
Abstract
A wide variety of effect sizes (ESs) has been used in the single-case design literature. Several researchers have “stress tested” these ESs by subjecting them to various degrees of problem data (e.g., autocorrelation, slope), resulting in the conditions by which different ESs can be considered valid. However, on the back end, few researchers have considered how prevalent and severe these problems are in extant data and as a result, how concerned applied researchers should be. The current study extracted and aggregated indicators of violations of normality and independence across four domains of educational study. Significant violations were found in total and across fields, including low levels of autocorrelation and moderate levels of absolute trend. These violations affect the selection and interpretation of ESs at the individual study level and for meta-analysis. Implications and recommendations are discussed.
Recent legislation (e.g., Individuals With Disabilities Education Improvement Act, 2004; No Child Left Behind Act, 2002) as well as public and private entities (e.g., What Works Clearinghouse, The Wing Institute, Task Force on Evidence-Based Interventions in School Psychology) have prioritized the science of establishing evidence-based practice in education. As part of this dialogue, there has been renewed interest in developing the technology of effect sizes (ESs), significance testing, and research synthesis for single-case designs (SCDs; see reviews by Franklin, Allison, & Gorman, 1997; Levin, Ferron, & Kratochwill, 2012; Parker & Brossart, 2003; Parker, Vannest, & Davis, 2011; Shadish, Rindskopf, & Hedges, 2008). The purpose of such statistics is not to replace more venerable methods for determining outcomes with SCDs but to supplement them with a common language of effects.
There is no universal set of statistics that are accepted under all conditions for group-design analyses. Rather, certain statistics should be avoided in the case of severe violations of assumptions in favor of tests robust against such threats (e.g., nonparametric statistics), often at the cost of power and precision of estimation. It stands to reason that the same logic should apply to SCDs—ESs should control for detrimental data characteristics, but in the name of parsimony, only those characteristics that are influential. Few researchers defend their selection of single-case ESs, leaving the reader to wonder how valid these statistics are and whether a more simple or elaborate ES would be more appropriate.
ES selection should be justified based on the robustness of the statistic against specific threats present, power, interpretability, concurrent validity with other metrics, and Type I/II error rates. Given the small sample size of many SCDs (Shadish & Sullivan, 2011), power in particular must be balanced against robustness to threats. Examples of such comparative studies include Manolov and Solanas (2013), Manolov and Solanas (2008), and Parker and Brossart (2003). These studies used either simulated or existing data to outline conditions by which certain ESs function optimally. However, these conditions now need to be matched to properties of the data.
Assumptions of Single-Case Data
Specific assumptions that must be fulfilled for valid analysis depend on the statistic used. A discussion of all contemporary ESs and their data assumptions is beyond the scope of this review. However, Table 1 identifies many contemporary ESs and what is known about their vulnerability to the assumptions germane to this study. Single-case regression techniques may be able to correct certain violations of independence at the cost of vulnerabilities to other assumptions. Nonparametric options, including the large family of ESs based on nonoverlap of observations, do not assume normality and homogeneity of variance and have the desirable characteristic of being comparatively easy to calculate and interpret. However, these ESs may suffer complications resulting from severe violations of independence more so than some other ESs, have lower power relative to their parametric counterparts when parametric assumptions are met, and also can have range limits. Simply put, ESs should be carefully selected and the rational for selection explained.
Sampling of Contemporary ESs and Their Related Assumptions.
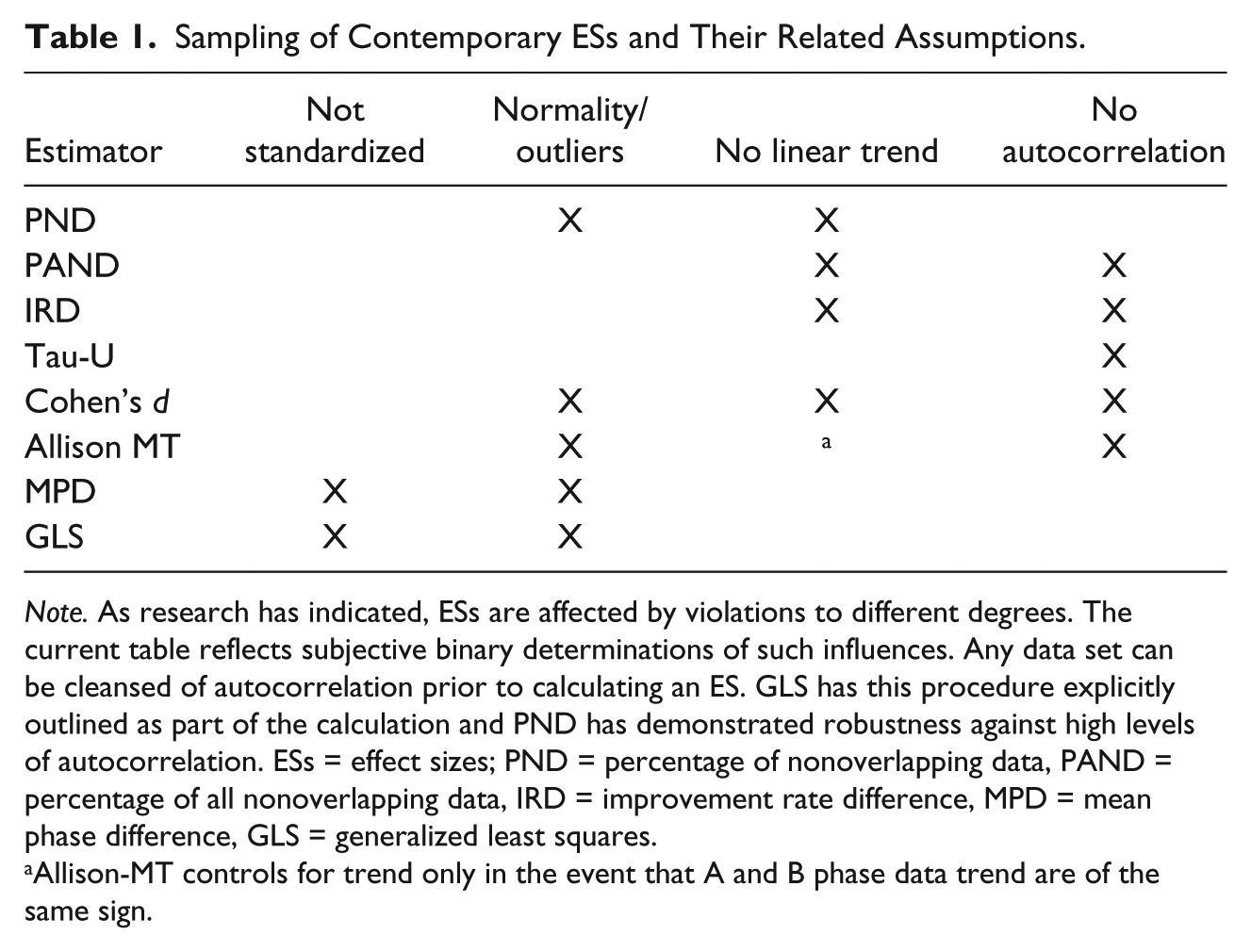
Note. As research has indicated, ESs are affected by violations to different degrees. The current table reflects subjective binary determinations of such influences. Any data set can be cleansed of autocorrelation prior to calculating an ES. GLS has this procedure explicitly outlined as part of the calculation and PND has demonstrated robustness against high levels of autocorrelation. ESs = effect sizes; PND = percentage of nonoverlapping data, PAND = percentage of all nonoverlapping data, IRD = improvement rate difference, MPD = mean phase difference, GLS = generalized least squares.
