
Abstract
In principle, the fundamental concepts
Recent advances in natural language processing (NLP) have enabled researchers to use the linguistic output of millions of individuals to characterize human concepts at a massive, previously inconceivable scale. Here, we used NLP tools (specifically, static word embeddings trained on the Common Crawl corpus) to investigate collective understanding of three fundamental concepts:
The concept
A secondary goal of the present research was to provide a preliminary exploration of White-centric biases in collective concepts. In principle,
Investigating Collective Concepts Using NLP Tools
According to classic arguments in linguistics, aspects of the meaning and function of a word—and the content of the concept denoted—can be captured by observing the word’s linguistic context (Harris, 1954; Lenci, 2018). This is known as the distributional semantics hypothesis. For instance, in the sentence, “Each morning, Joe boiled water in the balak for tea,” a naive reader might guess that balak means something similar to kettle, because the other words alongside balak also frequently co-occur with kettle (McDonald & Ramscar, 2001). Inspired by this idea, vector-based language models distill information about a word’s co-occurrences with other words in a corpus into a word embedding—a multidimensional vector that carries information about the word’s context, and thus its meaning (Mikolov et al., 2013, 2018; Pennington et al., 2014). These NLP tools thus create vector-based representations of word meaning based on information about a word’s linguistic contexts (syntactic and semantic) in a language corpus.
Because the vector embedding for a word is constructed based on information about which other words it co-occurs with (i.e., its typical linguistic context), the similarity between any two words’ embeddings captures the similarity between the two words’ linguistic contexts—and thus, according to the distributional semantics hypothesis, the similarity in their meanings. Notably, two words can have similar word embeddings even if they rarely co-occur with each other. For instance, consider the words scientist and researcher. These two words might rarely co-occur in the span of a single sentence (because they are redundant with each other, so speakers tend to use one or the other), but they nevertheless have similar word embeddings (similarity score = 0.77) because they often occur in similar contexts (e.g., alongside words such as lab, data, and rigorous; Mikolov et al., 2018). Word embeddings can thus capture complex semantic relationships with high precision—for example, that brother is to sister as grandson is to granddaughter (Mikolov et al., 2013).
When word embeddings are trained on large-scale corpora of text written by millions of individuals, they begin to capture collective concepts (see also collective representations; Durkheim, 1915; Moscovici, 1963). Collective concepts reflect consensus, widely shared views in a community (Momennejad, 2022). These ideas are “in the air” and familiar to people in a community regardless of whether they personally endorse them. The fact that collective concepts can persist regardless of any individual’s personal endorsement makes them resistant to change, and thus particularly important to understand.
Recently, researchers have begun to use word embeddings to investigate social biases in collective concepts (Caliskan et al., 2017; Charlesworth et al., 2021; Goodhew et al., 2022; Lewis & Lupyan, 2020). Some of this NLP work draws on the now classic implicit association test (IAT); for instance, IAT research consistently finds that science and math concepts are more associated with men in individuals’ minds and arts and humanities concepts are more associated with women—that is,
Theory and Prior Evidence on Androcentrism
So far, research using NLP tools has tended to focus on well-studied social biases, in part to establish the validity of this approach. Here, we investigated a less well-studied, but perhaps more fundamental, social bias: androcentrism. Interdisciplinary theories of androcentrism argue that societies are androcentric (or male-centric
3
), in that men are collectively understood to be a gender-neutral standard whereas women are regarded as a gendered exception to this norm (Bem, 1993; de Beauvoir, 1949/2010; Gilman, 1911; P. Martin & Papadelos, 2017). In terms of psychological processes, theories of androcentrism propose that men are (proto)typical exemplars of the generic, superordinate
Empirical studies using traditional social-psychological methods have found evidence for androcentrism, including a tendency to associate (a) men with generic
Androcentrism is less commonly studied compared with other forms of gender bias (e.g.,
The first goal of the present investigation was to extend this prior work to assess both aspects of androcentrism at a broad, societal-level scale of analysis: that is, both (a) the tendency to associate
Intersectional Approaches to Investigating Gender and Racial/Ethnic Biases
A chief goal of the present work was to investigate whether and how androcentrism intersects with race/ethnicity. Biases and beliefs about gender and about race/ethnicity tend to be investigated separately, an approach that can isolate systematic differences between beliefs about, say, women in general and men in general. However, intersectionality theories highlight the drawbacks inherent in investigating each identity dimension in isolation. These theories note that individuals’ gender, their race/ethnicity, and their other social identities cannot be separated but operate together to co-create social meaning (Bowleg, 2008; Cole, 2009; Crenshaw, 1990; Goff & Kahn, 2013; Lorde, 1984). Thus, each individual is an amalgamation of multiple overlapping identities that mutually influence each other. For instance, what it means to be a woman differs for a queer White woman from the Midwest in her early 40s, etc., compared with a straight Hispanic woman in Los Angeles in her 70s, etc. (Lorde, 1984). Although it is not feasible to investigate all possible overlapping identities, gender and race/ethnicity are two primary dimensions of identity (Fiske & Neuberg, 1990; Lei et al., 2023). Gender and race/ethnicity are perceived within a few hundred milliseconds of seeing a face (Amodio et al., 2014), and they automatically elicit basic reactions such as positive/negative attitudes and attributions of humanity (this is true especially for gender; Connor et al., 2022; A. Martin & Mason, 2022). It is thus particularly important to investigate possible intersections between androcentric gender bias and biases based on race/ethnicity.
