
Abstract
In modern industry, it is of great significance to employ data-driven virtual metrology technique to improve production efficiency and quality by predicting key quality variables in an economical and reliable way. Among data-driven algorithms, the transformer is yielding promising results in predicting time series data and handling vast amounts of complex industrial data, due to the superior attention mechanism. In this paper, a novel target adaptive attention (TAA) mechanism is first developed for guiding transformer to focus more on characteristics relating quality variables, by ensuring that the encoder would adaptively identify and capture features with higher correlation with the target quality variables. To handle large-scale industrial data while both the dimensionality and scale of data expanding, the number of encoder layers would increase accordingly, such that the predictive performance of the model would decline; thus successively, the inter-level fusion attention (IFA) mechanism is proposed to add the weighted evaluation of interlevel correlations among different encoder layers to transformer for improving capabilities of feature extraction and enhancing prediction accuracy. Experiments on virtual metrology tasks on the DC process and the primary reformer process illustrate the merits of the proposed method in a sense that the target quality variable is accurately predicted.
Introduction
In practical industrial manufacturing engineering, diverse industrial quality prediction tasks possess distinct critical quality variables (Yuan et al., 2016, 2018, 2020a). The control of quality variables is of great significance and constitutes the core crux of industrial quality prediction tasks. To ensure the quality of industrial products, it is imperative to conduct real-time monitoring of various key parameters during the production process. Nevertheless, due to multiple reasons such as complex production processes, harsh industrial environments, difficult machine operations, hazardous production procedures, and expensive operating instruments, it is challenging to obtain measurements of key quality variables directly through hardware sensors (Ge, 2017; He et al., 2023; Yuan et al., 2020b; Zhou et al., 2018). Hence, virtual metrology techniques are required for predicting critical parameters in an economical and reliable way (Wang et al., 2024).
Among virtual metrology techniques, data-driven methods are attracting more and more attentions due to high economy and reliability (Liu and Xie, 2020; Yuan et al., 2020d); based on easily detectable variables, data-driven methods utilize the relationships between easily measured variables and hard-to-measure variables to make predictions through various mathematical algorithms (Alassery, 2022). Traditional data-driven methods mainly include statistical and deep learning methods, such as principal component regression (PCR) (Kawano et al., 2015; Lyu et al., 2023; Qi et al., 2022), partial least squares (PLS) (Yang et al., 2020), support vector regression (SVR) (Chen et al., 2008), and their derivations.
Real data of industrial production processes are often characterized by complex features like high dimensionality, nonlinearity, time variance, and long-term dependencies (Vijayan et al., 2023). To better address these challenges, deep learning was introduced and improved to data-driven virtual metrology that can effectively extract useful information from massive process data (Shakiba et al., 2023). Ou et al. (2024) proposed a new position-encoding denoising autoencoder (PE-DAE), motivated by the advantages of DAE in data reconstruction. Yan et al. (2016) proposed an SAE-based model capable of estimating the oxygen content in flue gas for a 1000 MW ultra-supercritical unit. Wu and Zhao (2018) proposed a CNN-based model for two-dimensional process fault diagnosis. Yuan et al. (2020c) proposed a multi-channel CNN for representing various local dynamic features in soft sensors. Ke et al. (2017) achieved favorable results in sulfur recovery unit (SRU) predictions using a long short-term memory (LSTM)-based model. Yuan et al. (2019) demonstrated the effectiveness of a supervised LSTM network in penicillin fermentation and industrial dehydrogenation towers. Chen et al. (2022) proposed a gated recurrent unit (GRU)-based cascade structure soft compensation model that outperformed conventional time series prediction models.
Traditional neural network structures may suffer from low computational efficiency and difficulty in capturing long-range dependencies when processing long sequential data, leading to decreased performance. Specifically, LSTM addresses the vanishing and exploding gradient problems encountered by naive RNN when handling long-term dependencies through its gating mechanism, and has demonstrated comparable performance in prediction tasks (Guesbaya et al., 2023; Xu et al., 2023). Industrial process time-series data often contain temporal information with complex dynamic dependencies between past and future observations (Gupta et al., 2024). While LSTM mitigates the vanishing gradient problem through its gating mechanism, the recurrent architecture still limits its modeling capability for ultra-long sequences. In contrast, the self-attention mechanism in transformer (Vaswani et al., 2017) can explicitly capture temporal dependencies at arbitrary distances without relying on progressively propagated hidden states. Moreover, the sequential nature of LSTM prevents parallel computation, whereas transformer’s multi-head attention mechanism enables parallelized learning of complex nonlinear relationships in the data. In addition, transformer’s modular architecture offers greater extensibility, allowing adaptation to more sophisticated prediction tasks through stacking of encoder layers.
The transformer (Vaswani et al., 2017), a special deep learning network model based on self-attention mechanisms, stands out for its multi-head attention mechanism, enabling the model to access historical data. This allows the model to learn relevant information in different feature subspaces, focusing on various time scales and feature dimensions. Consequently, it enhances the complexity and flexibility of the model, making it more suitable for dynamic time series data and capturing repetitive patterns with long-term dependencies. The application of transformers has expanded to various industrial domains. Zhang et al. (2021) achieved favorable classification results using the original transformer model on a dataset from Seagate manufacturing factories. Chang et al. (2023) proposed a novel transformer network applied to urban wastewater treatment processes. Geng et al. (2021) proposed a novel gated convolutional neural network-based transformer (GCT) for dynamic soft sensor modeling of polypropylene and purified terephthalic acid industrial processes. Liu et al. (2022) proposed a novel data mode-related interpretable transformer network (DMRI-Former) for predictive modeling and key sample analysis in industrial processes. Yang et al. (2024) proposed a difference metric attention with position distance-based weighting for transformer (DMA-trans) in industrial time series modeling.
Despite the extension of transformer-based methods to industrial data modeling, several shortcomings remain: (1) The prediction of critical quality variables in industrial processes is closely related to target tasks and different industrial processes have varying demands; the transformer lacks guidance related to task-relevant feature variables when extracting features, which may introduce unnecessary noise in the feature extraction process, leading to decreased prediction accuracy; (2) with the expansion of industrial task scales, both the dimensionality and scale of data will increase; to address large-scale industrial data effectively, the number of encoder layers will also need to increase accordingly; consequently, as a result, some features may be lost during the transmission process, leading to a certain degree of decline in the predictive performance of the model.
To resolve the aforementioned issues, this paper proposes a target adaptive-interlevel fusion transformer framework (TAIF-TF) for virtual metrology modeling in industrial quality prediction tasks, enhancing the predictive accuracy of critical data in industrial processes. In this novel framework, the input features would be adaptively weighted upon the guidance of targets, while the interlevel correlations are weighted among different encoder layers, respectively to capture the correlation between input variables and target quality variables and prevent the loss of hidden state vectors that have a greater relationship with quality variables as the number of encoder layers increases. The main contributions are summarized as follows:
A novel target adaptive attention (TAA) mechanism is proposed, which utilizes key quality variables of the task objective to guide feature extraction from auxiliary variables and capture their interrelationships. This approach ensures the retention of input features with higher relevance to the target features. The TAA mechanism demonstrates significant advantages by dynamically adjusting feature weights according to task objectives, thereby eliminating interference from irrelevant features while capturing complex relationships between key quality variables and auxiliary variables. This method substantially improves prediction accuracy and enhances the model’s adaptability to complex industrial processes.
A novel attention mechanism, named the interlevel fusion attention (IFA) mechanism, is proposed to address the issue of partial loss of important features after passing through multiple encoder layers. The IFA mechanism assigns an interlevel attention weight to each encoder layer’s output, enabling the preservation of extracted feature information when increasing model depth to accommodate large-scale or high-dimensional data processing requirements, and preventing the loss of some feature information from the input sequence during transmission, thereby enhancing prediction accuracy for key quality variables in real industrial production settings.
An enhanced transformer framework named TAIF-TF is developed with higher prediction performance for virtual metrology tasks, enjoying the advantages of both TAA and IFA mechanisms. The TAIF-TF framework employs the TAA mechanism to capture complex relationships between key quality variables and auxiliary variables, adaptively adjusting weights to extract feature information according to different industrial tasks. Building upon this foundation, through the IFA mechanism, it prevents the loss of critical feature information during transmission. The TAIF-TF framework presents adaptability to varying time-delay characteristics and data distribution shifts across different industrial processes, exhibiting strong robustness and generalization capability for diverse industrial scenarios. It efficiently processes large-scale and high-dimensional data while meeting stringent requirements for both processing efficiency and real-time performance in modern industrial applications. Experimental results on real industrial datasets verify that the proposed framework exhibits superior predictive performance and accuracy.
The remaining of this paper is organized as follows. Section II briefly presents the naive transformer framework. Section III provides detailed descriptions of the newly proposed TAA mechanism, while Section IV proposes the newly proposed IFA mechanism. In Section V, the enhanced TAIF-TF framework is developed, along with correlative techniques for virtual metrology tasks. In Section VI, the advantages of the TAIF-TF framework for the industrial virtual metrology dataset are explained. Experimental results are provided and discussed in Section VII. Finally, Section VIII summarizes the proposed work and outlines expectations for future researches.
