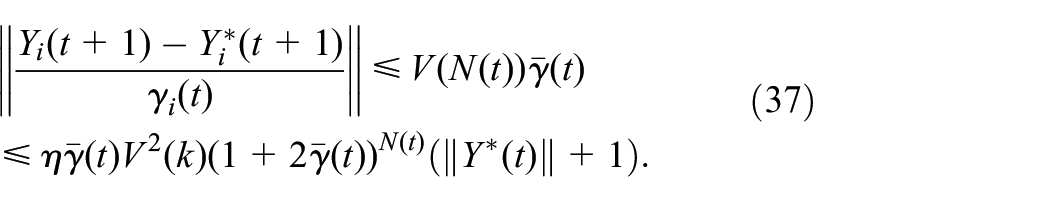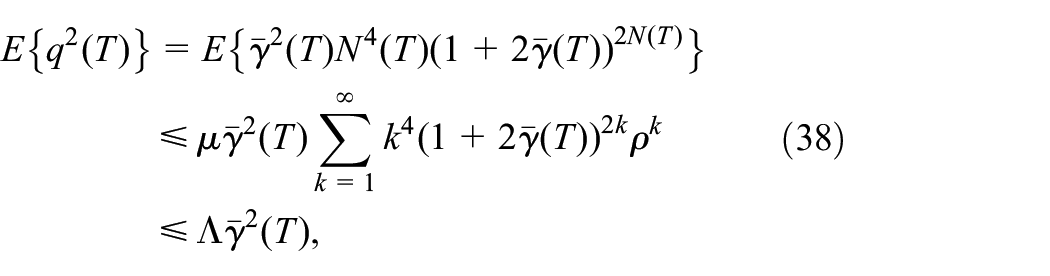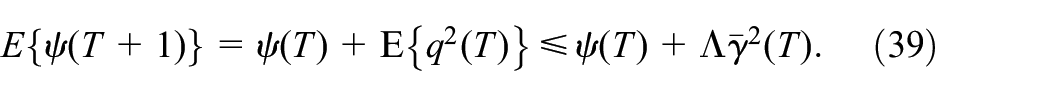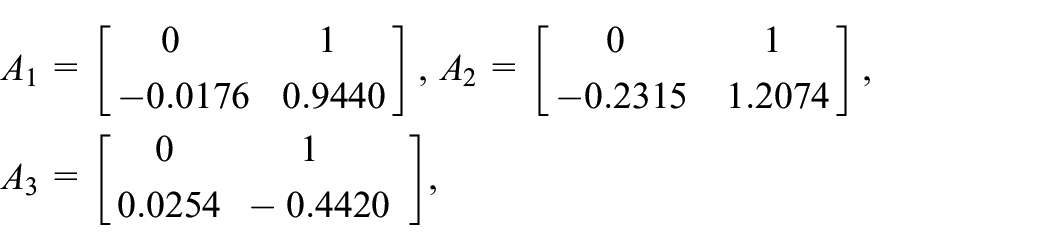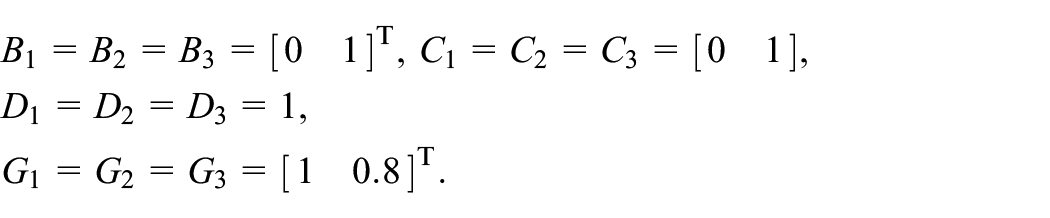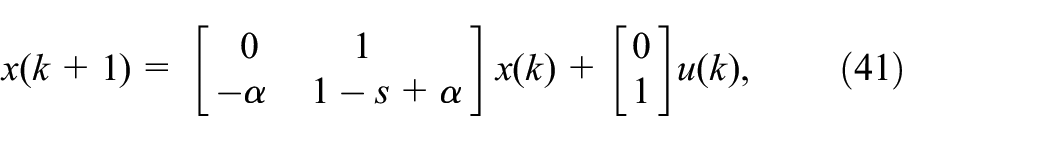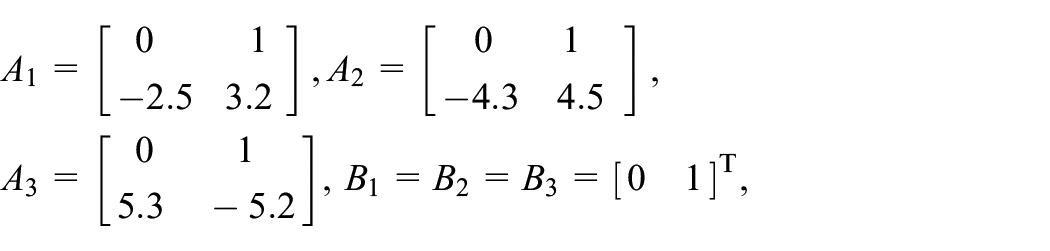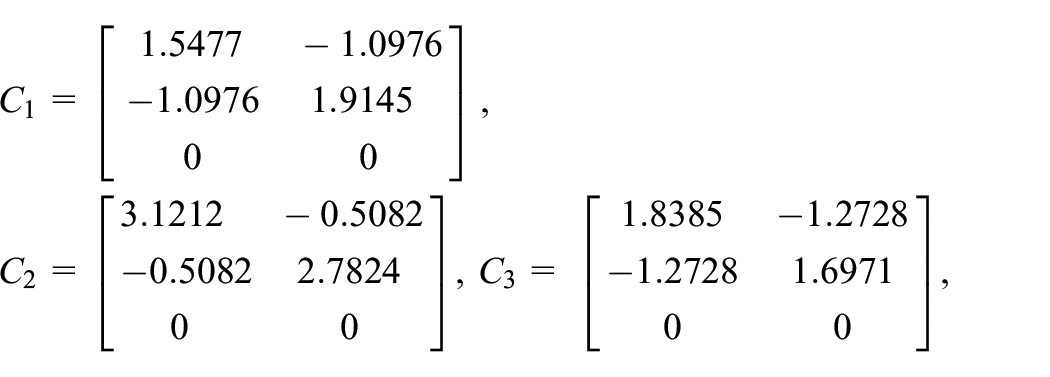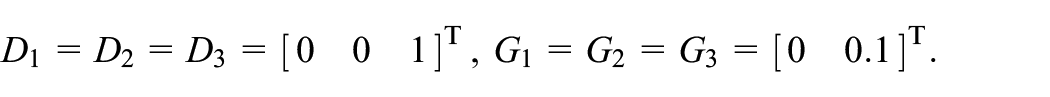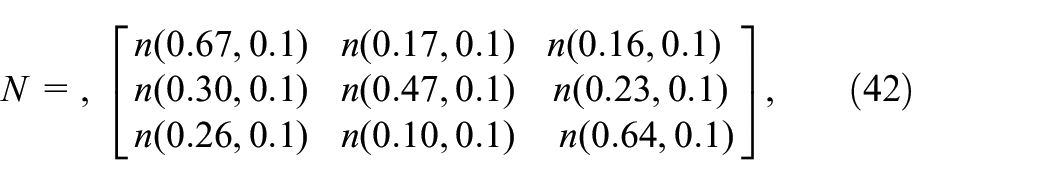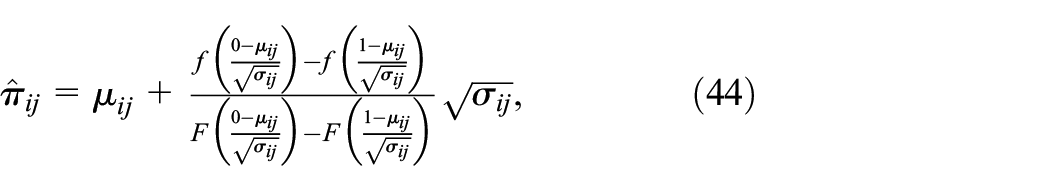In this paper, an online temporal differences (TD) learning approach is proposed to solve the robust control problem for discrete-time Markov jump linear systems (MJLS) subject to completely unknown transition probabilities (TP). The TD learning algorithm consists of two parts: policy evaluation and policy improvement. In the first part, by observing the mode jumping trajectories instead of solving a set of coupled algebraic Riccati equations, value functions are updated and approximate the TP related matrices. In the second part, new robust controllers can be obtained until value functions converge in the previous part. Moreover, the convergence of the value functions is proved by initializing a feasible control policy. Finally, two examples are presented to illustrate the effectiveness of the proposed approach by comparing with existing results.
The past decades have witnessed great advances of Markov jump linear systems (MJLS) with an ever-increasing complexity. The systems can effectively model stochastic dynamical processes governed by a Markov chain. To name a few, fault-tolerant control systems with abrupt random faults and networked control systems where network-induced imperfections vary in a random way (see, for example, Costa et al., 2006); do Valle Costa et al., 2012); Shi and Li, 2015).
As an essential factor, transition probabilities (TP) depict the stochastic jumping and also determine the system behaviour. Under the assumption that TPs are precisely known, partially known, or involve uncertainties, many issues on MJLS have been investigated. For example, stability and stabilization have been studied in Bolzern et al. (2006); Hou and Ma (2015) and Xiao et al. (2010); Zhang and Boukas (2009c). Linear quadratic optimal control problem has