
Abstract
In complex industrial environments such as power plants, traditional methods for monitoring safety compliance often face significant limitations due to complex environmental constraints, such as severe occlusion, extreme lighting variations, and visual clutter. To enhance the practicality and robustness of safety supervision systems in real-world conditions, this paper proposes a structurally optimized detection model named DMD-DETR, based on the RT-DETR architecture, for identifying whether power plant workers are wearing personal protective equipment (PPE) correctly. Specifically, we integrate a Diverse Branch Block (DBB) to fortify feature extraction against low-contrast backgrounds, introduce a Modulation Fusion Module (MFM) to suppress industrial noise and accentuate small PPE targets, and employ a lightweight DySample operator to preserve fine-grained spatial details during upsampling. Extensive experiments were conducted on both a self-constructed dataset from representative complex scenarios and a public benchmark dataset. The results demonstrate that on the self-constructed dataset, the improved model achieves a mAP@0.5:0.95 of 62.94%, which is 1.53% higher than the baseline RT-DETR, while tests on the public dataset further confirm the model’s robust generalization capability. Meanwhile, the model’s GFLOPs decreased to 54.5 and the number of parameters reduced to 19.39 million, all while maintaining excellent real-time performance. These findings confirm that the proposed method significantly improves detection accuracy under complex conditions and provides a reliable technical foundation for safety supervision in power plants and similar industrial settings.
Introduction
In recent years, with the increasing demand for power supply, the operational efficiency of power supply enterprises has continued to grow. However, safety issues persist in on-site production environments. Construction sites and power plants are high-risk environments where adherence to Health, Safety, and Environment (HSE) regulations is essential (López et al., 2025). Real-time monitoring of workers’ compliance with personal protective equipment (PPE) regulations is crucial for safe operations.
Currently, safety monitoring in power operation sites primarily relies on two approaches: traditional image processing and deep learning-based techniques. While early traditional methods (Chang et al., 2020; Li et al., 2021) laid the groundwork, they heavily relied on handcrafted features and lacked robustness in complex, variable environments. Consequently, the industry has shifted toward deep learning object detection technologies, particularly the YOLO series (Redmon et al., 2016). Although recent studies have attempted to adapt YOLO for industrial safety through various architectural improvements, convolutional neural network (CNN)-based detectors still face inherent limitations when applied to the specific challenges of power plants:
Small object detection: Critical safety gear–like insulating gloves and shoes occupy a negligible number of pixels in surveillance views, leading to high missed detection rates.
Severe occlusion and non-maximum suppression (NMS) bottleneck: The industrial environment is cluttered with machinery, frequently occluding workers. YOLO relies on NMS for post-processing. In dense occlusion scenarios, NMS often mistakenly suppresses true positive boxes of overlapping targets, representing a fundamental bottleneck in improving recall rates.
Background interference (visual camouflage): The color and texture of PPE (e.g. helmets, uniforms) are often highly similar to the industrial background (e.g. metal structures, dim lighting). This low contrast creates a “camouflage” effect, leading to severe detection ambiguity.
To overcome the limitations of NMS and CNNs, Transformer-based architectures have emerged as a new paradigm. Carion et al. (2020) introduced DETR (DEtection TRansformer), which eliminates NMS via bipartite matching, enabling end-to-end detection. This architecture theoretically handles occlusion better by leveraging global attention. However, the high computational cost of standard transformers limits their industrial application. Recently, Zhao et al. (2024) proposed RT-DETR, the first real-time end-to-end detector, offering a promising balance between speed and accuracy.
Although RT-DETR provides a strong baseline, it is not optimized for the specific granularities of PPE detection. It still struggles with small, low-contrast targets and retains a relatively high computational overhead for multi-stream industrial monitoring tasks. To address these gaps, this paper proposes DBB-enhanced MFM-fused Dysample DETR (DMD-DETR), a structurally optimized detector based on RT-DETR. We introduce a Diverse Branch Block (DBB) to enhance feature representation without inference cost, a Modulation Fusion Module (MFM) for effective multi-scale fusion under background interference, and a lightweight DySample module to preserve spatial details of small objects.
The main contributions of this paper are summarized as follows:
We propose a novel object detection framework, DMD-DETR, tailored for complex power plant environments. By integrating DBB re-parameterization, we enhance the feature extraction capability of the backbone without increasing inference latency.
We design an MFM to replace standard concatenation in the neck, effectively suppressing background noise and highlighting small-target features under visual camouflage conditions.
We introduce a lightweight DySample dynamic upsampling operator to replace standard interpolation, significantly reducing computational complexity (GFLOPs) and parameter count while improving the localization accuracy of small and occluded objects.
Extensive experiments on a self-constructed dataset and the public dataset SHEL5K demonstrate that our method achieves a superior trade-off between accuracy and speed compared to state-of-the-art models like YOLO series and DETR series.
Related work
CNN-based object detection
CNNs have long dominated the field of object detection, generally categorized into two-stage and one-stage detectors. Two-stage algorithms, such as faster R-CNN, offer high accuracy but often suffer from slow inference speeds due to the region proposal generation step. Conversely, one-stage detectors, represented by the YOLO series, treat detection as a regression problem, achieving a better balance between speed and accuracy.
To adapt YOLO for complex industrial scenarios, researchers have proposed numerous improvements. For instance, Hayat et al. (2022) proposed a deep learning–based automatic safety helmet detection (SHD) system for construction safety, demonstrating the feasibility of vision-based safety monitoring in construction environments. He et al. (2023) proposed an improved YOLOv7-Tiny algorithm to tackle the complexity of power operation sites, where diverse and partially occluded objects challenge intelligent safety monitoring. Barlybayev et al. (2024) conducted a comparative study on PPE detection using the YOLOv8 architecture on object detection benchmark datasets, demonstrating the effectiveness of YOLO-based methods for PPE monitoring tasks. Despite the advantages of YOLO models in speed and ease of deployment, they often struggle with small, densely packed, or distant targets, leading to missed detections. In addition, YOLO relies on NMS for filtering candidate boxes, a heuristic post-processing step that hinders end-to-end optimization. In scenarios with severe occlusion, NMS may mistakenly discard true positives or retain redundant boxes, reducing detection accuracy. To address these challenges, researchers have proposed various YOLO improvements. Chen et al. (2024) introduced a PConv-based C2f-PConv module to replace repetitive convolutions in the CSP module, reducing parameter overhead while improving detection efficiency. Wu et al. (2024) proposed the Pyramid Convolutional Efficient Multi-scale Attention (PC-EMA) module with multi-scale attention mechanisms to enhance wind turbine surface defect detection.Su et al. (2024) employed a perception-enhanced convolution module to improve small object detail recognition. Qu et al. (2023) added an extra prediction head to YOLOv5s for detecting small traffic signs under different weather conditions. Huang et al. (2022) proposed shallow feature fusion and anchor clustering strategies for detecting tiny defects in semiconductors using YOLOv4. Qu et al. (2024) designed the YOLOv8-LA model based on AP-FasterNet to improve underwater small object detection. Lin et al. (2024) used deformable convolutions for better feature extraction in remote sensing images. Jin et al. (2024) utilized composite feature extraction to mitigate domain differences and enhance generalization. Mittal et al. (2022) combined a Cascade-FPN architecture to address scale variation and small object loss, improving detection robustness. More recently, Wang (2025) evaluated the performance of YOLOv10 combined with transformer backbones, demonstrating state-of-the-art results among CNN-based methods. Despite these advancements, CNN-based detectors inherently rely on NMS for post-processing. In power plant environments characterized by dense equipment and frequent personnel occlusion, NMS often erroneously suppresses the bounding boxes of overlapping targets, creating a bottleneck in recall performance that structural improvements to CNNs cannot fully resolve.
Transformer-based object detection
To overcome the limitations of local receptive fields and NMS in CNNs, transformer architectures have been introduced to object detection. Carion et al. (2020) pioneered DETR, which models detection as a set prediction problem and utilizes the Hungarian algorithm for bipartite matching. This end-to-end paradigm eliminates the need for NMS and anchors, leveraging global self-attention to better handle long-range dependencies and occlusions. However, the original DETR suffers from slow convergence and high computational complexity.
To address these issues, a number of improved DETR-based detectors have been proposed. Zhu et al. (2021) proposed Deformable DETR, which attends only to a small set of key sampling points, significantly accelerating convergence. Zhang et al. (2023) introduced DINO, which improves detection performance and training efficiency through contrastive denoising training and mixed query selection. Subsequently, Zhao et al. (2024) proposed RT-DETR, the first real-time end-to-end detector, which achieves a favorable balance between accuracy and inference speed by designing an efficient hybrid encoder to decouple intra-scale interaction and cross-scale fusion. More recently, Huang et al. (2025) proposed DETR with Improved Matching (DEIM), which accelerates the convergence of real-time DETR-based detectors by refining the matching strategy, while Peng et al. (2025) introduced Dynamic Fine-grained Distribution Refinement (D-FINE), which reformulates bounding box regression as a fine-grained distribution refinement process to improve localization accuracy.
Although these DETR variants have continuously advanced the performance of end-to-end object detection, their suitability for industrial deployment remains different. In particular, advanced detectors such as DEIM and D-FINE are typically developed under relatively large-scale training settings and substantial computational budgets, which may limit their direct applicability in resource-constrained industrial environments. In contrast, RT-DETR provides a more practical trade-off between detection accuracy and inference efficiency, while preserving the anti-occlusion advantages of transformer-based detectors. Therefore, RT-DETR is adopted in this work as the baseline framework for further improvement.