Preliminary
The basic structure of the naive transformer is the classical encoder–decoder structure to address sequence-to-sequence modeling problems (Sutskever et al., 2014; Vaswani et al., 2017). The encoder transforms the input sequence into a sequence of hidden states and then converts into a fixed-length vector. Successively, the decoder predicts a target output sequence based on the previously generated fixed vector. Specifically, encoders include multi-head attention mechanisms, feed-forward network layers, residual connections, and layer normalization. The multi-head attention mechanism has multiple parallel and independent attention heads to solve the problem that the eigenvector of a single attention head may be inadequate, extending the ability to focus on different subspaces at different locations. Feed-forward networks could improve the model’s representation performance by introducing more complex feature representations through activation functions. Residual connections mitigate the problem of disappearing gradients, while layer normalization is used to normalize the inputs at each layer and stabilize the training process. The decoder has one more mask multi-head attention mechanism than the encoder, which can rely only on known information when predicting key quality variables, avoiding revealing future information.
It should be noted that unlike natural language processing tasks, only the encoder module is employed for the transformer framework in virtual metrology tasks to extract key features from time series data and capture temporal dependencies and patterns among the data, while the decoder is degenerated to a regression layer to reduce computation load and improve prediction speed.
TAA mechanism
This section will provide detailed descriptions of the TAA mechanism. The core mechanism of transformer is the multi-head attention mechanism, which extracts features from input variables. The self-attention mechanism generates three matrices Q, K, and V for the input sequence, calculated based on information from the entire sequence. This may lead the model to allocate attention weights even to noise or irrelevant information in the input sequence, affecting the model’s performance. Particularly in various industrial process requirements, without the guidance of target features, the predictive performance of the model could significantly decrease. To address this issue, a novel TAA mechanism is proposed to capture the correlations between input quality variables and target quality variables.
Initially, data samples collected from industrial processes are divided into input feature sequences
The structure of TAA is illustrated in Figure 1(a). The aim is to guide input features with guidance features, calculating the correlation between guidance feature sequences and the hidden state output of each encoder layer to obtain the correlation between input features and guidance features, deriving the weight values for each input feature variable. These weight values are used to compute the sequences
where
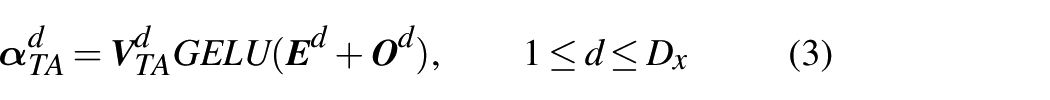
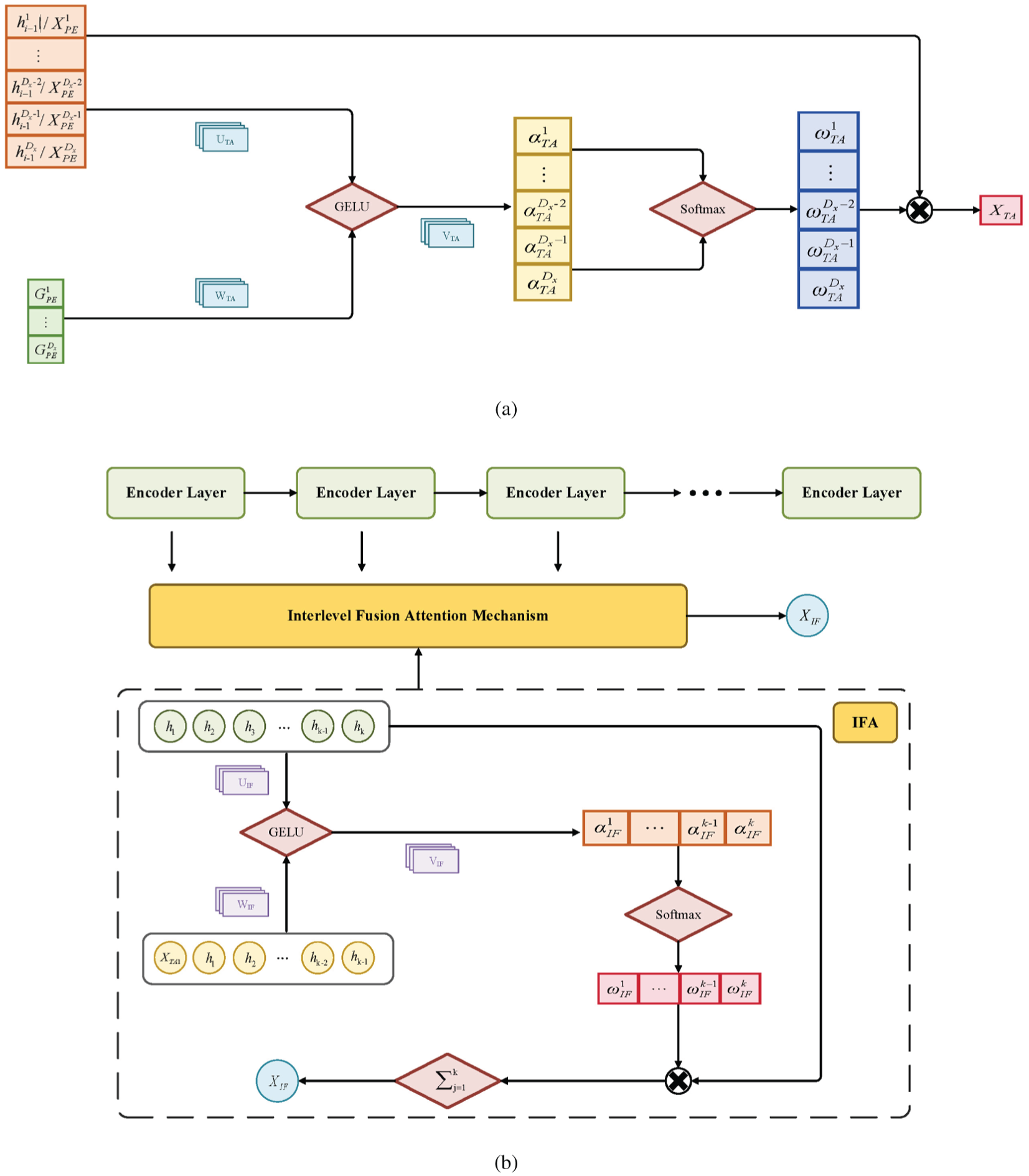
Detailed diagrams of (a) target adaptive attention mechanism, and (b) Inter-level fusion attention mechanism.
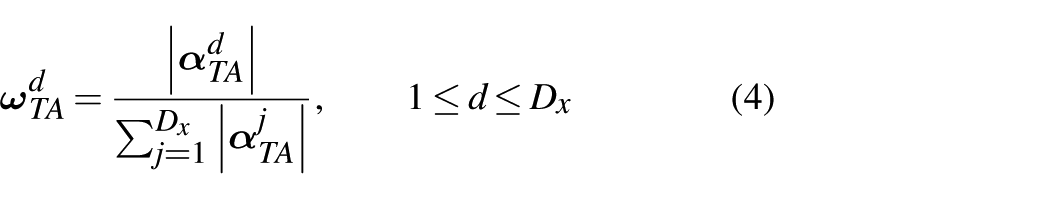
the parameters
By utilizing Equations (1)–(4), the target attention values for each feature vector after guidance are obtained. Then, the sequences are weighted by the attention values, expressed as follows
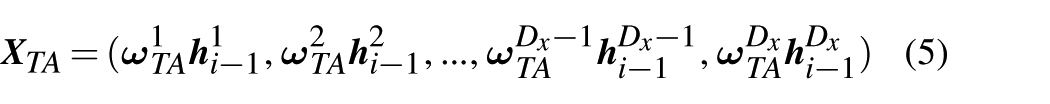
the learnable parameters of TAA will undergo iterative learning along with the entire transformer network through the backpropagation algorithm for updates.
Substituting the
IFA mechanism
In this section, a detailed explanation of IFA mechanism will be provided.
The output of each encoder layer in the transformer serves as input for the next encoder layer, with the final encoder layer’s output being the ultimate output of the encoder. As the number of encoder layers increases, some feature information of the input sequence may be lost during transmission, leading to a decrease in transformer performance. To address this issue, an IFA mechanism is proposed to adaptively link the output vectors of different encoder layers by applying relevance-weighted sums. Each output of an encoder layer is assigned a interlevel attention weight. Ultimately, the interlevel attention-weighted vectors are derived based on these weights to serve as the final output of the encoder.
Based on the representation in Figure 1(b), the computation of IFA can be expressed as follows


k represents the number of encoder layers.
