
Abstract
The current study examined how morpho-semantic processing of derivational morphology develops from later childhood through adolescence to adulthood in Finnish. Finnish is a synthetic language rich both in derivation and inflection. It has been suggested that children gradually acquire the ability to process morphologically complex word structures. However, this development could be delayed because of the complex derivational morphology in Finnish. To assess this, three age groups of Finnish native speakers participated in a priming study, in which they made a visual lexical decision for the target words. There were three types of primes: morphologically related words, pseudowords, and unrelated words. The reaction times results showed a significant difference between all the groups, which implies that the word processing is still developing in adolescence. The error rates unveiled a similar pattern to reaction times. The prime type affected the recognition: words with morphological primes were processed faster than words with pseudoword primes, which in turn were processed faster than words with unrelated primes. Moreover, males made significantly more errors than females with morphological and pseudoword prime conditions.
Introduction
The current study explores how morpho-semantic processing of derivational morphology develops from later childhood (6th graders) through adolescence (9th graders) to adulthood in a derivationally very rich non-Indo-European language, Finnish. Languages differ in the word-formation options available to them, as well as in their productivity. Finnish is a synthetic language rich both in inflection and derivation that relies on only two means to construct new words, derivation, and compounding (Kiefer & Laakso, 2014; Koivisto, 2013). Derivation is possible with all major word classes, but compounding only with nominal stems; compound verbs are typically new coinages or borrowed from Indo-European languages. This type of synthetic language differs from more analytic languages such as English, which uses many means to construct new words: compounding, affixation, conversion, and reduplication. For example, compounding is more important than derivation in English and noun derivatives are more frequent than verbal ones (Sailaja, 2014; Štekauer, Valera, & Körtvélyessy, 2012).
English and Finnish derivation differ also in terms of complexity. In Finnish, there is a large number of derivational suffixes (approximately 140), which are used recursively. Typically, there are one or two derivative suffixes in a word, but there can be several with the practical limit being five (Koivisto, 2013). Furthermore, their order varies to a degree. This productivity makes it understandable that fewer than 10% of all lexemes in the largest Finnish dictionary are non-derived, albeit the most productive derivative words are omitted from dictionaries, because they are transparent and their meaning is predictable. The number of Finnish non-derived stems is as low as 6000, with loan words excluded (Koivisto, 2013).
Finnish and English also differ in terms of grapheme–phoneme correspondence. Finnish has a nearly perfect grapheme–phoneme correspondence which, next to the relatively simple syllabic structure, offers beginning readers an advantage compared to beginning readers in English and other languages with deep orthography and syllabic complexity (Seymour, Aro, & Erskine, 2003). In addition, as the morpho-phonological transparency is high in Finnish, the morpheme boundaries are also quite clear as regards derivations: prototypical lexical stems consist of two-syllable words ending with a, ä, e, while three-syllable or longer words are derivatives with suffixes typically consisting of one to three phonemes (Koivisto, 2013). This transparency may facilitate reading development.
It has been suggested (e.g., Carlisle, 2000; Seymour, 1997) that children acquire the ability to process morphologically complex word structures during childhood, and that this ability develops gradually. This development is most rapid during the 4th to 8th grade (Larsen & Nippold, 2007, p. 65; Marinellie & Kneile, 2012; Nippold & Sun, 2008). Both Carlisle (2000) and Seymour (1997) seem to indicate that morphological skills start to develop, to a large extent, as a result of reading instruction, and that the skills are fully acquired when children become fluent readers. However, in a language with very complex derivational morphology (e.g., Finnish) it is possible that this development continues to an older age. In fact, a prior study (Ravid & Avidor, 1998) implies a later derivational development in another derivationally complex language, Hebrew. This production study argues that the acquisition of derived nominals (e.g., writing) starts at the age of 8 but is not complete until the age of 15.
Since the development of derivational morphology might still be underway for Finnish school-aged children, it comes as no surprise that long words, i.e., derivatives and compounds, are often difficult for them (see e.g., Ahvenainen & Holopainen, 2000). This is not due to visual-cognitive constraints; it has been shown that 6th grade readers already resemble adults regarding the size of their perceptual span when reading in Finnish (Häikiö, Bertram, Hyönä, & Niemi, 2009) and in English (Rayner, 1986). In other words, they are able to read long words. Interestingly, even if long words are known to be a challenge for readers, there is almost no research on the topic (see, however, Bertram, Laine, & Virkkala, 2000). One reason for this difficulty might be that derivation is not taught in Finnish schools although it is known that morphological instruction improves literacy outcomes in English (e.g., Bowers & Bowers, 2017; Goodwin & Ahn, 2010, 2013), and in French (e.g., Casalis & Louis-Alexandre, 2000).
In addition to language itself, there are other factors that may influence language development. For instance, word learning is affected by parts of speech (e.g., Gentner, 1978, 1982): non-derived verbs and adjectives are more difficult to learn than nouns, partly because nouns refer to concrete and imageable things. With regard to morphologically complex verbs, adjectives, and nouns, the results appear to be inconclusive. For example, Nagy, Anderson, and Herman (1987), as well as Steele and Watkins (2010), found no relation between complex word learning and parts of speech. On the other hand, according to Schwanenflugel and McFalls (1997) and Wagovich and Newhoff (2004), children learn complex non-nouns better than nouns. Thus, it is unclear whether children’s ability to acquire knowledge of morphologically complex words differs by part of speech (Marinellie & Kneile, 2012). One reason for the inconclusive results might be that all of these studies were conducted in English. Verb derivation is comparatively simple and less transparent (cf. conversion) in English compared to Finnish. There are only a few verbal derivational affixes in English while Finnish has verbal derivative suffixes that change the word class, alternate the valency, and modify the aktionsart. Both nominal and verbal derivations are equally frequent in Finnish, and derived words belong to everyday usage. Probably both the language-specific properties (the small number of non-derived words and clear word structure) and the richness of the derivational system (a considerable number of suffixes and recursivity) have an impact on morphological knowledge (for verbal derivations in English see Bauer, 1983, and for Finnish, see Koivisto, 2013). Based on the derivational complexity of Finnish, we predict that the adolescent readers in the study will not yet have reached adult-like processing, albeit they are more developed than children.