Allison-MT controls for trend only in the event that A and B phase data trend are of the same sign.
Normality and independence are two common assumptions most researchers are familiar with. Normality is defined as whether the theoretical distribution a sample is drawn from follows the well known “bell-shaped” curve (Cohen, Cohen, West, & Aiken, 2003). Independence in the current study is defined as the degree residuals among adjacent observations are uncorrelated—one observation should convey no information about the next. SCDs consistently violate this assumption due to their within-subject focus. This can result in the presence of trend and autocorrelation. Trend is defined as any systematic pattern within or across phases other than a level shift across conditions. There has been discussion in the literature regarding whether single-case ESs should control for trend, allow trend to contribute to ESs, model trend in isolation, or ignore trend all together, with linear trend nearly always being the focal point (e.g., Parker et al., 2011b). Recently published statistics have included trend parameters (Maggin et al., 2011; Manolov & Solanas, 2013; Parker et al., 2011b).
Autocorrelation, or serial dependency, is defined as the degree of relationship between each datum point and a preceding datum point, most often the immediately preceding observation (Lag 1 autocorrelation). This can be interpreted as how well a time-series data set is explained by a lagged version of itself (Bence, 1995; Huitema & McKean, 1991). Addressing autocorrelation is challenging given the complexity of estimation and cleansing at the individual phase level, especially with lower phase n (Huitema & McKean, 1991). The severity of autocorrelation in SCDs and the need for corrections have been debated thoroughly in the literature (e.g., Bence, 1995; Busk & Marascuilo, 1988; Huitema, 1985; Jones, Weinrott, & Vaught, 1978; Shadish & Sullivan, 2011). Contemporary research has demonstrated that if autocorrelation is present, such fixes are worth considering (Bence, 1995; Levin et al., 2012; Manalov & Sonalas, 2008).
Manolov and Solanas (2008) used Monte Carlo simulations to test the relative merits of five different ESs: percentage of nonoverlapping data (PND), Cohen’s d, Gorsuch’s trend analysis, White et al.’s d, and Allison and Gorman. The authors found that autocorrelation had a general positive linear relationship with ES magnitude with regression-based procedures being the most affected relative to simpler indices (PND, Cohen’s d).
Manolov and Solanas (2012) found that the appropriate use of two recently published SCD ESs—the generalized least squares (GLS) and the mean phase difference (MPD)—was contingent on the properties of the data. Under the specific occurrence of positive baseline autocorrelation and negative intervention phase autocorrelation, GLS was preferable to the MPD. Modeling trend differences were more accurately represented by GLS as well. However, MPD performed well overall, could be calculated more easily, and avoided possible complications in the estimation and cleansing of autocorrelation. The study highlights how knowledge of violations of assumptions can guide the researcher to an appropriate statistic.
To highlight the effects of autocorrelation, Figure 1 recreates data from baseline and intervention of Participant 3 from a math intervention (MI) study authored by McDougall and Brady (1998). Baseline serial dependency was ρ = −.05 (virtually none) and intervention autocorrelation ρ = .44 (severe). Cleansing was applied to the intervention condition, shrinking autocorrelation to −.12. The change shrinks Tau-U by 14%, R2 by 10%, and the MPD by 12%, providing an example of why knowledge of the properties of the data is useful in framing the magnitude of the ES. One may also note that the positive autocorrelation leads to visible positive trend in the intervention phase. Indeed, positive autocorrelation and positive trend share data characteristics (Yue, Pilon, Phinney, & Cavadias, 2002), making them correlated in many circumstances.
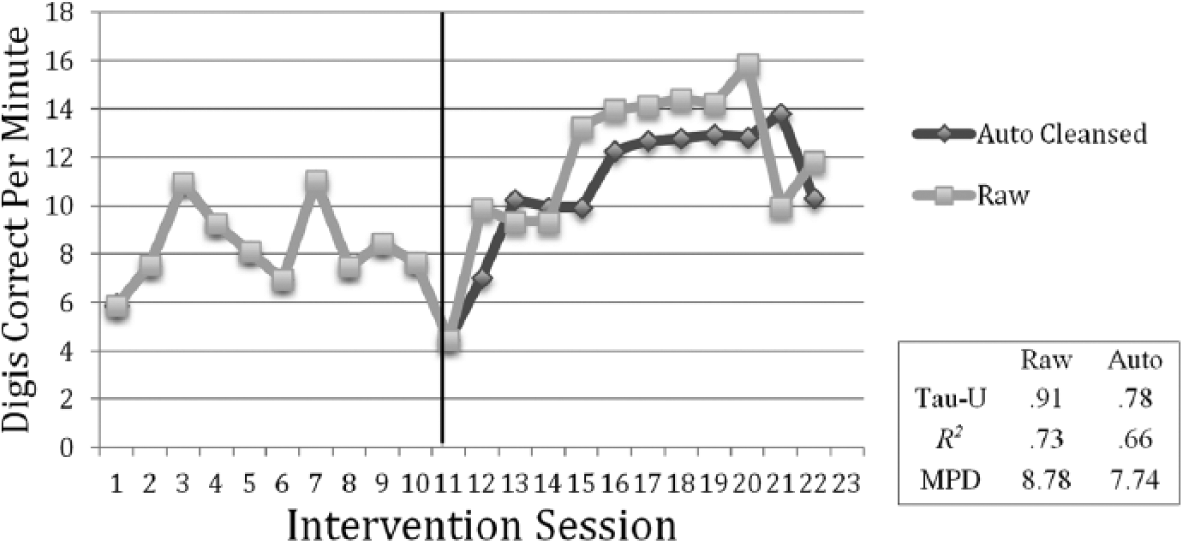
Sample single-case data from McDougall and Brady (1998).
Prior research has suggested that autocorrelation is present in SCDs in low and variable amounts. Shadish and Sullivan (2011), in a large cross-disciplinary sample of SCD studies, calculated a meta-analytic mean of
In summarizing these assumptions, it is worth noting that autocorrelation and trend are not necessarily problematic from an experimenter’s perspective. Perfect autocorrelation and trend would yield a perfectly stable trend line, stability being a desirable characteristic for many SCD researchers (Kazdin, 1982). Thus, such features are not to be necessarily avoided. Rather, researchers must become knowledgeable about the likelihood of such occurrences, be knowledgeable about the suitable transformations and ESs, and be able to interpret them appropriately given the nature of the data.