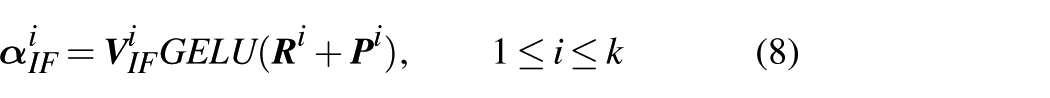
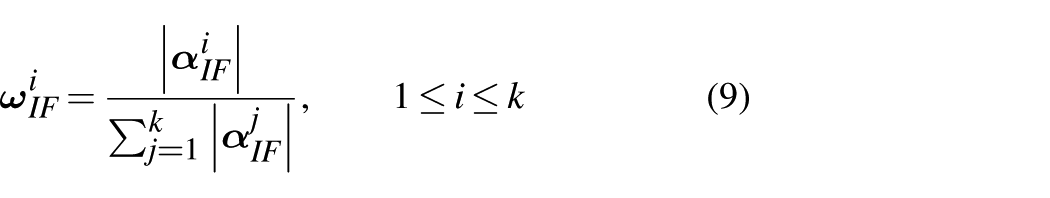
where
By utilizing Equations (6)–(9) to obtain the interlevel attention weights for each encoder layer, the output of each encoder layer is then weighted with interlevel attention as follows
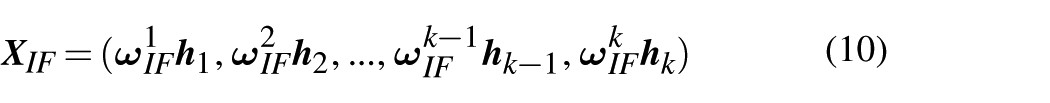
The proposed IFA mechanism allows the model to establish connections between the output vectors of different encoder layers, capturing the interlevel correlations between the outputs of each encoder layer and thus preventing the loss of relationships with more significant quality variables due to an increase in encoder layers. This mechanism enhances the framework’s ability to extract features, thereby aiding in the better prediction of crucial quality variables in industrial processes.
Target adaptive-IFA transformer
In order to enhance the accuracy of quality prediction tasks in industrial processes, the TAA and the IFA are applied to the transformer framework. Guided by these two mechanisms, the industrial data soft measurement transformer framework TAIF-TF is established. The specific architecture of the framework is illustrated in Figure 2.
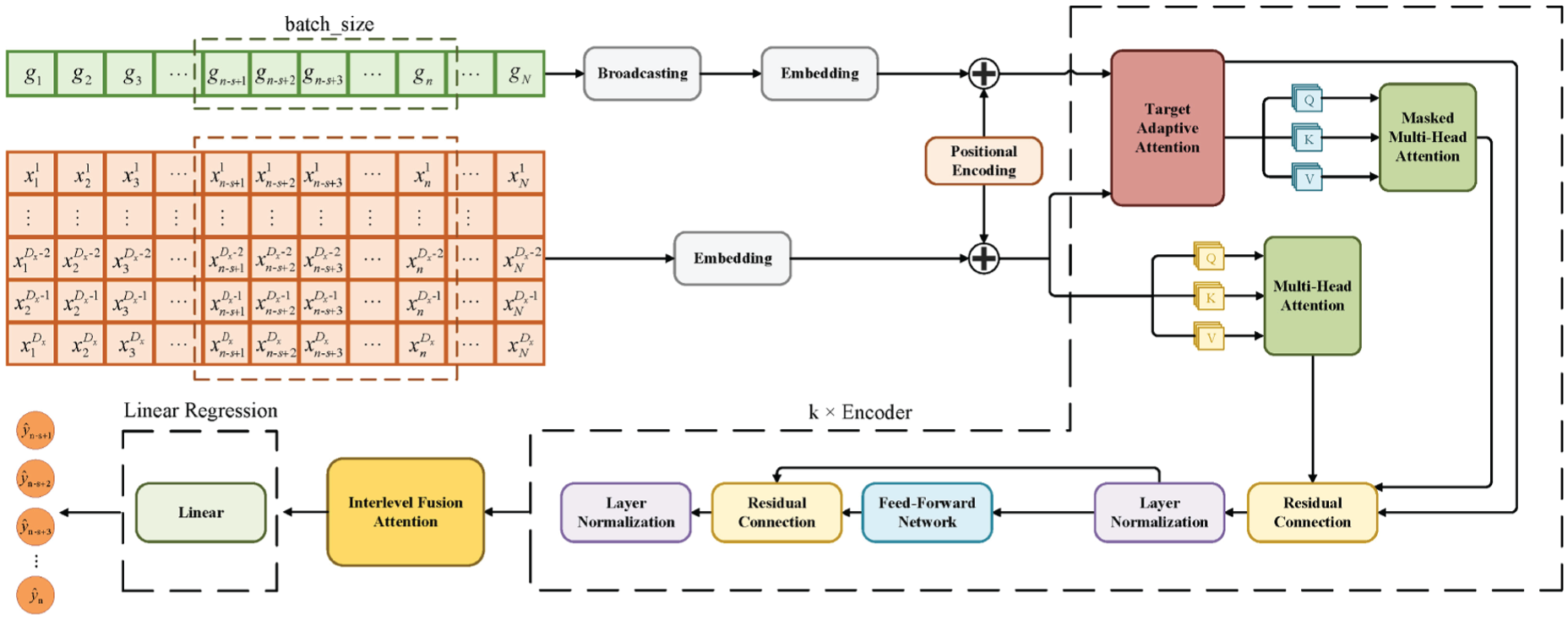
Target adaptive-interlevel fusion attention transformer.
This section will provide a detailed explanation of all key mechanisms utilized in TAIF-TF, with the most essential being four attention mechanisms: the previously proposed TAA and IFA, the multi-head attention mechanism, and the masked multi-head attention mechanism. Furthermore, a detailed introduction to the algorithm of the entire framework will be presented.
Multi-head attention mechanism
The multi-head attention mechanism is a core component of the TAIF-TF, operating multiple independent attention heads in parallel to overcome the insufficiency of feature vector representation from a single attention head. It also enhances the model’s ability to focus on different subspaces at various positions, diversifying its feature representation capability.
Initially, three matrices
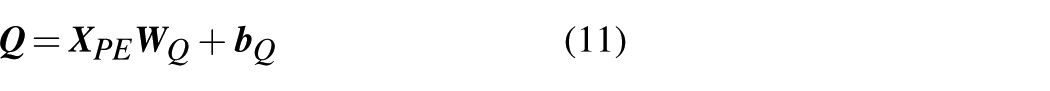
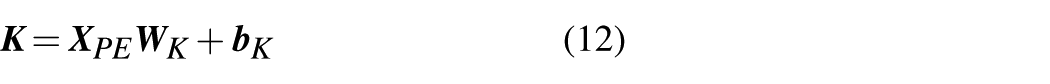
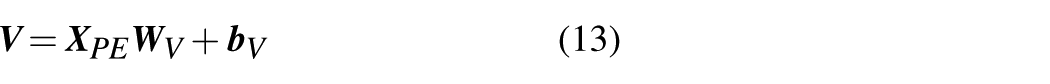
where
Before multi-head attention, the scaled dot-product attention is calculated to extract features related to the query matrix from key-value pairs. The detailed computation is represented as
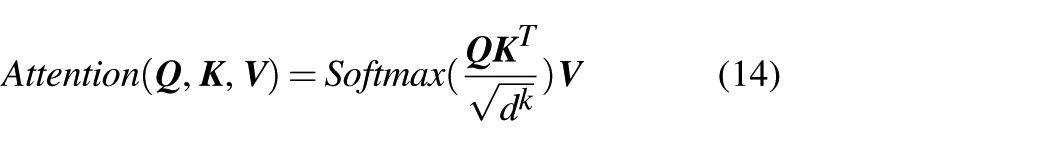
where
Multi-head attention enables the model to jointly attend to information from different representation subspaces at various positions. This is achieved by executing h attention heads independently and in parallel, with
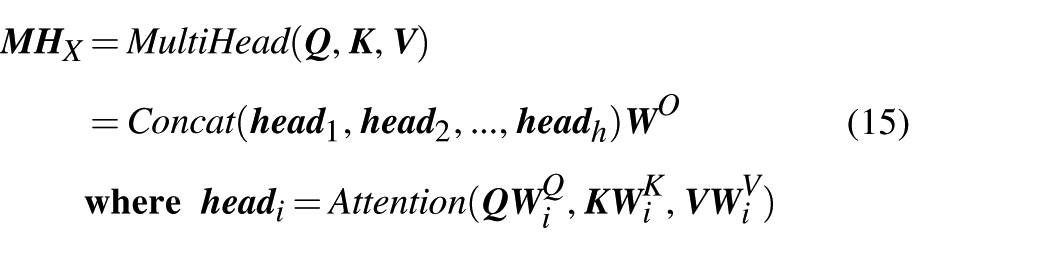
where
Masked multi-Head attention mechanism
By proposing a masking mechanism in the multi-head attention mechanism, the model can rely only on known information when predicting key quality variables, thus preventing the leakage of future information to the model.