Finally, it is also well-known that there are gender differences in favor of girls in terms of both reading and writing Finnish (Pajunen, 2012; Sulkunen, 2007). One explanation for these disparities is the differences in maturation rates between boys and girls. Typically, however, motivational and socio-cultural differences are evaluated as being more important than linguistic and cognitive differences (see Hyde, 2005; Hyde & Linn, 1988; Linnakylä, 2007; Van de Gaer, Pustjens, Van Damme, & De Munter, 2009). As regards Finnish, there is almost no research on gender differences in language achievements (see, however, Pajunen, Itkonen, & Vainio, 2015) and even less on knowledge of morphologically complex words (Kusnetsoff, 2017).
Prior studies on children’s processing of derivational morphology
Previous studies have used a variety of methods, namely priming, visual lexical decision, naming and definition tasks, in order to investigate children’s processing of derivational morphology.
Priming
In the only prior study in which pseudoword (a combination of a real word root and suffix which does not form a real word) primes were used with children, Beyersmann, Grainger, Casalis, and Ziegler (2015) investigated whether developing French 2nd to 5th grade readers show a grade and reading proficiency effect in masked morphological priming. The target word (e.g., TRISTE) was preceded by a suffixed word (tristesse), a suffixed nonword (tristerie; pseudoword in current discussion), a non-suffixed nonword (tristald), or an unrelated prime (direction). Suffix frequency was also manipulated. The results showed a suffixed word priming effect independent of grade and reading proficiency. In contrast, reading proficiency modulated pseudoword priming and non-suffixed nonword priming, so that they facilitated high-proficiency children and inhibited low-proficiency children. Both word and morpheme frequency affected the participants, but the effect decreased as the age increased. The authors concluded that reading proficiency is an important predictor for embedded stem activation mechanisms in primary school children.
Quémart, Casalis, and Colé (2011) conducted a masked priming study in French with 3rd graders, 5th graders, 7th graders, and adults. Participants made lexical decisions for the targets that were preceded by morphologically derived, pseudoderived (i.e., real words with a suffix-like word ending), orthographic, and semantic primes. The most interesting results were related to the age group effect with different prime times: children showed a priming effect with the morphological (derived) and pseudoderived primes in both 60 ms and 250 ms prime times, whereas the adults showed this pattern only in a 60 ms prime time. Instead, adults showed a significant priming effect with the morphological prime and a marginal effect with the semantic prime in 250 ms prime time. It was concluded that developing readers of French process both the form and meaning properties of morphemes as early as the 3rd grade.
Beyersmann, Castles, and Coltheart (2012) studied whether developing readers show structural morphological decomposition in masked morphological priming in English. They used derivational and inflectional suffixes with real (prime: golden – target: GOLD) and pseudosuffixed words (mother–MOTH) and monomorphemic controls (spinach–SPIN). The results showed that for adults both suffixed and pseudosuffixed primes caused facilitation, whereas only suffixed words facilitated 8–9 and 10–11 year-old children. The authors concluded that unlike adults’, children’s morpho-orthographic decomposition mechanisms are not yet automatized.
Schiff, Raveh, and Fighel (2012) used masked priming of Hebrew words with varied semantic transparency for 4th and 7th graders. The results indicated that 7th graders depended more on the formal morphological structure of the root rather than its semantic properties, suggesting more abstract mental lexicons compared to 4th graders.
Clahsen and Fleischhauer (2014) conducted a cross-modal priming study with naming the target. The participants were 8 and 10 year-old German children and adults. They found that for regular derivations the priming effects with children and adults were parallel, but for irregular derivations there was a significant age difference: only the older children showed a similar priming effect to adults. This result indicates that regularity is an important variable in acquiring derivational morphology. A study in Hebrew (Schiff, Raveh, & Kahta, 2008) suggests the same.
Visual lexical decision
Quémart, Casalis, and Duncan (2012) studied French 3rd and 5th graders in a lexical decision study, of which the critical point for the present discussion is how the real suffixed words and pseudowords were processed compared to non-suffixed words and nonwords. The results indicated that 3rd graders had longer reaction times (RTs) and higher error rates than 5th graders for real words. In addition, for 3rd graders the stem facilitated RTs in real words only when there was no suffix. In contrast, for 5th graders the stem and suffix facilitation was constant. Overall, the results showed that the stem, the suffix, and the whole word have an influence on the development of readers of French.
Burani, Marcolini, and Stella (2002) used pseudowords as stimuli in their naming and visual word recognition study in Italian. The participants were 8–10 year-old children with an adult control group. High root frequency facilitated the processing time and pseudowords made of a real root and a suffix were the most demanding to be rejected in lexical decision for all age groups. The participants named pseudowords more slowly than nonwords without morphological structure, and were more likely to choose pseudowords as real words in the visual word recognition task. Burani et al. concluded that young readers of a language with a shallow orthography are already capable of efficient morpho-lexical reading.
Both Lázaro, Camacho, and Burani (2013) and Lázaro, Acha, de la Rosa, García, and Sainz (2017) used a lexical decision task to investigate how children process derived words in Spanish. The results showed that both the base frequency of the word (Lázaro et al., 2013) and suffix frequency (Lázaro et al., 2017) affect 2nd graders’ processing.
