
Abstract
Energy consumption forecasting for buildings plays a significant role in building energy management, conservation and fault diagnosis. Owing to the ease of use and adaptability of optimal solution seeking, data-driven techniques have proved to be accurate and efficient tools in recent years. This study provides a comprehensive review on the existing data-driven approaches for building energy forecasting, such as regression models, artificial neural networks, support vector machines, fuzzy models, grey models, etc. On this basis, the paper puts emphasis to the discussion on evolutionary algorithms hybridized models that combine evolutionary algorithms with regular data-driven models to improve prediction accuracy and robustness. Various combinations of such hybrid models are classified and their characteristics are analyzed. Finally, a detailed discussion on the advantages and challenges of current predictive models is provided.
Introduction
In recent years, global economic growth has strongly influenced the trend of global energy consumption. 1 In Europe, building-related energy consumption accounts for 40% of the total energy consumption and 36% of the total carbon dioxide emissions. 2 In China, total energy use reached 819 million tons of standard coals in 2014, more than twice in 2001. In addition, 36% of total energy consumption of the whole society comes from buildings. 3 Many countries have accelerated the establishment of energy codes and regulations for new buildings aiming to achieve the purpose of reducing final energy consumption and related CO2 emissions. Several simulation programs have been widely used for building energy efficient design, e.g. EnergyPlus, a eQUEST,b TRNSYS,c etc. However, once the building is put into use, future energy consumption is very difficult to estimate because so many factors affect the building energy behaviors, e.g. weather factors, building thermal performances, occupant behaviors, etc. Meanwhile, to save energy consumption and reduce CO2 emissions, building energy usage prediction is of great importance. To this end, data-driven techniques for building energy analysis of existing buildings are very important.
In the past decades, numerous data-driven techniques have been developed and modelled different building energy use patterns based on recorded time series data. Recent review papers have offered major classifications of building energy forecasting case studies.4–13 More than 100 papers since 2010 have been reviewed on this topic to better understand current research trends of building energy predictions. These reports can be categorized from four aspects, i.e. energy scale, energy type, time scale and input data selection.
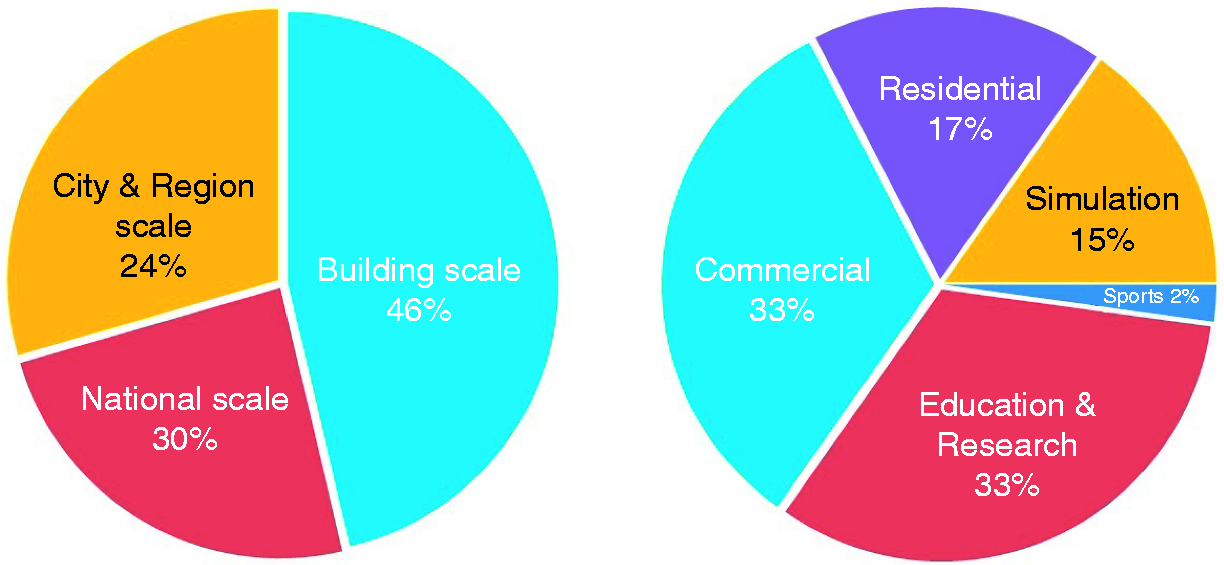
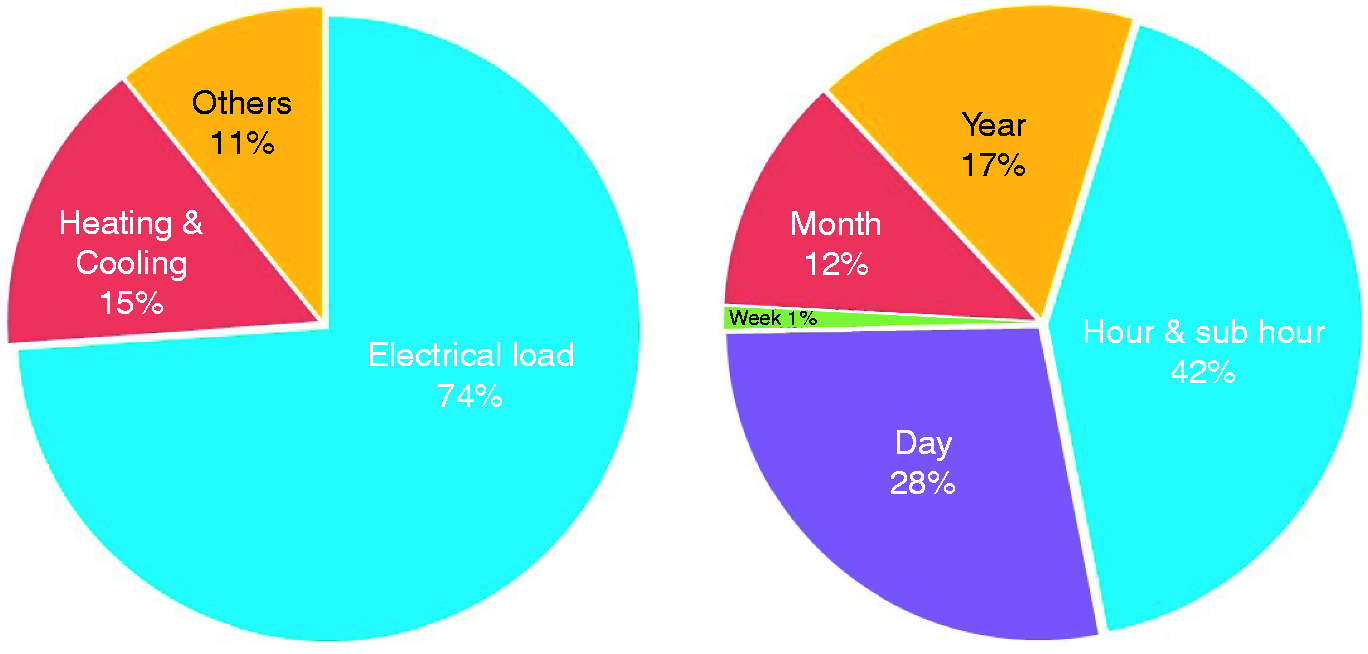
Energy scale. As shown in Figure 1 (left), there are 30 papers (30%) for national scale’s load prediction14–16 and 24 papers’ predictions (24%) are at city and region scale.17–19 It is recognized that most prediction models (46 papers, 46%) were used for energy prediction at building scale. Further, five building categories are classified, e.g., commercial, residential, educational and research, sports and simulation-based building types as shown in Figure 1 (right). Due to the easy access to the available energy data, the commercial and educational and research building types (both 33%) were largely applied for energy forecasting. Although the residential buildings accounted for the largest proportion of building energy use, there were limited energy prediction cases reported (17%). In addition, there are also seven prediction cases (15%) based on building energy simulations.20–24 Energy type. Based on the emphasis of different studies, the predicted energy may be classified into three categories, e.g., whole building electrical load, heating and cooling energy and all others as shown in Figure 2 (left). Nearly three-quarters of the studies focused on the whole buildings electrical load prediction. The prediction of building heating and cooling consumption relates to 15% of all the studies. There is also 11% of all studies that focuses on other energy-related outputs such as cooling energy load25,26 or air temperature.