been solved in Costa and Fragoso (1995) and Chizeck et al. (1986). High-order moment stabilization and filtering problems for MJLS have been addressed in Luan et al. (2018); Wan et al. (2018) and Zhou et al. (2020) The purpose of robust control is to maintain some performance of the system when the system contains unknown or uncertain information or is subject to external interference. One of the common methods is control, which has received extensive attention. For instance, with known TPs, robust stability condition for MJLS with parameter uncertainty has been studied in de Souza (2006). The robust control problem has been addressed in Chen et al. (2019) by adding a state observer. Asynchronous controllers have been designed for Markov jump time-delay systems and two-dimensional MJLS in Shen et al. (2019) and Wu et al. (2018), respectively. The approach in Shi and Li (2015) utilized quantized signals to design a sliding mode observer, which can be applied to state estimation field. With partially unknown TPs, robust finite-time state feedback control and dynamic output control have been investigated in Zong et al. (2013) and Zhang and Boukas (2009a), respectively. The methods in Zhang and Boukas (2009b) solved filtering design problem. In some cases, some uncertainties or time-varying properties may exist in TPs of the jump mechanism. As a result, there are many literatures on MJLS with uncertain TPs. For example, robust stability and output feedback control problems have been addressed in Xiong et al. (2005) and Fioravanti et al. (2013), respectively. Based on Zhang and Boukas (2009b), the partly known TPs model is proved to be a particular case of polytopic uncertain TPs and corresponding filter has been designed in Gonҫalves et al. (2011). An element-wise method has been proposed in Xiong and Lam (2006), where the system matrix and the transition rate matrix are assumed to be bounded. Luan et al. (2012) assumed that TP uncertainties can be depicted by a Gaussian density function. Robust stability conditions for continuous-time MJLS are developed in Faraji-Niri et al. (2014, 2017), where the time-varying information of transition rates can be described by a piecewise constant.
