
Abstract
This study examines the role of the lexicon and grammatical structure building in early grammar. Parent-report data in CDI format from a sample of 1151 German-speaking children between 1;6 and 2;6 and longitudinal spontaneous speech data from 22 children between 1;8 and 2;5 were used. Regression analysis of the parent-report data indicates that grammatical words have a stronger influence on concurrent syntactic complexity than lexical words. Time-lagged correlations using the spontaneous speech data showed that lexical words at 1;8 predict subsequent MLU at 2;1 significantly; grammatical words do not. MLU at 2;5 is significantly predicted by grammatical words and no longer by lexical words. The influence of different grammatical subcategories on subsequent MLU varies. Use of articles and the copula at 2;1 most strongly predicts MLU at 2;5. Children use both types of articles and multiple determiners before a noun to the same extent as adults. The present results are suggestive of early grammatical structure building.
Introduction
The lexical base of children’s early grammar has been a subject of discussion for some time (Bates & Goodman, 1999; Fenson et al., 1994; Pine & Lieven, 1997; Tomasello, 2000). There is considerable cross-linguistic evidence of a powerful concurrent and predictive relation between vocabulary size and grammatical complexity (Bates & Goodman, 1999; Caselli, Casadio, & Bates, 1999; Maital, Dromi, Sagi, & Bornstein, 2000; Marchman, Martínez-Sussmann, & Dale, 2004; Szagun, Stumper, & Schramm, 2014). During early language development, word combinations and use of grammatical morphemes increase as a function of vocabulary size. Grammar is understood to build on the lexicon in the sense that a critical mass of words is required before these can be related to one another by free and bound morphemes in multiword utterances (Bates & Goodman, 1999).
The lexical base of grammar is perhaps most plausible in the area of inflectional learning. A well-known example is the acquisition of the English past tense (Plunkett & Elman, 1997; Plunkett & Marchman, 1993). Empirical evidence and neural network modelling suggests that children initially use individual regular and irregular past tense forms as single lexical items without having extracted the rules for building regular past tense forms. When a sufficient verb vocabulary has been acquired they segment stored verbs into stem and affixes, which in turn allows generalization to new verbs and produces errors of regularization on irregular verbs. Thus, growing morphological productivity depends on a growing lexicon.
A more far-reaching view of the role of the lexicon in grammar building is that early syntax is lexically specific (Tomasello, 2000). According to this view, early multiword utterances are based on lexically specific patterns without knowledge of abstract syntactic categories (Lieven, Pine, & Baldwin, 1997; Pine & Lieven, 1997; Tomasello, 2000). Spontaneous speech data suggest that 2-year olds’ utterances are organized around individual verbs (Tomasello, 1992). Thus, a particular transitive verb may combine with a sentence subject, another with an object or a prepositional phrase, but the same verbs will not be used intransitively. Other verbs may be used only intransitively when transitive use would also be permissible. According to experimental evidence with nonce verbs, 2- to 3-year-old children use a new verb in the sentence type in which it was presented, and only from around 4 years in another possible sentence type, e.g. transitively, when the verb was presented intransitively or vice versa (Akhtar & Tomasello, 1997; Tomasello, 2000). Young children’s failure to use all possible syntactic relations is seen to indicate that they do not start into grammar with abstract syntactic relations (Tomasello, 2000). A similar argument is made for the determiner category (Pine & Lieven, 1997). Analysing the spontaneous speech of 1- to 3-year-old English-speaking children, Pine and Lieven (1997) found that the children used a set of nouns with definite articles and a different set of nouns with indefinite articles, with hardly any overlap between the sets of nouns. The authors conclude that the early use of articles occurs in lexically specific patterns and there is not sufficient evidence for the attribution of the syntactic category of determiner (Pine & Lieven, 1997). Proponents of the ‘lexical specificity’ approach argue that in early grammar children use lexically specific sentence patterns and have no knowledge of abstract syntactic categories (Pine & Lieven, 1997; Tomasello, 2000).
This approach is not undisputed. In a carefully controlled study Valian, Solt, and Stewart (2009) showed that English-speaking children between 1;10 and 2;8 did not use definite and indefinite articles in a lexically specific way. From the beginning there was an ‘overlap’ set of nouns, i.e. nouns which the children used with the definite and indefinite article. The overlap set was even larger when multiple determiners were considered. Both overlap sets grew with the children’s growing noun vocabulary. Furthermore, children used nouns with multiple determiners to the same extent as their mothers. The authors conclude that children use the abstract category ‘determiner’ right from the beginning of combinatorial speech (Valian et al., 2009). They do not rely on lexically specific knowledge in building a first grammar, but start with abstract syntactic categories. The authors view their results as support for innate syntactic categories (Valian et al., 2009).
Another approach to examining whether early multiword utterances are based on lexically specific patterns or make use of grammatical categories is to examine to what extent lexical and grammatical words predict grammatical complexity (Le Normand, Moreno-Torres, Parisse, & Dellatolas, 2013). Le Normand et al. (2013) argue that, if early grammar is lexically driven, increases in grammatical complexity, as measured by MLU, should be predicted by increases in lexical words. If it is grammatically organized, increases in MLU should be predicted by increases in grammatical words. Analysing spontaneous speech data from a large sample of French-speaking children between 2 and 4 years, they found that the number of grammatical word types was a more powerful predictor of grammatical complexity than the number of lexical word types (Le Normand et al., 2013). A closer look at different grammatical subcategories revealed that the more frequent ones, i.e. determiners, prepositions and subject pronouns, predicted MLU better than less frequent ones. They conclude that diversity of grammatical words has the most significant effect on building an early grammar. This would argue for a productive use of grammar from an early age (Le Normand et al., 2013).
A study of German-speaking children with cochlear implants showed that the early use of determiners was highly predictive of the children’s subsequent grammatical progress (Szagun & Schramm, 2016). Type and token frequency of determiners in the children’s earliest multiword utterances were more strongly related to subsequent MLU than was early vocabulary size. This may point to a decisive role of early determiners in grammar building. Diversity of determiners furthers grammar building by generalizing the same grammatical relation over different items of the noun class. Frequent determiner use practises the grammatical relations of case and gender. The strong impact of determiners on grammatical progress suggests that some generalized knowledge of how sentence constituents relate to one another is present in early multiword utterances and drives the construction of grammar.
The research reported so far casts doubt on an approach which postulates that grammar emerges purely from the lexicon. Valian et al.’s (2009) result of increasing determiner overlap with increasing noun vocabulary raises doubt whether the small vocabulary averaging 26 nouns in the Pine and Lieven (1997) study was large enough to capture overlapping determiner use. Regarding the toddler experiments with nonce verbs (Akhtar & Tomasello, 1997; Tomasello, 2000), it is argued that the experimental situation allowed multiple interpretations and thus responses by the children, and that such responses, while not intended by the experimenter, could be considered productive (Naigles, 2002). Alternative approaches to a lexically based early grammar state that early multiword utterances are based on at least rudimentary knowledge of grammatical relations. Such knowledge is viewed as the product of learning. Children make use of formal distributional features in the input language to build generalized knowledge of basic grammatical relations (Le Normand et al., 2013; Ninio, 2006).