Dawson, Rastle, and Ricketts (2018) tested whether children, adolescents, and adults automatically decompose complex words during visual word recognition in English. The critical targets were nonwords with a real suffix (earist) and without a suffix (earilt). The results showed that adults and older adolescents were slower in rejecting suffixed nonwords, whereas children were equally slow with all nonwords. The authors conclude that even though all age groups are sensitive to morphological structure, some important changes still occur over the course of adolescence.
Naming
Burani, Marcolini, De Luca, and Zoccolotti (2008) investigated the role of morphology in naming latencies to words and pseudowords composed of morphemes (roots and derivational suffixes) and corresponding simple words and pseudowords. They used three age groups: 8 year-olds, 11 year-olds (normal and dyslexic), and adults. Both dyslexics and younger children benefited from morphological structure in naming words, whereas older children and adults did not show such an effect. Moreover, all groups read pseudowords composed of root and suffix faster and more accurately than simple pseudowords.
Marcolini, Traficante, Zoccolotti, and Burani (2011) have studied whether word frequency affects word naming in Italian 11 year-old children and adults. Word frequency affected all the groups, with the more frequent words being named faster than less frequent words; this was the only result for adult readers. In addition, skilled young readers named low-frequency morphologically complex words significantly faster than simple words, but there was no significant difference in the high-frequency condition. However, the age-matched poor readers displayed an advantage with morphologically complex words irrespective of word frequency.
Traficante, Marcolini, Luci, Zoccolotti, and Burani (2011) used pseudowords in an Italian 6th graders’ naming study, and Burani, Arduino, and Marcolini (2006) in a naming study of adult speakers of Italian. Both studies implied that the root and the suffix facilitate naming times, but that the effect of the root is stronger. Moreover, for 6th graders the suffix facilitates naming accuracy, but not naming speed.
Definition tasks
There are some prior studies concerning children’s processing of derivational morphology that have used definition tasks. For example, Bertram et al. (2000) used a word complexity definition test with Finnish 3rd and 6th graders. It was concluded that older children were more effective at morphological processing than younger children, as the differences between simple and complex words composed of infrequent constituents only appeared among the oldest children.
Lázaro (2012) used a pseudoword definition task for 7–9 year-old Spanish children. He concluded that children were able to take advantage of the stem frequency in defining the meaning of the pseudowords.
To summarize, the above studies suggest several important issues concerning the development of derivational morphology. First, young children are already sensitive to the word stem frequency (Lázaro, 2012; Lázaro et al., 2013). Second, older children are better at recognizing word boundaries of infrequent constituents than younger children (Bertram et al., 2000). Third, regular derivations are acquired earlier than irregular derivations (Clahsen & Fleischhauer, 2014; Schiff et al., 2008). In addition, both root and affix affect reaction times for both children (Traficante et al., 2011) and adults (Burani et al., 2006) but the whole word also has an influence on developing readers (Quémart et al., 2012). Furthermore, even in the early school years readers process both the meaning and form (Quémart et al., 2012) and are capable of morpho-lexical reading (Burani et al., 2002).
Typically, experimental stimuli consist of real words and nonwords, i.e., words that have no existing stem in a language. An interesting additional stimulus type in the current theme is pseudowords that have a real stem and a real affix, but whose combination does not exist in the language (Burani et al., 2006; Burani et al., 2002; Quémart et al., 2012; Traficante et al., 2011). It seems that pseudowords are difficult to process in lexical decision tasks, presumably because they are reminiscent of real words, albeit they do not exist in the language. However, thus far, pseudoword processing has been mainly tested by unprimed naming and lexical decision tasks. There is only one study, by Beyersmann et al. (2015), that studied the influence of derived pseudowords as primes in a lexical decision study that adopted the priming technique. Based on the prior studies it seems likely that derived pseudowords could provide an insight into derivational processing and its development.
The current study
The current study tests whether there are differences in morphological knowledge between the age groups of fluent readers of a morphologically complex language. Recent results for English indicate that adults and adolescents process pseudowords differently from children (Dawson et al., 2018). The current study explores how morpho-semantic processing of derivational morphology develops from late childhood through adolescence to adulthood in a derivationally very rich language, Finnish. Arguably, this study is also the first to test participant gender and parts of speech differences in morphological processing in Finnish. Furthermore, most of the relevant literature concerning derivational knowledge is written in English and other Indo-European languages (Clark, 2014). It has been assessed that over 60% of the new words that English-speaking upper-level comprehensive school readers encounter have relatively transparent morphological structures, and, therefore, the morphemes can help to infer the meaning of the whole word (Nagy, Anderson, Schommer, Scott, & Stallman, 1989). Apparently, there are no relevant statistics available in Finnish, but because derivation is the essential way to construct new words in Finnish (Koivisto, 2013), the percentage is likely to be substantially higher. Thus, the importance of knowledge concerning derivational morphology cannot be overestimated as regards word processing in Finnish.
Consequently, three age groups – 6th graders, 9th graders, and adults – of native Finnish speakers took part in a priming study, in which they made a visual lexical decision about the target word. Both nouns and verbs were used as targets. In addition, there were three types of primes: morphologically related, pseudowords, and unrelated. The primes in the morphological condition were real derivations of the target, whereas the primes in the unrelated condition had no semantic or morphological connection to the target. However, at least two initial letters were identical. The primes in the pseudoword condition were formed by combining the target word as a stem with a real derivational suffix. However, the combination was non-existing.