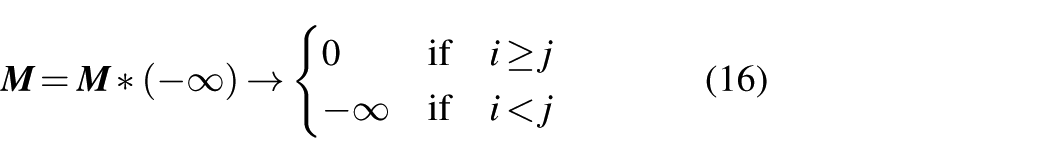
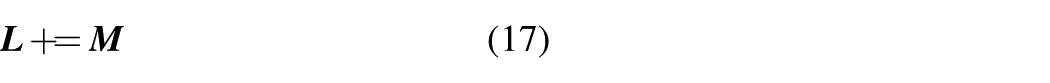
The
The effect of masking is to block out the weights at masked positions during attention weight computation, ensuring that the model does not consider these masked positions during calculations. This approach achieves the masking of future information, guaranteeing that the model does not rely on future information for predictions.
Positional encoding
Assuming the input sequence in the framework is

Although the self-attention mechanism in the TAIF-TF can recognize relationships among input data samples, it trains in parallel and neglects the sequential order of data, lacking the ability to perceive their positional relationships. To address this limitation, a technique known as positional encoding is proposed, which encodes the temporal sequence of input data to establish positional relationships in time series data. This process can be expressed as
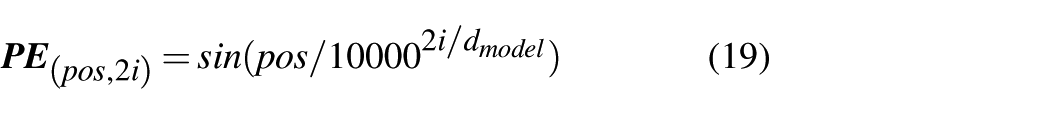
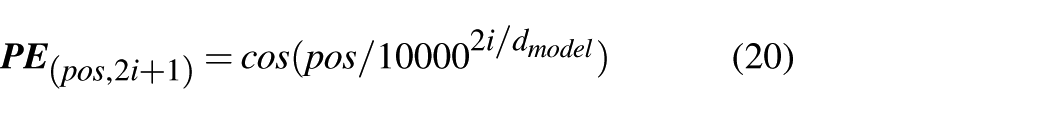
where pos refers to the current position of the data in this sequence, i is the ordinal number of the original data position in the sequence, and
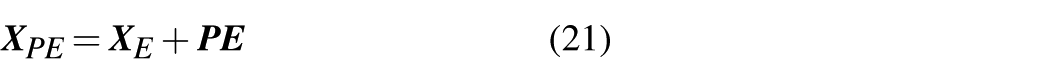
where
The positional encoding in transformer assigns consecutive integer position indices (pos = 1, 2, 3,…) by default, which inherently assumes equally sampling intervals. However, whether the actual time series data follows uniform sampling depends entirely on the specific dataset. When the sampling intervals vary, this may lead to temporal information distortion. Particularly when interval differences are substantial, the model may confuse different time scales, resulting in prediction bias. For instance, if three data points are sampled with actual intervals of 1 minute and 1 hour respectively, but are simply encoded as pos=1, pos=2, pos=3, and the model may fail to perceive the true temporal spans, consequently losing long-term dependencies. Therefore, for industrial data with missing values or non-uniform sampling, incorporating the actual time intervals as additional features combined with the standard positional encoding can effectively recover the crucial temporal information.
Residual connections, layer normalization, and feed-forward network
In the TAIF-TF, residual connections are implemented by concatenating the outputs of the three attention mechanisms to achieve the network’s residual mechanism, addressing the vanishing gradient problem, simplifying network training, and aiding the network in learning more effective representations. Layer normalization normalizes the input of each layer, stabilizing the training process, accelerating convergence, and enhancing generalization capabilities, represented as

The feed-forward network layer proposes non-linearity through an activation function, enabling the model to learn more complex feature representations, thereby improving its representation capability and performance, expressed as
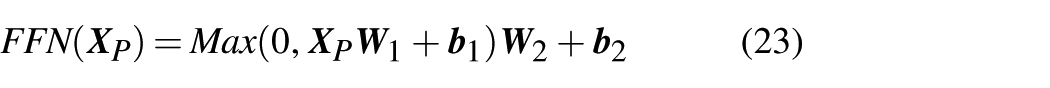
Finally, the residual connection and layer normalization are performed again, expressed as

where
Algorithm description
The TAIF-TF comprises a positional encoding module, a TAA module, a multi-head attention module, a masked multi-head attention module, residual connections and layer normalization module, a feed-forward network layer module, an IFA module and a linear regression layer module. Algorithm 1 outlines the specific algorithm based on which TAIF-TF is constructed.

Assuming the input feature sequence

Broadcast is the broadcast function, which gives
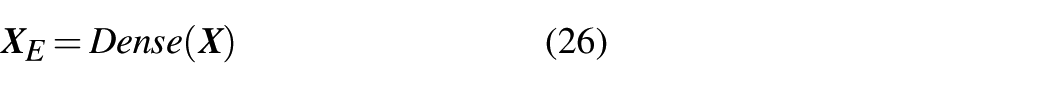
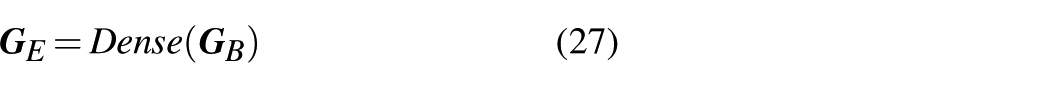


after embedding and positional encoding, feature vectors
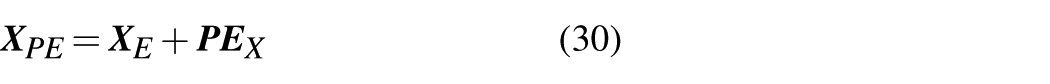
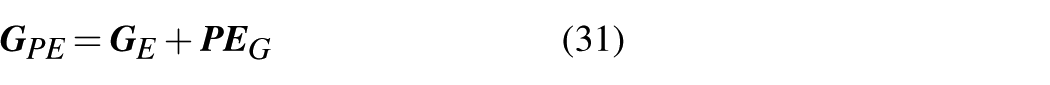
After completing the aforementioned preparatory data processing, the feature vectors
The feature vector


The output of each encoder layer is further guided by IFA to obtain different interlevel attention weights. These weights are used to aggregate the final vector output, as detailed below:

After feature guidance and extraction by the encoder, essential information regarding input and target features has been obtained. After processing with IFA, more crucial feature information is retained. The predicted value is then calculated through the final linear regression fully connected layer, represented as
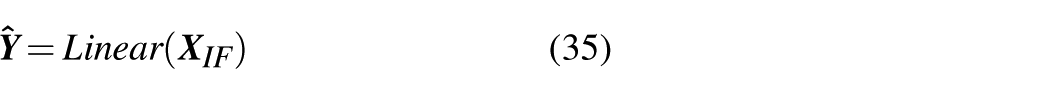
where

N represents the number of training data samples,
Target adaptive-IFA transformer for industrial virtual metrology
The proposed TAIF-TF framework is applied to industrial time-series prediction tasks in this study. The industrial virtual metrology dataset, such as industrial time-series data, often exhibit complex temporal dependencies where past and future observations are intricately correlated, making accurate prediction inherently challenging. Unlike image-to-image or text-to-text prediction tasks, which benefit from rich spatial features or contextual information, industrial time-series data typically contain more limited feature representations, further increasing the difficulty of temporal forecasting. Furthermore, in certain industrial time-series prediction tasks, neural network models are established to predict dependent variables solely from other dependent variables, without incorporating the processing of independent variables. In contrast, the industrial virtual metrology dataset usually contains both independent and dependent variables, making the proposed model more challenging as with requirement of additional processing for independent variable information.
The proposed TAIF-TF framework is capable of processing independent variable information, while both the TAA and IFA mechanisms are specifically designed to handle time-series data.
Figure 3 illustrates the two stages of building a quality prediction architecture based on the TAIF-TF framework.