Data from early inflectional learning in German would support this view. In acquiring German noun plural inflection, rule-based errors are made right from the beginning (Behrens, 2002; Szagun, 2001). German plural marking is characterized by several regularities involving five suffixes and combinations of suffixes and stem vowel changes. Children’s earliest errors reflect these regularities. Thus, they must be applying the regularities right from the beginning (Behrens, 2002; Szagun, 2001). This means that children have abstracted formal grammatical information from the input. In the case of noun plurals such information consists of distributional co-occurrence relationships between phonological patterns in noun stem endings and specific plural allomorphs.
Early generalization of formal grammatical regularities may not be restricted to inflectional learning but function at the syntactic level as well. Children’s use of grammatical words may help to answer this question. Grammatical words provide relatively abstract information. They indicate structural relations between words in a sentence. In German, for instance, determiners express gender and case relations. Formally marked determiners thus indicate congruence relations within the noun phrase and syntactic relations, e.g. case, within the sentence. Some prepositions introduce an oblique object of the verb, e.g. abhängen von (to depend on) or einwilligen in (to consent to), each with its requirement of a specific case. Furthermore, some grammatical words have features which make them very easy to learn: they are extremely frequent and have a highly predictable distribution. Determiners are an example. They are highly frequent and restricted in their distribution to placement within the context of a noun. It is possible that such distributional regularities are readily learned by children and constitute their early generalized syntactic knowledge.
The aim of this study is to examine whether German-speaking children’s early grammar is lexically driven or based on generalized grammatical categories. The following questions are addressed:
What is the relation between lexical words and grammatical words to early morphosyntactic complexity? In view of the results for French-speaking children (Le Normand et al., 2013) and similarities in use of grammatical words in French and German, we hypothesize that grammatical words predict grammatical complexity more strongly than lexical words.
Which subsets of grammatical words relate most strongly to morphosyntactic complexity? Based on our results with German-speaking children with cochlear implants (Szagun & Schramm, 2016), we hypothesize that articles and other determiners are most strongly related to morphosyntactic growth.
In a further exploration of children’s use of determiners we will examine whether children use articles and other determiners freely combining different determiner types with the same noun. Such determiner use would be indicative of a generalized syntactic determiner category. If, however, one determiner, e.g. the definite article, is used for one set of nouns, and the indefinite article for another, this would indicate some lexical restriction and less generalization of the determiner category. We hypothesize that children use multiple determiners before a noun.
Method
Data sets and design
The present investigation uses an existing data set from a norming study of parent report in CDI (i.e. Communicative Development Inventory) format (Szagun, Stumper, & Schramm, 2009) and an existing corpus of spontaneous speech (MacWhinney, 2000). The vocabulary part of the CDI presents a list of words, and parents are asked to indicate whether their child produces the word or not (Fenson et al., 1994). To examine the relation of lexical and grammatical words to morphosyntactic complexity (research question 1), parent-report and spontaneous speech data are used. In testing concurrent relations parent-report data are used. The influence of children’s age, gender, birth rank and of parental SES is also examined. In a time-lagged design the relation between lexical and grammatical words to subsequent morphosyntactic complexity is explored. All measures are based on spontaneous speech using the existing corpus (MacWhinney, 2000). The same data are used to explore how different grammatical subcategories relate to subsequent morphosyntactic complexity (research question 2). In addressing research question 3, the lexically based or abstract nature of determiners, again data from the same corpus are used to calculate and compare noun sets with overlapping articles between children and adults.
Participants
Parent-report sample
Participants were 1151 German-speaking children between the ages of 1;6 and 2;6 in 13 monthly age groups with a roughly equal number of girls and boys per age group. Most of the children lived in Hannover, Oldenburg, Bremen, Essen (Ruhr), and a smaller number in a variety of towns and small locations all over Germany (Szagun et al., 2009).
Corpus
A large corpus of the spontaneous speech of 22 German-speaking children (MacWhinney, 2000), 12 girls and 10 boys, between 1;4 and 2;10, was used for the present analyses. The data are longitudinal. Per child and per data point, two hours of spontaneous speech in a free play situation are available at ages 1;4, 1;8, 2;1, 2;5 and 2;10. For a subsample of 6 children, 4 girls and 2 boys, there are additional recordings every 5–6 weeks between these major data points and for a longer time period, rendering 22 speech samples per child between 1;4 and 3;8. The children had no diagnosed developmental delays and demonstrated age-appropriate object permanence knowledge at the start of data collection (Sarimski, 1987). They were monolingual speakers of German resident in Oldenburg, northern Germany, and were recruited from day care centres and paediatricians’ practices.
Data collection, transcription and coding of transcripts for data analysis
Data collection took place in a playroom at the Department of Psychology at the University of Oldenburg. The situation was free play with a parent and/or investigator. There was a set of toys including cars and garage, dolls, dolls’ house, zoo animals, farm animals, forest animals, picture books, puzzles, medical kit, ambulance and fire station. Audio recording was performed.
Everything spoken by the child and the first 500 parental utterances at data points 1;4, 1;8, 2;1 and 2;5 were transcribed using CHILDES (MacWhinney, 2000). In the present analyses, measures of language based on spontaneous speech are MLU and grammatical words. Calculating MLU and analysing grammatical words in context presuppose morphosyntactic analysis. This was performed as part of previously published studies (Szagun, 2001, 2004). Rules for coding utterance types and inflectional morphology on nouns, verbs, adjectives and determiners, such as prefixes, suffixes and fusions, follow CLAN conventions (MacWhinney, 2000) and Brown’s (1973) rules, and are laid down in a Manual for Transcribing and Analysing Child Speech in German (unpublished). The coding system takes account of inflectional form and function. The gender and case paradigm on articles, for example, is coded as follows. Gender marked nominatives are encoded as one morpheme each derMas, dieFem, dasNeu (the). Within the case paradigm, changes from the nominative which are formally marked are counted as two morphemes, e.g. de-nAccMas and de-rDatFem. Plural di-eNomAccPl is also encoded as two morphemes. The rationale is that children have made grammatical progress when they have learned that der can change to den, die to der, and that across the gender paradigm der, die and das are die in the plural. This is consistent with the aim of MLU, which is intended as a measure of grammatical complexity and progress. Other determiners are treated accordingly. In accordance with Brown’s (1973) rules, forms of the copula are coded as one morpheme.
Reliability checks on transcription were calculated for 7.3% of the total transcripts for different pairs of altogether eight trained transcribers. Percentage agreements were between 96% and 100%. Coding for MLU and morphosyntax was performed by three researchers on 20% of the transcripts. There was good to very good agreement between the three pairs of coders, with Cohen’s kappas of .94, .98 and .96.