It is possible that androcentrism varies in magnitude across collective concepts of different racial/ethnic groups (Eagly & Kite, 1987). Much of the research on androcentrism—and psychological research more generally—tends to directly or indirectly investigate representations of White people more than people of other races/ethnicities (Cundiff, 2012; McGorray et al., 2023; Roberts & Mortenson, 2023). For instance, the androcentrism IAT described previously used names for women and men in general (e.g., John; Bailey et al., 2020), but there is reason to suspect that these names were more likely to be perceived as belonging to White people than to people of other races/ethnicities (Cotton et al., 2014; Devos & Banaji, 2005; Hegarty, 2017). This raises the possibility that much of what is known about androcentrism is limited to beliefs about White people specifically. Perhaps it is not the case that the collective concept
Theory and research on intersectional gender and racial/ethnic biases provide insights into how androcentrism might differ in collective concepts of different races/ethnicities. One prominent theory, intersectional invisibility (Purdie-Vaughns & Eibach, 2008), argues that the tendencies to regard men and White people as more prototypical combine such that women of color are especially overlooked or “invisible” (Coles & Pasek, 2020; Lei et al., 2023; Phills et al., 2018; Sesko & Biernat, 2010). Consistent with this claim, when asked to select three examples of the concept
Although research on intersectionality initially focused on a Black-White race contrast, 4 newer works on this topic (Lei et al., 2023; Zou & Cheryan, 2017) encompass other groups and often make different predictions about perceptions of Asian people by incorporating insights from gendered race theory. Gendered race theory argues that traits associated with the Asian group overlap more with stereotypes about women (resulting in “feminization”), whereas traits associated with the Black and Hispanic groups overlap more with stereotypes about men (resulting in “masculinization”; Galinsky et al., 2013; Johnson et al., 2012). For instance, U.S. participants imagine a Black person and a White person as a man more often than a woman but imagine an Asian person as a man or a woman at chance (Schug et al., 2015). Similarly, traits associated with Americans of different races/ethnicities overlap more with traits associated with the men of those groups for Black, Latino, Middle Eastern, and White Americans but not for Asian Americans (Ghavami & Peplau, 2013).
Extrapolating insights from intersectionality theories and research to the present work, we thus might expect to find
White-Centric Bias
In addition to our primary goal of investigating androcentrism and its intersection with race/ethnicity, the present research provides a preliminary investigation of White-centric biases in collective concepts. In principle, the generic concepts of
Research using traditional social-psychological methods suggests that people are more likely to think of a generic person as being White than other races/ethnicities. For instance, as described previously, when U.S. participants were asked to select images to represent humanity, they selected more images of White than Black people (Bailey & LaFrance, 2017; for a non-U.S. investigation, see Sibley & Liu, 2007). Participants also associate the idea of an American and other generic human concepts (
The Present Research
The primary goal of the present research was to provide an investigation of androcentric bias in collective concepts (including both its
Within both of these approaches to examining androcentric bias—with its components considered both jointly and separately—we investigated whether the strength of androcentric bias differs across collective concepts of different racial/ethnic groups. This is a crucial contribution because prior work has often indirectly or directly investigated androcentrism about White people. We expected to find androcentrism across racial/ethnic groups, but we also expected this bias to be somewhat attenuated in collective concepts of Asian people. With respect to specific components, we expected to find (a) weaker
Third and finally, we provided an initial investigation of possible White-centric biases in collective concepts—testing whether the
General Method
To investigate intersectional androcentric and White-centric biases in collective concepts, we compared three different sets of words: words denoting
Lists of

Note. Analyses that do not involve the race/ethnicity variables include the full list of 4,061 names (3,995 names have race/ethnicity designations). We also conducted supplementary analyses using continuous probabilities instead of discretizing names into gender and racial/ethnic groups; conclusions do not change (SI.8). Complete lists of words are reported in supplementary materials (SI.9).