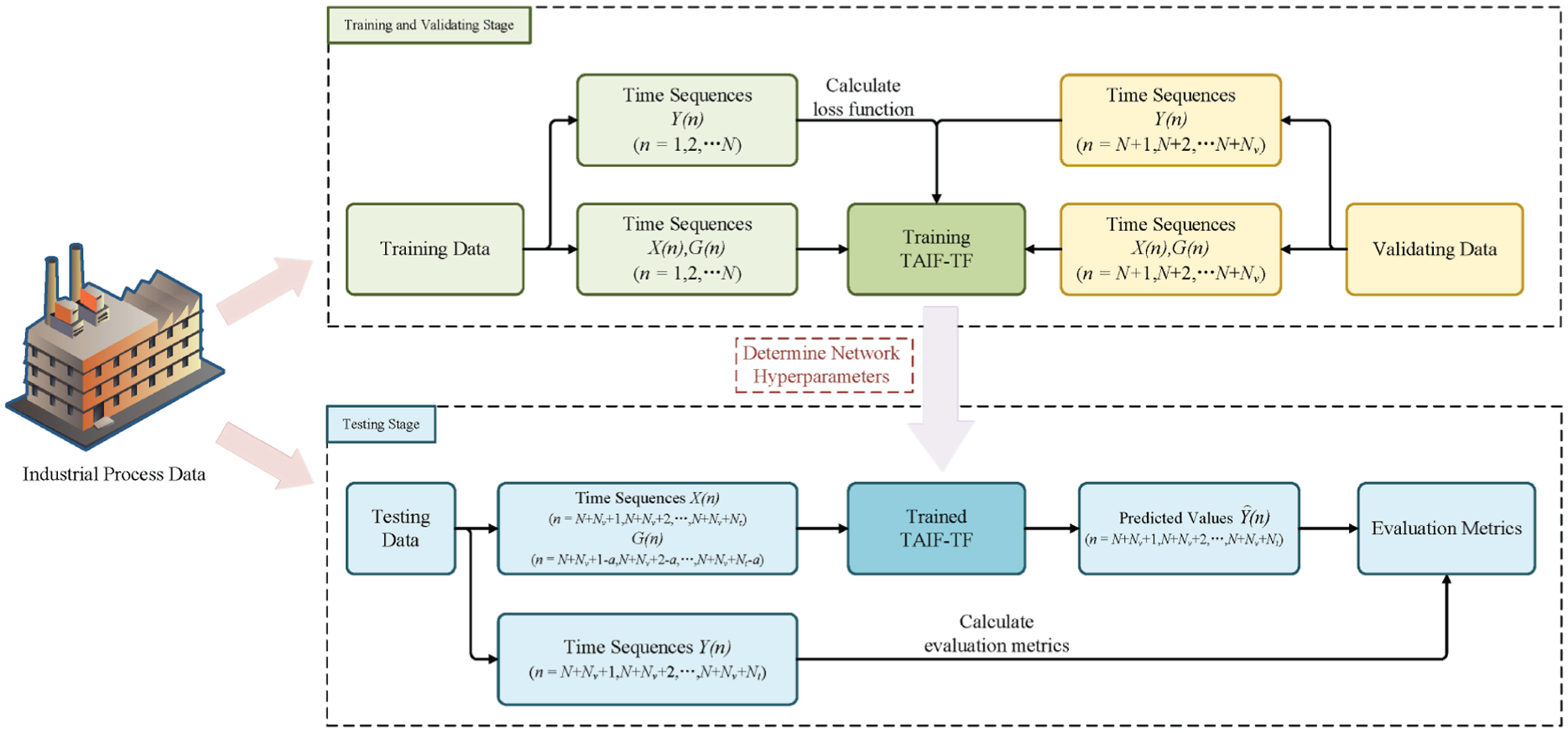
Flowchart for the TAIF-TF framework based virtual metrology.
Experiment and analysis
To validate the predictive efficacy of the TAIF-TF, the framework is applied to the debutanizer column (DC) process to predict the butane concentration of the bottom and the primary reformer experiment during ammonia synthesis to predict the oxygen content at the top of the furnace. TAIF-TF will be compared with PCR, SVR, SAE, LSTM, and LSTnet, and also with TA-TF, which only adds TAA mechanism proposed in this paper to Transformer.
To determine the optimal combination of hyperparameters and model architecture configuration, the following parameter search spaces were defined recommended by Geng et al. (2021): learning rate in
For performance comparison regarding quality prediction of virtual metrology, the MAE, root mean squared error (RMSE), and the coefficient of determination
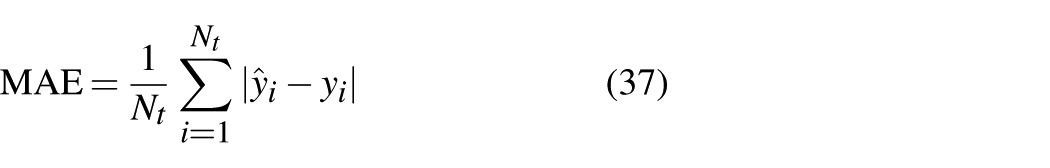
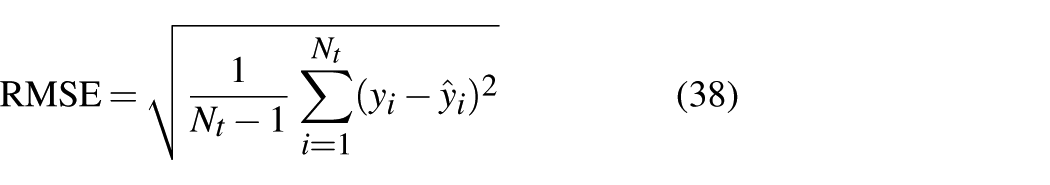

where
DC process
Description of the DC process
The DC process is a part of the desulfurization and naphtha separation unit, aiming to remove propane and butane in the naphtha gas. An overall flowchart diagram of the DC process is shown in Figure 4(a). The most important quality indicator for the DC process is butane concentration of the bottom. There is total 45 minutes (about five timestamps) time-delay for the available information about butane concentration. The virtual metrology technique is needed, since this may adversely affect real-time control.
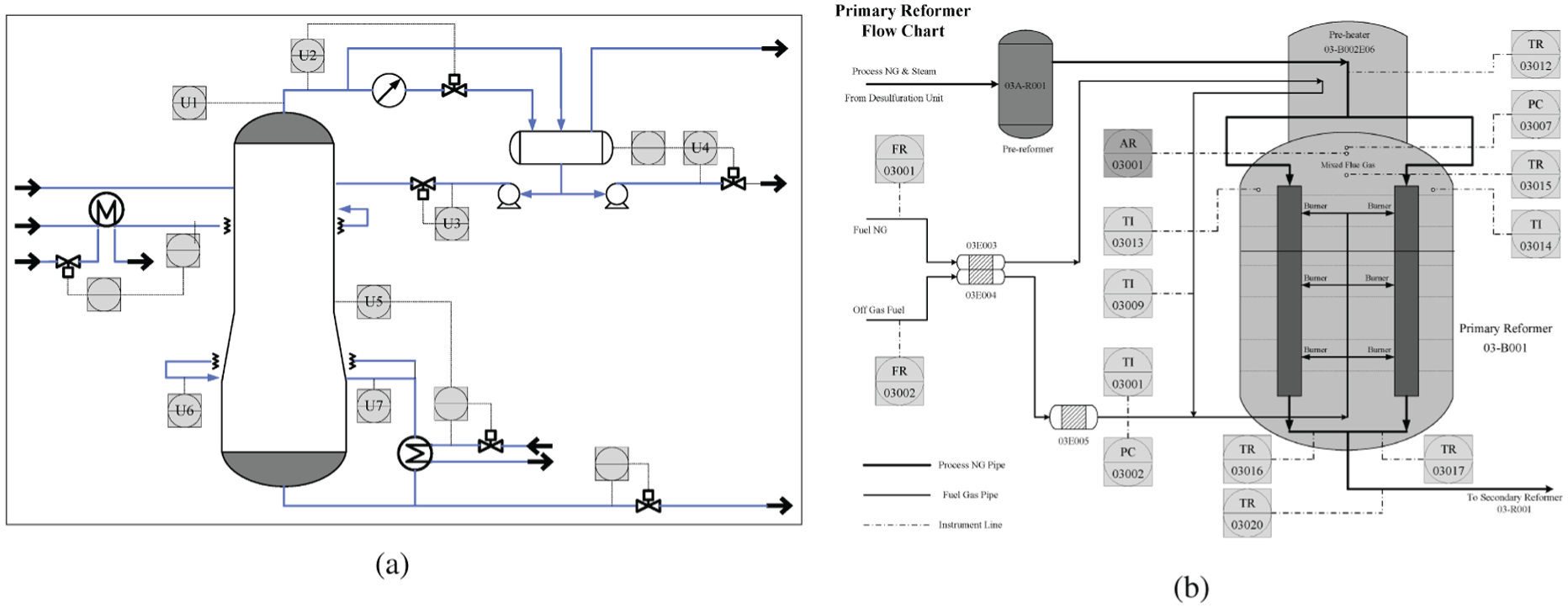
The flow chart of the (a) debutanizer column process, and the (b) primary reformer process.