At the same time, several studies have explored adaptations of RT-DETR for small object detection in specific scenarios. Zhou et al. (2025) proposed Multi-Scale Real-Time DETR. (MSRT-DETR), which enhances dense and multi-scale cell detection by introducing multi-scale feature sequence fusion and an additional small object detection layer. Tian et al. (2025) improved RT-DETR for underground coal mine environments, where small targets are easily affected by cluttered backgrounds and adverse illumination conditions. Madan and Reich (2025) strengthened small object detection in an adapted RT-DETR framework through robust enhancement strategies, further demonstrating the potential of RT-DETR for challenging small-target tasks. However, most of these methods are still designed for specific application scenarios, and their generalization ability in complex industrial safety monitoring environments remains to be further validated.
The RT-DETR framework
RT-DETR is an efficient end-to-end real-time object detection model that removes the need for anchor-based preprocessing and NMS post-processing. When contrasted with other object detection networks, the system achieves real-time performance and minimizes computational overhead, maintaining accuracy in detection. The architecture of RT-DETR is made up of three core components: a Backbone Network, an Efficient Hybrid Encoder, and a Transformer Decoder featuring detection heads. The backbone network is responsible for initial feature extraction and outputs three feature maps at different scales. These multi-scale features are further processed and fused by the encoder module, which incorporates the Cross-Scale Collaborative Fusion Module (CCFM) to enhance collaborative representation among features. In the object query stage, an IOU-Aware Query Selection strategy is adopted to select a fixed number of high-quality features as initial queries. This approach addresses the inconsistency between classification scores and localization confidence in traditional methods and improves object localization accuracy by introducing an IOU constraint mechanism. Finally, the transformer decoder, aided by auxiliary detection heads, refines the query features and outputs object bounding boxes along with confidence scores. The backbone of the RT-DETR model is based on residual networks. There are two types of residual blocks: the BasicBlock, mainly used in ResNet-18 and ResNet-34, and the Bottleneck structure, used in deeper variants such as ResNet-50, ResNet-101, and ResNet-152. The basic architecture of RT-DETR is illustrated in Figure 1. Considering the real-world power plant environment and the need for fast training and inference speeds, this study adopts the lightweight ResNet-18 as the backbone. However, despite its efficiency, the standard RT-DETR backbone and upsampling modules are not specifically optimized for the small, low-contrast targets prevalent in our scenario. This motivates the structural improvements detailed in the following section.
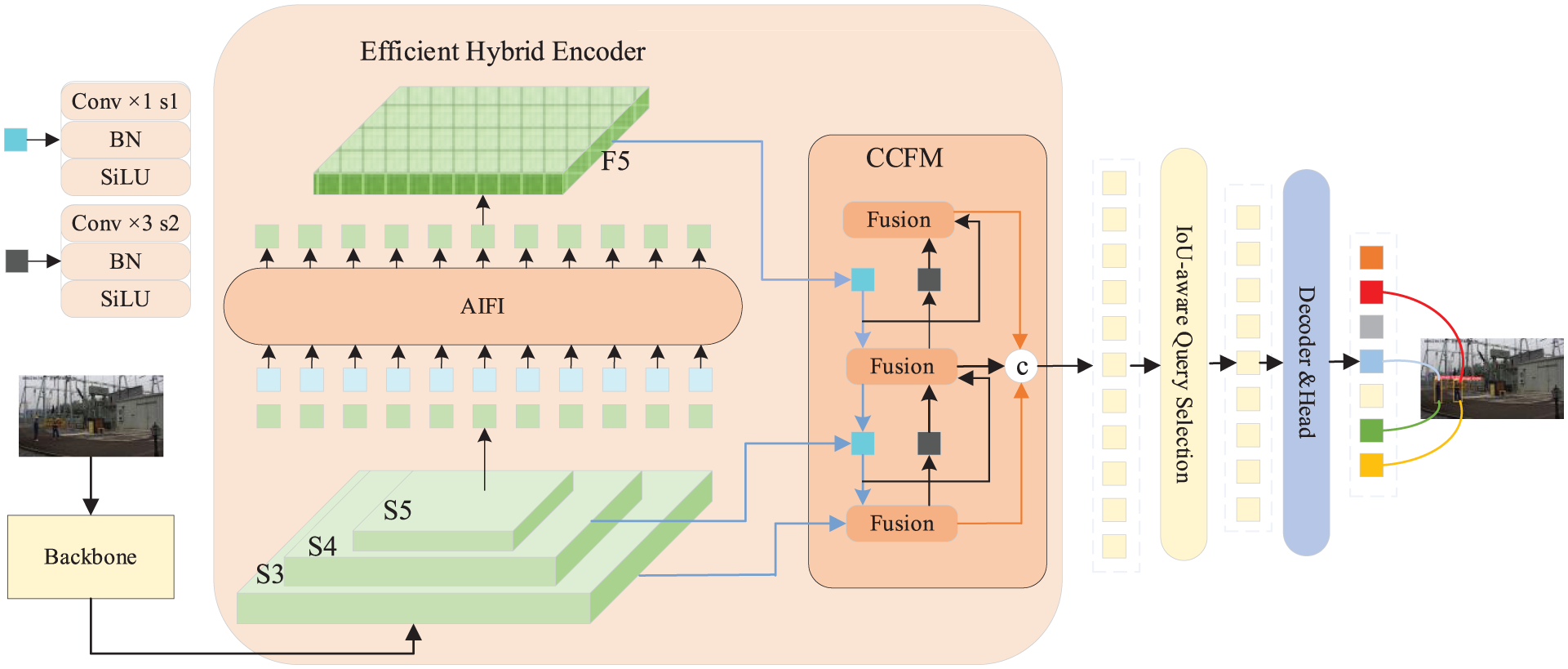
Architecture of the RT-DETR network.
Method
Striking an optimal balance between detection accuracy and inference latency remains a formidable challenge in complex power plant environments, particularly when facing visual camouflage (low contrast between PPE and background) and small object loss during feature sampling. To address these specific challenges, we propose DMD-DETR, a structurally optimized architecture based on RT-DETR. As illustrated in Figure 5, our design philosophy is not merely to stack advanced modules, but to reconstruct the feature extraction and fusion pipeline for specific industrial constraints:
Backbone enhancement: To extract richer features from low-contrast images without increasing inference latency, we integrate the DBB. This allows the model to learn complex representations during training while compressing them into a single convolution during inference.
Noise suppression in feature fusion: To prevent background noise from overwhelming small PPE targets (e.g. gloves), we introduce the MFM in the encoder, replacing standard concatenation to dynamically weight informative features.
Detail preservation: Standard interpolation often blurs the boundaries of small objects. We employ DySample, a dynamic upsampling operator, to preserve fine-grained spatial details crucial for small object localization.
Finally, a post-processing logic is designed to determine safety compliance based on the spatial relationship of detected objects.