The training corpus (Common Crawl) is a snapshot of the internet and thus includes multiple languages, but it overrepresents English-language text (e.g., in 2017, over 60% of the web pages in the corpus were exclusively in English; Mehmood et al., 2017). Because of this and because our lists of words were all in English and/or came from U.S. and Canadian sources (described next), it is likely that our investigation captures collective concepts from a predominantly English-language, U.S. and Canadian perspective. Next, we describe each of our three lists of words.
Words for person
To examine biases in the collective concept
Words for woman and man
To examine biases in collective gender concepts, we used 78 words: 38 words denoting
First Names
We used a large list of first names (Tzioumis, 2018; SI.9) because first names can simultaneously capture gender and race/ethnicity information, allowing us to test intersectional androcentric and White-centric biases. This list came from proprietary mortgage lender applications from the United States and Canada, which included over 2 million individuals’ self-identified race/ethnicity information. Although the proprietary data are not publicly available, the list of names has been processed and shared in prior work (Tzioumis, 2018).
Additional Processing and Validation Steps
For each name, we computed the probability that it refers to a woman or a man (Hannak et al., 2023) and to an Asian, Black, Hispanic, or White individual based on self-identifications (Tzioumis, 2018). We undertook additional processing and validating steps to ensure that the list of first names corresponded to the expected gender and race/ethnicity concepts (summarized in Figure 1 and described in full in SI.1 and SI.2). As part of this process, we removed the Black names from the main analyses because these names were not unambiguously associated with Black people more than White people in the training corpus. Thus, these names were not a valid measure of collective concepts of Black people. However, analyses with the Black names are reported in supplementary materials for completeness (SI.3).
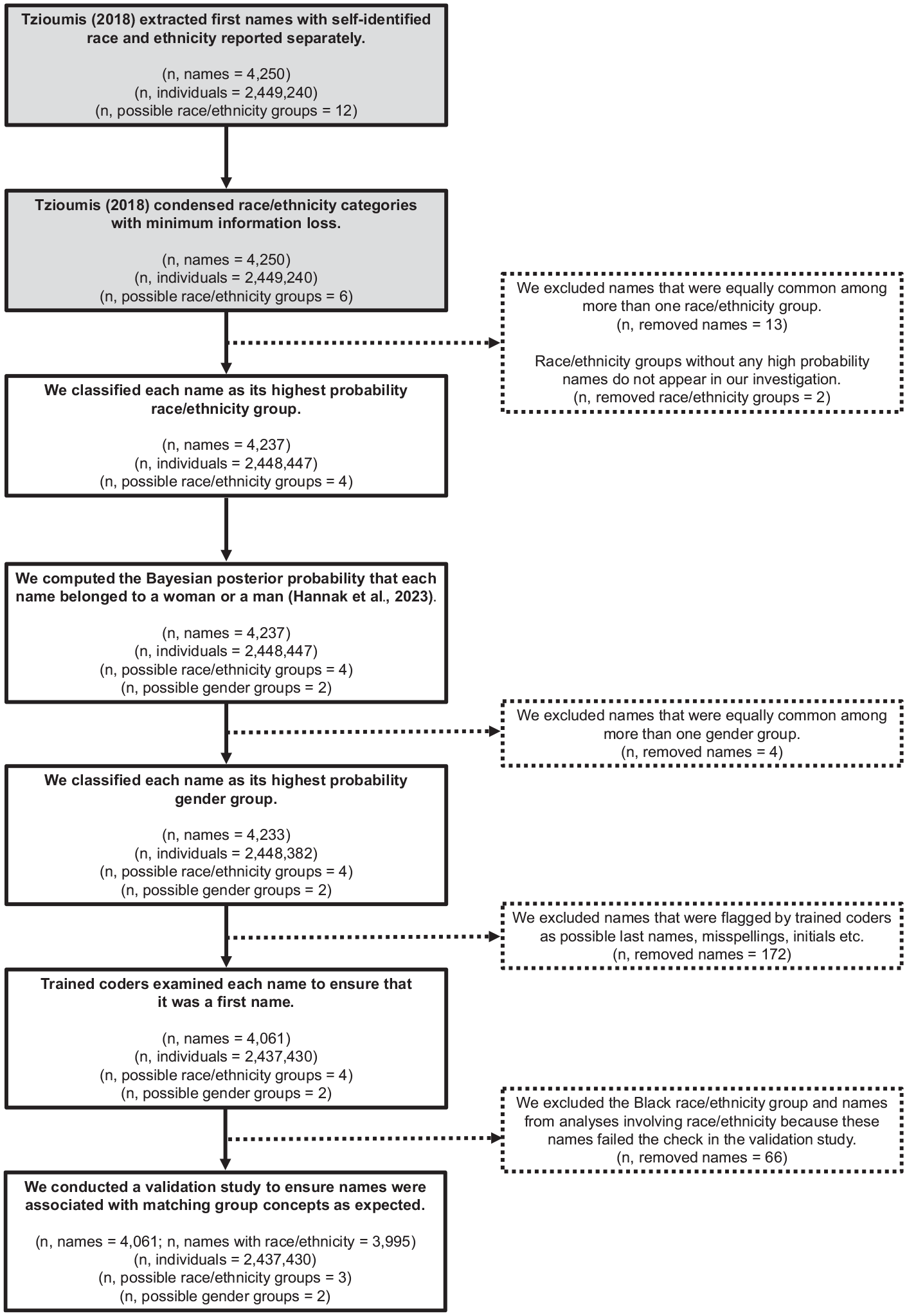
Summary of the Steps Undertaken to Process and Validate the First Names.
Final List of First Names
Our final list consisted of 4,061 names (see Table 1 for examples and SI.9 for complete lists). White names were overrepresented on this list (73%). This is likely because White people are the majority racial/ethnic group in the source countries (e.g., 62% in the United States and 70% in Canada; Jones et al., 2021; Statistics Canada, 2022), and because White people are disproportionately represented among those seeking mortgage applications (e.g., 82% of the people in the mortgage names database self-identified as White; see also Aladangady & Forde, 2021). However, because of the large size of the original list of names, there were also substantial numbers of names that had a high probability of belonging to other races/ethnicities. Notably, although our main analyses discretize each name into a single gender and racial/ethnic group, we also conducted supplementary analyses using continuous probabilities instead (SI.8); conclusions do not change.