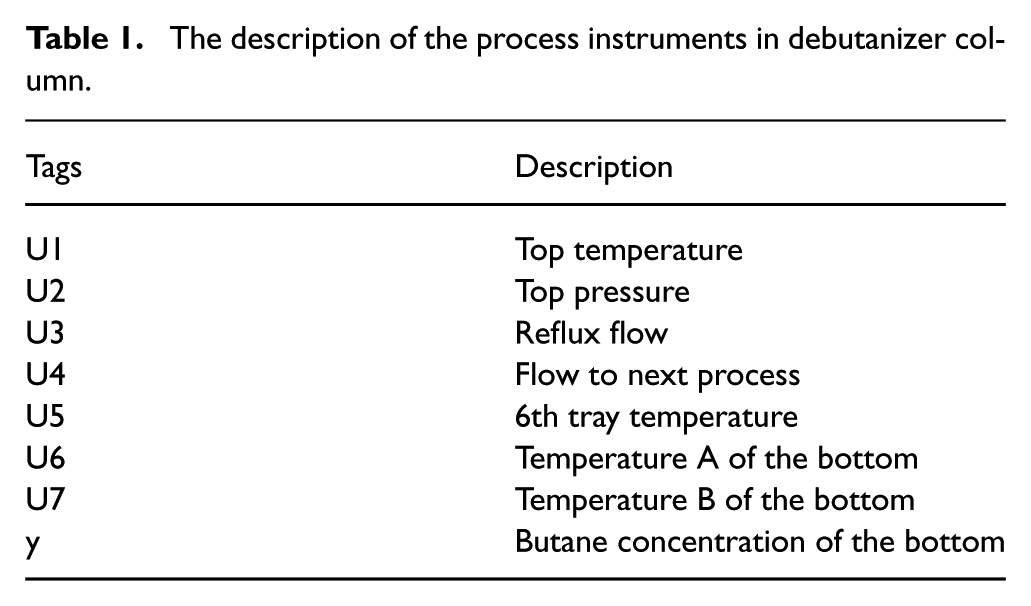
For constructing virtual metrology models, seven process variables, related to butane concentration, are selected as inputs based on expert experiences. Variable descriptions are given in Table 1.
The description of the process instruments in debutanizer column.
In this case study, the DC dataset shared by Fortuna et al. (2007) is employed, which is a popular benchmark for data-driven virtual metrology modeling. The data were measured by sensors installed in a DC and a measuring device on the overhead of a deisopentanizer column with a measuring cycle of 15 min (Fortuna et al., 2007). A total of 2379 samples were collected during the DC process. Subsequently, the data were divided into approximately 60% for the training set (1427 samples), around 20% for the validation set (476 samples), and the remaining 20% for the test set (476 samples). Due to a delay of approximately five timestamps in the measurement of butane concentration, the study employed a sliding window technique. During testing, the current observation of butane concentration (i.e., the butane concentration from five timestamps ago) was utilized as a guiding feature variable, dynamically leveraging historical data for prediction. As a result, the test set effectively utilized 471 samples.
Hyperparameter setting
Through experiments, the optimal combination was determined within the range of hyperparameters and architectural configurations mentioned earlier, setting the learning rate at 0.0007, the number of model training epochs is set as 50, the batch size of 32, the number of encoder layer is 5, the number of attention head is 4, the dimension of hidden layer is 512, the dimension of FFN’s hidden layer is 1024, the dimension of TAA’s hidden layer is 256.
The hyperparameters of TA-TF are the same as those of TAIF-TF. In PCR, the number of features after dimensionality reduction is consistent with the number of features in the dataset. The radial basis function (RBF) is used as the kernel function in SVR. The hidden layer size for both LSTM and LSTnet is set to 64, the LSTnet convolution kernel size is set to 3, with the number of training epochs and batch size being the same as those in TAIF-TF.
Analysis of experimental results of the DC process
The results of each model are presented in Table 2. The TAIF-TF demonstrated the highest predictive performance, with the optimal results presented in bold. The TA-TF achieved the second-best predictive performance, as indicated by underlined values. Comparative experiments verify the superior performance of TAIF-TF in terms of MAE, RMSE, and
Prediction results of different methods.
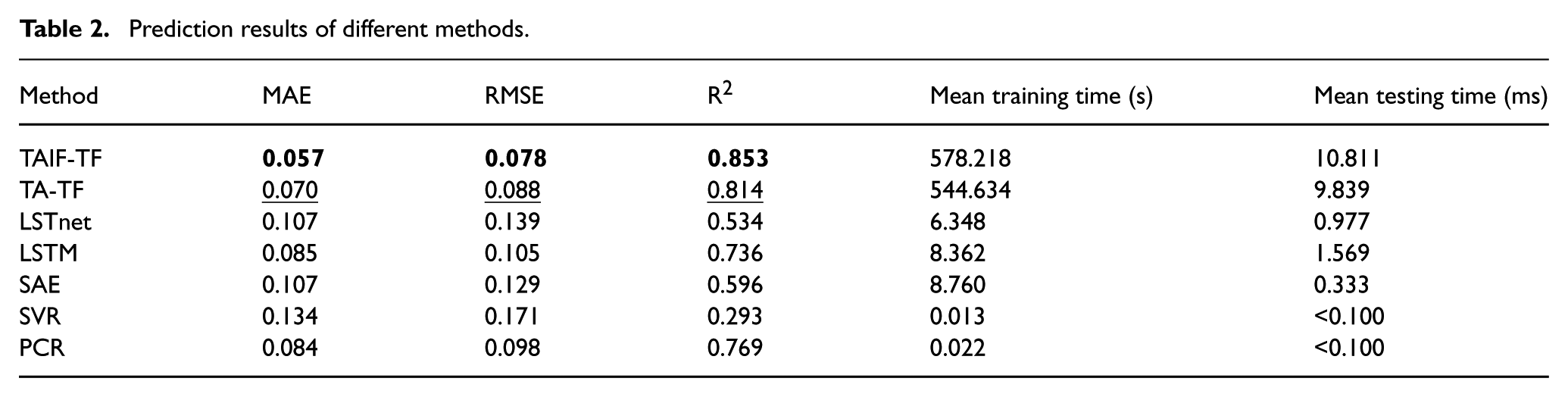
Furthermore, the experiment recorded multiple timing measurements in Table 2; the average training time and testing time(every point) across 10 runs for each model are tabulated in Table 2. The TAIF-TF requires longer training and testing time compared to other models; however, these durations remain significantly shorter than the time needed for industrial field data acquisition, making them fully acceptable. For example, it usually takes at least several minutes between quality variables in real industry process.
For a visual evaluation of the predictive performance of each model, Figure 5(a)–(g) illustrate the fitting curves of predicted values against true values and the corresponding error curves. The plots reveal that the TAIF-TF framework closely follows the true values, capturing both peaks and troughs effectively. Moreover, TAIF-TF framework exhibits the smallest fluctuations in its error curve. Figures clearly verify that TAIF-TF’s predicted values exhibit closer alignment with real values and smaller errors across the final 200 samples. Additionally, Figure 5(h) displays scatter plots of the prediction results for each model, with the x-axis denoting real values and the y-axis representing predicted values. The diagonal line signifies a perfect prediction match. As clearly illustrated in the figure, the prediction results of TAIF-TF are closer to the diagonal, indicating that TAIF-TF exhibits the optimal predictive performance.
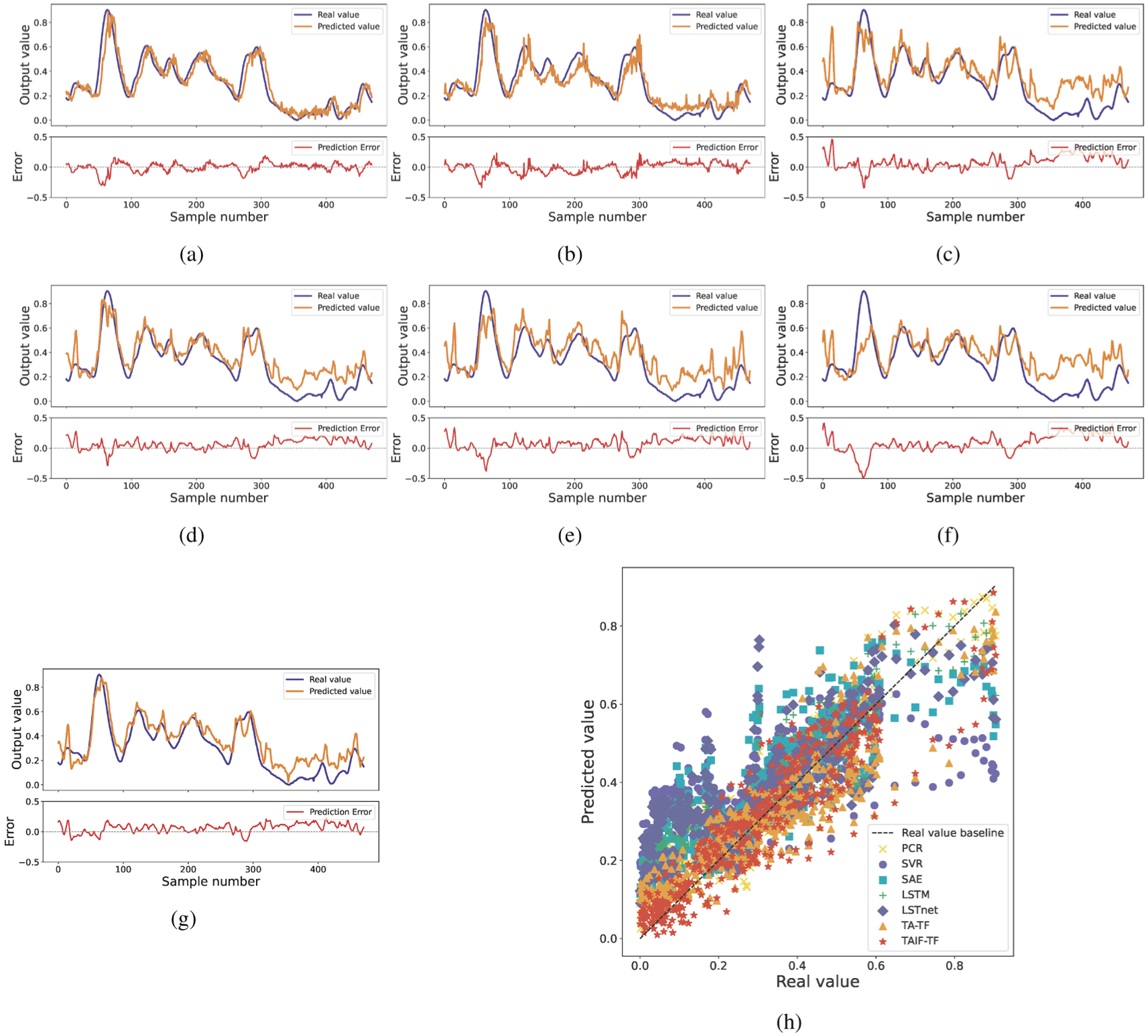
Butane concentration prediction results of (a) TAIF-TF, (b) TA-TF, (c) LSTnet, (d) LSTM, (e) SAE, (f) SVR, (g) PCR, and (h) scatter chart.