Backbone optimization via DBB Re-parameterization
The backbone network is responsible for extracting fundamental features from input images. In power plant surveillance, targets like safety shoes often lack distinctive texture features due to distance and lighting. While deepening the network can improve feature extraction, it inevitably increases latency. To resolve this conflict, we redesign the BasicBlocks of the ResNet-18 backbone using DBB (Ding et al., 2021). The core advantage of DBB lies in its structural re-parameterization strategy. As shown in Figure 2, during training, DBB employs a multi-branch topology to enrich the feature space and capture diverse patterns. However, during inference, these complex branches are mathematically merged into a single convolutional layer using linear transformations. The structure is illustrated in Figure 2. During training, the DBB module consists of multiple branches, each performing independent convolution operations. These branches can be equivalently transformed into a single convolution layer for deployment during inference. The outputs of these branches are then aggregated through a feature fusion mechanism, as defined in equation (1). This design facilitates the capture and integration of various feature representations, thereby enhancing the representational power of /the module and improving overall performance
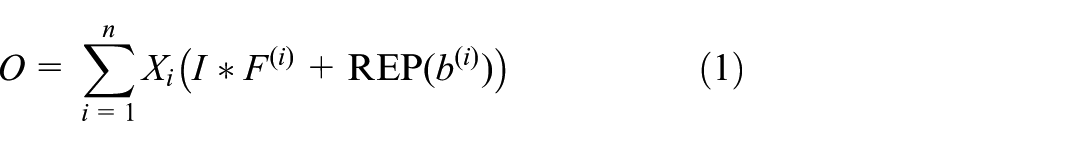
In equation (1), n denotes the number of branches in the DBB module,

In equation (2),

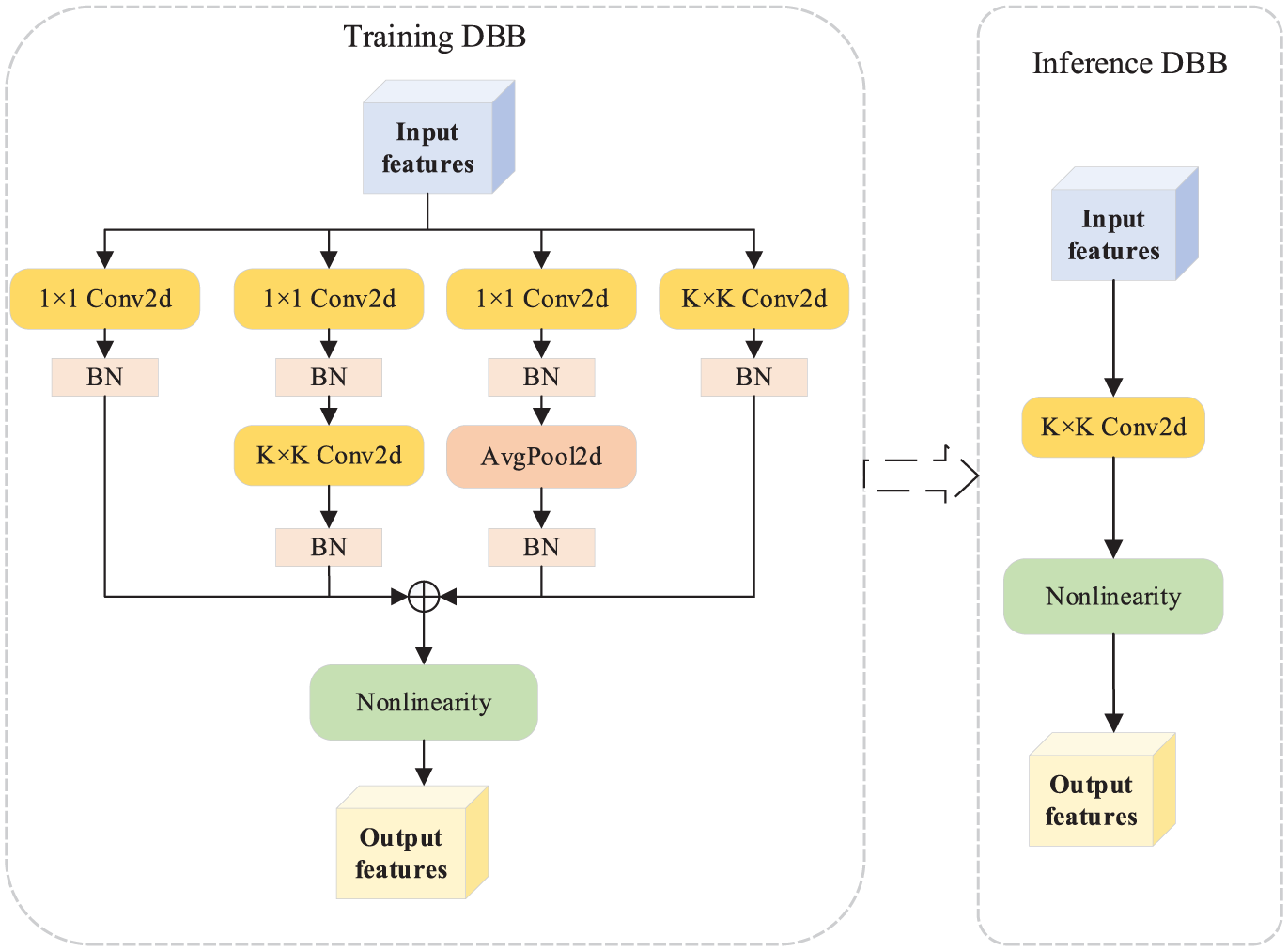
Structure of the Diverse Branch Block (DBB) module.
Feature fusion with MFM
Although the DBB-enhanced backbone extracts richer features, simply aggregating them is insufficient when PPE items share similar colors with the industrial background (visual camouflage). To further strengthen feature interaction and information integration, this paper introduces the MFM during the feature fusion stage. MFM dynamically adjusts the weights of features from different sources, highlighting the information that contributes more to the detection task while suppressing redundant or distracting features. This effectively enhances the model’s global feature representation capability. Unlike traditional concatenation which treats target features and background noise equally, MFM acts as a dynamic filter to selectively emphasize discriminative channels, resulting in more discriminative fused features. This improves the model’s adaptability to small objects, occluded targets, and complex backgrounds (Zhang et al., 2024). The structure of the module is shown in Figure 3, and the fusion process is defined in equation (4). In this module, the inputs
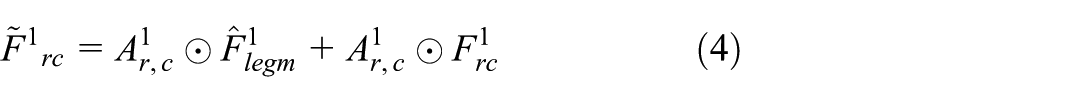
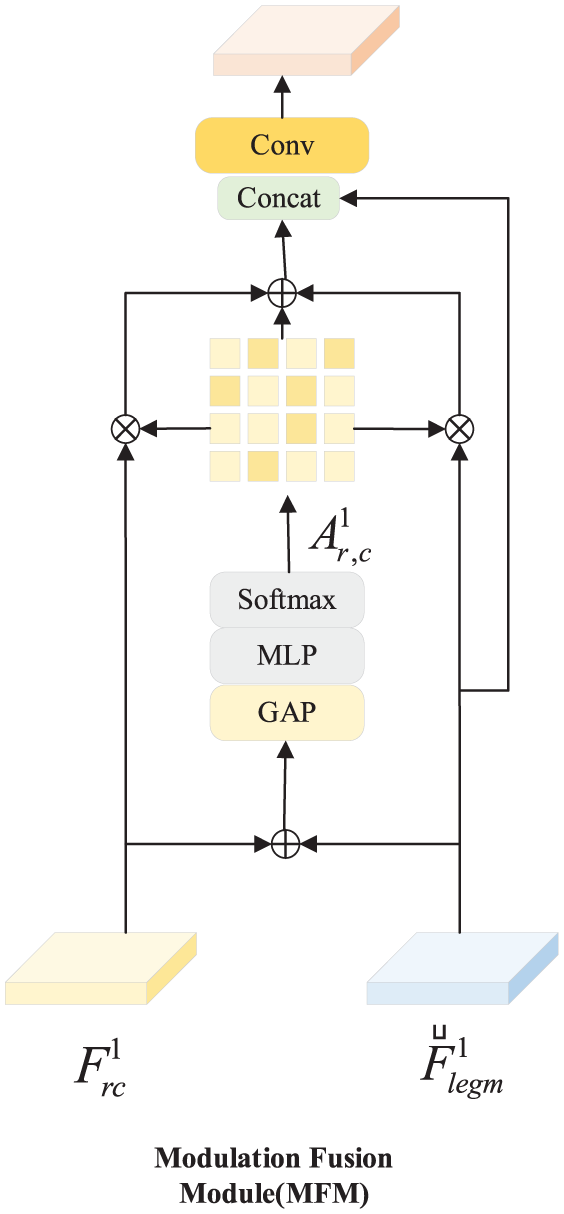
Schematic diagram of the Modulation Fusion Module (MFM).
Efficient upsampling with DySample
In the original RT-DETR18 model, the upsampling layer uses the UpSample function, which employs interpolation methods to upscale the feature map to a higher resolution. However, such content-agnostic operations often blur the boundaries of small objects, leading to feature degradation. Furthermore, since the previously introduced DBB and MFM modules have slightly increased the model complexity, employing heavy kernel-based dynamic upsamplers would compromise real-time performance. To reconcile high-quality reconstruction with efficiency, this paper introduces the DySample module (Liu et al., 2023) to replace the original mechanism. Compared with traditional kernel-based dynamic upsamplers, DySample adopts a point-based sampling approach. This method has fewer parameters, lower floating-point operations (FLOPs (Floating-point Operations Per Second)), reduced GPU memory usage, and lower latency compared to previous kernel-based dynamic upsampling methods. The structure of DySample is shown in Figure 4(a). Given a feature map X of size

In this paper, the sampling point generator used in DySample adopts a static range factor, as illustrated in Figure 4(b). Given an upsampling scale factor s and a feature map X of size
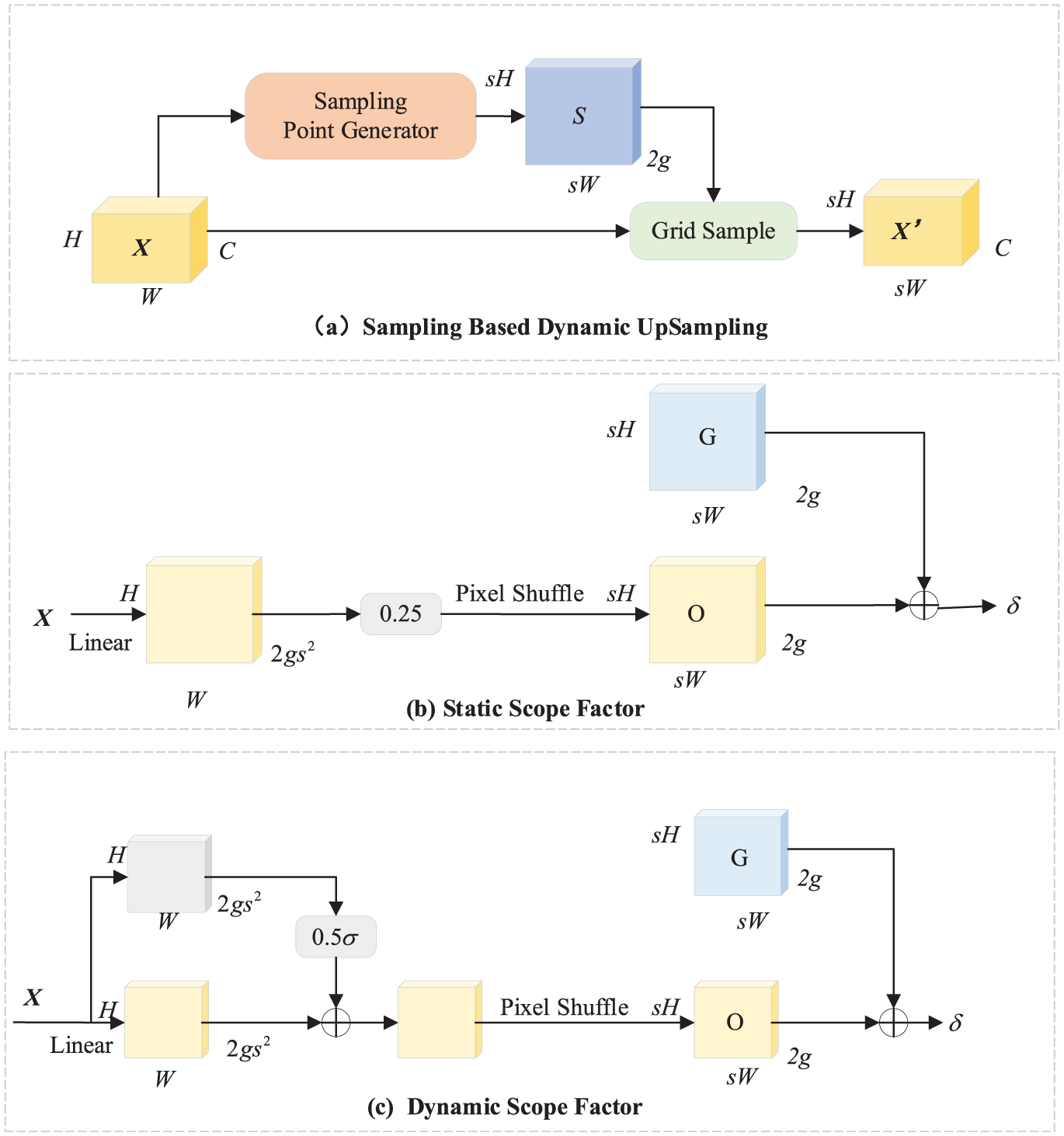
Architecture of the DySample upsampling module: (a) Sampling-Based Dynamic UpSampling, (b) Static Scope Factor, and (c) Dynamic Scope Factor.