As the study by Quémart et al. (2011) implies, the priming time has to be relatively long to achieve results with young children, so we chose a long prime time in the current study. It is also of note that there is prior evidence suggesting that a longer stimulus onset asynchrony (SOA; the amount of time between the start of prime and the start of target) increases both semantic and morphological priming and decreases orthographic priming, at least in English (e.g., Feldman, 2000) and Greek (Orfanidou, Davis, & Marslen-Wilson, 2011). However, it has also been suggested that priming effects with a long SOA with adults might depend on the representation of the prime in participants’ episodic memory (e.g., Diependaele, Grainger, & Sandra, 2012). Perhaps the clearest evidence of semantic influence in morphological priming with a long SOA has been found in the studies concerned with the semantic transparency in derivations: the meaning of the whole word has to be semantically related to the meaning of the stem and affix in order to have a significant morphological priming effect (e.g., Feldman, Barac-Cikoja, & Kostić, 2002). However, the focus is on the morpho-semantic influence in the present context. Therefore, the relative portion of semantic and morphological influence is not crucial.
There are different ways in which the age group differences might be seen in the current study. First, there might only be a general age group difference showing that the youngest participants are the slowest in visual word recognition and/or their error rates are the highest. Second, it might be that there is an interaction between morphological knowledge and age group, which would indicate that morphological knowledge in an age group would be faster or slower than the general word processing development. Third, target word frequency may influence its processing (cf. Marcolini et al., 2011), i.e., participants are expected to have shorter reaction times and a smaller error rate with more frequent words. Moreover, the priming difference between related and unrelated primes should be smaller with more frequent words.
Method
Participants
Participating in the experiment were 104 6th graders (age 11–13, median 12, males 46, females 58), 107 9th graders (age 14–16, median 15, males 52, females 55), and 97 adult polytechnic students (age 18–41, median 23, males 52, females 45). All the participants were native speakers of Finnish and had normal or corrected-to-normal vision. None of them had any diagnosed language disorder. Four 6th graders and two 9th graders were excluded from the analyses because their performance was too close to chance level.
Materials
The materials consisted of three types of primes and the target word; the target word was always in a dictionary form. There were both nouns (e.g., koura = ‘fist’) and verbs (e.g., hypätä = ‘to jump’) as target words. The target was preceded by either:
Morphological prime (a word that is morphologically derived from the target word);
e.g., kouraista → koura = ‘to grab’ → ‘fist’, e.g., hypähtää → hypätä = ‘to jump once quickly’ → ‘jump’
Unrelated prime (a derived word that is unrelated to the target word); e.g., kohdattu → koura = ‘met’ → ‘fist’, e.g., hyödyntää → hypätä = ‘to utilize’ → ‘to jump’
Pseudoword prime (a derived word form that has the same stem as the target word, but the combination of the stem and real derivational suffix does not exist); e.g., kourahtaa → koura e.g., hypästyä → hypätä
According to Koivisto (2013), a word is a pseudoword if at least one of the following formal constraints is fulfilled: it does not follow the possible structure of Finnish morpho-phonological words; the stem has a wrong word class for the suffix; the word form has the wrong type or form for the suffix; or the suffix has semantic constraints for the stem.
Complex, productive, and transparent derivation
We gathered our stimuli to reflect the derivational complexity of Finnish word formation, and we also made use of its productive and transparent nature. There were 504 derivative words in three sets in our stimuli representing both one-suffix derivatives and derivational chains (see examples 1a–1d). The stem of the word was either nominal or verbal; both can function as stems for nominal and verbal derivatives, but conversion is impossible in Finnish. The nominal words derived were adjectives (20% of all stimuli), adverbs (3%), or nouns (29%). In other words, half of the derivatives were nominal (= participate in case and number inflection), the other half verbal (= participate in tempus and modus inflection). Some suffixes functioned as nominalizers (e.g., action suffixes like minen, see 1a), others as verbalizers (e.g., short causative suffix a/ta, see 1b). Nominal derivatives in the stimuli expressed eight different functions (i.e., action, agent, collective, possessive, caritative, property, moderative, and manner) (see 1c). Verbal derivatives expressed six functions: four of them alternated verb valency (causative, second causative, in other words curative, passive, reflexive) and two aktionsart (frequentative and momentative) (see 1d). There were approximately 40 different suffixes (and their combinations) in total.
Types of derivative suffixes
1a. action nominalizer: verbal stem+minen (e.g., puhu-a ‘to talk’ > puhu-minen ‘talking’)
1b. causative verbalizer: nominal stem+ta (e.g., kohu ‘stir’ > kohu-ta ‘to stir’)
1c. collective: e.g., nominal stem+kko/sto; (e.g., kivi ‘stone’ > kivikko ‘stony ground’; luola ‘cave’ > luola-sto ‘many caves, a set of caves’)
1d. causative: e.g., verbal stem+tta/nta/oitta; passive/reflexive: verbal stem+utu/antu; frequentative: verbal stem+ile/ele (e.g., kantaa ‘carry’ > kanta-utu-a ‘carry far’; elää ‘live’ > elä-ttää ‘support’; kiehu-a ‘to boil’ > kiehu-ttaa ‘to make something boil’; kaivaa ‘to dig’ > kaiva-utua ‘to dig into something’).
There were also both nominal and verbal chains of suffixes in the stimuli (cf. Pajunen, 2015). The most frequent ones were nominal, causative–action noun chains, and verbal causative–(second) causative, and causative–passive chains (90% of the chains). Each participant received the same number of verbal and nominal chains of suffixes.
There were also nonword fillers to make the participants’ task meaningful. The nonwords were words that do not have a real stem. There was a word class (noun/verb) and frequency (high/low) manipulation in 252 target words. There were also 252 fillers as phonologically possible nonword targets. There were morphological, unrelated, and pseudoword primes for both the nouns and verbs. Thus, there were 504 prime–target pairs altogether. Each participant received 252 prime–target pairs of which 126 were real experimental pairs. There were 63 pairs with nominal and verbal derivational prime and a base form target for each participant. The prime type (morphological, pseudoword, unrelated, as well as nominal, verbal) was counterbalanced between the participants.