The exceptional predictive performance of the TAIF-TF framework can be attributed to its superior internal mechanisms compared to other models. The TAIF-TF framework incorporates positional encoding to capture temporal information of input data. Furthermore, by employing multi-head attention mechanisms to run multiple independent attention heads in parallel, it addresses the issue of potentially insufficient feature representation by a single attention head, enhancing the model’s capability to focus on different positions and subspaces, thereby diversifying feature representations. Additionally, the residual connections and layer normalization mechanisms in the TAIF-TF framework address the problem of gradient vanishing in deep networks. Crucially, the proposed TAA mechanism assists the transformer in learning crucial information about target features, while the IFA mechanism helps the model retain a greater amount of feature information. This further enhances the model’s fitting capability, resulting in improved stability of model performance.
Primary reformer process
Description of a primary reformer process
This case is extracted from hydrogen manufacturing units in the ammonia synthesis process of which production
The flow chart of the device is shown in Figure 4(b), and the main chemical reactions in the device are shown in the following equations
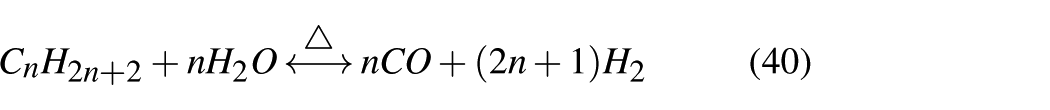


According to site conditions, the reaction temperature is the critical factor to guarantee the hydrogen production in the primary reformer. Thus the condition of burning should be monitored in time to make the temperature stay stably at a certain level. To stabilize the burning condition, one of the key means is to control the oxygen content in the furnace varying in a setting range. In the real process, the oxygen content is measured by an expensive mass spectrometer. However, due to the fast burning speed, the content of oxygen in the furnace varies frequently. Therefore, it is necessary to apply virtual metrology modeling.
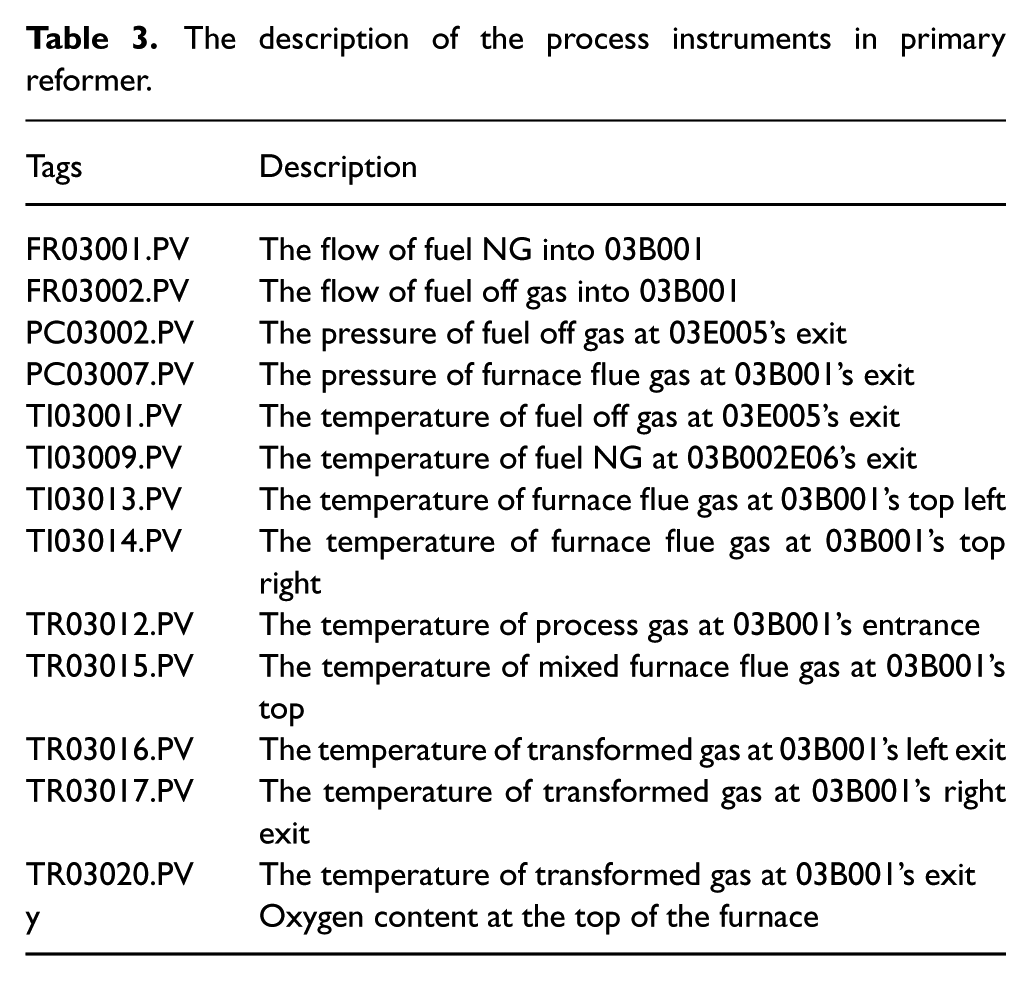
The primary reformer process dataset used in this experiment is a private dataset for a real-industrial process. For confidentiality reasons, all the variables are normalized to the range 0 to 1. There are 13 process variables chosen as inputs for virtual metrology modeling, which include temperatures, pressures, and flows. The process instruments are noted in Figure 4(b) in grey blocks. The light grey blocks represent the process variables and the heavy grey block means the critical variable the oxygen content. Detailed descriptions of the process variables are given in Table 3.
The description of the process instruments in primary reformer.
A total of 2500 samples were collected from the actual primary reformer process. These data were divided into a training set containing the first 60% of the dataset, a validation set with the subsequent 20%, and a test set containing the final 20%. Like the DC experiment, the test set here uses a sliding window and uses the oxygen content before three timestamps as the guiding feature variable.
Hyperparameter setting
Through experiments, the optimal combination was determined within the range of hyperparameters and architectural configurations mentioned earlier, setting the learning rate at 0.0005, the number of model training epochs is set as 50, the batch size of 32, the number of encoder layer is 5, the number of attention head is 4, the dimension of hidden layer is 512, the dimension of FFN’s hidden layer is 1024, the dimension of TAA’s hidden layer is 256.
The hyperparameters of TA-TF are the same as those of TAIF-TF. In PCR, the number of features after dimensionality reduction is consistent with the number of features in the dataset. The RBF is used as the kernel function in SVR. The hidden layer size for both LSTM and LSTnet is set to 64, the LSTnet convolution kernel size is set to 3, with the number of training epochs and batch size being the same as those in TAIF-TF.
Analysis of experimental results of a primary reformer process
The results of MAE, RMSE and
Prediction results of different methods.