Finally, O is reshaped through pixel-wise random shuffling into a tensor of size
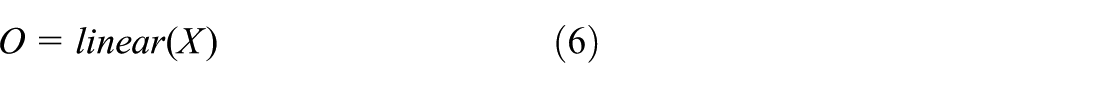
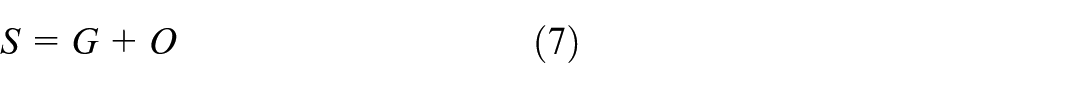
The overall improved network structure is shown in Figure 5. First, in the backbone network, this study adopts DBB re-parameterization technology to enhance the feature extraction capability of the BasicBlock modules. In the efficient hybrid encoder section, several structural modifications are made: the convolutional layers before the two upsampling operations in the CCFM module are replaced with MFM multi-scale feature fusion modules to improve multi-scale information integration. In addition, the point-sampling-based DySample module is introduced to optimize the upsampling process, thereby enhancing the quality of spatial feature reconstruction. Although these improvements increase the model’s computational complexity to some extent, they achieve significant gains in small object detection accuracy. The overall optimization strategy is thus better suited for small object recognition tasks in complex multi-scale scenarios.
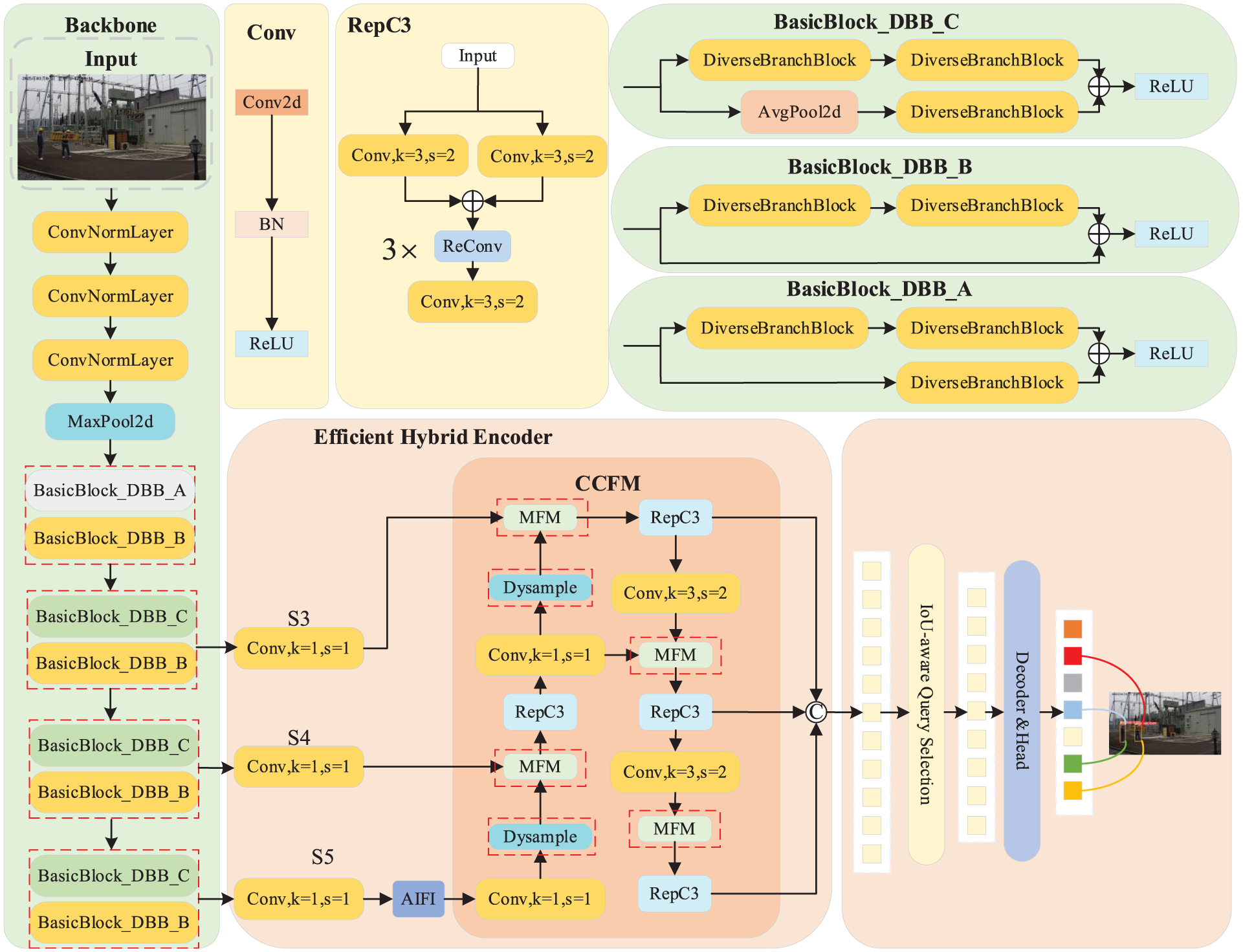
The overall architecture of the proposed DMD-DETR.
Safety compliance logic based on spatial topology
Although DMD-DETR ensures precise object localization, raw bounding boxes are insufficient for a holistic safety audit. A mechanism is required to distinguish between “equipped status” (e.g. wearing a helmet) and “disassociated status” (e.g. holding a helmet or helmet placed on a table). To address this, we propose a logic module based on Anthropometric Spatial Topology, which models the relationship between workers and PPE as a geometric inclusion problem subject to anatomical constraints.
Problem formulation
Let the set of detected workers in a frame be
Geometric constraint criteria
To determine
Spatial subordination constraint (SSC): A PPE item worn by a worker must be spatially contained within the worker’s two-dimensional (2D) projection. We utilize Intersection over Area (IoA) rather than standard IoU to measure this inclusion relationship, as PPE boxes are significantly smaller than worker boxes. The SSC is shown in equation (8)
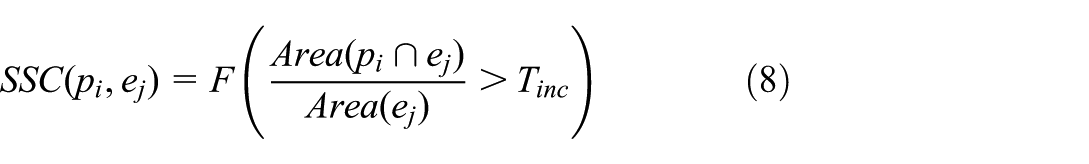
where
2. Anthropometric topology constraint (ATC): To differentiate “wearing” from “carrying,” we leverage the topological invariance of the human body. Even under varying camera angles, the head is invariably located at the top extremity, and feet at the bottom extremity of the bounding box.