Apparatus and procedure
Reaction times were collected by an internet-based reaction time program (Pohjankukka & Vainio, 2013); the participants worked independently with the program on their computer in the computer class of their school or college. Lexical-morphological knowledge was tested with a priming test in an electronic form: participants were first shown a prime (800 ms), then the target word (maximum of 3000 ms) and so on in an individually random order. The task for the participants was to make a lexical decision for the target word. They pressed a button to answer whether the target word was a real Finnish word (button ‘F’) or not (button ‘J’). The experiment started with a background information questionnaire. Next there was a short practice session, and the participants could repeat the practice session if they felt they needed more practice. Each participant received one third of critical stimuli: i.e., one version of the prime–target pairs on a given target word. The material was divided into three counterbalanced blocks. Block 1 was composed of the following: the morphological prime of the first prime–target triplet, the pseudoword of the second prime–target triplet, and the unrelated prime of the third prime–target triplet, and then again the morphological prime, etc. Block 2 was composed of the following: the pseudoword of the first, the unrelated prime of the second, and the morphological prime of the third prime–target triplet. The third block started with an unrelated prime, the morphological prime of the second, and the pseudoword of the third prime–target triplet. Each participant completed one block, which had one of the three prime conditions for each target word.
Dependent variables and predictors
We used two standard, word-based measures for the dependent variables, the RTs, and the error rates. The critical predictors were the prime type (morphological, pseudoword, or unrelated), the word class (noun or verb), the lexical family size (continuous variable; defined as a set of all words sharing the same stem word as a constituent), the lemma frequency (continuous variable), the word length in characters (continuous variable), the suffix frequency (continuous variable), the age (6th graders, 9th graders, or adults), and the gender (male or female).
Statistical considerations
The analyses were conducted using the lme4 package (version lme4_1.1.14; Bates, Maechler, Bolker, & Walker, 2015) for R statistical software (version 3.4.2; R Core Team, 2017). The RT measurements were log-transformed to normalize the data. Finally, all the continuous predictor variables were transformed to a z scale. For the RT, we used linear mixed-effects modeling, and for the error rate, we used the binomial variant of generalized linear mixed-effects modeling. We have only reported models where the effects retain statistical significance in the stepwise backward elimination procedure. In this procedure, we first included all the predictors (including all relevant interactions) in the model. We then removed the least predictive predictor in each round using the drop1 command of the lme4 package (Bates et al., 2015), comparing the new model with the full model until we attained a model in which all the predictors and interactions were significant as indicated by a likelihood ratio test. Furthermore, we followed the guidelines of Barr, Levy, Scheepers, and Tily (2013) in fitting the maximal random structure. The final models are reported in Appendix 1. When there was a significant interaction between two categorical variables or a main effect with three levels, all contrasts have been presented.
Results
Reaction times
The trials with incorrect answers as well as RTs shorter than 500 ms were removed from the RT analysis (cf. Quémart et al., 2011; Quémart et al., 2012). Furthermore, RTs longer than 2.5 SD above the age group average were removed. The error rate for 6th graders, 9th graders, and adults was on average 11.1%, 9.4%, and 5.8%, respectively. The 500 ms cut-off removed 2.3% of the data for 6th graders, 3.4% for 9th graders, and 2.5% for adults. The 2.5 SD cut-off removed 1.9%, 2.3%, and 2.1% of the remaining data, respectively. The means for the RTs are presented in Figure 1, and the means for the error rates in Figure 2.
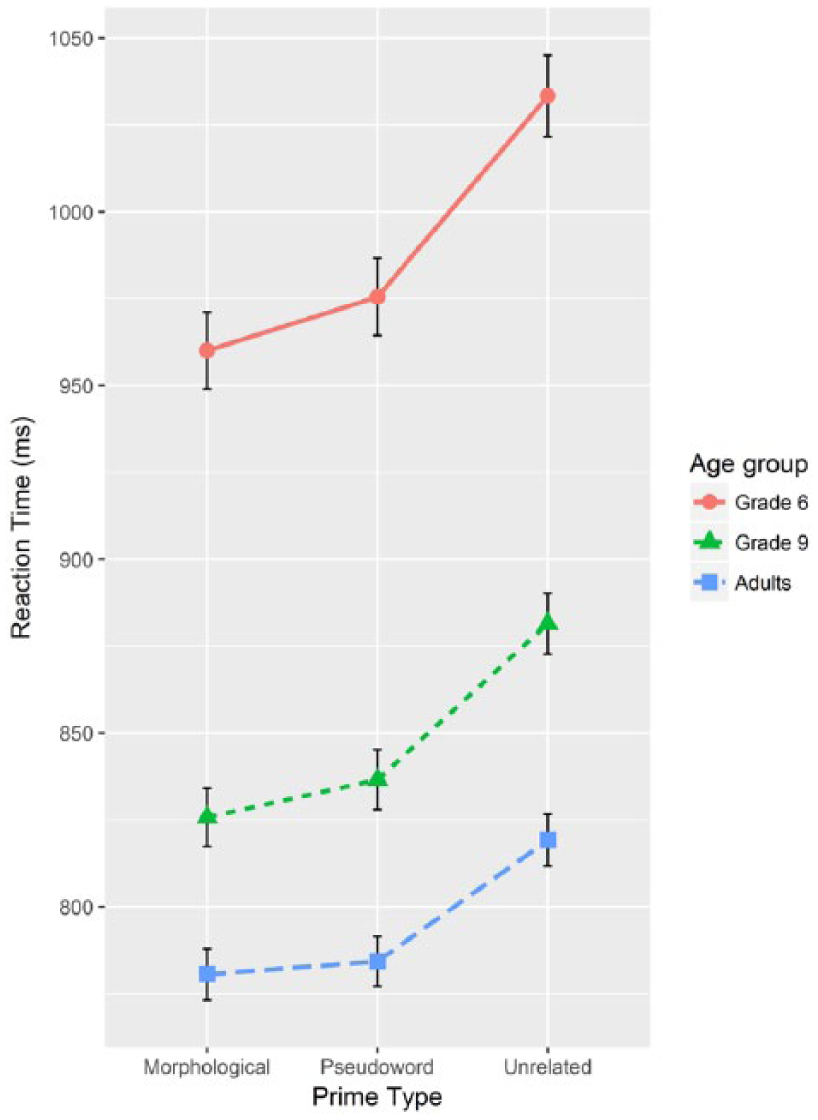
The effect of prime type on reaction time for each age group. The error bars denote the 95% confidence intervals.