SCDs and Meta-Analysis
While widely accepted methods for meta-analysis exist for group-design data, such a framework has yet to emerge for SCD synthesis. A variety of methods have been proposed, involving parametric and nonparametric statistics (e.g., Beretvas & Chung, 2008; Parker & Vannest, 2012; Shadish et al., 2008). Researchers have often attempted to account for this uncertainty by calculating meta-analytic results across different ESs. This procedure constitutes a form of sensitivity analysis (The Cochrane Colloboration, 2012) and—theoretically—allows one to evaluate the robustness of findings by examining the convergence of results calculated using different methods.
If ESs within the same meta-analysis are differentially affected by existing violations stemming from a single data set, this form of sensitivity analysis may no longer be valid because disparate results would be expected. This raises the question as to why one would compare, for example, a nonparametric with a parametric procedure or would expect more generalizable conclusions if two similar nonoverlap procedures are used as opposed to one. If violations of assumptions were moderate to severe, this would have implications for how past and future meta-analyses are interpreted that have used this form of sensitivity analysis.
Current Study
While the extant literature highlights the pitfalls of selecting an ES that is mismatched with violations or interpreted without respect to these violations, it is not known how concerned applied researchers should be. With this in mind, the current study seeks to answer the following questions:
What is the prevalence and severity of violations of normality and independence within the school-based SCD literature?
Are these violations consistent across disciplines or phase types?
If violations were found to be ubiquitous across the literature, this would have significant implications for researchers. While knowledge of such violations does not directly lead to a complimenting ES, an understanding of the context of the data allows more informed choices based on what is known about how certain statistics respond.
It seems unlikely that the same combination of violations would occur consistently across the different applied areas that use SCDs. Therefore, data from four independent domains of school-based research were compared. Phase type (Baseline, Intervention, Maintenance) was also selected as a moderator, as it is possible that trend or nonnormality may be more present in one phase over another. As an example, it may be that baseline phases have higher levels of nonnormality because subjects often show a floor effect on a skill to be learned during intervention.
Method
Sample
Single-case data from three domains within the school-based intervention literature were collected in prior studies. This included populations of studies focused on the application of school-wide positive behavior support (SWPBS), teacher performance feedback (PF) to enhance treatment integrity, and individual math interventions (MI). These data sets were gathered for the purpose of traditional SCD meta-analysis for the former two groups and are described in detail in Solomon, Klein, Hintze, Cressey, and Peller (2012) and Solomon, Klein, and Politylo (2012). The latter group of studies was collected as part of a recent effort to evaluate an outcome efficiency metric for SCD MI’s (Poncy, Solomon, Moore, Simons, & Duhon, 2013). As such, these research syntheses represented the entirety of the peer-reviewed literature within their respective fields at the time of publication. Dependent variables (DVs) for SWPBS included office discipline referrals and various direct measures of student problem behavior. For PF, DVs included completed treatment steps and the frequency of target behaviors (e.g., behavior specific praise). The MI DV was exclusively digits correct per minute.
A fourth data set was gathered specifically for inclusion in this study. This data set focused on the remediation of general education, classroom-based, individual student externalizing problems (Behavior). The application of individual interventions over classwide interventions separates this discipline from SWPBS and there were no shared studies between these two areas. This discipline was chosen because it represented an area of the SCD field that is popular, applicable to school-based interventionists, and was not covered by the other three domains. The search for this pool of studies occurred in the PsychINFO, ERIC, and Academic Search Premier databases in December of 2012 using the search terms “classroom,” and “behavior” and “single subject” or “single case,” yielding 235 and 130 results, respectively. From this pool, a convenience sample of 24 studies was selected, which was the median number of studies for the other three groups. DVs included off-task and on-task student behaviors and correct student responses. The 24 studies selected were the first ones to meet criteria within the search results. Table 2 describes characteristics of each group of studies. Overall, 104 studies were included, which amounted to 1,576 phases of data.
Characteristics of Sample.
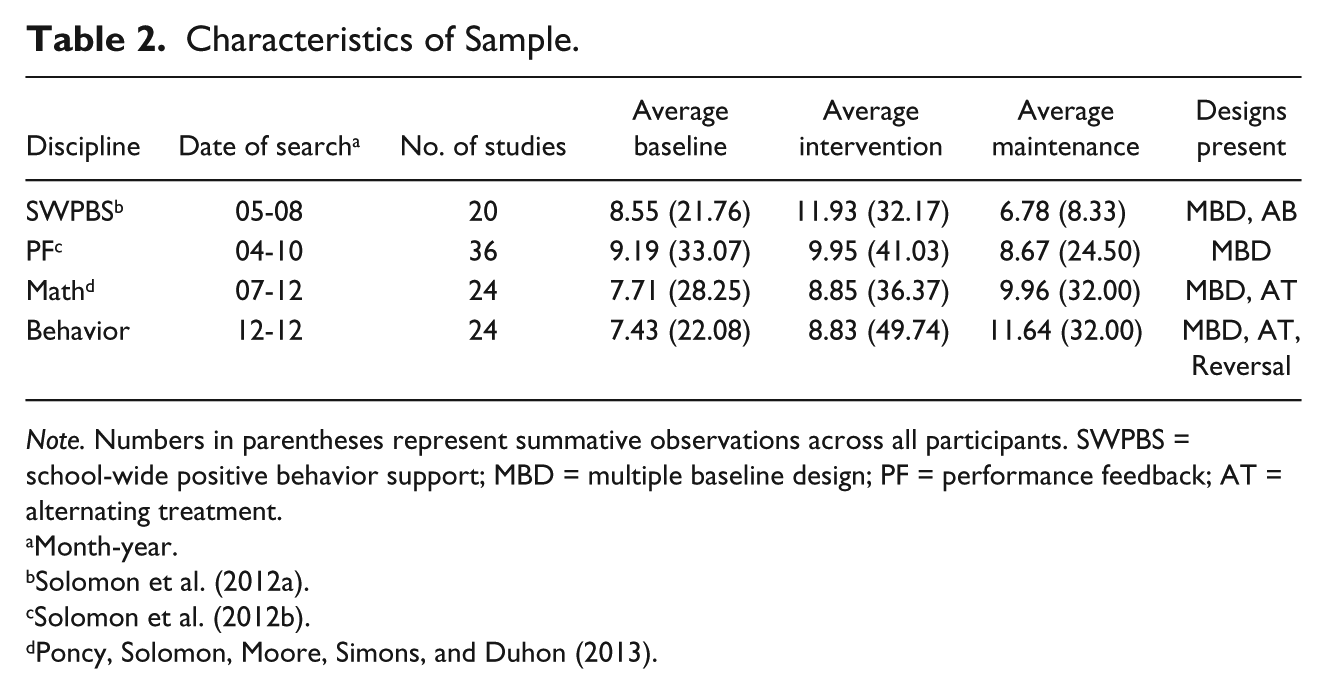
Note. Numbers in parentheses represent summative observations across all participants. SWPBS = school-wide positive behavior support; MBD = multiple baseline design; PF = performance feedback; AT = alternating treatment.
Month-year.