In the above literatures, it is always assumed that some information of TPs matrix must be known. Then, the stability condition or optimal control objective is achieved by solving coupled algebraic Riccati equations (CARE) or transformed into linear matrix inequalities (LMI). However, in some practical applications, the transition between each jumping mode of MJLS is not clear, that is, the TPs of the Markov chain are unpredictable or unknown in advance. Therefore, it is difficult to directly obtain feasible solutions from CAREs or LMIs. As a result, there are many studies on the estimation for TPs, for example, online Bayesian estimation (Jilkov and Li, 2004) and maximum likelihood estimation (Beirigo et al., 2017; Orguner and Demirekler, 2008). In another way, MJLS with unknown TPs are regarded as arbitrary switched systems and the sufficient condition for control is given in Zhang and Boukas (2009a). Recently, reinforcement learning (RL) (Sutton and Barto, 2018) and adaptive dynamic programming (ADP) have been widely used in the systems control field. For instance, Q-learning algorithms are developed to solve optimal control problems for discrete-time linear systems with unknown dynamics in Kiumarsi et al. (2014) and Jiang et al. (2019). The optimal control problem for continuous-time nonlinear system, which is described as two-player zero-sum game, has been addressed by formulating an actor-critic neural network in Vamvoudakis and Lewis (2012) and a novel critic-only algorithm in Zhang et al. (2016). Based on ADP, time-triggered and event-triggered constrained control schemes for strict-feedback nonlinear large-scale systems have been investigated in Tan (2018) and Tan (2019), respectively. A self-triggered control method has been proposed in Wan et al. (2020) to further reduce the resource occupation. Passive filter has been designed to estimate the neuron state of semi-Markov jump systems by the model of neural network in Shi et al. (2016). Costa and Aya (2002) developed an offline Monte Carlo TD method to solve the optimal control problem of MJLS with unknown TPs, where the historical data of Markov chains are observed to update the value function of the proposed iterative algorithm. Such an algorithm has been improved to the online scenario in Beirigo et al. (2018).
In this work, inspired by offline (Costa and Aya, 2002) and online (Beirigo et al., 2018) TD methods which deal with the jump linear quadratic problem, an improved TD approach is presented to address the robust control for MJLS, where the TP matrix including both deterministic and uncertain cases is completely unknown. Different from traditional methods to solve CAREs, TP related matrices are approximated by designed value functions, which are updated via observing modes jumpings in online algorithm. The main challenge is to ensure the convergence of the value function under the condition that the unknown TPs of MJLS are time-varying, which is proved in this paper. Moreover, the proposed algorithm is implemented online so that fast convergence can be achieved. We demonstrate the strength of our approach by a numerical example and Samuelson’s macroeconomic model with uncertain TPs by comparing with the existing results in Beirigo et al. (2018) and Luan et al. (2012), respectively.
The main contribution of this paper is to design an improved TD learning algorithm and prove that the value function converges to TP related matrices of CAREs. The method in Beirigo et al. (2017) has weak disturbance attenuation capability and is only applicable in the constant TPs scenario. The estimation approaches, such as Orguner and Demirekler (2008) and Beirigo et al. (2017), have limited capability to deal with time-varying or uncertain TPs. The exiting results of Zhang and Boukas (2009a) in terms of LMIs are very conservative because they totally ignore TPs knowledge in the case that TPs are unknown but do exist. By contrast, the method in this paper can greatly reduce the conservatism and obtain more effective controller by comparing with Zhang and Boukas (2009a), because it takes advantage of the information of mode jumping information. In addition, the proposed approach can not only guarantee a desired attenuation level, but also handle the case that the unknown TP matrix is actually random varying.
The structure of the paper is as follows. In the following section, MJLS is introduced and the robust control problem is formulated. Next, an online TD learning algorithm is proposed and the proof of convergence is given. The simulation results are provided to show the effectiveness of proposed methods, and the paper ends with some concluding remarks.
Notation: The notations used throughout this paper are standard. denotes -dimensional Euclidean space, denotes the set of positive semi-definite -by- matrices, and represent the transpose and the inverse of matrix, respectively, is the Euclidean norm of matrix , stands for the mathematics statistical expectation of the stochastic process, denotes the space of square summable infinite sequence and is the spectral radius of the linear operator.
Problem formulations
Considering the following MJLS with uncertain TPs:
where is the state vector, is the control input, is the disturbance, is the control output. represents the state of a Markov chain taking values in a given finite set with TP matrix , , and the TP from the mode at time to mode at time are considered as
where is a random variable which denotes the uncertain information of TPs, for , the system matrices are denoted by (, , , , ) with appropriate dimensions.
Assumption 1. The uncertainty of TPs can be represented by a distribution and there is an expectation of TPs , for .
Definition 1. System (1) with and any initial condition and is said to be mean square stable (MSS) if
Definition 2. Given a scalar , system (1) is said to be MSS and has an attenuation level if
holds for all nonzero under zero initial condition.
The purpose of robust control is to design state feedback controllers for system (1) with unknown TPs such that the closed-loop system is MSS and has a prescribed attenuation level. Then, the operators and are defined as, respectively,
where , with and .