Language and demographic measures in the parent-report study
Language measures are the number of lexical word types and number of grammatical word types out of a total of 468 lexical words and a total of 80 grammatical words. The checklists are based on the total vocabulary checklist of the German CDI (Szagun et al., 2009), which is available via Wordbank (Frank, Braginsky, Yurovsky, & Marchman, 2017). Examples of grammatical words are presented using the category headings of the original and the German CDI (Fenson et al., 1994; Szagun et al., 2009): articles and quantifiers: der, die, das (the), ein, eine (a), nicht (no); pronouns: dieser, diese, dieses (this), mein, meine (my), ich (I), du (you); question words: wo (where), was (what); prepositions: in (in), mit (with); helping words: kann (can), muss (must); connecting words: und (and), oder (or). As a measure of grammatical complexity we used the CDI sentence complexity scale, which captures morphological and syntactic phenomena. It consists of 32 sentence pairs with an easier and a more complex version per pair. Examples of sentence pairs: Tiger kämpfe (tiger fight) – Tiger kämpft (tiger fights); da zwei Enten (there two ducks) – da sind zwei Enten (there are two ducks). Parents are asked to tick the version of the sentence which is closest to what their child produces. A score of 1 is given for the more complex version. The maximum score is 32. In accordance with other CDIs (Bleses et al., 2008), socioeconomic status (SES) was assessed using mothers’ educational level. It was measured on a four-point scale, depending on years of schooling. The lowest level is 9 years (= 1), the next level 10 years (= 2), followed by 13 years (= 3), the highest level adding university education (= 4). Child birth rank scores are 1 = first born, 2 = second born, 3 = third or higher rank.
Language measures based on spontaneous speech data
Language measures are number of lexical word types, number of grammatical word types, MLU in morphemes as a measure of grammatical complexity, number of word types per grammatical subcategory (research questions 1 and 2) and number of noun types used with multiple determiners (research question 3). Inflected forms of lexical and grammatical words were counted as separate types. Language measures were calculated using CLAN programs (MacWhinney, 2000). All child and adult utterances were used for the analyses.
Statistical analysis
Multiple regression analysis was performed to examine the relative effects of lexical words, grammatical words, age, gender and SES on morphosyntactic complexity. Time-lagged correlational analyses were used to test the relation between lexical word types and grammatical word types and subsequent MLU as well as the relation between subsets of grammatical words and subsequent MLU. Numbers of nouns used with multiple determiners by children and adults were tested for difference by non-parametric tests for independent samples.
Results
Predictive relation between lexical and grammatical words and grammatical complexity
Regression
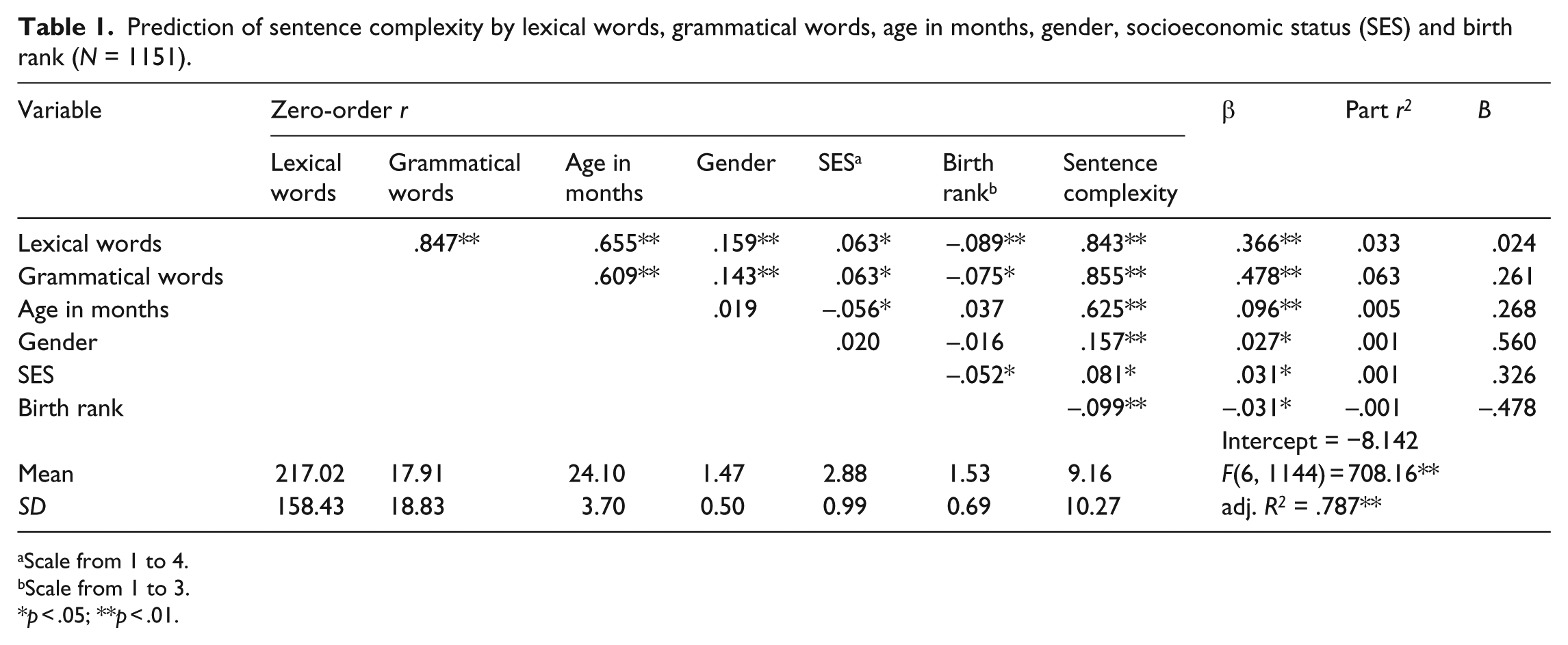
Using the parent-report data, multiple regression analysis was performed to assess the influence of lexical words, grammatical words, age, gender, birth rank and parent SES on sentence complexity (research question 1). Lexical word score, grammatical word score, age, gender and SES were entered as predictor variables, sentence complexity score as the dependent variable. Table 1 shows the relevant statistics of the regression analysis. All predictor variables relate significantly to sentence complexity. However, the influence of the linguistic variables, and in particular of grammatical words, weighs much more strongly than that of the demographic variables, as indicated by the β coeffients (see Table 1). As borne out by the zero-order correlations, the linguistic variables are mutually influential and, to a less extent, the linguistic and demographic variables (see Table 1). In order to control for the variance shared by the predictors we calculated the squared semi-partial correlation coefficients for each predictor. The semi-partial correlation coefficient expresses the correlation between a predictor and the criterion variable after the variance it has in common with other predictors has been removed. The square of the semi-partial correlation coefficient (part²) can be used to determine the unique contribution of each predictor to the criterion variance. As indicated by part², grammatical words explain the largest amount of variance in sentence complexity, 6.3%, followed by lexical words with 3.3%. The variance explained by the demographic factors is negligible, age explaining the most with 0.5%. Altogether, the unique effects of the predictor variables, although significant, are small. This is due to the large amount of shared variance between them. Altogether the predictor variables explain 78.7% of the variance in sentence complexity (adj. R²).
Prediction of sentence complexity by lexical words, grammatical words, age in months, gender, socioeconomic status (SES) and birth rank (N = 1151).
Scale from 1 to 4.
Scale from 1 to 3.
p < .05; **p < .01.