27
Time scale. Figure 2 (right) presents five time scales and their proportions based on the survey of 90 papers’ specifications (the rest of surveyed papers did not specify their time scales clearly). Short-term prediction that includes day-ahead14,26,28–31 and hour and sub-hour time scale is found accounting for the majority (70% of all studies). Among them, 60% researchers chose hourly prediction32–36 or sub-hourly prediction37–39 as their preferred time scale. Long-term prediction that includes weekly,
40
monthly19,41–44 and annual time scales45–48 is found accounting for 30% of all the studies. For long-term energy predictions, most researches focused on large scale energy use, i.e., city and region scale46,49 or national scale.16,50–52 For building energy usage prediction, researches preferred choosing day, hour or sub-hour time scales, which indicated that short-term scales were more appropriate for such predictions. Input data selection. For data-driven models, the selection of input variables is very important because superfluous or improper input variables may cause convergence and low accuracy problems.
53
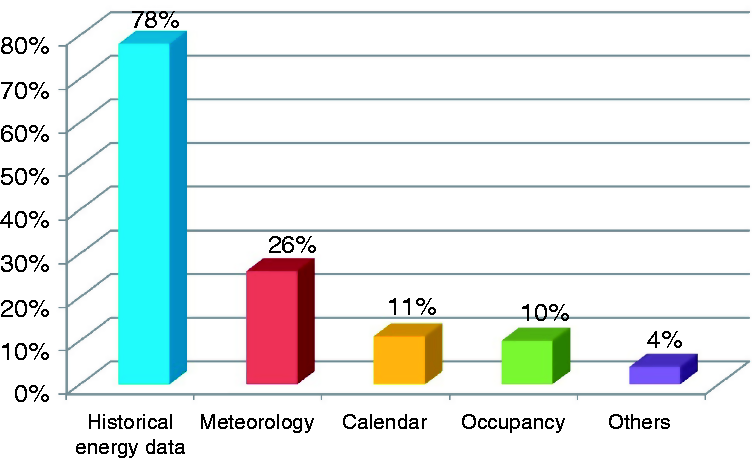
Figure 3 records the frequency of different types of input data used in the reviewed papers. In addition, 78% of the articles used historical energy data to conduct their prediction; 26% of the articles used meteorological data as input variables, which included outdoor temperature, humidity, wind speed, precipitation and solar radiation. Among them, outdoor temperature had the strongest correlation with energy consumption.54–56 But for larger scale (regional and national scale), the percentage is low (only six papers55,57–61). Some researchers reported that meteorology data have no strong correlation with large scale’s energy forecast.
14
The calendar information (weekday, weekend, holiday, etc.) was widely collected for energy consumption forecast.29,38,62–64 A few reviewed studies also adopted occupancy information as input data.20,62,65,66 For input data selection, principal component analysis was usually used to recognize the most relevant inputs.54,67,68 For regional or larger energy scales, wavelet transform (WT) was widely applied to filter irrelevant input variables.55,57,58,60,69–71 The composition of load scale (left) and building type (right). The composition of energy type (left) and time scale (right). The frequency of different types of input data.
The emphasis of this review is on the analysis of different data-driven methods applied to building energy prediction, such as regression model, artificial neural networks (ANNs), support vector regression (SVR), fuzzy model, grey model, etc. On this basis, we provides insight into recently applied evolutionary algorithms (EAs) for building energy forecasting, that is, the EA-data-driven models that combine EA methods to improve prediction accuracy and robustness. After reviewing various EA-based hybrid models, a detailed discussion on the advantages and challenges of current used predictive techniques are summarized.
Data-driven prediction models
Based on the review of the recent literature, the scope of energy prediction methods covers all available data-driven models, such as regression model, ANN, fuzzy model, grey model, support vector machine (SVM), etc. For this review, we primarily focus on the methods that are employed in the field of energy use prediction for buildings or larger scales. Figure 4 shows the frequency of different types of data-driven models used in the reviewed papers. Six most popular forecasting techniques as observed in the area of building energy consumption forecasting are reviewed in the following section.