We normalize the worker’s bounding box coordinate space to

Here,
Violation decision
For each worker
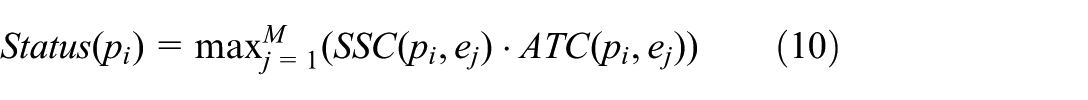
If
Experiments and results analysis
Experimental environment and parameter settings
The experimental environment for model training was established on an Intel(R) Xeon(R) Platinum 8269CY CPU and an NVIDIA GeForce RTX3090 GPU (24 GB memory), ensuring adequate computational resources. Hardware acceleration was supported by the CUDA 11.8 library, and the system was operated under Ubuntu 20.04.6 LTS. The deep learning experiments were conducted using the PyTorch framework with Python 3.8 as the primary programming language.
The training parameters were configured as follows: a total of 200 epochs was executed with a batch size of 16, and the AdamW optimizer was employed for parameter optimization. The initial learning rate was set to 0.0001, with a momentum of 0.9. A warm-up strategy was applied for the first 2000 iterations, during which the initial momentum was set to 0.8. To balance convergence efficiency and the preservation of image feature information, the input image resolution was fixed at 640×640.
Specifically, the proposed DMD-DETR adopts the same basic training configuration as the baseline RT-DETR, including an input size of 640 × 640, a batch size of 16, 200 training epochs, and the AdamW optimizer with an initial learning rate of 0.0001. For fair comparison, the other comparison models were trained using their official implementations or widely adopted settings under the same input resolution, number of epochs, and batch size whenever possible. For the proposed DMD-DETR, the newly introduced module-related settings were determined through preliminary validation experiments. In practice, these parameters were selected by jointly considering detection accuracy, computational complexity, and inference efficiency, so as to better satisfy the requirements of real-time industrial deployment.
Dataset construction
To comprehensively evaluate the performance, robustness, and generalization ability of the proposed method in complex industrial environments, we utilized two datasets in this study: a self-constructed dataset captured in a real-world power plant and the public SHEL5K dataset.
Self-constructed power plant dataset
The data in this study were collected from seven cameras in the real working environment of a power plant, totaling 2910 photos. The dataset includes four categories: safety helmets, insulating gloves, insulating shoes, and workers. Each category contains both positive and negative samples. The dataset is divided into training, testing, and evaluation sets in a ratio of 7:1.5:1.5. The overall dataset composition and distribution are illustrated in Figure 6.
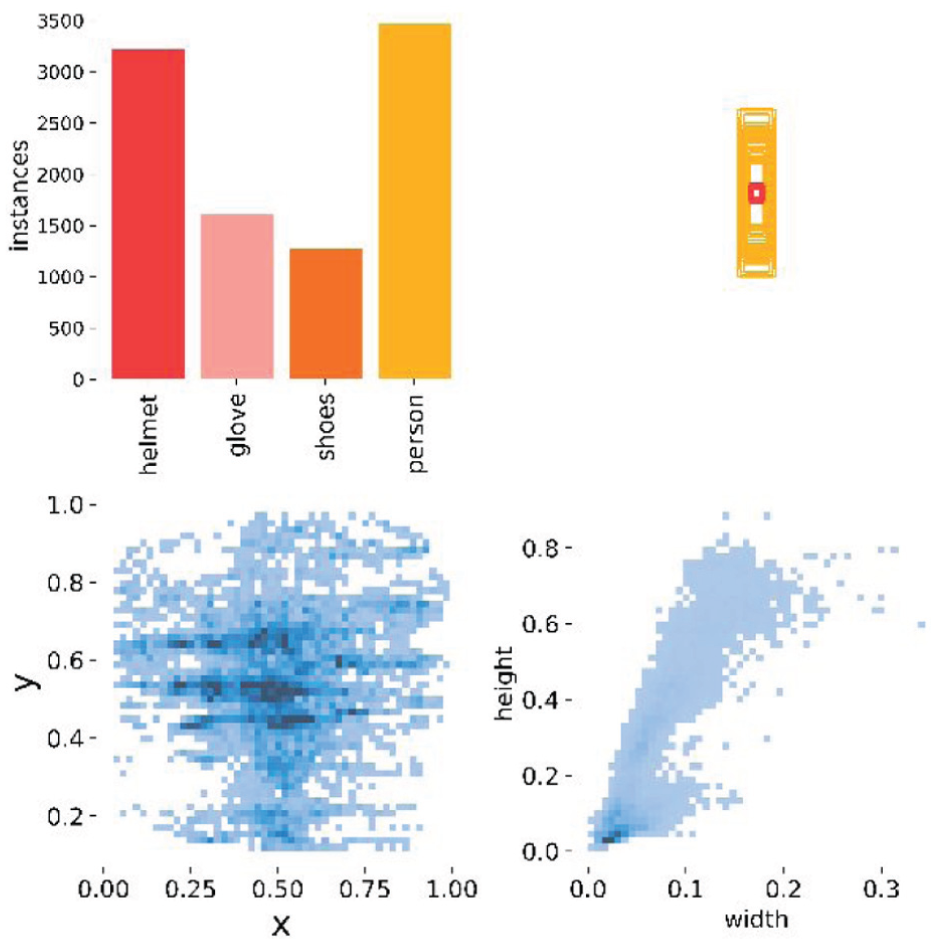
Category distribution of the self-constructed power plant dataset.
SHEL5K public benchmark dataset
To verify the generalization capability of our model on external data, we incorporated the SHEL5K (Safety Helmet and Ex-proof Jacket Detection Dataset) (Otgonbold et al., 2022). SHEL5K consists of 5000 images and serves as an enhanced version of the SHD dataset. Its primary improvements include (a) the refinement and completion of missing labels from the original dataset and (b) the expansion of category types from 3 to 6. We selected SHEL5K for auxiliary experiments because its application scenarios (PPE detection) closely align with ours. Furthermore, the detection difficulty and the complexity of the background scenes in SHEL5K are highly similar to our self-constructed power plant dataset, making it an ideal benchmark for evaluating the model’s robustness in industrial settings. The dataset was divided into training, testing, and evaluation sets in the ratio of 8:1:1, forming the complete dataset. The overall dataset composition and distribution are illustrated in Figure 7.
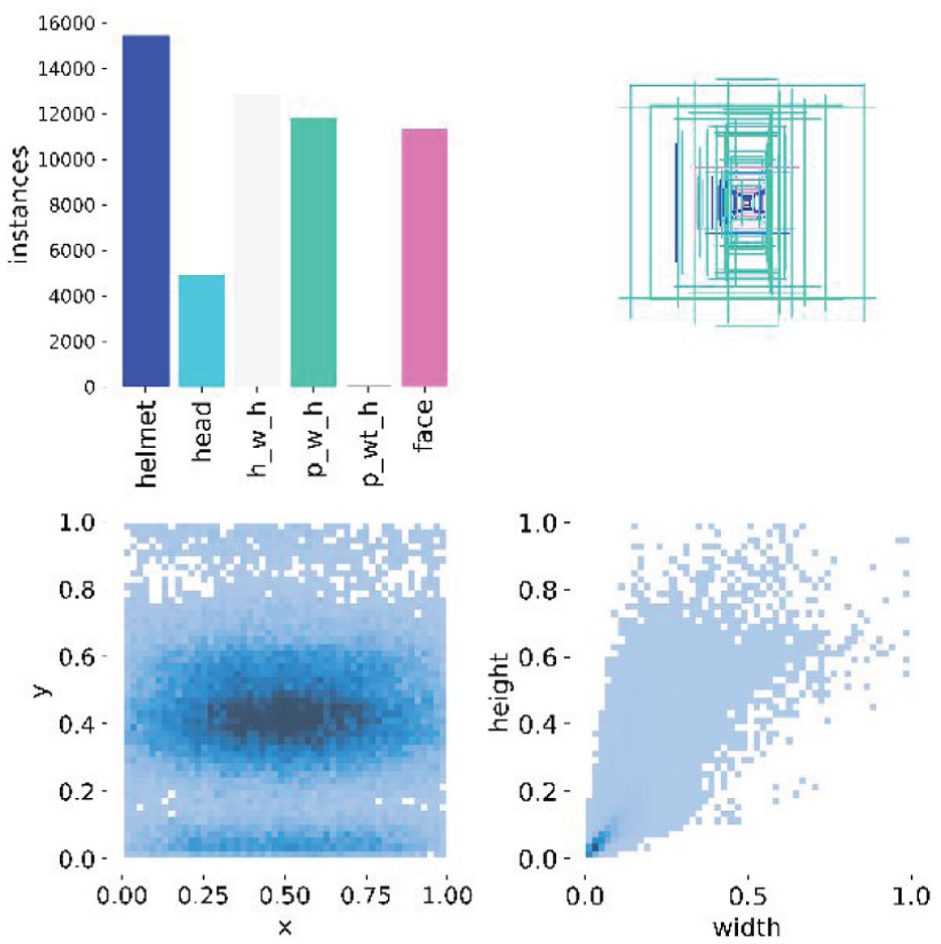
Category distribution of the public SHEL5K dataset.