A strength of our approach is that the probabilities that names were associated with a race/ethnicity or gender were calculated based on reports by actual people with those identities, rather than being based on stereotypic beliefs about which names “sound White,” etc. Also notable, other possible lists of names we could have used for this purpose were either much smaller (e.g., 5 names per group) and based on beliefs about stereotypical names for races/ethnicities (Caliskan et al., 2017; Greenwald et al., 1998), or they were lists of last names (Jones et al., 2021). Last names were not viable because they do not convey information about gender.
Transparency and Openness
Datafiles, analysis scripts, and the preregistration are available online https://osf.io/myfsg/?view_only=ed08b5c8671b41caa36e693974f2d342. We conducted preregistered replication studies using word embeddings trained on the same corpus (the Common Crawl) but via a different algorithm (GloVe, 300 dimensions; Pennington et al., 2014). GloVe has a different training architecture than fastText: It uses the global co-occurrence statistics of a word within a corpus to calculate its embedding, whereas in fastText a word’s embedding consists of the weights of a shallow neural network that was trained to encode information about the context of that word. Aside from using a different type of word embedding (GloVe vs. fastText), these replication studies were identical to main studies reported here. The findings from the replication studies are summarized throughout, and the results are reported in full in the supplementary materials (SI.5).
Study 1: Testing Androcentrism in a Word Embedding Association Test
To investigate androcentrism in collective concepts of different racial/ethnic groups, we conducted a WEAT (Caliskan et al., 2017). The WEAT was developed to be analogous to the influential IAT (Greenwald et al., 1998). The androcentrism WEAT we conducted here was modeled on the androcentrism IAT (Bailey et al., 2020) and consisted of two components: (a) the relative associations of the generic
Analyses
We conducted the androcentrism WEAT across all 4,061 names and separately for each racial/ethnic group using formulas adapted from prior work (Caliskan et al., 2017). p values were obtained using permutation tests. Bias-corrected and accelerated bootstraped 95% confidence intervals (CIs) were calculated to facilitate comparisons among groups.