Time-lagged correlations
The regression analysis covered the time span of 1;6 to 2;6 using cross-sectional data. In order to test the influence of lexical and grammatical words during the course of development on the basis of longitudinal data, we used the spontaneous speech data from 22 children. Three data points were selected for a time-lagged design, 1;8, 2;1 and 2;5, corresponding roughly to the time span covered by the parent-report study. Word forms were counted according to form and function. For lexical words this involved noun plurals and person inflection on main verbs. Regarding grammatical words, the nominative and the oblique cases of determiners and pronouns were counted separately. Person-marked forms of auxiliaries, modals and copula were counted per inflection and function. Only correct forms were counted. A word type was counted as correct if at least one token occurrence was correctly marked. It was counted as incorrect if no token occurrence was correctly marked. For lexical words, errors involved noun plurals and verb inflections. Examples with correct form and English translation in parentheses are: Auter (Autos, cars), das pass (das passt, that fits), gefallt (gefallen, fallen). Proportions of correct forms out of all lexical word types were 99.1% at 1;8 and 97.0% at 2;1. For grammatical words, errors involved inflections on determiners and modals, ‘protoforms’ of articles and unmarked pronouns. Examples: kein (keine) Katze (no cat), mein (meine) Kuh (my cow), der Papa musst (muss) (Daddy must), protoform de for definite and a for indefinite article, unmarked pronominal determiners ein (a), mein (mine). (In German pronominally used determiners require gender marking, e.g. einerNomMas when replacing a masculine noun.) At 1;8 proportions of correct forms out of all respective word types were 92.7% for determiners, 94.4% for pronouns, 100% for modals. At 2;1 the corresponding figures were 90.0% for determiners, 92.5% for pronouns and 98.3% for modals.
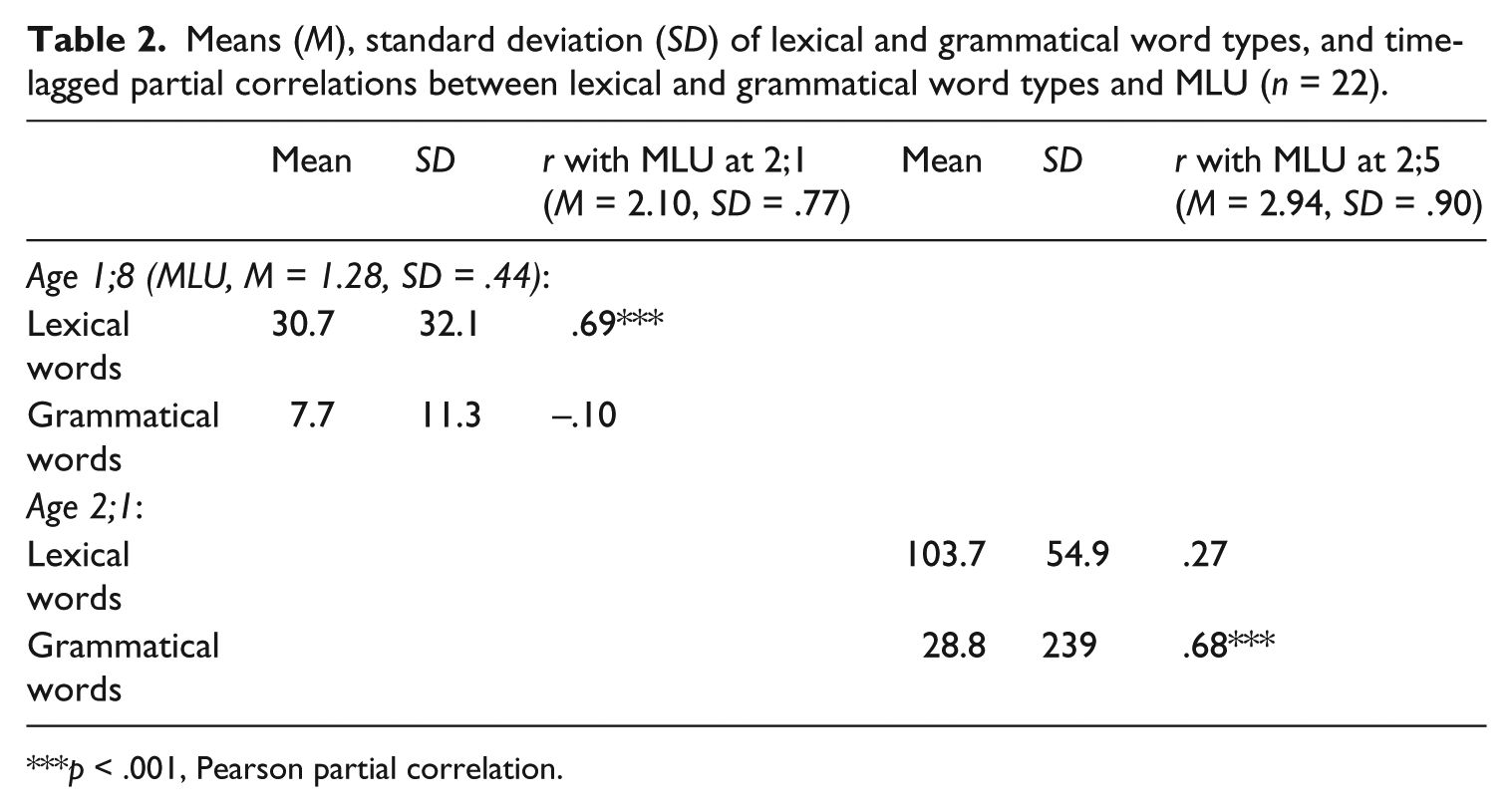
Time-lagged partial correlations (Pearson) were calculated. MLU in morphemes was the measure of morphosyntactic complexity. Number of lexical word types and number of grammatical word types at a preceding data point were correlated with MLU at the following data point (see Table 2). When lexical words are the predictor variable, grammatical words are partialled out and vice versa. Lexical words at 1;8 correlate significantly with MLU at 2;1 (p < .001), grammatical words do not. This reverses at the next time interval. Grammatical words at 2;1 correlate significantly with MLU at 2;5 (p < .001), lexical words do not (see Table 2). While MLU is predicted by the number of lexical words initially, a few months later it is predicted by the number of grammatical words. At 2;1, 48% of the variance in MLU is explained by lexical words. At 2;5, 46% of the variance in MLU is explained by grammatical words.
Means (M), standard deviation (SD) of lexical and grammatical word types, and time-lagged partial correlations between lexical and grammatical word types and MLU (n = 22).
p < .001, Pearson partial correlation.
Subcategories of grammatical words
Next, we examined how different grammatical subcategories relate to morphosyntactic complexity (research question 2). We used the time period when grammatical words predicted subsequent MLU significantly, 2;1 to 2;5. Grammatical words were placed into 15 subcategories. The subcategories with examples are: (1) articles: der, die, das (the) ein, eine (a), (2) articles used as pronouns (in German pronominal articles are used as personal pronouns). Categories (3) to (5) comprise various determiners: (3) demonstratives, dieser, diese, dieses (this), (4) possessives, mein, meine (my), (5) indefinites, kein, keine (no), alle (all), and categories (6) to (8) the same words used as pronouns. The other grammatical subcategories are: (9) personal pronouns: ich (I), du (you), (10) prepositions, mit (with), in, für (for), (11) interrogative pronouns: wer (who), was (what), (12) conjunctions: und (and), weil (because), (13) copula: sein (be), (14) modals: wollen (want), können (can), (15) auxiliaries: haben (have), sein (be).