Evaluation metrics
The performance of the algorithm in this study is assessed using these metrics: mean Average Precision (mAP), FPS (frames per second), model parameter size (P/MB), and GFLOPs (billion floating-point operations per second), and Parameters (the total number of trainable parameters in the model).
mAP is frequently utilized as a metric to assess the accuracy of object detection. It is calculated by averaging the areas under the Precision-Recall (P-R) curves for each class. In the P-R curve, Precision (P) refers to the proportion of correctly predicted positive samples among all predicted positives, and Recall (R) refers to the proportion of correctly predicted positives among all actual positives. The definitions of Precision (P), Recall (R), and mAP are shown in equation (14)
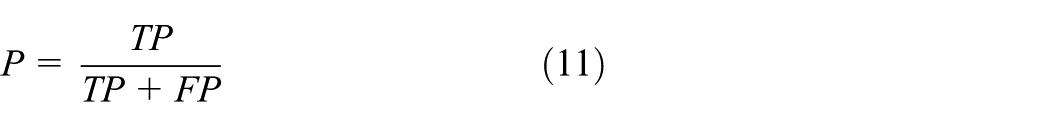
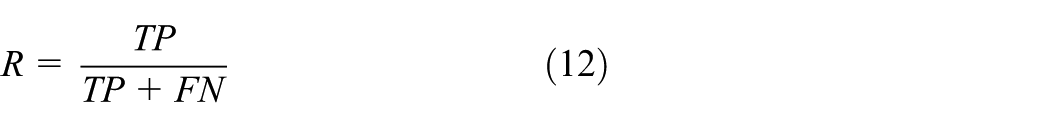


TP (True Positives) are true positive cases; FP (False Positives) are false positive cases; FN (False Negatives) are false negative cases; and TN (True Negatives) are true negative cases. The larger the mAP value, the better the algorithm performance.
In the electric power industry, the basic acceptance standard typically requires an mAP@0.5 (IoU threshold = 0.5) exceeding 90% to ensure high recall. Our proposed model achieves an mAP@0.5 of over 95%, fully satisfying this industrial deployment requirement. However, this study primarily uses mAP@0.5:0.95 (averaged over IoU 0.5–0.95) as the critical evaluation metric rather than the looser mAP@0.5. This is because the proposed Safety Violation Logic relies on precise spatial topological relationships. Mere detection presence is insufficient; high localization quality is essential to provide accurate bounding boxes for the logic module, thereby minimizing system-level false alarms. Therefore, the mAP values reported in the subsequent tables refer to the rigorous mAP@0.5:0.95 metric.
FPS is used to measure whether the object detection model meets real-time requirements. In this study, the FPS results are obtained by first performing 300 warm-up iterations, followed by averaging over 500 repeated inferences. The size of the object detection model can be measured by the number of parameters, computational complexity, and storage space. Generally, it is expressed in megabytes (MB). The model file size mainly affects performance in terms of loading speed, memory usage, inference speed, as well as generalization ability and accuracy. GFLOP is a derived unit from FLOPs (Floating-point Operations Per Second), representing the number of billion floating-point operations performed per second. Floating-point operations mainly include matrix multiplication and convolution operations. In fields such as deep learning and computer vision, GFLOPs are widely used to evaluate the computational requirements of models and hardware devices.
Ablation study analysis
To rigorously validate the efficacy of each proposed component and their synergistic contribution to the overall architecture, we conducted a step-by-step ablation study based on the RT-DETR baseline, which achieved an initial mAP of 61.41%. Integrating the DBB into the backbone yielded a significant 0.8% performance gain; this improvement is attributed to DBB’s multi-branch topology, which enriches the feature space during training, while its structural re-parameterization technique ensures these branches are merged into a single convolution during inference, achieving enhanced representation with zero additional inference cost. Subsequently, the introduction of the MFM boosted the mAP by another 0.8%, validating its capability as a dynamic filter that suppresses complex industrial background noise while accentuating the semantic information of small, occluded targets like gloves. Furthermore, replacing standard upsampling with the DySample module resulted in a 0.22% increase in mAP; more critically, this content-aware operator preserved fine-grained spatial details essential for localization while drastically reducing the model’s GFLOPs to 54.5 and parameters to 19.39M. Collectively, these optimizations culminated in a final mAP of 62.94% (a 1.53% total improvement), demonstrating that our method achieves a superior Pareto frontier between detection robustness and deployment efficiency, making it highly suitable for resource-constrained industrial scenarios.
Comparative experiments
To further evaluate the comprehensive performance of the proposed model, it was evaluated against the current mainstream single-stage object detection algorithms, including the YOLO series models and RT-DETRv2. The related results are shown in Table 2. As can be seen from the table, the proposed model demonstrates excellent performance across multiple key metrics. Specifically, the mAP reaches 62.94%, the highest among all models, significantly outperforming RT-DETRv2’s 60.70% and the highest value in the YOLO series, YOLO11m, at 61.42%, fully validating the efficiency of the proposed model in detection accuracy. At the same time, in terms of the number of parameters, the proposed model has 19.39M, which is lower than YOLO8m (25.84M) and RT-DETRv2 (20.11M), making it more lightweight in structure. Regarding computational complexity, the proposed model’s GFLOPs is 54.5, which is lower than RT-DETRv2’s 60.0 and also lower than the YOLO series models, demonstrating higher computational efficiency. In terms of inference speed (FPS), the proposed model achieves 164.62 FPS. Although slightly lower than YOLO10m and YOLO11m, it is faster than other models, indicating strong real-time capability while maintaining high accuracy. In summary, the improved model proposed in this study achieves a good balance among accuracy, model complexity, and inference efficiency, making it particularly suitable for practical applications that require both high speed and precision.
Figure 8 shows the training curve changes of the model before and after improvement. Among them, Figure 8(a) is the comparison curve of mAP (0.5–0.95) during training. It can be seen that the model converges at around 100 epochs, and the improved model shows a significant increase in mAP, demonstrating better performance. Figure 8(b) is the comparison curve of the loss function during training. From the figure, it can be observed that the improved model has a lower loss convergence value and faster convergence speed. After 200 epochs, both models have converged stably.
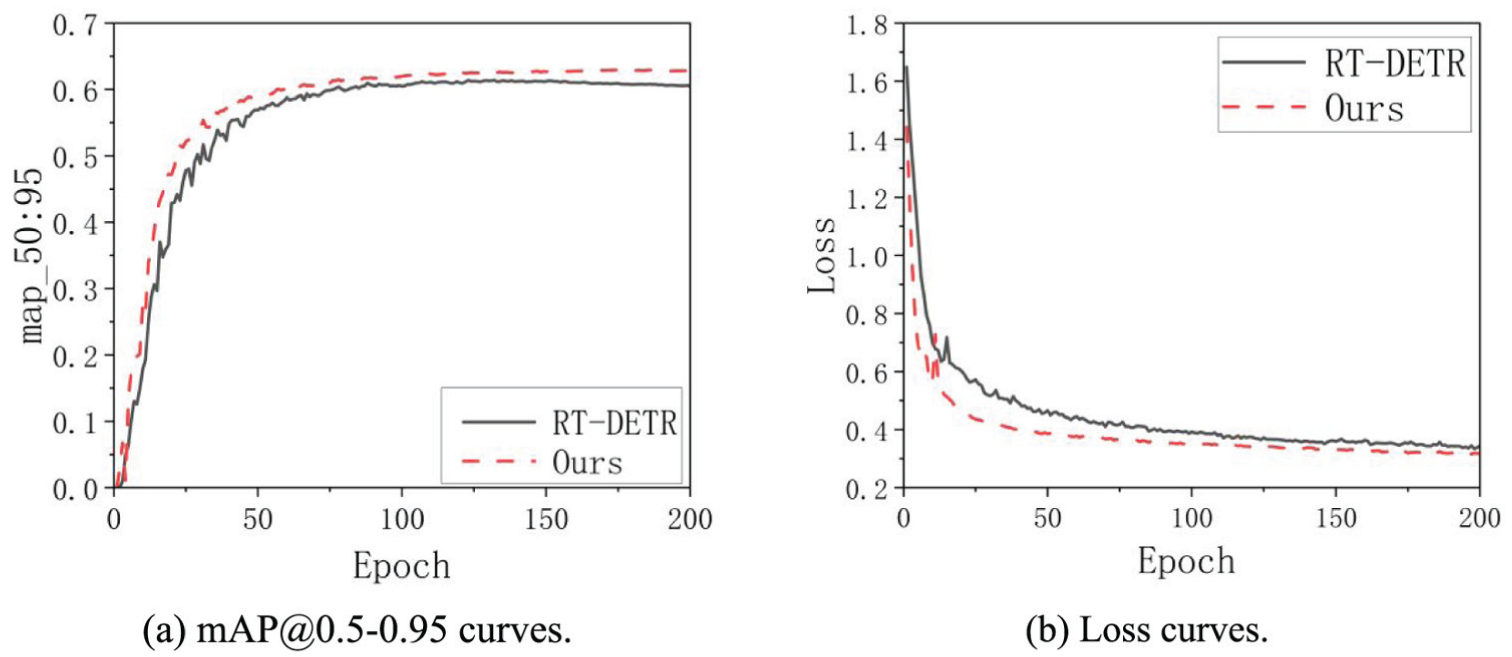
Training dynamics comparison: (a) mAP@0.5-0.95 curves and (b) loss curves.
As shown in Figure 9(a), the detection results of the original RT-DETR model reveal significant challenges in complex scenarios with cluttered backgrounds and small targets. The model exhibits three critical limitations: (a) false positives (e.g. misclassifying fences as workers), (b) missed detections (particularly workers’ boots and insulating gloves), and (c) consistently low confidence scores across predictions. In contrast, the improved model, which incorporates the DBB to enhance feature representation and the MFM to improve feature fusion, significantly strengthens the detection capability for small objects. As a result, it avoids false and missed detections and achieves higher confidence scores, as shown in Figure 9(b).

Visualization of detection results: (a) baseline RT-DETR and (b) proposed DMD-DETR.
To validate the robustness and effectiveness of the improved model, comparative experiments were conducted on the public SHEL5K dataset. Representative models from the YOLO and RT-DETR series were selected as baselines for comparison. The experimental results are presented in Table 3.