To compute the androcentrism WEAT, we first calculated the mean similarity of the
Formally, let M represents our set of men’s first names and W represents our set of women’s first names. Let P and G represent our set of person concept words and corresponding gender concept words, respectively. Let cos
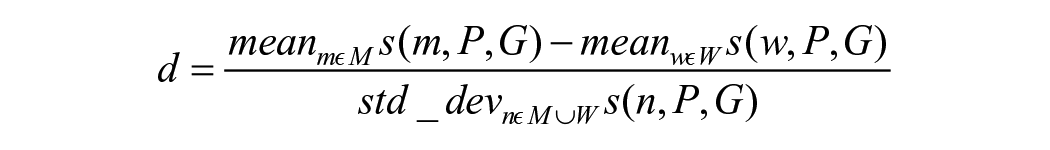
where for each man or woman first name (n),
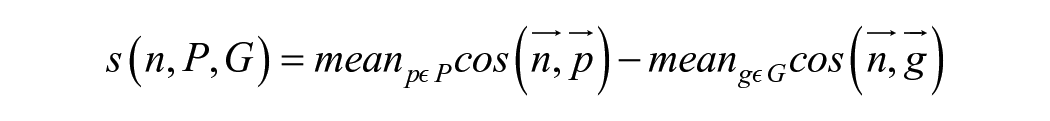
Results
We found evidence for androcentric
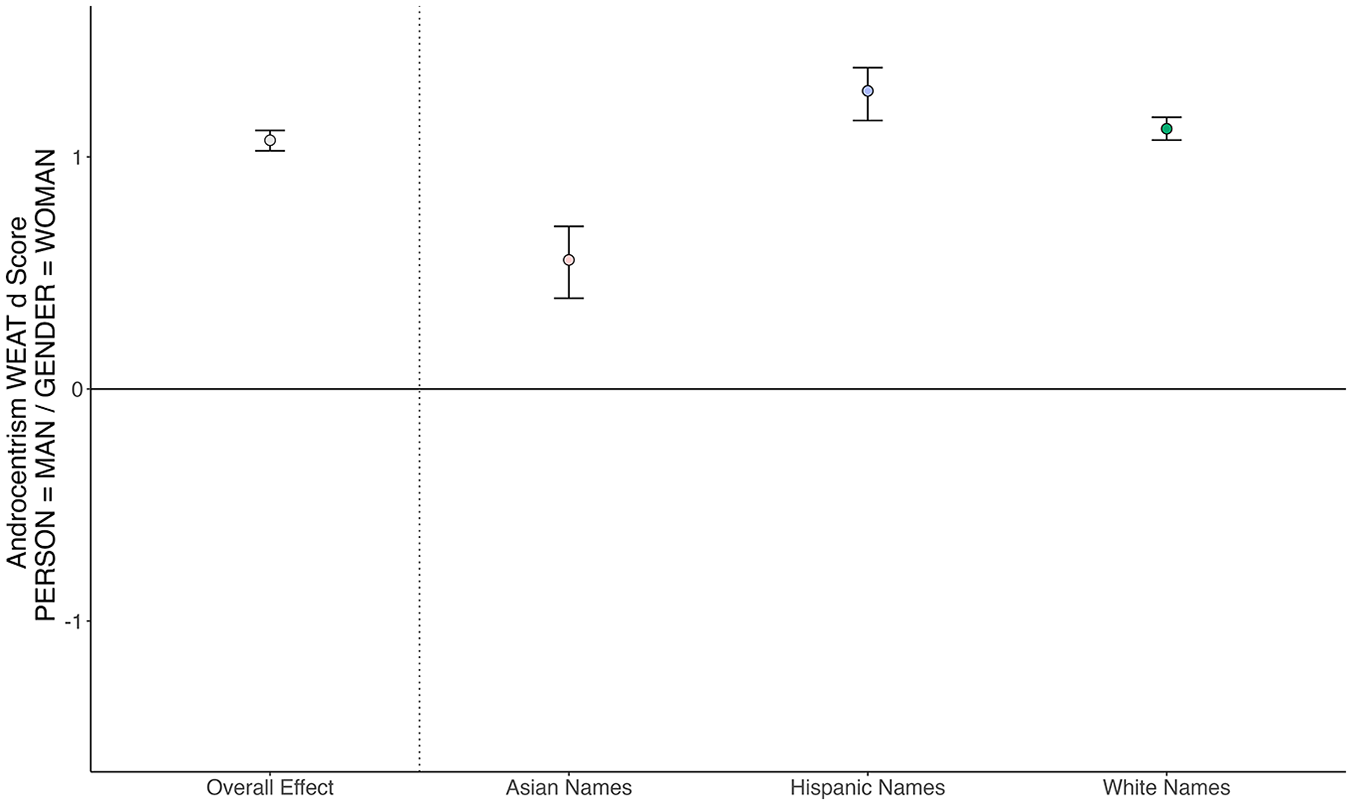
Androcentrism WEAT Capturing
East vs. South Asian Names
Asian sub-groups vary substantially in their experiences and in how they are stereotyped (Goh & McCue, 2021), even though they are often lumped together in research conducted from a Western perspective. Thus, in a supplementary analysis, we re-classified the Asian names into two subgroups, East Asian and South Asian, based on ratings given by trained, culturally competent coders. We found evidence for reduced androcentrism only in collective concepts of East Asian people (SI.4).