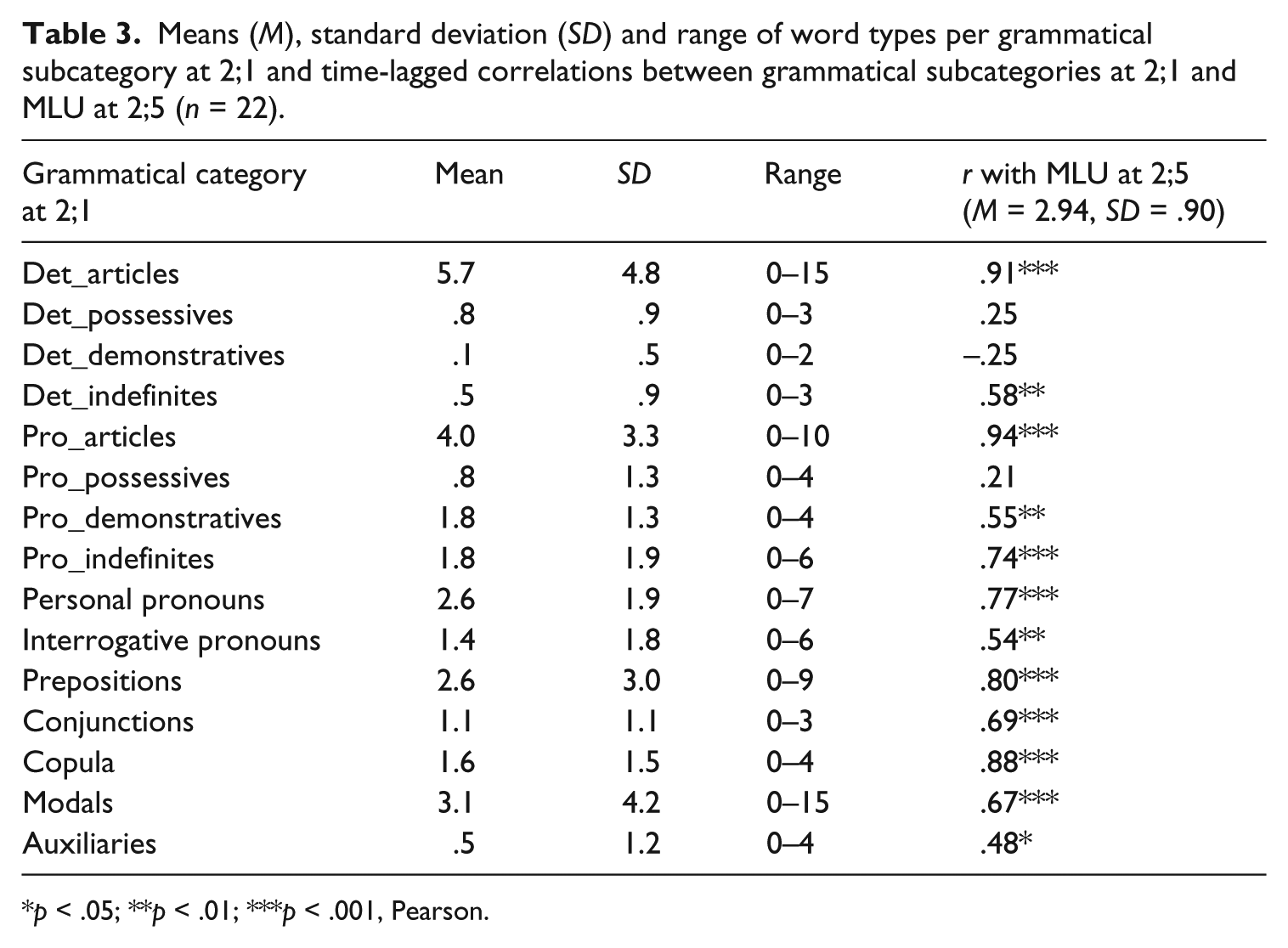
Time-lagged correlations (Pearson) were calculated. Number of words per subcategory at 2;1 was correlated with MLU at 2;5. Most grammatical categories correlated significantly with subsequent MLU (significance levels p < .001, p < .01 and p < .05, see Table 3). MLU at 2;5 is most strongly predicted by articles at 2;1 used in both syntactic functions, i.e. as determiners and as pronouns substituting a noun phrase, and by the copula (see Table 3). MLU at 2;5 is also predicted strongly by prepositions, personal and indefinite pronouns, conjunctions and modals at 2;1. Also significantly correlated with MLU at 2;5 are indefinite determiners, demonstrative pronouns, interrogative pronouns and auxiliaries at 2;1, although correlation coefficients are considerably lower. Possessives, whether used as determiners or pronouns, and demonstrative determiners at 2;1 are not related significantly to MLU at 2;5. Depending on the subcategory, between 23% and 88% of the variance in MLU at 2;5 is predicted significantly by a grammatical subcategory at 2;1.
Means (M), standard deviation (SD) and range of word types per grammatical subcategory at 2;1 and time-lagged correlations between grammatical subcategories at 2;1 and MLU at 2;5 (n = 22).
p < .05; **p < .01; ***p < .001, Pearson.