The frequency of different types of prediction models. ARIMA: autoregressive integrated moving average; ANN: artificial neural network; SVM: support vector machine.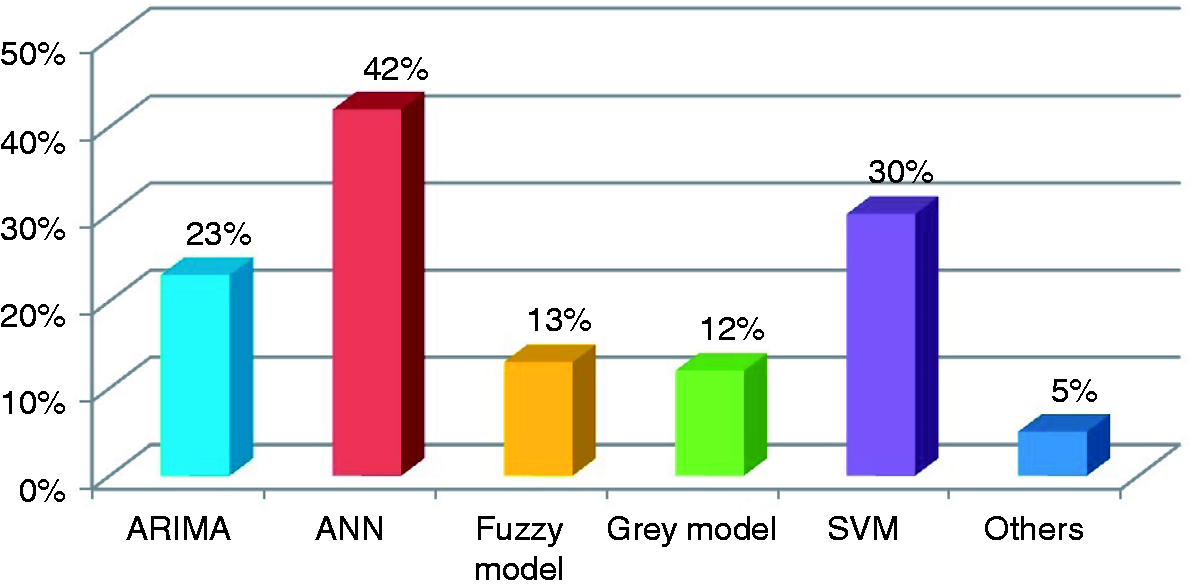
Regression model
Regression models are the basic form of time series forecasting techniques, which are generally based on the idea of transforming the time series to be stationary by the differencing process. As a common used regression model, the autoregressive integrated moving average (ARIMA) equation is a linear equation. Because of its ease of use, ARIMA model has been widely used to predict energy consumption at building or larger scales.
For building scale, Yun et al., 36 in 2012, applied an indexed fourth-order autoregressive model for short time heat load prediction of buildings. In their study, different sets of time and temperature coefficients were indexed in the regressive equation, which allowed choosing leading factors at a given time. Simulation results indicated that the proposed model was suitable for energy prediction applications involving real-time operation. Korolija et al., 72 in 2013, used multivariate regression models for long-term loads forecasting. A large number of building parameters such as building location, building envelope features and internal gains formed 3840 office building models. Totally, 23,040 possible scenarios were modelled via EnergyPlus. Statistical error analysis proved the high accuracy of the proposed regression models for heating, ventilation and air conditioning (HVAC) systems’ energy requirements prediction. Zhang et al., 73 in 2015, proposed four different regression models for predictions of building HVAC hot water energy consumptions. Results showed that the Gaussian mixture regression model had the better statistical performance compared to all other three models.
For regional and national scales, Rallapalli and Ghosh, 42 in 2012, used a multiplicative seasonal ARIMA (MSARIMA) model for monthly peak demand forecasting in India. The authors carried out both in-sample static and out-sample dynamic predictions, and both revealed that the MSARIMA model outperformed the India’s electricity authority’s forecasting to a great degree. Wu et al., 74 in 2013, combined regression model with seasonal exponential adjustment method to forecast one-week-ahead daily load of Victoria grid in Australia. Wang et al., 75 in 2012, combined particle swarm optimization (PSO)-based Fourier method with ARIMA model for forecasting electrical demand in the Northwest electricity grid of China. The proposed model was reported more efficient than the single ARIMA model.
Artificial neural networks
ANNs, analogous to the biological neurons of human brain, are composed of a number of simple and highly interconnected processors.
76
The processors, called neurons, are connected by weighted links that pass signals from one unit to another. For instance, a three-layer network’s mapping function is formulated as follows
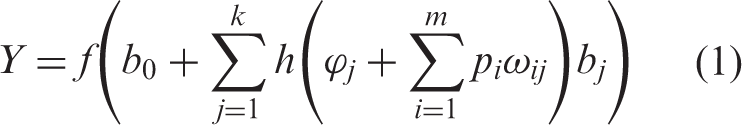
In the past two decades, the ANN has been applied to predict various types of energy usage for buildings and larger scales. Recently, Mena et al., 77 in 2014, applied a three-layer neural network model for short-term electricity demand prediction. From 17 input variables, the study indicated that the outdoor temperature and the solar radiation were the more influential factors on the building energy consumption. Chae et al., 38 in 2016, developed a short-term building energy prediction method using ANN model. Random forests algorithm 78 was introduced to estimate the correlation of input variables via testing their influences on the response of prediction. A similar study can be found in Deb’s report. 26 In his study, the author found that the air conditioning systems run almost irrelevantly of the outdoor climatic conditions. Li et al., 34 in 2014, proposed a hybrid quantized Elman neural network to forecast hourly power load in Chongqing, China. The quantum extended error back propagation (EBP) training algorithm extended the context-layer weights into the hidden-layer weights matrix. Results indicated that the proposed approach can provide a higher accuracy for the short-term power load forecasting. A fast discrete wavelet transform was used for the decomposition of the load time series in Kouhi and Keynia’s report. 70 Chang et al., 43 in 2011, combined fuzzy theory and ANN for long-term electrical energy load prediction. A weighted factor was adopted to count the similarity of each factor among different fuzzy rules. The historical electrical load data of Taiwan was used for model training and test. Results indicated that the mean absolute percent error (MAPE) of the proposed model was better than that of other four data-driven approaches.
Support vector machines
Support vector machines were initially developed for classification problems. Shortly after that, this method was extended to regression problems.