Lemma 1. Suppose that is mean square detectable for all and is a given scalar. Then there exists such that the closed-loop system is mean square stable with an index , if and only if there exists satisfying the following conditions:
for all and some , where is as defined in (6) with , and are calculated by (10) and (11).
Remark 1. Lemma 1 is a sufficient and necessary condition proved in Costa et al. (2006) and can be also applied to the case where TPs are certain when is a constant. In order to obtain the solution of CARE (8) with known expectation of TPs, a standard method and a recursive algorithm are respectively proposed in Shi et al. (1999) and Costa et al. (2006). Then, if the solution satisfies (7) and (9), the robust controller of system (1) can be obtained by (10). However, the method of obtaining the TP related matrices by solving the CAREs (8) will be invalid when TP matrix is completely unknown.
Main results
In this paper, an TD-learning algorithm is proposed to approximate online without any transition knowledge. By observing subsequent trajectories of Markov chains, the value function keeps updated and eventually converges to the TP related matrices . Proof of convergence of the algorithm is also provided in this section.
Online TD learning algorithm
The value function in each mode of the proposed algorithm is given by
where stands for the time step, is the episode of the algorithm, and stepsize satisfies
the eligibility coefficients is given by
for , where , , and the temporal difference is defined as
where the reward function , for .
Note that the form of (12)–(16) is a standard online updating algorithm which is a branch of RL. As can be seen from Algorithm 1, the initial feasible policies and ensure the closed-loop stability of system (1). The above algorithm consists of two steps: policy evaluation and policy improvement. In the first step, the algorithm starts with an initial mode and eligibility coefficients with zero. Then, the value function is updated immediately when a mode jumping occurs. To ensure the convergence of at the th Markov mode trajectory, for example, can be the length of th trajectory or be defined as
where is precision parameter. In the second step, new policies and are obtained using learned in the first step. Until the value function converges, the robust controllers are obtained by step 11 in Algorithm 1.
Algorithm 1. TD learning
Start with feasible stabilizing control policies
and , , , the iteration number
Policy evaluation.
1:
2: Start with ,
3: , ,
4:
5: Observe the next mode
6: Update via (15)
7: Update via (12)
8:
9:
10:
11:
12:
, for a small positive value
of , Otherwise set and go to step 1
Remark 2. In Algorithm 1, the value function is updated quickly based on the real-time observations of the mode trajectories which contain the time-varying information of TPs. The convergence value of is used to calculate a new control policy . Then, the improved policy is applied to next policy evaluation step. The entire process repeats until the control policy converges and the desired robust controller is obtained. Compared with the results in Costa and Aya (2002) and Beirigo et al. (2018), the proposed approach can not only ensure the system (1) mean square stability with a desire disturbance attenuation, but also deal with the case of uncertain or time-varying TPs. Compared with the method in Luan et al. (2012), where the uncertainty of TPs is assumed to be depicted by Gaussian distribution and then the expected TP matrix is calculated via the mean and variance known in advance, the approach in this paper does not require any information of TPs.
Proof of convergence
Lemma 2. If is a sequence generated by
and satisfies the following conditions:
(a) The stepsize satisfies .
(b) For every , and there exist constants and such that
(c) is a contraction mapping, and there exists a vector , a scalar , such that
Then, converges to with probability 1.
Theorem 1. If policies and satisfies , , and for some scalars and , , then the value function converges to with probability 1.
Proof. Inspired by some simulation methods presented in Bertsekas and Tsitsiklis (1996), we develop complete proof for the convergence of the online TD method. First, the offline form is defined as
where . (21) also can be written as
where , , .
Since , it is easy to get and , satisfying the condition (a) of Lemma 2. is defined by
Obviously, . Note that , then, , where is an upper bound for . In this case,
which satisfies the condition (b) of Lemma 2.
Let , then,
So, we obtain . Also, it can be proved that is a contraction mapping in Bertsekas and Tsitsiklis (1996) (see 215-217). In this case,
The condition (c) of Lemma 2 is satisfied. Therefore, it is proved that converges with probability 1, that is, .
And (21) can be also written in incremental form as
Note that , we obtain that
Then, we try to prove the following
by induction approach for some , where . Note that (28) makes sense for with . For , (28) is assumed as an induction hypothesis. Then, we obtain that
Using (29) and , we obtain
Then, using (28) and (30), one has
Hence, the proof of induction (28) is complete, with
Let , we have
for some constant , and
Hence, using (33) and (34) yields
Let , and is large enough such that . Note that , we obtain
for some constant . Define , note that
Since , converges with probability 1. Thus, converges to zero, and will converge to the same value by (35) as goes to infinity. The proof is complete.
Remark 3. Theorem 1 illustrates a prerequisite that the value function eventually converges to TP-related matrix in Algorithm 1. The entire proof of convergence involves two steps: () we learn from Lemma 2 that the offline value function defined by (21) converges to ; () the difference between and tends to zero as goes to infinity for every .
Illustrative examples
Example 1. To compare the TD learning method in this paper with previous approach Beirigo et al. (2018), we consider the MJLS (1) with following parameters:
And the TP matrix of the model is given by
The TD learning algorithms in Beirigo et al. (2018) and in this paper for the above MJLS follow the same settings: , , and . In Beirigo et al. (2018), the jump linear quadratic optimal control problem was considered, where the controlled output index was required to be minimized. By previous online TD algorithm, the corresponding optimal controller can be obtained by = , = , = .
Then, giving the performance index and executing Algorithm 1, the robust controller is given by = , = , = .