Preregistered Replication Study
A preregistered replication study using GloVe word embeddings (Pennington et al., 2014) replicated all findings in direction and significance (see SI.5).
Discussion
We examined word embeddings for approximately 4,000 first names belonging to millions of individuals to assess androcentric bias in collective concepts. We jointly examined the two components of androcentrism:
Study 2: Testing person = man
As with all traditional IATs and WEATs, the androcentrism WEAT from Study 1 does not differentiate between two possible sources of bias: here,
To investigate whether
Analyses
We computed two mixed-effects models. First, we computed a model with the names’ similarity to
In these two models, we also included weights based on frequency information. Including these weights meant that our analyses relied more on names that were more frequent in the corpus—and thus had more accurate word embeddings (Mu & Viswanath, 2018)—and names that were more frequent in the database for people of that self-identified race/ethnicity, which meant that their race/ethnicity classifications were based on more information. For instance, the name Jun was weighed more than Xuejun (respective weights = 6.069 and 1.494) despite both being high-probability Asian names (respective probabilities = 0.966 and 1.000) because Jun was more frequent in the training corpus and belonged to 262 compared with 15 self-identified Asian people in the names database. For details about how we computed these weights, see the supplementary materials (SI.6).
Results
Words for
Androcentric Bias, White-Centric Bias, and Intersectionality Bias in Collective

Note. This table shows two different models: Similarity to
p < .05. ***p < .001.
In the same model, words for
To examine intersectionality in androcentrism, we tested whether the
Finally, we conducted a preregistered replication study using GloVe embeddings rather than fastText (see Table S2 in SI.5). With respect to androcentrism, we found an overall
Discussion
In Study 2, we uncovered a
Study 3: Testing gender = woman
Using a similar approach to Study 2, in Study 3, we isolated the second component of the androcentrism WEAT. We tested the prediction that women are more associated with their matching gender concept (
We expected to find a
Analyses
As in the preceding study, we computed two mixed-effects models. First, we computed a model with the first names’ similarity to
Results
As expected, women’s first names were more similar in meaning to
Androcentric Bias, White-Centric Bias, and Intersectionality Bias in Collective Gender Concepts

Note. This table shows two different models: Similarity to matching gender concepts is predicted by name gender and name race/ethnicity without the name Gender × Name Race/Ethnicity interaction terms (Model 1) and with the interaction terms included (Model 2). The coefficients are from a model with a standardized outcome variable and can thus be interpreted as a measure of effect size analogous to Cohen’s d. Each model was re-computed 2 to 3 times, each time changing the reference group to facilitate interpretation. For Model 2, the simple slopes for race/ethnicity are not reported here for brevity but were included when computing the model.
p < .05. **p < .01. ***p < .001.
In the same model,
In terms of intersectionality, we tested whether the
Finally, we conducted another preregistered replication study using GloVe embeddings rather than fastText (see Table S3 in SI.5). With respect to androcentrism, the preregistered replication study found an overall
Discussion
Study 3 provides evidence for a
General Discussion
We investigated three collective concepts that are foundational to human psychology and societal functioning:
As a secondary goal, we also conducted an initial investigation of three possible White-centric biases in collective concepts:
In summary, the present research reveals pervasive androcentric and White-centric biases in collective concepts extracted from over 600 billion words written by millions of individuals. This work contributes nuanced, theory-driven findings to interdisciplinary literatures on androcentrism and intersectionality, and begins to address analogous race-based White-centric biases. Next, we enumerate and expand on the contributions of the present work.
Androcentrism in Collective Concepts
First, we found evidence for androcentrism in collective concepts. We found a greater
Our analyses also confirmed that the two components of androcentrism made independent contributions to the overall effect. Study 2 identified a
Androcentrism Intersects With Race/Ethnicity
Second, we tested whether androcentrism would emerge and/or differ in magnitude about people of different races/ethnicities. We found evidence for androcentrism in collective concepts of all three races/ethnicities investigated: Asian, Hispanic, and White. This is a critical contribution because prior work on this topic has typically focused either directly or indirectly on White people, leaving open the possibility that androcentrism might not emerge about other race/ethnicity groups. In the present work, we found slightly stronger androcentrism about Hispanic people than White people and substantially stronger androcentrism about Hispanic and White people compared with Asian people (especially East Asian people, Study 1).