79
The common used formulation of SVM regression is Vapnik’s ɛ-tube SVR (ɛ-SVR). In this approach, the goal is to find a function f(ċ) that has the maximum deviation from all training samples and is as flat as possible
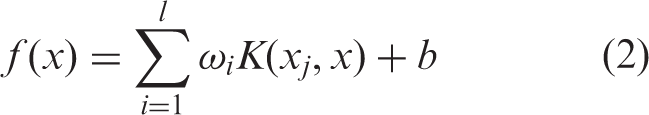
Inspired by the strong nonlinear learning ability, many researchers applied SVR for energy consumption forecasting at different scales. In 2005, Dong et al. 82 firstly applied SVR to forecast long-term buildings electrical load in tropical regions. The analysis on three years’ data revealed SVM’s great performance in energy prediction. Since 2010, over 25 papers have been recognized using SVM methods for energy consumption prediction. Božić et al., 64 in 2010, presented least squares SVMs (LS-SVMs) for hourly load forecasting. The data used for experiments are from New England region which involved calendar information, hourly electric load and hourly temperatures. Results showed that the maximum deviations are 643 MW which is at 7:00 a.m., and the number of hours with an absolute percentage error (APE) of less than 2% is 11, between 2% and 3% is 10 and there are three hours with APE between 3% and 4%. Similarly, Kaytez et al., 16 in 2015, implemented the same method (LS-SVMs) for annual electrical load forecasting in Turkey. Installed capacity, gross electricity generation, population and other data were chosen as model inputs. The proposed model had resulted in absolute training and testing errors of 0.876% and 1.004%, respectively, which was reported much better than multiple linear regression (MLR) analysis and ANN models. Jain et al. 83 built a sensor-based forecasting model using SVR. The authors examined the influence of spatial and temporal granularity on sensor-based forecasting models. Results indicated that the most effective models were developed with hourly consumption at the floor level. Fan et al. 37 forecasted energy load of New South Wales and New York electricity market using SVR model combined with the differential empirical mode decomposition (DEMD) method and auto regression (AR). To achieve better performances, the raw data was divided into two parts (the high frequency item and the residuals) by DEMD. The SVR and AR methods then were employed to forecast the two parts’ data, respectively. Two case studies demonstrated that the proposed model had better interpretability, forecasting accuracy and generalization ability than other alternative models.
A detailed review on the applications of SVR and ANN for building electrical consumption prediction was discussed in Ahmad et al. 7 It is noted that the limitation of SVR method is the determination of kernel function. Researchers have to determine the kernel function based on the characteristics of the data as well as their own experience.
Fuzzy model
The fuzzy set theory, initially developed by Zadeh, 84 in 1965, is designed to mathematically treat uncertainty and vagueness. For energy load forecasting, the fuzzy set theory is recognized as an important technique because of its capability to generate decisions by approximating information and uncertainty.
Fuzzy time series (FTS) is one of the fuzzy methods that combine conventional time series models with fuzzy set theory for forecasting issues.30,85–87 Boltürk et al. 85 applied FTS with Singh’s method for Turkish company’s monthly electrical energy consumption prediction. In 2013, Enayatifar et al. 86 developed a hybrid algorithm based on refined high-order weighted FTS model and employed it for forecasting sub-hourly electricity load of UK and France. In 2015, Efendi et al. 30 proposed a linguistic out-sample approach of FTS for daily electricity load demand prediction in Malaysian. The linguistic index number method was used to assign the weight of the fuzzy logical relationship in the fuzzy logical group. Comparative results indicated that the proposed method had superior forecasting accuracy than other three methods.
Adaptive neuro-fuzzy inference system (ANFIS) is a neuro-fuzzy network that was firstly developed by Jang in 1993. This method covers advantages of fuzzy logic and ANNs in same structure. For building energy forecasting, Ekici and Aksoy, 24 in 2011, applied ANFIS for predicting building energy load. Five-year climatic data were collected for building energy modelling using a FORTRAN program. Results revealed that ANFIS had great capability of predicting energy loads for different buildings with superior performance. Li et al. 35 presented an optimized ANFIS model for predicting electrical load of a library building in East China. A hierarchical ANFIS structure was used to solve the curse-of-dimensionality problem of input data. Comparative results revealed that the proposed model had better performance than ANN in term of prediction accuracy. Hooshmand et al., 58 in 2013, combined ANN, WT and ANFIS in two steps to forecast primary load of power systems in Iran and New South Wales of Australia. Results proved the improvement of the forecasting accuracy via the proposed method when the weather conditions were frequently changed.
Grey model
This concept of grey model was introduced by Deng in the early 1980s.
88
The purpose of the model is to describe the characteristics of systems which could not be identified with fuzzy or other methods with limited samples. The basic grey model is the GM (1,1), which is a kind of time series equation as the following
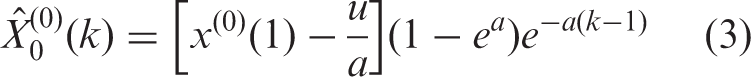
For energy forecasting, Bianco et al., 51 in 2010, combined GM (1,1) grey model with rolling mechanism to predict nonresidential electricity in Romania. Compared with another prediction method (called Holt-Winters exponential smoothing model in their study), the proposed grey model had acceptable results with a relative error of 5% based only on the historical consumption series. To enhance the accuracy, Li et al. 32 proposed an improved grey model GM (2,1) for short-term load forecasting (STLF) problems. In their method, cubic spline function was used to estimate the derivative and background value, and Taylor approximation method was applied to improve the forecasted accuracy. Results revealed that the proposed grey model GM (2,1) had better forecasting accuracy than GM (1,1) when original data have strongly properties of randomness. Pao et al., 90 in 2012, employed the nonlinear grey Bernoulli model to predict carbon emissions, energy consumption and economic growth in China. Using recent years’ historical data, the proposed model reached robust results ranging from 1.10% to 6.26% for out-of-sample period 2004–2009, which were better than ARIMA and GM models. In 2014, Hamzacebi and Es 45 employed GM(1,1) to predict the annual electrical energy load of Turkey. To improve the prediction performance, two parameters θ and k were adjusted by trial method. Also, optimization algorithms can be applied to improve prediction performance of GM, which will be reviewed in the next section.
Others
In addition to the common used prediction methods that reviewed above, some other data-driven methods were also reported for energy load forecasting.