Lexically restricted or abstract nature of determiners
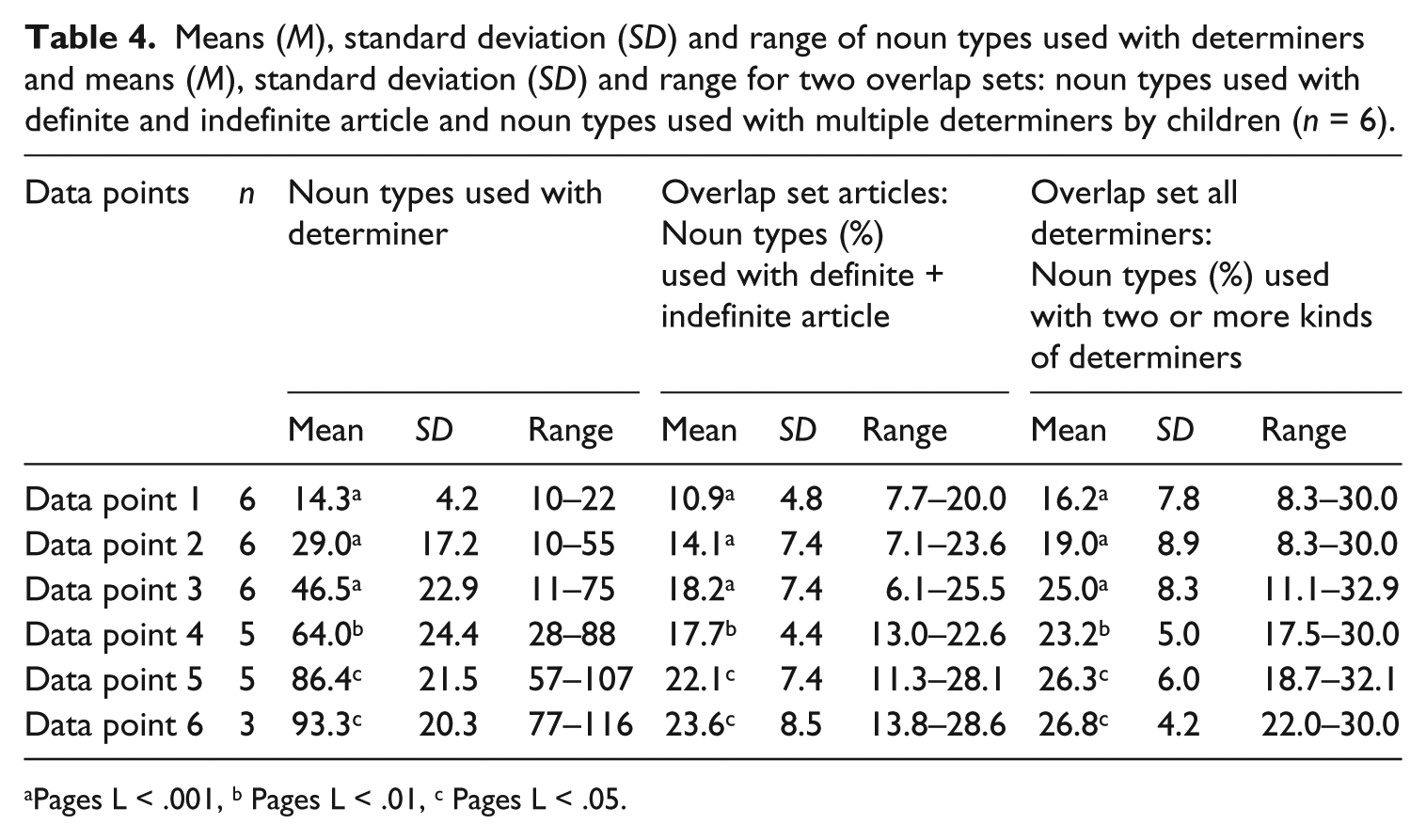
In investigating whether early determiner use is lexically specific or reflects an underlying abstract grammatical category (research question 3) we used the spontaneous speech data from the subsample of 6 children with 2-hourly recordings every 5–6 weeks. This includes the additional data points in between the four major ones (see Methods section). As we are interested in early grammar, data points selected for the analysis of child speech capture early multiword speech, ranging from an average initial MLU of 2.70 (SD .16, range 2.45–2.97) to an average final MLU of 3.22 (SD .22, range 2.94–3.60). Individual children reached the final MLU level at different speeds. Therefore the number of data points used for the analysis varied and involved six data points for 3 children, five for 2 children and three for 1 child. The children’s ages during the relevant time period varied widely. The average initial age was 26.5 months (SD 3.5, range 24–33), the average final age was 28.7 months (SD 3.0, range 26–34). For the analysis of adult speech all four data points with transcribed adult speech were used. Per child and adult noun types used with a definite and indefinite article or with any two or more different determiners were counted cumulatively over the data points. Examples: der Hammer (the hammer) and ein Hammer (a hammer); die Puppe (the doll) and meine Puppe (my doll); die Katze (the cat), eine Katze (a cat), meine Katze (my cat) and keine Katze (no cat). Erroneous forms involving gender and case marking were included. We considered such errors as irrelevant for the current analyses, as children are still combining different determiner types with the same noun, even if formal errors occur, as in die Auto (the car, correct: das) – meine Auto (my car, correct: mein). Often, a mixture of incorrect and correct marking occurred. Examples: der Flasche (the bottle, correct: die) – eine Flasche (a bottle). The proportion of noun types used with incorrectly marked determiners out of all noun types was 7.4%. Per data point two scores were calculated: (1) number of noun types used with definite and indefinite article and (2) number of noun types used with multiple determiners of any kind. These nouns constitute the overlap sets. From a total of 10 nouns per overlap set onwards percentage scores of overlap were calculated out of the total of all nouns used with (1) articles and (2) all determiners per data point.
To control how an increase in noun types affects overlap sets, the increase in overlap sets over the data points was checked using Pages L test for ordered alternatives. For children this was calculated three times due to the different number of data points per child (see above), for adults it involved four data points. Noun types increased significantly over the data points for children and adults (Pages L test for ordered alternatives, p < .001). Overlap sets (%) also increased significantly over data points for children (Pages L, p < .05, p < .01, p < .001) and adults (p < .001). Descriptive statistics for noun types and overlap sets are presented in Table 4 for children and Table 5 for adults. We then selected two data points with roughly similar numbers of noun types used by children and adults, level 1 averaging around 50 nouns, level 2 around 100. Exact figures for means and standard deviations are presented in Table 6. The use of the two types of overlap sets by children and adults was tested for difference at the two noun size levels. Results show that there is no significant difference between children and adults in the overlap percentages for noun types used with articles (Mann–Whitney U-test, p = 1.000, p = .093). There is also no significant difference between children and adults in the overlap percentages of noun types used with any determiner (Mann–Whitney U-test, p = .818, p = .589). Table 6 presents the median values for children and adults at each noun size level.
Means (M), standard deviation (SD) and range of noun types used with determiners and means (M), standard deviation (SD) and range for two overlap sets: noun types used with definite and indefinite article and noun types used with multiple determiners by children (n = 6).
Pages L < .001, b Pages L < .01, c Pages L < .05.
Means (M), standard deviation (SD) and range of noun types used with determiners and means (M), standard deviation (SD) and range for two overlap sets: noun types used with definite and indefinite article and noun types used with multiple determiners by adults (n = 6).