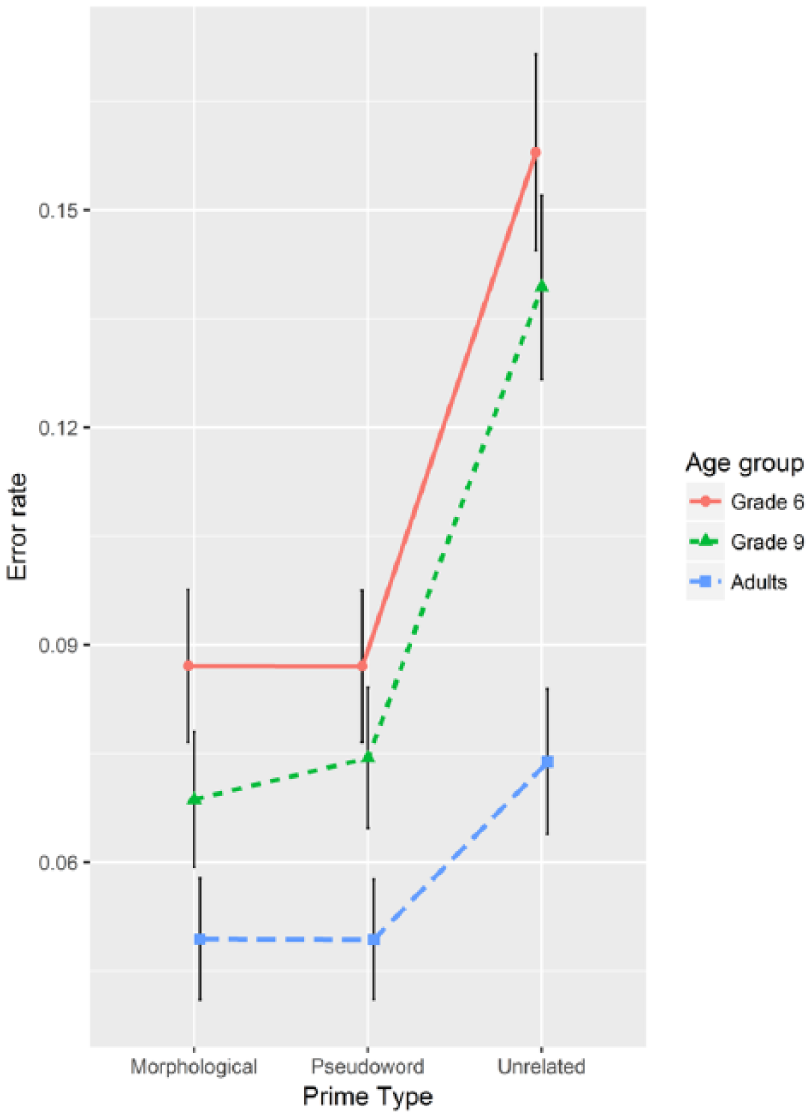
The effect of prime type on error rate for each age group. The error bars denote the 95% confidence intervals.
There was a significant lemma frequency × prime type interaction, χ2(2) = 8.07, p = .018. The nature of the interaction is depicted in Figure 3. The interaction reflects the fact that while the words following unrelated primes were processed considerably more slowly than the words following other prime types, the effect was smaller for the more frequent target words. As shown in Figure 3, target words were processed faster as the lemma frequency increased. With regard to prime type, words following unrelated primes were processed more slowly than words following pseudoword primes, χ2(1) = 339.23, p < .001, Δ = 46 ms, which in turn were processed more slowly than words following morphological primes, χ2(1) = 11.66, p = .001, Δ = 9 ms.