Ensemble model is defined as an approach using multiple learning algorithms/models to obtain better predictive performance than that could be obtained from any of the constituent learning algorithms/models. 9 The concept of ensemble learning was first proposed by Hansen and Salamon in 1990 to solve classification problems. 91 In 2014, this method was introduced for energy consumption forecast by Fan et al. 92 The authors used eight data-driven models including MLR, ARIMA, SVR, the random forests (RF), the multi-layer perceptron (MLP), the boosting tree (BT), the multivariate adaptive regression splines (MARS) and the k-nearest neighbors (kNN) as base models. The ensemble model was thus developed and the genetic algorithm (GA) was applied for the selection of model weights. Forecasting results revealed that the proposed ensemble model had superior accuracy for the next-day energy consumption prediction compared with individual base models. Jovanovic et al., 29 in 2015, employed ensemble of three neural networks to predict daily heating energy consumption of mixed-use buildings in university campus. Back-propagation (BP)/radial basis function (RBF) neural network and ANFIS were selected as base models. Three different combinations of models were analyzed by the prediction task. Results revealed that all proposed models could predict energy consumption with great accuracy individually, and the ensemble one achieved the best accuracy. Wang et al., 93 in 2018, employed an ensemble model, “Ensemble Bagging Trees,” for hourly electricity demand prediction. A detailed review on the applications of ensemble learning for building consumption prediction was discussed in Wang and Srinivasan. 9
Case-based reasoning (CBR) falls into the category of the machine-learning artificial intelligence (AI) techniques. The initial formulation of the concept is derived from the study on the role of reminding in human reasoning. CBR is based on the recalling of information from a prior case to solve a new case. 94 More details on the theoretical fundamentals can be found in Aamodt and Plaza. 95 For building energy prediction, Monfet et al., 96 in 2014, presented a CBR-based method for forecasting the energy demand of commercial buildings. A case library including data from May 2008 to April 2009 was created for the evaluation of the performance of CBR. New cases were created and added in to the library of cases hourly. Platon et al., 67 in 2015, developed a CBR-based predictive model to forecast electricity consumption of a building located in Calgary, Canada. Although the CBR model had higher predictive error compared with ANN method, the error of proposed method was within the recommended American Society of Heating, Refrigerating and Air-Conditioning Engineers (ASHRAE) limits for short-term predictions.
Considering the complex and unpredictable nature of human behavior, Virote and Neves-Silva 20 proposed a stochastic Markov model-based method for indoor occupant behavior in relation to building energy consumption. Results demonstrated that their proposed energy consumption model could learn occupant behavioral patterns from buildings, predict building energy load and recognize potential fields of energy waste.
Lü et al. 33 presented a physical–statistical approach for energy demand prediction considering the complexity and variation of building environments and weather conditions. The indoor thermal physical model was simplified to characterize the general thermal mechanism of buildings. A stochastic model was developed for the construction of the stochastic energy use patterns. By a great number of measurements with different district energy use profiles, the detailed assessment of the model performance was carried out which proved the great accuracy improvement of the proposed hybrid methodology.
Energy scale/type, time scale and input data type of data-driven applications.

ARIMA: autoregressive integrated moving average; ANN: artificial neural network; SVM: support vector machine; CBR: case-based reasoning; HVAC: heating, ventilation and air conditioning; GDP: gross domestic product; AHU: air handling unit.
Hybrid data-driven models based on EAs
Numerous data-driven models have been adopted for building energy forecasting by most of literatures in the past. However, when the data set of forecasting is very large, single data-driven model may lead to convergence problems and poor model accuracy. Recently, a plenty of AI-based hybrid models have been successfully applied in the field of building energy forecasting. In general, these models are more robust and have better forecasting accuracy because they can combine the advantages of the individual techniques involved. According to the literature reviewed, evolutionary and swarm intelligence algorithms have been widely adopted to solve a variety of optimization problems in the field of energy analysis. In this article, various combinations of EA hybridized prediction methods will be reviewed in the next section.
GA-based hybrid model
GA is a stochastic method of searching the optimal solution by simulating the natural evolutionary process. 97 By simplifying the gene coding process, genetic operators were designed for combination, crossover and mutation in each generation until optimal population obtained. In the area of energy forecasting, GAs have been widely hybridized with other methods to improve prediction’s robustness and accuracy. Multiple data-driven predictive models are found being combined with GA, which will be reviewed in classifications.
To improve the performance of ANN-based forecasting, GAs were applied for designing parameters of ANNs, including the architecture, connection weights, etc. Moazzami et al., 60 in 2013, developed a GA hybridized ANN model for Iran’s daily peak load forecasting. Different from single data-driven models, the input variables and model parameters were adjusted by GA. Results demonstrated the effectiveness and the advantages of the hybrid strategy. Similarly, Defilippo et al., 98 and Chaturvedi et al., 69 in 2015, also applied a GA-based ANN model for electrical load forecasting. Chang et al. 43 developed an improved evolving fuzzy neural network for long-term (monthly) electrical demand forecasting in Taiwan power system. The traditional BP-based weight learning method was replaced by GA, which had stronger global searching ability and could avoid trapping into local optimums. Experimental results revealed that the proposed model was more accurate than other gradient-based approaches for long-term electrical demand prediction.
For SVM method, GA was also introduced to improve its modelling accuracy and avoid local optimum issues. Hong et al., 99 in 2013, hybridized SVR with GA for forecasting monthly electrical loads in Northeast China. The proposed chaotic GA, which employed internal randomness of chaos iterations, was adapted to overcome premature local optimum when selecting SVR parameters. A numerical experiment indicated that the proposed model can obtain more accurate results than other ordinary methods. Jung et al., 100 in 2015, proposed an improved GA-based LS-SVM for building energy usage prediction. In the proposed method, SVM’s regularization parameter γ and kernel width parameter σ were determined using a hybridized real-coded GA. Prediction results indicated that the method had superior performances not only in term of forecasting accuracy but also in term of convergence speed.
As a kind of adaptive network, ANFIS uses linear partitioning as basic rule base creating approach. Due to the strong nonlinearity, distributed parameters and heterogeneity of the building energy system, there is no exiting expert knowledge for rule base arrangement in advance. To this end, Li et al.35,101 proposed a GA-based subtractive clustering technique for rule bases arrangement. By the proposed clustering method, the fuzzy rules would reveal some features of the complex building energy function, which was hardly depicted by gradient methods. Case studies on campus building’s short-term electrical energy prediction confirmed the superior performances of the proposed method in terms of forecasting accuracy (coefficient of variation (CV)) and time consuming.
To increase the forecasting accuracy of grey model, Lee and Tong, 102 in 2011, combined modified genetic programming (GP) method with GM(1,1) grey model to enhance the power of minimizing forecasting residual errors. To demonstrate the effectiveness of the improved grey model, historical data of China’s annual energy consumption were used as training data. The errors (MAPE) of four predictive models, i.e., the GM(1,1) model, the model of literature, 103 the linear regression model and the proposed GPGM(1,1) model were 4.13%, 3.61%, 4.20% and 2.59%, respectively. It demonstrated that the proposed model had a higher prediction accuracy compared with other three forecasting methods.
PSO-based hybrid model
PSO is a population-based stochastic optimization technique that was firstly proposed by James Kennedy and Russell Eberhart in 1995. 104 Similar to the EA, PSO uses a population to search for more regions in the solution space at the same time. Each particle in the population is characterized by its position, velocity and a record of its previous performance. Compared with GA, PSO has the advantages of fast convergence and simple structure which are well-suited for discontinuous and multimodal missions.