As presented in Table 3, the original RT-DETR demonstrates a leading advantage in inference speed (186.11 FPS); however, its detection accuracy (57.03% mAP) is slightly inferior to the state-of-the-art YOLO series. In contrast, our proposed model exhibits a clear advantage in detection performance, achieving an mAP of 58.62%, which represents a 1.59% improvement over the baseline RT-DETR. Furthermore, the model optimization has proven effective in reducing complexity, with Parameters and GFLOPs decreasing to 19.42 M and 54.5, respectively. Although the inference speed of our method (167.68 FPS) shows a marginal decrease compared to the original RT-DETR due to the structural enhancements, it remains well within the requirements for real-time applications and is notably faster than the high-accuracy YOLO12m (139.84 FPS). These results demonstrate that the proposed method achieves a superior trade-off between accuracy and efficiency, validating its practical applicability.
Figure 10 illustrates the training dynamics of the improved model compared to the baseline RT-DETR. As depicted in Figure 10(a), the mAP curve of the proposed model consistently outperforms the baseline, with both models tending toward convergence and reaching their optimal states at approximately 120 epochs. Correspondingly, Figure 10(b) presents the training loss curves, which also exhibit stability around the 100th epoch. Collectively, these curves demonstrate that the improved model not only achieves higher accuracy and lower loss but also maintains robust stability during the training process.
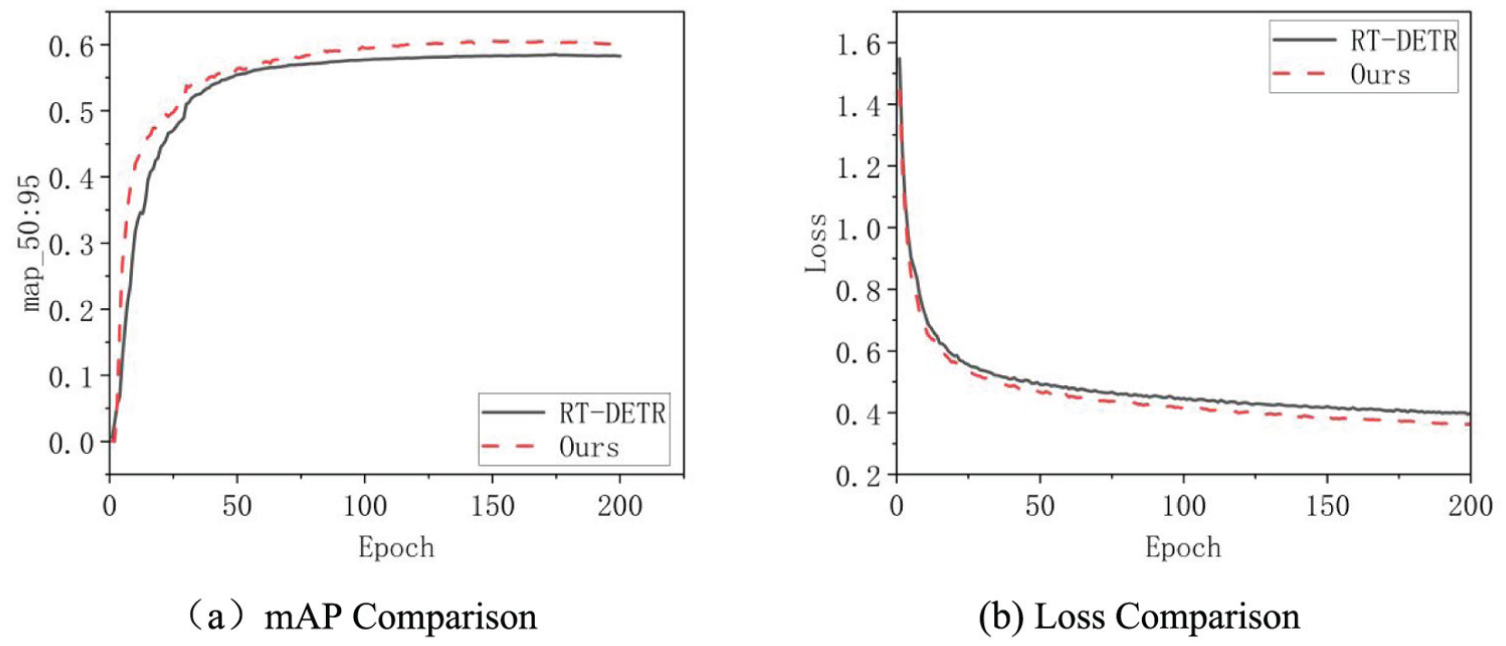
Training process curve: (a) mAP comparison and (b) loss comparison.
Discussion
Efficacy of structural optimizations
The ablation study (Table 1) elucidates the specific contributions of each proposed module to the overall network performance. First, the integration of the DBB yields an mAP improvement of 0.8%. This indicates that the multi-branch architecture enhances the model’s ability to capture rich feature representations during training, which is essential for distinguishing safety gear from complex industrial backgrounds. Notably, due to the re-parameterization strategy, this accuracy gain is achieved without incurring additional inference latency. Second, the MFM contributes a further 0.8% increase in mAP, suggesting that MFM effectively mitigates the loss of high-dimensional semantic information during the feature fusion process. Finally, the introduction of the DySample module proves critical for model efficiency. While it contributes a modest 0.22% to accuracy, its primary significance lies in the reduction of GFLOPs to 54.5 and parameter count to 19.39M. This demonstrates that point-sampling-based upsampling is significantly more efficient than traditional kernels. The cumulative improvement of 1.53% confirms that these components function synergistically to enhance detection robustness.
Ablation study of the proposed modules on the self-constructed dataset.
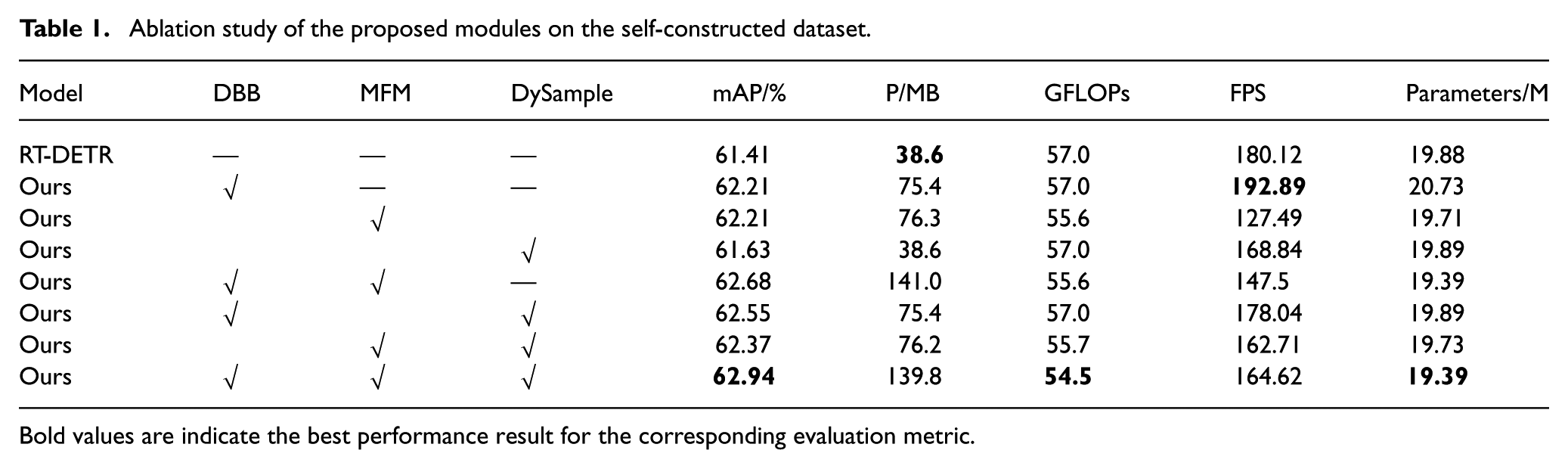
Bold values are indicate the best performance result for the corresponding evaluation metric.
Performance comparison and trade-offs
Comparative evaluations on both the self-constructed and SHEL5K datasets (Tables 2 and 3) highlight the superior trade-off achieved by the proposed method. Quantitatively, our model attains the highest accuracy (62.94% mAP) on the proprietary dataset, significantly outperforming RT-DETRv2 and YOLOv11m. This performance consistency is mirrored in the public dataset results (58.62%), where our model surpasses the baseline RT-DETR by 1.59%, validating its generalization capability across different data distributions.
Performance comparison with SOTA methods on the self-constructed dataset.