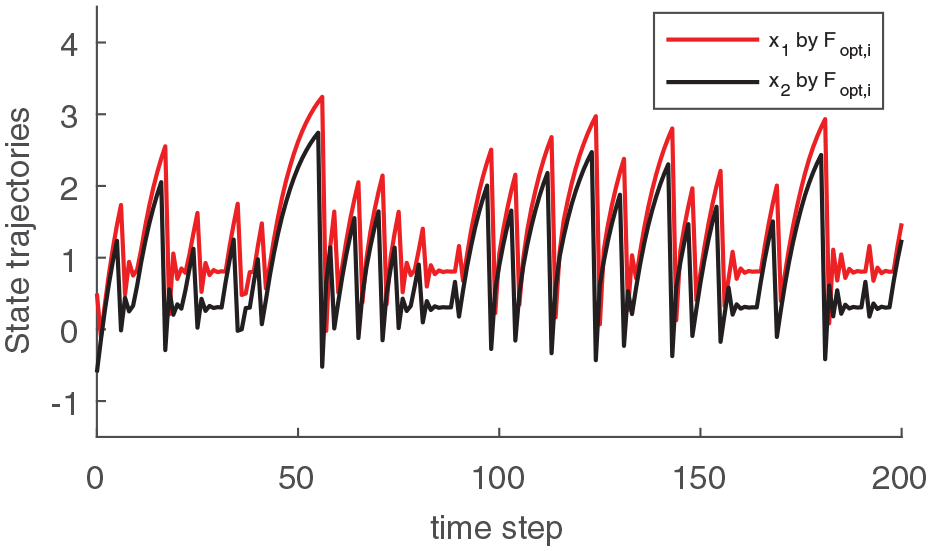
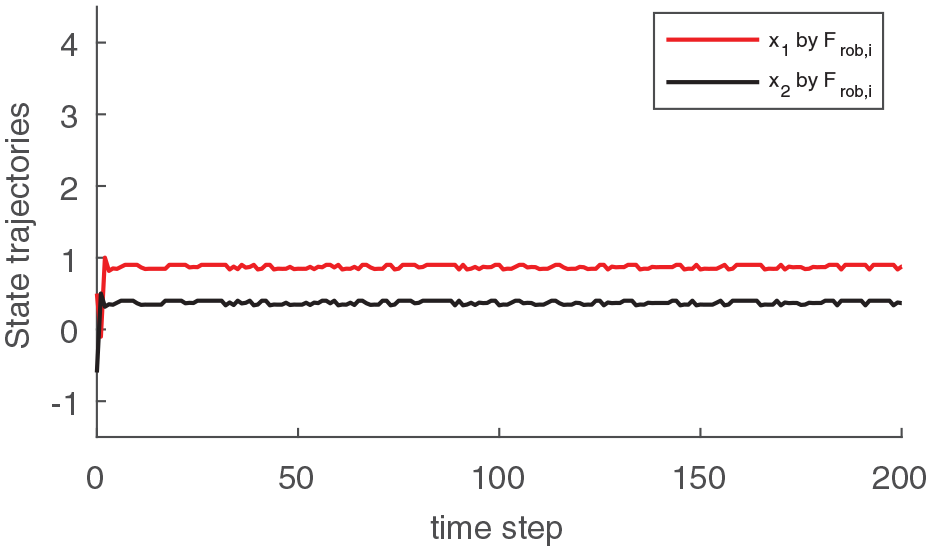
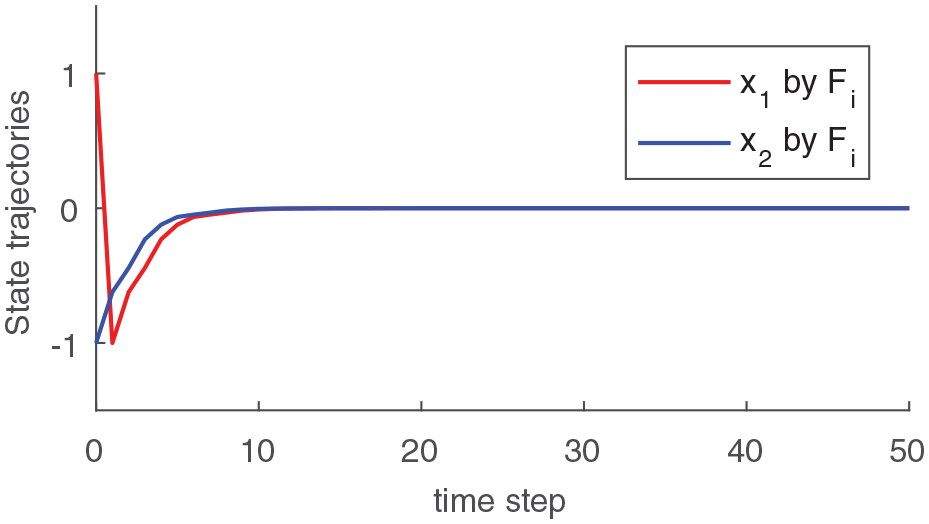
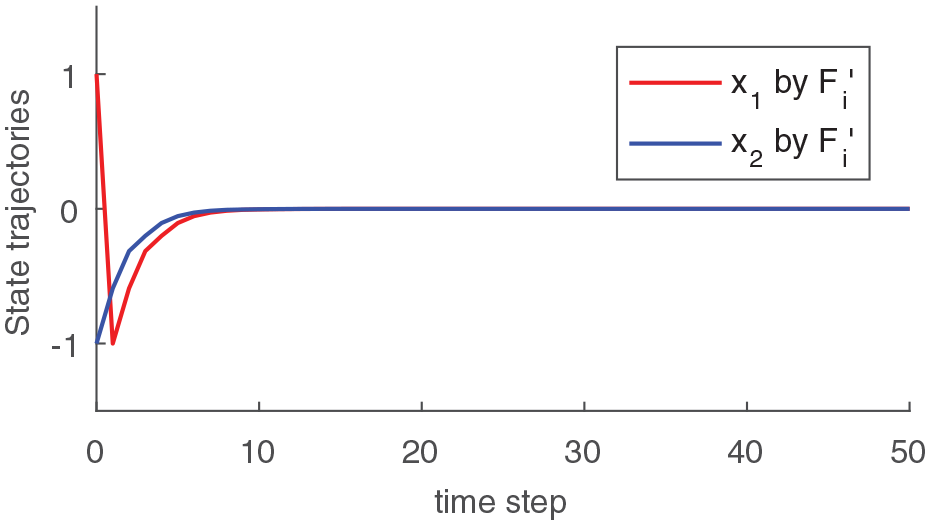
Letting the initial condition = and the external disturbance , the simulation results of the state response of closed-loop system (1) by optimal controller and robust controller are shown in Figure 1 and Figure 2, respectively. By observing the two figures, it can be found that both trajectories vibrate violently due to external disturbance in Figure 1, while the state curves are regulated approximately to equilibrium point in Figure 2. This implies the control policy obtained by proposed TD learning algorithm has better disturbance attenuation capability.