For energy forecasting, Wang et al., 75 in 2012, proposed residual modification models to improve ARIMA model for electricity demand forecasting. In their method, PSO was used to search for optimal parameters of Fourier approach. To verify the effectiveness and feasibility of the methods, the historical data of Northwest China’s electricity demand were collected for prediction comparison.
Performance comparison between ANN, GA-ANN and iPSO-ANN. 54
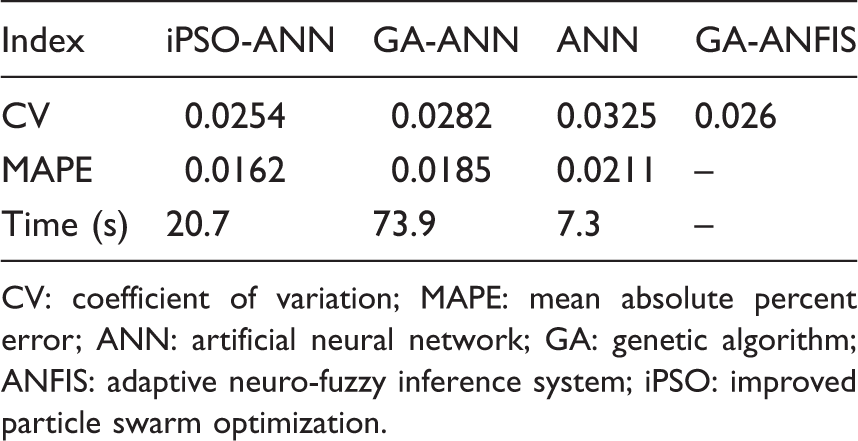
CV: coefficient of variation; MAPE: mean absolute percent error; ANN: artificial neural network; GA: genetic algorithm; ANFIS: adaptive neuro-fuzzy inference system; iPSO: improved particle swarm optimization.
Chen et al., 105 in 2015, combined PSO and SVM model for electrical load forecasting. The same parameters optimized using GA by Jung et al. 106 were adjusted by PSO in this study. Simulation results showed that the proposed ESPLSSVM had better forecasting accuracy than other three prediction models. Son and Kim 107 used PSO to find the optimal variable subset for SVM training. Simulation results confirmed the efficiency of the proposed method. Similarly, for variable subset selection of SVM, another swarm intelligence algorithm, ant colony optimization (ACO), was introduced by Niu et al. 108 in 2010. Using the ACO method, the slow processing speed when constructing SVM model was conquered.
Differential evolution-based hybrid model
The differential evolution (DE) algorithm is a simple and powerful stochastic search technique proposed by Storn and Price in 1990s. 109 Like other EAs, DE is a population-based heuristic search algorithm in which each individual corresponds to a solution vector. There are also three main genetic operations at each generation, i.e., mutation, crossover and selection, through which the population moves toward the global optimum. Compared with GA, DE has the characteristics of simple structure, easy implementation, fast convergence and strong robustness, which make it widely applied in diverse fields.
For energy prediction, Kouhi et al., 110 in 2014, introduced DE to avoid ANN training’s local minimum problem. After the initial training by traditional LM algorithm, the weights and bias values of ANN structure were adjusted by DE to minimize the validation error. Historical energy data of PJM and New England electricity markets were used for performance tests.
Zhang et al., 39 in 2016, combined DE algorithm with SVR for building energy consumption prediction. Because the capability of SVR heavily depends on its parameter settings, DE was adapted to adjust parameters of the SVR models, i.e. cost (c), gamma (γ), epsilon (ɛ), nu (ν) and weights of real value type. Compared with other two optimization algorithm GA and PSO, the proposed DE model was more accurate and exhibited a better accuracy for short-term load forecasting.
Hybrid model of teaching learning-based optimization and ANN
A new EA called teaching learning-based optimization (TLBO) was developed by Rao et al. 111 in 2011. The method simulates the effect of teaching and learning phases between teacher and learners in a class to improve the learners’ academic performance.111,112
Performance comparison of TLBO-ANN, iPSO-ANN and GA-ANN models. 113
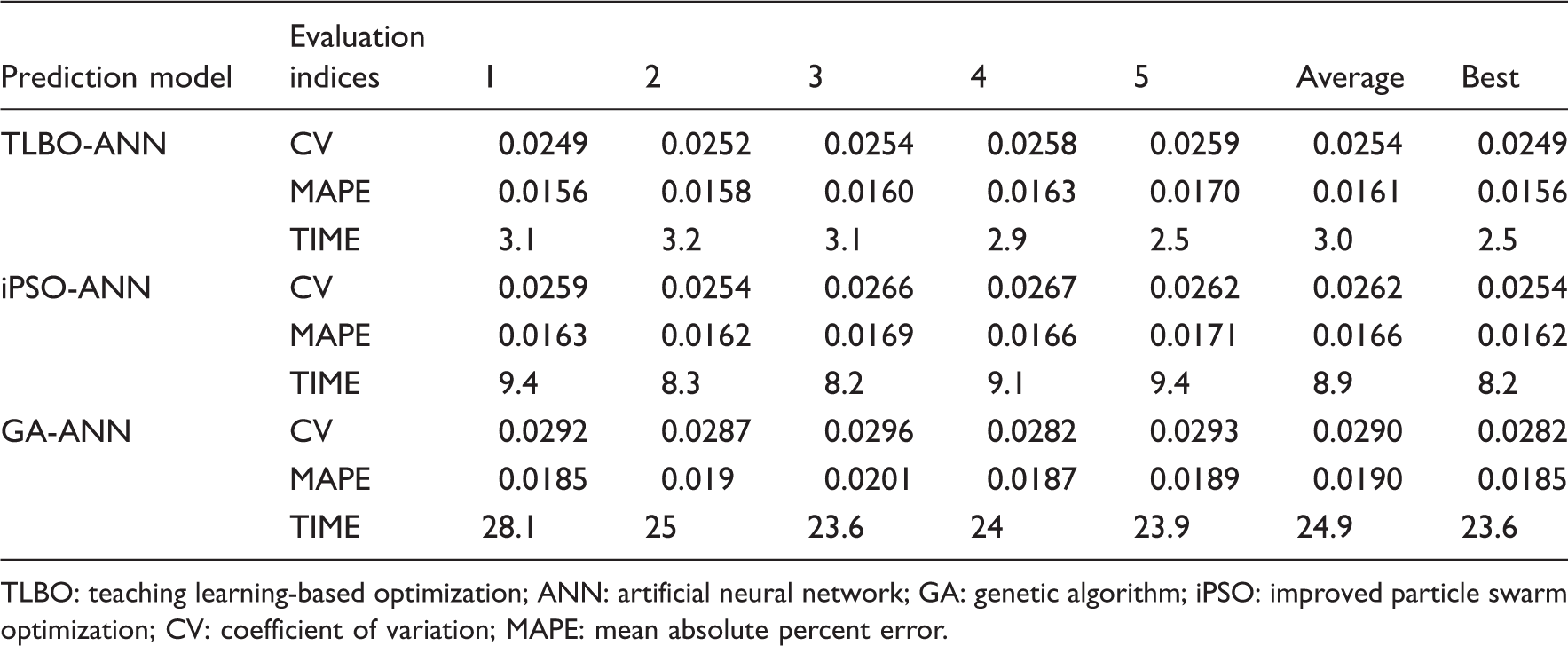
TLBO: teaching learning-based optimization; ANN: artificial neural network; GA: genetic algorithm; iPSO: improved particle swarm optimization; CV: coefficient of variation; MAPE: mean absolute percent error.