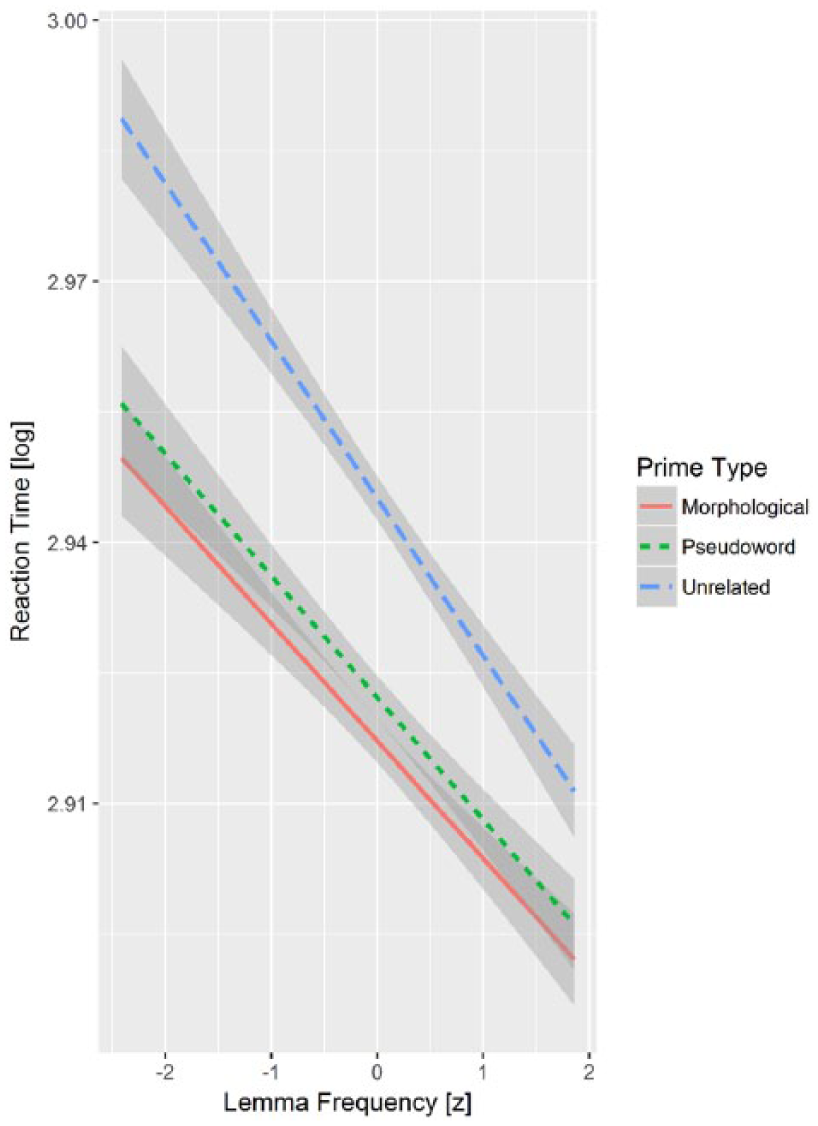
The effect of prime type on reaction time as a function of lemma frequency. The envelopes denote the 95% confidence intervals.
There was also a significant main effect of Age, χ2(2) = 94.28, p < .001. The differences between all age groups were significant: between 6th graders and 9th graders, χ2(1) = 40.74, p < .001, Δ = 141 ms; between 6th graders and adults, χ2(1) = 86.44, p < .001, Δ = 195 ms; and between 9th graders and adults, χ2(1) = 12.65, p < .001, Δ = 53 ms. As expected, 6th graders were much slower than the older groups. However, a more interesting aspect was that 9th graders were significantly slower than adults, which indicates that 9th graders are still developing their word processing compared to adults. With regard to Word class, nouns were processed faster than verbs, χ2(1) = 11.53, p < .001, Δ = 39 ms. Finally, there was a significant main effect of Lexical family size, χ2(1) = 6.33, p = .012. Words with larger families were processed faster than those with smaller families.
Error rates
There was a gender × prime type interaction, χ2(2) = 9.46, p = .009. While the error rates were on average 2.5% higher for males than for females, this pattern of results was restricted to words following morphological and pseudoword primes, χ2(1) = 8.17, p = .004, Δ = 2.5%, and χ2(1) = 12.00, p < .001, Δ = 3.3%, respectively. The difference was not significant for words following unrelated primes, χ2(1) = 1.65, p = .199, Δ = 1.8%. Words following unrelated primes (error rate 12.5%) elicited more errors than words following pseudowords (7.1%) or morphological primes (6.9%), χ2(1) = 177.52, p < .001, and χ2(1) = 171.06, p < .001, respectively. However, words following pseudowords did not differ from words following morphological primes in this respect, χ2(1) = 0.26, p = .613.
There was also a significant main effect of Age, χ2(2) = 25.62, p < .001. Older participants made fewer errors than younger participants, and the differences between all age groups were significant: between 6th graders and 9th graders, χ2(1) = 40.74, p < .001, Δ = 1.7%; between 6th graders and adults, χ2(1) = 26.53, p < .001, Δ = 5.3%; and between 9th graders and adults, χ2(1) = 7.10, p = .008, Δ = 3.6%.
Finally, there was a significant main effect of lemma frequency, χ2(1) = 20.90, p < .001. Participants made more errors with less frequent words.
Discussion
The current study examined how morpho-semantic processing of derivational morphology develops in Finnish from later childhood through adolescence to adulthood. The results imply that overall word processing is still developing in later childhood and adolescence compared to the processing of adults. One factor that might influence this relative late acquisition is that in basic education the curriculum concentrates on reading and writing instruction; derivation is not mentioned at all and vocabulary is studied only in passing (see the homepage of the Finnish National Agency for Education https://www.oph.fi). Even if well-planned instruction might shorten the time to master the derivational system, it is still comparatively complex and seems to require a level of cognitive maturity that 12 year-olds do not yet have (Kusnetsoff, 2017). Note, however, that Dawson et al. (2018) showed that some changes occur over the course of adolescence even in English, which is morphologically simpler.
The reaction time (RT) results showed an expected lemma frequency × prime type interaction. The target words in unrelated prime condition were processed more slowly than the targets of other prime types, but the effect was smaller for the more frequent words. In addition, target words with morphological prime were processed faster than targets with pseudoword prime, which in turn were processed faster than targets with unrelated prime. Moreover, the RT results showed expected age group differences: the youngest group (6th graders) had the longest RT, and the adults had the fastest RT. The adolescents (9th graders) were between these extremes. Numerically, the 9th graders were closer to the adults than the 6th graders, but nevertheless, all the group differences were clearly significant. Moreover, nouns were processed faster than verbs, and words with large families were processed faster than those of smaller families.