State trajectories of the closed-loop system by .
State trajectories of the closed-loop system by .
In Example 1, under the same conditions, our improved TD learning algorithm achieves better robustness by comparing with Beirigo et al. (2018). Next, we will provide another practical example to illustrate the convergence rapidity and accuracy of the proposed algorithm in the case that TPs are time-varying.
Example 2. In this part, the Samuelson’s multiplier-accelerator model (Blair Jr and Sworder, 1975) which explains the periodic fluctuation phenomenon in the process of economic growth is used to show the effectiveness of our result by comparing with the existing method in Luan et al. (2012). The state-space form which shows the effect of government expenditure on national income is as follows:
where and denote national income and government expenditure, respectively, is the accelerator coefficients and is the multiplier. Based on the historical data from 1929 to 1971 by the US Department of Commerce, the model (40) can be classified by three modes according to different groups of and : norm (both and in mid-range), boom ( in low or in high range) and slump ( in high or in low range). And the corresponding parameters for the model with disturbance (net export capital) are as follows:
Here, different from Example 1, TPs of the above MJLS are time-varying and the uncertainty is described by a Gaussian distribution. The Gaussian transition probability density function (PDF) defined in Luan et al. (2012) is given by
where is the truncated Gaussian transition PDF of , and are the mean and variance respectively.
Then by Algorithm 1, is initialized with zeros, the length of the Markov chains , , , the performance index and the stepsize for all . The simulation results are illustrated in Figure 3, which show the evolutions of of three modes with appropriate policies. In Figure 3, all three value functions converge rapidly in the policy evaluation step and the slight fluctuations are due to the single jump of the modes. To show the accuracy of our results, we define the error as follows:
where is final output convergence value of and is the standard solution of CARE (8). Then, we get the following results by , , , which implies the precision of the proposed TD learning algorithm. The robust control gains can be obtained by as follows: = , = , = .
Evolution of under 3 jumping modes.
In Luan et al. (2012), the expectation of TPs can be calculated from the truncated Gaussian transition PDF , which is assumed to be known in advance, by
where is the PDF of the standard normal distribution and is the cumulative distribution function of . Based on the obtained , sufficient conditions for existence of the desired controllers within LMIs are presented in Luan et al. (2012) and a feasible controller is given by: = , = , = .
Based on the parameters above, some further simulations are performed to show the closed-loop stability and disturbance attenuation performance with initial condition = and disturbance input . Applying the obtained controllers and , the trajectories of state are given in Figure 4 and Figure 5, where both state curves in the two figures are very similar and tend to zero, which means that the closed-loop system is mean square stable.
State trajectories of the closed-loop system by .
State trajectories of the closed-loop system by .
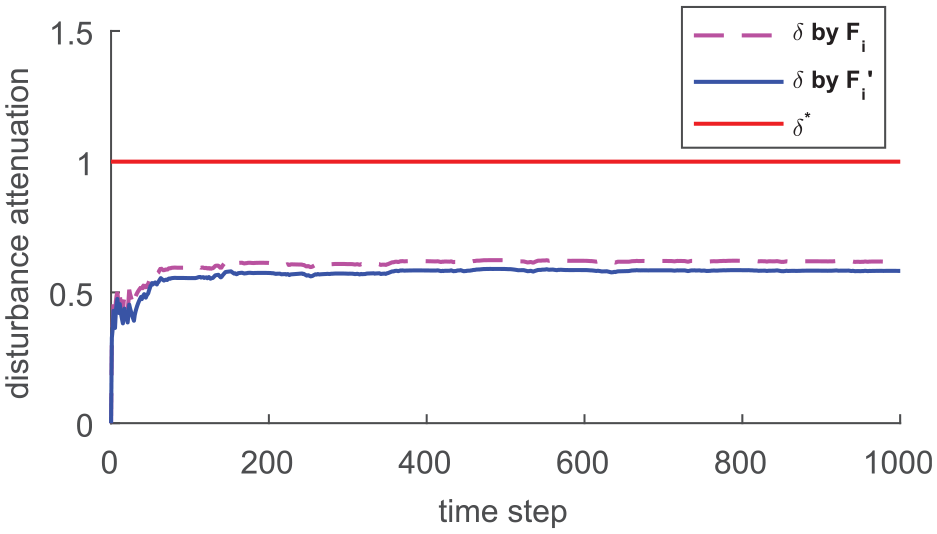
To show the disturbance attenuation performance, we define a ratio as
It can be seen in Figure 6 that two convergence values of the ratio are very approximate ( by is 0.6181, by is 0.5824) and smaller than the upper bound , which implies that the proposed controller can achieve a prescribed attenuation capability for the closed-loop system.