Data Extraction
Single-case articles typically do not present the requisite information required to calculate ESs, autocorrelation, trend, or skew. Fortunately, Parker et al. (2005) outlined procedures for digitizing time-series graphs. Shadish et al. (2009), using a similar procedure with the program UnGraph, reported high reliability and found that the digitized data were a faithful representation of the original observations. All data analyzed in the current study were recreated using this digitizing procedure.
Moderators and DVs
The two moderators evaluated were phase type and discipline. The levels of discipline were previously defined as SWPBS, PF, MI, and Behavior. The levels of phase type were Baseline, Intervention, and Maintenance. These two moderators addressed whether violations occur in greater severity for certain types of populations and for different phases. To evaluate violations of assumptions along these dimensions, measures of autocorrelation, trend, and normality were calculated for each phase of each study. Only phases greater than six datum points were included, as this was the minimum number of points Huitema and McKean (1991) reviewed in their analysis of the effects of small sample bias in the estimation of Lag 1 autocorrelation. This eliminated 31% of individual phases across all studies.
Autocorrelation
Lag 1 serial dependency was measured using a common formula, as reported in Huitema and McKean (1994) and Shadish, Rindskopf, Hedges, and Sullivan (2013):
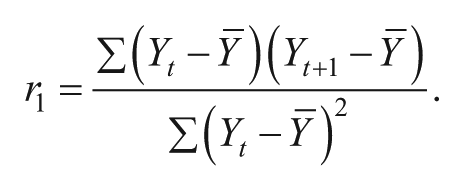
One may note the similarity to the Pearson’s correlation coefficient, which is how the resulting statistic is interpreted. Raw and absolute values of autocorrelation were calculated, because autocorrelation in either a positive or negative direction poses challenges in the interpretation of ESs. Because the term
Trend
Linear trend can be calculated in a variety of ways, most commonly by regressing the DV onto time. The resulting ordinary least squares (OLS) unstandardized
Normality
Normality was evaluated by calculating estimates of skew and kurtosis using the standard values provided by SPSS 20. Absolute values were calculated because excessive skew and kurtosis result in similar accommodations (e.g., nonparametric analysis).
Analysis
Meta-analytic procedures were used to control for sampling error. Procedures outlined by Shadish et al. (2012) for the random-effects meta-analysis of serial dependency were used to calculate weighted autocorrelation values. Trend values were synthesized using a standard random-effects model (Cooper, Hedges, & Valentine, 2009). Monotonic slope was accommodated by converting Kendall τ’s to Pearson r’s using the equation drawn from Kendall (1970), rτ = sin(.5πτ). Heterogeneity within and across moderators (Q) was measured, which was also converted into a percentage of present heterogeneity (I2; Higgens & Thompson, 2002) to aid interpretation. Due to small sample size for monotonic trend, only the omnibus mean is reported without comparisons within moderators.
Skew and kurtosis were synthesized using a fixed effects meta-analysis (Cooper et al., 2009). Data were doubly weighted so that each article could only contribute up to three ESs: one for Baseline, Intervention, and Maintenance. At the article level, data were weighted by sample size. At the meta-analysis level, studies were weighted by the inverse of their variance, which was corrected for overall sample heterogeneity in the case of random-effects synthesis.
Planned comparisons were conducted using analog ANOVA for the DVs of autocorrelation and parametric trend. This was composed of comparisons of all disciplines (i.e., SWPBS, PF, MI, Behavior) collapsed across phases and between phases (i.e., Baseline, Intervention, Maintenance) collapsed across discipline. The Bonferonni correction was applied to control for multiplicity issues, although this did not invalidate any previously significant findings.
Results
Autocorrelation
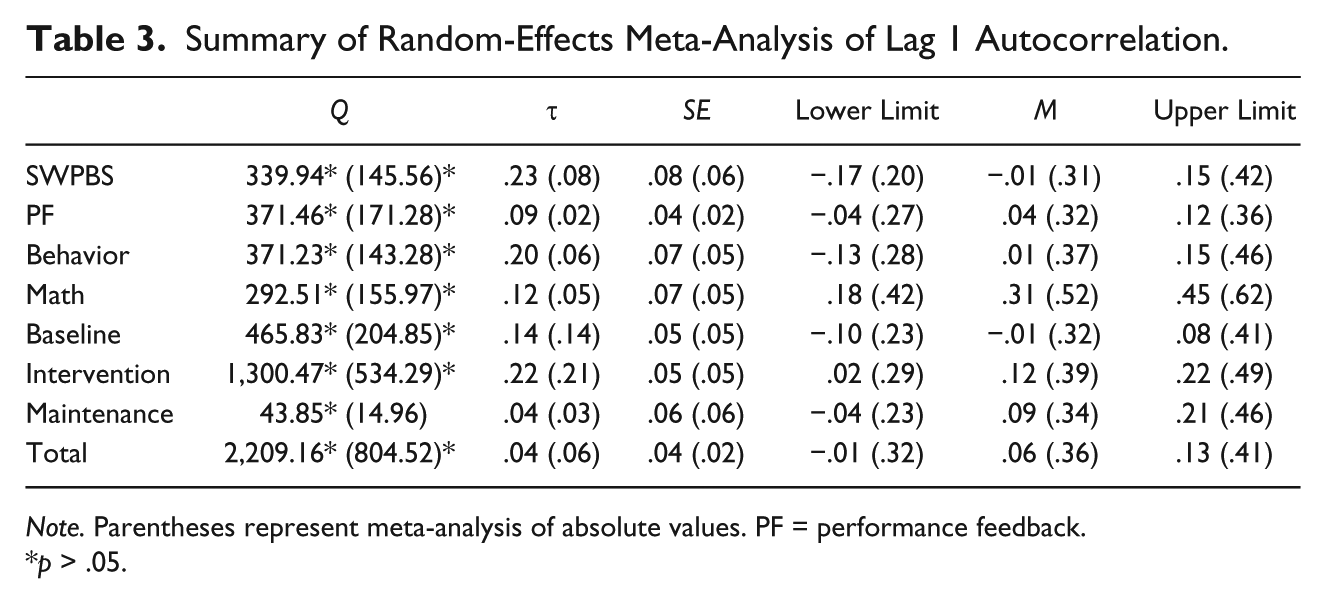
Autocorrelation across studies was low and heterogeneous (see Table 3). The overall mean was not significantly different than 0,
Summary of Random-Effects Meta-Analysis of Lag 1 Autocorrelation.
Note. Parentheses represent meta-analysis of absolute values. PF = performance feedback.
p > .05.