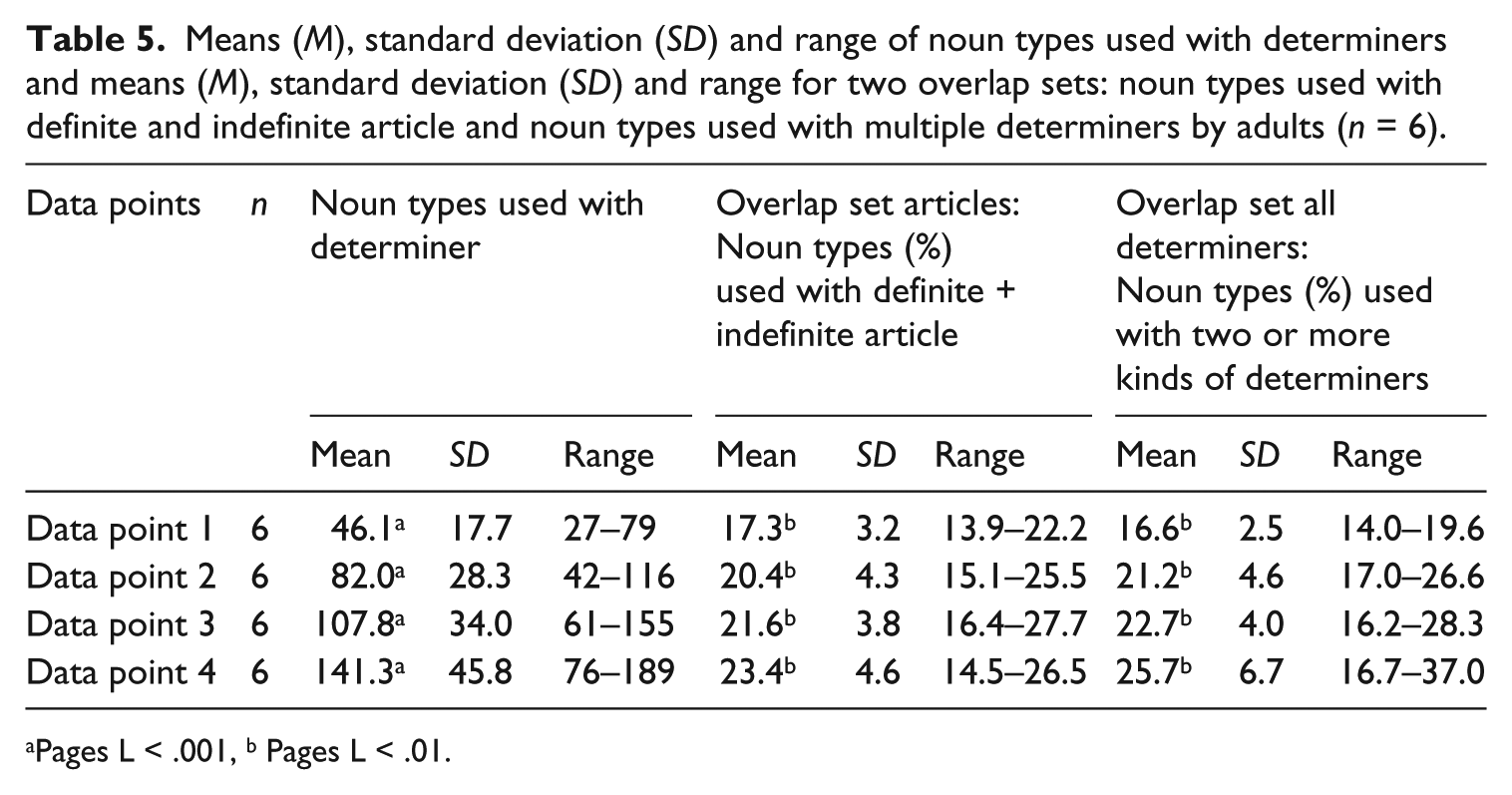
Pages L < .001, b Pages L < .01.
Mean frequency (%) and standard deviation (SD) of noun types used with definite and indefinite article or with multiple determiners in child and adult speech at two vocabulary levels (n = 6 children, n = 6 adults).
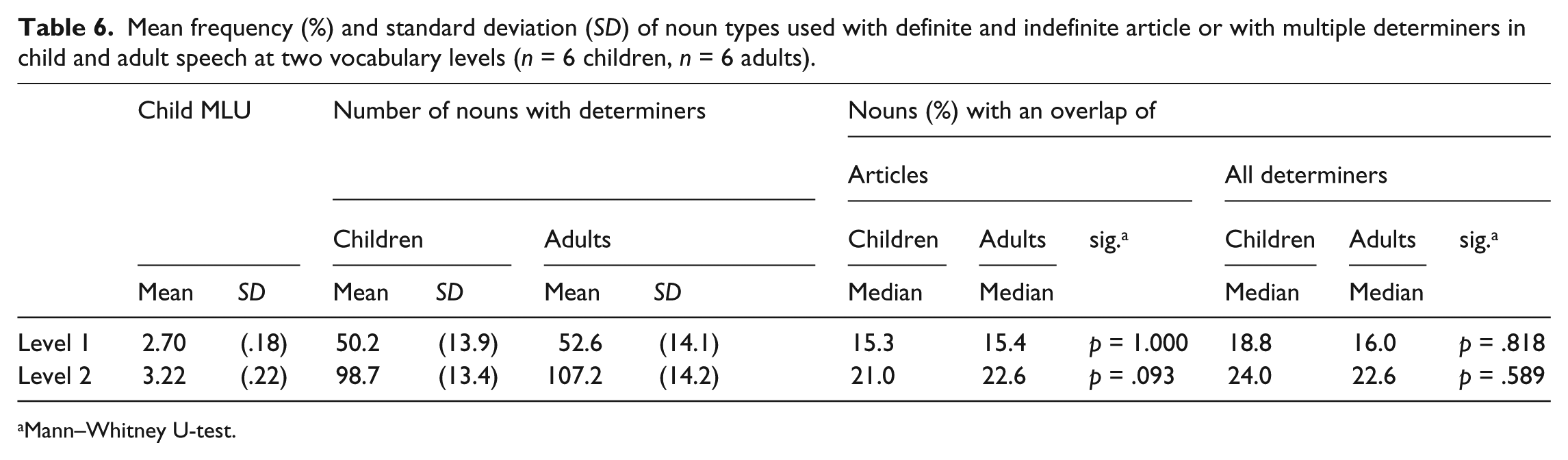
Mann–Whitney U-test.
Discussion
The main aim of this study was to examine whether children’s early grammar is lexically driven or based on grammatical organization. First, we tested the hypothesis that grammatical words predict syntactic complexity more strongly than lexical words. We used different data sets, different kinds of data and different language measures of syntactic complexity. Parent-report data for children between 1;6 and 2;6 showed that grammatical words explained a larger proportion of variance in sentence complexity than lexical words, when variables are related concurrently. Age, gender, birth rank and SES had a mild influence. Time-lagged analyses based on longitudinal spontaneous speech data covering the age span 1;8 to 2;5 rendered a more differentiated result. While lexical words at 1;8 significantly predicted subsequent MLU at 2;1, grammatical words did not. This reversed over the subsequent time span, so that MLU at 2;5 was significantly predicted by grammatical words at 2;1 and no longer by lexical words. Second, we examined how different grammatical subcategories relate to MLU, assuming the strongest influence from articles and other determiners. The results show that articles at 2;1, used as pronouns and as determiners, predicted subsequent MLU at 2;5 most strongly, followed by the copula. Third, we tested the hypothesis that children use articles and other determiners freely, combining multiple determiners with the same noun. This would be indicative of an underlying generalized syntactic structure. Our results show that the overlap set of nouns used with the definite and indefinite article and with multiple determiners increased with the number of noun types used. When matched on number of noun types, children and adults used both types of articles or multiple determiners before a noun to the same extent.
The present results demonstrate convincingly that early grammar building is guided more strongly by grammatical than lexical words. We have presented evidence for this from different data sets, different kinds of data and different measures of grammatical complexity. Each analysis confirms the strong influence of grammatical words on early grammar building, and, at the same time, throws a different light on the influence of grammatical and lexical words. The strength of the parent-report based study with its large sample size is that it allows the assessment of the unique and conjoint effects of different linguistic and demographic factors on syntactic complexity. While, uniquely, grammatical words clearly explain a larger proportion of the variance in sentence complexity than lexical words, it must be noted that both effects are low in absolute terms. Due to the large amount of shared variance between lexical and grammatical words their conjoint effect is strongest. Only a negligible amount of variance in sentence complexity is explained by non-linguistic factors, even including age.