The analyses on the separate
The
White-Centric Bias in Collective Concepts
Third and finally, we examined potential White-centric biases in collective concepts, testing whether the concepts of a
Although investigating White-centric bias was a secondary research goal in the present investigation, this contribution is no less important, both theoretically and societally. White people are prioritized in individuals’ concepts (Hegarty, 2017) as well as in research practices (McGorray et al., 2023; Roberts & Mortenson, 2023) and scientific writing (Cundiff, 2012). Here, we show a similar pattern in collective concepts. Because collective concepts reflect the shared worldview of a community, demonstrating White-centric bias at this level of analysis is particularly troubling.
Broader Implications
The present work has implications for researchers in psychology and artificial intelligence (AI), as well as for society at large. For psychologists, NLP methods applied to large corpora of naturalistic text have unique benefits: They can bypass the thorny problems of demand characteristics and observer effects. In traditional psychological studies, participants often try to guess the researcher’s hypothesis and change their responses accordingly; this tendency is likely heightened when the study concerns sensitive topics, such as gender and race/ethnicity. Even when such task demands are avoided, a study’s measures can themselves influence how participants respond in ways that cannot be fully anticipated or accounted for by researchers. For instance, a prior study of
For researchers working on AI, the present work also adds to a growing literature showing that word embeddings and other AI tools encode social biases, including complex and nuanced intersectional biases (e.g., Caliskan, 2023; Ghai et al., 2021; Guo & Caliskan, 2021; Jiang & Fellbaum, 2020; Lalor et al., 2022; Nelson, 2021; Sabbaghi et al., 2023; Tan & Celis, 2019). This means that even if individual-level biases were hypothetically eliminated, society would still be inequitable because these biases are embedded in active AI tools. Our work thus underscores the importance of rigorously auditing and “debiasing” word embeddings to increase fairness in AI applications. Word embeddings provide a valuable window into where social biases persist in machine learning models. By identifying bias “blind spots” at the intersection of key collective concepts such as gender and race/ethnicity, the present research highlights priority areas for intervention. Concrete next steps should include constructing debiasing techniques tailored to the intersections revealed here and incentivizing commercial providers of AI tools to allow independent scrutiny of their models, including the source code. In addition, because the biases uncovered here stem in part from the underlying training data itself (i.e., the text being analyzed, which reflects systemic prejudices in society), effective mitigation requires an interdisciplinary approach that incorporates expertise from the humanities and social sciences, as well as greater diversity among AI researchers and greater collaboration with stakeholders from marginalized groups. Fostering a culture of transparency and inclusion will help the field make progress toward fairer AI.
Our work also has broader implications for society. Throughout, we have argued that collective concepts are important to understand. Why? These concepts reflect widely shared ideas that are “in the air” for people in a community (see related theorizing on the bias of crowds; Payne et al., 2017). These collective ideas exist independently of personal endorsement. For instance, any given individual might disagree that “
This is troubling because the collective concepts we focused on—
Can anything be done to change (biases in) collective concepts? The fact that these concepts are encoded and perpetuated through language and other cultural artifacts suggests a path forward. For instance, gendered language can be used as a flexible tool to remind people that women exist and are people too (e.g., “A person . . . she”; Atir, 2022). Laws and policies might also be able to shape collective concepts. For instance, legalizing marriage equality produced substantial changes in large-scale attitudes toward sexual minorities (Ofosu et al., 2019). Policy can be leveraged to address the effects of androcentric and White-centric biases as well, not just the biases themselves. For instance, several funders now require medical researchers seeking grants to include racial minorities and women (as well as female rats) in their patient samples, although enforcement is still an outstanding question (Shansky & Murphy, 2021). Our work underscores the need for such systemic solutions to mitigate (the effects of) androcentric, White-centric, and intersectional biases.