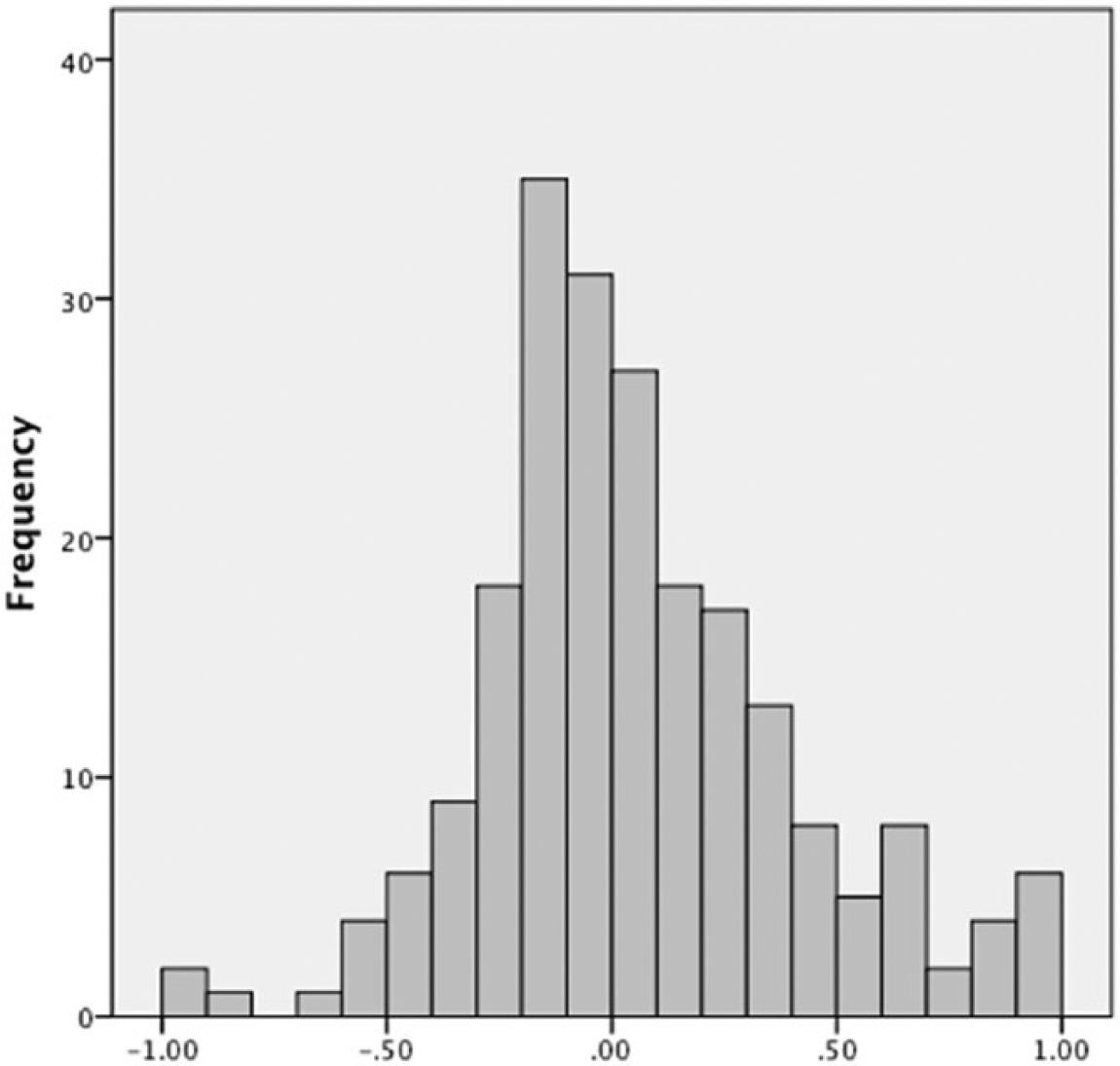
Histogram of phase-level autocorrelation.
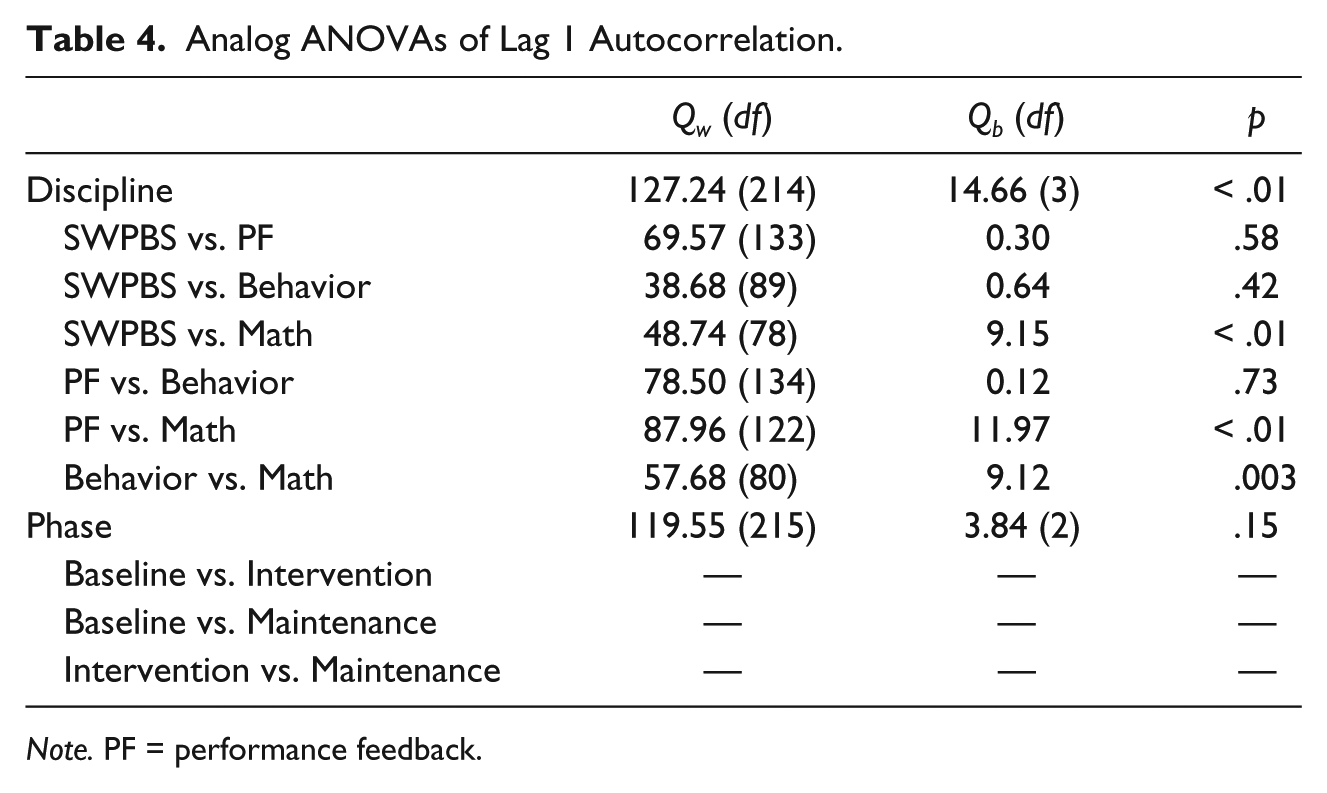
Analog ANOVAs (Table 4) resulted in significance for the discipline moderator (Qb = 15.66, p = .001) but not for phase type. Post hoc analysis yielded significant differences between SWPBS and MI (Qb = 9.15, p < .01), PF and MI (Qb = 11.97, p < .01), and Behavior and MI (Qb = 9.12, p < .01), with MI being greater in all cases.