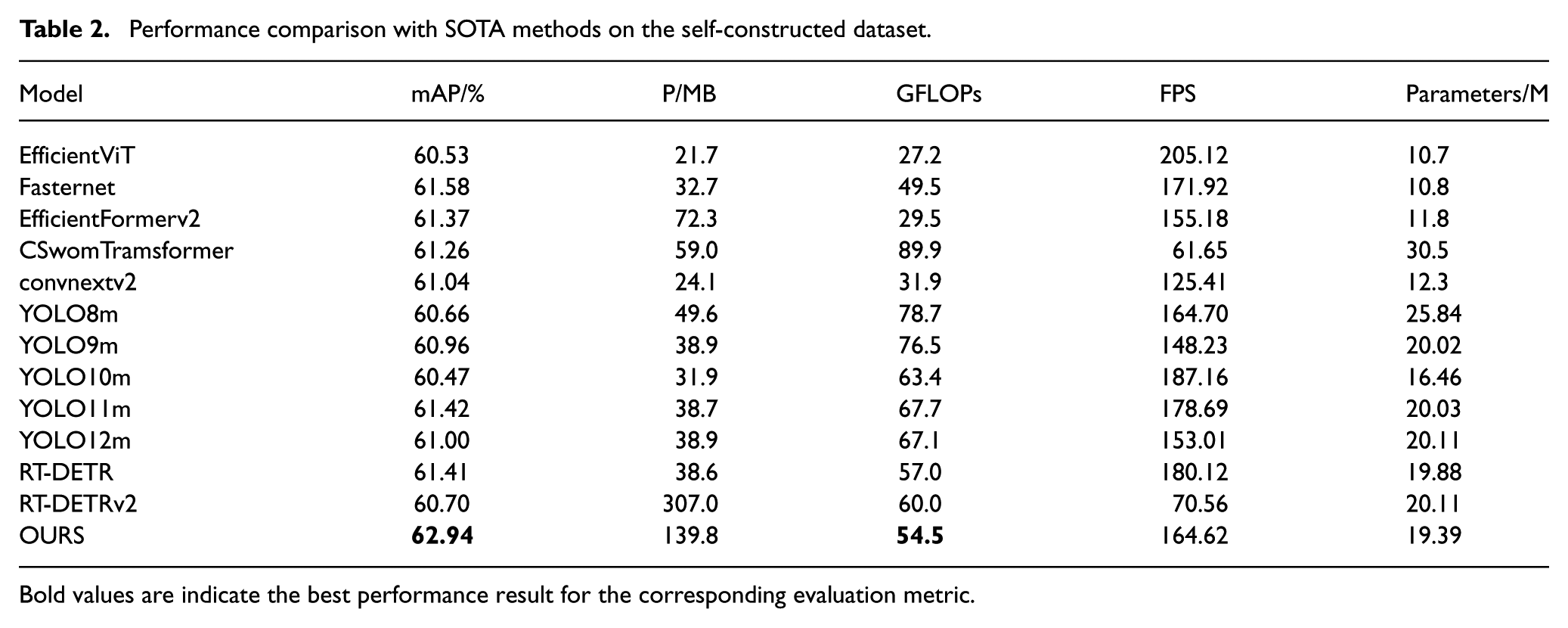
Bold values are indicate the best performance result for the corresponding evaluation metric.
Comparative evaluation results on the public SHEL5K dataset.
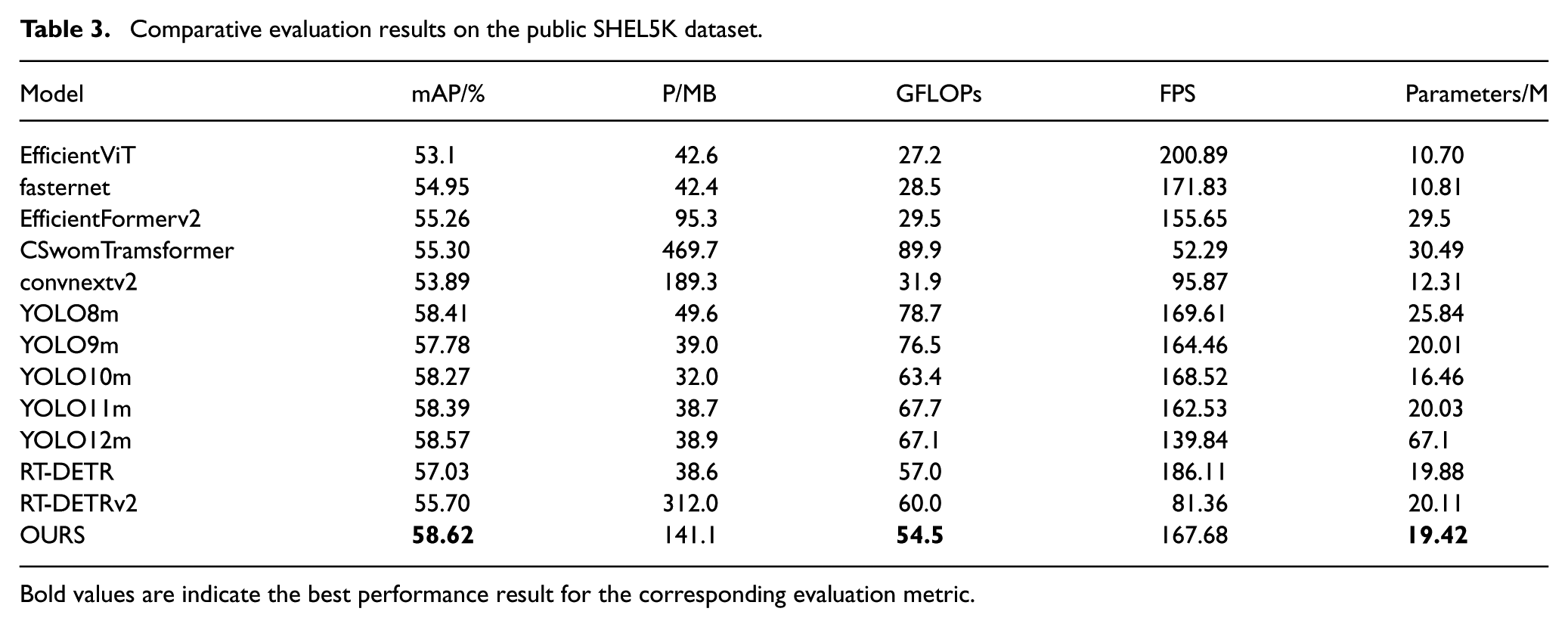
Bold values are indicate the best performance result for the corresponding evaluation metric.
A critical analysis of the efficiency-accuracy trade-off reveals that although the inference speed (167.68 FPS) is marginally lower than the baseline (186.11 FPS) due to the added computational complexity, it remains well above the real-time threshold (>30 FPS) and is superior to the high-accuracy YOLO12m (139.84 FPS). Consequently, the proposed model achieves an optimal balance, offering the highest accuracy with the lowest computational cost (54.5 GFLOPs). This characteristic renders it highly suitable for large-scale centralized deployment in power plants, where high-density video stream processing is required.
Training dynamics and convergence
The training curves presented in Figures 8 and 10 provide further evidence of the model’s stability. Both the mAP and loss curves indicate that the improved model converges stably between 100 and 120 epochs. Notably, the proposed model achieves a lower final loss value and a higher accuracy plateau compared to the baseline. The smoothness of the loss curve suggests that the introduced modules facilitate robust feature fitting without destabilizing the training process, thereby reducing the risk of overfitting on limited industrial datasets.
Visual analysis and practicality
Qualitative analysis (Figure 9) corroborates the quantitative metrics. The baseline model exhibits typical failure modes, such as misclassifying fences as workers (false positives) and missing small objects like gloves (false negatives). In contrast, the proposed model, empowered by MFM and DBB, effectively suppresses background noise and enhances the feature extraction of small targets. This visual superiority translates directly into system practicability: by ensuring the accurate detection of small safety gear, the downstream logic module receives correct inputs, thereby minimizing false violation alarms in the safety supervision system.
Limitations
Despite these advancements, this study acknowledges certain limitations. First, detection performance degrades under extreme environmental conditions, such as severe fog or low-light scenarios. Second, the current system relies on 2D bounding boxes, which limits the capability to resolve complex spatial relationships—for instance, distinguishing whether a helmet is being worn or is merely positioned behind a worker. Future research will focus on integrating depth estimation or multi-view fusion techniques to address these spatial reasoning challenges.
Conclusion
This paper addressed the critical safety challenge of detecting Protective Equipment (PPE) compliance for power workers. We proposed a structurally optimized real-time detection model based on RT-DETR to overcome issues like complex backgrounds and multi-object interference. By redesigning the backbone with DBBs, introducing an MFM for enhanced feature integration, and employing the DySample module for lightweight upsampling, we successfully improved the model’s architecture.
The core findings and contributions are summarized as follows:
High accuracy and efficiency: The improved model achieves an mAP@0.5 of 62.94% on the power plant dataset, significantly outperforming the baseline and YOLO series, while maintaining a lightweight size (19.39M parameters) and low computational load (54.5 GFLOPs).
Real-world applicability: With an inference speed of 164.62 FPS, the model demonstrates strong real-time performance, providing a resource-efficient technical foundation for intelligent safety supervision systems. The model’s low latency and high throughput ensure immediate violation alerts even under heavy multi-camera workloads. Generalization: Experiments on both self-constructed and public datasets confirm the robustness and generalization ability of the proposed improvements.
Although the proposed DMD-DETR improves detection accuracy and robustness, the introduced enhancement modules also increase model complexity and computational cost. Future work will focus on lightweight optimization while maintaining detection performance, and on further improving robustness under extreme conditions and integrating multi-object tracking for continuous behavior analysis.
Footnotes
Acknowledgements
We sincerely thank Professor Zhao for his expert guidance and valuable suggestions throughout this research. Special gratitude is extended to Mr. Huang for his crucial technical assistance.
Ethical considerations
This article does not contain any studies with animals performed by any of the authors.
Consent to participate
All participants gave informed consent prior to inclusion.
Consent for publication
Obtained
Funding
The authors received no financial support for the research, authorship, and/or publication of this article.
Declaration of conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Data availability statement
The datasets generated during the current study are available from the corresponding author on reasonable request.