Collective Concepts About Other Groups
One of the limitations of the present work is the absence of the Black names from the main analyses, despite the fact that much of the original theory (e.g., Crenshaw, 1990; Purdie-Vaughns & Eibach, 2008) and research (e.g., Coles & Pasek, 2020) on intersectionality focuses on Black women’s experiences and biases about this group. We omitted these names because the results from an initial validation study (see SI.2) indicated that they would not yield interpretable results: Black names were not a valid measure of collective concepts of Black people; they seemed to track collective concepts of White people instead. (Analyses with the Black names are reported in SI.3 for completeness)
One reason why the Black names on our list did not sufficiently differentiate collective concepts of Black and White people could be that the names came from mortgage databases and thus belonged to disproportionately high-income Black individuals. There is evidence that high-income Black families are more likely to choose less distinctively “Black” names and instead choose names that are also common among White people (Fryer & Levitt, 2004). Another reason why the Black names were less distinct could be that, historically, both the United States and Canada have been dominated by White, English-speaking people of European descent. Black people differ from the Asian and Hispanic groups in how recently and how fully they have joined—or been forced to join—this English-language context (Cox & Tamir, 2022). These points do not undermine our findings about high-probability Asian, Hispanic, and White names, but they do suggest that future text-based research should rely on markers of race/ethnicity other than names, particularly in cultural contexts where the racial/ethnic groups in question have high degrees of linguistic overlap.
Another limitation of the present work is that we only investigated representations of binary gender groups: women and men. We also think it is important for future work to spotlight representations of non-binary people and other gender minorities, who might be particularly marginalized in the
Androcentrism Across Contexts
In the present research, we used word embeddings extracted from large-scale text corpora that collapsed across a wide range of different contexts and authors (e.g., news outlets, personal blogs, instructional manuals, and government websites; Dodge et al., 2021; Mehmood et al., 2017). This approach has both advantages and disadvantages. An important advantage is that a 600+ billion word corpus that consists of language from millions of individuals discussing a huge range of topics enables us to capture widely shared, truly collective understandings of what it means to be a person, a woman, and a man. A disadvantage of the present approach, however, is that we are not in a position to describe variation across contexts, authors, or sub-communities. Theories of intersectionality note that the dimensions of identity that are most salient (e.g., gender vs. race/ethnicity) vary across individuals, contexts, and communities (Petsko et al., 2022). In addition, the specific attributes attached to gender groups can also vary based on the local context and comparison sets (A. Martin, 2022). One way to characterize such variation would be to use word embeddings trained on different, more specialized text (Charlesworth et al., 2021). However, once a certain threshold for the size of the text is reached, the resulting embeddings can be quite similar, even with respect to social biases, regardless of whether they are trained on general-purpose text written by a wide range of authors (e.g., text on the internet) or on more specialized text written by a narrower set of authors (e.g., biomedical text or child-directed text; Bailey et al., 2022; Charlesworth et al., 2021).
It is also noteworthy that collective concepts likely reflect the views of high-power, majority-group members, whose views are more likely to be reflected in public language and institutions. Thus, the intersectional biases we found here likely reflect biases about marginalized groups from a White-majority perspective rather than biases coming from these subcommunities themselves. Future research on androcentrism and intersecting racial/ethnic biases should strive to use methods besides those we used here, specifically methods that allow for greater control, to precisely identify boundary conditions, moderating contexts, and the role of author identity.
Although we investigated collective concepts by using language output across a range of contexts and authors, in terms of cultural context the present investigation is likely tapping a Western perspective. Although the training corpus (the Common Crawl) does include text from multiple cultures and in multiple languages, it nevertheless overrepresents English-language text (Dodge et al., 2021; Mehmood et al., 2017). Our lists of words were also all in English and/or came from U.S. and Canadian sources. Little is known about androcentrism in other cultural contexts. Future research should investigate androcentric gender bias and its intersection with race/ethnicity-based biases in multiple different linguistic and cultural contexts around the world.
Conclusion
We investigated androcentric, White-centric, and intersectional biases in the collective understanding of three fundamental concepts (
Supplemental Material
sj-docx-1-psp-10.1177_01461672241232114 – Supplemental material for Intersectional Male-Centric and White-Centric Biases in Collective Concepts
Supplemental material, sj-docx-1-psp-10.1177_01461672241232114 for Intersectional Male-Centric and White-Centric Biases in Collective Concepts by April H. Bailey, Adina Williams, Aashna Poddar and Andrei Cimpian in Personality and Social Psychology Bulletin
Footnotes
Acknowledgements
The authors thank Nicholas DiMaggio for assistance with manuscript preparation.
Author Contributions
A.H.B.: conceptualization, project administration, methodology, investigation, formal analysis, data curation, visualization, writing—original draft. A.W.: conceptualization, methodology, investigation, software. A.P.: conceptualization, methodology, investigation, writing—review and editing. A.C.: conceptualization, methodology, supervision, and writing—review and editing.
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.
Data and Materials Availability
Supplemental Material
Supplemental material is available online with this article.
Notes
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.