Analog ANOVAs of Lag 1 Autocorrelation.
Note. PF = performance feedback.
Trend
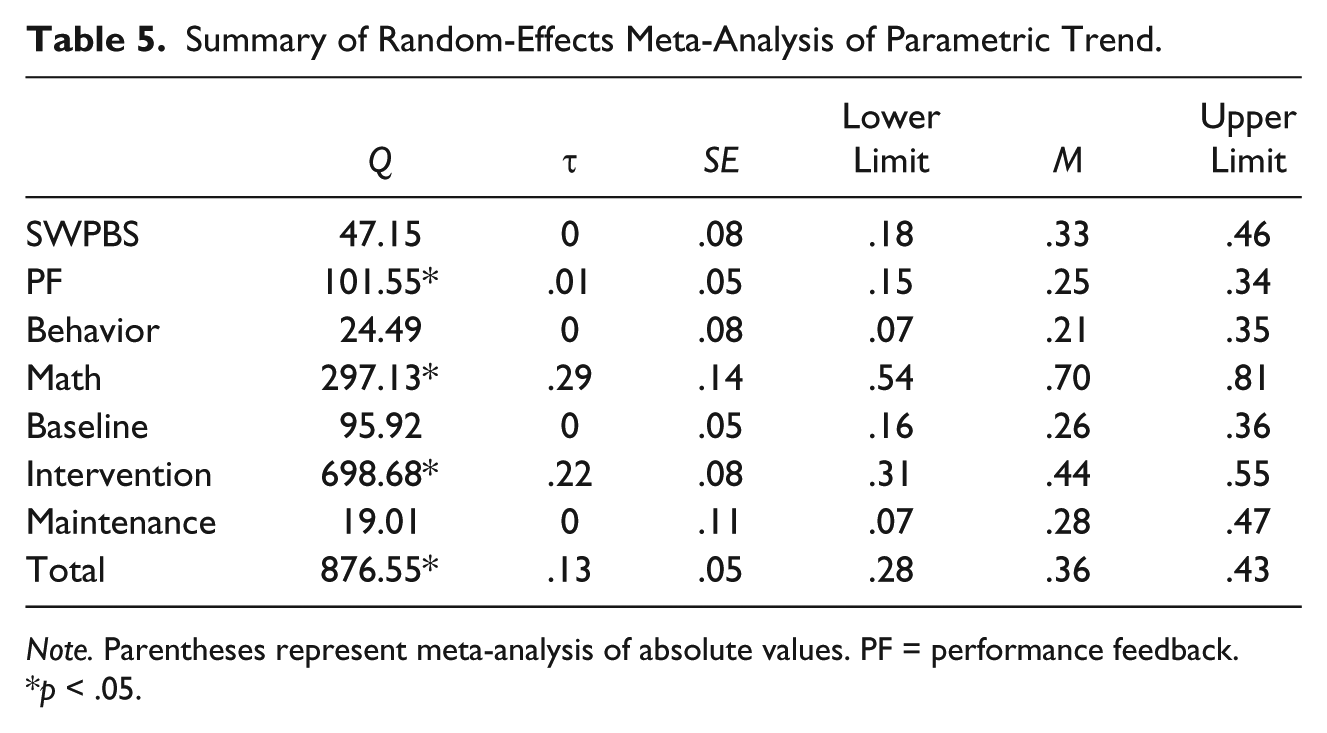
Parametric trend values (
Summary of Random-Effects Meta-Analysis of Parametric Trend.
Note. Parentheses represent meta-analysis of absolute values. PF = performance feedback.
p < .05.
Analog ANOVAs of Parametric Trend.
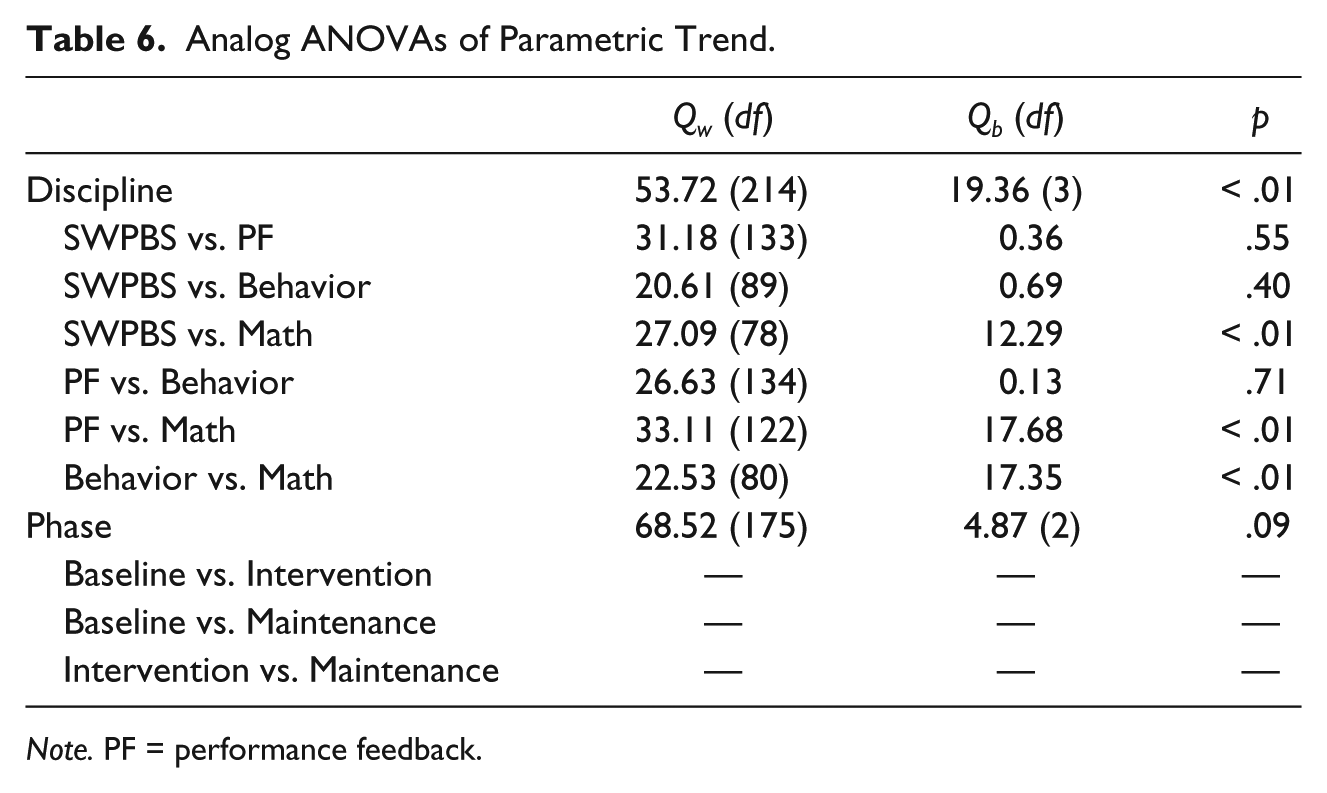
Note. PF = performance feedback.