Energy scale/type, time scale and input data type of hybrid data-driven applications.
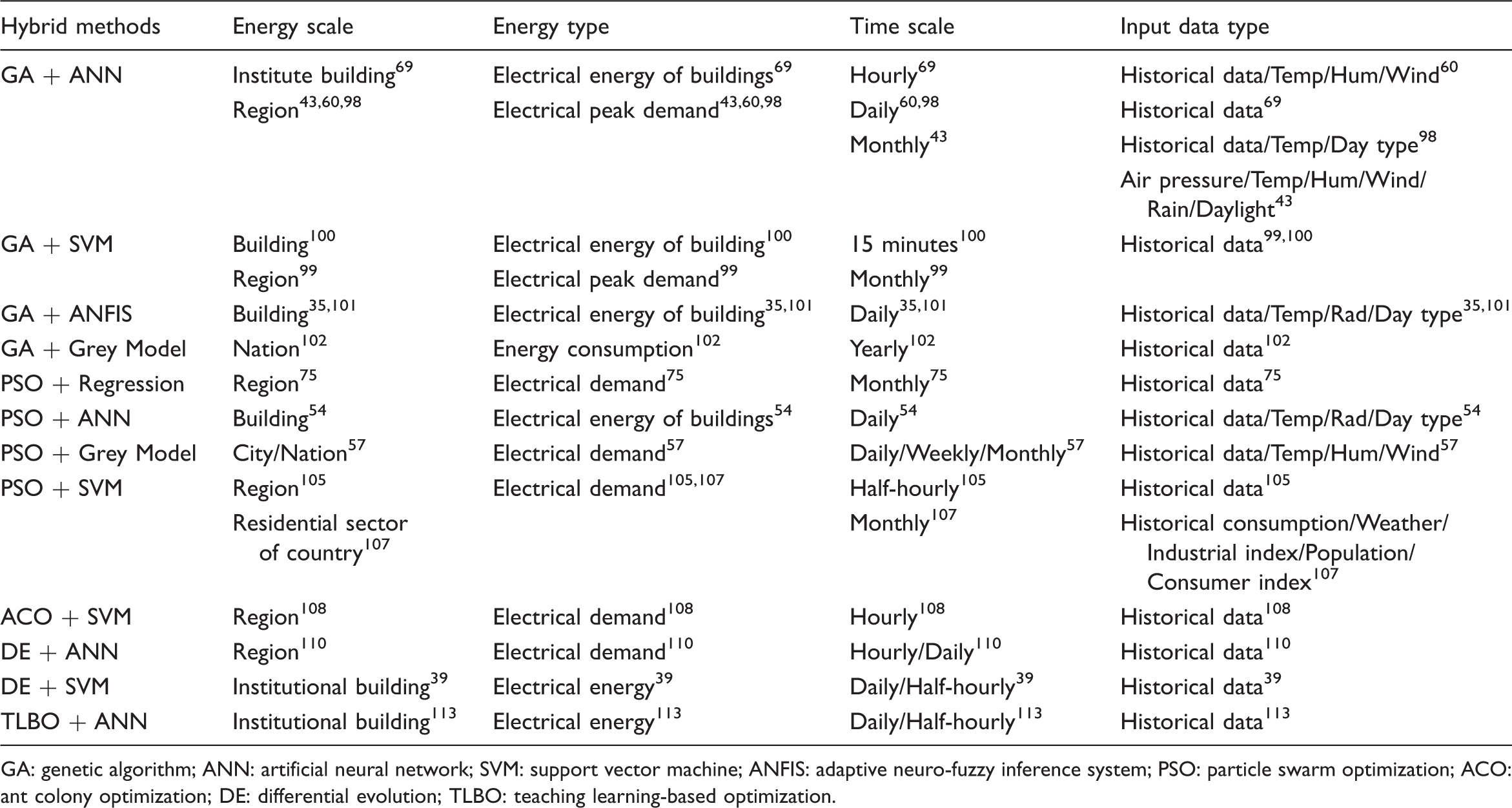
GA: genetic algorithm; ANN: artificial neural network; SVM: support vector machine; ANFIS: adaptive neuro-fuzzy inference system; PSO: particle swarm optimization; ACO: ant colony optimization; DE: differential evolution; TLBO: teaching learning-based optimization.
Discussion
From above analysis, it is seen that advanced data-driven models with AI are really needed for building energy analysis from single building level to regional and national level. Each predictive method possesses its own advantageous characteristics in certain cases of applications. This section provides a short discussion on the advantages and disadvantages of commonly used techniques reviewed before.
Note on single data-driven models
For regression model, it deals with a sequence of values obtained in accordance with an observation time. Generally, a regression model is relatively easy to develop with enough elements regressed and averaged. Yet, its weaknesses are also obvious: no structural interpretation and lack of flexibility. Also, compared with other data-driven methods, the regression models cannot capture nonlinear characteristics of the data series and thus have relatively low accuracy.
Thanks to the functions of model training and parameter learning, ANNs can perform nonlinear modelling without any prior knowledge about the relationships between the input and output variables. Therefore, ANN is good at treating nonlinear problems, which makes it very suitable for building energy prediction. However, ANNs are dependent on the initialization of weight values and suffer from local minima and slow convergence problems.
SVM is also able to achieve accurate prediction as long as kernel functions and parameter settings are well performed. Specially, the SVM method is very suitable for energy prediction when dealing with issues of small sample, high dimension and long-term data. But just like ANN method, SVM depends heavily on certain parameters of kernel function, which has to be optimized for good results.