Comparisons between and .
It requires 500 mode trajectories, each of which contains 20 jump modes, to execute Algorithm 1 to get the desired controller. In the Samuelson’s macroeconomic system (41), the interaction between the multiplier analysis and the acceleration principle may lead to temporal business cycles. Base on the multiplier analysis, the national income is driven by the multiplier effect of investment and government expenditure. The acceleration principle states that changes in national income and consumption affect government expenditure in turn. This implies that the government can regulate the economic performance by changing fiscal and monetary policies to ensure the steady economic growth. Simulation results show that the obtained control signal can meet the desired requirements.
The method in Luan et al. (2012) has to know the distribution, mean and variance of TPs in advance so as to calculate the expected TP matrix and then obtain the controller by solving LMIs. However, the proposed approach is TP-free, that is, without any knowledge of TP matrix. By observing the Markov chains and updating the control policies, a desired robust controller can be obtained for the MJLS with unknown TP matrix, even if it involves randomness.
Conclusion
In this work, a temporal differences learning algorithm has been presented to solve the robust control problem for Markov jump systems, where the unknown transition probabilities contain random uncertainty. In the policy evaluation step, the value function in the proposed algorithm is updated quickly by observing modes jumping trajectories. Then in the policy improvement step, a new robust controller is obtained. The above process repeats until the value function converges to the expected solution of Riccati equations. The convergence of value functions is proved and Samuelson’s macroeconomic model with uncertain TPs is presented by comparing with existing methods, in which the mean and variance are assumed to be known in advance. As a result, an almost identical robust controller can be acquired, which implies the efficiency of the proposed TD algorithm. A possible direction for future work is to design reinforcement learning algorithm for MJLS control problems described by linear matrix inequalities.
Footnotes
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported by the National Natural Science Foundation of China (Grant Nos. 61722306, 61833007 and 61991402).
ORCID iDs
Jiwei Wen
Xiaoli Luan
References
1.
BeirigoRLTodorovMGBarretoAdMS (2017) Count-based quadratic control of Markov jump linear systems with unknown transition probabilities. In: IEEE 56th Annual Conference on Decision and Control (CDC). IEEE, pp. 4315–4320.
2.
BeirigoRLTodorovMGBarretoAdMS (2018) Online TD (λ) for discrete-time Markov jump systems. In: IEEE 57th Annual Conference on Decision and Control (CDC), Miami Beach, FL, USA, 17–19 December 2018 pp. 2229–2234. IEEE.
BlairWJrSworderD (1975) Feedback control of a class of linear discrete systems with jump parameters and quadratic cost criteria. International Journal of Control21(5): 833–841.
5.
BolzernPColaneriPDe NicolaoG (2006) On almost sure stability of continuous-time Markov jump linear systems. Automatica42(6): 983–988.
6.
ChenJHeTLiuF (2019) Observer-based robust H∞ control for uncertain Markovian jump systems via fuzzy lyapunov function. Transactions of the Institute of Measurement and Control41(3): 657–667.
7.
ChizeckHJWillskyASCastanonD (1986) Discrete-time Markovian jump linear quadratic optimal control. International Journal of Control43(1): 213–231.
8.
CostaOLAyaJC (2002) Monte Carlo TD (λ)-methods for the optimal control of discrete-time Markovian jump linear systems. Automatica38(2): 217–225.
9.
CostaOLFragosoMD (1995) Discrete-time LQ-optimal control problems for infinite Markov jump parameter systems. IEEE Transactions on Automatic Control40(12): 2076–2088.
10.
CostaOLVFragosoMDMarquesRP (2006) Discrete-time Markov jump linear systems. Springer Science & Business Media.
11.
de SouzaCE (2006) Robust stability and stabilization of uncertain discrete-time Markovian jump linear systems. IEEE Transactions on Automatic Control51(5): 836–841.
12.
do Valle CostaOLFragosoMDTodorovMG (2012) Continuous-time Markov jump linear systems. Springer Science & Business Media.
13.
Faraji-NiriMJahed-MotlaghMRBarkhordari-YazdiM (2014) Stochastic stabilization of uncertain Markov jump linear systems with time varying transition rates. In: 22nd Iranian Conference on Electrical Engineering (ICEE). IEEE, pp. 1186–1191.
14.
Faraji-NiriMJahed-MotlaghMRBarkhordari-YazdiM (2017) Stochastic stability and stabilization of a class of piecewise-homogeneous Markov jump linear systems with mixed uncertainties. International Journal of Robust and Nonlinear Control27(6): 894–914.
15.
FioravantiARGonçalvesAPGeromelJC (2013) Discrete-time output feedback for Markov jump systems with uncertain transition probabilities. International Journal of Robust and Nonlinear Control23(8): 894–902.
16.
GonçalvesAPFioravantiARGeromelJC (2011) Filtering of discrete-time Markov jump linear systems with uncertain transition probabilities. International Journal of Robust and Nonlinear Control21(6): 613–624.