Given the small number of slopes analyzed using the KRC, only omnibus statistics are reported. Overall heterogeneity was significant, Q = 101.08, p < .01, and I2 = 60%. The overall mean was
Skew and Kurtosis
Tables 7 and 8 show that skew and kurtosis were present at significant levels for all levels of both moderators. However, levels were low, typically mild to moderate if values within the range of −2 to 2 are used as a rough benchmark. Inspection of the data showed that only seven study phases, collapsed across studies, yielded skew values outside this range, which represented 3% of included study phases. Thirty-seven study phases (17%) had excessive kurtosis values. Organized by level, Intervention conditions had the highest level of skew and kurtosis means were fairly equal across moderators.
Summary of Generic Estimate Meta-Analysis of Skew.
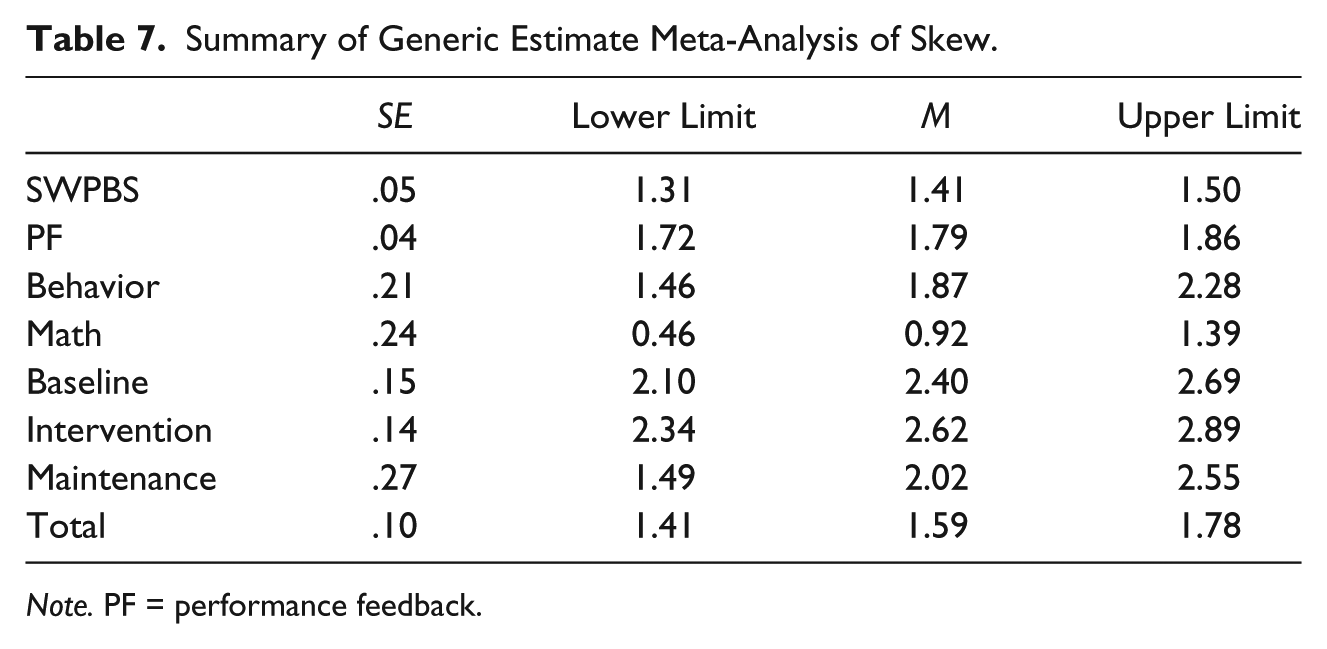
Note. PF = performance feedback.
Summary of Generic Estimate Meta-Analysis of Kurtosis.
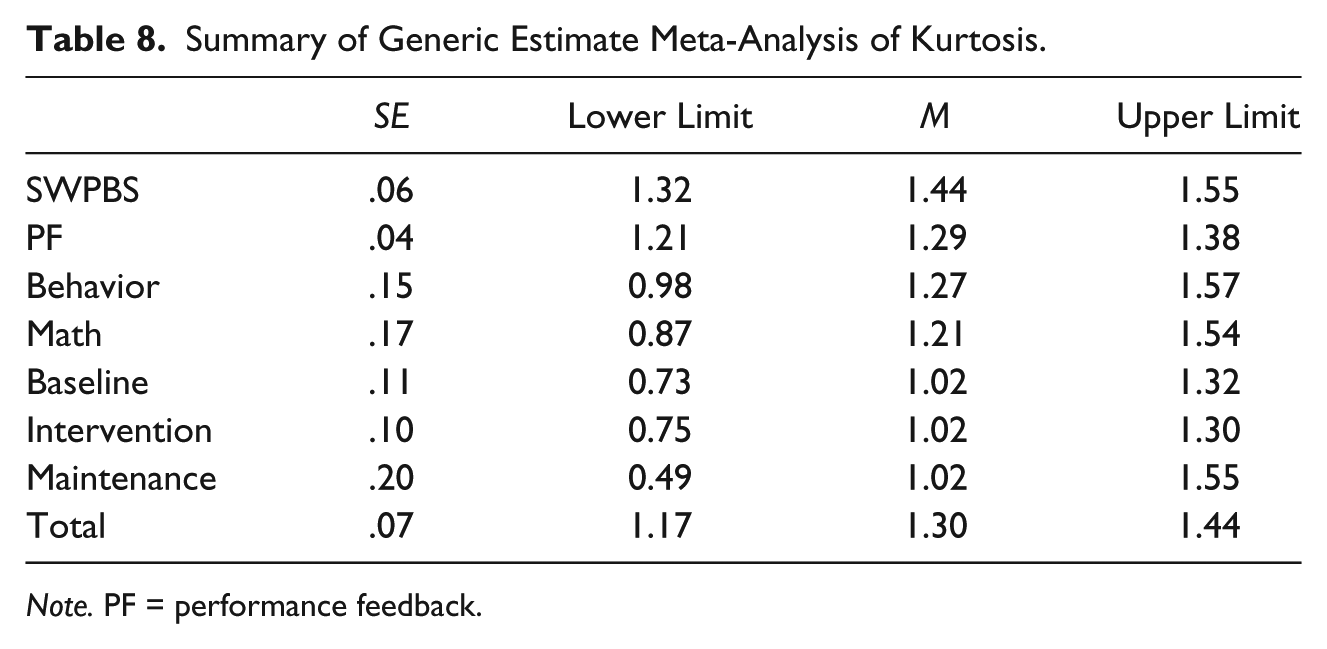
Note. PF = performance feedback.