Our second exploration of the relation between lexical and grammatical words and early grammatical structure building used spontaneous speech data, and it looked at this relation over time. This data set consisted of a considerably smaller sample than that of the parent-report study. Its advantage lies in being able to derive language measures based on spontaneous speech and enabling an examination of the effects of lexical and grammatical words on grammar building over time. Word counts based on spontaneous speech may, arguably, be regarded as more adequate, as they are based on word use in context and not a selection of isolated words, as in the CDI word lists. However carefully the words in a checklist are chosen, they may capture less individual variation than spontaneous speech and consequently capture fewer different words. A retest using spontaneous speech data is therefore worthwhile. The same can be said about the measures of grammatical complexity. Based on spontaneous speech MLU is the chosen measure. It captures complexity brought about by the number of words in a sentence and by the number of morphemes, i.e. inflectional changes on word form, and is thus a measure of morphosyntax. The CDI measure of sentence complexity contains items which capture the same kinds of changes, but, again, is a selection of sentences.
So far we have seen that there is a concurrent relation between lexical words and sentence complexity and between grammatical words and sentence complexity during the age span of 1;6 to 2;6. Examining the same relations covering roughly the same time span (1;8 to 2;5) with a time-lagged design renders more differentiated information. Initially, from 1;8 to 2;1 grammar building is based on lexical words. After this, from 2;1 to 2;5 increases in lexical vocabulary lose their significance for grammar building, and increases in grammatical words have a significant influence on grammar building (MLU). Thus, the time-lagged analysis differentiates the conjoint effect of lexical words and grammatical words on morphosyntactic complexity. The change in impact of the two variables could be related to other developmental changes during the same age range. In German increases in lexical words tend to precede increases in function words (Szagun et al., 2009). CDI studies in several languages have further shown that during the time period of 2;1 to 2;5 children typically change to multiword utterances (Bleses et al., 2008; Fenson et al., 1994; Szagun et al., 2009). Building such utterances requires grammatical words in German. The results of the time-lagged analysis, on the one hand, confirm the view that grammar builds on the lexicon (Bates & Goodman, 1999), but on the other, that early grammar building is guided by grammatical words (Le Normand et al., 2013). The two variables just change the size of their impact during the course of early development.
Investigating how strongly subcategories of grammatical words relate to subsequent MLU confirmed our assumption that articles would predict subsequent MLU most strongly, but not our assumption that this would be true of other determiners. Some were predictive of MLU, but not particularly strongly; others, notably possessives, were not. This is probably due to the fact that determiners other than articles are relatively infrequent. In spoken German articles are used as pronouns replacing personal pronouns or demonstrative pronouns. Whether in pronominal or determiner function, articles predicted MLU most strongly. A convincing indication that young children used articles as an abstract grammatical category is that gender marking of pronominally used articles agreed with the noun’s gender in the replaced noun phrase. There was also pronominal article use when this was not the case or could not be ascertained, but, here, we counted only correctly marked forms which presuppose that reference to the replaced noun phrase is clear. Next to articles, use of the copula predicted subsequent MLU strongly, followed by prepositions and personal pronouns. Overall, there is quite some variation in the strength of the relation between grammatical subcategories and subsequent MLU which may, in part, be explained by lower type frequencies within a subcategory or, conversely, by high token frequency in the language.
We view our results regarding the impact of grammatical words on the growth of grammar as limited to German and probably languages which are structurally similar. Thus, articles, personal pronouns and prepositions are good predictors of MLU for children learning German and French (Le Normand et al., 2013). Both languages have articles as separate words, express personal pronouns and mark many case relations by prepositions. The strong effect of pronominally used articles, on the other hand, may be specific to German. Pronominal articles are very frequent, and during the age range considered in this study are mostly correctly marked for gender. Expressing this type of relational knowledge may be a path to building early abstract syntactic categories in German. We would not generalize our results of the impact of grammatical words as applicable to languages with a different morphological and syntactic structure, for instance, languages which do not have articles or mark case relations largely by inflections only.
Frequent article use does not necessarily imply an understanding of articles as an abstract grammatical category. Definite articles could be used with some nouns, and indefinite articles with others, as claimed by Pine and Lieven (1997) for English-speaking children. This is clearly not the case in our study with German-speaking children. We calculated overlapping noun sets used either with definite and indefinite articles or with multiple determiners from the beginning. The present evidence suggests an underlying generalized syntactic structure of determiner. It is possible that Pine and Lieven’s (1997) result of lexically restricted article use is due to the low number of noun types they examined, ranging between 10 and 51 per child. As shown in this and Valian et al.’s (2009) study, overlap of nouns used with multiple determiners increases with increasing noun vocabulary. However, in our percentage calculations, which started from 10 nouns used with articles, there was overlap even with this small noun vocabulary. It is also possible that Pine and Lieven (1997) over-interpreted their data in the direction of lexical specificity of article use. In fact, 6 of the 11 children in their sample did use nouns with both types of articles, overlap sets ranging between 3% and 22%. This is not an irrelevant amount of overlap, considering that in our study the overlap noun set for articles lay between an average of 10.9% and 23.6% for a noun vocabulary averaging between 14.3 and 93.3 (see Table 4). Only a comparison with adult article use on the basis of matched numbers of noun types can clarify whether an overlap size is child-specific or standard use in the language. Such a comparison is lacking in Pine and Lieven’s (1997) study, but when performed – here and in Valian et al.’s study (2009) – shows that overlap size does not differ between children and adults.
What relevance do the present results have for the theoretical question of whether early grammar is lexically driven or based on grammatical organization? In one sense, grammar is lexically based: it needs a critical mass of lexical and grammatical words to combine these in multiword utterances and to change word form by bound morphemes (Bates & Goodman, 1999; Fenson et al., 1994). Our result of the conjoint influence of lexical and grammatical words on morphosyntactic complexity and the stronger impact of lexical words initially supports this view. However, on the basis of the data presented from German-speaking children we do not see any support for the more far-reaching view that early grammar is based on lexically specific patterns with no representation of abstract syntactic and morphological categories (Lieven et al., 1997; Pine & Lieven, 1997; Tomasello, 1992, 2000). The evidence presented here shows that after an initial time period increases in MLU are most strongly predicted by increases in grammatical words, indicating that grammar building is driven by the grammatical relations coded by such words. Regarding the determiner category, we cannot see how German-speaking children’s early use of determiners can be explained without granting children some degree of abstract syntactic knowledge.
Does this imply that abstract grammatical categories are innate? We do not think so. As pointed out by Le Normand et al. (2013), some grammatical words, and certainly the ones relating most strongly to MLU, are extremely frequent and have a highly predictable distribution. Articles, used as determiners and pronouns, and some forms of the copula, particularly ist (is) and sind3PL (are3PL), are extremely frequent. Articles in determiner function also have a highly predictable distribution having to be placed within the context of a noun. At least some prepositions, in, mit (with), für (for), are very frequent and define the case marking of their argument, in some cases in conjunction with the predicate. Such constraints make their distribution highly predictable. Children abstract and generalize such highly predictable distributional regularities from the input language starting with the most basic and frequent grammatical words. According to this view, early syntactic relations are abstract in the sense that they represent generalized structures learnt from the input.
Footnotes
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This research was funded by Deutsche Forschungsgemeinschaft (German Science Foundation), grants No. Sz 41/5-1, 2 and No. Sz 41/11-1, 2 to the first author.