17.
HouTMaH (2015) Exponential stability for discrete-time infinite Markov jump systems. IEEE Transactions on Automatic Control61(12): 4241–4246.
18.
JiangYKiumarsiBFanJChaiTLiJLewisFL (2019) Optimal output regulation of linear discrete-time systems with unknown dynamics using reinforcement learning. IEEE Transactions on Cybernetics50(7): 3147–3156.
19.
JilkovVPLiXR (2004) Online Bayesian estimation of transition probabilities for Markovian jump systems. IEEE Transactions on Signal Processing52(6): 1620–1630.
20.
KiumarsiBLewisFLModaresHKarimpourANaghibi-SistaniMB (2014) Reinforcement Q-learning for optimal tracking control of linear discrete-time systems with unknown dynamics. Automatica50(4): 1167–1175.
21.
LuanXHuangBLiuF (2018) Higher order moment stability region for Markov jump systems based on cumulant generating function. Automatica93: 389–396.
22.
LuanXZhaoSLiuF (2012) H∞ control for discrete-time Markov jump systems with uncertain transition probabilities. IEEE Transactions on Automatic Control58(6): 1566–1572.
23.
OrgunerUDemireklerM (2008) Maximum likelihood estimation of transition probabilities of jump Markov linear systems. IEEE Transactions on Signal Processing56(10): 5093–5108.
24.
ShenYWuZGShiPShuZKarimiHR (2019) H∞ control of Markov jump time-delay systems under asynchronous controller and quantizer. Automatica99: 352–360.
25.
ShiPLiF (2015) A survey on Markovian jump systems: Modeling and design. International Journal of Control, Automation and Systems13(1): 1–16.
26.
ShiPBoukasEKAgarwalRK (1999) Robust control for Markovian jumping discrete-time systems. International Journal of Systems Science30(8): 787–797.
27.
ShiPLiFWuLLimCC (2016) Neural network-based passive filtering for delayed neutral-type semi-Markovian jump systems. IEEE Transactions on Neural Networks and Learning Systems28(9): 2101–2114.
28.
ShiPLiuMZhangL (2015) Fault-tolerant sliding-mode-observer synthesis of Markovian jump systems using quantized measurements. IEEE Transactions on Industrial Electronics62(9): 5910–5918.
29.
SuttonRSBartoAG (2018) Reinforcement Learning: An Introduction. Cambridge, MA: MIT Press.
30.
TanLN (2018) Distributed H∞ optimal tracking control for strict-feedback nonlinear large-scale systems with disturbances and saturating actuators. IEEE Transactions on Systems, Man, and Cybernetics: Systems. Epub ahead of print. DOI: 10.1109/TSMC.2018.2861470.
31.
TanLN (2019) Event-triggered distributed H∞ constrained control of physically interconnected large-scale partially unknown strict-feedback systems. IEEE Transactions on Systems, Man, and Cybernetics: Systems. Epub ahead of print. DOI: 10.1109/TSMC.2019.2914160.
32.
VamvoudakisKGLewisFL (2012) Online solution of nonlinear two-player zero-sum games using synchronous policy iteration. International Journal of Robust and Nonlinear Control22(13): 1460–1483.
33.
WanHLuanXKarimiHRLiuF (2018) High-order moment filtering for Markov jump systems in finite frequency domain. IEEE Transactions on Circuits and Systems II: Express Briefs66(7): 1217–1221.
34.
WanHLuanXKarimiHLiuF (2020) Dynamic self-triggered controller co-design for Markov jump systems. IEEE Transactions on Automatic Control. Epub ahead of print. DOI: 10.1109/TAC.2020.2992564.
35.
WuZGShenYShiPShuZSuH (2018) Control for 2-D Markov jump systems in roesser model. IEEE Transactions on Automatic Control64(1): 427–432.
36.
XiaoNXieLFuM (2010) Stabilization of Markov jump linear systems using quantized state feedback. Automatica46(10): 1696–1702.
37.
XiongJLamJ (2006) Fixed-order robust H∞ filter design for Markovian jump systems with uncertain switching probabilities. IEEE Transactions on Signal Processing54(4): 1421–1430.
38.
XiongJLamJGaoHHoDW (2005) On robust stabilization of Markovian jump systems with uncertain switching probabilities. Automatica41(5): 897–903.
39.
ZhangLBoukasEK (2009a) H∞ control for discrete-time Markovian jump linear systems with partly unknown transition probabilities. International Journal of Robust and Nonlinear Control: IFAC-Affiliated Journal19(8): 868–883.
40.
ZhangLBoukasEK (2009b) Mode-dependent H∞ filtering for discrete-time Markovian jump linear systems with partly unknown transition probabilities. Automatica45(6): 1462–1467.
41.
ZhangLBoukasEK (2009c) Stability and stabilization of Markovian jump linear systems with partly unknown transition probabilities. Automatica45(2): 463–468.
42.
ZhangQZhaoDZhuY (2016) Event-triggeredH∞ control for continuous-time nonlinear system via concurrent learning. IEEE Transactions on Systems, Man, and Cybernetics: Systems47(7): 1071–1081.
43.
ZhouZLuanXLiuF (2020) High-order moment stabilization for Markov jump systems with attenuation rate. Journal of the Franklin Institute356: 9677–9688.
44.
ZongGYangDHouLWangQ (2013) Robust finite-time H∞ control for Markovian jump systems with partially known transition probabilities. Journal of the Franklin Institute350(6): 1562–1578.