Discussion
The purpose of the current study was to investigate the severity of assumption violations within SCDs. A greater knowledge of these patterns may help guide researchers in selecting appropriate ESs and provide additional context for their interpretation. Results demonstrated that low and variable levels of autocorrelation, moderate and significant levels of trend, and relatively normal data patterns emerged across studies. Moderation was present, suggesting that certain types of studies have more severe levels of trend and autocorrelation than others. Overall levels of heterogeneity affirm the need for researchers to review assumption violations in their data. This is a good habit regardless of whether visual analysis, ESs, or both techniques are used.
Autocorrelation
Shadish and Sullivan (2011) found that autocorrelation within a sample of 113 studies was significant; however, the average effect was small and variable. The current study affirms this at the omnibus level. However, studies that focused on MI had more elevated yet inconsistent levels of autocorrelation.
Resulting ESs drawn from this area may need to be taken with a grain of salt; ESs will likely be inflated due to suppressed standard errors and significance tests more generous than their nominal levels. As an example, Manolov and Solanas (2008) found that positive autocorrelation of ρ = .30 inflated the Allison and Gorman R2 (a mean + trend procedure) by roughly .09 and inflated the point biserial R2 by .04 (
Given these results, it can only be stressed that this assumption should be reviewed prior to the calculation of ESs, if anything to provide a more accurate context for the magnitude of effect. High levels of heterogeneity suggest that there is no magic bullet ES, even within discipline. The researcher will need to make an informed choice, recognizing that within any pool of studies, some effects will be more biased than others. To clarify this issue, researchers conducting meta-analysis may want to graph their review of assumptions. Shadish and Sullivan (2011) provided one example of how to graph autocorrelation by study sample size.
It also is worth noting that given the high frequency of phases with small n (<6) in the current sample, reliable cleansing would often not be possible. For the GLS, Maggin et al. (2011) recommended that there be at least 5 datum points per phase and at least 20 total points. Although the authors suggested that points could be summative across participants, the assumption of equal serial dependency comes with this adjustment. A similar issue occurs with trend; the estimation of such trend should be reliable, which is largely a function of baseline n. If trend cannot be reliably estimated, the effect on trend-control ESs can be severe, and level change ESs may be a wiser choice.
Trend
Results indicate that absolute levels of parametric trend were consistently present, with values ranging from small to moderate. MI in particular showed high levels of trend (on average, 49% of explained variability of within-phase data), while trend within behavior interventions studies was fairly modest (4% of explained variability). Levels of nonparametric trend were also elevated, suggesting that this is a concern for studies with nonnormal data as well.
These significant levels of trend pose challenges to researchers and will affect statistical outcomes by increasing decision error. A classic example is in the case of across-phase trend. If a trend extends across phases, as it did in 57% of the current sample, Type I error rates will be elevated for mean difference or overlap procedures. A similar effect occurs for visual analysis in the presence of trend (Mercer & Sterling, 2012). This can be controlled through proper design specification, because phase reversals would expose the phenomena if such reversals are possible. It is worth noting that few meta-analyses have attempted to account for trend. None of the extant MI meta-analyses have done so.
The discussion on how best to model trend is still active, with recommendations, including combining the effects of trend- and mean-level difference (e.g., GLS, Tau-U + Trend, MPD), controlling for trend (e.g., ALLISON-M, Gorsuch’s trend analysis, Tau-U), ignoring the issue (e.g., Cohen’s d, NAP, percentage of all nonoverlapping data [PAND]), or modeling trend and/or level differences separately (Theil-Sen, SLC). The more recent generation of trend-control ESs including the GLS, SLC/MPD, and Tau-U each have their own advantages and disadvantages, but as a whole, pose distinct benefits over their older counterparts.
Normality
Sample data can deviate from expected normality due to small n, outliers, or an underlying nonnormal population of observations. While ceiling and floor effects, which occurred for a number of reviewed graphs, would skew distributions, generally speaking across disciplines and phases data, normality was evenly distributed. This violation was most pronounced for Intervention and then Baseline phases, where data had the greatest tendency to hit minimum or maximum y-axis values. In the event of nonnormality, ignoring other issues, nonparametric procedures such as permutation tests or nonoverlap ESs (e.g., PAND, Tau-U) are well suited.
Summary
Current findings suggest that for most experiments, simple level difference ESs will be calculated in the presence of trend. However, trend estimates varied, and in the situation of low levels of trend or questionable trend, level difference approaches (e.g., improvement rate difference [IRD], Cohen’s d, PAND) are probably the most appropriate. In the majority of cases where trend is present, certainly trend-controlled procedures are called for and should be used far more often then they currently are. These methods also are generally robust to autocorrelation; however, the GLS remains a strong option to handle trend and autocorrelation when its assumptions are met and the researcher possesses the technical ability to calculate it.
Limitations
Autocorrelation was likely underestimated, with increasing negative bias as study N decreased. While corrections for this bias have been proposed (Huitema & McKean, 1991, 1994), this introduces new problems in the synthesizing of data. To combat this issue, random-effects meta-analysis was used and phases with less than six datum points were removed. Research has shown, however, that even with samples of six or more datum points, estimates of autocorrelation can still be suppressed (Huitema & McKean, 1991, 1994), which is a concern for meta-analysis and estimation at the individual study level.
Measurement issues also affect trend in the rescaling of the x-axis time variable. For example, studies that sampled participant behavior once a month would have trend treated in the same way as a study that sampled behavior every hour, despite the fact that different trends might have emerged over the broader time scale. This would complicate meta-analysis as well and is something researchers should be weary of, yet have largely ignored. Various time scales may also be present within a single phase; it is not always that the case observations occur on a perfectly regular schedule. This is a limit of all current trend-control ESs and represents a circumstance where mean-level statistics may be a wiser choice.
The current study only addressed linear trend in the case of the parametric estimates. It is plausible that curvilinear trends exist frequently in SCDs. However, this is more difficult to reliably test for, if not impossible in some cases, given the small within-phase n that was frequently observed. High levels of heterogeneity also limit generalizable conclusions. Although significant differences were noted, the results were not clear enough to absolve researchers of performing their own review of assumptions.
Finally, it is worth reiterating that the current study sheds light on the context of ES selection and interpretation, but results do not lead to clear links between specific data sets, chosen ESs, and the degree of over- or underestimation of effects. These relationships change based on a number factors, one of which is the constantly evolving literature on the nature of these relatively new parameters.
Conclusion
The purpose of the current study was to investigate the severity of some common violations of assumptions in the SCD literature. Converging with extant research, it was found that autocorrelation exists in small to moderate amounts for certain groups of studies and varies significantly. Trend was more pronounced, although was heterogeneous for two levels of the moderators, while normality violations occurred at fairly modest levels. Moderator analysis explained significant yet small amounts of heterogeneity in the sample.
Given these results, the accommodation of autocorrelation and trend must be decided on a study by study basis and may inflate Type I error rates for MI studies or closely related disciplines in particular. These parameters were significant enough that trend-control ESs should be considered far more often than they currently are. Given that single-case methods, as opposed to group-design analysis, are intended to be used as much in applied practice as in research, a variety of ESs, ranging in complexity as a function of precision, may be required. Within a research context, an investigation of assumptions is always highly encouraged and will be crucial in informing the best practice in analysis.
Footnotes
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.