Error rates showed a participant gender × prime type interaction. This reflects the fact that while the error rates were higher for males than for females, this was restricted to morphological and pseudoword primes. There was also an effect of prime type: unrelated primes elicited more errors than pseudoword or morphological primes. The latter two did not differ from each other. There was also a main effect of age. Adults made fewer errors than 9th graders, who in turn made fewer errors than 6th graders. Finally, there was a main effect of lemma frequency: participants made more errors with less frequent words.
The results on gender differences tend to vary according to language use vs. linguistic knowledge (see e.g., Hartig & Jude, 2008); gender differences tend to be indecisive. Related to this, the current results that morphological and pseudoword prime caused slightly higher error rates for males than for females indicate that females were better at recognizing the word stem in a prime.
As regards the morpho-syntactic typology, Finnish represents a synthetic language with a complex system of inflectional and derivational suffixes. As such, Finnish resembles Semitic languages like Hebrew that use complex derivations, and therefore differs from analytic English with an impoverished morphology. The further differences between Finnish and English are that in Finnish verbal derivation is as frequent as nominal, whereas in English noun derivatives are more frequent. Moreover, in English, verbal derivation is simpler than noun derivation. Furthermore, Finnish verbal derivation is used for word class change, valency alternation, and for evaluative functions (aktionsart). In English, it is used primarily for a word class change. As a result, we found a word class difference in morphological processing in Finnish: nouns were processed faster than verbs. In English, the results have been inconsistent (e.g., Marinellie & Kneile, 2012).
Generally speaking, the current results and those of Beyersmann et al. (2015) imply that the pseudoword condition that has successfully been used in naming and lexical decision tasks (e.g., Burani et al., 2006; Burani et al., 2008; Burani et al., 2002; Lázaro et al., 2013; Quémart et al., 2012; Traficante et al., 2011) can also be used as a prime in priming studies. In other words, when these critical words are used as primes in a priming experiment and their stems are the targets, the effect between the morphologically derived words and derived pseudowords follows the same direction as in simple lexical decision tasks, even though the effect is numerically smaller. It seems that using pseudowords as primes has one natural disadvantage: the effects in a primed lexical decision task may be less robust that in an unprimed lexical decision task. However, we think that the strengths overcome this potential weakness.
The most important strength of using pseudowords as primes is naturally the fact that the aim is not to compare the processing of existing and non-existing words in a language. A pseudoword as prime apparently influences the processing of the real word target, but one can compare the processing of the same real word target in different conditions. Another advantage is that it is easier to match the material, especially as for word length. Naturally, both pseudoderived words and real derived words are usually longer than monomorphemic words and many affixes are relatively long at least in languages like Finnish; this means that it is only possible to use a small proportion of derivational affixes in an experiment if the pseudoderived words are used as targets. By using pseudoderived words as primes one can counterbalance and match word length and keep the same word as the target in different conditions, therefore there are no challenges concerning the potential differences between the targets.
Footnotes
Appendix 1
Output from drop1 function in lme4 package for the final model glmer(ErrorRate~1+PrimeType*Gender+Age+zFrequency+(1|Participant)+(0+PrimeType+Age|Item).
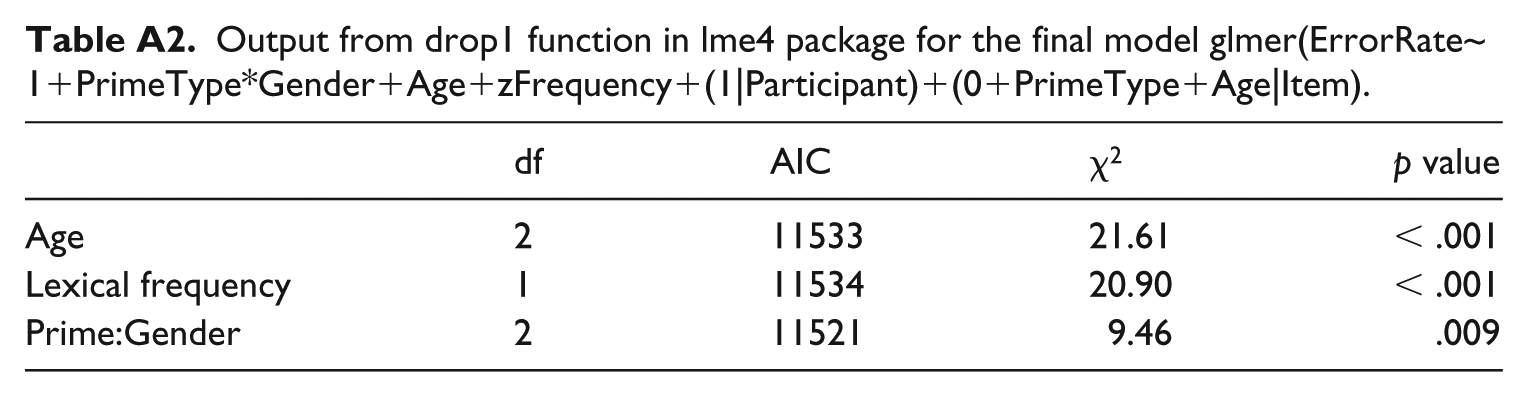
| df | AIC | χ2 | p value | |
|---|---|---|---|---|
| Age | 2 | 11533 | 21.61 | < .001 |
| Lexical frequency | 1 | 11534 | 20.90 | < .001 |
| Prime:Gender | 2 | 11521 | 9.46 | .009 |
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This research was supported by KONE Foundation for Seppo Vainio, granted to Anneli Pajunen [grant number 35-2243].