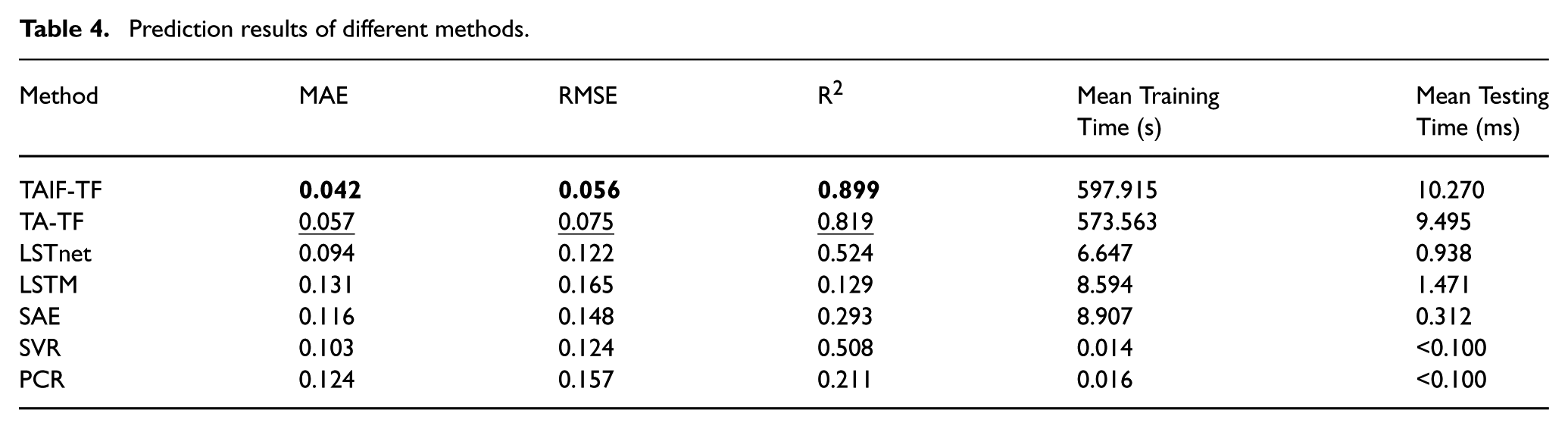
From the results in Table 4, it is evident that the predictive performance of TAIF-TF is the best, followed by TA-TF. The best results are highlighted in bold, and the second-best results are indicated with an underline. Compared to other models, TAIF-TF exhibits superior accuracy performance. The inferior performance of other models compared to TAIF-TF can be attributed to reasons similar to those observed in the first experiment.
Furthermore, the experiment recorded multiple timing measurements in Table 4; the average training time and testing time (each sample) across 10 runs for each model are tabulated in Table 4. While the TAIF-TF demands more computational time for both training and testing phases compared with other models, this would still be reasonable since the additional time remains substantially less than the duration of industrial field data acquisition.
For a more visual assessment of the predictive efficacy of each model, Figure 6(a)–(g) illustrate the fitting curves of predicted values against true values and the corresponding error curves for each model. The fitting curves clearly demonstrate that the TAIF-TF framework closely aligns with the true values, both at peaks and troughs. TAIF-TF framework exhibits the smallest fluctuations in its error curve. Moreover, TAIF-TF acquires significantly better predictive performance than TA-TF on the first 80 and middle portions of the data, primarily due to the IFA mechanism preserving more critical feature information. Figure 6(h) presents scatter plots of each model’s prediction results. It is evident that the TAIF-TF framework’s predictions are the most concentrated and closest to the diagonal line, indicating superior predictive performance.
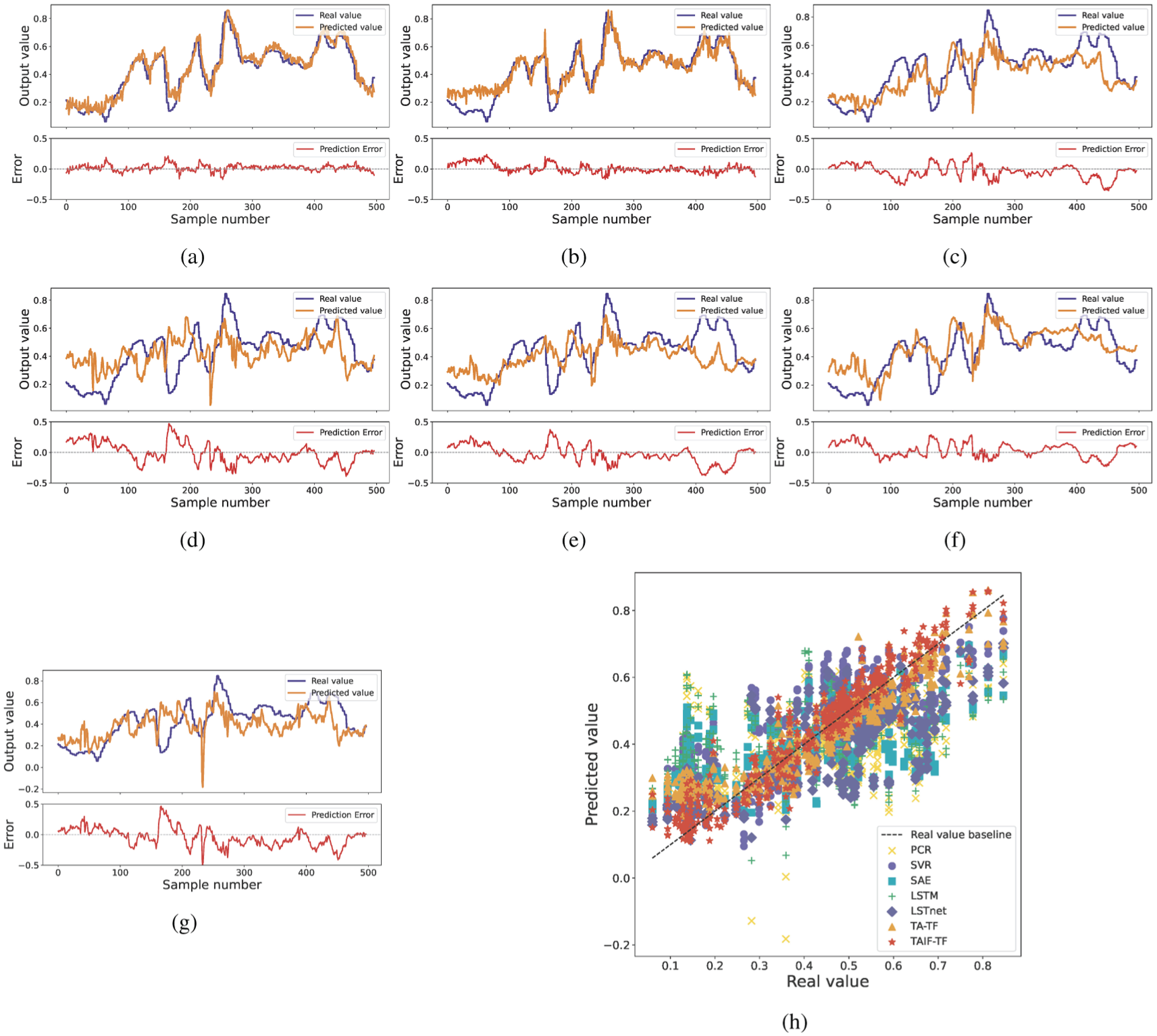
Oxygen content prediction results of (a) TAIF-TF, (b) TA-TF, (c) LSTnet, (d) LSTM, (e) SAE, (f) SVR, (g) PCR, and (h) scatter chart.
Owing to the superior attention mechanism incorporated in TAIF-TF, it consistently demonstrated the most significant predictive performance in this experiment. The experimental results from both experiments collectively demonstrate that compared to existing time series models and basic models, the proposed TAIF-TF framework is more suitable for industrial quality prediction tasks. Its strong predictive performance on the DC dataset and the primary reformer dataset underscores its robustness and applicability in industrial settings.
Conclusion
In this paper, a new TAA mechanism is proposed to capture the correlation between input quality variables and target quality variables, and an IFA mechanism is further developed to allocate different weights to different encoder layers. By applying these two mechanisms to the transformer, a TAIF-TF framework is proposed, which adaptively identifies input feature variables with a stronger relationship to target quality variables, capturing their correlation. It also prevents the loss of hidden state vectors with a greater relationship to quality variables as the number of encoder layers increases. This approach enhances the prediction of critical quality variables in industrial processes, thereby improving network performance and strengthening the model’s fitting capability. Applying the TAIF-TF to the DC process to predict the butane concentration of the bottom and an experiment in an ammonia synthesis process within a primary reformer to predict oxygen content at the top of the furnace verify its superior performance compared to other models, validating the effectiveness of the TAIF-TF.
In the future, the goal is to delve deeper into more intricate industrial quality prediction tasks, paying attention to non-uniform sampling industrial data, developing more precise virtual metrology models to further enhance the model performance in predicting critical quality variables.
Footnotes
Declaration of conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This research was supported by the Zhejiang Provincial Natural Science Foundation of China under grant no. LY23F030002 and National Natural Science Foundation of China under grant nos. 62103364 and 62173344.
Data availability statement
Data sharing is not applicable to this article, as no data sets were generated or analyzed during the current study.