Fuzzy model has been applied for energy forecasting because it is close to human experience through proper membership functions and rule base. In the absence of expert experience, neuro-fuzzy network also can create a FIS whose membership function parameters are adjusted by learning algorithms similar like ANNs. However, when dealing with high-dimensional data, fuzzy models will suffer from the curse of dimensionality problem. At the same time, to avoid being trapped into local minima, parameters of the membership function and rule base should be further optimized by EAs. Otherwise, the accuracy of fuzzy models is uncompetitive.
Grey model method can describe the behavior of systems which are inaccessible by ANNs, SVMs or fuzzy methods with limited data. The ease of calculation has made them well applied to load predictions of large scales, such as regional and national levels. However, when the initial data are noisy, the prediction accuracy will decrease.
Note on EA hybridized models
From what has been discussed above, it is obvious that single data-driven model may not be able to capture the entire characteristics of the building energy system. Under this situation, utilization of the EA hybridized model is a beneficial choice. By combining different EA methods, complex autocorrelation structures in the energy system can be modelled more stably and accurately. For instance, as one of the most important and widely used data-driven models, the ANN’s architecture and connection weights are designed by expert experience and gradient-based training, respectively. For a complex building energy system, there could be no expert knowledge to arrange the network structure in advance, and the gradient-based training algorithm is possibly trapped into local minima. For this reason, the combination of EAs and ANN takes advantage of the strength of EAs in global searching ability. The robustness and accuracy of the hybrid models may be both improved. The combination scheme is expanded to SVM method, fuzzy model method, etc. The benefits of such hybrid methods appear to be substantial which have been reported by a number of studies.
Comparative analysis of EA hybridized methods for building energy consumption forecast.
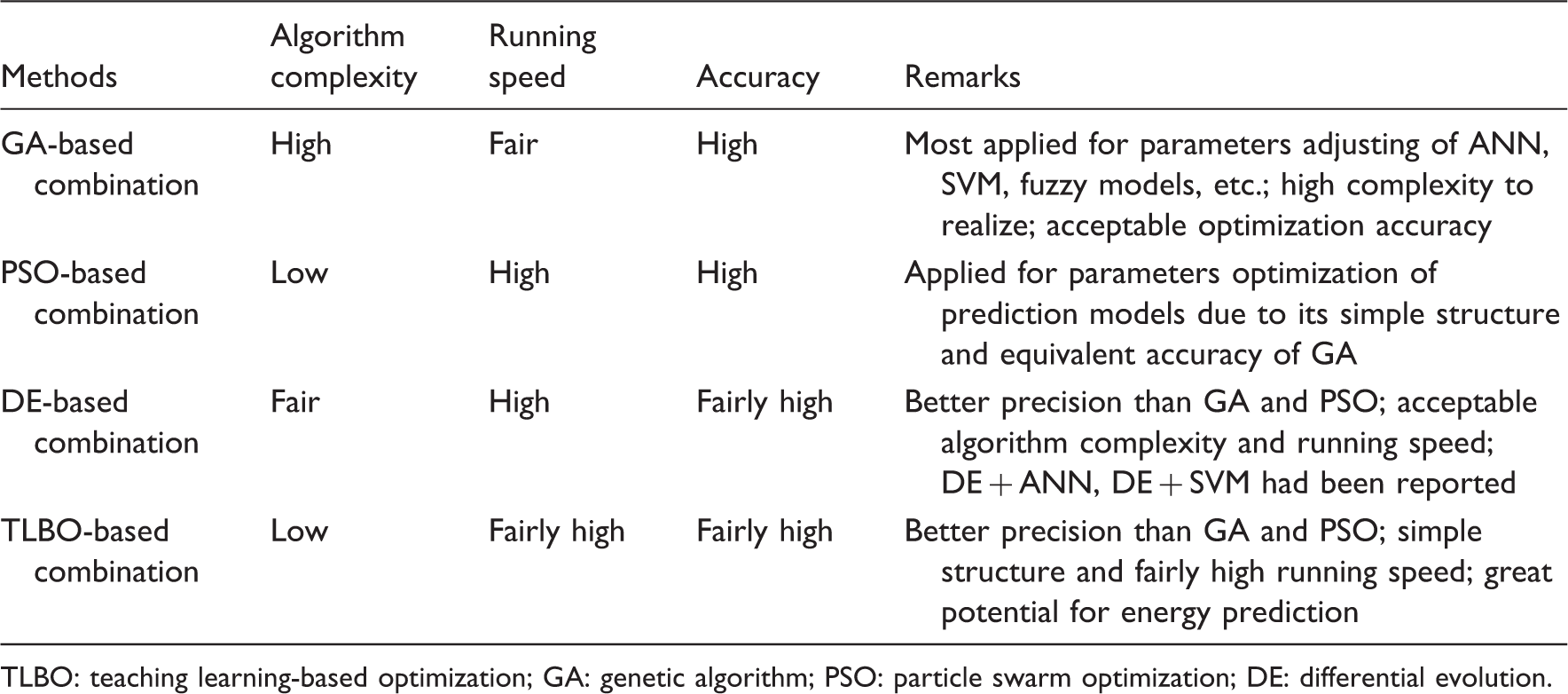
TLBO: teaching learning-based optimization; GA: genetic algorithm; PSO: particle swarm optimization; DE: differential evolution.
Conclusion
Building energy consumption prediction is important for building energy management, efficiency and fault diagnosis. This paper reviewed previous research works on forecasting energy consumption of buildings and in larger scales using data-driven models and EAs. Current research trends of energy prediction are analyzed from four aspects, namely, the scales of predicted energy, the types of predicted energy, the time scale of the prediction and the selection of input data. The theory and application of five commonly used data-driven models for energy prediction, i.e. regression model, ANNs, SVR, fuzzy model and grey model are reviewed. Each method has its own advantages and disadvantages for different types of applications. Furthermore, the combination and characteristics of hybrid models based on EAs are reviewed. From the survey, GA, PSO and DE are most popular algorithms used for data-driven models’ improvement. The capability of each EA hybridized model has been discussed in the above section. All of the hybrid models have shown significant potential in improving the robustness and accuracy of load forecasting.
In the future, several promising research directions of data-driven approaches applied in building energy forecasting would be: (1) For buildings without smart meters, how to extract key factors and predict energy consumption by analogous buildings; (2) Research on more targeted data-driven model construction for building energy prediction through more accurate big data mining; and (3) How people’s random behavior affects building energy consumption? The human random behavior model should be introduced into the building energy analysis.
Footnotes
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported by National Natural Science Foundation of China (Grant No. 61873114, 51705206) and China Postdoctoral Science Foundation (Grant No. 2018T110457, 2016M601741).